Embed Size (px)
Citation preview

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
1
Nonlinear Structural Hashing for ScalableVideo Search
Zhixiang Chen, Jiwen Lu,Senior Member, IEEE, Jianjiang Feng,Member, IEEE, and Jie Zhou,SeniorMember, IEEE
Abstract—In this paper, we propose a nonlinear structuralhashing (NSH) approach to learn compact binary codes forscalable video search. Unlike most existing video hashing methodswhich consider image frames within a video separately for binarycode learning, we develop a multi-layer neural network to learncompact and discriminative binary codes by exploiting boththe structural information between different frames within avideo and the nonlinear relationship between video samples. Tobe specific, we learn these binary codes under two differentconstraints at the output of our network: 1) the distance betweenthe learned binary codes for frames within the same sceneis minimized, and 2) the distance between the learned binarymatrices for a video pair with the same label is less than athreshold and that for a video pair with different labels is largerthan a threshold. To better measure the structural information ofthe scenes from videos, we employ a subspace clustering methodto cluster frames into different scenes. Moreover, we designmultiple hierarchical nonlinear transformations to preserve thenonlinear relationship between videos. Experimental results onthree video datasets show that our method outperforms state-of-the-art hashing approaches on the scalable video search task.
Index Terms—Hashing, scalable video search, neural network,structural information.
I. I NTRODUCTION
OVER the past decade, we have witnessed the exponentialgrowth of the video collections on the Internet. In con-
trast to the rapid growth of video contents, most existing videosearch engines still rely on textual keyword based indexing,which cannot present all pieces of information in a video and
Copyright (c) 20xx IEEE. Personal use of this material is permitted.However, permission to use this material for any other purposes must beobtained from the IEEE by sending an email to [email protected] work was supported in part by the National Key Research and De-velopment Program of China under Grant 2016YFB1001001, in part by theNational Natural Science Foundation of China under Grant 61672306, Grant61225008, Grant 61572271, Grant 61527808, Grant 61373074, and Grant61373090, in part by the National 1000 Young Talents Plan Program, theNational Basic Research Program of China under Grant 2014CB349304, inpart by the Ministry of Education of China under Grant 20120002110033,and in part by the Tsinghua University Initiative Scientific Research Program.(Corresponding author: Jiwen Lu.)
Zhixiang Chen is with Department of Automation, Tsinghua University, Ts-inghua National Laboratory for Information Science and Technology (TNList),Beijing, 100084, P. R. China (e-mail: [email protected]).
Jiwen Lu and Jianjiang Feng are with the Department of Automation,Tsinghua University, State Key Lab of Intelligent Technologies and System-s, Tsinghua National Laboratory for Information Science and Technology(TNList), Beijing, 100084, P. R. China (e-mail: [email protected];[email protected]).
Jie Zhou is with the Department of Automation, Tsinghua University, StateKey Lab of Intelligent Technologies and Systems, Tsinghua National Labo-ratory for Information Science and Technology (TNList), Beijing, 100084, P.R. China and School of Management, University of Shanghai for Science andTechnology, Shanghai, 200093, P. R. China (e-mail: [email protected]).
often misses videos due to the absence of text metadata. Toleverage the rich visual content of a video, content-based videosearch uses a set of example videos as queries to retrieverelated videos, in which videos are represented by high-dimensional feature representations. While many efforts havebeen made to improve the accuracy of content based videosearch [1]–[7], the development of efficient video retrievaltechnique is still under-explored. Furthermore, video retrievalcannot directly use the text retrieval technique because theextracted video representations are not text-based [8]. Hence,both the tremendous video corpus and high-dimensional videofeatures pose a really important and challenging topic forresearchers to develop new search techniques.
As one of the most efficient retrieval methods, the emerginghashing based approximate nearest neighbor search approachhas become a popular tool for tackling a variety of large-scalevisual analysis problems and has been extensively studied toencode documents or images by a set of short binary codes.Most existing video hashing methods [9]–[12] directly adoptthe existing image hashing algorithm to learn a single linearprojection matrix to generate binary codes with the goal ofpreserving similarity between frames. However, different fromthe imagery data, video clips not only contain many imageryframes but also carry specific structure information, whichwas ignored in most existing learning-based hashing methods.Therefore, the consistency between frames within the samescene is not encoded in the learned binary representations.Furthermore, such methods can not explicitly encode thenonlinear relationship between videos in the learned binaryrepresentations.
To address the abovementioned issues, we propose inthis paper a nonlinear structural hashing (NSH) method tolearn an efficient neural network for scalable video search.Fig. 1 illustrates the basic idea of our NSH. Specifically,we formulate video hashing as a structure-regularized lossminimization problem to achieve both the video level andthe frame level similarity preservations. We design a neuralnetwork of multiple hierarchical nonlinear transformations tolearn video representations so that inter-class variations ofvideo representations are maximized and intra-class variationsof video representations are minimized. Furthermore, we p-reserve the similarity for binary codes of frames within thesame scene, which is constructed by employing the subspaceclustering method. Specifically, the hashing model is learnedby enforcing two constraints on the neural network: 1) thedistance of each positive video pair is less than a thresholdand that of each negative pair is higher than the threshold, and

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
2
Fig. 1: Illustration of our proposed nonlinear structural hashingmethod. Firstly, we develop a multi-layer neural network topreserve nonlinear relationship between videos. Secondly, weconstruct scenesSi,1, Si,2 and Si,3 from the i-th video Vi
through subspace clustering to leverage the statistical knowl-edge and structural information between frames. Furthermore,similarity constraint is enforced on the binary codes of frameswithin the same scene to exploit the scene consistency.
2) the variations of the learned binary codes for consecutiveframes is minimized. In order to evaluate the performance ofthe proposed method, we conduct extensive experiments onthree large video collections. These datasets contain humanactivities in unconstrained real-world environments and arechallenging for content-based video retrieval. We show theeffectiveness of the proposed method and demonstrate that ourmethod achieves significant performance gains compared withprevious representative hashing methods for scalable videosearch.
We summarize the main contributions of this paper asfollows:
• We present a hashing learning framework to exploit boththe nonlinear relationship between video samples and thestructural information between different frames.
• We measure the similarity between video samples basedon a set-to-set calculation with frames clustered intodifferent scenes.
The rest of this paper is organized as follows. Section IIpresents the related work on hashing learning and videoretrieval. Section III details our proposed nonlinear structuralhashing approach. Section IV presents the experimental result-s. Finally, Section V concludes this work.
II. RELATED WORK
In this section, we first review several representativelearning-based hashing methods and then show some recentprogress on video search.
A. Learning-based Hashing
To achieve efficient approximate nearest neighbor search,hashing methods encode high dimensional data as compact bi-nary codes while preserving the similarity of the original data.The hashing methods can be categorized into two classes: data-independent and data-dependent. Data-independent hashing
methods adopt random projections to map samples into binarycodes. To avoid the recall decrease of long codes for goodprecision in randomized hash functions [13], data-dependenthashing methods generate compact binary codes by leveragingtraining sample properties or data label supervision. Existingdata-dependent hashing methods can be mainly categorizedinto two classes: unsupervised and supervised. For the firstcategory, the hashing learning procedure is accomplishedwithout the label information. The binary codes of datasamples are learned by employing discrete optimization tech-niques to preserve the similarity relationship between originalhigh-dimensional features with the goal to be informative.The recent representative algorithms in this category includespectral hashing (SH) [14], iterative quantization (ITQ) [15],Restricted Boltzmann Machines (RBMs) (or semantic hash-ing) [16], Anchor Graph Hashing (AGH) [17], K-MeansHashing (KMH) [18], Bilinear Projection-based Binary Codes(BPBC) [19], Binary Autoencoder (BA) [20], Sparse BinaryEmbedding (SBE) [21] and Deep Hashing (DeepH) [22].While unsupervised hashing is promising to retrieve metricdistance neighbors, e.g.,ℓ2 neighbors, the label informationis helpful to improve accuracy for searching semanticallysimilar neighbors [23]. In supervised hashing methods, bothlabel information and data properties are utilized to learn hashfunctions. The hashing model is learned with the goal tominimize the differences between the Hamming affinity overthe binary codes and the similarity over the data items, whichis determined by the real value features and the data labels.Recent progress in this category has been made in SequentialProjection Learning for Hashing (SPLH) [24], DiscriminativeBinary Codes (DBC) [25], Minimal Loss Hashing (ML-H) [26], Hamming Distance Metric Learning (HDML) [27],LDA Hashing [28], Ranking-Based Supervised Hashing [29],Graph Cuts Coding [30], Kernel-Based Supervised Hash-ing (KSH) [31], FastHash [32], Supervised Discrete Hash-ing (SDH) [33], Semisupervised kernel hyperplane learning(SKHL) [34], Semantics-Preserving Hashing (SePH) [35] andDeep Semantic Ranking based Hashing (DSRH) [36].
B. Video Search
Recently, the visual search for video contents has attractedmuch attention of researchers. The search task can be splitinto two main phases: feature extraction and search. Featureextraction aims to generate effective, efficient and discrimina-tive representations of videos, and search is to find relevantvideos by utilizing the previously extracted features for a givenquery video. While much research have been devoted intothe improvement of search accuracy [1]–[7], [37]–[41], theefficient search algorithm for video search is less studied inthe literature. To find relevant videos efficiently, approximatenearest neighbor search is proposed to reduce the complexityof conventional linear scan. Representative efficient approx-imate nearest neighbor search algorithms include tree-basedmethods [42]–[45] and quantization methods [8], [46], [47].However, these methods suffer from the high dimensionalitycurse and are not suitable for large scale video search. Toaddress this, several learning-based hashing methods have

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
3
been proposed for scalable video search. For example, Caoetal. [10] propose to combine feature pooling with hashing forefficient large scale video retrieval. Liet al. [9] take advantageof Riemannian Manifold for face video retrieval. Wangetal. [12] take account of visual saliency for hash generation. Yeet al. [11] exploit the discriminative local visual commonalityand temporal consistency to design hash functions. Note thatthe structure in [11] stands for the spatial structure informationwithin a video frame, while we emphasize the relationshipbetween frames of a video by mentioning structure. Whilereasonably good performances are demonstrated by thesehashing methods, most of them usually learn a single lineartransform and ignore the video structural information, whichcannot well capture the nonlinear structure of video clips toproduce more effective compact hash codes [33]. To this end,we propose a nonlinear structural hashing method by utilizingboth the nonlinear relationship between videos and the scenestructure, where multi-layer neural network is learned forscalable video search.
III. STRUCTURAL V IDEO HASHING
In this section, we present a structural hashing model forscalable video search. Assume there areN training videos{Xi}
Ni=1 with category labels{yi}Ni=1 whereyi is the label
information for videoXi. Each videoXi is represented bya collection ofni sequential frames{xi,1,xi,2, . . . ,xi,ni
} ∈R
d×ni . Thea-th column ofXi, xi,a ∈ Rd, is thea-th frame
of videoXi with a feature length ofd. The videos are sampledas representative frames to make the video hashing approachapplicable to long videos. The frame sampling method isrelated to the video summarization [48]–[52]. In this work,we select frames based on uniform sampling. Our goal is tolearn anL-bit binary code for each frame. By denoting thebinary code of the framexi,a asbi,a ∈ {−1, 1}L, a videoXi
with ni frames can be represented as the binary code matrixBi ∈ {−1, 1}L×ni.
A. Model
To facilitate efficient video retrieval, the learned binarycodes are expected to maintain the local structure of thetraining videos. First, similar videos are expected to havebinary codes with small Hamming distance. We call suchsimilarity between videos as the inter-video similarity. Second,rather than considering video frames as images [11] or video-level feature representation [33], [53], the intra-video similar-ity is also taken into consideration in the proposed method.The intra-video similarity characterizes the similarity betweenframes within a video. Thus, the learning objective of theproposed method is to preserve both inter- and intra-videosimilarities, which is formulated as,
argmin{Bi}N
i=1
L = Lv + λ1Lf , (1)
whereLv andLf measure the inter- and intra-video similaritylosses, respectively. The parameterλ1 is the parameter tobalance the effects of two kinds of similarity losses.
Fig. 2: The workflow of the proposed approach. Firstly,the gallery videos are passed through the learned multilayerneural network to yield the corresponding binary matrices,B1, ...Bn, which are stored to constitute the database for thefollowing retrieval. Given a query video, the correspondingbinary matrix Bquery is generated with the learned model.Then, the distances between the binary matrix of query videoand those in the database,D1, ...Dn, are computed. Finally,a ranking list of database videos is constructed for similaritysearch.
We define the inter-video similarity loss based on thediscriminative distance metric [54] to pursue efficient binarycode matrices. The specific form is expressed as,
Lv =
N∑
i=1
N∑
j=1
ℓi,j(D(Bi,Bj)− τ), (2)
whereD(Bi,Bj) represents the distance between two learnedbinary code matricesBi,Bj for videos Xi,Xj , which isfurther defined in Section III-C to leverage the video statisticalinformation. Specifically, (2) aims to seek binary code matricessuch that the distanceD(Bi,Bj) betweenXi and Xj issmaller than a pre-specified thresholdτ if Xi and Xj arewith the same category (ℓi,j = 1), and larger thanτ if videosXi andXj are with different categories (ℓi,j = −1), wherethe pairwise labelℓi,j denotes the similarity or dissimilaritybetween a video pairXi andXj. Note that the value ofτ doesnot influence the minimization of (2) as long asτ is fixed. Tomake (2) meaningful,τ is assigned a value related to the bitlength of the binary code.
The intra-video similarity loss term is to embed the sceneconsistent constraint between frames of the same scene intothe learning objective, which is defined as follows:
Lf =1
2
N∑
i=1
ui∑
m=1
∑
bi,a1∈Si,m
∑
bi,a2∈Si,m
‖bi,a1 − bi,a2‖22
=1
2
N∑
i=1
∥
∥RiBTi
∥
∥
2
2, (3)
whereRi is a constant coefficient matrix related to the scenestructure of videoXi, Si,m represents one scene of videoXi andui is the number of scenes in videoXi. Each item‖bi,a1 − bi,a2‖
22 is corresponding to a row ofRi with the
a1-th element being 1, thea2-th element being -1 and theother elements being zeros. Since the scene structure is onlyrelated to the content of each video, it is computed before the

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
4
generation of binary codes as will be stated in Section III-C.Here ‖·‖2 denotes the matrixL2-norm. (3) aims to pursuesmall difference between binary codes for the frames of thesame scene in a video, which enforces the smoothly change ofbinary codes of frames in a scene, and thus explicitly embedsthe scene structure into the learned binary codes. This equationintroduces the binary code similarity enforcement betweenframes within the same scene and can be combined with anyscene construction method. By combining (2) and (3) together,the frames of the same scene with the same class label aremore likely to be mapped to close binary codes.
B. Hashing with Multilayer Neural Network
Given a video framexi,a, a set of hash functionsfh(x) =[h1(x), h2(x), . . . , hL(x)] is learned to produce anL-bitbinary codebi,a ∈ {+1,−1}L. A good form of hash functionsis critical to obtain the desirable binary codes. In this work,the form of multi-layer neural network is adopted to generatethe compact binary codes through multiple nonlinear transfor-mations. Compared to most previous works, which only learna single linear projection matrix [15], [18], [26], [47], [55],multi-layer neural network can better capture the nonlinearmanifold of frames. While the kernel trick can project framesinto the kernel space to learn the binary codes, the lackof explicit nonlinear mapping functions usually leads to thescalability problem [31], [56].
As shown in Fig. 2, we develop a network withK + 1stacked layers of nonlinear transformations to compute thebinary representationbi,a for each framexi,a. Let p(k) be thenumber of units at thek-th layer, where1 ≤ k ≤ K. Theoutput of thek-th layer is recurrently computed ash(k)
i,a =
s(W (k)h(k−1)i,a + c(k)) ∈ R
p(k)
with h(1)i,a = s(W (1)xi,a +
c(1)) ∈ Rp(1)
, wheres(·) is a nonlinear activation function,e.g., the tanh or sigmoid function.W (k) and c(k) are theprojection matrix and bias vector to be learned at thek-thlayer of the network, respectively. Specifically, the output ofthe network is calculated as:
gh(xi,a) = h(K)i,a = s(W (K)h
(K−1)i,a + c(K)) ∈ R
p(K)
, (4)
where the mappinggh : Rd 7→ Rp(K)
is a parametric nonlinearfunction determined by parameters{W (k), c(k)}Kk=1. Then,the binary codes are generated by taking the sign of the outputof the top layer of the network:
bi,a = sgn(h(K)i,a ). (5)
The binary vectors of all frames in a video can be rewrittenas the matrix formB ∈ {−1,+1}L×ni. On the base of therelationships in (4) and (5), both the parameterized networkand a set of binary code matrices of the given training videoscan be learned by solving an optimization problem to minimizethe predefined loss measurement. As shown in (5), the binaryrepresentation of a new video can be obtained by passing eachframe through the learned network.
C. Subspace-based Video Distance
The distance between two videosXi and Xj in theHamming space is converted to the distance between two
1101100111010101
1101100111010101
Mean
0110111010011101
1101100111010101
Subspace
clustering
1101100111010101
0110111010011101
iB
jB
1sD
2sD
3sD
4sD
( , )i jD B B
Fig. 3: The computation of distance between binary codematrices of videos. Firstly, the binary matrix of each videoBi
is clustered into subspaces to exploit the structural information.Then, the Hamming distances between subspaces of differentvideos Ds1, Ds2, Ds3 and Ds4 are computed. Finally, thedistance between the two binary matrices of videosD(Bi,Bj)is derived on the base of distances between subspaces.
sets of binary codessbi := {bi,1, bi,2, . . . , bi,ni} and sbj :=
{bj,1, bj,2, . . . , bj,nj}. A naive method is to calculate the
difference between the mean values of the two setssbi andsbj .However, it does not take into consideration the set attribute,i.e. the distribution of elements within the set. Considering thescene structure within a video, the frames from a video couldbe assumed to be distributed on a nonlinear manifold. Hence,a more desirable approach is to measure video distance withthe distance between subspaces.
As shown in Fig. 3, to facilitate the computation of thevideo to video distance, a subspace clustering method isapplied for each video, where a nonlinear video representationis decomposed into as a set of linear subspaces. A videoXi, which is assumed to come from a low-dimensionalmanifold, is partitioned into a collection ofui disjoint sub-spaces{Si,1,Si,2, . . . ,Si,ui
}. Each subspace is a linear spacespanned by a subset of frames,Si,m = span(Xi,m), whereXi,m = XiTi,m is a matrix consisting of several columns ofXi. That is,Xi =
⋃ki
m=1 Xi,m andXi,m
⋂
Xi,n = ∅(m 6=n,m, n = 1, 2, . . . , ui). Each subspace represents a scene inthe video, and the procedure of scene clustering is to constructthe subspaces for videos. To better construct subspaces forvideos we employ the local linear model construction methodin [57] to explicitly guarantee the linear property of eachsubspace. In the one-shot clustering method [57], a seed pointis used to generate each new maximal linear patch under thelinearity constraint. The maximal linear patch is defined tospan a maximal linear subspace. The deviation between thegeodesic distances and Euclidean distances in the patch reflectsits linear perturbation.
The video to video distance is represented as the integrationof distances between pair of subspaces. Typically, a videoconsists of several clips describing different scenes of an eventand similar videos are with a certain overlap in scenes. Toclassify two videos as the same category, one effective solutionis to find the common scenes and measure the similarity ofthose scenes. Therefore, we define video to video distance

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
5
by the average distance between subspace pair from the twoclusters of subspaces as follows:
D(Xi,Xj) =1
uiuj
ui∑
m=1
uj∑
n=1
Ds(Si,m,Sj,n), (6)
whereD(Si,m,Sj,n) is the distance between two subspacesSi,m and Sj,n of videos Xi and Xj , respectively. TheHamming distance between the hash codes of framesxi,m,a
andxj,n,b of subspacesSi,m andSj,n is adopted to computethe Hamming distance between two subspaces from differentvideos. In particular, it is computed as the average Hammingdistance between frames,
Ds(Si,m,Sj,n) =1
ki,mkj,n
ki,m∑
a=1
kj,n∑
b=1
dH(xi,m,a,xj,n,b), (7)
wheredH is the Hamming distance of two binary codes andki,m and kj,n are the numbers of frames in the subspacesSi,m andSj,n, respectively. The distance is symmetric and isaveraged by the number of frames in subspaces to make thedistance less dependent on the size of subspaces.
D. Optimization
Based on the hashing learning function presented in SectionIII-B and the video distance defined in Section III-C, theobjective in (1) can be rewritten as:
argmin{W (k),c(k)}K
k=1
L = Lv + λ1Lf + λ2Lr
=1
2
N∑
i=1
N∑
j=1
ℓi,j(
D(Bi,Bj)− τ)
+λ1
2
N∑
i=1
∥
∥RiBTi
∥
∥
2
2
+λ2
2
K∑
k=1
(
∥
∥
∥W (k)
∥
∥
∥
2
2+∥
∥
∥c(k)
∥
∥
∥
2
2
)
. (8)
The first two termsLv and Lf enforce inter-/intra-videosimilarity constraints and are defined in (2) and (3), respec-tively. These two terms characterize the nonlinear relationshipbetween videos and the scene structure within each video.The last termLr is a regularizer to control the scales ofthe parameters.λ1 andλ2 are two parameters to balance theimpact of the corresponding terms.
However, the above objective function is intractable dueto the discrete constraint introduced by thesgn function togenerate binary codes. Following the same signed magnituderelaxation as in [15], [24], we rewrite the objective functionas:
argmin{W (k),c(k)}K
k=1
L =1
2
N∑
i=1
N∑
j=1
ℓi,j(
D(H(K)i ,H
(K)j )− τ
)
+λ1
2
N∑
i=1
∥
∥
∥Ri(H
(K)i )T
∥
∥
∥
2
2
+λ2
2
K∑
k=1
(
∥
∥
∥W (k)
∥
∥
∥
2
2+∥
∥
∥c(k)
∥
∥
∥
2
2
)
, (9)
by substituting the binary codes with the output of the deepnetwork H
(K)i . Simultaneously, the distance measurement
between video subspaces in (7) is redefined as:
Ds(H(K)i,m ,H
(K)j,n )
=1
ki,mkj,n
ki,m∑
a=1
kj,n∑
b=1
(h(K)i,m,a − h
(K)j,n,b)
T (h(K)i,m,a − h
(K)j,n,b)
=1
ki,mkj,ntr(
(Φ(K)i,m −Ψ
(K)j,n )T (Φ
(K)i,m −Ψ
(K)j,n )
)
, (10)
where Φ(K)i,m and Ψ
(K)j,n are the hidden representations of
subspacesH(K)i,m andH(K)
j,n .To solve the optimization problem in (9), we use the s-
tochastic sub-gradient descent scheme to obtain the parameters{W (k), c(k)}Kk=1. The gradients of the objective functionLwith respect to the parametersW (k) andc(k) can be computedas follows:
∂L
∂W (k)=
N∑
i=1
N∑
j=1
ℓi,j
( ui∑
m=1
uj∑
n=1
δm,ni,j
(
∆(k)Φ
(Φ(k−1)i,m )T
−∆(k)Ψ
(Ψ(k−1)j,n )T
)
)
+ λ1
N∑
i=1
F(k)i
(
H(k−1)i
)T+ λ2W
(k), (11)
∂L
∂c(k)=
N∑
i=1
N∑
j=1
ℓi,j
(
ui∑
m=1
uj∑
n=1
δm,ni,j
(
∆(k)Φ
−∆(k)Ψ
)
)
+ λ1
N∑
i=1
F(k)i + λ2c
(k), (12)
where the coefficientδm,ni,j = 1
uiuj· 1ki,mkj,n
for the subspace
pair {H(K)j,n ,H
(K)i,m }.
The updating equations are computed as follows:
∆(K)Φ
= (Φ(K)i,m −Ψ
(K)j,n )⊙ s′(Z
(K)Φi,m
))
, (13)
∆(K)Ψ
= (Φ(K)i,m −Ψ
(K)j,n )⊙ s′(Z
(K)Ψj,n
))
, (14)
F(K)i =
(
RTi Ri(H
(K)i )T
)T⊙ s′(Z
(K)i ), (15)
∆(k)Φ
=(
(W (k+1))T∆(k+1)Φ
)
⊙ s′(Z(k)Φi,m
), (16)
∆(k)Ψ
=(
(W (k+1))T∆(k+1)Ψ
)
⊙ s′(Z(k)Ψj,n
), (17)
F(k)i =
(
(W (k+1))TF(k+1)i
)
⊙ s′(
Z(k)i
)
, (18)
wherek = 1, 2, . . . ,K − 1. Here the operation⊙ denotes theelement-wise multiplication, andZ(k+1)
Φi,m= W (k+1)
Φ(k)i,m +
c(k+1), Z(k+1)Ψj,n
= W (k+1)Ψ
(k)j,n + c(k+1), Z
(k+1)i =
W (k+1)H(k)i + c(k+1).
The gradient descent algorithm is adopted to update theparameters of the network until convergence, and the specificupdating rule is as follows:
W (k) = W (k) − η∂L
∂W (k), (19)

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
6
Algorithm 1: NSHInput : Training videosX and label, iterative numberR,
learning rateη, network layer numberK,parametersλ1, λ2, and convergence errorε.
Output : Network parameters{W (k), c(k)}Kk=1.Initialization: Construct subspaces for each video;initialize {W (k), c(k)}Kk=1 by getting the topp(1)
eigenvectors.for r = 1, 2, . . . , R do
for i = 1, 2, . . . , N doInitially settingH(0)(Xi) = Xi .
endfor k = 1, 2, . . . ,K do
for i = 1, 2, . . . , N doComputeH(k)(Xi) according to (4).
endendfor k = K,K − 1, . . . , 1 do
Calculate the gradients with (11) and (12).endfor k = 1, 2, . . . ,K do
UpdateW (k) and c(k) according to (19) and (20).endCalculateL using (9).If r > 1 and |Lr − Lr−1| < ε, go to Return.
endReturn: {W (k), c(k)}Kk=1.
c(k) = c(k) − η∂L
∂c(k), (20)
whereη is the learning rate.The step by step description of the proposed NSH approach
is provided inAlgorithm 1 .
E. Implementation Details
To apply our approach for video search, similar videos areretrieved by the Hamming distance. Specifically, the binarycodes of the database videos are generated along with thescene clustering offline. Given a query video, all video framesare firstly used to construct the frame set. These framesare further processed to generate binary codes by using thelearned hashing model and accomplish scene clustering viathe subspace construction method. With the binary codes andscene structure of the query video and the database videos, thedistance between query video and every database video canbe computed according to (6) and (7). Then, a ranking list ofdatabase videos can be constructed for similarity search.
F. Discussion
In this subsection, we highlight the difference between ournonlinear scalable video retrieval approach and some recentlyproposed hashing methods.
1) Nonlinear Scalable Hashing [22], [32]: Some recentlyproposed hashing approaches harness the nonlinear manifoldstructures of data samples and have achieved superior perfor-mance [22], [32]. Currently, these methods are designed for the
retrieval on imagery datasets. Such methods only consider thesimilarity relationship between data samples, i.e., image-to-image or video-to-video similarity. However, videos containrich structure information at each data point compared toimagery data. Different from these methods, our video hashingmethod exploits both the relationship between videos and thestructure information in each video to learn binary codes.
2) Video Hashing for Retrieval [11]: Ye et al. [11] proposeto learn effective hash functions by exploring the structurelearning techniques and have demonstrated promising results.Their work exploits the common local visual patterns in videoframes with the same class label, together with the temporalconsistency over consecutive frames, to learn hash functions.In contrast, our hashing learning approach leverages both thenonlinear relationship between videos and the scene consis-tency between frames within a video to learn discriminativebinary codes. Hence, both the relationship between videos andthe scene structure are exploited.
IV. EXPERIMENTS
To evaluate the effectiveness of our proposed nonlinearstructural hashing (NSH) method, we perform extensive ex-periments on three large video collections, i.e., ColumbiaConsumer Video (CCV) [58], YLI Multimedia Event Detec-tion (YLI-MED) [59], [60] and ActivityNet [61] datasets, andcompare our method with several state-of-the-art methods.These datasets are challenging for retrieval due to the presenceof large intra-class variation between videos and the motions inthe wild between frames. The following subsections describethe details of the experiments and results.
A. Experimental Settings
We compare our NSH with several representative linearhashing methods. Specifically, we take Iterative Quantization(ITQ) [15] and Canonical Correlation Analysis Iterative Quan-tization (CCA-ITQ) [15] as baselines. These methods includeboth unsupervised (ITQ) and supervised (CCA-ITQ) hashingparadigms. Since our NSH method is nonlinear, we alsocompare it with four state-of-the-art nonlinear hashing meth-ods, Deep Hashing (DeepH) [22], Supervised Deep Hashing(SDeepH) [22], Kernel-Based Supervised Hashing (KSH) [31]and Supervised Discrete Hashing (SDH) [33]. The sourcecodes of these baseline methods were kindly provided by theauthors. We use the suggested parameters of these methodsfrom the corresponding authors. While several video hashingmethods are recently presented in the literature [10], [11],[62], most of them adopt data-independent techniques, and re-quire specific settings, such as multiple-feature extraction [62]or submodular representation [10]. Therefore, they are notconsidered as comparable baselines. We followed the widelyused evaluation protocols in [11], [24], i.e., Hamming rankingand hash lookup, and adopted the following two evaluationmetrics for consistent evaluations across different methods: 1)mean average precision (mAP), which represents the overallperformance of different hashing methods by the area underthe precision-recall curve; and 2) Hamming look-up result withthe hamming radius set asr, which measures the precision

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
7
over all retrieved samples that fall into the buckets within aset hamming radius, i.e.,r = 2. We followed [31] to set zeroprecision for conditions failing to find any hash bucket for aquery, different from previous work which computed the meanhash lookup precision over all queries by ignoring the failedqueries. As stated in [62], mAP has been demonstrated tohave especially good discrimination and stability. The nearestvideo sequences are returned by computing and ranking theHamming distance between query video and gallery videosaccording to (6). For the calculation of Hamming look-upprecision, we followed the protocol in [11]. The ground-truthrelevant instances for a query are defined as those sharing atleast one category label with it.
For our NSH method, we trained our deep model with a 3-layer model with the dimensions of each layer being 512, 200,L, to produceL-bit long binary codes. We set the value ofτto beL/nC with nC as the number of category of trainingsamples. We set parametersλ1 and λ2 to 0.1 and 0.001,respectively, through 5 fold cross validation with one fifth ofthe training set as validation set. We optimized our hashingmodel with 5 iteration updates. In our models, we adoptedthe hyperbolic tangent function as the nonlinear activationfunction. In addition, for all the supervised algorithms, werandomly select a small subset of labeled samples to trainthe learned hash functions on all three datasets. For a faircomparison, we trained NSH and supervised baselines onthe same set of training data. During batch training for theimage-based hashing methods, we randomly selected framesfrom different videos to ensure large diversity of the trainingsamples.
B. Experimental Comparison on CCV
The Columbia Consumer Video (CCV) dataset [58] hasbeen widely adopted in several recent studies on video hash-ing. There are 9,317 videos gathered from YouTube, whichcovers 20 categories annotated based on Amazon’s MTurkplatform. On average, the video duration is around 80 seconds.Interested readers are referred to [58] for more details. Wefollowed the experimental settings in [11] for our experiments.Specifically, we randomly selected 20, 20 and 100 videos percategory to construct the training, query and gallery sets. Wesampled each video every 2 seconds to extract frames andensure a minimum of 30 frames for each video.
1) Results on the Hand-Crafted Feature: The SIFT de-scriptors over key points on each frame are extracted withtwo different key point detectors, i.e., Different of Gaus-sian [63] and Hessian Affine [64]. The 128-dimensional SIFTfeatures are then fed into the quantization procedure to derive5,000-dimensional BoW representation [65] for each frame.Fig. 4(a) presents the comparison between NSH and otherbaseline methods in terms of mAP on the CCV dataset withrespect to different number of bits. We see that our NSHmethod outperforms all other methods in all bit numbers,including the previous state-of-the-art SDeepH and DeepH.We see that the supervised methods generally perform betterthan unsupervised methods. Moreover NSH shows superiorperformance compared to SDeepH. This is because both the
video label information and the frame level label informationare important to the learning of binary codes. Furthermore,the nonlinear hashing methods such as DeepH, SDeepH andNSH show better performance than other linear methods. Thereason is that the nonlinear relationship between samples ispreserved. However, the KSH method surprisingly deliverslow performance in our results. This may be due to thatthe provided kernel model does not fit the video sampleswell. We also see that the results of SDH increase withlonger bit length, which is consistent with the importanceof minimization quantization for long binary codes. Fig. 4(b)presents the comparison on results in terms of the precision offirst 500 retrieved samples. We see that our method is superiorto the best competitor. The precisions of ITQ and CCA-ITQincrease for longer binary codes, which implies that reducingthe quantization error is a reasonable objective. In Fig. 4(c), weshow the precision recall curves for different methods whenthe length of binary codes is 32 bits. We see that our methodpresents the best performance. This is because that the videostructure is exploited in our hashing learning model.
2) Results on the CNN Feature: Besides hand-crafted bag-of-SIFT feature, based on SIFT descriptors, we also evaluatedour NSH with the state-of-the-art deep Convolutional NeuralNetwork (CNN) features. To extract the representation for eachframe, we adopted the VGG model [66] pretrained on the Ima-geNet [67], and used the output of the layer ’fc7’ as suggestedin [68]. Fig. 5 and 6 summarize the performance of differenthashing methods. As expected, the overall performances arehigher than those on the hand-crafted features for both thebaseline methods and our NSH. In Fig. 5(a), we see that NSHoutperforms all the competitors by a large margin in terms ofthe mAP. Note that the substitution of hand-crafted featureswith CNN features enlarges the gaps between different hashingmethods, which indicates a well designed hashing methodis important to capture the similarity structure of originalfeatures. The results in Fig. 5(b) show the precisions of top500 retrieved samples for different hashing methods. Fig. 5(c)presents the comparison on precision within Hamming radius2, where our method is competitive to the remaining hashingmethods. However, the precisions of most methods drop withlonger binary codes. The reason is that longer codes result inlower probability that samples fall in the same bucket.
Besides the performance, we also compare the testing timeof our NSH method with those of other baseline methods. InTable I, we report the testing time of all involved methods forvarious lengths of binary codes on the CCV dataset. The timeis measured in seconds over all testing videos. The computingplatform is equipped with 4.0GHz Intel CPU and 32GB RAM.From the table, we can see that the testing time consumed byour NSH method is comparable to those of existing methods.
C. Experimental Comparison on YLI-MED
The YLI-MED dataset [59] is the video subset of the YahooFlickr Creative Commons 100 Million (YFCC100M) datasetspecialized for Multimedia Event Detection research, which issimilar to the existing TRECVID MED’s HAVIC corpus. Inparticular, the 10 current available annotated events in YLI-MED, such as Birthday, Wedding and Woodworking, were

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
8
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) mean Average Precision
Length of Bits16 32 64 96
Ave
rage
pre
cisi
on
0.07
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0.15
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) Precision @500
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) Precision-recall @32bit
Fig. 4: The results of different hashing methods on the CCV dataset with hand-craft features.
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) mean Average Precision
Length of Bits16 32 64 96
Ave
rage
pre
cisi
on
0.1
0.11
0.12
0.13
0.14
0.15
0.16
0.17
0.18
0.19
0.2
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) Precision @500
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) Precision within Hamming radius 2
Fig. 5: The comparison of different hashing methods on the CCV dataset with CNN features.
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) 32 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) 64 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) 96 bits
Fig. 6: The comparison of precision-recall curves for different hashing methods on the CCV dataset with binary codes ofdifferent lengths.
TABLE I: Testing time in seconds of different hashing meth-ods on the CCV dataset.
Methodslength of binary code
16 32 64 96
ITQ [15] 4.63 5.12 4.94 5.41DeepH [22] 4.42 4.95 5.53 5.99CCA-ITQ [15] 19.95 19.99 19.95 19.79KSH [31] 16.38 17.15 16.52 16.66SDeepH [22] 32.43 33.65 32.42 32.77SDH [33] 92.75 97.13 97.49 95.99NSH 18.71 19.22 19.03 19.18
included in the TRECVID MED 2011 evaluation run by theNational Institute of Standards and Technology (NIST). YLI-MED is one of the largest public available video collectionswith manual annotation. A subset of the videos in the YFC-C100M is adopted for the MED task in the TRECVID bench-
mark organized by NIST. There are around 2000 annotatedvideos in the YLI-MED dataset. The video duration variesfrom 2 to 200 seconds with average value around 40 seconds.Here, we selected frames every second and ensure at least 30frames for each video. We randomly selected 20 and 20 videosin each category to construct the training set and query set,respectively. We selected another 100 videos each category asgallery set for retrieval.
1) Results on the Hand-Crafted Feature: For each frame,we followed the same feature extraction procedure as in theexperiments on the CCV dataset. In Fig. 7(a), we show themAP results of NSH as well as other representative hashingmethods. We see that out method outperforms other methodsby a large margin. Similar with the results on the CCV dataset,the performance of NSH is better than those of image-basedsupervised methods and linear projection based methods. Thisis because that both the video structure and the nonlinear

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
9
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.1
0.12
0.14
0.16
0.18
0.2
0.22
0.24
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) mean Average Precision
Length of Bits16 32 64 96
Ave
rage
pre
cisi
on
0.1
0.15
0.2
0.25
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) Precision @100
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) Precision-recall @32bit
Fig. 7: The results of different hashing methods on the YLI dataset with hand-crafted features.
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.15
0.2
0.25
0.3
0.35
0.4
0.45
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) mean Average Precision
Length of Bits16 32 64 96
Ave
rage
pre
cisi
on
0.15
0.2
0.25
0.3
0.35
0.4
0.45
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) Precision @100
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) Precision within Hamming radius 2
Fig. 8: The comparison of different hashing methods on the YLI dataset with CNN features.
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) 32 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) 64 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) 96 bits
Fig. 9: The comparison of precision-recall curves for different hashing methods on the YLI dataset with binary codes ofdifferent lengths.
transformation play an important role to map samples intobinary codes. In Fig. 7(b), we show that our NSH deliversbetter performance than the competitors, which is similar tothe results on CCV dataset. Fig. 7(c) shows the precision-recallcurves with binary codes of 32 bits, which is the detailedpresentation of the mAP. The results show that our NSHmethod delivers the best retrieval performance.
2) Results on the CNN Feature: Similar to the CCV dataset,we extracted the CNN feature for each sampled frame in YLIdataset to test the retrieval performance. Fig. 8(a) and (b)show the mAP and precision of top 100 retrieved samplesfor each hashing method, respectively. We see that the CNNfeature enhances the performance. Nevertheless, our NSHmethod is still comparable to the best competitor. Similar tothe results on the CCV dataset, the performance of SDH isslightly better than our NSH due to the careful optimizationof the quantization loss. In Fig. 8(c), we show the results of
Hamming lookup precision within radius 2. We see that ourmethod produces comparable precision to other representativehashing methods. In Fig. 9, we show the precision-recallcurves of different hashing methods for different lengths ofbinary codes. These results clearly show the superiority ofour NSH method.
D. Experimental Comparison on ActivityNet
We also evaluate our approach on a large-scale videobenchmark dataset, ActivityNet. The ActivityNet dataset [61]is recently released for human activity recognition and under-standing. ActivityNet consists of around 20,000 video clips in200 classes with 10,024 training, 4,926 validation and 5,044testing videos, totaling 648 hours of video. Compared to theabove two datasets, ActivityNet is more challenging, since itcontains more videos, more classes of fine-grained actions, hasgreater intra-class variance and consists of longer, untrimmed

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
10
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) mean Average Precision
Length of Bits16 32 64 96
Ave
rage
pre
cisi
on
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) Precision @100
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) Precision within Hamming radius 2
Fig. 10: The comparison of different hashing methods on the AcitvityNet dataset with CNN features.
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(a) 32 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(b) 64 bits
Recall0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
ITQ [15]DeepH [22]CCA-ITQ [15]KSH [31]SDeepH [22]SDH [33]NSH
(c) 96 bits
Fig. 11: The comparison of precision-recall curves for different hashing methods on the ActivityNet dataset with binary codesof different lengths.
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
NSHNSH-singleNSH-none
(a) CCV
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0.15
0.2
0.25
0.3
0.35
0.4
0.45
NSHNSH-singleNSH-none
(b) YLI
Length of Bits16 32 64 96
Mea
n av
erag
e pr
ecis
ion
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
NSHNSH-singleNSH-none
(c) AcitivityNet
Fig. 12: Scene structure evaluations on CCV, YLI and ActivityNet datasets.
videos. The experimental setting for this dataset is the sameas that on YLI-MED dataset. Since the authors of ActivityNethave not released the test set, we use the validation set asour query set, take 30 videos per categories as the trainingset and use the remaining videos as the gallery set. For eachframe, we followed the same feature extraction procedureas in the experiments on two previous datasets. Because theperformance with hand-crafted feature on this dataset is toolow, we only show the results with CNN feature.
In Fig. 10(a), we show the mAP values for different hashingmethods. We see that the performance is much lower thanthose on the CCV and YLI datasets due to the greater intra-class variation, more videos, more classes and untrimmedvideos. Nevertheless, our method still ranks top comparedwith the baseline methods. In Fig. 10(b), we show the pre-cisions of top 100 retrieved samples, where our method iscompetitive to other hashing methods. Fig. 10(c) shows the
TABLE II: MAP comparison of different video hashing meth-ods on the CCV dataset.
16 32 48 64
SH [10], [14] 7.7 7.8 7.8 7.8SVH [11] 11.2 13.0 14.6 15.8NSH 12.7 13.1 15.2 16.1
results of Hamming lookup precision within radius 2. We seethat our NSH achieves the best performance. To provide adetailed observation of the retrieval performance, we show theprecision-recall curves for 32, 64 and 96 bits binary codes inFig. 11.

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
11
E. Comparison with Existing Video Hashing Methods
In order to give a quantitative performance comparison withexisting video hashing methods, we followed the experimentalsettings in [11] to evaluate the performance of our NSH. Here,we compared our NSH with the spectral hashing used in [10],[14] and the structure learning-based video hashing [11].In Table II, we show the mAP values of different hashingmethods for different lengths of binary codes. We see thatour NSH achieves competitive results compared to SVH. Thereason is that the learned neural network model encodesboth the nonlinear relationship between videos and the sceneconsistency between frames within a video.
F. Effect of Scene Structure
To evaluate the effectiveness of scene structure, we com-pared the comprehensive mAP metric across different hashingmethods to present an overall measurement of retrieval per-formance. Fig. 12(a), (b) and (c) present the results on CCV,YLI and ActivityNet with CNN features. We compared NSHwith NSH-single, which considers the whole video as a singlesubspace, and NSH-none, which ignores the scene structureby setting λ1 in (8) as 0. These comparisions show thatour NSH consistently achieves better retrieval performance.Note that the scene is related to the video content and isconstructed on the base of the original features. Therefore, thescene information of each video is precomputed and storedoff-line. Furthermore, the scene clustering and binary codescomputation are performed simultaneously for a query video.Hence, this reduces the retrieval time.
G. Analysis
Comparing the results in terms of mean average precision,we can find that the performances are almost similar for CCVand YLI datasets with the length of bits increasing from 16to 96. We attribute this to both the dataset and the feature.First, the performance in terms of mean average precisionmay encounter saturation with the specified length of bitsand the number of categories. The numbers of categories inthe CCV and YLI datasets are 20 and 10. Note that thelength of bits shown in the figures is related to a frame.This means that the length of bits for each video is at least480 (16*30). Thus, the performance of hashing methods mayencounter saturation with the given length of bits and numberof categories. This is further validated by the results on theActivityNet dataset, which contains 200 categories. For sucha dataset with several times of categories against the previoustwo datasets, the performance improvement reduces whenincreasing the length of bits of 64 to 96 compared againstthat from 32 to 64. Second, the saturation of performancein terms of mean average precision may be related to thediscriminative ability of the original feature. For features withgood discriminative ability, it requires longer binary codes topreserve the discrimination. Comparing the results with theCNN features in Figs. 5 and 8 against the results with the hand-craft features in Figs. 4 and 7, we can observe performanceimprovement for some hashing methods with the increase ofbit length when provided with more discriminative features.
To provide more discriminative video representations, it ispromising to combine the proposed hashing learning frame-work with the motion extraction. With the motion informationcaptured by the optical flow or RNN feature, we can applysuch feature extraction on the clustered scenes of each video.And both the motion information and the frame representationcan be utilized to learn hashing codes jointly in a multi-view hashing way, such as [69]. While the proposed hashingleaning framework uses the pre-extracted CNN features asinput, the pooling strategies [4], [70] can be combined with itby applying the pooling on the shots of each video scene. Suchcombination can reduce the computation complexity, elimi-nate irrelevant frames and enhance the discriminative power.Furthermore, as stated in [71], the semantic representation iscomparable to hand-crafted low-level features in performancefor event detection. Thus, it is also feasible to apply hashing onthe semantic representations to retrieve the semantic neighbor.
V. CONCLUSIONS
In this paper, we have proposed a nonlinear structuralhashing (NSH) approach to map videos as binary codes forscalable video search. The success of the proposed structurevideo hashing is attributed to three primary aspects: 1) theexploration of structure information between frames in a video,which is described as the scene in a video and represented bysubspace; 2) the preservation of similar relationship betweenframes of the same scene to achieve the similarity of theirbinary codes; and 3) the design of multilayer neural network topreserve the nonlinear relationship between videos. Extensiveexperiments on three large scale datasets fully verify theefficacy of our approach.
There are three interesting directions for future work:
1) How to extend our approach to explore motion infor-mation, such as optical flow and RNN, to improve theperformance.
2) How to extend our approach to explore more effec-tive video representations, such as semantic representa-tion [71] and video representation with complex poolingstrategy [4], [70], to reduce the computation complexity.
3) How to extend our approach to represent videos by morediscriminative image features with the integration ofextra features, such as audio, motion and text, to furtherimprove the retrieval performance.
REFERENCES
[1] S. Wei, Y. Zhao, Z. Zhu, and N. Liu, “Multimodal fusion for video searchreranking,” IEEE Transactions on Knowledge and Data Engineering,vol. 22, no. 8, pp. 1191–1199, 2010.
[2] L. Jiang, A. G. Hauptmann, and G. Xiang, “Leveraging high-level andlow-level features for multimedia event detection,” inACM MultimediaConference, 2012, pp. 449–458.
[3] A. Habibian, T. Mensink, and C. G. M. Snoek, “Videostory: A newmultimedia embedding for few-example recognition and translation ofevents,” inACM Multimedia Conference, 2014, pp. 17–26.
[4] Z. Xu, Y. Yang, and A. G. Hauptmann, “A discriminative CNN videorepresentation for event detection,” inIEEE Conference on ComputerVision and Pattern Recognition, 2015, pp. 1798–1807.
[5] Y. Yang, Z. Ma, Z. Xu, S. Yan, and A. G. Hauptmann, “How relatedexemplars help complex event detection in web videos?” inIEEEInternational Conference on Computer Vision, 2013, pp. 2104–2111.

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
12
[6] A. Tamrakar, S. Ali, Q. Yu, J. Liu, O. Javed, A. Divakaran, H. Cheng,and H. S. Sawhney, “Evaluation of low-level features and their combi-nations for complex event detection in open source videos,” inIEEEConference on Computer Vision and Pattern Recognition, 2012, pp.3681–3688.
[7] P. Natarajan, S. Wu, S. N. P. Vitaladevuni, X. Zhuang, S. Tsakalidis,U. Park, R. Prasad, and P. Natarajan, “Multimodal feature fusion forrobust event detection in web videos,” inIEEE Conference on ComputerVision and Pattern Recognition, 2012, pp. 1298–1305.
[8] S. Yu, L. Jiang, Z. Xu, Y. Yang, and A. G. Hauptmann, “Content-basedvideo search over 1 million videos with 1 core in 1 second,” inACMInternational Conference in Multimedia Retrieval, 2015, pp. 419–426.
[9] Y. Li, R. Wang, Z. Huang, S. Shan, and X. Chen, “Face video retrievalwith image query via hashing across euclidean space and riemannianmanifold,” in IEEE Conference on Computer Vision and Pattern Recog-nition, 2015, pp. 4758–4767.
[10] L. Cao, Z. Li, Y. Mu, and S. Chang, “Submodular video hashing:a unified framework towards video pooling and indexing,” inACMMultimedia Conference, 2012, pp. 299–308.
[11] G. Ye, D. Liu, J. Wang, and S. Chang, “Large-scale video hashingvia structure learning,” inIEEE International Conference on ComputerVision, 2013, pp. 2272–2279.
[12] J. Wang, J. Sun, J. Liu, X. Nie, and H. Yan, “A visual saliency basedvideo hashing algorithm,” inIEEE International Conference on ImageProcessing, 2012, pp. 645–648.
[13] A. Gionis, P. Indyk, and R. Motwani, “Similarity search in highdimensions via hashing,” inInternational Conference on Very LargeData Bases, 1999, pp. 518–529.
[14] Y. Weiss, A. Torralba, and R. Fergus, “Spectral hashing,” inAdvancesin Neural Information Processing Systems, 2008, pp. 1753–1760.
[15] Y. Gong, S. Lazebnik, A. Gordo, and F. Perronnin, “Iterative quantiza-tion: A procrustean approach to learning binary codes for large-scaleimage retrieval,”IEEE Transactions on Pattern Analysis and MachineIntelligence, vol. 35, no. 12, pp. 2916–2929, 2013.
[16] R. Salakhutdinov and G. E. Hinton, “Semantic hashing,”InternationalJournal Approximate Reasoning, vol. 50, no. 7, pp. 969–978, 2009.
[17] W. Liu, J. Wang, S. Kumar, and S. Chang, “Hashing with graphs,” inInternational Conference on Machine Learning, 2011, pp. 1–8.
[18] K. He, F. Wen, and J. Sun, “K-means hashing: An affinity-preservingquantization method for learning binary compact codes,” inIEEEConference on Computer Vision and Pattern Recognition, 2013, pp.2938–2945.
[19] Y. Gong, S. Kumar, H. A. Rowley, and S. Lazebnik, “Learning binarycodes for high-dimensional data using bilinear projections,” inIEEEConference on Computer Vision and Pattern Recognition, 2013, pp. 484–491.
[20] M. A. Carreira-Perpinan and R. Raziperchikolaei, “Hashing with binaryautoencoders,” inIEEE Conference on Computer Vision and PatternRecognition, 2015, pp. 557–566.
[21] M. Rastegari, C. Keskin, P. Kohli, and S. Izadi, “Computationallybounded retrieval,” inIEEE Conference on Computer Vision and PatternRecognition, 2015, pp. 1501–1509.
[22] V. E. Liong, J. Lu, G. Wang, P. Moulin, and J. Zhou, “Deep hashingfor compact binary codes learning,” inIEEE Conference on ComputerVision and Pattern Recognition, 2015, pp. 2475–2483.
[23] A. Torralba, R. Fergus, and Y. Weiss, “Small codes and large imagedatabases for recognition,” inIEEE Conference on Computer Vision andPattern Recognition, 2008, pp. 1–8.
[24] J. Wang, S. Kumar, and S. Chang, “Semi-supervised hashing for large-scale search,”IEEE Transactions on Pattern Analysis and MachineIntelligence, vol. 34, no. 12, pp. 2393–2406, 2012.
[25] M. Rastegari, A. Farhadi, and D. A. Forsyth, “Attribute discovery viapredictable discriminative binary codes,” inEuropean Conference onComputer Vision, 2012, pp. 876–889.
[26] M. Norouzi and D. J. Fleet, “Minimal loss hashing for compact binarycodes,” in International Conference on Machine Learning, 2011, pp.353–360.
[27] M. Norouzi, D. J. Fleet, and R. Salakhutdinov, “Hamming distancemetric learning,” inAdvances in Neural Information Processing Systems,2012, pp. 1070–1078.
[28] C. Strecha, A. M. Bronstein, M. M. Bronstein, and P. Fua, “LDAHash:Improved matching with smaller descriptors,”IEEE Transactions onPattern Analysis and Machine Intelligence, vol. 34, no. 1, pp. 66–78,2012.
[29] J. Wang, W. Liu, A. X. Sun, and Y. Jiang, “Learning hash codes withlistwise supervision,” inIEEE International Conference on ComputerVision, 2013, pp. 3032–3039.
[30] T. Ge, K. He, and J. Sun, “Graph cuts for supervised binary coding,” inEuropean Conference on Computer Vision, 2014, pp. 250–264.
[31] W. Liu, J. Wang, R. Ji, Y. Jiang, and S. Chang, “Supervised hashingwith kernels,” in IEEE Conference on Computer Vision and PatternRecognition, 2012, pp. 2074–2081.
[32] G. Lin, C. Shen, Q. Shi, A. van den Hengel, and D. Suter, “Fastsupervised hashing with decision trees for high-dimensional data,” inIEEE Conference on Computer Vision and Pattern Recognition, 2014,pp. 1971–1978.
[33] F. Shen, C. Shen, W. Liu, and H. T. Shen, “Supervised discrete hashing,”in IEEE Conference on Computer Vision and Pattern Recognition, 2015,pp. 37–45.
[34] M. Kan, D. Xu, S. Shan, and X. Chen, “Semisupervised hashing viakernel hyperplane learning for scalable image search,”IEEE Transac-tions on Circuits and Systems for Video Technology, vol. 24, no. 4, pp.704–713, 2014.
[35] Z. Lin, G. Ding, M. Hu, and J. Wang, “Semantics-preserving hashingfor cross-view retrieval,” inIEEE Conference on Computer Vision andPattern Recognition, 2015, pp. 3864–3872.
[36] F. Zhao, Y. Huang, L. Wang, and T. Tan, “Deep semantic rankingbased hashing for multi-label image retrieval,” inIEEE Conference onComputer Vision and Pattern Recognition, 2015, pp. 1556–1564.
[37] J. Hsieh, S. Yu, and Y. Chen, “Motion-based video retrieval by trajec-tory matching,” IEEE Transactions on Circuits and Systems for VideoTechnology, vol. 16, no. 3, pp. 396–409, 2006.
[38] D. Zhong and S. Chang, “An integrated approach for content-based videoobject segmentation and retrieval,”IEEE Transactions on Circuits andSystems for Video Technology, vol. 9, no. 8, pp. 1259–1268, 1999.
[39] L. Gao, Z. Li, and A. K. Katsaggelos, “An efficient video indexing andretrieval algorithm using the luminance field trajectory modeling,”IEEETransactions on Circuits and Systems for Video Technology, vol. 19,no. 10, pp. 1566–1570, 2009.
[40] Y. Liu, T. Mei, X. Wu, and X. Hua, “Multigraph-based query-independent learning for video search,”IEEE Transactions on Circuitsand Systems for Video Technology, vol. 19, no. 12, pp. 1841–1850, 2009.
[41] Y. Lai and C. Yang, “Video object retrieval by trajectory and appear-ance,”IEEE Transactions on Circuits and Systems for Video Technology,vol. 25, no. 6, pp. 1026–1037, 2015.
[42] J. L. Bentley, “Multidimensional binary search trees used for associativesearching,”Communication of the ACM, vol. 18, no. 9, pp. 509–517,1975.
[43] J. K. Uhlmann, “Satisfying general proximity/similarity queries withmetric trees,”Information Processing Letters, vol. 40, no. 4, pp. 175–179, 1991.
[44] P. N. Yianilos, “Data structures and algorithms for nearest neighborsearch in general metric spaces,” inACM/SIGACT-SIAM Symposium onDiscrete Algorithms, 1993, pp. 311–321.
[45] S. Arya, D. M. Mount, N. S. Netanyahu, R. Silverman, and A. Y. Wu,“An optimal algorithm for approximate nearest neighbor searching fixeddimensions,”Journal of the ACM, vol. 45, no. 6, pp. 891–923, 1998.
[46] H. Jegou, M. Douze, and C. Schmid, “Product quantization for nearestneighbor search,”IEEE Transactions on Pattern Analysis and MachineIntelligence, vol. 33, no. 1, pp. 117–128, 2011.
[47] Y. Gong, S. Kumar, V. Verma, and S. Lazebnik, “Angular quantization-based binary codes for fast similarity search,” inAdvances in NeuralInformation Processing Systems, 2012, pp. 1205–1213.
[48] Y. Ma, L. Lu, H. Zhang, and M. Li, “A user attention model for videosummarization,” inACM Multimedia Conference, 2002, pp. 533–542.
[49] C. Ngo, Y. Ma, and H. Zhang, “Video summarization and scene detectionby graph modeling,”IEEE Transactions on Circuits and Systems forVideo Technology, vol. 15, no. 2, pp. 296–305, 2005.
[50] K. Sze, K. Lam, and G. Qiu, “A new key frame representation for videosegment retrieval,”IEEE Transactions on Circuits and Systems for VideoTechnology, vol. 15, no. 9, pp. 1148–1155, 2005.
[51] Z. Cernekova, I. Pitas, and C. Nikou, “Information theory-based shotcut/fade detection and video summarization,”IEEE Transactions onCircuits and Systems for Video Technology, vol. 16, no. 1, pp. 82–91,2006.
[52] Y. Peng and C. Ngo, “Clip-based similarity measure for query-dependentclip retrieval and video summarization,”IEEE Transactions on Circuitsand Systems for Video Technology, vol. 16, no. 5, pp. 612–627, 2006.
[53] B. Coskun, B. Sankur, and N. D. Memon, “Spatio-temporal transformbased video hashing,”IEEE Transactions on Multimedia, vol. 8, no. 6,pp. 1190–1208, 2006.
[54] J. Hu, J. Lu, and Y. Tan, “Discriminative deep metric learning for faceverification in the wild,” in IEEE Conference on Computer Vision andPattern Recognition, 2014, pp. 1875–1882.

1051-8215 (c) 2016 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TCSVT.2017.2669095, IEEETransactions on Circuits and Systems for Video Technology
13
[55] B. Kulis and T. Darrell, “Learning to hash with binary reconstructiveembeddings,” inAdvances in Neural Information Processing Systems,2009, pp. 1042–1050.
[56] J. He, W. Liu, and S. Chang, “Scalable similarity search with optimizedkernel hashing,” inACM SIGKDD Conferences on Knowledge Discoveryand Data Mining, 2010, pp. 1129–1138.
[57] R. Wang, S. Shan, X. Chen, Q. Dai, and W. Gao, “Manifold-manifolddistance and its application to face recognition with image sets,”IEEETransactions on Image Processing, vol. 21, no. 10, pp. 4466–4479, 2012.
[58] Y. Jiang, G. Ye, S. Chang, D. P. W. Ellis, and A. C. Loui, “Consumervideo understanding: a benchmark database and an evaluation of hu-man and machine performance,” inACM International Conference inMultimedia Retrieval, 2011, p. 29.
[59] J. Bernd, D. Borth, B. Elizalde, G. Friedland, H. Gallagher, L. R.Gottlieb, A. Janin, S. Karabashlieva, J. Takahashi, and J. Won, “TheYLI-MED corpus: Characteristics, procedures, and plans,”CoRR, vol.abs/1503.04250, 2015.
[60] B. Thomee, D. A. Shamma, G. Friedland, B. Elizalde, K. Ni, D. Poland,D. Borth, and L. Li, “YFCC100M: the new data in multimedia research,”Communication of the ACM, vol. 59, no. 2, pp. 64–73, 2016.
[61] F. C. Heilbron, V. Escorcia, B. Ghanem, and J. C. Niebles, “Activitynet:A large-scale video benchmark for human activity understanding,” inIEEE Conference on Computer Vision and Pattern Recognition, CVPR2015, Boston, MA, USA, June 7-12, 2015, 2015, pp. 961–970. [Online].Available: http://dx.doi.org/10.1109/CVPR.2015.7298698
[62] J. Song, Y. Yang, Z. Huang, H. T. Shen, and J. Luo, “Effective multiplefeature hashing for large-scale near-duplicate video retrieval,”IEEETransactions on Multimedia, vol. 15, no. 8, pp. 1997–2008, 2013.
[63] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,”International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110,2004.
[64] K. Mikolajczyk and C. Schmid, “Scale & affine invariant interest pointdetectors,”International Journal of Computer Vision, vol. 60, no. 1, pp.63–86, 2004.
[65] J. Sivic and A. Zisserman, “Video google: A text retrieval approachto object matching in videos,” inIEEE International Conference onComputer Vision, 2003, pp. 1470–1477.
[66] K. Simonyan and A. Zisserman, “Very deep convolutional networks forlarge-scale image recognition,”CoRR, vol. abs/1409.1556, 2014.
[67] J. Deng, W. Dong, R. Socher, L. Li, K. Li, and F. Li, “ImageNet: A large-scale hierarchical image database,” inIEEE Conference on ComputerVision and Pattern Recognition, 2009, pp. 248–255.
[68] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, andT. Darrell, “Decaf: A deep convolutional activation feature for genericvisual recognition,” inInternational Conference on Machine Learning,2014, pp. 647–655.
[69] D. Zhang, F. Wang, and L. Si, “Composite hashing with multiple infor-mation sources,” inProceeding of the 34th International ACM SIGIRConference on Research and Development in Information Retrieval,SIGIR 2011, Beijing, China, July 25-29, 2011, 2011, pp. 225–234.
[70] X. Chang, Y.-L. Yu, Y. Yang, and E. P. Xing, “Semantic pooling forcomplex event analysis in untrimmed videos,”IEEE Transactions onPattern Analysis and Machine Intelligence, 2016.
[71] X. Chang, Z. Ma, Y. Yang, Z. Zeng, and A. G. Hauptmann, “Bi-levelsemantic representation analysis for multimedia event detection,”IEEETransactions on Cybernetics, 2016.
Zhixiang Chen received the B.S. degree in mi-croelectronics from the Xi’an Jiaotong University,Xi’an, China. He is currently pursuing the Ph.D.degree with the Department of Automation, Ts-inghua University, Beijing, China. His current re-search interests include large scale visual search,binary embedding and hashing learning.
Jiwen Lu received the B.Eng. degree in mechanicalengineering and the M.Eng. degree in electricalengineering from the Xian University of Technology,Xian, China, in 2003 and 2006, respectively, and thePh.D. degree in electrical engineering from NanyangTechnological University, Singapore, in 2012. From2011 to 2015, he was a Research Scientist withthe Advanced Digital Sciences Center, Singapore.He is currently an Associate Professor with theDepartment of Automation, Tsinghua University,Beijing, China. His current research interests include
computer vision, pattern recognition, and machine learning. He has authoredor co-authored over 150 scientific papers in these areas, where 40 werethe IEEE Transactions papers. He is the Workshop Chair/Special SessionChair/Area Chair for over ten international conferences. He was a recipientof the National 1000 Young Talents Plan Program in 2015. He serves as anAssociate Editor of the Pattern Recognition Letters, the Neurocomputing, andthe IEEE ACCESS, a Guest Editor for Special Issue of 5 journals includingPattern Recognition, Computer Vision and Image Understanding, and Imageand Vision Computing, and an Elected Member of the Information Forensicsand Security Technical Committee of the IEEE Signal Processing Society.
Jianjiang Feng is an associate professor in theDepartment of Automation at Tsinghua University,Beijing. He received the B.S. and Ph.D. degrees fromthe School of Telecommunication Engineering, Bei-jing University of Posts and Telecommunications,China, in 2000 and 2007. From 2008 to 2009, hewas a Post Doctoral researcher in the PRIP lab atMichigan State University. He is an Associate Editorof Image and Vision Computing. His research in-terests include fingerprint recognition and computervision.
Jie Zhou received the B.S. and M.S. degrees fromthe Department of Mathematics, Nankai Universi-ty, Tianjin, China, in 1990 and 1992, respectively,and the Ph.D. degree from the Institute of PatternRecognition and Artificial Intelligence, HuazhongUniversity of Science and Technology, Wuhan, Chi-na, in 1995. From 1995 to 1997, he served asa Post-Doctoral Fellow with the Department ofAutomation, Tsinghua University, Beijing, China.Since 2003, he has been a Full Professor with theDepartment of Automation, Tsinghua University. In
recent years, he has authored over 100 papers in peer-reviewed journals andconferences. Among them, over 40 papers have been published in top journalsand conferences, such as the IEEE PAMI, TIP, and CVPR. His current researchinterests include computer vision, pattern recognition, and image processing.He received the National Outstanding Youth Foundation of China Award. Heis an Associate Editor of the International Journal of Robotics and Automationand two other journals.
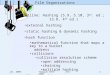


![PNNU: Parallel Nearest-Neighbor Units for Learned …htk/publication/2015-lcpc-kung...k-d trees [21], locality sensitive hashing [3], and nearest-neighbor methods in machine learning](https://img.dokumen.tips/doc/110x75/5fbe9d25ff5bee0d24257997/pnnu-parallel-nearest-neighbor-units-for-learned-htkpublication2015-lcpc-kung.jpg)
![LazyLSH: Approximate Nearest Neighbor Search for Multiple ...atung/gl/publications/lazyLSH.pdf · sensitive hashing (LSH) [26] is widely used for its theoretical guarantees and empirical](https://img.dokumen.tips/doc/110x75/5fd2ff2f834f64074e63ffc8/lazylsh-approximate-nearest-neighbor-search-for-multiple-atungglpublications.jpg)























