Embed Size (px)
Citation preview

Neural Nets & Deep Learning

The Inspiration
Inputs Outputs
Our brains are pretty amazing, what if we could do something similar with
computers?Image Source: http://ib.bioninja.com.au/_Media/neuron_med.jpeg

The Perceptron
i1
i2
i3
i4
σPoisonous orEdible
● Idea dates from the 1950s● Let i be our input features,
try to predict a binary class ● Output = σ(i1w1 + i2w2 + i3w3 + i4w4)● σ is some function that scales the sum to between 0 and 1.● If output < 0.5 we say class poison, otherwise we predict class edible
w1
w2
w3
w4
Color
Size of Cap
Height
Found in clusters? Image Source:https://www.linkedin.com/pulse/logistic-regression-sigmoid-function-explained-plain-english-hsu/

Perceptron: Loss
● We have a model, how do we find weights that gives the best results?
● We need to define a measure of how “bad” our starting weights are (cost/loss)
● Must be smooth● A small change in the weights
= A small change in the loss● This rules out accuracy on our training data,
will change in discrete jumps○ Use the decimal output to represent a
“confidence” of a class○ Can tweak for regression
Bad Good
Image Source:https://associationsnow.com/wp-content/uploads/2017/07/0710_happysad-800x480.jpg

Perceptron: Training with Gradient Descent
● Once we have our loss, we perform gradient descent.
● See what happens if we tweak our weights in different directions,If we get an improvement in our loss, keep going!
● Take slope at point and move in negative direction
● Once we stop improving, we’re done!
Image Source:https://thoughtsaheaddotcom.files.wordpress.com/2017/01/3d-surface-plot.pnghttps://www.safaribooksonline.com/library/view/hands-on-machine-learning/9781491962282/assets/mlst_0402.png

Perceptron: The Problem
● So we have a model and a way to train it, how do we do?○ Not great : (
● You might have noticed that what we’re doing is essentially linear regression except squishing the output at the end
● Can only divide regions linearly○ Similar to how regression can
only fit linear relations
Image Source:https://qph.ec.quoracdn.net/main-qimg-48d5bd214e53d440fa32fc9e5300c894
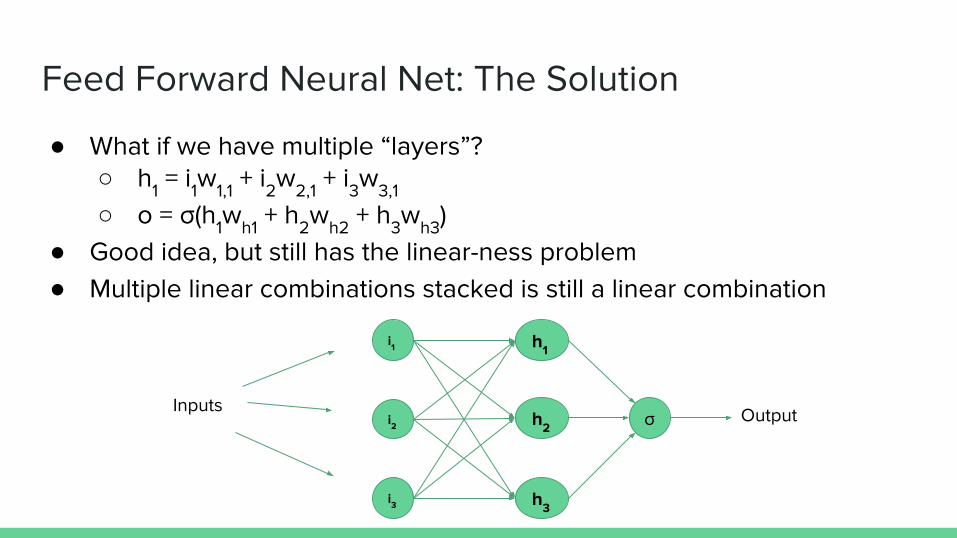
Feed Forward Neural Net: The Solution
● What if we have multiple “layers”?○ h1 = i1w1,1 + i2w2,1 + i3w3,1
○ o = σ(h1wh1 + h2wh2 + h3wh3)● Good idea, but still has the linear-ness problem● Multiple linear combinations stacked is still a linear combination
i1
i2
i3
h2
Inputs Output
h1
h3
σ

Feed Forward Neural Net: The Solution● Another idea: What if we squish the hidden layer as well as the output?
○ h1 = σ(i1w1,1 + i2w2,1 + i3w3,1 ) ← Similar to what we did with log space!○ o = σ(h1wh1 + h2wh2 + h3wh3)
● No longer can only fit around linear boundaries!● Note: Gradient descent is now a bit harder, but essentially the same idea
○ New algorithm called backprop
i1
i2
i3
σ2
Inputs Output
σ1
σ3
σo

People came up with backprop & FFNNs in the 70s / 80s, but they were very, very slow (and hard to interpret)
What changed?

GPUs

Feed Forward Neural Net: The Solution
● High-end 3D video games require lots of processing power● But most of this processing is simple adds and multiplies
○ CPUs are good at doing a lot of different operations pretty fast
○ GPUs do simple operations SUPER fast (and in parallel)● Multiply and add… That sounds familiar….
○ Neural Nets are now super fast!

Types of Neural Nets

Applying NNs to Images
● Feed forward works forYou have some featuresPredict an output
● What about images?○ Naive way: Take each pixel value and feed it in as a different
feature (in a 100x100 image that’s 10,000 features!)● Is there a better way?
Image Source:https://www.tensorflow.org/images/MNIST-Matrix.png

Convolutional Neural Nets (CNNs)
● Pass the same small neural net overdifferent parts of the image○ Called a “filter” or “kernel”
● Learn the weights of this neural net● These “filters” start picking up on
higher level features○ Vertical line, horizontal line, etc.
● Stack enough of these and you get really good results!○ 99.9% on digit recognition!
Image Source:http://www.mdpi.com/technologies/technologies-05-00037/article_deploy/html/images/technologies-05-00037-g002.pnghttp://blog.welcomege.com/wp-content/uploads/2017/08/2017-08-08_14-39-24.png

Applying NNs to Series
● How do we work with series of things of non-fixed length?○ A sentence○ Stock prices○ A person’s medical history
● One option is CNNs, same idea but in 1 dimension instead of 2○ Fast but not the best, especially for language○ Doesn’t capture long-term information, only the size of the
filter

Recurrent Neural Nets (RNNs)
● Idea: Take a FFNN and have it output two things○ An answer you can use○ A “state” that it passed onto feed back into itself as a new input○ State contains info we want to keep around for the future
● Work really well for language, but is slow!
English Word
French Word
State
Image Source:http://www.mdpi.com/technologies/technologies-05-00037/article_deploy/html/images/technologies-05-00037-g002.png

Representing Words
- Stock prices are easy, just numbers- What about words?- Could create a “class” for each word, “apple” is 55, “food” is 72
- These numbers are arbitrary, apple and pear are “similar” but could have totally different numerical ids
- Idea: Create an “embedding”- Try to summarize a word with a point in space- Similar words are near each other in the space
- How do we create these embeddings?
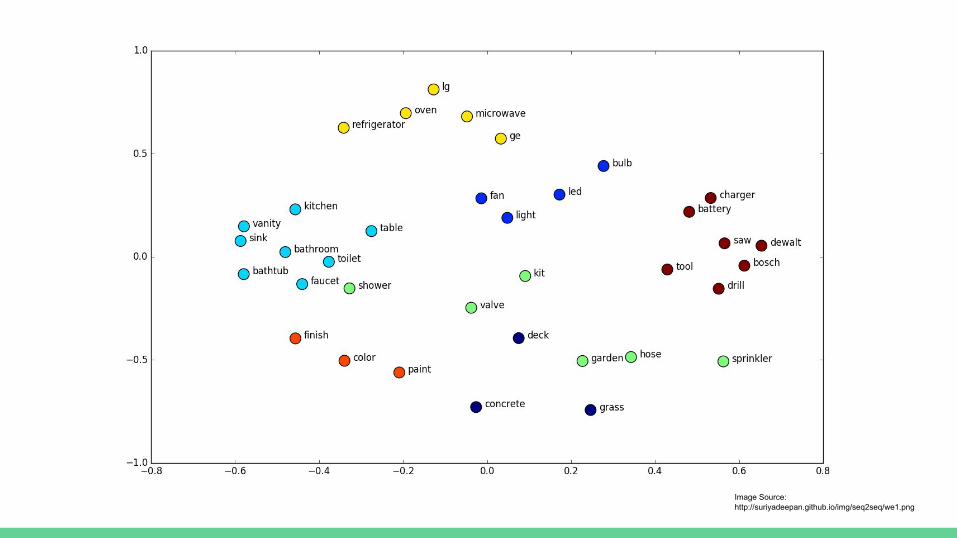
Image Source:http://suriyadeepan.github.io/img/seq2seq/we1.png

Word2Vec
● Words that are similar are used in similar contexts○ “I am going to eat a pear today”○ “I love eatings apples”○ Both words are near “eat” and “I”
● Make a neural net that given a word, predict the words around it
● Take the values that show up in the hidden layer and use that to represent the word
○ [22.5, 45.2, … ] ← List of 50 numbers
● Problems○ Hypothesis is kind of flawed, “I am happy” and “I am sad”○ Bias in language!
“Apple”
Hidden Layer of 50 neurons
20% near eat20% near I60% other stuff

Reinforcement Learning
● How do we teach neural nets to play games?● Create a neural network that given the current game board,
predict a move○ Pretty much random at first
● If we make some moves and end up winning/scoringa point/surviving, reward it with our loss function!
● If we lose/get scored on/die don’t reward those actions● Slowly get better over time!
Image Source:https://storage.googleapis.com/deepmind-live-cms/images/Nature-Go-game-cover.original.width-440_Q7hC1Rg.jpg

Generative Adversarial Networks
- Take the problem of colorizing black and white photos
- Create two neural nets- One will generate color images from black and white
ones- One will try to discriminate between the “generated”
color images and “real” color images
- Slowly the generator will get better at creating “forgeries”
- When you’re done training, you have a program that can colorize images!
Figure from pix2pix Isola et al
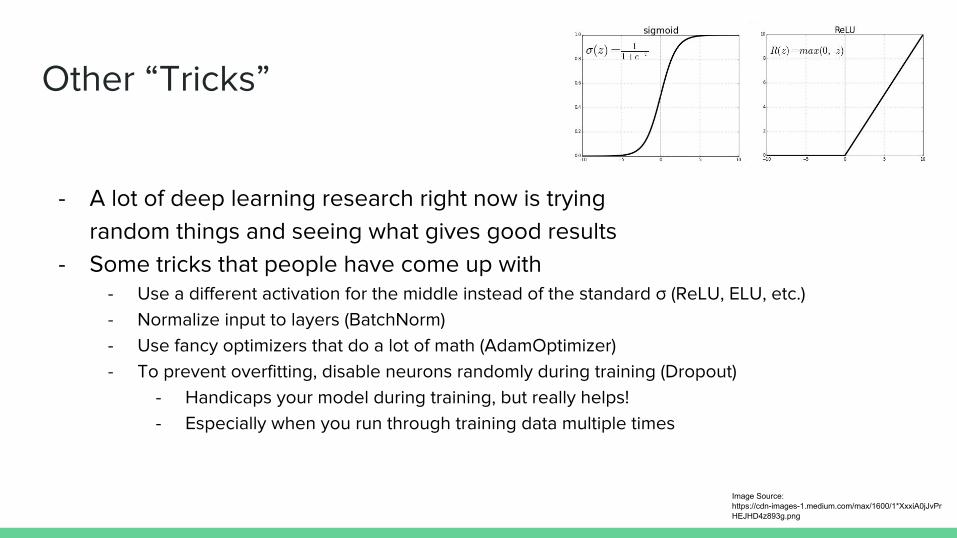
Other “Tricks”
- A lot of deep learning research right now is tryingrandom things and seeing what gives good results
- Some tricks that people have come up with- Use a different activation for the middle instead of the standard σ (ReLU, ELU, etc.)- Normalize input to layers (BatchNorm)- Use fancy optimizers that do a lot of math (AdamOptimizer)- To prevent overfitting, disable neurons randomly during training (Dropout)
- Handicaps your model during training, but really helps!- Especially when you run through training data multiple times
Image Source:https://cdn-images-1.medium.com/max/1600/1*XxxiA0jJvPrHEJHD4z893g.png

Creating a Neural Net Model
1. Get your data, clean it, decide what your input/output is2. Define your model
What type/“tricks”, how many layers3. Define your loss function
What am I using to measure my performance?4. Decide how you’re going to train
How long, with what optimizer, on one computer or many, etc.
This is hard!

Pros & Cons
- Pros- Are really, REALLY powerful/accurate- Very easy to make larger/smaller, lots of hyperparameters- Work well in vastly different fields, same central ideas
- Cons- Are blackboxes, things go in, answers come out but often unclear why
- Especially troubling when it gets things wrong- Application to medicine
- Still very simple, lack large-scale understanding- Classic ML dangers: overfitting, bias, etc.- People are working on fixing these things!
Image Source:https://cdn-images-1.medium.com/max/2000/1*uwAos6ZGW0SYqipwn2DpAw.png

Yann LeCun
- Giving a talk in List 120 @ 4PM- “Father of Convolutional Neural Nets”- Director of research at Facebook- Talk Title: How Could Machines Learn as Efficiently as Animals
and Humans?- Check it out!

Demos: Style Transfer

Demo: Image Translation with CycleGAN

Demo: Image Translation with CycleGAN
Demo: Rock Paper Scissors
- Play rock paper scissors with your camera































