Embed Size (px)
Citation preview


Nearest Neighbor (NN) Rule &k-Nearest Neighbor (k-NN) Rule
Non-parametric : • Can be used with arbitrary distributions,• No need to assume that the form of the underlying
densities are known
NN RulesA direct classification using learning samplesAssume we have learning samples
Assume a distance measure between samples
....,.........,......,, 1211 jkXXXikX
jlXd
),( jlik XXd

• A general distance metric should obey the following rules:
• Most standard: Euclidian Distance
0),( ijij XXd
),(),( ijjljlij XXdXXd ),(),(),( YZdZXdYXd
X
Y
Z
2/12/1
1
2 )()()(),( YXYXyxYXYXd Tn
iii

1-NN Rule: Given an unknown sample X decide if
for
That is, assign X to category if the closest neighbor of X is from category i.
i
),(),( jlik XXdXXd ikjl
i
X
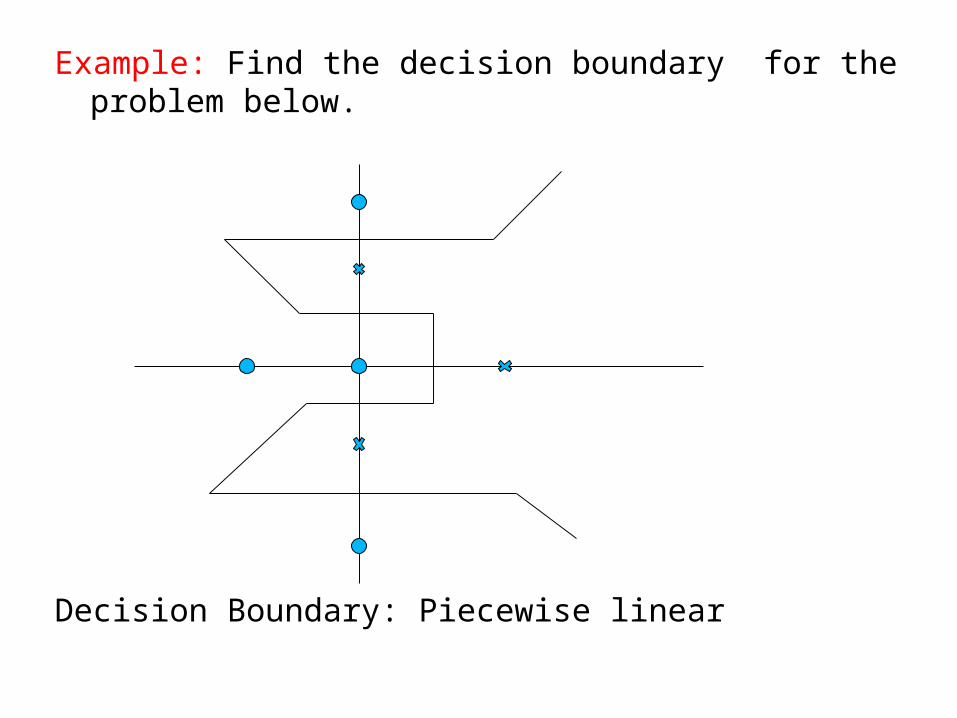
Example: Find the decision boundary for the problem below.
Decision Boundary: Piecewise linear

Voronoi Diagrams
Decision boundary
is a polygon such that any point that falls in
is closer to than any other sample .
iS iV
iV iV
iS jS

k-NN rule: instead of looking at the closest sample, we look at k nearest neighbors to X and we take a vote. The largest vote wins. k is usually taken as an odd number so that no ties occur.


k-NN rule is shown to approach optimal classification when k becomes very large but
k-l NN ( NN with a reject option)Decide if majority is over a given threshold l.
Otherwise reject.
k=5
If we threshold l=4 then,For above example is rejected to be classified.
0M
k

Analysis of NN rule is possible when and it was shown that it is no worse than twice of the minimum-error classification (in error rate).
EDITING AND CONDENSINGNN rule becomes very attractive because of its
simplicity and yet good performance.So, it becomes important to reduce the
computational costs involved.Do an intelligent elimination of the samples.
Remove samples that do not contribute to the decision boundary.
M

So the editing rule consists of throwing away all samples that do not have a voronoi polygon that has a common boundary with a voronoi polygon belonging to a sample from other category.
Let’s assume we have random samples that are labeled as belonging to different categories
1-NN Rule:Assume a distance measure d between two samples with following properties
nXXX .,,........., 21
ji XX ,),( ji XXd
0),( ji XXd),(),( ijji XXdXXd
),(),(),( jkkiji XXdXXdXXd

Advantage of NNR:No learning – no estimationso easy to implement
Disadvantage:Classification is more expensive. So people found
ways to reduce the cost of NNR.
Analysis of NN and k-NN rules:when• When , X(unknown sample) and
X’(nearest neighbor) will get very close. Then,• that is, we are selecting
the category with probability (a-posteriori probability).
nn
)'|()|( XPXP ii i )|( XP i

Error Bounds and Relation with Bayes Rule:Assume - Error bound for Bayes Rule - Error bound for 1-NN - Error bound for k-NN
It can be shown that
for 2 categories and
for c categoriesAlways better than twice the Bayes error rate!
*E1EkE
***1
* 2)1(2 EEEEE ***
1* 2)
)1(21(2 EE
c
cEEE

Highest error occurs whenthen,
*EE
*2E
*E
c
c 1
)1(2 ** EE
3k5k
0
........)()( 21 xPxP
cP i
1)(
c
c
cerrorP
111)(

Distance Measures(Metrices)Non-negativity
Reflexivity when only x = y
Symmetry
Triangle inequality
Euclidian distance satisfies.Not always a meaningful measure.Consider 2 features with different units scaling
problem.
0),( yxD
0),( yxD
),(),( xyDyxD
),(),(),( yxDyzDzxD
)(2
hight
X
)(1
weight
X
Scale of changed to half.1X

Minkowski MetricA general definition
norm – City block (Manhattan) distance norm – Euclidian
Scaling: Normalize the data by re-scaling (Reduce the range to 0-1) (equivalent to changing the metric)
kd
i
k
iik yxyxL/1
1
),(
1L2L
Y
b
a
X
baL 1

Computational ComplexityConsider n samples in d dimensions
in crude 1-nn rule, we measure the distance from X to all samples.
for classification. )(dnO

To reduce the costs:-Partial Distance: Calculate the distances using some
subset r of the full d dimensions, and if the partial distance is too great we do not compute further.

To reduce the costs:-Editing(condensing): eliminate prototypes that are
surrounded by training points.
All neighbors black
All neighbors red
Voronoi neighborhoods

NN Editing Algorithms
Consider the Voronoi diagrams for all samples Find Voronoi neighbors of X’ If any neighbor is from other category, keep X’.
Else remove from the set. Construct the Voronoi diagram with the remaining
samples and use it for classification.
All neighbors black
All neighbors red

References
R.O. Duda, P.E. Hart, and D.G. Stork, Pattern Classification, New York: John Wiley, 2001. N. Yalabık, “Pattern Classification with Biomedical Applications Course Material”, 2010.





























