Embed Size (px)
Citation preview

Natural Language Understandingusing Knowledge Bases
and Random Walks
Eneko Agirreixa2.si.ehu.eus/eneko
IXA NLP GroupUniversity of the Basque Country
PROPOR 2016 - Tomar
In collaboration with: Ander Barrena, Josu Goikoetxea, OierLopez de Lacalle, Arantxa Otegi, Aitor Soroa, Mark Stevenson
Agirre (UBC) NLU using KBs and Random Walks July 2016 1 / 70

Large Graphs and Random Walks
History of search in the WWW
In the beginning (early 90’s) there was keyword search:Return documents which contained query termsGood for small libraries, document collections, early WWW
How do you rank documents about “Tomar”?
First try, count occurrences of “Tomar” in document
Does not work, all hotels and restaurants would spam!It lead to Yahoo and similar hand-edited directories
What else could one do?
source: http://sixrevisions.com/web_design/popular-search-engines-in-the-90s-then-and-now/
Agirre (UBC) NLU using KBs and Random Walks July 2016 2 / 70

Large Graphs and Random Walks
History of search in the WWW
In the beginning (early 90’s) there was keyword search:Return documents which contained query termsGood for small libraries, document collections, early WWW
How do you rank documents about “Tomar”?
First try, count occurrences of “Tomar” in document
Does not work, all hotels and restaurants would spam!It lead to Yahoo and similar hand-edited directories
What else could one do?
source: http://sixrevisions.com/web_design/popular-search-engines-in-the-90s-then-and-now/
Agirre (UBC) NLU using KBs and Random Walks July 2016 2 / 70

Large Graphs and Random Walks
History of search in the WWW
In the beginning (early 90’s) there was keyword search:Return documents which contained query termsGood for small libraries, document collections, early WWW
How do you rank documents about “Tomar”?
First try, count occurrences of “Tomar” in document
Does not work, all hotels and restaurants would spam!It lead to Yahoo and similar hand-edited directories
What else could one do?
source: http://sixrevisions.com/web_design/popular-search-engines-in-the-90s-then-and-now/
Agirre (UBC) NLU using KBs and Random Walks July 2016 2 / 70

Large Graphs and Random Walks
History of search in the WWW
In the beginning (early 90’s) there was keyword search:Return documents which contained query termsGood for small libraries, document collections, early WWW
How do you rank documents about “Tomar”?
First try, count occurrences of “Tomar” in document
Does not work, all hotels and restaurants would spam!It lead to Yahoo and similar hand-edited directories
What else could one do?
source: http://sixrevisions.com/web_design/popular-search-engines-in-the-90s-then-and-now/
Agirre (UBC) NLU using KBs and Random Walks July 2016 2 / 70
Large Graphs and Random Walks
History of search in the WWW
In the beginning (early 90’s) there was keyword search:Return documents which contained query termsGood for small libraries, document collections, early WWW
How do you rank documents about “Tomar”?
First try, count occurrences of “Tomar” in document
Does not work, all hotels and restaurants would spam!It lead to Yahoo and similar hand-edited directories
What else could one do?
source: http://sixrevisions.com/web_design/popular-search-engines-in-the-90s-then-and-now/
Agirre (UBC) NLU using KBs and Random Walks July 2016 2 / 70

Large Graphs and Random Walks
Vision: WWW is a graph!
source: http://opte.org
Agirre (UBC) NLU using KBs and Random Walks July 2016 3 / 70

Large Graphs and Random Walks
Vision: WWW is a graph! Prefer well-connected webpages
source: http://opte.org
Agirre (UBC) NLU using KBs and Random Walks July 2016 3 / 70

Large Graphs and Random Walks
How do we know which webpages are well-connected
Each webpage is a nodeHyperlink in a webpage is a directed edge to another nodeWe prefer webpages with many incoming edges (in-degree)
Wait! This can also be easily spammed with fake webpages!Edges from webpages with many incoming edges should be morerelevant
Mathematical formalization: markov models and random walks
Random walks, PageRank and Google
Agirre (UBC) NLU using KBs and Random Walks July 2016 4 / 70

Large Graphs and Random Walks
How do we know which webpages are well-connected
Each webpage is a nodeHyperlink in a webpage is a directed edge to another nodeWe prefer webpages with many incoming edges (in-degree)
Wait! This can also be easily spammed with fake webpages!Edges from webpages with many incoming edges should be morerelevant
Mathematical formalization: markov models and random walks
Random walks, PageRank and Google
Agirre (UBC) NLU using KBs and Random Walks July 2016 4 / 70

Large Graphs and Random Walks
How do we know which webpages are well-connected
Each webpage is a nodeHyperlink in a webpage is a directed edge to another nodeWe prefer webpages with many incoming edges (in-degree)
Wait! This can also be easily spammed with fake webpages!Edges from webpages with many incoming edges should be morerelevant
Mathematical formalization: markov models and random walks
Random walks, PageRank and Google
Agirre (UBC) NLU using KBs and Random Walks July 2016 4 / 70

Large Graphs and Random Walks
How do we know which webpages are well-connected
Each webpage is a nodeHyperlink in a webpage is a directed edge to another nodeWe prefer webpages with many incoming edges (in-degree)
Wait! This can also be easily spammed with fake webpages!Edges from webpages with many incoming edges should be morerelevant
Mathematical formalization: markov models and random walks
Random walks, PageRank and Google
Agirre (UBC) NLU using KBs and Random Walks July 2016 4 / 70

Large Graphs and Random Walks
Knowledge Bases are also large graphs!
sources: http://sixdegrees.hu/ http://www2.research.att.com/˜yifanhu/http://www.cise.ufl.edu/research/sparse/matrices/Gleich/ http://www.ebremer.com/
Agirre (UBC) NLU using KBs and Random Walks July 2016 5 / 70

Text Understanding with Knowledge Bases
Understanding of broad language, what’s behind the surface stringsFrom string to semantic representation (e.g. First Order Logic). . . with respect to some Knowledge Base
Understanding requires grounding text to Entities and Concepts
Agirre (UBC) NLU using KBs and Random Walks July 2016 6 / 70

Text Understanding with Knowledge Bases
Understanding of broad language, what’s behind the surface stringsFrom string to semantic representation (e.g. First Order Logic). . . with respect to some Knowledge Base
Understanding requires grounding text to Entities and Concepts
Barcelona coach praises Jose Mourinho
Agirre (UBC) NLU using KBs and Random Walks July 2016 6 / 70

Text Understanding with Knowledge Bases
Understanding of broad language, what’s behind the surface stringsFrom string to semantic representation (e.g. First Order Logic). . . with respect to some Knowledge Base
Understanding requires grounding text to Entities and Concepts
Barcelona coach praises Jose Mourinho
Agirre (UBC) NLU using KBs and Random Walks July 2016 6 / 70

Text Understanding with Knowledge Bases
Understanding of broad language, what’s behind the surface stringsFrom string to semantic representation (e.g. First Order Logic). . . with respect to some Knowledge Base
Understanding requires grounding text to Entities and Concepts
Barcelona coach praises Jose Mourinho
Agirre (UBC) NLU using KBs and Random Walks July 2016 6 / 70

Text Understanding with Knowledge Bases
Understanding of broad language, what’s behind the surface stringsFrom string to semantic representation (e.g. First Order Logic). . . with respect to some Knowledge Base
Understanding requires grounding text to Entities and Concepts
Barcelona coach praises Jose Mourinho
Agirre (UBC) NLU using KBs and Random Walks July 2016 6 / 70

Text Understanding with Knowledge Bases
Understanding requires inference capability, e.g. textual similarity
jewel ∼ gemjewel 6∼ dirt
Barcelona coach ∼ Luis Enrique
Also longer textsBarcelona coach praises Mourinho∼ Luis Enrique honors Mourinho6∼ Mourinho travels to Barcelona by coach
Agirre (UBC) NLU using KBs and Random Walks July 2016 7 / 70

Text Understanding with Knowledge Bases
Understanding requires inference capability, e.g. textual similarity
jewel ∼ gemjewel 6∼ dirt
Barcelona coach ∼ Luis Enrique
Also longer textsBarcelona coach praises Mourinho∼ Luis Enrique honors Mourinho6∼ Mourinho travels to Barcelona by coach
Agirre (UBC) NLU using KBs and Random Walks July 2016 7 / 70

Text Understanding with Knowledge Bases
Understanding requires inference capability, e.g. textual similarity
jewel ∼ gemjewel 6∼ dirt
Barcelona coach ∼ Luis Enrique
Also longer textsBarcelona coach praises Mourinho∼ Luis Enrique honors Mourinho6∼ Mourinho travels to Barcelona by coach
Agirre (UBC) NLU using KBs and Random Walks July 2016 7 / 70

Text Understanding with Knowledge Bases
Understanding requires inference capability, e.g. textual similarity
jewel ∼ gemjewel 6∼ dirt
Barcelona coach ∼ Luis Enrique
Also longer textsBarcelona coach praises Mourinho∼ Luis Enrique honors Mourinho6∼ Mourinho travels to Barcelona by coach
Agirre (UBC) NLU using KBs and Random Walks July 2016 7 / 70

Text Understanding with Knowledge Bases
From string to semantic representation (First Order Logic)
Barcelona coach praises Jose Mourinho.
Exist e1, x1, x2, x3 such thatFC Barcelona=x1 and coach:n:1(x1,x2) andpraise:v:2(e1,x2,x3) and Jose Mourinho=x3 . . .
Disambiguation: Concepts, Entities and Semantic RolesQuantifiers, modality, negation, connotations, . . .
Inference and Reasoning
. . . with respect to some Knowledge Base
Agirre (UBC) NLU using KBs and Random Walks July 2016 8 / 70

Text Understanding with Knowledge Bases
From string to semantic representation (First Order Logic)
Barcelona coach praises Jose Mourinho.
Exist e1, x1, x2, x3 such thatFC Barcelona=x1 and coach:n:1(x1,x2) andpraise:v:2(e1,x2,x3) and Jose Mourinho=x3 . . .
Disambiguation: Concepts, Entities and Semantic RolesQuantifiers, modality, negation, connotations, . . .
Inference and Reasoning
. . . with respect to some Knowledge Base
Agirre (UBC) NLU using KBs and Random Walks July 2016 8 / 70

Text Understanding with Knowledge Bases
From string to semantic representation (First Order Logic)
Barcelona coach praises Jose Mourinho.
Exist e1, x1, x2, x3 such thatFC Barcelona=x1 and coach:n:1(x1,x2) andpraise:v:2(e1,x2,x3) and Jose Mourinho=x3 . . .
Disambiguation: Concepts, Entities and Semantic RolesQuantifiers, modality, negation, connotations, . . .
Inference and Reasoning
. . . with respect to some Knowledge Base
Agirre (UBC) NLU using KBs and Random Walks July 2016 8 / 70

Text Understanding with Knowledge Bases
How far can we go with current KBs and graph-basedalgorithms?
Ground words in context to KB concepts and instancesWord Sense DisambiguationNamed Entity DisambiguationSimilarity between concepts, instances and words
Improve ad-hoc information retrieval
Results in the state-of-the-art
Knowledge-based methods and corpus-based methods arecomplementary
Agirre (UBC) NLU using KBs and Random Walks July 2016 9 / 70

Text Understanding with Knowledge Bases
How far can we go with current KBs and graph-basedalgorithms?
Ground words in context to KB concepts and instancesWord Sense DisambiguationNamed Entity DisambiguationSimilarity between concepts, instances and words
Improve ad-hoc information retrieval
Results in the state-of-the-art
Knowledge-based methods and corpus-based methods arecomplementary
Agirre (UBC) NLU using KBs and Random Walks July 2016 9 / 70

Text Understanding with Knowledge Bases
How far can we go with current KBs and graph-basedalgorithms?
Ground words in context to KB concepts and instancesWord Sense DisambiguationNamed Entity DisambiguationSimilarity between concepts, instances and words
Improve ad-hoc information retrieval
Results in the state-of-the-art
Knowledge-based methods and corpus-based methods arecomplementary
Agirre (UBC) NLU using KBs and Random Walks July 2016 9 / 70

Text Understanding with Knowledge Bases
How far can we go with current KBs and graph-basedalgorithms?
Ground words in context to KB concepts and instancesWord Sense DisambiguationNamed Entity DisambiguationSimilarity between concepts, instances and words
Improve ad-hoc information retrieval
Results in the state-of-the-art
Knowledge-based methods and corpus-based methods arecomplementary
Agirre (UBC) NLU using KBs and Random Walks July 2016 9 / 70

Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 10 / 70
PageRank and Personalized PageRank
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 11 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Imagine a person on a random walk in the WWW:Start at random pageFollow one of the links at random
At the limit (“steady state”) each pagehas a long-term visit rateUse this as the score of the pagePROBLEM. Stuck in dead-ends (webpages with no links)SOLUTION: Teleporting
Dead-ends: jump at random to any webpageOther nodes:15% jump at random to any webpage85% follow one of the links
Equivalent to adding links to all webpagesAll webpages get visited at some point
Agirre (UBC) NLU using KBs and Random Walks July 2016 12 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Imagine a person on a random walk in the WWW:Start at random pageFollow one of the links at random
At the limit (“steady state”) each pagehas a long-term visit rateUse this as the score of the pagePROBLEM. Stuck in dead-ends (webpages with no links)SOLUTION: Teleporting
Dead-ends: jump at random to any webpageOther nodes:15% jump at random to any webpage85% follow one of the links
Equivalent to adding links to all webpagesAll webpages get visited at some point
Agirre (UBC) NLU using KBs and Random Walks July 2016 12 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Imagine a person on a random walk in the WWW:Start at random pageFollow one of the links at random
At the limit (“steady state”) each pagehas a long-term visit rateUse this as the score of the pagePROBLEM. Stuck in dead-ends (webpages with no links)SOLUTION: Teleporting
Dead-ends: jump at random to any webpageOther nodes:15% jump at random to any webpage85% follow one of the links
Equivalent to adding links to all webpagesAll webpages get visited at some point
Agirre (UBC) NLU using KBs and Random Walks July 2016 12 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Imagine a person on a random walk in the WWW:Start at random pageFollow one of the links at random
At the limit (“steady state”) each pagehas a long-term visit rateUse this as the score of the pagePROBLEM. Stuck in dead-ends (webpages with no links)SOLUTION: Teleporting
Dead-ends: jump at random to any webpageOther nodes:15% jump at random to any webpage85% follow one of the links
Equivalent to adding links to all webpagesAll webpages get visited at some point
Agirre (UBC) NLU using KBs and Random Walks July 2016 12 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Markov chains
N states (nodes)N × N transition probability matrix M
For all iN
∑j=1
Mij = 1
Ergodic: path from any state to any other,for any start state after a finite time T0,the probability of being in any state is non-zeroFor any ergodic Markov chain there is a unique long-term visit rateSteady-state probability distributionIt does not matter where we start
Agirre (UBC) NLU using KBs and Random Walks July 2016 13 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Markov chains
N states (nodes)N × N transition probability matrix M
For all iN
∑j=1
Mij = 1
Ergodic: path from any state to any other,for any start state after a finite time T0,the probability of being in any state is non-zeroFor any ergodic Markov chain there is a unique long-term visit rateSteady-state probability distributionIt does not matter where we start
Agirre (UBC) NLU using KBs and Random Walks July 2016 13 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Probability vectors P = [p1 . . . pn]
the walk is in state i with probability piFor instance [00 . . . 1 . . . 00], we are at state i (start)
Given Pj at step j, what is Pj+1 if we take one step? Pj+1 = Pj ×MAlgorithm: iterate until convergence
The steady state: Ps = Ps ×M. For instance:
Agirre (UBC) NLU using KBs and Random Walks July 2016 14 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Probability vectors P = [p1 . . . pn]
the walk is in state i with probability piFor instance [00 . . . 1 . . . 00], we are at state i (start)
Given Pj at step j, what is Pj+1 if we take one step? Pj+1 = Pj ×MAlgorithm: iterate until convergence
The steady state: Ps = Ps ×M. For instance:
Agirre (UBC) NLU using KBs and Random Walks July 2016 14 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Probability vectors P = [p1 . . . pn]
the walk is in state i with probability piFor instance [00 . . . 1 . . . 00], we are at state i (start)
Given Pj at step j, what is Pj+1 if we take one step? Pj+1 = Pj ×MAlgorithm: iterate until convergence
The steady state: Ps = Ps ×M. For instance:
Agirre (UBC) NLU using KBs and Random Walks July 2016 14 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Probability vectors P = [p1 . . . pn]
the walk is in state i with probability piFor instance [00 . . . 1 . . . 00], we are at state i (start)
Given Pj at step j, what is Pj+1 if we take one step? Pj+1 = Pj ×MAlgorithm: iterate until convergence
The steady state: Ps = Ps ×M. For instance:
Agirre (UBC) NLU using KBs and Random Walks July 2016 14 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
How to compute long-term visit rate?Probability vectors P = [p1 . . . pn]
the walk is in state i with probability piFor instance [00 . . . 1 . . . 00], we are at state i (start)
Given Pj at step j, what is Pj+1 if we take one step? Pj+1 = Pj ×MAlgorithm: iterate until convergence
The steady state: Ps = Ps ×M. For instance:
[0.25 0.75
]=
[0.25 0.75
]×
[0.25 0.750.25 0.75
]Agirre (UBC) NLU using KBs and Random Walks July 2016 14 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Let’s factor out teleporting:
M: N × N transition probability matrixv: 1× N teleport probability vectorP: 1× N Pagerank vector
Ps = (1− c)× Ps ×M + c× v
walker follows edgeswalker jumps to any node with probability 1/N
c: teleport ratio, the way in which these two terms are combined (e.g. 0.15)
Agirre (UBC) NLU using KBs and Random Walks July 2016 15 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Let’s factor out teleporting:
M: N × N transition probability matrixv: 1× N teleport probability vectorP: 1× N Pagerank vector
Ps = (1− c)× Ps ×M + c× v
walker follows edgeswalker jumps to any node with probability 1/N
c: teleport ratio, the way in which these two terms are combined (e.g. 0.15)
Agirre (UBC) NLU using KBs and Random Walks July 2016 15 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Let’s factor out teleporting:
M: N × N transition probability matrixv: 1× N teleport probability vectorP: 1× N Pagerank vector
Ps = (1− c)× Ps ×M + c× v
walker follows edgeswalker jumps to any node with probability 1/N
c: teleport ratio, the way in which these two terms are combined (e.g. 0.15)
Agirre (UBC) NLU using KBs and Random Walks July 2016 15 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Let’s factor out teleporting:
M: N × N transition probability matrixv: 1× N teleport probability vectorP: 1× N Pagerank vector
Ps = (1− c)× Ps ×M + c× v
walker follows edgeswalker jumps to any node with probability 1/N
c: teleport ratio, the way in which these two terms are combined (e.g. 0.15)
Agirre (UBC) NLU using KBs and Random Walks July 2016 15 / 70

PageRank and Personalized PageRank
Random Walks: PageRank
Let’s factor out teleporting:
M: N × N transition probability matrixv: 1× N teleport probability vectorP: 1× N Pagerank vector
Ps = (1− c)× Ps ×M + c× v
walker follows edgeswalker jumps to any node with probability 1/N
c: teleport ratio, the way in which these two terms are combined (e.g. 0.15)
Agirre (UBC) NLU using KBs and Random Walks July 2016 15 / 70

PageRank and Personalized PageRank
Random Walks: Personalized PageRank
PageRank gives a static view of the graph.We need to include context:
Importance of nodes according to some node(s) of interest.
Personalized PageRank: non-uniform v [Haveliwala, 2002]Assign stronger probabilities to certain nodes in vBias PageRank to prefer these nodes
Ps = (1− c)× Ps ×M + c× v
For ex. if we concentrate all mass on node i for v (e.g. Tomar website):All random jumps return to niRank of ni will be highHigh rank of ni will make all the nodes in its vicinity also receive a high rankImportance of ni given by the initial v spreads along the graph(e.g. websites closely related to Tomar)
Agirre (UBC) NLU using KBs and Random Walks July 2016 16 / 70

PageRank and Personalized PageRank
Random Walks: Personalized PageRank
PageRank gives a static view of the graph.We need to include context:
Importance of nodes according to some node(s) of interest.
Personalized PageRank: non-uniform v [Haveliwala, 2002]Assign stronger probabilities to certain nodes in vBias PageRank to prefer these nodes
Ps = (1− c)× Ps ×M + c× v
For ex. if we concentrate all mass on node i for v (e.g. Tomar website):All random jumps return to niRank of ni will be highHigh rank of ni will make all the nodes in its vicinity also receive a high rankImportance of ni given by the initial v spreads along the graph(e.g. websites closely related to Tomar)
Agirre (UBC) NLU using KBs and Random Walks July 2016 16 / 70

PageRank and Personalized PageRank
Random Walks: Personalized PageRank
PageRank gives a static view of the graph.We need to include context:
Importance of nodes according to some node(s) of interest.
Personalized PageRank: non-uniform v [Haveliwala, 2002]Assign stronger probabilities to certain nodes in vBias PageRank to prefer these nodes
Ps = (1− c)× Ps ×M + c× v
For ex. if we concentrate all mass on node i for v (e.g. Tomar website):All random jumps return to niRank of ni will be highHigh rank of ni will make all the nodes in its vicinity also receive a high rankImportance of ni given by the initial v spreads along the graph(e.g. websites closely related to Tomar)
Agirre (UBC) NLU using KBs and Random Walks July 2016 16 / 70

Random walks for Disambiguation
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 17 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Word Sense Disambiguation
Goal: determine senses of the open-class words in a text.“Nadal is sharing a house with his uncle and coach, Toni.”“Our fleet comprises coaches from 35 to 58 seats.”
Knowledge Base (e.g. WordNet):coach#1 someone in charge of training an athlete or a team....coach#5 a vehicle carrying many passengers; used for public transport.
Agirre (UBC) NLU using KBs and Random Walks July 2016 18 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Word Sense Disambiguation
Goal: determine senses of the open-class words in a text.“Nadal is sharing a house with his uncle and coach, Toni.”“Our fleet comprises coaches from 35 to 58 seats.”
Knowledge Base (e.g. WordNet):coach#1 someone in charge of training an athlete or a team....coach#5 a vehicle carrying many passengers; used for public transport.
Agirre (UBC) NLU using KBs and Random Walks July 2016 18 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Word Sense Disambiguation (WSD)
Many potential applications, enable natural language understanding, link textto knowledge base, deploy semantic web.
Supervised corpus-based WSD performs bestTrain classifiers on hand-tagged data (typically SemCor)Data sparseness, e.g. coach 20 examples (20,0,0,0,0,0)Results decrease when train/test from different sources (even Brown, BNC)Decrease even more when train/test from different domains
Knowledge-based WSDUses information in a KB (WordNet)Relation coverage
Agirre (UBC) NLU using KBs and Random Walks July 2016 19 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Word Sense Disambiguation (WSD)
Many potential applications, enable natural language understanding, link textto knowledge base, deploy semantic web.
Supervised corpus-based WSD performs bestTrain classifiers on hand-tagged data (typically SemCor)Data sparseness, e.g. coach 20 examples (20,0,0,0,0,0)Results decrease when train/test from different sources (even Brown, BNC)Decrease even more when train/test from different domains
Knowledge-based WSDUses information in a KB (WordNet)Relation coverage
Agirre (UBC) NLU using KBs and Random Walks July 2016 19 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Word Sense Disambiguation (WSD)
Many potential applications, enable natural language understanding, link textto knowledge base, deploy semantic web.
Supervised corpus-based WSD performs bestTrain classifiers on hand-tagged data (typically SemCor)Data sparseness, e.g. coach 20 examples (20,0,0,0,0,0)Results decrease when train/test from different sources (even Brown, BNC)Decrease even more when train/test from different domains
Knowledge-based WSDUses information in a KB (WordNet)Relation coverage
Agirre (UBC) NLU using KBs and Random Walks July 2016 19 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
WordNet is the usual KB for WSD
WordNet is the most widely used hierarchically organizedlexical database for English (Fellbaum, 1998)
Broad coverage of nouns, verbs, adjectives, adverbs
Main unit: synset (concept)
coach#1, manager#3, handler#2someone in charge of training an athlete or a team.
A word is associated to several concepts (word senses)A concept can be lexicalised with several words (variants)Relations between concepts:synonymy (built-in), hyperonymy, antonymy, meronymy, entailment,derivation, gloss
Agirre (UBC) NLU using KBs and Random Walks July 2016 20 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
WordNet is the usual KB for WSD
Representing WordNet as a graph [Hughes and Ramage, 2007]:Nodes represent conceptsEdges represent relations (undirected)In addition, directed edges from words to corresponding concepts(senses)
Agirre (UBC) NLU using KBs and Random Walks July 2016 21 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
WordNet is the usual KB for WSD
coach#n1
managership#n3
sport#n1
trainer#n1
handle#v6
coach#n2
teacher#n1
tutorial#n1
coach#n5
public_transport#n1
fleet#n2
seat#n1
holonym
holonym
hyperonym
domain
derivation
hyperonym
derivation
hyperonym
derivationcoach
Agirre (UBC) NLU using KBs and Random Walks July 2016 22 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Using Personalized PageRank for WSD[Agirre et al., 2014]
“Our fleet comprises coaches from 35 to 58 seats.”
Ps = (1− c)× Ps ×M + c× v
For each word Wi i = 1 . . . m in the context (e.g. coach)
Initialize v with uniform probabilities over words Wj 6=i
(e.g. fleet, comprise, seat)Context words act as source nodesinjecting probability mass into the concept graph
Run Personalized PageRank, yielding Ps
Choose highest ranking sense for target word Wi in Ps (e.g. coach)
This is called word-to-word Personalized PageRank, PPRw2w
Agirre (UBC) NLU using KBs and Random Walks July 2016 23 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Using Personalized PageRank (PPR)
“Our fleet comprises coaches from 35 to 58 seats.”
coach#n1
managership#n3
sport#n1
trainer#n1
handle#n8
coach#n2
teacher#n1
tutorial#n1
coach#n5
public_transport#n1
fleet#n2
seat#n1
coach fleet comprise ... seat
comprise#v1 ...
Agirre (UBC) NLU using KBs and Random Walks July 2016 24 / 70

Random walks for Disambiguation Word Sense Disambiguation (WSD)
Results and comparison to related work
System S2AW S3AW S07CG (N)[Agirre and Soroa, 2008] KB 57.7 56.8 79.4[Tsatsaronis et al., 2010] KB 58.8 57.4[Ponzetto and Navigli, 2010] KB (79.4)[Moro et al., 2014] KB (84.6)PPRw2w KB 59.7 57.9 80.1 (83.6)PPRw2w + MFS KB 62.6 63.0 81.4 (82.1)[Taghipour and Ng, 2015] SUP 68.2 67.6 82.6 (82.3)
Agirre (UBC) NLU using KBs and Random Walks July 2016 25 / 70

Random walks for Disambiguation WSD on the biomedical domain
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 26 / 70

Random walks for Disambiguation WSD on the biomedical domain
Biomedical WSD and UMLS [Agirre et al., 2010]
Ambiguity believed not to occur on specific domainsOn the Use of Cold Water as a Powerful Remedial Agent in ChronicDisease.Intranasal ipratropium bromide for the common cold.
11.7% of the phrases in abstracts added to MEDLINE in 1998 wereambiguous (Weeber et al. 2011)
Unified Medical Language System (UMLS) MetathesaurusConcept Unique Identifiers (CUIs)
C0234192: Cold (Cold Sensation) [Physiologic Function]C0009264: Cold (cold temperature) [Natural Phenomenon or Process]C0009443: Cold (Common Cold) [Disease or Syndrome]
Agirre (UBC) NLU using KBs and Random Walks July 2016 27 / 70

Random walks for Disambiguation WSD on the biomedical domain
Biomedical WSD and UMLS [Agirre et al., 2010]
Ambiguity believed not to occur on specific domainsOn the Use of Cold Water as a Powerful Remedial Agent in ChronicDisease.Intranasal ipratropium bromide for the common cold.
11.7% of the phrases in abstracts added to MEDLINE in 1998 wereambiguous (Weeber et al. 2011)Unified Medical Language System (UMLS) MetathesaurusConcept Unique Identifiers (CUIs)
C0234192: Cold (Cold Sensation) [Physiologic Function]C0009264: Cold (cold temperature) [Natural Phenomenon or Process]C0009443: Cold (Common Cold) [Disease or Syndrome]
Agirre (UBC) NLU using KBs and Random Walks July 2016 27 / 70

Random walks for Disambiguation WSD on the biomedical domain
Biomedical WSD and UMLS [Agirre et al., 2010]
UMLS is a Metathesarus: (∼1M CUIs)Alcohol and other drugs, Medical Subject Headings, Crisp Thesaurus, SNOMEDClinical Terms, etc.Relations in the Metathesaurus between CUIs (∼5M):parent, can be qualified by, related possibly sinonymous, related other
We applied Personalized PageRank.Evaluated on NLM-WSD, 50 ambiguous terms (100 instances each)
KB #CUIs #relations Acc. TermsAOD 15,901 58,998 51.5 4MSH 278,297 1,098,547 44.7 9CSP 16,703 73,200 60.2 3SNOMEDCT 304,443 1,237,571 62.5 29all above 572,105 2,433,324 64.4 48all relations - 5,352,190 70.4 50[Jimeno and Aronson, 2011] - - 68.4 50
Agirre (UBC) NLU using KBs and Random Walks July 2016 28 / 70

Random walks for Disambiguation WSD on the biomedical domain
Biomedical WSD and UMLS [Agirre et al., 2010]
UMLS is a Metathesarus: (∼1M CUIs)Alcohol and other drugs, Medical Subject Headings, Crisp Thesaurus, SNOMEDClinical Terms, etc.Relations in the Metathesaurus between CUIs (∼5M):parent, can be qualified by, related possibly sinonymous, related other
We applied Personalized PageRank.Evaluated on NLM-WSD, 50 ambiguous terms (100 instances each)
KB #CUIs #relations Acc. TermsAOD 15,901 58,998 51.5 4MSH 278,297 1,098,547 44.7 9CSP 16,703 73,200 60.2 3SNOMEDCT 304,443 1,237,571 62.5 29all above 572,105 2,433,324 64.4 48all relations - 5,352,190 70.4 50[Jimeno and Aronson, 2011] - - 68.4 50
Agirre (UBC) NLU using KBs and Random Walks July 2016 28 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 29 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation[Agirre et al., 2015, Barrena et al., 2015]
Given a Named Entity mention, ground to instance in KB(aka Entity Linking, Wikification)KB is Wikipedia (∼ DBpedia), represented as graph:∼5M articles, nodes, represent concepts and instances∼90M hyperlinks, edges, represent relations
Alan Kourie, CEO of the Lions franchise,had discussions with Fletcher in Cape Town.
Agirre (UBC) NLU using KBs and Random Walks July 2016 30 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation[Agirre et al., 2015, Barrena et al., 2015]
Given a Named Entity mention, ground to instance in KB(aka Entity Linking, Wikification)KB is Wikipedia (∼ DBpedia), represented as graph:∼5M articles, nodes, represent concepts and instances∼90M hyperlinks, edges, represent relations
Alan Kourie, CEO of the Lions franchise,had discussions with Fletcher in Cape Town.
Agirre (UBC) NLU using KBs and Random Walks July 2016 30 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation
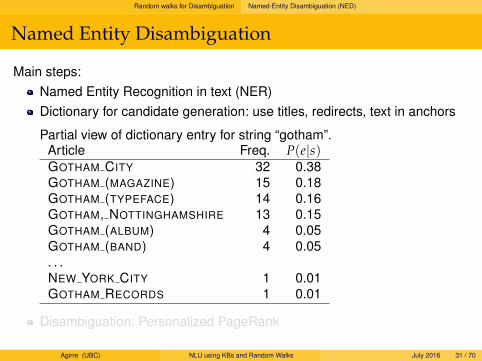
Main steps:Named Entity Recognition in text (NER)Dictionary for candidate generation: use titles, redirects, text in anchors
Partial view of dictionary entry for string “gotham”.Article Freq. P(e|s)GOTHAM CITY 32 0.38GOTHAM (MAGAZINE) 15 0.18GOTHAM (TYPEFACE) 14 0.16GOTHAM, NOTTINGHAMSHIRE 13 0.15GOTHAM (ALBUM) 4 0.05GOTHAM (BAND) 4 0.05. . .NEW YORK CITY 1 0.01GOTHAM RECORDS 1 0.01
Disambiguation: Personalized PageRank
Agirre (UBC) NLU using KBs and Random Walks July 2016 31 / 70
Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation
Main steps:Named Entity Recognition in text (NER)Dictionary for candidate generation: use titles, redirects, text in anchors
Partial view of dictionary entry for string “gotham”.Article Freq. P(e|s)GOTHAM CITY 32 0.38GOTHAM (MAGAZINE) 15 0.18GOTHAM (TYPEFACE) 14 0.16GOTHAM, NOTTINGHAMSHIRE 13 0.15GOTHAM (ALBUM) 4 0.05GOTHAM (BAND) 4 0.05. . .NEW YORK CITY 1 0.01GOTHAM RECORDS 1 0.01
Disambiguation: Personalized PageRank
Agirre (UBC) NLU using KBs and Random Walks July 2016 31 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation
Main steps:Named Entity Recognition in text (NER)Dictionary for candidate generation: use titles, redirects, text in anchors
Partial view of dictionary entry for string “gotham”.Article Freq. P(e|s)GOTHAM CITY 32 0.38GOTHAM (MAGAZINE) 15 0.18GOTHAM (TYPEFACE) 14 0.16GOTHAM, NOTTINGHAMSHIRE 13 0.15GOTHAM (ALBUM) 4 0.05GOTHAM (BAND) 4 0.05. . .NEW YORK CITY 1 0.01GOTHAM RECORDS 1 0.01
Disambiguation: Personalized PageRank
Agirre (UBC) NLU using KBs and Random Walks July 2016 31 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation
TAC2009 TAC2010 TAC2013 AIDAPPRw2w 78.8 83.6 81.7 79.9Best system 76.5 80.6 77.7 83.3
Evaluation: accuracy for KB mentions (we don’t do NILs)Best: best in each competition, [Houlsby and Ciaramita, 2014] for AIDA
Key for performance: only keep hyperlinks which have a reciprocalhyperlink (e.g. Tomar and Santarem district)
Agirre (UBC) NLU using KBs and Random Walks July 2016 32 / 70

Random walks for Disambiguation Named-Entity Disambiguation (NED)
Named Entity Disambiguation
TAC2009 TAC2010 TAC2013 AIDAPPRw2w 78.8 83.6 81.7 79.9Best system 76.5 80.6 77.7 83.3
Evaluation: accuracy for KB mentions (we don’t do NILs)Best: best in each competition, [Houlsby and Ciaramita, 2014] for AIDA
Key for performance: only keep hyperlinks which have a reciprocalhyperlink (e.g. Tomar and Santarem district)
Agirre (UBC) NLU using KBs and Random Walks July 2016 32 / 70

Random walks for Disambiguation Complementary to other resources?
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 33 / 70

Random walks for Disambiguation Complementary to other resources?
Combining graphs & supervised NED[Barrena et al., 2015]
We set up a generative framework:entity knowledge P(e)name knowledge P(s|e)context knowledge P(cbow|e)context knowledge P(cgrf|e)
Return entity which maximizes joint probability
arg maxe
P(s, c, e)
= arg maxe
P(e)P(s|e)P(cbow|e)P(cgrf|e)
Agirre (UBC) NLU using KBs and Random Walks July 2016 34 / 70

Random walks for Disambiguation Complementary to other resources?
Combining graphs & supervised NED[Barrena et al., 2015]
We set up a generative framework:entity knowledge P(e)name knowledge P(s|e)context knowledge P(cbow|e)context knowledge P(cgrf|e)
Return entity which maximizes joint probability
arg maxe
P(s, c, e)
= arg maxe
P(e)P(s|e)P(cbow|e)P(cgrf|e)
Agirre (UBC) NLU using KBs and Random Walks July 2016 34 / 70

Random walks for Disambiguation Complementary to other resources?
Combining graphs & supervised NED
Beck Hansen Jeff BeckP(e) 0.70 0.23P(s|e) 0.63 0.10P(cbow|e) 0.12 0.80P(cgrf|e) 0.01 0.97
Agirre (UBC) NLU using KBs and Random Walks July 2016 35 / 70

Random walks for Disambiguation Complementary to other resources?
Combining graphs & supervised NED
Results
Best system in each competition, [Houlsby and Ciaramita, 2014] for AIDAKnowledge-Based and Supervised are competitive and complementary!
Agirre (UBC) NLU using KBs and Random Walks July 2016 36 / 70

Random walks for similarity
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 37 / 70

Random walks for similarity
Similarity (and relatedness)
Given two words or multiword-expressions,estimate how similar they are.
gem jewel
Features shared, superclass shared
Relatedness is a more general relationship,including other relations like topical relatedness or meronymy.
movie star
Similarity and disambiguation are closely related!
Gold Standard: a numeric value of similarity/relatedness.
Agirre (UBC) NLU using KBs and Random Walks July 2016 38 / 70

Random walks for similarity
Similarity (and relatedness)
Given two words or multiword-expressions,estimate how similar they are.
gem jewel
Features shared, superclass shared
Relatedness is a more general relationship,including other relations like topical relatedness or meronymy.
movie star
Similarity and disambiguation are closely related!
Gold Standard: a numeric value of similarity/relatedness.
Agirre (UBC) NLU using KBs and Random Walks July 2016 38 / 70

Random walks for similarity
Similarity (and relatedness)
Given two words or multiword-expressions,estimate how similar they are.
gem jewel
Features shared, superclass shared
Relatedness is a more general relationship,including other relations like topical relatedness or meronymy.
movie star
Similarity and disambiguation are closely related!
Gold Standard: a numeric value of similarity/relatedness.
Agirre (UBC) NLU using KBs and Random Walks July 2016 38 / 70

Random walks for similarity
Similarity (and relatedness)
Given two words or multiword-expressions,estimate how similar they are.
gem jewel
Features shared, superclass shared
Relatedness is a more general relationship,including other relations like topical relatedness or meronymy.
movie star
Similarity and disambiguation are closely related!
Gold Standard: a numeric value of similarity/relatedness.
Agirre (UBC) NLU using KBs and Random Walks July 2016 38 / 70

Random walks for similarity
Similarity datasets
RG dataset WordSim353 datasetcord smile 0.02 king cabbage 0.23
rooster voyage 0.04 professor cucumber 0.31. . . . . .
glass jewel 1.78 investigation effort 4.59magician oracle 1.82 movie star 7.38
. . . . . .cemetery graveyard 3.88 journey voyage 9.29
automobile car 3.92 midday noon 9.29midday noon 3.94 tiger tiger 10.00
80 pairs, 51 subjects 353 pairs, 16 subjectsSimilarity Relatedness
Evaluation: Spearman correlation
Agirre (UBC) NLU using KBs and Random Walks July 2016 39 / 70

Random walks for similarity
Similarity datasets
RG dataset WordSim353 datasetcord smile 0.02 king cabbage 0.23
rooster voyage 0.04 professor cucumber 0.31. . . . . .
glass jewel 1.78 investigation effort 4.59magician oracle 1.82 movie star 7.38
. . . . . .cemetery graveyard 3.88 journey voyage 9.29
automobile car 3.92 midday noon 9.29midday noon 3.94 tiger tiger 10.00
80 pairs, 51 subjects 353 pairs, 16 subjectsSimilarity Relatedness
Evaluation: Spearman correlation
Agirre (UBC) NLU using KBs and Random Walks July 2016 39 / 70

Random walks for similarity
Similarity
Many potential applications:Overcome brittleness (word match)NLP subtasks (parsing, semantic role labeling)Information retrievalQuestion answeringSummarizationMachine translation optimization and evaluationInference (textual entailment)
Two main approaches:Knowledge-basedCorpus-based, also known as distributional similarity (embeddings!)
Agirre (UBC) NLU using KBs and Random Walks July 2016 40 / 70

Random walks for similarity
Similarity
Many potential applications:Overcome brittleness (word match)NLP subtasks (parsing, semantic role labeling)Information retrievalQuestion answeringSummarizationMachine translation optimization and evaluationInference (textual entailment)
Two main approaches:Knowledge-basedCorpus-based, also known as distributional similarity (embeddings!)
Agirre (UBC) NLU using KBs and Random Walks July 2016 40 / 70

Random walks for similarity Using Random walks
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 41 / 70

Random walks for similarity Using Random walks
Random walks [Hughes and Ramage, 2007][Eneko Agirre and Soroa, 2010, Agirre et al., 2015]
Given two words estimate how similar they are.
gem jewel
Given a pair of words (w1, w2):Initialize teleport probability mass v with w1
Run Personalized Pagerank, obtaining ~w1 = Ps
Initialize v with w2 and obtain ~w2 = Ps
Measure similarity between ~w1 and ~w2 (e.g.cosine)
Ps = (1− c)× Ps ×M + c× v
Agirre (UBC) NLU using KBs and Random Walks July 2016 42 / 70

Random walks for similarity Using Random walks
Random walks [Hughes and Ramage, 2007][Eneko Agirre and Soroa, 2010, Agirre et al., 2015]
Given two words estimate how similar they are.
gem jewel
Given a pair of words (w1, w2):Initialize teleport probability mass v with w1
Run Personalized Pagerank, obtaining ~w1 = Ps
Initialize v with w2 and obtain ~w2 = Ps
Measure similarity between ~w1 and ~w2 (e.g.cosine)
Ps = (1− c)× Ps ×M + c× v
Agirre (UBC) NLU using KBs and Random Walks July 2016 42 / 70

Random walks for similarity Using Random walks
Using Random Walks
Probability vectors on Wikipedia for drink and alcohol.
drink alcoholDRINK .124 ALCOHOL .145ALCOHOLIC BEVERAGE .036 ALCOHOLIC BEVERAGE .026DRINKING .028 ETHANOL .018COFFEE .020 ALKENE .006TEA .017 ALCOHOLISM .006CIDER .016 ALDEHYDE .005MASALA CHAI .014 KETONE .004WINE .014 ESTER .004SUGAR SUBSTITUTE .014 ALKANE .004CAPPUCCINO .013 ISOPROPYL ALCOHOL .003HOT CHOCOLATE .013 ETHER .003. . . . . .
Agirre (UBC) NLU using KBs and Random Walks July 2016 43 / 70
Random walks for similarity Using Random walks
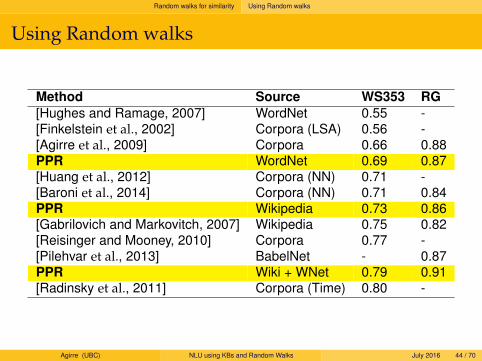
Using Random walks
Method Source WS353 RG[Hughes and Ramage, 2007] WordNet 0.55 -[Finkelstein et al., 2002] Corpora (LSA) 0.56 -[Agirre et al., 2009] Corpora 0.66 0.88PPR WordNet 0.69 0.87[Huang et al., 2012] Corpora (NN) 0.71 -[Baroni et al., 2014] Corpora (NN) 0.71 0.84PPR Wikipedia 0.73 0.86[Gabrilovich and Markovitch, 2007] Wikipedia 0.75 0.82[Reisinger and Mooney, 2010] Corpora 0.77 -[Pilehvar et al., 2013] BabelNet - 0.87PPR Wiki + WNet 0.79 0.91[Radinsky et al., 2011] Corpora (Time) 0.80 -
Agirre (UBC) NLU using KBs and Random Walks July 2016 44 / 70

Random walks for similarity Embedding random walks
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 45 / 70

Random walks for similarity Embedding random walks
Low-dimensional word representations[Goikoetxea et al., 2015]
Vectors produced by PPR contain thousand (millions) of dimensions
Feed random walk (WordNet) into neural network language model (word2vec)
Agirre (UBC) NLU using KBs and Random Walks July 2016 46 / 70

Random walks for similarity Embedding random walks
Low-dimensional word representations[Goikoetxea et al., 2015]
Vectors produced by PPR contain thousand (millions) of dimensions
Feed random walk (WordNet) into neural network language model (word2vec)
Agirre (UBC) NLU using KBs and Random Walks July 2016 46 / 70

Random walks for similarity Embedding random walks
Low-dimensional word representations[Goikoetxea et al., 2015]
Vectors produced by PPR contain thousand (millions) of dimensions
Feed random walk (WordNet) into neural network language model (word2vec)
Agirre (UBC) NLU using KBs and Random Walks July 2016 46 / 70

Random walks for similarity Embedding random walks
Low-dimensional word representations
Producing pseudo-corpus:1 start random walk at any synset,2 emit lexicalization,3 with probability 85% follow edge, goto step 24 else restart, goto step 1
Examples of text generated by random walks on WordNet
yucatec mayan quiche kekchi speak sino-tibetan tone languagewest chadicamphora wine nabuchadnezzar bear retain longgraphology writer write scribble scrawler heedlessly in haste jot notenotebook
Agirre (UBC) NLU using KBs and Random Walks July 2016 47 / 70

Random walks for similarity Embedding random walks
Low-dimensional word representations
Producing pseudo-corpus:1 start random walk at any synset,2 emit lexicalization,3 with probability 85% follow edge, goto step 24 else restart, goto step 1
Examples of text generated by random walks on WordNet
yucatec mayan quiche kekchi speak sino-tibetan tone languagewest chadicamphora wine nabuchadnezzar bear retain longgraphology writer write scribble scrawler heedlessly in haste jot notenotebook
Agirre (UBC) NLU using KBs and Random Walks July 2016 47 / 70
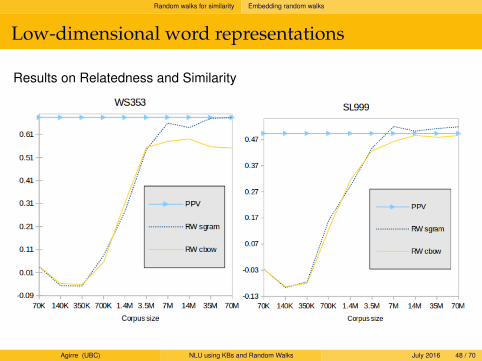
Random walks for similarity Embedding random walks
Low-dimensional word representations
Results on Relatedness and Similarity
Agirre (UBC) NLU using KBs and Random Walks July 2016 48 / 70

Random walks for similarity Embedding random walks
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 49 / 70

Random walks for similarity Complementary to other resources?
Combining graph- and text-based embeddings[Goikoetxea et al., 2016]
Given two sources of embeddings:Large corporaRandom Walks on WordNet
Combine embeddings into single embeddings:Using centroid (CEN)Concatenating embeddings (CAT)Dimensionality reduction of CAT (PCA)
Combine cosines from each embeddings space:Average of cosines (AVG)
Agirre (UBC) NLU using KBs and Random Walks July 2016 50 / 70

Random walks for similarity Complementary to other resources?
Combining graph- and text-based embeddings[Goikoetxea et al., 2016]
Given two sources of embeddings:Large corporaRandom Walks on WordNet
Combine embeddings into single embeddings:Using centroid (CEN)Concatenating embeddings (CAT)Dimensionality reduction of CAT (PCA)
Combine cosines from each embeddings space:Average of cosines (AVG)
Agirre (UBC) NLU using KBs and Random Walks July 2016 50 / 70

Random walks for similarity Complementary to other resources?
Combining graph- and text-based embeddings[Goikoetxea et al., 2016]
Given two sources of embeddings:Large corporaRandom Walks on WordNet
Combine embeddings into single embeddings:Using centroid (CEN)Concatenating embeddings (CAT)Dimensionality reduction of CAT (PCA)
Combine cosines from each embeddings space:Average of cosines (AVG)
Agirre (UBC) NLU using KBs and Random Walks July 2016 50 / 70

Random walks for similarity Complementary to other resources?
Combining graph- and text-based embeddings
Improvement of combination with respect to corpus-based embeddings:
RG SL WSS WSR MTU MEN WS allCorpus 76.4 39.7 76.6 61.5 64.6 74.6 67.3 64.5WordNet 82.3 52.5 76.2 58.7 62.1 75.4 68.7 68.2
CEN 4.6 9.6 2.7 -1.1 1.3 3.2 2.3 4.2AVG 8.0 12.1 5.5 6.5 7.0 6.2 7.4 8.2CAT 7.8 12.5 6.7 6.5 7.5 6.0 8.0 8.4PCA 10.8 12.5 5.7 5.3 8.3 5.6 6.9 8.9
Random walks on WordNet competitive with corpus-basedVery large improvements, showing that they are highly complementary!
Agirre (UBC) NLU using KBs and Random Walks July 2016 51 / 70

Random walks for similarity Complementary to other resources?
Combining graphs with text-based embeddings
Other alternatives provide smaller improvements(e.g. retro-fitting [Faruqui et al., 2015])
Agirre (UBC) NLU using KBs and Random Walks July 2016 52 / 70

Similarity and Information Retrieval
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 53 / 70

Similarity and Information Retrieval
Similarity and Information Retrieval[Otegi et al., 2014]
In information retrieval, given a query, we need to retrieve a document,but mismatches happen (example from Yahoo! Answer):
I can’t install DSL because of the antivirus program, any hints?You should turn off virus and anti-spy software. And thats done within eachof the softwares themselves. Then turn them back on later after setting upany DSL softwares.
Document expansion (aka clustering and smoothing) has been shown tobe successful in IR
Use WordNet and similarity to expand documents
Method:Initialize random walk with document wordsRetrieve top k synsetsIntroduce words on those k synsets in a secondary indexWhen retrieving, use both primary and secondary indexes
Results: better results, particularly with domain changes and shortdocuments
Agirre (UBC) NLU using KBs and Random Walks July 2016 54 / 70

Similarity and Information Retrieval
Similarity and Information Retrieval[Otegi et al., 2014]
In information retrieval, given a query, we need to retrieve a document,but mismatches happen (example from Yahoo! Answer):
I can’t install DSL because of the antivirus program, any hints?You should turn off virus and anti-spy software. And thats done within eachof the softwares themselves. Then turn them back on later after setting upany DSL softwares.
Document expansion (aka clustering and smoothing) has been shown tobe successful in IR
Use WordNet and similarity to expand documents
Method:Initialize random walk with document wordsRetrieve top k synsetsIntroduce words on those k synsets in a secondary indexWhen retrieving, use both primary and secondary indexes
Results: better results, particularly with domain changes and shortdocuments
Agirre (UBC) NLU using KBs and Random Walks July 2016 54 / 70

Similarity and Information Retrieval
Similarity and Information Retrieval[Otegi et al., 2014]
In information retrieval, given a query, we need to retrieve a document,but mismatches happen (example from Yahoo! Answer):
I can’t install DSL because of the antivirus program, any hints?You should turn off virus and anti-spy software. And thats done within eachof the softwares themselves. Then turn them back on later after setting upany DSL softwares.
Document expansion (aka clustering and smoothing) has been shown tobe successful in IR
Use WordNet and similarity to expand documents
Method:Initialize random walk with document wordsRetrieve top k synsetsIntroduce words on those k synsets in a secondary indexWhen retrieving, use both primary and secondary indexes
Results: better results, particularly with domain changes and shortdocuments
Agirre (UBC) NLU using KBs and Random Walks July 2016 54 / 70

Similarity and Information Retrieval
Example of document expansionYou should turn off virus and anti-spy software. And thats done within each of thesoftwares themselves. Then turn them back on later after setting up any DSLsoftwares.
Agirre (UBC) NLU using KBs and Random Walks July 2016 55 / 70

Similarity and Information Retrieval
Example of document expansion
Agirre (UBC) NLU using KBs and Random Walks July 2016 56 / 70

Conclusions
Outline
1 PageRank and Personalized PageRank
2 Random walks for DisambiguationWord Sense Disambiguation (WSD)WSD on the biomedical domainNamed-Entity Disambiguation (NED)Complementary to other resources?
3 Random walks for similarityUsing Random walksEmbedding random walksComplementary to other resources?
4 Similarity and Information Retrieval
5 Conclusions
Agirre (UBC) NLU using KBs and Random Walks July 2016 57 / 70

Conclusions
Conclusions
Knowledge-based method for WSD, NED and similarityVery good results in all tasks, with all KBs:
Exploits whole structure of very large KB, simple, few parametersKey for performance: selection of relations in the graph
Complementary to corpus-based methods: state-of-the-art results indisambiguation and similarity
Multilingual and cross-lingual
Publicly available at http://ixa2.si.ehu.eus/ukbBoth programs and data (WordNet, UMLS, Wikipedia)(NEW) Word representationsIncluding program to construct graphs from KBsGPL license, open source, free, mailing list
Agirre (UBC) NLU using KBs and Random Walks July 2016 58 / 70

Conclusions
Conclusions
Knowledge-based method for WSD, NED and similarityVery good results in all tasks, with all KBs:
Exploits whole structure of very large KB, simple, few parametersKey for performance: selection of relations in the graph
Complementary to corpus-based methods: state-of-the-art results indisambiguation and similarity
Multilingual and cross-lingual
Publicly available at http://ixa2.si.ehu.eus/ukbBoth programs and data (WordNet, UMLS, Wikipedia)(NEW) Word representationsIncluding program to construct graphs from KBsGPL license, open source, free, mailing list
Agirre (UBC) NLU using KBs and Random Walks July 2016 58 / 70

Conclusions
Conclusions
Knowledge-based method for WSD, NED and similarityVery good results in all tasks, with all KBs:
Exploits whole structure of very large KB, simple, few parametersKey for performance: selection of relations in the graph
Complementary to corpus-based methods: state-of-the-art results indisambiguation and similarity
Multilingual and cross-lingual
Publicly available at http://ixa2.si.ehu.eus/ukbBoth programs and data (WordNet, UMLS, Wikipedia)(NEW) Word representationsIncluding program to construct graphs from KBsGPL license, open source, free, mailing list
Agirre (UBC) NLU using KBs and Random Walks July 2016 58 / 70

Conclusions
Conclusions
Knowledge-based method for WSD, NED and similarityVery good results in all tasks, with all KBs:
Exploits whole structure of very large KB, simple, few parametersKey for performance: selection of relations in the graph
Complementary to corpus-based methods: state-of-the-art results indisambiguation and similarity
Multilingual and cross-lingual
Publicly available at http://ixa2.si.ehu.eus/ukbBoth programs and data (WordNet, UMLS, Wikipedia)(NEW) Word representationsIncluding program to construct graphs from KBsGPL license, open source, free, mailing list
Agirre (UBC) NLU using KBs and Random Walks July 2016 58 / 70

Conclusions
Future
Thriving area of researchEmbedding knowledge-bases in low-dimensional spacesSophisticated methods to combine corpus-based and knowledge-basedmethodsInclude supervision in knowledge-based embeddings
Cross-linguality, also to improve monolingual resultsCompositionality of word meanings and textual inference
Agirre (UBC) NLU using KBs and Random Walks July 2016 59 / 70

Conclusions
Future
Thriving area of researchEmbedding knowledge-bases in low-dimensional spacesSophisticated methods to combine corpus-based and knowledge-basedmethodsInclude supervision in knowledge-based embeddings
Cross-linguality, also to improve monolingual resultsCompositionality of word meanings and textual inference
Agirre (UBC) NLU using KBs and Random Walks July 2016 59 / 70

Conclusions
Natural Language Understandingusing Knowledge Bases
and Random Walks
Eneko Agirreixa2.si.ehu.eus/eneko
IXA NLP GroupUniversity of the Basque Country
PROPOR 2016 - Tomar
In collaboration with: Ander Barrena, Josu Goikoetxea, OierLopez de Lacalle, Arantxa Otegi, Aitor Soroa, Mark Stevenson
Agirre (UBC) NLU using KBs and Random Walks July 2016 60 / 70

Conclusions
References I
Agirre, E., Arregi, X. and Otegi, A. (2010).Document Expansion Based on WordNet for Robust IR.In Proceedings of the 23rd International Conference on ComputationalLinguistics (Coling) pp. 9–17,.
Agirre, E., Barrena, A. and Soroa, A. (2015).Studying the Wikipedia Hyperlink Graph for Relatedness andDisambiguation.CoRR abs/1503.01655.
Agirre, E., de Lacalle, O. L. and Soroa, A. (2009).Knowledge-Based WSD on Specific Domains: Performing better thanGeneric Supervised WSD.In Proceedings of IJCAI, Pasadena, USA.
Agirre, E., Lacalle, d. O. L. and Soroa, A. (2014).Random Walks for Knowledge-Based Word Sense Disambiguation.Computational Linguistics 40.
Agirre (UBC) NLU using KBs and Random Walks July 2016 61 / 70

Conclusions
References II
Agirre, E. and Soroa, A. (2008).Using the Multilingual Central Repository for Graph-Based Word SenseDisambiguation.In Proceedings of LREC ’08, Marrakesh, Morocco.
Agirre, E. and Soroa, A. (2009).Personalizing PageRank for Word Sense Disambiguation.In Proceedings of EACL-09, Athens, Greece.
Agirre, E., Soroa, A., Alfonseca, E., Hall, K., Kravalova, J. and Pasca, M.(2009).A Study on Similarity and Relatedness Using Distributional andWordNet-based Approaches.In Proceedings of annual meeting of the North American Chapter of theAssociation of Computational Linguistics (NAAC), Boulder, USA.
Agirre (UBC) NLU using KBs and Random Walks July 2016 62 / 70

Conclusions
References III
Agirre, E., Soroa, A. and Stevenson, M. (2010).Graph-based Word Sense Disambiguation of Biomedical Documents.Bioinformatics 26, 2889–2896.
Baroni, M., Dinu, G. and Kruszewski, G. (2014).Don’t count, predict! A systematic comparison of context-counting vs.context-predicting semantic vectors.In Proceedings of The 52nd Annual Meeting of the Association forComputational Linguistics (ACL), Baltimore, USA.
Barrena, A., Soroa, A. and Agirre, E. (2015).Combining Mention Context and Hyperlinks from Wikipedia for NamedEntity Disambiguation.In Proceedings of the Fourth Joint Conference on Lexical andComputational Semantics pp. 101–105, Association for ComputationalLinguistics, Denver, Colorado.
Agirre (UBC) NLU using KBs and Random Walks July 2016 63 / 70

Conclusions
References IV
Eneko Agirre, Montse Cuadros, G. R. and Soroa, A. (2010).Exploring Knowledge Bases for Similarity.In Proceedings of the Seventh conference on International LanguageResources and Evaluation (LREC’10), (Calzolari, N., ed.), pp. 373–377,European Language Resources Association (ELRA), Valletta, Malta.
Faruqui, M., Dodge, J., Jauhar, S. K., Dyer, C., Hovy, E. and Smith, N. A.(2015).Retrofitting Word Vectors to Semantic Lexicons.In Proceedings of NAACL-HLT pp. 1606–1615,.
Finkelstein, L., Gabrilovich, E., Matias, Y., Rivlin, E., Solan, Z., Wolfman,G. and Ruppin, E. (2002).Placing Search in Context: The Concept Revisited.ACM Transactions on Information Systems 20, 116–131.
Agirre (UBC) NLU using KBs and Random Walks July 2016 64 / 70

Conclusions
References V
Gabrilovich, E. and Markovitch, S. (2007).Computing Semantic Relatedness using Wikipedia-based ExplicitSemantic Analysis.In Proceedings of the 20th International Joint Conference on ArtificialIntelligence pp. 6–12,.
Goikoetxea, J., Soroa, A. and Agirre, E. (2015).Random Walks and Neural Network Language Models on KnowledgeBases.In Proceedings of NAACL-HLT pp. 1434–1439, ACL.
Goikoetxea, J., Soroa, A. and Agirre, E. (2016).Single or Multiple Combining Word Representations IndependentlyLearned from Text and WordNet.In Proceedings of AAAI AAAI.
Agirre (UBC) NLU using KBs and Random Walks July 2016 65 / 70

Conclusions
References VI
Haveliwala, T. H. (2002).Topic-sensitive PageRank.In WWW ’02: Proceedings of the 11th international conference on WorldWide Web pp. 517–526, ACM, New York, NY, USA.
Huang, E., Socher, R., Manning, C. and Ng, A. (2012).Improving Word Representations via Global Context and Multiple WordPrototypes.In Proceedings of the 50th Annual Meeting of the Association forComputational Linguistics (Volume 1: Long Papers) pp. 873–882,Association for Computational Linguistics, Jeju Island, Korea.
Hughes, T. and Ramage, D. (2007).Lexical Semantic Relatedness with Random Graph Walks.In Proceedings of the 2007 Joint Conference on Empirical Methods inNatural Language Processing and Computational Natural LanguageLearning (EMNLP-CoNLL) pp. 581–589,.
Agirre (UBC) NLU using KBs and Random Walks July 2016 66 / 70

Conclusions
References VII
Moro, A., Raganato, A. and Navigli, R. (2014).Entity Linking meets Word Sense Disambiguation: a Unied Approach.Transactions of the Association of Computational Linguistics 2, 231–244.
Otegi, A., Arregi, X. and Agirre, E. (2011).Query Expansion for IR using Knowledge-Based Relatedness.In Proceedings of the International Joint Conference on Natural LanguageProcessing.
Otegi, A., Arregi, X., Ansa, O. and Agirre, E. (2014).Using knowledge-based relatedness for information retrieval.Knowledge and Information Systems In press, 1–30.
Pilehvar, M. T., Jurgens, D. and Navigli, R. (2013).Align, Disambiguate and Walk: a Unified Approach for MeasuringSemantic Similarity.In Proceedings of the 51st Annual Meeting of the Association forComputational Linguistics pp. 1341–1351,, Sofia, Bulgaria.
Agirre (UBC) NLU using KBs and Random Walks July 2016 67 / 70

Conclusions
References VIII
Ponzetto, S. P. and Navigli, R. (2010).Knowledge-rich word sense disambiguation rivaling supervised systems.In Proceedings of the 48th annual meeting of the association forcomputational linguistics pp. 1522–1531, Association for ComputationalLinguistics.
Radinsky, K., Agichtein, E., Gabrilovich, E. and Markovitch, S. (2011).A word at a time: computing word relatedness using temporal semanticanalysis.In Proceedings of the 20th international conference on World wide webWWW ’11 pp. 337–346, ACM, New York, NY, USA.
Reisinger, J. and Mooney, R. (2010).A Mixture Model with Sharing for Lexical Semantics.In Proceedings of the 2010 Conference on Empirical Methods in NaturalLanguage Processing pp. 1173–1182, Association for ComputationalLinguistics, Cambridge, MA.
Agirre (UBC) NLU using KBs and Random Walks July 2016 68 / 70

Conclusions
References IX
Stevenson, M., Agirre, E. and Soroa, A. (2011).Exploiting Domain Information for Word Sense Disambiguation of MedicalDocuments.Journal of the American Medical Informatics Association ,, 1–6.
Taghipour, K. and Ng, H. T. (2015).One Million Sense-Tagged Instances for Word Sense Disambiguation andInduction.In Proceedings of the Nineteenth Conference on Computational NaturalLanguage Learning pp. 338–344, Association for ComputationalLinguistics, Beijing, China.
Tsatsaronis, G., Varlamis, I. and Nørvag, K. (2010).An experimental study on unsupervised graph-based word sensedisambiguation.In Computational Linguistics and Intelligent Text Processing pp.184–198. Springer Berlin Heidelberg.
Agirre (UBC) NLU using KBs and Random Walks July 2016 69 / 70

Conclusions
References X
Yeh, E., Ramage, D., Manning, C., Agirre, E. and Soroa, A. (2009).WikiWalk: Random walks on Wikipedia for Semantic Relatedness.In ACL workshop ”TextGraphs-4: Graph-based Methods for NaturalLanguage Processing.
Agirre (UBC) NLU using KBs and Random Walks July 2016 70 / 70





























