Embed Size (px)
Citation preview

Natural Language Processing (CSE 490U):Generation: Translation & Summarization
Noah Smithc© 2017
University of [email protected]
March 6–8, 2017
1 / 68

No office hours Thursday.
2 / 68

analysisgeneration RNL
3 / 68

Natural Language Generation
The classical view: R is a meaning representation language.
I Often very specific to the domain.
I For a breakdown of the problem space and a survey, see Reiterand Dale (1997).
Today: considerable emphasis on text-to-text generation, i.e.,transformations:
I Translating a sentence in one language into another language
I Summarizing a long piece of text by a shorter one
I Paraphrase generation (Barzilay and Lee, 2003; Quirk et al.,2004)
4 / 68

Machine Translation
5 / 68

Warren Weaver to Norbert Wiener, 1947
One naturally wonders if the problem of translation could beconceivably treated as a problem in cryptography. When I look atan article in Russian, I say: ‘This is really written in English, but ithas been coded in some strange symbols. I will now proceed todecode.’
6 / 68

Evaluation
Intuition: good translations are fluent in the target language andfaithful to the original meaning.
Bleu score (Papineni et al., 2002):
I Compare to a human-generated reference translation
I Or, better: multiple references
I Weighted average of n-gram precision (across different n)
There are some alternatives; most papers that use them reportBleu, too.
7 / 68

Noisy Channel ModelsReview
A pattern for modeling a pair of random variables, X and Y :
source −→ Y −→ channel −→ X
I Y is the plaintext, the true message, the missing information,the output
I X is the ciphertext, the garbled message, the observableevidence, the input
I Decoding: select y given X = x.
y∗ = argmaxy
p(y | x)
= argmaxy
p(x | y) · p(y)
p(x)
= argmaxy
p(x | y)︸ ︷︷ ︸channel model
· p(y)︸︷︷︸source model
8 / 68

Noisy Channel ModelsReview
A pattern for modeling a pair of random variables, X and Y :
source −→ Y −→ channel −→ X
I Y is the plaintext, the true message, the missing information,the output
I X is the ciphertext, the garbled message, the observableevidence, the input
I Decoding: select y given X = x.
y∗ = argmaxy
p(y | x)
= argmaxy
p(x | y) · p(y)
p(x)
= argmaxy
p(x | y)︸ ︷︷ ︸channel model
· p(y)︸︷︷︸source model
9 / 68

Noisy Channel ModelsReview
A pattern for modeling a pair of random variables, X and Y :
source −→ Y −→ channel −→ X
I Y is the plaintext, the true message, the missing information,the output
I X is the ciphertext, the garbled message, the observableevidence, the input
I Decoding: select y given X = x.
y∗ = argmaxy
p(y | x)
= argmaxy
p(x | y) · p(y)
p(x)
= argmaxy
p(x | y)︸ ︷︷ ︸channel model
· p(y)︸︷︷︸source model
10 / 68

Noisy Channel ModelsReview
A pattern for modeling a pair of random variables, X and Y :
source −→ Y −→ channel −→ X
I Y is the plaintext, the true message, the missing information,the output
I X is the ciphertext, the garbled message, the observableevidence, the input
I Decoding: select y given X = x.
y∗ = argmaxy
p(y | x)
= argmaxy
p(x | y) · p(y)
p(x)
= argmaxy
p(x | y)︸ ︷︷ ︸channel model
· p(y)︸︷︷︸source model
11 / 68

Bitext/Parallel Text
Let f and e be two sequences in V† (French) and V† (English),respectively.
We’re going to define p(F | e), the probability over Frenchtranslations of English sentence e.
In a noisy channel machine translation system, we could use thistogether with source/language model p(e) to “decode” f into anEnglish translation.
Where does the data to estimate this come from?
12 / 68

IBM Model 1(Brown et al., 1993)
Let ` and m be the (known) lengths of e and f .Latent variable a = 〈a1, . . . , am〉, each ai ranging over {0, . . . , `}(positions in e).
I a4 = 3 means that f4 is “aligned” to e3.I a6 = 0 means that f6 is “aligned” to a special null symbol,e0.
p(f | e,m) =∑a1=0
∑a2=0
· · ·∑am=0
p(f ,a | e,m)
=∑
a∈{0,...,`}mp(f ,a | e,m)
p(f ,a | e,m) =
m∏i=1
p(ai | i, `,m) · p(fi | eai)
=1
`+ 1· θfi|eai
13 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s
14 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
15 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, 6, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
· 1
17 + 1· θwar|was
16 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, 6, 8, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
· 1
17 + 1· θwar|was ·
1
17 + 1· θnicht|not
17 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, 6, 8, 7, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
· 1
17 + 1· θwar|was ·
1
17 + 1· θnicht|not
· 1
17 + 1· θvoller|filled
18 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, 6, 8, 7, ?, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
· 1
17 + 1· θwar|was ·
1
17 + 1· θnicht|not
· 1
17 + 1· θvoller|filled ·
1
17 + 1· θProductionsfactoren|?
19 / 68

Example: f is German
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈4, 5, 6, 8, 7, ?, . . .〉
p(f ,a | e,m) =1
17 + 1· θNoahs|Noah’s ·
1
17 + 1· θArche|ark
· 1
17 + 1· θwar|was ·
1
17 + 1· θnicht|not
· 1
17 + 1· θvoller|filled ·
1
17 + 1· θProductionsfactoren|?
Problem: This alignment isn’t possible with IBM Model 1! Eachfi is aligned to at most one eai!
20 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null
21 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null
22 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, 1, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null ·
1
10 + 1· θNoah’s|Noahs
23 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, 1, 2, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null ·
1
10 + 1· θNoah’s|Noahs
· 1
10 + 1· θark|Arche
24 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, 1, 2, 3, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null ·
1
10 + 1· θNoah’s|Noahs
· 1
10 + 1· θark|Arche ·
1
10 + 1· θwas|war
25 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, 1, 2, 3, 5, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null ·
1
10 + 1· θNoah’s|Noahs
· 1
10 + 1· θark|Arche ·
1
10 + 1· θwas|war
· 1
10 + 1· θfilled|voller
26 / 68

Example: f is English
Mr President , Noah's ark was filled not with production factors , but with living creatures .
Noahs Arche war nicht voller Produktionsfaktoren , sondern Geschöpfe .
a = 〈0, 0, 0, 1, 2, 3, 5, 4, . . .〉
p(f ,a | e,m) =1
10 + 1· θMr|null ·
1
10 + 1· θPresident|null
· 1
10 + 1· θ,|null ·
1
10 + 1· θNoah’s|Noahs
· 1
10 + 1· θark|Arche ·
1
10 + 1· θwas|war
· 1
10 + 1· θfilled|voller ·
1
10 + 1· θnot|nicht
27 / 68

How to Estimate Translation Distributions?
This is a problem of incomplete data: at training time, we see eand f , but not a.
28 / 68

How to Estimate Translation Distributions?
This is a problem of incomplete data: at training time, we see eand f , but not a.
Classical solution is to alternate:
I Given a parameter estimate for θ, align the words.
I Given aligned words, re-estimate θ.
Traditional approach uses “soft” alignment.
29 / 68

“Complete Data” IBM Model 1
Let the training data consist of N word-aligned sentence pairs:
〈e(1)1 ,f (1),a(1)〉, . . . , 〈e(N),f (N),a(N)〉.Define:
ι(k, i, j) =
{1 if a
(k)i = j
0 otherwise
Maximum likelihood estimate for θf |e:
c(e, f)
c(e)=
N∑k=1
∑i:f
(k)i =f
∑j:e
(k)j =e
ι(k, i, j)
N∑k=1
m(k)∑i=1
∑j:e
(k)j =e
ι(k, i, j)
30 / 68

MLE with “Soft” Counts for IBM Model 1
Let the training data consist of N “softly” aligned sentence pairs,
〈e(1)1 ,f (1), 〉, . . . , 〈e(N),f (N)〉.
Now, let ι(k, i, j) be “soft,” interpreted as:
ι(k, i, j) = p(a(k)i = j)
Maximum likelihood estimate for θf |e:
N∑k=1
∑i:f
(k)i =f
∑j:e
(k)j =e
ι(k, i, j)
N∑k=1
m(k)∑i=1
∑j:e
(k)j =e
ι(k, i, j)
31 / 68

Expectation Maximization Algorithm for IBM Model 1
1. Initialize θ to some arbitrary values.
2. E step: use current θ to estimate expected (“soft”) counts.
ι(k, i, j)←θf(k)i |e
(k)j
`(k)∑j′=0
θf(k)i |e
(k)
j′
3. M step: carry out “soft” MLE.
θf |e ←
N∑k=1
∑i:f
(k)i =f
∑j:e
(k)j =e
ι(k, i, j)
N∑k=1
m(k)∑i=1
∑j:e
(k)j =e
ι(k, i, j)
32 / 68

Expectation Maximization
I Originally introduced in the 1960s for estimating HMMs whenthe states really are “hidden.”
I Can be applied to any generative model with hidden variables.
I Greedily attempts to maximize probability of the observabledata, marginalizing over latent variables. For IBM Model 1,that means:
maxθ
N∏k=1
pθ(f (k) | e(k)) = maxθ
N∏k=1
∑a
pθ(f (k),a | e(k))
I Usually converges only to a local optimum of the above,which is in general not convex.
I Strangely, for IBM Model 1 (and very few other models), it isconvex!
33 / 68

IBM Model 2(Brown et al., 1993)
Let ` and m be the (known) lengths of e and f .
Latent variable a = 〈a1, . . . , am〉, each ai ranging over {0, . . . , `}(positions in e).
I E.g., a4 = 3 means that f4 is “aligned” to e3.
p(f | e,m) =∑
a∈{0,...,n}mp(f ,a | e,m)
p(f ,a | e,m) =
m∏i=1
p(ai | i, `,m) · p(fi | eai)
= δai|i,`,m · θfi|eai
34 / 68

IBM Models 1 and 2, Depicted
x1 x2 x3 x4
hidden Markov model
y1 y2 y3 y4
f1 f2 f3 f4
IBM 1 and 2 a1 a2 a3 a4
e e e e
35 / 68

Variations
I Dyer et al. (2013) introduced a new parameterization:
δj|i,`,m ∝ exp−λ∣∣∣∣ im − j
`
∣∣∣∣(This is called fast align.)
I IBM Models 3–5 (Brown et al., 1993) introduced increasinglymore powerful ideas, such as “fertility” and “distortion.”
36 / 68

From Alignment to (Phrase-Based) Translation
Obtaining word alignments in a parallel corpus is a common firststep in building a machine translation system.
1. Align the words.
2. Extract and score phrase pairs.
3. Estimate a global scoring function to optimize (a proxy for)translation quality.
4. Decode French sentences into English ones.
(We’ll discuss 2–4.)
The noisy channel pattern isn’t taken quite so seriously when webuild real systems, but language models are really, reallyimportant nonetheless.
37 / 68

Phrases?
Phrase-based translation uses automatically-induced phrases . . .not the ones given by a phrase-structure parser.
38 / 68

Examples of PhrasesCourtesy of Chris Dyer.
German English p(f | e)
das Thema
the issue 0.41the point 0.72the subject 0.47the thema 0.99
es gibtthere is 0.96there are 0.72
morgen tomorrow 0.90
fliege ichwill I fly 0.63will fly 0.17I will fly 0.13
39 / 68
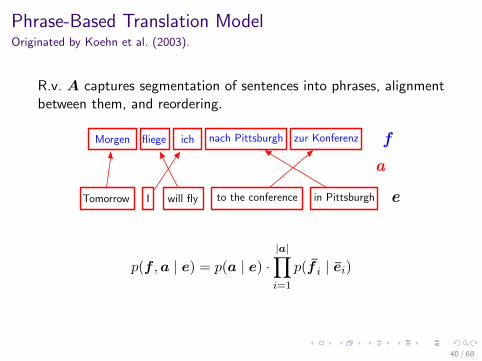
Phrase-Based Translation ModelOriginated by Koehn et al. (2003).
R.v. A captures segmentation of sentences into phrases, alignmentbetween them, and reordering.
to the conference
Morgen fliege ich nach Pittsburgh zur Konferenz
Tomorrow I will fly in Pittsburgh e
fa
p(f ,a | e) = p(a | e) ·|a|∏i=1
p(f i | ei)
40 / 68

Extracting Phrases
After inferring word alignments, apply heuristics.
41 / 68
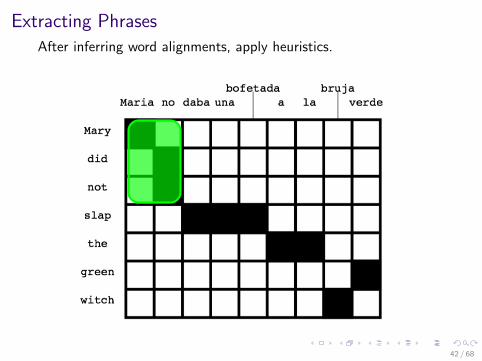
Extracting Phrases
After inferring word alignments, apply heuristics.
42 / 68
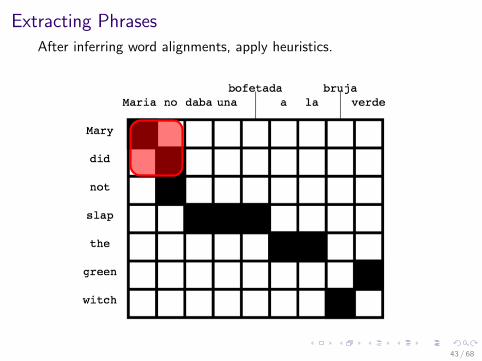
Extracting Phrases
After inferring word alignments, apply heuristics.
43 / 68
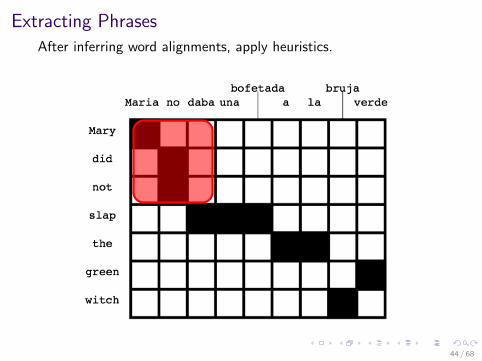
Extracting Phrases
After inferring word alignments, apply heuristics.
44 / 68
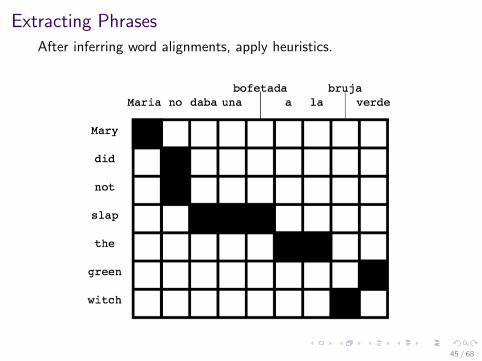
Extracting Phrases
After inferring word alignments, apply heuristics.
45 / 68
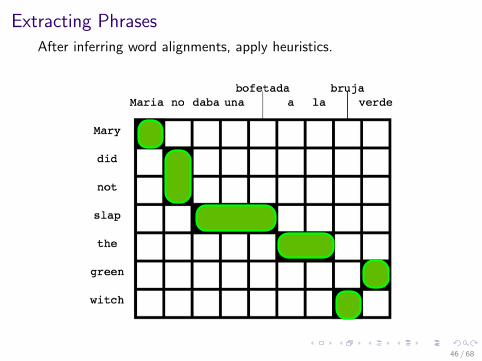
Extracting Phrases
After inferring word alignments, apply heuristics.
46 / 68
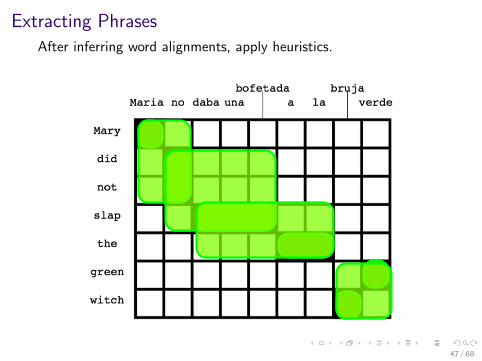
Extracting Phrases
After inferring word alignments, apply heuristics.
47 / 68
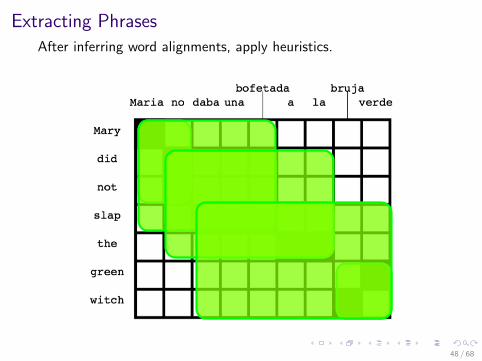
Extracting Phrases
After inferring word alignments, apply heuristics.
48 / 68

Scoring Whole Translations
s(e,a;f) = log p(e)︸ ︷︷ ︸language model
+ log p(f ,a | e)︸ ︷︷ ︸translation model
Remarks:
I Segmentation, alignment, reordering are all predicted as well(not marginalized).
I This does not factor nicely.
I I am simplifying!
I Reverse translation model typically included.I Each log-probability is treated as a “feature” and weights are
optimized for Bleu performance.
49 / 68

Scoring Whole Translations
s(e,a;f) = log p(e)︸ ︷︷ ︸language model
+ log p(f ,a | e)︸ ︷︷ ︸translation model
+ log p(e,a | f)︸ ︷︷ ︸reverse t.m.
Remarks:
I Segmentation, alignment, reordering are all predicted as well(not marginalized).
I This does not factor nicely.I I am simplifying!
I Reverse translation model typically included.
I Each log-probability is treated as a “feature” and weights areoptimized for Bleu performance.
50 / 68

Scoring Whole Translations
s(e,a;f) = βl.m. log p(e)︸ ︷︷ ︸language model
+βt.m. log p(f ,a | e)︸ ︷︷ ︸translation model
+ βr.t.m.log p(e,a | f)︸ ︷︷ ︸reverse t.m.
Remarks:
I Segmentation, alignment, reordering are all predicted as well(not marginalized).
I This does not factor nicely.I I am simplifying!
I Reverse translation model typically included.I Each log-probability is treated as a “feature” and weights are
optimized for Bleu performance.
51 / 68

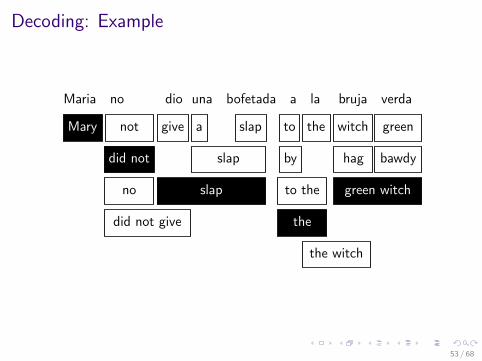
Decoding: Example
Maria no dio una bofetada a la bruja verdaMary not give a slap to the witch green
no
did not
did not give
slap
slap
by
to the
the
the witch
hag bawdy
green witch
52 / 68
Decoding: Example
Maria no dio una bofetada a la bruja verdaMary not give a slap to the witch green
no
did not
did not give
slap
slap
by
to the
the
the witch
hag bawdy
green witch
53 / 68
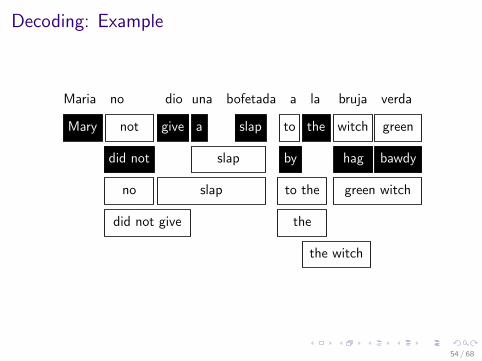
Decoding: Example
Maria no dio una bofetada a la bruja verdaMary not give a slap to the witch green
no
did not
did not give
slap
slap
by
to the
the
the witch
hag bawdy
green witch
54 / 68

DecodingAdapted from Koehn et al. (2006).
Typically accomplished with beam search.
Initial state: 〈◦ ◦ . . . ◦︸ ︷︷ ︸|f |
, “”〉 with score 0
Goal state: 〈• • . . . •︸ ︷︷ ︸|f |
, e∗〉 with (approximately) the highest score
Reaching a new state:
I Find an uncovered span of f for which a phrasal translationexists in the input (f , e)
I New state appends e to the output and “covers” f .
I Score of new state includes additional language model,translation model components for the global score.
55 / 68

Decoding Example
Maria no dio una bofetada a la bruja verdaMary not give a slap to the witch green
no
did not
did not give
slap
slap
by
to the
the
the witch
hag bawdy
green witch
〈◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦, “”〉, 0
56 / 68

Decoding Example
Maria no dio una bofetada a la bruja verdaMary not give a slap to the witch green
no
did not
did not give
slap
slap
by
to the
the
the witch
hag bawdy
green witch
〈• ◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦, “Mary”〉, log pl.m.(Mary) + log pt.m.(Maria | Mary)
57 / 68
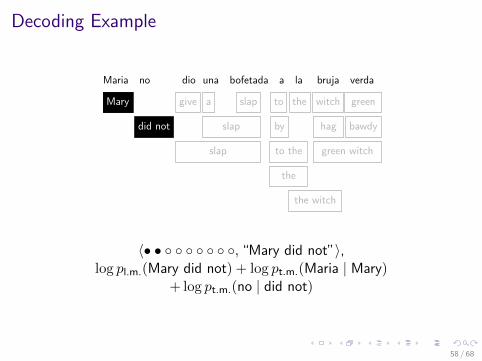
Decoding Example
Maria no dio una bofetada a la bruja verdaMary give a slap to the witch green
did not slap
slap
by
to the
the
the witch
hag bawdy
green witch
〈• • ◦ ◦ ◦ ◦ ◦ ◦ ◦, “Mary did not”〉,log pl.m.(Mary did not) + log pt.m.(Maria | Mary)
+ log pt.m.(no | did not)
58 / 68

Decoding Example
Maria no dio una bofetada a la bruja verdaMary to the witch green
did not
slap
by
to the
the
the witch
hag bawdy
green witch
〈• • • • • ◦ ◦ ◦ ◦, “Mary did not slap”〉,log pl.m.(Mary did not slap) + log pt.m.(Maria | Mary)
+ log pt.m.(no | did not) + log pt.m.(dio una bofetada | slap)
59 / 68

Machine Translation: Remarks
Sometimes phrases are organized hierarchically (Chiang, 2007).
Extensive research on syntax-based machine translation (Galleyet al., 2004), but requires considerable engineering to matchphrase-based systems.
Recent work on semantics-based machine translation (Jones et al.,2012); remains to be seen!
Neural models have become popular and are competitive (e.g.,Devlin et al., 2014); impact remains to be seen!
Some good pre-neural overviews: Lopez (2008); Koehn (2009)
60 / 68

Summarization
61 / 68

Automatic Text Summarization
Survey from before statistical methods came to dominate: Mani,2001
Parallel history to machine translation:
I Noisy channel view (Knight and Marcu, 2002)
I Automatic evaluation (Lin, 2004)
Differences:
I Natural data sources are less obvious
I Human information needs are less obvious
We’ll briefly consider two subtasks: compression and selection
62 / 68

Sentence Compression as Structured Prediction(McDonald, 2006)
Input: a sentence
Output: the same sentence, with some words deleted
McDonald’s approach:I Define a scoring function for compressed sentences that
factors locally in the output.I He factored into bigrams but considered input parse tree
features.
I Decoding is dynamic programming (not unlike Viterbi).
I Learn feature weights from a corpus of compressed sentences,using structured perceptron or similar.
63 / 68

Sentence Selection
Input: one or more documents and a “budget”
Output: a within-budget subset of sentences (or passages) fromthe input
Challenge: diminishing returns as more sentences are added tothe summary.
Classical greedy method: “maximum marginal relevance”(Carbonell and Goldstein, 1998)
Casting the problem as submodular optimization: Lin and Bilmes(2009)
Joint selection and compression: Martins and Smith (2009)
64 / 68

To-Do List
I Course evaluation due March 12!
I Collins (2011, 2013)
I Assignment 5 due Friday
65 / 68

References I
Regina Barzilay and Lillian Lee. Learning to paraphrase: an unsupervised approachusing multiple-sequence alignment. In Proc. of NAACL, 2003.
Peter F. Brown, Vincent J. Della Pietra, Stephen A. Della Pietra, and Robert L.Mercer. The mathematics of statistical machine translation: Parameter estimation.Computational Linguistics, 19(2):263–311, 1993.
Jaime Carbonell and Jade Goldstein. The use of MMR, diversity-based reranking forreordering documents and producing summaries. In Proc. of SIGIR, 1998.
David Chiang. Hierarchical phrase-based translation. computational Linguistics, 33(2):201–228, 2007.
Michael Collins. Statistical machine translation: IBM models 1 and 2, 2011. URLhttp://www.cs.columbia.edu/~mcollins/courses/nlp2011/notes/ibm12.pdf.
Michael Collins. Phrase-based translation models, 2013. URLhttp://www.cs.columbia.edu/~mcollins/pb.pdf.
Jacob Devlin, Rabih Zbib, Zhongqiang Huang, Thomas Lamar, Richard M. Schwartz,and John Makhoul. Fast and robust neural network joint models for statisticalmachine translation. In Proc. of ACL, 2014.
Chris Dyer, Victor Chahuneau, and Noah A Smith. A simple, fast, and effectivereparameterization of IBM Model 2. In Proc. of NAACL, 2013.
Michel Galley, Mark Hopkins, Kevin Knight, and Daniel Marcu. What’s in atranslation rule? In Proc. of NAACL, 2004.
66 / 68

References II
Bevan Jones, Jacob Andreas, Daniel Bauer, Karl Moritz Hermann, and Kevin Knight.Semantics-based machine translation with hyperedge replacement grammars. InProc. of COLING, 2012.
Kevin Knight and Daniel Marcu. Summarization beyond sentence extraction: Aprobabilistic approach to sentence compression. Artificial Intelligence, 139(1):91–107, 2002.
Philipp Koehn. Statistical Machine Translation. Cambridge University Press, 2009.
Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-basedtranslation. In Proc. of NAACL, 2003.
Philipp Koehn, Marcello Federico, Wade Shen, Nicola Bertoldi, Ondrej Bojar, ChrisCallison-Burch, Brooke Cowan, Chris Dyer, Hieu Hoang, and Richard Zens. Opensource toolkit for statistical machine translation: Factored translation models andconfusion network decoding, 2006. Final report of the 2006 JHU summer workshop.
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Proc. ofACL Workshop: Text Summarization Branches Out, 2004.
Hui Lin and Jeff A. Bilmes. How to select a good training-data subset fortranscription: Submodular active selection for sequences. In Proc. of Interspeech,2009.
Adam Lopez. Statistical machine translation. ACM Computing Surveys, 40(3):8, 2008.
Inderjeet Mani. Automatic Summarization. John Benjamins Publishing, 2001.
67 / 68

References III
Andre FT Martins and Noah A Smith. Summarization with a joint model for sentenceextraction and compression. In Proc. of the ACL Workshop on Integer LinearProgramming for Natural Langauge Processing, 2009.
Ryan T. McDonald. Discriminative sentence compression with soft syntactic evidence.In Proc. of EACL, 2006.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method forautomatic evaluation of machine translation. In Proc. of ACL, 2002.
Chris Quirk, Chris Brockett, and William B. Dolan. Monolingual machine translationfor paraphrase generation. In Proc. of EMNLP, 2004.
Ehud Reiter and Robert Dale. Building applied natural-language generation systems.Journal of Natural-Language Engineering, 3:57–87, 1997. URLhttp://homepages.abdn.ac.uk/e.reiter/pages/papers/jnle97.pdf.
68 / 68





























