Embed Size (px)
Citation preview

1
Multicore DSPs – Karol Desnos ([email protected])
MULTICORE DIGITAL
SIGNAL PROCESSING
Maxime Pelcat – [email protected]
Slides from M. Pelcat, K. Desnos, J.-F. Nezan, D.
Ménard, M. Raulet, J. Gorin, F. Pescador

3
Multicore DSPs – Karol Desnos ([email protected])
Design Challenges for MPSoC-Based Systems
• Exploit architecture parallelism
• Express application parallelism
• Balance computational load on PEs
• Hardware/Software co-design process
• Complex design-space exploration
• Respect constraints
• Predict/guarantee application performances
• Reuse legacy code
Previously on MDSPs

4
Multicore DSPs – Karol Desnos ([email protected])
Grail of Heterogeneous MPSoCs Programming
Previously on MDSPs
Multicore Compiler
Simulator
+ Debugger
+ Profiler
Algorithm
Architecture
Portable Multicore Program
PE
Main
Proc.
Main
Proc.
Main
Proc.
Main
Proc.
PE PE PE PE
Peripherals
Main
Memory
Multicore Runtime

5
Multicore DSPs – Karol Desnos ([email protected])
Properties
• Synchronous Dataflow (SDF)
• Data-driven execution: An actor is fired when its input FIFOs contain
enough data-tokens.
Previously on MDSPs
B
A C D E
Core1 A B C C D E
2
2
1
1
1 2 1 1
Source: E. Lee and D. Messerschmitt, “Synchronous data flow”, Proceedings of the IEEE, 1987.

6
Multicore DSPs – Karol Desnos ([email protected])
Properties
• Synchronous Dataflow (SDF)
• Parallelisms: / / /
Previously on MDSPs
Source: E. Lee and D. Messerschmitt, “Synchronous data flow”, Proceedings of the IEEE, 1987.
2
2
1
1
1 2 1 1
B
A C D E
Core1
Core2
Core3
x2
A B C C E A C +1 +1
B C +1 +1
D E +1 +1
D
Task parallelism Data parallelism Pipeline parallelism Internal parallelism
Data Pipeline Internal Task

7
Multicore DSPs – Karol Desnos ([email protected])
• Lecture 1 – Maxime Pelcat
• Introduction to the course
• Applications for MDSPs
• Lecture 2 – Karol Desnos
• Languages and MoCs
• Programming MPSoCs
• Dataflow MoCs
• Lecture 3 – Maxime Pelcat
• Hardware Architectures
Course Outline

8
Multicore DSPs – Karol Desnos ([email protected])
• Lecture 4 – Karol Desnos
• Theoretical Bounds
• Mapping/Scheduling Strategies
• Lecture 5 – Karol Desnos
• Lab Session
Course Outline

10
Multicore DSPs – Karol Desnos ([email protected])
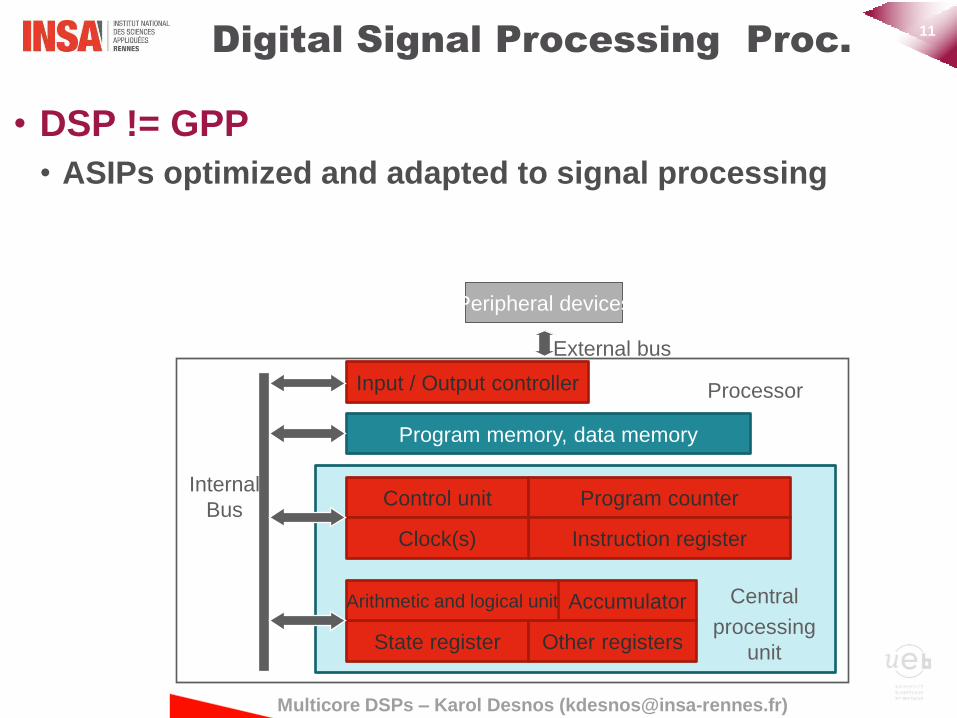
Von Neumann Architecture
Program memory, data memory
Input / Output controller
Control unit Program counter
Instruction register Clock(s)
State register
Accumulator
Other registers
Arithmetic and logical unit Central
processing unit
Peripheral devices
Internal
Bus
External bus
Processor
11
Multicore DSPs – Karol Desnos ([email protected])
• DSP != GPP
• ASIPs optimized and adapted to signal processing
Digital Signal Processing Proc.
Program memory, data memory
Input / Output controller
Control unit Program counter
Instruction register Clock(s)
State register
Accumulator
Other registers
Arithmetic and logical unit Central
processing
unit
Peripheral devices
Internal
Bus
External bus
Processor

14
Multicore DSPs – Karol Desnos ([email protected])
• GP-GPU != GPP != DSP
• Control units are shared in a cluster
GP-GPU

15
Multicore DSPs – Karol Desnos ([email protected])
• Processor types :
• Microcontroller
• Digital Signal Processors (DSP)
• General purpose processors (GPP)
• GP-GPU (General-Purpose Processing on Graphics
Processing Units)
• Choice factors:
• Price (architecture complexity, production technology)
• Power consumption
• CPU Performances
• I/O performances
• Memory capacity (data/code)
Processor Types
+ Programmability

16
Multicore DSPs – Karol Desnos ([email protected])
• Optimization of the compilation and instruction set
for signal processing and real-time
• Memory Management Unit (MMU)
• In DSPs, any memory is accessed by addresses:
registers, stack, heap, OS memory…
• Advanced OS need pagination: a virtual memory space in
pages
• The MMU converts the virtual addresses into the physical
addresses of the hardware
• The MMU can protect memory spaces from unwanted
accesses
• Kalray VLIW core is an exception: a DSP with MMU
DSP Cores vs. GPP

17
Multicore DSPs – Karol Desnos ([email protected])
• SoC are everywhere
• Microcontroller Timer
• Digital Signal Processors DMA + co-processors
• General purpose processors video co-processors
• GP-GPU many-cores
• Interconnects are complex
• Bus + arbiter
• Crossbar
• NoC
System-on-Chip

19
Multicore DSPs – Karol Desnos ([email protected])
TI Processors and Applications
Digital Media
Processors
OMAP
Applications
Processors
C6000
Digital Signal
Processors
C5000
Digital Signal
Processors
C2000
Microcontrollers
MSP430
Microcontrollers
Stellaris 32-Bit
ARM Cortex-M3
MCUs
Audio
Automotive
Communications
Industrial
Medical
Security
Video
Wireless
Key Feature Complete tailored
video solution
Low power and
high performance
High
performance
Power-efficient
performance
Performance,
integration for
greener industrial
applications
Ultra-low power Open architecture
software, rich
communications
options
Source: TI

20
Multicore DSPs – Karol Desnos ([email protected])
• Locosto (TCS2305)
• Very cheap ARM7 CPU + c54x
• 65-nm technology telephone functionalities
Low cost System-on chip

21
Multicore DSPs – Karol Desnos ([email protected])
• Da Vinci
TMS320DM642
• 1 DSP tms320c64x
(720MHz max)
Video I/O
Video Processing DSP

22
Multicore DSPs – Karol Desnos ([email protected])
• Da Vinci TMS320DM644x
• 1 DSP tms320c64x+ (720MHz max) Video I/O for screen
• 1 ARM9 1 Video Accelerator
Video Processing DSP

23
Multicore DSPs – Karol Desnos ([email protected])
• OMAP 4 Platform: OMAP4430/OMAP4440
• 2 General purpose ARM Cortex A9 cores (1GHz)
• IVA Supporting 1080p video encoding/decoding
Smartphone System on Chip

24
Multicore DSPs – Karol Desnos ([email protected])
• Samsung Exynos 5
• 4 General purpose ARM Cortex A7 cores
• 4 General purpose ARM Cortex A15 cores
• Supporting 4K video encoding/decoding
Smartphone System on Chip

25
Multicore DSPs – Karol Desnos ([email protected])
• Less than 2W:
• Limited dissipation
problem
• 2 to 7W:
• heat sink and hot spot
management
• 7W+:
• heat sink, fan and complex
hot spot management
Power Dissipation

26
Multicore DSPs – Karol Desnos ([email protected])
• Frequency increase power consumption heat
• heat need for cooling, more faults, reduced longevity
• Power = capacity x voltage2 x frequency
• But augmenting frequency augments leakage so voltage
must be higher
• Frequency x1.5 Power x2 on Freescale MPC8641 1
• Cores x2 Power x1.3 on Freescale MPC8641 1
• Moreover, augmenting frequency requires longer pipeline
Why Go Multicore?
Source:Freescale « Embedded Multicore: An Introduction»

27
Multicore DSPs – Karol Desnos ([email protected])
• To increase MIPS and limit Watts
• Increase number of core instead than frequency
Why Go Multicore?
Embedded
FPGA
EE : Efficiency : OPS / Watt
Reconfigurable
Processor
Embedded
Processor
SA-110
400 MOPS/W
DSP
DSP
3 GOPS/W
Pleiades
10-50 GOPS/W
ASIC
1 TOPS/W
1 100
Fle
xib
ilit
y
10
ASIP
TI C6678
~20 GOPS / W
Multicore DSP

28
Multicore DSPs – Karol Desnos ([email protected])
• But new GPPs are good on energy
• Exynos 5420
• 109 Gflops @ 8W
• 13.5 Gflop/W
• Comparing to HPC
Why Go Multicore?

29
Multicore DSPs – Karol Desnos ([email protected])
• 3 types of heterogeneity
• Non uniform cores implementing different instruction
sets
• Combining software cores with hardware IPs
• Non uniform communication performance
• Heterogeneity improves performance
• Repetitive and costly actors can be efficiently computed
by hardware logic (ASIC)
• Actors with some control and reconfiguration needs are
suited for DSPs
• Control tasks with many conditions are suited to be run
on GPP
Why Go Heterogeneous?

30
Multicore DSPs – Karol Desnos ([email protected])
• Towards multicore DSPs
• TCI6488: Tri-core Telecommunication oriented DSP
• Up to 1GHz/24GOPS, each core is programmed
independantly, 3MB L2 memory
TMS320TCI6488 (2007)
Source:TI

31
Multicore DSPs – Karol Desnos ([email protected])
TMS320TCI6488 (2007)
Source:TI
L2 RAM
Core
Core
Core
Switch
FabricCoprocessors
and
Peripherals

32
Multicore DSPs – Karol Desnos ([email protected])
• TCI6486: Exa-core Telecommunication oriented
DSP
• Up to 700MHz, Each core is programmed independantly,
4.4MB L2 memory, I/O driven by EDMA and shared 768 kB
TMS320TCI6486 (2008)
Source:TI

35
Multicore DSPs – Karol Desnos ([email protected])
• TCI6678: Octo-core DSP demo
• Up to 1.25GHz/320 GMACs/160 GFlops
• 8MB L2 memory
• I/O and IPCdriven by Multi-core Navigator
• Fixed and floating-point ALUs
TMS320C6678 – Keystone I (2011)
Source:TI
16 fixed multipliescycle (per side)
4 floating multipliesper cycle (per side)
C66x DSP .M C66x
A B
D
Registerfile
L
S M
D
Registerfile
L
S M
16x16MPY
16x16MPY
16x16MPY
16x16MPY
Float
16x16MPY
16x16MPY
16x16MPY
16x16MPY
Float
16x16MPY
16x16MPY
16x16MPY
16x16MPY
Float
16x16MPY
16x16MPY
16x16MPY
16x16MPY
Float
Adders

37
Multicore DSPs – Karol Desnos ([email protected])
• 8 C66x @ 1.2GHz
• 38.4 GMacs/Core for Fixed Point
• 19.2 GFlops/Core for Floating Point
• Memory
• 1MB Local L2 Per Core
• 6 MB MSM SRAM Memory Shared by 8 DSPs
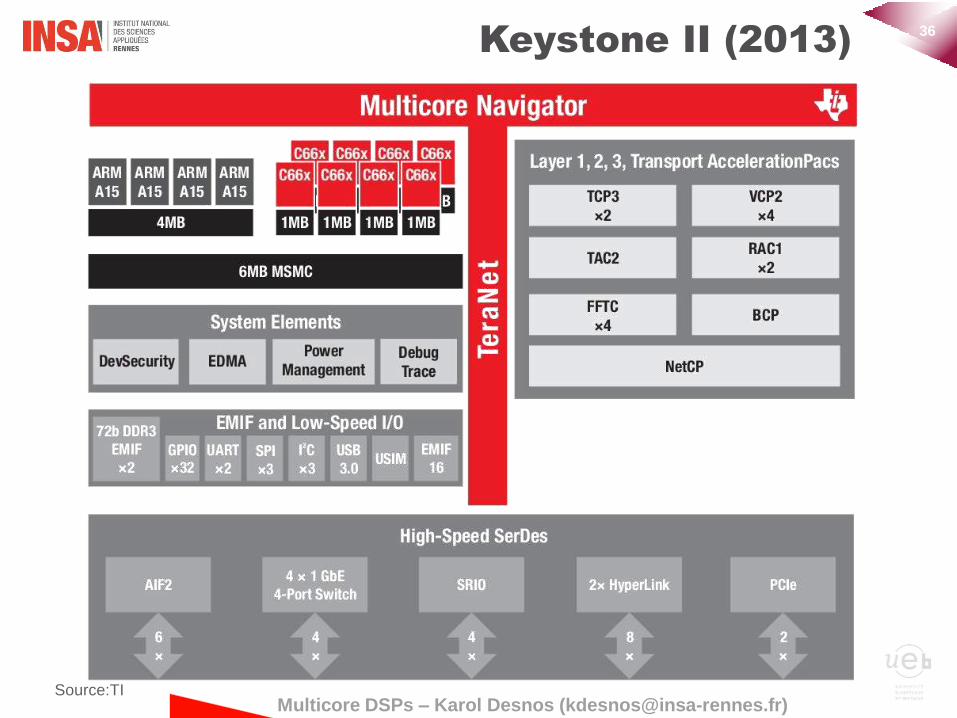
• ARM Cortex A15 Quad Core Cluster @ 1.2GHz
• 4MB L2 Cache Memory Shared by Quad Core
• Multicore Navigator
• 16k Multi-purpose Hardware Queues with hardware queue
manager
TMS320TCI6636 Keystone II (2013)
Source:TI

38
Multicore DSPs – Karol Desnos ([email protected])
Freescale MSC8144 Starcore (2009)
Source: Freescale

39
Multicore DSPs – Karol Desnos ([email protected])
Kalray MPPA (2013)
Source: Kalray
Shared memory costs much energy
Putting a NoC at high level instead

41
Multicore DSPs – Karol Desnos ([email protected])
EVM: Evaluation Module for the TMS320C6678
• Advantech Board TDMSEVM6678L
Demo Setup

42
Multicore DSPs – Karol Desnos ([email protected])
EVM: Evaluation Module for the TMS320C6678
Demo Setup
ECC = Error Correcting Code (Physically more than 512MB)
MMC = Module Management Controller (control of the Advanced Mezzanine Card)
EMU = TI 60-pin JTAG connector for XDS560v2
PCIE = Peripheral Component Interconnect Express
SGMII = Serial Gigabit Media Independent Interface (Connected to Ethernet Phy)
I2C = Inter Integrated Circuit (control bus by NXP)

43
Multicore DSPs – Karol Desnos ([email protected])
Board Features
• 8-Core DSP • 8 C66x DSP Core Subsystems (C66x CorePacs), Each with:
• – 1.0 GHz or 1.25 GHz C66x Fixed/Floating-Point CPU Core
40 GMAC/Core for Fixed Point @ 1.25 GHz
20 GFLOP/Core for Floating Point @ 1.25 GHz
• – 2 levels of Core Memory
32K Byte L1P Per Core
32K Byte L1D Per Core
512K Byte Local L2 Per Core
• 4 MB of Internal Shared Memory • Multicore Shared Memory Controller (MSMC)
• L1D and L1P with automatic cache coherency in local
• Non coherent cache of the shared memory
• Unified memory space for internal/external memory
Demo Setup

44
Multicore DSPs – Karol Desnos ([email protected])
Board Features
• 512 MB of Shared DDR3 on the emulation board
• Any core can access DDR3, 8G Byte of DDR3 Addressable Memory
• Hardware coprocessors • For repetitive common operations
• Reduced because multi-purpose processor
• Cryptography
• Network
• XDS510 JTAG • via USB
• Possibility to extend to XDS560 via extension
• Packaging • 40nm technology, 841-Pin Flip-Chip Plastic BGA (CYP)
Demo Setup

45
Multicore DSPs – Karol Desnos ([email protected])
Board Features
• KeyStoneTeraNet switch fabric (Network on Chip)
• Core Interrupt Controller
• Enhanced Direct Memory Access v3 (EDMA3) • Data movement
• Like a core with only MOV instructions
• Multicore Navigator • 8192 Multipurpose Hardware Queues with Queue Manager
• Data movement or zero-copy
• Shared MSMC and DDR3 • Data movement or zero-copy
Demo Setup

46
Multicore DSPs – Karol Desnos ([email protected])
Board Features: Inputs/Outputs
• Four Lanes of SRIO 2.1 • 1.24 to 5 GBaud Operation Supported Per Lane up to 20 Gbauds
• PCIe Gen2 • Single port supporting 1 or 2 lanes
• Supports Up To 5 GBaud Per Lane up to 10 Gbauds
• HyperLink • Supports Connections to Other KeyStone up to 50 Gbauds
• Architecture Devices Providing Resource Scalability
• Gigabit Ethernet (GbE) Switch Subsystem • Two SGMII Ports
• Supports 10/100/1000 Mbps operation up to 2 Gbps
• Other ports • UART Interface, I2C Interface, 16 GPIO Pins, SPI Interface
• Remark: Uncompressed 1920x1080 4:2:0 video @ 60Hz = 1.5 Gbps
Demo Setup

47
Multicore DSPs – Karol Desnos ([email protected])
Inter-core communications
• Multicore Navigator
• Queue Manager Subsystem (QMSS)
• Packet DMA (PKTDMA) for Zero-Overhead Transfers
• Packet passing system between cores
• Abstracts real data transfer
• Open Event Machine
• Software runtime system provided by TI to offload code on cores
• Event driven processing runtime for multicore
Demo Setup

49
Multicore DSPs – Karol Desnos ([email protected])
Inter-core communications
Demo Setup
256-bit VLIW
Data switch fabric
+ Configuration Switch
fabric
(not shown)

50
Multicore DSPs – Karol Desnos ([email protected])
Cache configuration 1
• L2 can cache MSMC and external DDR3
Demo Setup
core
L1D
L2
MSMC DDR3
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
L1
L2
L3

51
Multicore DSPs – Karol Desnos ([email protected])
Cache configuration 2
• L2 can cache only external DDR3
• MSMC is then Layer 2 memory
Demo Setup
core
L1D
MSMC
DDR3
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
L1
L2
L3
L2
L2

52
Multicore DSPs – Karol Desnos ([email protected])
Cache configuration 3
• L2 cache is deactivated
• MSMC is then Layer 2 memory
Demo Setup
core
L1D
MSMC
DDR3
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
core
L1D
L2
L1
L2
L2
L2
L2

53
Multicore DSPs – Karol Desnos ([email protected])
• Cache behavior and terms
• A cache hit means Ln-1 cache memory already contained the data
requested from Ln
• A cache miss means a cache line must be copied from Ln to Ln-1
• A cache victim line is a line that must be « written back » because of
a cache miss requesting a new line
• A cache line must be invalidated when the memory it caches
changes. If the same data is requested, it must be reloaded in cache
• Before being loaded from Ln memory, a cached data must be written
back from Ln-1 cache memory
Cache Configurations

54
Multicore DSPs – Karol Desnos ([email protected])
• Cache operations
• The L1 has automatic cache coherence if local L2 is modified
• L1 has no automatic cache coherence if non local memory is modified
• L2 has no automatic cache coherency
L1 and L2 cache « write back » and « invalidate » must be called
Cache Configurations
Core Shared L2 cache L1 cache
Core
or DMA
Store to external memory
Core Shared L2 cache L1 cache
Core
or DMA Load from external memory
Write back
Invalidate

55
Multicore DSPs – Karol Desnos ([email protected])
• Caches have a strong effect on memory latency
Cache Configurations
Single
Read Single
Read Burst Read Burst Read
L1 Cache L2 Cache XMC
Prefetch No Victim Victim No Victim Victim
All Hit NA NA 0 NA 0 NA
Local L2 Miss NA NA 7 7 3,5 10
MSMC
(SL2) Miss NA Hit 7,5 7,5 7,4 11
MSMC
(SL2) Miss NA Miss 19,8 20,1 9,5 11,6
MSMC
(SL3) Miss Hit NA 9 9 4,5 4,5
MSMC
(SL3) Miss Miss Hit 10,6 15,6 9,7 129,6
MSMC
(SL3) Miss Miss Miss 22 28,1 11 129,7
DDR (SL2) Miss NA Hit 9 9 23,2 59,8
DDR (SL2) Miss NA Miss 84 113,6 41,5 113
DDR (SL3) Miss Hit NA 9 9 4,5 4,5
DDR (SL3) Miss Miss Hit 12,3 59,8 30,7 287
DDR (SL3) Miss Miss Miss 89 123,8 43,2 183

64
Multicore DSPs – Karol Desnos ([email protected])
Parallelisms
Overhead
Operation size
small
large
small large
Perfect world
ILP
SIMD
SW Pipe.
Cores + interconnect
Chips + L/WAN
Threads

65
Multicore DSPs – Karol Desnos ([email protected])
DPS Evolution
1980 1985 1990 1995 2000 2005 2010 201510
0
101
102
103
104
105
TMS320C20 (5 MIPS)
TMS320C10 (2.5 MIPS)
DSP56001 (13MIPS)
ADSP21xx (13MIPS)
TMS320C50 First generation
Second generation
Improved conventional architecture
Conventional architecture
Third generation
Fourth generation
Fifth generation
No
rmal
ized
per
form
ance
Years
MAC Multi- MAC VLIW Multi Pro. SoCs
High performance
DSP
Low power
DSP
DSP56301 TMS320C54x (100MIPS)
ADSP2183 (50MIPS)
VLIW SWP TMS320C62x
StareCore TigerSharc
Multi-core VLIW SWP
TMS320C66x (8 cores) MSC815x (6cores)
SIMD
SW Pipelining
Cores + interconnection
Multi Cores
H-MPSoCs Many
Cores
OMAPx (ARM+C64) SC8144 (4cores)
Sixth generation
Heterogeneous multicores with HW accelerators

66
Multicore DSPs – Karol Desnos ([email protected])
• SIMD: Splitting ALU into subparts
• Example: 2 16-bit additions on a 32-bit adder
• Increases the number of instructions
• X86 MMX, SSE, AVX
• C66x 32-bit vector processing
Single Instruction Multiple Data
16 bits
x,+,-
16 bits 16 bits
x,+,-
16 bits
16 bits 16 bits
32-bit word 32-bit word

67
Multicore DSPs – Karol Desnos ([email protected])
• VLIW: Very Long Instruction Word
• Architecture made-up of parallel FUs
• Several instructions par cycle embedded in a macro-
instruction
• Uniform register file made-up of several register
Architecture for Software Pipelining

68
Multicore DSPs – Karol Desnos ([email protected])
C64x Software Pipelining
MPY ADD MPY ADD MV STW ADD ADD
MPY ADD SHL SUB STW STW ADDK B
ADD LDW SUB LDW B MVK NOP NOP
MPY ADD MPY ADD STW STW ADDK NOP
256
Functional
Unit
.D2
Functional
Unit
.M2
Functional
Unit
.S2
Functional
Unit
.L2
Register File B
Functional
Unit
.L1
Functional
Unit
.S1
Functional
Unit
.M1
Functional
Unit
.D1
Register File A
Data Memory Controller
Internal Memory
Data Address 1 Data Address 2
Fetch
Dispatch Unit
32x8=256 bits
L:ALU
S:Shift+ALU
M:Multplier
D:Address U

69
Multicore DSPs – Karol Desnos ([email protected])
WLIV Compiler: Loop unrolling
LOAD
MULT
ACC
LOAD
MULT
ACC
LOAD
MULT
ACC
100%
N/3
Processor usage rate
For(i=0;i<N;i++)
{ ACC=ACC + x[i].h[i]
}
For(i=0;i<N;i+=3)
{
ACC=ACC + x[i].h[i]
ACC=ACC + x[i+1].h[i+1]
ACC=ACC + x[i+2].h[i+2]
}

71
Multicore DSPs – Karol Desnos ([email protected])
• Limitation in software parallelism
• SIMD is limited to vector operations
• VLIW is limited to instruction parallelism
• VLIW compilers can not address efficiently more than 8
ALUs
Architecture for Software Pipelining

72
Multicore DSPs – Karol Desnos ([email protected])
• Maths
• Matlab
Convolution code, VLIW and SIMD
1
0
)mod)(()()(
N
l
NklClZkY
function z = circonv(x, y);
N = length(x);
for n=1:N
z(n) = sum(x.*circshift(y,n-1));
end

73
Multicore DSPs – Karol Desnos ([email protected])
• Maths
• C
Convolution code, VLIW and SIMD
1
0
)mod)(()()(
N
l
NklClZkY

74
Multicore DSPs – Karol Desnos ([email protected])
• Maths
• C with intrinsics
Convolution code, VLIW and SIMD
1
0
)mod)(()()(
N
l
NklClZkY

75
Multicore DSPs – Karol Desnos ([email protected])
• C: 4,4Mcycles:
• 4,3 op/cycle
• Intr: 2Mcycles:
• 9.4 op/cycle
• +118% performance
• Even with 8 ALUs, the
compiler has
difficulties to use
SIMD and VLIW
Convolution code, VLIW and SIMD
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
4500000
5000000
240 300 600 1200
C code
Intrinsics
Tendency (3*size²)
1
0
)mod)(()()(
N
l
NklClZkY
N=1200:
5.8 Mloads 16b
7.2Madds 16b
5.8Mmults 16b

76
Multicore DSPs – Karol Desnos ([email protected])
Parallelisms
Overhead
Operation size
small
large
small large
Perfect world
ILP
SIMD
SW Pipe.
Cores + interconnect
Chips + L/WAN
Threads
1
2
3
Cluster?

77
Multicore DSPs – Karol Desnos ([email protected])
• In order to use core-level parallelism
• Manage Inter-Processor Communication
Inter-Processor Communication
Multicore Compiler
Algorithm
Architecture
Portable Multicore Program
+ IPC

79
Multicore DSPs – Karol Desnos ([email protected])
• Porting a signal processing dataflow application
on a multicore
• Transmit tokens from one core to another
• via inter-processor communication or shared memory
• Cores: asynchronous independent machines
• Timings are unpredictable due to caches and
interruptions
• Communication protocol
• Signal that the receiver is ready for reception
• Make the token available
• Signal that the token is available
Inter-processor communication

80
Multicore DSPs – Karol Desnos ([email protected])
• Transmitting one token
• via inter-processor communication or shared memory
• Direct Signaling
• Interrupting a core from another core to either push or
pull data
• Indirect Signaling
• Delegating the transmission to a DMA (Direct Memory
Access) element
• Atomic arbitration
• Shared buffer access and semaphores
Inter-processor communication

81
Multicore DSPs – Karol Desnos ([email protected])
Snd Rcv
data-driven demand-driven
Direct Signaling Communication
Rcv Snd
Interrupt
Push data via IPC
notify
Interrupt
notify
Pull data via IPC

82
Multicore DSPs – Karol Desnos ([email protected])
demand-driven
• Distributed or shared memory
• In demand-driven case, first interrupt maybe avoided
• if core A is constantly demanding data and core B cannot erase data
befor e it is consumed (or if data can be discarded)
• Inter-Processor communication can be ethernet, SRIO…
Direct Signaling Communication
Rcv Snd
Interrupt
Push data via IPC
notify
Snd Rcv
Interrupt
Pull data via IPC
notify
data-driven

83
Multicore DSPs – Karol Desnos ([email protected])
Demand driven
Indirect Signaling Communication
Program
Move data
Interrupt
notify notify
Rcv DMA
Move data
Snd
Interrupt
notify notify
Snd DMA Rcv
Data driven
Program

84
Multicore DSPs – Karol Desnos ([email protected])
Demand driven
• Distributed or shared memory
• DMA must be able to access the whole memory space
• DMA is another master on the memory bus
• Cores A and B are free to compute during DMA transfer
Indirect Signaling Communication
Data driven
Snd DMA
Program
Move data
notify
Rcv
Interrupt
notify
Rcv DMA
Program
Move data
notify
Snd
Interrupt
notify

85
Multicore DSPs – Karol Desnos ([email protected])
• Protecting shared memory by semaphores
• 1-place FIFO
• Possibility to create an N-places FIFO with a round buffer and read and
write indexes, special case of a 2-place FIFO = « ping-pong » buffer
• More than a mutex
• The 2 semaphores ensure alternate accesses from cores Snd and Rcv
Atomic Arbitration: hardware or
software semaphores
Shared mem Snd Rcv

86
Multicore DSPs – Karol Desnos ([email protected])
• Inter-processor communication libraries mask the
complexity
• MPI, MCAPI…
Inter-Processor Communication
Multicore Compiler
Algorithm
Architecture
Portable Multicore Program
+ IPC
But we also want to simulate their
performance

88
Multicore DSPs – Karol Desnos ([email protected])
Hardware Physical Implementation
• SPIRIT IP-XACT
• SystemC TLM
• UML Marte
• AADL
• S-LAM
Hardware Abstraction
Models of Parallel Architecture

89
Multicore DSPs – Karol Desnos ([email protected])
• SPIRIT IP-XACT
• More a syntax for serialization than a real model
• Used to represent components, hardware busses and
memory maps
Models of Parallel Architecture

90
Multicore DSPs – Karol Desnos ([email protected])
• SystemC Transaction Level Modeling 2.0
• C++ templates and libraries used to simulate hardware
modules and separate concerns
• Focus is put on timing simulation of RTL code
Models of Parallel Architecture

91
Multicore DSPs – Karol Desnos ([email protected])
• UML Marte
• Modeling both algorithm and architecture with UML class
diagrams
• Generic Component Modeling for architecture
• Iterative structure expressivity
Models of Architecture

92
Multicore DSPs – Karol Desnos ([email protected])
• AADL
• Separating hardware and software
• Specifying both in AADL
• Thread, process, data
• Memory, bus processor
Models of Parallel Architecture

93
Multicore DSPs – Karol Desnos ([email protected])
• Custom models for scheduling
• In MAPS compiler,
• in SynDEx rapid prototyping tool,
• in PREESM: System-Level Architecture Model (S-LAM)
• An architecture model for dataflow applications
Models of Architecture

94
Multicore DSPs – Karol Desnos ([email protected])
Operator
Processing Element
Directed Data Link Undirected Data Link
Set-up Link
RAM DMA
Communication Enablers
Parallel Node Contention Node
Communication Nodes
System-Level Architecture Model

95
Multicore DSPs – Karol Desnos ([email protected]) 95
core1 core2 CN
1 Gbit/s
core3
RAM
DMA
S-LAM Examples

96
Multicore DSPs – Karol Desnos ([email protected])
SC
R
DMA
TCP2
RI
O
VCP2
core1
core2
core3
SC
R
DMA
TCP2 VCP2
core1
core2
core3
DSP 1 DSP 2
2 GB/s 2 GB/s
1 Gbit/s
S-LAM of a Board with 2 TCI6488 96

98
Multicore DSPs – Karol Desnos ([email protected])
Overview
Demo Setup
PREESM +CCStudio
Simulator
+ Debugger
+ Profiler
Dataflow
S-LAM PE
DSP DSP
DSP DSP
PE PE PE PE
Peripherals
Main
Memory
SysBIOS
TI TMS320C6678

99
Multicore DSPs – Karol Desnos ([email protected])
Code Composer Studio
• Code Composer Studio v5 (CCS) IDE
• Based on Eclipse 3.7 Indigo
• Runs under Windows and Linux
• Integrable in an existing Eclipse
• C66x compiler, linker, assembler, simulator…
• Delivered with CCS IDE
• EVM Drivers
• Installed with CCS
• Connect to the EVM JTAG (breakpoints…)
Demo Setup

100
Multicore DSPs – Karol Desnos ([email protected])
PREESM • Developed at IETR under Eclipse
• From a dataflow graph to a multicore code execution
• Automates multicore communication/synchronization
Demo Setup

101
Multicore DSPs – Karol Desnos ([email protected])
Generating Code in Demo
• From a dataflow graph application description
• Generating code for each of the 8 cores
• Cores communicate through shared memory
• Cache management is automatically generated
• Goal is to understand parallelization possibilities
Demo Setup