Embed Size (px)
Citation preview

Multi-Agent Shared Multi-Agent Shared HierarchyHierarchy
Reinforcement LearningReinforcement LearningNeville Mehta
Prasad Tadepalli
School of Electrical Engineering and Computer Science
Oregon State University

22
HighlightsHighlights
Sharing value functions Coordination Framework to express sharing &
coordination with hierarchies RTS domain

33
Previous WorkPrevious Work
MAXQ, Options, ALisp Coordination in the hierarchical
setting (Makar, Mahadevan) Sharing flat value functions (Tan) Concurrent reinforcement learning for
multiple effectors (Murthi, Russell, …)

44
OutlineOutline
Average Reward Learning RTS domain Hierarchical ARL MASH framework Experimental results Conclusion & future work

55
SMDPSMDP
Semi-Markov Decision Process (SMDP) extends MDPs by allowing for temporally extended actions– States S– Actions A– Transition function P(s’, N|s, a)– Reward function R(s’|s, a)– Time function T(s’|s, a)
Given an SMDP, an agent in state s following policy ,Gain ½¼(s) = limN ! 1
E(P Ni =0 r i )
E(P Ni =0 ti )

66
Average Reward LearningAverage Reward Learning Taking action a in state s
– Immediate reward r(s, a)– Action duration t(s, a)
Average-adjusted reward = Optimal policy * maximizes the RHS, and leads to the
optimal gain
h¼(s0) = E [(r(s0;a) ¡ ½t(s0;a)) + (r(s1;a) ¡ ½t(s1;a)) +¢¢¢]
) h¼(s0) = E [r(s0;a) ¡ ½t(s0;a)]+h¼(s1)
s0 s1 s2 sn
s0 sn
r(s0;a0) ¡ ½t(s0;a0) r(s0;a1) ¡ ½t(s0;a1) r(s0;a2) ¡ ½t(s0;a2)
Parent task
Child task
r(s;a) ¡ ½¼t(s;a)½¼¤ ¸ ½¼

77
RTS DomainRTS Domain
Grid world domain Multiple peasants
mine resources (wood, gold) to replenish the home stock
Avoid collisions with one another
Attack the enemy’s base

88
RTS Domain Task HierarchyRTS Domain Task Hierarchy
Root
Harvest(l)
Deposit
Goto(k)
EastSouthNorth West
Pick Put
Offense(e)
Idle
AttackPrimitive Task
Composite Task
MAXQ task hierarchy– Original SMDP is split into sub-SMDPs (subtasks)– Solving the Root task solves the entire SMDP
Each subtask Mi is defined by <Bi, Ai, Gi>– State abstraction Bi
– Actions Ai
– Termination (goal) predicate Gi

99
Hierarchical Average Reward Hierarchical Average Reward LearningLearning
Value function decomposition for a recursively gain-optimal policy in Hierarchical H learning:
If the state abstractions are sound, Root task = Bellman equation
hi (s) = r(s) ¡ ½¢t(s); if i is a primitive subtask
= 0; if s is a terminal/ goal state for i; otherwise
= maxa2A i (s)
½ha(Ba(s)) +
X
s02S
P(s0js;a) ¢hi (s0)¾
ha(Ba(s)) = ha(s)

1010
Hierarchical Average Reward Hierarchical Average Reward LearningLearning
No pseudo rewards No completion function Scheduling is a learned behavior

1111
Hierarchical Average Reward Hierarchical Average Reward LearningLearning
Sharing requires coordination Coordination part of state not action
(Mahadevan) No need for each subtask to see
reward

1212
Single Hierarchical AgentSingle Hierarchical Agent
Root
Harvest(W1)
Goto(W1)
North
Root
Harvest(l)
Deposit
Goto(k)
EastSouthNorth West
Pick Put
Offense(e)
Idle
Attack

1313
Simple Multi-Agent SetupSimple Multi-Agent Setup
Root
Harvest(l)
Deposit
Goto(k)
EastSouthNorth West
Pick Put
Offense(e)
Idle
Attack
Root
Offense(E1)
Attack
Root
Harvest(l)
Deposit
Goto(k)
EastSouthNorth West
Pick Put
Offense(e)
Idle
Attack
Root
Harvest(W1)
Goto(W1)
North

1414
MASH SetupMASH Setup
Root
Harvest(l)
Deposit
Goto(k)
EastSouthNorth West
Pick Put
Offense(e)
Idle
Attack
Root
Offense(E1)
Attack
Root
Harvest(W1)
Goto(W1)
North

1515
Experimental ResultsExperimental Results
2 agents in a 15 x 15 grid, Pr(Resource Regeneration) = 5%; Pr(Enemy) = 1%; Rewards = (-1, 100, -5, 50); 30 runs
4 agents in a 25 × 25 grid, Pr(Resource Regeneration) = 7.5%; Pr(Enemy) = 1%; Rewards = (0, 100, -5, 50); 30 runs
Couldn’t run separate agents coordination for 4 agents 25 × 25
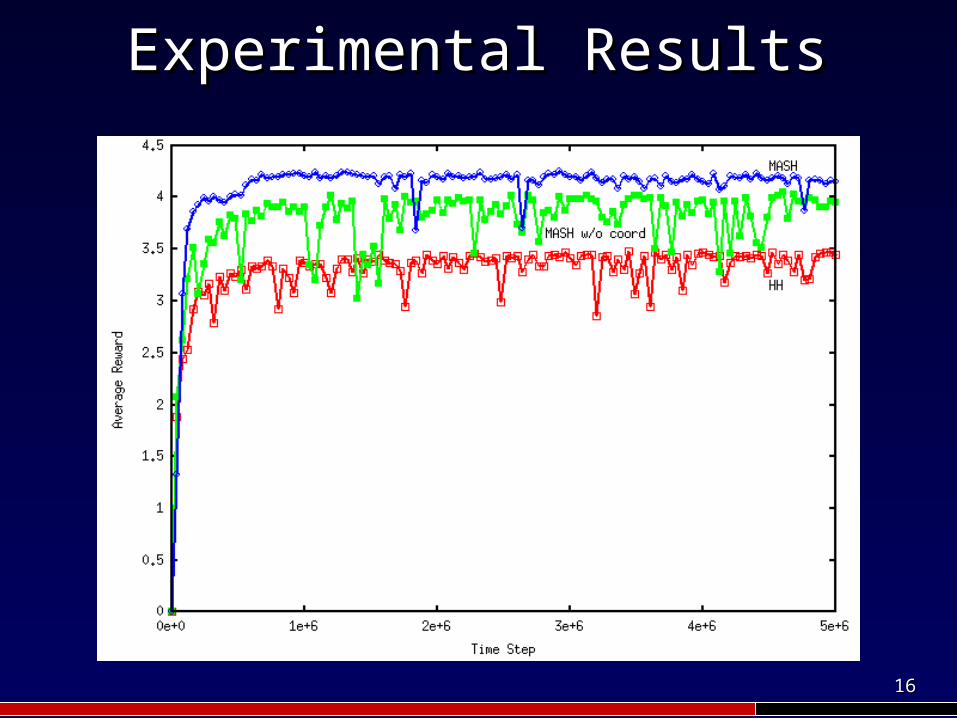
1616
Experimental ResultsExperimental Results

1717
Experimental Results (2)Experimental Results (2)

1818
ConclusionConclusion
Sharing value functions Coordination Framework to express sharing &
coordination with hierarchies

1919
Future WorkFuture Work
Non-Markovian & non-stationary Learning the task hierarchy
– Task – subtask relationships– State abstractions– Termination conditions
Combining MASH framework with factored action models
Recognizing opportunities for sharing & coordination

2020
Current WorkCurrent Work
Murthi, Russell features





























