Embed Size (px)
Citation preview

MUESTREO E INFERENCIA ESTADÍSTICA
(Tomado de http://mx.geocities.com/fracosta11/dmuestral.html)
En estudios pasados de Estadísticas centramos nuestra atención en técnicas que describen los datos, tales como organizar datos en distribuciones de frecuencias y calcular diferentes promedios y medidas de variabilidad. Estábamos concentrados en describir algo que ya ocurrió. También comenzamos a establecer los fundamentos de la estadística inferencial, con el estudio de los conceptos básicos de la probabilidad, las distribuciones de probabilidad discretas y continuas. Distribuciones que son principalmente generadas para evaluar algo que podría ocurrir. Ahora veremos otro tipo de distribución de probabilidad, que se llaman distribuciones muestrales.
¿Por qué muestrear? Muestrear es una forma de evaluar la calidad de un producto, la opinión de los consumidores, la eficacia de un medicamento o de un tratamiento. Muestra es una parte de la población. Población es el total de resultados de un experimento. Hacer una conclusión sobre el grupo entero (población) basados en información estadística obtenida de un pequeño grupo (muestra) es hacer una inferencia estadística. A menudo no es factible estudiar la población entera. Algunas de las razones por lo que es necesario muestrear son: 1. La naturaleza destructiva de algunas pruebas 2. La imposibilidad física de checar todos los elementos de la población. 3. El costo de estudiar a toda la población es muy alto. 4. El resultado de la muestra es muy similar al resultado de la población. 5. El tiempo para contactar a toda la población es inviable. Métodos de Muestreo Muestra Aleatoria. Es una muestra seleccionada de tal forma que cada artículo o persona de una población que está siendo estudiada tiene la misma probabilidad de ser incluida en la muestra No hay un mejor método para seleccionar una muestra aleatoria de una población de interés. El método utilizado dependerá de las características de la población. Sin embargo, todos los métodos de muestreo aleatorios tienen una meta similar, dar la misma oportunidad a todos los elementos de la población de ser incluidos en la muestra.
Muestreo Aleatorio Simple
Muestro aleatorio simple es cuando una muestra es formulada de tal manera que cada elemento en la población tiene la misma oportunidad de

ser incluido.
Una forma podría ser escribir en papelitos los nombres de los elementos de la población y depositarlos en una caja, si la muestra fuera de diez elementos, entonces sacamos diez papelitos. Otra forma es usar un número de identificación para cada uno de los integrantes de la población y seleccionar la muestra mediante una tabla de números aleatorios. Como su nombre lo indica estos números han sido generados mediante un proceso aleatorio en una computadora. Para cada dígito de un número la probabilidad es la misma. Entonces la probabilidad de que el elemento 22 sea seleccionado es igual a la del elemento 382. Ejemplo En una compañía con 750 trabajadores se quiere obtener una muestra aleatoria de 14 elementos para un chequeo médico. Los trabajadores fueron numerados del 1 al 750 y mediante una tabla de números aleatorios (al final de este documento) se procedió a seleccionarlos. El punto de arranque en la tabla se fijó mediante la hora en ese momento, 3:04, por lo tanto se inició en la columna 3, renglón 4. Como los números de los trabajadores van desde 1 hasta 750 solo se toman en cuenta las primeras 3 cifras de cada número que se encuentren en ese rango. En seguida se muestra una parte de la tabla, con el primer y segundo seleccionado:
Es decir
Tabla de números aleatorios
xxx 11286 88258 58925 03638 52862 62733 33451 77455 86859 19558
66432 16706 05219 81619 10651 67079 92511 59888 84502 72095 83463 75577
11258
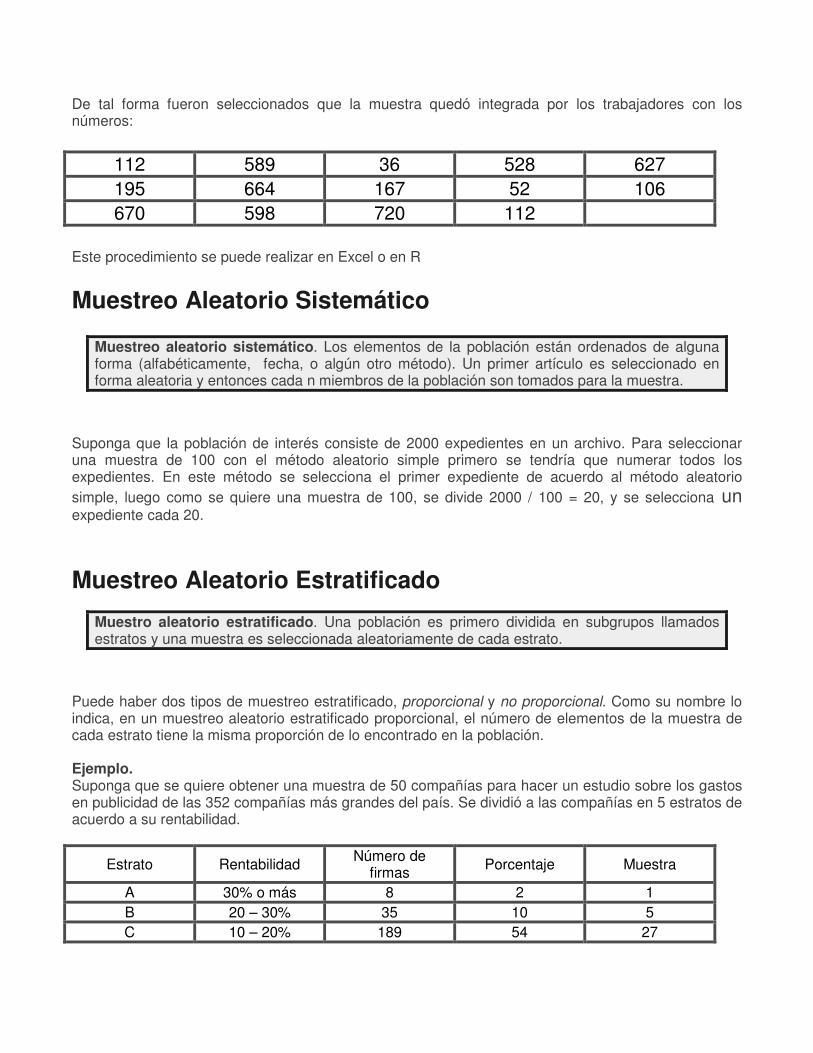
De tal forma fueron seleccionados que la muestra quedó integrada por los trabajadores con los números:
112 589 36 528 627
195 664 167 52 106
670 598 720 112
Este procedimiento se puede realizar en Excel o en R
Muestreo Aleatorio Sistemático
Muestreo aleatorio sistemático. Los elementos de la población están ordenados de alguna forma (alfabéticamente, fecha, o algún otro método). Un primer artículo es seleccionado en forma aleatoria y entonces cada n miembros de la población son tomados para la muestra.
Suponga que la población de interés consiste de 2000 expedientes en un archivo. Para seleccionar una muestra de 100 con el método aleatorio simple primero se tendría que numerar todos los expedientes. En este método se selecciona el primer expediente de acuerdo al método aleatorio
simple, luego como se quiere una muestra de 100, se divide 2000 / 100 = 20, y se selecciona un expediente cada 20.
Muestreo Aleatorio Estratificado
Muestro aleatorio estratificado. Una población es primero dividida en subgrupos llamados estratos y una muestra es seleccionada aleatoriamente de cada estrato.
Puede haber dos tipos de muestreo estratificado, proporcional y no proporcional. Como su nombre lo indica, en un muestreo aleatorio estratificado proporcional, el número de elementos de la muestra de cada estrato tiene la misma proporción de lo encontrado en la población. Ejemplo. Suponga que se quiere obtener una muestra de 50 compañías para hacer un estudio sobre los gastos en publicidad de las 352 compañías más grandes del país. Se dividió a las compañías en 5 estratos de acuerdo a su rentabilidad.
Estrato Rentabilidad Número de
firmas Porcentaje Muestra
A 30% o más 8 2 1
B 20 – 30% 35 10 5
C 10 – 20% 189 54 27

D 0 – 10% 115 33 16
E Con pérdida 5 1 1
Total 352 100 50
En un muestreo estratificado no proporcional, el número de elementos estudiado en cada estrato es desproporcionado con respecto a su número en la población. Por ejemplo, si un muestreo no proporcional fuese utilizado en el caso anterior, se deberán pesar los resultados de cada estrato multiplicándose por .02 en el estrato 1, por .10 en el estrato 2, por .54 en el tres, etc. El muestro estratificado tiene la ventaja de reflejar con más exactitud las características de la población.
Muestreo por bloque Este método de muestro es empleado para reducir el costo de muestrear una población cuando está dispersa sobre una gran área geográfica. El muestreo por bloque consiste en dividir el área geográfica en sectores, seleccionar una muestra aleatoria de esos sectores, y finalmente obtener una muestra aleatoria de cada uno de los sectores seleccionados.
Error de Muestreo Si seleccionamos una muestra por el método de muestreo aleatorio simple, por muestreo sistemático, por muestreo estratificado, por muestreo por bloques o por una combinación de estos métodos, es poco probable que la media de la muestra sea idéntica a la media de la población de donde fue obtenida. De la misma forma, es probable que la desviación estándar de la muestra no sea exactamente igual al valor correspondiente de la población. Por lo tanto podemos esperar alguna diferencia entre un estadístico muestral y el correspondiente parámetro poblacional. Esta diferencia es llamada error de muestreo.
Error de muestreo es la diferencia entre un estadístico muestral y su correspondiente parámetro poblacional

Una población de 5 empleados de producción que tienen ratings de eficiencia de 97, 103, 96, 99 y 105. Una muestra de 2 ratings (97 y 105) fue seleccionada de esa población para estimar la media poblacional. La media de esa muestra sería 101. Otra muestra de 2 es seleccionada (103 y 96) con una media de 99.5. La media de todos los ratings (la media poblacional) es igual a 100. El error de muestreo para la primera muestra es 1 y para la segunda es -.5.
Distribución Muestral de las Medias El ejemplo de los ratings de eficiencia muestra como las medias de muestras de un tamaño específico varían de muestra a muestra. La media de la primera muestra fue 101 y la media de la segunda fue 99.5. En una tercera muestra probablemente resultaría una media diferente. Si organizamos las medias de todas las posibles muestras de tamaño 2 en una distribución de probabilidad, obtendremos la distribución muestral de las medias.
Distribución muestral de las medias. Es una distribución de probabilidad de todas las posibles medias muestrales, de un tamaño de muestra dado, seleccionadas de una población.
El siguiente ejemplo ilustra la construcción de una distribución muestral de medias. Ejemplo. Tortas “Don Pepe” tiene 5 parrilleros (población), a los cuales se les paga por hora según su trabajo. Las percepciones de los parrilleros son las siguientes:
Parrillero Percepción por hora Adrián $ 9.00
Bitia $ 8.00
Carmen $ 8.00
Diana $ 8.00
Enrique $ 7.00
1. ¿Cuál es la media poblacional? 2. ¿Cuál es la distribución muestral de las medias para una muestra de tamaño2? 3. ¿Cuál es la media de la distribución muestral? 4. ¿Qué observaciones se pueden hacer con respecto a la población y a la distribución muestral? Solución. 1. La media poblacional son:
µ = 9 + 8 + 8 + 8 + 7
= 8.0 5
2. Para construir la distribución muestral de las medias, Las medias de todas las posibles muestras
de tamaño 2 son calculadas Es decir combinaciones de 5 elementos tomadas de dos en dos:

102
20
!3*)1*2(
!3*4*5
)!25!*(2
!5)2,5( ===
−=C
y son las siguientes:
Muestra Parrilleros percepciones Media de la muestra 1 A – B 9.00 8.00 8.50
2 A – C 9.00 8.00 8.50
3 A – D 9.00 8.00 8.50
4 A – E 9.00 7.00 8.00
5 B – C 8.00 8.00 8.00
6 B – D 8.00 8.00 8.00
7 B – E 8.00 7.00 7.50
8 C – D 8.00 8.00 8.00
9 C – E 8.00 7.00 7.50
10 D - E 8.00 7.00 7.50
DISTRIBUCIÓN MUESTRAL DE LAS MEDIAS para n = 2
Media muestral Número de medias Probabilidad
7.50 3 0.3
8.00 4 0.4
8.50 3 0.3
Σ 10 1.0
3. La media de la distribución muestral de medias es:
Los histogramas de la distribución de probabilidad de la población y de la distribución muestral de medias son:

4. Se pueden hacer las siguientes observaciones:
a. La media de las medias muestrales es igual a la media de la población. b. La dispersión de las medias muestrales es menor que la dispersión en la población c. La forma de la distribución muestral presenta un cambio respecto a la forma de la
población.
Resolver el problema 1 1.- La Señora López da a sus seis hijos “domingo” para que se lo gasten en dulces. Las cantidades son las siguientes:
niño Domingo Javier $ 10.00 Antonio 9.00 José 10.00 Ignacio 8.00 Adolfo 8.00 Andrés 9.00
a) ¿Cuántas muestras diferentes de tamaño 3 se pueden seleccionar de esta población? b) Construya la distribución muestral de las medias de muestras tamaño 3. c) Compare la media de la población con la media de la distribución muestral d) Compare la desviación estándar de la población con la desviación estándar de la distribución
muestral de las medias. e) Compare los histogramas de la población y de la distribución muestral de las medias.
Teorema del Límite Central El tamaño de la población y el tamaño de la muestra en los problemas anteriores son intencionalmente pequeños para enfatizar dos conceptos: (1) La media de las medias muestrales es exactamente la

misma que la media de la población y (2) que la forma de la distribución de las medias muestrales no es necesariamente igual que la forma de la distribución. Las siguientes gráficas corresponden al ejemplo anterior, note como la forma de la distribución de la población no es igual a la forma de la distribución muestral. La distribución muestral de las medias se aproxima mucho a una distribución normal.
Si la población está normalmente distribuida, la distribución muestral de las medias también estará normalmente distribuida. En el primer problema (ingresos de los parrilleros) la forma de la distribución de la población es aproximadamente normal y la forma de la distribución muestral también es aproximadamente normal. Estas son las bases del teorema del límite central, uno de los más importantes teoremas en estadísticas.
Teorema del Límite Central. Para una población con una media µ y una varianza σ², la

distribución de las medias de todas las muestras posibles de tamaño n generadas de la población estarán distribuidas de forma aproximadamente normal asumiendo que el tamaño de la muestra es suficientemente grande. Con relación al teorema del límite central debemos enfatizar en: 1. Si el tamaño de la muestra n es suficientemente grande (n > 30) la distribución normal de las
medias será aproximadamente normal. No importa si la población es normal, sesgada u uniforme, si la muestra es grande el teorema se aplicará.
2. La media de la población y la media de todas las posibles muestras son iguales. Si la población es grande y un gran número de muestras son seleccionadas de esa población entonces la media de las medias muestrales se aproximará a la media poblacional.
3. La desviación estándar de la distribución muestral de las medias, a la que llamaremos error estándar, es determinado por
4.
Estimación Puntual y Estimación por Intervalos para una variable
Estimación Puntual Cuando no se conoce alguna característica de la población, como podría ser la media, el estadístico correspondiente de la muestra, en este caso la media de la muestra, puede ser utilizado como estimador del parámetro poblacional. Esta técnica estadística se llama estimación puntual.
Estimación puntual es cuando un estadístico de la muestra es usado para estimar un parámetro poblacional.
Ejemplo. Los siguientes datos corresponden a una muestra aleatoria de los pesos, en kilogramos, del equipaje personal que lleva en un vuelo un jugador de un equipo de baloncesto.
15.4 17.7 18.6 12.7 15.0 15.9 16.3 18.1 16.8 14.1 13.6 16.3
Hacer una estimación puntual de la media poblacional del peso promedio del equipaje de un basquetbolista. La media de la muestra de los pesos del equipaje de un basketbolista en un vuelo es

La estimación puntual consiste en considerar que la media poblacional es el valor que se obtuvo como media de la muestra.
µ = 15.87
Estimación por Intervalo para una variable El intervalo dentro del cual se espera que se encuentre un parámetro poblacional usualmente es conocido como intervalo de confianza. Por ejemplo, el intervalo de confianza para la media poblacional es el intervalo de valores que tiene una alta probabilidad de contener a la media de la población.
Estimación por Intervalo. Establece el rango de valores dentro del cual se espera que se encuentre un parámetro poblacional.
El nivel de confianza es la probabilidad de que el parámetro poblacional se encuentre dentro del intervalo. Los niveles de confianza más ampliamente usados son 0.95 y 0.99, sin embargo puede usarse cualquier probabilidad cercana a 1.
Para entender mejor el concepto de intervalo de confianza vamos a suponer que seleccionamos 100 muestras de una población y calculamos la media de las muestras e intervalos de confianza del 95% para cada muestra. Descubriremos que cerca de 95 de los 100 intervalos de confianza contienen la media poblacional. Pasos para construir un intervalo de confianza (n>30) 1. Establecer el nivel de confianza 2. Determinar el valor de la variable aleatoria estándar 3. Calcular los estadísticos de la muestra 4. Calcular el error estándar

5. Calcular el error máximo de estimación 6. Determinar los límites del intervalo de confianza e interpretar. Ejemplo. Los resultados siguientes representan las calificaciones de una muestra aleatoria de calificaciones de estudiantes en estadística elemental.
23 60 79 32 57 74 52 70 82 36
80 77 81 95 41 65 92 85 55 76
52 10 64 75 78 25 80 98 81 67
41 71 83 54 64 72 88 62 74 43
60 78 89 76 84 48 84 90 15 79
34 67 17 82 69 74 63 80 85 61
a) Haga un intervalo de confianza del 95% para estimar la media poblacional b) Haga un intervalo de confianza del 99% para estimar la media poblacional c) Compare los anteriores resultados anteriores Solución del inciso (a) Haga un intervalo de confianza del 95% para estimar la media poblacional 1.- El nivel de confianza ya está establecido como 95%, se simboliza de la siguiente forma:
1 – α = .95
2.- Cuando se trata de estimar la media poblacional la variable aleatoria estándar es el valor Z de la distribución normal, siempre y cuando la muestra sea grande (n > 30). Como 1 – α es la probabilidad de que la media poblacional se encuentre dentro del intervalo (centro de la curva), α es la probabilidad de que no se encuentre en el intervalo (extremos de la curva), y cada extremo de la curva o cola corresponde a α/2. En la tabla de la distribución normal se busca el valor Z que corresponde al área de α/2 de la siguiente manera:
1 – α = .95 α = 1 - .95 = .05 α/2 = .025

Se busca en la tabla normal:
Z 6
1.9 .02500
Entonces Z = 1.96 es el valor que corresponde a la cola positiva de la curva, y Z = - 1.96 es el valor que corresponde a la cola negativa. 3.- Para estimar la media poblacional necesitamos calcular la media y la desviación estándar de la muestra:
Esta última formula es lo mismo que

4.- Se calcula el error estándar, como no conocemos el tamaño de la población se elimina la segunda parte de la fórmula. Hacemos lo mismo si la población es 20 o más veces más grande que la muestra. Si no se conoce σ, como en este caso, se utiliza S.
Es decir que N es muy grande, mucho más grande que el tamaño de la muestra n (N>>>n) por lo que el numerador N-n es casi N y el denominador N-1 es N. Es decir que
5.- Se calcula el error máximo de estimación
6.- Se calculan los límites del intervalo de confianza, restando a la media de la muestra el error máximo de estimación se obtiene el límite inferior. Sumando a la media de la muestra el error máximo de estimación se obtiene el límite superior.
En realidad la formula para calcular el intervalo de confianza, para una muestra aleatoria simple, es :

Este resultado se interpreta de la siguiente manera: “Hay una probabilidad de .95 de que la calificación media de todos los estudiantes de estadísticas, se encuentre entre 60.13 y 70.83”. Estimación por intervalos con muestras pequeñas (n ≤ 30) Para poder utilizar la distribución normal es necesario que las muestras sean grandes (n > 30) y conocer σ. Si no se conoce σ se utiliza S, pero si además la muestra es chica los resultados no serán satisfactorios. En estos casos se utiliza la distribución t de student. Características de la Distribución t de Student Esta distribución fue desarrollada por William Gosset, un trabajador de la cervecería Guinness en Irlanda, quien la publicó utilizando el seudónimo de “Student”. Gossett se interesó en el comportamiento del valor z cuando se utilizaba S en vez de σ, y particularmente en la discrepancia entre S y σ cuando S se calcula de muestras muy pequeñas. En la siguiente gráfica se muestra como la distribución t extendida que la distribución normal Z.
Las características de la distribución t son: 1. Es una distribución continua. 2. Tiene forma de campana y es simétrica. 3. Es una familia de curvas. Todas tienen la misma media de cero, pero sus desviaciones estándar
difieren de acuerdo al tamaño de la muestra. 4. La distribución t es más baja y dispersa que la distribución normal. Cuando el tamaño de la
muestra se incrementa, la distribución t se aproxima a la normal.
Pasos para construir intervalos de confianza para muestras pequeñas

Se siguen los mismos pasos de los intervalos de confianza para muestras grandes. Ejemplo. Una muestra aleatoria de 12 secretarias escriben a máquina un promedio 85.2 palabras por minuto con una desviación estándar de 9.3 palabras por minuto. Encuentre un intervalo de confianza de 95% para el número promedio de palabras por minuto escritas por todas las secretarias. Solución. 1.- El nivel de confianza es
1 – α = .95 2.- Como la muestra es pequeña (n ≤ 30) se determina el valor de t, para lo cual, antes se determinan los grados de libertad Φ. El valor de α de la tabla corresponde al área que se encuentra a la derecha del valor positivo de t que buscamos, por lo tanto en los intervalos de confianza sería α/2
Φ = n – 1 = 12 – 1 = 11 α/2 = .025
Se busca en la tabla t
Φ α .025 11 2.20099
t = 2.20099
En las tablas del apendice se obtiene 2.201 3.- Los estadísticos de la muestra son:
Χ Χ Χ Χ = 85.2 S = 9.3 4.- Se calcula el error estándar
Observe que esta formula proviene de
5.- Se calcula el error máximo de estimación
6.- El intervalo de confianza resultante es:
P( Χ Χ Χ Χ - E ≤ µ ≤ Χ Χ Χ Χ + E ) = 1 – α

P( 85.2 – 5.68 ≤ µ ≤ 85.2 + 5.68) = .95
P( 79.52 ≤ µ ≤ 90.88 ) = .95
Lo que quiere decir que hay una probabilidad de .95 de que la cantidad promedio de palabras por minuto que escriben todas las secretarias se encuentre entre 79.52 y 90.88 En este caso se usa la función de probabilidad t student y en realidad la formula para el intervalo de confianza, a un nivel de confianza del 95% con n-1 grados de libertad es decir 11 es
Intervalo de confianza para estimar una proporción Un intervalo de confianza para estimar una proporción poblacional se construye de manera similar al procedimiento usado anteriormente. Ejemplo. En un estudio de mercado para estimar la proporción de amas de casa que pueden reconocer la marca de un limpiador basándose en la forma y color del envase. De 1400 amas de casa, solo 420 pudieron identificar la marca. Hacer un intervalo de confianza del 99% para estimar la proporción poblacional. 1.- El nivel de confianza ya está establecido:
1 – α = .99 2.- Como n > 30 entonces se determina Z: 1 – α = .99 α = 1 - .99 = .01 α/2 = .005 El valor .005 no está en la tabla normal, pero debería encontrarse entre estas dos cantidades
Z 7 ? 8

2.5 .00508 .005 .00494 se procede entonces con un procedimiento llamado interpolación, identificando la primer z como z1 y la segunda como z2. Las áreas como A1 y A2 respectivamente.
Z1 Z Z2 Z 7 ? 8
2.5 .00508 .005 .00494 Α1 A Α2
Luego se aplica la siguiente fórmula
Z= Z1 + ( Z2 – Z1) (A1 - A)
= 2.57 + (2.58-2.57) (.00508-.005)
= 2.5757 (A1 – A2) (.00508-.00494)
3.- Los estadísticos de la muestra es la proporción de éxitos en la muestra (p) y la proporción de fracasos (q)
p = x
= 420
= .3 n 1400
q = 1 – p = 1 - .3 = .7
4.- Se calcula el error estándar de la proporción con la siguiente fórmula
5.- Se calcula el error máximo de estimación
E = Z σp = (2.5757)(.0122) = .0314 6.- El intervalo que resulta es:
P( p – E ≤ ππππ ≤ p + E) = 1 – α
P(.3 - .0314 ≤ ππππ ≤ .3 + .0314) = .99
P(.2686 ≤ ππππ ≤ .3314) = .99 Hay una probabilidad de .99 de que la proporción de amas de casa que pueden identificar la marca del limpiador se encuentre entre .2686 y .3314

Resolver los siguientes problemas, modificando el enunciado y si necesario los datos de tal forma que se describa un problema relacionado con su carrera. 1 (1 pt).- El propietario de una estación de gasolina quiere estimar el número promedio de litros de gasolina vendida a sus clientes. De sus registros seleccionó una muestra de 60 ventas y encontró lo siguiente:
39 32 30 22 54 27 24 29 23 42 35 21
26 35 36 39 20 25 43 34 29 21 21 30
41 27 44 45 27 33 33 36 11 33 38 24
39 28 33 27 28 31 35 37 40 32 46 37
34 40 29 32 28 25 36 23 26 24 30 34
a) Haga un intervalo de confianza del 94% para estimar el número promedio de litros de gasolina
vendida a sus clientes b) Haga un intervalo de confianza del 98% para estimar la proporción de clientes que compraron más
de 30 litros de gasolina vendida.
2 (5 pts).- De acuerdo a la explicación dada en clase para fabricar helicópteros de papel con las medidas que se le indicaron. a) Fabricar 25 helicópteros, numerarlos del 1 al 25, elegirlos al azar usando la tabla de números
aleatorios (esto es muy importante) y lanzarlos uno por uno desde un edificio de 3 pisos. Obtener los tiempos de vuelo y calcular los intervalos de confianza del 90%y del 95% para estimar la media poblacional de los tiempos de vuelo.
b) De los 25 helicopteros elija uno al azar (vea la hora elija la columna, recorra la tabla hasta encontrar un númerodonde las dos primeras cifras estén entre 1 y 25) y lanzarlo 25 veces Obtener los tiempos de vuelo y obtener el intervalo de confianza del 90% y del 95% para estimar la media poblacional de los tiempos de vuelo.
c) Establecer las conclusiones comparando las respuestas a) y b) Si desea mas instrucciones consultar

6 a 12 cm
3 cm a 6 cm
6 a 12 cm
1 cm a 2 cm
4.5 cm

min max
wing lenght= longitud de ala 6 12
body lenght =longitud del cuerpo 6 12
body width = ancho del cuerpo 3 6
Fold0 doblar 1 cm 2 cm
Poner clip 0 1

Modo de lanzamiento
Sujetar el helicóptero del cuerpo y soltar, no impulsar
Materiales
25 clips Tijeras Regla Cronómetro (no redondear tomar el tiempo en segundos) Usar solamente papel bond blanco, no reciclado, Se deben entregar todos los helicópteros Fecha de entrega en archivo electrónico word viernes 10 de diciembre a las 13 P.M. (última hora pues las calificaciones finales se entregan el mismo día). Todos los datos y errores deben ser presentados. Indicar como mejoraría esta práctica
3 (2 pts).- Cierto banco encuentra que el uso de cajeros automáticos reduce el costo de las transacciones bancarias de rutina. Este banco instaló un cajero automático en las instalaciones de Fun Toy Company. Este cajero es para uso exclusivo de los 500 empleados de Fun Toy Company. Después de algunos meses de operación, se realizó un estudio sobre el uso del cajero y se encontró lo siguiente:
NÚMERO DE VECES QUE USÓ EL CAJERO EL ÚLTIMO MES
4 2 2 3 3 3 2 1 3 5 2 3 3 1 4 1 3 4 2 2
1 4 5 1 3 3 4 2 4 3 2 1 3 3 2 3 2 1 4 5
2 2 1 3 3 3 4 2 1 3 2 1 2 2 1 3 2 2 2 1
0 2 2 0 2 1 3 1 2 1 3 2 5 2 1 3 1 0 2 2
1 4 2 3 2 1 2 2 2 4 2 2 4 1 1 1 2 1 4 2
4 2 5 2 3 1 2 4 2 1 4 1 3 1 3 1 1 4 2 5
2 3 3 1 4 3 1 2 0 4 1 1 2 2 2 1 1 2 3 3
2 3 2 3 4 2 3 3 4 3 1 2 0 3 1 3 1 2 3 2
4 3 4 1 3 4 2 2 4 2 2 1 2 2 3 3 2 4 3 4
2 2 2 2 3 2 2 3 2 2 2 0 3 2 1 2 1 2 2 2
1 4 2 3 0 3 2 1 1 2 2 3 1 2 2 5 1 1 4 2
2 2 2 3 2 3 3 2 4 1 1 2 2 2 2 3 1 2 2 2
5 0 1 2 3 1 0 2 2 1 2 3 1 2 3 0 3 5 0 1
4 2 3 0 3 0 2 1 2 2 1 2 2 4 3 2 2 4 2 3
2 2 2 4 0 2 0 2 2 4 2 3 3 1 2 0 3 2 2 2
2 3 2 2 1 3 2 1 3 2 2 3 2 1 2 2 3 2 3 2
2 0 2 2 2 2 3 3 2 3 2 2 2 2 1 2 1 2 0 2
3 1 3 3 2 2 3 2 4 1 2 3 2 2 4 3 3 3 1 3

4 2 2 1 3 2 1 1 2 4 1 3 0 3 2 2 2 4 2 2
3 3 4 1 1 2 1 1 3 2 3 4 2 1 3 3 1 3 3 4
2 2 3 3 3 3 2 3 3 2 3 3 2 2 3 3 3 2 2 3
3 3 1 1 2 0 1 0 3 4 2 2 2 2 1 2 1 3 3 1
2 3 2 2 1 3 0 2 3 2 3 1 2 2 2 2 2 2 3 2
2 2 2 2 3 2 1 1 0 3 4 3 0 2 2 3 1 2 2 2
0 2 2 2 3 1 2 0 2 2 3 2 3 5 1 1 2 0 2 2
a) ¿Cuál es el método de muestro más apropiado para este caso? b) Obtenga una muestra aleatoria de 40 empleados de Fun Toy Company y haga un intervalo de
confianza del 98% para estimar la media poblacional de las veces que usó el cajero en el mes. c) Obtenga una muestra de 25 empleados de Fun Toy Company y estime la proporción poblacional
de empleados que no utilizaron el cajero en el mes con un intervalo de confianza de 96% d) ¿De que tamaño deberá ser la muestra si el error máximo de estimación es igual a 1?
4 (2 pts).- Los siguientes datos son las calificaciones dadas a una línea aérea, por los 250 pasajeros del vuelo Nueva York – Los Angeles. Las calificaciones pueden ir de 0 a 10.
4 5 3 6 6 6 7 5 4 6 7 5 7 5 7 5 5 4 5 3 6 6 6 7 5
6 4 6 6 7 5 3 6 5 6 5 7 6 3 7 4 5 6 4 6 6 7 5 3 6
4 6 5 6 6 6 4 9 4 8 5 6 7 6 6 6 3 4 6 5 6 6 6 4 9
6 2 7 6 6 5 5 5 6 6 6 5 6 4 4 5 4 6 2 7 6 6 5 5 5
5 5 7 3 6 7 5 7 6 6 5 4 6 6 2 7 6 5 5 7 3 6 7 5 7
6 7 7 4 7 2 9 2 8 4 6 6 6 7 6 5 6 6 7 7 4 7 2 9 2
6 5 6 6 8 4 2 5 5 8 5 7 3 4 6 7 7 6 5 6 6 8 4 2 5
5 2 9 4 3 6 6 6 4 4 6 6 5 5 5 8 4 5 2 9 4 3 6 6 6
6 5 9 4 5 7 5 4 6 5 5 5 4 5 6 8 7 6 5 9 4 5 7 5 4
7 5 6 6 7 7 5 5 6 4 6 6 6 10 6 7 7 7 5 6 6 7 7 5 5
d) Obtenga una muestra aleatoria de 35 pasajeros y haga un intervalo de confianza del 95% para
estimar la media poblacional de las calificaciones otorgadas por los pasajeros. e) Obtenga una muestra de 10 pasajeros y estime con un intervalo de confianza de 90% la proporción
poblacional de pasajeros que otorgaron una calificación reprobatoria (proporción debe de contar cuales aprueban y cuales no)
f) ¿De que tamaño deberá ser la muestra si el error máximo de estimación es igual a .5?

Tablas
Distribución t
Valores de t tales que la probabilidad sea menor o igual a la especificada (1)
Grados de Probabilidad a la derecha del valor dado en la tabla
libertad v 0.4 0.30 0.20 0.15 0.10 0.075 0.050 0.025 0.010 0.005
1 0.325 0.727 1.376 1.963 3.078 4.165 6.314 12.706 31.821 63.656
2 0.289 0.617 1.061 1.386 1.886 2.282 2.920 4.303 6.965 9.925
3 0.277 0.584 0.978 1.250 1.638 1.924 2.353 3.182 4.541 5.841
4 0.271 0.569 0.941 1.190 1.533 1.778 2.132 2.776 3.747 4.604
5 0.267 0.559 0.920 1.156 1.476 1.699 2.015 2.571 3.365 4.032
6 0.265 0.553 0.906 1.134 1.440 1.650 1.943 2.447 3.143 3.707
7 0.263 0.549 0.896 1.119 1.415 1.617 1.895 2.365 2.998 3.499
8 0.262 0.546 0.889 1.108 1.397 1.592 1.860 2.306 2.896 3.355
9 0.261 0.543 0.883 1.100 1.383 1.574 1.833 2.262 2.821 3.250
10 0.260 0.542 0.879 1.093 1.372 1.559 1.812 2.228 2.764 3.169
11 0.260 0.540 0.876 1.088 1.363 1.548 1.796 2.201 2.718 3.106
12 0.259 0.539 0.873 1.083 1.356 1.538 1.782 2.179 2.681 3.055
13 0.259 0.538 0.870 1.079 1.350 1.530 1.771 2.160 2.650 3.012
14 0.258 0.537 0.868 1.076 1.345 1.523 1.761 2.145 2.624 2.977
15 0.258 0.536 0.866 1.074 1.341 1.517 1.753 2.131 2.602 2.947
16 0.258 0.535 0.865 1.071 1.337 1.512 1.746 2.120 2.583 2.921
17 0.257 0.534 0.863 1.069 1.333 1.508 1.740 2.110 2.567 2.898
18 0.257 0.534 0.862 1.067 1.330 1.504 1.734 2.101 2.552 2.878
19 0.257 0.533 0.861 1.066 1.328 1.500 1.729 2.093 2.539 2.861
20 0.257 0.533 0.860 1.064 1.325 1.497 1.725 2.086 2.528 2.845
21 0.257 0.532 0.859 1.063 1.323 1.494 1.721 2.080 2.518 2.831
22 0.256 0.532 0.858 1.061 1.321 1.492 1.717 2.074 2.508 2.819
23 0.256 0.532 0.858 1.060 1.319 1.489 1.714 2.069 2.500 2.807
24 0.256 0.531 0.857 1.059 1.318 1.487 1.711 2.064 2.492 2.797
25 0.256 0.531 0.856 1.058 1.316 1.485 1.708 2.060 2.485 2.787
26 0.256 0.531 0.856 1.058 1.315 1.483 1.706 2.056 2.479 2.779
27 0.256 0.531 0.855 1.057 1.314 1.482 1.703 2.052 2.473 2.771

28 0.256 0.530 0.855 1.056 1.313 1.480 1.701 2.048 2.467 2.763
29 0.256 0.530 0.854 1.055 1.311 1.479 1.699 2.045 2.462 2.756
30 0.256 0.530 0.854 1.055 1.310 1.477 1.697 2.042 2.457 2.750
> 30 0.253 0.524 0.842 1.036 1.282 1.440 1.645 1.960 2.326 2.576
(1) Valores calculados usando la función DISTR.T.INV() del Excel.
La probabilidad corresponde al área a la derecha del valor dado en la tabla.
0.6 0.7 0.8 0.85 0.9 0.925 0.95 0.975 0.99 0.995

Distribución normal acumulada -N(0,1)
Valores de la probabilidad acumulada por debajo de z (1)
Z 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359
0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753
0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141
0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517
0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879
0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224
0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549
0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852
0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
1.0 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621
1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830
1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015
1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319
1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441
1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545
1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633
1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9761 0.9767
2.0 0.9772 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817
2.1 0.9821 0.9826 0.9830 0.9834 0.9838 0.9842 0.9846 0.9850 0.9854 0.9857
2.2 0.9861 0.9864 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.9890
2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916
2.4 0.9918 0.9920 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936
2.5 0.9938 0.9940 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952
2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.9960 0.9961 0.9962 0.9963 0.9964
2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.9970 0.9971 0.9972 0.9973 0.9974
2.8 0.9974 0.9975 0.9976 0.9977 0.9977 0.9978 0.9979 0.9979 0.9980 0.9981
2.9 0.9981 0.9982 0.9982 0.9983 0.9984 0.9984 0.9985 0.9985 0.9986 0.9986
3.0 0.9987 0.9987 0.9987 0.9988 0.9988 0.9989 0.9989 0.9989 0.9990 0.9990
3.1 0.9990 0.9991 0.9991 0.9991 0.9992 0.9992 0.9992 0.9992 0.9993 0.9993
3.2 0.9993 0.9993 0.9994 0.9994 0.9994 0.9994 0.9994 0.9995 0.9995 0.9995
3.3 0.9995 0.9995 0.9995 0.9996 0.9996 0.9996 0.9996 0.9996 0.9996 0.9997
3.4 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9998
3.5 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998
(1) Valores calculados usando la función DISTR.NORM.ESTAND() del Excel.




longitud ala longitud cuerpo ancho cuerpo doblar
wing lenght body lenght body width fold clip
1 6 6 3 1 si
2 6 6 3 1 no
3 6 6 3 2 si
4 6 6 3 2 no
5 6 6 6 1 si
6 6 6 6 1 no
7 6 6 6 2 si
8 6 6 6 2 no
9 6 12 3 1 si
10 6 12 3 1 no
11 6 12 3 2 si
12 6 12 3 2 no
13 6 12 6 1 si
14 6 12 6 1 no
15 6 12 6 2 si
16 6 12 6 2 no
17 12 6 3 1 si
18 12 6 3 1 no
19 12 6 3 2 si
20 12 6 3 2 no
21 12 6 6 1 si
22 12 6 6 1 no
23 12 6 6 2 si
24 12 6 6 2 no
25 12 12 3 1 si
26 12 12 3 1 no
27 12 12 3 2 si
28 12 12 3 2 no
29 12 12 6 1 si
30 12 12 6 1 no
31 12 12 6 2 si
32 12 12 6 2 no



























