Embed Size (px)
Citation preview

MPI+X: Opportunities and Limitationsfor Heterogeneous Systems
Karl Rupp
https://karlrupp.net/
now:Freelance Scientist
formerly:Institute for Microelectronics, TU Wien
in collaboration with colleagues at TU Wien:J. Weinbub, F. Rudolf, A. Morhammer, T. Grasser, A. Jungel
...and in discussion with colleagues all over the world
MS35 - To Thread or Not To ThreadSIAM PP, ParisApril 13, 2016

2
OverviewOverview
Part 1: Why bother about MPI+X?
Part 2: What about X = threads?

3
The Big PictureThe Big Picture
���������������
� The next large NERSC produc)on system “Cori” will be IntelXeon Phi KNL (Knights Landing) architecture: � >60 cores per node, 4 hardware threads per core� Total of >240 threads per node
� Your applica)on is very likely to run on KNL with simpleport, but high performance is harder to achieve.
� Many applica)ons will not fit into the memory of a KNLnode using pure MPI across all HW cores and threadsbecause of the memory overhead for each MPI task.
� Hybrid MPI/OpenMP is the recommended programmingmodel, to achieve scaling capability and code portability.
� Current NERSC systems (Babbage, Edison, and Hopper) canhelp prepare your codes.
-‐ 85 -‐
“OpenMP Basics and MPI/OpenMP Scaling”, Yun He, NERSC, 2015

4
The Big PictureThe Big Picture
“OpenMP Basics and MPI/OpenMP Scaling”, Yun He, NERSC, 2015

5
The Big PictureThe Big Picture
�����������
� OpenMP is a fun and powerful language for sharedmemory programming.
� Hybrid MPI/OpenMP is recommended for manynext genera)on architectures (Intel Xeon Phi forexample), including NERSC-‐8 system, Cori.
� You should explore to add OpenMP now if yourapplica)on is flat MPI only.
-‐ 123 -‐
“OpenMP Basics and MPI/OpenMP Scaling”, Yun He, NERSC, 2015

6
Future SystemsFuture Systems

7
Future SystemsFuture Systems
Some Systems are Hybrid
Multi-core CPUs + many-core GPUs
Multi-core CPUs + FPGAs?
Multi-core CPUs + custom accelerators?
Why MPI+X for Hybrid Systems?
MPI not available onGPUs/FPGAs/accelerators
http://geco.mines.edu/tesla/cuda tutorial mio/pic/mpi cuda.jpg

8
Simple MPI ModelSimple MPI Model
node node
nodenode
MPI rank MPI rank
MPI rankMPI rank
Hybridization Easy?
#pragma omp parallel for

9
Simple MPI ModelSimple MPI Model
Mind the Details
NUMA domains: Data locality matters
CPU internals: Ring buses
http://images.anandtech.com/doci/10158/v4 24coresHCC.png

10
NUMA-aware MPI ModelNUMA-aware MPI Model
node node
nodenode
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI

11
Hybrid MPI ModelHybrid MPI Model
Hybridization
One or multiple multi-core CPUs
One or multiple GPUs/FPGAs/accelerators
CPU Starvation
Use one MPI rank per GPU (shepard process)
Problem: Waste of CPU resources

12
GPUs in the MPI ModelGPUs in the MPI Model
node node
nodenode
MPI
MPI
MPI
MPI
MPI
MPI
GPU
GPU
MPI
MPI
GPU
GPU
GPU
GPUGPU
GPU

13
GPUs in the MPI ModelGPUs in the MPI Model
node node
nodenode
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
GPU GPU
GPUGPU
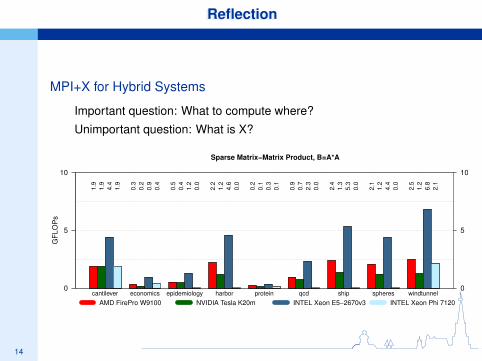
14
ReflectionReflection
MPI+X for Hybrid Systems
Important question: What to compute where?
Unimportant question: What is X?
0
5
10
0
5
10
GF
LO
Ps
cantilever economics epidemiology harbor protein qcd ship spheres windtunnel
1.9
1.9
4.4
1.9
0.3
0.2
0.9
0.4
0.5
0.4
1.2
0.0
2.2
1.2
4.6
0.0
0.2
0.1
0.3
0.1
0.9
0.7
2.3
0.0
2.4
1.3
5.3
0.0
2.1
1.2
4.4
0.0
2.5
1.2
6.8
2.1
AMD FirePro W9100 NVIDIA Tesla K20m INTEL Xeon E5−2670v3 INTEL Xeon Phi 7120
Sparse Matrix−Matrix Product, B=A*A

15
PCI-Express BottleneckPCI-Express Bottleneck
Vector Addition
x = y + z with N elements each
1 FLOP per 24 byte in double precision
Limited by memory bandwidth⇒ T2(N)?≈ 3× 8× N/Bandwidth + Latency
10-6
10-5
10-4
10-3
102
103
104
105
106
107
Exe
cu
tio
n T
ime
(se
c)
Vector Size
Execution Time for x = y + z in Double Precision
NVIDIA Tesla K20mBandwidth LimitBandwidth + Latency Limit

16
PCI-Express BottleneckPCI-Express Bottleneck
10-5
10-4
10-3
10-2
10-1
100
101
102
103
104
105
106
107
108
Tim
e p
er
Itera
tion (
sec)
Unknowns
Unpreconditioned Conjugate Gradients, NVIDIA Tesla K20m
ViennaCLPARALUTIONMAGMACUSPPETSc (2x Ivy Bridge)

17
PCI-Express BottleneckPCI-Express Bottleneck
10-2
10-1
100
101
102
103
104
105
106
107
Exe
cu
tio
n T
ime
(se
c)
Unknowns
Total Solver Execution Times, Poisson Equation in 2D
Dual INTEL Xeon E5-2670 v3, No PreconditionerDual INTEL Xeon E5-2670 v3, Smoothed AggregationAMD FirePro W9100, No PreconditionerAMD FirePro W9100, Smoothed AggregationNVIDIA Tesla K20m, No PreconditionerNVIDIA Tesla K20m, Smoothed AggregationINTEL Xeon Phi 7120, No PreconditionerINTEL Xeon Phi 7120, Smoothed Aggregation

18
PCI-Express BottleneckPCI-Express Bottleneck
Example: Algebraic Multigrid
SpGEMM on CPU (AMG setup)
SpMV & friends on GPUs (AMG solve)
Model 1: Side-by-Side
Use MPI ranks for CPU
How to decompose problem?
Model 2: GPU shepards only
Overlapping of GPU and CPU workwithin rank
Reimplement message passing onMPI rank level?
N. Bell et al., SISC 34(4), 2012

19
OverviewOverview
Part 2: What about X = threads?
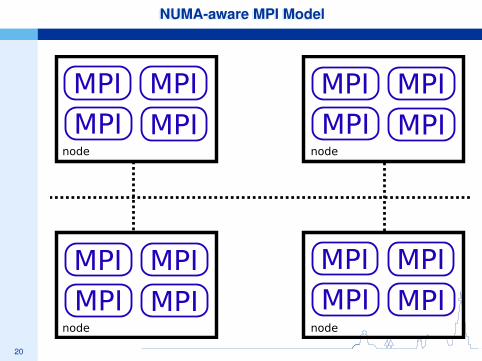
20
NUMA-aware MPI ModelNUMA-aware MPI Model
node node
nodenode
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
MPI MPI
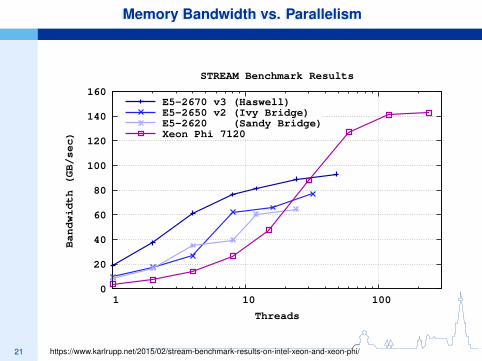
21
Memory Bandwidth vs. ParallelismMemory Bandwidth vs. Parallelism
0
20
40
60
80
100
120
140
160
1 10 100
Bandwidth (GB/sec)
Threads
STREAM Benchmark Results
E5-2670 v3 (Haswell) E5-2650 v2 (Ivy Bridge) E5-2620 (Sandy Bridge)Xeon Phi 7120
https://www.karlrupp.net/2015/02/stream-benchmark-results-on-intel-xeon-and-xeon-phi/

22
Threads and Library InterfacesThreads and Library Interfaces
Attempt 1
Library spawns threads
void library_func(double *x, int N) {#pragma omp parallel forfor (int i=0; i<N; ++i) x[i] = something_complicated();
}
Problems
Call from multi-threaded environment?
void user_func(double **y, int N) {#pragma omp parallel forfor (int j=0; j<M; ++j) library_func(y[j], N);
}
Incompatible OpenMP runtimes (e.g. GCC vs. ICC)

23
Threads and Library InterfacesThreads and Library Interfaces
Attempt 2
Use pthreads/TBB/etc. instead of OpenMP to spawn threads
Fixes incompatible OpenMP implementations (probably)
Problems
Still a problem with multi-threaded user environments
void user_func(double **y, int N) {#pragma omp parallel forfor (int j=0; j<M; ++j) library_func(y[j], N);
}

24
Threads and Library InterfacesThreads and Library Interfaces
Attempt 3
Hand back thread management to user
void library_func(ThreadInfo ti, double *x, int N) {int start = compute_start_index(ti, N);int stop = compute_stop_index(ti, N);for (int i=start; i<stop; ++i)x[i] = something_complicated();
}
Implications
Users can use their favorite threading model
API requires one extra parameter
Extra boilerplate code required in user code

25
Threads and Library InterfacesThreads and Library Interfaces
Reflection
Extra thread communication parameter
void library_func(ThreadInfo ti, double *x, int N) {...}
Rename thread management parameter
void library_func(Thread_Comm c, double *x, int N) {...}
Compare:
void library_func(MPI_Comm comm, double *x, int N) {...}
Conclusion
Prefer flat MPI over MPI+OpenMP for a composable software stack
MPI automatically brings better data locality

26
SummarySummary
MPI+X Opportunities
CPUs for sequential potions
Non-CPUs for fine-grained parallel potions
Get funding for reimplementing existing things
MPI+X Challenges
Use all components of a hybrid system
Productivity?
Scientific progress?





























