Embed Size (px)
DESCRIPTION
3 The goal: extending last week‘s interactions between relational DBs and text-analysis tools 3
Citation preview

More on texts as relational data:An Introduction to Text Mining
‹#›
Bettina Berendt
Department of Computer ScienceKU Leuven, Belgiumhttp://people.cs.kuleuven.be/~bettina.berendt/
Information Structures and Implications 2015Last updated: 24 November 2015
22
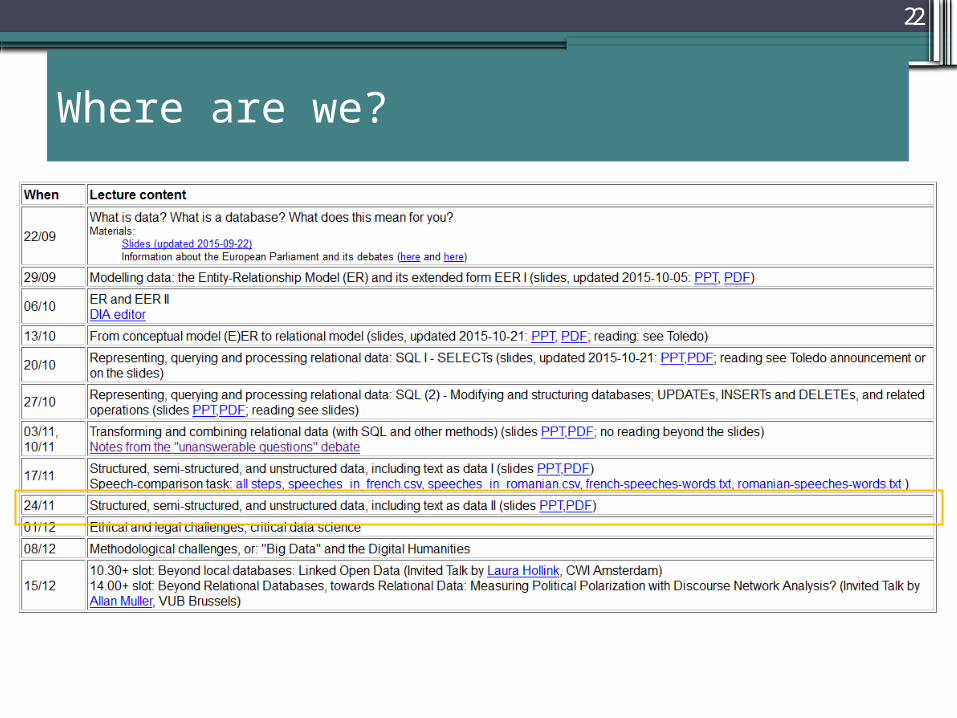
Where are we?

3
3
The goal: extending last week‘s interactions between relational DBs and text-analysis tools
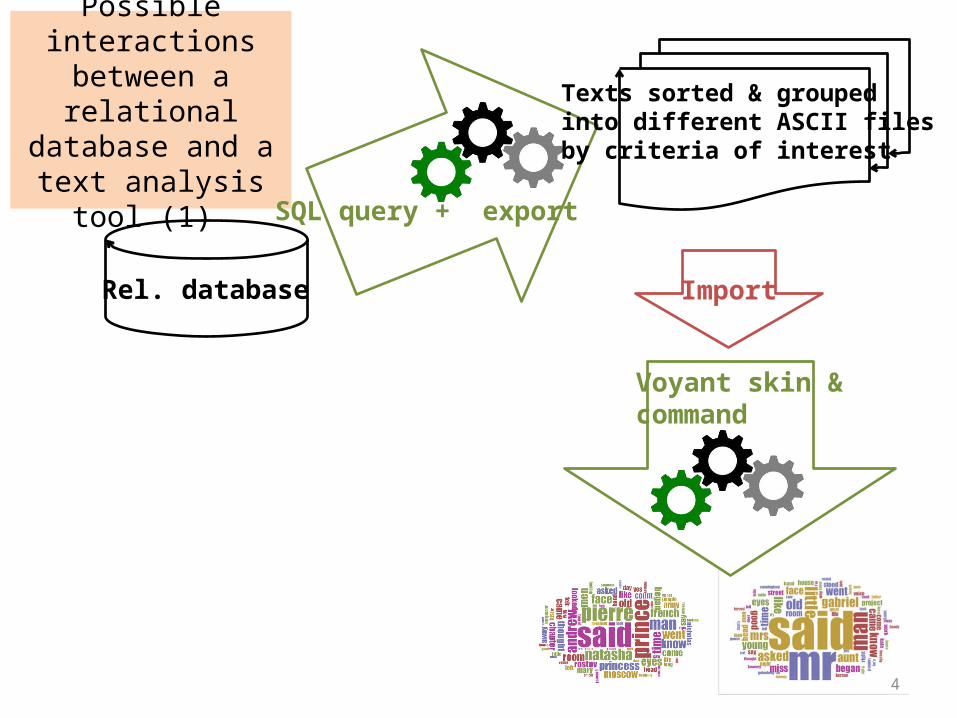
Possible interactions between a relational database and a text
analysis tool (1)
4
Rel. database
SQL query + export
Import
Voyant skin &command
Texts sorted & grouped into different ASCII filesby criteria of interest
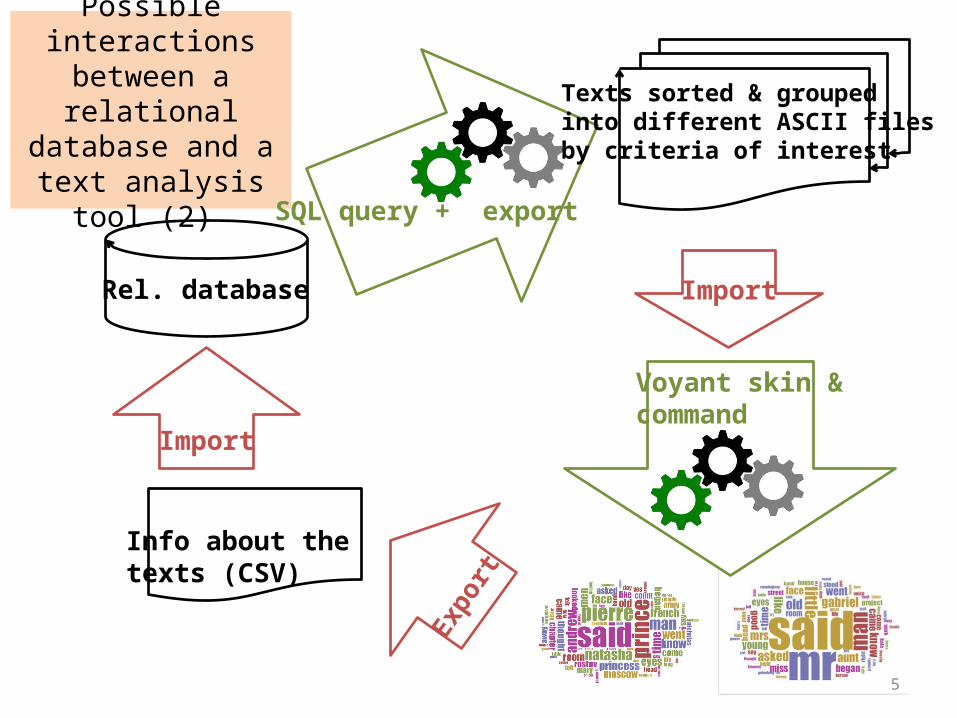
Possible interactions between a relational database and a text
analysis tool (2)
5
Rel. database
SQL query + export
Import
Voyant skin &command
Texts sorted & grouped into different ASCII filesby criteria of interest
Import
Info about thetexts (CSV)
Expo
rt

Possible interactions between a relational database and a text
analysis tool (3)
6
Rel. database
SQL query + export
Import
WEKA filters& analyses
Texts sorted & grouped into CSV file, e.g. withclass labels by criteria of interest
Import
Info about thetexts, e.g. cluster labels (CSV)
Expo
rt
Texts as strings and feature vectors Text mining: steps and basic tasksEvaluation
‹#›
8
8
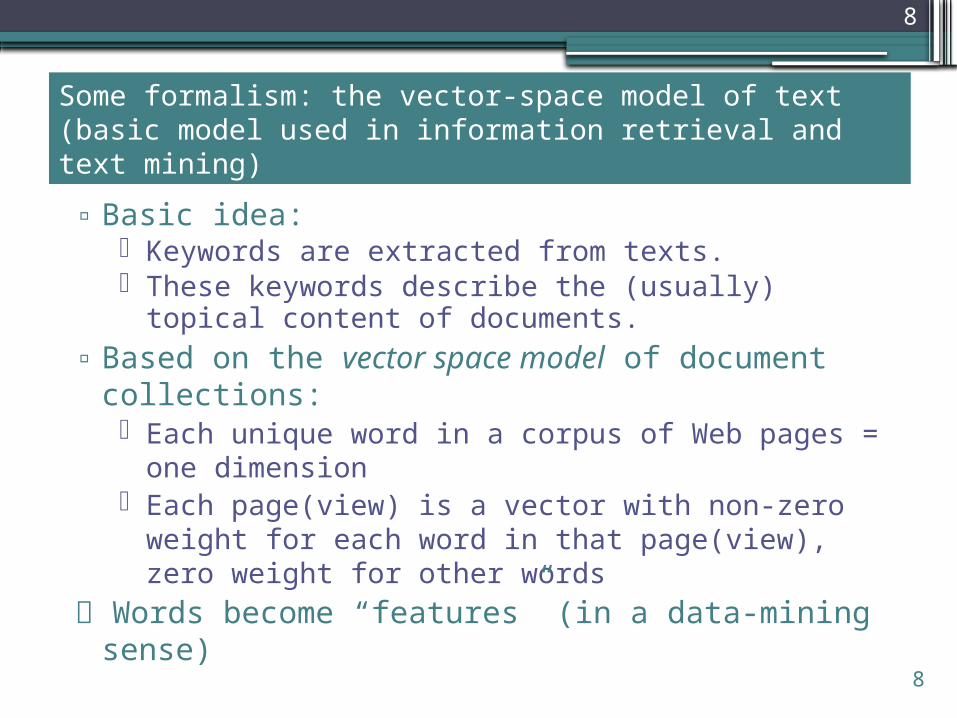
Some formalism: the vector-space model of text (basic model used in information retrieval and text mining)
▫ Basic idea: Keywords are extracted from texts. These keywords describe the (usually) topical
content of documents. ▫ Based on the vector space model of document
collections: Each unique word in a corpus of Web pages = one
dimension Each page(view) is a vector with non-zero weight
for each word in that page(view), zero weight for other words
Words become “features” (in a data-mining sense)

9
• Starting point is the raw term frequency as term weights• Other weighting schemes can generally be obtained by applying
various transformations to the document vectors
nova galaxy heat actor film rolediet
A 1.0 0.5 0.3
B 0.5 1.0
C 0.4 1.0 0.8 0.7
D 0.9 1.0 0.5
E 0.5 0.7 0.9
F 0.6 1.0 0.3 0.2 0.8
Document Ids
a documentvector
Features
Document Representation as Vectors
10
10
Other features (usually metadata of different sorts) can be added•Tags or other categories•Special content (e.g. URLs, images, Twitter
mentions)•Source•Number of followers of source• ...

11

12
12
https://aeshin.org/textmining/

13
Texts as strings and feature vectors Text mining: steps and basic tasksEvaluation
‹#›

15
The idea of text mining ...
•... is to go beyond frequency-counting•... is to go beyond the search-for-
documents framework•... is to find patterns (of meaning) within
and especially across documents
•(but boundaries are not fixed)

16
16
Data mining (aka Knowledge Discovery)
The non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data
(Fayyad, Platetsky-Shapiro, Smyth, 1996)

17
17
CRISP-DM: Cross-Industry Standard Process for Data Mining

18
The steps of text mining
1.Application understanding 2.Corpus generation3.Data understanding4.Text preprocessing5.Search for patterns / modelling
Topical analysis Sentiment analysis / opinion mining
6.Evaluation 7.Deployment

19
Application understanding; Corpus generation
▫What is the question?▫What is the context?▫What could be interesting sources, and where
can they be found?
▫Use an existing corpus▫Crawl▫Use a search engine and/or archive and/or API
▫Get help!
20
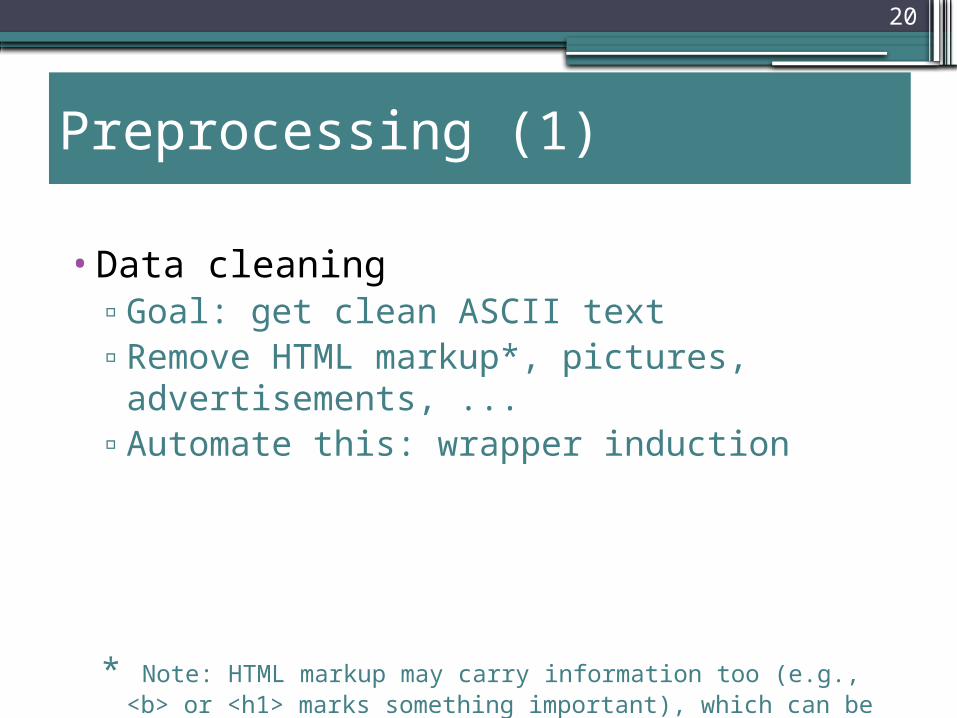
Preprocessing (1)
•Data cleaning▫Goal: get clean ASCII text▫Remove HTML markup*, pictures,
advertisements, ...▫Automate this: wrapper induction
* Note: HTML markup may carry information too (e.g., <b> or <h1> marks something important), which can be extracted! (Depends on the application)

21
Preprocessing (2)• Goal: get processable lexical / syntactical units• Tokenize (find word boundaries)• Lemmatize / stem
▫ ex. buyers, buyer buyer / buyer, buying, ... buy• Remove stopwords• Find Named Entities (people, places, companies, ...);
filtering• Resolve polysemy and homonymy: word sense
disambiguation; “synonym unification“• Part-of-speech tagging; filtering of nouns, verbs,
adjectives, ...• ...
• Most steps are optional and application-dependent!• Many steps are language-dependent; coverage of non-
English varies• Free and/or open-source tools or Web APIs exist for most
steps
Do you see a problemhere for DH?What implicit assumptions are made?

22
Preprocessing (3)
•Creation of text representation▫Goal: a representation that the modelling
algorithm can work on▫Most common forms: A text as
a set or (more usually) bag of words / vector-space representation: term-document matrix with weights reflecting occurrence, importance, ...
a sequence of words a tree (parse trees)

23
An important part of preprocessing:Named-entity recognition (1)
This 2009 OpenCalais screenshot visualizes nicely what today is mostly markup. E.g. in the tool http://www.alchemyapi.com/api/entity-extraction

24
An important part of preprocessing:Named-entity recognition (2)•Technique: Lexica, heuristic rules, syntax
parsing•Re-use lexica and/or develop your own
▫configurable tools such as GATE•An example challenge: multi-document
named-entity recognition▫Several solution proposals
•A more difficult problem: Anaphora resolution

25
25
Styles of statistics-based analysis• Statistics: descriptive – inferential• Data mining: descriptive – predictive (D – P)• Machine learning, data mining: unsupervised –
supervised
• Typical tasks in text analysis:▫D: Frequency analysis, collocation analysis,
association rules ▫D: Cluster analysis▫P: Classification▫ Interactive knowledge discovery: combines various
forms and involves “the human in the loop“
“It involves Russia.“
“It‘s about Russia.“

26
26
https://aeshin.org/textmining/

27
27
Tools we will see (you‘ll have to choose, based on your prior knowledge)• Frequency analysis, collocation analysis
▫Voyant ▫ (also offers many other forms, see
http://docs.voyant-tools.org/tools/) • More visualization (based on clustering)
▫DocumentAtlas• Classification
▫ Weka (can also do lots of other data mining tasks, such as association rules, and it is not made specifically for texts)
• Interactive knowledge discovery ▫Ontogen: Ontology learning based on clustering and
manual post-processing; includes DocumentAtlas
28
28
Basic process of classification/predictionGiven a set of documents and their classes, e.g.
▫Spam, no-spam▫Topic categories in news: current affairs,
business, sports, entertainment, ...▫Any other classification
1. Learn which document features characterise the classes = learn a classifier
2. Predict, from document features, the classes
▫For old documents with known classes▫For new documents with unknown classes
29
What makes people happy?

30
Happiness in blogosphere
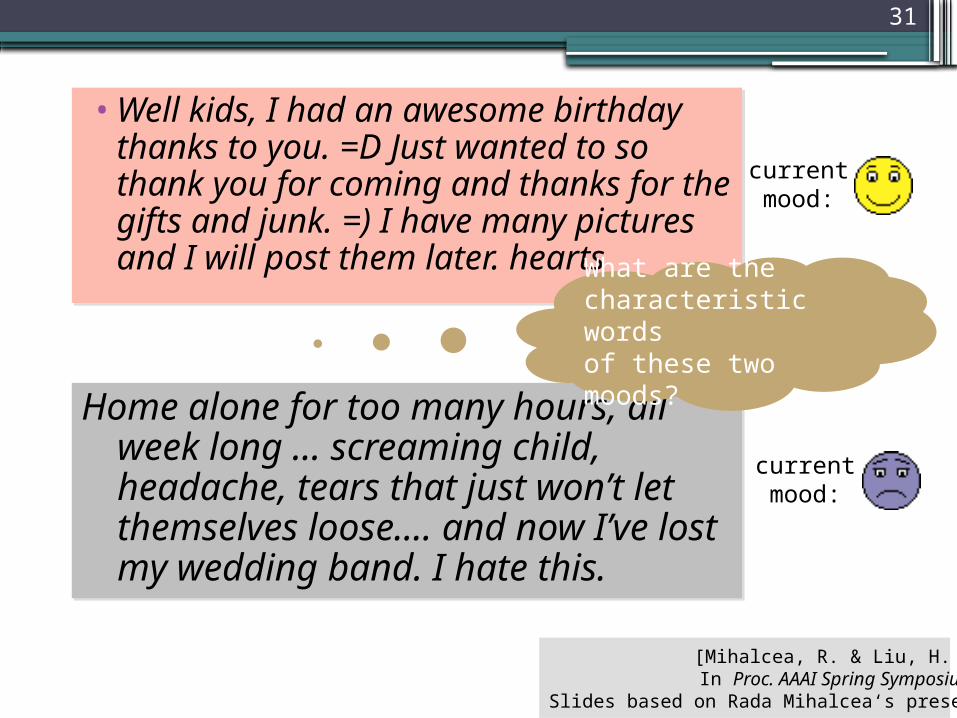
31
• Well kids, I had an awesome birthday thanks to you. =D Just wanted to so thank you for coming and thanks for the gifts and junk. =) I have many pictures and I will post them later. hearts
current mood:
Home alone for too many hours, all week long ... screaming child, headache, tears that just won’t let themselves loose.... and now I’ve lost my wedding band. I hate this.
current mood:
What are the characteristic words of these two moods?
[Mihalcea, R. & Liu, H. (2006). In Proc. AAAI Spring Symposium CAAW.]
Slides based on Rada Mihalcea‘s presentation.
32
Data, data preparation and learning
•LiveJournal.com – optional mood annotation
•10,000 blogs: ▫5,000 happy entries / 5,000 sad entries▫average size 175 words / entry▫pre-processing – remove SGML tags,
tokenization, part-of-speech tagging

Results: Corpus-derived happiness factorsyay 86.67shopping 79.56awesome 79.71birthday 78.37lovely77.39concert 74.85cool 73.72cute 73.20lunch 73.02books73.02
goodbye 18.81hurt 17.39tears 14.35cried 11.39upset 11.12sad 11.11cry 10.56died 10.07lonely 9.50crying 5.50happiness factor of a word =
the number of occurrences in the happy blogposts / the total frequency in the corpus
‹#›
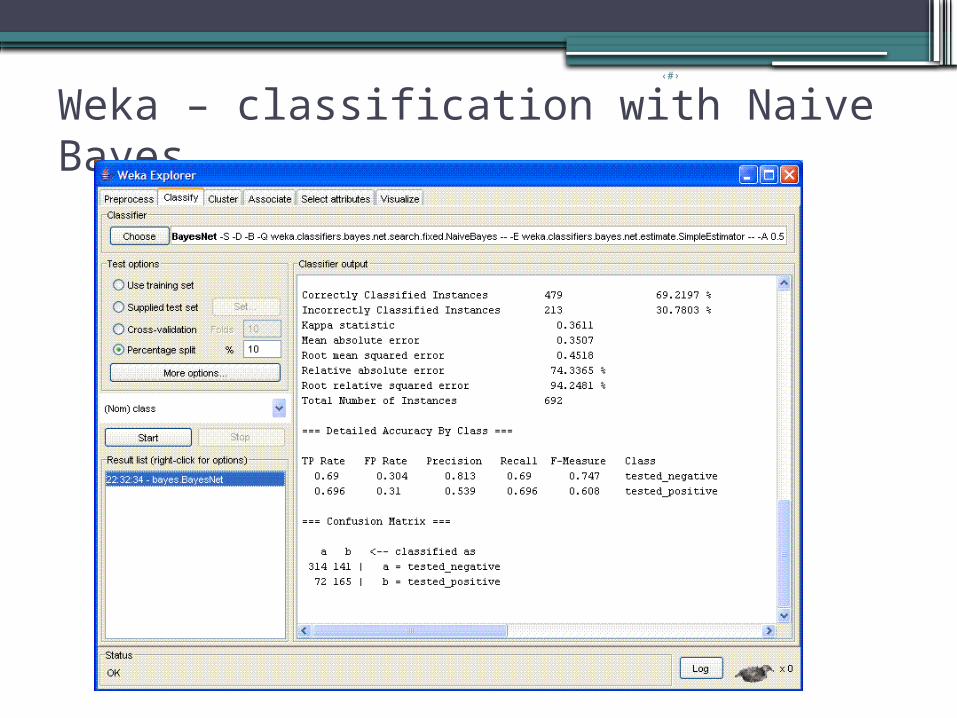
Weka – classification with Naive Bayes
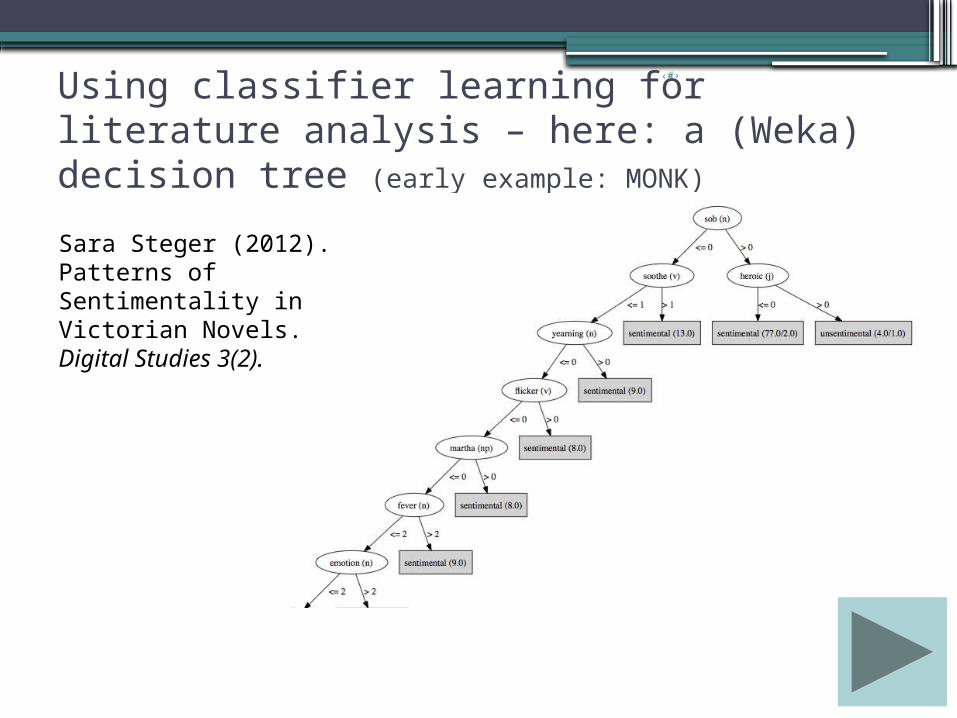
‹#›Using classifier learning for literature analysis – here: a (Weka) decision tree (early example: MONK)
Sara Steger (2012).Patterns of Sentimentality in Victorian Novels.Digital Studies 3(2).

Possible interactions between a relational database and a text
analysis tool (3)
36
Rel. database
SQL query + export
Import
WEKA filters& analyses
Texts sorted & grouped into CSV file, e.g. withclass labels by criteria of interest

37
37
Many other tasks (ex. news/blogs mining)Tasks in news / (micro-)blogs mining can be grouped by different criteria:• Basic task and type of result: description, classification and
prediction (supervised or unsupervised, includes for example topic identification, tracking, and/or novelty detection; spam detection); search (ad hoc or filtering); recommendation (of blogs, blog posts, or (hash-)tags); summarization
• Higher-order characterization to be extracted: especially topic or event; opinion or sentiment
• Time dimension: nontemporal; temporal (stream mining); multiple streams (e.g., in different languages, see cross-lingual text mining)
• User adaptation: none (no explicit mention of user issues and/or general audience); customizable; personalized
Berendt (Encyclopedia of Machine Learning and Data Mining, in press).

38
38
Real-world applications of news/blogs miningReal-world applications increasingly employ selections or, more often, combinations of these tasks by their intended users and use cases, in particular:• News aggregators allow laypeople and professional users (e.g. journalists) to see “what’s in
the news” and to compare different sources’ texts on one story. Reflecting the presumption that news (especially mainstream news – sources for news aggregators are usually whitelisted) are mostly objective/neutral, these aggregators focus on topics and events. News aggregators are now provided by all major search engines.
• Social-media monitoring tools allow laypeople and professional users to track not only topical mentions of a keyword or named entity (e.g. person, brand), but also aggregate sentiment towards it. The focus on sentiment reflects the perceptions that even when news-related, social media content tends to be subjective and that studying the blogosphere is therefore an inexpensive way of doing market research or public-opinion research. The whitelist here is usually the platforms (e.g. Twitter, Tumblr, LiveJournal, Facebook) rather than the sources themselves, reflecting the huge size and dynamic structure of the blogosphere / the Social Web. The landscape of commercial and free social-media monitoring tools is wide and changes frequently; up-to-date overviews and comparisons can easily be found on the Web.
• Emerging application types include text mining not of, but for journalistic texts, in particular natural language generation in domains with highly schematized event structures and reporting, such as sports and finance reporting (e.g. Allen et al., 2010; narrativescience.com) and social-media monitoring tools for helping journalists find sources (Diakopoulos et al., 2012).
Berendt (Encyclopedia of Machine Learning and Data Mining, in press).

Texts as strings and feature vectors Text mining: steps and basic tasksEvaluation
‹#›

40
Evaluation of unsupervised learning: e.g. clustering•Do the clusters make sense?•Are the instances within one cluster
similar to one another?•Are the instances in different clusters
dissimilar to one another?•(There are quantitative metrics of #2 and
#3)
41
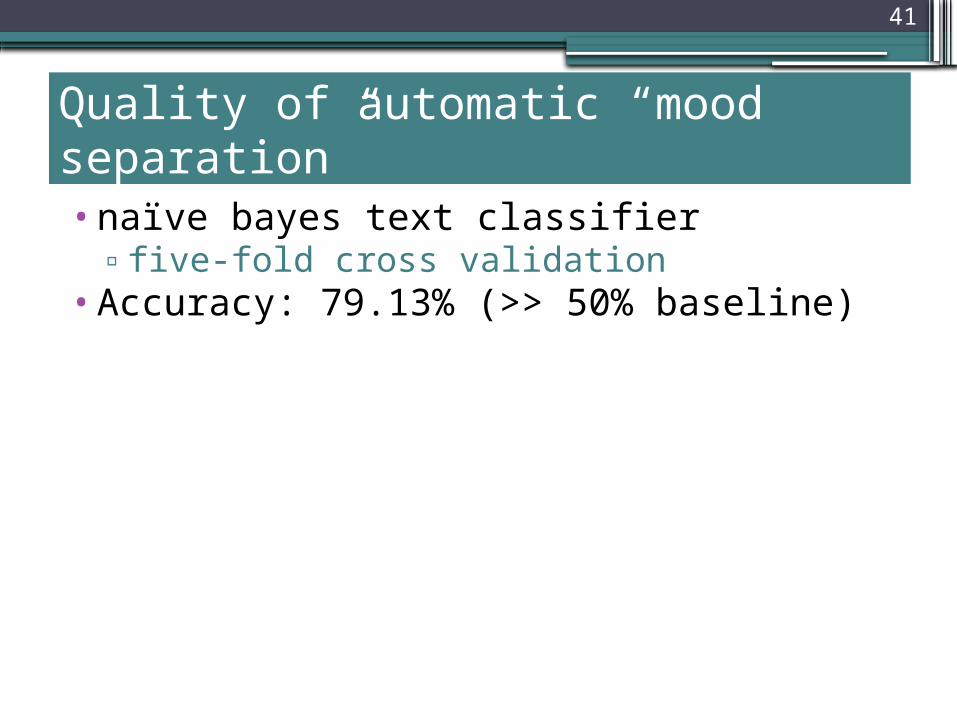
Quality of automatic “mood separation”•naïve bayes text classifier
▫five-fold cross validation•Accuracy: 79.13% (>> 50% baseline)

42
42
https://aeshin.org/textmining/

43
43
https://aeshin.org/textmining/

44
44
https://aeshin.org/textmining/
45
45
https://aeshin.org/textmining/
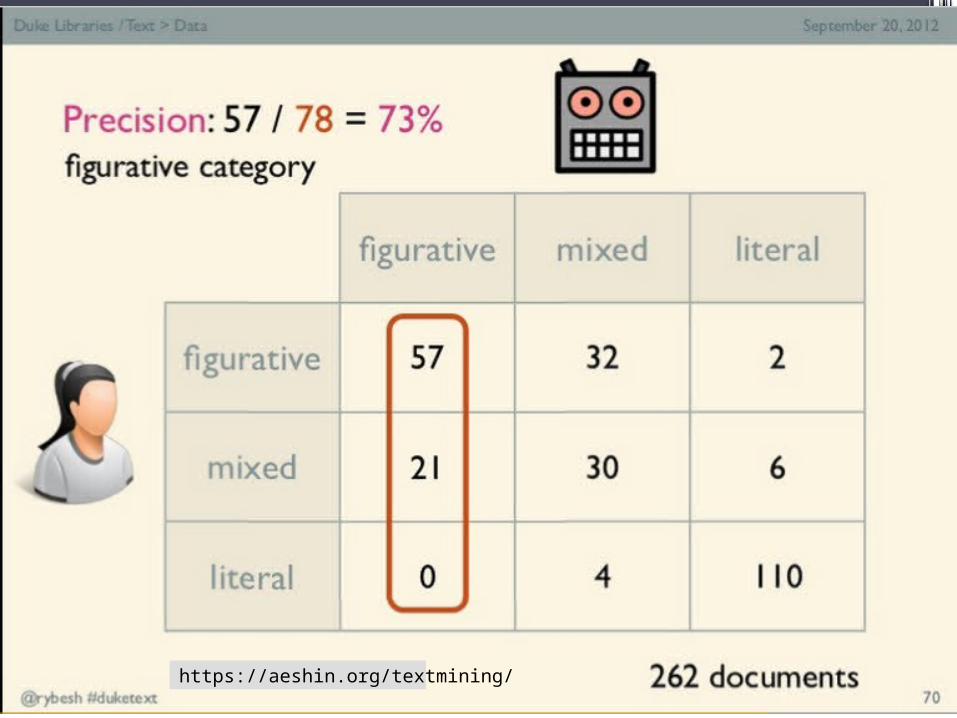
46
46
https://aeshin.org/textmining/
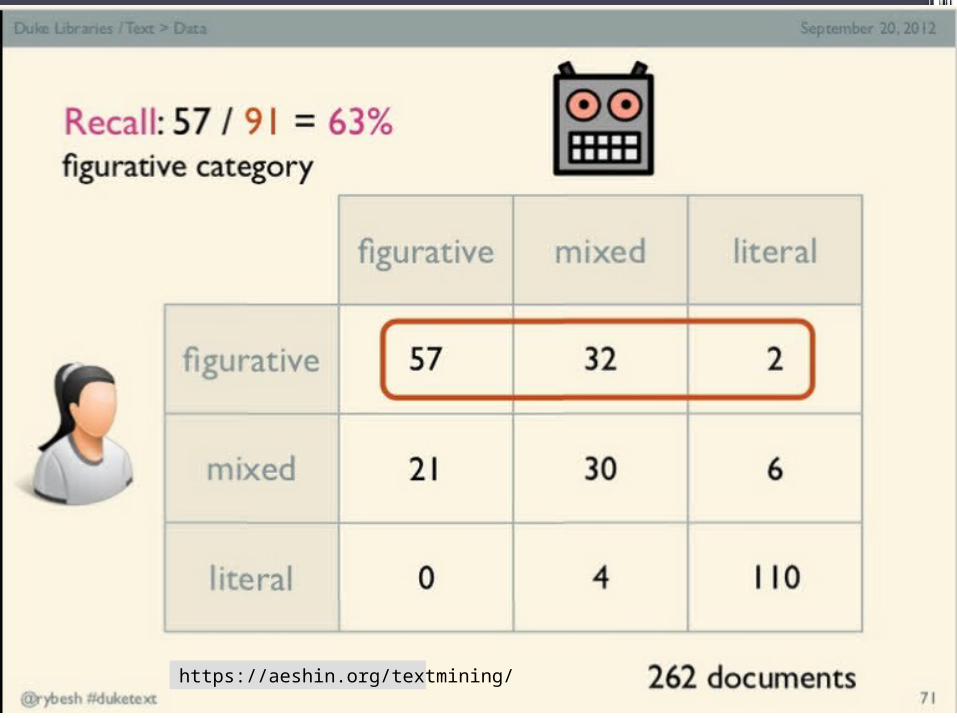
47
47
https://aeshin.org/textmining/

48
48
Who defines which class a document belongs to?•The researcher?•The author?•The reader?•Someone paid to do exactly this (e.g. a
worker on mTurk)?•Several of them?•Someone else?

49
49
The importance of consensusIllustration: ESP game (“Games with a purpose“)
von Ahn (2005, 2006)

50
50
Measuring inter-rater reliability• Popular measure of inter-rater agreement from content
analysis• Non-trivial formula (see references), but software exists.

51
51
How good is good: Magic numbers?
• (Kappa is a related measure; the boundaries are the same)• Boundaries are disputed and tend to get higher• Inter-rater agreement often systematically low, e.g. in text
summarization: slightly over 50% (Berendt et al., 2014)• Recent approaches attempt to accept this ambiguity and
work with it: e.g. Poesio et al. (2013)

52
52
In what sense is this an alternative?• “Given that there is no ground truth is a discipline like
literary criticism, it is difficult to know how influential these results will prove.
• A scholar would have to write them up in traditional article or monograph form, wait for the article or monograph to move through the peer-review process (this can take months or years) and then other scholars in the field will have to read it, be influenced by its arguments, and adjust their own interpretations of Dickinson—in turn publishing these in their own articles and monographs.
• Nonetheless, we believe that the Nora system has suggested that classification and prediction can be useful agents of provocation in humanistic study.”
(Kirschenbaum, 2007)

53
Thank you!
I‘ll be more than happy to hear your
s?
54
ReferencesA good textbook on Text Mining:• Feldman, R. & Sanger, J. (2007). The Text Mining Handbook. Advanced Approaches in Analyzing
Unstructured Data. Cambridge University Press.An introduction similar to this one, but also covering unsupervised learning in some detail, and with lots of pointers to books, materials, etc.:• Shaw, R. (2012). Text-mining as a Research Tool in the Humanities and Social Sciences. Presentation at the
Duke Libraries, September 20, 2012. https://aeshin.org/textmining/ An overview of news and (micro-)blogs mining:• Berendt, B. (in press). Text mining for news and blogs analysis. To appear in C. Sammut & G.I. Webb (Eds.),
Encyclopedia of Machine Learning and Data Mining. Berlin etc.: Springer. http://people.cs.kuleuven.be/~bettina.berendt/Papers/berendt_encyclopedia_2015_with_publication_info.pdf
See http://wiki.esi.ac.uk/Current_Approaches_to_Data_Mining_Blogs for more articles on the subject.
Individual sources cited on the slides• Fortuna, B., Galleguillos, C., & Cristianini, N. (2009). Detecting the bias in media with statistical learning
methods. In Text Mining: Classification, Clustering, and Applications, Chapman & Hall/CRC, 2009. • Qiaozhu Mei, ChengXiang Zhai: Discovering evolutionary theme patterns from text: an exploration of
temporal text mining. KDD 2005: 198-207• Mihalcea, R. & Liu, H. (2006). A corpus-based approach to finding happiness, In Proc. AAAI Spring
Symposium on Computational Approaches to Analyzing Weblogs. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.79.6759
• Kirschenbaum, M. "The Remaking of Reading: Data Mining and the Digital Humanities." In NGDM 07: National Science Foundation Symposium on Next Generation of Data Mining and Cyber-Enabled Discovery for Innovation. http://www.cs.umbc.edu/~hillol/NGDM07/abstracts/talks/MKirschenbaum.pdf
• Mueller, M. “Notes towards a user manual of MONK.” https://apps.lis.uiuc.edu/wiki/display/MONK/Notes+towards+a+user+manual+of+Monk, 2007.
• Massimo Poesio, Jon Chamberlain, Udo Kruschwitz, Livio Robaldo and Luca Ducceschi, 2013. Phrase Detectives: Utilizing Collective Intelligence for Internet-Scale Language Resource Creation. ACM Transactions on Intelligent Interactive Systems, 3(1). http://csee.essex.ac.uk/poesio/publications/poesio_et_al_ACM_TIIS_13.pdf
• Luis von Ahn (2005). Human Computation. PhD Dissertation. Computer Science Department, Carnegie Mellon University. http://reports-archive.adm.cs.cmu.edu/anon/usr0/ftp/usr/ftp/2005/abstracts/05-193.html
• Luis von Ahn: Games with a Purpose. IEEE Computer 39(6): 92-94 (2006)

55
55
More DH-specific toolsOverviews of 71 tools for Digital Humanists•Simpson, J., Rockwell, G., Chartier, R.,
Sinclair, S., Brown, S., Dyrbye, A., & Uszkalo, K. (2013). Text Mining Tools in the Humanities: An Analysis Framework. Journal of Digital Humanities, 2 (3), http://journalofdigitalhumanities.org/2-3/text-mining-tools-in-the-humanities-an-analysis-framework/
•See also the link collection on the Voyant documentation Web page

56
Tools (powerful, but require some computing experience)• Ling Pipe
▫ linguistic processing of text including entity extraction, clustering and classification, etc.▫ http://alias-i.com/lingpipe/
• OpenNLP▫ the most common NLP tasks, such as POS tagging, named entity extraction, chunking and
coreference resolution. ▫ http://opennlp.apache.org/
• Stanford Parser and Part-of-Speech (POS) Tagger ▫ http://nlp.stanford.edu/software/tagger.shtm/
• NTLK▫ Toolkit for teaching and researching classification, clustering and parsing▫ http://www.nltk.org/
• OpinionFinder▫ subjective sentences , source (holder) of the subjectivity and words that are included in
phrases expressing positive or negative sentiments.▫ http://code.google.com/p/opinionfinder/
• Basic sentiment tokenizer plus some tools, by Christopher Potts▫ http://sentiment.christopherpotts.net
• Twitter NLP and Part-of-speech tagging▫ http://www.ark.cs.cmu.edu/TweetNLP/
57
57
Further tools (thanks for your suggestions!)•Atlas TI: “Qualitative data analysis“
▫http://atlasti.com/▫Commercial product, has free trial version
58
58
More sources•Please find the URLs of pictures and
screenshots in the Powerpoint “comment“ box
•Thanks to the Internet for them!

















![1 Bettina Berendt KU Leuven, Dept. of Computer Science, Hypermedia & Databases berendt 3 December 2007 [updated version] Intelligent](https://img.dokumen.tips/doc/110x75/56649e5c5503460f94b53c9e/1-bettina-berendt-ku-leuven-dept-of-computer-science-hypermedia-databases.jpg)











