Embed Size (px)
Citation preview

Mining High Speed Mining High Speed Data StreamsData Streams
Authors:Authors:(1) Pedro Domingos(1) Pedro Domingos
University of WashingtonUniversity of WashingtonSeattle, WA 98195-2350,U.S.A.Seattle, WA 98195-2350,U.S.A.
(2) Geoff Hulten(2) Geoff HultenUniversity of WashingtonUniversity of Washington
Seattle, WA 98195-2350, U.S.ASeattle, WA 98195-2350, U.S.A
Presented by:Presented by:NimaNima
[Poornima Shetty][Poornima Shetty]Date: 11/15/2011Date: 11/15/2011
Course: Data Mining [CS332]Course: Data Mining [CS332]
Computer Science Department Computer Science Department University of VermontUniversity of Vermont

Mining High Speed Data Streams
2
Copyright Note:Copyright Note:• This presentation is based on the papers:
Mining High-Speed Data Streams, with Geoff Hulten. Proceedings of the Sixth International Conference on Knowledge Discovery and Data Mining (pp. 71-80), 2000. Boston, MA: ACM Press.
A General Framework for Mining Massive Data Streams, with Geoff Hulten (short paper). Journal of Computational and Graphical Statistics, 12, 2003
– The original presentation made by the author has been used to produce this presentation.

Mining High Speed Data Streams
3
OverviewOverview• Introduction• Background Knowledge• The Problem• Design Criteria• General Framework• Hoeffding Trees• Hoeffding bounds• Hoeffding Tree algorithm• Properties of Hoeffding Trees• The Basic algorithm concepts• The VFDT system• Study and comparison• A real world example• Conclusion

Mining High Speed Data Streams
4
IntroductionIntroduction• In today’s information society, extraction of knowledge is
becoming a very important task for many people. We live in an age of knowledge revolution.
• The digital universe in 2007 was estimated to be 281 exabytes(10^18), but in 2011 it is estimated to be 10 times the size it was 5 years before.
• To deal with these huge amount of data in a responsible way, green computing is becoming a necessity.– A main approach to green computing is based on algorithmic
efficiency.

Mining High Speed Data Streams
5
Introduction (Introduction (Contd.Contd.))• Many organizations such as Wall Mart, K Mart etc. have very large
databases that grow without limit at a rate of several million records per day.
• Mining these continuous data streams brings unique opportunities but also new challenges.
• The most efficient algorithms available today, concentrate on mining database that do not fit in main memory by only requiring sequential scans of the disk.

Mining High Speed Data Streams
6
Introduction (Introduction (Contd.Contd.))• Knowledge based systems are constrained by three main limited
resources:– Time– Memory – Sample Size
• In traditional applications of machine learning and statistics, sample size tends to be the dominant limitation.
– Computational resources for a massive search are available, but carrying out such a search over the small samples available often leads to “Overfitting”.
• In today’s data mining applications the bottleneck is time and memory, not examples.
– The examples are typically in over supply and it is impossible with current KDD (Knowledge based Discovery and Data mining) systems to make use of all of them within the available computational resources.
– As a result most of the examples go unused and resulting in “Underfitting”.

Mining High Speed Data Streams
7
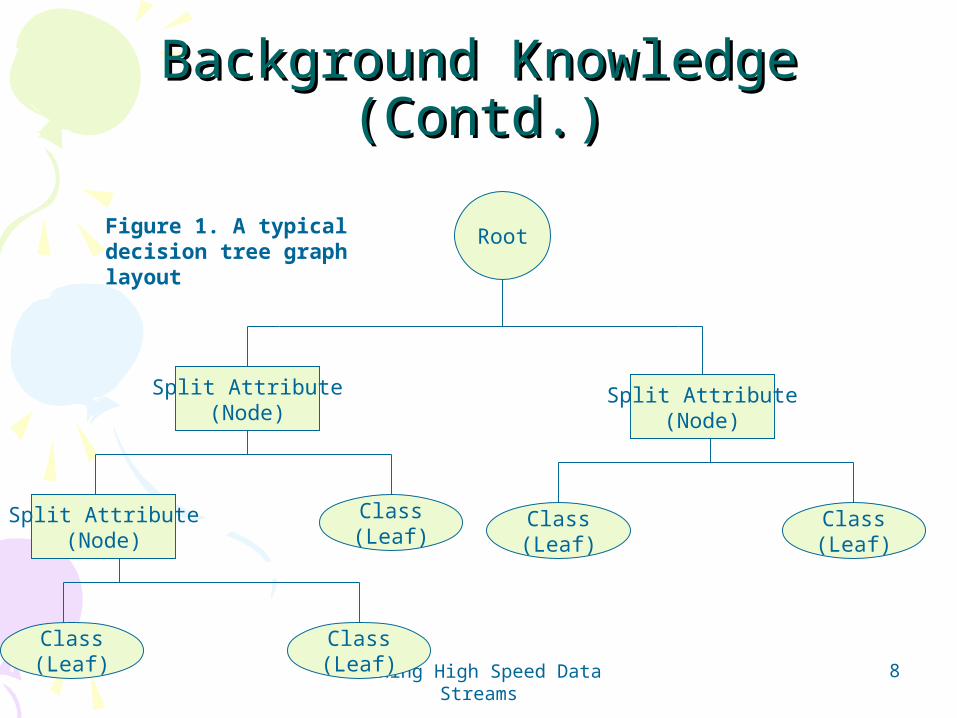
Background KnowledgeBackground Knowledge• Decision Tree Classification:
– “Traditional Decision Tree (TDT) model” can be implemented by using classical algorithms (induction and information gain theories).
• Some classical algorithms can be found for ID3, C4.5, and for CART that have been very widely used in the past decades.
• These algorithms need scan through all the data from a database for multiple times in order to construct a tree-like structure.
– One example is given in Figure below.
Mining High Speed Data Streams
8
Background Knowledge Background Knowledge ((Contd.Contd.))
Class(Leaf)
Class(Leaf)
Split Attribute(Node)
Class(Leaf)
Class(Leaf)
Class(Leaf)
Split Attribute(Node)
Split Attribute(Node)
RootFigure 1. A typical decision tree graph layout

Mining High Speed Data Streams
9
Background Knowledge Background Knowledge ((Contd.Contd.))
• Decision Tree in Stream Mining:– Maron and Moore in 1993 first highlighted that a small amount of
available data may be sufficient to be used as sample at any given node, for picking the split attribute for building a decision tree.
– Small amount of data must come in continuously at high speed.
– But exactly how many such streaming data are needed?• Hoeffding Bound (additive Chernoff Bound)

Mining High Speed Data Streams
10
The ProblemThe Problem• Many organizations today produce an electronic record of
essentially every transaction they are involved in.
• This results in tens or hundreds of millions of records being produced everyday.– Eg. In a single day WalMart records 20 million sales transactions,
Google handles 150 million searches, and AT&T produces 270 million call records.
– Scientific data collection (e.g., by earth sensing satellites or astronomical observations) routinely produces gigabytes of data per day.
• Data rates of this level have significant consequences for data mining.– A few months’ worth data can easily add up to billions of records, and
the entire history of transactions or observations can be in hundreds of billions.

Mining High Speed Data Streams
11
The Problem (The Problem (Contd.Contd.))• Current algorithms for mining complex models from data (e.g.,
decision trees, set of rules) can not mine even a fraction of this data in useful time.
• Mining a day’s worth of data can take more than a day of CPU time.– Data accumulates faster than it can be mined.– The fraction of the available data that we are able to mine in useful
time is rapidly dwindling towards zero.
• Overcoming this state of affairs requires a shift in our frame of mind FROM mining database TO mining data streams.

Mining High Speed Data Streams
12
The Problem (The Problem (Contd.Contd.))• In the traditional data mining process, data loaded into a stable,
infrequently–updated databases.– Mining it can take weeks or months.
• The data mining system should be continuously on.– Processing records at the speed they arrive.– Incorporating them into the model it is building even if it never sees
them again.

Mining High Speed Data Streams
13
Design Criteria for mining Design Criteria for mining High Speed Data StreamsHigh Speed Data Streams
• A system capable of overcoming these problems needs to meet a number of stringent design criteria / or requirements:
1. It must be able to build a model using at most one scan of the data.
2. It must use only a fixed amount of main memory.
3. It must require small constant time per record.
4. It must make a usable model available at any point in time, as opposed to only when it is done processing the data, since it may never be done processing.
– Ideally, it should produce a model that is equivalent to the one that would be obtained by the corresponding ordinary database mining algorithm, operating without the above constraints.
– When the data-generating phenomenon is changing over time, the model at any time should be up-to-date.

Mining High Speed Data Streams
14
Data Stream Classification Data Stream Classification CycleCycle
(1) Input requirement 1
(2) Learning requirements
2 & 3
(3) Model requirement
4
Test examples
Training examples
Predictions
Figure 2. Data stream classification cycle

Mining High Speed Data Streams
15
Data Stream Classification Data Stream Classification Cycle (Contd.)Cycle (Contd.)
• The algorithm is passed the next available examples from the stream (requirement 1)
• The algorithm processes the example, updating the data structures. – Without exceeding memory bounds (requirement 2) – As quickly as possible (requirement 3)
• The algorithm is ready to accept the next example. On request it is able to supply a model that can be used to predict the class of unseen examples (requirement 4).

Mining High Speed Data Streams
16
General Framework for mining General Framework for mining high speed data streamshigh speed data streams
• The authors Pedro Domingos and Geoff Hulten developed a general framework for mining high speed data streams that satisfies all above mentioned constraints.
• They have designed and implemented massive stream versions of Decision tree induction, Bayesian network learning, k-means clustering, and the EM algorithm for mixtures of Gaussians.– E.g., VFDT the decision tree learning system based on HT.
• The probability that the Hoeffding and conventional tree learners will choose different tests at any given node decreases exponentially with the number of examples.

Mining High Speed Data Streams
17
Hoeffding treesHoeffding trees• Given N training examples (x, y)
• Goal: Produce Model y = f (x)
• Why statistical rule?
– C4.5, CART, etc. assume data is in RAM
– SPRINT, SLIQ make multiple disk scans
– Hence the goal is to design a Decision tree learner from extremely large (potentially infinite) datasets.

Mining High Speed Data Streams
18
Hoeffding trees (Contd.)Hoeffding trees (Contd.)• In order to pick an attribute for a node looking at a few examples
may be sufficient
• Given a stream of examples– Use first ones to pick root test– Pass succeeding ones to leaves– Pick best attributes there– … And so on recursively
• How many examples are sufficient?

Mining High Speed Data Streams
19
Hoeffding boundsHoeffding bounds
• Real-valued random variable r with range R
• n independent observations, and compute their mean, r’
• Hoeffding bound states that, with probability 1- δ, the true mean of the variable is at least r’ – ε, where
ε = sqrt[R^2 ln(1/δ) / 2n]

Mining High Speed Data Streams
20
Hoeffding bounds (Contd.)Hoeffding bounds (Contd.)• Let G(Xi) be the heuristic measure used to choose the attribute.
– E.g., the measure could be information gain or Gini index.
• Goal: – Ensure that, with a high probability, the attribute chosen using n examples, is the same as that would be chosen using infinite
examples.
• Assuming G is to be maximized, Let Xa be the attribute with the highest observed G’ and Xb be with second highest attribute, after seeing n examples.
• Let ΔG’ = G’(Xa) – G’(Xb) >= 0 be the difference between the observed heuristic values.
• Then given a desired δ, Hoeffding bound guarantees that Xa is the correct choice with probability 1- δ if n examples have been seen at this node and
ΔG’ > ϵIn other words,
If the observed ΔG’ > ϵ, then the Hoeffding bound guarantees that the true ΔG >= ΔG’ - ϵ >0 with probability 1 – δ, and therefore that Xa is indeed the best attribute with probability 1 – δ.
• Thus a node needs to accumulate examples from the stream until ϵ becomes smaller than ΔG.
• The node can be split using the current best attribute and succeeding examples will be passed to the new leaves.

Mining High Speed Data Streams
21
The Hoeffding tree The Hoeffding tree algorithmalgorithm
The algorithm constructs the tree using the same procedure as ID3. It calculates the information gain for the attributes and determines the best two attributes.
• At each node it checks for condition ΔG > ϵ. If the condition is satisfied, then it creates child nodes based on the test at the node.
• If not it streams in more training examples and carries out the calculations till it satisfies the condition.

Mining High Speed Data Streams
22
The Hoeffding tree algorithm The Hoeffding tree algorithm (Contd.)(Contd.)
• If – X is the number of attributes, – v is the maximum number of values per attribute, and – Y is the number of classes,
– The Hoeffding tree algorithm requires O(XvY) memory to store the necessary counts at each leaf.
• If l is the number of leaves in the tree,The total memory required is O(lXvY).

Mining High Speed Data Streams
23
The Hoeffding tree The Hoeffding tree algorithm (Contd.)algorithm (Contd.)
• Inputs:
S -> is a sequence of examples,
X -> is a set of discrete attributes,G(.) -> is a split evaluation function, δ -> is one minus the desired probability of choosing the
correct attribute at any given node.
• Outputs: HT -> is a decision tree.

Mining High Speed Data Streams
24
The Basic algorithmThe Basic algorithm• Hoeffding tree induction algorithm.
– 1: Let HT be a tree with a single leaf (the root)– 2: for all training examples do– 3: Sort example into leaf l using HT– 4: Update sufficient statistics in l– 5: Increment nl, the number of examples seen at l– 6: if nl mod nmin = 0 and examples seen at l not all of same class then– 7: Compute Gl(Xi) for each attribute– 8: Let Xa be attribute with highest Gl– 9: Let Xb be attribute with second-highest Gl– 10: Compute Hoeffding bound =
ε = sqrt[R^2 ln(1/ δ) / 2n]
– 11: if Xa != Xϕ ; and (Gl(Xa) - Gl(Xb) > ϵ or < T) then– 12: Replace l with an internal node that splits on Xa– 13: for all branches of the split do– 14: Add a new leaf with initialized sufficient statistics– 15: end for– 16: end if– 17: end if– 18: end for

Mining High Speed Data Streams
25
The Basic algorithm conceptsThe Basic algorithm concepts• Split Confidence
• Sufficient Statistics
• Grace Period
• Pre-pruning
• Tie-breaking

Mining High Speed Data Streams
26
Split ConfidenceSplit Confidence• The δ parameter is used in the
Hoeffding bound.– It is one minus the desired probability
that the correct attribute is chosen at every point in the tree.
• With probability close to one, this parameter is generally set to a small value.
• For VFDT, the default value of δ is set to 10^-7.
• The figure 3, shows a plot of the Hoeffding bound using the default parameters for a two-class problem (R = log2(2) = 1, δ = 10^-7).

Mining High Speed Data Streams
27
Sufficient StatisticsSufficient Statistics• The statistics in a leaf need to be sufficient.• Efficient storage is important.
– Storing unnecessary information would result in an increase in total memory requirement.
• For attributes with discrete values,– Statistics required are, counts of the class label that apply for each attribute value.– E.g., An attribute with v unique attribute values and c possible classes, then the information can
be stored in a table with vc entries.

Mining High Speed Data Streams
28
Grace PeriodGrace Period
• It is costly to evaluate information gain of the attributes after each and every training examples.
• The nmin parameter, or grace period, says how many examples since the last evaluation should be seen in a leaf before revisiting the decision.

Mining High Speed Data Streams
29

Mining High Speed Data Streams
30
Pre-pruningPre-pruning– Pre – pruning is carried out by considering at each node a NULL
attribute X0, that consists of not splitting the node.
– The split will only be made if, with confidence 1– δ, the best split found is better according to G than not splitting.
– X0 will determine the leaf nodes.

Mining High Speed Data Streams
31
Tie-BreakingTie-Breaking• A situation may occur where two or more competing attributes
can not be separated.– Even with very small Hoeffding bound, it would not be able to separate
them and the tree growth would stall.
• Waiting for too long to decide between them may harm the accuracy of the tree.
• If the Hoeffding bound is sufficiently small, less than T [tie breaking parameter], then the node is split on the current best attribute.

Mining High Speed Data Streams
32
Tie-breakingTie-breaking• Without tie-breaking the tree grows much slower, ending up around five
times smaller after 700 million training examples.
• Without tie breaking the tree takes much longer to come close to the same level of accuracy as the tie-breaking variant.

Mining High Speed Data Streams
33
Hoeffding trees - TheoremHoeffding trees - Theorem
• Disagreement between two decision trees:Δ(DT1, DT2) = Px[Path1(x) !=Path2(x)]
Theorem:Let E[Δ(HTδ, DT*)] be the expected value of Δ(HTδ, DT*)].If HTδ is the tree produced by the Hoeffding tree algorithm with desired probability δ, given infinite examples, DT* is the
asymptotic Batch tree, and p is the leaf probability, then
E[Δ(HTδ, DT*)] <= δ /p.
[for proof, please refer Author’s paper “Mining High-speed data streams”]

Mining High Speed Data Streams
34
The VFDT systemThe VFDT system• The VFDT system is based on the Hoeffding tree algorithm seen above: It
uses either the information gain or gini index as the attribute evaluation measure.
• VFDT is able to mine on the order of a billion examples per day. It mines examples in less time than it takes to input them from the disk.
VFDT allow the user to specify some parameters as:• Ties :
– two attributes with very close G’s will lead to examination of a large number of examples to determine the best one.
• G computation: – Is the most time consuming part of the algorithm and it makes sense that just
one example will not dramatically change the G. – So user can specify a number nmin of new examples before recompilation.

Mining High Speed Data Streams
35
The VFDT system (The VFDT system (contd.contd.))• Memory and poor attribute :
– The VFDT system leads to minimize memory usage using two techniques:
• Deactivation of non-promising leaf.• Dropping of non-promising attribute.
– This allows the system to keep memory available for new leaf.
• Rescan:– The VFDT can rescan previously-seen examples.
• This option can be activated if either data arrives slowly or• If dataset is small enough that it is feasible to scan multiple times

Mining High Speed Data Streams
36
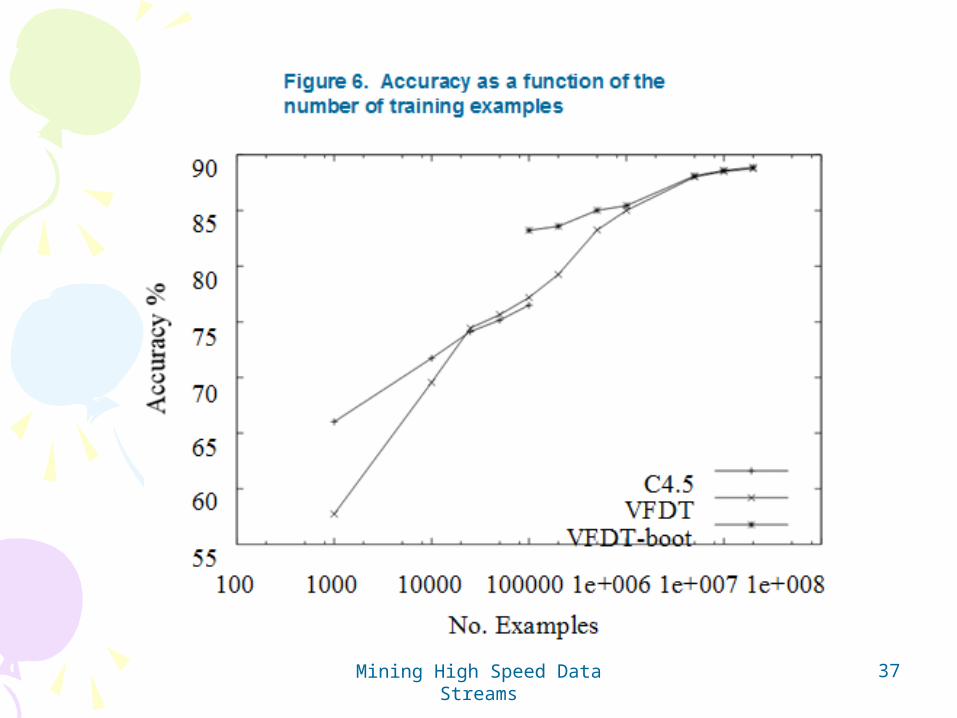
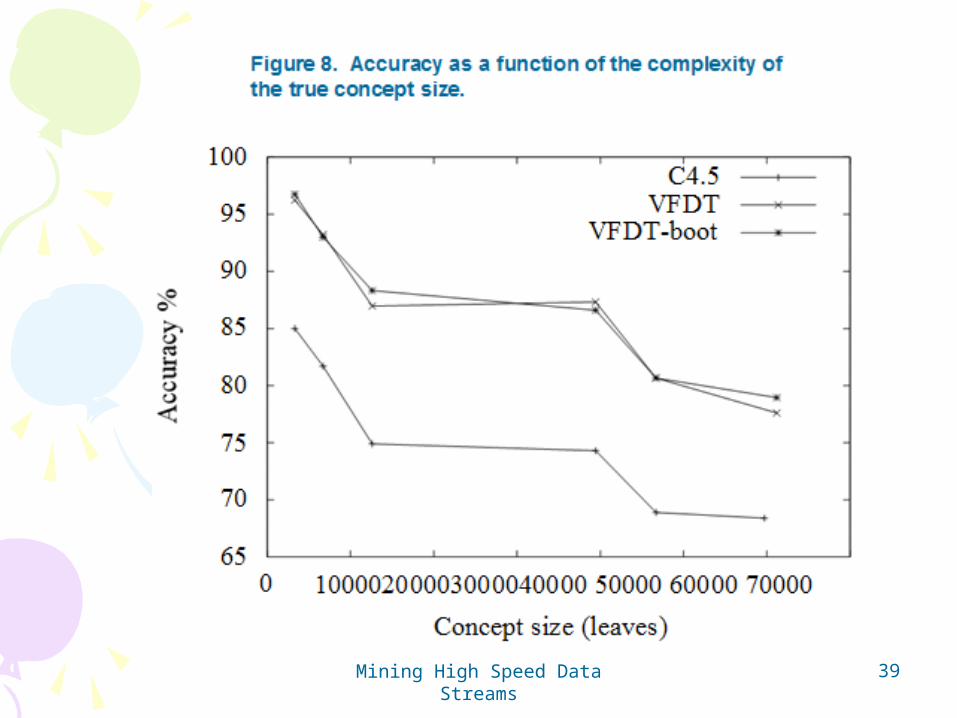
Study and comparisonStudy and comparison• To be interesting, VFDT should at least give results comparable to
conventional decision tree learners.
• Compared VFDT with C4.5 (Quinlan, 1993)
• Same memory limit to both (40MB)– 100K examples for C4.5
• These datasets have been created by sampling random trees (depth = 18 and between 2.2k to 61k leaves) and adding noise, from 0 to 30%, to it.
• This study will so compare C4.5, VFDT and VFDT-boot, a VFDT system bootstrapped with an over-pruned tree produced by C4.5.
Mining High Speed Data Streams
37

Mining High Speed Data Streams
38
Mining High Speed Data Streams
39

Mining High Speed Data Streams
40
A real world exampleA real world example• The authors have made a real world study.
• They tried to mine all the web page requests that were made from the University of Washington main campus during a week in May 1999.
• The estimated population of the University is 50,000 people (students, faculty and staff).
• During this week they registered 23,000 active internet clients.
• The traced requests summed up to 82.2 million by the end of the week and the peak rate of which they were received was 17,400 per minute.
• The size of the trace file was around 20 GB.

Mining High Speed Data Streams
41
A real world example (A real world example (contd.contd.))• Testing was carried out on the last day’s log.
• The VFDT was run on 1.61 million examples and took 1277 seconds to learn a decision stump (DT with only one node).
• They also ran the C4.5 algorithm, they could only use 74.5k examples (what fits in 40MB of memory).
• It took the C4.5 2975 seconds to learn the tree.
• They used a machine with 1GB of RAM.– They could fit the 1.61 million examples in the memory to run it with the
C4.5– The run time now increased to 24 hours.
• The VFDT is much faster than the C4.5 and that it can achieve similar accuracy in a fraction of time.

Mining High Speed Data Streams
42
ConclusionConclusion• Many organizations today have more than very large databases.
• This paper introduces Hoeffding Trees and VFDT system.
• VFDT uses Hoeffding bounds to guarantee that its output is asymptotically nearly identical to that of conventional learner.
• Emperical studies show VFDT’s effectiveness in learning from massive and continuous stream of data.
• VFDT is currently being applied to mining the continuous stream of web access data from the whole University of Washington main campus.

Mining High Speed Data Streams
43
Questions:Questions:Qn.1 Give the Hoeffding bound formula and describe its components
ANS:• Real-valued random variable r with range R
• n independent observations, and compute their mean, r’
• Hoeffding bound states that, with probability 1- δ, the true mean of the variable is at least r’ – ε, where
ε = sqrt[R^2 ln(1/δ) / 2n]

Mining High Speed Data Streams
44
Questions (Contd.)Questions (Contd.)Qn.2 Compare Mining high speed data streams with Database Mining
ANS:• Data mining:
– The data mining approach may allow larger data sets to be handled, but it still does not address the problem of Continuous supply of data.
– Typically, a model that was previously induced can not be updated when new information arrives.
• Instead, the entire training process must be repeated with the new examples included.
• Data Stream Mining:– In data stream mining the arriving data come in streams, which potentially can
sum to infinity.
– Algorithms written in data streams can naturally cope with data sizes many times greater than memory, and can extend to challenging real-time applications, not previously tackled by machine learning or data mining.

Mining High Speed Data Streams
45
Questions (Contd.)Questions (Contd.)Qn.3 state Design Criteria (requirements) for mining High Speed Data
Streams
ANS:• Process an example at a time, and inspect it only once (at most)
• Use a limited amount of memory
• Work in a limited amount of time
• Be ready to predict at any time

Mining High Speed Data Streams
46
More Questions?More Questions?

Mining High Speed Data Streams
47
ReferencesReferences– Mining High-Speed Data Streams, with Geoff Hulten. Proceedings of the
Sixth International Conference on Knowledge Discovery and Data Mining (pp. 71-80), 2000. Boston, MA: ACM Press.
– A General Framework for Mining Massive Data Streams, with Geoff Hulten (short paper). Journal of Computational and Graphical Statistics, 12, 2003
– http://www.ir.iit.edu/~dagr/DataMiningCourse/Spring2001/Presentations/Summary_10.pdf
– http://www.sftw.umac.mo/~ccfong/pdf/simonfong_2011_biomed_stream_mining.pdf
– Learning Model Trees from Data Streams by Elena Ikonomovska and Joao Gama
– http://www.cs.waikato.ac.nz/~abifet/MOA/StreamMining.pdf





























