Embed Size (px)
Citation preview

SaturdayDec 6th 2008
MGA Molecular Genome Analysis -Biostatistics and Modelling
CAMDA 2008:
Extending pathways with inferred
regulatory interactions from microarray
data and protein domain signatures
Prof. Dr. Tim Beissbarth
University of Göttingen
Christian Bender
German Cancer Research Center (DKFZ)
Department Molecular Genome Analysis
DKFZ-B050INF 580D-69120 Heidelberg
+49 6221 42 4716

Tim Beissbarth Biostatistics - Molecular Genome Analysis
Contents
1) Introduction
a) The CAMDA Dataset: Apoptosis time-course of Affara 2007
b) Our goals
2) Methods
a) KEGG pathway prediction using InterPro domain signatures
b) Overrepresentation of predicted pathways
c) Dynamical Bayesian Networks
d) Verification of inferred regulations by Ingenuity
3) Results
a) Analysis of differential expression and prediction of KEGG pathway memberships with InterPro domain signatures
b) Overrepresentation test of pathways
c) Reconstruction of gene regulatory networks with G1DBN
d) Comparison to Ingenuity based literature network
4) Summary/Outlook

Tim Beissbarth Biostatistics - Molecular Genome Analysis
1a) Introduction: The CAMDA Dataset
• Questions:
– What is the kinetics of the transriptome change during EC apoptosis?
– What is the role of EC apoptosis in blood vessel development?
• Experimental setup: as described in Affara et.al. 2007
– Expose primary human umbilical vein EC (HUVEC) to partial survival
factor deprivation (SFD)
0h 0.5h 1.5h 3h 6h 9h 12h 24h
Gene1
…..
Gene 20265
3 replicates

Tim Beissbarth Biostatistics - Molecular Genome Analysis
1b) Introduction: Our goals
1) Extract differentially expressed genes during the timecourse
2) Predict membership of genes to corresponding KEGG pathways via InterPro domain signatures and find overrepresented pathways
3) Reconstruct gene regulatory networks of the differentially expressed genes in these pathways
4) Compare the learned networks to literature knowledge
Protein InterPro

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) Motivation of pathway prediction: Functional Characterization of Genes
•Molecular function (e.g. kinase)
•Cellular localization (e.g. nucleus)
•Biological processes (e.g. apoptosis)
•Pathways (e.g. MAPK signaling)
•...
Pathway annotation often not available
• Only ~25% of all genes (~4,000 / ~20,000) have an annotation in the KEGG database (Kanehisa et al., 2008)
Tim Beissbarth Biostatistics - Molecular Genome Analysis
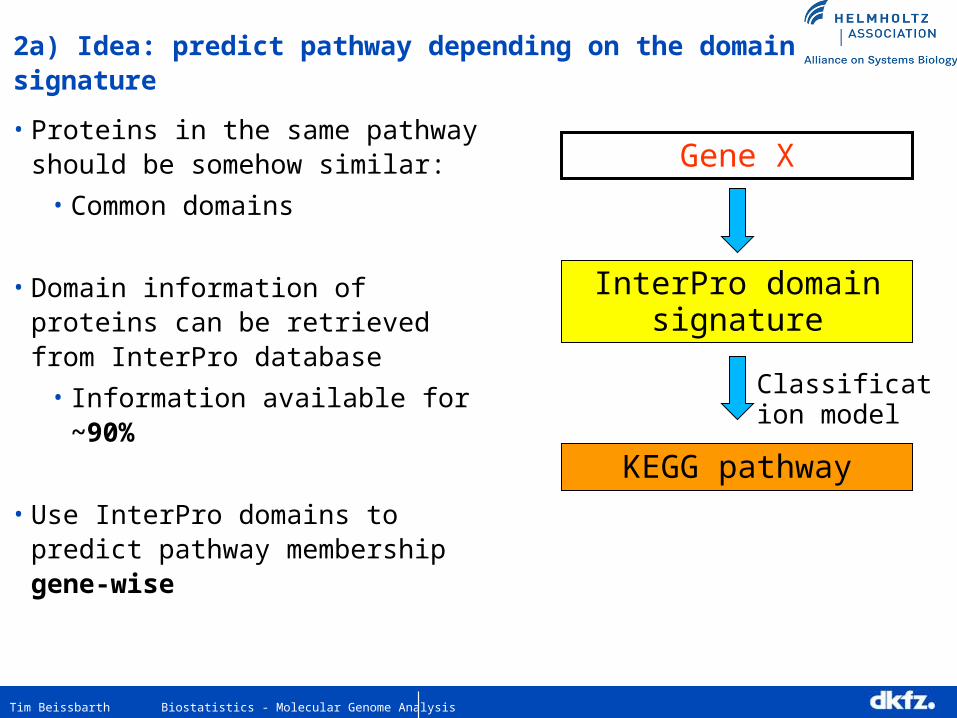
2a) Idea: predict pathway depending on the domain signature
• Proteins in the same pathway should be somehow similar:
• Common domains
• Domain information of proteins can be retrieved from InterPro database
• Information available for ~90%
• Use InterPro domains to predict pathway membership gene-wise
Gene X
InterPro domain signature
Classification model
KEGG pathway

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) Why should this work?

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) The KEGG Ontology
KEGG
01100
Metabolism
01200
Genetic Inf. Processing
01300
Envir. Inf. Processing
01400
Cellular Processes
01310
Membrane Transport
01320
Signal Transduction
...
... 04010
MAPK pathwayGene X
KEGG
01100
Metabolism
01200
Genetic Inf. Processing
01300
Envir. Inf. Processing
01400
Cellular Processes
01320
Signal Transduction
...
04010
MAPK pathway

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) Hierarchical Classification Model
• Classifier should take into account KEGG hierarchy
• Predicting something wrong at the top hierarchy (e.g. Metabolism vs. Envir. Inf. Proc.) is worse than confusing e.g. MAPK with WNT pathway.
• A specific gene can play a rule in multiple pathways!
• => Solution: encoding into a specific loss function
01
10
0 01
20
0 01
30
0 01
40
0 01
31
0 ...
04
01
0
0 0 1 0 1 ... 1
y =
1 0 1 0 1 ... 0
u =
||
|at rooted subtree|
)]([),(1
KEGG
ic
iAncjuyuyc
i
n
ijjiii
uy

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) Hierarchical Classification Model
KEGG
01100
Metabolism
01200
Genetic Inf. Processing
01300
Envir. Inf. Processing
01400
Cellular Processes
01310
Membrane Transport
...
... 04010
MAPK pathway
01100
Metabolism
01200
Genetic Inf. Processing
01300
Envir. Inf. Processing
01400
Cellular Processes
01310
Membrane Transport
01320
Signal Transduction
...
04010
MAPK pathway
1 0 1 0 1 ... 1
x =
Here or other?
Here or other?
Here or other?

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2b) Overrepresentation test
• Fisher‘s Exact Test• Groups:
– Differential/not differential– Predicted path p/ not predicted as path p
• Example:
• Test for probability of seeing 22 or more differential genes in path p by chance
• Done for sets:– pathways already annotated in KEGG– Pathways already annotated in KEGG or predicted by DS
path p ¬ path p Total
diff 22 246 268
¬ diff 84 3033 3117
total 106 3279 3385

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2c) Dynamical Bayesian networks (DBN)
Gene 1 Gene2 Gene3
t-1 Xt-11 Xt-1
2 Xt-13
t Xt1 Xt
2 Xt3
t+1 Xt+11 Xt+1
2 Xt+13
G1
G2
G3
Microarray data:Xt-1
1 Xt-12 Xt-1
3
Xt1 Xt
2 Xt3
Xt+11 Xt+1
2 Xt+13
≙
Pi Nt
it
it GXpaXFXf )),(|()(
DBN G: Regulation motif:
Lebre et. al. 2008

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2d) Finding interactions with Ingenuity
• We use this information to verify the reconstruction quality of our network
• Given a list of genes, which interactions are already known?
• Example: What is known about Cyclins D and E, CDK 4 and 6 and Rb?
Ingenuity network:

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3a. Workflow for the analysis
18310 informative genes
Limma analysisSmyth et. al 2004
18310 informative genes1002 differentially expressed
Pathway prediction via DSFröhlich et. al. 2004
10630 genes to predict
3385 in KEGG268 differential
7591 via KEGG and DS651 differential
Fisher's exact test for each pathway
Fisher's exact test for each pathway
Construct regulatory network for genes in significantly
overrrepresented pathways by DBN

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3b) Overrepresentation results
p_KEGG p_DS KEGG DS
Cell Cycle 0,003 0,000 22 30
Metabolism 1,000 0,032 96 364
Cell Growth and Death 0,388 0,045 26 43
Nuclear Metabolism 0,316 0,056 22 22
• Pathways Cell Cycle, Metabolism, Cell Growth and Death significantly overrepresented within the DS prediction group at a 0.05 level
• Since we were analyzing an apoptosis study, we chose the pathway cell cycle for further experiments

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3. Selected gene profiles for DBN reconstruction
• Genes predicted in pathway cell cycle
• Only those that were found as differentially expressed

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2c) For verification: Ingenuity network for our selected genes

Tim Beissbarth Biostatistics - Molecular Genome Analysis
4. Inferred network

Tim Beissbarth Biostatistics - Molecular Genome Analysis
4) Cellcycle pathway from KEGG

Tim Beissbarth Biostatistics - Molecular Genome Analysis
4) Howto integrate the inferred net into the pathway

Tim Beissbarth Biostatistics - Molecular Genome Analysis
4. Some details on inferred interactions
• NASP -> PLK1
• NASP: H1 histone binding protein that is involved in transporting histones into the nucleus of dividing cells
• NASP -> MCM
• MCM: highly conserved mini-chromosome maintenance proteins that are essential for the initiation of eukaryotic genome replication
• UACA -> BUB1
• UACA: regulates morphological alterations required for cell growth and motility
• BUB1: gene encodes a kinase involved in spindle checkpoint function

Tim Beissbarth Biostatistics - Molecular Genome Analysis
5. Summary
• Combine pathway prediction and network inference
• Find differential genes, predict pathways and find overrepresented
pathways
• Compute regulatory network from the expression data
• integrate the inferred interactions in known pathway maps
• Uses two freely available R-packages
• gene2pathway
• G1DBN

Tim Beissbarth Biostatistics - Molecular Genome Analysis
Molecular Genome Analysis
Biostatistics & Modelling
• Christian Bender• Holger Fröhlich• Marc Johannes
Acknowledgements
Department head
Annemarie Poustka(MGA – Department Head)Died May 2008Stefan Wiemann acting head of division MGA

Tim Beissbarth Biostatistics - Molecular Genome Analysis

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3b. Overrepresentation of pathways
• given: List of genes with corresponding pathway annotation or prediction
• test for overrepresentation of all pathways:
• Fisher's exact test
• once for genes being annotated in KEGG
• once for genes with additional pathway membership prediction by DS

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3a. Differential expression and pathway prediction
• Use R-package limma to find differential genes
• Results in 1002 differentially expressed genes during the timecourse
• Map all genes on the UniSet Array to KEGG pathways via InterPro domain
signatures (DS)
• for 10630 genes InterPro DS could be found
• 3385 already annotated in KEGG, 268 differential
• 4206 genes were assigend to kegg pathways via DS, 353 differential
Smyth et al 2004

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2b) Approach used in this work
Idea:
)1(~GG
X11
X12
X21
X22
X31
X32
X 12∥X 31∣X X 11
X 12∥X 31∣X X 21
Example: Test if X_12 || X_31 | pa(X_12)=> yesBut: consider only first order dependencies:X_12 || X_31 | pa(1)(X_12) = X_12 || X_31 | X_11 orX_12 || X_31 | X_21=> no
So spurious edges can occur in G(1) whichdisappear in Gschlange.
Lebre et. al. 2008
esdependenciorder -full thecontaining G~
DAG infer G From 2)
GDAG dependenceorder 1st Infer the 1)(1)
(1)

Tim Beissbarth Biostatistics - Molecular Genome Analysis
Melvin et al., 2007
2a) Hierarchical Classification Model
jjj bf xwx ,)(
))(),...,(( 1 xxf Kff
SVMs
1 0 1 0 1 ... 1
x =
Decision values f
Ranking Perceptron
(loss function l)
0 0 1 0 1 ... 1
y =
Most probable pathways
Domain signature
zfCCy *,maxarg ii
Taken from dictionary of possible position vectors
Trainable weight vector

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2a) Hierarchical Classification Model: Training Procedure
Data set of domain signatures for each gene
Train SVMs
Position labeled data set
)},(),...,,{( 11 nnD CfCf
Train ranking perceptron using
loss function lweight vector z

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2b) Dynamical Bayesian networks
G
Kim et. al. 2003
Gene 1
Gene 2
Gene 3
Gene p
Pi Nt
it
it GXpaXFXf )),(|()(

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2b). Dynamical Bayes Networks, Lebre et. Al 2008
• Define DAG Gfull
as DAG that contains all edges between successive
Variables:G full=X , {X t−1
j , X ti}i , j∈P , t1
G=X ,{X t−1j , X t
i ; X ti∥X t−1
j ∣X t−1P j }i , j∈P , t∈N
• Then it exists a minimal DAG describing a BN containing all conditional dependencies between variables in successive timepoints:
• This minimal BN description factorizes according to
• It will be used to define low-order conditional dependence DAGs for the inference of
G
• Any pair of successive variables (X_t-1^j, X_t^i) not adjacent in are conditionally independent given the parents:
G
X ti∥X t−1
j ∣pa X ti , G
G

Tim Beissbarth Biostatistics - Molecular Genome Analysis
Xt-11 Xt-1
2 Xt-13
Xt1 Xt
2 Xt3
Xt+11 Xt+1
2 Xt+13
p_KEGG p_DS KEGG DS Cell cycle 0,003 0,000 22 30 Metabolism 1,000 0,032 96 364 Cell Growth and Death 0,388 0,045 26 43 Nucleotide Metabolism 0,316 0,056 22 22 Insulin signaling pathway0,316 0,279 2 2

Tim Beissbarth Biostatistics - Molecular Genome Analysis
2c) Approach used in this work
Lebre et. al. 2008
Xt-11 Xt-1
2 Xt-13
Xt1 Xt
2 Xt3
Xt+11 Xt+1
2 Xt+13
1) Infer DAG G(1) , containing all 1st order dependencies
2) Key observation: G´ ⊆ G(1)
3) Derive G´ from G(1)
Goal: Infer DAG G´, containing full conditional dependencies

Tim Beissbarth Biostatistics - Molecular Genome Analysis
3a. Workflow for the analysis
18310 informative genes
Limma analysisSmyth et. al 2004
18310 informative genes1002 differentially expressed
Pathway prediction via DSFröhlich et. al. 2004
10630 genes to predict
3385 in KEGG268 differential
7591 via KEGG and DS651 differential
Fisher's exact test for each pathway
Fisher's exact test for each pathway
Construct regulatory network for genes in significantly
overrrepresented pathways by DBN





























