Embed Size (px)
Citation preview

UNIVERSIDADE FEDERAL DA PARAÍBA CENTRO DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA DE PRODUÇÃO
JOSÉ RENATO MONTEIRO NASCIMENTO DE ALMEIDA
METODOLOGIA PARA ANÁLISE DA CONFIABILIDADE DE UM CONJUNTO DE
ALTA CRITICIDADE DE UMA PLANTA SIDERÚRGICA INTEGRADA
JOÃO PESSOA - PB 2007

Livros Grátis
http://www.livrosgratis.com.br
Milhares de livros grátis para download.

JOSÉ RENATO MONTEIRO NASCIMENTO DE ALMEIDA
METODOLOGIA PARA ANÁLISE DA CONFIABILIDADE DE UM CONJUNTO DE
ALTA CRITICIDADE DE UMA PLANTA SIDERÚRGICA INTEGRADA
Projeto de Dissertação a ser submetido à apreciação da banca examinadora do Programa de Pós-Graduação em Engenharia de Produção da Universidade Federal da Paraíba como parte dos requisitos necessários para obtenção do grau de Mestre em Engenharia de Produção. Área de Concentração: Tecnologia, Trabalho e Organizações Professor Orientador: Prof. Dr. Luiz Bueno da Silva
JOÃO PESSOA - PB 2007

A447m Almeida, José Renato Monteiro Nascimento de
Metodologia para análise da confiabilidade de um conjunto de alta criticidade de uma planta siderúrgica integrada / Marcos Antonio dias de Souza - João Pessoa, 2008.
178 f. il.:
Orientador: Prof. Dr. Luiz Bueno da Silva
Dissertação (Mestrado em Engenharia de Produção)
PPGEP / Centro de Tecnologia / Campus I / Universidade Federal da Paraíba – UFPB.
1. Confiabilidade 2. Métodos estatísticos multivariados 3.
Componentes de alta criticidade I.Título.
CDU: 658.511.3 (043)

JOSÉ RENATO MONTEIRO NASCIMENTO DE ALMEIDA
METODOLOGIA PARA ANÁLISE DA CONFIABILIDADE DE UM CONJUNTO DE
ALTA CRITICIDADE DE UMA PLANTA SIDERÚRGICA INTEGRADA
Projeto de Dissertação de Pós-Graduação a ser apresentada à apreciação da banca examinadora do Programa de Pós-graduação em Engenharia de Produção da Universidade Federal da Paraíba como parte dos requisitos necessários para obtenção do grau de Mestre em Engenharia de Produção.
BANCA EXAMINADORA
__________________________________________________ Prof. Dr. Luiz Bueno da Silva Universidade Federal da Paraíba
__________________________________________________
Prof. Dr. Ulisses Umbelino dos Anjos Universidade Federal da Paraíba
__________________________________________________
Profa Dra. Adriana Zenaide Clericuzi Universidade Federal da Paraíba

AGRADECIMENTOS
Agradeço a DEUS, guia espiritual que me deu forças para superar todos os obstáculos
enfrentados ao longo do desenvolvimento deste trabalho;
À toda minha família, particularmente aos meus pais, José Carlos e Nely pelas orações
que fizeram para que eu pudesse chegar até aqui;
A Sílvio José Martins Netto, que abriu caminho em minha empresa para que iniciasse
meus estudos na área da engenharia de produção;
Ao professor Luiz Bueno da Silva, meu orientador, pelo incentivo e confiança em meu
potencial desde o período da especialização em que cursava a disciplina Métodos
Quantitativos. Sou grato também por ter me despertado o interesse no ramo na estatística
multivariada;
A todos os professores e funcionários do PPGEP/UFPB, especialmente o Josemildo
(Duca) por seu apoio e assistência, sempre cordial em todo o momento que foi solicitado;
A Eugênio Schmidt (in memorian), pelo incentivo no estudo no ramo da
confiabilidade e ter me legado, ainda na especialização, minha primeira referência teórica
nesta área;
A Fabrício Coelho Alves por ter sido o meu primeiro colaborador na assistência e
fornecimento dos dados utilizados na pesquisa;
A Luiz Augusto Wasem pela sua colaboração, sobretudo, nas entrevistas gentilmente
cedidas ainda na fase de coleta de dados da pesquisa;
A Ricardo Sodré pelo empréstimo de suas apostilas de confiabilidade e ter me
indicado o primeiro software de confiabilidade tornando-se a principal fonte computacional
da pesquisa;
A Jorge de Carvalho Pires e João Geraldo Pedrini da Penha pelas entrevistas cedidas e
pelo fornecimento de informações tornando possível entender e compreender as atuais
técnicas de controle de falhas utilizadas na empresa;
Por fim, agradeço a todos que diretamente ou indiretamente contribuíram para que este
trabalho se concretizasse.

“SE ENXERGUEI MAIS LONGE, FOI POR
QUE ME APOIEI NOS OMBROS DE
GIGANTES”
(NEWTON)

RESUMO
O conhecimento da Confiabilidade de componentes de alta criticidade influencia diretamente o desempenho dos ativos produtivos das empresas. Seu estudo envolve um tratamento sistematizado de uma grande massa de dados e informações sendo necessário simplificar a base de informações sem, contudo, perder qualidade e precisão dos dados. Isto se dá por meio da redução de dimensionalidade da base original de dados. Esta dissertação tem por objetivo propor uma metodologia para analisar a confiabilidade de um conjunto de alta criticidade utilizando-se técnicas estatísticas multivariadas mediante estudo de seu tempo de vida. A metodologia utilizada envolveu a pesquisa de campo e documentos operacionais. Foram consideradas na pesquisa 10 amostras com 38 variáveis cada uma. Foi utilizada a Análise de Componentes Principais como ferramenta estatística de redução de dimensionalidade que simplificou a análise a apenas 9 Componentes Principais. A Análise de Confiabilidade envolveu a determinação da função Confiabilidade, a Taxa de Falhas e o Tempo Médio entre Falhas do componente crítico. Nestas análises, foi necessário utilizar os tempos de vida apenas do primeiro componente (CP1), pois o mesmo absorveu 40% da variabilidade dos dados, o que se tornou suficiente devido a pouca variabilidade dos demais componentes. A análise envolveu avaliação do primeiro componente (CP1) em cinco distribuições de probabilidade: Normal, Log-normal, Exponencial, Gamma e Weibull. Os testes de ajustes de distribuição e de aderência apontaram a distribuição Log-normal como a mais adequada. Os resultados obtidos pela análise da função Confiabilidade mostraram probabilidades de não ocorrências de falhas de 82,17%, 60,47% e 9,00% para os percentis 10, 50 e 90 respectivamente. A Taxa de Falhas mostrou um pico em 542 dias de operação, ponto de extremo risco operacional por se tratar de um componente altamente crítico. Por fim, o Tempo Médio entre Falhas atingiu 230 dias confirmando a ocorrência de 2 falhas no ano do componente crítico. Os resultados advindos da aplicação da metodologia proposta mostraram-se consistentes e coerentes com os dados históricos do componente crítico. A previsibilidade do tempo ótimo de vida do componente crítico possibilitou a sua substituição no momento certo, reduzindo o risco de paradas não programadas, aumentando a estabilidade operacional e consequentemente reduzindo o risco de interrupções no processo produtivo da unidade industrial estudada. Palavras-chave: Confiabilidade. Métodos estatísticos multivariados. Componentes de alta
criticidade.

ABSTRACT
The knowledge of the critical components reliability has influenced the performance of the productive assets of the productive units. Its study involves a systematized treatment of a great amount of data and information. The diversity of involved variables difficults the comprehension of interrelated information being necessary to simplify the information base without losing quality and precision of the data. This is possible through the dimension reduction of the original data base. The aim of this dissertation is to propose a methodology in order to determine the reliability of the critical components based on multivariate statistics techniques through the study of their life time. The methodology previously demanded on site researches and operational documents studies. It was considered 10 samples with 38 variables each one. Principal Components Analysis was the statistical tool used to reduce the data dimension that simplified the analysis to 9 Principal Components. The Reliability Analysis involved the evaluation of the Reliability Function, Failures Rate Function and MTBF (Mean Time Between Failures) of the critical components. It was necessary to use only the first component (PC1) because it has absorbed 40% of the data variability which it was enough due to the little variability of the other components. The Reliability Analysis of the first component (PC1) was tested and compared with five probability distributions: Normal, Log-normal, Exponential, Gamma and Weibull. The goodness distribution and adherence tests both indicated the Log-normal distribution as the most appropriate. The outcomes obtained by Reliability Function presented non-failures occurrences of 82,17%, 60,47% and 9,00% for the percentis 10, 50 and 90 respectively. The Failures Rate Function showed a extreme point in 542 days of operation, presenting a condition of extreme risk to a critical component. The MTBF reached 230 days ratifying the occurrence of 2 failures of the critical component during one year. The global results estimated by proposed methodology application showed consistent and coherent with the critical component historical data. The previsibility of the critical component optimal time life was able to indicate its substitution in the right time, decreasing non-programmed shutdowns, increasing operational stability and consequently reducing the risk of stoppages in the studied industrial unit. Keywords: Reliabilit. Multivariate Statistical Techniques. Critical Components.

LISTA DE ABREVIATURAS
AAH – Análise de Agrupamento Hierárquico
ABNT – Associação Brasileira de Normas Técnicas
ACP – Análise de Componentes Principais
AF – Análise de Fatores
CP – Componente Principal
CRAAF – Centro de Recirculação de Água do Alto Forno 1
DW – Data Warehouse
df – Degree of freedom
FMEA - Failure Mode Effects Analysis
FTA - Fault Tree Analysis
HCA – Hierarchical Cluster Analysis
MTBF – Mean Time Between Failures
NBR – Norma Brasileira
PCA – Principal Component Analysis
SISMANA – Sistema de Gestão de Ativos
SISCORP – Sistema de Controle de Padrões

LISTA DE FIGURAS
Figura 1 – Seleção da técnica estatística multivariada ............................................................24
Figura 2 – Fluxo para obtenção dos componentes principais...................................................38
Figura 3 – Elipsóide de densidade de probabilidade constante ................................................38
Figura 4 – Gráfico scree-plot dos autovalores .........................................................................46
Figura 5 – Curva da Banheira...................................................................................................52
Figura 6 – Método de classificação das falhas ........................................................................53
Figura 7 – Estrutura para desenvolver uma árvore de falha ....................................................57
Figura 8 – Função probabilidade de falha F(t) .........................................................................62
Figura 9 – Função de confiabilidade R(t) .................................................................................62
Figura 10 – Função densidade de probabilidade Normal para valores de desvio padrão 0,2; 0,5
e 0,8 ........................................................................................................................71
Figura 11 – Função densidade de probabilidade Log-normal para µ=1 e alguns valores de σ 73
Figura 12 – Influência do parâmetro β na função densidade de probabilidade de falha ..........75
Figura 13 – Influência do parâmetro β na função confiabilidade.............................................76
Figura 14 – Influência do parâmetro β na função taxa de falha ...............................................76
Figura 15 – Função densidade de falhas Exponencial monoparamétrica para alguns valores de
λ ..............................................................................................................................77
Figura 16– Função de densidade de probabilidade Gamma para alguns valores de δ .............78
Figura 17 – Fluxo de Análise de Vibrações na empresa estudada ..........................................95
Figura 18 – Alto Forno 1 ..........................................................................................................98
Figura 19 – Fluxo de produção do ferro gusa no Alto Forno 1 ................................................98
Figura 20 – Desenho esquemático de um conjunto de insuflação de ar de um Alto Forno .....99
Figura 21 – Conjunto de insuflação de ar do Alto Forno 1 ....................................................100
Figura 22 – Casa de Corridas do Alto Forno 1.......................................................................101
Figura 23 – Desenho em CAD em uma ventaneira ................................................................101
Figura 24 – Ventaneira do alto forno 1...................................................................................101
Figura 25 – Lote de ventaneiras em fim de vida útil ..............................................................102
Figura 26 – Ventaneiras novas (recém fabricadas) ................................................................102
Figura 27 – Fluxograma para Análise de Confiabilidade......................................................107
Figura 28 – Diagrama da metodologia para desenvolvimento da Dissertação.......................110
Figura 29 – Dendograma dos 38 componentes críticos.........................................................114

Figura 30 – Dendograma dos anos (período do tempo de amostragem) dos os tempos de vida
dos 38 componentes críticos.................................................................................116
Figura 31 – Gráfico do percentual acumulado de explicação da variância ...........................130
Figura 32 – Gráfico (scree-plot) com o peso dos autovalores dos componentes principais .131
Figura 33 – Gráfico de scores entre os componentes principais CP1 e CP2.........................135
Figura 34 – Gráfico de loadings entre os componentes principais CP1 e CP2 .....................136
Figura 35 – Gráfico do tempo de vida do primeiro componente principal (CP1).................137
Figura 36 – Gráfico do tempo de vida do CP1, CP2 e CP3 versus o período de tempo de
amostragem........................................................................................................138
Figura 37 – Função densidade de falhas f(t) para o primeiro componente principal .............139
Figura 38 – Função Confiabilidade do modelo Lognormal para o CP1.................................143
Figura 39 – Gráfico Probabilidade de falhas do modelo Lognormal para o CP1 ..................144
Figura 40 – Função Densidade de falhas do modelo Lognormal para o CP1 ........................144
Figura 41 – Função Taxa de falhas do modelo Lognormal para o CP1 .................................145

LISTA TABELAS
Tabela 1 – Impacto na confiabilidade dos equipamentos.........................................................50
Tabela 2 – Causas de falhas nas fases da Curva da Banheira...................................................53
Tabela 3 – Visão geral das técnicas para Estudos de Confiabilidade.......................................58
Tabela 4 – Principais distribuições de probabilidade utilizada em Confiabilidade e suas
aplicações ...............................................................................................................70
Tabela 5 – Valores críticos da estatística teste A2 para as funções Normal e Lognormal ........86
Tabela 6 – Valores críticos da estatística teste A2 para as funções Weibull, Gamma e Gumbel
................................................................................................................................86
Tabela 7 – Valores críticos da estatística teste A2 para a função Exponencial.........................86
Tabela 8 – Controle de óleo lubrificante em uso e desgaste ...................................................94
Tabela 9 – Controle de recebimentos de lubrificante novos ...................................................94
Tabela 10 – Resumo das atuais técnicas de análise de controle de vida (controle sistemático)
................................................................................................................................95
Tabela 11 – Características técnicas do Alto Forno 1 ..............................................................97
Tabela 12 – Quantidade de ventaneiras fabricadas nas Oficinas entre 2001 e 2005..............103
Tabela 13 – Áreas Operacionais do Alto Forno 1 agrupadas por grau de criticidade............104
Tabela 14 – Equipamentos de Criticidade Alta do Forno Próprio (Alto Forno 1) agrupados em
função do grau de priorização dentro da unidade operacional ..........................104
Tabela 15 - Componentes críticos com as respectivas quantidades de trocas........................113
Tabela 16 – Medidas descritivas para o tempo de vida (dias) dos 38 componentes críticos .117
Tabela 17 – Matriz de correlação dos 38 componentes críticos.............................................119
Tabela 18 - Matriz de correlação dos 38 componentes críticos (continuação) ......................120
Tabela 19 – Coeficiente de correlação de Person e a estatística teste “t” para os 703 pares de
38 componentes críticos ....................................................................................124
Tabela 20 – Autovalores da matriz de variância-covariância e seus respectivos coeficientes de
explicação ..........................................................................................................130
Tabela 21 – Autovetores definidos para os componentes principais......................................132
Tabela 22 – Correlação entre os tempos de vida originais e os componentes principais.......133
Tabela 23 – Comunalidades dos 38 componentes críticos .....................................................134
Tabela 24 – Medidas descritivas para os três primeiros componentes...................................138

Tabela 25 – Parâmetros estimados para os modelos probabilísticos.....................................139
Tabela 26 – Valores da função de confiabilidade R(t) para os tempos de vida do 1o
componente principal dos modelos propostos e o estimador Kaplan-Meier.....140
Tabela 27 – Erro-padrão do Estimador Kaplan-Meier dos modelos propostos .....................140
Tabela 28 – Estatísticas testes: Qui-quadrado, Kolmogorov-Smirnov e Anderson-Darling .141
Tabela 29 – Coeficientes de Correlação, Determinação, Teste F e Valor p dos Componentes
Críticos para o modelo de probabilidade Lognormal ........................................142
Tabela 30 – MTBF e Confiabilidade para os percentis 10, 50 e 90 para o CP1 do modelo
Lognormal .........................................................................................................142

SUMÁRIO
CAPÍTULO 1 - INTRODUÇÃO ...........................................................................................15 1.1 CONTEXTUALIZAÇÃO DO PROBLEMA............................................................15 1.2 JUSTIFICATIVA PARA SE ESTUDAR O PROBLEMA.......................................16 1.3 DELIMITAÇÃO DA PESQUISA.............................................................................17 1.4 OBJETIVOS..............................................................................................................18 1.4.1 Objetivo geral ............................................................................................................18 1.4.2 Objetivos Específicos ................................................................................................18 1.5 ESTRUTURAÇÃO DA PESQUISA ........................................................................18 CAPÍTULO 2 - REFERENCIAL TEÓRICO......................................................................21 2.1 ANÁLISE MULTIVARIADA..................................................................................21 2.2 ANÁLISE EXPLORATÓRIA ..................................................................................26 2.3 TEOREMA DA DECOMPOSIÇÃO ESPECTRAL .................................................28 2.4 NORMAS TÉCNICAS BRASILEIRAS UTILIZADAS EM ANÁLISES
ESTATÍSTICAS E DE CONFIABILIDADE ...........................................................29 CAPÍTULO 3 - ANÁLISE DE COMPONENTES PRINCIPAIS (ACP) ..........................31 3.1 DIFERENÇAS ENTRE A ANÁLISE FATORIAL E A ANÁLISE DE
COMPONENTES PRINCIPAIS...............................................................................31 3.2 ALGUNS TESTES ESTATÍSTICAS PARA VERIFICAÇÃO DA
APLICABILIDADE DA ACP ..................................................................................31 3.3 DESCRIÇÃO DA ANÁLISE DE COMPONENTES PRINCIPAIS........................35 3.4 GERAÇÃO DOS COMPONENTES PRINCIPAIS VIA MATRIZ DE
COVARIÂNCIAS.....................................................................................................37 3.5 NÃO CORRELAÇÃO ENTRE OS COMPONENTES PRINCIPAIS .....................39 3.6 SELEÇÃO DO NÚMERO DE COMPONENTES PRINCIPAIS ............................41 3.7 GERAÇÃO DOS COMPONENTES PRINCIPAIS VIA MATRIZ DE
CORRELAÇÃO ........................................................................................................42 3.8 CRITÉRIOS PARA DETERMINAÇÃO DO NÚMERO “K” DE COMPONENTES
PRINCIPAIS .............................................................................................................44 3.8.1 Análise de representatividade em relação à variância total.......................................45 3.8.2 Análise da qualidade de aproximação da matriz de covariâncias ou correlação.......46 3.8.3 Análise prática das componentes...............................................................................47 3.9 ANÁLISES ESTATÍSTICAS ASSOCIADAS À ACP ............................................47 3.10 LIMITAÇÕES DA ACP ...........................................................................................48 CAPÍTULO 4 - ANÁLISE DE CONFIABILIDADE ..........................................................50 4.1 INTRODUÇÃO.........................................................................................................50 4.2 ORIGEM, DEFINIÇÃO E CLASSIFICAÇÃO DAS FALHAS ..............................51

4.3 TÉCNICAS DE ANÁLISES DE CONFIABILIDADE............................................54 4.3.1 Análise do Modo e Efeito da Falha – FMEA (Failure Mode and Effects Analysis).55 4.3.2 Árvore de Falhas – FTA (Fault Tree Analysis) .........................................................56 4.3.3 Testes de Vida Acelerados ........................................................................................57 4.3.4 Análise de Tempos de Falha......................................................................................58 4.4 CONCEITOS BÁSICOS SOBRE CONFIABILIDADE ..........................................58 4.5 FUNÇÕES FUNDAMENTAIS DA CONFIABILIDADE.......................................60 4.6 TIPOS DE DADOS DE VIDA..................................................................................63 4.7 MODELOS DE CONFIABILIDADE NÃO PARAMÉTRICOS .............................65 4.8 MÉTODOS DE CONFIABILIDADE NÃO PARAMÉTRICOS .............................66 4.9 MODELOS DE CONFIABILIDADE PARAMÉTRICOS.......................................69 4.9.1 Distribuição Normal ..................................................................................................70 4.9.2 Distribuição Log-normal ...........................................................................................72 4.9.3 Distribuição Weibull ..................................................................................................74 4.9.4 Distribuição Exponencial mono e bi-paramétrica .....................................................77 4.9.5 Distribuição Gamma bi-paramétrica .........................................................................78 4.10 MÉTODOS DE ESTIMATIVAS DE PARÂMETROS............................................79 4.11 TESTE DE HIPÓTESES DAS ESTIMATIVAS DE PARÂMETROS....................80 4.12 TESTES DE ADERÊNCIA DAS DISTRIBUIÇÕES ..............................................81 4.12.1 Técnica gráfica ..........................................................................................................81 4.12.2 Testes de adequação de ajustes de distribuição.........................................................82 CAPÍTULO 5 - PESQUISAS DESENVOLVIDAS .............................................................87 5.1 APLICAÇÕES EM ENGENHARIA DE PRODUÇÃO...........................................87 5.2 APLICAÇÕES EM OUTRAS ÁREAS ....................................................................90 CAPÍTULO 6 - PROCEDIMENTO ATUAL DE ANÁLISE DE EQUIPAMENTOS
CRÍTICOS ...............................................................................................................93 CAPÍTULO 7 - CONJUNTO DE ALTA CRITICIDADE E COMPONENTE CRÍTICO
...................................................................................................................................97 7.1 DESCRIÇÃO DO FUNCIONAMENTO DO ALTO FORNO 1..............................97 7.2 DESCRIÇÃO DO FUNCIONAMENTO DO CONJUNTO DE ALTA
CRITICIDADE E COMPONENTE CRÍTICO.........................................................99 CAPÍTULO 8 - PROCEDIMENTOS METODOLÓGICOS ...........................................106 CAPÍTULO 9 - RESULTADOS..........................................................................................111 9.1 AVALIAÇÃO DOS DADOS PARA UTILIZAÇÃO DA ACP .............................113 9.2 DETERMINAÇÃO DO NÚMERO DE COMPONENTES PRINCIPAIS ............129 9.4 CORRELAÇÃO ENTRE OS TEMPOS DE VIDA ORIGINAIS E OS
COMPONENTES PRINCIPAIS.............................................................................133

9.5 ANÁLISES DE COMUNALIDADES....................................................................134 9.6 ANÁLISE DOS COMPONENTES PRINCIPAIS CP1 E CP2 ..............................135 9.7 ANÁLISE DE CONFIABILIDADE DO PRIMEIRO COMPONENTE PRINCIPAL
(CP1)........................................................................................................................138 9.8 ANÁLISE DE CONFIABILIDADE DO MODELO DE PROBABILIDADE
LOGNORMAL........................................................................................................141 9.9 SÍNTESE DA ANÁLISE DOS RESULTADOS ....................................................145 910 COMPARATIVO ENTRE A METODOLOGIA PROPOSTA E O SISTEMA
ATUAL....................................................................................................................147 CAPÍTULO 10 - CONCLUSÃO .........................................................................................150 CAPÍTULO 11 - RECOMENDAÇÕES PARA TRABALHOS FUTUROS ...................152 REFERÊNCIAS ...................................................................................................................154 APÊNDICE A – Gráficos de Dispersão do Estimador Kaplan-Meier com os modelos
propostos..................................................................................................................164 APÊNDICE B – Histograma do número de falhas observadas nas Ventaneiras (componentes
críticos) ....................................................................................................................165 APÊNDICE C – Função de Confiabilidade das Ventaneiras (componentes críticos) ...........169 APÊNDICE D – Gráficos de scores do CP1 e CP3/CP2 e CP3 ............................................172 APÊNDICE E – Gráficos de loadings do CP1 e CP3 ............................................................173 APÊNDICE F – Parâmetros e percentis 10, 50 e 90 da Distribuição Lognormal (componentes
críticos) ....................................................................................................................174 APÊNDICE G – Matriz de dados de tempos de vida original dos 38 componentes críticos
coletados nos 10 anos (1994 a 2003) de amostragem .............................................175 APÊNDICE H – Ventaneiras usadas (em fim de vida útil) do Alto Forno 1 .........................176 APÊNDICE I – Ventaneiras novas (disponíveis para uso) do Alto Forno 1..........................177 APÊNDICE J – Vista da área de Processamento de Matérias-primas da Empresa estudada (ao
centro o Alto Forno 1) .............................................................................................178

CAPÍTULO 1 - INTRODUÇÃO
1.1 CONTEXTUALIZAÇÃO DO PROBLEMA
As indústrias de bens e serviços buscam cada vez mais a excelência na qualidade de
fornecimento de bens ou prestação de serviços, fato hoje essencial para a sobrevivência no
mundo de globalização em que vive a economia mundial.
Devido ao aumento da concorrência e às alterações no mercado consumidor nas
últimas décadas, as empresas necessitam gerar esforços cada vez maiores para se manterem
competitivas. A obtenção de prazos e preços competitivos, a flexibilidade produtiva ou ainda
o aumento na qualidade dos produtos, são alguns dos modos de sobrevivência diante dos
competidores.
No caso de uma unidade industrial siderúrgica, como é o caso da empresa focada neste
estudo não é diferente, pois a demanda por produtos com estreitos limites de especificação
está se tornando cada vez maior. Isto implica obrigatoriamente na existência de equipamentos
com altos níveis de confiabilidade.
Segundo Sandberg (1987) a confiabilidade e a qualidade têm muito em comum e as
pessoas pagam para tê-las, mas a confiabilidade apresenta ainda uma dimensão extra: o
tempo. No caso de eventualmente ocorrer uma falha, o tempo de funcionamento e o número
de intervenções relativas a um determinado equipamento ou unidade produtiva são igualmente
tomados como indicativos de qualidade. Assim, para assegurar um bom desempenho e
assegurar a sua função no processo produtivo, as empresas procuram aumentar a
confiabilidade de seus ativos produtivos.
Para poder garantir a confiabilidade de um produto, é necessário que a empresa possua
um método para se avaliar a confiabilidade dos equipamentos críticos ou que sejam
“gargalos” de produção. Um programa de confiabilidade deve ser definido e delineado pela
alta direção, desdobrando-se aos níveis imediatamente inferiores de forma clara, evidenciando
aos envolvidos diretamente ou indiretamente os benefícios e ganhos alcançados pela
implantação nas áreas estratégicas pela empresa.
Segundo Dias (1996, p. 2) a confiabilidade está embasada em quatro elementos
principais:

16
• probabilidade, demostrando que confiabilidade pode ser traduzida em termos
mensuráveis, através da distribuição das falhas;
• desempenho, que é o conjunto de requisitos de uso que definem uma função a ser
executada, de preferência sem falha;
• tempo de operação está vinculado a operar, sem falhas, num período previamente
definido;
• condições de operação são as circunstâncias ambientais e operacionais a qual o
produto é submetido.
Deste modo, defini-se confiabilidade como a probabilidade de um produto, submetido
a condições previamente estabelecidas, desempenhar as funções especificadas no projeto,
durante um período de tempo também especificado.
Logo, para se alcançar uma alta confiabilidade é fundamental conhecer o tempo de
vida dos equipamentos. Essa informação pode ser obtida, por exemplo, através da análise dos
dados de campo, obtidos junto às unidades de produção. Para analisar as informações
proveniente dessas unidades, a empresa precisa implementar um sistema de registro da
confiabilidade, isto é, montar um sistema de coleta de informações tais como: tempo
acumulado de operação, número de falhas, condições apresentadas no momento da ocorrência
de cada falha (BURGESS, 1987).
A proposta desta dissertação é desenvolver uma metodologia com base em estudos de
estatística multivariada para monitorar o tempo de vida, o tempo médio de falhas e a
confiabilidade do conjunto de insuflação de ar com foco nas ventaneiras (componente de alta
criticidade) de uma planta siderúrgica integrada.
1.2 JUSTIFICATIVA PARA SE ESTUDAR O PROBLEMA
O conhecimento prévio da vida útil dos equipamentos da cadeia produtiva é
fundamental, pois a redução do número de falhas destes equipamentos implica em redução de
variabilidades do produto final. Portanto, a busca pela melhoria da confiabilidade dos ativos
produtivos nas empresas é essencial. O alcance de um nível ótimo de confiabilidade permite
maximizar o ciclo de vida dos equipamentos e minimizar os custos de produção tornando o
preço do produto final mais competitivo no mercado.

17
A maioria das empresas não possui de forma estruturada uma função de engenharia de
confiabilidade e nem programas que tratem do assunto de forma sistemática. No caso da
unidade industrial estudada, um planejamento eficiente de produção de todo ciclo produtivo
da planta, pressupõe estabilidade operacional do conjunto principal (Alto Forno) e está
diretamente relacionada à confiabilidade de seus subconjuntos, como é o caso das ventaneiras,
considerado um componente de alta criticidade.
Tornar o subconjunto ventaneiras mais confiável implica em tornar o seu conjunto
principal também mais confiável. Neste contexto, a elaboração de uma proposta metodológica
científica com um adequado tratamento estatístico de dados se torna essencial.
A proposta metodológica utilizando a confiabilidade de componentes de alta
criticidade permitirá o controle e o monitoramento das variáveis que interferem no ciclo de
vida dos mesmos. Isto se torna fundamental, já que, pela própria concepção do equipamento
em estudo não há interferência humana direta em sua operação ao qual as ventaneiras estão
atreladas.
Adicionalmente, esta metodologia servirá de instrumento de apoio à tomada de
decisão, auxiliando no planejamento de manutenção e no levantamento de possíveis ajustes e
oportunidades de melhorias na unidade fabril estudada.
1.3 DELIMITAÇÃO DA PESQUISA
A pesquisa envolverá a análise de componentes de alta criticidade do Alto Forno 1, em
operação desde novembro de 1983, e instalado na área de processamento de matérias-primas
da unidade industrial. A empresa está localizada no Espírito Santo, município da Serra, a 10
km da Capital, Vitória.
O estudo focará a análise das ventaneiras (componentes de alta criticidade) já
fabricadas, em pleno uso, sem entrar na discussão de custos dos mesmos. O tratamento de
dados do modelo enfatizará exclusivamente os dados referentes à operação das ventaneiras. A
avaliação dos dados referentes à operação do componente analisará a influência apenas das
variáveis operacionais.
Sob outro aspecto, a pesquisa constitui-se de uma metodologia que visa avaliar a
confiabilidade das ventaneiras através de técnicas exploratórias multivariadas, mais
especificamente a análise de componentes principais e a análise de agrupamento hierárquico.

18
Portanto, não houve extensão de análise de dados e comparações a outros métodos
estatísticos, mesmo que com objetivos exploratórios ou de simplificação de dados.
1.4 OBJETIVOS
1.4.1 Objetivo geral
Propor uma metodologia para avaliar a confiabilidade de componentes de alta
criticidade de uma planta siderúrgica integrada.
1.4.2 Objetivos Específicos
Estimar a função Confiabilidade, a função Taxa de Falhas e o Tempo Médio Entre
Falhas de componentes críticos;
Conhecer os métodos e técnicas atuais de análise, controle e monitoramento de
falhas dos equipamentos críticos utilizados da empresa estudada;
Realizar estudos de métodos e técnicas estatísticas multivariadas e as técnicas de
análises de Confiabilidade;
Conhecer o sistema de funcionamento do componente crítico pesquisado.
1.5 ESTRUTURAÇÃO DA PESQUISA
Esta dissertação contém além deste capítulo inicial, mais 10 capítulos e 10 anexos.
Neste primeiro capítulo consta a Introdução, onde se apresenta a contextualização do
problema, os Objetivos Propostos, a Justificativa do Estudo que aborda a importância dos
objetivos propostos, a Delimitação da Pesquisa e, por fim, a Estrutura da Pesquisa.
Capítulo 2: Referencial Teórico. Inicia-se por uma abordagem sobre métodos
estatísticos multivariados, a análise exploratória de dados e finaliza mostrando as principais
normas brasileiras para análises estatísticas e de confiabilidade.

19
Capítulo 3: Análise de Componentes Principais. Neste capítulo descreve-se o
equacionamento matemático da análise de componentes principais, o processo de geração dos
componentes principais (via matriz de covariâncias e correlação), os principais métodos de
seleção, os critérios para determinação das componentes, a análise da qualidade das
componentes e suas limitações.
Capítulo 4: Análise de Confiabilidade. O capítulo traz a revisão bibliográfica, onde
são descritos os conceitos de confiabilidade, as principais técnicas, os tipos de dados de vida,
os modelos paramétricos e não-paramétricos, as principais distribuições de probabilidades
utilizadas em confiabilidade, as estimativas de parâmetros para os modelos paramétricos,
finalizando com os testes de aderência para verificação de ajuste de distribuição.
Capítulo 5: Pesquisas desenvolvidas. Contém uma revisão bibliográfica sobre os
trabalhos acadêmicos já desenvolvidos, que tratam da utilização da estatística multivariada,
auxiliando a análise de confiabilidade de componentes ou equipamentos.
Capítulo 6: Procedimento atual de análise e acompanhamento de vida útil dos
equipamentos críticos. São descritas as técnicas de análise e monitoramento de vida útil dos
equipamentos na empresa. São abordadas com maior profundidade as técnicas de análise de
óleo e a análise de vibrações.
Capítulo 7: Conjunto de Alta Criticidade e Componentes Críticos. Neste capítulo
são descritos o funcionamento do Alto Forno 1 e do Conjunto de Alta Criticidade dando
ênfase aos Componentes Críticos.
Capítulo 8: Procedimentos Metodológicos. Neste capítulo são descritos todas as
etapas dos procedimentos metodológicos propostos para o desenvolvimento do estudo em
epígrafe.
Capítulo 9: Resultados. Neste capítulo são apresentados os resultados advindos da
implementação dos procedimentos metodológicos descritos no capítulo anterior, descrevendo
as análises estatísticas de verificação da qualidade e representatividade dos dados coletados,
os testes de ajuste das distribuições de probabilidades, as estimativas dos parâmetros das
distribuições, os testes de hipóteses para estimativas dos parâmetros e os testes de aderência

20
para avaliação do nível de precisão da distribuição adotada de confiabilidade ao conjunto de
dados coletados. Por fim é realizada uma análise comparativa entre a metodologia proposta e
o sistema atual.
Capítulos 10 e 11: Conclusões e recomendações para trabalhos futuros. O capítulo
10 apresenta as considerações finais com base na revisão da literatura e no desenvolvimento
metodológico proposto; a partir das limitações apontam-se sugestões para pesquisas futuras
no capítulo 11.

CAPÍTULO 2 - REFERENCIAL TEÓRICO
2.1 ANÁLISE MULTIVARIADA
Em qualquer decisão que se toma na vida sempre se leva em conta um grande número
de fatores. Obviamente nem todos estes fatores pesam da mesma maneira na hora de uma
escolha. Às vezes, por se tomar uma decisão usando a intuição, não se identifica de maneira
sistemática estes fatores, ou seja, quais as variáveis que afetaram a decisão.
Estabelecer relações, encontrar ou propor leis explicativas é o papel próprio da
ciência. Para isso é necessário controlar, manipular, medir as variáveis que são consideradas
relevantes ao entendimento de algum fenômeno analisado. Muitas são as dificuldades em
traduzir as informações obtidas em conhecimento. Isto implica e condiciona a uma
padronização metodológica. Um aspecto essencial desta padronização é a avaliação estatística
das informações. A maneira própria de fazer ciência, procurando reduzir a poucas variáveis,
desenvolveu muito um ramo da estatística que olha as variáveis de maneira isolada - a
estatística univariada (MOITA NETO, 2004).
Às vezes, analisa-se as variáveis isoladamente e a partir desta análise faz-se
inferências sobre a realidade. Esta simplificação tem vantagens e desvantagens. Quando um
fenômeno depende de muitas variáveis, geralmente este tipo de análise falha, pois não basta
conhecer informações estatísticas isoladas, mas é necessário também conhecer a totalidade
destas informações fornecida pelo conjunto das variáveis. No caso restrito de variáveis
independentes entre si é possível, com razoável segurança, interpretar um fenômeno
complexo usando as informações estatísticas de poucas variáveis.
Segundo Moita Neto (2004), a denominação “Análise Multivariada” corresponde a um
grande número de métodos e técnicas que utilizam simultaneamente todas as variáveis na
interpretação teórica do conjunto de dados obtidos.
Mingoti (2005) define análise multivariada como sendo um conjunto de métodos
estatísticos utilizados em situações nas quais várias variáveis são medidas simultaneamente,
em cada elemento amostral.
Virgillito (2004) define a análise multivariada como sendo um conjunto de técnicas
estatísticas que possibilitam analisar, ao mesmo tempo, varias dimensões (multidimensional)
de cada uma das variáveis em estudo.

22
Os modelos multivariados possuem em geral, um propósito através do qual o
pesquisador pode testar ou inferir a respeito de uma hipótese sobre um determinado
fenômeno. No entanto a sua utilização adequada depende do conhecimento das técnicas e das
suas limitações.
Diante de situações em que há necessidade de se estudar o relacionamento de mais de
duas variáveis simultaneamente, a estatística univariada não é capaz de explicar ou gerar
informações envolvendo várias variáveis ao mesmo tempo. Neste caso, recorre-se aos
métodos quantitativos multivariados com suas técnicas de verificação e quantificação dos
relacionamentos existentes entre as variáveis em estudo.
Em linhas gerais, os métodos de estatística multivariada são utilizados com o propósito de simplificar ou facilitar a interpretação do fenômeno que está sendo estudado através da construção de índices ou variáveis alternativas que sintetizem a informação original dos dados; construir grupos de elementos amostrais que apresentem similaridade entre si, possibilitando a segmentação do conjunto de dados original; investigar as relações de dependência entre as variáveis respostas associadas ao fenômeno e outros fatores (variáveis explicativas), muitas vezes, como objetivo de predição; comparar populações ou validar suposições através de teste de hipóteses (MINGOTTI, 2005, p. 22).
Segundo John e Wichern (1998 apud SCREMIN, 2003, p. 2), a análise multivariada
conduz aos seguintes objetivos:
a) Redução de dados ou simplificação estrutural: o fenômeno estudado deve ser representado da maneira mais simples possível, sem sacrificar valiosas informações;
b) Ordenação e agrupamento: agrupamento de objetos, tratamentos, ou variáveis similares baseados em dados amostrais ou experimentais;
c) Investigação da dependência entre variáveis: o estudo das relações estruturais entre variáveis muitas vezes de interesse do pesquisador;
d) Predição: relações entre variáveis devem ser determinadas para o propósito de predição de uma ou mais variáveis com base na observação de outras variáveis;
e) Construção e testes de hipóteses.
Virgillito (2004, p. 353) divide as técnicas de análise multivariada em:
a) Técnicas preparatórias ou exploratórias: destinam a explorar a natureza dos dados em análise para testar os pressupostos básicos ou pré-requisitos para aplicação dos métodos escolhidos posteriormente pelo observador;
b) Técnicas de dependência: utilizam-se das variáveis estruturadas de maneira que diversas chamadas independentes predizem ou explicam uma ou mais variáveis dependentes;

23
c) Técnicas de interdependência: analisam a estrutura das variáveis em estudo não formulando nenhum tipo de inferência a respeito da contribuição individual das variáveis para o modelo matemático a ser construído pelo analista. A escolha de uma destas técnicas depende dos pressupostos teóricos sobre distribuição de freqüência das variáveis envolvidas. Questões como normalidade das variáveis desempenha um papel fundamental esta escolha.
A Figura 1 mostra um quadro para a seleção da técnica estatística multivariada
conforme as características dos dados e da relação a ser aplicada.

24
Figura 1 – Seleção da técnica estatística multivariada Fonte: Anderson et al (1998 apud VIRGILLITO, 2004, p. 363).
Que tipo de relação esta
sendo examinada?
Quantas variáveis
estão sendo previstas?
A estrutura do relacionamento
esta entre:
Qual a escala da Medida da
Variável Dependente?
Modelo Estrutural de Equações
Qual a escala da Medida da
Variável Dependente?
Análise de Fatores
Como são Medidos
seus Atributos?
Análise de Grupos
Qual a escala da Medida da Variável de previsão?
Análise Canônica de Correlação
Regressão Multipla
Análise Discriminante Multipla ou Modelo de Probabilidade Linear
(LOGIT)
Análise Multidimensional
Análise de Correspondência
Análise Canônica de Correlação
Análise Multivariada da
Variancia
Técnica Multivariada selecionada
Ponto de DecisãoLegenda:
Dependência
Relação Multipla de Dependência e
Variáveis Independentes
Algumas Variáveis
Dependentes com Relação Simples
Uma Variável Dependente com Relação Simples
Métrica Não Métrica
Métrica Não Métrica
Métrica Não Métrica Métrica Não Métrica
Variáveis Casos Objetos
Interdependência

25
Segundo Silva (2005, p.7) as principais técnicas multivariadas e as condições em que
podem ser aplicadas são as seguintes:
a) Regressão Múltipla: método mais usado e conhecido. Relaciona-se com a
dependência de uma única variável, a variável dependente sobre um conjunto de
outras (variáveis preditoras);
b) Análise Discriminante: usado quanto se tem uma variável (ou mais) que está
relacionada com alguma característica da amostra. Por exemplo: idade, sexo, tipo
de investidor, nível de escolaridade. E se quer saber dentro do grupo da variável,
qual é a tendência de expressar alguma discriminação ou não;
c) Análise Logit: é apropriado quando um critério simples de mensuração é discreto e
todas as variáveis preditoras são categóricas na sua natureza;
d) Manova: a análise de variância multivariada é usada quando múltiplos critérios de
mensuração são avaliados e o objetivo é avaliar o impacto de vários níveis de uma
ou mais variáveis experimentais sobre o critério de medida. Assim, o foco primário
da Manova é testar as diferenças significantes de um conjunto de variáveis ou o
perfil destas devido às relações sobre uma ou mais variáveis controladas;
e) Análise de Correlação Canônica: este método busca determinar a associação linear
entre o conjunto de variáveis preditoras e os critérios de mensuração. No processo
busca-se ter duas combinações lineares, uma do conjunto preditor e outra do
critério maximizante.
f) Análise de Componentes Principais (ACP): é uma técnica de redução de dados
onde o objetivo principal é a construção de uma combinação linear das variáveis
principais que representam a totalidade;
g) Análise Fatorial: é uma técnica de redução de dados. Em contraste com o modelo
anterior, este visa apenas a parte da variação total mais robusta do que a totalidade;
h) Análise Escalonada Multidimensional Métrica: é usada para explorar, por
exemplo, como as pessoas formam percepções sobre as (dis) similaridades entre as
preferências de vários objetos. Um aspecto importante deste método é um mapa de
alternativas que representa este comportamento de (dis) similaridades;
i) Análise de Agrupamento Hierárquico (AAH): é uma técnica de conglomerado (ou
cluster) e pode ser considerado um método de redução de dados. O objetivo na
maioria dos estudos que usam esta técnica é identificar um número pequeno de
agrupamentos para um todo, que tem aspectos semelhantes. Em geral o subgrupo
homogêneo é baseado nas (dis) similaridades dos perfis dos respondentes;

26
j) Análise Escalonada Multidimensional Não Métrica: o objetivo deste método é
transformar as (dis) similaridades percebidas no interior de um conjunto de objetos
em distâncias no espaço multidimensional;
k) Modelo Loglinear: este modelo permite ao pesquisador investigar as inter-relações
as variáveis categóricas a partir de uma contingência. Expressa também as
probabilidades multidimensionais em termos dos efeitos principais.
2.2 ANÁLISE EXPLORATÓRIA
Antes de se iniciar um tratamento de dados deve-se primeiramente organizá-los e
proceder a uma avaliação prévia, pois dependendo da natureza dos dados pode ser necessário
um tratamento prévio, ou a transformação dos dados, ou até mesmo para saber o tipo de
método de análise mais adequada (RIBEIRO, 2001).
O objetivo dos métodos de análise exploratória é fazer a avaliação inicial dos dados
para descobrir que tipo de informação é possível extrair deles, e assim definir as diretrizes para
um tratamento mais aprofundado. A necessidade de avaliação é um passo importante para
validação dos resultados, pois se evita o risco de invalidar a pesquisa e de obterem-se
conclusões equivocadas.
Uma adequada organização e avaliação dos dados também são essenciais para que a
análise seja feita de forma correta. Deve-se investigar de que forma os dados foram gerados, os
métodos de medidas utilizados e a fonte que originou tais dados. Outro fator importante é a
representatividade do grupo de amostras que se deseja analisar.
Segundo Ribeiro (2001, p. 4), “de nada adianta um conjunto extenso de dados com
informações interessantes se o grupo de amostras não for representativo o suficiente para
fornecer informações adequadas ao tratamento que se propõe fazer”.
Uma das primeiras etapas é a padronização dos dados que visa tornar as escalas e
unidades de medida equivalentes sem a perda de informações. Esta etapa é denominada de pré-
processamento. Beebe et al (1998 apud RIBEIRO, 2001, p. 7) ressalta que, para esta etapa, há
três métodos mais indicados, a saber:
a) Dados centrados na média: neste caso, a média de cada variável é subtraída de seus
respectivos elementos fazendo com que a origem dos eixos os quais os dados se
encontram, seja deslocada de modo a colocar os dados numa forma mais
conveniente à análise e à visualização.

27
b) Escalonamento pela variância: neste método, cada variável é dividida pelo seu
desvio padrão fazendo com que o peso das variáveis em diferentes escalas seja
considerado equivalente, minimizando o risco de perdas de informações relevantes.
c) Auto-escalonamento: este método aplica ambas as técnicas descritas acima de uma
só vez, de modo que a transformação realizada sobre o conjunto original de dados
permita que cada variável apresente média zero e variância um. Desta forma é dada
a mesma importância para todas as variáveis independente de sua dimensão.
A análise exploratória de dados normalmente é feito através da utilização de algoritmos
matemáticos que permite reduzir a dimensão dos dados, ou organizá-los numa estrutura que
facilite a visualização de todo o conjunto, de forma global.
Segundo Virgillito (2004, p. 354), entre os principais métodos exploratórios, alguns dos
mais utilizados são:
a) Testes de Normalidade: verifica a aderência dos dados e descrição gráfica. Alguns
exemplos são os testes de Shapiro-Wilk, Cramer–von Mises e Kolmogorov-
Smirnov, dentre os mais utilizados;
b) Análise de Variância (ANOVA): testa a igualdade das médias amostrais e verifica
se as amostras foram extraídas de populações de médias iguais;
c) Análise de Fatores: explora as correlações entre as variáveis em estudo e ajuda a
definir a estrutura dos dados para as análises subseqüentes;
d) Análise de Componentes Principais (ACP): que reduz o número de dados e
fornece uma visão estatisticamente privilegiada do conjunto de dado;
e) Análise de Agrupamento Hierárquico (AAH): que identifica agrupamentos de
aspectos semelhantes;
f) Análise de Confiabilidade: que avalia a probabilidade de não ocorrência de falhas
ou defeitos de um sistema ou componentes utilizando de distribuições de
probabilidade de seus respectivos tempos de vida.
A análise exploratória permite ainda avaliar a possibilidade da construção de modelos de
regressão ou de classificação.

28
2.3 TEOREMA DA DECOMPOSIÇÃO ESPECTRAL
Objetivando fornecer subsídios teóricos ao entendimento da Análise de Componentes
Principais a ser apresentada posteriormente, será abordado neste capítulo, o Teorema da
decomposição espectral que relaciona as matrizes de variâncias-covariâncias e de correlação
em seus autovalores e respectivos autovetores (GRAYBILL, 1983 apud MINGOTI, 2005).
Considerando pxpΣ , uma matriz de variâncias-covariâncias, simétrica, não negativa
definida (n.n.d) ou positiva definida (p.d.), então se pode afirmar que existe uma matriz
ortogonal pxpO ,
]...[
....
....
....
21
211
22212
12111
p
pppp
p
p
pxpeee
eee
eeeeee
O =
=ΜΜΜ
tal que, pxpIOOOO =′=′ , onde:
sendo p21λ...λλ ≥≥≥ os autovalores ordenados em ordem decrescente da matriz pxp
Σ , ie o
respectivo autovetor normalizado sendo ]...[21 ipiii
eeee = e pxpI a matriz identidade
correspondente. Neste caso, diz-se que a matriz pxpΣ é similar à matriz pxp
Λ , o que implica:
pxppxppxp
p
iΛ=Σ=Σ=Π
=)det(
1λ
)()(...211 pxppxppi
p
itraçotraço Λ=Σ=+++=Σ
=λλλλ
(1)
Λ=
=Σ′
p
OO
λ
λλ
0
0
2
1
ΜΜΜ(2)
(3)
(4)

29
O produtório i
p
iλ
1=Π é o determinante da matriz de variâncias-covariâncias
pxpΣ também
denominado de variância generalizada. O somatório i
p
iλ
1=Σ é denominado variância total ou
traço da matriz de covariâncias. Ambas as quantidades em valores elevados indicam uma
maior dispersão global das variáveis envolvidas. Ao contrário da variância total, a variância
generalizada é influenciada pelas covariâncias (ou correlações) entre variáveis (MINGOTI,
2005).
Então, a matriz O é dada por ]...[21 p
eeeO = e pelo teorema da decomposição espectral
tem-se que a seguinte igualdade é válida:
iii
p
ipxpeeOO ′Σ=′Λ=Σ
=λ
1
sendo ie um vetor de comprimento unitário com 0=′
jiee , ∀ i # j e 1=′
jiee ∀ i = 1, 2, ...,p
pela propriedade de ortogonalidade da matriz pxpO . Os pressupostos e as propriedades
matemáticas acima expostas são condições necessárias à aplicação da análise de componentes
principais.
2.4 NORMAS TÉCNICAS BRASILEIRAS UTILIZADAS EM ANÁLISES
ESTATÍSTICAS E DE CONFIABILIDADE
Existem diversas normas da Associação Brasileira de Normas Técnicas (ABNT)
empregadas em análises estatísticas e de confiabilidade. Serão comentadas a seguir apenas as
mais utilizadas, das quais algumas poderão ser citadas no decorrer do texto.
NB-11153:1988 - Interpretação estatística de resultados de ensaio. Estimação da
Média - Intervalo de Confiança: é uma norma utilizada para estimação da média e intervalos
de confiança. Estabelece as condições exigíveis para o tratamento estatístico de resultados de
ensaios necessários para se calcular um intervalo de confiança para a média de uma população.
Limita-se à estimação da média de uma população com distribuição normal e trata de casos
onde a variância é desconhecida.
(5)

30
NBR-11154:1989 - Interpretação estatística de dados. Técnicas de estimação e
testes relacionados às médias e variâncias: é uma norma utilizada para estimação da média
ou variâncias de uma população. Examina certas hipóteses no que se refere aos valores destes
parâmetros, a partir de amostras.
NB-11155:1988 - Interpretação estatística de dados. Determinação de intervalo de
tolerância estatístico: especifica métodos para determinação de um intervalo de tolerância
estatístico baseado em uma amostra cujo intervalo exista uma probabilidade de que o mesmo
contenha ao menos uma proporção “p” da população da qual uma amostra é retirada.
NBR-11156:1988 - Interpretações estatísticas de dados. Comparação de duas
médias no caso de observações emparelhadas: fixa um método para comparar a média de
uma população de diferenças entre observações emparelhadas com zero ou outro valor
prefixado.
NBR-11157:1990 - Interpretação estatística de dados. Potência de testes
relacionados às médias e variâncias: especifica as técnicas para determinação da potência de
testes relacionados às médias e variâncias, complementando a norma NBR-11154.
NBR-5462:1994 - Confiabilidade e Mantenabilidade: define os termos relacionados
com a confiabilidade em geral.
NBR-6534:1986 - Cálculos de estimativas por ponto e limites de confiança
resultante de ensaios de determinação da confiabilidade de equipamentos. Procedimento:
define os procedimentos de cálculo de estimativas por ponto e limites de confiança resultante
de ensaios de determinação da confiabilidade de equipamentos.
NBR-6742:1987 - Utilização da distribuição de Weibull para interpretação dos
estágios de durabilidade por fadiga: fixa procedimentos à obtenção e manuseio dos dados
para a interpretação dos ensaios de fadiga de modo a serem representativos do comportamento
da população, com uma confiabilidade prefixada através da aplicação de um tratamento
estatístico, baseado na função de distribuição de probabilidade Weibull, a certo número de
amostras ensaiadas.

CAPÍTULO 3 - ANÁLISE DE COMPONENTES PRINCIPAIS (ACP)
3.1 DIFERENÇAS ENTRE A ANÁLISE FATORIAL E A ANÁLISE DE
COMPONENTES PRINCIPAIS
O objetivo da Análise Fatorial é interpretar a estrutura de um conjunto de dados
multivariado e correlacionado e, a partir da matriz de correlação ou mais especificamente, da
matriz de variâncias-covariâncias, poder agrupar um conjunto de “p” de variáveis no menor
número possível, em novas variáveis chamadas componentes principais. Essa técnica pode ser
utilizada através de dois procedimentos básicos: Análise de Componentes Principais (ACP) e
Análise de Fatores (AF).
A ACP consiste numa combinação linear das “p” variáveis originais em “k” novas
variáveis, de tal modo que o primeiro componente seja responsável pela maior variação
possível no conjunto de dados original; o segundo pelo maior possível restante e assim
sucessivamente até que toda a variação tenha sido explicada. Já a análise de fatores, como já
foi colocada na Análise Discriminante, é utilizada quando se quer, através dos fatores,
formarem grupos homogêneos entre as variáveis originais, chamados de comunalidades
(HARRIS, 2001). Apesar de possuírem muitos aspectos em comum, a análise das componentes
principais não é "sinônima" da análise fatorial e essa confusão terminológica deve ser evitada.
3.2 ALGUNS TESTES ESTATÍSTICAS PARA VERIFICAÇÃO DA
APLICABILIDADE DA ACP
Atendendo a proposta metodológica do estudo deverão ser adotadas técnicas
estatísticas que permitam avaliar os inter-relacionamentos entre as ventaneiras (componente
crítico) cujas falhas tiveram maior freqüência no período em análise.
Devido ao grande volume de variáveis e dados envolvidos, um método indicado para
identificar quais variáveis estariam influenciando na ocorrência ou não de problema com as
ventaneiras é a Análise de Componentes Principais (ACP). Antes, porém, torna-se necessário
certificar-se da validação dos dados para utilização da ACP.

32
Para se aplicar a ACP recomenda-se proceder a uma avaliação inicial do conjunto de
dados mediante análise da correlação entre as variáveis originais, condição necessária para se
utilizar a análise de componentes principais sendo justificável na medida em que as
correlações entre as variáveis sejam significativas. O objetivo é avaliar a “força” da associação
entre cada par de variáveis para se verificar se a mesma é estatisticamente significativa.
Uma alternativa para a avaliação consiste na realização de um teste de hipóteses cuja
configuração é a seguinte:
Hipótese nula (H0): Não há correlação entre as 2 populações amostrais (ρ = 0)
Hipótese alternativa (H1): Há correlação entre as 2 populações amostrais (ρ ≠ 0)
O teste de hipóteses acima está condicionado à assunção de normalidade das
distribuições das amostras estudadas. Segundo Chernick (2003, p. 258), o teste “t” empregado
para o coeficiente de correlação de Pearson é dado pela seguinte expressão:
21 2
−−
= nr
rtdf
onde df = n-2 e n = número de pares de amostras.
Se a estatística tdf não ultrapassar o valor crítico tabelado para o grau de liberdade df
(do inglês degree of freedom) n – 2, haverá evidências para não se rejeitar a hipótese nula.
Caso contrário, ou seja, se a estatística tdf ultrapassar o valor crítico tabelado, haverá
evidências para se aceitar a hipótese alternativa. Há indicações na literatura de uma razoável
quantidade de testes estatísticos que dependem também da suposição de normalidade da
distribuição a ser testada, dentre os mais difundidos destacam-se o teste de Shapiro-Wilk e o
teste de esfericidade de Bartlet.
Como alternativa para distribuições não necessariamente normais, há um teste que
verifica a igualdade da estrutura da correlação de um conjunto de dados originais. O teste
considera uma estrutura de correlação especial com ρσσkkiiki
XXCov =),( ou
ρ=),(ki
XXCorr , para todo i ≠ k onde os autovalores da matriz de covariâncias não são
distintos (JOHN; WICHERN, 1992, p.364).
(6)

33
No teste de hipótese são considerados:
==
1
11
:)(
00
ΛΜΟΜΜ
ΛΛ
ρρ
ρρρρ
ρρpxp
H
01 : ρρ ≠H
Este teste é baseado na estatística da verossimilhança. Lawle (1966 apud JOHN;
WICHERN, 1992, p.365) propõe um teste equivalente que pode ser construído utilizando os
elementos de fora da diagonal da matriz de correlação. O procedimento requer o cálculo prévio
dos seguintes termos:
ikkiik
p
kii
k rpp
rpkrp
r<
−
≠−
−
ΣΣ−
==Σ−
=)1(
2;,...2,11
11
2
22^
)1)(2(])1(1[)1(
−
−
−−−
−−−=
rpprpγ
Sendo,
p, o número de autovalores da matriz de correlação;
kr−
, a média dos elementos de fora da diagonal na k-ésima coluna ou fila da matriz de
correlação e −
r , a média global de todos os elementos de fora da diagonal.
Para uma amostra relativamente grande, o teste de significância α possui a seguinte
forma:
Rejeitar H0 em favor de H1 se,
)(])()([)1(
)1(2/)2)(1(
22
1
^2
2αχγ −+
−−
=
−
<− >−Σ−−ΣΣ−
−= ppk
p
kikkirrrr
r
nT
Onde )(22/)2)(1( αχ −+ pp é avaliado na calda superior do α-ésimo percentil da distribuição qui-
quadrado com (p+1)(p-2)/2 graus de liberdade. Este teste é preferível aos anteriores, pois
(7)
(8)
(9)
(10)
(11)

34
independem da suposição de normalidade da distribuição a ser testada sendo, portanto
utilizável em qualquer distribuição com amostras relativamente grandes.
Por último, há uma técnica exploratória e complementar a ACP cuja principal função é
detectar anomalias ou inconsistências na associação de dados de uma população. Esta técnica
denominada Análise de Agrupamento Hierárquico (AAH) ou (HCA), do inglês Hierarchical
Cluster Analysis, que tem por objetivo observar a formação de agrupamentos naturais a partir
de suas similaridades.
Esta técnica interliga as amostras por suas associações, produzindo um dendrograma
onde a amostras semelhantes, segundo as variáveis escolhidas, são agrupadas entre si.
Dendrogramas ou diagrama de árvores são gráficos bidimensionais que representam a
similaridade entre pares de amostras (ou grupos de amostras) numa escala que vai de um
(identidade) a zero (nenhuma similaridade). Através destes dendogramas é possível observar
as correlações e similaridades entre as amostras (MOITA; MOITA NETO, 1997).
A similaridade entre as amostras é avaliada medindo-se inicialmente as distâncias entre os pares de amostras e colocando num mesmo agrupamento aquelas amostras com menores distâncias entre si. A seguir, a distância entre estes pequenos agrupamentos é medida e estabelece-se então novos agrupamentos e assim por diante até que todas as amostras tenham sido enquadraras neste ou naquele grupo (segundo diferentes graus de similaridade). (RIBEIRO, 2001. p. 18).
A medida da similaridade é calculada numa escala de medida dada conforme a equação
abaixo em que Dab é a distância entre as amostras “a” e “b” e Dmax é a distância máxima entre
todas as amostras consideradas, ou seja:
max1
DDdeSimilarida ab
ab −=
Existem vários métodos para se medir as distâncias entre os pares das amostras e
agrupamentos, entre eles, estão a distância Euclidiana e a distância de Mahalanobis
(RIBEIRO, 2001, p.18). A suposição básica é que quanto menor a distância entre os pontos,
maior a semelhança entre as amostras. A distância Euclidiana é uma medida invariante às
translações, porém assume covariâncias iguais entre as classes e em geral não é invariante às
transformações lineares. É a medida mais utilizada na prática. A distância de Mahalanobis
considera que as superfícies de cada classe são elipsóides centradas na média. No caso especial
em que a covariância é zero e a variância é a mesma para todas as variáveis, as superfícies
serão esferas, e a distância de Mahalanobis fica idêntica a distância Euclidiana. Esta métrica
(12)

35
supre muitas das limitações da distância Euclidiana, porém pode ser bastante difícil determinar
precisamente as matrizes de covariâncias, e o custo computacional cresce muito com o número
de variáveis envolvidas.
Após o cálculo das similaridades, as duas amostras mais próximas são conectadas
formando um agrupamento. Este processo é repetido até que todas as amostras sejam
conectadas formando um único grupo. Uma vez que as amostras são conectadas pela
proximidade entre elas, é necessário definir a distância entre uma amostra e um grupo ou, entre
grupos de amostras. Há várias técnicas para medir a distância. As mais usuais são: conexão
pelo vizinho mais próximo (single linkage ou nearest neighbour); conexão pelo vizinho mais
distante (complete link ou farthest neighbour); conexão pela distância média (average link) e o
método de Ward. O método de Ward é um método de agrupamento de dados que forma grupos
de maneira a atingir sempre o menor erro interno entre os vetores que compõe cada grupo e o
vetor médio do grupo. Isto equivale a buscar o mínimo desvio padrão entre os dados de cada
grupo.
Por ser uma técnica complementar a ACP não serão feitos estudos mais aprofundados,
pois foge ao objetivo deste trabalho. Informações mais detalhadas podem ser encontradas em
Beebe et al, Sharaf et al, Kowalski,(1998; 1996; 1983 apud RIBEIRO, 2001).
3.3 DESCRIÇÃO DA ANÁLISE DE COMPONENTES PRINCIPAIS
A Análise de Componentes Principais é uma técnica de redução de variáveis de vasta
aplicação em dados multivariados. Está diretamente relacionada com a transformação de
variáveis, através do cálculo dos autovalores e correspondentes autovetores da matriz de
variâncias e covariâncias ou da matriz de correlação entre variáveis, de forma a preservar a
variabilidade total. A geração desta estrutura de variâncias-covariâncias, seus autovalores e
respectivos autovetores está fundamentada no teorema da decomposição espectral já abordada
nos capítulos precedentes.
A Análise de Componentes principais tem o objetivo de explicar a estrutura de
variância e covariância de um vetor aleatório composto de “p” variáveis aleatórias através de
combinações lineares das variáveis originais. Estas combinações lineares são chamadas de
componentes principais e são não correlacionadas entre si. Se temos “p” variáveis originais é
possível obter-se “redução do número de variáveis a serem avaliadas e interpretação das
combinações lineares construídas”, ou seja, a informação contida nas “p” variáveis originais é

36
substituída pela informação contida em k (k<p) componentes principais não correlacionadas.
Desta forma, o sistema de variabilidade composto das “p” variáveis originais é aproximado
pelo sistema de variabilidade do vetor aleatório que contém as “k” componentes principais. A
qualidade da aproximação depende do número de componentes mantidas nos sistema e pode
ser medida através da avaliação da proporção de variância total explicada por essas.
Portanto, as componentes principais são novas variáveis geradas através de uma
transformação matemática especial realizada sobre as variáveis originais. Esta operação
matemática está disponível em diversos softwares estatísticos especializados. Há duas
características que as tornam mais efetivas que as variáveis originais para a análise do conjunto
das amostras.
A primeira é que as variáveis podem guardar entre si correlações que são suprimidas
nas componentes principais. Ou seja, as componentes principais são ortogonais entre si. Deste
modo, cada componente principal traz uma informação estatística diferente das outras. A
segunda característica importante é decorrente do processo matemático-estatístico de geração
de cada componente que maximiza a informação estatística para cada uma das coordenadas
que estão sendo criadas. As variáveis originais têm a mesma importância estatística, enquanto
que as componentes principais têm importância estatística decrescente. Ou seja, as primeiras
componentes principais são tão mais importantes que podemos até desprezar as demais.
Destas características podemos compreender como a análise de componentes
principais:
a) podem ser analisadas separadamente devido à ortogonalidade, servindo para
interpretar o peso das variáveis originais na combinação das componentes
principais mais importantes;
b) podem servir para visualizar o conjunto da amostra apenas pelo gráfico das duas ou
três primeiras componentes principais, que detêm maior parte da variabilidade do
conjunto de dados.
Algebricamente o comprimento dos eixos das componentes principais é representado
pelos autovalores que são medidos em unidade de variância. Associados a cada autovalor
existe um vetor de módulo unitário chamado autovetor. A matriz formada por estes vetores
unitários é denomina matriz dos “loadings”. Os autovetores representam as direções dos eixos
das componentes principais. São fatores de ponderação que definem a contribuição de cada
componente principal, numa combinação aditiva e linear.

37
Quando a distribuição de probabilidade amostral é normal, as componentes principais,
além de não correlacionadas, são também independentes. Entretanto, a suposição de
normalidade não é requisito necessário para que a técnica de componentes principais possa ser
realizada. A obtenção das componentes principais envolve a decomposição da matriz de
covariâncias do vetor aleatório de interesse. Caso seja feita alguma transformação deste vetor
aleatório, as componentes deverão ser determinadas utilizando-se a matriz de covariâncias
relativa a vetor transformado. Uma transformação muito usual é a padronização das variáveis
do vetor pelas respectivas médias e desvios padrões, gerando-se novas variáveis centradas em
zero e com variâncias iguais a 1, o que é denominado auto-escalonamento de dados já visto
anteriormente. Neste caso, as componentes principais são determinadas a partir da matriz de
covariâncias das variáveis originais padronizadas, o que é equivalente a extrair-se as
componentes principais utilizando-se a matriz de correlação das variáveis originais.
Uma vez determinadas as componentes principais, os seus valores numéricos,
denominados “scores”, podem ser calculados para cada elemento amostral. Deste modo, os
valores de cada componente principal podem ser analisados, usando-se técnicas usuais, como
análise variâncias e de regressão, dentre outras.
3.4 GERAÇÃO DOS COMPONENTES PRINCIPAIS VIA MATRIZ DE
COVARIÂNCIAS
Algebricamente, componentes principais são combinações lineares particulares das “p”
variáveis aleatórias 1X , 2X ,..., pX . Geometricamente, essas combinações lineares representam
a relação de um novo sistema de coordenadas obtido por deslocamento e rotação do sistema
original com 1X , 2X ,..., pX como eixos. Os novos eixos representam as direções com
variabilidade máxima e fornecem uma descrição mais simples e mais parcimoniosa da
estrutura de covariância (LOPES, 2001, p.30).
Os componentes principais dependem da matriz de correlação r ou da matriz de
covariâncias Σ de 1X , 2X ,..., pX . O seu desenvolvimento não necessita da suposição de
normalidade. A Figura 2 mostra o processo para obtenção de “p” componentes principais.

38
Figura 2 – Fluxo para obtenção dos componentes principais Fonte: Lopes, (2001, p.31).
Supondo apenas duas variáveis em um sistema 1X e 2X , com distribuição normal
bidimensional, observa-se na Figura 3, a elipsóide de densidade de probabilidade constante.
Figura 3 – Elipsóide de densidade de probabilidade constante Fonte: Lopes, (2001, p.31).
O primeiro componente corresponde ao maior eixo da elipsóide ( 1CP ) e o comprimento
desse eixo é proporcional a 1λ . O eixo de menor variância ( 2CP ) é perpendicular ao eixo
maior. Esse eixo chama-se segundo componente principal e seu comprimento é proporcional a
2λ . Assim, a análise dos componentes principais toma os eixos 1X e 2X e os coloca na
direção da maior variabilidade (JOHNSON; WICHERN, 1992).

39
Ao estudar um conjunto de “n” elementos, mediante “p” variáveis de um sistema é
possível encontrar novos componentes, denominados iCP , i = 1,...,p, que são combinações
lineares das variáveis originais X(p), e impor a esse sistema certas condições que permitam
satisfazer os objetivos da análise de componentes principais.
Isso implica encontrar (p x p) constantes tais que CP(k) pode ser escrito de acordo com
a equação (13):
CP(k) = ∑=
p
jkj
1)(α X(j) , k=1,...,
onde cada )( kjα é uma dessas constantes. Observa-se que devido ao somatório em cada nova
variável CP(k), uma intervenção ocorrerá em todos os valores das variáveis originais X(j). O
valor numérico de )( jα indica o grau de contribuição de cada variável definida pela
transformação linear. É possível que )( jα tenha em algum caso particular, o valor zero, ou
muito próximo de zero, o qual indica que essas variáveis não influem no valor da nova variável
CP(k). O grau de contribuição )( jα de cada variável definida pela transformação linear é dado
pela relação [ ])( iji CPVα , quando os componentes são obtidos a partir da matriz de
correlação (JOHNSON; WICHERN, 1992).
3.5 NÃO CORRELAÇÃO ENTRE OS COMPONENTES PRINCIPAIS
O vetor aleatório ],...,,[ 21 pXXXX =′ com matriz de covariância Σ com os autovalores
1λ > 2λ > pλ > 0, e as seguintes combinações lineares;
1CP = XK .1′ = 111Xk + 221Xk + ...+ pp Xk 1
2CP = XK .2′ = 112 Xk + 222 Xk + ...+ pp Xk 2
ΜΜΜΜΜ
pCP = XK p .′ = 11 Xk p + 22 Xk p + ...+ ppp Xk
(13)
(14)

40
definem a matriz das combinações lineares.
Seja Kpp uma matriz,
=
pppp
p
p
pp
kkk
kkk
kkk
K
ΛΜΟΛΛ
Λ
Λ
21
22212
12111
que nos permite escrever CP = Kpp.X
Observa-se ainda que:
a) Se Z é uma combinação linear de “p” componentes de um sistema Xi, i = 1, 2,...,p. Sendo Z =K.X, então a esperança de Z é dada por E(Z) = E(K'.X) = K'.E(X) e a variância é:
V(Z) = V(K'.X) = K'.V(X).K
b) Se Z' é igual a Z= ],...,,[ 21 qZZZ , e é também um vetor de “q” combinações lineares, então; Z = K.X com Kqq sendo a matriz de combinações lineares. Logo a esperança de Z é dada por:
E(Z) = E(K.X) = K.E(X)
A covariância é dada por
Cov(Z) = Cov(K.X) = K.Cov(X).K' = K.EX .K'
Assim a variância de CPi é V(CPi) = V(Ki'.X) = Ki
'.ΣKi e a covariância é expressa como Cov(CPi , CPk) = Cov(CP) = Cov(K.X) = K∑ K'
Segundo Anderson e Morrison (1958; 1976 apud LOPES, 2001), os componentes
principais são combinações lineares não-correlacionadas 1CP , 2CP ,..., pCP cujas variâncias são
tão grandes quanto possível. Assim, pode-se afirmar as seguintes proposições:
1- O primeiro componente principal é a combinação linear com variância máxima, isto
é, a combinação linear K1'.X que maximiza V(K1
'.X), sujeito a restrição K1'. K1 = 1,
no qual K1 é de comprimento unitário para evitar uma indeterminação;
2- O segundo componente principal é a combinação linear K2'.C que maximiza
V(K2'.C), sujeito a restrição K2
'.K2 = 1;
3- No i-ésimo passo, o i-ésimo componente principal é a combinação linear Ki'.X que
maximiza V(Ki'.X) sujeito a Ki
'.Ki = 1 e Cov(CPi, CPi ) = 0;
(15)
(16)
(17)
(18)
(19)
(20)

41
4- Em todos os casos Cov (Ki'.X.Kj
'.X) = 0; j < i.
As restrições acima garantem que o sistema tenha solução única e que os componentes
principais sejam não-correlacionados e apresentem variâncias decrescentes.
3.6 SELEÇÃO DO NÚMERO DE COMPONENTES PRINCIPAIS
Seja Σ a matriz de covariâncias associada ao vetor aleatório X' = [X1, X2,...,Xp], cujo Σ
tem os pares de (autovalores/autovetores) (λ1, ℓ1), (λ2 ℓ2),...,(λp, ℓp), no qual λ1 > λ2 > ...> λp >
0, o i-ésimo componente principal é dado por
CPi = ℓ1'X = ℓ1iX1 + ℓ2iX2 +...+ ℓpiXp , i=1,2,...,p
com
V(CPi) = ℓ'i Σ ℓi = λi, , i=1,2,..p
e
Cov(CPi , CPj ) = ℓ'i Σℓj = 0, i≠ j
Se algum λi for igual ao outro, autovalores múltiplos, na escolha do correspondente
vetor de coeficientes ( ℓi, yi), haverá uma indeterminação.
Seja o vetor aleatório X' = [X1, X2,...,Xp] com matriz Z e covariância Σ que tem os
pares de (autovalores/autovetores) (λ1, ℓ1), (λ1, ℓ1), ..,(λp, ℓp), cujo λ1 > λ2 > ...> λp > 0.
Sejam CP1 = ℓ'1X, CP2 = ℓ'
2X,... CPp = ℓ'pX , os componentes principais, então
σ11 + σ12 +...+ σpp = ∑=
p
iXV11
)(
σ11 + σ12 +...+ σpp = 1λ + 2λ + ... + pλ
σ11 + σ12 +...+ σpp = ∑=
p
iCPV11
)(
Conforme Johnson e Wichern (1992), a variância total da população σ11 + σ12 +...+ σpp
é igual à soma dos autovalores 1λ + 2λ + ... + pλ da matriz Σ. Conseqüentemente, a proporção da
variância total explicada devido ao k-ésimo componente principal é p
kλλλ
λ+++ ...21
, k=1,2...p.
(22)
(21)
(23)
(24)

42
Deste modo, as variáveis com maior peso na combinação linear dos primeiros
componentes principais são as mais importantes sob o ponto de vista estatístico.
3.7 GERAÇÃO DOS COMPONENTES PRINCIPAIS VIA MATRIZ DE
CORRELAÇÃO
As componentes principais obtidas a partir da matriz de covariâncias são influenciadas
pelas variáveis de maior variância, sendo, portanto, de pouca utilidade nos casos em que exista
uma discrepância muito acentuada entre estas variâncias. A discrepância muitas vezes é causa
das diferenças nas unidades de medidas das variáveis.
Este problema pode ser amenizado se uma transformação for efetuada nos dados
originais, de modo a equilibrar os valores da variância ou colocar os dados numa mesma escala
de medida. Uma transformação comum é aquela em que cada variável é padronizada pela sua
média e desvio-padrão, sendo a técnica de componentes principais aplicada à matriz de
covariâncias das variáveis padronizadas. Este procedimento é equivalente a obterem-se as
componentes principais através da matriz de correlação r das variáveis originais. Como já
citado anteriormente por Beebe et al (1998 apud RIBEIRO, 2001), este método de
padronização das variáveis denomina-se Auto-escalonamento.
Seja
pp
ppp
xZxZxZ
σµ
σµ
σµ −
=−
=−
= ,,,22
222
11
111 Λ
que em uma notação matricial é:
( )µ−
=
−
XVZ .
1
21
onde,
(25)
(26)

43
=
pp
V
σ
σ
σ
00
00
00
22
11
21
ΜΜΜ
sendo E(Z) = 0 e também é fácil de verificar que
Σ=21
21
VV ρ
é a matriz de covariâncias e, 1
211
21 −−
Σ
= VVρ
é a matriz de correlação. Então, ′
−
=
−− 1
211
21
)cov()cov( VXVZ µ
Logo,
ρ=
′
Σ
=
−− 1
211
21
)cov( VVZ
sendo Σ a matriz de covariâncias de X, e ρ sendo a matriz de correlação de X. Os componentes
principais Z podem ser obtidos pelo par de autovalores e autovetores da matriz Ζ de correlação
de X.
Tem-se que o i-ésimo componente principal das variáveis padronizadas Z' = [Z1, Z2,...,Zp] com
cov(Z') = ρ é dado por:
Yi = ℓi'Z = ℓi
'﴾ V½ ﴿-1 ﴾X − µ﴿
com
ρ=Σ=Σ==
)()(11
i
p
ii
p
iZVCPV
e
(27)
(28)
(29)
(30)
(31)
(32)
(33)

44
ijiZCP jiλρ λ=,
Neste caso (λ1, ℓ1), (λ1, ℓ1), ..,(λp, ℓp) são pares de autovalores e autovetores obtidos de ρ
com λ1 > λ2 > ...> λp > 0.
Assim, pelo exposto, pode-se ver que a proporção da variância populacional
padronizada devido ao j-ésimo componente principal é dada por:
pjp
j ,...,2,1, =λ
onde os λk's são os autovalores de ρ.
Mingoti (2005) ressalta que não ocorrem diferenças significativas nas primeiras
componentes principais entre os métodos de extração pela matriz de covariâncias e matriz de
correlação havendo inclusive consistência, principalmente no tratamento de variáveis com
baixa variância.
Johnson e Wichern (1992) concluem que os componentes principais derivados da
matriz de covariância Σ são diferentes daqueles derivados da matriz de correlação ρ. Além
disto, num conjunto de componentes principais, os componentes não são em função
simplesmente um do outro. Isto sugere que a padronização ou auto-escalonamento não é
incoerente. As variáveis devem ser padronizadas, se elas estão em escalas de medidas
diferentes ou se as unidades de medidas não são a mesma (LOPES, 2001).
3.8 CRITÉRIOS PARA DETERMINAÇÃO DO NÚMERO “K” DE
COMPONENTES PRINCIPAIS
Quando o objetivo é a redução da dimensionalidade do espaço amostral, isto é, a
sumarização da informação das “p” variáveis originais em “k” componentes principais, k<p, é
necessário estabelecer-se critérios de escolha para o valor de componentes, que deverão ser
mantidas no sistema. A seguir, serão apresentados três procedimentos que podem ser
utilizados, sendo dois puramente matemáticos e um terceiro que alia o ponto de vista prático.
(34)
(35)

45
3.8.1 Análise de representatividade em relação à variância total
Sob este critério, deve-se manter no sistema um número de componentes “k” que
conjuntamente representem um percentual γ da variância total que poderá ser pré-determinado
pelo pesquisador. Portanto, na prática, busca-se o valor “k” tal que:
γλ
λ=
Σ
Σ
=
=
jp
j
ik
i^
1
^
1
onde os λ's são os autovalores do sistema.
Não há um limite definido para o valor γ e sua escolha deverá ser feita de acordo com a
natureza do fenômeno investigado. Em algumas situações, é possível obter-se um percentual
de explicação de variância total acima de 90% ou 95% com 1 ou 2 componentes, enquanto que
em outras, é necessário um número muito maior.
A utilidade prática das componentes decresce com o crescimento do número de
componentes necessárias para se chegar ao valor escolhido γ, uma vez que quanto maior o
número de componentes, maior será a dificuldade de interpretação das mesmas. Assim sendo,
em alguns casos torna-se necessário trabalhar com percentuais de explicação abaixo de 90%.
Em geral, quando as componentes principais são extraídas da matriz de correlação,
necessita-se de um número maior de componentes para se alcançar o valor de γ, em
comparação com o número requerido quando as componentes são extraídas da matriz de
covariâncias (MINGOTI, 2005).
No mesmo raciocínio, quando a matriz de correlação é utilizada para a extração das
componentes principais, a variância total é igual ao número de variáveis originais “p”. Assim,
um critério que é utilizado para a escolha das “k” componentes é o de manter no sistema
apenas as componentes relacionadas àqueles autovalores 1^
≥iλ , ou seja, mantêm-se as
combinações lineares que conseguem explicar pelo menos a quantidade de variância de uma
variável padronizada. Este procedimento é conhecido como critério de Kaiser (1958).
Similarmente, quando a análise é feita com a matriz de covariâncias, podem-se manter no
sistema as componentes relacionadas aos autovalores que são maiores ou iguais a ^mλ ,
definido por:
(36)

46
n
jn
jm
^
1^ λλ
Σ==
E que representa a variância média das variáveis originais iX , i=1,2,...,n.
Johnson e Wichern (1992) também recomenda, como regra geral, reter aqueles
componentes principais com variância maior que a unidade ou equivalentemente somente
componentes que individualmente expliquem no mínimo a proporção 1/k da variância total,
sendo “k” o número de componentes principais.
Cattel (1966 apud TINN, 2002) sugere um gráfico denominado scree-plot (Figura 4)
que compara os autovalores estimados com os componentes principais. Basta apenas observar
no gráfico o ponto em que os valores de i
^
λ tendem a se estabilizar, pois esse é ponto a partir
do qual os autovalores i
^
λ se aproximam de zero. Segundo o mesmo autor o ideal é que sejam
necessário apenas duas componentes para se avaliar o conjunto de dados amostrais de um
sistema.
0
2
4
6
8
10
12
1 2 3 4 5 6 7 8 9 10
Número de Autovalores
Aut
oval
ores
Est
imad
os
Figura 4 – Gráfico scree-plot dos autovalores Fonte: Tinn (2002).
3.8.2 Análise da qualidade de aproximação da matriz de covariâncias ou correlação
Quando as componentes são extraídas das matrizes de covariâncias ou de correlação
amostrais, tem-se as seguintes aproximações para as matrizes Σpxp e rpxp, respectivamente:
(37)

47
'^^^
1iii
k
ipxp eeλΣ
=≈Σ
'^^^
1r iii
k
ipxp eeλΣ
=≈
Onde em cada caso, ( i
^
λ , ie^
) representam os respectivos autovalores e autovetores de Σpxp e
rpxp.
Assim, o valor “k” poderia ser escolhido de modo a se ter uma aproximação razoável
para as matrizes Σpxp e rpxp. As parcelas que mais contribuem para a aproximação dessas
matrizes são as correspondentes aos autovalores significativamente maiores que zero. Logo, as
componentes associadas a autovalores pequenos ou próximos a zero poderiam ser eliminadas.
É preciso ser cauteloso na análise da qualidade da aproximação, uma vez que um grau de
exigência elevado está geralmente relacionado com um valor elevado de “k”, o que não é o
desejado.
3.8.3 Análise prática das componentes
Para que as componentes possam ser utilizadas adequadamente o mais indicado é que
sejam passíveis de interpretação. A escolha do valor “k” pode ser pautada pela natureza
prática das componentes encontradas. A situação ideal é aquela em que as componentes
principais de maior interesse do pesquisador são as de maior explicação relativa à da variância
total e levam a um valor pequeno de “k”, mas isto nem sempre ocorre, obrigando ao
pesquisador a eleger uma componente de autovalor de menor peso ou equivalentemente à
variância de menor valor (MINGOTI, 2005).
3.9 ANÁLISES ESTATÍSTICAS ASSOCIADAS À ACP
Os testes estatísticos associados a um modelo utilizando a análise multivariada de
componentes principais são necessários, pois além de auxiliar nas análises estatísticas,
minimizam o risco de invalidação da pesquisa ou de se fazer conclusões equivocadas.
Destacam-se:
a) Análise dos autovalores ou variância dos componentes principais: permitem verificar a porcentagem da variância total que é explicada por cada um dos componentes principais;
(38)
(39)

48
b) Análise dos autovetores correspondentes (“loadinds”) de cada um dos autovalores: permitem identificar em cada um dos componentes principais, quais variáveis têm maior ou menor influência na composição do componente principal;
c) Análise de carga ou correlação de cada componente principal e as variáveis do problema: permite verificar o grau de associação de cada variável do problema nos componentes principais;
d) Análise dos “scores” ou componentes para cada amostra: permite ordenar os elementos amostrais observados com o intuito de identificar aqueles com maiores ou menores valores globais das componentes;
e) Análise de regressão múltipla: permite simplificar a análise, utilizando os “scores” como variável resposta. Neste caso, deve-se primeiramente validar a aplicação do modelo de regressão pelos testes usuais, como por exemplo, a análise de resíduos;
f) Teste de Adequacidade (teste KMO): comparam a magnitude dos coeficientes de correlação simples observados em relação a magnitude dos coeficientes de correlação parcial. Valores KMO entre 0.5 e 1, análise apropriada. Valores KMO inferiores a 0.5, análise inadequada (SILVA, 2005).
g) Teste de Esfericidade de Bartlet: examina a hipótese de que as variáveis não sejam correlacionadas à população;
h) Análise de Comunalidades: porção da variância que uma variável compartilha com todas as outras variáveis consideradas. Ou seja, representa a proporção da variável explicada por fatores comuns;
i) Análise de Resíduos: verifica-se a diferença entre as correlações observadas e as reproduzidas.
j) Teste “t-student”: no caso de padronização das variáveis, verifica-se o p-value da matriz de correlação para se verificar o grau de aproximação ou distanciamento dos elementos amostrais da população. Neste caso, deve-se validar a aplicação do teste “t” verificando as condições das variáveis amostrais, como por exemplo, a suposição de normalidade.
3.10 LIMITAÇÕES DA ACP
Embora a análise de componentes principais seja extensamente utilizada, existem
limitações em relação ao seu uso quando o objetivo é a mera ordenação dos dados amostrais.
Segundo Mingoti (2005), isto se explica porque, em geral, nenhuma medida de
variabilidade que possa traduzir a confiabilidade da classificação final é calculada. A
ordenação é feita levando-se em consideração puramente o valor numérico dos “scores” dos
componentes. Assim, dois elementos amostrais podem ter “scores” muito próximos, mas
ficarem em posições diferentes.

49
Medidas de variabilidade poderiam ser construídas através da metodologia de
reamostragem, como sugerido por Efron e Tibshirni (1993 apud MINGOTI, 2005). Caso o
usuário disponha de uma amostra de tamanho grande, ele poderia tentar validar a solução de
componentes obtida através da divisão da amostra original em dois conjuntos de dados
disjuntos e da aplicação da técnica ACP a cada um dos conjuntos separadamente. Ao final,
comparar-se-ia as duas soluções verificando-se elas se assemelham.
Ainda segundo Mingoti (2005), outra crítica vem do fato de que as componentes
principais se alteram quando transformações são efetuadas nos dados originais, o que,
consequentemente altera a classificação final dos elementos da amostra.
A autora também analisou a extração dos componentes via matriz de covariância e via
matriz de correlação (variável normalizada) de dados relativos de 12 empresas considerando
três variáveis: ganho bruto, ganho líquido e patrimônio num determinado período. Observou-se
que as componentes decompostas pela matriz de correlação apresentaram coeficientes de
ponderação numericamente mais equilibrados que aqueles obtidos quando da decomposição de
matriz de covariâncias amostral. Com a padronização das variáveis, todas ficaram com
variância igual a um, não havendo dominância direta de nenhuma delas. A única fonte
contribuindo para diferença entre os coeficientes é a correlação entre as variáveis. A
porcentagem de explicação pela matriz de covariância foi mais concentrada na primeira
componente, ao contrário do que ocorreu com a matriz de correlação, na qual a concentração é
menor e, portanto, houve uma melhor distribuição da explicação para as outras duas
componentes. As duas análises foram concordantes na indicação das três primeiras empresas
com melhor desempenho global e na empresa com pior desempenho. No entanto, as análises
discordaram em algumas posições, no que se referiram as empresas com desempenhos
moderados. A proporção total de concordância foi de apenas 41,7%, pois se obteve 5
concordância em 12 classificações. Em resumo, a diferença se deveu ao fato de que na análise
pela matriz de correlação, a primeira componente forneceu uma indicação da posição relativa
da empresa em relação às demais, levando-se em conta a média do conjunto de 12 empresas
em cada variável original, o mesmo não ocorrendo na solução obtida pela matriz de
covariância amostral.
Mesmo após estas ponderações, a análise de componentes principais se apresenta como
uma excelente técnica exploratória de dados multivariados, podendo ser utilizada em conjunto
com outras técnicas como análise fatorial, análise de agrupamentos e análise discriminante.

CAPÍTULO 4 - ANÁLISE DE CONFIABILIDADE
4.1 INTRODUÇÃO
Em várias situações de ordem prática, nossa atitude quanto à manutenção de um
equipamento, tanto no ponto de vista econômico quanto no operacional é determinada pela
durabilidade dos componentes utilizados na produção do bem ou serviço. Desta forma, a
confiabilidade está associada com a operação de um produto ou equipamento com sucesso, ou
seja, que este execute as funções para o qual foi projetado, preferencialmente com ausência de
paradas para manutenção ou falhas.
O assunto confiabilidade nas indústrias em geral, ainda se encontra em um estágio
bastante embrionário, pouco entendido e tratado com elevado grau de empirismo, misticismo e
dúvidas, constituindo-se numa verdadeira “caixa preta” (CASTRO, 1998 apud BARROS
FILHO, 2003, p. 34).
A maioria das plantas industriais não possui de forma estruturada uma função de
Engenharia de Confiabilidade e nem programas que tratem do assunto de uma maneira
sistemática. E é de conhecimento que a grande maioria dos problemas relacionados com
confiabilidade não pode ser atribuída exclusivamente à função Manutenção.
Kelly (1997 apud BARROS FILHO, 2003) comenta que estudos e levantamentos
realizados em um grande número de indústrias têm mostrado que a função manutenção é
responsável por somente cerca de 20% dos problemas de confiabilidade dos equipamentos.
Como mostrado na Tabela 1 mesmo na condição ideal de que a manutenção fizesse tudo de
maneira correta, ainda assim 80% dos problemas relativos a confiabilidade, ficariam
dependentes das outras funções.
Tabela 1 -- Impacto na confiabilidade dos equipamentos
ORIGEM PORCENTAGEM (%) Produção (Operação) 39 Manutenção 18 Planejamento e Controle de Produção (PCP) 15 Engenharia de Fábrica 12 Compras 11 Vendas e Marketing 5
Fonte: Adaptado de Kelly (1997 apud BARROS FILHO, 2003).

51
Com raríssimas exceções, a indústria como um todo e a grande maioria dos
profissionais ainda não atentaram para essa realidade. Dessa forma, enquanto os programas de
confiabilidade continuar a serem direcionados e focados exclusivamente na função
manutenção, os seus resultados, na melhor das hipóteses, serão de alcance muito limitados.
A confiabilidade deve ser considerada no planejamento estratégico da organização, podendo a mesma ser aplicada nas áreas de pesquisa e desenvolvimento (engenharia), nas áreas de operação e manutenção e respectivas áreas de planejamento, nas áreas de marketing e compras/vendas e na de pós-vendas. (KELLY, 1997 apud BARROS FILHO, 2003)
Segundo Lafraia (2001 apud HAVIARAS, 2005, p.23) para uma adequada análise de
confiabilidade devem ser considerados os seguintes aspectos:
a) definição das funções para os quais o produto foi projetado;
b) definição do que se entende por desempenho satisfatório (especificação de
desempenho, definição de falha, etc.,);
c) definição das condições de operação (temperatura, vibração, etc,);
d) definição do período de tempo durante o qual o produto ou equipamento deve
funcionar bem (isto é, número de horas, ciclos, etc.).
4.2 ORIGEM, DEFINIÇÃO E CLASSIFICAÇÃO DAS FALHAS
O problema com relação a especificar critérios de falha é que normalmente a
classificação é muito subjetiva, diferentes usuários podem ter expectativas diferentes com
relação ao desempenho do produto. Também pode haver uma diversidade entre usuário e
fabricante em relação ao que é exatamente um desempenho degradado ou falha (BLASHE,
1994 apud VOLLERTT, 1996).
Os métodos de análise de confiabilidade envolvem o tempo que está intimamente
relacionado à falha. Portanto, o primeiro passo é definir precisamente o que é uma falha, ou
seja, quando é que o equipamento deixa de funcionar corretamente (LOPES, 2001).
A análise do comportamento da taxa de falha de um equipamento por um longo
período de tempo pode ser representada por uma curva que possuí a forma de uma banheira.
Por isto, conhecida como Curva da Banheira.
Segundo Castro (2003, p. 18), há três regiões distintas nesta curva.

52
Figura 5 – Curva da Banheira
Região I: corresponde as falhas no início de funcionamento, que surgem devido a
problemas no uso inicial dos equipamentos. Esta fase é conhecida como falhas de juventude.
Região II: representa o tempo de vida útil do componente. Neste período, as falhas
ocorrem de forma aleatória. A taxa de falha constante é uma característica de componentes
eletrônicos;
Região III: caracteriza os processos de fadiga de material e degradação, típicos de
equipamentos mecânicos. Esta fase é conhecida como falhas da velhice ou envelhecimento.
Segundo Lafraia (2001 apud HAVIARAS, 2005, p.29), a Tabela 2 mostra as principais
causas de falhas conforme as etapas da Curva da Banheira.

53
Tabela 2 – Causas de falhas nas fases da Curva da Banheira
Fase da Juventude Fase de vida útil Fase do Envelhecimento Processos de fabricação deficientes
Interferência indevida Envelhecimento
Controle de qualidade deficiente
Fator de Segurança Insuficiente Desgaste/abrasão
Mão-de-obra desqualificada Cargas Aleatórias maiores que as esperadas
Degradação de resistência
Amaciamento insuficiente Resistência menor que a esperada Fadiga Depuração insuficiente Defeitos abaixo do limite de
sensibilidade dos ensaios Fluência
Materiais fora de especificação
Aplicação indevida Deteriorização mecânica, elétrica, química ou hidráulica
Componentes não especificados
Abusos Manutenção insuficiente ou deficiente
Componentes não testados Falhas não detectáveis pelo melhor programa de MP
Vida de projeto muito curta
Componentes que falham devido estocagem e transporte indevido
Falhas não detectáveis durante o melhor debugging
Sobrecarga no primeiro teste Causa inexplicáveis Contaminação Fenômenos naturais imprevistos Erro humano Instalação imprópria
Fonte: Lafraia (2001 apud Haviaras, 2005, p.29)
Um critério de classificação dos tipos de falhas proposto por Blashe (1994 apud
VOLLERTT, 1996, p.9) é mostrado na Figura 6.
Figura 6 – Método de classificação das falhas Fonte: Blashe (1994 apud VOLLERTT, 1996, p.9).

54
A definição de cada tipo de falha é descrita abaixo:
Falha Intermitente: falha que resulta na falta de alguma função do produto, apenas
por um curto período de tempo. O componente volta completamente ao seu estado funcional
imediatamente após a falha.
Falha Extendida: falha que resulta em uma falta de algumas funções, e que
continuarão até que as partes falhadas sejam substituídas ou reparadas. Falhas extendidas se
dividem em dois tipos:
Falha Completa: falha que causa uma falta completa de uma função exigida.
Falha Parcial: falha que conduz a uma falta de algumas funções, mas não como a
falha completa, pois pode-se utilizar redundâncias para contornar oproblema até
que a falha seja corrigida.
Ambas as falhas completa e parcial ainda podem ser classificadas de acordo com a
rapidez com que acontece a falha:
Falha Súbita: falhas que não poderiam ser prevenidas através de testes e inspeção.
Falha Gradual: falha que poderia ser prevista através de teste e inspeção.
As falhas ainda podem ser combinadas conforme a seguinte classificação:
Falhas Catastróficas: falhas que são ambas Súbita e Completa.
Falha de Degradação: falhas que são ambas Parcial e Gradual
4.3 TÉCNICAS DE ANÁLISES DE CONFIABILIDADE
Para garantir a confiabilidade de um equipamento deve-se primeiramente saber se
existem dados para análise estatística ou não. Quando há dados estatísticos disponíveis, ou
seja, quando há um histórico de falhas, com dados suficientes para determinar a confiabilidade,
pode-se usar um dos dois caminhos: métodos para medir e prever falha; métodos para
acomodar falhas. Se não existir dados estatísticos, recomenda-se utilizar os métodos para
prevenir falhas (DIAS, 1996).
Os métodos para medir e prever falhas são adequados para estimativas de falhas no
tempo através de representações analíticas. Esse enfoque, normalmente, se concentra em
estudar cada componente que constitui o sistema, processando as informações através de
distribuições de probabilidade, determinando parâmetros como taxa de falha e tempo médio
entre falha.

55
Os métodos para acomodar falhas apresentam um enfoque intermediário entre os
métodos para medir e prever falhas e os métodos para prevenir as falhas. São assim
caracterizados por que, em princípio, admite-se a ocorrência das falhas de alguns itens, mas
procura-se diminuir o efeito dos mesmos sobre a função. Nesse caso é recomendável utilizar
algumas ferramentas ou processos de análise como: modelos confiabilísticos, critérios de
redundância, análise dos modos de falhas e efeitos (FMEA - Failure Mode Effects Analysis),
árvore de falha (FTA - Fault Tree Analysis) (DIAS, 1996, p.7).
Os métodos para prevenir falhas são utilizados quando não existem dados estatísticos.
Nesse método várias ações podem ser necessárias para garantir confiabilidade do equipamento.
Em nível de sistema, deve-se utilizar ferramentas de análise que identifiquem o caminho
crítico da falha como; relações causa-efeito e diagrama de Ishikawa. Para utilizar os métodos
para prevenir a falha é recomendável conhecer todos os itens do sistema, o ambiente de
operação, a função de cada item no sistema de forma a identificar os possíveis modos e
mecanismos de falha.
A seguir serão apresentados as 4 principais técnicas utilizadas em análises de
confiabilidade, a saber: Análise do Modo e Efeito de Falha; Análise de Árvore de Falhas,
Teste de Vida Acelerados e Análise de Tempos de Falha.
4.3.1 Análise do Modo e Efeito da Falha – FMEA (Failure Mode and Effects Analysis)
Esta análise começou a ser utilizada no final dos anos 50 e tem como finalidade a
análise crítica de projetos de produtos e processo. O objetivo de um FMEA é identificar todos
os modos de falha em potencial dentro de um projeto (de produto ou processo), todas as
probabilidades de falhas catastróficas e críticas de tal maneira que elas possam ser eliminadas
ou minimizadas através da correção do projeto, o mais cedo possível (FREITAS; COLOSIMO,
1997, p.32).
A FMEA tem as seguintes características gerais:
a) Pode ser implementada tanto para o projeto de um produto como de um processo;
b) Tem como ponto de partida a definição precisa da função do componente ou da
etapa do processo;
c) Relaciona os tipos (modos) de falha com os efeitos, as causas do tipo de falha, os
rsicos de ocorrerem falhas e os mecanismos atuais para prevenção da ocorrência;

56
d) Na análise de cada tipo (modo) de falha em potencial no tempo, assume-se que todas
as demais características estão conforme especificado no projeto. Consequentemente, a FMEA
é restrita à consideração de falhas simultâneas no produto (ou processo), não fornecendo
elementos para a quantificação da confiabilidade do produto ou processo.
Algumas críticas, feitas por praticantes, quanto ao método FMEA são:
o tempo e o custo para aplicar o método são grandes;
a técnica é percebida como difícil, demorada e monótona;
o tempo para conduzir a análise é insuficiente;
há uma falta de incentivo da gerência para aplicar o método.
4.3.2 Árvore de Falhas – FTA (Fault Tree Analysis)
Segundo Hellman e Andery (1995 apud VOLLERTT, 1996), a FTA é um método
sistemático e padronizado, capaz de fornecer bases objetivas para funções diversas tais como
análise de modos comuns de falhas em sistemas, justificação de alterações em sistemas, e
demonstração de atendimentos a requisitos regulamentares ou contratuais. É uma
representação gráfica, associada ao desenvolvimento de uma falha particular do sistema
(efeito), chamada de evento de topo (top event), e às falhas básicas (causas), denominadas de
eventos principais (primary events). Os benefícios de uma árvore de falha segundo Henley e
Kumamoto (1981 apud VOLLERTT, 1996, p.26), são:
- auxiliar a identificação dos modos de falha;
- pontuar os aspectos importantes do sistema para a falha de interesse;
- fornecer auxílio gráfico para dar visibilidade às mudanças necessárias;
- fornecer opções para análise de confiabilidade quantitativa e qualitativa;
- permitir ao analista se concentrar em uma falha do sistema por vez.

57
A estrutura para aplicar uma árvore de falhas é mostrada na Figura 7.
Encontrar o evento de topo do sistema
Identificar a sequência de eventos do sistema que levaria o sistema a
falhar
Verificar a sequência de eventos que poderia causar uma falha ou acidente são construídas por símbolos lógicos ou “gates”
Figura 7 – Estrutura para desenvolver uma árvore de falha Fonte: Henley e Kumamoto (1981 apud VOLLERTT, 1996, p. 27)
4.3.3 Testes de Vida Acelerados
Uma forma utilizada para obter dados de falha em condições mais severas e extrapolá-
la para as condições de uso nominal é o que se denomina testes de vida acelerados. Em
termos práticos, isto significa que as informações referentes à confiabilidade dos produtos
necessitam ser obtidas em um curto período de tempo para que possam ser utilizadas em novos
projetos e na melhoria dos já existentes. Em geral, as informações obtidas sob altos níveis de
estresse (ex: taxa de uso, temperatura, voltagem) é extrapolada através de um modelo
estatístico-físico razoável para se conseguir estimativas, por exemplo, do tempo médio ou
mediano de vida nas condições de uso.
Os testes acelerados podem ser divididos em dois tipos:
a) Testes de vida acelerados: são aqueles onde a resposta de interesse é o tempo até a
ocorrência da falha.
b) Testes de degradação acelerados: quando a resposta de interesse é alguma medida
de performance do produto ou componente, por ex:, resistência à tração, oxidação, obtida ao
longo do tempo.

58
4.3.4 Análise de Tempos de Falha
De maneira geral, a Análise de Tempos de Falhas é definida como o conjunto de
técnicas estatísticas para a análise de dados de durabilidade provenientes tanto de dados de
campo quanto de testes de vida. A Análise de Tempos de Falhas se propõe a estimar com base
nestas duas fontes de informações, quantidades de interesse como, por exemplo, o tempo
médio até a falha e a taxa de falhas.
A Tabela 3 fornece resumidamente uma visão geral das técnicas clássicas descritas
anteriormente.
Tabela 3 – Visão geral das técnicas para Estudos de Confiabilidade
TÉCNICA FINALIDADE 1. Análise do Modo e Efeito de Falhas - FMEA (Failure Mode and Effect Analysis)
- Identificação das falhas críticas em cada componente, suas causas e conseqüências no sistema e no produto como um todo. - Hierarquizar as falhas.
2. Análise de Árvore de Falhas – FTA (Fault-Tree Analysis)
- Verificação das possíveis causas primárias das falhas. - Elaboração de uma relação lógica entre falhas primárias e falha final do produto.
3. Testes de vida acelerados
- Acelerar o aparecimento de falhas em testes de vida realizados com produtos (ou componentes). Os resultados obtidos do teste conduzido em condições estressantes são utilizados pata estimar figuras de mérito nas condições de projeto.
4. Análise de tempos de falha
- Utiliza dados amostrais referentes a tempos de falha do produto (ou componentes) e os modela segundo algumas das distribuições estatísticas, como Weibull, Log-normal, etc. A distribuição que “melhor explicar ” o comportamento do tempo de falha do produto (ou componente) será utilizada para estimar percentis, frações de falhas, taxas de falhas, etc.
Fonte: Freitas e Colosimo (1997, p.32, 46, 65 ;149).
4.4 CONCEITOS BÁSICOS SOBRE CONFIABILIDADE
Segundo O’Connor (1988 apud VOLLERTT, 1996, p.7), Confiabilidade é o estudo
sobre as falhas que podem ocorrer com o produto ou componente durante o seu ciclo de vida,
ou seja, não é um simples cálculo da taxa de falha ou da probabilidade de um componente ou
sistema falhar, mas sim a procura, análise, avaliação e correção de todas as falhas que podem
ocorrer com o produto ou componente, em todo o seu ciclo de vida. Embora existam várias

59
definições sobre confiabilidade, a mais utilizada é: “confiabilidade é a probabilidade de que
um item desempenhe a sua função pretendida sem falhar, sob determinadas condições
especificadas e por um determinado período de tempo especificado”. Por exemplo, um
produto pode possuir uma confiabilidade de 99,9% durante algumas horas e em determinadas
condições como estar sob temperatura ambiente, pressão atmosférica, isento de poeiras e
umidade, baixas vibrações e com uso correto por parte do usuário. Mas, se qualquer uma
destas condições variarem, normalmente a confiabilidade também variará. Portanto
confiabilidade não é apenas a probabilidade de um item não falhar, mas também o estudo de
todos os fatores que contribuem para a ocorrência da falha.
O termo confiabilidade pode ser empregado nos vários ramos de atividades da ciência e
da engenharia. Em uma indústria todos os sistemas, do mais simples ao mais complexo, podem
se beneficiar com a implementação dos conceitos de avaliação da confiabilidade, nas diversas
fases de planejamento, desenvolvimento, projeto, operação, manutenção, marketing e vendas.
A engenharia da confiabilidade e todo o desenvolvimento da mesma constituem um importante
degrau na escalada da manufatura de classe mundial.
O grande problema que a Teoria da Confiabilidade deve encarar é a predição da
confiabilidade e a avaliação da mesma. A predição consiste na criação de modelos
matemáticos que permitem predizer a confiabilidade de um sistema, sugerir métodos para
melhorá-la, desenvolver princípios de projetos de sistemas e componentes, novos materiais e
tecnologias de processo. A avaliação da confiabilidade consiste na utilização de técnicas, que
permitem medir os valores reais de confiabilidade, verificar as predições efetuadas com base
nos modelos e controlar a manutenção de um nível exigido de confiabilidade.
A confiabilidade é também definida ou representada por uma expressão matemática. A expressão matemática é uma codificação, cujo objetivo é sintetizar um conjunto ou histórico de informações, num percentual, visando facilitar decisão de projeto e/ou gerencial. Evidentemente, muitas são as possibilidades de cálculo quando se dispõe de dados estatísticos, mas exige também um formalismo matemático para representá-la (DIAS, 1996, p. 3).
Haviaras (2005, p.23) define confiabilidade como a possibilidade de um componente,
equipamento, ou sistema executar sua função, sob condições de operação estabelecidas, por
um período de tempo específico, sem apresentar falhas.
Ou “a probabilidade de um produto desempenhar sua função prevista por um período
de tempo especificado e sob condições específicas” (DIAS, 1996, p.2).

60
Esta probabilidade usualmente representa a probabilidade de falha, obedecendo a
critérios bem definidos. Isto possibilita determinar a partir de que momento o produto ou
equipamento sob análise é considerado com desempenho abaixo daquele apontado como
aceitável.
A noção de confiabilidade de um equipamento está associada à sua capacidade de
funcionar de maneira satisfatória durante um período de tempo considerado longo o suficiente
para não comprometer a função a qual foi concebido. Percebe-se que neste contexto, o termo
capacidade soa um tanto abstrata. Consequentemente, para que se possa estabelecer metas
relacionadas a confiabilidade de qualquer equipamento é necessário encontrar uma maneira de
mensurar esta capacidade (ou equivalentemente, mensurar a sua confiabilidade ou taxa de
falhas).
A probabilidade de falha é o complementar da confiabilidade. Portanto, é definida
como sendo a probabilidade de que um dispositivo, ou sistema, falhe, ou deixe de
desempenhar suas funções de projeto, em um período temporal definido, sob certas condições
operacionais.
Sendo a confiabilidade, para um período de tempo t, representada pela função R(t), a
probabilidade de falha pela função F(t) é dada por:
F(t) = 1 – R(t)
4.5 FUNÇÕES FUNDAMENTAIS DA CONFIABILIDADE
Segundo Sotslov (1972 et al apud BARROS FILHO, 2003), as quatro principais
funções fundamentais, por estarem relacionadas com termos como probabilidade e o tempo,
que são as principais características para a análise da confiabilidade são: Função da
confiabilidade R(t), a função Probabilidade de falha F(t), a função densidade probabilidade de
falha f(t) e a função taxa de falha λ(t).
Dado um conjunto de condições operacionais, a confiabilidade de um componente ou
sistema é a probabilidade que o sistema não venha a falhar (sobreviva) durante um período
especificado de tempo. Isto pode ser expresso em termos de uma variável aleatória T (o tempo
decorrido até o sistema falhar).
(40)

61
A representação matemática do tempo de falha T é caracterizada por funções de
distribuições concentradas em R+ (reais não-negativos), correspondendo à hipótese de que o
tempo de vida é uma variável aleatória não-negativa (BORGES, 1979 apud LOPES, 2001).
A função densidade de probabilidade (fdp) ou do inglês pdf (probability density
function) representada por f(t), correspondente tem o seguinte significado: é a probabilidade
que a falha venha a ocorrer no tempo entre t e t + ∆t. A densidade de probabilidade de falha
f(t) é um poderoso instrumento de visualização de como ocorrem as falhas e como elas estão
estatisticamente distribuídas.
Segundo Pagés e Gondran (1980 apud BARROS FILHO, 2003), considerando:
=∆+≤≤ )( ttTtP ttf ∆).(
Seja a função de distribuição da variável aleatória T, a probabilidade que a falha venha
a ocorrer no tempo T ≤ t, denotada por:
)()( ttTPtF ∆+≤=
Definindo a função de confiabilidade R(t), como a probabilidade que o sistema não
venha a falhar num instante inferior a t, denotada por:
)()( tTPtR >=
Da definição de função de distribuição acumulada, tem-se:
∫−=t
dttftR0
)(1)(
As Figuras 8 e 9 ilustram as definições acima.
(41)
(42)
(43)
(44)
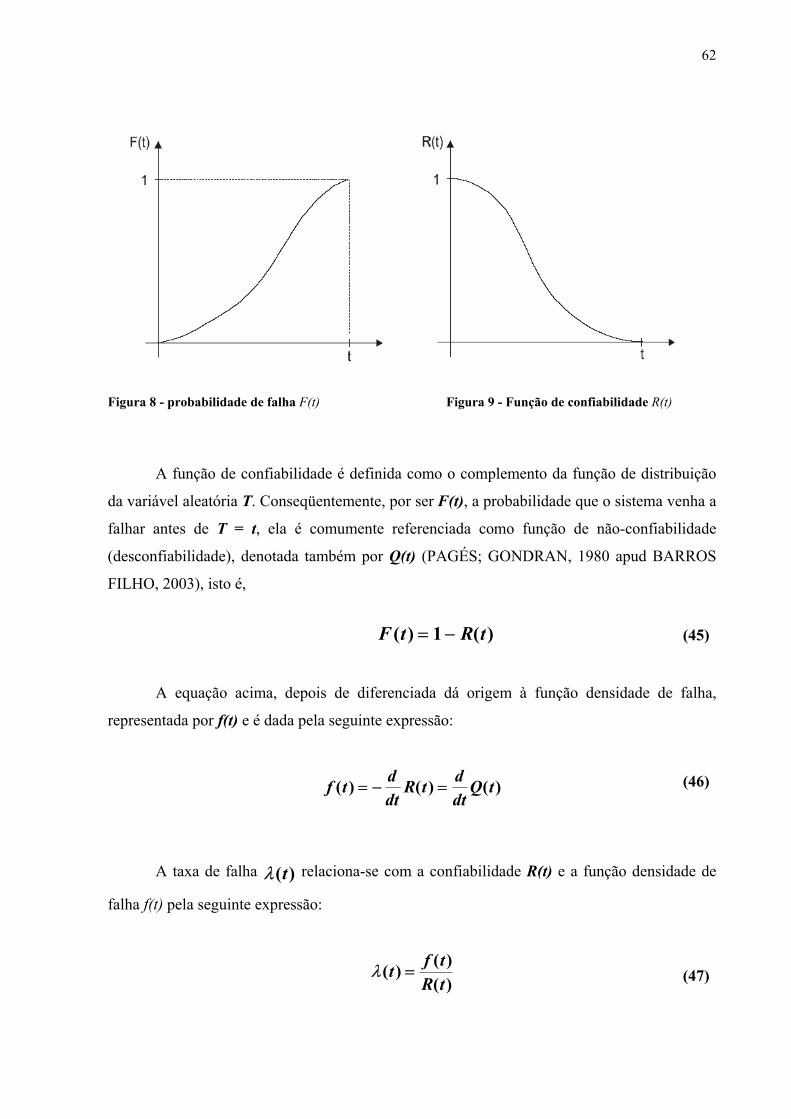
62
Figura 8 - probabilidade de falha F(t) Figura 9 - Função de confiabilidade R(t)
Figura 8 – Função probabilidade de falha F(t)
Figura 9 – Função de confiabilidade R(t)
A função de confiabilidade é definida como o complemento da função de distribuição
da variável aleatória T. Conseqüentemente, por ser F(t), a probabilidade que o sistema venha a
falhar antes de T = t, ela é comumente referenciada como função de não-confiabilidade
(desconfiabilidade), denotada também por Q(t) (PAGÉS; GONDRAN, 1980 apud BARROS
FILHO, 2003), isto é,
)(1)( tRtF −=
A equação acima, depois de diferenciada dá origem à função densidade de falha,
representada por f(t) e é dada pela seguinte expressão:
)()()( tQdtdtR
dtdtf =−=
A taxa de falha )(tλ relaciona-se com a confiabilidade R(t) e a função densidade de
falha f(t) pela seguinte expressão:
)()()(
tRtft =λ
(46)
(47)
(45)

63
Esta função em teoria da confiabilidade também é conhecida como função de risco ou
taxa de falhas instantânea.
Outro parâmetro muito usado na caracterização da confiabilidade é o tempo médio
entre falhas, do inglês Mean Time Between Failures (MTBF). Analiticamente, o tempo médio
entre falhas ou valor esperado de uma variável aleatória contínua T é dado por:
∫∞
=0
).( dttRMTBF
Esse parâmetro geralmente é utilizado para produtos reparáveis, medindo o tempo
médio decorrido entre falhas sucessivas.
4.6 TIPOS DE DADOS DE VIDA
Em algumas situações, há necessidade de realização de testes devido à
indisponibilidade de dados ou impossibilidade de obtenção dos mesmos pelos meios
mensuráveis. Por serem demorados, usualmente os testes são terminados antes que todos os
itens falharam ou os dados disponibilizados possuem informações incompletas ou parciais. São
chamadas de observações censuradas (LOPES, 2001).
Neste caso, quando ocorrem estas limitações, deve-se avaliar e adotar com cautela um
tratamento estatístico diferenciado e adequado para tais tipos de dados. Por exemplo, se não
houver censuras, pode-se usar para o tratamento estatístico as técnicas clássicas de estatística,
como análise de regressão e análise de variância. Se houver censuras, tais técnicas não poderão
ser utilizadas. Nestes casos, devem-se adotar técnicas estatísticas especiais que permitam
incorporar as informações parciais contidas nas observações censuradas (FREITAS;
COLOSIMO, 1997).
Mesmo que se tenham encontrado observações censuradas, todos os resultados
provenientes do teste devem ser utilizados na análise estatística. Existem duas razões que
justificam tal procedimento: a primeira é que os dados censurados também fornecem
informações sobre o tempo de vida do componente em questão; e a segunda é que com as
observações das censuras, pode-se obter o efeito da omissão das censuras no cálculo das
medidas de confiabilidade.
(48)

64
Como cada componente apresenta uma particular condição de teste, o procedimento de
análise deve considerar os seguintes tipos principais (PALLEROSI, 2000 apud BARROS
FILHO, 2003):
a) Tempo até falha (ou recolocação), sem suspensão (censura): todos os itens
completam o ensaio;
b) Tempo até falha (ou recolocação), com suspensão (censura à direita): nem todos os
itens completam o ensaio;
c) Tempo até falha (ou recolocação), com intervalos (intervalo e censura à esquerda):
os itens são inspecionados em dados intervalos, com itens falhos (ou recolocados) após a
última inspeção;
d) Tempo até falha (ou recolocação), com intervalos e suspensões (intervalo, censura à
esquerda ou à direita): os itens são inspecionados em dados intervalos, com itens falhos (ou
recolocados) após a última inspeção, com ocorrência também de itens com ou sem suspensões,
e censura múltipla.
Borges (1979 apud LOPES, 2001), classifica os mecanismos de censura em três tipos:
a) Censura Tipo I: é aquela cujo teste será terminado após um tempo pré-estabelecido;
b) Censura Tipo II: é aquela cujo teste será terminado quando certo número de
produtos pré-estabelecidos falharem;
c) Censura Tipo Aleatória: é a que ocorre quando, por força maior, tira-se um produto
do teste sem ter ocorrido uma falha. Geralmente esse tipo de censura está associada a outro
tipo de falha qualquer, fora daquelas que estavam sendo analisadas.
Na prática, o tratamento estatístico usado para os três tipos de censura é o mesmo, mas
existem algumas vantagens em usar um determinado tipo de censura, principalmente quando
tivermos informações históricas sobre o produto em estudo.
Outra forma de realizar um teste é utilizar uma amostra completa, ou seja, dados sem
censura, supondo que todos os elementos amostrais tenham falhado.
Para analisar o tempo de falha num conjunto de dados sem censura, em primeiro lugar
deve-se distribuir o tempo de falha em intervalos contínuos e, logo em seguida distribuir o
número de equipamento que falharam dentro de cada intervalo; assim teremos uma
distribuição do tempo de falha. Uma forma de representar um conjunto de dados sem censura é
através de um histograma ou um gráfico de barra, em que fica fácil visualizar os intervalos
com as suas respectivas falhas.

65
Quando ocorre censura, não se aconselha construir um histograma, pois não se sabe a
freqüência exata associada ao intervalo. Por esse motivo, é que existem técnicas paramétricas e
não-paramétricas para analisar dados de tempo de falha na presença de censuras (LEITCH,
1995 apud LOPES, 2001).
Em resumo, os tipos de dados de vida podem ser classificados como completos ou
censurados e os censurados podem ser censurados à direita, censurados em intervalos e
censurados à esquerda (BARROS FILHO, 2003).
4.7 MODELOS DE CONFIABILIDADE NÃO PARAMÉTRICOS
A análise de confiabilidade segundo (HAVIARAS, 2005, p. 35): [...] possibilita caracterizar através de estimativas, os comportamentos da confiabilidade, da probabilidade de falha e da taxa de falha em relação ao tempo de um componente, equipamento, ou sistema e podem ser classificadas em duas categorias: paramétrica e não paramétricas [...]
Independente de qual método de análise for eleito, o estudo deve ser realizado a partir
da coleta experimental do fenômeno estudado. Caso se prossiga com a análise utilizando
métodos estatísticos que permitam ajustar a distribuição que melhor representa a função de
densidade de probabilidade dos tempos de falha f(t), e respectivas funções de confiabilidade
R(t) e taxa de falha λ(t), o método denomina-se paramétrico. Quando estas funções são estimadas, mas sem a utilização de técnicas estatísticas de
ajuste de uma distribuição específica ao fenômeno de interesse, e a respectiva determinação de
seus parâmetros, esta análise é denominada não-paramétrica. Segundo Haviaras (2005),
diversos fatores podem influenciar na escolha de qual tipo de análise utilizar para a estimativa
da função confiabilidade R(t) e demais funções pertinentes em relação ao tempo. Mas é
recomendável iniciar o experimento realizando a análise não-paramétrica, já que a análise
paramétrica requer, normalmente, maior disponibilidade de tempo e recursos para sua
realização. Deste modo, a análise não-paramétrica fornecerá uma estimativa relativamente
rápida e de menor custo para as funções de interesse, com resultados bastante significativos e
muitas vezes suficientes para o objetivo que se deseja atingir.
Quando o objetivo do experimento é definir a variação temporal da confiabilidade de
um componente, equipamento ou produto ao longo de sua vida recomenda-se obter-se o
máximo de informações sobre o comportamento das unidades que compõem a amostra, e para

66
tanto é necessária a execução do ensaio até o instante em que ocorram as falhas em todas as
unidades empregadas no experimento. As análises não-paramétricas podem ser realizadas
considerando-se duas formas de coleta de dados: agrupada ou não-agrupada. Considerou-se na
análise corrente, testes completos de confiabilidade onde todos os componentes analisados
falharam.
Dodson (1994 apud BARROS FILHO, 2003, p.54) classifica os dados das amostras em
três tipos, conforme o arranjo dos itens a serem avaliados ou testados:
a) Não-agrupados (itens testados ou avaliados individualmente);
b) Agrupados (itens testados ou avaliados em grupos selecionados);
c) Na forma livre (dados admitidos).
No caso de dados agrupados, as quantidades de elementos que falharam estão
agrupadas em intervalos de tempo correspondentes e não há informação do exato instante em
que ocorreu a falha de um elemento específico, visto o teste considerar intervalos de tempo de
falha nos quais são registradas as quantidades respectivas de elementos que falharam em cada
um desses períodos. Já nos testes utilizando dados não agrupados, a partir da observação da
seqüência de falha dos elementos da amostra são obtidos os tempos de falha para cada um dos
seus componentes. Os dados admitidos na forma livre simplesmente são coletados sem
nenhuma restrição de procedimento.
4.8 MÉTODOS DE CONFIABILIDADE NÃO PARAMÉTRICOS
Tabelas de Vida
Estimador Kaplan-Meier
A tabela de vida ou método atuarial é uma das mais antigas técnicas estatísticas
utilizadas para estimar características associadas à distribuição dos tempos de falha. A sua
construção é simples e consiste em incorporar censuras no cálculo da função confiabilidade.

67
A construção de uma tabela de vida considera que existam “n” equipamentos (ou
componentes) sob teste e “k” falhas distintas nos pontos de corte t1 < t2 < ... < tk, para k < n,
dividido em k+1 intervalos e t0 = 0. Para cada um dos intervalos, estima-se a seguinte
probabilidade:
[ ) )/,( 11 −− ≥∈= iiii tTttTPq
Isto é, iq é a probabilidade de um item falhar no intervalo [ )ii tt ,1− sabendo-se que ele
não falhou até 1−it . A partir destes valores obtêm-se a função confiabilidade. Desta forma,
uma estimativa para iq no intervalo [ )ii tt ,1− pode ser escrita como:
[ )[ )( ) 2/,
,
11
1^
iio
io
iio
i ttemcensuradontemriscosobitensdenttemfalharamqueitensdenq
−−
−
−=
A explicação para o segundo termo do denominador da expressão acima é que produtos
ou equipamentos para os quais a censura ocorreu no intervalo [ )ii tt ,1− são tratados como se
estivessem sob risco durante a metade do intervalo considerado (FREITAS; COLOSIMO,
1997).
Pode-se observar que, dado que o item não falhou até 1−it , a sua probabilidade de
falhar no intervalo [ )ii tt ,1− é iq , e consequentemente a probabilidade de não falhar é 1- iq . A
função de confiabilidade é a probabilidade de um item não falhar até o tempo it , i=1,...,k. Isto
é dado em termos dos q`s como:
)1)...(1()( 1 ii qqtR −−=
Uma estimativa gráfica para a função de confiabilidade é uma escada, com valor
constante para cada intervalo de tempo. A função de confiabilidade estimada no primeiro
intervalo, [ )1,0 t , é naturalmente a unidade. A função de confiabilidade estimada no último
intervalo, [ )∞,kt , é zero se o maior tempo observado for uma falha, e não atingirá o zero se
for uma censura.
(49)
(50)
(51)

68
O segundo método, o estimador Kaplan-Meier ou limite-produto é mais difundido e
utilizado que o primeiro. O estimador de Kaplan-Meier nada mais é que uma função escada
com degraus dos tempos observados de falha.
Suponha que existam “n” equipamentos (ou componentes) sob teste e “k” falhas
distintas nos tempos t1 < t2 < ... < tk, para k < n, podendo ocorrer mais de uma falha num
mesmo tempo, ou seja, simultaneamente, o que é chamado de empate. Para solucionar esse
problema, admite-se que os tempos de censura ocorreram imediatamente após o tempo de
falha. Assim, tem-se que:
id : número de falhas no instante it ;
in : número de equipamentos sob risco, isto é, que não falharam e não foram
censurados no tempo i ( it ). Assim a função de confiabilidade é dada por:
−
−
−=
o
oo
t
tti n
dnn
dnn
dntR .....)(2
22
1
11
cujo ot é o maior tempo de falha menor que t .
A principal diferença entre os dois métodos está no número de intervalos usados para o
cálculo de cada um deles. O estimador de Kaplan-Meier é sempre baseado em um número de
intervalos igual ao número de tempos de falha distintos enquanto na tabela de vida os tempos
de falha são agrupados em intervalos de forma arbitrária. Isto faz com que a estimativa obtida
pelo estimador de Kaplan-Meier seja baseada frequentemente em um número de intervalos
maior que a obtida através da tabela de vida. O uso do estimador da tabela de vida não é
recomendável em conjunto de dados com poucas observações. Por outro lado, ajusta-se bem às
situações em que os tempos de falha exatos são desconhecidos, mas sabe-se que ocorreram em
certo intervalo de tempo.
Deste modo, o estimador de Kaplan-Meier torna-se mais eficiente, por ser um
estimador não-viciado para a função de confiabilidade, tanto para grandes como para pequenas
amostras (KAPLAN; MEIER, 1958 apud LOPES, 2001).
(52)

69
4.9 MODELOS DE CONFIABILIDADE PARAMÉTRICOS
Conforme já visto anteriormente a análise paramétrica utiliza distribuições estatísticas
para estimativa do tempo de falha e suas respectivas funções de confiabilidade e taxa de falhas.
Portanto, a utilização de estimadores paramétricos requer a estimação de parâmetros da
distribuição escolhida.
Por exemplo, os modelos probabilísticos de Weibull e Log-normal são caracterizados
por até três e dois parâmetros respectivamente. Há distribuições de probabilidade que exigem
um número maior de parâmetros para aderência de dados o que requer um maior esforço
matemático no tratamento estatístico da distribuição escolhida.
Uma vez escolhida a distribuição de probabilidade que melhor se ajustou ao
comportamento do tempo de falha do produto ou componentes, é possível estimar as medidas
de confiabilidade. Se a distribuição de probabilidade for corretamente especificada, as técnicas
paramétricas serão mais eficientes que as não-paramétricas. A essas distribuições de
probabilidade dá-se o nome de modelos probabilísticos para o tempo de falha (BORGES et al,
1996 apud LOPES, 2001).
Cavalca (1998 apud BARROS FILHO, 2003) ressalta que são várias as funções que
podem modelar a distribuição probabilística de uma variável aleatória. E que a escolha de um
modelo matemático estatístico a ser utilizado está diretamente relacionada aos tipos de testes
de falhas realizados, bem como ao tipo e tamanho de amostragem analisada.
Lipson e Sheth e Moras (1973; 2002 apud BARROS FILHO, 2003, p.45) apresentam
as principais aplicações práticas das distribuições mais utilizadas no estudo da Confiabilidade,
as quais se encontram resumidas na Tabela 4.

70
Tabela 4 – Principais distribuições de probabilidade utilizada em Confiabilidade e suas aplicações
DISTRIBUIÇÕES ESTATÍSTICAS APLICAÇÕES
Distribuição Binomial Aplicada para número elevado de amostras no controle de qualidade. Modela o número de falhas em relação ao tamanho inicial da amostra.
Distribuição de Poisson Aplicada no controle de qualidade e modela o número de falhas em relação ao tempo de produção.
Distribuição Exponencial Modela o número de falhas durante o período de vida útil de componentes eletrônicos.
Distribuição Retangular Aplicações restritas, caso em que a densidade é constante num intervalo de tempo.
Distribuição de Rayleigh
Modela as regiões da curva da banheira para o caso de falhas iniciais e por desgaste, por uma progressão linear.
Distribuição Normal Analisa produtos durante o início de vida e na fase de degradação natural. Modela falha por fadiga ou desgaste.
Distribuição de Weibull Modela falha aleatória.
Distribuição Gamma Modela tempo de falhas em componentes com reparo ideal.
Distribuição Lognormal Caracteriza o tempo de reparo para uma manutenção normal de falhas de desgaste.
Distribuição Beta Aplicações Especiais
Distribuição de Valores Extremos Normalmente utilizadas em situações em que o número de variáveis, dos quais os dados são obtidos, são muito grandes.
Fonte: Lipson e Sheth e Moras (1973; 2002 apud BARROS FILHO, 2003, p. 45).
Pallerosi (2000 apud BARROS FILHO, 2003, p.46), menciona os cinco tipos principais
de distribuições estatísticas utilizadas no estudo da confiabilidade, sendo as mesmas:
- Weibull (com 1,2 e 3 parâmetros);
- Weibull - Mista (Bi-Weibull, Tri-Weibull) ou Multimodal;
- Exponencial (com 1 ou 2 parâmetros);
- Lognormal (com 2 parâmetros);
- Normal (com 2 parâmetros).
4.9.1 Distribuição Normal
Utiliza-se a distribuição Normal tipicamente para representar erros de medição,
variabilidade dimensional e propriedades mecânicas de materiais. A função de densidade para
uma distribuição Normal é dada por:

71
+∞<<∞−
−−
∏= ∫
∞−TdTTTf
t
T
T
T
2
21exp
21)(
σµ
σ
A distribuição Normal é caracterizada por dois parâmetros: a média µ e o desvio-
padrão σ da população. Considerando as dificuldades envolvidas na integração na função
densidade de probabilidade, a função distribuição acumulada é dada em forma de tabela.
Buscando a padronização desta tabela, apresenta-se a função distribuição acumulada a partir da
denominada distribuição normal reduzida para o qual tem-se 0=t
µ e 1=t
σ . A distribuição
Normal reduzida é encontrada em tabelas de publicações diversas, relacionadas a conceitos de
probabilidade, estatística, controle de qualidade e confiabilidade, embora possa haver alguma
variação na forma de apresentação dos dados.
A distribuição é simétrica, centrada na média da população, sendo coincidentes os
valores da moda, mediana e média. Desta forma, 50% da distribuição encontram-se à direita da
média e, os outros 50%, à esquerda desse parâmetro. As caldas da distribuição são abertas em
ambas as extremidades, ou seja, para as situações em que as regiões de interesse para análise
de confiabilidade localizam-se próximas às caudas; qualquer variação nas condições dos dados
experimentais implica em alterações sensíveis de probabilidade, o que influencia sobremaneira
a análise de confiabilidade.
O achatamento da distribuição de probabilidade é determinado pela variância, sendo
que quanto maior este valor, maior será a dispersão da distribuição e mais achatada será a
curva da função densidade de probabilidade.
A Figura 10 ilustra uma função Normal para valores de desvio-padrão 0,2; 0,5 e 0,8.
f(t)
41 2 3 30
3
1
2
Des
d.p.=0,8
d.p.=0,5
d.p.=0,2
4
Figura 10 – Função densidade de probabilidade Normal para valores de desvio padrão 0,2; 0,5 e 0,8
(53)

72
4.9.2 Distribuição Log-normal
A distribuição Log-normal é muito utilizada para caracterizar tempo de vida de
equipamentos ou componentes. A função de densidade para uma distribuição Log-normal é
dada por:
[ ]
−
−
=22
2)ln(
21)( σ
µ
πσ
T
eT
Tf
sendo,
µ : a média do logaritmo do tempo de falha,
σ : o desvio-padrão no domínio logaritmo.
seguindo as mesmas condições de uma distribuição Normal. Os dados provenientes de uma
distribuição Log-normal podem ser analisados segundo uma distribuição Normal, trabalhando-
se com o logaritmo dos dados ao invés dos valores originais.
A distribuição Log-normal é a que melhor descreve os tempos de vida de componentes
semicondutores cujos mecanismos de falha envolvem interações químicas, como as
encontradas em processos de corrosão, acúmulo superficial de cargas elétricas e degradação de
contatos, sendo “a que melhor descreve dos mecanismos de falha por fadiga em materiais”
(HAVIARAS, 2005).
As principais aplicações da distribuição Log-normal correspondem a falhas em
rolamentos, motores e geradores, fadiga em metais, componentes do estado sólido
(semicondutores, diodos e outros), isolantes elétricos e resistências elétricas (LIPSON;
SHETH, 1973 apud BARROS FILHO, 2003). Esta distribuição possui as seguintes
características:
a) É assimétrica;
b) É bi-paramétrica, onde o valor médio (µ) corresponde ao parâmetro de escala e o
desvio-padrão (σ) ao parâmetro de forma.
A função Confiabilidade R(T) de uma distribuição Lognormal é dada por:
[ ]
∫∞
−
−
=)ln(
22
2)ln(
21)(
T
T
dTeT
TR σ
µ
πσ
(54)
(55)

73
ou, segundo Haviaras (2005),
[ ]{ }σµ /)ln()( −−Φ= TTR
sendo ( ).Φ , a função acumulada de uma distribuição Normal padrão, ou seja, de uma Normal
com média igual a zero e desvio-padrão igual a um.
A função taxa de falhas )(Tλ é dado por:
[ ]
[ ]
∫∞
−
−
−
−
=
)ln(
22
2)ln(
22
2)ln(
21
21
)(
T
T
T
dTeT
eTT
σ
µ
σ
µ
πσ
πσλ
O MTBF é dado por:
[ ]
∫∞
−
−
=0
22
2)ln(
21 dTe
TMTBF
T
σ
µ
πσ
A Figura 11 ilustra uma função Log-normal com µ = 1 e alguns valores de σ.
Figura 11 – Função densidade de probabilidade Log-normal para µ=1 e alguns valores de σ
(56)
(57)
(58)

74
4.9.3 Distribuição Weibull
A distribuição Weibull foi proposta por Weibull (1954) em estudos relacionados ao
tempo de falha devido à fadiga de metais. Ela é muito utilizada para descrever o tempo de
falha para produtos industrializados, pois é um tipo de distribuição com uma grande
variabilidade de formas. A função de densidade de probabilidade da distribuição de Weibull é
dada por:
γηγ
ηγβ β
β
β≥
−−
−=
−TTTTf ,exp)()(
1
sendo;
γ (gama): parâmetro de localização ou vida mínima 0 < γ < ∞
η (eta): parâmetro de escala ou vida característica 0 < η < ∞
β (beta): parâmetro de forma 0 < β < ∞
Vale salientar que se,
γ > 0 → produto ou equipamento recondicionado; ou,
γ < 0 → produto ou equipamento passível de falha antes de entrar em operação, ex.;
produtos perecíveis.
O parâmetro η permite obter informações relativas aos intervalos de tempo que em
média ocorrerão as falhas; sendo β o parâmetro mais importante, pois define a forma da
distribuição.
O modelo físico que ajusta a distribuição Weibull origina-se da teoria dos valores
extremos, mais especificamente as distribuições de Gumbell. Segundo Meyer (1982 apud
LOPES, 2001), a distribuição Weibull representa um modelo adequado para o estudo das leis
de falhas, sempre que o equipamento for composto de vários componentes, e a falha tenha
acontecido devido “à mais grave” irregularidade dentre muitas existentes no equipamento.
Esta distribuição é a mais representativa dentre todas as outras possíveis distribuições
utilizadas no estudo da Confiabilidade. Ela pode englobar, com suficiente precisão, a maioria
dos casos práticos. Isto é possível devido a influência do parâmetro de forma beta (β).
A distribuição geral Weibull apresenta as seguintes características:
a) Permite uma aplicação à maioria dos casos práticos, com boa precisão, motivo de
seu largo emprego;
(59)

75
b) A distribuição Exponencial resulta como um caso particular, e as do tipo Normal,
Log-normal, Rayleigh, ou do Valor Extremo, como uma razoável aproximação, suficiente em
grande número de aplicações práticas;
c) Permite caracterizar as falhas durante a juventude, vida útil e velhice (senilidade)
dos componentes;
d) Na sua forma simplificada (bi-paramétrica) resulta aplicável a muitos casos práticos,
por sua maior simplicidade e facilidade de entendimento;
e) Na sua forma tri-paramétrica permite a análise dos casos onde o início da operação
do produto não coincide com o início da análise, por exemplo, quando um componente
apresenta uma dada quantidade de horas trabalhadas antes do início do registro de falhas.
- Influência dos parâmetros de forma de Weibull nas principais Funções de
Confiabilidade
A distribuição Weibull é muito flexível e pode representar outras distribuições segundo
os valores do parâmetro de forma β. As Figuras 12, 13 e14 apresentam a influência deste
parâmetro variando de 0,5 a 5 nas funções densidade de probabilidade f(t), confiabilidade R(t)
e taxa de falhas λ(t) respectivamente.
Figura 12 – Influência do parâmetro β na função densidade de probabilidade de falha

76
Figura 13 – Influência do parâmetro β na função confiabilidade
Figura 14 – Influência do parâmetro β na função taxa de falha

77
4.9.4 Distribuição Exponencial mono e bi-paramétrica
É uma distribuição de probabilidade que se caracteriza por ter uma função de taxa de
falha constante. A forma geral da função de densidade para um tempo de falha T com dois
parâmetros é dada por:
( )γλλ −−= TeTf )( , γλ ≥>≥ TTf ,0,0)(
onde,
µλ 1=
sendo,
λ : taxa de falhas e, µ a média entre ou até a falha
γ : parâmetro de localização ou vida mínima
Quando γ é igual a zero, a distribuição torna-se monoparamétrica e toma a seguinte
forma: ( )TeTf λλ −=)( , 0,0)( >≥ λTf
A Figura 15 ilustra a função densidade de falhas monoparamétrica para alguns valores
de λ .
Figura 15 – Função densidade de falhas Exponencial monoparamétrica para alguns valores de λ
(60)
(61)

78
Por ser a função taxa de falha constante, uma unidade de amostra mais antiga que ainda
não falhou possui a mesma probabilidade de falhar em um intervalo futuro que uma unidade
amostral nova (HAVIARAS, 2005).
É um caso particular da distribuição de Weibull, com parâmetro de forma β = 1. Sua
grande aplicação prática ocorre nos sistemas com significativa quantidade de componentes em
série, caso típico de equipamentos eletrônicos, onde a taxa de falha do sistema é constante.
4.9.5 Distribuição Gamma bi-paramétrica
A função Gamma é uma distribuição muito usada para descrever variáveis aleatórias
limitadas à esquerda. Um sistema apresentará essa distribuição se a falha do mesmo associar-
se a ocorrência de “n” sub-falhas a uma taxa exponencial constante λ. A função de densidade
de probabilidade da distribuição Gamma é dada por:
0,0,)(
)(1
>≥Γ
=
−−
δαδα
αδ
δetettf
t
Defini-se α como um parâmetro de escala e δ um parâmetro de forma. Γ(x) representa a
função Gamma. Esta função é muito flexível, mudando sua forma de acordo com a variação de
δ. A Figura 16 ilustra a função Gamma para alguns valores de δ.
Figura 16– Função de densidade de probabilidade Gamma para alguns valores de δ
(62)

79
4.10 MÉTODOS DE ESTIMATIVAS DE PARÂMETROS
Os modelos probabilísticos são caracterizados por quantidades desconhecidas,
denominadas parâmetros. Estas quantidades conferem uma forma geral aos modelos
probabilísticos. Entretanto, em cada estudo de confiabilidade, tais parâmetros devem ser
estimados a partir de observações amostrais, de tal forma que o modelo fique determinado e
possibilite responder as perguntas de interesse. Existem alguns métodos conhecido na
literatura clássica.
Um dos mais conhecidos é o método dos mínimos quadrados, bastante limitado pela
incapacidade de incorporar censuras no seu processo de aquisição. É completamente adequado
a funções que possam ser linearizadas. Seus cálculos são fáceis e diretos, utilizando o
coeficiente de correlação para avaliar se a distribuição escolhida se adequa aos dados
amostrais. Porém sua utilização se torna complicada para algumas combinações de dados e
distribuições e, em alguns casos, extremamente difícil ou impossível de ser implementada.
Surge como alternativa mais adequada, o método de máxima verossimilhança, pois
permite a incorporação de censuras além possuir propriedades que permite construir intervalos
de confiança para as quantidades de interesse. Este método só poderá ser utilizado após ter
sido definido um modelo probabilístico adequado para os dados.
Um estimador de máxima verossimilhança tem por finalidade determinar quais são os
parâmetros para a distribuição de probabilidade em estudo, que mais provavelmente se
aplicariam a uma dada amostra. No caso da distribuição de Weibull, o estimador de máxima
verossimilhança tem a finalidade de escolher qual dos parâmetros α e δ “melhor explica” a
amostra observada. Para representar o método de máxima verossimilhança, necessita-se de
algumas definições:
A função de verossimilhança para um parâmetro genérico “θ”, dados os valores de t1,
t2,..., tn, é:
( ) ( ) ( )θθθ ;,...,,/1
21 in
in tfLtttL
=Π==
Para a função acima, tem-se a seguinte pergunta: “Qual o melhor valor θ que maximiza
a função L(θ)?” Busca-se, então, “quais são os parâmetros da distribuição que melhor
explicam a amostra em questão?” (HARTER; MOORE, 1969 apud LOPES, 2001, p. 20).
(63)

80
Como as observações não-censuradas são relacionadas à função de densidade de
probabilidade e as censuradas não o são, essas observações somente informam que o tempo de
falha é maior que o tempo de censura, observando, portanto, que a contribuição para L(θ) é
dada pela sua função de confiabilidade R(t);
Assim, segundo Lawless (1983 apud LOPES, 2001), a função de verossimilhança é
dada por:
( ) ( ) ( )θθθ ;;11
in
rii
r
itRtfL
+==ΠΠ=
em que as “r” primeiras observações são as não-censuradas e as “n – r” seguintes são as
censuradas.
( ) ( ) ( )θθθ ;;11
ir
ii
n
itZtRL
==ΠΠ=
As expressões acima são equivalentes, ressaltando que esta última se aplica a casos de
amostras censuradas.
É sempre conveniente trabalhar com o logaritmo da função de verossimilhança, em que
os estimadores de θ que maximizam L(θ) são equivalentes aos que maximizam log [L(θ)].
Os estimadores de máxima verossimilhança são encontrados, resolvendo-se o sistema
de equações a seguir:
( ) ( )[ ] 0log=
∂∂
=θθθ LU
4.11 TESTE DE HIPÓTESES DAS ESTIMATIVAS DE PARÂMETROS
Dentre os principais métodos de se avaliar os intervalos de confiança para os
parâmetros, destacam-se os três mais utilizados: o método da relação verossimilhança (LR), os
limites de confiança beta binomial e a utilização da matriz de Fisher (FM).
A matriz de Fisher é recomendada quando se utiliza dados censurados na amostra.
Estes limites são utilizados em muitas estatísticas e pacotes de análise de vida. Em geral,
tendem a ser mais rígidos do que os limites da binomial não paramétrica ou da relação
verossimilhança.
(64)
(65)
(66)

81
Os limites de confiança da relação verossimilhança tende a serem mais conservadores
do que o método da matriz de Fisher.
Conceitualmente o método da relação verossimilhança (LR) é mais simples do que o
método da matriz de Fisher (FM), mas exige muito mais cálculos computacionais. Quando se
trabalha com amostras pequenas, o método LR é mais adequado do que o método da FM. As
justificativas matemáticas de ambas as metodologias são bastante complexas e podem ser
melhor estudadas em Cox e Hinkley e Cordeiro (1974; 1992 apud FREITAS; COLOSIMO,
1997).
4.12 TESTES DE ADERÊNCIA DAS DISTRIBUIÇÕES
Os testes de aderência ou de precisão de ajuste de distribuição são testes de hipóteses
não paramétricos que dizem respeito a formas da distribuição populacional, ou seja, testam
como os dados de uma amostra “aderem” ou não a uma distribuição.
Os modelos paramétricos somente deverão ser usados após se ter cuidadosamente
certificado de sua adequação. Portanto é necessária a verificação da distribuição que “melhor”
adere e explica os dados amostrais. Isto é feito com auxílio de testes não paramétricos.
Existem duas formas de discriminar tais modelos: através de técnicas gráficas e dos
testes de adequação (FREITAS; COLOSIMO, 1997).
4.12.1 Técnica gráfica
A técnica gráfica mais indicada para avaliação do ajuste de distribuições é o método de
comparação direta da função de confiabilidade do modelo proposto com o estimador de
Kaplan-Meier.
Neste procedimento, ajustam-se os modelos propostos ao conjunto de dados e a partir
das estimativas dos parâmetros de cada modelo, a função de confiabilidade é estimada.
Considerando, por exemplo, as distribuições estimadas Gamma, Weibull, Exponencial,
Normal e Log-normal, representados por )(^
tGaR , )(
^tWR ,
)(^
tER , )(
^tNR ,
)(^
tLNR ,
respectivamente, determina-se a estimativa de Kaplan-Meier para a função de confiabilidade
)(^
tMKR − para o mesmo conjunto de dados. Ao comparar cada modelo paramétrico com a

82
estimativa de Kaplan-Meier, o modelo mais adequado ao conjunto de dados é aquele cuja
curva se aproxima do estimador de Kaplan-Meier, ou seja, é aquele cujos pontos estarão mais
próximos da curva x = y,em que, x = RK-M e y = RMC , sendo “MC” o modelo de confiabilidade
testado (LOPES, 2001).
Esta técnica utiliza para análise quantitativa, o coeficiente de correlação R ou o
coeficiente de determinação R2 do método dos mínimos quadrados da estatística univariada
sendo este último mais freqüentemente utilizado por apresentar uma indicação mais precisa
particularmente na inserção probabilística de dados (HAVIARAS, 2005; LOPES, 2001).
4.12.2 Testes de adequação de ajustes de distribuição
Para o caso univariado, os testes de adequação são amplamente explorados. O mesmo
não ocorre para o caso multivariado, onde poucas referências sobre o assunto podem ser
encontradas.
Estes testes consistem em se calcular uma estatística-teste sob a hipótese de que
modelo é adequado em obter uma probabilidade que reflita a plausibilidade desta hipótese. Se
a probabilidade for pequena (usualmente menor que 0,05) não se aceita o modelo. Caso
contrário, o modelo não é rejeitado (FREITAS; COLÓSIMO, 1997).
Os testes de adequação de ajuste que serão explorados neste estudo são os seguintes:
- Teste analítico de Qui-quadrado (Estatística 2χ );
- Teste analítico de Kolmogorov-Smirnov (Estatística K-S);
- Teste analítico Anderson-Darling (Estatística A2).
Método analítico de Qui-quadrado - Estatística teste2χ
Este teste foi idealizado por Karl Person (1857) que o interpretava como um teste de
significância estatística. O método de qui-quadrado baseia-se na comparação das freqüências
observadas e esperadas (ou cálculos usando a distribuição do ajuste).
Para isso é necessário agrupar as observações em intervalos, obtendo-se xii e xis como
limite inferior e superior do intervalo “i”. Para cada intervalo, determina-se:

83
ie
2ieio
12
f)f(f −
Σ==
k
icχ
cujo foi vem a ser a freqüência observada no intervalo “i” e fei a freqüência esperada no
mesmo intervalo “i” e k é o número de intervalos. O valor fei é determinado através da função
de probabilidade acumulada, obtida da seguinte forma:
[ ]n))F(xF(xf isiiie −=
O qui-quadrado calculado é comparado com o qui-quadrado tabelado ou crítico2critχ e,
logo após, conclui-se quanto ao ajuste ou não do modelo aos dados.
Para extrair este valor das tabelas estatísticas é necessário conhecer previamente o nível
de significância adotado e o número de graus de liberdade. Este último é dado pelo número de
classes observadas subtraído do número de parâmetros populacionais que devem ser estimados
do modelo de confiabilidade (VIRGILLITO, 2004).
A prova do 2χ deve ser usada quando o número de observações for grande, acima de
30 observações. É comum usá-la em amostras pequenas, porém aconselha-se muita cautela ao
fazê-lo (LOPES, 2001).
Quando se obtém um valor de 2χ significativo, mas nota-se que a amostra é pequena
e/ou que a freqüência esperada em uma das classes é pequena (tipicamente, quando for menor
que 5) a fórmula de obtenção de 2χ poderá produzir um valor maior que o real. Segundo Viali
(2006) é recomendado observar a seguinte restrição: utilizar o teste 2χ somente se o número
de observações em cada classe ou agrupamento da tabela for maior ou igual a 5 e a menor
freqüência esperada for maior ou igual a 5. Caso contrário, em cada classe deve ser utilizada a
correção de Yates (correção de continuidade) dada pela seguinte expressão:
ie
2ieio
12
f)5,0f(f −−
Σ==
k
icχ
Evidentemente, não é preciso usar a correção de Yates se o valor de 2χ for menor que
2tabχ , pois o novo valor será menor que o primeiro, continuando a não ser significativo. De
modo geral, usa-se a correção de Yates quando:
O valor de qui-quadrado obtido é maior que o crítico;
(68)
(69)
(67)

84
O tamanho da amostra é menor que 40;
Há pelo menos uma classe com número de valor esperado menor que 5.
Método analítico de Kolmogorov-Smirnov - Estatística teste K-S
A estatística teste K-S avalia se duas ou mais amostras foram extraídas da mesma
população (ou de populações com a mesma distribuição).
O método Kolmogorov-Smirnov consiste na comparação das freqüências acumuladas
observadas com as estimativas para a distribuição do ajuste diferentemente do método de qui-
quadrado que utiliza freqüências agrupadas.
Se as amostras foram extraídas da mesma população, então é de esperar que as
distribuições acumuladas das amostras sejam muito próximas uma da outra, acusando apenas
desvios causais em relação à distribuição da população. Se as distribuições acumuladas são
“diferentes” ou “distantes” uma da outra em qualquer ponto, então as amostras provêem de
populações também distintas.
Assim para cada índice “i” de x: i = 1 a n, determina-se:
a freqüência acumulada observada para o valor ordenado xi, a qual é dada por
)( in xS = 100ni ;
a freqüência acumulada teórica, usando a F( ix ) da distribuição teórica;
o máximo das distâncias entre )( in xS e F( ix ), isto é:
{ })x(F)x(SMaxDM iin −=
Se a distância é suficientemente pequena (com p value < 0,05), conclui-se que o
modelo escolhido para o ajuste dos dados deve ser aceito.
Este método possui a vantagem de não depender de uma classificação arbitrária dos
dados em intervalos, o que pode influenciar os resultados do ajuste. Outra vantagem é que
pode ser usada para valores de amostras pequenas (n < 4).
(70)

85
Método analítico Anderson-Darling – Estatística teste A2
O método Anderson-Darling é um teste geral para comparar a distribuição de uma
distribuição observada acumulada com uma distribuição esperada acumulada. O teste é
aplicado somente a conjuntos de dados completos (sem censuras).
A estatística teste A2 tem vantagens em relação aos métodos apresentados
anteriormente, especificamente o Kolmogorov-Smirnov (K-S), pois é mais sensível a desvios
ou variações nas caldas das distribuições sendo, portanto, mais indicada nos casos em que há
maior rigor ou equivalentemente menores níveis de significância para a distribuição adotada
(ANNIS, 2007).
Pode ser aplicada a qualquer distribuição, sendo as tabelas dos valores críticos não tão
fáceis de serem encontradas.
Segundo D’agostinho e Stephens (1986 apud ANNIS, 2007), o cálculo dos valores
críticos para as distribuições Normal, Log-normal, Gamma, Weibull, Gumbel e Exponencial
são dadas conforme a seguir.
Para as distribuições Normal e Lognormal, a estatística teste A2 é calculada por meio
da seguinte expressão:
[ ])1ln()ln()12()/1( 11
2+−
=−+−−−= Σ ini
n
iwwinnA
Onde n representa o tamanho da amostra e w é a distribuição acumulada normal
padrão, [ ]σµ)/-(xΦ .
No caso de amostras pequenas, a expressão acima precisa ser corrigida pela seguinte
expressão:
++= 2
22 25.275.01nn
AAm
Os valores calculados devem ser comparados com o valor crítico apropriado dado em
função do nível de significância α; 0.1, 0.05, 0.025 e 0.01 mostrados na Tabela 5 abaixo:
(71)
(72)

86
Tabela 5 – Valores críticos da estatística teste A2 para as funções Normal e Lognormal
α 0.1 0.05 0.025 0.01 2critA 0.631 0.752 0.873 1.035
D’agostinho e Stephens (1986 apud ANNIS, 2007)
Para as distribuições Weibull, Gama e Gumbel, a estatística teste A2 é calculada por
meio da seguinte expressão:
[ ])1ln()ln()12()/1( 11
2+−
=−+−−−= Σ ini
n
iwwinnA
Onde n representa o tamanho da amostra e wi é a distribuição acumulada da
distribuição considerada.
Para o caso de amostras pequenas e, semelhante ao caso anterior, a expressão acima
precisa ser ajustada pela seguinte expressão:
+=
nAAm
2.0122
Os valores calculados devem ser comparados com o valor crítico apropriado dado em
função do nível de significância α 0.1, 0.05, 0.025 e 0.01 mostrados na Tabela 6 abaixo:
Tabela 6 – Valores críticos da estatística teste A2 para as funções Weibull, Gamma e Gumbel
α 0.1 0.05 0.025 0.01 2critA 0.637 0.757 0.877 1.038
Fonte: D’agostinho e Stephens (1986 apud ANNIS, 2007).
Para a distribuição Exponencial, a expressão ajustada é a seguinte:
+=
nAAm
3.0122
E os valores críticos a serem comparados com os valores calculados são dados
conforme a Tabela 7 a seguir:
Tabela 7 – Valores críticos da estatística teste A2 para a função Exponencial
α 0.1 0.05 0.025 0.01 2
critA 1.062 1.321 1.591 1.959
Fonte: D’agostinho e Stephens (1986 apud CALZADA, 2006).
(73)
(74)
(75)

CAPÍTULO 5 - PESQUISAS DESENVOLVIDAS
5.1 APLICAÇÕES EM ENGENHARIA DE PRODUÇÃO
A Análise de Confiabilidade e a Análise de Componentes Principais são bastante
utilizadas em pesquisas da Engenharia de Produção. Evidencia-se este fato pelo grande número
de trabalhos desenvolvidos nesta área. Na seqüência discorre-se sobre alguns destes trabalhos.
Haviaras (2005) desenvolveu uma metodologia de análise de confiabilidade de pneus
utilizados em frotas de transporte rodoviário. Nas amostras analisadas (pneus sucatados de 10
frotas), verificou-se que a distribuição de probabilidade Weibull de dois parâmetros foi a que
melhor se ajustou ao modelo proposto. Para o cálculo dos parâmetros de forma e escala da
distribuição Weibull, desenvolveu-se um método utilizando a média e o desvio padrão das
amostras. As análises de confiabilidade mais freqüentes foram feitas utilizando EXCELTM.
Barros Filho (2003) desenvolveu um trabalho onde estuda a confiabilidade de um
conjunto de elementos resistivos de fornos de espera, utilizados em uma planta de produção de
alumínio. O estudo de caso sugeriu um período ótimo para a realização das manutenções
preventivas baseada nos índices de confiabilidade para cada resistência estudada através dos
programas Weibull++ e BlockSim. No seu trabalho foram abordados aspectos da
confiabilidade como parte integrante das ações que caracterizam a manutenção de classe
mundial como o TPM e RCM, bem como abordar os aspectos da produção, descrevendo de
forma sucinta o sistema Toyota de produção e suas ferramentas no contexto da Manufatura de
Classe Mundial, que abrangem as ações que tornam as empresas mais competitivas.
Em Scremin (2003) apresentou um método para a seleção do número de componentes
principais com base na Lógica Difusa. Em seu trabalho, o uso da Lógica Difusa contribuiu
para o aperfeiçoamento do método de Análise de Componentes Principais, pois permitiu
agregar o conhecimento do pesquisador sobre o problema em estudo às informações
estatísticas, tais como a variância explicada, as porcentagens acumuladas de variância
explicada e as cargas fatoriais. Simulou-se amostras normais multivariadas com número de
variáveis entre 5 e 20, com número de componentes principais significativos variando entre 2 a
6 componentes. Na busca da validação do método proposto, realizou-se um estudo
comparativo de seus resultados, por meio de amostras simuladas, com os resultados dos
métodos de Kaiser e da Porcentagem Acumulada de Variância Explicada (MPAVE). Neste

88
estudo de comparação, o método proposto apresentou-se mais eficiente na determinação do
número adequado de componentes principais.
Lopes (2001) desenvolveu uma metodologia multivariada utilizando análise de
componentes principais para determinar a confiabilidade e o tempo médio de falha de peças de
um equipamento da empresa alemã STIHL de São Leopoldo-RS. No estudo foram
selecionadas três componentes principais em substituição as 80 variáveis envolvidas. A nova
metodologia, além de determinar o grau de confiabilidade de um equipamento e o tempo
médio de falha, pode ser considerada, quanto ao custo benefício, uma atividade de apoio
melhorada. A seleção das componentes principais foi realizada pelos métodos de Kaiser, do
diagrama de autovalores e da porcentagem acumulada de variância explicada (superior a 70%).
No estudo foi possível reduzir um número muito grande de variáveis (80 itens) para apenas
três componentes principais, no qual se verificou que o primeiro componente principal
forneceu muitas informações devido à excelente absorção de variabilidade do tempo de vida
das peças originais e em função de sua correlação com os demais componentes.
Afonso (2001) apresenta um estudo sobre regras de reconhecimento e classificação
baseadas nas técnicas da análise multivariada para construir um sistema de avaliação de
desempenho acadêmico dos alunos de Engenharia Mecânica do Cefet-PR. Utilizou-se um
programa computacional que foi modelado para fornecer regras de reconhecimento e
classificação baseado na função discriminante linear de Fisher e Regressão Logística, e o
Método de Lachenbrusch para a avaliação da eficiência das regras de reconhecimento e
classificação técnica da análise multivariada. O processo descrito neste trabalho aliado a uma
base de dados confiável conduziu a uma redução da evasão escolar, permitindo uma orientação
acadêmica para o sucesso dos alunos.
Um modelo para estudar as barreiras ao empreendimento de novos negócios,
percebidos por futuros empresários é proposto por Malheiros (2001). O trabalho teve por
objetivo comprovar se, diferenças de gênero, nível de atividade (empregado, desempregado,
nunca empregado ou aposentado), experiência e ramo de atividade pretendido podem resultar
em diferentes fatores de barreiras percebidos. Para tanto foi utilizada uma amostra
institucional, de 168 indivíduos, com desejo de iniciar negócio próprio. Pelo método de
Análise Fatorial e Análise de Componentes Principais foi determinado o grau de correlação
entre a condição dos empreendedores e os fatores de barreira de ordem pessoal (risco,
experiência, auto-estima, conhecimento, autonomia e independência), de projetos (idéia,
sócios, recursos iniciais, pesquisa de mercado) e ambiental (disponibilidade de capital de risco,
os sistemas fiscal e legal, mercado consumidor, políticas econômicas e procedimentos

89
governamentais). Na seleção dos fatores foi utilizado o critério da porcentagem acumulada de
variância explicada acima de 70%. Como este percentual de variância explicada indicou um
baixo padrão de associação entre as variáveis (acumulando 46,45% até a 5ª componente),
foram explorados os agrupamentos destas variáveis pela Análise Fatorial por Componentes
Principais. Os resultados encaminharam a discussão sobre as principais barreiras percebidas
por potenciais empresários e a validade do modelo proposto. Ainda, os resultados poderão
orientar políticas públicas, que visem à transformação da realidade de falência empresarial
precoce estabelecida no Brasil.
Em Souza (2000), encontra-se uma metodologia multivariada para a minimização da
produção de itens defeituosos. Controle estatístico do processo e o controle de engenharia do
processo foram utilizados. A metodologia proposta, considerada auxiliar na monitoração e/ou
realimentação de um sistema multivariado, foi aplicada na empresa CECRISA de Tubarão
(SC), em um forno de queima de azulejo 15x15. A metodologia consiste em fazer a avaliação
de um conjunto multivariado, verificando a estabilidade do sistema, considerando as variáveis
originais na avaliação global, por meio do gráfico de Hotelling. Quando existe um sinal de
instabilidade no sistema, é utilizado componentes principais, e estas, após selecionadas pelos
métodos de Kaiser, do Diagrama de Autovalores e Porcentagem Acumulada de Variância
Explicada são submetidas a um gráfico de controle EWMA (Exponentially weighted moving
average), permitindo uma análise mais detalhada. Ainda, possibilita identificar os períodos e
etapas do processo em que houve uma falha no controle do processo. A metodologia proposta
possibilitou a monitoração e/ou realimentação de um processo multivariado, deixando clara
todas as etapas a serem cumpridas e fazendo a ligação entre o controle estatístico e o controle
de engenharia do processo.
Vedana (1999) investigou de forma exploratória o desempenho dos fundos de pensão
fechados brasileiros frente a uma carteira hipotética de investimentos utilizando a Análise de
Componentes Principais e a Análise de Agrupamento. O trabalho teve fundamentação das
teorias estatísticas e teorias de finanças. Dentro das teorias estatísticas utilizou-se uma
metodologia de Análise de Dados, através de uma descrição sucinta do Modelo Fatorial, que
serviu como pré-requisito para o entendimento da Análise de Componentes Principais e
Análise de Agrupamento.

90
5.2 APLICAÇÕES EM OUTRAS ÁREAS
Neste item, apresentam-se de forma sucinta, algumas aplicações de Análise de
Componentes Principais e Analise Fatorial por Componentes Principais. O objetivo é mostrar
o tipo de aplicação e os métodos utilizados na seleção do número de componentes principais
nas diversas áreas.
Uma análise exploratória foi apresentada por Ribeiro (2001) para análise de
componentes principais num estudo do perfil de distribuição de hidrocarbonetos em amostras
de sedimentos coletados ao longo de duas bacias em Prince Willian Sound, Alaska, onde em
1989 ocorreu o derramamento de óleo do petroleiro Exxon Valdez. Através da observação dos
gráficos de escores e dos pesos foi possível visualizar o perfil de distribuição dos teores dos
compostos orgânicos depositados. Conclusões importantes também foram tiradas a respeito
dos processos de formação destes compostos ao longo das áreas costeiras e do movimento das
correntes marítimas.
Uma redução da dimensionalidade de dados por componentes principais é realizada por
Scremin e Bastos (2000) para identificar as variáveis mais representativas da variabilidade dos
dados e um posterior agrupamento de propriedades rurais do Estado de Santa Catarina,
utilizando variáveis contábeis. No estudo 27 variáveis originais foram reduzidas para 6
componentes principais e estabelecido, por uma rede neural artificial, quatro grupos com
características bem definidas. A caracterização em grupos homogêneos, neste caso, pôde
auxiliar na definição de medidas que conduzam ao sucesso de empreendimentos agrícolas. Na
seleção das componentes principais foi utilizado o método de Kaiser, onde foi observado um
acúmulo da porcentagem de variância explicada superior a 70%.
Khattree e Naik 2000 (apud SCREMIN, 2003, p.43) apresentam alguns exemplos de
aplicação, dentre eles:
• um estudo sobre o sono dos mamíferos em que foi utilizada uma análise fatorial com
o objetivo de verificar se a variação do sono de uma espécie para outra pode
depender das características particulares de cada espécie. Na seleção do número de
componentes principais, utilizando o método de Kaiser foram identificados dois
fatores de 9 variáveis originais;
• um estudo sobre a dependência de drogas, com o objetivo de verificar se uma pessoa
pode ser caracterizada por um padrão de dependência do uso da droga. Utilizando

91
uma análise de componentes principais, de um total de 13 variáveis, foram
selecionados 10 fatores que acumularam uma variância explicada de 90%;
• uma análise fatorial em dados fotográficos, para controle estatístico de qualidade,
com o objetivo de obter fatores para representar diferentes níveis (baixo, normal e
alto) de exposição de uma parte especial de um filme. Utilizando uma análise de
componentes principais em 14 variáveis foram selecionadas as 5 primeiras
componentes, as quais acumulavam 90% da variância total dos dados.
Em Melià e Sesé 1999 (apud SCREMIN, 2003, p. 41) relata-se um estudo sobre uma
aplicação das propriedades psicométricas e estrutura fatorial de um questionário orientando a
medida do clima organizacional para a segurança trabalhista. Utilizando o método de Kaiser
foram retidas as três primeiras componentes, as quais explicaram 58,9% da variância total dos
dados. Na interpretação dos fatores, foram consideradas as componentes que possuíam cargas
fatoriais iguais ou superiores a 0,4. Assim foram identificados os fatores “estrutura e segurança
da empresa”, “política de segurança da empresa” e “ações de intervenção em segurança da
empresa”.
Em um estudo de caso, Pereira 1999 (apud SCREMIN, 2003, p. 41) realizou uma
análise fatorial dos impactos de projetos de pesquisa financiada pela Fapesp (Fundação de
Amparo a Pesquisa do Estado de São Paulo). Na seleção dos fatores foi utilizado o método de
Kaiser, este, permitiu extrair dois fatores que juntos explicam 64,9% da variância total.
Utilizando uma carga fatorial superiores a 0,5 foram identificados os fatores “impactos
políticos e sociais” e “impactos acadêmicos”.
Uma aplicação em psiquiatria encontra-se em Artes 1998 (apud SCREMIN, 2003,
p.43), que trata da análise fatorial de escalas de avaliação em itens da forma traço do
Inventário de Ansiedade Traço-Estado aplicado a uma amostra de universitários. Extrai-se os 4
primeiros fatores, de 20 variáveis originais, que explicam juntos 54% da variabilidade total dos
dados e na análise das correlações dos fatores com as variáveis originais considera as variáveis
com cargas fatoriais superiores a 0,4.
Em Souza Neto et al 1995 (apud SCREMIN, 2003, p.42) foi realizada uma análise
socioeconômica da exploração de caprinos e ovinos, do estado do Piauí. Nela, foram
caracterizados os sistemas de produção e identificados os fatores responsáveis pela adoção ou
não de tecnologias, estimando os principais fatores pelo aumento da produção desses animais.
A Análise Fatorial foi utilizada para reduzir a dimensionalidade e identificar as relações

92
existentes entre as variáveis. Foram selecionados 5 fatores perfazendo 56,6% do total de
variância explicada e na Análise Fatorial utilizou as variáveis que possuíam cargas fatoriais
superiores a 0,5.
Encontra-se em Baxter 1995 (apud SCREMIN, 2003, p.42) uma aplicação em
arqueologia para identificar ou exibir a estrutura química de artefatos arqueológicos. Nela são
selecionadas duas componentes, para a maioria das análises, que respondem por 50% ou mais
da variação dos dados e quatro componentes que acumulam pelo menos 80% desta variação.
Dent e McGregor 1994 (apud SCREMIN, 2003, p.41) realizaram um estudo, sobre os
objetivos de fazendeiros e suas interações com negócios e estilo de vida, no qual observaram
que as sete primeiras componentes principais acumulavam um pouco mais da metade da
variabilidade total dos dados. Entretanto, as três primeiras componentes foram suficientes para
identificar os fatores “monetários”, “estilo de vida” e “independência”, acumulando 32% da
variabilidade total dos dados. A carga fatorial para a interpretação foi considerada superior a
aproximadamente 0,5.
Na pesquisa de Yamamoto et al 1993 (apud SCREMIN, 2003, p.42), com o objetivo de
conservar as áreas verdes na cidade de Sakai, para explicar as relações entre o estado de
urbanização na cidade e a transformação da estrutura dos espaços verdes, foi realizada uma
análise de componentes principais. Na seleção das componentes principais foi utilizado o
método de Kaiser retendo para estudo as três primeiras componentes principais, que
explicaram 70% da variabilidade total dos dados. Para a interpretação foram utilizados os
fatores cujas cargas fatoriais eram superiores a 0,4. Identificando os fatores “áreas com
construções e alta densidade residencial”, “áreas de uso comercial, industrial e mista (de uso
comercial e industrial)” e “áreas de uso com agricultura”.
Kubrusly 1988 (apud SCREMIN, 2003, p.42) apresenta uma aplicação em um
problema de dosagem de fósforo para ovinos. Onde, na seleção das componentes principais foi
utilizado o método da variância explicada acumulada, extraindo 4 fatores com 77% de
variabilidade total dos dados e na análise das cargas fatoriais foram as superiores a 0,5.
Com o objetivo de conhecer a situação do setor leiteiro, Pla 1986 (apud SCREMIN,
2003, p.42) reuniu, em seu estudo de caso, informações sobre uma série de variáveis que
influem na produção total por propriedade e na produtividade por propriedade e por vaca. Para
a seleção das componentes principais foram utilizados os métodos de Kaiser e do diagrama de
autovalores, retendo para análise as três primeiras componentes com um acúmulo de 67% da
variância total explicada.

CAPÍTULO 6 - PROCEDIMENTO ATUAL DE ANÁLISE DE
EQUIPAMENTOS CRÍTICOS
Semelhante ao que ocorre na maioria das empresas, o processo de controle de
manutenção e prolongamento da vida útil dos ativos físicos produtivos na empresa estudada
está fundamentado nos sistemas tradicionais de manutenção corretiva, preventiva e preditiva,
sendo esta última com foco em inspeção sensitiva ou apoiada em instrumentos dedicados.
As análises de falhas são realizadas de forma pontual e somente quando dá ocorrência
de excepcionalidades ou solicitados para uma função específica. A responsabilidade pelas
análises de falhas é executada pelo setor de engenharia. O setor é dividido em equipes de
engenheiros cada uma sob o comando de uma coordenação específica conforme a área de
atuação.
A Área de Análise Preditiva e de Materiais é a responsável pelos estudos e análises de
falhas. São realizados ensaios destrutivos quando é possível a retirada de amostra ou ensaios
não destrutivos quando são feitas análises de campo no próprio equipamento. As informações
sobre as análises são incluídas em relatório técnico de engenharia sendo armazenadas no
sistema de documentos técnicos digital da empresa para acesso e consulta interna.
As equipes de manutenção e inspeção utilizam um sistema informatizado denominado
SISMANA (Sistema de Gestão de Ativos) que armazena os dados necessários ao planejamento
das atividades de inspeção e manutenção. As informações sobre o estado e a condição dos
equipamentos são levantadas nas inspeções dos equipamentos, identificando falhas potenciais
ou com monitoramento de pontos de controle mediante instrumentos que registram a evolução
das falhas. A empresa utiliza as técnicas tradicionais de análise, a saber:
a) Análise de Vibrações: utilizada para detecção de falhas em mancais e rolamentos,
mas limitada a máquinas rotativas;
b) Análise de Óleo Lubrificante: baseia-se na contagem de partículas metálicas
(ferrografia) e na análise físico-química de óleos lubrificantes, como por exemplo, óleos de
mancais e caixas de redução;
c) Análise Termográfica: utiliza a imagem térmica com o objetivo de propiciar
informações relativas à condição operacional de um componente, equipamento ou processo. É
utilizada também para estimar o nível de obstrução dos tubulões de gases gerados no processo
produtivo;

94
d) Ensaio Ultra-sônico: é o método não destrutivo mais utilizado na empresa para
detecção de descontinuidades internas nos materiais;
e) Líquido Penetrante: é utilizado para a detecção de descontinuidades superficiais de
materiais isentos de porosidade tais como aço, cobre e alumínio. Também são utilizados para a
detecção de vazamentos em tubos, tanques, soldas e componentes.
Dentre todas as técnicas mencionadas, as técnicas de análise de vibrações e análise de
óleo lubrificante são empregadas de maneira sistemática, mesmo que com um universo de
aplicação limitado, possuindo este último, inclusive, um laboratório instalado na empresa.
Para a análise de óleo é utilizado um sistema informatizado (SISLUB) que faz o
controle de homologação e recebimentos de óleos e graxas. O método é baseado na coleta de
óleo e nos planos de inspeção de pontos de lubrificação, num total de aproximadamente 1.300
pontos. Os serviços de coleta de óleo são terceirizados e as inspeções são executadas pelo
pessoal da própria empresa. Os equipamentos críticos são monitorados em intervalos de tempo
estabelecidos em função da criticidade dos mesmos no processo. Os resultados são descritos
em laudos específicos e disponibilizados para as áreas clientes de manutenção em sete dias
corridos. As Tabelas 8 e 9 mostram exemplos de análises de óleo e controle de lubrificantes de
um mês.
Tabela 8 – Controle de óleo lubrificante em uso e desgaste
No de pontos/equipamento No de amostras realizadas (mês) Ferrografia 501 215 Físico-químico 997 377
Tabela 9 – Controle de recebimentos de lubrificante novos
Volume Aprovado Reprovado Índice de dev. (%) Índice de dev. (%) (últimos 12 meses)
Combustível (litros) 305.000 0 0,00 0,00
A análise de vibrações é utilizada em equipamentos rotativos que são divididos em
críticos e normais. Há dois sistemas de monitoramento: on line e off line.
No sistema on line, utilizado essencialmente em equipamentos de alta criticidade, há
um controle descentralizado em estações fixas das unidades de produção. Em outra opção, o
sistema é centralizado nas salas de controle sendo utilizado no monitoramento dos
equipamentos críticos. Há um total de 200 equipamentos monitorados via análise global e 4

95
equipamentos de alta criticidade monitorados via análise espectral do sinal de vibração. Isto
equivale a 1.100 pontos monitorados. Nos sistemas off line, aplicados a equipamentos
considerados normais, há cerca de 1.900 equipamentos ou aproximadamente 10.000 pontos de
controle que alimentam o SISMANA manualmente. A Figura 17 mostra o fluxo de análise de
vibrações na empresa estudada.
Figura 17 – Fluxo de Análise de Vibrações na empresa estudada
Os resultados produzidos por ambas as técnicas (análise de óleo e vibrações) são
informados às unidades responsáveis e introduzidos no sistema informatizado de manutenção
em etapa posterior, servindo de fonte histórica para acompanhamento e monitoramento dos
equipamentos. Esta sistemática é executada pelas equipes de inspeção das áreas utilizando-se
instrumentos portáteis ou análises sensitivas. O procedimento é repetido e atualizado
periodicamente ou quando da intervenção para correção de qualquer anormalidade
identificada.
A Tabela 10 mostra um resumo da análise de óleo e de vibrações com as quantidades
de pontos de monitorados, freqüência de inspeção e respectivos percentuais de falhas
detectadas.
Tabela 10 – Resumo das atuais técnicas de análise de controle de vida (controle sistemático)
ANALISTA DE VIBRAÇÕES DA ENGENHARIA
SOLICITA ANÁLISES QUANDO
NECESSÁRIO
EFETUA ANÁLISES DOS PROBLEMAS E EMITE RELATÓRIO COM DIAGNÓSTICO DAS CAUSAS
PROVÁVEIS QUANDO NECESSÁRIO
EQUIPES DE INSPEÇÃO
PROVIDENCIA INTERVENÇÃO NO
EQUIPAMENTO QUANDO NECESSÁRIO
EFETUA ANÁLISES E ESTUDOS MAIS
DETALHADOS DOS PROBLEMAS QUANDO
NECESSÁRIO
Ferrografia 1.911 2 13,5Físico-química 3.470 3 16,25Monitoramento Off-line 1.900 10.000 - 14,57Monitoramento On-line 204 1.100 - nd
Frequência de Inspeção Anual
Percentual de Falha Detectada (%)
Análise de ÓleoAnálise de Vibrações
1.300
Técnicas de Análises de Controle de Vida (controle sistemático)
Qde de pontos monitorados
Qde de equiptos monitorados

96
Mesmo com esta estrutura de acompanhamento ainda existem equipamentos críticos
que não são monitorados, ou por que não dispõem de instrumentos específicos de controle e
medição, ou por que não estão sujeitos a inspeções devido à concepção do próprio
equipamento, como é o caso das ventaneiras. Nestes casos, a freqüência e complexidade das
intervenções são diretamente ligadas às condições do próprio equipamento e do local onde se
encontra o equipamento instalado.
Ressalta-se que a empresa não utiliza sistematicamente nenhuma técnica ou
metodologia que leva em consideração a influência dos tempos de vida associada ao nível de
degradação ou envelhecimento de seus equipamentos. Há apenas o acompanhamento de
determinados parâmetros de controle através de gráficos de tendência. Neste caso nem todos
os equipamentos são monitorados e, a avaliação, na maioria das vezes, é executada de maneira
pontual e com freqüência irregular. Alguns dos equipamentos mais críticos são monitorados,
mas não associam a análise estatística de confiabilidade em suas avaliações.
De maneira geral, observa-se não haver uma metodologia sistematizada de verificação
e controle baseada na confiabilidade dos equipamentos. Todo o processo de aquisição de
ativos ainda não se fundamenta em controle estatístico de confiabilidade que compreende
desde a fase de projeto ou identificação da necessidade de novos equipamentos até a fase de
colocação em operação ou produção com monitoramento de dados.

CAPÍTULO 7 - CONJUNTO DE ALTA CRITICIDADE E COMPONENTE
CRÍTICO
Este capítulo descreve o funcionamento do conjunto de insuflação de ar (conjunto de
alta criticidade) dando ênfase às ventaneiras (componente crítico) por se tratar da origem e ter
motivado o desenvolvimento da pesquisa.
7.1 DESCRIÇÃO DO FUNCIONAMENTO DO ALTO FORNO 1
O Alto Forno 1 é a unidade responsável pela produção do da principal matéria-prima
da produção de aço: o ferro gusa. Entrou em operação em novembro de 1983. Sua produção
nominal é de 10.000 ton/dia de ferro gusa. Atualmente é o mais antigo em operação em todo o
mundo com uma produção acumulada próxima de 80 milhões de toneladas de ferro gusa. A
Tabela 11 mostra as características técnicas do Alto Forno 1.
Tabela 11 – Características técnicas do Alto Forno 1
Projeto/Fornecedor KSC/IHI Produção 10.000 ton/dia
Volume de sopro 6.800 Nm3/min Temperatura de sopro 1.250 oC
Pressão de sopro 4,4 kgf/cm2 Volume interno 4.415 m3
Volume útil 3.707 m3 Diâmetro do cadinho 14 m
Furos de gusa 4 No de ventaneiras 38
Sistema de refrigeração Stave cooler
A Figura 18 e 19 mostram respectivamente o Alto Forno 1 e de forma simplificada, o
fluxo de produção do ferro gusa .

98
Figura 18 – Alto Forno 1
Figura 19 – Fluxo de produção do ferro gusa no Alto Forno 1
As unidades a montante consistem dos Silos de Minérios que abastecem o Alto Forno
com carga metálica em ligas de ferro e carbono, como exemplos, pelotas de minério de ferro,
coque mineral ou vegetal e sinter; Regeneradores que fornecem oxigênio aquecido e sob alta
pressão e, de uma unidade de fornecimento de carvão pulverizado – Pulverized Coal Injection
(PCI) que juntamente com o coque adicionado na parte superior do Alto Forno promovem a
combustão (redução) do elemento ferro da carga metálica. A jusante está a unidade de limpeza
CRAAF
ALTO FORNO 1
SISTEMA DE LIMPEZA
TRT
FERRO GUSA
REGENERADORES
PCI
SILOS DE MINÉRIOS

99
de gases; uma turbina geradora de energia acionada por esses mesmos gases e uma unidade de
tratamento de água – Centro de Recirculação de Água do Alto Forno (CRAAF) responsável
pela recirculação de água e pelo tratamento dos subprodutos gerados no processo de produção
de ferro gusa.
O processo de produção do ferro gusa ou, em linguagem técnica, o processo de
elaboração do ferro gusa é descrito a seguir: o oxigênio a alta temperatura e carvão
pulverizado são injetados sob alta pressão no interior do Alto Forno através do conjunto de
insuflação de ar, especificamente através das ventaneiras. A reação de redução promovida pelo
oxigênio a alta temperatura com a carga metálica adicionada na parte superior do Alto Forno
gera o ferro gusa. Este processo se dá continuamente com a extração do ferro gusa produzido
em certos intervalos de tempo que são determinados conforme o rendimento de transformação
da carga metálica e perfil térmico do Alto Forno, dentre outras variáveis.
7.2 DESCRIÇÃO DO FUNCIONAMENTO DO CONJUNTO DE ALTA
CRITICIDADE E COMPONENTE CRÍTICO
O conjunto de insuflação de ar (conjunto crítico) é o subconjunto responsável pela
injeção de oxigênio e carvão pulverizado que têm a função de promover a redução da carga
metálica do Alto Forno e consequentemente produzir o ferro gusa. No caso do Alto Forno 1 há
38 destes conjuntos. A Figura 20 mostra um desenho esquemático de um conjunto de
insuflação de ar. A Figura 21 mostra o conjunto de insuflação de ar do Alto Forno 1.
Figura 20 – Desenho esquemático de um conjunto de insuflação de ar de um Alto Forno

100
Figura 21 – Conjunto de insuflação de ar do Alto Forno1
Cada conjunto de insuflação de ar é formado pelos seguintes subconjuntos: junta de
expansão, joelho, algaraviz, caixa de refrigeração e ventaneiras. As suas funções são as
seguintes:
a) Junta de expansão: faz ligação estrutural do anel de ar quente ao algaraviz e atua
como compensador térmico;
b) Joelho: faz a ligação estrutural da junta de expansão ao algaraviz;
c) Algaraviz: recebe o oxigênio aquecido e o carvão pulverizado a alta temperatura e
pressão e direciona para as ventaneiras;
d) Caixa de refrigeração: aloja a ventaneira e auxilia na sua refrigeração;
e) Ventaneira: possibilita a injeção da mistura oxigênio e carvão pulverizado no interior
do Alto Forno.
As ventaneiras, denominada neste estudo de componente crítico, estão localizadas na
Casa de Corridas, local de onde se faz a extração do ferro gusa produzido. A Figura 22 mostra
a Casa de Corridas do Alto Forno 1.

101
Figura 22 – Casa de Corridas do Alto Forno 1
As ventaneiras são peças de cobre, em formato de tronco de cone, refrigeradas
internamente com água. São fabricadas nas próprias Oficinas da empresa e pesam
aproximadamente 200 Kg. As Figuras 23 e 24 mostram o desenho de uma ventaneira em CAD
e uma ventaneira do Alto Forno 1 respectivamente.
Figura 23 – Desenho em CAD em uma ventaneira
Figura 24 – Ventaneira do alto forno 1 Figura 23 – Desenho em CAD de uma ventaneira Figura 24 – Ventaneira do Alto Forno 1

102
As Figuras 25 e 26 mostram respectivamente um lote de ventaneiras retiradas de
operação pelo fim de vida útil e um lote de duas peças recém fabricadas nas oficinas.
Figura 25 – Lote de ventaneiras em fim de vida útil
Figura 26 – Ventaneiras novas (recém fabricadas)
As ventaneiras quando em operação estão sujeitas aos diversos tipos de falha, sejam
ligadas a fatores externos ou internos ao funcionamento do Alto Forno. Tais falhas, além de
comprometer a sua vida útil, conduzem instabilidade ao processo produtivo afetando

103
diretamente todo ciclo produtivo do aço, haja vista que, o ferro-gusa é origem de todo o
processo de fabricação do aço.
Em função desta instabilidade é necessário manter-se estoques de segurança caso haja
falhas no conjunto de insuflação de ar decorrente de falhas relacionadas a si mesmo, ou
motivados por outros problemas operacionais. Dentre os itens estocados do conjunto de
insuflação de ar, o de ventaneiras se sobressai, pois é o subconjunto de maior desgaste.
Conforme o padrão técnico de produção (PT-PRO-AF01-01-0028, 2006), o número
total de ventaneiras montadas no Alto Forno 1 é 38, com vida útil prevista de 270 dias. De
acordo com os procedimentos operacionais descritos no padrão, deve-se manter em estoque
uma quantidade correspondente a uma vez e meia do total de um conjunto montado, ou seja,
cinqüenta e sete peças além de oito disponibilizadas estrategicamente na área operacional
como reserva emergencial.
Este procedimento demanda um planejamento de fabricação que deve levar em
consideração também as trocas de ventaneiras efetuadas nas paradas programadas para
manutenção preventiva do Alto Forno 1.
Conforme o plano de manutenção do Alto Forno 1 no Sistema de Gestão de Ativos
(SISMANA), há quatro paradas do Alto Forno 1 previstas por ano. Nestas paradas são
trocadas, em média, catorze ventaneiras ou cinqüenta e seis ventaneiras por ano, que é
confirmado pelas inspeções “in loco” realizadas pelas equipes de manutenção e operação, a
avaliação do perfil térmico do Alto Forno 1 e outras variáveis operacionais.
A Tabela 12 mostra a quantidade de ventaneiras fabricadas nas Oficinas da empresa
entre 2001 e 2005.
Tabela 12 – Quantidade de ventaneiras fabricadas nas Oficinas entre 2001 e 2005
Ano de fabricação 2001 2002 2003 2004 2005 No Ventaneiras fabricadas 107 104 123 105 97 Reserva estratégica de estoque 57 57 57 57 57
No Ventaneiras trocadas em manutenção preventiva 56 56 56 56 56
Verifica-se que há cerca de 57% de ventaneiras a mais em estoque devido ao
desconhecimento da vida útil real atingida por cada ventaneira em uma campanha operacional.
Segundo o banco de dados da manutenção DW (Data Warehouse), a unidade
operacional Alto Forno 1 é subdividida em 10 áreas operacionais: carregamento, topo do
forno, forno próprio, casa de corridas, regeneradores, limpeza de gases, granulador de escória,

104
CRAAF, sistema elétrico/controle e áreas auxiliares. Estas áreas possuem um total de 311
equipamentos, sendo 117 de baixa criticidade, 91 de média criticidade e 103 de alta criticidade.
O conjunto de insuflação de ar, o qual as ventaneiras (componente crítico) estão atreladas está
contido na área operacional Forno Próprio. A Tabela 13 mostra as 10 áreas operacionais que
compõem o Alto Forno 1 com detalhamento do grau de criticidade dos respectivos
equipamentos.
Tabela 13 – Áreas Operacionais do Alto Forno 1 agrupadas por grau de criticidade
Fonte: Banco de Dados da Manutenção DW (Data Warehouse) (2007).
Considerando a área operacional Forno Próprio, constata-se que há 11 equipamentos
no total, sendo que 7 de criticidade alta, o que representa cerca de 70% do total da unidade
operacional. A Tabela 14 mostra os equipamentos de criticidade alta, destacando o sistema de
insuflação de ar como o 3o mais crítico no ranking, que leva em consideração para
estabelecimento da pontuação, o grau de influência e importância no processo produtivo do
Alto Forno 1.
Tabela 14 – Equipamentos de Criticidade Alta do Forno Próprio (Alto Forno 1) agrupados em função do grau de priorização dentro da unidade operacional
Equipamento de Criticidade Alta Pontuação RankingCarcaça do Alto Forno 262 1°Cadinho/Subcadinho 262 1°Sistema de Refrigeração das Ventaneiras 242 2°Sistema de Refrigeração dos Staves e Refrigeração de Emergência 242 2°
Sistema de Insuflação de Ar 220 3°Sistema de Ar Frio 216 4°Stave Coolers 188 5°
ÁREA OPERACIONAL - Forno Próprio
Fonte: Banco de Dados da Manutenção DW (Data Warehouse) (2007).
BAIXA MÉDIA ALTA TOTALCarregamento 66 35 14 115Topo do Forno 7 4 14 25Forno Próprio 2 2 7 11Casa de Corrida 13 5 19 37Regeneradores 4 11 7 22Limpeza de Gás 3 3 5 11Granulador de Escória 9 12 12 33CRAAF 4 12 15 31Sist. Elétrico/Controle 0 4 9 13Áreas Auxiliares 9 3 1 13TOTAL 117 91 103 311
CRITICIDADEÁREA OPERACIONAL

105
Analisando os dados e informações expostas, percebe-se que há necessidade de um
controle rigoroso da vida útil das ventaneiras, no sentido de maximizá-la, pois a mesma possui
a menor vida útil prevista dentre todos os subconjuntos, sendo um gargalo do conjunto de
insuflação de ar.

CAPÍTULO 8 - PROCEDIMENTOS METODOLÓGICOS
As etapas propostas para atender os objetivos desta dissertação estão discriminadas a
seguir:
1a Etapa - Compreensão do sistema de funcionamento do conjunto de insuflação de
ar do Alto Forno 1
Nesta etapa foi necessário conhecer o sistema de funcionamento do conjunto de
insuflação de ar, especificamente as ventaneiras (subconjunto crítico), caracterizando-se como
o ponto de partida para embasar todo o planejamento para desenvolvimento da dissertação.
2a Etapa - Estudos e aplicações de métodos e técnicas multivariadas
A segunda etapa objetivou o levantamento de todo o referencial teórico necessário ao
desenvolvimento da pesquisa, constituindo-se na realização de estudos de métodos e técnicas
multivariadas e pesquisas de trabalhos correlatos já desenvolvidos em Engenharia de Produção
e outras áreas;
3a Etapa - Levantamento de pesquisas na área de confiabilidade
Na revisão da teoria de confiabilidade foram explorados os principais modelos de
probabilidade utilizados, ou seja, as distribuições Normal, Lognormal, Weibull, Exponencial e
Gamma. Foi abordado as técnicas estatísticas para validação dos modelos bem como uma
revisão de trabalhos acadêmicos aplicados em conjunto com a análise exploratória de dados.
Foi dado um tratamento aprofundado na Análise de Tempos de Falhas, pois as demais
abordadas não tiveram relevância na pesquisa. Realizou-se também um levantamento de
softwares para cálculo de confiabilidade existente no mercado e difundido na academia com
aplicações em estudos de caso. Foram pré-selecionados os seguintes softwares: Weibull++7,
Minitab 15 e o Statistica 6.0. Os dados de confiabilidade processados pelo programa de
confiabilidade seguiu o fluxo sugerido por Pallerosi 2000 (apud BARROS FILHO, 2003, p.67)
conforme mostrado na Figura 27 a seguir.
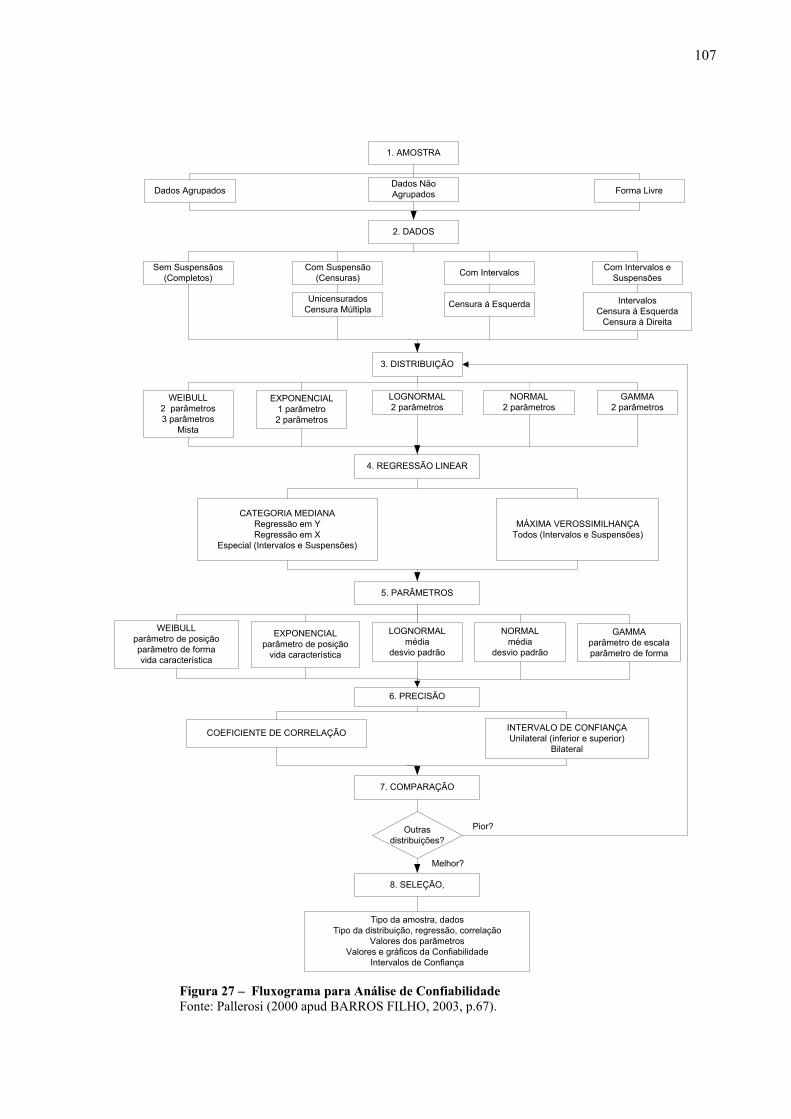
107
1. AMOSTRA
Dados AgrupadosDados Não Agrupados Forma Livre
2. DADOS
Sem Suspensãos (Completos)
Com Suspensão (Censuras)
Com Intervalos e SuspensõesCom Intervalos
UnicensuradosCensura Múltipla
IntervalosCensura à Esquerda
Censura à Direita
Censura à Esquerda
3. DISTRIBUIÇÃO
WEIBULL2 parâmetros3 parâmetros
Mista
EXPONENCIAL1 parâmetro2 parâmetros
GAMMA2 parâmetros
LOGNORMAL2 parâmetros
NORMAL2 parâmetros
4. REGRESSÃO LINEAR
MÁXIMA VEROSSIMILHANÇATodos (Intervalos e Suspensões)
CATEGORIA MEDIANARegressão em YRegressão em X
Especial (Intervalos e Suspensões)
5. PARÂMETROS
WEIBULLparâmetro de posiçãoparâmetro de formavida característica
EXPONENCIALparâmetro de posição
vida característica
GAMMAparâmetro de escalaparâmetro de forma
LOGNORMALmédia
desvio padrão
NORMALmédia
desvio padrão
6. PRECISÃO
INTERVALO DE CONFIANÇAUnilateral (inferior e superior)
Bilateral
COEFICIENTE DE CORRELAÇÃO
7. COMPARAÇÃO
Outras distribuições?
8. SELEÇÃO,
Tipo da amostra, dadosTipo da distribuição, regressão, correlação
Valores dos parâmetrosValores e gráficos da Confiabilidade
Intervalos de Confiança
Pior?
Melhor?
Figura 27 – Fluxograma para Análise de Confiabilidade Fonte: Pallerosi (2000 apud BARROS FILHO, 2003, p.67).

108
4a Etapa - Definição das variáveis da pesquisa
Nesta etapa foram definidas as variáveis da pesquisa. Os tempos de vida das 38
ventaneiras foram as variáveis consideradas com a unidade de medida em dias.
5a Etapa - Coleta de dados
Nesta etapa desenvolveu-se a pesquisa exploratória de campo, tendo sido realizado o
reconhecimento e levantamento de dados de campo, além de ter sido o ponto de partida das
observações. Estas se deram focadas na obtenção de dados para a análise dos tempos de vida
do conjunto de insuflação de ar. Para avaliar e analisar o desempenho da vida útil das
ventaneiras foram previamente verificados: número de ventaneiras do sistema, número de
trocas, tipos de falhas em operação, vida útil atual, etc.
Uma pesquisa de dados envolve a solicitação de informações verbais de pessoas a respeito das sensações delas mesmas. A meta final da pesquisa é permitir que os pesquisadores generalizem a respeito de uma população, estudando somente uma pequena parcela da mesma. Uma generalização precisa provém somente da aplicação do conjunto de procedimentos sistemáticos, científicos e metódicos conhecidos como pesquisa por amostragem. Esses procedimentos especificam que informações devem ser obtidas, como serão coletadas e de quem serão solicitadas (SILVA, 2006. p.4).
Baseado neste autor coletou-se os dados através de pesquisas de campo mediante
avaliações, entrevistas com profissionais da área e, pesquisa em banco de dados como, por
exemplo, o DataWarehouse (banco de dados da Manutenção). A pesquisa documental também
foi contemplada pela utilização de documentos internos da área operacional. Adicionalmente
foram utilizados fluxogramas e mapofluxogramas de processo.
6a Etapa - Avaliação exploratória dos dados
Nesta fase foi efetuado o tratamento dos dados, ordenamento, estudo da relação entre
eles através da aplicação de técnicas preparatórias (média, desvio-padrão, mediana, análise de
correlação, variância e covariância, etc.) e exclusão de dados discrepantes ou não significativos
através de métodos estatísticos apropriados. Na análise exploratória foi necessário remover
outliers do conjunto de dados. Para a realização de um teste estatístico o conjunto inicial de
dados foi padronizado. Os dados foram avaliados segundo sua função dentro do conjunto, sua

109
importância e representatividade. As ferramentas computacionais pré-selecionadas para fazer
estas análises foram o MatLab 5.3, SPSS 15, Minitab 15 e Statistica 6.0.
A partir do conhecimento dos subsídios discorridos anteriormente, apresenta-se nesta
última etapa, as fases que formaram a proposta metodológica para o estudo em epígrafe. Estas
fases podem ser visualizadas na Figura 28.
De forma simplificada, o diagrama mostra além das quatro principais fases da análise, as
principais ações, os recursos necessários, os resultados a serem alcançados e o objetivo
principal.

110
FASES
Coletar dados e informações do
conjunto de insuflação de ar do
Alto Forno 1
Análises paramétricas e não
paramétricas
Banco de dados, pesquisa
documental, entrevistas, visitas de
campo, etc.
Quantidade de registros mínima de
380 (tamanho da amostra)
Coleta e Tratamento de Dados
AÇÕES
RECURSOS NECESSÁRIOS
RESULTADOS
Análise de Confiabilidade
Avaliar a técnica multivariada
adequada ao tipo de dado coletado
Consultar o modelo proposto por Anderson
et al (1998)
Definição da técnica estatística multivariada
Obtenção dos dados estatísticos das
ventaneiras
Consultar o modelo proposto Palerosi
(2000)
Estimativa da função de
confiabilidade
Extrair os dados estatísticos da
amostra
Suporte computacional
(STATÍSTICA e outros)
Extrair os dados de confiabilidade na função adotada
Suporte computacional (WEIBULL++,
STATISTICA e outros)
Discussões Finais/ConclusãoAnálise Estatística
Estimar os parâmetros da
função e fazer os testes de aderência
Utilizar as técnicas gráficas e testes
analíticos
Obtençaõ da função de confiabilidade
Avaliar e tratar os dados amostrais
Aluno candidato do projeto de pesquisa
e suporte computacional
Organização dos dados de vida das
ventaneiras
Utilizar técnicas clássicas de
estatística descritiva para analisar a
variabilidade dos dados
Conclusão da Análise Estatístitica
Multivariada
Metodologia para análise de
confiabilidade do cj de insuflação de ar
(ventaneiras) do Alto Forno 1
Obtenção dos dados de confiabilidade das
ventaneiras
Obtenção de modelo não paramétrico
Figura 28 - Diagrama da metodologia para desenvolvimento da Dissertação

CAPÍTULO 9 - RESULTADOS
Levando-se em consideração as etapas delineadas nos procedimentos metodológicos
propostos, explicita-se a seguir, os resultados obtidos a partir da aplicação da metodologia
proposta.
Os dados utilizados nesta dissertação referem-se ao tempo de vida das ventaneiras do
conjunto de insuflação de ar (conjunto crítico) da unidade de produção de ferro gusa de uma
unidade produtora de aço, localizada na cidade de Serra, ES. Os tempos de vida desses
componentes foram considerados completos (sem censuras), pois não foram levantados os
tempos de vida anteriores à data inicial (1994) de aquisição dos dados amostrados. Esses
dados foram obtidos no setor operacional da empresa através de consulta aos bancos de dados
de controle de vida útil dos equipamentos de alta criticidade da área operacional. Recorreu-se
também à entrevista técnica de campo, especificamente ao Sr. Luis Augusto Wasem,
supervisor da unidade produtiva a quem nos auxiliou para dirimir dúvidas e prestar os
esclarecimentos sobre o funcionamento dos componentes críticos ora em avaliação.
É importante salientar que os componentes envolvidos nesta pesquisa foram
fabricados nas Oficinas da própria empresa e passaram por um rigoroso controle de qualidade
antes de serem liberados para verificação da integridade estrutural, como testes de
estanqueidade, hidrostático e de vazão de água necessários à garantia de qualidade de
fabricação pelas Oficinas.
A pesquisa foi desenvolvida com a coleta de informações a respeito das quantidades
de trocas das 38 ventaneiras refletindo consequentemente na quantidade de falhas das mesmas
durante o período avaliado. Adicionalmente foi consultado o banco de dados do setor de
manutenção DW (Data Warehouse), o SISMANA (Sistema de Gestão de Ativos) e
informações do SISCORP (Sistema de Controle de Padrões) servindo de instrumentos de
apoio dos quesitos de identificação e rastreabilidade de cada uma das ventaneiras pesquisadas.
Os dois primeiros sistemas armazenam informações de todos os equipamentos da unidade
industrial pesquisada.
A pesquisa teve início no dia 2 de outubro de 2005. Primeiramente foi elaborado um
plano de ação para realização dos estudos, extração e tratamento de dados. Entre o conjunto
de ações elaboradas, destacaram-se como as principais:

112
Visita a área operacional para conhecer o equipamento sobre o qual as ventaneiras são
montadas bem como o funcionamento do conjunto de insuflação de ar do qual fazem
parte;
Entrevistas com o pessoal dos setores operacional e de manutenção;
Identificação das fontes de pesquisa para extração dos dados de vida, seja através da
pesquisa de campo (pesquisa documental) ou digital (SISMANA, SISCORP e DW);
Coleta física de dados;
Identificação de datas de trocas e medições do tempo de vida útil das ventaneiras;
Triagem para expurgo de causas não relacionadas às efetivamente relacionadas a
atividade operacional em si das ventaneiras.
Verificação de metodologia similar com reprodução de todos os dados de uma tese de
doutorado (LOPES, 2001).
Dentre estas ações, a que demandou maior disponibilidade de tempo foi a que
envolveu a consulta e identificação das datas de trocas e realização de medições em cada uma
das 38 ventaneiras que foi retirada de operação, o que obrigou a execução de
aproximadamente 760 intervenções entre 1994 e 2003. Estas informações foram “cruzadas”
com as informações disponíveis nos bancos de dados digitais a fim de garantir a precisão na
extração dos dados e a aquisição de dados não tendenciosos. A pesquisa foi finalizada no dia
2 de março de 2007.
Os conjuntos de alta criticidade foram organizados e ordenados conforme
identificação e estrutura de codificação corporativa dos equipamentos de toda a unidade
produtiva. As ventaneiras, parte deste conjunto e objeto de avaliação neste estudo passarão a
denominar-se daqui por diante, simplesmente componentes críticos para simplificação de
análise e direcionamento ao objetivo principal do trabalho.
A Tabela 15 mostra a quantidade de falhas em cada uma dos 38 componentes críticos
ao longo de 10 anos de operação, iniciando em 1994 e terminando em 2003.

113
Tabela 15 - Componentes críticos com as respectivas quantidades de trocas
1994 1995 1996 1997 1998 1999 2000 2001 2002 2003VA1 3 1 3 3 4 1 1 1 1 2VA2 1 2 1 4 2 1 2 1 4 2VA3 1 2 2 3 1 1 2 1 3 1VA4 1 2 2 3 1 1 2 2 3 2VA5 1 2 2 2 1 2 1 2 3 3VA6 1 2 2 3 2 2 2 2 4 2VA7 1 2 2 3 1 3 2 2 4 2VA8 1 2 2 2 2 5 1 2 3 3VA9 1 2 2 4 1 2 2 2 3 2VA10 1 2 4 2 1 1 1 2 3 2VA11 1 2 2 1 1 2 1 1 3 1VA12 2 1 3 1 3 1 2 2 3 1VA13 1 2 2 1 2 2 2 2 2 1VA14 1 2 3 1 1 2 2 2 4 4VA15 1 2 2 1 2 1 1 2 2 4VA16 2 1 2 1 1 1 1 1 4 3VA17 1 2 2 1 1 2 2 1 3 4VA18 1 2 2 2 1 1 2 2 2 4VA19 1 2 2 1 2 1 1 2 4 1VA20 2 2 2 1 2 2 1 2 1 2VA21 2 2 2 2 1 1 1 2 2 2VA22 2 2 3 2 1 1 2 2 2 1VA23 2 2 3 1 2 1 2 1 3 2VA24 2 2 2 2 1 1 2 2 2 1VA25 2 3 2 2 1 1 1 2 1 1VA26 2 2 3 1 2 1 2 2 2 2VA27 2 3 2 2 2 1 2 2 3 2VA28 1 4 2 2 1 2 3 3 2 2VA29 2 1 2 2 1 2 1 3 2 1VA30 1 3 3 2 1 1 2 2 2 1VA31 1 3 2 2 1 2 2 2 1 2VA32 2 2 2 2 1 1 2 1 2 1VA33 2 2 2 2 1 2 2 2 3 2VA34 1 2 1 1 2 2 1 2 2 3VA35 1 2 1 2 1 1 2 2 2 2VA36 2 2 1 1 3 2 1 2 2 2VA37 2 1 1 1 3 1 1 2 2 2VA38 3 1 1 2 1 1 2 3 2 2
Total de Falhas 57 76 79 71 58 58 62 71 96 77
Número de FalhasComponente
O número de trocas que corresponderá ao número de falhas neste estudo situou-se
entre 1 e 4. Já a quantidade total de falhas em cada ano atingiu um mínimo de 57 não
ultrapassando 96 falhas.
9.1 AVALIAÇÃO DOS DADOS PARA UTILIZAÇÃO DA ACP
Considerando um conjunto de 38 componentes críticos em cada um dos dez anos de
1994 a 2003, antes de efetivamente iniciar esta análise deve-se garantir que todas as variáveis
escolhidas guardem as informações singulares quando da redução de dimensionalidade
através da técnica de componentes principais. Isto é, deverão ser excluídas as variáveis

114
“pouco importantes do ponto de vista estatístico”. Serão consideradas “pouco importantes”
aquelas variáveis que, se excluídas da análise estatística, não alterem seu resultado.
Preliminarmente foi realizada a Análise de Agrupamento Hierárquico (AAH). O
objetivo foi verificar previamente a existência de anomalias das amostras (anos) coletadas e
avaliar semelhanças entre os componentes críticos, ratificando ou não a aplicação da análise
de componentes principais.
As Figuras 29 e 30 mostram os dendogramas dos 38 componentes críticos e dos dez
anos em que foram avaliados seus respectivos tempos de vida. O método adotado para medir
a distância entre as variáveis (componentes críticos e os anos de amostragem) foi a distância
Euclidiana e a técnica de conexão utilizada foi o método de Ward.
Nesta análise foi utilizado um algoritmo de redução do número de componentes
críticos, fazendo com que aqueles de variância semelhante se juntassem em grupos ou classes.
O método hierárquico fez com que as classes se associassem em níveis de dissimilaridade
(distância Euclidiana) cada vez mais altos, até que houvesse apenas uma classe única.
0 20 40 60 80 100
(Dlink/Dmax)*100
VA14VA9VA5
VA29VA13VA36VA33VA8VA4VA2
VA31VA30VA28VA25VA22VA21VA16VA24VA11VA3
VA20VA23VA19VA27VA12VA18VA15VA35VA34VA32VA17VA10VA38VA7
VA26VA6
VA37VA1
Figura 29 – Dendograma dos 38 componentes críticos

115
A árvore de classificação acima mostrou as ligações resultantes da aplicação da AAH,
e definiu os grupos homogêneos. Quanto mais próximo de zero, mais os componentes críticos
se assemelharam em termos de tempo de vida.
Como pode ser observado na Figura 29, o dendograma mostrou a similaridade entre
38 componentes críticos. Verificou-se o surgimento de quatro grupos principais:
1o grupo: VA1, VA37, VA6, VA26, VA7 e VA38;
2o grupo: VA10, VA17, VA32, VA34, VA35, VA15, VA18, VA12, VA27, VA19,
VA23 e VA20;
3o grupo: VA3, VA11, VA24, VA16, VA21, VA22, VA25, VA28, VA30 e VA31 ;
4o grupo: VA2, VA4, VA8, VA33, VA36, VA13, VA29, VA5, VA9 e VA14.
As maiores similaridades foram identificadas entre os seguintes pares de componentes
críticos: VA2 e VA4 ; VA17 e VA32 ; VA11 e VA24; VA25 e VA28.
A avaliação das ligações de dendogramas requer algumas ponderações. Se a análise
for elaborada em um nível alto de semelhança (muito perto de zero), a mesma perde sua maior
função, que é a simplificação. Por outro lado, se a determinação dos grupos for muito distante
de zero, a dispersão das semelhanças poderia dificultar uma análise confiável por agregar
características (tempos de vida) cada vez menos parecidas. Examinando as ligações da Figura
29 optou-se, então, por manter os todos os componentes críticos por não influenciarem a
análise, ou seja, todos os níveis permitiram encontrar períodos de tempo de vida perfeitamente
dimensionados, atendendo assim, aos objetivos do estudo.
A AAH também foi realizada entre os anos que foram extraídos os tempos de vida de
cada um dos 38 componentes críticos. A Figura 30 mostra o dendograma dos dez anos (1994
a 2003) em que foram coletados os tempos de vida.

116
10 20 30 40 50 60 70 80 90 100
(Dlink/Dmax)*100
1999
1998
1996
1995
2002
2001
1997
2003
2000
1994
Figura 30 – Dendograma dos anos (período do tempo de amostragem) dos os tempos de vida dos 38 componentes críticos
Observando-se os anos em que foram coletadas as informações referentes aos tempos
de vidas dos 38 componentes críticos, percebe-se que as maiores similaridades ocorreram
entre os anos 1994 e 2000; 1997 e 2001; 1995 e 1996. Isto evidencia que ocorreram
semelhanças entre anos com alto espaçamento de tempo (1994 e 2000), semelhanças de
médio espaçamento de tempo (1997 e 2001) e semelhanças sem nenhum espaçamento de
tempo (1995 e 1996). Infere-se que nenhum dentre os dez anos que tiveram seus dados de
vida coletados não influenciaram a extração de componentes principais evidenciando desta
forma, certa homogeneidade entre os dados de vida em todo o período de tempo avaliado.
Na Tabela 16 foram inseridas as medidas descritivas dos 38 componentes críticos.
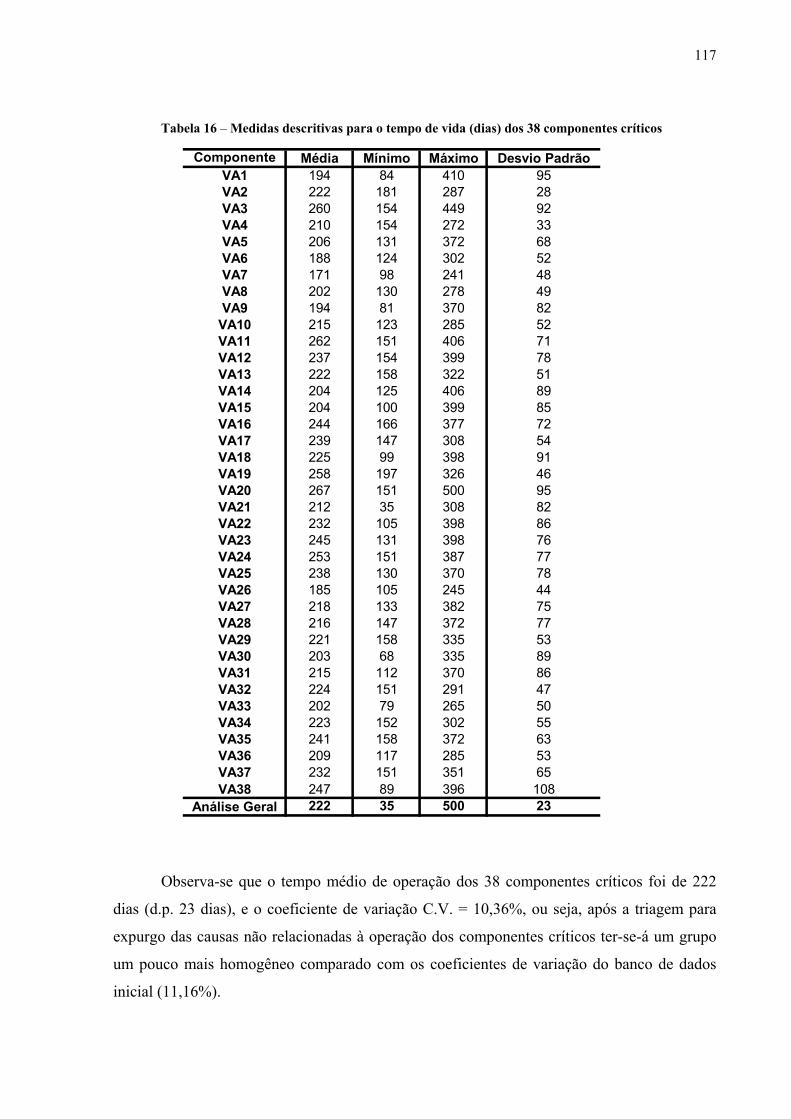
117
Tabela 16 – Medidas descritivas para o tempo de vida (dias) dos 38 componentes críticos
Componente Média Mínimo Máximo Desvio PadrãoVA1 194 84 410 95VA2 222 181 287 28VA3 260 154 449 92VA4 210 154 272 33VA5 206 131 372 68VA6 188 124 302 52VA7 171 98 241 48VA8 202 130 278 49VA9 194 81 370 82
VA10 215 123 285 52VA11 262 151 406 71VA12 237 154 399 78VA13 222 158 322 51VA14 204 125 406 89VA15 204 100 399 85VA16 244 166 377 72VA17 239 147 308 54VA18 225 99 398 91VA19 258 197 326 46VA20 267 151 500 95VA21 212 35 308 82VA22 232 105 398 86VA23 245 131 398 76VA24 253 151 387 77VA25 238 130 370 78VA26 185 105 245 44VA27 218 133 382 75VA28 216 147 372 77VA29 221 158 335 53VA30 203 68 335 89VA31 215 112 370 86VA32 224 151 291 47VA33 202 79 265 50VA34 223 152 302 55VA35 241 158 372 63VA36 209 117 285 53VA37 232 151 351 65VA38 247 89 396 108
Análise Geral 222 35 500 23
Observa-se que o tempo médio de operação dos 38 componentes críticos foi de 222
dias (d.p. 23 dias), e o coeficiente de variação C.V. = 10,36%, ou seja, após a triagem para
expurgo das causas não relacionadas à operação dos componentes críticos ter-se-á um grupo
um pouco mais homogêneo comparado com os coeficientes de variação do banco de dados
inicial (11,16%).

118
Outra observação é referente aos tempos de falha. O menor foi de 35 dias e o maior de
500 dias. Uma variação tão representativa considerando inclusive tempos próximos ou
superiores a 400 dias ocorreu em cerca de 9 dos 38, ou aproximadamente 24% dos
componentes, não revelando ainda muita coisa a respeito do comportamento e distribuição de
falhas dos componentes ora em análise.
Nas Tabelas 17 e 18 foram inseridas a matriz de correlação e a matriz de variâncias e
covariâncias respectivamente dos 38 componentes críticos.

119
Tabela 17 – Matriz de correlação dos 38 componentes críticos
VA1 VA2 VA3 VA4 VA5 VA6 VA7 VA8 VA9 VA10 VA11 VA12 VA13 VA14 VA15 VA16 VA17 VA18 VA19VA1 1,000VA2 0,482 1,000VA3 -0,026 -0,165 1,000VA4 -0,128 0,376 0,343 1,000VA5 -0,081 0,028 0,187 0,540 1,000VA6 0,818 0,236 0,017 -0,282 0,067 1,000VA7 0,158 0,447 -0,463 -0,361 -0,479 0,294 1,000VA8 -0,269 0,586 -0,168 0,477 0,333 -0,119 0,460 1,000VA9 -0,387 0,307 -0,006 0,665 0,755 -0,310 -0,073 0,758 1,000
VA10 0,470 0,497 0,258 0,237 0,143 0,395 -0,042 0,108 -0,019 1,000VA11 0,037 0,110 0,574 0,386 0,635 0,191 -0,434 0,177 0,372 0,641 1,000VA12 0,511 -0,052 -0,032 -0,286 -0,168 0,336 -0,127 -0,625 -0,393 0,255 0,074 1,000VA13 -0,220 -0,037 0,836 0,642 0,449 -0,169 -0,580 0,149 0,315 0,249 0,707 -0,308 1,000VA14 -0,286 0,334 0,312 0,771 0,652 -0,112 -0,109 0,754 0,779 0,391 0,665 -0,453 0,641 1,000VA15 0,758 0,432 -0,008 0,273 0,380 0,706 -0,129 -0,021 0,011 0,628 0,444 0,420 0,088 0,226 1,000VA16 0,348 -0,077 0,480 0,261 0,712 0,543 -0,499 -0,114 0,179 0,493 0,801 0,244 0,503 0,408 0,687 1,000VA17 0,307 0,611 0,033 0,564 0,477 0,325 0,039 0,503 0,462 0,776 0,631 0,116 0,250 0,719 0,732 0,522 1,000VA18 0,477 0,321 0,050 0,294 0,686 0,597 -0,170 0,189 0,330 0,681 0,689 0,250 0,173 0,491 0,850 0,831 0,823 1,000VA19 0,523 0,254 0,386 0,244 -0,168 0,230 -0,330 -0,384 -0,398 0,740 0,364 0,510 0,298 0,011 0,564 0,335 0,431 0,319 1,000VA20 0,654 0,260 -0,016 0,089 0,278 0,474 -0,353 -0,320 -0,121 0,637 0,482 0,695 0,023 -0,004 0,852 0,613 0,573 0,730 0,680VA21 0,051 -0,298 0,433 0,039 0,606 0,150 -0,622 -0,211 0,117 0,004 0,447 -0,215 0,465 0,094 0,108 0,606 -0,141 0,297 -0,089VA22 0,306 -0,139 0,392 0,050 0,322 0,192 -0,656 -0,523 -0,111 0,465 0,654 0,701 0,325 -0,013 0,493 0,674 0,285 0,501 0,608VA23 0,668 0,260 0,339 -0,162 -0,126 0,531 -0,109 -0,389 -0,442 0,814 0,482 0,611 0,103 -0,118 0,556 0,461 0,386 0,468 0,806VA24 0,337 0,080 0,537 0,165 0,379 0,402 -0,362 -0,166 0,041 0,724 0,865 0,534 0,456 0,333 0,586 0,798 0,593 0,694 0,610VA25 0,245 0,151 0,691 0,530 0,462 0,234 -0,474 -0,036 0,226 0,486 0,802 0,346 0,726 0,487 0,551 0,738 0,547 0,536 0,563VA26 0,149 0,287 0,198 -0,089 0,140 0,415 0,174 0,343 0,026 0,451 0,608 -0,211 0,359 0,378 0,296 0,371 0,377 0,381 0,099VA27 0,592 0,204 -0,073 -0,220 -0,146 0,396 -0,091 -0,444 -0,383 0,632 0,287 0,866 -0,222 -0,257 0,591 0,307 0,398 0,453 0,711VA28 0,069 -0,200 0,559 0,375 0,595 0,176 -0,611 -0,185 0,252 0,250 0,751 0,419 0,600 0,381 0,464 0,805 0,392 0,539 0,336VA29 -0,742 -0,269 0,152 0,482 0,409 -0,511 -0,278 0,389 0,563 0,045 0,422 -0,266 0,431 0,697 -0,174 0,155 0,339 0,125 -0,120VA30 0,311 0,111 0,384 0,324 0,515 0,229 -0,383 -0,155 0,310 0,347 0,580 0,647 0,271 0,227 0,492 0,646 0,453 0,571 0,358VA31 0,221 0,273 0,266 0,487 0,584 0,320 -0,179 0,235 0,454 0,587 0,747 0,397 0,353 0,621 0,665 0,715 0,839 0,796 0,378VA32 0,401 0,535 0,121 0,222 0,479 0,380 -0,061 0,249 0,361 0,689 0,760 0,385 0,218 0,430 0,643 0,590 0,754 0,768 0,361VA33 -0,121 0,158 0,195 0,199 0,051 -0,208 -0,021 0,103 0,215 0,588 0,360 0,294 0,051 0,307 -0,014 0,085 0,447 0,240 0,363VA34 0,552 0,446 -0,275 0,254 -0,008 0,294 -0,106 -0,076 -0,142 0,331 0,072 0,369 -0,036 -0,004 0,745 0,168 0,467 0,375 0,561VA35 0,603 0,379 -0,031 0,130 0,321 0,552 -0,109 -0,052 0,070 0,445 0,495 0,614 0,066 0,132 0,834 0,580 0,606 0,693 0,435VA36 0,172 0,637 -0,085 0,031 -0,444 0,006 0,410 0,299 -0,133 0,564 0,158 0,094 -0,002 0,151 0,147 -0,271 0,421 0,010 0,468VA37 0,565 0,051 -0,347 -0,336 -0,224 0,647 0,423 -0,190 -0,403 0,201 -0,358 0,276 -0,605 -0,322 0,377 0,073 0,125 0,279 0,115VA38 0,221 -0,205 -0,145 0,152 0,256 0,377 -0,038 -0,112 0,059 -0,311 -0,162 0,242 -0,125 -0,014 0,416 0,311 0,101 0,258 -0,117

120
Tabela 18 - Matriz de correlação dos 38 componentes críticos (continuação)
VA20 VA21 VA22 VA23 VA24 VA25 VA26 VA27 VA28 VA29 VA30 VA31 VA32 VA33 VA34 VA35 VA36 VA37 VA38
VA20 1,000VA21 0,133 1,000VA22 0,804 0,356 1,000VA23 0,720 0,090 0,682 1,000VA24 0,708 0,247 0,846 0,765 1,000VA25 0,552 0,241 0,717 0,485 0,841 1,000VA26 0,194 0,224 0,140 0,364 0,429 0,322 1,000VA27 0,858 -0,193 0,731 0,832 0,658 0,364 0,117 1,000VA28 0,531 0,346 0,781 0,303 0,796 0,897 0,174 0,319 1,000VA29 -0,166 -0,109 0,042 -0,336 0,182 0,244 0,027 -0,231 0,379 1,000VA30 0,616 0,172 0,759 0,435 0,765 0,778 -0,075 0,513 0,814 0,108 1,000VA31 0,609 -0,025 0,573 0,389 0,806 0,793 0,251 0,458 0,778 0,429 0,800 1,000VA32 0,716 0,125 0,621 0,595 0,785 0,647 0,536 0,604 0,539 0,060 0,683 0,781 1,000VA33 0,182 -0,272 0,301 0,407 0,473 0,223 -0,139 0,408 0,154 0,403 0,423 0,466 0,379 1,000VA34 0,712 -0,227 0,317 0,313 0,200 0,316 0,148 0,533 0,194 -0,194 0,160 0,311 0,363 -0,236 1,000VA35 0,855 0,005 0,652 0,519 0,665 0,652 0,375 0,690 0,618 -0,123 0,656 0,716 0,798 -0,022 0,724 1,000VA36 0,213 -0,556 0,016 0,452 0,206 0,115 0,483 0,434 -0,205 -0,024 -0,122 0,141 0,406 0,323 0,396 0,260 1,000VA37 0,173 -0,232 -0,189 0,230 -0,068 -0,317 -0,220 0,260 -0,289 -0,388 -0,088 0,003 -0,146 0,040 0,098 0,033 -0,135 1,000VA38 0,158 -0,085 -0,001 -0,280 -0,026 0,177 -0,304 -0,051 0,369 0,041 0,269 0,314 -0,128 -0,386 0,310 0,343 -0,520 0,409 1,000

121
Tabela 18 - Matriz de variâncias e covariâncias dos 38 componentes críticos
VA1 VA2 VA3 VA4 VA5 VA6 VA7 VA8 VA9 VA10 VA11 VA12 VA13 VA14 VA15 VA16 VA17 VA18 VA19VA1 9025,88VA2 1288,83 792,056VA3 -228,19 -424,944 8391,57VA4 -399,63 347,722 1032,12 1081,567VA5 -522,22 52,889 1159,89 1201,667 4580,22VA6 4066,70 347,833 80,01 -485,544 238,89 2736,01VA7 720,77 602,611 -2034,86 -568,522 -1553,78 736,48 2297,43VA8 -1254,42 808,222 -752,62 769,378 1105,22 -306,07 1081,02 2404,62VA9 -3020,18 710,333 -41,80 1798,422 4201,00 -1333,02 -288,73 3055,47 6760,93
VA10 2331,44 730,444 1231,56 407,444 506,33 1077,44 -106,11 276,00 -81,11 2722,89VA11 249,60 218,556 3715,98 895,533 3036,67 705,31 -1470,07 612,91 2160,82 2360,00 4985,82VA12 3783,41 -114,389 -230,57 -733,233 -888,22 1371,99 -475,59 -2389,04 -2520,98 1037,67 409,13 6077,79VA13 -1070,14 -53,056 3923,10 1080,878 1554,67 -451,57 -1423,03 373,73 1326,69 665,78 2556,24 -1229,43 2622,01VA14 -2405,02 833,889 2535,18 2247,178 3910,33 -519,38 -464,91 3274,49 5679,64 1807,78 4162,87 -3127,18 2909,82 7853,29VA15 6142,90 1036,278 -65,92 766,411 2193,11 3150,63 -526,66 -89,47 78,73 2795,78 2673,40 2790,59 382,26 1704,24 7271,878VA16 2392,03 -156,167 3180,23 621,456 3486,11 2052,68 -1727,63 -402,84 1064,42 1861,67 4088,20 1372,88 1863,32 2615,07 4238,300 5227,79VA17 1575,78 929,778 162,78 1003,333 1744,78 919,00 101,00 1334,33 2055,00 2190,11 2409,22 486,89 692,00 3445,00 3376,444 2040,56 2922,667VA18 4145,59 826,611 417,68 882,900 4241,11 2853,57 -745,30 848,82 2478,76 3247,67 4446,20 1779,77 809,77 3974,07 6627,967 5492,34 4066,333 8354,678VA19 2281,70 327,389 1623,23 368,456 -523,00 552,68 -725,30 -864,29 -1499,91 1770,67 1178,76 1823,10 699,43 44,07 2206,856 1111,68 1068,111 1339,233 2105,34VA20 5893,63 694,944 -140,12 278,767 1783,33 2350,21 -1605,59 -1488,82 -941,87 3151,22 3230,69 5140,57 111,12 -31,84 6894,144 4200,99 2936,000 6326,767 2960,77VA21 399,24 -689,444 3259,93 105,600 3369,22 642,49 -2448,31 -850,60 789,58 16,22 2592,91 -1378,38 1956,73 683,04 757,533 3596,60 -626,222 2233,156 -335,29VA22 2491,12 -335,722 3076,97 141,633 1867,33 863,63 -2697,54 -2199,58 -780,71 2080,67 3962,73 4690,70 1426,14 -95,98 3609,878 4178,30 1322,444 3926,411 2393,97VA23 4815,47 555,333 2355,93 -404,067 -648,44 2109,82 -397,76 -1447,60 -2761,20 3223,89 2583,36 3613,73 401,40 -790,62 3600,422 2530,60 1583,667 3248,933 2806,93VA24 2478,48 175,167 3802,23 419,789 1984,89 1626,79 -1342,52 -629,96 260,87 2920,33 4721,42 3217,10 1804,21 2282,40 3861,967 4464,46 2478,333 4908,122 2164,01VA25 1816,59 330,944 4933,23 1357,456 2437,22 952,34 -1772,19 -135,84 1450,53 1974,89 4412,64 2101,88 2896,54 3365,07 3659,300 4159,68 2305,111 3817,567 2012,68VA26 622,12 355,500 796,63 -128,478 415,78 954,41 367,01 740,09 94,29 1034,00 1888,84 -723,52 808,48 1473,91 1109,767 1178,74 895,889 1530,078 199,74VA27 4211,63 430,056 -500,79 -541,678 -741,89 1550,43 -324,92 -1628,16 -2354,53 2469,22 1516,24 5052,12 -850,32 -1704,84 3771,144 1663,32 1609,444 3100,100 2440,77VA28 506,03 -433,167 3932,01 947,233 3091,56 708,57 -2249,97 -696,51 1592,31 1000,67 4071,42 2508,88 2356,66 2593,07 3035,189 4466,01 1625,222 3784,900 1183,23VA29 -3731,19 -400,056 738,46 838,900 1465,56 -1414,99 -706,30 1010,49 2450,20 123,33 1577,76 -1099,23 1168,77 3267,40 -786,144 594,46 970,222 606,789 -290,88VA30 2637,91 278,000 3134,38 949,822 3109,67 1069,82 -1637,64 -677,60 2274,80 1616,33 3649,24 4497,29 1239,51 1796,60 3743,644 4164,60 2185,778 4651,822 1464,16VA31 1799,83 657,944 2085,17 1372,056 3383,89 1436,28 -734,72 988,33 3202,22 2625,11 4517,11 2651,94 1549,39 4713,56 4859,611 4429,17 3885,667 6234,611 1486,61VA32 1792,71 709,000 522,76 342,867 1526,44 936,20 -137,84 574,80 1396,27 1693,22 2526,16 1411,24 524,80 1793,64 2579,733 2006,76 1918,556 3305,978 779,20VA33 -574,56 223,778 895,22 328,778 173,44 -545,89 -50,00 253,89 885,44 1539,00 1275,22 1150,22 132,33 1366,78 -60,222 309,56 1212,667 1098,889 836,56VA34 2860,87 684,667 -1374,82 456,400 -28,56 837,84 -275,91 -203,18 -636,47 941,44 277,20 1567,16 -100,51 -21,49 3466,244 663,40 1377,889 1868,733 1404,51VA35 3590,43 668,278 -177,97 268,144 1362,22 1809,70 -326,46 -158,31 363,04 1452,89 2189,16 2997,52 212,86 733,76 4451,900 2625,37 2050,778 3967,922 1251,26VA36 857,72 942,722 -411,17 52,944 -1579,56 17,50 1032,72 770,78 -574,00 1548,89 587,89 387,39 -6,61 705,67 659,500 -1029,61 1197,000 46,833 1130,72VA37 3466,34 93,167 -2053,59 -712,700 -976,89 2184,30 1310,68 -602,36 -2141,04 677,89 -1631,60 1391,37 -1999,97 -1844,53 2076,767 339,97 437,444 1645,411 341,30VA38 2262,67 -620,889 -1431,44 539,778 1866,44 2125,33 -195,33 -591,89 520,11 -1747,44 -1232,56 2035,78 -690,89 -130,33 3823,000 2422,89 591,111 2536,556 -579,67

122
Tabela 18 - Matriz de variâncias e covariâncias dos 38 componentes críticos (continuação)
VA20 VA21 VA22 VA23 VA24 VA25 VA26 VA27 VA28 VA29 VA30 VA31 VA32 VA33 VA34 VA35 VA36 VA37 VA38
8996,681036,73 6745,076543,26 2505,31 7359,215183,51 563,51 4443,09 5761,295191,88 1567,93 5610,97 4493,04 5980,684082,32 1544,49 4794,08 2867,71 5066,34 6073,34807,48 809,98 528,88 1213,42 1458,08 1104,52 1932,996093,90 -1183,71 4691,26 4728,29 3807,66 2125,66 383,70 5603,123867,10 2181,93 5141,97 1766,71 4724,12 5367,79 585,63 1835,99 5893,57-831,68 -473,40 191,74 -1349,07 745,57 1008,12 63,63 -914,01 1539,34 2799,795208,73 1261,18 5808,53 2947,07 5275,16 5405,16 -294,36 3425,29 5574,38 508,82 7952,624950,83 -174,67 4210,61 2532,22 5341,39 5294,39 947,28 2936,83 5120,72 1943,83 6112,78 7342,7223196,13 483,91 2506,96 2127,36 2857,98 2374,09 1108,62 2126,47 1948,42 148,20 2864,91 3150,889 2215,156864,00 -1122,44 1294,22 1549,11 1836,11 873,11 -307,67 1531,56 592,56 1069,33 1893,78 2005,333 895,111 2518,223684,93 -1016,62 1481,36 1294,71 843,18 1341,73 355,24 2178,16 811,29 -559,38 780,38 1453,667 931,533 -647,11 2975,295076,19 24,91 3505,01 2468,36 3220,59 3183,92 1031,57 3233,86 2973,48 -407,74 3666,47 3844,500 2353,600 -69,56 2473,42 3922,5441062,17 -2404,00 74,17 1804,56 836,83 471,17 1116,61 1710,06 -827,94 -68,17 -574,56 636,278 1004,444 854,00 1137,11 856,722 2767,611056,59 -1228,91 -1048,90 1125,09 -342,03 -1595,70 -625,34 1258,59 -1430,37 -1327,14 -504,36 17,833 -442,378 128,56 345,58 132,456 -460,06 4169,211609,56 -756,33 -11,22 -2289,78 -217,11 1482,56 -1438,33 -415,33 3051,00 230,89 2586,22 2899,556 -649,444 -2087,89 1821,67 2314,000 -2946,00 2846,44 11607,78

123
Visando ratificar a aplicabilidade da análise de componentes principais aos dados de
tempo de vida dos componentes foram feitos dois testes estatísticos cujo objetivo foi avaliar a
correlação entre os dados originais dos tempos de vida dos componentes críticos.
Nesta primeira avaliação foi necessário normalizar as variáveis amostradas que é uma
condição para se realizar o teste “t” para o coeficiente de correlação de Pearson, dado pela
seguinte expressão:
21 2
−−
= nr
rtdf
Onde df = n-2 e n = número de pares de variáveis de todas as amostras.
A Tabela 19 mostra o coeficiente de correlação de Person e a estatística-teste dos 703
pares de componentes críticos calculados pela expressão acima com seus respectivos valores
críticos dados para um nível de significância α = 0,05.
(9.1)

124
Tabela 19 – Coeficiente de correlação de Person e a estatística teste “t” para os 703 pares de 38 componentes críticos
VA1 VA2 0,48 1,5561 1,9633 S VA2 VA16 -0,08 -0,2177 1,9633 S VA3 VA31 0,27 0,77934 1,9633 S VA5 VA14 0,65 2,43216 1,9633 NVA1 VA3 -0,03 -0,0742 1,9633 S VA2 VA17 0,61 2,1836 1,9633 N VA3 VA32 0,12 0,34549 1,9633 S VA5 VA15 0,38 1,162 1,9633 SVA1 VA4 -0,13 -0,3648 1,9633 S VA2 VA18 0,32 0,9598 1,9633 S VA3 VA33 0,19 0,56157 1,9633 S VA5 VA16 0,71 2,87146 1,9633 NVA1 VA5 -0,08 -0,2305 1,9633 S VA2 VA19 0,25 0,7413 1,9633 S VA3 VA34 -0,28 -0,8095 1,9633 S VA5 VA17 0,48 1,53454 1,9633 SVA1 VA6 0,82 4,0274 1,9633 N VA2 VA20 0,26 0,7626 1,9633 S VA3 VA35 -0,03 -0,0878 1,9633 S VA5 VA18 0,69 2,66378 1,9633 NVA1 VA7 0,16 0,4534 1,9633 S VA2 VA21 -0,30 -0,8839 1,9633 S VA3 VA36 -0,09 -0,2422 1,9633 S VA5 VA19 -0,17 -0,4833 1,9633 SVA1 VA8 -0,27 -0,7908 1,9633 S VA2 VA22 -0,14 -0,3972 1,9633 S VA3 VA37 -0,35 -1,0471 1,9633 S VA5 VA20 0,28 0,81796 1,9633 SVA1 VA9 -0,39 -1,1857 1,9633 S VA2 VA23 0,26 0,7615 1,9633 S VA3 VA38 -0,15 -0,4146 1,9633 S VA5 VA21 0,61 2,1557 1,9633 NVA1 VA10 0,47 1,5073 1,9633 S VA2 VA24 0,08 0,2284 1,9633 S VA4 VA5 0,54 1,81421 1,9633 S VA5 VA22 0,32 0,96077 1,9633 SVA1 VA11 0,04 0,1053 1,9633 S VA2 VA25 0,15 0,4317 1,9633 S VA4 VA6 -0,28 -0,8322 1,9633 S VA5 VA23 -0,13 -0,3599 1,9633 SVA1 VA12 0,51 1,6806 1,9633 S VA2 VA26 0,29 0,8484 1,9633 S VA4 VA7 -0,36 -1,0937 1,9633 S VA5 VA24 0,38 1,15926 1,9633 SVA1 VA13 -0,22 -0,6378 1,9633 S VA2 VA27 0,20 0,5898 1,9633 S VA4 VA8 0,48 1,53537 1,9633 S VA5 VA25 0,46 1,47382 1,9633 SVA1 VA14 -0,29 -0,8431 1,9633 S VA2 VA28 -0,20 -0,5788 1,9633 S VA4 VA9 0,67 2,51889 1,9633 N VA5 VA26 0,14 0,39914 1,9633 SVA1 VA15 0,76 3,2894 1,9633 N VA2 VA29 -0,27 -0,7888 1,9633 S VA4 VA10 0,24 0,69131 1,9633 S VA5 VA27 -0,15 -0,4187 1,9633 SVA1 VA16 0,35 1,0507 1,9633 S VA2 VA30 0,11 0,3152 1,9633 S VA4 VA11 0,39 1,18221 1,9633 S VA5 VA28 0,60 2,0941 1,9633 NVA1 VA17 0,31 0,9117 1,9633 S VA2 VA31 0,27 0,8021 1,9633 S VA4 VA12 -0,29 -0,8441 1,9633 S VA5 VA29 0,41 1,26867 1,9633 SVA1 VA18 0,48 1,5367 1,9633 S VA2 VA32 0,54 1,7923 1,9633 S VA4 VA13 0,64 2,36743 1,9633 N VA5 VA30 0,52 1,70043 1,9633 SVA1 VA19 0,52 1,7375 1,9633 S VA2 VA33 0,16 0,4539 1,9633 S VA4 VA14 0,77 3,4249 1,9633 N VA5 VA31 0,58 2,03224 1,9633 NVA1 VA20 0,65 2,4454 1,9633 N VA2 VA34 0,45 1,4094 1,9633 S VA4 VA15 0,27 0,80355 1,9633 S VA5 VA32 0,48 1,54432 1,9633 SVA1 VA21 0,05 0,1449 1,9633 S VA2 VA35 0,38 1,1589 1,9633 S VA4 VA16 0,26 0,76583 1,9633 S VA5 VA33 0,05 0,14464 1,9633 SVA1 VA22 0,31 0,9080 1,9633 S VA2 VA36 0,64 2,3356 1,9633 N VA4 VA17 0,56 1,93343 1,9633 S VA5 VA34 -0,01 -0,0219 1,9633 SVA1 VA23 0,67 2,5374 1,9633 N VA2 VA37 0,05 0,1452 1,9633 S VA4 VA18 0,29 0,86907 1,9633 S VA5 VA35 0,32 0,95993 1,9633 SVA1 VA24 0,34 1,0135 1,9633 S VA2 VA38 -0,20 -0,5917 1,9633 S VA4 VA19 0,24 0,71218 1,9633 S VA5 VA36 -0,44 -1,4002 1,9633 SVA1 VA25 0,25 0,7159 1,9633 S VA3 VA4 0,34 1,0314 1,9633 S VA4 VA20 0,09 0,25378 1,9633 S VA5 VA37 -0,22 -0,6487 1,9633 SVA1 VA26 0,15 0,4260 1,9633 S VA3 VA5 0,19 0,5387 1,9633 S VA4 VA21 0,04 0,11067 1,9633 S VA5 VA38 0,26 0,74896 1,9633 SVA1 VA27 0,59 2,0789 1,9633 N VA3 VA6 0,02 0,0472 1,9633 S VA4 VA22 0,05 0,14217 1,9633 S VA6 VA7 0,29 0,8692 1,9633 SVA1 VA28 0,07 0,1967 1,9633 S VA3 VA7 -0,46 -1,4792 1,9633 S VA4 VA23 -0,16 -0,464 1,9633 S VA6 VA8 -0,12 -0,3399 1,9633 SVA1 VA29 -0,74 -3,1327 1,9633 S VA3 VA8 -0,17 -0,4807 1,9633 S VA4 VA24 0,17 0,47334 1,9633 S VA6 VA9 -0,31 -0,922 1,9633 SVA1 VA30 0,31 0,9267 1,9633 S VA3 VA9 -0,01 -0,0157 1,9633 S VA4 VA25 0,53 1,76613 1,9633 S VA6 VA10 0,39 1,21521 1,9633 SVA1 VA31 0,22 0,6412 1,9633 S VA3 VA10 0,26 0,7542 1,9633 S VA4 VA26 -0,09 -0,2523 1,9633 S VA6 VA11 0,19 0,55026 1,9633 SVA1 VA32 0,40 1,2378 1,9633 S VA3 VA11 0,57 1,9852 1,9633 S VA4 VA27 -0,22 -0,638 1,9633 S VA6 VA12 0,34 1,01053 1,9633 SVA1 VA33 -0,12 -0,3434 1,9633 S VA3 VA12 -0,03 -0,0914 1,9633 S VA4 VA28 0,38 1,1448 1,9633 S VA6 VA13 -0,17 -0,4838 1,9633 SVA1 VA34 0,55 1,8727 1,9633 S VA3 VA13 0,84 4,3152 1,9633 N VA4 VA29 0,48 1,55632 1,9633 S VA6 VA14 -0,11 -0,3189 1,9633 SVA1 VA35 0,60 2,1403 1,9633 N VA3 VA14 0,31 0,9298 1,9633 S VA4 VA30 0,32 0,9682 1,9633 S VA6 VA15 0,71 2,82233 1,9633 NVA1 VA36 0,17 0,4927 1,9633 S VA3 VA15 -0,01 -0,0239 1,9633 S VA4 VA31 0,49 1,57657 1,9633 S VA6 VA16 0,54 1,82778 1,9633 SVA1 VA37 0,57 1,9372 1,9633 S VA3 VA16 0,48 1,5482 1,9633 S VA4 VA32 0,22 0,64249 1,9633 S VA6 VA17 0,32 0,97196 1,9633 SVA1 VA38 0,22 0,6411 1,9633 S VA3 VA17 0,03 0,0930 1,9633 S VA4 VA33 0,20 0,575 1,9633 S VA6 VA18 0,60 2,10399 1,9633 NVA2 VA3 -0,16 -0,4727 1,9633 S VA3 VA18 0,05 0,1413 1,9633 S VA4 VA34 0,25 0,7441 1,9633 S VA6 VA19 0,23 0,66931 1,9633 SVA2 VA4 0,38 1,1466 1,9633 S VA3 VA19 0,39 1,1842 1,9633 S VA4 VA35 0,13 0,37138 1,9633 S VA6 VA20 0,47 1,52136 1,9633 SVA2 VA5 0,03 0,0786 1,9633 S VA3 VA20 -0,02 -0,0456 1,9633 S VA4 VA36 0,03 0,08659 1,9633 S VA6 VA21 0,15 0,42783 1,9633 SVA2 VA6 0,24 0,6878 1,9633 S VA3 VA21 0,43 1,3599 1,9633 S VA4 VA37 -0,34 -1,0077 1,9633 S VA6 VA22 0,19 0,55475 1,9633 SVA2 VA7 0,45 1,4123 1,9633 S VA3 VA22 0,39 1,2036 1,9633 S VA4 VA38 0,15 0,43597 1,9633 S VA6 VA23 0,53 1,77431 1,9633 SVA2 VA8 0,59 2,0435 1,9633 N VA3 VA23 0,34 1,0186 1,9633 S VA5 VA6 0,07 0,19131 1,9633 S VA6 VA24 0,40 1,24237 1,9633 SVA2 VA9 0,31 0,9123 1,9633 S VA3 VA24 0,54 1,7991 1,9633 S VA5 VA7 -0,48 -1,5433 1,9633 S VA6 VA25 0,23 0,6796 1,9633 SVA2 VA10 0,50 1,6216 1,9633 S VA3 VA25 0,69 2,7040 1,9633 N VA5 VA8 0,33 0,99898 1,9633 S VA6 VA26 0,42 1,29019 1,9633 SVA2 VA11 0,11 0,3130 1,9633 S VA3 VA26 0,20 0,5707 1,9633 S VA5 VA9 0,75 3,25593 1,9633 N VA6 VA27 0,40 1,21972 1,9633 SVA2 VA12 -0,05 -0,1477 1,9633 S VA3 VA27 -0,07 -0,2071 1,9633 S VA5 VA10 0,14 0,40976 1,9633 S VA6 VA28 0,18 0,50704 1,9633 SVA2 VA13 -0,04 -0,1042 1,9633 S VA3 VA28 0,56 1,9074 1,9633 S VA5 VA11 0,64 2,32775 1,9633 N VA6 VA29 -0,51 -1,6825 1,9633 SVA2 VA14 0,33 1,0034 1,9633 S VA3 VA29 0,15 0,4360 1,9633 S VA5 VA12 -0,17 -0,4831 1,9633 S VA6 VA30 0,23 0,66646 1,9633 SVA2 VA15 0,43 1,3540 1,9633 S VA3 VA30 0,38 1,1752 1,9633 S VA5 VA13 0,45 1,41977 1,9633 S VA6 VA31 0,32 0,9568 1,9633 S
Componente Componente Componente ComponenteCorr. (r)Corr. (r) tdftcrit
(α = 5%)Sig. tdf
tcrit
(α = 5%)tdf
tcrit
(α = 5%)Sig. Corr. (r) Sig.Corr.
(r)tdf
tcrit
(α = 5%)Sig.

125
Tabela 19 – Coeficiente de correlação de Person e a estatística teste “t” para os 703 pares de 38 componentes críticos (continuação)
VA6 VA32 0,38 1,16298 1,9633 S VA8 VA21 -0,21 -0,6112 1,9633 S VA10 VA14 0,39 1,20133 1,9633 S VA11 VA37 -0,36 -1,084 1,9633 SVA6 VA33 -0,21 -0,6014 1,9633 S VA8 VA22 -0,52 -1,735 1,9633 S VA10 VA15 0,63 2,28425 1,9633 N VA11 VA38 -0,16 -0,4644 1,9633 SVA6 VA34 0,29 0,8689 1,9633 S VA8 VA23 -0,39 -1,1941 1,9633 S VA10 VA16 0,49 1,60458 1,9633 S VA12 VA13 -0,31 -0,9156 1,9633 SVA6 VA35 0,55 1,87442 1,9633 S VA8 VA24 -0,17 -0,4765 1,9633 S VA10 VA17 0,78 3,48389 1,9633 N VA12 VA14 -0,45 -1,4358 1,9633 SVA6 VA36 0,01 0,01799 1,9633 S VA8 VA25 -0,04 -0,1006 1,9633 S VA10 VA18 0,68 2,62972 1,9633 N VA12 VA15 0,42 1,30808 1,9633 SVA6 VA37 0,65 2,39833 1,9633 N VA8 VA26 0,34 1,03375 1,9633 S VA10 VA19 0,74 3,10753 1,9633 N VA12 VA16 0,24 0,71027 1,9633 SVA6 VA38 0,38 1,15174 1,9633 S VA8 VA27 -0,44 -1,3998 1,9633 S VA10 VA20 0,64 2,3353 1,9633 N VA12 VA17 0,12 0,32895 1,9633 SVA7 VA8 0,46 1,46502 1,9633 S VA8 VA28 -0,19 -0,5325 1,9633 S VA10 VA21 0,00 0,01071 1,9633 S VA12 VA18 0,25 0,72955 1,9633 SVA7 VA9 -0,07 -0,2078 1,9633 S VA8 VA29 0,39 1,19593 1,9633 S VA10 VA22 0,46 1,48481 1,9633 S VA12 VA19 0,51 1,67545 1,9633 SVA7 VA10 -0,04 -0,1201 1,9633 S VA8 VA30 -0,15 -0,4436 1,9633 S VA10 VA23 0,81 3,96312 1,9633 N VA12 VA20 0,70 2,73535 1,9633 NVA7 VA11 -0,43 -1,3639 1,9633 S VA8 VA31 0,24 0,68447 1,9633 S VA10 VA24 0,72 2,96584 1,9633 N VA12 VA21 -0,22 -0,6235 1,9633 SVA7 VA12 -0,13 -0,3629 1,9633 S VA8 VA32 0,25 0,72735 1,9633 S VA10 VA25 0,49 1,57133 1,9633 S VA12 VA22 0,70 2,78311 1,9633 NVA7 VA13 -0,58 -2,0128 1,9633 S VA8 VA33 0,10 0,29339 1,9633 S VA10 VA26 0,45 1,42805 1,9633 S VA12 VA23 0,61 2,1813 1,9633 NVA7 VA14 -0,11 -0,3114 1,9633 S VA8 VA34 -0,08 -0,2155 1,9633 S VA10 VA27 0,63 2,30763 1,9633 N VA12 VA24 0,53 1,78454 1,9633 SVA7 VA15 -0,13 -0,3675 1,9633 S VA8 VA35 -0,05 -0,146 1,9633 S VA10 VA28 0,25 0,72966 1,9633 S VA12 VA25 0,35 1,04291 1,9633 SVA7 VA16 -0,50 -1,6265 1,9633 S VA8 VA36 0,30 0,88553 1,9633 S VA10 VA29 0,04 0,12647 1,9633 S VA12 VA26 -0,21 -0,6108 1,9633 SVA7 VA17 0,04 0,11033 1,9633 S VA8 VA37 -0,19 -0,5481 1,9633 S VA10 VA30 0,35 1,04767 1,9633 S VA12 VA27 0,87 4,89246 1,9633 NVA7 VA18 -0,17 -0,4883 1,9633 S VA8 VA38 -0,11 -0,3189 1,9633 S VA10 VA31 0,59 2,05126 1,9633 N VA12 VA28 0,42 1,30595 1,9633 SVA7 VA19 -0,33 -0,9881 1,9633 S VA9 VA10 -0,02 -0,0535 1,9633 S VA10 VA32 0,69 2,69214 1,9633 N VA12 VA29 -0,27 -0,782 1,9633 SVA7 VA20 -0,35 -1,0677 1,9633 S VA9 VA11 0,37 1,13414 1,9633 S VA10 VA33 0,59 2,05467 1,9633 N VA12 VA30 0,65 2,39925 1,9633 NVA7 VA21 -0,62 -2,2465 1,9633 S VA9 VA12 -0,39 -1,2098 1,9633 S VA10 VA34 0,33 0,99133 1,9633 S VA12 VA31 0,40 1,22334 1,9633 SVA7 VA22 -0,66 -2,4586 1,9633 S VA9 VA13 0,32 0,93908 1,9633 S VA10 VA35 0,44 1,40376 1,9633 S VA12 VA32 0,38 1,17851 1,9633 SVA7 VA23 -0,11 -0,3111 1,9633 S VA9 VA14 0,78 3,51922 1,9633 N VA10 VA36 0,56 1,93293 1,9633 S VA12 VA33 0,29 0,87004 1,9633 SVA7 VA24 -0,36 -1,099 1,9633 S VA9 VA15 0,01 0,03176 1,9633 S VA10 VA37 0,20 0,58094 1,9633 S VA12 VA34 0,37 1,12129 1,9633 SVA7 VA25 -0,47 -1,5244 1,9633 S VA9 VA16 0,18 0,51472 1,9633 S VA10 VA38 -0,31 -0,925 1,9633 S VA12 VA35 0,61 2,19972 1,9633 NVA7 VA26 0,17 0,50024 1,9633 S VA9 VA17 0,46 1,4746 1,9633 S VA11 VA12 0,07 0,2108 1,9633 S VA12 VA36 0,09 0,26836 1,9633 SVA7 VA27 -0,09 -0,2572 1,9633 S VA9 VA18 0,33 0,98814 1,9633 S VA11 VA13 0,71 2,82754 1,9633 N VA12 VA37 0,28 0,81348 1,9633 SVA7 VA28 -0,61 -2,1857 1,9633 S VA9 VA19 -0,40 -1,2255 1,9633 S VA11 VA14 0,67 2,52031 1,9633 N VA12 VA38 0,24 0,7066 1,9633 SVA7 VA29 -0,28 -0,8201 1,9633 S VA9 VA20 -0,12 -0,3441 1,9633 S VA11 VA15 0,44 1,4015 1,9633 S VA13 VA14 0,64 2,36365 1,9633 NVA7 VA30 -0,38 -1,1732 1,9633 S VA9 VA21 0,12 0,33299 1,9633 S VA11 VA16 0,80 3,78127 1,9633 N VA13 VA15 0,09 0,24856 1,9633 SVA7 VA31 -0,18 -0,5143 1,9633 S VA9 VA22 -0,11 -0,315 1,9633 S VA11 VA17 0,63 2,30135 1,9633 N VA13 VA16 0,50 1,64733 1,9633 SVA7 VA32 -0,06 -0,1732 1,9633 S VA9 VA23 -0,44 -1,3953 1,9633 S VA11 VA18 0,69 2,68812 1,9633 N VA13 VA17 0,25 0,73022 1,9633 SVA7 VA33 -0,02 -0,0588 1,9633 S VA9 VA24 0,04 0,11613 1,9633 S VA11 VA19 0,36 1,10477 1,9633 S VA13 VA18 0,17 0,49685 1,9633 SVA7 VA34 -0,11 -0,3002 1,9633 S VA9 VA25 0,23 0,65732 1,9633 S VA11 VA20 0,48 1,55756 1,9633 S VA13 VA19 0,30 0,88199 1,9633 SVA7 VA35 -0,11 -0,3094 1,9633 S VA9 VA26 0,03 0,0738 1,9633 S VA11 VA21 0,45 1,41385 1,9633 S VA13 VA20 0,02 0,06473 1,9633 SVA7 VA36 0,41 1,26976 1,9633 S VA9 VA27 -0,38 -1,1711 1,9633 S VA11 VA22 0,65 2,44652 1,9633 N VA13 VA21 0,47 1,48677 1,9633 SVA7 VA37 0,42 1,32225 1,9633 S VA9 VA28 0,25 0,73732 1,9633 S VA11 VA23 0,48 1,55602 1,9633 S VA13 VA22 0,32 0,97087 1,9633 SVA7 VA38 -0,04 -0,1071 1,9633 S VA9 VA29 0,56 1,92761 1,9633 S VA11 VA24 0,86 4,86759 1,9633 N VA13 VA23 0,10 0,29368 1,9633 SVA8 VA9 0,76 3,28488 1,9633 N VA9 VA30 0,31 0,923 1,9633 S VA11 VA25 0,80 3,79619 1,9633 N VA13 VA24 0,46 1,44765 1,9633 SVA8 VA10 0,11 0,30687 1,9633 S VA9 VA31 0,45 1,44313 1,9633 S VA11 VA26 0,61 2,16847 1,9633 N VA13 VA25 0,73 2,9847 1,9633 NVA8 VA11 0,18 0,5087 1,9633 S VA9 VA32 0,36 1,09419 1,9633 S VA11 VA27 0,29 0,84699 1,9633 S VA13 VA26 0,36 1,08834 1,9633 SVA8 VA12 -0,62 -2,2641 1,9633 S VA9 VA33 0,21 0,62143 1,9633 S VA11 VA28 0,75 3,21776 1,9633 N VA13 VA27 -0,22 -0,6435 1,9633 SVA8 VA13 0,15 0,42573 1,9633 S VA9 VA34 -0,14 -0,4055 1,9633 S VA11 VA29 0,42 1,31766 1,9633 S VA13 VA28 0,60 2,11856 1,9633 NVA8 VA14 0,75 3,24185 1,9633 N VA9 VA35 0,07 0,19989 1,9633 S VA11 VA30 0,58 2,01138 1,9633 N VA13 VA29 0,43 1,35239 1,9633 SVA8 VA15 -0,02 -0,0605 1,9633 S VA9 VA36 -0,13 -0,3787 1,9633 S VA11 VA31 0,75 3,17379 1,9633 N VA13 VA30 0,27 0,79771 1,9633 SVA8 VA16 -0,11 -0,3235 1,9633 S VA9 VA37 -0,40 -1,2465 1,9633 S VA11 VA32 0,76 3,30885 1,9633 N VA13 VA31 0,35 1,06753 1,9633 SVA8 VA17 0,50 1,64753 1,9633 S VA9 VA38 0,06 0,16635 1,9633 S VA11 VA33 0,36 1,09103 1,9633 S VA13 VA32 0,22 0,63106 1,9633 SVA8 VA18 0,19 0,54551 1,9633 S VA10 VA11 0,64 2,35908 1,9633 N VA11 VA34 0,07 0,2041 1,9633 S VA13 VA33 0,05 0,14586 1,9633 SVA8 VA19 -0,38 -1,1768 1,9633 S VA10 VA12 0,26 0,74615 1,9633 S VA11 VA35 0,50 1,61142 1,9633 S VA13 VA34 -0,04 -0,1018 1,9633 SVA8 VA20 -0,32 -0,9556 1,9633 S VA10 VA13 0,25 0,72771 1,9633 S VA11 VA36 0,16 0,45334 1,9633 S VA13 VA35 0,07 0,18814 1,9633 S
Componente Componente Componente Corr. (r) tdftcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.Corr. (r) Sig.tdf
tcrit
(α = 5%)Componente

126
Tabela 19 – Coeficiente de correlação de Person e a estatística teste “t” para os 703 pares de 38 componentes críticos (continuação)
VA13 VA36 0,00 -0,0069 1,9633 S VA16 VA17 0,52 1,73115 1,9633 S VA18 VA26 0,38 1,16463 1,9633 S VA21 VA22 0,36 1,0761 1,9633 SVA13 VA37 -0,60 -2,1485 1,9633 S VA16 VA18 0,83 4,22634 1,9633 N VA18 VA27 0,45 1,4376 1,9633 S VA21 VA23 0,09 0,25673 1,9633 SVA13 VA38 -0,13 -0,357 1,9633 S VA16 VA19 0,34 1,00593 1,9633 S VA18 VA28 0,54 1,81177 1,9633 S VA21 VA24 0,25 0,72054 1,9633 SVA14 VA15 0,23 0,65473 1,9633 S VA16 VA20 0,61 2,19199 1,9633 N VA18 VA29 0,13 0,35768 1,9633 S VA21 VA25 0,24 0,70332 1,9633 SVA14 VA16 0,41 1,26447 1,9633 S VA16 VA21 0,61 2,15293 1,9633 N VA18 VA30 0,57 1,96571 1,9633 N VA21 VA26 0,22 0,65106 1,9633 SVA14 VA17 0,72 2,92668 1,9633 N VA16 VA22 0,67 2,57803 1,9633 N VA18 VA31 0,80 3,71961 1,9633 N VA21 VA27 -0,19 -0,555 1,9633 SVA14 VA18 0,49 1,59252 1,9633 S VA16 VA23 0,46 1,4698 1,9633 S VA18 VA32 0,77 3,39691 1,9633 N VA21 VA28 0,35 1,04329 1,9633 SVA14 VA19 0,01 0,03065 1,9633 S VA16 VA24 0,80 3,75072 1,9633 N VA18 VA33 0,24 0,69795 1,9633 S VA21 VA29 -0,11 -0,31 1,9633 SVA14 VA20 0,00 -0,0107 1,9633 S VA16 VA25 0,74 3,09537 1,9633 N VA18 VA34 0,37 1,1435 1,9633 S VA21 VA30 0,17 0,49444 1,9633 SVA14 VA21 0,09 0,26662 1,9633 S VA16 VA26 0,37 1,1293 1,9633 S VA18 VA35 0,69 2,7198 1,9633 N VA21 VA31 -0,02 -0,0702 1,9633 SVA14 VA22 -0,01 -0,0357 1,9633 S VA16 VA27 0,31 0,91346 1,9633 S VA18 VA36 0,01 0,02755 1,9633 S VA21 VA32 0,13 0,3569 1,9633 SVA14 VA23 -0,12 -0,3348 1,9633 S VA16 VA28 0,80 3,8322 1,9633 N VA18 VA37 0,28 0,8211 1,9633 S VA21 VA33 -0,27 -0,8006 1,9633 SVA14 VA24 0,33 0,999 1,9633 S VA16 VA29 0,16 0,44489 1,9633 S VA18 VA38 0,26 0,75397 1,9633 S VA21 VA34 -0,23 -0,6591 1,9633 SVA14 VA25 0,49 1,57817 1,9633 S VA16 VA30 0,65 2,39296 1,9633 N VA19 VA20 0,68 2,62532 1,9633 N VA21 VA35 0,00 0,0137 1,9633 SVA14 VA26 0,38 1,15588 1,9633 S VA16 VA31 0,71 2,89168 1,9633 N VA19 VA21 -0,09 -0,2527 1,9633 S VA21 VA36 -0,56 -1,894 1,9633 SVA14 VA27 -0,26 -0,7522 1,9633 S VA16 VA32 0,59 2,06524 1,9633 N VA19 VA22 0,61 2,16711 1,9633 N VA21 VA37 -0,23 -0,6738 1,9633 SVA14 VA28 0,38 1,16609 1,9633 S VA16 VA33 0,09 0,24219 1,9633 S VA19 VA23 0,81 3,8508 1,9633 N VA21 VA38 -0,09 -0,2427 1,9633 SVA14 VA29 0,70 2,7478 1,9633 N VA16 VA34 0,17 0,48265 1,9633 S VA19 VA24 0,61 2,1765 1,9633 N VA22 VA23 0,68 2,64012 1,9633 NVA14 VA30 0,23 0,6603 1,9633 S VA16 VA35 0,58 2,01255 1,9633 N VA19 VA25 0,56 1,92607 1,9633 S VA22 VA24 0,85 4,48337 1,9633 NVA14 VA31 0,62 2,23926 1,9633 N VA16 VA36 -0,27 -0,7953 1,9633 S VA19 VA26 0,10 0,28144 1,9633 S VA22 VA25 0,72 2,91006 1,9633 NVA14 VA32 0,43 1,34728 1,9633 S VA16 VA37 0,07 0,20651 1,9633 S VA19 VA27 0,71 2,85691 1,9633 N VA22 VA26 0,14 0,40057 1,9633 SVA14 VA33 0,31 0,91352 1,9633 S VA16 VA38 0,31 0,92563 1,9633 S VA19 VA28 0,34 1,0087 1,9633 S VA22 VA27 0,73 3,02609 1,9633 NVA14 VA34 0,00 -0,0126 1,9633 S VA17 VA18 0,82 4,09643 1,9633 N VA19 VA29 -0,12 -0,3413 1,9633 S VA22 VA28 0,78 3,53442 1,9633 NVA14 VA35 0,13 0,37724 1,9633 S VA17 VA19 0,43 1,3494 1,9633 S VA19 VA30 0,36 1,08384 1,9633 S VA22 VA29 0,04 0,11959 1,9633 SVA14 VA36 0,15 0,43311 1,9633 S VA17 VA20 0,57 1,97529 1,9633 S VA19 VA31 0,38 1,15519 1,9633 S VA22 VA30 0,76 3,29996 1,9633 NVA14 VA37 -0,32 -0,9632 1,9633 S VA17 VA21 -0,14 -0,403 1,9633 S VA19 VA32 0,36 1,09425 1,9633 S VA22 VA31 0,57 1,97648 1,9633 NVA14 VA38 -0,01 -0,0386 1,9633 S VA17 VA22 0,29 0,84146 1,9633 S VA19 VA33 0,36 1,10299 1,9633 S VA22 VA32 0,62 2,24039 1,9633 NVA15 VA16 0,69 2,67701 1,9633 N VA17 VA23 0,39 1,18326 1,9633 S VA19 VA34 0,56 1,91767 1,9633 S VA22 VA33 0,30 0,89158 1,9633 SVA15 VA17 0,73 3,04244 1,9633 N VA17 VA24 0,59 2,08184 1,9633 N VA19 VA35 0,44 1,36802 1,9633 S VA22 VA34 0,32 0,94397 1,9633 SVA15 VA18 0,85 4,57043 1,9633 N VA17 VA25 0,55 1,84877 1,9633 S VA19 VA36 0,47 1,49961 1,9633 S VA22 VA35 0,65 2,43455 1,9633 NVA15 VA19 0,56 1,93187 1,9633 S VA17 VA26 0,38 1,15098 1,9633 S VA19 VA37 0,12 0,32802 1,9633 S VA22 VA36 0,02 0,04649 1,9633 SVA15 VA20 0,85 4,60975 1,9633 N VA17 VA27 0,40 1,22604 1,9633 S VA19 VA38 -0,12 -0,334 1,9633 S VA22 VA37 -0,19 -0,5455 1,9633 SVA15 VA21 0,11 0,30774 1,9633 S VA17 VA28 0,39 1,20372 1,9633 S VA20 VA21 0,13 0,3798 1,9633 S VA22 VA38 0,00 -0,0034 1,9633 SVA15 VA22 0,49 1,60471 1,9633 S VA17 VA29 0,34 1,01977 1,9633 S VA20 VA22 0,80 3,82635 1,9633 N VA23 VA24 0,77 3,36426 1,9633 NVA15 VA23 0,56 1,89324 1,9633 S VA17 VA30 0,45 1,43871 1,9633 S VA20 VA23 0,72 2,93437 1,9633 N VA23 VA25 0,48 1,56778 1,9633 SVA15 VA24 0,59 2,0434 1,9633 N VA17 VA31 0,84 4,35729 1,9633 N VA20 VA24 0,71 2,83395 1,9633 N VA23 VA26 0,36 1,10402 1,9633 SVA15 VA25 0,55 1,86574 1,9633 S VA17 VA32 0,75 3,24683 1,9633 N VA20 VA25 0,55 1,87373 1,9633 S VA23 VA27 0,83 4,24517 1,9633 NVA15 VA26 0,30 0,8765 1,9633 S VA17 VA33 0,45 1,41336 1,9633 S VA20 VA26 0,19 0,55824 1,9633 S VA23 VA28 0,30 0,89991 1,9633 SVA15 VA27 0,59 2,0711 1,9633 N VA17 VA34 0,47 1,49484 1,9633 S VA20 VA27 0,86 4,73088 1,9633 N VA23 VA29 -0,34 -1,0087 1,9633 SVA15 VA28 0,46 1,48003 1,9633 S VA17 VA35 0,61 2,15297 1,9633 N VA20 VA28 0,53 1,77276 1,9633 S VA23 VA30 0,44 1,36792 1,9633 SVA15 VA29 -0,17 -0,5004 1,9633 S VA17 VA36 0,42 1,3123 1,9633 S VA20 VA29 -0,17 -0,4753 1,9633 S VA23 VA31 0,39 1,19551 1,9633 SVA15 VA30 0,49 1,59965 1,9633 S VA17 VA37 0,13 0,35726 1,9633 S VA20 VA30 0,62 2,21058 1,9633 N VA23 VA32 0,60 2,09659 1,9633 NVA15 VA31 0,67 2,51876 1,9633 N VA17 VA38 0,10 0,28853 1,9633 S VA20 VA31 0,61 2,17241 1,9633 N VA23 VA33 0,41 1,25917 1,9633 SVA15 VA32 0,64 2,37316 1,9633 N VA18 VA19 0,32 0,95308 1,9633 S VA20 VA32 0,72 2,90052 1,9633 N VA23 VA34 0,31 0,93119 1,9633 SVA15 VA33 -0,01 -0,0398 1,9633 S VA18 VA20 0,73 3,0189 1,9633 N VA20 VA33 0,18 0,52209 1,9633 S VA23 VA35 0,52 1,71842 1,9633 SVA15 VA34 0,75 3,16076 1,9633 N VA18 VA21 0,30 0,88131 1,9633 S VA20 VA34 0,71 2,86991 1,9633 N VA23 VA36 0,45 1,43288 1,9633 SVA15 VA35 0,83 4,26786 1,9633 N VA18 VA22 0,50 1,63623 1,9633 S VA20 VA35 0,85 4,6528 1,9633 N VA23 VA37 0,23 0,66712 1,9633 SVA15 VA36 0,15 0,42037 1,9633 S VA18 VA23 0,47 1,49906 1,9633 S VA20 VA36 0,21 0,61619 1,9633 S VA23 VA38 -0,28 -0,825 1,9633 SVA15 VA37 0,38 1,15187 1,9633 S VA18 VA24 0,69 2,729 1,9633 N VA20 VA37 0,17 0,49539 1,9633 S VA24 VA25 0,84 4,39001 1,9633 NVA15 VA38 0,42 1,29431 1,9633 S VA18 VA25 0,54 1,79546 1,9633 S VA20 VA38 0,16 0,45112 1,9633 S VA24 VA26 0,43 1,34265 1,9633 S
Componente Componente ComponenteComponente Corr. (r) tdftcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.

127
Tabela 19 – Coeficiente de correlação de Person e a estatística teste “t” para os 703 pares de 38 componentes críticos (continuação)
VA24 VA27 0,66 2,46994 1,9633 N VA28 VA31 0,78 3,50732 1,9633 N VA36 VA37 -0,14 -0,3866 1,9633 SVA24 VA28 0,80 3,7159 1,9633 N VA28 VA32 0,54 1,81113 1,9633 S VA36 VA38 -0,52 -1,7208 1,9633 SVA24 VA29 0,18 0,52411 1,9633 S VA28 VA33 0,15 0,44029 1,9633 S VA37 VA38 0,41 1,26833 1,9633 SVA24 VA30 0,76 3,35864 1,9633 N VA28 VA34 0,19 0,55857 1,9633 SVA24 VA31 0,81 3,8518 1,9633 N VA28 VA35 0,62 2,22589 1,9633 NVA24 VA32 0,79 3,58648 1,9633 N VA28 VA36 -0,21 -0,5924 1,9633 SVA24 VA33 0,47 1,51897 1,9633 S VA28 VA37 -0,29 -0,8524 1,9633 SVA24 VA34 0,20 0,577 1,9633 S VA28 VA38 0,37 1,12249 1,9633 SVA24 VA35 0,66 2,518 1,9633 N VA29 VA30 0,11 0,30678 1,9633 SVA24 VA36 0,21 0,59449 1,9633 S VA29 VA31 0,43 1,34219 1,9633 SVA24 VA37 -0,07 -0,1942 1,9633 S VA29 VA32 0,06 0,16862 1,9633 SVA24 VA38 -0,03 -0,0737 1,9633 S VA29 VA33 0,40 1,24444 1,9633 SVA25 VA26 0,32 0,9632 1,9633 S VA29 VA34 -0,19 -0,5588 1,9633 SVA25 VA27 0,36 1,10674 1,9633 S VA29 VA35 -0,12 -0,3507 1,9633 SVA25 VA28 0,90 5,74642 1,9633 N VA29 VA36 -0,02 -0,0693 1,9633 SVA25 VA29 0,24 0,71312 1,9633 S VA29 VA37 -0,39 -1,1923 1,9633 SVA25 VA30 0,78 3,49966 1,9633 N VA29 VA38 0,04 0,11465 1,9633 SVA25 VA31 0,79 3,67937 1,9633 N VA30 VA31 0,80 3,77039 1,9633 NVA25 VA32 0,65 2,4017 1,9633 N VA30 VA32 0,68 2,64176 1,9633 NVA25 VA33 0,22 0,64782 1,9633 S VA30 VA33 0,42 1,32106 1,9633 SVA25 VA34 0,32 0,94085 1,9633 S VA30 VA34 0,16 0,45972 1,9633 SVA25 VA35 0,65 2,43431 1,9633 N VA30 VA35 0,66 2,46136 1,9633 NVA25 VA36 0,11 0,32722 1,9633 S VA30 VA36 -0,12 -0,349 1,9633 SVA25 VA37 -0,32 -0,9457 1,9633 S VA30 VA37 -0,09 -0,2487 1,9633 SVA25 VA38 0,18 0,50739 1,9633 S VA30 VA38 0,27 0,79052 1,9633 SVA26 VA27 0,12 0,33203 1,9633 S VA31 VA32 0,78 3,54022 1,9633 NVA26 VA28 0,17 0,49832 1,9633 S VA31 VA33 0,47 1,49111 1,9633 SVA26 VA29 0,03 0,0774 1,9633 S VA31 VA34 0,31 0,92557 1,9633 SVA26 VA30 -0,08 -0,2129 1,9633 S VA31 VA35 0,72 2,90389 1,9633 NVA26 VA31 0,25 0,73479 1,9633 S VA31 VA36 0,14 0,40326 1,9633 SVA26 VA32 0,54 1,79464 1,9633 S VA31 VA37 0,00 0,00912 1,9633 SVA26 VA33 -0,14 -0,3983 1,9633 S VA31 VA38 0,31 0,93567 1,9633 SVA26 VA34 0,15 0,42365 1,9633 S VA32 VA33 0,38 1,15836 1,9633 SVA26 VA35 0,37 1,14283 1,9633 S VA32 VA34 0,36 1,10137 1,9633 SVA26 VA36 0,48 1,55919 1,9633 S VA32 VA35 0,80 3,75102 1,9633 NVA26 VA37 -0,22 -0,6387 1,9633 S VA32 VA36 0,41 1,25534 1,9633 SVA26 VA38 -0,30 -0,9014 1,9633 S VA32 VA37 -0,15 -0,4162 1,9633 SVA27 VA28 0,32 0,95366 1,9633 S VA32 VA38 -0,13 -0,3653 1,9633 SVA27 VA29 -0,23 -0,6708 1,9633 S VA33 VA34 -0,24 -0,6882 1,9633 SVA27 VA30 0,51 1,69094 1,9633 S VA33 VA35 -0,02 -0,0626 1,9633 SVA27 VA31 0,46 1,45669 1,9633 S VA33 VA36 0,32 0,96695 1,9633 SVA27 VA32 0,60 2,14125 1,9633 N VA33 VA37 0,04 0,11231 1,9633 SVA27 VA33 0,41 1,26298 1,9633 S VA33 VA38 -0,39 -1,1841 1,9633 SVA27 VA34 0,53 1,78392 1,9633 S VA34 VA35 0,72 2,96882 1,9633 NVA27 VA35 0,69 2,6948 1,9633 N VA34 VA36 0,40 1,22074 1,9633 SVA27 VA36 0,43 1,36353 1,9633 S VA34 VA37 0,10 0,27887 1,9633 SVA27 VA37 0,26 0,76284 1,9633 S VA34 VA38 0,31 0,92217 1,9633 SVA27 VA38 -0,05 -0,1459 1,9633 S VA35 VA36 0,26 0,76164 1,9633 SVA28 VA29 0,38 1,15822 1,9633 S VA35 VA37 0,03 0,09269 1,9633 SVA28 VA30 0,81 3,9671 1,9633 N VA35 VA38 0,34 1,03256 1,9633 S
Componente ComponenteComponente Corr. (r) tdftcrit
(α = 5%)Sig. Corr. (r) tdf
tcrit
(α = 5%)Sig.Corr. (r) tdf
tcrit
(α = 5%)Sig.

128
Como a estatística calculada tdf não ultrapassou o valor crítico tabelado de 1,9633 em
79,08% das correlações entre os 703 pares de componentes críticos, haverá evidências para
não se rejeitar a hipótese nula H0 ou equivalentemente aceitar a hipótese alternativa H1 (ρ ≠ 0,
há correlação entre 2 populações amostrais). Os resultados do teste de hipóteses, mesmo com
os dados normalizados, indicam que a distribuição dos tempos de vida dos componentes pode
ser utilizada pela análise de componentes principais.
Um segundo teste foi realizado e sua conceituação já foi abordada nos capítulos
precedentes. A estatística teste para se efetuar esta avaliação foi dada seguinte expressão:
)(])()([)1()1(
2/)2)(1(22
1
^2
2αχγ −+
−−
=
−
<− >−Σ−−ΣΣ
−
−= ppk
p
kikkirrrr
rnT
Sendo,
ikkiik
p
kii
k rpp
rpkrp
r<
−
≠−
−
ΣΣ−
==Σ−
=)1(
2;,...2,11
11
2
22^
)1)(2(])1(1[)1(
−
−
−−−
−−−=
rpprpγ
Sendo,
“ p”, o número de autovalores da matriz de correlação;
kr−
, a média dos elementos de fora da diagonal na k-ésima coluna ou fila da matriz de
correlação e −
r , a média global de todos os elementos de fora da diagonal da matriz de correlação.
De acordo com os dados da matriz de correlação mostrados na Tabela 19, as
quantidades a serem consideradas na expressão anterior são as seguintes:
38380 == pen
263161,0=−
r
(9.2)
(9.3)
(9.4)

129
78701,81)( 2 =−ΣΣ−
<rr
ikki
90652,33^
=γ
888227,0)( 2
1=−Σ
−−
=rr k
p
k
Logo, a estatística T é igual a:
T = 36.069,1
Comparando o valor acima a um nível de significância α de 5% e com um número de
graus de liberdade (g.l.) calculado conforme a expressão a seguir:
g.l.= (p + 1)*(p – 2)/2 = (38 + 1)*(38 – 2)/2 = 702
O valor crítico χ2 da distribuição qui-quadrado com α = 0,05 e g.l.= 702 é dado por:
χ2 = 764,7485
Como a estatística T calculada atingiu um valor bem superior ao valor crítico tabelado,
podemos considerar que há evidências de se rejeitar a hipótese nula H0 (igualdade de
correlações) ou equivalentemente aceitar a hipótese alternativa H1 (diferenças de correlações)
entre os dados da matriz original dos dados de tempos de vida, sendo coerente com o teste
executado com as variáveis normalizadas do teste anterior.
Concluiu-se, portanto, pelos resultados obtidos, que os dois testes são consistentes
indicando que os dados de tempos de vida dos 38 componentes críticos podem ser utilizados
pela análise de componentes principais.
9.2 DETERMINAÇÃO DO NÚMERO DE COMPONENTES PRINCIPAIS
Para determinar o número de componentes principais, adotou-se a extração dos
mesmos via matriz de variância-covariância. Na Tabela 20 são apresentados os autovalores e
seus respectivos coeficientes de explicação (% da variância explicada).

130
Tabela 20 – Autovalores da matriz de variância-covariância e seus respectivos coeficientes de explicação
Componente Principal Autovalor % Variância Variância Acumulada
% Variância Acumulada
CP1 77982,18 40,86445 77982,2 40,8645CP2 36258,42 19,00024 114240,6 59,8647CP3 21834,74 11,44191 136075,3 71,3066CP4 18105,65 9,48778 154181,0 80,7944CP5 12794,50 6,70461 166975,5 87,4990CP6 8542,86 4,47665 175518,4 91,9756CP7 6610,08 3,46383 182128,4 95,4395CP8 4828,90 2,53045 186957,3 97,9699CP9 3874,01 2,03007 190831,3 100,0000
Analisando a Tabela 20, observa-se que o primeiro componente principal (CP1)
explicou 40,86% da variabilidade total do tempo de vida das peças; o segundo componente
principal (CP2) explica 19,00%, e o terceiro componente principal (CP3) 11,44%, os demais
somados explicam somente 28,70% da variabilidade total. A Figura 31 mostra graficamente o
percentual acumulado de explicação da variância.
Figura 31 – Gráfico do percentual acumulado de explicação da variância
A observação da Tabela 20 e a Figura 31 é possível concluir que um modelo de três
componentes são suficientes para a obtenção de uma boa interpretação dos tempos de vida os
quais ocorreram as falhas, incorporando aproximadamente 71% dos tempos de vidas dos 38
componentes críticos.
A Figura 32 mostra o gráfico (scree-plot) com o peso de cada autovalor conforme
sugerido por Cattel (1966 apud TINN, 2002).
40,86%
59,86%71,30%
80,79%87,49% 91,97% 95,43% 97,96% 100,00%
0,00%10,00%20,00%30,00%40,00%50,00%60,00%70,00%80,00%90,00%
100,00%
CP1 CP2 CP3 CP4 CP5 CP6 CP7 CP8 CP9
Componente Principal

131
0 1 2 3 4 5 6 7 8 9 10 11
Ordem dos Componentes Principais
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
Aut
oval
ores
Média dos Autovalores = 21.203
Figura 32 – Gráfico (scree-plot) com o peso dos autovalores dos componentes principais
Observando ainda a mesma Figura 32 e, aplicando o critério de Kaiser (1958 apud
MINGOTTI, 2005) à matriz de covariâncias, encontrou-se a variância média dos tempos de
vida originais igual a 21.203, constando-se que apenas são necessários os três primeiros
componentes principais para representar o conjunto dos tempos de vida dos 38 componentes
críticos.
Pelo critério de Johnson e Wichern (1992), considerando o número de componentes
principais “p” igual a nove, a proporção de 1/9 ou aproximadamente 11,11%, foi o percentual
mínimo da variância acumulada atingido pelo terceiro componente principal, confirmando
mais uma vez a seleção dos três primeiros componentes principais eleitos para análise.

132
Na Tabela 21 são mostrados os autovetores derivados dos autovalores determinados
pela matriz de variância-covariância também denominados de loadings.
Tabela 21 – Autovetores definidos para os componentes principais
Componente CP1 CP2 CP3 CP4 CP5 CP6 CP7 CP8 CP9VA1 0,176377 0,337790 0,096149 0,028808 -0,310150 -0,153931 0,000120 0,381254 0,169142VA2 0,023749 0,014184 0,043848 0,152005 -0,035251 -0,034063 0,060846 0,204712 0,084723VA3 0,118977 -0,204539 -0,350155 -0,194689 -0,134759 -0,483816 -0,079705 0,121152 0,126986VA4 0,037132 -0,106130 0,050369 0,032915 0,028262 -0,082545 0,112662 0,042918 0,291603VA5 0,125434 -0,226305 0,155902 -0,089267 -0,109851 0,265623 -0,052095 0,052373 0,092350VA6 0,094194 0,127967 0,105668 -0,014299 -0,226605 -0,132694 -0,139124 0,046008 -0,257704VA7 -0,066293 0,078054 0,108786 0,189747 -0,006512 -0,146536 -0,158618 0,174374 -0,290276VA8 -0,020103 -0,147744 0,145861 0,230605 -0,034623 -0,039492 0,005738 0,145078 -0,078306VA9 0,040490 -0,337121 0,222339 0,125276 0,102204 0,213175 -0,041812 0,339570 0,122914
VA10 0,130332 0,024903 -0,073298 0,222959 -0,086878 -0,057086 -0,099100 -0,132913 0,147060VA11 0,198476 -0,183990 -0,117085 0,070721 -0,084505 0,031765 -0,007945 -0,099532 -0,195688VA12 0,155110 0,253244 -0,067106 -0,116707 0,325792 0,057256 -0,118964 0,086707 -0,063131VA13 0,068945 -0,187859 -0,121549 -0,046269 -0,083907 -0,175868 0,183923 -0,031515 0,084520VA14 0,111117 -0,372943 0,135744 0,251350 -0,037980 -0,151416 0,024264 -0,103464 0,089900VA15 0,251101 0,123457 0,220739 0,062621 -0,169159 -0,048777 0,164266 -0,078427 0,137204VA16 0,220878 -0,086161 0,032109 -0,147357 -0,197426 0,011326 -0,114811 -0,158624 -0,088013VA17 0,138122 -0,054187 0,122941 0,224316 0,008803 -0,051222 -0,013409 -0,072006 0,098773VA18 0,275796 -0,036434 0,217580 0,114502 -0,198663 0,168669 -0,190550 -0,154921 0,001196VA19 0,101595 0,083310 -0,118700 0,059850 0,015884 -0,150620 0,109297 -0,130800 0,286361VA20 0,292054 0,191277 0,015365 0,037777 0,018433 0,253731 0,205306 -0,114986 0,153075VA21 0,074658 -0,142950 -0,124345 -0,291979 -0,466558 0,322015 -0,013977 0,044134 0,041725VA22 0,252989 0,043905 -0,227615 -0,157679 0,130708 0,223333 0,078126 -0,080796 -0,007869VA23 0,187572 0,179526 -0,240348 0,126572 -0,104317 -0,077144 -0,125178 -0,026290 0,012853VA24 0,255228 -0,031592 -0,154616 0,021948 0,034279 -0,053260 -0,137892 -0,076566 -0,190545VA25 0,236545 -0,122895 -0,088598 -0,072397 0,068955 -0,251019 0,177324 0,134726 -0,019241VA26 0,052197 -0,038260 -0,045370 0,134869 -0,182489 -0,036203 0,120436 -0,046685 -0,439846VA27 0,179769 0,239173 -0,108234 0,108700 0,170070 0,118910 -0,023603 -0,093469 -0,025052VA28 0,220943 -0,134869 -0,030477 -0,228035 0,147966 -0,060027 0,077409 -0,044462 -0,164978VA29 0,015556 -0,205273 0,026252 0,045897 0,206176 -0,001078 -0,026035 -0,366432 -0,028555VA30 0,260980 -0,048295 -0,010000 -0,149768 0,266122 0,048701 -0,207705 0,431419 0,099068VA31 0,266251 -0,118295 0,135189 0,091793 0,201061 -0,102063 -0,133776 -0,012712 -0,088448VA32 0,139370 -0,019296 -0,002950 0,136876 0,005847 0,113112 0,003294 0,173724 -0,154099VA33 0,056090 -0,037677 -0,106656 0,165196 0,193942 0,014999 -0,346013 -0,055488 0,221176VA34 0,090335 0,120224 0,112708 0,072535 0,026638 -0,013119 0,450185 -0,069395 0,133240VA35 0,186817 0,080666 0,099328 0,026570 0,056922 0,049317 0,230219 0,141237 -0,242544VA36 0,023076 0,059130 -0,096459 0,327416 0,068165 -0,118157 0,185313 0,019295 -0,110961VA37 0,009403 0,210030 0,193530 0,006002 -0,119059 -0,132601 -0,414580 -0,206406 0,135374VA38 0,080038 0,060186 0,539515 -0,436175 0,146954 -0,301969 0,047134 -0,139113 -0,058554
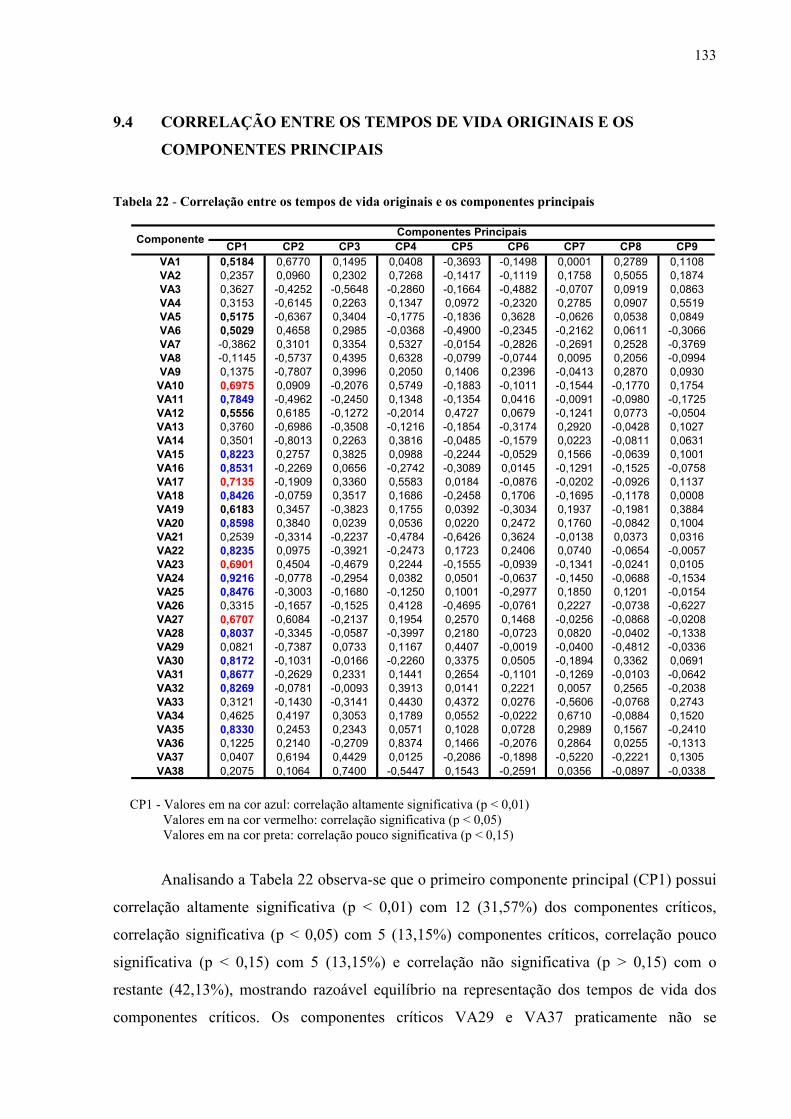
133
9.4 CORRELAÇÃO ENTRE OS TEMPOS DE VIDA ORIGINAIS E OS
COMPONENTES PRINCIPAIS
Tabela 22 - Correlação entre os tempos de vida originais e os componentes principais
CP1 CP2 CP3 CP4 CP5 CP6 CP7 CP8 CP9VA1 0,5184 0,6770 0,1495 0,0408 -0,3693 -0,1498 0,0001 0,2789 0,1108VA2 0,2357 0,0960 0,2302 0,7268 -0,1417 -0,1119 0,1758 0,5055 0,1874VA3 0,3627 -0,4252 -0,5648 -0,2860 -0,1664 -0,4882 -0,0707 0,0919 0,0863VA4 0,3153 -0,6145 0,2263 0,1347 0,0972 -0,2320 0,2785 0,0907 0,5519VA5 0,5175 -0,6367 0,3404 -0,1775 -0,1836 0,3628 -0,0626 0,0538 0,0849VA6 0,5029 0,4658 0,2985 -0,0368 -0,4900 -0,2345 -0,2162 0,0611 -0,3066VA7 -0,3862 0,3101 0,3354 0,5327 -0,0154 -0,2826 -0,2691 0,2528 -0,3769VA8 -0,1145 -0,5737 0,4395 0,6328 -0,0799 -0,0744 0,0095 0,2056 -0,0994VA9 0,1375 -0,7807 0,3996 0,2050 0,1406 0,2396 -0,0413 0,2870 0,0930VA10 0,6975 0,0909 -0,2076 0,5749 -0,1883 -0,1011 -0,1544 -0,1770 0,1754VA11 0,7849 -0,4962 -0,2450 0,1348 -0,1354 0,0416 -0,0091 -0,0980 -0,1725VA12 0,5556 0,6185 -0,1272 -0,2014 0,4727 0,0679 -0,1241 0,0773 -0,0504VA13 0,3760 -0,6986 -0,3508 -0,1216 -0,1854 -0,3174 0,2920 -0,0428 0,1027VA14 0,3501 -0,8013 0,2263 0,3816 -0,0485 -0,1579 0,0223 -0,0811 0,0631VA15 0,8223 0,2757 0,3825 0,0988 -0,2244 -0,0529 0,1566 -0,0639 0,1001VA16 0,8531 -0,2269 0,0656 -0,2742 -0,3089 0,0145 -0,1291 -0,1525 -0,0758VA17 0,7135 -0,1909 0,3360 0,5583 0,0184 -0,0876 -0,0202 -0,0926 0,1137VA18 0,8426 -0,0759 0,3517 0,1686 -0,2458 0,1706 -0,1695 -0,1178 0,0008VA19 0,6183 0,3457 -0,3823 0,1755 0,0392 -0,3034 0,1937 -0,1981 0,3884VA20 0,8598 0,3840 0,0239 0,0536 0,0220 0,2472 0,1760 -0,0842 0,1004VA21 0,2539 -0,3314 -0,2237 -0,4784 -0,6426 0,3624 -0,0138 0,0373 0,0316VA22 0,8235 0,0975 -0,3921 -0,2473 0,1723 0,2406 0,0740 -0,0654 -0,0057VA23 0,6901 0,4504 -0,4679 0,2244 -0,1555 -0,0939 -0,1341 -0,0241 0,0105VA24 0,9216 -0,0778 -0,2954 0,0382 0,0501 -0,0637 -0,1450 -0,0688 -0,1534VA25 0,8476 -0,3003 -0,1680 -0,1250 0,1001 -0,2977 0,1850 0,1201 -0,0154VA26 0,3315 -0,1657 -0,1525 0,4128 -0,4695 -0,0761 0,2227 -0,0738 -0,6227VA27 0,6707 0,6084 -0,2137 0,1954 0,2570 0,1468 -0,0256 -0,0868 -0,0208VA28 0,8037 -0,3345 -0,0587 -0,3997 0,2180 -0,0723 0,0820 -0,0402 -0,1338VA29 0,0821 -0,7387 0,0733 0,1167 0,4407 -0,0019 -0,0400 -0,4812 -0,0336VA30 0,8172 -0,1031 -0,0166 -0,2260 0,3375 0,0505 -0,1894 0,3362 0,0691VA31 0,8677 -0,2629 0,2331 0,1441 0,2654 -0,1101 -0,1269 -0,0103 -0,0642VA32 0,8269 -0,0781 -0,0093 0,3913 0,0141 0,2221 0,0057 0,2565 -0,2038VA33 0,3121 -0,1430 -0,3141 0,4430 0,4372 0,0276 -0,5606 -0,0768 0,2743VA34 0,4625 0,4197 0,3053 0,1789 0,0552 -0,0222 0,6710 -0,0884 0,1520VA35 0,8330 0,2453 0,2343 0,0571 0,1028 0,0728 0,2989 0,1567 -0,2410VA36 0,1225 0,2140 -0,2709 0,8374 0,1466 -0,2076 0,2864 0,0255 -0,1313VA37 0,0407 0,6194 0,4429 0,0125 -0,2086 -0,1898 -0,5220 -0,2221 0,1305VA38 0,2075 0,1064 0,7400 -0,5447 0,1543 -0,2591 0,0356 -0,0897 -0,0338
Componentes PrincipaisComponente
CP1 - Valores em na cor azul: correlação altamente significativa (p < 0,01) Valores em na cor vermelho: correlação significativa (p < 0,05) Valores em na cor preta: correlação pouco significativa (p < 0,15)
Analisando a Tabela 22 observa-se que o primeiro componente principal (CP1) possui
correlação altamente significativa (p < 0,01) com 12 (31,57%) dos componentes críticos,
correlação significativa (p < 0,05) com 5 (13,15%) componentes críticos, correlação pouco
significativa (p < 0,15) com 5 (13,15%) e correlação não significativa (p > 0,15) com o
restante (42,13%), mostrando razoável equilíbrio na representação dos tempos de vida dos
componentes críticos. Os componentes críticos VA29 e VA37 praticamente não se

134
correlacionaram com o CP1, fato este que não chegou a preocupar, por estarem em posições
distantes uma da outra e representarem apenas 5% do total. Isso reforça o princípio de que,
para analisar o tempo de vida do componente crítico, basta analisar o 1o componente principal
(CP1), pois o mesmo foi relativamente expressivo na sua absorção da variabilidade (40,86%)
com resultados relativamente satisfatórios de sua correlação com o tempo de vida dos
componentes críticos.
9.5 ANÁLISES DE COMUNALIDADES
Tabela 23 – Comunalidades dos 38 componentes críticos
Componente Inicial ExtraídaVA1 1,000 0,269VA2 1,000 0,056VA3 1,000 0,132VA4 1,000 0,099VA5 1,000 0,268VA6 1,000 0,253VA7 1,000 0,149VA8 1,000 0,013VA9 1,000 0,019VA10 1,000 0,486VA11 1,000 0,616VA12 1,000 0,309VA13 1,000 0,141VA14 1,000 0,123VA15 1,000 0,676VA16 1,000 0,728VA17 1,000 0,509VA18 1,000 0,710VA19 1,000 0,382VA20 1,000 0,739VA21 1,000 0,064VA22 1,000 0,678VA23 1,000 0,476VA24 1,000 0,849VA25 1,000 0,718VA26 1,000 0,110VA27 1,000 0,450VA28 1,000 0,646VA29 1,000 0,007VA30 1,000 0,668VA31 1,000 0,753VA32 1,000 0,684VA33 1,000 0,097VA34 1,000 0,214VA35 1,000 0,694VA36 1,000 0,015VA37 1,000 0,002VA38 1,000 0,043

135
As comunalidades representam a porcentagem da variância da variável explicada
pelos componentes principais, ou seja, definem a qualidade da representação dos
componentes principais. Inicialmente é considerado 1, ou seja, toda a variância é explicada
pelos componentes principais. Após a análise, os valores mudaram e atingiram os novos
valores dados na tabela 9.9. Os componentes críticos VA2, VA4, VA8, VA9, VA21, VA29,
VA33, VA36, VA37 e VA38 foram as que tiveram as maiores comunalidades e possuíram
também as menores correlações com as componentes principais. Já os componentes críticos
VA11, VA15, VA16, VA18, VA20, VA22, VA24, VA25, VA28, VA30, VA31, VA32 E
VA35 apresentaram destacadamente as maiores percentagens da variância possuindo de
forma semelhante as maiores correlações com os componentes principais. Os demais
componentes situaram-se em patamares intermediários evidenciando relativo equilíbrio do
conjunto de dados analisados.
9.6 ANÁLISE DOS COMPONENTES PRINCIPAIS CP1 E CP2
VA1
VA2
VA3
VA4
VA5
VA6 VA7
VA8
VA9
VA10
VA11
VA12
VA13
VA14
VA15
VA16 VA17 VA18
VA19
VA20
VA21
VA22
VA23
VA24
VA25
VA26
VA27
VA28
VA29
VA30
VA31
VA32 VA33
VA34 VA35 VA36
VA37
VA38
-50 0 50 100
CP1
-100
-50
0
50
100
CP
2
Figura 33 – Gráfico de scores entre os componentes principais CP1 e CP2

136
199419951996
1997
1998
1999
20002001
2002
2003
-500 -250 0 250 500 750 1000
CP1
-500
-250
0
250
500
CP
2
Figura 34 – Gráfico de loadings entre os componentes principais CP1 e CP2
Analisando conjuntamente o gráfico de scores e o gráfico de loadings para as duas
primeiras componentes principais (CP1 e CP2) nas figuras 9.5 e 9.6 respectivamente, notou-se
que a maioria dos componentes críticos apresentou scores positivos no CP1. Já os
componentes críticos VA7 e VA8 apresentaram scores negativos. Esta separação deveu-se à
influência dos anos 1998, 1999, 2000 e 2001 que contribuíram para este deslocamento.
Em relação ao CP2, houve regular equilíbrio ficando aproximadamente 50% dos
componentes críticos em scores negativos e 50% em scores positivos. O afastamento para as
extremidades de alguns componentes críticos, como o VA1 (extremo positivo) e VA9 e VA14
(extremo negativo) foi influenciado pelos tempos de vida do ano de 1999 (VA1) e pelo ano de
1998 (VA9 e VA14). Comportamento similar também foi observado nos gráficos de scores e
loadings entre os componentes VA1/VA3 e VA2/VA3 (vide Anexo D).
A Figura 35 representa o comportamento do tempo de vida para o primeiro
componente principal (CP1), considerando que os componentes críticos foram avaliados entre
os anos de 1994 a 2003.

137
0
50
100
150
200
250
300
350
400
1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004
Ano
Tem
po d
e V
ida
(dia
s)
Figura 35 – Gráfico do tempo de vida do primeiro componente principal (CP1)
Observa-se uma tendência de elevação no tempo de vida entre os anos 1994 e 1999,
aproximadamente cinco anos em marcha quase que ininterrupta que foi explicado segundo os
especialistas entrevistados pela estabilidade operacional do Alto Forno. Esta condição foi
reflexo da melhoria contínua, sustentada pela implantação de sistemas de qualidade nas outras
unidades operacionais; gestão integrada dos diversos ativos produtivos; práticas modernas de
manutenção reconhecida no planejamento estratégico de longo prazo, compartilhado e
acompanhado por todos os departamentos da empresa, entre eles, o Planejamento e Controle
de Produção e o Departamento de Manutenção.
Já a tendência de queda apresentada entre os anos de 2002 e 2003 de acordo com os
mesmos especialistas foi devido a um distúrbio interno do processo de elaboração do ferro
gusa gerando interrupções do processo produtivo e consequentemente afetando as diversas
partes e componentes do equipamento principal, dentre eles, o conjunto de insuflação de ar do
qual as ventaneiras fazem parte como principal componente crítico. Conforme visto
anteriormente na análise de agrupamento hierárquico (AAH) este desvio não comprometeu a
análise, haja vista que seus dados não prejudicaram a extração dos componentes principais.
Outra forma de verificar a eficiência do primeiro componente principal (CP1) é
comparar a variação de seus tempos de vida com os dos dois outros componentes principais
(CP2 e CP3), como mostrado na Figura 36.

138
050
100150200250300350400
1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004
Ano
Tem
po d
e Vi
da (d
ias)
CP1 CP2 CP3
Figura 36 – Gráfico do tempo de vida do CP1, CP2 e CP3 versus o período de tempo de amostragem
Analisando a Figura 36, observa-se que os componentes principais possuem pouca
diferenciação quanto a sua variabilidade, ou seja, os três componentes principais apresentaram
praticamente o mesmo comportamento, havendo sensível destaque do primeiro componente
(CP1) que teve um comportamento ligeiramente oscilante em relação ao segundo e terceiro
componentes principais.
Tabela 24 – Medidas descritivas para os três primeiros componentes
CP Média Desvio-padrão C.V.CP1 230 61 26,56%CP2 217 37 17,18%CP3 233 45 19,29%
Analisando a Tabela 24, pode-se constatar que o coeficiente de variação do primeiro
componente principal é maior que os demais, logo ele tem uma variação mais expressiva; em
conseqüência ele absorve mais a variação dos dados que o geraram.
9.7 ANÁLISE DE CONFIABILIDADE DO PRIMEIRO COMPONENTE
PRINCIPAL (CP1)
Para analisar o primeiro componente principal quanto a sua confiabilidade foi
necessário utilizar-se dos seguintes procedimentos:
1- Determinar a função densidade de confiabilidade f(t) para o primeiro componente
principal

139
Tempo (dias)
f(t)
100-125 125-150 150-175 175-200 200-225 225-250 250-275 275-300 300-325 325-350 350-375 375-4000,000
0,016
0,003
0,006
0,010
0,013
Figura 37 – Função densidade de falhas f(t) para o primeiro componente principal
O gráfico mostrado na Figura 37 dá uma mostra do perfil da distribuição densidade de
falhas dos tempos de vida dos 38 componentes críticos representados pelo primeiro
componente principal.
2- Ajustar um modelo de confiabilidade ao componente principal
Os modelos utilizados para o ajuste foram: Weibull, Gamma, Lognormal, Normal e
Exponencial. Para estimar os parâmetros do modelo, utilizou-se o método da máxima
verossimilhança. Os parâmetros encontrados estão dispostos na Tabela 25:
Tabela 25 – Parâmetros estimados para os modelos probabilísticos
Constante (λ) Média (µ) d.p.(σ) fator escala (η) fator forma (β)Weibull --- --- --- 253,0505 3,99336Gamma --- --- --- 12,9162 17,81490Lognormal --- 5,4102 0,24427 --- ---Normal --- 230,1000 61,15272 --- ---Exponencial 0,00434825 --- --- --- ---
Distribuição Parâmetros

140
3- Realizar testes de aderência para ajustes de distribuição
Para certificar-se da utilização do melhor modelo a ser adotado para análise de
confiabilidade foi necessário verificar o quanto os modelos propostos “aderem” a distribuição
dos tempos de vida do primeiro componente principal. Desta forma, foi feita uma avaliação
entre todas estas distribuições com objetivo de se definir o modelo que melhor se ajusta à
distribuição de falhas dos tempos de vida dos componentes críticos.
Primeiramente foi utilizado o estimador não paramétrico Kaplan-Meier aos dados
comparando-o aos modelos propostos já citados conforme mostrado na Tabela 26.
Tabela 26 – Valores da função de confiabilidade R(t) para os tempos de vida do 1o componente principal dos modelos propostos e o estimador Kaplan-Meier
Tempo de Vida (dias) Exp. Weibull Gamma Lognormal Normal Kaplan Meier
164 0,4901 0,8375 0,8547 0,8980 0,8601 0,9180 0,4572 0,7732 0,7743 0,8131 0,7937 0,8189 0,4396 0,7316 0,7225 0,7548 0,7492 0,7197 0,4246 0,6916 0,6737 0,6984 0,7058 0,6204 0,4119 0,6544 0,6294 0,6469 0,6652 0,5216 0,3909 0,5870 0,5523 0,5568 0,5912 0,4237 0,3568 0,4623 0,4210 0,4064 0,4551 0,3248 0,3402 0,3966 0,3576 0,3363 0,3849 0,2305 0,2655 0,1210 0,1244 0,1021 0,1103 0,1361 0,2081 0,0159 0,0330 0,0250 0,0162 0
Os gráficos de dispersão dos pontos dos tempos de vida do primeiro componente
principal (CP1) de cada modelo comparando ao estimador Kaplan-Meier são mostrados no
Anexo A.
Tabela 27 – Erro-padrão do Estimador Kaplan-Meier dos modelos propostos
Distribuição Estimativa R(t)
Weibull exp -(t/253,0505)^3,99336
Gamma exp -(t/12,9162)^17,8149
Lognormal 1/t·0,24427(2π)1/2* exp -1/2((log(t) - 5,4102)/0,24427)^2
Normal 1/61,15272(2π)1/2* exp -1/2((t - 230,1)/61,15272)^2
Exponencial (1/229,9776)*exp -t/229,9776 0,017210,06069
0,01732
Erro-padrão do Estimador Kaplan-Meier
0,011220,01119

141
A Tabela 27 mostra o erro-padrão do estimador Kaplan-Meier com cada um dos
modelos propostos. Por esta avaliação, os modelos que mais se aproximaram do estimador
Kaplan-Meier (bissetriz do primeiro quadrante) foram o modelo de distribuição Gamma e
Lognormal com ligeira vantagem para este último, pois apresentaram erros de estimativa de
0,01122 e 0,01119 respectivamente.
Em seguida foram realizados os testes de aderência analíticos ou paramétricos já
discutidos nas seções anteriores, a saber: as estatísticas Qui-quadrado 2χ , Kolmogorov-
Smirnov D e Anderson-Darling A2.
Tabela 28 – Estatísticas testes: Qui-quadrado, Kolmogorov-Smirnov e Anderson-Darling
(χ2calc) (χ2crit) p-value (Dcalc) (Dcrit) p-value (A2cal) (A2
crit) p-valueWeibull 8,721 15,507 n.s. 0,197 0,410 n.s. 0,577 0,757 0,05Gamma 8,037 15,507 n.s. 0,173 0,410 n.s. 0,406 0,752 0,05Lognormal 6,870 15,507 n.s. 0,157 0,410 n.s. 0,339 0,752 0,05Normal 8,110 15,507 n.s. 0,191 0,410 n.s. 0,575 0,752 0,05Exponencial 30,051 16,919 0,01 0,510 0,410 0,01 2,867 1,321 0,05
Teste Qui-quadrado ( χ2 ) Teste Kolmogorov-Smirnov (K-S)Distribuição
Teste Anderson-Darling (A2)
Analisando as estatísticas da Tabela 28, observa-se que o modelo Lognormal
apresentou as melhores estatísticas testes, motivo na qual foi adotada para a representação da
distribuição de falhas dos tempos de vida dos 38 componentes críticos amostrados.
9.8 ANÁLISE DE CONFIABILIDADE DO MODELO DE PROBABILIDADE
LOGNORMAL
Considerando o subconjunto ventaneiras definidas neste estudo como componentes
críticos e tendo a fadiga como principal mecanismo de falha confirma-se neste capítulo a
adequação do modelo probabilístico Lognormal para a representação estatística da
confiabilidade dos tempos de vidas dos componentes críticos ora em análise.
Analisando os dados da Tabela 29 mostrada a seguir, comprova-se mais uma vez que
o modelo Lognormal foi que melhor se ajustou ao dados, sendo mais robusto dentre todos os
modelos propostos, pois o coeficiente de determinação R2 ajustado situou-se entre 80,29% e
93,18% entre os 38 componentes críticos.

142
Tabela 29 – Coeficientes de Correlação, Determinação, Teste F e Valor p dos Componentes Críticos para o modelo de probabilidade Lognormal
Comp. Crítico R R² R² Ajust. Teste F Valor p
VA1 0,92002 0,84643 0,82723 44,09370 0,00016VA2 0,91998 0,84636 0,82716 44,07037 0,00016VA3 0,93597 0,87604 0,86055 56,53897 0,00007VA4 0,91325 0,83402 0,81327 40,19764 0,00022VA5 0,92207 0,85021 0,83149 45,40945 0,00015VA6 0,92788 0,86097 0,84359 49,54109 0,00011VA7 0,95023 0,90293 0,89079 74,41341 0,00003VA8 0,93715 0,87824 0,86302 57,70367 0,00006VA9 0,90964 0,82745 0,80588 38,36290 0,00026
VA10 0,92329 0,85246 0,83402 46,22340 0,00014VA11 0,90819 0,82480 0,80290 37,66288 0,00028VA12 0,9633 0,9279 0,9189 103,0139 0,0000VA13 0,93957 0,88279 0,86814 60,25617 0,00005VA14 0,9668 0,9347 0,9265 114,4300 0,0000VA15 0,90822 0,82486 0,80297 37,67851 0,00028VA16 0,9692 0,9394 0,9318 123,9087 0,0000VA17 0,94780 0,89833 0,88562 70,68674 0,00003VA18 0,92904 0,86311 0,84600 50,44059 0,00010VA19 0,95955 0,92074 0,91083 92,93234 0,00001VA20 0,91379 0,83501 0,81438 40,48663 0,00022VA21 0,88997 0,79204 0,76605 30,46975 0,00056VA22 0,92517 0,85593 0,83793 47,53026 0,00013VA23 0,90958 0,82734 0,80576 38,33474 0,00026VA24 0,94017 0,88393 0,86942 60,92141 0,00005VA25 0,94111 0,88568 0,87139 61,97972 0,00005VA26 0,94454 0,89215 0,87867 66,17523 0,00004VA27 0,94381 0,89077 0,87712 65,24234 0,00004VA28 0,9680 0,9371 0,9292 119,1667 0,0000VA29 0,94480 0,89265 0,87923 66,52056 0,00004VA30 0,92923 0,86347 0,84640 50,59360 0,00010VA31 0,96210 0,92565 0,91635 99,59239 0,00001VA32 0,94704 0,89688 0,88399 69,57946 0,00003VA33 0,87780 0,77054 0,74186 26,86415 0,00084VA34 0,9648 0,9308 0,9221 107,6027 0,0000VA35 0,93627 0,87660 0,86118 56,83168 0,00007VA36 0,91819 0,84307 0,82345 42,97771 0,00018VA37 0,96019 0,92197 0,91222 94,53014 0,00001VA38 0,94849 0,89964 0,88709 71,70916 0,00003
A Tabela 30 mostra o MTBF e a função de confiabilidade Lognormal para o primeiro
componente principal usando os percentis 10, 50 e 90, os quais foram utilizados por Lopes
(2001) na análise de tempo de falhas de sistemas complexos.
Tabela 30 – MTBF e Confiabilidade para os percentis 10, 50 e 90 para o CP1 do modelo Lognormal
tempo (dias) R(t) tempo (dias) R(t) tempo (dias) R(t)CP1 230 179 0,8217 210 0,6047 310 0,0900
MTBF (dias)
P50 P90Componente Principal
P10

143
Analisando a Tabela 30, em 179 dias de operação de trabalho do componente principal
CP1, a sua confiabilidade situou-se em torno de 82%, enquanto que em 310 dias ela cai para
aproximadamente 9%. O MTBF de 230 dias correspondeu a aproximadamente 2 falhas ou
trocas do componente crítico em um ano, sendo coerente aos valores apresentados na Tabela
15 mostrada anteriormente.
A seguir são apresentados os parâmetros e medidas de confiabilidade para o primeiro
componente principal (CP1) considerando o modelo probabilístico Lognormal, a saber:
função confiabilidade (Figura 38), função probabilidade de falha (Figura 39), função
densidade de probabilidade (Figura 40) e gráfico de Taxa de Falhas (Figura 41).
Gráfico da Confiabilidade vs T empo
Tempo, (dias)
Con
fiabi
lidad
e, R
(t)=
1-F(
t)
0 500100 200 300 4000,00
1,00
0,20
0,40
0,60
0,80
164;0,93
180;0,84
189;0,74
197;0,64
204;0,55
216;0,45
237;0,36
248;0,26
305;0,16
361;0,07
Confiabilidade
Dados 1Lognormal-2PMLE SRM MED FMF=10/S=0
Pontos de DadosLinha da Conf iabilidade
Figura 38 – Função Confiabilidade do modelo Lognormal para o CP1
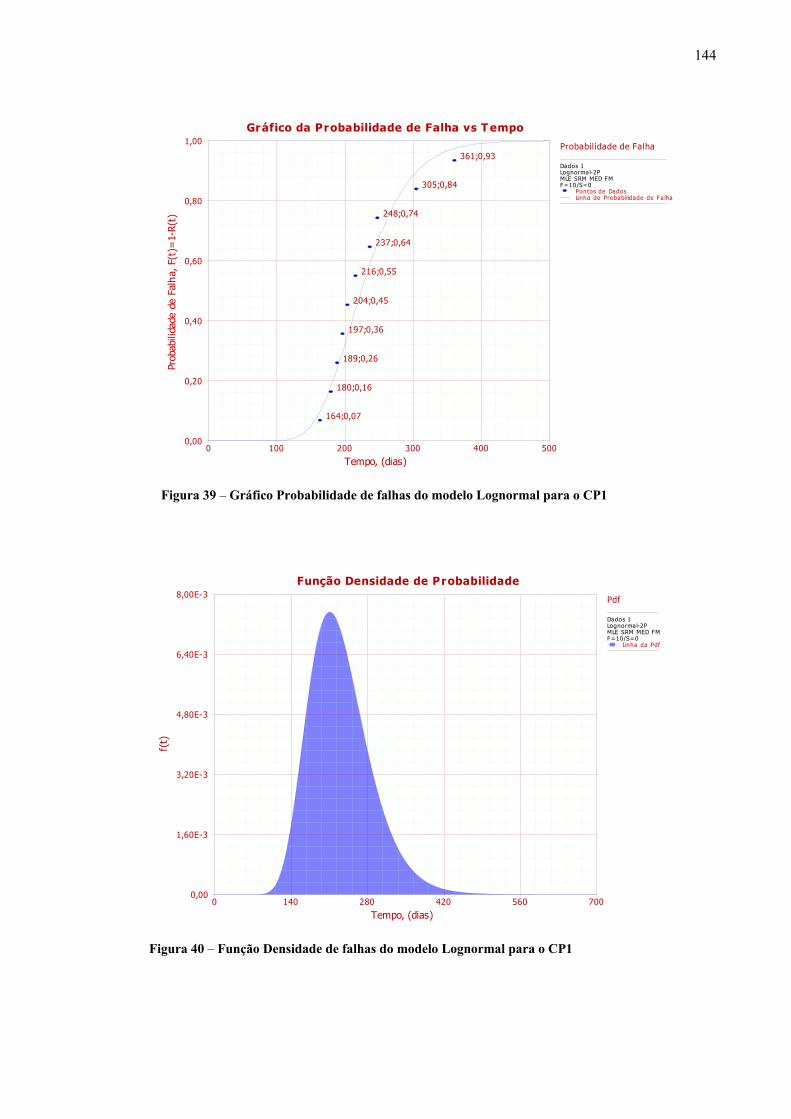
144
Gráfico da Probabilidade de Falha vs T empo
Tempo, (dias)
Prob
abili
dade
de
Falh
a, F
(t)=
1-R(
t)
0 500100 200 300 4000,00
1,00
0,20
0,40
0,60
0,80
164;0,07
180;0,16
189;0,26
197;0,36
204;0,45
216;0,55
237;0,64
248;0,74
305;0,84
361;0,93Probabilidade de Falha
Dados 1Lognorma l-2PMLE SRM MED FMF=10/S=0
Pontos de DadosLinha de Probabilidade de Fa lha
Figura 39 – Gráfico Probabilidade de falhas do modelo Lognormal para o CP1
Função Densidade de Probabilidade
Tempo, (dias)
f(t)
0 700140 280 420 5600,00
8,00E-3
1,60E-3
3,20E-3
4,80E-3
6,40E-3
Dados 1Lognorma l-2PMLE SRM MED FMF=10/S=0
Linha da Pdf
Figura 40 – Função Densidade de falhas do modelo Lognormal para o CP1

145
Gráfico da T axa de Falha vs T empo
Tempo, (dias)
Tax
a de
Fal
ha,
f(t)
/R(t
)
0 60001200 2400 3600 48000,00
0,04
8,00E-3
0,02
0,02
0,03
Taxa de Falha
Dados 1Lognormal-2PMLE SRM MED FMF=10/S=0
Linha da Taxa de Fa lha
Figura 41 – Função Taxa de falhas do modelo Lognormal para o CP1
9.9 SÍNTESE DA ANÁLISE DOS RESULTADOS
A análise envolveu 10 amostras representadas pelos anos de 1994 a 2003 constituídas
de 38 variáveis (ou componentes críticos). As informações coletadas constituíram-se de
quantidades de trocas realizadas e os respectivos tempos de vida alcançados por estes
componentes críticos. A unidade de tempo considerada foi “dia” sendo desprezadas as frações
inferiores a unidade. Alguns procedimentos estatísticos foram inicialmente extraídos das
amostras iniciais como a média, o desvio padrão com o propósito de melhor descrever e
caracterizá-las. Especial menção cabe destacar às condições de uso e ao tempo de missão ou
vida útil dos equipamentos críticos. No presente trabalho não se entrou no mérito das
variáveis que influenciaram na durabilidade dos 38 componentes críticos. Os dados com os
tempos de vida (tempo de missão) foram coletados diretamente de suas respectivas fontes sem
o julgamento do grau de distanciamento do tempo de vida ideal em operação.
A utilização da metodologia de ACP foi justificada pela avaliação das correlações
entre os tempos de vidas originais que se mostraram relativamente altas, ou seja, 79% das
correlações mostraram-se significativas dentre os 703 pares de componentes críticos

146
avaliados. Isto foi necessário, pois variáveis pouco relacionadas com as demais tendem a
apresentar baixa proporção da variância explicada inviabilizando a utilização da ACP.
Foram obtidos um total de 9 componentes principais, dos quais 3 responderam por
mais de 70% da variabilidade dos 380 dados de tempos de vida coletados. Isto foi possível
devido a utilização do critério de corte adotado (critério de Kaiser), ou seja, apenas 3 dos
componentes principais apresentaram variância acima da variância média 21.203 do total dos
9 componentes principais.
Conforme observado na matriz de autovetores, o primeiro componente principal teve
destacada contribuição dos componentes críticos VA15, VA16, VA18, VA20, VA22, VA24,
VA25, VA28, VA30 e VA31. Isto reforça o emprego desta componente na análise geral, pois
apresentou média e desvio-padrão próximo ao verificado do conjunto de dados sendo 230 e
21 dias respectivamente. Idêntico comportamento também foi reforçado quando se observou
as comunalidades das variáveis, havendo correspondência semelhante entre as correlações e a
carga de variância entre cada variável e o primeiro componente principal.
Neste ponto cabe uma importante observação: algumas aplicações da utilização da
análise de componentes principais requerem exclusão de variáveis pouco relacionadas ou
equivalentemente com baixos valores de comunalidades. Este procedimento visa antes de
tudo garantir a geração de poucos componentes principais que é o objetivo maior da ACP. No
presente trabalho esta recomendação não poderia ser adotada haja vista que um dos objetivos
específicos foi buscar identificar e mapear todos os 38 componentes críticos visando conhecer
o comportamento de cada um em todo o sistema. Mesmo diante desta situação, a estrutura de
variância e covariância da matriz dos dados de tempo de vida forneceu apenas 9 componentes
principais evidenciando não ter havido influência significativa das variáveis pouco
relacionadas ou de baixa comunalidades.
Adotou-se apenas o primeiro componente principal na análise de confiabilidade, pois
o mesmo representou sozinho aproximadamente 40% da variância total acumulada, o mesmo
critério adotado por Lopes (2001). Para a escolha da distribuição de confiabilidade que
melhor descrevesse o comportamento dos dados do primeiro componente principal
inicialmente foi construído um gráfico de barras tomando os dados de tempo de vida com o
número de suas respectivas ocorrências.
Utilizou-se o teste não paramétrico de Kaplan-Meier na pré-seleção das distribuições
analíticas (ou paramétricas) a serem adotadas. Este procedimento é recomendado em função
de que numa avaliação preliminar não se dispõe de informações a respeito da distribuição de
dados e de ser o passo inicial recomendado em análises de confiabilidade. Ao término da pré-

147
seleção das possíveis distribuições foram determinados os respectivos parâmetros e efetuados
testes de aderência para verificar e se definir a distribuição mais adequada aos dados de tempo
de vida do 1o componente principal. Segundo os testes adotados de adequação de ajuste de
adequação, a distribuição Lognormal foi a que melhor representou o conjunto de dados
através do primeiro principal. O estudo foi finalizado com o levantamento da função
densidade de falhas, a função confiabilidade e o tempo médio entre falhas.
Os resultados obtidos pela análise da função Confiabilidade mostraram probabilidades
de não ocorrências de falhas de 82,17%, 60,47% e 9,00% para os percentis 10, 50 e 90
respectivamente. A Taxa de Falhas mostrou um pico em 542 dias de operação, ponto de
extremo risco operacional por se tratar de um componente altamente crítico. Por fim, o
Tempo Médio entre Falhas atingiu 230 dias confirmando a ocorrência de 2 falhas no ano do
componente crítico. Os resultados advindos da aplicação da metodologia proposta mostraram-
se consistentes e coerentes com os dados históricos do componente crítico. A previsibilidade
do tempo ótimo de vida do componente crítico possibilitou a sua substituição no momento
certo, reduzindo o risco de paradas não programadas, aumentando a estabilidade operacional e
consequentemente reduzindo o risco de interrupções no processo produtivo da unidade
industrial estudada.
9.10 COMPARATIVO ENTRE A METODOLOGIA PROPOSTA E O SISTEMA
ATUAL
A fim de se avaliar a eficiência dos resultados alcançados pela aplicação da
metodologia proposta nos equipamentos críticos da empresa estudada foi feito um
levantamento de informações comparativas entre os dois cenários: metodologia proposta e
sistema atual de controle de vida, a saber:
1- Número de equipamentos críticos abrangidos:
Atualmente existem 1.300 pontos monitorados pela técnica de análise de óleos e 2.100
equipamentos monitorados pela análise de vibrações, sendo que deste último cerca de 200
apenas são considerados de alta criticidade. A nova metodologia poderá ser adotada para
equipamentos não rotativos, que é uma limitação da técnica de análise de vibrações
aumentando o universo de equipamentos monitorados.

148
2- A metodologia utilizando a análise de confiabilidade não requer parada de equipamentos
para análise. Isto é uma limitação da análise de óleo já que neste caso há necessidade de
parada do equipamento para a extração da amostra de óleo. A principal vantagem é que a
análise é realizada sem interferência com os equipamentos não afetando a disponibilidade dos
mesmos para operação.
3- A previsibilidade de quebra ou defeitos gerada pelo conhecimento prévio da vida útil dos
equipamentos auxilia as equipes de manutenção na decisão de antecipar ou postergar paradas
para reparo ou substituição otimizando consequentemente o tempo de uso. Isto se torna um
diferencial quando comparado a análise de óleo que requer tempos de coleta e análise,
gerando um atraso entre a identificação da falha e a ação para restabelecimento do
equipamento com defeito.
4- A metodologia poderá ser implementada utilizando a própria estrutura existente de
informação (sistemas informatizados de análises de vibrações, de gerenciamento de
manutenção e análise de óleo) de forma a complementar as atuais análises.
5- Os dados existentes nos bancos de dados atuais (digitais) poderão ser utilizados fazendo-se
simplesmente uma seleção dos demais equipamentos críticos a serem inseridos na
metodologia proposta de forma gradativa e sem gerar recursos adicionais tanto materiais
quanto humanos.
6- A análise de confiabilidade permite acumular no tempo todos os eventos de intervenção
nos pontos analisados, característica que não se enquadra a análise de óleo, pois o histórico
das análises de contaminantes avaliado a cada troca de óleo somente auxilia a análise de
defeitos até a sua substituição.
7- A metodologia proposta se mostra complementar as técnicas existentes, pois enquanto a
avaliação atual possibilita enxergar os motivos (causas) de geração de falhas, a metodologia
proposta fornecerá como resultados, informações tais como taxa de falhas e tempo médio
entre falhas propiciando uma visão global dos tipos de falhas. Esta avaliação poderás ser
complementada com auxílio de outras técnicas de confiabilidade, como análise do modo e
efeito de falhas e árvore de falhas.

149
8- A metodologia proposta permitirá maior rapidez nas análises de informações devido à
mesma ser baseada apenas no tempo de vida dos equipamentos, o que aumentará a quantidade
de pontos monitorados.
9- A implementação da nova metodologia não necessitará de mão-de-obra adicional e
altamente qualificada, pois poderá ser absorvida pela própria equipe do setor de engenharia.
10- Por último, cabe ressaltar que a adoção deste novo modelo de análise não requer
investimento ou recursos informatizados para a efetiva implementação, necessitando apenas
de um sistema confiável de coleta de dados já existente.

CAPÍTULO 10 - CONCLUSÃO
O objetivo deste trabalho foi desenvolver uma metodologia alternativa para determinar
a confiabilidade de um equipamento cujo sistema de funcionamento é complexo e com
variáveis de tempos de vida correlacionados. Inicialmente foi feito uma avaliação dos
primeiros dados coletados com o auxílio de um supervisor da unidade produtiva e técnicas
estatísticas apropriadas onde foi possível descartar variáveis sem importância no processo,
principalmente aquelas que raramente falhariam e que teriam o mesmo tempo de falha que
outras dentro das mesmas condições operacionais. Com a nova metodologia, além de
determinar o grau de confiabilidade do componente crítico como, por exemplo, o tempo
médio entre falhas através do uso de modelos probabilísticos, demonstra-se o quanto é
importante o uso de técnicas multivariadas para o desenvolvimento de novas metodologias de
análise de dados.
Como o interesse foi verificar como as amostras se relacionavam, ou seja, o quanto
estas são semelhantes segundo as variáveis utilizadas no trabalho foi utilizado a análise de
componentes principais. No entanto, previamente foram realizados alguns testes estatísticos
como a Análise de Agrupamento Hierárquico que não detectou discrepâncias (outliers) entre
os dados originais confirmando não haver nenhuma restrição quanto ao emprego da Análise
de Componentes principais aos tempos de vida coletados. A utilização da análise de
componentes principais (ACP) teve por finalidade determinar novas variáveis, capazes de
medir a confiabilidade do equipamento. Esta transformação de dados em informação útil
envolveu a redução de dimensionalidade dos dados originais. A ACP permitiu fazer uma
seleção adequada do número de componentes. Mediante ferramentas estatísticas apropriadas
foi possível analisar a estrutura de covariâncias e correlações baseada nas raízes
características e nos vetores gerados a partir delas em matrizes simétricas positivas definidas.
Neste ponto cabe avaliar os resultados alcançados pela aplicação da metodologia
proposta com objetivos estabelecidos da pesquisa, a saber:
A análise de componentes principais utilizada na pesquisa como técnica
multivariada de redução de dados atendeu ao objetivo a que foi proposta, pois permitiu definir
o primeiro componente principal (CP1) como elemento que representasse a totalidade dos
dados coletados pela excelente absorção de variabilidade. É evidente que o comportamento
dos dados em sua maioria pouco relacionados contribui para o alcance do objetivo proposto.

151
As funções Confiabilidade, Taxas de Falhas e o Tempo Médio entre Falhas obtidas
do conjunto crítico foram estimadas em intervalo de confiança (nível de significância α = 5%)
compatível ao nível de exigência (confiabilidade) esperada na prática. A modelo de
confiabilidade adotado utilizando a função Lognormal forneceu resultados com boa precisão
constatados pelos valores de confiabilidade obtidos do décimo, qüinquagésimo e nonagésimo
percentis;
Ao se conhecer as técnicas de análise, controle e monitoramento de evolução de
falhas dos equipamentos críticos constatou-se não haver uma sistemática integrada com as
áreas responsáveis pela operação e manutenção dos equipamentos críticos. Isto sugere que a
metodologia proposta servirá de alternativa já que pode ser inserida no Sistema de Gestão de
Ativos (SISMANA) aproveitando os tempos de vida útil (ou falhas) dos equipamentos críticos
já disponíveis no bando de dados. A metodologia poderá, inclusive, aumentar a gama de
equipamentos atualmente monitorados.
Adicionalmente o conhecimento do funcionamento do conjunto crítico
(especificamente do componente crítico) bem como a realização de estudos e pesquisas na
área de estatística multivariada e confiabilidade auxiliaram todo o desenvolvimento da
pesquisa.
Constata-se que a metodologia adotada permitiu sistematizar um conjunto de ações
pertinentes ao planejamento de trocas em futuras paradas programadas. Conclui-se por isso,
que os requisitos de confiabilidade poderão ser facilmente incorporados aos parâmetros
operacionais e as etapas do ciclo de vida, porque foram evidenciados na forma de dados
quantificáveis. O conhecimento da confiabilidade, taxa de falha e o tempo médio entre falhas
do componente crítico (ventaneiras) contribuirá para o aumento da confiabilidade do conjunto
principal (Alto Forno) e facilitará o planejamento de ações corretas de manutenção pela
previsibilidade da ocorrências de falhas, maximizando a vida útil do componente crítico e
consequentemente aumentado a estabilidade de todo processo de produção do aço.

CAPÍTULO 11 - RECOMENDAÇÕES PARA TRABALHOS FUTUROS
Recomenda-se que sejam testadas outras técnicas de estatística exploratórias,
buscando aprofundar ainda mais a análise. Sugere-se também verificar a aderência das
amostras analisadas a modelos probabilísticos com mais parâmetros, como a Exponencial de
dois parâmetros e a distribuição Weibull de três parâmetros o que, possivelmente podem
permitir uma melhor aderência dos dados das amostras ao modelo adotado. Estas distribuições
poderiam ter melhor comportamento que a distribuição Lognormal adotada.
No caso estudado, o desenvolvimento da metodologia considerou um nível de
confiabilidade p-value fixo de 5% na calda superior. Simulações com p-values com ligeiras
oscilações acima e abaixo (por ex. 7,5% e 2,5%) deste valor poderiam fornecer informações
novas sobre o comportamento do conjunto de dados coletados nos 10 anos de amostragem.
Consideração semelhante é aplicável a simulações comparando os resultados entre os três
métodos de avaliação dos intervalos de confiança abordados: matriz de Fisher (FM), relação
de verossimilhança (LR) e intervalo de confiança beta binomial. No presente estudo foi
utilizada apenas a matriz de Fisher.
Em relação aos testes de aderência dos parâmetros para verificação do ajuste a
distribuição de probabilidade a ser adotada, cabe relatar que a adoção de referências para
valores críticos seriam mais realistas, caso fosse feita a simulação de Monte Carlo aos dados
coletados, o que até foi sugerido em uma consulta a um especialista do instituto de estatística
norte-americano. No caso estudado foram utilizadas as tabelas com valores críticos
recomendado largamente pela literatura.
Cabe mencionar também a possibilidade de ampliação deste estudo realizando
simulações de amostras multivariadas, com diversas distribuições de probabilidade para
verificar a existência de diferenças significativas nos limites dos intervalos das funções de
pertinência. Estas simulações poderiam, inclusive, contemplar maior quantidade de amostras
pesquisadas além do período avaliado (10 anos).
É importante reforçar a necessidade de ampliação da análise aos demais subconjuntos,
composto do conjunto avaliado, estendendo inclusive ao conjunto principal (Alto Forno) o
qual contribuiria de sobremaneira para avaliação da eficiência global do conjunto de
insuflação de ar.

153
Como contribuição futura a empresa estudada, o estudo poderia auxiliar no
dimensionamento das equipes de manutenção e do tempo ótimo em operação dos
componentes críticos através de estimativas do número de quebras (taxa de falhas) e do tempo
médio de utilização entre as substituições definidas neste estudo.

REFERÊNCIAS
AYRES Jr., Frank. Schaum’s Outline of Theory and Problems of Matrices. USA: McGraw-Hill, Inc, 1962. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 5462: Confiabilidade e Mantenabilidade. Rio de Janeiro, 1994. 37 p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 6534: Cálculos de estimativas por ponto e limites de confiança resultante de ensaios de determinação da confiabilidade de equipamentos - Procedimento. Rio de Janeiro, 1986. 33p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 6742: Utilização da distribuição de Weibull para interpretação dos estágios de durabilidade por fadiga. Rio de Janeiro, 1987. 18p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 11153: Interpretação estatística de resultados de ensaio - Estimação da Média - Intervalo de Confiança. Rio de Janeiro, 1988. 7p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 11154: Interpretação estatística de dados - Técnicas de estimação e testes relacionados às médias e variâncias. Rio de Janeiro, 1989. 53p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 11155: Interpretação estatística de dados - Determinação de intervalo de tolerância estatístico. Rio de Janeiro, 1988. 15p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 11156: Interpretações estatísticas de dados - Comparação de duas médias no caso de observações emparelhadas. Rio de Janeiro, 1988. 7p. ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 11157: Interpretação estatística de dados - Potência de testes relacionados às médias e variâncias. Rio de Janeiro, 1990. 41p. AFONSO, César. Aplicação da análise multivariada para classificação e previsão de avaliação do desempenho acadêmico dos alunos de Engenharia Mecânica do CEFET-PR. Florianópolis: UFSC, 2001. (Dissertação de Mestrado)

155
ALMEIDA, J.C. de. Uma metodologia de projeto baseada na confiabilidade: aplicação a redes de distribuição de gás canalizado. Florianópolis: UFSC, 1999. (Dissertação de Mestrado) ANTONOV, A.V. Review and development of nonparametric methods for verification of trend hypothesis. Chepurko: Obninsk State Technical University of Nuclear Power Engineering. BARBACHAN, José S. F. et al. Goodness-of-fit Tests focuses on VaR Estimation. IBMEC Business School. São Paulo, August. 2003. BARBACHAN, José S. F. et al. Goodness-of-Fit Test focuses on Conditional Value at Risk: An Empirical Analysis of Exchange Rates. IBMEC Business School. São Paulo, 2004. BARROS FILHO, Adail. Utilização de ferramentas de confiabilidade em um ambiente de manufatura de classe mundial. Campinas: Faculdade de Engenharia Mecânica, UNICAMP, 2003. (Dissertação de Mestrado) BAXTER, M. J. Standartization and transformation in principal component analysis with application to Archaeometry. Applied Statistic, v.44. n.4. p.13-527, 1995. BEM, Amilton Barreto de. Confiabilidade e validade estatísticas da avaliação docente pelo discente: proposta metodológica e estudo de caso. Florianópolis: UFSC, 2004. (Tese de Doutorado) BERNARDES, Elaine M. Desenvolvimento do vale do rio tietê-paraná: um enfoque de estoques de capitais. Piracicaba: USP, 2002. (Tese de Doutorado) BOLDRINI, José L. et al. Álgebra linear. São Paulo: Harper & Row do Brasil, 1980. BRITO, Luiza T. de L. et al. Uso de análise multivariada na classificação das fontes hídricas superficiais da bacia hidrográfica do Rio Salitre-Bahia. Disponível em:<http://www.scielo.br/scielo.php>. Acesso em: 08 set 2005. BURGESS, J.A. Improving product reliability. Quality progress. dez. p.47-54, 1987.. CALZADA, Maria E., LOYOLA, Stephen M. S. Visual EDF (Empirical Distribution Function) Software to Check the Normality Assumption. New Orleans: University New Orleans.

156
CALZADA, Maria E., LOYOLA, Stephen M. S. EDF (Empirical Distribution Function) Tests and Visual Enhancements to Complement Probability Plotting. New Orleans: University New Orleans. CASTRO, Hélio Fiori de. Otimização da confiabilidade e disponibilidade em sistemas redundantes. Campinas: FEM/UNICAMP, 2003. (Dissertação de Mestrado). CHERNOBAI, Anna et al. Composite Goodness-of-Fit Tests for Left-Truncated: Loss Samples. Santa Barbara: University of California, June 4, 2005. CHERNICK, Michael R.; FRIIS, Robert H. Chapter 12. In:____. Introductory Biostatistics for the Health Sciences. Wiley-Interscience, 2003, p.251. COSTA NETO, Pedro L. de Oliveira. Estatística. São Paulo: Edgard Blücher, 1977. CULLEN, Simon. Detecting Deviations From Normality in Truncated Populations. Dublin: University of Dublin, july 16, 2004. D’AGOSTINHO and STEPHENS. Goodness-of-Fit Techniques. New York: Marcel Dekker, Table 4.7, p. 123, 1986. All of chapter 4, p. 97-193. Disponível em:<www.statisticalengineering.com/goodness.htm>. Acesso em: 10 maio 2007. DECOURSEY, W.J. Statistics and Probability for Engineering Applications with Microsoft® Excel. Saskatoon: Elsevier Science, 2003. DIAS, Acires. Metodologia para análise da confiabilidade em freios pneumáticos automotivos. Campinas: FEM/UNICAMP, 1996. (Tese de Doutorado). DIAS, Acires. Projeto para a confiabilidade aplicado ao processo de implantação de uma rede de gás. Florianópolis: UFSC, [s.d.]. DODSON, Bryan. The Weibull Analysis Handbook. 2. ed. Milwaukee: Quality Press, 2006. DUTRA, Ronyê Mitchell O. et al. O método ward de agrupamento de dados e sua aplicação em associação com os mapas auto-organizáveis de Kohonen. Florianópolis: UFSC. [s.d.].

157
ELIASSI-RAD, Tina et al. Statistical Modeling of Large-Scale Simulation Data. Livermore: Center for Applied Scientific Computing. [s.d.]. FREITAS, Marta Afonso; COLOSIMO, Enrico Antonio. Confiabilidade: Análise de tempo de falha e testes de vida acelerados. Belo Horizonte: Fundação Christiano Ottoni, 1997. (Série Ferramentas da Qualidade, v.12). GEISSER, Seymour. Modes of Parametric Statistical Inference. Wiley-Interscience, Minneapolis: Department of Statistics. University of Minnesota, 2005. INSTITUTE OF ELECTRICAL AND ELETRONICS ENGINERS. Reliability Allocation and Optimization for Complex Systems. In: 2000 PROCEEDINGS ANNUAL . RELIABILITY AND MAINTAINABILITY SYMPOSIUM. California: 2000. [CD-ROM] INSTITUTE OF ELECTRICAL AND ELETRONICS ENGINERS. Modeling & Analysis for Multiple Stress-Type Accelerated Life Data . In: 2000 PROCEEDINGS ANNUAL . RELIABILITY AND MAINTAINABILITY SYMPOSIUM. California: 2000. [CD-ROM]. HARRIS, Richard J. A Primer of Multivariate Statistics. 3. ed. Mahwah: Lawrence Erlbaum Associates, 2001. HÄRDLE, Wolfgang; SIMAR Léopold. Applied Multivariate Statistical Analysis. Tech: Method and Data Technologies. 29. ed. Version. 2003. HAVIARAS, Gilberto J. Metodologia para análise de pneus em frotas de caminhões de longa distância. São Paulo: USP, 2005. (Dissertação de Mestrado). HARMAN, Harry H. Modern Factor Analysis. 3. ed. Chicago and London: The University of Chicago Press, 1976. JOHNSON, R.A.; WICHERN, D.W. Applied Multivariate Statistical Analysis. 3. ed. New Jersey: Prentice Hall, 1992. KOCH, Gerda. Basic Allied Health Statistics and Analysis. Thomson Learning, 1999.

158
KUBRUSLY, L. S. Aplicação de análise multivariada a um problema de dosagem de fósforo para ovinos. Revista Brasileira de Estatística. Rio de Janeiro, v.49, n.191, p.47-53, 1988. KUBRUSLY, L. S. Um procedimento para calcular índices a partir de uma base de dados multivariados. Instituto de Economia, UFRJ, Rio de Janeiro, v.1, n.21, p.107-117, 2001. KUYPERS, Walter. Advance Principal Components Analysis: A Real-Life Application Using STATISTICA 6. Statsoft Inc., October 30. ed. ,2001. Disponível em:<www.statsoft.com.br/imagens/downloads/arquivos.advanced_principal_components_reallife. pdf>. Acesso em: 16 maio 2007. LAFRAIA, João Ricardo Barusso. Manual de confiabilidade, mantenabilidade e disponibilidade. Rio de Janeiro: Qualitymark, 2001. LEVINE, David M., BERENSON, Mark L., STEPHAN, David. Estatística: teoria e aplicações utilizando o microsoft excel em português. rio de janeiro: ltc, 2000. LIPSCHUTZ, Seymour. Schaum’s Outline of Theory and Problems of Linear Algebra. USA: McGraw-Hill, Inc, 1968. LITTLE. R.E. Mechanical Reliability Improvement: Probability and Statistics for Experimental Testing. New York: Marcel Dekker, 2001. LOPES, Luis F. Dias. Análise de componentes principais aplicada à confiabilidade de sistemas complexos. Florianópolis: UFSC, 2001. (Tese de Doutorado) MATH WORKS, INC. Software MATLAB – The Language of Technical Computing. Version 5.3.0.10183. License Number: 134521. January, 21, 1999. [CD-ROM] MALHEIROS, R. de C. da C. As principais barreiras ao empreendimento de novos negócios: Um modelo que considera as condições do empreendedor na configuração dessa percepção. Florianópolis: UFSC, 2001. (Tese de Doutorado) MARTINELLO, Gilmar Efrem et al. Divergência genética em acessos de quiabeiro com base em marcadores morfológicos. Horticultura Brasileira. Brasília, v.20, n.1, 2002. MASON, Robert L.; YOUNG, John C. Construction of Historical Data Set, chapter 4. In:____. Multivariate Statistical Process Control with Industrial Applications. Philadelphia: SIAM, 1946. p.53-80.

159
MICROSOFT OFFICE EXCEL. Versão 7. [s.l.]: Microsoft Corporation, 2003. MINGOTI, Sueli Aparecida. Análise de dados através de métodos de estatística multivariada: Uma abordagem aplicada. Belo Horizonte: UFMG Ed., 2005. MOITA, Graziella Ciaramella; José Machado, MOITA NETO. Uma introdução à análise exploratória de dados multivariados. Química Nova. Teresina, v.21, n.4, ago. 1998. MOITA NETO, José Machado. Estatística multivariada: uma visão didática-metodológica. Filosofia da Ciência, maio 2004. Disponível em:<www.criticanarede.com/cien_estatistica.html>. Acesso em: 03 abr. 2007. MORAS, F.C. Metodologia para implementação do modelo markoviano em análise confiabilística de sistemas. Campinas: FEM/UNICAMP, 2002. (Dissertação de Mestrado). MORGANO, Marcelo Antônio et al. Aplicação da análise exploratória na diferenciação de vegetais. Brazilian Journal of Food Technology. Campinas, v.2, n. 12, p. 73-79, 1999. MORRISON, D.F. Multivariate statistical methods. New York: McGraw Hill, 1976. MOUBRAY, John. Reliability-centred Maintenance. England: Butterworth-Heinemann, 1997. MÜLLER, Rolf; SCHWARZ, Erich. Confiabilidade: Tabelas e nomogramas para uso prático. São Paulo: Nobel, 1987. NETER, John et al. Applied linear statistical models. 3. ed. Boston: Irwin, 1990. PALLEROSI, C.A., Confiabilidade: conceitos básicos e método de cálculo. São Paulo: 2000. PEREIRA. J.C.R. Análise de dados qualitativos: estratégias metodológicas para as ciências da saúde, humanas e sociais. São Paulo: USP, 1999. PETERS, W. S.; SUMMERS, G. W. Análise estatística e processo decisório. Tradução por Nathanael C. Caixeiro. Rio de Janeiro: Edusp, 1973. Tradução de: Statistical Analysis for Business Decisions.

160
PINTO, Wilza da S. et al. Caracterização física, físico-química e química de frutos de genótipos de cajazeiras. Pesquisa Agropecuária Brasileira. Brasília, v.38, n.9, p. 1059-1066, set. 2003. PONTES, Antonio C. F. Análise de variância multivariada com a utilização de testes não-paramétricos e componentes principais baseados em matrizes de postos. Piracicaba: Escola Superior de Agricultura, USP, 2005. (Tese de Doutorado) PT-PRO-AF01-01-0028. Controle de vida útil do sistema de insuflação de ar para o Alto Forno 1. Serra, ES: SISCORP, 2006. 2p. RAGSDALE, Cliff T. Spreadsheet modeling and decision analysis. 3. ed. Cincinnati: Thonson Learning, 2001. p. 407-458. RELIASOFT BRASIL. Resumo teórico. engenharia da confiabilidade. São Paulo, 2001. [CD-ROM]. RENCHER, Alvin C. Methods of Multivariate Analysis. 2. ed. Wiley-Interscience, 2001. Brigham Young University. RIBEIRO, Fabiana A. de Lima. Aplicação de métodos de análise multivariada no estudo de hidrocarbonetos policíclicos aromáticos. Campinas: UNICAMP, 2001 (Dissertação de Mestrado) ROCHA, Ana C. B. da. A geoestatística aplicada à avaliação e caracterização de reservatórios petrolíferos. Campina Grande: Universidade Federal de Campina Grande, 2005. (Dissertação de Mestrado) ROSS, Sheldon M. Introduction to probability Models. 8. ed. Berkeley: Academic Press, 1997. SAKURADA, Eduardo Yuji. As técnicas de análises de modos de falha e seus efeitos e análise da árvore de falhas no desenvolvimento e na avaliação de produtos. Florianópolis: UFSC, 2001. (Dissertação de Mestrado) SANDBERG, JOEL B. Reliability for profit not just regulation. Quality Progress. p.51-54, august, 1987..

161
SANTOS, M. de Q.C. Sistematização para aplicar o projeto de experimentos na melhoria da confiabilidade de produtos. Florianópolis: UFSC, 2001. (Dissertação de Mestrado). SCREMIN, M. A. A. Método para seleção do número de componentes principais com base na lógica difusa. Florianópolis: UFSC, 2003. (Tese de Doutorado). SCREMIN, M. A. A.; BASTOS, R.C. Caracterização de grupos homogêneos de propriedades rurais do estado de Santa Catarina utilizando redes neurais artificiais. In: CONGRESSO E MOSTRA DE AGROINFORMÁTICA, 2000, Ponta Grossa,. Anais... Ponta Grossa, 2000. SIEGEL, Sidney. Nonparametric Statistics for the Behavior Sciences. Pennsylvania: The Pennsylvania State University. Disponível em:<http://www.psych.ufl.edu/~white/K-S_oneSample.pdf>. Acesso em: 05 mar. 2007. SILVA, Luiz Bueno da. Tópicos de estatística na pesquisa em engenharia de produção. Notas de aula. João Pessoa: Curso de Pós-graduação em Engenharia de Produção, UFPB, 2005. SILVA, Luiz Bueno da. Precisão científica no processo de pesquisa em engenharia de produção. Notas de aula. João Pessoa: Curso de Pós-graduação em Engenharia de Produção. UFPB, Agosto, 2006. SILVA, Nilza N. da. Amostragem probabilística: um curso introdutório. São Paulo: Edusp, 1998. SILVEIRA, Sidnéia S.; ANDRADE, Eunice M. Análise de componentes principais na investigação da estrutura multivariada da evapotranspiração. Engenharia Agrícola. Jaboticabal, v. 22, p. 171-177, maio 2002. SILVEIRA, Z. de C. Análise estatística e otimização de parâmetros de projeto em componentes de sistemas mecânicos. Campinas: Faculdade de Engenharia Mecânica, UNICAMP, 2003. Tese (Doutorado). SOFTWARE TRAINING GUIDE WEIBULL++6. Tucson, USA. Reliasoft Corporation, [s.d.] [CD-ROM]. SOFTWARE WEIBULL++7. Tucson, USA: Reliasoft Corporation, 1992-2007. Disponível em:<http://weibull.reliasoft.com>. Acesso em: 19 mar. 2007. (versão de demonstração).

162
SOUZA, A. M. Monitoração e ajuste de realimentação em processos produtivos multivariados. Florianópolis: UFSC, 2000. (Tese de Doutorado). SOUZA NETO, J.; BAKER G.A.; SOUZA F.B. de. Análise socioeconômica da exploração de caprinos e ovinos no estado do Piauí. Pesquisa Agropecuária Brasileira. Brasília, v.30, n.8, p. 1017-1030, ago. 1995. SPANÓ, CLÁUDIO CAIANI. Estudo de confiabilidade das pastilhas de freio dos veículos LS 1938. In: COLLOQUIUM INTERNACIONAL DE FREIOS DA SAE, 4, 1999, Gramado, RS. Anais... Gramado RS, 1999. SOFTWARE STATISTICA (Data Analysis Software System), Version 6. Tulsa, USA: Statsoft Inc., 2001. [CD-ROM]. SUBRAMANIAN, Anand et al. Application of Linear Regression and Discriminant Analysis for Predicting Thermo-environmental and Perceptive Variables. João Pessoa, PB, Brazil: Department of Production Engineering, Federal University of Paraíba. TABACHNICK, Bárbara G. Principal Components and Factor Analysis, chapter 12. In:____. Using Multivariate Statistics. New York: Donnelley & Sons, 1989. p.597-677. TADINI et al. Aplicação da análise de componentes principais na elaboração de cartas de controle de curvas de calibração na determinação do teor de glicose por espectrofotometria. São Paulo: USP, [s.d.]. TIMM, Neil, H. Applied Multivariate Analysis. Pittsburgh: University of Pittsburgh, Springer-Verlag, 2002. TONG, Y. L. The Engineering Handbook. Chapter 207 (Probability and Statistics). Georgia: Richard C. Dorf, 2000. TROSSET, Michael W. An Introduction to Statistical Inference and Its Applications. Department of Mathematics College of William & Mary. January 5, 2005. VEDANA, Edi L. Zulian. Análise multivariada e fronteira eficiente para diagnóstico do desempenho de fundos de pensão. Florianópolis: UFSC, 1999. (Dissertação de Mestrado). VIALI, Lori. Estatística não-paramétrica. Enfoque Sociais. Texto S1. (Série Tópicos Especiais). Disponível em:<www.pucrs.br/famat/viali/posgradua/man/mq2/material/apostilas/Noparame.pdf>. Acesso em: 17 fev. 2007.

163
VILLELA, José Roque Alves. Validação de processos num modelo utilizando ferramentas de qualidade e estatísticas. Campinas: FEM/UNICAMP, 2004. (Dissertação de Mestrado). VIRGILLITO, Salvatore Benito. Uma abordagem estatística estruturada na construção de modelos para análise do risco de crédito e previsão de insolvência de empresas. São Paulo: FEA-PUC, 2001. (Dissertação de Mestrado). VIRGILLITO, Salvatore Benito. Estatística aplicada: Técnicas básicas e avançadas para todas as áreas do conhecimento. São Paulo: Alfa-Omega, 2004. VOLLERTT Jr., João Rosaldo. Confiabilidade e falhas de campo: um estudo de caso para melhoria da confiabilidade de um produto e do reparo através de um procedimento sistemático de coleta de dados. Florianópolis: UFSC, 1996. (Dissertação de Mestrado). WERKEMA, M. C. C. Introdução ao software estatística. São Paulo: Werkema Consultores, 2004. WERNER, Liane. Modelagem dos tempos de falhas ao longo do calendário. Porto Alegre: UFRGS, 1996. (Dissertação de Mestrado).

164
APÊNDICE A – Gráficos de Dispersão do Estimador Kaplan-Meier com os
modelos propostos
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Estimador Kaplan-Meier
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
Dis
tribu
ição
Wei
bull
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Estimador Kaplan-Meier
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
Dis
tribu
ição
Gam
ma
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Estimador Kaplan-Meier
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
Dis
tribu
ição
Log
norm
al
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Estimador Kaplan-Meier
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
Dis
tribu
ição
Nor
mal
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Estimador Kaplan-Meier
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
Dis
tribu
ição
Exp
onen
cial

165
APÊNDICE B – Histograma do número de falhas observadas nas Ventaneiras (componentes críticos)
Componente Crítico VA1Kolmogorov-Smirnov d = 0,17825, p = n.s.
Chi-Square test = 8,68286, df = 7, p = 0,27623
42 84 126 168 210 252 294 336 378 420 462
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente Crítico VA2Kolmogorov-Smirnov d = 0,19372, p = n.s.
Chi-Square test = 9,82075, df = 7, p = 0,19896
169 182 195 208 221 234 247 260 273 286 299
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente Crítico VA3Kolmogorov-Smirnov d = 0,15329, p = n.s.
Chi-Square test = 6,64160, df = 7, p = 0,46712
108 144 180 216 252 288 324 360 396 432 468
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente Crítico VA4Kolmogorov-Smirnov d = 0,11939, p = n.s.
Chi-Square test = 4,43528, df = 7, p = 0,72850
135 150 165 180 195 210 225 240 255 270 285
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente Crítico VA5Kolmogorov-Smirnov d = 0,19608, p = n.s.
Chi-Square test = 15,07692, df = 7, p = 0,03503
90 120 150 180 210 240 270 300 330 360 390
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
5,5
No.
de
Obs
erva
ções
Componente Crítico VA6Kolmogorov-Smirnov d = 0,14126, p = n.s.
Chi-Square test = 5,17268, df = 7, p = 0,63890
110 132 154 176 198 220 242 264 286 308 330
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente Crítico VA7Kolmogorov-Smirnov d = 0,17044, p = n.s.
Chi-Square test = 7,58891, df = 7, p = 0,37023
72 90 108 126 144 162 180 198 216 234 252
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente Crítico VA8Kolmogorov-Smirnov d = 0,15843, p = n.s.
Chi-Square test = 8,33330, df = 7, p = 0,30412
114 133 152 171 190 209 228 247 266 285 304
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente Crítico VA9Kolmogorov-Smirnov d = 0,20438, p = n.s.
Chi-Square test = 7,94740, df = 7, p = 0,33726
36 72 108 144 180 216 252 288 324 360 396
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente Crítico VA10Kolmogorov-Smirnov d = 0,14236, p = n.s.
Chi-Square test = 5,25841, df = 7, p = 0,62846
105 126 147 168 189 210 231 252 273 294 315
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente Crítico VA11Kolmogorov-Smirnov d = 0,12908, p = n.s.
Chi-Square test = 5,32722, df = 7, p = 0,62010
128 160 192 224 256 288 320 352 384 416 448
Category (upper limits)
0,0
0,5
1,0
1,5
2,0
2,5
No.
of o
bser
vatio
ns
Componente Crítico VA12Kolmogorov-Smirnov d = 0,21391, p = n.s.
Chi-Square test = 9,88708, df = 7, p = 0,19506
128 160 192 224 256 288 320 352 384 416 448
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
166
APÊNDICE B – Histograma do número de falhas observadas nas Ventaneiras (continuação)
Componente Crítico VA13Kolmogorov-Smirnov d = 0,13807, p = n.s.
Chi-Square test = 9,92659, df = 7, p = 0,19277
140 160 180 200 220 240 260 280 300 320 340
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente Crítico VA14Kolmogorov-Smirnov d = 0,28054, p = n.s.
Chi-Square test = 11,74552, df = 7, p = 0,10924
72 108 144 180 216 252 288 324 360 396 432
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente Crítico VA15Kolmogorov-Smirnov d = 0,17610, p = n.s.
Chi-Square test = 8,60497, df = 7, p = 0,28227
76 114 152 190 228 266 304 342 380 418 456
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente Crítico VA16Kolmogorov-Smirnov d = 0,22080, p = n.s.
Chi-Square test = 9,58818, df = 7, p = 0,21314
130 156 182 208 234 260 286 312 338 364 390
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente VA17Kolmogorov-Smirnov d = 0,20732, p = n.s.
Chi-Square test = 12,03120, df = 7, p = 0,09954
120 140 160 180 200 220 240 260 280 300 320 340
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente Crítico VA18Kolmogorov-Smirnov d = 0,13976, p = n.s.
Chi-Square test = 6,40766, df = 7, p = 0,49303
76 114 152 190 228 266 304 342 380 418 456
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA19Kolmogorov-Smirnov d = 0,19118, p = n.s.
Chi-Square test = 11,83494, df = 7, p = 0,10612
176 192 208 224 240 256 272 288 304 320 336
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA20Kolmogorov-Smirnov d = 0,19865, p = n.s.
Chi-Square test = 8,34152, df = 7, p = 0,30344
90 135 180 225 270 315 360 405 450 495 540
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA21Kolmogorov-Smirnov d = 0,28265, p = n.s.
Chi-Square test = 10,28343, df = 7, p = 0,17307
0 34 68 102 136 170 204 238 272 306 340
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA22Kolmogorov-Smirnov d = 0,16160, p = n.s.
Chi-Square test = 3,54010, df = 7, p = 0,83096
76 114 152 190 228 266 304 342 380 418 456
Category (upper limits)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente VA23Kolmogorov-Smirnov d = 0,18246, p = n.s.
Chi-Square test = 9,37379, df = 7, p = 0,22692
102 136 170 204 238 272 306 340 374 408 442
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA24Kolmogorov-Smirnov d = 0,16822, p = n.s.
Chi-Square test = 5,37298, df = 7, p = 0,61455
120 150 180 210 240 270 300 330 360 390 420
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções

167
APÊNDICE B – Histograma do número de falhas observadas nas Ventaneiras (continuação)
Componente VA25Kolmogorov-Smirnov d = 0,17523, p = n.s.
Chi-Square test = 10,06586, df = 7, p = 0,18487
90 120 150 180 210 240 270 300 330 360 390
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA26Kolmogorov-Smirnov d = 0,30522, p = n.s.
Chi-Square test = 18,96866, df = 7, p = 0,00829
85 102 119 136 153 170 187 204 221 238 255
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
5,5
No.
de
Obs
erva
ções
Componente VA27Kolmogorov-Smirnov d = 0,14801, p = n.s.
Chi-Square test = 6,55451, df = 7, p = 0,47669
96 128 160 192 224 256 288 320 352 384 416
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA28Kolmogorov-Smirnov d = 0,21071, p = n.s.
Chi-Square test = 8,04873, df = 7, p = 0,32832
112 140 168 196 224 252 280 308 336 364 392
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA29Kolmogorov-Smirnov d = 0,15027, p = n.s.
Chi-Square test = 6,27591, df = 7, p = 0,50793
132 154 176 198 220 242 264 286 308 330 352
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA30Kolmogorov-Smirnov d = 0,14798, p = n.s.
Chi-Square test = 14,26509, df = 7, p = 0,04666
34 68 102 136 170 204 238 272 306 340 374
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5N
o. d
e O
bser
vaçõ
es
Componente VA31Kolmogorov-Smirnov d = 0,18659, p = n.s.
Chi-Square test = 5,65192, df = 7, p = 0,58093
64 96 128 160 192 224 256 288 320 352 384 416
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA32Kolmogorov-Smirnov d = 0,14022, p = n.s.
Chi-Square test = 6,63743, df = 7, p = 0,46758
126 144 162 180 198 216 234 252 270 288 306
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções
Componente VA33Kolmogorov-Smirnov d = 0,32561, p < 0,20
Chi-Square test = 25,05987, df = 7, p = 0,00074
48 72 96 120 144 168 192 216 240 264 288 312
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente VA34Kolmogorov-Smirnov d = 0,18907, p = n.s.
Chi-Square test = 12,23349, df = 7, p = 0,09314
133 152 171 190 209 228 247 266 285 304 323
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA35Kolmogorov-Smirnov d = 0,18870, p = n.s.
Chi-Square test = 12,42303, df = 7, p = 0,08748
112 140 168 196 224 252 280 308 336 364 392
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
No.
de
Obs
erva
ções
Componente VA36Kolmogorov-Smirnov d = 0,16262, p = n.s.
Chi-Square test = 8,40379, df = 7, p = 0,29834
110 132 154 176 198 220 242 264 286 308 330
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções

168
APÊNDICE B – Histograma do número de falhas observadas nas Ventaneiras (continuação)
Componente VA37Kolmogorov-Smirnov d = 0,25262, p = n.s.
Chi-Square test = 7,54338, df = 7, p = 0,37457
130 156 182 208 234 260 286 312 338 364 390
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
No.
de
Obs
erva
ções
Componente VA38Kolmogorov-Smirnov d = 0,14397, p = n.s.
Chi-Square test = 8,17429, df = 7, p = 0,31748
40 80 120 160 200 240 280 320 360 400 440
Tempo de Vida (dias)
0,0
0,5
1,0
1,5
2,0
2,5
No.
de
Obs
erva
ções

169
APÊNDICE C – Função de Confiabilidade das Ventaneiras (componentes críticos) Função de Confiabilidade Lognormal - Componente VA1
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
41 745182 323 463 6040,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA2
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
151 320185 219 253 2870,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA3
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
87 704210 334 457 5810,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA4
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
128 339170 212 254 2970,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA5
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
79 493162 245 327 4100,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA6
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
79 418147 215 282 3500,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA7
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
64 423136 207 279 3510,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA8
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
89 435158 227 297 3660,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA9
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
47 687175 303 431 5590,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA10
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
93 470168 244 319 3950,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA11
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
109 592205 302 399 4950,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA12
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
91 566186 281 376 4710,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA13
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
108 435173 239 304 3700,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA14
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
59 609169 279 389 4990,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA15
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
53 681178 304 429 5550,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA16
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
103 539191 278 365 4520,000
1,000
0,200
0,400
0,600
0,800

170
APÊNDICE C – Função de Confiabilidade das Ventaneiras (componentes críticos) (continuação) Função de Confiabilidade Lognormal - Componente VA17
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
111 489187 262 338 4130,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA18
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
59 737195 331 466 6020,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA19
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
144 449205 266 327 3880,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA20
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
94 686212 331 449 5680,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA21
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
26 1338289 551 813 10760,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA22
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
65 726197 330 462 5940,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA23
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
86 639197 307 418 5280,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA24
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
91 646202 313 424 5350,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA25
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
77 663194 312 429 5460,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA26
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
78 412145 212 278 3450,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA27
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
78 553173 268 363 4580,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA28
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
75 566173 271 370 4680,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA29
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
107 435173 238 304 3690,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA30
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
40 851202 364 526 6880,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA31
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
59 677183 306 430 5530,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA32
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
114 425176 238 301 3630,000
1,000
0,200
0,400
0,600
0,800
171
APÊNDICE C – Função de Confiabilidade das Ventaneiras (componentes críticos) (continuação) Função de Confiabilidade Lognormal - Componente VA33
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
69 548164 260 356 4520,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA34
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
98 480174 251 327 4040,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA35
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
107 511188 269 350 4310,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA36
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
88 463163 238 313 3880,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA37
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
99 508181 263 344 4260,000
1,000
0,200
0,400
0,600
0,800
Função de Confiabilidade Lognormal - Componente VA38
Tempo (dias)
Conf
iabi
lidad
e, R
(t)=
1-F(
t)
49 1012242 435 627 8200,000
1,000
0,200
0,400
0,600
0,800

172
APÊNDICE D – Gráficos de scores do CP1 e CP3/CP2 e CP3
VA1 VA2
VA3
VA4
VA5 VA6 VA7
VA8 VA9
VA10 VA11
VA12 VA13
VA14
VA15
VA16
VA17
VA18
VA19
VA20
VA21
VA22 VA23
VA24 VA25
VA26 VA27
VA28 VA29
VA30
VA31
VA32
VA33
VA34 VA35
VA36
VA37
VA38
-50 0 50 100
CP1
-100
-50
0
50
100C
P3
VA1 VA2
VA3
VA4
VA5 VA6 VA7
VA8 VA9
VA10 VA11
VA12 VA13
VA14
VA15
VA16
VA17
VA18
VA19
VA20
VA21
VA22 VA23
VA24 VA25
VA26 VA27
VA28 VA29
VA30
VA31
VA32
VA33
VA34 VA35
VA36
VA37
VA38
-100 -50 0 50 100
CP2
-100
-50
0
50
100
CP
3

173
APÊNDICE E – Gráficos de loadings do CP1 e CP3
1994
19951996
19971998 1999
2000
20012002
2003
-500 -250 0 250 500 750 1000
CP1
-500
-250
0
250
500
CP
3
1994
19951996
19971998 1999
2000
20012002
2003
-750 -500 -250 0 250 500
CP2
-500
-250
0
250
500
CP
3

174
APÊNDICE F – Parâmetros e percentis 10, 50 e 90 da Distribuição Lognormal
(componentes críticos)
Tempo R(t) Tempo R(t) Tempo R(t)VA1 5,1682 0,46756 93 0,9130 182 0,4695 287 0,1467VA2 5,3936 0,12165 199 0,7951 221 0,4850 235 0,2937VA3 5,5093 0,33899 155 0,9156 252 0,4763 370 0,1166VA4 5,3374 0,15816 181 0,8101 209 0,4936 239 0,1896VA5 5,2861 0,29602 140 0,8777 202 0,4702 236 0,2741VA6 5,2051 0,26848 129 0,9033 189 0,4457 220 0,2413VA7 5,1014 0,30613 104 0,9310 181 0,3790 214 0,1937VA8 5,2807 0,25733 131 0,9428 202 0,4574 252 0,1669VA9 5,1882 0,43508 104 0,8963 193 0,4320 274 0,1644VA10 5,3414 0,26252 155 0,8744 214 0,4662 284 0,1206VA11 5,5369 0,27373 192 0,8445 266 0,4351 320 0,1989VA12 5,4247 0,29547 179 0,7879 214 0,5818 350 0,0713VA13 5,3781 0,22585 160 0,9110 213 0,5297 280 0,1279VA14 5,2471 0,37677 133 0,8276 169 0,6251 285 0,1410VA15 5,2426 0,41436 101 0,9353 198 0,4561 242 0,2761VA16 5,4641 0,26717 197 0,7532 218 0,6203 372 0,0443VA17 5,4517 0,23936 192 0,7914 233 0,5047 294 0,1663VA18 5,3440 0,40750 149 0,8003 197 0,5593 349 0,1049VA19 5,5393 0,18340 201 0,9028 264 0,4208 301 0,1801VA20 5,5371 0,32181 178 0,8652 251 0,5169 301 0,2987VA21 5,2317 0,63663 136 0,6927 216 0,4108 287 0,2508VA22 5,3819 0,39032 150 0,8293 233 0,4297 308 0,1862VA23 5,4567 0,32450 149 0,9185 244 0,4529 287 0,2660VA24 5,4907 0,31704 155 0,9220 261 0,4103 349 0,1252VA25 5,4215 0,34816 135 0,9323 240 0,4349 323 0,1532VA26 5,1911 0,26818 128 0,8995 202 0,3345 220 0,2251VA27 5,3357 0,31706 147 0,8643 204 0,5252 301 0,1207VA28 5,3257 0,32796 153 0,8144 190 0,5979 311 0,1034VA29 5,3757 0,22630 169 0,8624 205 0,5921 265 0,1836VA30 5,2139 0,49577 114 0,8328 183 0,5058 326 0,1239VA31 5,2979 0,39472 135 0,8382 190 0,5539 320 0,1167VA32 5,3932 0,21360 177 0,8446 219 0,5077 287 0,1063VA33 5,2671 0,33641 172 0,6409 208 0,4199 235 0,2836VA34 5,3774 0,25770 154 0,9076 231 0,4004 274 0,1802VA35 5,4552 0,25303 181 0,8427 240 0,4632 274 0,2663VA36 5,3091 0,26797 157 0,8297 198 0,5310 273 0,1312VA37 5,4148 0,26385 181 0,7956 210 0,6012 323 0,0845VA38 5,4107 0,4883 146 0,8103 229 0,4830 377 0,1428
Média 153 0,8515 215 0,4863 291 0,1728D.P. 0,0671 0,0698 0,0674
Componente P10 P50 P90Média (µ) D.P.(σ)

175
APÊNDICE G – Matriz de dados de tempos de vida original dos 38 componentes críticos coletados nos 10 anos (1994 a
2003) de amostragem
Componente Crítico
VA1 VA2 VA3 VA4 VA5 VA6 VA7 VA8 VA9 VA10 VA11 VA12 VA13 VA14 VA15 VA16 VA17 VA18 VA19 VA20 VA21 VA22 VA23 VA24 VA25 VA26 VA27 VA28 VA29 VA30 VA31 VA32 VA33 VA34 VA35 VA36 VA37 VA38Estatística
Geral154 201 154 154 201 154 188 201 201 201 259 235 160 148 186 245 201 201 201 235 235 235 235 235 130 245 235 154 235 154 154 235 235 154 201 211 211 149105 203 203 203 203 203 216 203 203 203 198 210 203 209 15 154 203 203 203 194 163 146 165 165 188 154 143 181 210 190 203 198 210 203 203 122 282 7524 203 203 203 203 203 203 203 203 112 103 217 112 112 203 210 203 183 203 107 203 64 136 136 116 128 67 109 217 125 112 103 191 112 112 112 308 102187 218 127 218 218 218 218 218 218 217 218 182 217 217 112 217 218 147 218 218 218 217 127 178 102 82 189 116 182 191 181 218 118 245 154 285 55 199217 290 182 175 175 175 175 224 175 182 175 175 182 182 217 182 175 182 175 224 175 182 91 131 218 217 121 181 238 34 127 175 40 232 274 308 89 179182 179 238 154 154 154 154 245 154 66 285 154 238 93 182 238 294 199 294 245 154 66 175 238 175 182 175 218 274 175 175 154 250 174 272 98 323 308132 308 274 274 372 274 274 232 219 27 406 372 372 285 238 372 308 313 183 308 140 133 282 274 154 224 154 175 335 149 154 274 179 393 372 77 196 354101 111 370 272 257 272 98 272 55 285 393 77 272 406 372 377 343 349 308 271 308 179 308 349 274 245 274 154 86 20 274 272 232 211 223 158 287 196278 225 257 188 214 46 256 378 370 232 246 111 34 37 111 206 232 398 326 500 266 308 98 387 370 308 272 372 230 85 370 291 158 258 168 241 147 189229 203 236 218 215 393 8 13 159 284 223 399 360 230 399 225 287 105 287 287 287 398 398 196 323 98 64 307 188 326 393 203 241 287 274 196 209 16856 259 259 259 183 211 167 48 52 213 287 196 218 196 196 218 139 259 274 274 287 203 203 168 196 203 382 314 274 335 246 182 196 147 272 274 172 18318 287 287 183 236 61 21 33 189 274 220 168 259 150 274 114 287 274 237 237 76 259 259 274 274 203 203 203 181 157 140 287 168 265 265 272 196 9131 252 252 272 197 197 189 180 188 237 228 259 215 274 182 3 252 237 301 301 35 197 287 272 272 84 182 84 56 130 83 252 274 180 172 265 181203 196 196 252 18 183 210 179 275 126 272 175 237 257 218 198 14 209 272 90 270 181 252 265 265 274 287 175 265 274 274 196 181 80 196 172 172287 180 196 178 257 272 274 272 301 350 184 176 35 299 198 98 272 294 265 270 280 280 166 149 274 196 237 237 180 265 196 196 196252 181 172 110 176 117 181 97 270 242 209 14 283 81 14 283 294 176 301 236 265 265 172100 196 172 21 228 265 263 97 280 19 3 294 19 270 83 272 36 196 80 19687 175 180 98 81 270 19 90 90 97 240 196140 180 97 12 4 194 270 272 295 209181 181 110 11 295
272MÉDIA 148 219 231 211 194 187 172 183 178 196 251 220 221 183 176 217 219 197 249 251 207 211 224 237 222 182 198 202 211 179 204 215 194 209 226 199 206 183 206DP 83 50 61 41 71 83 75 98 90 83 79 89 81 99 118 92 85 103 51 94 83 85 86 75 79 74 87 84 71 90 89 54 57 77 67 74 84 73 23CV 56% 23% 26% 19% 36% 44% 44% 53% 51% 42% 31% 41% 37% 54% 67% 43% 39% 52% 21% 37% 40% 40% 38% 32% 36% 41% 44% 42% 34% 50% 44% 25% 29% 37% 30% 37% 41% 40% 11,16%

176
APÊNDICE H – Ventaneiras usadas (em fim de vida útil) do Alto Forno 1

177
APÊNDICE I – Ventaneiras novas (disponíveis para uso) do Alto Forno 1

178
APÊNDICE J – Vista da área de Processamento de Matérias-primas da
Empresa estudada (ao centro o Alto Forno 1)

Livros Grátis( http://www.livrosgratis.com.br )
Milhares de Livros para Download: Baixar livros de AdministraçãoBaixar livros de AgronomiaBaixar livros de ArquiteturaBaixar livros de ArtesBaixar livros de AstronomiaBaixar livros de Biologia GeralBaixar livros de Ciência da ComputaçãoBaixar livros de Ciência da InformaçãoBaixar livros de Ciência PolíticaBaixar livros de Ciências da SaúdeBaixar livros de ComunicaçãoBaixar livros do Conselho Nacional de Educação - CNEBaixar livros de Defesa civilBaixar livros de DireitoBaixar livros de Direitos humanosBaixar livros de EconomiaBaixar livros de Economia DomésticaBaixar livros de EducaçãoBaixar livros de Educação - TrânsitoBaixar livros de Educação FísicaBaixar livros de Engenharia AeroespacialBaixar livros de FarmáciaBaixar livros de FilosofiaBaixar livros de FísicaBaixar livros de GeociênciasBaixar livros de GeografiaBaixar livros de HistóriaBaixar livros de Línguas

Baixar livros de LiteraturaBaixar livros de Literatura de CordelBaixar livros de Literatura InfantilBaixar livros de MatemáticaBaixar livros de MedicinaBaixar livros de Medicina VeterináriaBaixar livros de Meio AmbienteBaixar livros de MeteorologiaBaixar Monografias e TCCBaixar livros MultidisciplinarBaixar livros de MúsicaBaixar livros de PsicologiaBaixar livros de QuímicaBaixar livros de Saúde ColetivaBaixar livros de Serviço SocialBaixar livros de SociologiaBaixar livros de TeologiaBaixar livros de TrabalhoBaixar livros de Turismo





























