Embed Size (px)
Citation preview

Meacutethodologie recueil et manipulation de donneacuteesChristophe Pallier
September 7-8 2017
Preacuteliminaires
Plan
1 Une peu drsquoeacutepisteacutemologie (Theacuteorie de la connaissance)2 Construction de questionnaires3 Deacutefinition drsquoune population et strateacutegies drsquoeacutechantillonages4 Manipulation et exploration de donneacutees (avec R)
Ressources
bull Lohr S (2010) Sampling Design and Analysis BrooksColebull Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springer
ndash Falissard B (2012) Analysis of Questionnaire Data with R CRCPress
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
Partie 1 Un peu drsquoeacutepisteacutemologie
La Meacutethode scientifique
bull Une bonne theacuteorie doit faire des preacutedictions testables
ldquoSi les pierres qursquoon trouve actuellement sur Terre tombent quand onles lacircche crsquoest parce que celles qui ne tombaient pas se sont toutesenvoleacutees dans lrsquoespacerdquo
meacutethodologie recueil et manipulation de donneacutees 2
Figure 1 Des allers-retours entreObservationExpeacuterimentation etTheacuteorie
Rien de plus pratique qursquoune bonne theacuteorie
La theacuteorie dit quoi regarder Autrement dit elle suggegravere les ques-tions pertinentes
Si vous nrsquoavez pas theacuteorie du fonctionnement drsquoun teacuteleacuteviseur ilest difficile de le deacutepanner (Meacutetaphore du ldquodeacutepannagerdquo voir aussideacuteveloppement logiciel meacutedecine etc)
Cependant au deacutebut drsquoune recherche (dans sa phase exploratoire) ilexiste souvent des questions a- theacuteoriques
Questions ldquoa-theacuteoriquesrdquo
Des questions purement empiriques ou descriptives peuvent preacutesenterde lrsquointeacuterecirct (ou non) Exemples
bull Lrsquoespeacuterance de vie deacutepend-elle du niveau socio-eacuteconomique(il faut le mettre en eacutevidence avant de rechercher les causesmeilleure hygiegravene de vie soins geacuteneacutetique )
bull Les champs eacutelectro-magneacutetiques ont-ils des effets deacuteleacutetaires sur lasanteacute
bull Y-a-t il un lien entre lrsquoacircge drsquoacquisition drsquoune seconde langue et leniveau qursquoon peut atteindre (indeacutependament des autres facteursquantiteacute drsquoexposition agrave la seconde langue type drsquoenseignement)
bull La taille ou la couleur de cheveux drsquoun invididu ont-ils des effetssur son revenu
bull Le signe astrologique a t-il une influence sur le caractegravere drsquounepersonne
meacutethodologie recueil et manipulation de donneacutees 3
Observation vs Expeacuterimentation
Observer Noter et rapporter les eacuteveacutenements de maniegravere systegravema-tique
Expeacuterimenter manipuler des conditions et deacutemontrer que des eacuteveacutene-ments se reproduisent sous certaines drsquoentre elles
Exemples de variables ne pouvant pas ecirctre manipuleacutees directe-ment
bull la taille drsquoune eacutetoile et sa couleurbull le poids la taille le sexe drsquoun individubull Le fait drsquoavoir une certaine maladie psychiatrique ou non
Exemples de variables pouvant ecirctre manipuleacutees (assigneacutees arbi-trairement agrave des individus)
bull meacutedicament actif vs placebobull aide sociale (eacuteconomie expeacuterimentale) Voir https80000hours
orgarticleseffective-social-program
Correacutelation et causaliteacute
bull Lrsquoexistence drsquoune correacutelation entre deux variables nrsquoimplique pasde lien de causaliteacute directe
Figure 2 effet du nombre de Pirates surle reacutechauffement climatique
bull Par exemple srsquoil existe une correacutelation entre la cylindreacutee de lavoiture familliale et le QI des enfants cela est certainement ducirc agrave
meacutethodologie recueil et manipulation de donneacutees 4
des variables tierces (niveau socio-eacuteconomique on srsquoen douteuniquement parce qursquoon a une theacuteorie)
Figure 3 relations entre variables
bull Lrsquoexpeacuterimentation mieux que lrsquoobservation permet de tester entermes de causaliteacute lrsquoimpact drsquoune ou plusieurs variable(s) in-deacutependantes sur une ou plusieurs variables deacutependantes
bull Neacuteanmoins mecircme avec des donneacutees drsquoobservation on peut cal-culer des coefficients de correacutelations partiels et ajuster pour les effetsde variables de ldquocontrocirclesrdquo
Claude Bernard (1877) Principes de meacutedecine expeacuterimentalesmaller
ldquoDans toutes les sciences il y a deux eacutetats bien distincts agrave consideacutererCe sont
1 lrsquoeacutetat de science drsquoobservation 2 lrsquoeacutetat de science expeacuterimentale
Ces deux eacutetats sont neacutecessairement et absolument subordonneacuteslrsquoun agrave lrsquoautre Jamais une science ne peut parvenir agrave lrsquoeacutetat de scienceexpeacuterimentale sans avoir passeacute par lrsquoeacutetat de science drsquoobservationMais il y a des sciences auxquelles il nrsquoest pas donneacute de pouvoirparvenir agrave lrsquoeacutetat de science expeacuterimentale telle est lrsquoastronomie parexemple
Une science drsquoobservation ou science naturelle se borne agrave ob-server agrave classer agrave contempler les pheacutenomegravenes de la nature et agravedeacutedire des observations les lois geacuteneacuterales des pheacutenomegravenes Mais
meacutethodologie recueil et manipulation de donneacutees 5
elle nrsquoagit pas sur les pheacutenomegravenes eux-mecircmes pour les modifier ouen creacuteer de nouveaux pour agir sur la nature en un mot Les sciencesqui comme lrsquoastronomie srsquooccupent de pheacutenomegravenes hors de notreporteacutee expeacuterimentale restent forceacutement des sciences drsquoobservation
Conseacutequence Claude Bernard ne prenait pas au seacuterieux la theacuteoriede lrsquoeacutevolution de Darwin
Conseacutequences pratiques
Choix de la proceacutedure statistique pour quantifier la degreacute de relationlineacuteaire entre 2 variables
bull Dans une situation drsquoobservation on privileacutegie la correacutelation simpleougrave les deux variables jouent un rocircle symeacutetrique
Figure 4 Correacutelation lineacuteaire entre deuxvariables
On calcule typiquement le coefficient de correacutelation de Pearson
r(X Y) =σ2
XY
σX σY
bull Dans une situation expeacuterimentale ougrave les variables jouent des rocirclesasymeacutetriques mdash avec une variable ldquodeacutependanterdquo et une variableldquoindeacutependanterdquo mdash on utilisera plutocirct la reacutegression
Yi = aXi + b + εi
Remarques sur le coefficient de correacutelation
Le coeff de correacutelation ne reflegravete que la composante lineacuteaire Mecircmequand il est nul il peut neacuteanmoins exister une relation non-lineacuteaireentre les deux variables
Ne jamais rapporter un coefficient de correacutelation sans examengraphique
Pour en savoir plus httpsenwikipediaorgwikiCorrelation_
and_dependence
meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 2
Figure 1 Des allers-retours entreObservationExpeacuterimentation etTheacuteorie
Rien de plus pratique qursquoune bonne theacuteorie
La theacuteorie dit quoi regarder Autrement dit elle suggegravere les ques-tions pertinentes
Si vous nrsquoavez pas theacuteorie du fonctionnement drsquoun teacuteleacuteviseur ilest difficile de le deacutepanner (Meacutetaphore du ldquodeacutepannagerdquo voir aussideacuteveloppement logiciel meacutedecine etc)
Cependant au deacutebut drsquoune recherche (dans sa phase exploratoire) ilexiste souvent des questions a- theacuteoriques
Questions ldquoa-theacuteoriquesrdquo
Des questions purement empiriques ou descriptives peuvent preacutesenterde lrsquointeacuterecirct (ou non) Exemples
bull Lrsquoespeacuterance de vie deacutepend-elle du niveau socio-eacuteconomique(il faut le mettre en eacutevidence avant de rechercher les causesmeilleure hygiegravene de vie soins geacuteneacutetique )
bull Les champs eacutelectro-magneacutetiques ont-ils des effets deacuteleacutetaires sur lasanteacute
bull Y-a-t il un lien entre lrsquoacircge drsquoacquisition drsquoune seconde langue et leniveau qursquoon peut atteindre (indeacutependament des autres facteursquantiteacute drsquoexposition agrave la seconde langue type drsquoenseignement)
bull La taille ou la couleur de cheveux drsquoun invididu ont-ils des effetssur son revenu
bull Le signe astrologique a t-il une influence sur le caractegravere drsquounepersonne
meacutethodologie recueil et manipulation de donneacutees 3
Observation vs Expeacuterimentation
Observer Noter et rapporter les eacuteveacutenements de maniegravere systegravema-tique
Expeacuterimenter manipuler des conditions et deacutemontrer que des eacuteveacutene-ments se reproduisent sous certaines drsquoentre elles
Exemples de variables ne pouvant pas ecirctre manipuleacutees directe-ment
bull la taille drsquoune eacutetoile et sa couleurbull le poids la taille le sexe drsquoun individubull Le fait drsquoavoir une certaine maladie psychiatrique ou non
Exemples de variables pouvant ecirctre manipuleacutees (assigneacutees arbi-trairement agrave des individus)
bull meacutedicament actif vs placebobull aide sociale (eacuteconomie expeacuterimentale) Voir https80000hours
orgarticleseffective-social-program
Correacutelation et causaliteacute
bull Lrsquoexistence drsquoune correacutelation entre deux variables nrsquoimplique pasde lien de causaliteacute directe
Figure 2 effet du nombre de Pirates surle reacutechauffement climatique
bull Par exemple srsquoil existe une correacutelation entre la cylindreacutee de lavoiture familliale et le QI des enfants cela est certainement ducirc agrave
meacutethodologie recueil et manipulation de donneacutees 4
des variables tierces (niveau socio-eacuteconomique on srsquoen douteuniquement parce qursquoon a une theacuteorie)
Figure 3 relations entre variables
bull Lrsquoexpeacuterimentation mieux que lrsquoobservation permet de tester entermes de causaliteacute lrsquoimpact drsquoune ou plusieurs variable(s) in-deacutependantes sur une ou plusieurs variables deacutependantes
bull Neacuteanmoins mecircme avec des donneacutees drsquoobservation on peut cal-culer des coefficients de correacutelations partiels et ajuster pour les effetsde variables de ldquocontrocirclesrdquo
Claude Bernard (1877) Principes de meacutedecine expeacuterimentalesmaller
ldquoDans toutes les sciences il y a deux eacutetats bien distincts agrave consideacutererCe sont
1 lrsquoeacutetat de science drsquoobservation 2 lrsquoeacutetat de science expeacuterimentale
Ces deux eacutetats sont neacutecessairement et absolument subordonneacuteslrsquoun agrave lrsquoautre Jamais une science ne peut parvenir agrave lrsquoeacutetat de scienceexpeacuterimentale sans avoir passeacute par lrsquoeacutetat de science drsquoobservationMais il y a des sciences auxquelles il nrsquoest pas donneacute de pouvoirparvenir agrave lrsquoeacutetat de science expeacuterimentale telle est lrsquoastronomie parexemple
Une science drsquoobservation ou science naturelle se borne agrave ob-server agrave classer agrave contempler les pheacutenomegravenes de la nature et agravedeacutedire des observations les lois geacuteneacuterales des pheacutenomegravenes Mais
meacutethodologie recueil et manipulation de donneacutees 5
elle nrsquoagit pas sur les pheacutenomegravenes eux-mecircmes pour les modifier ouen creacuteer de nouveaux pour agir sur la nature en un mot Les sciencesqui comme lrsquoastronomie srsquooccupent de pheacutenomegravenes hors de notreporteacutee expeacuterimentale restent forceacutement des sciences drsquoobservation
Conseacutequence Claude Bernard ne prenait pas au seacuterieux la theacuteoriede lrsquoeacutevolution de Darwin
Conseacutequences pratiques
Choix de la proceacutedure statistique pour quantifier la degreacute de relationlineacuteaire entre 2 variables
bull Dans une situation drsquoobservation on privileacutegie la correacutelation simpleougrave les deux variables jouent un rocircle symeacutetrique
Figure 4 Correacutelation lineacuteaire entre deuxvariables
On calcule typiquement le coefficient de correacutelation de Pearson
r(X Y) =σ2
XY
σX σY
bull Dans une situation expeacuterimentale ougrave les variables jouent des rocirclesasymeacutetriques mdash avec une variable ldquodeacutependanterdquo et une variableldquoindeacutependanterdquo mdash on utilisera plutocirct la reacutegression
Yi = aXi + b + εi
Remarques sur le coefficient de correacutelation
Le coeff de correacutelation ne reflegravete que la composante lineacuteaire Mecircmequand il est nul il peut neacuteanmoins exister une relation non-lineacuteaireentre les deux variables
Ne jamais rapporter un coefficient de correacutelation sans examengraphique
Pour en savoir plus httpsenwikipediaorgwikiCorrelation_
and_dependence
meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques
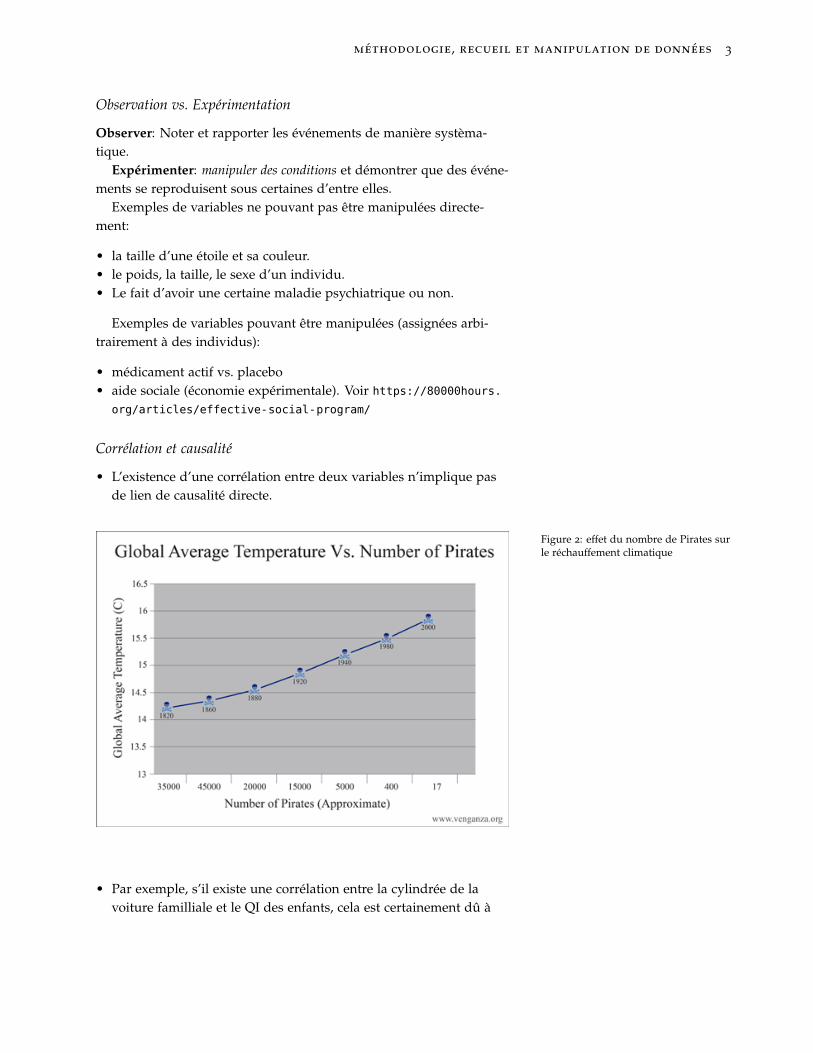
meacutethodologie recueil et manipulation de donneacutees 3
Observation vs Expeacuterimentation
Observer Noter et rapporter les eacuteveacutenements de maniegravere systegravema-tique
Expeacuterimenter manipuler des conditions et deacutemontrer que des eacuteveacutene-ments se reproduisent sous certaines drsquoentre elles
Exemples de variables ne pouvant pas ecirctre manipuleacutees directe-ment
bull la taille drsquoune eacutetoile et sa couleurbull le poids la taille le sexe drsquoun individubull Le fait drsquoavoir une certaine maladie psychiatrique ou non
Exemples de variables pouvant ecirctre manipuleacutees (assigneacutees arbi-trairement agrave des individus)
bull meacutedicament actif vs placebobull aide sociale (eacuteconomie expeacuterimentale) Voir https80000hours
orgarticleseffective-social-program
Correacutelation et causaliteacute
bull Lrsquoexistence drsquoune correacutelation entre deux variables nrsquoimplique pasde lien de causaliteacute directe
Figure 2 effet du nombre de Pirates surle reacutechauffement climatique
bull Par exemple srsquoil existe une correacutelation entre la cylindreacutee de lavoiture familliale et le QI des enfants cela est certainement ducirc agrave
meacutethodologie recueil et manipulation de donneacutees 4
des variables tierces (niveau socio-eacuteconomique on srsquoen douteuniquement parce qursquoon a une theacuteorie)
Figure 3 relations entre variables
bull Lrsquoexpeacuterimentation mieux que lrsquoobservation permet de tester entermes de causaliteacute lrsquoimpact drsquoune ou plusieurs variable(s) in-deacutependantes sur une ou plusieurs variables deacutependantes
bull Neacuteanmoins mecircme avec des donneacutees drsquoobservation on peut cal-culer des coefficients de correacutelations partiels et ajuster pour les effetsde variables de ldquocontrocirclesrdquo
Claude Bernard (1877) Principes de meacutedecine expeacuterimentalesmaller
ldquoDans toutes les sciences il y a deux eacutetats bien distincts agrave consideacutererCe sont
1 lrsquoeacutetat de science drsquoobservation 2 lrsquoeacutetat de science expeacuterimentale
Ces deux eacutetats sont neacutecessairement et absolument subordonneacuteslrsquoun agrave lrsquoautre Jamais une science ne peut parvenir agrave lrsquoeacutetat de scienceexpeacuterimentale sans avoir passeacute par lrsquoeacutetat de science drsquoobservationMais il y a des sciences auxquelles il nrsquoest pas donneacute de pouvoirparvenir agrave lrsquoeacutetat de science expeacuterimentale telle est lrsquoastronomie parexemple
Une science drsquoobservation ou science naturelle se borne agrave ob-server agrave classer agrave contempler les pheacutenomegravenes de la nature et agravedeacutedire des observations les lois geacuteneacuterales des pheacutenomegravenes Mais
meacutethodologie recueil et manipulation de donneacutees 5
elle nrsquoagit pas sur les pheacutenomegravenes eux-mecircmes pour les modifier ouen creacuteer de nouveaux pour agir sur la nature en un mot Les sciencesqui comme lrsquoastronomie srsquooccupent de pheacutenomegravenes hors de notreporteacutee expeacuterimentale restent forceacutement des sciences drsquoobservation
Conseacutequence Claude Bernard ne prenait pas au seacuterieux la theacuteoriede lrsquoeacutevolution de Darwin
Conseacutequences pratiques
Choix de la proceacutedure statistique pour quantifier la degreacute de relationlineacuteaire entre 2 variables
bull Dans une situation drsquoobservation on privileacutegie la correacutelation simpleougrave les deux variables jouent un rocircle symeacutetrique
Figure 4 Correacutelation lineacuteaire entre deuxvariables
On calcule typiquement le coefficient de correacutelation de Pearson
r(X Y) =σ2
XY
σX σY
bull Dans une situation expeacuterimentale ougrave les variables jouent des rocirclesasymeacutetriques mdash avec une variable ldquodeacutependanterdquo et une variableldquoindeacutependanterdquo mdash on utilisera plutocirct la reacutegression
Yi = aXi + b + εi
Remarques sur le coefficient de correacutelation
Le coeff de correacutelation ne reflegravete que la composante lineacuteaire Mecircmequand il est nul il peut neacuteanmoins exister une relation non-lineacuteaireentre les deux variables
Ne jamais rapporter un coefficient de correacutelation sans examengraphique
Pour en savoir plus httpsenwikipediaorgwikiCorrelation_
and_dependence
meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 4
des variables tierces (niveau socio-eacuteconomique on srsquoen douteuniquement parce qursquoon a une theacuteorie)
Figure 3 relations entre variables
bull Lrsquoexpeacuterimentation mieux que lrsquoobservation permet de tester entermes de causaliteacute lrsquoimpact drsquoune ou plusieurs variable(s) in-deacutependantes sur une ou plusieurs variables deacutependantes
bull Neacuteanmoins mecircme avec des donneacutees drsquoobservation on peut cal-culer des coefficients de correacutelations partiels et ajuster pour les effetsde variables de ldquocontrocirclesrdquo
Claude Bernard (1877) Principes de meacutedecine expeacuterimentalesmaller
ldquoDans toutes les sciences il y a deux eacutetats bien distincts agrave consideacutererCe sont
1 lrsquoeacutetat de science drsquoobservation 2 lrsquoeacutetat de science expeacuterimentale
Ces deux eacutetats sont neacutecessairement et absolument subordonneacuteslrsquoun agrave lrsquoautre Jamais une science ne peut parvenir agrave lrsquoeacutetat de scienceexpeacuterimentale sans avoir passeacute par lrsquoeacutetat de science drsquoobservationMais il y a des sciences auxquelles il nrsquoest pas donneacute de pouvoirparvenir agrave lrsquoeacutetat de science expeacuterimentale telle est lrsquoastronomie parexemple
Une science drsquoobservation ou science naturelle se borne agrave ob-server agrave classer agrave contempler les pheacutenomegravenes de la nature et agravedeacutedire des observations les lois geacuteneacuterales des pheacutenomegravenes Mais
meacutethodologie recueil et manipulation de donneacutees 5
elle nrsquoagit pas sur les pheacutenomegravenes eux-mecircmes pour les modifier ouen creacuteer de nouveaux pour agir sur la nature en un mot Les sciencesqui comme lrsquoastronomie srsquooccupent de pheacutenomegravenes hors de notreporteacutee expeacuterimentale restent forceacutement des sciences drsquoobservation
Conseacutequence Claude Bernard ne prenait pas au seacuterieux la theacuteoriede lrsquoeacutevolution de Darwin
Conseacutequences pratiques
Choix de la proceacutedure statistique pour quantifier la degreacute de relationlineacuteaire entre 2 variables
bull Dans une situation drsquoobservation on privileacutegie la correacutelation simpleougrave les deux variables jouent un rocircle symeacutetrique
Figure 4 Correacutelation lineacuteaire entre deuxvariables
On calcule typiquement le coefficient de correacutelation de Pearson
r(X Y) =σ2
XY
σX σY
bull Dans une situation expeacuterimentale ougrave les variables jouent des rocirclesasymeacutetriques mdash avec une variable ldquodeacutependanterdquo et une variableldquoindeacutependanterdquo mdash on utilisera plutocirct la reacutegression
Yi = aXi + b + εi
Remarques sur le coefficient de correacutelation
Le coeff de correacutelation ne reflegravete que la composante lineacuteaire Mecircmequand il est nul il peut neacuteanmoins exister une relation non-lineacuteaireentre les deux variables
Ne jamais rapporter un coefficient de correacutelation sans examengraphique
Pour en savoir plus httpsenwikipediaorgwikiCorrelation_
and_dependence
meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 5
elle nrsquoagit pas sur les pheacutenomegravenes eux-mecircmes pour les modifier ouen creacuteer de nouveaux pour agir sur la nature en un mot Les sciencesqui comme lrsquoastronomie srsquooccupent de pheacutenomegravenes hors de notreporteacutee expeacuterimentale restent forceacutement des sciences drsquoobservation
Conseacutequence Claude Bernard ne prenait pas au seacuterieux la theacuteoriede lrsquoeacutevolution de Darwin
Conseacutequences pratiques
Choix de la proceacutedure statistique pour quantifier la degreacute de relationlineacuteaire entre 2 variables
bull Dans une situation drsquoobservation on privileacutegie la correacutelation simpleougrave les deux variables jouent un rocircle symeacutetrique
Figure 4 Correacutelation lineacuteaire entre deuxvariables
On calcule typiquement le coefficient de correacutelation de Pearson
r(X Y) =σ2
XY
σX σY
bull Dans une situation expeacuterimentale ougrave les variables jouent des rocirclesasymeacutetriques mdash avec une variable ldquodeacutependanterdquo et une variableldquoindeacutependanterdquo mdash on utilisera plutocirct la reacutegression
Yi = aXi + b + εi
Remarques sur le coefficient de correacutelation
Le coeff de correacutelation ne reflegravete que la composante lineacuteaire Mecircmequand il est nul il peut neacuteanmoins exister une relation non-lineacuteaireentre les deux variables
Ne jamais rapporter un coefficient de correacutelation sans examengraphique
Pour en savoir plus httpsenwikipediaorgwikiCorrelation_
and_dependence
meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 6
Figure 5 Les droites de reacutegression de Xsur Y et de Y sur X diffegraverent
Figure 6 Exemples de relations possi-bles entre deux variables continues
meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 7
Figure 7 Les coefficients de correacutelationsont exactement les mecircmes dans cesquatre figures
Avantages de lrsquoobservation sur lrsquoexpeacuterimentation
Les enquecirctes ne font pas partie des recherches expeacuterimentales on nrsquoymanipule pas de variables on se contente de les enregistrer
Neacuteanmoins les enquecirctes preacutesentent certains avantages sur lestravaux expeacuterimentaux
bull Les enquecirctes sont typiquement moins coucircteuses par individu cequi permet drsquoobtenir des eacutechantillons plus larges et plus repreacutesen-tatifs (Les expeacuteriences sont typiquements reacutealiseacutees sur des eacutetudi-ants sains et volontaires)
bull Le reacutesultat drsquoune enquecircte (bien meneacutee) renseigne sur le ldquomondereacuteelrdquo alors que la geacuteneacuteralisabiliteacute des expeacuteriences en laboratoirepeut ecirctre mise en doute (manque de validiteacute eacutecologique)
En pratique les deux approches sont compleacutementaires Toutes lesmeacutethodes sont imparfaites et des reacutesultats convergents selon plusieursmeacutethodes sont tregraves appreacuteciables
Deacutemarche exploratoire vs descriptive explicative
Induction et Deacuteduction
bull Le scandale de lrsquoinduction aller du particulier au geacuteneral nrsquoestpas logiquement valide
meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 8
Figure 8 Il est important de bienidentifier le type de deacutemarche
Un physicien un matheacutematicien et un logicien voyagent dans un trainqui traverse la campagne Ils croisent un champ ougrave se trouve une vacheblanche
Le physicien ldquotiens dans ce pays les vaches sont blanchesrdquo Le math-eacutematicien ldquoNon il y au moins un vache blanche dans ce paysrdquo Lelogicien ldquoJe te corrige il y a au moins une vache avec un cocircteacute blancrdquo
bull Seule la deacuteduction est logiquement valide
Tous les hommes sont mortels Socrate est un homme donc Socrate estmortel
Et pourtant vive lrsquoinduction
En reacutealiteacute on peut souvent faire le pari qursquoil y a des reacutegulariteacutes dansles eacuteveacutenements
ldquoJusqursquoagrave preacutesent le soleil srsquoest leveacute tous les matins donc il se legraveveratous les jours (ou au moins avec une forte probabiliteacute)rdquo
Intuitivement si on a observeacute un eacuteveacutenement A il y a plus dechance qursquoil se reproduise qursquoun eacuteveacutenement B qui nrsquoa jamais eacuteteacuteobserveacute
En pratique scientifiques et autres utilisent lrsquoinduction en essayantde quantifier notre incertitude agrave lrsquoaide de meacutethodes statistiques (Analyserisquesbeacuteneacutefice cf Assurances)
meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 9
Les statistiques Baysiennes permettent de calculer la probabiliteacutedrsquoune hypothegravese en fonction des donneacutees ou la distribution de prob-abiliteacute drsquoun paramegravetre
En statistiques freacutequentistes la deacutecision drsquoaccepter une hypothegraveseest prise avec un seuil de risque typiquement 5 et on calcule desintervalle de confiance pour les paramecirctres
Karl Popper et la Falsification
Pour Karl Popper une theacuteorie scientifique doit pouvoir ecirctre reacutefuteacuteepar une observation (un ldquotest crucialrdquo) Lrsquoavanceacutee des connaissancesse fait en rejettant des theacuteories celles qui ne sont pas encore falsifieacuteessont les meilleures agrave un moment donneacute
Quand plusieurs theacuteories sont compatibles avec les donneacutees ex-istante o cherche alors si elles font des preacutedictions diffeacuterentes et onteste ces preacutedictions pour les deacutepartager (Voir John R Platt StrongInference Science 1964)
bull Lrsquoastrologie la psychanalyse lrsquoastronomie lrsquohistoire font-ellesdes preacutedictions falsifiables
En reacutealiteacute les choses sont beaucoup plus complexes On ne re-jette pas une theacuteorie degraves qursquoune expeacuterience la contredit On essayedrsquoabord de rejetter des hypothegraveses auxiliaires cagraved de modifier lemodegravele (Paul Duhem)
Pour aller plus loin
bull Thomas Kuhn (1962) La structure des Reacutevolutions Scientifiquesbull Imre Lakatos (1976) Conjectures et Refutationsbull Paul Fayerabend (1975) Contre la meacutethode Esquisse drsquoune theacuteorie
anarchiste de la connaissance
La pyramide de la qualiteacute des preuves
La deacutemarche scientifique en pratique
bull Choisir une problegravematiquebull Faire une revue de lrsquoeacutetat de lrsquoart (synthegravese de la litteacuterature scien-
tifique)bull Suggegraverer une ou plusieurs hypothegraveses opeacuterationnelles (une deacutefini-
tion opeacuterationnelle speacutecifie les proceacutedures effectives de mesuredrsquoune variable Ex lsquoanxieacuteteacutersquo)
bull Construire un plan drsquoacquisition de donneacuteesbull (deacuteposer des demandes de financement recommencer recom-
mencer )bull Recueillir les donneacutees
meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 10
Figure 9 La pyramide de la qualiteacute despreuves
meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 11
bull Tester le(s) hypothegraveses en utilisant des outils drsquoanalyse statistiquebull Reacutediger un compte rendu dans un article ou rapport de recherchebull Evaluation par les pairsbull Publicationbull Quelquefois Reproduction par drsquoautres chercheurs
Lrsquoobjectiviteacute scientifique
Nos sentiments personnels ou nos attentes ne doivent pas influencerles donneacutees que nous rapportons (pex biais de seacutelection des don-neacutees)
Drsquoougrave lrsquoimportance des expeacuteriences en double aveugleLes articles scientifiques distinguent soigneusement la partie meacuteth-
odesreacutesultats des parties interpreacutetatives(Lecture recommandeacutee Steven J Gould La mal-mesure de lrsquoHomme
Odile Jacob)
Principales eacutetapes drsquoune enquecircte
Figure 10 Principales eacutetapes drsquouneenquecircte
Partie 2 Construction drsquoun questionnaire
Les qualiteacutes fondamentales drsquoun questionnaire
bull lrsquooutil choisi mesure bien ce pour quoi il a eacuteteacute construit (validiteacute)
bull les mesures reacutealiseacutees sont bien reproductibles (fiabiliteacute (reliabil-ity)) et permettent de detecter les effets rechercheacutes (puissancestatistique)
meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 12
Veacuterification de la validiteacute
Lors de la phase de deacutefinition des hypothegraveses geacuteneacuterales de lrsquoenquecircteainsi que de ses objectifs il est neacutecessaire de bien preacuteciser lrsquoinformationdeacutesireacutee
ldquoconstruct validityrdquo Est ce que les deacutefinitions opeacuterationnelleschoisies capturent bien les concepts (pex anxieacuteteacute) pertinents Nesont-elles pas influenceacutees par des facteurs non pertinents
Exemple si je veux mesurer lrsquointelligence par le QI et que le testde QI que je construis est tregraves long je peux ecirctre en train de mesurerla perseacuteveacuterance plutocirct que lrsquointelligence (Au passage certains ques-tionnent si la mesure de QI est une bonne mesure de lrsquointelligence)
Lors de la conception du test il faut jouer lrsquoavocat du diable etchercher des explications alternatives Tant qursquoil y en a modifier letest
Introduire plusieurs instruments de mesures (pour une enquecircteplusieurs questions) dont certaines utilisant des meacutethodes ldquoeacuteprou-veacuteesrdquo (si elles existent) et veacuterifier a posteriori que leurs reacutesultatscorregravelent bien
Comment veacuterifier la fiabiliteacute
cross-validation (split-half k-fold leave-one out)Retest sur un nouveau groupe indepedant
Inter-rater reliability (IRR)
Srsquoil y a des reacuteponses qui doivent ecirctre classifieacutees par un humain ilfaut verifier si un autre humain donne des reacutesultats similaires
Exemple deux juges classent les reacuteponses des paticipants dansdeux cateacutegories
Juge1 Rep1 Rep2
Juge2
Rep1 a bRep2 c d
Pour eacutevaluer le degreacute drsquoaccord on calcule le Kappa de CohenPar exemple si deux psychiatres eacutevaluent 23 patients pour deacutecider
srsquoils ont un tristesse douloureuse Les donneacutees (accordqualcsv) sontdisponibles au format csv2 sur la page httphebergementu-psud
frbiostatistiqueslivreampid=02ampr=partie02
require(psy)
data = readcsv2(rsquo httphebergementu-psudfrbiostatistiquesincludeslivre02partie02fichiersaccordqualcsvrsquo)
table(data)
meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 13
ckappa(data)
Puissance statistique (sensibiliteacute)
bull au moment de la conception srsquoassurer qursquoon a un nombre adeacutequatde mesures (pour cela il faut estimer les tailles drsquoeffets et leursvariances)
bull apregraves-coup agrave partir des effets effectivement observeacutes et leur vari-abiliteacute on peux eacutevaluer le nombre de sujets qursquoil aurait fallu pourdeacutetecter une diffeacuterence avec une certaine probabiliteacute
Critegraveres drsquoinclusionexclusion
Il peut ecirctre neacutecessaire de deacutefinir des critegraveres drsquoexclusionPar exemple en imagerie cerebrale sur le sujet sain jrsquoevite les per-
sonnes qui consomment trop drsquoalcool ou de stupefiants les femmespotentiellement en enceintes etc
Cela fait parti de la deacutefinition de la population-megravere
Diffeacuterents modes de recueil des donneacutees
bull Questionnaires auto-administreacutes par courrier ou Par Internet (siteou email)
bull Interview teacuteleacutephonique
Avantage si les interviewers sont bons la qualiteacute des reacuteponsespeut ecirctre meilleure que dans les questionnaire auto administreacutes
Deacutesavantages dureacutee limiteacutee ne permettant que des questions assezsimples
bull Interview en face-agrave-face
ndash interview structureacutee les mecircmes questions sont poseacutees exacte-ment de la mecircme maniegravere agrave tous les participants
ndash interview non structureacutee interaction libre
bull Groupe de discussion
Petit groupe de personnes partageant des carateacuteriques (eg femmesentre 30 et 40 ans ) Lrsquointerviewer est un ldquofacilitateurrdquo qui posedes question ouvertes
Inteacuteressant pour preacutetester les questions drsquoune enquecircte afin dechoisir les plus pertinentes
meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 14
Construction pratique drsquoun questionnaire
Des logiciels permettent de construire des interfaces avec des masquesde saisie pour les diffeacuterentes questions permettant de speacutecifier deconditions de validiteacute des reacuteponses drsquoeffectuer des branchements enfonction des reacuteponses
Des modules permettent - la saisie des donneacutees - leur analysesstatistique ou leur exportation dans des fichiers (tables bases de don-neacutees ) exploitable par des logiciels comme R SAS SPSS Stata
Offline
bull epidata (httpwwwepidatadk) puissant multiplateforme (Win-dows Mac Linux) gratuit (cf TP sur httphebergementu-psudfrbiostatistiqueslivreampid=01ampr=partie01)
Online
bull google forms httpsdocsgooglecomforms tregraves pratique pourdes questionnaires simples (pex ne permet pas de branchement)Fourni les resultats sous form de feuille de calcul google
bull surveymonkey httpsfrsurveymonkeycom simple agrave utiliserpuissant 400ean (900e pour la version plus puissante)
bull limesurvey httpswwwlimesurveyorg libre tregraves puissantpeut ecirctre installeacute sur son propre serveur web
bull Moodle (plateforme de cours en ligne) utilise un format GIFT pourcontruire les questionnaires
Les questions
bull Quand elles portent sur des individus elles permettent drsquoobtenirtrois types de donneacutees
bull Factuelle Ex caracteacuteristiques deacutemographiques fumeur nonfumeur
bull Comportementales Ex style de vie (Ex prenez vous souvent lemetro)
bull Attitudinale opinions valeurs croyances (pensez-vous que lsquoXrsquosoit vraifaux)
bull Poser de bonnes questions est un art
Voir A N Oppenheim (1992) Questionnaire design Interviewing andAttitude Measurement Continuum
meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 15
ldquoThe world is full of well-meaning people who believe that anyonewho can write plain English and has a modicum of common sense canproduce a good questionnaire This book is not for themrdquo
bull Questions agrave choix fermeacute vs questions agrave choix ouvert
Exemples de questions agrave choix fermeacute
Likert scale
Strongly disagree | Disagree | Neither agree nor diwagree | Agree | Strongly Agree
Echelle seacutemantique diffeacuterentielle
This test is
difficult _____________________ easy
useless _____________________ useful
Choix multiple
During French class I would like
(a) to have a combination of French and English spoken
(b) to have as much English as possible spoken
(c) to have only French spoken
Questions agrave choix ouvert
A utiliser de preacutefeacuterence pour demander au sujet drsquoapporter des clari-fications
Exemples de questions agrave choix ouvert
Quel est votre programme teacuteleacute favori
Si vous avez mis une note infeacuterieure ou eacutegale agrave 2 agrave votre seacutejour merci drsquoexpliquer briegravevement vos raisons
Questions guideacutees
Une chose que jrsquoai appreacutecieacute est
Une chose que je nrsquoai pas appreacutecieacute est
Types de Variable
bull Nominale la variable peut prendre des valeurs dans un ensemblefini de cateacutegories distinctes Ex VraiFaux Couleur de cheveux
bull Ordinale les cateacutegories peuvent ecirctre ordonneacutees Ex
meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 16
bull intervalle la diffeacuterence numerique entre les cateacutegories a du sensEx temperature (la difference entre 40 degre C et 20 degreacute C est lameme qursquoentre 20 et 0 mais 40 nrsquoest pas deux fois plus chaud que20 degreacutes)
bull ratio le ratio entre deux valeur agrave du sens Ex poids (4 kg est 2
fois plus lourd que 2 kg)
Les proceacutedures statistiques deacutependent du type de donneacutees Parexemple
bull Pour comparer deux proportions (variable nominale agrave deuxvaleurs) on pourra utiliser un test de chi2 (eg chisqtest) uneregression logistique ou un modegravele loglineacuteraire
bull Pour comparer deux moyennes de variables de type intervalle ouratio on utilisera un test de Student ou de Welsh
Interlude rapports de cocircte et risque relatif
Une probabiliteacute p est un nombre entre 0 et 1Pour comparer deux probabliteacutes plutocirct que de regarder leur dif-
feacuterence on utilise plutocirct le risque relatif ou le rapport de cocircteLe risque relatif est simplement le ratioPar exemple Si 10 des fumeurs ont eu un cancer du poumon et
5 des non-fumeurs ont eu un cancer du poumon le risque relatif(RR) est 1005 = 2
On peut aussi transformer les probaliteacutes un cocirctes (ldquooddsrdquo enanglais) par example ldquo10 contre 1rdquo et on utilise des rapport de cocirctes(odd ratio) pour comparer des probabiliteacutes
c =p
1 minus p
odd = function(p) p (1 - p)
plot(odd(seq(0 1 by=01)) type=rsquolrsquo)
odd(1)odd(05)
2111111
On peut obtenir des intervalles de confiance pour le RR et les oddratio avec la function twoby2 du package Epi
require(Epi)
examples(twoby2)
meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 17
Figure 11 Convertion de probabiliteacute encocircte
Conseils pratiques pour des questionnaires auto-administreacutes
Afin de maximiser le taux de reacuteponse
bull Les questions doivent ecirctre simplesbull les questions doivent suivre un ordre logiquebull La concision doit lrsquoemporter sur la tentation drsquoecirctre exhaustifbull Faire une mise en page soigneacutee Aeacuterer le texte Format petit livret
preacutefeacuterable agrave pages A4bull Eviter drsquoavoir un saut de page au milieu drsquoun itembull Ideacutealement pas plus de 4 pages 30 minutes maxbull mettre les questions factuelles agrave la fin du questionnaire
Controcircle de qualiteacute
Nettoyage des donneacutees
bull Donneacutees absurdes Ex Si code numeacuterique devait petre entre 1 et7 une valeur en dehors de cet intervalle est ldquoabsurderdquo il faut laremplacer par un lsquoNArsquo (donneacutee manquante)
bull Reacuteponses contradictoires agrave des items distincts (il faut envisagerdrsquoeacuteliminer ces questionnaires)
meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 18
bull Donneacutees implausibles (outliers) Crsquoest le cas probleacutematique Celareflegravete t-il la veacuteriteacute ou une erreur Approches possibles
bull utiliser des statistiques robustes (pex meacutediane plutocirct que lamoyenne)
bull faire lrsquoanalyse avec et sans les outlier et si le resultat ne deacutependspas de ceux-ci tout va bien
bull Donneacutees manquantes
bull supprimer lrsquoenregistrement complet Ou ne pas lrsquoutiliser dans lesanalyses qui ont besoin de cette variable
bull interpoler avec les donneacutees des participants similaires (imputation)
Construction et validation psychomeacutetrique drsquoun questionnaire
Pour un bon questionnaire on srsquoattend essentiellement agrave ce que
bull les items doivent avoir suffisemment de variance (si toutes lesreacuteponses agrave un item sont bloqueacutees sur la mecircme valeur cet itemnrsquoapporte pas drsquoinformation)
bull les items censeacutes mesurer le mecircme ldquoconstructrdquo doivent corregraveler plusentre eux qursquoavec les autres items
Remarques
meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 19
bull On utilise eacutegalement lrsquoAnalyse Factorielle (Falissard Chap7)
bull Les graphiques de Bland-Altman sont aussi pertinents
bull Preacutevoir (au moins) une phase de pilotage ougrave une version preacutelim-inaire du questionnaire est distribueacutee puis analyseacutee de maniegravere agravene conserver que les items les plus efficaces
Traccedilabiliteacute des donneacutees
Identificateur unique sur chaque questionnaire
bull Le geacuteneacuterer lors de la production des questionnaires
bull Si le questionnaire est administreacute par ordinateur un bonne ideacuteeconsiste agrave geacuteneacuterer un idenfiant sur la base de la dateheureidentifiantde lrsquoordinateur (IP)
Une fois les donneacutees recueillies et saisies dans un logiciel
bull conserver la forme papier eacuteventuelle dans des archives pour veri-fier drsquoeventuelle erreurs de saisies (donneacutees aberrantes)
bull conserver la forme informatique sous forme de fichier TEXTE(Interdiction absolue de conserver les donneacutees dans un formatbinaire proprieacutetaire (feuille EXCEL base de donneacutees ACCESS)Privileacutegier des formats lisibles par lrsquohumain (json csv plutot queXML)
Seacutecuriteacute
bull calculer une somme de controcircle md5 pour chaque fichier de don-neacutees et les conserver dans un fichier qui ne peut pas ecirctre modifierCela permettra de veacuterifier plus tard lrsquointeacutegriteacute des donneacutees
bull proteacuteger les donneacutees brutes au minimum zip proteacutegeacute par motde passe lors drsquoenvois par email ou de partage sur des serveursInternet (Dropbox Google Drive ) mdash sauf si les donneacutees brutesde lrsquoenquecircte sont destineacutees agrave ecirctre rendues publiques
Anonymisation
Si les donneacutees drsquoune enquecircte doivent ecirctre partageacutees il est presquetoujours neacutecessaire drsquoanonymiser celles-ci crsquoest agrave dire de supprimerdes champs tels que nom addresse et toute information qui pourraitpermettre drsquoidentifier les participants
Le mieux est de faire cela au moment du codage des donneacutees
meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 20
Si on nrsquoa jamais besoin de revenir agrave lrsquoindividu jetter purement etsimplement ces donneacutees
Si on risque drsquoavoir besoin de remonter agrave lrsquoindividu mdash pex en-quecircte longitudinale mdash garder dans un fichier seacutepareacute un table reliantles identifiants anonymes et les informations identifiantes
Traccedilabiliteacute des traitements
AUCUNE intervention manuelle nrsquoest autoriseacutee sur les donneacutees TOUS les traitements (filtrage reacute-organisation des donneacutees calculs
statistiques) doivent ecirctre automatiseacutes par exemple avec des scriptseacutecrit en langage R
Les outils de ldquolitterate programingrdquo comme rmarkdown (logiciel R)ou les notebooks jupyter (Python) sont tregraves utiles pour documenter uneanalyse de donneacutees et produire des rapports Notamment cela eacuteviteles copier-coller entre les sorties du logiciels drsquoanalyse et les rapports
A faire Deacutemonstration de Rmarkdown
Partie 3 Deacutefinition drsquoune population et constitution drsquoun eacutechan-tillon
Effet drsquoune variable
bull Que signifie drsquoun point de vue statistique qursquoune variable ldquoagrave uneffet sur une autrerdquo
bull Y est influenceacutee par X si la distribution de Y change quand Xprend des valeurs diffeacuterentes
Population-megravere et eacutechantillon
On a rarement les moyens de contacter tous les membres de la pop-ulation drsquointeacuterecirct appeleacutee population-megravere (sauf en cas de ldquorecense-mentrdquo)
On doit se limiter agrave une population plus reacuteduite (lrsquoeacutechantillon)qui est censeacutee repreacutesenter la population-megravere et qui doit nous perme-ttre de geacuteneacuteraliser mdash par induction mdash les reacutesultats observeacutes
Problegraveme si pour comparer deux populations on compare deuxeacutechantillons il est quasiment certain qursquoon va observer des dif-feacuterences entre les eacutechantillons Mais celles-ci reflegravetent-elles des diffeacuterencesreacuteelles entre les populations
Autrement dit si on tire deux eacutechantillons drsquoune mecircme popula-tion megravere ils seront presque certainement diffeacuterents agrave cause de lavaribiliteacute des individus
meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 21
Figure 12 Distribution de Y en fonctionde X
meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 22
Exemple les Franccedilais et les Allemands ont-ils la mecircme taillemoyenne Si on prend 100 individus franccedilais et 100 individus alle-mands il est peu probable que la taille moyenne soit eacutegale au mil-limecirctre precirct
Statistiques descriptives et statistiques infeacuterentielle
Remarque Il est tregraves important de distinguer deux types drsquousage desstatistiques
bull descriptives qui fournissent des indicateurs qui deacutecrirent lesdonneacutees que lrsquoon possegravedent effecivement (moyenne ecart-type )
bull infeacuterentielles qui cherchent agrave infeacuterer des proprieacuteteacutes des popu-lations megraveres agrave partir des donneacutees observeacutes (test drsquohypothegraveseestimation )
Quand on reacutealise une analyse de donneacutees il faut bien seacuteparermentalement ces deux objectifs
Simulation de tirage aleacuteatoire
On va simuler des eacutechantillonages dans une populationLa population est constitueacutee de 1M drsquoindividus dont on considegravere
la variable lsquotaillersquo En lrsquoabsence de donneacutees reacuteelles on va simuler cesdonneacutees
pop = rnorm(1e+06 mean = 180 sd = 15)
hist(pop)
meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 23
Histogram of pop
pop
Fre
quen
cy
100 150 200 250
050
000
1000
0015
0000
2000
0025
0000
summary(pop)
Min 1st Qu Median Mean 3rd Qu
1088 1699 1800 1800 1901
Max
2619
samp1 = sample(pop 10)
samp2 = sample(pop 10)
samp3 = sample(pop 10)
boxplot(samp1 samp2 samp3)
meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 24
1 2 3
160
170
180
190
200
samples = replicate(100 sample(pop 10))
boxplot(samples)
1 6 12 19 26 33 40 47 54 61 68 75 82 89 96
140
160
180
200
220
meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 25
samplesm = replicate(100 mean(sample(pop 10)))
summary(samplesm)
Min 1st Qu Median Mean 3rd Qu
1715 1775 1806 1807 1840
Max
1943
Avec des tailles drsquoeacutechantillon plus grande (100)
sampmeans = replicate(100 mean(sample(pop 100)))
hist(sampmeans)
Histogram of sampmeans
sampmeans
Fre
quen
cy
177 178 179 180 181 182 183 184
05
1015
2025
30
boxplot(sampmeans)
meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 26
177
178
179
180
181
182
183
184
summary(sampmeans)
Min 1st Qu Median Mean 3rd Qu
1771 1791 1801 1801 1808
Max
1839
Ces exemples fournissent une ideacutee de la variabiliteacute drsquoeacutechantillonstireacutes dans une mecircme population Lrsquoecart-type de la distribution dela statistique calculeacutee sur les eacutechantillons est appeleacute erreur-standardElle fournit une indication de la preacutecision obtenue avec des eacutechantil-lons de taille fixeacutee
Dans la reacutealiteacute on ne connait pas la distribution parenteSi on en connait la forme on peut neacuteanmoins eacutevaluer la preacutecision
de la moyenne drsquoun eacutechantillon de taille n crsquoest agrave dire la taille delrsquointervalle de confiance (pour un certain degreacute de confiance)
Par exemple pour estimer une proportion Si on dispose drsquouneacutechantillon de taille 1000 et que la proprieacuteteacute drsquointeacuterecirct est preacutesentechez 100 individus la preacutecision peut ecirctre obtenue dans R par
proptest(100 1000)
meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 27
1-sample proportions test with
continuity correction
data 100 out of 1000 null probability 05
X-squared = 6384 df = 1 p-value lt
22e-16
alternative hypothesis true p is not equal to 05
95 percent confidence interval
008245237 012069092
sample estimates
p
01
On observe ici que lrsquointervalle de confiance agrave 95 est 82ndash12(Essayer avec drsquoautres valeurs)
Attention ce reacutesultat nrsquoest valide que pour un tirage compleacutete-ment aleacuteatoire (et une population ldquoinfinierdquo) Dans le cas de plans desondage plus complexes il faut utiliser une autre fonction (svycipropdu package survey cf exemple pages 53-54 of B Falissardrsquos Analysisof Questionnaire Data with R pour un echantillonage agrave deux niveaux)
Comparaison de deux populations
Supposons qursquoon tire des eacutechantillons dans deux populations pourcomparer celles-ci par exemple avec un test de T (test de Student)On peut refaire des stimulations
pop1 lt- rnorm(1e+06 mean = 180 sd = 15)
pop2 lt- rnorm(1e+06 mean = 185 sd = 15)
ttest(sample(pop1 1000) sample(pop2 1000)
varequal = T)
Two Sample t-test
data sample(pop1 1000) and sample(pop2 1000)
t = -89006 df = 1998 p-value lt
22e-16
alternative hypothesis true difference in means is not equal to 0
95 percent confidence interval
-7254835 -4635025
sample estimates
mean of x mean of y
1789381 1848830
On pourrait par essais et erreurs deacuteterminer la taille de lrsquoeacutechantillonneacutecessaire pour deacutetecter une diffeacuterence significative (au seuil de 5)
meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 28
dans 80 des cas Mais une fonction R permet cela automatique-ment
powerttest(delta=5 sd=5 siglevel=05 power=8 type=rsquotwosamplersquo)
Preacutecision et repreacutesentativiteacute drsquoun eacutechantillon
Ideacutealement pour permettre de geacuteneacuteraliser lrsquoeacutechantillon doit ecirctre
bull preacutecis drsquoune taille suffisante pour que lrsquoerreur drsquoestimation qursquoilintroduit soit acceptable
bull repreacutesentatif sa composition doit ecirctre semblable agrave celle de lapopulation-megravere
Echantillonage compleacutetement aleacuteatoire
bull Il srsquoagit drsquoun tirage parfaitement aleacuteatoire dans toute la popula-tion
Celle-ci ayant une taille N chaque individu agrave une probabiliteacute 1Ndrsquoecirctre inclu
bull Il faut disposer de la liste complegravete des membres de la population-megravere pour pouvoir mettre en oeuvre une veacuteritable seacutelection aleacutea-toire (et drsquoune fonction drsquoextraction aleacuteatoire comme sample)
Si lrsquoeacutechantillon ne respecte pas ce critegravere de repreacutesentativiteacute il estconsideacutereacute comme biaseacute et il faut envisager drsquoeffectuer un redresse-ment (du moins si lrsquoon veut absolument des estimateurs non biaiseacutes)
Redressement drsquoeacutechantillon
Le redressement par suppression
Afin de retrouver les proportions attendues (celles de la population-megravere) on supprime aleacuteatoirement des reacutepondants parmi les cateacute-gories sur-repreacutesenteacutees
Cela entraine la reacuteduction de la taille de notre eacutechantillon ce quiest frustrant vu les efforts reacutealiseacutes pour motiver les personnes contac-teacutees agrave reacutepondre et vus les coucircts engendreacutes Par ailleurs on va perdreen preacutecision puisque lrsquoerreur associeacutee va augmenter
Cette strateacutegie peut ecirctre neacuteanmoins une bonne solution dans unprotocole de collecte par Internet qui permet de contacter rapidementet agrave moindre coucirct un grand nombre drsquointerlocuteurs On peut ainsiextraire apregraves coup et selon une meacutethode aleacuteatoire un eacutechantillonrepreacutesentatif selon des quotas preacute-deacutefinis
meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 29
Application Redressement par suppression dans R
require(car)
data(SLID)
str(slid)
table(SLID$sex)
n = min(table(SLID$sex))
males = subset(SLID sex==rsquoMalersquo)
nrow(males)
females = subset(SLID sex==rsquoFemalersquo)
nrow(females)
females = females[sample(1nrow(females) n) ]
nrow(females)
Le redressement par pondeacuteration
On conserve toutes les reacuteponses enregistreacutees mais on attribue agravechaque reacutepondant un laquo poids raquo particulier en fonction de la cateacutegorieagrave laquelle il appartient
Par exemple si il y deux fois moins de femmes que preacutevu danslrsquoeacutechantillon le laquo poids raquo drsquoune femme sera 2 et la reacuteponse de chaquefemme comptera double
Voir httpwwwsuristatorgarticle27html
Pondeacuterer ou non un choix parfois deacutelicat
Consideacuterons une entreprise avec la structure de salaire suivante
Sexe Status Salaire moyen Effectif dans lrsquoentreprise
Femme cadre 3000 2
Femme non-cadre 2000 50
Homme cadre 3000 8
Homme non-cadre 2000 50
Question les hommes et les femmes perccediloivent-ils le mecircmesalaire
Application Pondeacuteration dans R
sal = c(3000 2000 3000 2000)
sex = c(rsquoFrsquo rsquoFrsquo rsquoHrsquo rsquoHrsquo)
status = c(rsquocrsquo rsquonrsquo rsquocrsquo rsquonrsquo)
eff = c(2 50 8 50)
dataframe(sex status sal eff)
salaire moyen dans lrsquoentreprise
mean(sal)
meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 30
weightedmean(sal eff)
salaire par sexe
non pondeacutereacute
for (s in unique(sex)) print(paste(s mean(sal[sex==s])))
tapply(sal sex mean)
pondeacutereacute
for (s in unique(sex))
print(paste(s weightedmean(sal[sex==s] eff[sex==s])))
Note Le package survey fournit des fonctions statistiques quiprennent systematiquement en compte des poids
Echantillonage stratifieacute (meacutethode des quotas)
La strateacutegie de redressement peut ecirctre eacuteviteacutee si on prend en comptela structure de la population degraves le plan de sondage
La population est deacutecoupeacutee en groupes (par exemple groupesdrsquoacircge de sexe de niveau socio eacuteconomique) dont on connait leseffectifs
On preacutelegraveve alors des eacutechantillons aleacuteatoires agrave lrsquointeacuterieur de chaquegroupe
Si les tailles des eacutechantillons respectent les proportions des groupesdans la populations on a une meilleure preacutecision que dans le cas dutirage compleacutetement aleacuteatoire
Par exemple pour comparer les tailles des franccedilais et des alle-mands on peut constituer des eacutechantillons qui respectent les propor-tions drsquohommes et de femmes dans chaque cateacutegorie drsquoacircge
Pour en savoir plus voir Thomas Lumley Complex Surveys A guideto analysis using R (package survey)
Echantillonage par ldquograppesrdquo (cluster sampling)
On effectue drsquoabord un tirage aleacuteatoire drsquouniteacutes plus grandes (pexvilles ou des eacutecoles) Puis on mesure tout ou parti des individusdans ces uniteacutes
bull Avantage Il est plus facile et moins coucircteux agrave mettre en oeuvreque les meacutethodes preacuteceacutedentes
bull Deacutesavantages
ndash Plus drsquoindividus sont neacutecessaire pour obtenir une preacutecisionidentique agrave lrsquoechantillonage aleacuteatoire complet
ndash Il faut tenir compte de la deacutependance entre les individu drsquounmecircme ldquoclusterrdquo Cela complique nettement les analyses analy-ses statistiques (on doit utiliser des modegraveles-hieacuterarchiques)
meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 31
Deacuteterminer la taille des eacutechantillons pour estimer une proportion
Dans le cas drsquoun tirage purement aleacuteatoire on doit fournir une esti-mation de la freacutequence attendue (p) et la demi-largeur de lrsquointervallede confiance agrave 95 (delta)
require(epiDisplay)
nforsurvey(p=01 delta=002)
Une formule approximative permet drsquoeacutevaluer la taille de lrsquoeacutechantillon
n =p(1 minus p)(e2)2
(remarque le maximum de p(1 minus p) est de 025)A retenir la preacutecision est proportionnelle agrave la racine carreacutee de de
la taille de lrsquoeacutechantillonPour les eacutechantillonages par strate ou par grappe les formules
sont nettement plus compliqueacuteesPour un eacutechantillonage par grappe il faut tenir compte du fait que
les donneacutees des deux individus dans le mecircme groupe sont correacuteleacuteesOn introduit la notion drsquoeffet de design (Falissard p72)
nforsurvey(p=01 delta=02 deff= 4)
Deacuteterminer la taille drsquoun eacutechantillon pour comparer deux groupes
require(epiDisplay)
Comparer 2 proportions
nfor2p (p1 p2 alpha = 005 power = 08 ratio = 1)
Comparer 2 moyennes
nfor2means (mu1 mu2 sd1 sd2 ratio = 1 alpha = 005 power = 08)
Arguments
p estimated probability
delta difference between the estimated prevalence and one side of the 95 percent confidence limit (precision)
popsize size of the finite population
deff design effect for cluster sampling
alpha significance level
mu1 mu2 estimated means of the two populations
sd1 sd2 estimated standard deviations of the two populations
ratio n2n1
Remarque sur les objectifs des analyses statistiques
1 Test drsquohypothegravese une variable influence-t-elle une autre
meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 32
2 Estimation quel est la taille de lrsquoeffet de X sur Y (dans les condi-tions Z W )
3 Preacutediction agrave partir des caracteacuteristiques de nouveaux individuspeut-on preacutedire la valeur des variables deacutependantes (pex proba-bilitteacute drsquoecirctre fumeur)
Ex si on veut tester si les droitiers reacuteagissent plus rapidementavec la main droite qursquoavec la main gauche on peux se contenter defaire lrsquoexpeacuterience sur des eacutetudiants drsquouniversiteacute si lrsquoeffet existe ils estraisonable qursquoil soit preacutesent chez tous les humains Mais lrsquoamplitudede lrsquoeffet peut deacutependre de lrsquoacircge
Dans des approches exploratoires un test biaiseacute nrsquoest pas un prob-legraveme car lrsquoimportant est de deacutetecter un effet
Si lrsquoon deacutesire tester la valeur preacutedictive des modegraveles on peututiliser des approches de cross-validation
Partie 4 Manipulation et Exploration des donneacutees
Importation des donneacutees
Les donneacutees sous forme de tables sont lues dans des dataframetypiquement avec les fonctions
readcsv(filename)
readtable(filename)
La librarie foreign permet de lire les formats Minitab S SASSPSS Stata Systat Weka dBase
On peut se faire une ideacutee du contenu drsquoun dataframe dataf
str(dataf)
head(dataf)
names(dataf)
On peut accegraveder au contenu drsquoune colonne drsquoun dataframe avec lasyntaxe dataf$colname
Manipulations
subset
merge
Recodage
isna
cut
ifelse(test value-if-yes value-if-no)
meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 33
require(car)
recode
Examiner des distributions
bull Variables discregravetes
table(x)
barplot(table(x))
bull Variables continues
summary(x)
stem(x)
stripchart(x method)=rsquostackrsquo)
boxplot(x)
plot(density(x))
rug(x)
Examiner des relations
bull variables discregravetes
table(x y z)
ftable(x y z)
xtabs(~ x + y +z)
mosaicplot(table(x y))
chisqtest()
bull variables continues
plot(x y)
require(car)
scatterplot(x y)
smoothScatter(SLID2$age SLID2$wages)
cortest(x y)
ttest(x y)
More than 2 variables
plot(x y col=z)
pairs(cbind(x y z))
meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 34
scatterplotmatrix(cbind(x y z))
coplot(x ~ y | a + )
lm(z ~ x + y) regression multiple
R graphics Gallery
httpwwwr-graph-gallerycom
Cartes geacuteographiques
bull ggmap Spatial Visualization with ggplot2 par David Kahle andHadley Wickham httpsjournalr-projectorgarchive
2013-1kahle-wickhampdf
bull Geacuteocoder en masse avec R et sans Google Maps par Timotheacutee Giraudhttprgeomatichypothesesorg622
bull Plotly Scatter Plots on Maps in R httpsplotlyrscatter-plots-on-maps
Donneacutees agrave analyser
bull caith Colours of Eyes and Hair of People in Caithness (packageMASS)
ndash A 4 by 5 table with rows the eye colours (blue light mediumdark) and columns the hair colours (fair red medium darkblack)
meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 35
bull SLID Survey of Labour and Income Dynamics (package car)
ndash wages Composite hourly wage rate from all jobsndash education Number of years of schoolingndash age in yearsndash sex A factor with levels lsquoFemalersquo lsquoMalersquondash language A factor with levels lsquoEnglishrsquo lsquoFrenchrsquo lsquoOtherrsquo
bull mtcars Motor Trend Car Road Tests
The data was extracted from the 1974 Motor Trend US magazineand comprises fuel consumption and 10 aspects of automobiledesign and performance for 32 automobiles (1973-74 models)
bull donneacutees du livre de Bruno Falissard Comprendre et utiliser les statis-tiques dans les sciences de la vie httphebergementu-psudfrbiostatistiqueslivreampid=02ampr=partie02
Reacutefeacuterences
bull Geacuteneral
ndash Lohr S (2010) Sampling Design and Analysis BrooksColendash Oppenheim A N (1992) Questionnaire Design Interviewing and
Attitude Measurement Continuum
bull Analyses avec R
ndash Zuur Ieno Meester (2009) A Beginnerrsquos Guide to R Springerndash Falissard B (2012) Analysis of Questionnaire Data with R CRC
Press
meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 36
ndash Lumley T (2010) Complex Surveys A guide to analysis using RWiley (package survey)
ndash Chongsuvivatwong V (2013) Analysis of epidemiological datausing R and Epicalc httpscranr-projectorgdoccontribEpicalc_Bookpdf (note le package epicalc a eacuteteacute renommeacuteepiDisplay)
ndash Aides meacutemoire httpswwwrstudiocomresourcescheatsheets
Appendice Quelques distributions
Distribution normale
plot(dnorm(seq(-5 5 1))) affiche la densiteacute de proba
pnorm(3) aire sous la courbe entre -inf et 3
qnorm(95) valeur de x telle que P(ZltX)=95
rnorm(1000) genere 1000 nombres aleacuteatoires
Distribution binomiale
barplot(dbinom(010 size=10 prob=5))
barplot(dbinom(010 size=10 prob=2))
pbinom(3 size=10 prob=5) proba drsquoobserver 0 1 2 ou 3 evemenents
qbinom(95 size=10 prob=5) valeur de X telle P(Blt=X)=95
Intervalles de confiance drsquoun odd ratio et drsquoun risque relatif
require(epi)
examples(twoby2)
2 by 2 table analysis
Outcome Yes
Comparing A vs B
Yes No P(Yes) 95 conf interval
A 16 10 06154 04207 0779
B 15 9 06250 04218 0792
95 conf interval
Relative Risk 09846 06379 15197
Sample Odds Ratio 09600 03060 30117
Conditional MLE Odds Ratio 09608 02623 34895
Probability difference -00096 -02602 02451
meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 37
Intervalle de confiance par Bootstrap
Pour obtenir un intervalle de confiance sans faire drsquohypothegravese surla forme de la distribution parente on peut utiliser une approchede bootstrap qui consiste agrave se dire que la meilleure estimation de ladistribution dans la population est la distribution dans lrsquoeacutechantillon
Pour obtenir une estimation de la preacutecision de statistiques calculeacuteesur lrsquoeacutechantillon on effectue des tirages avec remise dans celui-ci
data = c(164 164 164 164 165 165 166 166
170 170 171 173 175 185 190)
stripchart(data method = overplot)
165 170 175 180 185 190 parametric test
ttest(data)
One Sample t-test
data data
t = 82841 df = 14 p-value lt 22e-16
alternative hypothesis true mean is not equal to 0
95 percent confidence interval
1657285 1745381
sample estimates
mean of x
1701333
bootstrap
n = length(data)
ntirages = 5000
bs = NULL
for (i in 1ntirages)
indices = sample(c(1n) n replace = T)
bs[i] = mean(data[indices])
meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 38
hist(bs)
Histogram of bs
bs
Fre
quen
cy
165 170 175 180
060
0
summary(bs)
Min 1st Qu Median Mean 3rd Qu
1651 1687 1700 1701 1714
Max
1824
quantile(bs c(0025 0975))
25 975
1665333 1744000
Remarques
bull On peut srsquointeacuteresser agrave beaucoup drsquoautres statistiques que lamoyenne et obtenir des intervalles de confiance (par exemple leminimum une correacutelation etc )
bull Le package boot de R permet de faire cela de maniegravere plus effi-cace
Ref Efron B and Tibshirani R (1993) An Introduction to the Boot-strap Chapman amp Hall
Statistiques parameacutetriques et non parameacutetriques
bull Statistiques parameacutetriques calculs fondeacutes en faisant des hy-pothegraveses sur la forme des distributions sous-jacentes
bull Statistiques non parameacutetriques estimations sans faire drsquohypothegravesespreacutecises sur la forme des distributions
require(car)
meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 39
Loading required package car
require(hexbin)
Loading required package hexbin
data(SLID)
lsquolsquo(SLID)
str(SLID)
rsquodataframersquo 7425 obs of 5 variables
$ wages num 106 11 NA 178 NA
$ education num 15 132 16 14 8 16 12 145 15 10
$ age int 40 19 49 46 71 50 70 42 31 56
$ sex Factor w 2 levels FemaleMale 2 2 2 2 2 1 1 1 2 1
$ language Factor w 3 levels EnglishFrench 1 1 3 3 1 1 1 1 1 1
SLID2 = SLID[completecases(SLID) ]
plot(wages ~ age data = SLID2)
abline(lm(wages ~ age data = SLID2) col = blue
lwd = 2)
lines(lowess(SLID2$age SLID2$wages f = 01)
col = red lwd = 2)
20 30 40 50 60 70
1040
age
wag
es
smoothScatter(SLID2$age SLID2$wages)
20 30 40 50 60 70
1040
SLID2$age
SLI
D2$
wag
es
meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques

meacutethodologie recueil et manipulation de donneacutees 40
bin = hexbin(SLID2$age SLID2$wages
xbins=50) par(plot=rsquoNEWrsquo) plot(bin
main=rsquoHexagonal Binningrsquo) abline(lm(wages ~
age data= SLID))
Le Big Data est un champ drsquoapplication des meacutethodes non-parameacutetriques





























