Embed Size (px)
Citation preview

33
MECHANIZING ALICE:
AUTOMATING THE SUBJECT MATTER
ELIGIBILITY TEST OF ALICE V. CLS BANK1
Ben Dugan†
Abstract
This Article describes a project to mechanize the subject matter eligibility
test of Alice v. CLS Bank. The Alice test asks a human to determine whether or
not a patent claim is directed to patent-eligible subject matter. The core research question addressed by this Article is whether it is possible to automate
the Alice test. Is it possible to build a machine that takes a patent claim as input
and outputs an indication that the claim passes or fails the Alice test? We show that it is possible to implement just such a machine, by casting the Alice test as
a classification problem that is amenable to machine learning.
This Article describes the design, development, and applications of a machine classifier that classifies patent claims according to the Alice test. We employ supervised learning to train our classifier with examples of eligible and ineligible claims obtained from patent applications examined by the U.S. Patent Office. In an example application, the classifier is used as part of a patent claim evaluation system that provides a user with feedback regarding the subject matter eligibility of an input patent claim. Finally, we use the classifier to
quantitatively estimate the impact of Alice on the universe of issued patents.
TABLE OF CONTENTS
I. Introduction and Overview ................................................................... 34 A. Organization of the Article ............................................................ 35 B. Brief Review of the Alice Framework ........................................... 37
II. Rendering Legal Services in the Shadow of Alice ................................ 40 A. Intuition-Based Legal Services ...................................................... 42
1. An early discussion draft of this Article appeared as Estimating the Impact of Alice v. CLS Bank Based
on a Statistical Analysis of Patent Office Subject Matter Rejections (February 23, 2016). Available at SSRN:
https://ssrn.com/abstract=2730803. This Article significantly refines the statistical analysis of subject matter
rejections at the Patent Office. This Article also clarifies the performance results of our machine classifier, and
better accounts for classifier performance when estimating the number of patents invalidated under Alice v. CLS
Bank.
† Member, Lowe Graham Jones, PLLC. Affiliate Instructor of Law, University of Washington School
of Law. Opinions expressed herein are those of the author only. Copyright 2017 Ben Dugan. I would like to
thank Professor Bob Dugan and Professor Jane Winn for their feedback, advice, and support, and Sarah Dugan
for her love and encouragement.

34 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
B. Data-Driven Patent Legal Services ................................................ 43 C. Predicting Subject Matter Rejections Yields Economic
Efficiencies .................................................................................... 44 III. Data Collection Methodology ............................................................... 47 IV. Data Analysis Results ........................................................................... 52 V. Predicting Alice Rejections with Machine Classification ..................... 57
A. Word Clouds .................................................................................. 58 B. Classifier Training ......................................................................... 60 C. Performance of a Baseline Classifier ............................................. 61 D. Performance of an Improved Classifier ......................................... 64 E. Extensions, Improvements, and Future Work ............................... 66
VI. A Patent Claim Evaluation System ....................................................... 67 A. System Description ........................................................................ 68 B. Claim Evaluation System Use Cases ............................................. 70 C. Questions Arising From the Application of Machine
Intelligence to the Law .................................................................. 71 VII. Estimating the Impact of Alice on Issued Patents ................................. 73
A. The Classifier................................................................................. 73 B. Classifier Validation ...................................................................... 74 C. Evaluation of Issued Patent Claims ............................................... 76
VIII. Conclusion ............................................................................................ 79
I. INTRODUCTION AND OVERVIEW
In Alice v. CLS Bank, the Supreme Court established a new test for
determining whether a patent claim is directed to patent-eligible subject matter.2
The impact of the Court’s action is profound: the modified standard means that
many formerly valid patents are now invalid, and that many pending patent
applications that would have been granted under the old standard will now not
be granted.3
This Article describes a project to mechanize the subject matter eligibility
test of Alice v. CLS Bank. The Alice test asks a human to determine whether or
not a patent claim is directed to patent-eligible subject matter.4 The core
research question addressed by this Article is whether it is possible to automate
the Alice test. Is it possible to build a machine that takes a patent claim as input
and outputs an indication that the claim passes or fails the Alice test? We show
that it is possible to implement just such a machine, by casting the Alice test as
a classification problem that is amenable to machine learning.
This Article describes the design, development, and applications of a
machine classifier that approximates the Alice test. Our machine classifier is a
2. Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347, 2354–55 (2014).
3. See Robert Sachs, #Alicestorm: When it Rains, It Pours…, BILSKIBLOG (Jan. 22, 2016)
http://www.bilskiblog.com/blog/2016/01/alicestorm-when-it-rains-it-pours.html [hereinafter Sachs]
(illustrating that under Alice, the courts have invalidated a patent claim 72% of the time).
4. Alice, 134 S. Ct. at 2359.

No. 1] MECHANIZING ALICE 35
computer program that takes the text of a patent claim as input, and indicates
whether or not the claim passes the Alice test. We employ supervised machine
learning to construct the classifier.5 Supervised machine learning is a technique
for training a computer program to recognize patterns.6 Training comprises
presenting the program with positive and negative examples, and automatically
adjusting associations between particular features in those examples and the
desired output.7
The examples we use to train our machine classifier are obtained from the
United States Patent Office. Within a few months of the Alice decision,
examiners at the Patent Office began reviewing claims in patent applications for
subject matter compliance under the new framework.8 Each decision of an
examiner is publicly reported in the form of a written office action.9 We
programmatically obtained and reviewed many thousands of these office actions
to build a data set that associates patent claims with corresponding eligibility
decisions.10 We then used this dataset to train, test, and validate our machine
classifier.11
A. Organization of the Article
This Article is organized in the following manner. In Section I.B, we
provide an overview of the Alice framework for determining the subject matter
eligibility of a patent claim. The Alice test first asks whether a given patent
claim is directed to a non-patentable law of nature, natural phenomenon, or
abstract idea.12 If so, the claim is not patent eligible unless the claim recites
additional elements that amount to significantly more than the recited non-
patentable concept.13
In Section II, we motivate a computer-assisted approach for rendering legal
advice in the context of Alice. Alice creates a new patentability question that
must be answered before and during the preparation, prosecution, and
enforcement of a patent.14 Section II provides inspiration for a data-driven,
5. STUART RUSSELL & PETER NORVIG, ARTIFICIAL INTELLIGENCE: A MODERN APPROACH 693–95 (3d
ed. 2010) [hereinafter RUSSELL & NORVIG].
6. Id.
7. Id.
8. See, e.g., Memorandum from Deputy Commissioner Andrew H. Hirshfeld on Preliminary Examination
Instructions in View of the Supreme Court Decision in Alice Corporation Pty. Ltd. v. CLS Bank International, et al.
to Patent Examining Corps (June 25, 2014), http://www.uspto.gov/sites/default/files/patents/announce/alice_
pec_25jun2014.pdf [hereinafter Preliminary Examination Instructions] (providing a two-part analysis for
abstract ideas); see generally Subject Matter Eligibility, U.S. PAT. & TRADEMARK OFF. (Dec. 14, 2016, 11:38
PM) https://www.uspto.gov/patent/laws-and-regulations/examination-policy/subject-matter-eligibility
(discussing subject matter eligibility).
9. 37 C.F.R. § 1.104 (2015). See 35 U.S.C. § 132 (2012); MANUAL OF PATENT EXAMINING PROCEDURE
§ 706 (9th ed. rev. 7, Nov. 2015) (stating the procedure for rejection and reexamination).
10. Subject Matter Eligibility Court Decisions, U.S. PAT. & TRADEMARK OFF. (Apr. 22, 2016),
https://www.uspto.gov/sites/default/files/documents/ieg-may-2016-sme_crt_dec_0.pdf.
11. E.g., Ben Dugan, Ask Alice!, https://www.lawtomata.com/predict (last visited Mar. 12, 2018)
[hereinafter Dugan] (this site provides access to an example machine classifier constructed by the Author using
some of the techniques described in this paper).
12. Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347, 2354 (2014).
13. Id. at 2354–56.
14. See id. at 2355 (discussing the framework for the patentability question).

36 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
computer-assisted, predictive approach for efficiently answering the Alice
patentability question. Such a predictive approach can be usefully performed at
various stages of the lifecycle of a patent, including during initial invention
analysis, application preparation and claim development, and litigation risk
analysis. Computer-assisted prediction of Alice rejections stands in contrast to
traditional, intuition-driven methods of legal work, and can yield considerable
economic efficiencies by eliminating the legal fees associated with the
preparation and prosecution of applications for un-patentable inventions, or by
eliminating baseless litigation of invalid patent claims.15 In addition, a
predictive approach can be used to assist a patent practitioner in crafting patent
claims that are less likely to be subjected to Alice rejections, thereby reducing
the number of applicant-examiner interactions and corresponding legal fees
during examination.16
In Section III, we describe our data collection methodology. Section III
lays out our process for generating a dataset for training our machine classifier.
In brief, we automatically download thousands of patent application file
histories, each of which is a record of the interaction between a patent examiner
and an applicant. From these file histories we extract office actions, each of
which is a written record of an examiner’s analysis and decision of a particular
application. We then process the extracted office actions to determine whether
the examiner has accepted or rejected the claims of the application under Alice.
Finally, we construct our dataset with the obtained information. Our dataset is
a table that associates, in each row, a patent claim with an indication of whether
the claim passes or fails the Alice test, as decided by a patent examiner.
In Section IV, we present results from an analysis of our dataset. Our
analysis identifies trends and subject matter areas that are disproportionately
subject to rejections under Alice. Our dataset shows that the subject matter areas
that contain many applications with Alice rejections include data processing,
business methods, games, educational methods, and speech processing. This
result is consistent with the focus of the Alice test on detecting claims that are
directed to abstract ideas, including concepts such as economic practices,
methods of organizing human activity, and mathematical relationships.
In Section V, we build a machine that is capable of predicting whether a
claim is likely to pass the Alice test. In this Section, we initially perform an
analysis that identifies particular words that are associated with eligibility or
ineligibility under Alice. The presence of such associations indicates that there
exist patterns that can be learned by way of machine learning. Next, we describe
the training, testing, and performance of a baseline classifier. Our classifiers are
trained in a supervised manner using as examples the thousands of subject matter
patentability decisions made by examiners at the Patent Office. We then
describe an improved classifier that uses an ensemble of multiple distinct
classifiers to improve upon the performance of our baseline classifier. We
15. See generally Sachs, supra note 3 (illustrating that under Alice, the courts have invalidated a patent
claim 72% of the time).
16. Sarah Garber, Avoiding Alice Rejections with Predictive Analytics, IPWATCHDOG (May 31, 2016),
http://www.ipwatchdog.com/2016/05/31/avoiding-alice-rejections-predictive-analytics/id=69519/.

No. 1] MECHANIZING ALICE 37
conclude this Section with a brief outline of possible extensions, improvements,
and future work.
In Section VI, we describe a claim evaluation system. The system is a
Web-based application that takes a patent claim as input from a user, and
provides the text of the claim to a back-end classifier trained as described above.
The system provides the decision of the classifier as output to the user. It is
envisioned that a system such as this can be used by a patent practitioner to
provide improved Alice-related legal services at various stages of the lifecycle
of a patent, as discussed in Section II.
In Section VII, we utilize our machine classifier to quantitatively estimate
the impact of Alice on the universe of issued patents. While other studies have
tracked the actual impact of Alice in cases before the Federal Courts, our effort
is the first to use a machine classifier to quantitatively estimate the impact of
Alice on the entire body of issued patents.17 To obtain our estimate, we first
determine whether our classifier can be used as a proxy for the decision-making
of the Federal Courts. Since our classifier is trained based on decisions made by
examiners at the Patent Office, it is natural to ask whether the classifier
reasonably approximates the way that the courts apply the Alice test. To answer
this question, we evaluate the performance of our classifier on patent claims that
have been analyzed by the Court of Appeals for the Federal Circuit. The results
of this evaluation show that the outputs produced by our classifier are largely in
agreement with the decisions of the CAFC.18
Finally, we turn our classifier to the task of processing claims from a
random sample of 40,000 issued patents dating back to 1996. Extrapolating the
results obtained from our sample, we estimate that as many as 100,000 issued
patents have been invalidated due to the reduced scope of patent-eligible subject
matter under Alice v. CLS Bank.19 This large-scale invalidation of patent rights
represents a significant realignment of intellectual property rights at the stroke
of a judge’s pen.
B. Brief Review of the Alice Framework
The following procedure outlines the current test for evaluating a patent
claim for subject matter eligibility under 35 U.S.C. § 101. We will refer to this
test as the “Alice test,” although it was earlier articulated by the Supreme Court
in Mayo Collaborative Services v. Prometheus Laboratories, Inc.20
17. Jasper Tran, Two Years After Alice v. CLS Bank, 98 J. PAT. & TRADEMARK OFF. SOC’Y 354, 358
(2016) (using Federal Court decisions to estimate the impact of Alice on computer-related patents).
18. See infra Section VII.B (validating the performance of our classifier with respect to claims analyzed
by the Court of Appeals for the Federal Circuit).
19. Id.
20. See Mayo Collaborative Servs. v. Prometheus Labs., Inc., 132 S. Ct. 1289 (2012) (addressing a method
for administering a drug, and holding that a newly discovered law of nature is unpatentable and that the
application of that law is also normally unpatentable if the application merely relies on elements already known
in the art); Alice, 134 S. Ct. at 2355–60 (applying the Mayo analysis to claims to a computer system and method
for electronic escrow; holding the claims invalid because they were directed to an abstract idea, and did not
include sufficiently more to transform the abstract idea into a patent-eligible invention).

38 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Step 1: Is the claim to a process, machine, manufacture, or composition of matter? If YES, proceed to Step 2A; if NO, the claim is not eligible subject matter under 35 U.S.C. § 101.21
Step 2A: Is the claim directed to a law of nature, a natural phenomenon, or an abstract idea? If YES, proceed to step 2B; if NO, the claim qualifies as eligible subject matter under 35 U.S.C. § 101.22
Step 2B: Does the claim recite additional elements that amount to significantly more than the judicial exception? If YES, the claim is eligible; if NO, the claim is ineligible.23
The test has two main parts.24 The first part of the test, in Step 1, asks
whether the claim is to a process, manufacture, machine, or composition of
matter.25 This is simply applying the plain text of Section 101 of the patent
statute to ask whether a patentable “thing” is being claimed.26 As a general
matter, this part of the test is easy to satisfy. If the claim recites something that
is recognizable as an apparatus/machine, process, manufacture, or composition
of matter, Step 1 of the test should be satisfied.27 If Step 1 of the test is not
satisfied, the claim is not eligible, end of analysis.28
The second part of the test attempts to identify claims that are directed to
judicial exceptions to the statutory categories.29 The second part of the test has
two subparts.30 Step 2A is designed to ferret out claims that, on their surface,
claim something that is patent eligible (e.g., a computer), but contain within
them a judicial exception.31 Step 2A asks whether the claim is directed to one
of the judicial exceptions.32 If not, then the claim qualifies as patent eligible.33
If so, however, Step 2B must be evaluated.34
The judicial exceptions in Step 2A include laws of nature, abstract ideas,
and natural phenomena.35 The category of abstract ideas can be broken down
into four subcategories: fundamental economic practices, ideas in and of
themselves, certain methods of organizing human activity, and mathematical
relationships and formulas.36 Fundamental economic practices include, for
21. Alice, 134 S. Ct. at 2355.
22. Id.
23. 2014 Interim Guidance on Patent Subject Matter Eligibility, 79 Fed. Reg. 74618, 74621 (Dec. 16,
2014) [hereinafter 2014 Guidance] (to be codified at 37 C.F.R. pt. 1).
24. Alice, 134 S. Ct. at 2355.
25. Id.
26. 35 U.S.C. § 101 (2018) (“Whoever invents or discovers any new and useful process, machine,
manufacture, or composition of matter, or any new and useful improvement thereof, may obtain a patent
therefor.”).
27. Alice, 134 S. Ct. at 2355.
28. See, e.g., In re Ferguson, 558 F.3d 1359, 1364–66 (Fed. Cir. 2009) (holding that contractual
agreements and companies are not patentable subject matter); In re Nuijten, 500 F.3d 1346, 1357 (Fed. Cir.
2007) (holding that transitory signals are not patentable subject matter).
29. Alice, 134 S. Ct. at 2355.
30. Id.
31. Id.
32. Id.
33. Id.
34. Id.
35. Id.
36. Id. at 2355–56.

No. 1] MECHANIZING ALICE 39
example, creating contractual relationships, hedging, or mitigating settlement
risk.37 Ideas in and of themselves include, for example, collecting and
comparing known information, diagnosing a condition by performing a test and
thinking about the results, and organizing information through mathematical
correlation.38 Methods of organizing human activity include, for example,
creating contractual relationships, hedging, mitigating settlement risk, or
managing a game of bingo.39 Mathematical relationships and formulas include,
for example, an algorithm for converting number formats, a formula for
computing alarm limits, or the Arrhenius equation.40
In Step 2B, the test asks whether the claims recite additional elements that
amount to “significantly more” than the judicial exception.41 In the computing
context, this part of the test is trying to catch claims that are merely applying an
abstract idea within a computing system, without adding significant additional
elements or limitations.42 Limitations that may be enough to qualify as
“significantly more” when recited in a claim with a judicial exception include,
for example: improvements to another technology or technical field;
improvements to the functioning of the computer itself; effecting a
transformation or reduction of a particular article to a different state or thing; or
adding unconventional steps that confine the claim to a particular useful
application.43
Limitations that have been found not to be enough to qualify as
“significantly more” when recited in a claim with a judicial exception include,
for example: adding the words “apply it” with the judicial exception; mere
instructions to implement an abstract idea on a computer; simply appending
well-understood, routine and conventional activities previously known to the
industry, specified at a high level of generality, to the judicial exception; or
adding insignificant extra-solution activity to the judicial exception.44
The Alice test is now being applied by federal agencies and courts at the
beginning and end of the patent lifecycle.45 With respect to the application phase
of a patent, shortly after the Alice decision, the Patent Office issued to the
examination corps instructions for implementing the Alice test.46 These
preliminary instructions were supplemented in December 2014 by the 2014
Guidance.47 As we will show in Section IV, below, the Patent Office has applied
37. See, e.g., Bilski v. Kappos, 561 U.S. 593 (2010) (mitigating settlement risk).
38. See, e.g., Digitech Image Tech., LLC v. Elec. for Imaging, Inc., 758 F.3d 1344 (Fed. Cir. 2014)
(organizing information through mathematical correlations).
39. See, e.g., buySAFE Inc., v. Google, Inc.,, 765 F.3d 1350, 1353–55 (Fed. Cir. 2014) (involving
contractual relationships).
40. See, e.g., Gottschalk v. Benson, 409 U.S. 63, 64–67 (1972) (involving algorithm for converting
number formats); Diamond v. Diehr, 450 U.S. 175, 177–181 (1981) (involving Arrhenius equation).
41. 2014 Guidance, supra note 23, at 74619.
42. Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347, 2357–58 (2014).
43. 2014 Guidance, supra note 23, at 74624 (citations omitted).
44. Id.
45. Id. at 74631.
46. Preliminary Examination Instructions, supra note 8.
47. 2014 Guidance, supra note 23.

40 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
this test widely, with significant numbers of rejections appearing in specific
subject matter areas.48
With respect to the enforcement phase of the patent lifecycle, the Federal
Courts have been actively applying the Alice test to analyze the validity of patent
claims in the litigation context.49 As of June 2016, over 500 patents have been
challenged under Alice, with a resulting invalidation rate exceeding 65%.50 The
Court of Appeals for the Federal Circuit has itself heard over fifty appeals that
have raised the Alice issue.51
Note that when we speak of the “Alice test” in the context of the Patent
Office we include the entire body of case law that has developed in the wake of
the Mayo and Alice decisions.52 The cases following Alice have refined and
clarified the Alice two-step analysis with respect to particular fact contexts.53
The Patent Office has made considerable effort to keep abreast of these decisions
and to train the examining corps as to their import.54 To a large degree then, the
Patent Office embodies the current state of subject matter eligibility law.55 And
while this law is never static, it is also not changing so quickly as to undermine
one of the central premises of this article, which is that the Patent Office can be
used as a source of examples of a decision maker (in this case, a sort of “hive
mind” comprising many thousands of individual examiners) applying a legal
rule to determine whether a patent claim is subject matter eligible.56 Assuming
that the application of the rule is not completely random, as we will show in
Section IV, then it should be possible to train a machine to learn the rule (or its
approximation) based on our collection of examples.
II. RENDERING LEGAL SERVICES IN THE SHADOW OF ALICE
In this Section, we motivate a computer-assisted approach for rendering
legal advice in the context of Alice. Alice creates a new patentability question
that must be answered before and during the preparation, prosecution, and
48. See Tran, supra note 17, at 357 (discussing the increase in patent rejections resulting from the Alice
test).
49. Id. at 358.
50. Id.
51. Chart of Subject Matter Eligibility Court Decisions, USPTO, https://www.uspto.gov/sites/default/
files/documents/ieg-sme_crt_dec.xlsx (updated July 31, 2017).
52. See, e.g., Enfish LLC v. Microsoft Corp., 822 F.3d 1327 (Fed. Cir. 2016); Bascom Global Internet
Servs., Inc. v. AT&T Mobility LLC, 827 F.3d 1341 (Fed Cir. 2016); McRO, Inc. v. Bandai Namco Games Am.
Inc., 837 F.3d 1299 (Fed. Cir. 2016); Amdocs (Israel) Ltd. v. Openet Telecom, Inc., 841 F.3d 1288 (Fed. Cir.
2016); DDR Holdings, LLC v. Hotels.com, L.P., 773 F.3d 1245 (Fed. Cir. 2014); Ultramercial, Inc. v. Hulu,
LLC, 772 F.3d 709 (Fed. Cir. 2014).
53. See, e.g., McRO, Inc., 837 F.3d at 1303 (applying the Alice test to a patent relating to a method for
automation of 3-D animation of facial expressions).
54. See Recent Subject Matter Eligibility Decisions, USPTO (May 19, 2016), https://www.uspto.gov/
sites/default/files/documents/ieg-may-2016_enfish_memo.pdf (summarizing post-Alice Supreme Court
decisions); see also Recent Subject Matter Eligibility Decisions, USPTO (Nov. 2, 2016), https://www.uspto.gov/
sites/default/files/documents/McRo-Bascom-Memo.pdf [hereinafter Recent Subject Matter Eligibility
Decisions] (illustrating the Patent Office’s discussion of decisions of the Court of Appeals for the Federal Circuit,
including Enfish, McRO, and Bascom).
55. See Recent Subject Matter Eligibility Decisions, supra note 54 (discussing the Patent Office policy
mirroring eligibility law).
56. See id. (elaborating on how to predict the Patent Office’s application of the Alice test).

No. 1] MECHANIZING ALICE 41
enforcement of a patent.57 Increased access to data allows us to implement a
data-driven, predictive computer system for efficiently answering the Alice
patentability question, possibly yielding economic efficiencies.
Alice casts a shadow over virtually every phase of the lifecycle of a patent,
including preparation, prosecution, and enforcement.58 Inventors want to
understand as an initial matter whether to even attempt to obtain patent
protection for their inventions. The cost to prepare and file a patent application
of moderate complexity can easily exceed $10,000, and inventors would like to
know whether it is worth it even to begin such an undertaking.59
In addition, there are hundreds of thousands of “in flight” patent
applications, all prepared and filed prior to the Alice decision.60 These
applications likely do not include the necessary subject matter or level of detail
that may be required to overcome a current or impending Alice rejection.61 These
applications may not contain evidence of how the invention improves the
operation of a computing system or other technology.62 In such cases, patent
applicants want to know whether it is even worth continuing the fight, given that
they must pay thousands of dollars for every meaningful interaction with a patent
examiner.63
In the enforcement phase of the patent lifecycle, litigants want to know the
likelihood that an asserted patent will be invalidated under Alice. Both parties
to a suit rely on such information when deciding whether to settle or continue
towards trial.64 For plaintiffs, the increased likelihood of fee shifting raises the
stakes even further.65 From an economic welfare perspective, providing
patentees with accurate information regarding the likelihood of invalidation
should result in a reduction in the inefficient allocation of resources, by
shortening or reducing the number of lawsuits.
57. Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347, 2355 (2014).
58. See generally Tran, supra note 17 (discussing the recent implications of the Alice decision).
59. 2015 Report of the Economic Survey, AM. INTELL. PROP. L. ASSOC., I-85, https://www.aipla.org/
learningcenter/library/books/econsurvey/2015EconomicSurvey/Pages/ default.aspx (last visited Mar. 13, 2018)
[hereinafter 2015 Report] (the median legal fee to draft a relatively complex electrical/computer patent
application is $10,000).
60. See Tran, supra note 17, at 358 (discussing the significant decrease in patent grants after Alice was
handed down, this is likely due to the fact that the standard shift invalidated the patents next in the queue); see
U.S. Patent And Trademark Office Patent Technology Monitoring Team, U.S. Patent Statistics Chart Calendar
Years 1963–2015, USPTO.GOV, https://www.uspto.gov/web/offices/ac/ido/oeip/taf/us_stat.htm (last visited
Mar. 13, 2018) (showing that 615,243 patent applications were filed in 2014 and 629,647 patent applications
were filed in 2015).
61. Tran, supra note 17, at 357–58 (“Between July 1 and August 15, 2014, there were 830 patent
applications related [to] computer implemented inventions withdrawn from the U.S. Patent and Trademark
Office.”).
62. See generally Enfish LLC v. Microsoft Corp., 822 F.3d 1327, 1335–36 (Fed. Cir. 2016) (requiring
analysis of improvements to functioning of the computer or other related technology as a part of the Alice test);
Tran, supra note 17, at 358.
63. 2015 Report, supra note 59, at I-86 (stating that the median legal fee to prepare a response to an
examiner’s rejection for a relatively complex electrical/computer application is $3,000).
64. Id.
65. Octane Fitness, LLC v. Icon Health & Fitness, Inc., 134 S. Ct. 1749, 1753–54 (2014); see e.g., Edekka
LLC v. 3Balls.com, Inc., 2015 U.S. Dist. 168610, at *19–20 (E.D. Tex. Dec. 17, 2015) (awarding attorney fees
under 35 U.S.C. § 285 in a case dismissed for claims found invalid by Judge Gilstrap under Alice).

42 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
A. Intuition-Based Legal Services
Historically, attorneys have provided the above-described guidance by
applying intuition, folk wisdom, heuristics, and their personal and shared
historical experience. For example, in the context of patent prosecution
generally, the field is rife with (often conflicting) guiding principles,66 such as:
Make every argument you possibly can
To advance prosecution, amending claims is better than arguing
Keep argument to a minimum, for fear of creating prosecution history
estoppel or disclaimer
File appeals early and often
Interviewing the examiner expedites examination
Interviewing the examiner is a waste of time and money
Use prioritized examination—you’ll get a patent in twelve months!67
You are playing a lottery: if your case is assigned to a bad examiner,
give up hope!
Unfortunately, the above approaches are not necessarily effective or
applicable in all contexts. For example, while some approaches may have
worked in the past (e.g., during the first years of practice when the attorney
received her training), they may no longer be effective, given changes in Patent
Office procedures and training, changes in the law, and so on.68
Nor do the above approaches necessarily consider client goals. Different
clients may desire different outcomes, depending on their market, funding needs,
budget, and the like. Example client requirements include short prosecution
time (e.g., get a patent as quickly as possible), long prosecution time (e.g., delay
prosecution during clinical trials), obtaining broad claims, minimizing the
number of office actions (because each office action costs the client money), or
the like.69 It is clear that any one maxim or approach to patent prosecution is
not going to optimize the outcome for every client in every possible instance.
While a truly optimal outcome may not be possible, in view of the randomness
and variability in the examination system, it is undoubtedly possible to do better.
In the following Subsection, we assert that a data-driven approach can yield
improved outcomes and economic efficiencies for the client.
66. The following list is based on the Author’s personal experience as a patent prosecutor. At one time
or another, the Author has worked with a client, supervisor, or colleague who has insisted on following one or
more of the presented guidelines.
67. USPTO, Prioritized Examination, 76 FR 59050 (Sept. 23, 2011) (promising to provide a final
disposition for a patent application within one year).
68. E.g., The America Invents Act, Public L. No. 112-29, Effective September 16, 2012 (making
substantial changes to patent law, including moving from a first-to-invent to a first-to-file priority system); see
also, Summary of the America Invents Act, AM. INTELLECTUAL PROP. L. ASSOC., http://www.aipla.org/advocacy/
congress/aia/Pages/summary.aspx (last visited Mar. 19, 2018) (summarizing the changes made by the America
Invents Act).
69. See 2015 Report, supra note 59, at I-86 (discussing the expensive stages of filing patents).

No. 1] MECHANIZING ALICE 43
B. Data-Driven Patent Legal Services
A data-driven approach promises to address at least some of the
shortcomings associated with the traditional approach to providing patent-
related legal services. As a simple example, many clients are concerned with
the number of office actions required to obtain a patent.70 This is because each
office action may cost the client around $3,000 in attorney fees to formulate a
response.71 For large corporate clients, with portfolios numbering in the
thousands of yearly applications, reducing the average number of office actions
(even by a fractional amount on average) can yield significant savings in yearly
fees to outside counsel.72 For small clients and individual inventors, one less
office action may be the difference between pushing forward and abandoning a
case. Is it possible to use data about the functioning of the patent office to better
address the needs of these different types of clients?
In the academic context, prior studies considering patent-related data have
focused largely on understanding or measuring patent breadth, quality, and/or
value using empirical patent features. One body of literature uses patent citation
counts and other features (e.g., claim count, classification identifiers) of an
issued patent to attempt to determine patent value.73 Others have studied the
relationship between patent scope and firm value.74 Other empirical work has
analyzed prosecution-related data in order to determine patent quality.75
For this project, we are more interested in predicting how decision makers
(e.g., judges or patent examiners) will evaluate patent claims. We make such
predictions based on the prior behaviors and actions of those decision makers.
Fortunately, it is now becoming increasingly possible to cheaply obtain and
analyze large quantities of data about the behaviors of patent examiners and
judges.76
In the patent prosecution context, the Patent Office hosts the PAIR (Patent
Application Information Retrieval) system, which provides the “file wrapper”
for every published application or issued patent.77 The patent file wrapper
70. See, e.g., id. (excessive legal fees for patent applications are burdensome to clients).
71. E.g., id. (the median legal fee to prepare an amendment/argument for a relatively complex
electrical/computer application is $3,000).
72. E.g., 25 Years of Patent Leadership, IBM RES., https://www.research.ibm.com/patents/ (last visited
Mar. 19, 2018) (describing how IBM received over 9,000 patents in 2017; saving even $10,00 per patent would
yield significant savings).
73. See, e.g., John R. Allison et al., Valuable Patents, 92 GEO. L.J. 435 (2004); Nathan Falk & Kenneth
Train, Patent Valuation with Forecasts of Forward Citations, 12 J. OF BUS. VALUATION AND ECON. LOSS
ANALYSIS 101 (2017); Mark P. Carpenter et al., Citation Rates to Technologically Important Patents, 3 WORLD
PAT. INFO. 160 (1981).
74. See, e.g., Joshua Lerner, The Importance of Patent Scope: An Empirical Analysis, 25.2 RAND J. OF
ECON. 319 (1994) (describing that patent classification is used as a proxy for scope).
75. See, e.g., Ronald J. Mann & Marian Underweiser, A New Look at Patent Quality: Relating Patent
Prosecution to Validity, 9 J. EMPIRICAL LEGAL STUD. 1 (2012) (discussing two hand-collected data sets to
analyze patent quality).
76. Alumnus Winship Creates Juristat to Mine Patent Prosecution Data for Clients, WASH. U. L.,
http://law.wustl.edu/m/content.aspx?id=10059 (last visited Jan. 28, 2018).
77. Patent Application Information Retrieval, U.S. PAT. & TRADEMARK OFFICE,
http://portal.uspto.gov/pair/PublicPair (last visited Mar. 13, 2018). In addition, bulk data downloads are
available at: USPTO Bulk Downloads: Patents, GOOGLE, https://www.google.com/googlebooks/uspto-

44 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
includes every document, starting with the initial application filing, filed by the
applicant or examiner during prosecution of a given patent application.78
A number of commercial entities provide services that track and analyze
prosecution-related data.79 These services provide reports that summarize
examiner or group-specific behaviors and trends within the Patent Office,
including allowance rates, appeal dispositions, timing information, and the
like.80 Such information can be used to tailor prosecution techniques to a
specific examiner or examining group. For example, if the examiner assigned
to a particular application has, based on his work on other cases, shown himself
to be stubborn (e.g., as evidenced by a high appeal rate, high number of office
actions per allowance, or the like), then the client may elect to appeal the case
earlier than usual, given that further interaction with the examiner may be of
limited utility.
In the context of Alice, we can learn many things from patent prosecution
data. As one example, we can learn which art units or subject matter classes are
subject to the most Alice rejections.81 While this is useful, it is not always known
a priori how a new application will be classified by the Patent Office. As
another example, we can learn which examiners are particularly prone to issue
Alice rejections and, perhaps more interestingly, how likely an applicant is to
overcome that rejection based on the examiner’s decisions in other cases.
Dissecting the data even further, we may even be able to learn what types of
arguments are successful in overcoming Alice rejections.
C. Predicting Subject Matter Rejections Yields Economic Efficiencies
While the above types of information may be valuable to an applicant in
the midst of examination, it is not so useful in the pre-application or post-
issuance phases of the lifecycle of a typical patent.82 A client wishing to file an
application for an invention will want to know how likely he is to encounter an
Alice rejection. As another example, a client with an issued patent will want to
know how likely it is that her patent will be invalidated by a court.
In view of the above, the goal of this work is to predict whether a particular
patent claim will be considered valid or invalid under Alice, based on patent
prosecution-related data obtained from the Patent Office. As described in detail
below, such a prediction can be made based on relationships between specific
patents.html (last visited Mar. 13, 2018) [hereinafter USPTO Bulk Downloads]; USPTO Data Sets, REED TECH,
http://patents.reedtech.com/index.php (last visited Mar. 13, 2018).
78. MANUAL OF PATENT EXAMINING PROCEDURE § 719 (9th ed. rev. 7, Nov. 2015); 37 C.F.R. § 1.2
(2015).
79. See e.g., JURISTAT, https://www.juristat.com/ (last visited Mar. 13, 2018); LexisNexis PatentAdvisor,
REED TECH, http://www.reedtech.com/products-services/intellectual-property-solutions/lexisnexis-
patentadvisor (last visited Mar. 13, 2018).
80. Product Primers, JURISTAT, https://resources.juristat.com/product-primers/ (last visited Mar. 13,
2018).
81. See infra Section IV and Plots 1–3.
82. See Tara Klamrowski, How to Engineer Your Application to Avoid Alice Rejections, REED TECH (Oct.
19, 2017), http://knowledge.reedtech.com/intellectual-property-all-posts/how-to-engineer-your-application-to-
avoid-alice-rejections (describing other methods to avoid an Alice rejection).

No. 1] MECHANIZING ALICE 45
claim terms and the presence or absence of corresponding subject matter
rejections issued by the Patent Office.83
In related work, Aashish Karkhanis and Jenna Parenti have identified
correlations between specific terms in a patent claim with patent eligibility.84
Our work differs from and expands upon that of Karkhanis and Parenti in a
number of ways. First, we rely on the decisions made by patent examiners rather
than judges.85 The number of claims that have been evaluated for eligibility
under Alice in the Patent Office is several orders of magnitude larger than the
number of claims that have been similarly evaluated by the courts.86 This means
that we have significantly more data to utilize for analysis and machine learning
efforts. Second, we have developed a computer program that mechanizes a
human decision-making process by exploiting relationships between claim
terms and validity to classify claims as valid or invalid. Third, we use our
mechanism to estimate the impact on the body of patents issued prior to the Alice
decision.
Predicting potential Alice-based validity issues provides benefits in every
phase of the patent lifecycle.87 For example, such predictions can be employed
to determine whether to even file a patent application for a given invention.88 If
it is possible, a priori, to cheaply determine whether a particular invention is
directed to patent ineligible subject matter, then a client may be saved tens of
thousands of dollars in legal fees.89 While legal fees spent in pursuit of an
invalid patent will surely enrich the patent attorney who receives them, such fees
represent economic waste. Wasted legal fees are resources that could be more
productively and efficiently employed in some other context.
In patent preparation or prosecution, predicting subject matter eligibility
issues can help attorneys better craft or amend claims. For a given patent claim,
such a prediction may serve as an “early warning” sign that can help put the
client and attorney on notice that a claim as drafted may be rejected by the Patent
Office on subject matter grounds.90 The claim drafter can then iteratively
modify the claim to settle on more detailed claim language that may not suffer
from the abstractness issues that trigger a typical Alice rejection.91 Iteratively
obtaining feedback from a machine is much cheaper than doing so with a patent
examiner.92 As noted above, each interaction with an examiner results in
83. See infra Section V.
84. Aashish R. Karkhanis & Jenna L. Parenti, Toward an Automated First Impression on Patent Claim
Validity: Algorithmically Associating Claim Language with Specific Rules of Law, 19 STAN. TECH. L. REV. 205,
215 (2016).
85. Id.
86. See Tran, supra note 17, at 358 (indicating that 568 patents have been challenged in the courts under
Alice as of June 2016).
87. Karkhanis & Parenti, supra note 84, at 212.
88. Dugan, supra note 11 (an example system that provides such predictions).
89. 2015 Report, supra note 59 (demonstrating that the median legal fee to draft a relatively complex
electrical/computer patent application is $10,000).
90. Karkhanis & Parenti, supra note 84, at 212.
91. E.g., Dugan, supra note 11 (allowing iterative modification of patent claims).
92. See, e.g., Karkhanis & Parenti, supra note 84; How Much Does a Patent Cost: Everything You Need
to Know, UPCOUNSEL, https://www.upcounsel.com/how-much-does-a-patent-cost (last visited Mar. 13, 2018)
(describing the bottom line costs to filing a patent).

46 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
thousands of dollars in legal fees to the client.93 Reducing the number of
interactions with the examiner yields considerable savings to the client and the
examining corps, and thus increases economic efficiency.94
Provided that we can use the Patent Office as a proxy for the decision
making of the Federal Courts,95 our predictive techniques can be used to identify
weaknesses in asserted claims during the enforcement of a patent. For example,
during pre-suit investigation, a patentee could predict whether a given patent
claim is likely to be held invalid by the court.96 Providing patentees with such
pre-suit information, coupled with the threat of fee shifting under Octane Fitness,97 may result in a sharp decrease in baseless patent litigation.
Note that we are not claiming that our predictive tool will reduce the
amount of effort required to prepare patent claims. We instead assert that in at
least some of those cases where the invention is clearly directed to unpatentable
subject matter, no patent claims will be prepared at all, resulting in savings to
the client. In cases where the invention is on the borderline of patentability, the
patent attorney may in fact spend more time crafting claims that can avoid a
subject matter rejection.98 Although this will result in higher up-front costs to
the client,99 the client will typically save in the long run, as the number of
interactions with the patent office will be reduced.100
Nor does our system test claims for every possible basis of invalidity.
Patent claims may of course be invalid for many reasons, including for a lack of
utility, anticipation or obviousness in view of the prior art, indefiniteness, or a
lack of written description.101 Instead, our system only determines whether a
given claim is directed to patent-eligible subject matter under 35 U.S.C. § 101.
While automatically determining validity under other statutory grounds is an
open area of research, it is not addressed here.
In conclusion, we have presented a case for predictive technologies, such
as our machine classifier, which can assist patent practitioners in efficiently
93. E.g., 2015 Report, supra note 59, at I-86 (demonstrating that the median legal fee to prepare a response
to an examiner’s rejection for a relatively complex electrical/computer application is $3,000); see also USPTO
Fee Schedule, U.S. PAT. & TRADEMARK OFF., https://www.uspto.gov/learning-and-resources/fees-and-
payment/uspto-fee-schedule#exam (last visited Mar. 13, 2018) (providing information and fee rates for
examination services).
94. Id.
95. See infra Section VII.B (validating the performance of our classifier with respect to claims analyzed
by the Court of Appeals for the Federal Circuit).
96. Karkhanis & Parenti, supra note 84, at 212.
97. See generally, Octane Fitness, LLC v. Icon Health & Fitness, Inc., 134 S. Ct. 1749 (2014) (discussing
a standard for fee-shifting and attorney fees arrangements); Edekka LLC v. 3Balls.com, Inc., No. 2:15-CV-541-
JRG, 2015 WL 9225038, at *1 (E.D. Tex. Dec. 17, 2015).
98. See ROBIN JACOB ET AL., GUIDEBOOK TO INTELLECTUAL PROPERTY (2014), https://books.google.com/
books?id=FYvqAwAAQBAJ&h (“Borderline cases in this area will always be improved by ingenious framing
of claims, another reason why the services of an experienced patent attorney can be so valuable.”).
99. See Gene Quinn, The Cost of Obtaining a Patent in the US, IPWATCHDOG (Apr. 4, 2015),
http://www.ipwatchdog.com/2015/04/04/the-cost-of-obtaining-a-patent-in-the-us/id=56485/ (explaining the
more complex the invention, the higher attorney’s fee for patent prosecution).
100. See 2015 Report, supra note 59, at I-86 (demonstrating that the median legal fee to prepare a response
to an examiner’s rejection for a relatively complex electrical/computer application is $3,000); USPTO Fee
Schedule, supra note 93 (providing information and fee rates for examination services).
101. 35 U.S.C. §§ 101, 102, 103, 112 (2012) (explaining subject matter and utility, anticipation,
obviousness, and definiteness and written description).

No. 1] MECHANIZING ALICE 47
analyzing claims for compliance with Alice. Such analysis can yield significant
economic efficiencies at nearly every stage of the patent lifecycle, including
patent application preparation, prosecution, and enforcement. In the following
Section, we provide an overview of the data collection method that we use to
obtain data for training our machine classifier.
III. DATA COLLECTION METHODOLOGY
In this Section, we describe our data collection methodology, and more
specifically our process for creating a dataset for training our machine classifier.
In brief, we obtain thousands of office actions issued by the Patent Office, each
of which is a written record of an examiner’s analysis and decision of a particular
patent application. We then process the office actions to determine whether the
examiner has accepted or rejected the pending claims of the application under
Alice. We then create a table that associates, in each row, a patent claim with an
indication of whether the claim passes or fails the Alice test.
Our method relies on, as raw material, those patent applications that have
been evaluated by the Patent Office for subject-matter eligibility under Alice. In
the Patent Office, each patent application is evaluated by a patent examiner, who
determines whether or not to allow the application.102 Under principles of
“compact prosecution,” the examiner is expected to analyze the claims for
compliance with every statutory requirement for patentability.103 The core
statutory requirements include those of patent-eligible subject matter, novelty,
and non-obviousness.104 If the examiner determines not to allow an application,
the examiner communicates the rejection to an applicant by way of an “office
action.”105 An office action is a writing that describes the legal bases and
corresponding factual findings supporting the rejection of one or more claims.106
Our approach inspects office actions issued after the Alice decision in order
to find examples of patent eligible and ineligible claims. As will be described
in detail below, these examples are employed in a supervised machine learning
application that trains a classifier to recognize eligible and ineligible claims. If
the office action contains an Alice rejection, then the rejected claim is clearly an
example of a patent-ineligible claim.107 On the other hand, if the office action
does not contain an Alice rejection, then the claims of the application provide
examples of patent-eligible claims, because we assume that the examiner has
evaluated the claims with respect to all of the requirements of patentability,
102. 35 U.S.C. § 131 (2012); 37 C.F.R. § 1.104 (2017).
103. 35 U.S.C. § 132 (2012); MANUAL OF PATENT EXAMINING PROCEDURE § 2103 (9th ed. rev. July 2015)
(“Under the principles of compact prosecution, each claim should be reviewed for compliance with every
statutory requirement for patentability in the initial review of the application, even if one or more claims are
found to be deficient with respect to some statutory requirement.”).
104. 35 U.S.C. § 101, 102, 103 (2012).
105. 35 U.S.C. § 132 (2012); 37 C.F.R. § 1.104 (2017); MANUAL OF PATENT EXAMINING PROCEDURE,
supra note 103, at § 706.
106. 35 U.S.C. § 132 (2012); 37 C.F.R. § 1.104 (2017); MANUAL OF PATENT EXAMINING PROCEDURE,
supra note 103, at § 706.
107. Alice Corp. v. CLS Bank Int’l, 134 S. Ct. 2347, 2354 (2014) (ruling on patent eligibility).

48 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
including Alice compliance.108 If no Alice rejection is present in an office action,
then the examiner must have determined that the claims were directed to eligible
subject matter.109
The goal, therefore, is to find office actions issued after the time at which
the Patent Office at large began examining cases for compliance with the rule of
Alice. Alice was decided on June 19, 2014.110 The Patent Office issued
preliminary instructions for subject-matter eligibility examination on June 25,
2014.111 These instructions were supplemented and formalized in the 2014
Guidance, issued December 16, 2014.112 In view of this regulatory history of
the Patent Office, and partly based on personal experience receiving Alice
rejections, we selected October 2014 as the relevant cutoff date.113 Any office
action issued after the cutoff date therefore represents an evaluation of a patent
application under Alice.
The following outlines the steps of our data collection process. As a
background step, we created a patent document corpus. The patent document
corpus is based on full text data provided by the Patent Office of every patent
issued since 1996 and application published114 between 2001 and the present.115
We store some of the patent and application data in a full text index.116 The
index includes fields for document type (e.g., application or patent), dates (e.g., filing date, publication date, issue date), document identifiers (e.g., application
number, publication number, patent number), technical classification, title,
abstract, claim text, and the like.117 At the time of writing, approximately 4.8
million published applications and 4.0 million patents have been indexed. The
use of the patent document corpus will be described further below.
Figure 1, below, is a generalized flow diagram that illustrates data
collection operations performed to obtain office actions for analysis.
108. 2014 Guidance, supra note 23 (requiring consideration of Alice during examination).
109. Id.
110. Alice, 134 S. Ct. at 2347.
111. Preliminary Examination Instructions, supra note 8.
112. 2014 Guidance, supra note 23.
113. The data analysis presented in infra Plot 1 supports our decision to use October 2014 as the cutoff
date.
114. 35 U.S.C. § 122 (2012); 37 C.F.R. § 1.104 (2017).
115. USPTO Bulk Downloads: Patents, supra note 77; United States Patent and Trademark Office Bulk
Data Downloads, REED TECH, http://patents.reedtech.com/index.php (last visited Mar. 13, 2018). USPTO Bulk
Data includes Patent Grant Full Text Data and Patent Application Full Text Data. The data is hosted by the
USPTO and third party vendors, including Google USPTO Bulk Downloads and Reed Tech USPTO Data Sets.
116. See APACHE SOLR, http://lucene.apache.org/solr/ (last visited Mar. 13, 2018), to view the Apache
Software that was used for text indexing in our data collection process.
117. See Patent Application Full Text and Image Database, U.S. PATENT & TRADEMARK OFFICE,
http://appft.uspto.gov/netahtml/PTO/ search-adv.html (last visited Mar. 13, 2018) (listing identifiers for patent
application).

No. 1] MECHANIZING ALICE 49
Figure 1: Data Collection Process
Initially, we collect the file histories (“file wrappers”) for a randomly
selected set of application numbers.118 Each file history is a ZIP archive file that
includes multiple documents, including the patent application as filed, office
actions, notices, information disclosure statements, applicant responses, claim
amendments, and the like. At the time of this writing, over 180,000 file histories
have been downloaded.
As discussed above, we are interested in finding office actions issued by
the Patent Office on or after October 2014. The Patent Office uses a naming
convention to identify the files within a file history.119 For example, the file
12972753-2013-04-01-00005-CTFR.pdf is a Final Rejection (as indicated by the
document code CTFR) dated April 1, 2013, for application number
12/972,753.120 When a file history ZIP file is unpacked, the document code can
be used to identify relevant documents, which in this case are Non-Final and
Final Rejections.121
At the time of this writing, about 90,000 office actions have been obtained.
The number of office actions is smaller than the number of total file histories
because many of the file histories are associated with applications that have yet
to be examined, and therefore do not contain any office actions.122
118. See APACHE SOLR, supra note 116 (presenting Apache service used for data collection).
119. See Patent Application Information Retrieval, U.S. PAT. & TRADEMARK OFF., https://portal.uspto.gov/
pair/PublicPair (last visited Mar. 13, 2018) (providing access to patent application information with explanation
of document codes).
120. Id.
121. Identified by the document codes CTNF and CTFR, respectively.
122. See Patent Process Overview, U.S. PAT. & TRADEMARK OFF., https://www.uspto.gov/patents-getting-
started/patent-process-overview (last visited Mar. 13, 2018) (showing the timeline of patent prosecution); 35
U.S.C. § 122 (2012).

50 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Each office action in the file history is a PDF file that includes TIFF images
of the pages of the document produced by the examiner.123 As each page of an
office action is represented as a TIFF image, each page of the office action must
be run through an optical character recognition (OCR) module to convert the
PDF file to a text file.124
Once an office action is converted to text, it can be searched for strings that
are associated with Alice rejections. An example Alice rejection found in an
Office Action issued in U.S. Patent Application No. 14/543,715 reads as
follows:
Claim Rejections - 35 USC § 101
35 U.S.C. § 101 reads as follows: “Whoever invents or discovers any new and useful process, machine, manufacture, or composition of matter, or any new and useful improvement thereof, may obtain a patent therefor, subject to the conditions and requirements of this title.”
Claim 1, 9 & 17 are rejected under 35 U.S.C. § 101 because the claimed invention is not directed to patent eligible subject matter. Based upon consideration of all of the relevant factors with respect to the claim as a whole, claim(s) 1, 9 & 17 are determined to be directed to an abstract idea. . . . The claim(s) are directed to the abstract idea of organizing human activities utilizing well known and understood communication devices and components to request and receive multimedia content by a customer.125
Patent examiners tend to rely on form paragraphs provided by the Patent
Office when making or introducing a rejection, so, fortunately, there is a high
level of consistency across office actions.126 Text strings such as the following
were used to identify actions that contained an Alice rejection: “35 USC § 101,”
“abstract idea,” “natural phenomenon,” and the like.127
From the full set of obtained office actions, we selected those issued during
or after October 2014, a total of about 32,000 office actions. We then analyzed
each office action in this subset to determine whether it contained an Alice
rejection. If an office action did contain an Alice rejection, then the
corresponding application was tagged as including a patent-ineligible claim
(sometimes also termed REJECT); conversely, if an office action did not contain
an Alice rejection, then the corresponding application was tagged as including
123. See Patent Application Information Retrieval, supra note 119 (providing access to patent application
history in the format of PDF files).
124. See Tesseract-OCR, GITHUB, https://github.com/tesseract-ocr (last visited Mar. 13, 2018) (providing
an optical character recognition program).
125. Office Action dated Dec. 17, 2014 U.S. Patent Application No. 14/543,715.
126. See, e.g., MANUAL OF PATENT EXAMINING PROCEDURE §706.03(a), Form Paragraph 7.05.015, (8th
ed. Rev. 7, Sept. 2008) (explaining that “the claimed invention is directed to a judicial exception (i.e., a law of
nature, a natural phenomenon, or an abstract idea) without significantly more. Claim(s) [1] is/are directed to
[2]. The claim(s) does/do not include additional elements that are sufficient to amount to significantly more than
the judicial exception because [3].”).
127. Specifically, we identify Alice rejections by searching for the strings “abstract idea” and “natural
phenom*”. While this technique is efficient, it does result in the rare false positive, such as when an examiner
writes, “[t]he claims are not directed to an abstract idea.”

No. 1] MECHANIZING ALICE 51
eligible claims (or ACCEPT).128 Based on the 32,000 office actions issued
during the relevant period, about 26,000 applications have been identified as
eligible, and 3,000 as ineligible.
The next step of the process is to identify the claim that is subject to the
Alice rejection. Typically, the examiner will identify the claims rejected under
a particular statutory provision. For example, the examiner may write “Claims
1, 3–5, and 17–20 are rejected under 35 § USC 101. . . .” Ideally, we would
parse this sentence to identify the exact claims rejected under Alice. However,
we made the simplifying assumption that, at a minimum, the first independent
claim (typically claim 1) was being rejected under Alice.129
We make another simplifying assumption to find the actual claim text
rejected under Alice. In particular, we pull the text of the first independent claim
(“claim 1”) of the published patent application stored in the patent document
corpus described above. Note that this claim is typically the claim that is filed
with the original patent application, although it is not necessarily the claim that
is being examined when the examiner makes the Alice rejection. For example,
the applicant may have amended claim 1 at some time after filing and prior to
the particular office action that includes the Alice rejection. However, it is
unlikely that the claim 1 pending at the time of the Alice rejection is markedly
different from the originally filed claim 1. If anything, the rejected claim is
likely to be more concrete and less abstract due to further amendments that have
been made during examination.
We use claim 1 from the published application because it can be efficiently
and accurately obtained. Each patent file history contains documents that reflect
the amendments made to the claims by the applicant.130 It is therefore
technically possible to OCR those documents to determine the text of the claims
pending at the time of an Alice rejection. However, because applicants reflect
amendments to the claims by using strikethrough and underlining, these text
features greatly reduce the accuracy of our OCR system. In the end, we decided
to rely on the exact claim text available from the patent document corpus instead
of the degraded OCR output of the actual claim subjected to the Alice rejection.
Further work will show whether this assumption had a significant impact on the
results presented here.
For applications that were examined during the relevant time period but
that were not subject to an Alice rejection (that is, they “passed” the test), we
128. Note that it is possible for an application to be labeled both REJECT and ACCEPT, due to a first
office action that includes an Alice rejection and a second office action that does not include an Alice rejection.
129. It should never be the case that a dependent claim will be rejected under Alice if its corresponding
independent claim is not rejected under Alice, as dependent claims are strictly narrower than their parent claims.
Moreover, based on the author’s personal experience as a patent prosecutor, it is very rare that an examiner will,
within one set of claims, allow one independent claim under Alice while rejecting another. Typically, all of the
claims rise and fall together under Alice, since the analysis is intentionally designed to ferret out abstractions
even when they are claimed in the more mechanical claim formats (e.g., apparatus vs. method). Our simplifying
assumption was supported via a manual spot check of over a hundred cases: the examiner reached different
conclusions for different independent claims in only a handful of applications.
130. 37 C.F.R. § 1.121 (2003); see Quick Tip: Examining the File History, ARTICLE ONE PARTNERS,
https://www.articleonepartners.com/blog/quick-tip-examining-the-file-history/ (last visited Mar. 13, 2018)
(defining what is included in the file history of a patent application).

52 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
prefer to use claim 1 from the patent (if any) that issued on the corresponding
application. Claim 1 from the issued patent is preferred, because it reflects the
claim in final form, after it has been evaluated and passed all of the relevant
statutory requirements, including subject matter eligibility under Alice, based on
the existence of an office action issued after October 2014. If there is no issued
patent, such as because the applicant and examiner are still working through
issues of novelty or non-obviousness, we currently elect not to use claim 1 from
the published patent application. For machine learning purposes, this has
resulted in slightly improved performance, possibly because the claims
evaluated for Alice compliance were actually markedly different than the
published claim 1.
Note that the above-described process was iteratively and adaptively
performed. From an initial random sample of patent applications, it was possible
to identify those classes where Alice rejections were common. Then, we
preferentially obtained additional applications from those Alice rejection-rich
classes, in order to increase the likelihood of obtaining office actions that
contained Alice rejections.
Once we perform the above-described data collection, the identified claims
are stored in a table. Each row of the table includes an application number, a
patent classification identifier, an Alice-eligibility indicator (e.g., a tag of
“accept” or “reject”) denoting whether the claim was accepted or rejected by the
examiner, and the text of the claim itself. Patent classification is used by the
Patent Office to group patents and applications by subject matter area.131 The
patent classification identifier is a Cooperative Patent Classification (CPC)
scheme identifier that is obtained from the patent document corpus, as assigned
by the Patent Office to each patent application and issued patent.132 Retaining
the patent classification allows us to break down analysis results by subject
matter area.
In this Section we have described our process for creating our dataset. In
Section IV, next, we present an analysis of the obtained data. In Section V,
below, we use the obtained data to train a machine classifier to determine
whether or not a claim is directed to patent eligible subject matter.
IV. DATA ANALYSIS RESULTS
In this Section, we present results from a data analysis of office actions
issued by the Patent Office. Here, we are trying to answer the following
questions. First, can we “see” the impact of Alice in the actions of the Patent
Office? Put another way, do we see an increase in the number of subject matter
rejections coming out of the Patent Office? Second, which subject matter areas,
if any, are disproportionately subject to Alice rejections?
131. 35 U.S.C.S. § 8 (LexisNexis 2018); MANUAL OF PATENT EXAMINING PROCEDURE §§ 902–05 (8th ed.
Rev. 7, Sept. 2008).
132. MANUAL OF PATENT EXAMINING PROCEDURE, supra note 131, at § 905; Classification Standards and
Development, U.S. PAT. & TRADEMARK OFF., https://www.uspto.gov/patents-application-process/patent-
search/classification-standards-and-development (last visited Mar. 13, 2018).

No. 1] MECHANIZING ALICE 53
Our analysis provides an aggregate view of the impact of Alice in the Patent
Office. We show that, as our intuition would suggest, Alice has resulted in an
increase in subject matter rejections, and that these rejections fall
disproportionately into a few specific subject matter areas. Stepping back, our
analysis shows that the impact of Alice on the stream of data produced by the
Patent Office is not random—instead, it includes a pattern or signal that can be
recognized by machine learning techniques, as shown below in Section V.
To begin our data analysis, we pulled a set of file histories from a uniform
random sample of about 20,000 patent applications filed during or after 2013.133
In the random sample of 20,000 applications, we found a total of 7,367 office
actions arising from 7,160 unique applications which had received at least one
office action. Of the 7,160 unique applications, we found 460 (6.4%) that
included at least one Alice rejection.
Plot 1, below, supports our selection of the relevant time period as being
after October 2014. Subject matter rejections were identified by searching for
particular text strings in office actions, as described above. Plot 1 shows the
monthly fraction of office actions containing a subject matter rejection. The data
in Plot 1 is based on our random sample of about 20,000 patent applications.
We then counted the number of office actions associated with the sample and
issued in a given month that contained a subject matter rejection. The error bars
provide the 95% confidence interval for the measured proportion.
Plot 1: Subject Matter Rejections by Month
133. As described above, we preferentially search for applications in classes that are rich in Alice rejections.
This process, while useful for finding examples of rejections for purposes of machine learning, skews the data
set in favor of particular subject matter classes where Alice rejections are common. This skew complicates any
reporting of generalized statistics or distribution of rejections. For this reason, the data analysis presented here
is based on a random sample of applications.
54 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
In Plot 1, a marked increase in subject matter rejections occurs in the
July/August, 2014 timeframe. This increase is consistent with the publication
of preliminary examination instructions for subject-matter eligibility by the
Patent Office on June 25, 2014.134
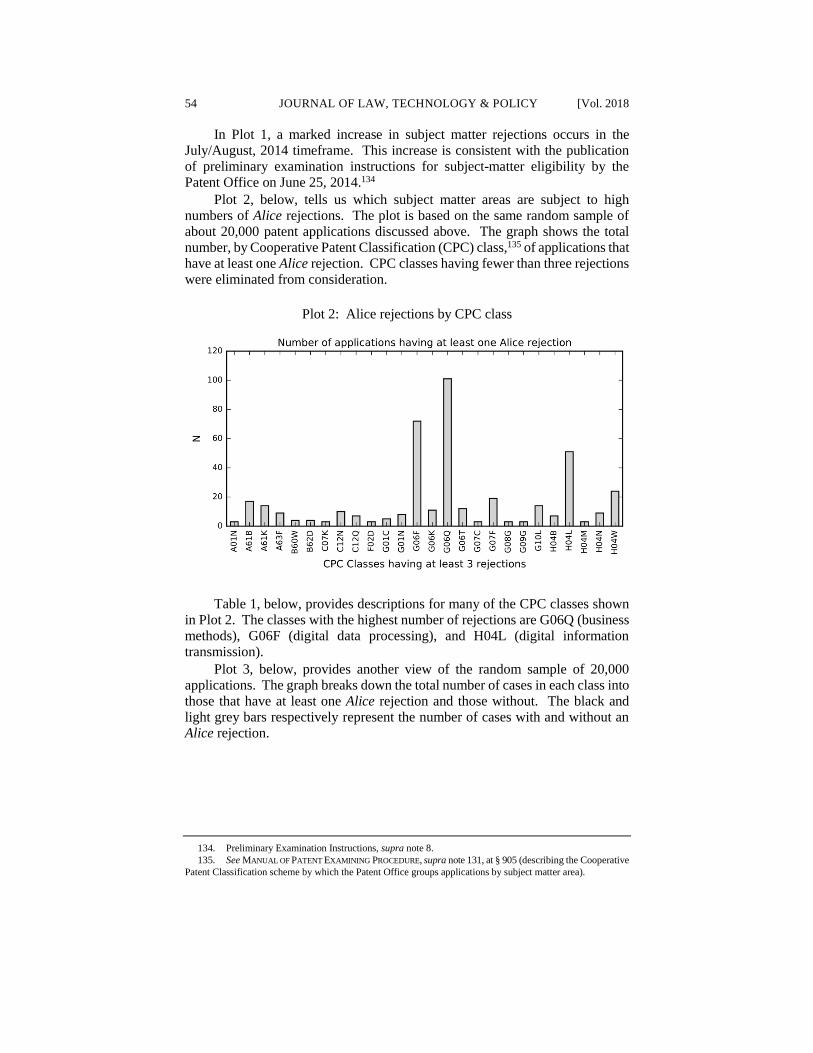
Plot 2, below, tells us which subject matter areas are subject to high
numbers of Alice rejections. The plot is based on the same random sample of
about 20,000 patent applications discussed above. The graph shows the total
number, by Cooperative Patent Classification (CPC) class,135 of applications that
have at least one Alice rejection. CPC classes having fewer than three rejections
were eliminated from consideration.
Plot 2: Alice rejections by CPC class
Table 1, below, provides descriptions for many of the CPC classes shown
in Plot 2. The classes with the highest number of rejections are G06Q (business
methods), G06F (digital data processing), and H04L (digital information
transmission).
Plot 3, below, provides another view of the random sample of 20,000
applications. The graph breaks down the total number of cases in each class into
those that have at least one Alice rejection and those without. The black and
light grey bars respectively represent the number of cases with and without an
Alice rejection.
134. Preliminary Examination Instructions, supra note 8.
135. See MANUAL OF PATENT EXAMINING PROCEDURE, supra note 131, at § 905 (describing the Cooperative
Patent Classification scheme by which the Patent Office groups applications by subject matter area).

No. 1] MECHANIZING ALICE 55
Plot 3: Cases With/Without Alice Rejection by CPC class
As can be seen in Plot 3, the total sample size is quite small for many of
the classes. In order to improve the statistical significance of our findings, we
performed further data collection, focusing on those CPC classes from our
random sample that included at least some Alice rejections. This additional data
collection resulted in a larger, non-uniform sample of about 38,000 office
actions, of which about 3,500 included an Alice rejection.
Plot 4, below, tells us the percentage of applications in each class that have
been subjected to an Alice rejection. Plot 4 was generated based on our larger,
non-uniform data sample described above. The data in this sample was
purposely skewed towards those classes where Alice rejections are more
common, in order to determine a more statistically accurate rejection rate for
those classes.
Plot 4: Percentage of Alice rejections by CPC class
56 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
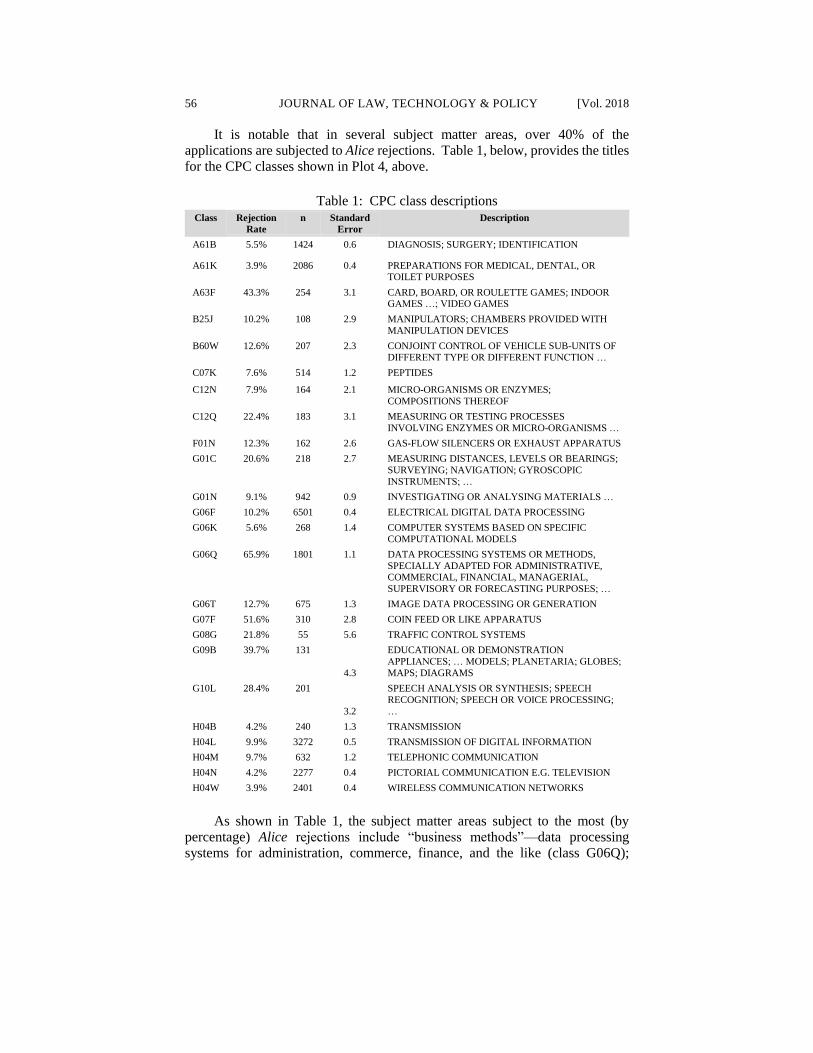
It is notable that in several subject matter areas, over 40% of the
applications are subjected to Alice rejections. Table 1, below, provides the titles
for the CPC classes shown in Plot 4, above.
Table 1: CPC class descriptions Class Rejection
Rate
n Standard
Error
Description
A61B 5.5% 1424 0.6 DIAGNOSIS; SURGERY; IDENTIFICATION
A61K 3.9% 2086 0.4 PREPARATIONS FOR MEDICAL, DENTAL, OR TOILET PURPOSES
A63F 43.3% 254 3.1 CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES …; VIDEO GAMES
B25J 10.2% 108 2.9 MANIPULATORS; CHAMBERS PROVIDED WITH
MANIPULATION DEVICES
B60W 12.6% 207 2.3 CONJOINT CONTROL OF VEHICLE SUB-UNITS OF
DIFFERENT TYPE OR DIFFERENT FUNCTION …
C07K 7.6% 514 1.2 PEPTIDES
C12N 7.9% 164 2.1 MICRO-ORGANISMS OR ENZYMES;
COMPOSITIONS THEREOF
C12Q 22.4% 183 3.1 MEASURING OR TESTING PROCESSES
INVOLVING ENZYMES OR MICRO-ORGANISMS …
F01N 12.3% 162 2.6 GAS-FLOW SILENCERS OR EXHAUST APPARATUS
G01C 20.6% 218 2.7 MEASURING DISTANCES, LEVELS OR BEARINGS;
SURVEYING; NAVIGATION; GYROSCOPIC
INSTRUMENTS; …
G01N 9.1% 942 0.9 INVESTIGATING OR ANALYSING MATERIALS …
G06F 10.2% 6501 0.4 ELECTRICAL DIGITAL DATA PROCESSING
G06K 5.6% 268 1.4 COMPUTER SYSTEMS BASED ON SPECIFIC
COMPUTATIONAL MODELS
G06Q 65.9% 1801 1.1 DATA PROCESSING SYSTEMS OR METHODS,
SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL,
SUPERVISORY OR FORECASTING PURPOSES; …
G06T 12.7% 675 1.3 IMAGE DATA PROCESSING OR GENERATION
G07F 51.6% 310 2.8 COIN FEED OR LIKE APPARATUS
G08G 21.8% 55 5.6 TRAFFIC CONTROL SYSTEMS
G09B 39.7% 131
4.3
EDUCATIONAL OR DEMONSTRATION
APPLIANCES; … MODELS; PLANETARIA; GLOBES;
MAPS; DIAGRAMS
G10L 28.4% 201
3.2
SPEECH ANALYSIS OR SYNTHESIS; SPEECH
RECOGNITION; SPEECH OR VOICE PROCESSING;
…
H04B 4.2% 240 1.3 TRANSMISSION
H04L 9.9% 3272 0.5 TRANSMISSION OF DIGITAL INFORMATION
H04M 9.7% 632 1.2 TELEPHONIC COMMUNICATION
H04N 4.2% 2277 0.4 PICTORIAL COMMUNICATION E.G. TELEVISION
H04W 3.9% 2401 0.4 WIRELESS COMMUNICATION NETWORKS
As shown in Table 1, the subject matter areas subject to the most (by
percentage) Alice rejections include “business methods”—data processing
systems for administration, commerce, finance, and the like (class G06Q);

No. 1] MECHANIZING ALICE 57
games (classes A63F and G07F); educational devices, globes, maps, and
diagrams (class G09B); and speech analysis, synthesis, and recognition (G10L).
In this Section, we have presented an analysis of our dataset. Our analysis
indicates that that the subject matter areas that contain many applications with
Alice rejections include data processing, business methods, games, educational
methods, and speech processing. In the following Section, we use our dataset to
train a machine classifier to predict Alice rejections.
V. PREDICTING ALICE REJECTIONS WITH MACHINE CLASSIFICATION
Our core research goal is to predict, based on the text of a patent claim,
whether the claim will be rejected under Alice. One way to make this prediction
is to cast the exercise as a document classification problem. In document
classification, a document is assigned to a particular class or category based on
features of the document, such as words, phrases, length, or the like.136
Document classification can be automated by implementing on a computer
the logic used to make classification decisions. One very successful example of
automated document classification is found in the “spam” filter provided by
most modern email services.137 A typical spam filter classifies each received
email into spam (i.e., junk mail) or non-spam (i.e., legitimate email) based on
features of the email, such as its words, phrases, header field values, and the
like.138
While it is possible to manually implement the decision logic used to
classify documents, it is more common to use machine learning.139 At a high
level of generality, machine learning is a technique for training a model that
associates input features with outputs.140 Machine learning can be supervised or
unsupervised.141 In supervised learning, a “teacher” trains a model by presenting
it with examples of input and output pairs.142 The model is automatically
adjusted to express the relationship between the observed input-output pairs.143
The model can then be validated by testing it against novel inputs and tallying
how often the model makes the correct classification.144 In unsupervised
learning, the goal is to identify patterns in a dataset without guidance provided
by a teacher.145 In unsupervised learning, a model is generated without the use
of input-output pairs as training examples.146
Our methodology employs supervised learning. Our goal is to teach a
machine to classify a patent claim as eligible or ineligible based on its words.
136. RUSSELL & NORVIG, supra note 5, at 865.
137. Mehran Sahami et al., A Bayesian Approach to Filtering Junk E-Mail, in AAAI TECHNICAL REPORT
1998, at 55–56 (No. WS–98–05).
138. Id.
139. RUSSELL & NORVIG, supra note 5, at 693–95.
140. Id.
141. Id. at 695.
142. Id.
143. See id. at 697–703 (discussing an approach to generating a decision tree based on observed examples).
144. Id. at 708–09.
145. Id. at 694.
146. Id.

58 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
The input-output pairs used for training are obtained from our dataset, described
above, which associates patent claims with corresponding classifications—
eligible or not eligible—made by human examiners at the Patent Office. As
described in detail below, these classifications can be used to train and evaluate
various common supervised machine learning models.
In the following Subsections, we begin with an exploratory analysis that
identifies particular words that are associated with eligibility or ineligibility
under Alice.147 The presence of such associations indicates that there exist
patterns that can be learned by way of machine learning.148 Next, we describe
the training, testing, and performance of a baseline classifier, in addition to
techniques for an improved classifier.
A. Word Clouds
When initially exploring whether it would even be possible to predict
subject matter rejections based on the words of a patent claim, we first explored
the associations between claim terms and Alice rejections. Plot 5, below,
includes two word clouds that can be used to visualize such associations. In Plot
5, the left word cloud depicts words that were highly associated with acceptable
subject matter, where the words are sized based on frequency. The right word
cloud depicts words highly associated with unacceptable subject matter. Each
word cloud was formed by building a frequency table, which mapped each word
to a corresponding frequency. A first frequency table was built for eligible
claims, and a second frequency table was built for ineligible claims. The highest
N words from each table were then displayed as a word cloud, shown below.
Plot 5: Raw frequency word clouds
Eligible: Ineligible:
147. See generally Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347 (2014) (stating the standard
for subject matter eligibility).
148. See RUSSELL & NORVIG, supra note 5, at 2 (stating that machine learning extracts and extrapolates
patterns).

No. 1] MECHANIZING ALICE 59
Note that many terms, such as “method,” “data,” and “device” appear with
high frequency in both accepted (left cloud) and rejected claims (right cloud).
This is not surprising as these are very common words in the patent claim
context. However, for our purposes, these terms are not useful for distinguishing
which words are more commonly associated with exclusively one class or the
other.
Plot 6, below, includes two frequency word clouds without common terms.
Put another way, the words shown in the clouds of Plot 6 are sized based on the
absolute value of the difference of the frequencies in Plot 5. Thus, a word that
is equally common in both data sets (accepted and rejected claims) should not
appear in either cloud.
Plot 6: Raw frequency without common terms
Eligible: Ineligible:
The word clouds of Plot 5 do a better job of matching our intuition about
what kinds of words might be associated with Alice rejections.149 In the right
(ineligible) word cloud, we see terms such as “method,” “computer,”
“information,” “associated,” “transaction,” “payment,” “account,” and
“customer.” These are all words that would be used to describe business and
financial methods, techniques that are in the crosshairs of Alice.150 On the left
side, in the eligible word cloud, there are more terms that are associated with
physical structures, including “portion,” “formed,” “surface,” “connected,”
“disposed,” “configured,” “material,” and the like.
Table 2, below, lists the top twenty claim terms that are respectively
associated with patent eligibility or ineligibility.151
149. See Alice, 134 S. Ct. at 2349 (relating to terms closely related to a financial transaction).
150. See id. (regarding a financial transactions scheme).
151. See generally id. at 2355–57 (explaining the types of claims that are not patent eligible).

60 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Table 2: Words Strongly Associated With (In)eligibility
Eligible Claims Ineligible Claims
surface control method implemented
portion layer computer providing
connected signal associated transaction
end substrate determining generating
disposed body receiving identifying
formed material information storing
configured light user account
direction arranged system database
extending member data payment
side form processor game
B. Classifier Training
As noted above, predicting whether a patent claim will be subject to an
Alice rejection is a classification problem, similar to that of detecting whether
an email message is spam.152 At the end of the above-described data collection
process, we are in possession of a data set that includes about 20,000 claims,
each of which is labeled as “accept” (subject matter eligible—no Alice rejection
issued) or “reject” (subject matter ineligible—Alice rejection issued).153
Roughly 85% of the claims in the data set are patent eligible, while the remaining
15% are ineligible.154
The dataset is then used to train a classifier, which is a mathematical model
that maps input features of a document to one or more classes.155 For example,
as discussed above in the context of a spam filter for email, a classifier
determines the class of an email (i.e., spam or not spam) based on its features
(e.g., words).156 Similarly, in our application, we generate a classifier that
determines the class of a patent claim (i.e., valid or invalid) based on its features
(e.g., words).
In machine learning, a classifier can be trained in a supervised manner by
showing the classifier many examples of each class.157 The classifier learns that
certain features or combinations of features are associated with one class or the
other.158 In our case, we elected to show the classifier the words of a claim,
without reference to their order, meaning, or location in the claim. This is
sometimes known as a “bag of words” approach, in which a text passage is
152. RUSSELL & NORVIG, supra note 5, at 710.
153. As discussed in detail above, the “accept” claims in the data set were those obtained from applications
that had received an office action during the relevant time period (post Oct. 2014), so that we could be reasonably
certain that an examiner had evaluated the claim for Alice compliance. For machine learning purposes, we
limited the claims in the ACCEPT class to those from patents that issued during the relevant time period, because
we could be confident that those claims were in the form actually examined and approved by the examiner. This
reduced the number of total claims from about 29,000 to 22,000.
154. Our full training set included 21,693 claims, of which 2,963 (about 13.7%) were rejected as abstract.
155. See generally RUSSELL & NORVIG, supra note 5, at 696 (explaining the use of classifiers).
156. Id. at 710.
157. See id. at 697–703 (discussing an approach to generating a decision tree based on observed examples).
158. Id.

No. 1] MECHANIZING ALICE 61
converted into a frequency table of terms.159 The words of the claim provide the
input features for the classifier; the output of the classifier is an indication of
whether the claim is patent eligible or not.160
Prior to training, we stemmed the words of the claims.161 Stemming
converts distinct words having the same roots but different endings and suffixes
into the same term.162 Stemming reduces the number of distinct words being
analyzed in a machine learning scenario.163 For example, words such as
“associate,” “associated,” “associating,” and “associates” may all be converted
to the term “associ.”164
When training a classifier, the dataset is typically split into two subsets, a
training set and a testing set.165 The classifier is not exposed to examples in the
testing set until after training is complete, in order to obtain a true gauge of the
classifier’s performance.166 In our case, we set aside 20% of the cases for the
test set and used the remaining cases for training.
We then trained our classifiers using the remaining ineligible claims (about
2,400) and the same number of randomly selected eligible claims. By adjusting
the mix of eligible and ineligible claims, a classifier can be biased towards
classifying examples towards the majority class.167 In our case, the use of an
even split was used to make the classifier more likely to recognize claims as
ineligible, at the cost of introducing additional false positives—claims classified
as ineligible that are in fact eligible. As discussed further below, the mix of
eligible and ineligible training examples can be adjusted to tune classifiers to
emphasize particular performance metrics.
C. Performance of a Baseline Classifier
There exist many different machine classification techniques.168 Modern
machine-learning toolkits provide implementations of multiple classifiers via
uniform programming interfaces.169 In this study, we started by training a
159. Id. at 866.
160. E.g., Dugan, supra note 11.
161. Martin Porter, An Algorithm for Suffix Stripping, 14 PROGRAM 130–38 (1980).
162. Alvise Susmel, Machine Learning: Working with Stop Words, Stemming, and Spam, CODE SCHOOL
BLOG (Mar. 25, 2016), https://www.codeschool.com/blog/2016/03/25/machine-learning-working-with-stop-
words-stemming-and-spam/; see also RUSSELL & NORVIG, supra note 5, at 870 (showing examples of
stemming).
163. RUSSELL & NORVIG, supra note 5, at 870.
164. By converting variations of a word onto a single term, stemming has the effect of condensing a sparse
feature set. With a sufficiently large number of samples, stemming may not be necessary, and may even degrade
classifier performance. CHRISTOPHER MANNING ET AL., AN INTRODUCTION TO INFORMATION RETRIEVAL 339
(Cambridge University Press Online ed. 2009), https://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf.
165. RUSSELL & NORVIG, supra note 5, at 695.
166. Id. at 695–96.
167. See Yanmin Sun et al., Classification of Imbalanced Data: A Review, 23 INT’L J. PATTERN
RECOGNITION & ARTIFICIAL INTELLIGENCE 687–719 (2009) (explaining how a classifier can be biased towards
the majority class).
168. See, e.g., RUSSELL & NORVIG, supra note 5, at 717–53 (discussing various approaches to supervised
learning, including decision trees, logistic regression, and neural networks).
169. See Fabian Pedregosa et al., Scikit-learn: Machine Learning in Python, 12 J. MACHINE LEARNING
RES. 2825–30 (2011), (explaining how scikit-learn works); see also Scikit-learn Online Documentation,
http://scikit-learn.org (last visited Mar. 13, 2018) (demonstrating an example of a machine learning tool kit).
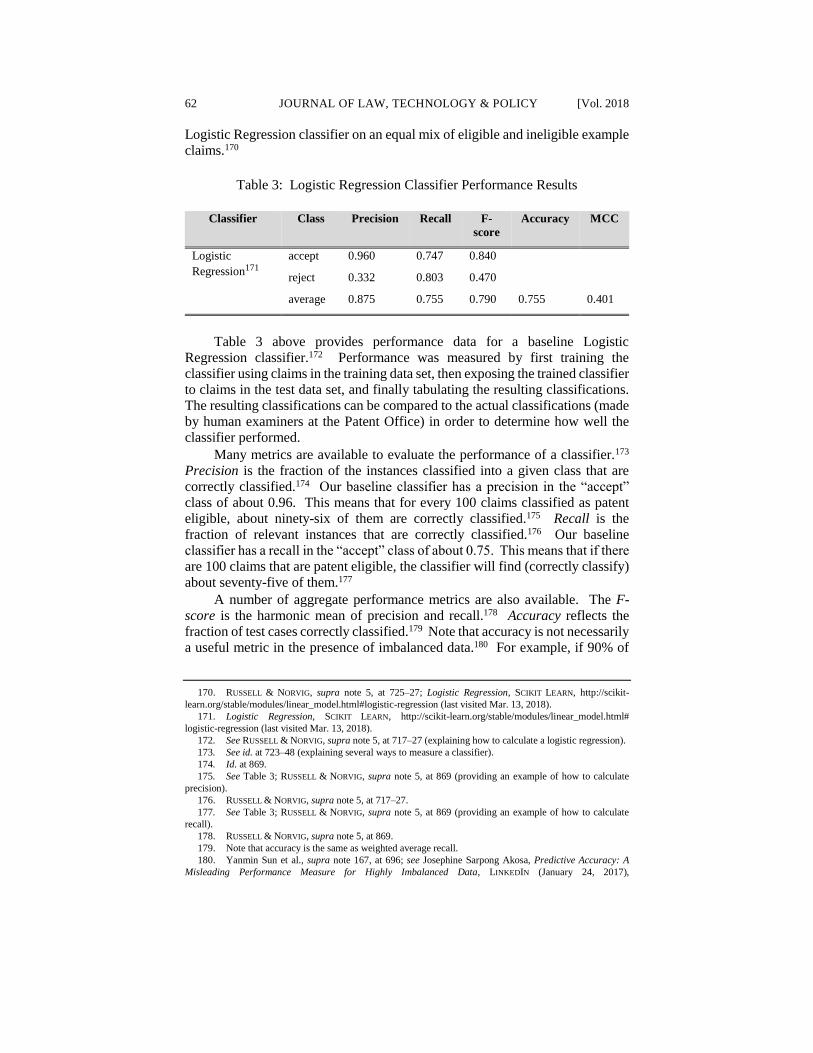
62 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Logistic Regression classifier on an equal mix of eligible and ineligible example
claims.170
Table 3: Logistic Regression Classifier Performance Results
Classifier Class Precision Recall F-
score
Accuracy MCC
Logistic
Regression171
accept 0.960 0.747 0.840
reject 0.332 0.803 0.470
average 0.875 0.755 0.790 0.755 0.401
Table 3 above provides performance data for a baseline Logistic
Regression classifier.172 Performance was measured by first training the
classifier using claims in the training data set, then exposing the trained classifier
to claims in the test data set, and finally tabulating the resulting classifications.
The resulting classifications can be compared to the actual classifications (made
by human examiners at the Patent Office) in order to determine how well the
classifier performed.
Many metrics are available to evaluate the performance of a classifier.173
Precision is the fraction of the instances classified into a given class that are
correctly classified.174 Our baseline classifier has a precision in the “accept”
class of about 0.96. This means that for every 100 claims classified as patent
eligible, about ninety-six of them are correctly classified.175 Recall is the
fraction of relevant instances that are correctly classified.176 Our baseline
classifier has a recall in the “accept” class of about 0.75. This means that if there
are 100 claims that are patent eligible, the classifier will find (correctly classify)
about seventy-five of them.177
A number of aggregate performance metrics are also available. The F-score is the harmonic mean of precision and recall.178 Accuracy reflects the
fraction of test cases correctly classified.179 Note that accuracy is not necessarily
a useful metric in the presence of imbalanced data.180 For example, if 90% of
170. RUSSELL & NORVIG, supra note 5, at 725–27; Logistic Regression, SCIKIT LEARN, http://scikit-
learn.org/stable/modules/linear_model.html#logistic-regression (last visited Mar. 13, 2018).
171. Logistic Regression, SCIKIT LEARN, http://scikit-learn.org/stable/modules/linear_model.html#
logistic-regression (last visited Mar. 13, 2018).
172. See RUSSELL & NORVIG, supra note 5, at 717–27 (explaining how to calculate a logistic regression).
173. See id. at 723–48 (explaining several ways to measure a classifier).
174. Id. at 869.
175. See Table 3; RUSSELL & NORVIG, supra note 5, at 869 (providing an example of how to calculate
precision).
176. RUSSELL & NORVIG, supra note 5, at 717–27.
177. See Table 3; RUSSELL & NORVIG, supra note 5, at 869 (providing an example of how to calculate
recall).
178. RUSSELL & NORVIG, supra note 5, at 869.
179. Note that accuracy is the same as weighted average recall.
180. Yanmin Sun et al., supra note 167, at 696; see Josephine Sarpong Akosa, Predictive Accuracy: A
Misleading Performance Measure for Highly Imbalanced Data, LINKEDIN (January 24, 2017),
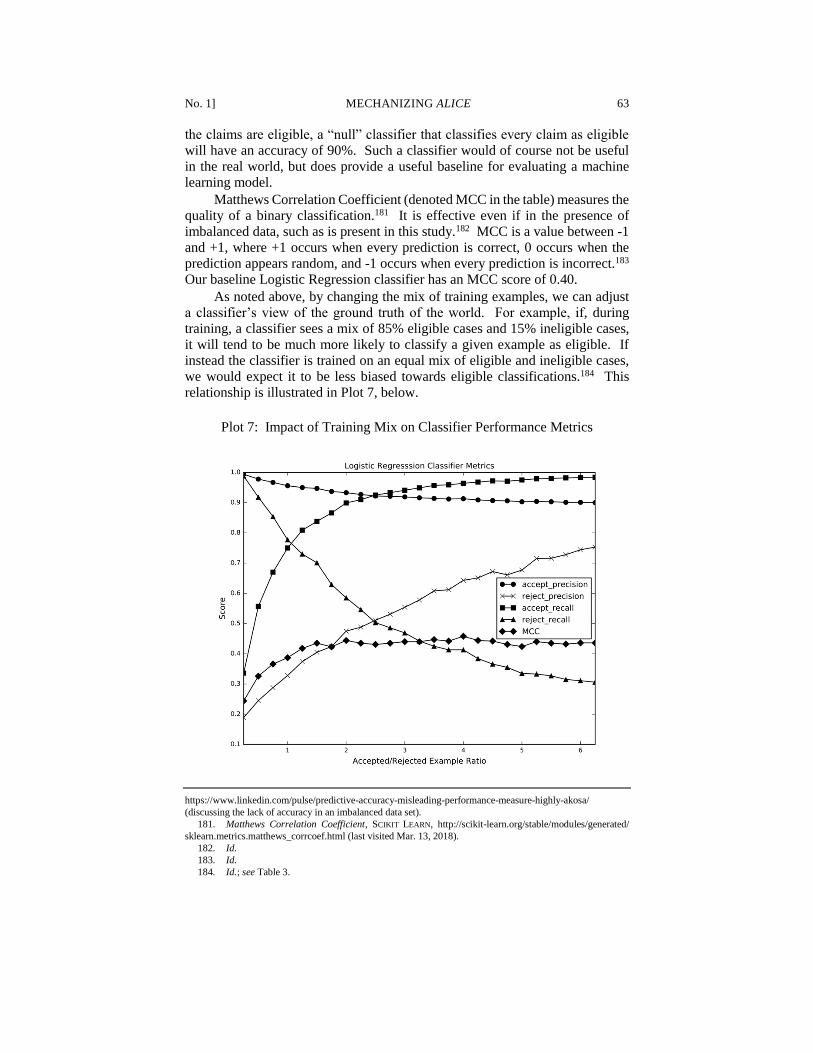
No. 1] MECHANIZING ALICE 63
the claims are eligible, a “null” classifier that classifies every claim as eligible
will have an accuracy of 90%. Such a classifier would of course not be useful
in the real world, but does provide a useful baseline for evaluating a machine
learning model.
Matthews Correlation Coefficient (denoted MCC in the table) measures the
quality of a binary classification.181 It is effective even if in the presence of
imbalanced data, such as is present in this study.182 MCC is a value between -1
and +1, where +1 occurs when every prediction is correct, 0 occurs when the
prediction appears random, and -1 occurs when every prediction is incorrect.183
Our baseline Logistic Regression classifier has an MCC score of 0.40.
As noted above, by changing the mix of training examples, we can adjust
a classifier’s view of the ground truth of the world. For example, if, during
training, a classifier sees a mix of 85% eligible cases and 15% ineligible cases,
it will tend to be much more likely to classify a given example as eligible. If
instead the classifier is trained on an equal mix of eligible and ineligible cases,
we would expect it to be less biased towards eligible classifications.184 This
relationship is illustrated in Plot 7, below.
Plot 7: Impact of Training Mix on Classifier Performance Metrics
https://www.linkedin.com/pulse/predictive-accuracy-misleading-performance-measure-highly-akosa/
(discussing the lack of accuracy in an imbalanced data set).
181. Matthews Correlation Coefficient, SCIKIT LEARN, http://scikit-learn.org/stable/modules/generated/
sklearn.metrics.matthews_corrcoef.html (last visited Mar. 13, 2018).
182. Id.
183. Id.
184. Id.; see Table 3.

64 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
The data for Plot 7 was obtained by training a Logistic Regression classifier
using different mixes of eligible and ineligible example claims. Note that at a
1:1 ratio of eligible to ineligible training examples, the recall rate for the accept
(eligible) and reject (ineligible) classes is roughly equal at 0.75. However, at
that ratio, the reject precision is quite low, around 0.3, meaning that the classifier
produces many false positives. The MCC metric, which considers true and false
positives and negatives, begins to level off at around 0.45 at a ratio of about 2:1.
D. Performance of an Improved Classifier
We next attempted to develop a classifier that improved upon the MCC
score for our baseline Logistic Regression classifier. We implemented our
improved classifier as an ensemble of multiple different classifiers.185 Each
classifier was trained using an adjusted example mix, using Plot 7 as a guide.
By inspecting Plot 7, and running a number of trials, we learned that training our
classifiers on a ratio of eligible to ineligible examples of 5:2 tended to maximize
the MCC score.
The selection of the particular types of classifiers was to a large extent
exploratory and arbitrary. The machine learning toolkit utilized in this study
provides many different classifiers that each have a uniform interface for
training and prediction.186 Thus, given our initial data set, it is almost trivial to
experiment with different classification approaches known in the art. Training
and testing multiple distinct classification schemes allowed us to understand
whether some types of classifiers outperformed our baseline Logistic Regression
classifier, above.
Ensemble classification aggregates the outputs of multiple classifiers,
thereby attempting to overcome misclassifications made by any particular
classifier.187 In our ensemble, we employed a voting scheme, in which a final
classification was based on the majority outputs for a given test case provided
to each of our multiple classifiers. Table 4, below, provides the performance
results of our improved classifier.
185. Supervised Learning, SCIKIT LEARN, http://scikit-learn.org/stable/supervised_learning.html (last
visited Mar. 13, 2018) (providing examples of different classifiers, in addition to Logistic Regression, such as a
Naïve Bayesian classifier, a Decision Tree classifier, a Random Forest classifier, a Support Vector Machine
classifier, a Stochastic Gradient Descent classifier, an AdaBoost classifier, a K-Neighbors classifier, and a
Gradient Boosting classifier).
186. Id.
187. RUSSELL & NORVIG, supra note 5, at 748–52.
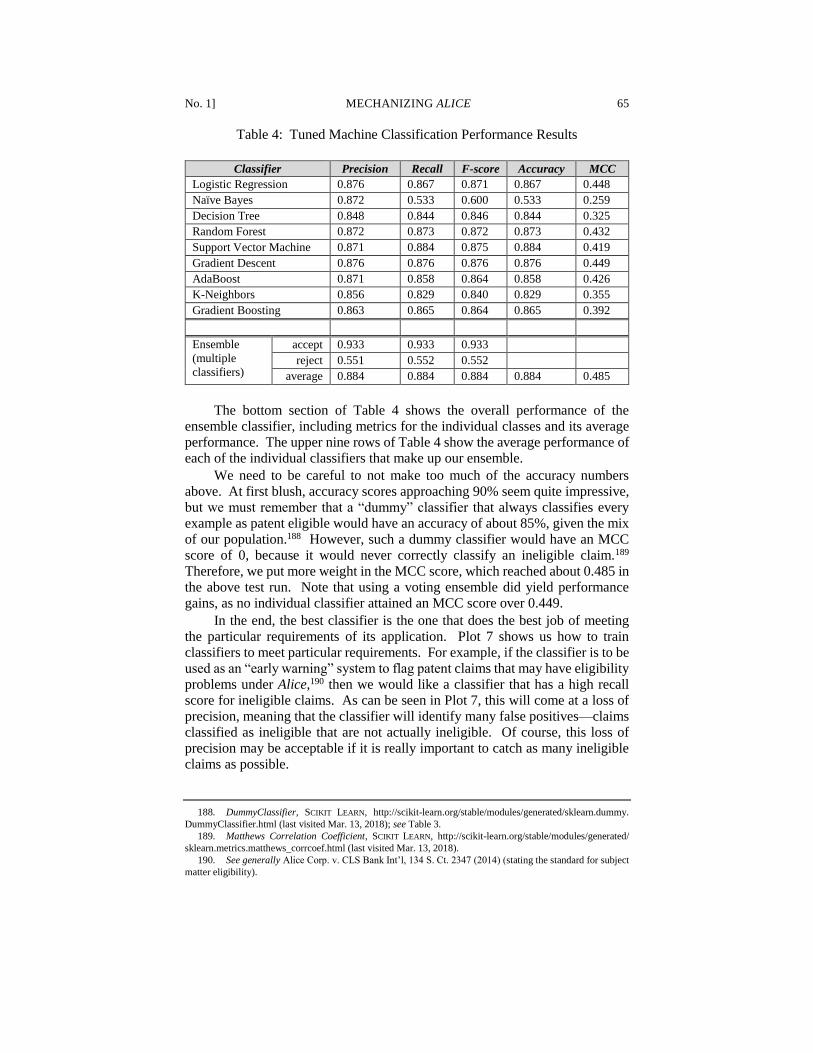
No. 1] MECHANIZING ALICE 65
Table 4: Tuned Machine Classification Performance Results
Classifier Precision Recall F-score Accuracy MCC
Logistic Regression 0.876 0.867 0.871 0.867 0.448
Naïve Bayes 0.872 0.533 0.600 0.533 0.259
Decision Tree 0.848 0.844 0.846 0.844 0.325
Random Forest 0.872 0.873 0.872 0.873 0.432
Support Vector Machine 0.871 0.884 0.875 0.884 0.419
Gradient Descent 0.876 0.876 0.876 0.876 0.449
AdaBoost 0.871 0.858 0.864 0.858 0.426
K-Neighbors 0.856 0.829 0.840 0.829 0.355
Gradient Boosting 0.863 0.865 0.864 0.865 0.392
Ensemble
(multiple
classifiers)
accept 0.933 0.933 0.933
reject 0.551 0.552 0.552
average 0.884 0.884 0.884 0.884 0.485
The bottom section of Table 4 shows the overall performance of the
ensemble classifier, including metrics for the individual classes and its average
performance. The upper nine rows of Table 4 show the average performance of
each of the individual classifiers that make up our ensemble.
We need to be careful to not make too much of the accuracy numbers
above. At first blush, accuracy scores approaching 90% seem quite impressive,
but we must remember that a “dummy” classifier that always classifies every
example as patent eligible would have an accuracy of about 85%, given the mix
of our population.188 However, such a dummy classifier would have an MCC
score of 0, because it would never correctly classify an ineligible claim.189
Therefore, we put more weight in the MCC score, which reached about 0.485 in
the above test run. Note that using a voting ensemble did yield performance
gains, as no individual classifier attained an MCC score over 0.449.
In the end, the best classifier is the one that does the best job of meeting
the particular requirements of its application. Plot 7 shows us how to train
classifiers to meet particular requirements. For example, if the classifier is to be
used as an “early warning” system to flag patent claims that may have eligibility
problems under Alice,190 then we would like a classifier that has a high recall
score for ineligible claims. As can be seen in Plot 7, this will come at a loss of
precision, meaning that the classifier will identify many false positives—claims
classified as ineligible that are not actually ineligible. Of course, this loss of
precision may be acceptable if it is really important to catch as many ineligible
claims as possible.
188. DummyClassifier, SCIKIT LEARN, http://scikit-learn.org/stable/modules/generated/sklearn.dummy.
DummyClassifier.html (last visited Mar. 13, 2018); see Table 3.
189. Matthews Correlation Coefficient, SCIKIT LEARN, http://scikit-learn.org/stable/modules/generated/
sklearn.metrics.matthews_corrcoef.html (last visited Mar. 13, 2018).
190. See generally Alice Corp. v. CLS Bank Int’l, 134 S. Ct. 2347 (2014) (stating the standard for subject
matter eligibility).

66 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
E. Extensions, Improvements, and Future Work
Our machine learning process described above may be improved in many
ways. First, other features could be considered. Currently, the only features
being considered are term frequencies. Other features that are not currently
being considered include claim length in words, the number of syntactic claim
elements (e.g., the number of clauses separated by semi-colons),191 the number
of gerunds (e.g., receiving, transmitting),192 or the like.
Also, the current approach measures only the occurrences of single terms,
using a “bag of words” approach.193 In this approach, each claim is reduced to
a frequency table that associates each claim term with the number of times it
occurs in the claim. Therefore, no information is retained about the location or
co-occurrence of particular words. This issue can be addressed at least in part
by the use of n-grams. An n-gram is a sequence of terms of length n that appear
in the given text.194 For example, bigrams (2-grams) represent sequential pairs
of words in the claim.
It is possible that an n-gram-based representation will provide additional
features (e.g., specific 2- or 3-word sequences) that are highly correlated with
eligible or ineligible claims.195 For example, “computer interface” might be
differently correlated with eligible or ineligible claims than the word “computer”
or “interface” taken individually.196 This may be because, for example, the word
“interface” has many definitions, including: (1) the interaction between two
entities or systems; (2) a device or software for connecting computer
components; (3) fabric used to make a garment more rigid.197 The first of these
definitions is probably highly associated with ineligible claims, while the last of
these definitions is probably highly associated with eligible claims, with the
second definition likely appearing somewhere in the middle. By using 2-grams
in this case, it may be possible to distinguish which of these three cases applies.
Other potential improvements include the use of a larger dictionary.198 The
current approach has typically utilized just the most significant terms in the data
set, generally set around 1,000 terms.199 Keeping the term dictionary small
facilitates rapid classifier training time, and thus the ability to experiment with
many different classifier parameter settings. In a production setting, however,
191. Clauses and Clause Elements, http://folk.uio.no/hhasselg/grammar/Week2_syntactic.htm (last visited
Mar. 13, 2018).
192. Gerund, DICTIONARY.COM, www.dictionary.com/browse/gerund (last visited Mar. 13, 2018).
193. RUSSELL & NORVIG, supra note 5, at 866.
194. Id. at 861.
195. Id.
196. Id.
197. Technically, this fabric is called “interfacing,” although if stemming is employed, then “interface” and
“interfacing” will likely be stemmed to the same term.
198. See RUSSELL & NORVIG, supra note 5, at 921 (providing examples of dictionaries with numerous word
entries).
199. JURE LESKOVEC, ANAND RAJARAMAN & JEFFREY D. ULLMAN, MINING OF MASSIVE DATASETS 8
(2014), http://infolab.stanford.edu/~ullman/mmds/book.pdf. Significance is determined using the TF-IDF
(Term Frequency times Inverse Document Frequency) measure, which reduces the weight of words that are very
common in a given corpus.

No. 1] MECHANIZING ALICE 67
using a larger dictionary may yield marginal but useful performance
improvements.200
In this Section, we have described the supervised training and performance
of machine classifiers that are capable of predicting whether a given patent claim
is valid under Alice. Using the Matthews Correlation Coefficient as our
preferred metric, we have developed classifiers that obtain scores in excess of
0.40 when evaluated against test data held out from our overall dataset. In the
following Sections, we describe two applications for our machine classifier.
First, in Section VI, we present a Web-based patent claim evaluation system that
uses our classifier to predict Alice compliance for a given patent claim. Next, in
Section VII, we use classifier to quantitatively estimate the impact of Alice on
the universe of issued patents.
VI. A PATENT CLAIM EVALUATION SYSTEM
In the present Section, we describe a Web-based patent claim evaluation
system that employs our automatic predictive classification techniques
described above. After presenting our system, we describe a number of uses
cases for the system within the context of the patent lifecycle, including
application preparation, prosecution, enforcement, valuation, and transactions.
We conclude with a brief outline of some of the issues presented by the use of
“machine intelligence” in the context of legal work.
Our patent claim evaluation system is an example of a computer-assisted legal service, the application of computer function and intelligence to the
efficient rendering of legal services. While the legal field has been slow to adopt
the efficiencies obtained from information technologies, it has not been immune
to change.201 The word processing department in a law firm is gradually giving
way to self-service word processing and speech recognition dictation
software.202 While many attorneys still like to “look it up in the book,” legal
research is increasingly being performed via computer.203 Manual document
review during litigation is being replaced by electronic discovery, including
machine classification to discover responsive documents.204 The claim
evaluation system described below supports the analytic functions traditionally
performed by an attorney, by helping the attorney identify problematic claims,
200. Preliminary results do not show significant improvement with a larger dictionary. This may be due
to our sample size in relation to the size of the dictionary—there are likely not enough samples to determine the
true relationship between a rare feature (term) and an eligible or ineligible classification.
201. Blair Janis, How Technology is Changing the Practice of Law, A.B.A., https://www.americanbar.org/
publications/gp_solo/2014/may_june/how_technology_changing_practice_law.html (last visited Mar. 13,
2018).
202. Nerino J. Petro, Jr., Speech Recognition: Is it Finally Ready for the Law Office, A.B.A.,
https://www.americanbar.org/publications/law_practice_home/law_practice_archive/lpm_magazine_articles_v
33_is2_an3.html (last visited Mar. 13, 2018).
203. Sally Kane, Legal Technology and the Modern Law Firm, BALANCE (May 15, 2017),
https://www.thebalance.com/technology-and-the-law-2164328.
204. Id.

68 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
much in the same way as a doctor would employ a medical test to identify
disease.205
A. System Description
We have implemented a proof-of-concept Web-based classification
application (“the claim evaluator”) that can be used to evaluate patent claim text
for subject matter eligibility.206 The claim evaluator receives a patent claim
input into an HTML form presented in a Web browser.207 The claim text is
stemmed and presented to one or more machine classifiers trained as described
above.208 The classifiers provide a result that is presented on the displayed Web
page.209
Below is a screenshot showing an example output of the claim evaluator,
given as input an example claim directed to a programmable computer memory
system. This claim is obtained from U.S. Patent No. 5,953,740210 and was not
used to train our classifier.211 The evaluator classifies this as eligible, with five
out of nine (55%) classifiers of the ensemble in agreement.
This claim was also analyzed on appeal by the CAFC in Visual Memory v. NVIDIA Corp.212 There, a three-judge panel held the claim to be patent eligible
under Alice by a two-to-one vote.213 Interestingly, the five-to-four vote of our
ensemble of classifiers indicates that this was also a somewhat close case for our
classification system.214
205. Dugan, supra note 11; see Gene Quinn, Understanding Patent Claims, IPWATCHDOG, (July 12, 2014)
http://www.ipwatchdog.com/2014/07/12/understanding-patent-claims/id=50349/ (providing a brief summary of
patent claims and the challenges in drafting them).
206. The use of a proof-of-concept helps determine how a software system would actually work, and
whether it is viable as a tool or solution. Odysseas Pentakolos, Proof-of-Concept Designs, MICROSOFT
DEVELOPER NETWORK, (Jan. 2008) https://msdn.microsoft.com/en-us/library/cc168618.aspx; Dugan, supra
note 11.
207. Dugan, supra note 11.
208. At the time of writing, the ensemble consists of the nine classifiers listed in Table 4 and footnote 185
above. The output of the evaluator is based on the “votes” of each of the classifiers.
209. Dugan, supra note 11.
210. U.S. Patent No. 5,953,740 (filed Oct. 5, 1993).
211. Dugan, supra note 11; see RUSSELL & NORVIG, supra note 5, at 444–45 (explaining that using test
data that was not present in the training set tests the actual accuracy of the training set data, and will help
determine whether more training is necessary).
212. Visual Memory LLC v. NVIDIA Corp., 867 F.3d 1253, 1257 (Fed. Cir. Aug. 2017).
213. See id. at 1260–62.
214. Id.

No. 1] MECHANIZING ALICE 69
Screenshot 1
At the bottom of the screenshot, shown above, stemmed claim terms are
highlighted red or green to respectively indicate a positive or negative
association with patent eligibility under Alice.215 This feature can help the user
redraft an example claim to recharacterize the invention at a lower level of
abstraction. In the example above, the stemmed terms “comput,” “data,”
“processor,” and “store” are colored red to indicate a correlation with patent
ineligibility. Terms such as “oper,” “main,” “memori,” “configur,” “cache,”
“connect,” and “determine” are colored green to indicate a correlation with
patent eligibility. The remaining terms are colored black to indicate a lack of
strong correlation in either direction.
Below is a second screenshot of the claim evaluator. This time the
evaluator has been asked to evaluate a claim directed to a method for providing
a performance guarantee in a transaction. This claim is obtained from U.S.
Patent No. 7,644,019.216
215. See Logistic Regression, SCIKIT LEARN, http://scikit-learn.org/stable/modules/linear_model.html#
logistic-regression (last visited Mar. 13, 2018) (highlighting a term is based on a coefficient for that term
determined by the logistic regression classifier of the ensemble).
216. U.S. Patent No. 7,644,019 (filed Apr. 21, 2003).

70 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Screenshot 2
In Screenshot 2, the evaluator classifies this claim as ineligible, with all
nine classifiers in the ensemble in agreement. This result is consistent with our
intuition that business-method type claims are more likely than memory system
claims (as in Visual Memory, above) to be invalid under Alice.217 This result is
also consistent with the decision of the CAFC, which held this claim invalid
under Alice in buySAFE v. Google.218
B. Claim Evaluation System Use Cases
The described claim evaluator is first and foremost useful for helping
understand whether it is even worth applying for a patent directed to a particular
invention. There are many hurdles that must be crossed before obtaining a
patent.219 It is frustrating for clients that a patent attorney cannot give reasonable
assurances that he or she will be able to draft a patent application having claims
that can overcome all of these hurdles.220 For example, while a prior art search
can uncover at least some of the relevant prior art, it is very difficult to predict
how an examiner might combine the teachings of multiple prior art references
to generate a rejection for obviousness.221
217. See generally Alice Corp. Pty. Ltd. v. CLS Bank Int’l, 134 S. Ct. 2347 (2014); Visual Memory LLC
v. NVIDIA Corp., 867 F.3d 1253 (Fed. Cir. Aug. 2017). (finding that a business-method claim was invalid in
Alice, but a memory system claim in Visual Memory was valid).
218. buySAFE, Inc. v. Google, Inc., 765 F.3d 1350, 1355 (Fed. Cir. 2014).
219. Patent Process Overview, U.S. PATENT & TRADEMARK OFFICE, https://www.uspto.gov/patents-
getting-started/patent-process-overview#step1 (last visited Mar. 13, 2018).
220. Gene Quinn, Why Patent Attorneys Don’t Work on Contingency, IPWATCHDOG, (Jul. 8, 2017)
http://www.ipwatchdog.com/2017/07/08/why-patent-attorneys-dont-work-on-contingency-2/id=85514/.
221. Gene Quinn, Understanding Obviousness: John Deere and the Basics, IPWATCHDOG, (Oct. 10, 2015)
http://www.ipwatchdog.com/2015/10/10/understanding-obviousness-john-deere-and-the-basics-2/id=62393/.

No. 1] MECHANIZING ALICE 71
With the described evaluator, however, it is now at least possible to flag
inventions that that may be subjected to a higher level of scrutiny under the Alice
subject matter test.222 For example, the client or the attorney can draft an abstract
or overview of the invention, which is then used as input to the evaluator. If the
evaluator tags the given text as ineligible, the client has reason to be concerned.
The evaluator is also useful when preparing the claims of a patent
application, and more generally for determining the preferred terms used to
describe the invention in the application text. For example, the attorney may
prepare a draft independent claim and provide it to the evaluator. Depending on
the output of the evaluator, the attorney may revise the claim to use different
terms, to describe the invention at a lower level of generality or abstraction, or
to claim the invention from a different aspect. Also, one can imagine extending
the function of the evaluator to suggest synonyms or related terms that are less
highly correlated with Alice rejections.
The described evaluator can also be used to analyze issued patent claims.
For example, a patentee could use the evaluator to determine whether an issued
patent claim is likely to survive a challenge under Alice if asserted during
litigation. As another example, a defendant or competitor could use the
evaluator to assess the likelihood of success of challenging the validity of a claim
under Alice in litigation or via a post-grant review.
It is also possible to imagine using the evaluator as part of an automated
(or computer-assisted) patent analysis or valuation system. Patent analysis,
whether performed as part of rendering an opinion of invalidity or determining
a patent valuation, is expensive business.223 Legal fees paid for patent analysis
are a source of high transaction costs faced by parties attempting to determine
whether or how to manage the risk presented by a patent, such as via acquisition,
license, or litigation.224 The described evaluator can be used to reduce these
costs because it can perform an initial analysis in an automated manner. This
analysis can be used as a data point in a patent valuation formula, as part of a
due diligence checklist, or the like.
C. Questions Arising From the Application of Machine Intelligence to the Law
The claim evaluation system described above demonstrates that machine
learning can be employed to at least support the analytic functions traditionally
performed by an attorney.225 The application of machine learning in this context
222. Alice, 134 S. Ct. at 2354–55.
223. See 2015 Report, supra note 59 at I-95, (stating the median legal fee to prepare an invalidity opinion
is $10,000. While non-compliance with 35 U.S.C. § 101 is only one of several bases for invalidity, our claim
evaluator could still reduce the cost of a typical invalidity opinion, by flagging for further review and analysis
claims that are likely invalid under Alice).
224. See generally, Rebecca S. Eisenberg, Patent Costs and Unlicensed Use of Patented Inventions, 78 U.
CHI. L. REV. 53 (2011).
225. See Roitblat et al., Document Categorization in Legal Electronic Discovery: Computer Classification
vs. Manual Review, 61 J. AM. SOC. INFO. SCI. & TECH. 70, 79 (2009), http://apps.americanbar.org/litigation/
committees/corporate/docs/2010-cle-materials/09-holding-line-reasonableness/09c-document-
categorization.pdf (exemplifying we are not the first to make this claim; for example, automatic document

72 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
of course raises a host of questions. While answers to many of these questions
are beyond the scope of this Article, we will briefly address some of them below.
The first area of concern relates to the substitutability of machine
intelligence for human analysis. To address this issue, we first need to
understand whether the performance of the machine intelligence is even
comparable to a trained human analyst. Above, we have compared the
performance of our “proof of concept” classifier to the aggregated performance
of the human examination corps of the Patent Office. While we find that our
classifier is certainly better than guessing, it is still wrong over 10% of the time.
Is this an acceptable margin of error? The answer to that question depends on
the context. If the classifier is used to give a client an initial “heads up”
regarding a patentability issue (possibly without the cost of consulting an
attorney), then the answer is probably yes. If the classifier is used to determine
whether to file a multi-million dollar lawsuit, then the answer may be no.
The possibility of failure raises the specter of legal malpractice. It is
possible to construct a hypothetical in which an attorney is found liable for
malpractice for relying on an incorrect assessment provided by a machine
classifier or other “intelligent” agent. Yet, we think the benefits to clients
outweigh the risks, so long as the client is made to understand the uncertainties
that accompany any prediction.
In some ways, using our machine classifier is not so different from
performing a prior art search prior to preparing a patent application. Many
clients request searches in order to identify any “knock out” prior art.226 As an
initial matter, no patent attorney will assert that the results of a particular search
will guarantee smooth sailing before the Patent Office.227 There are simply too
many unknowns, including the limitations of search engines and the fact that
patent applications remain non-public and thus unsearchable for at least eighteen
months after filing.228 If knock out art is found, the client may elect to redirect
her legal resources to a different project.229 And if instead the client elects to
move forward, the patent attorney can use the search results to obtain a better
understanding of the prior art, which should result in claims that require fewer
interactions with the Patent Office, thereby also saving the client legal fees.230
Machine classification to identify Alice-related issues early in the process can
be used to similarly to help a client decide where to best apply their limited
resources, and, further, to help an attorney craft better claims in borderline cases.
The second area of concern and inquiry is more philosophical in nature.
What does it mean when our classifier determines that a particular claim is not
classification employed in the context of electronic discovery has been shown to be at least as accurate as human
review).
226. Gene Quinn, Patent Search 101: Why US Patent Searches are Critically Important, IPWATCHDOG
(Jan. 13, 2018), http://www.ipwatchdog.com/2018/01/13/patent-search-101-patent-searches/id=92305/.
227. Id.
228. See 35 U.S.C. § 112 (2012) (requiring an application publishes eighteen months after its earliest filing
date for which benefit is sought); 37 C.F.R. § 1.211 (2017) (requiring that when the applicant files a non-
publication request, the application will not publish until and unless it issues into a patent).
229. Quinn, supra note 226.
230. Id.

No. 1] MECHANIZING ALICE 73
patent eligible? How can we rely on a system that first reduces an English
language sentence, with all of its syntactic structure and semantic import, to a
bag of stemmed tokens, and then feeds those tokens to a mathematical model
that computes a thumbs up or down, without any understanding of language and
without any explicit instruction in the rules of the Alice test? Questions such as
these have been debated since the earliest attempts to build intelligent
machines.231
We take no position on whether our classifier understands language or can
otherwise be considered intelligent. At a minimum, our classifier reasonably
approximates the behavior of an aggregated group of human patent examiners
that are doing their best to implement the Alice test in the examination context.
And while there may be nothing like understanding or rule processing in our
classifier, this does not mean that it does not have useful, practical applications.
In this Section, we have presented a claim evaluation system that employs
our machine classifier. We have also discussed its potential applications in the
context of rendering legal services in a post-Alice world. We have concluded
by briefly outlining some of the concerns and issues related to the use of machine
intelligence in the context of legal work. We conclude that our application of
machine intelligence can support the traditional analytic functions provided by
attorneys, while at the same time allowing clients to make better informed
decisions about the application of their limited economic resources.
VII. ESTIMATING THE IMPACT OF ALICE ON ISSUED PATENTS
In this Section, we use our approach to estimate the impact of the Alice
decision on the millions of in-force patents. For this Article, we estimated the
number of patents invalidated under Alice by classifying claims from a sample
of patents issued prior to the Alice decision. To perform the evaluation, we
employed the following approach. First, we trained a machine classifier as
discussed above. Second, we determined whether our classifier can serve as an
acceptable proxy for the decision making of the Federal Courts. Third, we
evaluated the first independent claim from 1% of the issued patents in our patent
corpus: about 40,000 patents issued between 1996 and 2016.
A. The Classifier
For this analysis, we used a Logistic Regression classifier. We used a
Logistic Regression classifier because, compared to the ensemble classifier
discussed above, it is quick to train and can efficiently process the large number
of patent claims in our sample. In addition, the performance of the Logistic
231. See, e.g., John R. Searle, Minds, Brains, and Programs, in MIND DESIGN 282–306 (John Haugeland
ed., 1981) (describing intentionality in the human brain in relation to computer programs’ lack of intentionality);
HUBERT DREYFUS, WHAT COMPUTERS STILL CAN’T DO: A CRITIQUE OF ARTIFICIAL REASON (1992) (explaining
the history and origin of artificial intelligence).

74 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Regression classifier is not much worse than our ensemble classifier.232 The
classifier was trained on a 1:1 ratio of eligible to ineligible examples. As shown
in Plot 7, this ratio results in a classifier with roughly equal precision and recall
scores for the ineligible class. Note that such a classifier is somewhat aggressive
with respect to classifying claims as ineligible. Such a classifier is “good” at
finding ineligible claims, at the expense of additional false positives (claims
classified as ineligible that are actually eligible).233
B. Classifier Validation
We next determined whether our classifier could serve as an acceptable
proxy for the decision making of the Federal Courts. Our classifier was trained
based upon decisions made by examiners at the Patent Office. It is thus natural
to ask whether such a classifier replicates the decision making of judges in the
Federal Courts. If it does not, then it is unlikely that our classifier can tell us
with any precision how many patents have been invalidated under Alice.
To validate the performance of our classifier, we evaluated claims from
post-Alice cases appealed to Court of Appeals for the Federal Circuit. The Patent
Office maintains a record of subject matter eligibility court decisions.234 From
this record, we obtained a list of patents that had been the subject of appeals
heard by the CAFC in the post-Alice timeframe. The list included seventy-seven
patents that were each associated with an indicator of whether the patent claim
at issue was held eligible or ineligible.235 We then pulled the relevant
independent patent claims from each patent in our list.236 Of these seventy-seven
claims, the CAFC held that sixty-three (82%) were not directed to patent-eligible
subject matter.237
After training, we next evaluated the Federal Circuit claims using our
classifier. Table 5, below, compares the performance of our classifier on test
claims drawn from our Patent Office dataset to its performance on the claims of
the Federal Circuit dataset. Note that the classifier was not exposed to any of
these claims during training. In the case of the Patent Office data set, the test
claims were held out and not used during training.
232. The ensemble discussed with respect to Table 4 has an MCC score of 0.485 while the Logistic
Regression classifier has a score of 0.448. While the ensemble is better, its use is not necessary to obtain a rough
estimate of the number of invalid patents.
233. From Plot 7, such a classifier has an ineligible recall rate of about 0.80 but an ineligible precision of
around 0.35.
234. Chart of Subject Matter Eligibility Court Decisions, U.S. PATENT & TRADEMARK OFFICE,
https://www.uspto.gov/sites/default/ files/documents/ieg-sme_crt_dec.xlsx (last updated Jul. 31, 2017).
235. Id.
236. For some patents, the Chart of Subject Matter Eligibility Court Decisions identifies the specific claims
analyzed by the court. For these patents, we pulled the first independent claim from the list of identified claims;
for other patents, we used claim 1 as the representative claim).
237. Chart of Subject Matter Eligibility Court Decisions, supra note 234.
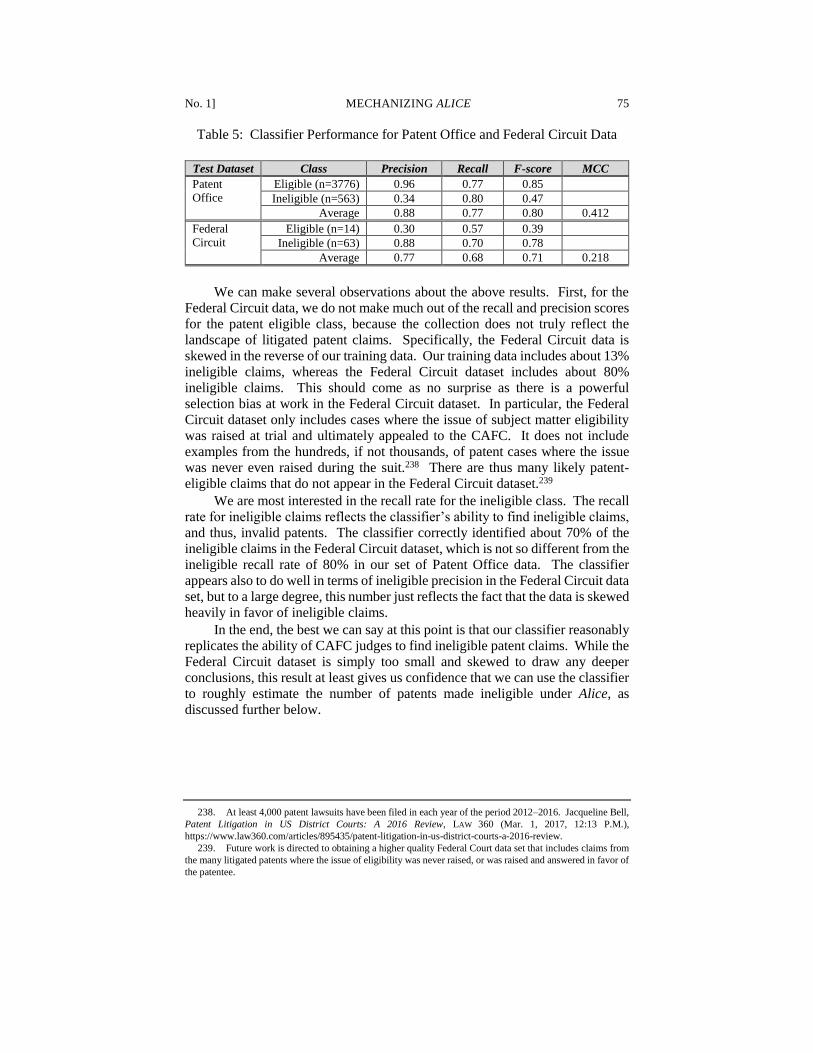
No. 1] MECHANIZING ALICE 75
Table 5: Classifier Performance for Patent Office and Federal Circuit Data
Test Dataset Class Precision Recall F-score MCC
Patent
Office
Eligible (n=3776) 0.96 0.77 0.85
Ineligible (n=563) 0.34 0.80 0.47
Average 0.88 0.77 0.80 0.412
Federal
Circuit
Eligible (n=14) 0.30 0.57 0.39
Ineligible (n=63) 0.88 0.70 0.78
Average 0.77 0.68 0.71 0.218
We can make several observations about the above results. First, for the
Federal Circuit data, we do not make much out of the recall and precision scores
for the patent eligible class, because the collection does not truly reflect the
landscape of litigated patent claims. Specifically, the Federal Circuit data is
skewed in the reverse of our training data. Our training data includes about 13%
ineligible claims, whereas the Federal Circuit dataset includes about 80%
ineligible claims. This should come as no surprise as there is a powerful
selection bias at work in the Federal Circuit dataset. In particular, the Federal
Circuit dataset only includes cases where the issue of subject matter eligibility
was raised at trial and ultimately appealed to the CAFC. It does not include
examples from the hundreds, if not thousands, of patent cases where the issue
was never even raised during the suit.238 There are thus many likely patent-
eligible claims that do not appear in the Federal Circuit dataset.239
We are most interested in the recall rate for the ineligible class. The recall
rate for ineligible claims reflects the classifier’s ability to find ineligible claims,
and thus, invalid patents. The classifier correctly identified about 70% of the
ineligible claims in the Federal Circuit dataset, which is not so different from the
ineligible recall rate of 80% in our set of Patent Office data. The classifier
appears also to do well in terms of ineligible precision in the Federal Circuit data
set, but to a large degree, this number just reflects the fact that the data is skewed
heavily in favor of ineligible claims.
In the end, the best we can say at this point is that our classifier reasonably
replicates the ability of CAFC judges to find ineligible patent claims. While the
Federal Circuit dataset is simply too small and skewed to draw any deeper
conclusions, this result at least gives us confidence that we can use the classifier
to roughly estimate the number of patents made ineligible under Alice, as
discussed further below.
238. At least 4,000 patent lawsuits have been filed in each year of the period 2012–2016. Jacqueline Bell,
Patent Litigation in US District Courts: A 2016 Review, LAW 360 (Mar. 1, 2017, 12:13 P.M.),
https://www.law360.com/articles/895435/patent-litigation-in-us-district-courts-a-2016-review.
239. Future work is directed to obtaining a higher quality Federal Court data set that includes claims from
the many litigated patents where the issue of eligibility was never raised, or was raised and answered in favor of
the patentee.

76 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
C. Evaluation of Issued Patent Claims
We next turned our classifier onto a 1% sample of the patents in our patent
document corpus. Our corpus contains about four million utility patents issued
between 1996–2016. The sample therefore contains about 40,000 patents. Plot
8, below, shows the predicted invalidity rate by year, as produced by our
classifier.
Plot 8: Predicted Invalidity Rate by Year
Plot 8 has a number of interesting features. As an initial matter, the graph
shows a predicted invalidity rate in excess of 10% for most years. This number
is too high for reasons that will be discussed below. At this point we are more
interested in year-over-year changes than in the exact predicted rate. First, the
graph shows a marked drop in the invalidity rate after 2014, which coincides
with the implementation of the Alice-review standards within the Patent Office.
Second, between 1996 and 2014, there is a clear upward trend in predicted
invalidity rate. This trend appears to be due at least in part to the rise of
computer-related industry sectors over time. As shown above, in Plot 4 and
Section IV, the Alice decision has disproportionately impacted computer-related
technologies compared to, for example, the mechanical arts. Over the last two
decades, the share of issued patents that are directed to computer-related
technologies has increased over time, which explains at least some of the rise in
predicted invalidity rate.240 This effect can be seen in Plot 9, below.
240. U.S. PATENT & TRADEMARK OFFICE, Patent Counts By Class By Year, https://www.uspto.gov/web/
offices/ac/ido/oeip/taf/cbcby.htm (last updated Dec. 2015).
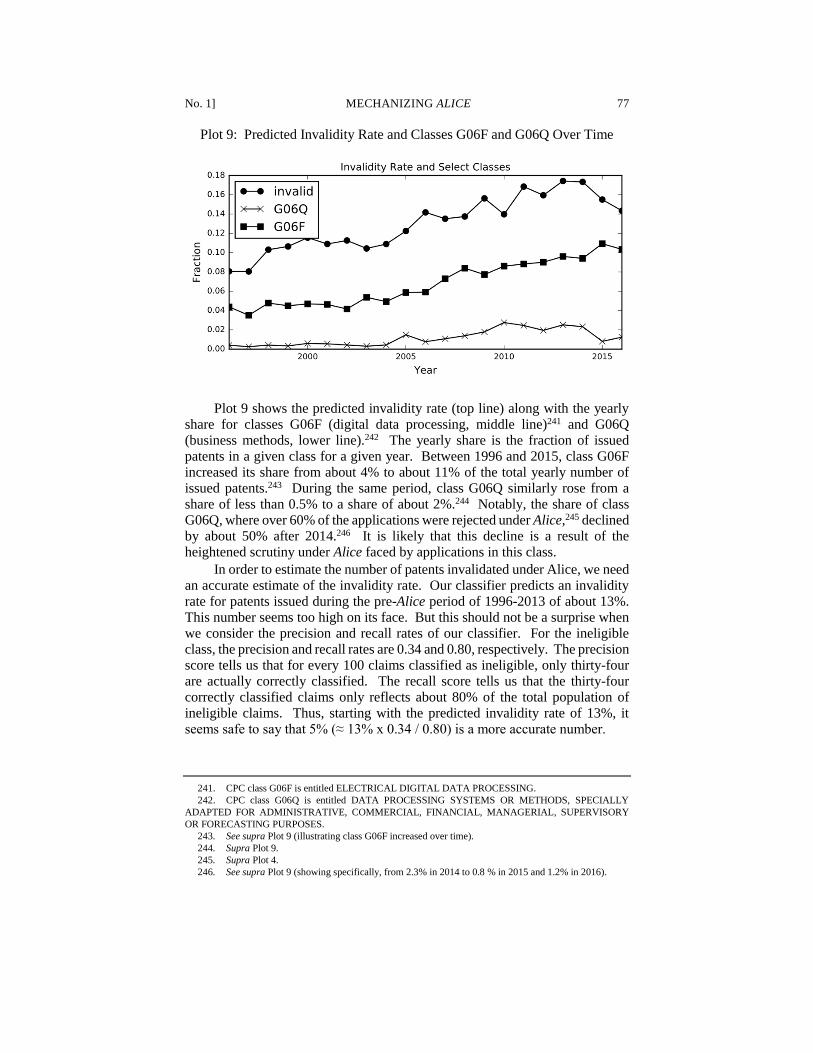
No. 1] MECHANIZING ALICE 77
Plot 9: Predicted Invalidity Rate and Classes G06F and G06Q Over Time
Plot 9 shows the predicted invalidity rate (top line) along with the yearly
share for classes G06F (digital data processing, middle line)241 and G06Q
(business methods, lower line).242 The yearly share is the fraction of issued
patents in a given class for a given year. Between 1996 and 2015, class G06F
increased its share from about 4% to about 11% of the total yearly number of
issued patents.243 During the same period, class G06Q similarly rose from a
share of less than 0.5% to a share of about 2%.244 Notably, the share of class
G06Q, where over 60% of the applications were rejected under Alice,245 declined
by about 50% after 2014.246 It is likely that this decline is a result of the
heightened scrutiny under Alice faced by applications in this class.
In order to estimate the number of patents invalidated under Alice, we need
an accurate estimate of the invalidity rate. Our classifier predicts an invalidity
rate for patents issued during the pre-Alice period of 1996-2013 of about 13%.
This number seems too high on its face. But this should not be a surprise when
we consider the precision and recall rates of our classifier. For the ineligible
class, the precision and recall rates are 0.34 and 0.80, respectively. The precision
score tells us that for every 100 claims classified as ineligible, only thirty-four
are actually correctly classified. The recall score tells us that the thirty-four
correctly classified claims only reflects about 80% of the total population of
ineligible claims. Thus, starting with the predicted invalidity rate of 13%, it
seems safe to say that 5% (≈ 13% x 0.34 / 0.80) is a more accurate number.
241. CPC class G06F is entitled ELECTRICAL DIGITAL DATA PROCESSING.
242. CPC class G06Q is entitled DATA PROCESSING SYSTEMS OR METHODS, SPECIALLY
ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL, SUPERVISORY
OR FORECASTING PURPOSES.
243. See supra Plot 9 (illustrating class G06F increased over time).
244. Supra Plot 9.
245. Supra Plot 4.
246. See supra Plot 9 (showing specifically, from 2.3% in 2014 to 0.8 % in 2015 and 1.2% in 2016).

78 JOURNAL OF LAW, TECHNOLOGY & POLICY [Vol. 2018
Next, we estimate the total number of in-force patents issued during the
pre-Alice period prior to 2014. One accounting estimates that there were about
2.5 million patents in force in 2014.247 We reduce this number to 2 million
patents to exclude patents issued during 2014.248
Assuming a 5% invalidity rate and about 2 million patents in force at the
time of the Alice decision, we estimate that about 100,000 patents have at least
one claim that is likely invalid under Alice. How reliable is this estimate? It is
of course possible that the classifier overestimated the number of ineligible
claims. As discussed above, we have attempted to account for the classifier’s
bias by reducing the original estimate of 13% to 5%. Even if our process still
grossly overestimates (e.g., by a factor of two) the number of invalid patents, the
total would still number around 50,000 patents.
If anything, our process may be conservative compared to the application
of Alice by the Federal Courts. One study indicates that as of June 2016, over
500 patents have been challenged under Alice, with a resulting invalidation rate
exceeding 65%.249 An earlier study of over 200 Federal Court decisions showed
an invalidation rate of over 70%.250 Of course, these studies focus only on cases
where a defendant has moved to invalidate a patent under Alice, and is thus
skewed towards cases selected from suspect subject matter areas, such as
business methods, advertising, software, and the like.
The outcome of our analysis is even more profound in specific subject
matter areas. For example, over 80% of about 400 pre-2014 claims in CPC class
G06Q (data processing systems/methods for administrative, commercial,
financial, and managerial purposes) were classified as ineligible by the
classifier.251 There are over 50,000 issued patents in this class.252 If we scale,
as above, the 80% ineligibility finding to 35% to account for the classifier’s bias
towards invalidity,253 this still means that the Supreme Court may well have
invalidated over 15,000 patents in the class alone. Perhaps this impact was the
Court’s intent, although it certainly seems an extreme realignment of property
rights at the stroke of a judge’s pen.
247. See Dennis Crouch, The Number of U.S. Patents in Force, PATENTLY-O, https://patentlyo.com/
patent/2014/10/number-patents-force.html (last updated Oct. 25, 2014) (estimating that about 2.5 million U.S.
patents in force in 2014).
248. See U.S. Patent Statistics Chart Years 1963–2015, USPTO, https://www.uspto.gov/web/offices/ac/
ido/oeip/taf/us_stat.htm (last visited Jan. 28, 2018) (specifying that by 2014, the patent office was issuing
roughly 300,000 patents per year, which justifies reducing our estimate to 2 million from 2.5 million).
249. Tran, supra note 17, at 358.
250. See Sachs, supra note 3 (analyzing 208 Federal Court Alice decisions).
251. As a sanity check, the classifier processed a sampling of 3,731 pre-2014 claims from CPC class F02B
(internal combustion piston engines) and predicted only 184 (about 5%) to be patent ineligible. This result again
matches our intuition that claims that are mechanical in nature ought to be more likely to be patent eligible.
252. U.S. Patent Statistics Chart Years 1963–2015, supra note 248.
253. We are conservatively scaling the predicted rate by 0.4 based on ineligible precision and recall rates
of 0.34 and 0.80, respectively. Note that the justification for scaling in this context is not as strong as for the
average case (general population), because class G06Q undoubtedly contains a higher than average ratio of
ineligible to eligible claims.

No. 1] MECHANIZING ALICE 79
VIII. CONCLUSION
We have shown that it is possible to predict, with a reasonably high degree
of confidence, whether a patent claim is patent eligible under the Alice test. This
prediction is based on thousands of decisions made by human patent examiners
charged with implementing the Alice test during the patent examination process.
The approach developed in this Article has many practical applications,
including providing support for patent practitioners and clients during the patent
preparation, prosecution, assertion, and valuation. Using machine intelligence
to identify Alice-related validity issues may yield economic efficiencies, by
diverting legal fees away from non-patentable inventions, by improving claims
and thereby streamlining the interactions between applicants and examiners, and
by reducing baseless litigation of invalid patent claims. Our use of machine
intelligence can assist and improve the analytic functions provided by attorneys,
while at the same time providing clients with better information for deciding
how to allocate and apply legal resources.
We have also used our machine classification approach to quantitatively
estimate, for the first time, how many issued patents have been invalidated under
Alice, thereby demonstrating the profound and far-reaching impact of the
Supreme Court’s recent subject matter eligibility jurisprudence on the body of
granted patents. Specifically, by invalidating at least tens of thousands of issued
patents, the Court’s actions represent a judicial remaking of patent law that has
resulted in a considerable realignment of existing intellectual property rights.



![Mechanizing Game-Based Proofs of Security Protocolssuggested to use tools for mechanizing these proofs, and several techniques have been used for reaching this goal. CryptoVerif [22–25],](https://img.dokumen.tips/doc/110x75/5f3819613699251ffb59c03e/mechanizing-game-based-proofs-of-security-protocols-suggested-to-use-tools-for-mechanizing.jpg)

























