Embed Size (px)
Citation preview

Measuring Semantic Similarity between Words Using Web
Search Engines
WWW 07

Abstract
• Semantic web-related applications– Community chain mining– Relation extraction– Automatic meta data extraction– Entity disambiguation results
• This paper consists of four page-count-based similarity scores and automatically extracted lexico-syntactic patterns from text snippets.

Introduction – 1/2
• Page counts and snippets are two useful information sources provided by most Web search engines.
• Some problems– Page count analyses ignore the position of a word i
n a page • two words appear in a page, they might not be related
– Polysemous word (a word with multiple senses)• apple as a fruit
• apple as a company

Introduction – 2/2
• Lexico-syntactic patterns
– various semantic relations• also known as,
• is a,
• part of,
• is an example of

Method (Page-count-based)
• Page-count-based Similarity Scores (co-occurrence measures)
C = 5

Method (Lexico-Syntactic Patterns) – 1/4
• Extracting Lexico-Syntactic Patterns from Snippets– is a (X is a Y)
– and (X and Y)

Method (Lexico-Syntactic Patterns) – 2/4
• Given a set S of synonymous
– n-grames : n=2,3,4, and 5

Method (Lexico-Syntactic Patterns) – 3/4
• A set S of synonymous word-pairs– 5000 word pairs of synonymous nouns from Word
Net– 4,562,471 unique patterns– 80% occur less than 10 times
• A set of non-synonymous word-pairs– 5000 word pairs of non-synonymous nouns from W
ordNet

Method (Lexico-Syntactic Patterns) – 4/4

Integrating Patterns and Page Counts

Experiments
• WebOverlap (rank=18,weight=2.45)
• Web-Jaccard (rank=66, weight=0.618)
• WebPMI (rank=138,weight=0.0001)

Benchmark Dataset
– Rubenstein-Goodenough 28 word-pairs

Experiments

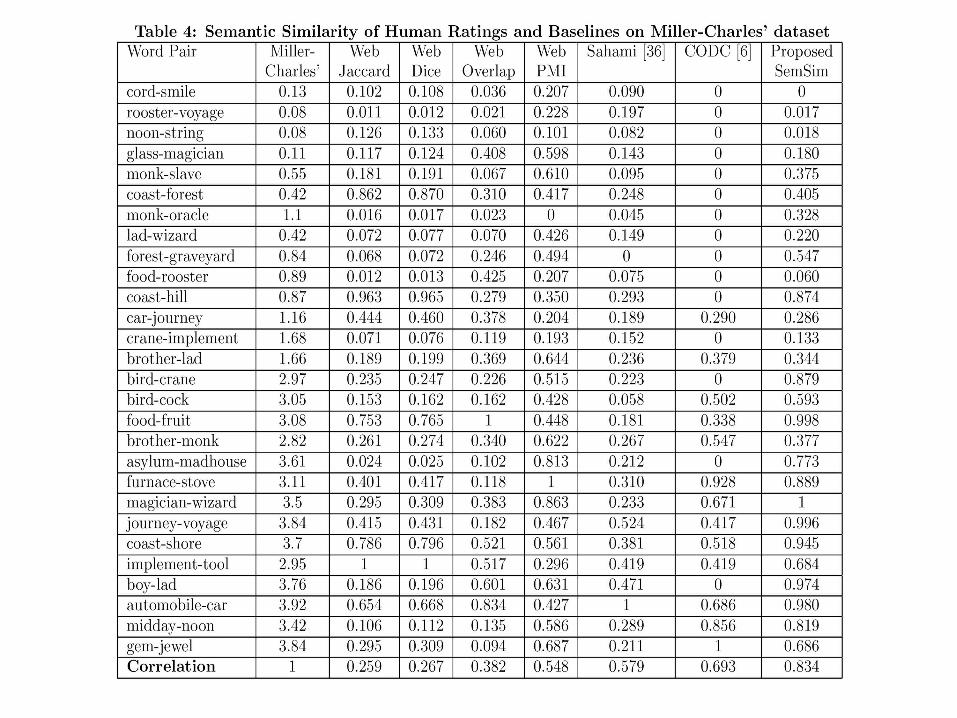
Semantic Similarity

Taxonomy-Based Methods

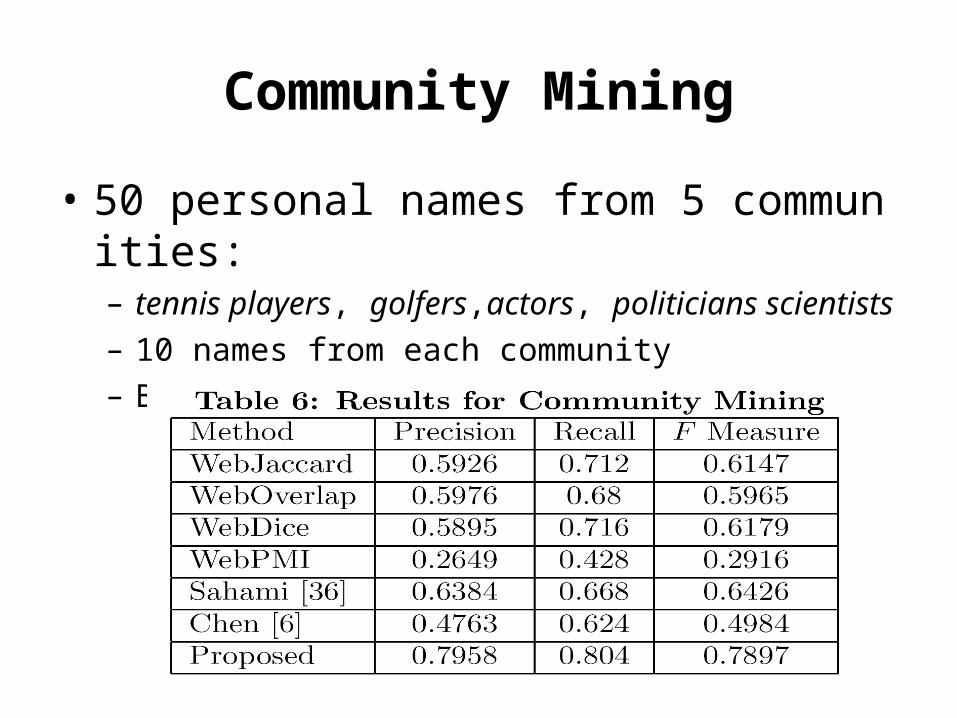
Community Mining
• 50 personal names from 5 communities: – tennis players, golfers,actors, politicians scientists
– 10 names from each community
– B-CUBED

Conclusion
• Semantic web-related applications– Community chain mining– Relation extraction– Automatic meta data extraction– Entity disambiguation results
• This paper consists of four page-count-based similarity scores and automatically extracted lexico-syntactic patterns from text snippets.





























