Embed Size (px)
DESCRIPTION
MBP1010H – Lecture 4: March 26,2012. 1.Multiple regression Survival analysis. Multifactorial Analyses – chapter posted in Resources. Reading: Introduction to the Practice of Statistics: Chapters 2, 10 and 11. Simple Linear Regression. to assess the linear relationship between - PowerPoint PPT Presentation
Citation preview

MBP1010H – Lecture 4: March 26,2012
1. Multiple regression
2. Survival analysis
Reading: Introduction to the Practice of Statistics: Chapters 2, 10 and 11
Multifactorial Analyses – chapter posted in Resources

• to assess the linear relationship between 2 variables
• predict the response (y) based on a change in x
Simple Linear Regression

Multiple Linear Regression
• explore relationships among multiple variables to find out which x variables are associated with the response (y)
• devise an equation to predict y from several x variables
• adjust for potential confounding (lurking) variables- effect of one particular x variable after adjusting for
differences in other x variables

Confounding/
Causation Lurking Variable (z)
Association
Causation

Simple Linear Regression Model
observed y intercept slope residual
DATA = FIT + RESIDUALS
where the i are independent and normally distributed N(0,).

Statistical model for n sample data (i = 1, 2, … n) and p
explanatory variables :
Data = fit + residual
yi = (0 + 1x1i … + pxpi) + εi
Where the ei are independent and normally distributed
N(0, σ).
Multiple Regression

Analysis of Variance (ANOVA) table for linear regression
2)ˆ( yyi 2)( yyi 2)ˆ( ii yy= +
SS Total = SS model + SS error
SS = sum of squares
Data = fit + residual yi = (0 + 1x1i …+ pxpi) + εi
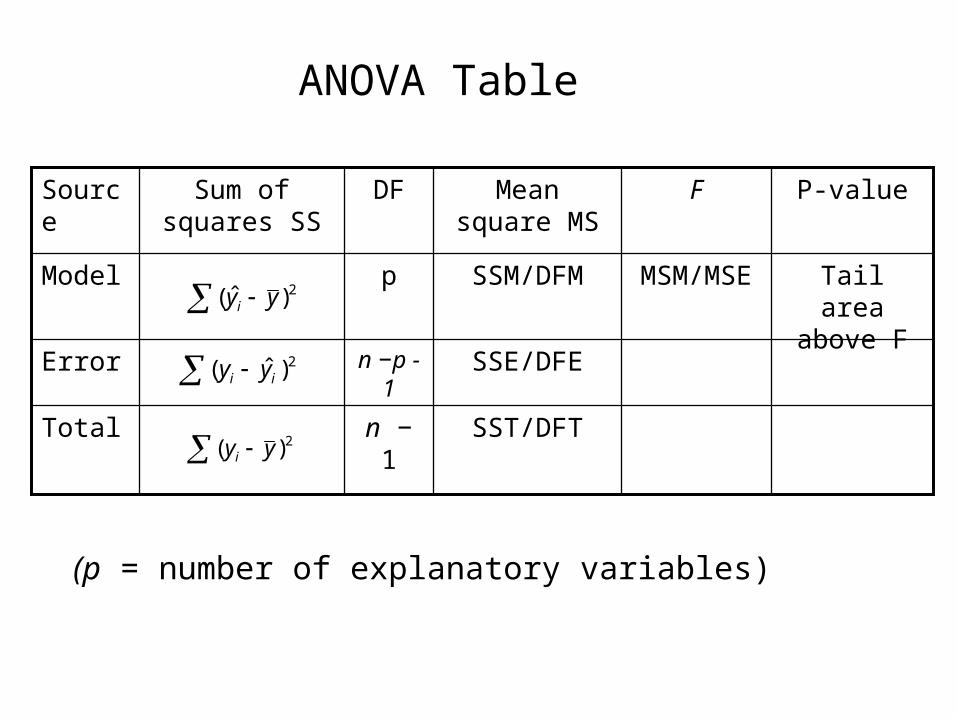
Tail area above F
P-value
SST/DFTn − 1Total
SSE/DFEn −p -1
Error
MSM/MSESSM/DFMpModel
FMean square MS
DFSum of squares SS
Source
2)ˆ( yyi
2)( yyi
2)ˆ( ii yy
ANOVA Table
(p = number of explanatory variables)

ŷi = b0 + b1x1i … + bkxpi
- least-squares regression method minimizes the sum of
squared deviations ei (= yi – ŷi) to express y as a linear
function of the p explanatory variables
- regression coefficients (b1,…bp) reflect the unique association
of each independent variable with the y variable.
- analogous to the slope in simple regression.
In the sample: Note: b1 or β can beused for sample in notation
^

Case Study of Multiple Regression
Goal: to predict success in early universityyears.
Measure of Success: GPA after 3 semesters

Data on 224 first-year computer science majors at a large
university in a given year. The data for each student include:
* Cumulative GPA (y, response variable)
* Average high school grade in math (HSM, x1, explanatory variable)
* Average high school grade in science (HSS, x2, explanatory variable)
* Average high school grade in English (HSE, x3, explanatory variable)
* SAT math score (SATM, x4, explanatory variable)
* SAT verbal score (SATV, x5, explanatory variable)
What factors are associated with GPAduring first year of college?

Summary statistics for the data (from SAS software)
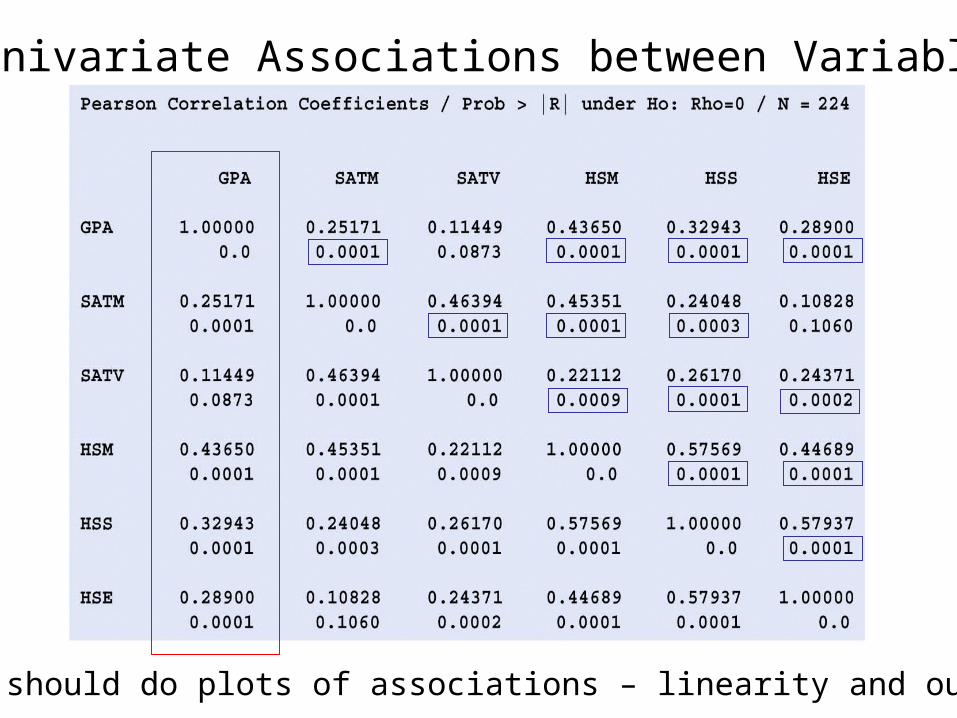
Univariate Associations between Variables
- should do plots of associations – linearity and outliers

ANOVA table for model with HSM, HSS and HSE
F test - highly significant at least one of the regression
coefficients is significantly different from zero.
R2 : HSM, HSS and HEE explain 20% of variation in GPA.

ANOVA F-test for multiple regression
H0: 1 = 2 = … = p = 0 versus Ha: at least one 0
F statistic: F = MSM / MSE
A significant p-value means that at least one
explanatory variable has a significant influence
on y.

ANOVA table for model with HSM, HSS and HSE
F test - highly significant at least one of the regression
coefficients is significantly different from zero.
R2 : HSM, HSS and HEE explain about 20% of variation in
GPA.

R Square and Adjusted R Square
-adjusted R-square equal or smaller than regular R square
- adjusts for a bias in R-square- regular R square tends to be an overestimate,
especially when many predictors and small sample size
- statisticians and researcher differ on whether to use adjusted R-square
- adjusted R-square not often used or reported

Multiple linear regression using HS grade averages:
When all 3 high school averages are used together in the multiple regression
analysis, only HSM contributes significantly to our ability to predict GPA.

Drop the least significant variable from the previous model: HSS.
Conclusions are about the same - but actual regression
coefficients have changed.

SATM and SATV

Multiple linear regression with the two SAT scores only.
ANOVA test very significant at least one slope is not zero.
R2 is really small (0.06) only 6% of GPA variations are explained by
these tests.

Multiple regression model with all the variables together
The overall test is significant, but only the average high school math score (HSM) makes a significant contribution in this model to predicting the cumulative GPA.
P-value very significant
R2 fairly small (21%)
HSM significant

Next Steps:
- refine the model- drop out non significant variables
check residuals- histogram or Q-Q plot of residuals- plot residuals against predicted GPA- plot residuals against explanatory
variables

Assumptions for Linear Regression
• The relationship is between x and y is linear.
• Equal variance of y for all values of x.
• Residuals are approximately normally distributed.
• The observations are independent.

Residuals are randomly scattered
good!
Curved pattern
the relationship is not linear.
Change in variability across plot
variance not equal for all
values of x.
(transform)
(transform y)

Do x and y need to have normal distributions?
Regression:- y (probably) doesn’t matter- x doesn’t matter
BUT: check for errors/outliers – could be influential
In practice, most analysts prefer y to be reasonably normal
-Residuals from the model should be -normally distributed





























