Embed Size (px)
Citation preview

MATH 3104: NEURAL DECODING AND BAYES THEOREM
A/Prof Geoffrey Goodhill, Semester 1, 2009
Taking the organism’s point of view
Spikes are the language of the brain. So far we have just discussed the “dictionary” stimulus →response. However, from the organism’s point of view, what’s needed is the dictionaryresponse → stimulus. In general, we would like to construct the complete 2-way dictionary.
But what does this mean when encoding is probabilistic? It means we would like to know the jointprobability distribution of the stimulus and the response.
Notation
P (r) = prior distribution of spike trains r.
P (s) = prior distribution of stimuli s.
P (r|s) = probability of spike train r given stimulus s, a conditional distribution.
P (s|r) = probability of stimulus s given spike train r, the “response-conditional ensemble”.
P (r, s) = joint distribution of all stimuli and spike trains.
If there is no correlation between the two this is simply P (r) × P (s).
Identities between distributions
P (r) =∑
s
P (r|s)P (s)
P (s) =∑
r
P (s|r)P (r)
P (r, s) = P (r|s) × P (s)
P (r, s) = P (s|r) × P (r)
From these we can derive Bayes’ rule:
P (s|r) =P (r|s)P (s)
P (r)
Example: fly data
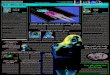
Fig 1 illustrates the above probabilities for data from an experiment on a motion sensitive cell (H1)in the blowfly. The fly viewed a spatial pattern displayed on an oscilliscope screen, and this patternmoved randomly, diffusing across the screen. At the same time, spikes from H1 were recorded. Seethe figure caption and the Rieke et al book for more details.
A simple example of the application of Bayes theorem
Unfortunately the true significance of Bayes theorem is not easy to understand. We will thereforebriefly digress from it’s applications in neuroscience and consider instead how it can be applied insome “real-world” circumstances.
1

FACT: Most people who are Australian citizens speak English. That is P (SE|A) is close to 1. Butit is clearly wrong to conclude from this that most English speakers are Australian citizens. That isP (A|SE) 6= P (SE|A). In fact the two are related by
P (A|SE) = P (SE|A)P (A)
P (SE)≈
P (A)
P (SE)
This appears straightforward. However, we will now consider the use of Bayes’ theorem in legalarguments regarding the guilt or innocence of someone accused of a crime, where issues analogousto the Australian/English example above are often grossly misunderstood.
The Prosecutor’s fallacy
The so-called “Prosecutor’s fallacy” is that Because the story before the court is highly improbable,the defendant’s innocence must be equally improbable.Imagine the facts of a particular case are as follows:
• The defendent’s DNA matched that found at the scene.
• The probability of a match between a person chosen at random and the DNA found at the sceneis 1 in a million.
The “Prosecutor’s fallacy” is to conclude from this that
• The likelihood of this DNA being from any other person than the defendent is 1 in a million.
That this is a fallacy is straightforwardly revealed by Bayes’ theorem. Letting M mean “DNA match”and G mean “guilty”, we want to know how we should update our estimate of the probability thedefendent is guilty, P (G), given the evidence of the DNA match: we want to know P (G|M). Bayes’theorem in this case says
P (G|M) =P (M |G)P (G)
P (M)(1)
=P (M |G)P (G)
P (M |G)P (G) + P (M |NG)P (NG)(2)
=P (M |G)
P (M |G)P (G) + P (M |NG)P (NG)P (G) (3)
where P (M |NG) is the probability of the DNA match when not guilty. If we now assume thatP (M |G) = 1, i.e., if the defendent really was guilty their DNA would definitely match, and dividethrough by P (G), we get
P (G|M) =1
1 + P (M |NG)1−P (G)P (G)
For P (M |NG) = 10−6 look at how P (G|M) varies with P (G):
P (G) P (G|M)10−9 0.00110−8 0.0110−7 0.0910−6 0.510−5 0.910−4 0.99
The key point here is that, although in all cases the existence of the match dramatically increasesthe probability of guilt, whether it proves guilt beyond reasonable doubt depends strongly on the priorprobability of guilt P (G). Put another way, if there’s no other evidence except the DNA match, and it’sa crime one believes the defendent is a priori very unlikely to have committed, the match should notbe enough to convict. Unfortunately however, people who are probably innocent have been sent tojail because this statistical point is not well understood by judges, juries, or lawyers.
2

The defence attorney’s fallacy
Because several innocent people will have false matches, the defendent’s match tells us little.
Consider some facts from the well-known OJ Simpson murder trial:
• OJ’s DNA matched that found at the scene.
• The probability of a match between a person chosen at random and the DNA found at the scenewas 1 in 4 million.
The fallacy (in this case articulated by Johnnie Cochran), is that
• In a city of 20 million people one would expect 5 false DNA matches. Therefore the defendent’smatch only means that the probability of guilt is 1/5.
This is a fallacy for the same reason as the previous example: it fails to take into account the priorprobability of the defendent’s guilt.
Cochran asserted OJ’s prior P (G) to be the same as any person selected at random from the city ofLos Angeles. However, crime statistics show that if a woman is murdered, the probability it was herhusband/partner is about 0.25.1 Therefore, a much more reasonable starting estimate for OJ’s P (G)might be 0.25 rather than 1 / 20 million. With P (M |NG) = 1 in 4 million this gives P (G|M) = 0.999999.
A note about Bayesian versus frequentist statistics
All statisticians agree that Bayes theorem is mathematically true. However, some statisticians do notbelieve it is very useful, because of the difficulty of choosing values for the prior probabilities (“priors”).Alternatively to the “Bayesian” school, the “frequentist” school argue that probabilities should only beassigned based on direct measurements.
As a simple example, if you were handed a random coin to toss you might assign P (heads) = 0.5;however, a strict frequentist would argue that a number for P (heads) should only be assigned aftergathering data by tossing that coin a large number of times.
Most computational neuroscientists are Bayesians, as this approach has turned out to be very fruitfulfor understanding various aspects of how the brain works.
Suggested reading
Dayan, P. & Abbott, L.F. (2001). Theoretical Neuroscience. MIT Press (pp 87-89).
Rieke, F., Warland, D., de Ruyter van Steveninck, R. & Bialek, W. (1999). Spikes: Exploring theNeural Code. MIT Press (chapter 2).
Doya, K. Ishii, S., Pouget, A. & Rao, R.P.N. (2007). Bayesian Brain: Probabilistic Approaches toNeural Coding. MIT Press (chapter 1).
There are also many good sources online to be found be searching for “Bayes theorem”, “Bayesianstatistics”, “Bayesian inferences” etc.
1Women may be interested to apply Bayes theorem to reassure themselves that this does NOT mean that there’s a 25%chance you will be murdered by your partner.
3

Figure 1: Statistical relations between the stimulus velocity v and a spike count n for a fly neuron.v is the value of the stimulus velocity averaged over a 200ms time window, measured in ommatidiaper second. n is the number of spikes counted in this time window. A. Probability density P (v)for all the 200ms windows in the expt. B. Probability P (n) of finding n spikes in a 200ms window.C. Joint probability density P (n, v) for n and v; P (v) and P (n) are the two marginal distributions ofP (n, v). As can be seen, P (n, v) 6= P (n).P (v), which means there is indeed a correlation betweenstimulus and response. We can look at this correlation in two ways, either forward or reverse. Thereverse description is summarized in P (v|n) shown in D, while the forward description is summarizedin P (n|v) shown in E. The white lines in panels F and G, replotted in more standard format in H andI, show the average values of v given n, and n given v, respectively (i.e. Bayesian estimator with asquared loss function). The average value vav in F and H gives the best estimate of the stimulus giventhat a response n is observed; this is akin to the problem an observer of the spike train must solve.The average nav in G and I gives the average response as a function of the stimulus, corresponding tothe forward description. Notice that the reverse estimator can be quite linear, even when the forwarddescription is clearly nonlinear.
4