Embed Size (px)
Citation preview

Material der Folien zur Vorlesung„Zeitreihenanalyse in den Wirtschaftswissenschaften“
Sommersemester 2019
Prof. Dr. Hans-Jörg StarkloffTechnische Universität Bergakademie Freiberg (Sachsen),
Institut für Stochastik
Letzte Änderung: 7. Juli 2019
(Hinweise und Bemerkungen bitte an: [email protected])
1

Inhaltsverzeichnis1 Organisatorisches und Einführung 3
1.1 Zeitreihen und ihre Analyse . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Elemente der deskriptiven Zeitreihenanalyse . . . . . . . . . . . . . . . . 51.3 Komponentenmodelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2 Stochastische Prozesse 172.1 Einige Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2 Stationäre stochastische Prozesse . . . . . . . . . . . . . . . . . . . . . . 23
3 ARMA-Prozesse 263.1 MA(q)-Prozesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.2 AR(p)-Prozesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.3 ARMA(p, q)-Prozesse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4 Schätzung von Erwartungswert- und Kovarianzfunktion 554.1 Schätzung des Mittelwerts . . . . . . . . . . . . . . . . . . . . . . . . . . 564.2 Schätzung der Kovarianzfunktion . . . . . . . . . . . . . . . . . . . . . . 58
5 Prognose einer Zeitreihe 605.1 Prognose mit dem additiven Komponentenmodell . . . . . . . . . . . . . 605.2 Einfaches exponentielles Glätten . . . . . . . . . . . . . . . . . . . . . . . 615.3 Beste lineare Prognose bezüglich des mittleren quadratischen Fehlers . . 62
6 Die partielle Autokorrelationsfunktion 65
7 Die Schätzung von ARMA-Modellen 72
8 Integrierte Prozesse 76
9 ARCH- und GARCH-Modelle 80
10 Zeitreihenanalyse mit Singulärspektrumanalyse 91
2

1 Organisatorisches und Einführung
1.1 Zeitreihen und ihre Analyse
• Eine (konkrete) Zeitreihe ist eine Sammlung von Daten, die in einer zeitlichenFolge beobachtet wurden bzw. die bestimmten geordneten Zeitpunkten zugeordnetwerden.
• In dieser Vorlesung werden nur diskrete Zeitreihen betrachtet, bei denen Wertefür diskrete Zeitmomente t1, t2, . . . , tn vorliegen, z.B. xt1 , xt2 , . . . , xtn . Danebengibt es kontinuierliche Zeitreihen, bei denen die Beobachtungen kontinuierlich inder Zeit gemacht werden. Sie sollen hier nicht untersucht werden.
• Bei univariaten Zeitreihen liegt für jeden betrachteten Zeitpunkt ein reeller Zahlen-wert vor, bei multivariaten oder vektoriellen Zeitreihen wird für jeden betrachtetenZeitpunkt eine endliche Anzahl von Merkmalen beobachtet (gemessen). In dieserVorlesung werden vor allem univariate Zeitreihen untersucht.
Aufgabenstellungen
Eine möglichst konkrete und klare Zielstellung einer Zeitreihenanalyse sollte schon vorihrer Durchführung angestrebt werden.
Aufgabenstellungen bzw. Ziele einer Zeitreihenanalyse können unter anderem sein:
• eine (kompakte) Beschreibung der Daten;
• eine Erklärung der Daten, z.B. durch bestimmte mathematische Modelle;
• die Vorhersage zukünftiger bzw. die Schätzung nicht beobachteter Werte;
• die Bestimmung geeigneter Algorithmen und Einstellgrößen zum Zwecke der Steue-rung und Regelung;
• die Überprüfung von bestimmten Modellannahmen oder Hypothesen;
• die Bereitstellung geeigneter Modelle zur Durchführung von Simulationen.
Weitere Gesichtspunkte
Es sollten möglichst genügend Informationen über die Datenerhebung zur Verfügungstehen und genutzt werden, z.B.
• um die Zuverlässigkeit der Daten einschätzen zu können, oder
• beim Vergleich von Daten Unterschiede, die durch verschiedene Erhebungsproze-duren entstehen, leichter und genauer zuordnen zu können.Beispiel: Arbeitslosenstatistik in der BRD und in den USA.
Auch kann z.B. von Bedeutung sein, ob
3

• ein Datenwert der Wert einer interessierenden Größe zu genau diesem Zeitpunktist oder
• sich summarisch z.B. auf die Zeitperiode vor diesem Zeitpunkt bezieht. In diesemFall können Unterschiede in den Werten allein schon daher kommen, dass z.B. dieAnzahl der Tage in den Monaten unterschiedlich ist.
Herangehensweisen und Verfahren
• Deskriptive Verfahren werden meistens zuerst benutzt. Mit ihnen kann man sichanhand von Grafiken einen ersten Überblick über die die konkrete Zeitreihe ver-schaffen, ggf. einen Trend, Periodizitäten, Ausreißer, Strukturbrüche, etc. erken-nen und z.B. einen Trend, saisonale Komponenten, etc. mit einfachen Algorithmenberechnen.
• Für weiterführende Analysen werden oft stochastische Modelle benutzt, da Zeitrei-hen in der Regel ein mehr oder weniger stark ausgeprägtes irreguläres Verhaltenzeigen, was sich häufig besser durch zufällige Einflüsse modellieren lässt. Dabei un-terscheidet man eine Analyse im Zeitbereich und eine Analyse im Frequenzbereich(die Spektralanalyse).
• Daneben gibt es aber auch andere mathematische Modelle zur Zeitreihenanalyse,bei denen keine vordergründige stochastische Modellierung erfolgt. Ein moderne-res Beispiel dafür ist die „Singulärspektrum Analysis“ (SSA, ”Singular SpectrumAnalysis”), bei dem Konzepte der linearen Algebra eine große Rolle spielen.
Statistische Zeitreihenanalyse
• Im Allgemeinen lässt sich kein stochastisches Modell für eine Zeitreihe theoretischableiten, deshalb spielen statistische Fragen eine große Rolle.
• In der klassischen Statistik beruht die Wirksamkeit der Methoden darauf, dassman (im günstigen Fall viele) Realisierungen von unabhängigen Zufallsgrößen mitidentischer Verteilung für die statistischen Schlüsse nutzen kann.
• In der statistischen Zeitreihenanalyse steht allerdings für einen Zeitpunkt üblicher-weise nur ein Zahlenwert zur Verfügung.
• Desweiteren kann man in der Regel davon ausgehen, dass die Werte für unter-schiedliche Zeitmomente nicht stochastisch unabhängig sind (es interessiert geradedie Abhängigkeit dieser Werte).
• Auch kann man oft nicht davon ausgehen, dass die Zufallsgrößen, welche die Wertefür die unterschiedlichen Zeitmomente modellieren, identisch verteilt sind.
4

Das Programmpaket „R“
• „R“ ist ein freies Statistik-Softwarepaket.
• Es kann unter http://www.cran.r-project.org/ kostenlos heruntergeladenwerden.
• R ist ein kommandozeilenorientiertes Programm. Man gibt Befehle ein, die sofortausgeführt werden und oft Ausgabeinformationen erzeugen.
• Benutzeroberflächen, wie z.B. „RStudio“ erleichtern das Arbeiten mit R.
• Mit Hilfe von Skripten können aufeinanderfolgende Befehlsketten zur Verarbeitungvorbereitet und dann jedes Mal bei Bedarf ausgeführt werden.
• Durch die Mitarbeit vieler Personen wächst der Umfang der Programme und damitder Umfang der mit R bearbeitbaren Probleme ständig.
1.2 Elemente der deskriptiven Zeitreihenanalyse
Es ist günstig, eine Zeitreihenanalyse mit einer grafischen Darstellung der zu untersu-chenden Zeitreihe zu beginnen. So kann man schon rein deskriptiv erkennbare Eigen-schaften der Zeitreihe entdecken. Dabei kann auch die Darstellung von Zeitreihen nütz-lich sein, die sich durch unterschiedliche geeignete Transformationen aus der gegebenenZeitreihe ergeben.
Im Folgenden werden einige Grafiken am Beipiel von Quartalsdaten des Bruttoinlands-produkts (BIP) der BRD (in Milliarden Euro) vorgestellt. Die Daten stammen aus derGENESIS-Online Datenbank des Statistischen Bundesamtes (Ergebnis - 81000-0002).
Die Grafiken wurden mit dem Statistik-Programmpaket R erzeugt. Der genutzte Pro-grammcode und die zugrundeliegenden Daten können von der Webseite zur Vorlesungheruntergeladen werden.
Beispiel: Bruttoinlandsprodukt der BRD 1991-2013
5

Beispiel: Bruttoinlandsprodukt der BRD 1991-2013
Beispiel: Bruttoinlandsprodukt der BRD 1991-2013
Beispiel: Bruttoinlandsprodukt der BRD 1991-2013
6

Beispiel: BIP Ausschnitt 1991-2000
Grafisches Erkennen von Abhängigkeiten
• Abhängigkeiten zwischen den Daten x1, x2, . . . , xn bzw. zwischen den Zufalls-größen X1, X2, . . . , Xn bei einer stochastischen Modellierung (mit den Daten alsRealisierungen) kann man oft mit Hilfe von Streudiagrammen erkennen.
• In der folgenden Grafik werden die Punkte (x2, x1), (x3, x2), . . . , (x92, x91) in einKoordinatensystem gezeichnet und man kann eine deutliche Abhängigkeit einesQuartalswertes vom dem entsprechenden Wert des vorherigen Quartales erkennen.
• Danach folgt analog eine Grafik mit den Punkten (x5, x1), (x6, x2), . . . , (x92, x88) ,in ihr kann man eine näherungsweise lineare Beziehung zwischen den Quartalswer-ten und den Werten des entsprechenden Vorjahresquartals ablesen.
• Zu beachten ist, dass hier die Punkte keine Realisierungen von unabhängigen zwei-dimensionalen Zufallsvektoren sind.
Beispiel BIP: Streudiagramm (voriges Quartal)
7

Beispiel BIP: Streudiagramm (Vorjahresquartal)
Transformationen von Zeitreihen
• Von Interesse sind oft die Veränderung eines Wertes zum Wert für den vorherigenZeitpunkt, hier also zu dem vorherigen Quartal, BIPt−BIPt−1 , bzw. bei zyklischemVerhalten auch die Veränderung zum entsprechenden Zeitpunkt des davorliegen-den Zyklus, hier also zum entsprechenden Quartal des Vorjahres, BIPt − BIPt−4 .Entsprechende Grafiken folgen.
• Aus mathematischer Sicht betrachtet man hier Transformationen der konkretenZeitreihe. Diese können gut mit dem Verschiebungs- oder Lagoperator L (auchB von ”backshift”) bzw. mit dem (Rückwärts-)Differenzenoperator ∆ (auch ∇)beschrieben werden:
LBIPt := BIPt−1 , L2 BIPt := L (LBIPt) = BIPt−2 , usw.∆BIPt := BIPt − BIPt−1 = (1− L)BIPt = (I− L)BIPt ,
∆2 BIPt := BIPt − BIPt−2 = (1− L2)BIPt , usw.
(Zu beachten ist, dass die transformierte Zeitreihe für eine andere Zeitmenge de-finiert ist.)
Beispiel BIP: Veränderung zum vorigen Quartal
8

Beispiel BIP: Veränderung zum Vorjahresquartal
Relative Veränderungen
• Zur Untersuchung der relativen Veränderungen von Quartal zu Quartal könnendie Quartalswachstumsraten (z.B. in Prozent) betrachtet werden. Diese werdenüblicherweise durch die Formel
BIPt − BIPt−1BIPt−1
· 100
berechnet. Allerdings liegt hier eine Asymmetrie bezüglich positiver und negativerÄnderungsraten vor. (Ein Anstieg von 100 auf 125 ergibt einen Zuwachs von 25%,ein Rückgang von 125 auf 100 eine Abnahme um 20%. Dies kann z.B. bei der Be-rechnung durchschnittlicher Wachstumraten zu Problemen führen). Deshalb nutztman im Allgemeinen kontinuierliche Wachstumsraten, hier
wq = (ln (BIPt)− ln (BIPt−1)) · 100 .
Wachstumsraten
• Dabei nutzt man die Beziehung ln(1 + x) ≈ x für Werte x nahe der Null.
• Diese Quartalswachstumsraten werden in der nächsten Grafik dargestellt. Danachwerden die jährlichen Wachstumsraten
wj = (ln (BIPt)− ln (BIPt−4)) · 100
dargestellt, die ökonomisch aussagefähiger sind.
9

Beispiel BIP: Quartalswachstumsraten
Beispiel BIP: Jahreswachstumsraten
Gleitende Mittel zum Glätten einer Zeitreihe
• Eine andere Möglichkeit, zyklischen Schwankungen zu eliminieren, aber ohne dieNiveauentwicklung herauszufiltern, besteht in der Nutzung von geeigneten gleiten-den Mitteln, hier z.B.
BIPGMRt :=1
4(BIPt + BIPt−1 + BIPt−2 + BIPt−3) .
Dabei wurde ein rückwärtiges gleitendes Mittel gewählt, um Daten bis zum ak-tuellen Zeitpunkt zur Verfügung zu haben. Die Ordnung 4 des gleitenden Mittelsbietet sich hier an, da es sich um Quartalsdaten handelt.
• Die nächste Grafik zeigt dieses gleitendes Mittel, danach werden die Ausgangs-zeitreihe und die glatte Komponente zusammen gezeigt.
10

Beispiel BIP: Gleitendes Mittel 4. Ordnung
Beispiel BIP: Gleitendes Mittel 4. Ordnung und BIP
1.3 Komponentenmodelle
• In der klassischen Zeitreihenanalyse für ökonomische Zeitreihen zerlegt man eineZeitreihe (xt; t = 1, . . . , T ) in verschiedene Komponenten:
– die glatte Komponente (gt; t = 1, . . . , T ) ,darunter versteht man den Trend, d.h. die Grundrichtung der Zeitreihe, ggf.auch unter Einschluss langfristiger Schwingungen;
– die Konjunkturkomponente (kt; t = 1, . . . , T ) ,welche kurz- und mittelfristige Konjunkturschwankungen beschreibt;
– die Saisonkomponente (st; t = 1, . . . , T ) ,welche Saisonschwankungen beschreibt und
– die irreguläre Komponente (rt; t = 1, . . . , T ) ,welche irreguläre Schwankungen beschreibt, die durch nicht genauer bestimm-bare Störfaktoren hervorgerufen werden; diese Komponente wird auch als
11

unsystematische Komponente bezeichnet, wenn die anderen Komponentensystematische Einflüsse modellieren sollen.Bei einer traditionellen stochastischen Modellierung wird die irreguläre Kom-ponente als Realisierung eines stochastischen („Rausch-“)Prozesses angese-hen.
Bemerkungen
• Zum Teil werden der Trend und die Konjunktur zur glatten Komponente und dieKonjunktur und Saison zur zyklischen Komponente zusammengefasst.
• Die Art der zyklischen oder periodischen Komponenten hängt natürlich stark vonder Art der Zeitreihe bzw. dem Anwendungsgebiet ab. Es können in bestimmtenAnwendungen auch andere zyklische Komponenten als die konjunkturellen bzw.saisonalen Komponenten oder noch andere Komponenten vorkommen bzw. einigeder Komponenten fehlen.
• In langen ökonomischen Zeitreihen kann man unter Umständen langfristige Schwin-gungen (mit Perioden von 50 bis 100 Jahren) finden (vgl. z.B. Kondratjew-Zyklen).
Additive und multiplikative Komponentenmodelle
• Bei einem additiven Komponentenmodell überlagern sich die Komponenten addi-tiv,
xt = gt + kt + st + rt , t = 1, . . . , T .
• Bei einem multiplikativen Komponentenmodell werden die Komponenten multi-pliziert,
xt = gt · kt · st · rt , t = 1, . . . , T ,
damit verstärken die Einflüsse einander. Durch Logarithmieren (Voraussetzung:alle Komponenten sind positiv) erhält man wieder eine additive Verknüpfung, wasfür Berechnungen vorteilhaft sein kann.
• Daneben werden mitunter auch gemischte Verknüpfungsmodelle verwendet, sieerfordern oft spezielle Berechnungsverfahren.
12

Beispielzeitreihe multiplikatives Komponentenmodell
Beispielzeitreihe additives Komponentenmodell
Beispielzeitreihe additives Modell – Trend
13

Beispielzeitreihe additives Modell – Saison
Beispielzeitreihe additives Modell – irreguläre Komponente
Bemerkungen
• Die Komponenten in einem Komponentenmodell sind nicht eindeutig bestimmt,unterschiedliche Modellansätze für einzelne Komponenten können zu sehr unter-schiedlichen Zeitreihen für die Komponenten führen. Deshalb sind Ergebnisse einerUntersuchung, wie z.B. die Angabe von saisonbereinigten Zeitreihen, in der Regelabhängig vom verwendeten Verfahren.
• Für die Komponenten kann ein globales Modell angenommen werden, z.B. einglobales Regressionsmodell für den Trend. Dann muss bei Vorliegen weiterer Da-tenwerte in der Regel die gesamte Komponente neu berechnet werden.
• Alternativ werden auch lokale Komponentenmodelle genutzt. Dabei wird ein Mo-dellansatz für die entsprechende Komponente nur für einen bestimmten Zeitbereichangenommen, dieser Zeitbereich wird dann jeweils verschoben, um die Komponen-te für den gesamten Zeitraum zu berechnen.
14

Bestimmung der glatten Komponente mittels Regression
Hat man eine Zeitreihe der Form xt = gt+rt , t = 1, . . . , T , vorliegen (d.h. ein additivesKomponentenmodell mit Trend und irregulärer Komponente), kann man die glatteKomponente erkennen z.B. durch eine kleinste-Quadratanpassung (Regression) anein vorgegebenes Funktionenmodel f(t, β) , z.B. f(t, β) = β1 + β2t+ β3t
2 .
Dabei ist der Parametervektor β als Lösung β von
Q(β) :=T∑t=1
(xt − f(t, β)
)2 != min
zu bestimmen.
Die geschätzte (empirische) glatte Komponente ist dann
gt := f(t, β) , t = 1, . . . , T .
Nutzung der Regression
Häufig findet man die Lösung des Extremwertproblems der vorigen Folie, in dem man dienotwendige Bedingung für einen Extrempunkt einer differenzierbaren Funktion mehrererVariabler nutzt: bei einem vektoriellen Parameter β = (β1, . . . , βn) lauten diese
∂Q(β)
∂βk
!= 0 , k = 1, . . . , n .
Dies führt im Allgemeinen zu einem nichtlinearen Gleichungssystem zur Bestimmungvon β .
Gehen die Parameter β1, . . . , βn linear in die Ansatzfunktion ein, d.h. im Fall von
f(t, β) =n∑k=1
βkgk(t)
mit vorgegeben Funktionen g1, . . . , gn von t , erhält man ein lineares Gleichungssystemzur Bestimmung von β .
Spezialfall lineare Trendfunktion
Angenommen eine lineare Trendfunktion
gt = β1 + β2t
ist angebracht. Die Methode der kleinsten Quadrate führt dann bei einer Zeitreihe(xt ; t = 1, . . . , T ) zu Schätzungen der Parameter
β2 =(tx)− t · xt2 −
(t)2 , β1 = x− β2t
mit den arithmetischen Mittelwerten
15

x =
∑Ts=1 xsT
, t =
∑Ts=1 s
T, t2 =
∑Ts=1 s
2
T, (tx) =
∑Ts=1 s · xsT
.
Die Trendgerade ist dann gt = β1 + β2t = x+ β2(t− t
).
Vereinfachte Formeln erhält man, wenn die Zeitachse so verschoben wird, dass der arith-metische Mittelwert der verschobenen Zeitmomente gleich 0 ist (und man z.B. symme-trische Zeitpunkte um deren Mittelpunkt wählt).
Bestimmung der glatten Komponente mittels Glättung
Eine weitere Methode der Erkennung der glatten Komponente bei einem additivenKomponentenmodell mit Trend und irregulärer Komponente besteht in einer Glättung(”smoothing”). Dazu kann insbesondere ein gleitender Durchschnitt (”moving average”)gebildet werden, z.B. (mit k ∈ N)
• ein (symmetrischer) gleitender Durchschnitt der Ordnung 2k + 1
x∗t =1
2k + 1
k∑j=−k
xt+j , t = k + 1, . . . , T − k ;
• ein (symmetrischer) gleitender Durchschnitt der Ordnung 2k
x∗t =1
2k
(1
2xt−k +
k−1∑j=−k+1
xt+j +1
2xt+k
), t = k + 1, . . . , T − k .
Die Schätzung für die glatte Komponente ist dann gt = x∗t .
Trendabspaltung
Möglichkeiten der Trendabspaltung (-elimination) bei additiven Komponentenmo-dellen mit Trend und irregulärer Komponente sind z.B.
• die Bildung der empirischen irregulären Komponente
rt := xt − gt ;
• die (ggf. wiederholte) Differenzenbildung :1. Differenz d
(1)t = ∆xt = xt − xt−1 ,
2. Differenz d(2)t = ∆2xt = d
(1)t − d
(1)t−1 ,
. . .q-te Differenz d
(q)t = ∆qxt = d
(q−1)t − d(q−1)t−1 .
Wenn d(q)t irregulär um Null schwankt, dann hat xt einen polynomialen Trend
der Ordnung q − 1 und man definiert
rt := d(q)t .
(Künstliches Beispiel: xt : 1 4 9 16 25 36 .)
16

Zeitreihen mit Saisonkomponente
Wir betrachten nun eine Zeitreihe der Form xt = gt+st+rt , t = 1, . . . , T, mit konstanterSaisonfigur, d.h. einer konstanten Periode p mit st = st+p für alle geeigneten Wertet .
Außerdem setzen wir voraus, dass die Saisonkomponente periodisch um 0 schwankt, d.h.
dass giltp−1∑j=0
st+j = 0 (ist dieser Summenwert gleich a 6= 0 , kann mana
pvon jedem
Wert st abziehen und zu jedem Wert gt addieren, so dass diese Beziehung erfüllt ist).
Bildet man symmetrische gleitende Durchschnitte der Ordnung k = ` · p mit einernatürlichen Zahl ` , kann man wie oben eine erste Schätzung der glatten Komponenteberechnen, gt = x∗t .
Schätzung der Saisonkomponente
Die trendbereinigte Zeitreihe yt := xt−x∗t setzt sich näherungsweise aus der saisonalenund der irregulären Komponente zusammen. Für j = 1, . . . , p sei nj die Anzahl dervollständig beobachteten Perioden ab dem Zeitpunkt j (die Zählung der Zeitmomentebeginne wieder bei 1) .Dann ist nach dem Phasendurchschnittsverfahren
yj :=1
nj
nj−1∑`=0
yj+`p
ein Schätzwert für die Werte yj, yj+p, . . . und ein Schätzer für die Saisonkomponenteist
sj+`p = yj −1
p
p∑m=1
ym .
Die Differenz zwischen der ursprünglichen Zeitreihe und der geschätzten Saisonkom-ponente xt − st nennt man auch saisonbereinigte Zeitreihe (nach dem Phasendurch-schnittsverfahren).
2 Stochastische Prozesse
2.1 Einige Grundlagen
• Bei einer stochastischen Modellierung werden die Zahlenwerte einer konkreten(univariaten diskreten) Zeitreihe xt1 , . . . , xtn als Realisierungen von ZufallsgrößenXt1 , . . . , Xtn angesehen. Diese Zufallsgrößen werden mit Hilfe eines stochastischenProzesses (Xt ; t ∈ T) mit T ⊆ R modelliert.
• Für Anwendungen bedeutet dies, dass im Allgemeinen keine genauen Werte derGrößen Xt1 , . . . , Xtn berechnet oder vorgegeben werden, sondern dass man mit
17

Wahrscheinlichkeiten oder davon abgeleiteten Kenngrößen für Zufallsgrößen, wieErwartungswerten, Varianzen, Kovarianzen, etc. rechnet bzw. diese vorgibt.
• Da hier nur zeitdiskrete Zeitreihen behandelt werden, beschränken wir uns all-gemein auf Zeitmengen T ⊆ Z , d.h. wir gehen davon aus, dass die relevantenZeitmomente durchnummeriert sind und nutzen die Nummern.
Definition 2.1.1
(i) Ein (zeitdiskreter reeller) stochastischer Prozess (eine (reelle) zufällige Folge odereine (univariate) mathematische Zeitreihe) ist eine mit Elementen t aus T ⊆ Zindizierte Familie (Xt ; t ∈ T) von Zufallsgrößen, definiert auf einem Wahrschein-lichkeitsraum (Ω,F ,P) (d.h. Xt : Ω 3 ω 7→ Xt(ω) , t ∈ T) .
(ii) Die Menge T heißt Zeitmenge, Indexmenge oder Parametermenge.
(iii) Entsprechend nennt man eine Familie (Xt ; t ∈ T) von Zufallsvektoren, definiertauf einem Wahrscheinlichkeitsraum (Ω,F ,P) , einen vektoriellen stochastischenProzess (eine mathematische multivariate Zeitreihe oder eine vektorielle zufälli-ge Folge).
Bemerkung 2.1.2Ein Wahrscheinlichkeitsraum (Ω,F ,P) besteht aus
• einer nichtleeren Menge Ω , die man (oft) als Menge aller möglicher Versuchser-gebnisse in einem (möglicherweise sehr komplexen) Zufallsversuch ansehen kann;
• der Menge der zufälligen Ereignisse F , diese sind Teilmengen von Ω und die übli-chen Mengenoperationen (höchstens abzählbar viele) führen wieder zu Elementenaus F ;
• dem Wahrscheinlichkeitsmaß P , welches jedem zufälligen Ereignis A ∈ F seineWahrscheinlichkeit P(A) zuordnet, so dass die Grundeigenschaften der Wahr-scheinlichkeiten erfüllt werden.
Dieses mathematische Objekt dient dazu, dass die mathematische Behandlung von sto-chastischen Modellen exakt und fundiert geschehen kann, bei sehr vielen Anwendungenwird aber keine explizite Definition des Wahrscheinlichkeitsraumes benötigt.
Spezifizierung von stochastischen Prozessen
Bemerkung 2.1.3
(i) Ein stochastischer Prozess (Xt ; t ∈ T) wird oft dadurch gegeben, dass mandie sogenannte Familie der endlichdimensionalen Verteilungen des stochastischenProzesses spezifiziert. Dies kann
– direkt oder
18

– durch eine indirekte Definition mit einem anderen stochastischen Prozess,in der Regel einem einfachen stochastischen Prozess mit definierter Familieendlichdimensionaler Verteilungen, erfolgen.
(ii) Daneben werden für stochastische Prozesse oft auch nur bestimmte Kenngrößen,insbesondere die Erwartungswerte und Kovarianzen, definiert. Dann erhält manbei Berechnungen in der Regel auch keine Aussagen über Wahrscheinlichkeitsver-teilungen, sondern wieder nur Aussagen über Erwartungswerte und Kovarianzen.Außerdem muss man sich in der Regel auf lineare Operationen beschränken.
Definition 2.1.4Die Familie der endlichdimensionalen Verteilungen eines stochastischen Prozesses (Xt ; t ∈T) besteht aus den Verteilungen aller Zufallsvektoren (Xt1 , Xt2 , . . . , Xtn) für alle mög-lichen n ∈ N und Auswahlen t1 < t2 < . . . < tn mit ti ∈ T , i = 1, . . . , n .
Bemerkung 2.1.5
(i) Die Familie der endlichdimensionalen Verteilungen von (Xt ; t ∈ T) wird z.B.durch die Verteilungsfunktionen F
(Xt1,Xt2
,...,Xtn )oder im Fall von stetigen Zu-
fallsvektoren durch die Dichtefunktionen f(Xt1
,Xt2,...,Xtn )
gegeben, sie erfüllt dieVerträglichkeitsbedingungen: für beliebige (x1, . . . , xn) ∈ Rn gilt
F(Xt1
,...,Xtn−1)(x1, . . . , xn−1) = lim
xn→∞F
(Xt1,...,Xtn−1
,Xtn )(x1, . . . , xn−1, xn).
(ii) Sind für alle möglichen n ∈ N und Auswahlen t1 < t2 < . . . < tn mit ti ∈ T , i =1, . . . , n , Verteilungsfunktionen F
(t1,...,tn)(jeweils für einen n−dimensionalen Zu-
fallsvektor) gegeben, so dass die Verträglichkeitsbedingungen gelten, dann existiertnach einem Theorem von Kolmogorow auch ein stochastischer Prozess mit die-sen Verteilungsfunktionen als endlichdimensionale Verteilungsfunktionen.
Definition 2.1.6Es sei (Xt ; t ∈ T) ein reeller stochastischer Prozess. Existieren die entsprechendenKenngrößen, dann heißt die Funktion
(i) mX
(t) := E[Xt] ∈ R , t ∈ T , seine Erwartungswertfunktion ;
(ii) vX
(t) := Var [Xt] ≥ 0 , t ∈ T , seine Varianzfunktion ;
(iii) γX
(s, t) := Cov[Xs, Xt] ∈ R , s, t ∈ T , seine (Auto)-Kovarianzfunktion ;
(iv) ρX
(s, t) := Corr[Xs, Xt] ∈ [−1; 1] , s, t ∈ T , seine (Auto)-Korrelationsfunktion .
Bemerkung 2.1.7
(i) Falls die Kenngrößen existieren, gelten für s, t ∈ T ρX
(s, t) =γ
X(s, t)√
vX
(s)vX
(t)und
vX
(t) = γX
(t, t).
19

(ii) Im Allgemeinen kann die Erwartungswertfunktion eine beliebige reelle Funktionauf T sein und die Varianzfunktion kann eine beliebige Funktion auf T mitnichtnegativen Werten sein.
(iii) Die Kovarianzfunktion ist symmetrisch, d.h. γX
(s, t) = γX
(t, s) , s, t ∈ T .
(iv) Die Korrelationsfunktion ist auch symmetrisch und es gilt zusätzlich ρX
(t, t) =1 , t ∈ T .
Definition 2.1.8Es sei (Xt ; t ∈ T) ein reeller stochastischer Prozess.Dann heißen die für jeweils ein festes Elementarereignis ω ∈ Ω definierten Funktionen(hier: endlichen oder unendlichen Folgen)
T 3 t 7→ Xt(ω) ∈ R (ω ∈ Ω)
Realisierungen (oder Realisationen, Pfade, Trajektorien) des stochastischen Prozesses.
Bemerkung 2.1.9
(i) Eine konkrete Zeitreihe wird bei einer stochastischen Modellierung als eine Reali-sierung eines Abschnittes (für endlich viele Zeitpunkte) eines stochastischen Pro-zesses angesehen.
(ii) Man kann die Gesamtheit aller möglicher Realisierungen, verbunden noch mitentsprechenden Wahrscheinlichkeitscharakteristiken, als anschauliches Bild einesstochastischen Prozesses ansehen.Man erhält so eine Vorstellung von allen theoretisch möglichen Zeitentwicklungeneiner Größe (zusätzlich versehen mit Wahrscheinlichkeitsbewertungen), wobei aberin der Wirklichkeit nur eine realisiert oder beobachtet wird.Man spricht auch von einem „Ensemble der Realisierungen“ eines stochastischenProzesses.
Definition 2.1.10Ein stochastischer Prozess (Xt ; t ∈ T) heißt Gaussscher Zufallsprozess oder normal-verteilter Zufallsprozess, wenn alle seine endlichdimensionalen Verteilungen Normalver-teilungen sind.Dies ist äquivalent zu der folgenden Bedingung:
Für beliebige n ∈ N , t1, . . . , tn ∈ T , a1, . . . , an ∈ R ist die Zufallsgrößen∑i=1
aiXti
normalverteilt,n∑i=1
aiXti ∼ N(µ, σ2), µ ∈ R , σ2 ≥ 0 .
Bemerkung 2.1.11
(i) Gausssche Zufallsprozesse spielen eine große Rolle, oft wird eine Normalverteilunga priori angenommen.
20

(ii) Die Verteilungen eines Gaussschen Zufallsprozesses werden durch die Erwartungswert-und Kovarianzfunktion eindeutig bestimmt. Unkorrelierte Werte sind auch stocha-stisch unabhängig.
Definition 2.1.12Ein stochastischer Prozess (Xt ; t ∈ T) heißt lognormaler Zufallsprozess, wenn für einenGaussschen Zufallsprozess (Yt ; t ∈ T) gilt
Xt := eYt = exp(Yt) , t ∈ T .
Bemerkung 2.1.13
(i) Lognormale Zufallsprozesse spielen z.B. in der stochastischen Finanzmathematikeine große Rolle.
(ii) Auch die Verteilungen eines lognormalen Zufallsprozesses werden durch die Erwartungswert-und Kovarianzfunktion eindeutig bestimmt. Unkorrelierte Werte sind auch stocha-stisch unabhängig.
Definition 2.1.14
(i) Ein stochastischer Prozess (Xt ; t ∈ T ⊆ Z) heißt (zeitdiskretes) Weißes Rauschen(White noise), falls für s, t ∈ T gelten:
E[Xt] = 0 , Cov[Xs, Xt] =
σ2 > 0 , s = t ,0 , s 6= t .
Dies wird durch (Xt) ∼WN(0, σ2) bezeichnet. (Oft betrachtet man T = N oderT = Z .)
(ii) Sind die Zufallsgrößen Xt, t ∈ T , eines Weißen Rauschens zusätzlich unabhängigund identisch verteilt, dann wird dies durch (Xt) ∼ IID(0, σ2) bezeichnet.
(iii) Sind die Zufallsgrößen Xt, t ∈ T , eines Weißen Rauschens zusätzlich unabhängigund identisch normalverteilt, dann wird dies durch (Xt) ∼ IIN(0, σ2) bezeichnet(„Gausssches Weißes Rauschen“).
Definition 2.1.15Ist (Yt ; t ∈ N) ein stochastischer Prozess, bei dem die Zufallsgrößen unabhängig undidentisch verteilt sind, dann wird der stochastische Prozess
Xt := Y1 + . . .+ Yt , t ∈ N ,
zufällige Irrfahrt („random walk“) genannt.
21

Eine Realisierung eines Gaußschen Weißen Rauschens
Weitere Realisierung eines Gaußschen Weißen Rauschens
Eine Realisierung einer Irrfahrt mit N(0,1) Summanden
22

Weitere Realisierung einer Irrfahrt mit N(0,1) Summanden
2.2 Stationäre stochastische Prozesse
• Stationäre stochastische Prozesse sind dadurch gekennzeichnet, dass sich bei Zeit-verschiebungen Wahrscheinlichkeitscharakteristiken nicht ändern. Dadurch spieltz.B. der Startzeitpunkt keine besondere Rolle. In technischen und anderen Anwen-dungen kann häufig das Verhalten der betrachteten Systeme nach einer gewissen„Einschwingzeit“ durch stationäre stochastische Prozesse beschrieben werden. Au-ßerdem werden vom Charakter her gleichbleibende Rauschprozesse durch statio-näre stochastische Prozesse (ggf. verallgemeinerte) beschrieben.
• In der Theorie der stochastischen Prozesse werden zwei Typen von stationärenProzessen untersucht, stark bzw. schwach stationäre Prozesse. Bei der Zeitreihen-analyse spielen die schwach stationären stochastischen Prozesse eine größere Rolle.
Definition 2.2.1Den stochastischen Prozess (Xt ; t ∈ T) nennt man einen stark stationären stocha-stischen Prozess (auch strikt stationär, stationär im engeren Sinne), wenn die Fami-lie der endlichdimensionalen Verteilungen invariant bezüglich Zeitverschiebungen ist,d.h. für alle möglichen n ∈ N , h ∈ R , Auswahlen t1 < t2 < . . . < tn mitti ∈ T , ti + h ∈ T , i = 1, . . . , n und (x1, . . . , xn) ∈ Rn gilt
F(Xt1
,...,Xtn )(x1, . . . , xn) = F
(Xt1+h,...,Xtn+h)(x1, . . . , xn) .
Behauptung 2.2.2Für einen stark stationären stochastischen Prozess (Xt ; t ∈ T) gelten:
(i) Die Zufallsgrößen Xt , t ∈ T sind identisch verteilt (sie besitzen alle ein- unddieselbe Verteilung).
(ii) Existiert der Erwartungswert E[Xt] für ein t ∈ T , dann ist die Erwartungswert-funktion konstant, E[Xt] = E[Xs] für beliebige s, t ∈ T .
23

(iii) Falls Var [Xt] < ∞ für ein t ∈ T , dann ist die Varianzfunktion konstant,Var [Xs] = Var [Xt] für beliebige s, t ∈ T .
(iv) Falls Var [Xt] < ∞ für ein t ∈ T , dann hängt die Kovarianzfunktion nur vonder Differenz der Argumente ab, Cov[Xs, Xt] = Cov[Xs+h, Xt+h] =: γ
X(s−t) für
beliebige s, t ∈ T . Dasselbe gilt für die Korrelationsfunktion wenn sie existiert,Corr[Xs, Xt] = Corr[Xs+h, Xt+h] =: ρ
X(s− t) für beliebige s, t ∈ T .
Beispiel 2.2.3
(i) Sei Xs = Xt für s, t ∈ T . Dann ist der konstante (in der Zeit) stochastischeProzess (Xt ; t ∈ T) stark stationär.
Existieren Erwartungswert- bzw. Kovarianzfunktion, dann sind sie konstant, ana-log die Korrelationsfunktion (falls die Varianz größer Null ist), die dann einenkonstanten Wert 1 annimmt.
(ii) Sind die Zufallsgrößen Xs, Xt unabhängig und identisch verteilt für s 6= t , s, t ∈T , dann ist der stochastische Prozess (Xt ; t ∈ T) stark stationär.
Der Wert der Kovarianz- bzw. Korrelationsfunktion ist, wenn sie existiert, gleich 0für Argumente ungleich Null, ansonsten nichtnegativ bzw. gleich 1.
Definition 2.2.4Den stochastischen Prozess (Xt ; t ∈ T) nennt man einen schwach stationären sto-chastischen Prozess (auch stationär im weiteren Sinne, stationär zweiter Ordnung,. . . ),wenn für alle Zufallsgrößen Xt, t ∈ T , Erwartungswerte und Varianzen existieren undfür beliebige s, t, s+ h, t+ h ∈ T gilt
E[Xt] = E[Xt+h] ,
Cov[Xs, Xt] = Cov[Xs+h, Xt+h] =: γX
(s− t) .
(Ein stochastischer Prozess mit endlichen zweiten Momenten wird auch mittelwertsta-tionär genannt, wenn die Erwartungswertfunktion konstant ist, varianzstationär, wenndie Varianzfunktion konstant ist und kovarianzstationär, wenn die Kovarianzfunktionnur von Differenz der beiden Argumente abhängt.)
Behauptung 2.2.5
(i) Ist (Xt ; t ∈ T) ein stark stationärer stochastischer Prozess mit endlichen zwei-ten Momenten, d.h. Erwartungswert und Varianz existieren für jede ZufallsgrößeXt , t ∈ T , dann ist der stochastische Prozess auch schwach stationär.
(ii) Ist (Xt ; t ∈ T) ein Gaussscher oder lognormaler schwach stationärer stochasti-scher Prozess, dann ist er auch stark stationär.
24

(iii) Ist (Xt ; t ∈ T) ein schwach stationärer stochastischer Prozess mit positiverVarianz, dann gelten auch
Corr[Xs, Xt] = Corr[Xs+h, Xt+h] =: ρX
(s− t) =γ
X(s− t)γ
X(0)
,
ρX
(0) = 1 .
Beispiel 2.2.6
(i) Sei Xs = Xt = X für s, t ∈ T mit einer Zufallsgröße X , wobei E[X] undVar [X] existieren. Dann ist der (in der Zeit) konstante stochastische Prozess(Xt ; t ∈ T) schwach stationär.
Erwartungswert- bzw. Kovarianzfunktion sind konstant, analog die Korrelations-funktion (falls Var [X] > 0), sie nimmt einen konstanten Wert 1 an.
(ii) Sind die Zufallsgrößen Xs, Xt für s 6= t , s, t ∈ T , unkorreliert mit übereinstim-menden Erwartungswerten und positiven Varianzen, dann ist der stochastischeProzess (Xt ; t ∈ T) schwach stationär.
Der Wert der Kovarianz- bzw. Korrelationsfunktion ist gleich 0 für Argumenteungleich Null, ansonsten nichtnegativ bzw. gleich 1.
(iii) Insbesondere ist jedes zeitdiskretes Weißes Rauschen ein schwach stationärer sto-chastischer Prozess.
Gegenbeispiele
Die Mengen der schwach und der stark stationären Prozesse überlappen sich, aber esist nicht so, dass jeder stark stationäre stochastische Prozess auch schwach stationär istund natürlich auch nicht umgekehrt.
Beispiel 2.2.7
(i) Es seien X1, X3, . . . , X2k+1, . . . standardnormalverteilte Zufallsgrössen und außer-dem X2, X4, . . . , X2k, . . . auf dem Intervall [−
√3;√
3] gleichverteilte Zufallsgrös-sen (dann gelten E[X2] = 0 ,Var [X2] = 1), so dass alle Zufallsgrößen vollständigunabhängig sind.Dann ist der stochastische Prozess (Xt ; t ∈ T) schwach stationär aber nicht starkstationär.
(ii) Sei Xs = Xt = X für s, t ∈ T mit einer Zufallsgröße X , für die der Erwartungs-wert (und folglich auch die Varianz) nicht existieren. Dann ist der (in der Zeit)konstante stochastische Prozess (Xt ; t ∈ T) stark stationär, aber nicht schwachstationär.
25

3 ARMA-Prozesse• Nun soll eine wichtige Klasse von schwach stationären stochastischen Prozessen,
die in der Zeitreihenanalyse eine sehr große Rolle spielt, vorgestellt werden. Dies istdie Klasse der ARMA(p, q)-Prozesse, zu der auch die Moving-Average-Prozesse unddie autoregressiven Prozesse gehören. Diese Prozesse werden durch eine (kleine)endliche Anzahl von Parametern beschrieben.
• Bei der Definition dieser Prozesse wird ein Weißes Rauschen wesentlich mit ge-nutzt. In Anwendungen werden durch das Weiße Rauschen häufig zufällige Beein-flussungen (engl. „shocks“) modelliert, die auf das betrachtete System zu bestimm-ten Zeitpunkten einwirken.
• Einfachheitshalber definieren wir die stochastischen Prozesse für t ∈ Z (es gibtkeinen natürlichen Startzeitpunkt für ökonomische Systeme). Im Allgemeinen kannman die Definitionen und Eigenschaften leicht auf andere diskrete Zeitmengenübertragen.
3.1 MA(q)-Prozesse
Def. 3.1.1Der stochastische Prozess (Xt ; t ∈ Z) heißt Moving-Average-Prozess erster Ordnungoder MA(1)-Prozess (auch Prozess der gleitenden Mittel erster Ordnung, . . . ), falls mitreellen Zahlen θ0 6= 0, θ1 6= 0 und einem Weißen Rauschen (Zt ; t ∈ Z) , d.h. (Zt) ∼WN(0, σ2) mit σ2 > 0 , für beliebige t ∈ Z gilt
Xt = θ0Zt + θ1Zt−1 . (MA1)
Bem.
(i) Ohne Beschränkung der Allgemeinheit kann man in der Definition θ0 = 1 an-nehmen, da auch (Zt := θ0Zt ; t ∈ Z) ein Weißes Rauschen ist, d.h. (Zt) ∼WN(0, θ20σ
2) .
(ii) θ0, θ1 und σ2 nennt man die Parameter des MA(1)-Prozesses.
Satz 3.1.2Sei (Xt ; t ∈ Z) ein MA(1)-Prozess mit den Parametern θ0, θ1, σ
2 .
(i) Dann gilt für die Erwartungswertfunktion E[Xt] = 0 , t ∈ Z .
(ii) Es gilt für die Kovarianz- bzw. Korrelationsfunktion mit h ∈ Z
Cov[Xt+h, Xt] = γX
(h) =
(θ20 + θ21)σ
2 , h = 0 ,θ0θ1σ
2 , h = ±1 ,0 , |h| > 1 ;
Corr[Xt+h, Xt] = ρX
(h) =
1 , h = 0 ,θ0θ1θ20+θ
21, h = ±1 ,
0 , |h| > 1 .
26

Insbesondere sind Xs und Xt unkorreliert, falls |s− t| ≥ 2 gilt.
(iii) (Xt ; t ∈ Z) ist ein schwach stationärer stochastischer Prozess.
Satz 3.1.3Sei (Xt ; t ∈ Z) ein MA(1)-Prozess mit den Parametern θ0, θ1, σ
2 .
(i) Es gilt |ρX
(1)| =∣∣∣∣ θ0θ1θ20 + θ21
∣∣∣∣ ≤ 1
2.
(ii) Ist (Yt ; t ∈ Z) ein MA(1)-Prozess mit den Parametern θ1, θ0, σ2 , dann besitzen
die MA(1)-Prozesse (Xt ; t ∈ Z) und (Yt ; t ∈ Z) übereinstimmende Kovarianz-und Korrelationsfunktionen.
(iii) Ist (Yt ; t ∈ Z) ein MA(1)-Prozess mit Parametern θ0,θ20θ1, σ2 , dann besitzen die
MA(1)-Prozesse (Xt ; t ∈ Z) und (Yt ; t ∈ Z) übereinstimmende Korrelations-funktionen.
Bem.Die Parameter eines MA(1)-Prozesses werden also nicht eindeutig durch dessen Korre-lationsfunktion bestimmt (selbst im Fall θ0 = 1).
Grafik der Funktionx
1 + x2
Korrelationsfunktion eines MA(1)-Prozesses
Satz 3.1.4Sei ρ ∈ [−1; 1]. Dann gibt es einen MA(1)-Prozess (Xt ; t ∈ Z) mit der (Auto-)Korrelationsfunktion(”ACF”)
ρX
(h) =
1 , h = 0 ,ρ , h = ±1 ,0 , |h| > 1, h ∈ Z ,
27

genau dann, wenn 0 < |ρ| ≤ 0.5 gilt. Sind 1, θ, σ2 die Parameter des MA(1)-Prozesses,dann gilt
θ =
1 , ρ = 0.5 ,−1 , ρ = −0.5 ,12ρ±√
14ρ2− 1 , 0 < |ρ| < 0.5 ,
wobei1
2ρ+
√1
4ρ2− 1 =
(1
2ρ−√
1
4ρ2− 1
)−1für 0 < |ρ| < 0.5 .
Bsp. 3.1.5 MA(1)-Prozess, θ = 1, ACF
Xt = Zt + Zt−1 , t ∈ Z .
Realisierung Gauss-MA(1)-Prozess, θ = 1 , σ2 = 12
(Skalierung, damit die Varianz des Prozesses 1 wird)
Xt = Zt + Zt−1 , (Zt) ∼ IIN
(0,
1
2
), t ∈ Z .
28

Streudiagr. Lag 1 Gauss-MA(1)-Proz., θ = 1, σ2 = 12
Streudiagr. Lag 2 Gauss-MA(1)-Proz., θ = 1, σ2 = 12
29

Bsp. 3.1.6 MA(1)-Prozess, θ = −1, ACF
Xt = Zt − Zt−1 , t ∈ Z .
Realisierung Gauss-MA(1)-Prozess, θ = −1, σ2 = 12
(Skalierung, damit die Varianz des Prozesses 1 wird)
Xt = Zt − Zt−1 , (Zt) ∼ IIN
(0,
1
2
), t ∈ Z .
30

Streudiagr. Lag 1 Gauss-MA(1)-Proz., θ = −1, σ2 = 12
Streudiagr. Lag 2 Gauss-MA(1)-Proz., θ = −1, σ2 = 12
31

Bsp. 3.1.7 MA(1)-Prozess mit θ = 2, ACF
Xt = Zt + 2Zt−1 , t ∈ Z .
Bsp. 3.1.8 MA(1)-Prozess mit θ = −2, ACF
Xt = Zt − 2Zt−1 , t ∈ Z .
Bsp 3.1.9 MA(1)-Prozess mit θ = −0.5, ACF
Xt = Zt − 0.5Zt−1 , t ∈ Z .
32

Bsp. 3.1.10 MA(1)-Prozess mit θ = −0.1, ACF
Xt = Zt − 0.1Zt−1 , t ∈ Z .
Realisierung Gauss-MA(1)-Prozess, θ = −0.1, σ2 = 11.01
(Skalierung, damit die Varianz des Prozesses 1 wird)
Xt = Zt − 0.1Zt−1 , (Zt) ∼WN
(0,
1
1.01
), t ∈ Z .
33

Streudiagr. Lag 1 Gauss-MA(1)-Pr., θ = −0.1, σ2 = 11.01
Streudiagr. Lag 2 Gauss-MA(1)-Pr., θ = −0.1, σ2 = 11.01
34
Definition MA(q)-Prozesse
Definition 3.1.11Es sei q ∈ N0 . Der stochastische Prozess (Xt ; t ∈ Z) heißt Moving- Average-Prozessq-ter Ordnung oder MA(q)-Prozess (oder auch Prozess der gleitenden Mittel q-ter Ord-nung,. . . ), falls mit reellen Zahlen θ0 6= 0, θ1, . . . , θq−1, θq 6= 0 und einem WeißenRauschen (Zt ; t ∈ Z) , d.h. (Zt) ∼WN(0, σ2) mit σ2 > 0 , für beliebige t ∈ Z gilt
Xt = θ0Zt + θ1Zt−1 + . . .+ θqZt−q . (MAq)
Bem.
(i) Ohne Beschränkung der Allgemeinheit kann man in der Definition θ0 = 1 anneh-men, da auch (Zt := θ0Zt ; t ∈ Z) ein Weißes Rauschen ist, (Zt) ∼WN(0, θ20σ
2) .
(ii) θi , i = 0, . . . , q , und σ2 nennt man die Parameter des MA(q)-Prozesses.
(iii) Im Fall q = 0 erhält man ein Weißes Rauschen.
Bsp. 3.1.12 Realisierung Gausssches Weißes Rauschen mit σ2 = 1
Bsp. 3.1.13 Realisierung Gauss-MA(1)-Prozess mit θ0 = θ1 = 1 , σ2 = 12
(Skalierung, damit die Varianz des Prozesses 1 wird)
35
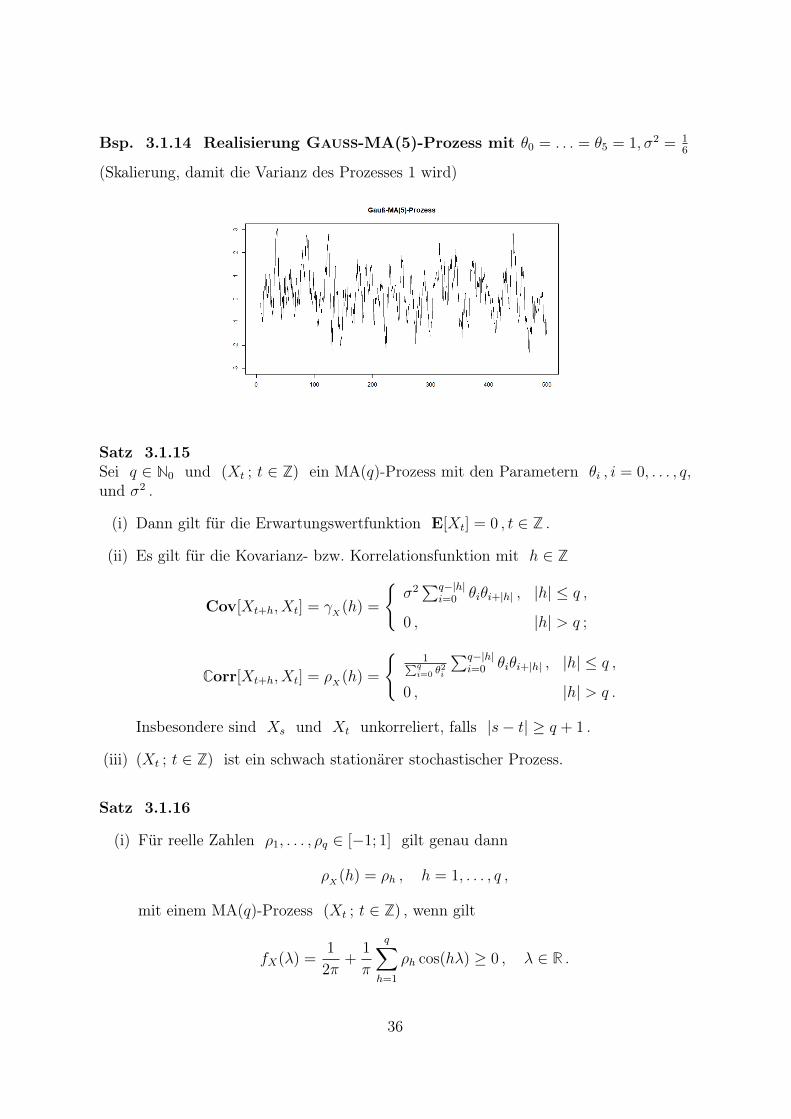
Bsp. 3.1.14 Realisierung Gauss-MA(5)-Prozess mit θ0 = . . . = θ5 = 1, σ2 = 16
(Skalierung, damit die Varianz des Prozesses 1 wird)
Satz 3.1.15Sei q ∈ N0 und (Xt ; t ∈ Z) ein MA(q)-Prozess mit den Parametern θi , i = 0, . . . , q,und σ2 .
(i) Dann gilt für die Erwartungswertfunktion E[Xt] = 0 , t ∈ Z .
(ii) Es gilt für die Kovarianz- bzw. Korrelationsfunktion mit h ∈ Z
Cov[Xt+h, Xt] = γX
(h) =
σ2∑q−|h|
i=0 θiθi+|h| , |h| ≤ q ,
0 , |h| > q ;
Corr[Xt+h, Xt] = ρX
(h) =
1∑q
i=0 θ2i
∑q−|h|i=0 θiθi+|h| , |h| ≤ q ,
0 , |h| > q .
Insbesondere sind Xs und Xt unkorreliert, falls |s− t| ≥ q + 1 .
(iii) (Xt ; t ∈ Z) ist ein schwach stationärer stochastischer Prozess.
Satz 3.1.16
(i) Für reelle Zahlen ρ1, . . . , ρq ∈ [−1; 1] gilt genau dann
ρX
(h) = ρh , h = 1, . . . , q ,
mit einem MA(q)-Prozess (Xt ; t ∈ Z) , wenn gilt
fX(λ) =1
2π+
1
π
q∑h=1
ρh cos(hλ) ≥ 0 , λ ∈ R .
36
(ii) Die Parameter θ1, . . . , θq des MA(q)-Prozesses (Xt ; t ∈ Z) können dann mitHilfe des nichtlinearen Gleichungssystems
ρh =1∑qi=0 θ
2i
q−|h|∑i=0
θiθi+|h| , h = 1, . . . , q ,
(mit θ0 := 1) bestimmt werden.
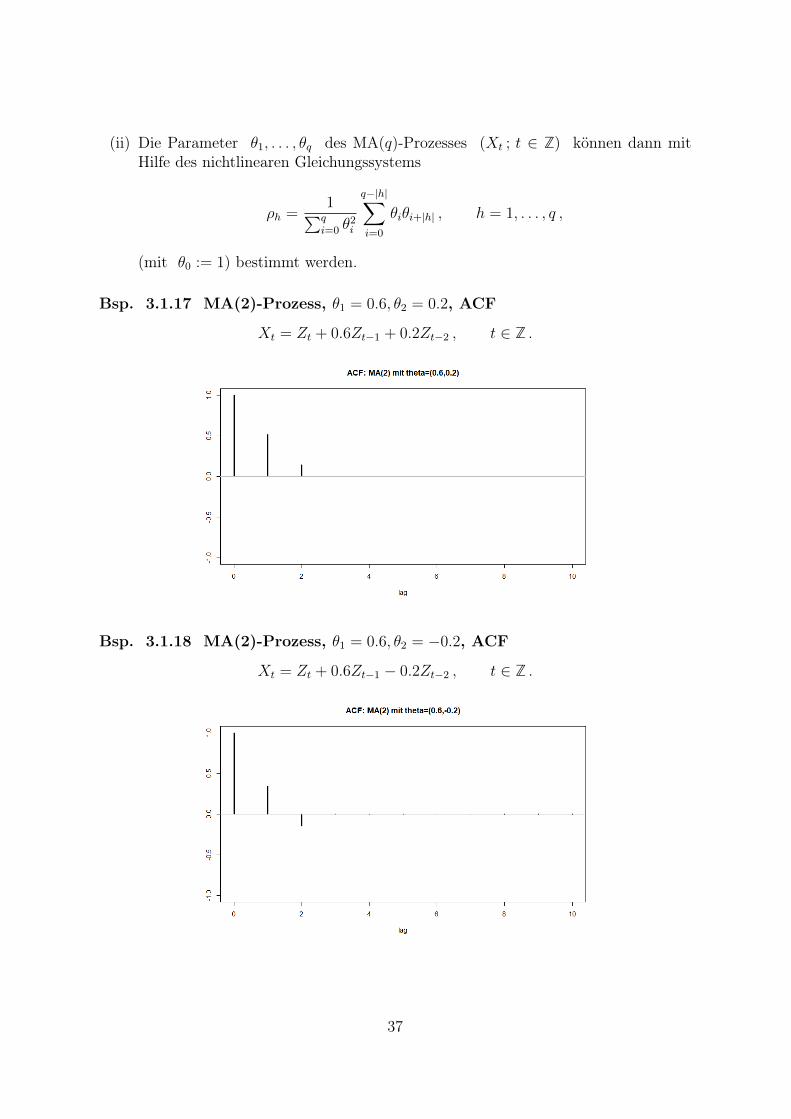
Bsp. 3.1.17 MA(2)-Prozess, θ1 = 0.6, θ2 = 0.2, ACF
Xt = Zt + 0.6Zt−1 + 0.2Zt−2 , t ∈ Z .
Bsp. 3.1.18 MA(2)-Prozess, θ1 = 0.6, θ2 = −0.2, ACF
Xt = Zt + 0.6Zt−1 − 0.2Zt−2 , t ∈ Z .
37

Bsp. 3.1.19 MA(2)-Prozess, θ1 = −0.6, θ2 = 0.2, ACF
Xt = Zt − 0.6Zt−1 + 0.2Zt−2 , t ∈ Z .
Bsp. 3.1.20 MA(2)-Prozess, θ1 = −0.6, θ2 = −0.2, ACF
Xt = Zt − 0.6Zt−1 − 0.2Zt−2 , t ∈ Z .
Bsp. 3.1.21 MA(2)-Prozess, θ1 = 0.2, θ2 = 0.6, ACF
Xt = Zt + 0.2Zt−1 + 0.6Zt−2 , t ∈ Z .
38

Definition mit Verschiebungsoperator
Bem. 3.1.22Es ist nützlich, für die Definition von MA(q)-Prozessen und bei Operationen mit ihnenden Verschiebungsoperator L zu nutzen. Definiert man
Θ(L) := θ0 + θ1L+ . . .+ θqLq ,
dann kann die Definitionsbeziehung eines MA(q)-Prozesses als
Xt = Θ(L)Zt
geschrieben werden.
3.2 AR(p)-Prozesse
Definition 3.2.1Der stochastische Prozess (Xt ; t ∈ Z) heißt autoregressiver Prozess erster Ordnungoder AR(1)-Prozess, falls
• er schwach stationär ist und
• mit einer reellen Zahl φ 6= 0 und einem Weißen Rauschen (Zt ; t ∈ Z) , d.h.(Zt) ∼WN(0, σ2) mit σ2 > 0 , für beliebige t ∈ Z gilt
Xt = φXt−1 + Zt . (AR1)
Der stochastische Prozess (Xt ; t ∈ Z) heißt AR(1)-Prozess mit Mittelwert µ ∈ R , falls(Xt − µ ; t ∈ Z) ein AR(1)-Prozess ist.
Bem.Die Definitionsgleichung ist eine zufällige Differenzengleichung (ein zeitdiskretes Analogzu einer zufälligen Differentialgleichung). Der zufällige Einfluss kommt durch das WeißeRauschen zustande.
Satz 3.2.2Eine schwach stationäre Lösung (Xt; t ∈ Z) der zufälligen Differenzengleichung (AR1)mit φ 6= 0 und (Zt) ∼WN(0, σ2) existiert genau dann, wenn |φ| 6= 1 gilt. Die Lösungist P fast sicher eindeutig,
Xt =
∑∞j=0 φ
jZt−j , |φ| < 1 ,
−∑∞
j=1 φ−jZt+j , |φ| > 1 ;
und es gilt für t, h ∈ Z
E[Xt] = 0 ;
Cov[Xt+h, Xt] = γX
(h) =
φ|h|
1−φ2σ2 , |φ| < 1 ,
φ−|h|
1−φ−2σ2 , |φ| > 1 ;
Corr[Xt+h, Xt] = ρX
(h) =
φ|h| , |φ| < 1 ,φ−|h| , |φ| > 1 .
39

Zur Konvergenz im Quadratmittel
Satz 3.2.3Gegeben sei eine Folge (Yn;n ∈ N) von Zufallsgrößen mit E[Y 2
n ] < ∞ (n ∈ N) .Existiert für beliebige ε > 0 ein N = N(ε) ∈ N , so dass E
[(Yn − Ym)2
]< ε für
beliebige n,m ≥ N(ε) gilt, dann existiert eine Zufallsgröße Y mit
limn→∞
E[(Yn − Y )2
]= 0
und umgekehrt. In dieser Situation sind für eine Zufallsgröße Y die Beziehungen
limn→∞
E
[(Yn − Y
)2]= 0 und P
(Y = Y
)= 1 äquivalent. Weiterhin gelten dann
limn→∞
E[Yn] = E[Y ] sowie
limn→∞
E[Y 2n
]= E
[Y 2]
und limn→∞
Var [Yn] = Var [Y ] .
Bsp. 3.2.4 AR(1)-Prozess, φ = 0.6, ACF
Xt = 0.6Xt−1 + Zt , t ∈ Z .
Bsp. 3.2.5 AR(1)-Prozess, φ = −0.6, ACF
Xt = −0.6Xt−1 + Zt , t ∈ Z .
40

Bsp. 3.2.6 AR(1)-Prozess, φ = 0.9, ACF
Xt = 0.9Xt−1 + Zt , t ∈ Z .
Bsp. 3.2.7 AR(1)-Prozess, φ = −0.9, ACF
Xt = −0.9Xt−1 + Zt , t ∈ Z .
Bsp. 3.2.8 AR(1)-Prozess, φ = 0.1, ACF
Xt = 0.1Xt−1 + Zt , t ∈ Z .
41

Bsp. 3.2.9 AR(1)-Prozess, φ = −0.1, ACF
Xt = −0.1Xt−1 + Zt , t ∈ Z .
Definition von AR(p)-Prozessen
Def. 3.2.10Der stochastische Prozess (Xt ; t ∈ Z) heißt autoregressiver Prozess p-ter Ordnung oderAR(p)-Prozess (p ∈ N) , falls• er schwach stationär ist und
• mit reellen Zahlen φp 6= 0, φp−1, . . . , φ1 und einem Weißen Rauschen (Zt ; t ∈ Z) ,d.h. (Zt) ∼WN(0, σ2) mit σ2 > 0 , für beliebige t ∈ Z gilt
Xt = φ1Xt−1 + . . .+ φpXt−p + Zt . (ARp)
Im Fall p = 0 gelte Xt = Zt , t ∈ Z .Der stochastische Prozess (Xt ; t ∈ Z) heißt AR(p)-Prozess mit Mittelwert µ ∈ R , falls(Xt − µ ; t ∈ Z) ein AR(p)-Prozess ist.
Bem. 3.2.11Auch bei der Definition von AR(p)-Prozessen und bei Operationen mit ihnen ist esangebracht den Verschiebungsoperator L zu nutzen. Mit
Φ(L) := 1− φ1L− . . .− φpLp
kann die Definitionsbeziehung eines AR(p)-Prozesses als
Φ(L)Xt = Zt
geschrieben werden. Verwendet man die alternative Definitionsgleichung
Xt + φ1Xt−1 + . . .+ φpXt−p = Zt , t ∈ Z ,
ist mit Φ(L) := 1 + φ1L + . . . + φpLp zu rechnen (dies ist ggf. bei der Nutzung von
Rechnerprogrammen zu berücksichtigen).Die Existenz von schwach stationären Lösungen dieser Gleichung muss extra untersuchtwerden. Möglichkeiten der Berechnung der Kovarianz- bzw. Autokorrelationsfunktion(”ACF”) werden später behandelt.
42

Bsp. 3.2.12 AR(2)-Prozess, φ1 = 0.6, φ2 = 0.2, ACF
Xt = 0.6Xt−1 + 0.2Xt−2 + Zt , t ∈ Z .
Bsp. 3.2.13 AR(2)-Prozess, φ1 = 0.6, φ2 = −0.2, ACF
Xt = 0.6Xt−1 − 0.2Xt−2 + Zt , t ∈ Z .
Bsp. 3.2.14 AR(2)-Prozess, φ1 = −0.6, φ2 = 0.2, ACF
Xt = −0.6Xt−1 + 0.2Xt−2 + Zt , t ∈ Z .
43

Bsp. 3.2.15 AR(2)-Prozess, φ1 = −0.6, φ2 = −0.2, ACF
Xt = −0.6Xt−1 − 0.2Xt−2 + Zt , t ∈ Z .
Bsp. 3.2.16 AR(2)-Prozess, φ1 = 0.2, φ2 = 0.6, ACF
Xt = 0.2Xt−1 + 0.6Xt−2 + Zt , t ∈ Z .
Bsp. 3.2.17 AR(2)-Prozess, φ1 = 0.2, φ2 = −0.6, ACF
Xt = 0.2Xt−1 − 0.6Xt−2 + Zt , t ∈ Z .
44

Bsp. 3.2.18 AR(2)-Prozess, φ1 = −0.2, φ2 = 0.6, ACF
Xt = −0.2Xt−1 + 0.6Xt−2 + Zt , t ∈ Z .
Bsp. 3.2.19 AR(2)-Prozess, φ1 = −0.2, φ2 = −0.6, ACF
Xt = −0.2Xt−1 − 0.6Xt−2 + Zt , t ∈ Z .
3.3 ARMA(p, q)-Prozesse
Def. 3.3.1Der stochastische Prozess (Xt ; t ∈ Z) heißt autoregressiver Moving- Average-Prozessder Ordnung (p, q) oder ARMA(p, q)-Prozess (p, q ∈ N0) , falls
• er schwach stationär ist und
• mit reellen Zahlen φp 6= 0, φp−1, . . . , φ1 , θ0 6= 0, . . . , θq 6= 0 und einem WeißenRauschen (Zt ; t ∈ Z) , d.h. (Zt) ∼WN(0, σ2) mit σ2 > 0 , für beliebige t ∈ Zgilt
Xt = φ1Xt−1 + . . .+ φpXt−p + θ0Zt + θ1Zt−1 + . . .+ θqZt−q . (ARMA)
45

Der stochastische Prozess (Xt ; t ∈ Z) heißt ARMA(p, q)-Prozess mit Mittelwert µ ∈ R ,falls (Xt − µ ; t ∈ Z) ein ARMA(p, q)-Prozess ist.
Bem. 3.3.2
(i) Ohne Beschränkung der Allgemeinheit kann man wieder θ0 = 1 annehmen, wasim Folgenden oft auch gemacht wird.
(ii) Mit Hilfe des Verschiebungsoperators L und
Φ(L) := 1− φ1L− . . .− φpLp ,Θ(L) := θ0 + θ1L+ . . .+ θqL
q ,
kann die Definitionsbeziehung eines ARMA(p, q)-Prozesses als
Φ(L)Xt = Θ(L)Zt
geschrieben werden.(Ggf. ist wieder die Variante Φ(L) := 1 + φ1L+ . . .+ φpL
p zu nutzen.)
(iii) Für weitere Betrachtungen ist die Klasse der MA(∞)-Prozesse nützlich.
MA(∞)-Prozesse
Def. 3.3.3Ein stochastischer Prozess (Xt ; t ∈ Z) heißt Moving-Average-Prozess unendlicherOrdnung oder MA(∞)-Prozess, falls mit einem Weißen Rauschen (Zt ; t ∈ Z) , d.h.
(Zt) ∼WN(0;σ2) , und einer Folge (ψj ; j ∈ N0) mit∞∑j=0
|ψj| <∞ gilt
Xt =∞∑j=0
ψjZt−j , t ∈ Z .
Mit Ψ(L) :=∞∑j=0
ψjLj wird dies auch als Xt = Ψ(L)Zt geschrieben.
Man sagt auch, (Xt ; t ∈ Z) sei ein MA(∞)-Prozess bezüglich des Weißen Rauschens(Zt) ∼WN(0, σ2) .
Satz 3.3.4Ist der stochastische Prozess (Xt ; t ∈ Z) ein MA(∞)-Prozess bezüglich des WeißenRauschens (Zt) ∼ WN(0, σ2) , dann ist (Xt ; t ∈ Z) ein schwach stationärer Prozessmit Erwartungswertfunktion
µt = E[Xt] = 0 , t ∈ Z ,
(Auto-)Kovarianzfunktion
Cov[Xt+h, Xt] = γX
(h) = σ2
∞∑j=0
ψjψj+|h| , h ∈ Z ,
46

und (Auto-)Korrelationsfunktion
Corr[Xt+h, Xt] = ρX
(h) =
∞∑j=0
ψjψj+|h|
∞∑j=0
ψ2j
, h ∈ Z .
Kausale ARMA(p, q)-Prozesse
Für das praktische Arbeiten mit ARMA(p, q)-Prozessen nimmt man an, dass diese zu-sätzlich kausal und invertierbar sind. Dies stellt in der Regel keine wesentliche Ein-schränkung dar und erleichtert die Untersuchungen.
Def. 3.3.5Ein ARMA(p, q)-Prozess (Xt ; t ∈ Z) mit Φ(L)Xt = Θ(L)Zt heißt kausal bezüglichdes Weißen Rauschens (Zt) ∼ WN(0, σ2) , falls eine Folge (ψj ; j ∈ N0) existiert mit∞∑j=0
|ψj| <∞ , so dass gilt
Xt = ψ0Zt + ψ1Zt−1 + ψ2Zt−2 + . . . =∞∑j=0
ψjZt−j , t ∈ Z .
Bem.Man beachte, dass sich diese Definition auf eine Eigenschaft von (Xt ; t ∈ Z) relativ zu(Zt) ∼WN(0, σ2) bezieht. Auch hier kann in der Regel ψ0 = 1 angenommen werden.
Invertierbare ARMA(p, q)-Prozesse
Def. 3.3.6Ein ARMA(p, q)-Prozess (Xt ; t ∈ Z) mit Φ(L)Xt = Θ(L)Zt heißt invertierbarbezüglich des Weißen Rauschens (Zt) ∼ WN(0, σ2) , falls eine Folge (πj ; j ∈ N0)
existiert mit∞∑j=0
|πj| <∞ , so dass gilt
Zt = π0Xt + π1Xt−1 + π2Xt−2 + . . . =∞∑j=0
πjXt−j , t ∈ Z .
Bem.Man beachte, dass sich auch diese Definition auf eine Eigenschaft von (Xt ; t ∈ Z)relativ zu (Zt) ∼WN(0, σ2) bezieht. Ist sie erfüllt, kann man prinzipiell die zufälligenBeeinflussungen (Schocks) zt , t ∈ Z , (näherungsweise) aus den vergangenen Beobach-tungen xt, xt−1, . . . berechnen.
47

Bemerkungen
• Bedingungen für die Existenz von ARMA(p, q)-Prozessen (Xt ; t ∈ Z) mit Φ(L)Xt =Θ(L)Zt und deren Eigenschaften können mit Hilfe der Polynome Φ(z) und Θ(z) ,die dadurch entstehen, dass in den entsprechenden Ausdrücken L durch die kom-plexwertige Variable z und die Potenzen Lj durch zj , j = 0, 1, . . . ersetzt wird,angegeben werden. So erhält man
Φ(z) = 1− φ1z − . . .− φpzp und Θ(z) = 1 + θ1z + . . .+ θqzq .
• Heuristisch könnte man die Definitionsgleichung Φ(L)Xt = Θ(L)Zt umschreibenzu
Xt = Φ(L)−1Θ(L)Zt ,
dies lässt sich aber nicht so leicht definieren und nutzen. Ein mathematisch einfa-cheres Objekt ist die gebrochen rationale Funktion
Θ(z)
Φ(z)=
1 + θ1z + . . .+ θqzq
1− φ1z − . . .− φpzp.
Satz über die Nullstellen von Polynomen
Für das Weitere benötigen wir die folgenden Resultate.
Satz 3.3.7Ein Polynom n−ten Grades (n ∈ N)
f(z) = a0 + a1z + . . .+ anzn , z ∈ C ,
mit an 6= 0 besitzt genau n Nullstellen (oder Wurzeln) z1, . . . , zn im Bereich derkomplexen Zahlen, d.h f(zk) = 0 , k = 1, . . . , n , und es gilt
f(z) = an(z − z1) · (z − z2) · . . . · (z − zn) , z ∈ C .
Sind die Koeffizienten des Polynoms a0, a1, . . . an reelle Zahlen und ist zk eine nichtre-elle Nullstelle, dann ist auch die zu zk konjugiert komplexe Zahl zk eine der Nullstellen.
Satz über gebrochen rationale Funktionen
Satz 3.3.8Gegeben seien zwei Polynome f(z) = a0+a1z+. . .+anz
n und g(z) = b0+b1z+. . .+bmzm
mit m,n ∈ N , an·bm 6= 0 , z ∈ C und betrachtet werde die gebrochen rationale Funktion
r(z) =f(z)
g(z). Besitzt das Nennerpolynom g keine Nullstelle, deren Betrag kleiner oder
gleich 1 ist, (d.h. nur „Nullstellen außerhalb des Einheitskreises“), dann ist die Funktionr auf jeden Fall für alle komplexen Zahlen z mit |z| ≤ 1 definiert und sie kann dortals konvergente Potenzreihe
r(z) =∞∑j=0
cjzj
48

dargestellt werden. Die Koeffizienten (cj ; j ∈ N0) können aus g(z)r(z) = f(z) durchKoeffizientenvergleich bestimmt werden, d.h.
(b0 + b1z + . . .+ bmzm)
(∞∑j=0
cjzj
)= a0 + a1z + . . .+ anz
n .
Existenz kausaler ARMA(p, q)-Prozesse
Satz 3.3.9Gegeben sei die Definitionsgleichung Φ(L)Xt = Θ(L)Zt für einen ARMA(p, q)-Prozess,wobei die beiden Polynome Φ(z) und Θ(z) keine gemeinsamen Nullstellen besitzen. Dannexistiert ein ARMA(p, q)-Prozess (Xt ; t ∈ Z) , der kausal bezüglich (Zt) ∼WN(0, σ2)ist genau dann, wenn Φ(z) 6= 0 für komplexe Zahlen |z| ≤ 1 ist (d.h. die Nullstellenoder Wurzeln außerhalb des Einheitskreises liegen).
Die Koeffizienten ψj , j ∈ N0 , der MA(∞)-Darstellung Xt =∞∑j=0
ψjZt−j sind durch
Ψ(z) =∞∑j=0
ψjzj =
Θ(z)
Φ(z), |z| ≤ 1 ,
eindeutig bestimmt.
Bem. 3.3.10Die Koeffizienten ψj, j ∈ N0, können mit Hilfe des Koeffizientenvergleichs bestimmt wer-den. Dies kann numerisch oder gegebenenfalls auch analytisch mit Hilfe der Lösungsfor-mel für lineare homogene Differenzengleichungen geschehen.
Diese Koeffizienten besitzen in der Makroökonomie eine große Bedeutung, da ψj (j ∈ N)den Effekt von Zt−j auf Xt bzw. von Zt auf Xt+j angibt.
Bsp. 3.3.11Φ(L) = 1− 0.05L− 0.6L2 ,Θ(L) = 1 mit Nullstellen von Φ : z1 = −4/3 , z2 = 5/4 .
Andere Fälle
Bem. 3.3.12
(i) Besitzen Φ(z) und Θ(z) gemeinsame Nullstellen, dann kann man zeigen:
• ist für keine der gemeinsamen Nullstellen der Betrag gleich 1, dann kann manZähler und Nennerpolynom durch die entsprechenden Linearfaktoren teilenund Satz 3.3.9 anwenden;
• ist mindestens eine der gemeinsamen Nullstellen vom Betrag gleich 1, dannkann es mehr als eine stationäre Lösung der Definitionsgleichung geben.
49

(ii) Besitzen Φ(z) und Θ(z) keine gemeinsamen Nullstellen und gilt Φ(z) = 0 fürein z mit |z| = 1 , dann existiert keine stationäre Lösung. Man spricht in diesemFall von einer Einheitswurzel (”unit root”).
(iii) Besitzen Φ(z) und Θ(z) keine gemeinsamen Nullstellen und gilt Φ(z) 6= 0 füralle z mit |z| = 1 , dann existiert eine eindeutige stationäre Lösung.
Existenz invertierbarer ARMA(p, q)-Prozesse
Satz 3.3.13Sei (Xt ; t ∈ Z) ein ARMA(p, q)-Prozess mit Definitionsgleichung Φ(L)Xt = Θ(L)Zt ,wobei die beiden Polynome Φ(z) und Θ(z) keine gemeinsamen Nullstellen besitzen.(Xt ; t ∈ Z) ist genau dann invertierbar bezüglich (Zt) ∼WN(0, σ2) , wenn Θ(z) 6= 0für komplexe Zahlen |z| ≤ 1 ist (d.h. die Nullstellen oder Wurzeln außerhalb desEinheitskreises liegen).Die Koeffizienten πj , j ∈ N0 , der MA(∞)-Darstellung von (Zt ; t ∈ Z) bezüglich(Xt ; t ∈ Z) :
Zt =∞∑j=0
πjXt−j , t ∈ Z ,
sind eindeutig bestimmt durch
Π(z) =∞∑j=0
πjzj =
Φ(z)
Θ(z), |z| ≤ 1 .
Bsp. 3.3.14
(i) Ein MA(q)-Prozess (Xt ; t ∈ Z) mit Definitionsgleichung Xt = Θ(L)Zt ist kausalbezüglich (Zt) ∼WN(0, σ2) .
(ii) Ein ARMA(1,q)-Prozess (Xt ; t ∈ Z) mit Definitionsgleichung
Xt = φ1Xt−1 + Θ(L)Zt
(und insbesondere ein AR(1)-Prozess) ist kausal bezüglich (Zt) ∼ WN(0, σ2)genau dann, wenn |φ1| < 1 gilt.
(iii) Ein AR(p)-Prozess (Xt ; t ∈ Z) mit Definitionsgleichung Φ(L)Xt = Zt istinvertierbar bezüglich (Zt) ∼WN(0, σ2) .
(iv) Ein ARMA(p,1)-Prozess (Xt ; t ∈ Z) mit Definitionsgleichung
Φ(L)Xt = Zt + θ1Zt−1
(und insbesondere ein MA(1)-Prozess) ist invertierbar bezüglich (Zt) ∼WN(0, σ2)genau dann, wenn |θ1| < 1 gilt.
50

Kovarianzfunktionen von kausalen ARMA(p, q)-Prozessen
Bem. 3.3.15Zur Berechnung der Kovarianzfunktion bzw. der Korrelationsfunktion eines kausalenARMA(p, q)-Prozesses (Xt ; t ∈ Z) können verschiedene Berechnungsverfahren genutztwerden. Ausgangspunkte sind die Definitionsgleichung
Φ(L)Xt = Θ(L)Zt
oder die MA(∞)-Darstellung
Xt =∞∑j=0
ψjZt−j , t ∈ Z ,
aus der Definition eines kausalen ARMA(p, q)-Prozesses mit
Ψ(z) =∞∑j=0
ψjzj =
Θ(z)
Φ(z), |z| ≤ 1 .
Erstes Verfahren
Bem. 3.3.16Kennt man die Koeffizienten ψj , j ∈ N0 , kann man mit Hilfe der Formel
γX
(h) = σ2
∞∑j=0
ψjψj+|h| , h ∈ Z ,
die Kovarianzfunktion von (Xt ; t ∈ Z) berechnen. Die Koeffizienten ψj , j ∈ N0 ,ergeben sich wiederum durch Koeffizientenvergleich aus dem linearen Gleichungssystem
ψj −∑
0<k≤j
φkψj−k = θj , 0 ≤ j < maxp, q + 1 ;
ψj −∑
0<k≤p
φkψj−k = 0 , j ≥ maxp, q + 1 .
Das Gleichungssystem kann rekursiv gelöst werden, der zweite Teil kann auch als homo-gene lineare Differenzengleichung aufgefasst und gelöst werden.
Zweites Verfahren
Bem. 3.3.17Multipliziert man die Definitionsgleichung sukzessiv mit Xt−h , h = 0, 1, . . . , und bildetman anschließend den Erwartungswert, erhält man ein lineares Gleichungssystem fürγ
X(h) , h ≥ 0 :
γX
(h)− φ1γX(h− 1)− . . .− φpγX
(h− p) = σ2∑h≤j≤q
θjψj−h ,
h < maxp, q + 1 ;
γX
(h)− φ1γX(h− 1)− . . .− φpγX
(h− p) = 0 , h ≥ maxp, q + 1 .
51

Der zweite Teil des Gleichungssystems stellt wieder eine homogene lineare Differenzen-gleichung p-ter Ordnung mit konstanten Koeffizienten dar, wobei die Anfangsbedingun-gen aus dem ersten Teil des Gleichungssystems bestimmt werden, nach dem ψ1, . . . , ψpberechnet worden ist. Der zweite Teil kann auch rekursiv numerisch berechnet werden,nachdem γ
X(0), . . . , γ
X(p) bestimmt wurden.
Bsp. 3.3.18 ARMA(1,1)-Prozess, φ = 0.3, θ = 0.7, ACF
Xt = 0.3Xt−1 + Zt + 0.7Zt−1 , t ∈ Z .
Bsp. 3.2.19 ARMA(1,1)-Prozess, φ = 0.3, θ = −0.7, ACF
Xt = 0.3Xt−1 + Zt − 0.7Zt−1 , t ∈ Z .
52

Bsp. 3.2.20 ARMA(1,1)-Prozess, φ = −0.3, θ = 0.7, ACF
Xt = −0.3Xt−1 + Zt + 0.7Zt−1 , t ∈ Z .
Bsp. 3.2.21 ARMA(1,1)-Proz., φ = −0.3, θ = −0.6, ACF
Xt = −0.3Xt−1 + Zt − 0.7Zt−1 , t ∈ Z .
Bsp. 3.2.22 ARMA(1,1)-Prozess, φ = 0.7, θ = 0.3, ACF
Xt = 0.7Xt−1 + Zt + 0.3Zt−1 , t ∈ Z .
53
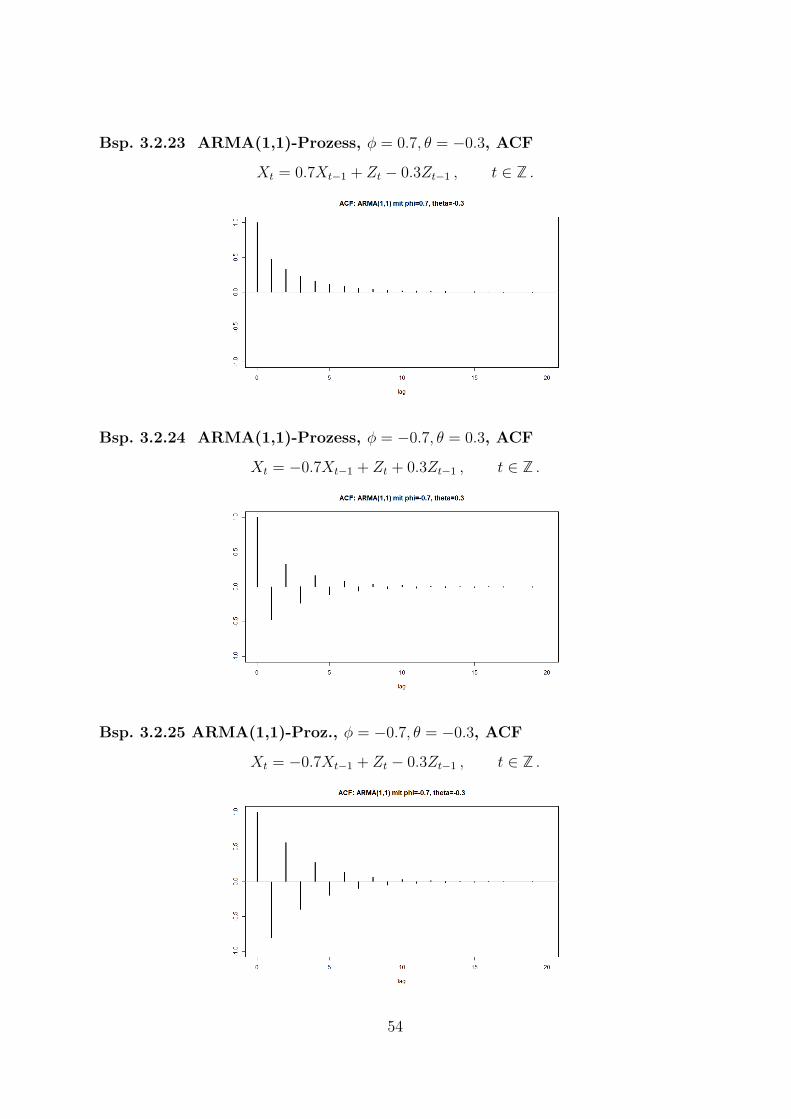
Bsp. 3.2.23 ARMA(1,1)-Prozess, φ = 0.7, θ = −0.3, ACF
Xt = 0.7Xt−1 + Zt − 0.3Zt−1 , t ∈ Z .
Bsp. 3.2.24 ARMA(1,1)-Prozess, φ = −0.7, θ = 0.3, ACF
Xt = −0.7Xt−1 + Zt + 0.3Zt−1 , t ∈ Z .
Bsp. 3.2.25 ARMA(1,1)-Proz., φ = −0.7, θ = −0.3, ACF
Xt = −0.7Xt−1 + Zt − 0.3Zt−1 , t ∈ Z .
54

Bsp. 3.2.26 ARMA(1,1)-Prozess, φ = 0.7, θ = 0.7, ACF
Xt = 0.7Xt−1 + Zt + 0.7Zt−1 , t ∈ Z .
Bsp. 3.2.27 ARMA(1,1)-Prozess, φ = 0.7, θ = −0.7, ACF
Xt = 0.7Xt−1 + Zt − 0.7Zt−1 , t ∈ Z .
4 Schätzung von Erwartungswert- und Kovarianzfunk-tion
In praktischen Situationen sind in der Regel die Erwartungswertfunktion und die Au-tokovarianzfunktion bzw. die Varianzfunktion und die Autokorrelationsfunktion des zurModellierung genutzten stochastischen Prozesses unbekannt. Sie müssen dann anhandvorliegender Realisierungswerte geschätzt werden.
Voraussetzung 4.0.1Wir gehen hier davon aus, dass (nur) ein Abschnitt (x1 , . . . , xT
) mit T ∈ N ei-ner Realisierung eines schwach stationären stochastischen Prozesses (Xt ; t ∈ Z) mit
55

Erwartungswert µ ∈ R , Varianz σ2X> 0 , Kovarianzfunktion γ
X(h) , h ∈ Z , und Kor-
relationsfunktion ρX
(h) , h ∈ Z , vorliegt und gegebenenfalls zusätzliche Bedingungenerfüllt sind.
4.1 Schätzung des Mittelwerts
Satz 4.1.1Unter Voraussetzung 4.0.1 gilt
(i) Der arithmetische Mittelwert
µ = XT
:=1
T(X1 +X2 + . . .+X
T)
ist ein erwartungstreuer Schätzer für den Erwartungswert µ .
(ii) Falls limh→∞
γX
(h) = 0 , dann gilt limT→∞
Var[X
T
]= 0 , d.h. der Schätzer ist konsi-
stent.
(iii) Falls∞∑
h=−∞
|γX
(h)| <∞ , dann gilt
limT→∞
T ·Var[X
T
]=
∞∑h=−∞
γX
(h) .
Bem.Die Bedingungen im Satz 4.1.1 sind für ARMA(p, q)-Prozesse erfüllt.
Für einen kausalen ARMA(p, q)-Prozess (Xt ; t ∈ Z) folgt dies z.B. aus der Darstellung
Xt =∞∑j=0
ψjZt−j mit∞∑j=0
|ψj| <∞ und
∞∑h=1
|γX(h)| ≤∞∑h=1
∣∣∣∣∣σ2
∞∑j=0
ψjψj+h
∣∣∣∣∣ ≤ σ2
∞∑h=1
∞∑j=0
|ψj||ψj+h|
= σ2
∞∑j=0
|ψj|∞∑h=1
|ψj+h| ≤ σ2
(∞∑j=0
|ψj|
)2
<∞ .
Satz 4.1.2Für einen schwach stationären Prozess
Xt = µ+∞∑
j=−∞
ψjZt−j , t ∈ Z ,
56

mit (Zt) ∼ IID(0, σ2) ,∞∑
j=−∞
|ψj| <∞ ,∞∑
j=−∞
ψj 6= 0 gilt:
die Verteilungsfunktionen von√T(X
T− µ
)konvergieren für T → ∞ gegen die
Verteilungsfunktion einer Normalverteilung mit Erwartungswert 0 und Varianz
∞∑h=−∞
γX
(h) = σ2
(∞∑
j=−∞
ψj
)2
,
d.h. die Zufallsgrößen√T(X
T− µ
)konvergieren für T → ∞ in Verteilung gegen
eine normalverteilte Zufallsgröße mit den angegebenen Parametern.
Bem. 4.1.3
(i) Ist (Xt ; t ∈ Z) ein normalverteilter stochastischer Prozess, der der Voraussetzung4.0.1 genügt, dann gilt
√T(X
T− µ
)∼ N
(0, γ
X(0) + 2
T−1∑h=1
(1− h
T
)γ
X(h)
).
(ii) Für T →∞ erhält man so eine asymptotische Normalverteilung mit Erwartungs-wert 0 und Varianz
∞∑h=−∞
γX
(h) = γX
(0) + 2∞∑h=1
γX
(h) ,
die auch bei statistischen Tests genutzt wird.
(iii) Folglich spielt nicht nur die Varianz σ2X
= γX
(0) des stationären Prozesses(Xt ; t ∈ Z) eine Rolle, sondern ebenso die langfristige Varianz (”long range va-riance”)
J :=∞∑
h=−∞
γX
(h) = γX
(0)
(1 + 2
∞∑h=1
ρX
(h)
),
die auch die „bezüglich der Heteroskedastizität und der Autokorrelation konsisten-te Varianz“ (”heteroskedasticity and autocorrelation consistent (HAC) variance”)genannt wird. Sie kann im Allgemeinen größer oder kleiner als Var [Xt] = σ2
X=
γX
(0) sein.
(iv) Für kausale ARMA(p, q)-Prozesse gilt
J = σ2
(∞∑j=0
ψj
)2
= σ2
(Θ(1)
Φ(1)
)2
.
57

4.2 Schätzung der Kovarianzfunktion
Bem. 4.2.1
(i) Genügt (Xt ; t ∈ Z) der Voraussetzung 4.0.1, dann sind Schätzer für Werte derKovarianzfunktion γ
X(h) bzw. der Korrelationsfunktion ρ
X(h) (für h von 0
bis maximal T − 1)
γX
(h) =1
T
T−h∑t=1
(Xt −XT
) (Xt+h −XT
),
ρX
(h) =γ
X(h)
γX
(0).
(ii) Laut Box und Jenkins können vernünftige Schätzwerte nur dann erwartet wer-den, wenn T mindestens 50 und h nicht größer als T/4 ist.
(iii) Diese Schätzer sind verzerrt.
(iv) Allerdings besitzen diese Schätzer die gute Eigenschaft, dass die darauf beruhendenSchätzer Γ
Tbzw. R
Tder Kovarianz- bzw. Korrelationsmatrix von (X1, . . . , XT
)T
immer nichtnegativ definit und im Fall γX
(0) > 0 regulär sind.
ΓT
=
γ
X(0) γ
X(1) . . . γ
X(T − 1)
γX
(1) γX
(0) . . . γX
(T − 2)...
... . . . ...γ
X(T − 1) γ
X(T − 2) . . . γ
X(0)
,
RT
=1
γX
(0)Γ
T.
Satz 4.2.2
Für einen schwach stationären Prozess Xt = µ+∞∑
j=−∞
ψjZt−j mit
(Zt) ∼ IID(0, σ2) ,∞∑
j=−∞
|ψj| <∞ ,∞∑
j=−∞
|j|ψ2j <∞
konvergieren für T →∞ die Verteilungen der Zufallsvektoren√T((ρ
X(1), . . . , ρ
X(h))T − (ρ
X(1), . . . , ρ
X(h))T
)mit h ∈ N (im Sinne der Verteilungskonvergenz) gegen eine multivariate Normal-verteilung mit Erwartungswert (0, . . . , 0)T und Kovarianzmatrix W = (wij)i,j=1,...,h
mit
wij =∞∑k=1
[ρX
(k + i) + ρX
(k − i)− 2ρX
(i)ρX
(k)]
· [ρX
(k + j) + ρX
(k − j)− 2ρX
(j)ρX
(k)] .
58

Bem. 4.2.3
(i) Im Fall (Xt ; t ∈ Z) ∼ IID(0, σ2) gilt ρX
(h) = 0 für |h| > 0 und folglich imSatz 4.2.2 wii = 1 und wij = 0 falls i 6= j . Damit sind
√T ρ
X(1), . . . ,
√T ρ
X(h)
für h ∈ N asymptotisch unabhängig und standardnormalverteilt.
(ii) Für feste Werte h ∈ N können Konfidenzintervalle (bzw. Tests) für ρX
(h) mitHilfe der Standard-Normalverteilung berechnet werden.
(iii) Die verbundene Hypothese H0 : ρX
(1) = . . . = ρX
(N) = 0 (N ∈ N) kann mitHilfe der Box-Pierce-Statistik
Q = T
N∑h=1
ρ2X
(h)
geprüft werden. Unter der Nullhypothese H0 : (Xt ; t ∈ Z) ∼ IID(0, σ2) ist Qasymptotisch χ2
N-verteilt .
(iv) Bei der verfeinerten Ljung-Box-Statistik
Q′ = T (T + 2)N∑h=1
1
T − hρ2
X(h)
wird berücksichtigt, dass die Schätzung der Korrelationen ρX
(h) für große Wer-te h ∈ N auf weniger Werten beruht als für kleine. Auch diese Statistik istasymptotisch χ2
N-verteilt .
(v) Die beiden Tests werden auch als Portmanteau-Tests bezeichnet, sie werden vor al-lem bei der Untersuchung der Residuen für angepasste Zeitreihenmodelle genutzt.
Bem. 4.2.4 (Anwendung auf MA(q)-Prozesse)Ist (Xt ; t ∈ Z) ein MA(q)-Prozess mit q ∈ N und (Zt) ∼ IID(0, σ2) , dann gilt wij = 0falls i, j > q und
wii = 1 + 2ρX
(1) + . . .+ 2ρX
(q) für i > q .
Nutzung von R
Für eine konkrete Zeitreihe x berechnet bzw. plottet man in R mit
• mean(x) den arithmetischen Mittelwert;
• var(x) die empirische Varianz;
• sd(x) die empirische Standardabweichung;
• acf(x) die empirische Autokorrelationsfunktion;
59

• acf(x,type=”covariance”) die empirische Autokovarianzfunktionfunktion;
• Box.test(x,lag=N) den Box-Pierce-Test auf ein Vorliegen eines Weißes Rau-schens basierend auf N Lags;
• Box.test(x,lag=N,type=”Ljung”) den Ljung-Box-Test auf ein Vorliegen ei-nes Weißes Rauschens basierend auf N Lags.
5 Prognose einer Zeitreihe(i) Oft wird ein Zeitreihenanalyse zur Prognose zukünftiger Werte durchgeführt, d.h.
man möchte den noch unbekanntenWert xT+h
bei vorliegendenWerten x1, . . . , xT
der konkreten Zeitreihe prognostizieren. Der Wert h ∈ N wird auch Prognoseho-rizont genannt.
(ii) Aus mathematischer Sicht nutzt man eine Berechnungsvorschrift (Prognosefunk-tion) v
1:T ;hvon T Variablen mit guten Eigenschaften.
(iii) Man kann eine Prognosefunktion z.B.
– aus heuristischen Überlegungen heraus definieren, oder
– aus einem mathematischen Modell (z.B. einem stochastischen Modell) miteiner gewählten Bewertungsmethode für die Güte der Prognose ableiten.
(iv) Für ein stochastisches Modell sei Prog1:TX
T+h= v
1:T ;h(X1, . . . , XT
) die Zufalls-größe, die den Prognosewert zu X
T+hauf Basis von X1, . . . , XT
beschreibt, beigeschätzten Parameterwerten wird die Bezeichnung Prog
1:Tgenutzt.
5.1 Prognose mit dem additiven Komponentenmodell
Bei einem additiven Komponentenmodell für eine Zeitreihe, z.B.
xt = gt + st + rt , t = 1, 2, . . . ,
kann die irreguläre Komponente rT+h
zum Zeitpunkt T +h im Allgemeinen nicht vor-hergesagt oder prognostiziert werden (bei einer stochastischen Modellierung wird mandiese Komponente oft als Weißes Rauschen modellieren), so dass man sie mit demWert 0prognostiziert. Die anderen Komponenten allerdings werden (oft) als (zwar unbekannte,aber) deterministische Funktionen von t angesehen.
Hat man diese Komponenten mit Hilfe der Werte x1, . . . , xTgeschätzt (für den Trend
z.B. durch ein Regressionsmodell, etwa ein Polynom in t), dann kann man in die ge-schätzten Funktionen gt und st für t den Wert T + h einsetzen und erhält denPrognosewert
Prog1:Tx
T+h= g
T+h+ s
T+h.
60

Bem. 5.1.1
(i) Wird im additiven Komponentenmodell die irreguläre Komponente durch einenschwach stationären stochastischen Prozess, z.B. einen ARMA(p, q)-Prozess mo-delliert, können Methoden zur Prognose von stationären stochastischen Prozessengenutzt werden.
(ii) Gilt zum Beispiel gt = β ∈ R , st = 0 , t ∈ N , dann kann β durch denarithmetischen Mittelwert geschätzt werden, folglich für h ∈ N
Prog1:Tx
T+h= β = x
T=
1
T
T∑t=1
xt .
In diese Formel gehen alle Werte mit gleicher Wichtung ein.
(iii) Für die Einschrittprognose erhält man in der Situation von (ii) auch die rekursiveBerechnungsvorschrift
Prog1:Tx
T+1= Prog
1:T−1x
T+
1
T
(x
T− Prog
1:T−1x
T
).
5.2 Einfaches exponentielles Glätten
Bem. 5.2.1
(i) Oft scheint es bei der Berechnung von Prognosewerten besser zu sein, jüngerenBeobachtungen ein größeres und älteren Beobachtungen ein geringeres Gewicht zugeben, zum Beispiel im Fall eines sich langsam ändernden Mittelwerts.
(ii) Lässt man die Gewichte exponentiell abklingen, führt dies auf
Prog1:Tx
T+1=
α
1− (1− α)T
T−1∑t=0
(1− α)txT−t
mit einem Glättungsfaktor α mit |α| < 1 bzw. Diskontfaktor 1 − α . Dabeibewirkt der Faktor
α
1− (1− α)T, dass die Summe der Gewichte gleich 1 ist.
(iii) Für große Werte T ist der Ausdruck im Nenner der Konstante ungefähr gleich 1,so dass man ihn vernachlässigen kann.
Def. 5.2.2Die Einschrittprognosefunktion des einfachen exponentiellen Glättens ist definiert durch
Prog1:Tx
T+1:= α
T−1∑t=0
(1− α)txT−t
= αxT
+ (1− α)Prog1:T−1
xT
= Prog1:T−1
xT
+ α(x
T−Prog
1:T−1x
T
).
61

Bem. 5.2.3Man kann mit diesem Verfahren rekursiv die Prognosewerte berechnen („adaptive Pro-gnose“), beginnend mit einem Startwert y0 :
Prog0x1 := y0 ;
Prog1x2 := αx1 + (1− α)Prog0x1 ;
Prog1:2x3 := αx2 + (1− α)Prog1x2 ; . . .
Bem. 5.2.4
(i) Der Einfluss des Startwerts y0 nimmt mit der Zeit exponentiell ab.
(ii) In der Praxis wird oft y0 = x1 oder y0 = xT
gewählt, die Wahl y0 = 0 führtzu den in Definition 5.2.2, erste Formelzeile, gegebenen Formeln.
(iii) Der Diskontfaktor 1− α wird oft a priori zwischen 0.7 und 0.95 gewählt.
(iv) Der Diskontfaktor 1−α kann auch empirisch durch Minimierung der quadratischenEinschrittprognosefehler bestimmt werden, d.h.
T∑t=1
(xt −Prog1:t−1xt
)2 → min|α|<1
.
(v) In der Literatur werden Verallgemeinerungen des einfachen exponentiellen Glät-tens beschrieben, die in speziellen Situationen genutzt werden können.
5.3 Beste lineare Prognose bezüglich des mittleren quadrati-schen Fehlers
Bem. 5.3.1
(i) In einem gegebenen stochastischen Modell wird die beste lineare Prognose einerZufallsgröße Y bei gegebenen Zufallsgrößen X1, . . . , XT
bezüglich des mittlerenquadratischen Fehlers durch eine Zufallsgröße
Y = a0 + a1XT+ . . .+ a
TX1
realisiert, wobei gefordert wird, dass E[(Y − Y )2
]minimal wird
(bei freier Wahl der Koeffizienten a0, a1, . . . , aT).
(ii) Für Y = XT+h
wird diese Zufallsgröße auch linearer Prädiktor genannt und mitProg
1:TX
T+h= Prog
1,X1,...,XTX
T+hbezeichnet.
(iii) Eine solche Zufallsgröße Y existiert immer.
62

Bem. 5.3.2
(i) Durch die Wahl des Gütemaßes mittlerer quadratischer Fehler zur Prognose wer-den Über- und Unterschätzungen als gleichwertig betrachtet, dies ist nicht immerwünschenswert.
(ii) Oft liefern lineare Prädiktoren gute Ergebnisse. In der Regel sind optimale nicht-lineare Prädiktoren sehr viel schwieriger zu berechnen.
(iii) Zur Bestimmung von Y als linearer Prädiktor benötigt man die Erwartungswerteund Kovarianzen der Zufallsgrößen Y,X1, . . . , XT
.
(iv) Die optimalen Koeffizienten a0, a1, . . . , aTergeben sich als Lösung eines linearen
Gleichungssystems. Dieses erhält man z.B. aus den notwendigen Bedingungen fürExtrempunkte der Funktion
g(a0, . . . , aT) := E
[(Y − (a0 + a1XT
+ . . .+ aTX1))
2]
von T + 1 Variablen a0, . . . , aT(die partiellen Ableitungen nach allen Variablen
sind in einem Extrempunkt gleich Null).
Bem. 5.3.3Für einen schwach stationären Prozess (Xt ; t ∈ Z) mit Erwartungswert µ undKovarianzfunktion γ
Xbzw. Korrelationsfunktion ρ
Xerhält man so die Gleichung
a0 = µ−T∑i=1
aiµ
und das lineare Gleichungssystem mit T Gleichungenγ
X(0) γ
X(1) . . . γ
X(T − 1)
γX
(1) γX
(0) . . . γX
(T − 2)...
... . . . ...γ
X(T − 1) γ
X(T − 2) . . . γ
X(0)
a1a2...a
T
=
γ
X(h)
γX
(h+ 1)...
γX
(h+ T − 1)
.
Teilt man jede Gleichung durch γX
(0) , erhält man ein äquivalentes Gleichungssystem,bei dem die Werte der Autokovarianzfunktion durch die Werte der Autokorrelations-funktion ersetzt werden.
Bem. 5.3.4
(i) Aus der ersten Gleichung in Bemerkung 5.3.3 folgt, dass
Prog1:TX
T+h= µ+
T∑i=1
ai(X
T+1−i− µ
),
und so auch E[X
T+h
]= E
[Prog
1:TX
T+h
]= µ .
63

(ii) Von Interesse ist für den Prognosehorizont h ∈ N auch der mittlere quadriertePrognosefehler (”mean squared error”, ”MSE”) der gleich der Varianz des Progno-sefehlers ist und mit ν
1:T(h) bezeichnet werden soll. Man erhält
ν1:T
(h) = γX
(0)−T∑i=1
aiγX(h+ i− 1)
= γX
(0)
(1−
T∑i=1
aiρX(h+ i− 1)
).
5.3.5 Bem.
(i) Sind der Erwartungswert und/oder die Kovarianz- bzw. Korrelationsfunktion un-bekannt, ersetzt man in den Formeln in Bemerkung 5.3.3 die theoretischen Wertedurch die entsprechenden Schätzwerte.
(ii) Zur numerischen Lösung des linearen Gleichungssystems existieren effektive Algo-rithmen.
Bsp. 5.3.6 (Beispiel AR(1)-Prozess)Es gelte Xt = φXt−1 + Zt mit |φ| < 1 , (Zt) ∼WN(0, σ2) .Das lineare Gleichungssystem ist dann
1 φ φ2 . . . φT−1
φ 1 φ . . . φT−2
φ2 φ 1 . . . φT−3
......
... . . . ...φT−1 φT−2 φT−3 . . . 1
a1a2a3...a
T
=
φh
φh+1
φh+2
...φh+T−1
mit Lösung a1 = φh , ai = 0 , i = 2, . . . , T und so für h ∈ N
Prog1:TX
T+h= φhX
T.
Für die Prognose ist deshalb nur der letzte Wert von Bedeutung. Die Varianz des Pro-gnosefehlers ist
ν1:T
(h) = σ21− φ2h
1− φ2, insbesondere ν
1:T(1) = σ2 .
Bsp. 5.3.7 (Beispiel AR(p)-Prozess)Für einen kausalen AR(p)-Prozess Xt = φ1Xt−1 + . . . + φpXt−p + Zt mit (Zt) ∼WN(0, σ2) erhält man analog für den Einschrittprädiktor
Prog1:TX
T+1= φ1XT
+ φ2XT−1+ . . .+ φpXT−p+1
64

(falls T > p), also werden hier nur die letzten p Werte zur Prognose genutzt. Fürh > 1 kann man die Prognosefunktionen rekursiv herleiten:
Prog1:TX
T+2= Prog
1:T(φ1XT+1
) + . . .+ Prog1:T
(φpXT+2−p)
+ Prog1:T
(ZT+2
)
= φ1(φ1XT+ φ2XT−1
+ . . .+ φpXT+1−p)+
+ φ2XT+ . . .+ φpXT+2−p
= (φ21 + φ2)XT
+ (φ1φ2 + φ3)XT−1+ . . .
+ (φ1φp−1 + φp)XT+2−p+ φ1φpXT+1−p
,
usw. Man beachte, dass hier die Koeffizienten der Prognosefunktion nicht von T abhän-gen.
Bsp. 5.3.8 (Beispiel MA(1)-Prozess)Es gelte Xt = Zt + θZt−1 mit |θ| < 1 , (Zt) ∼WN(0, σ2) .Das Gleichungssystem zur Bestimmung des Einschrittprädiktors ist dann
1 θ1+θ2
0 . . . 0θ
1+θ21 θ
1+θ2. . . 0
0 θ1+θ2
1 . . . 0...
...... . . . ...
0 0 0 . . . 1
a1a2a3...a
T
=
θ
1+θ2
00...0
,
für welches die Lösungswerte a1, . . . , aTim Allgemeinen alle von Null verschieden sind
und von T abhängen. Somit hängt die Prognose von allen vergangenen XT−j
mitj = 0, 1, . . . , T − 1 ab.
Die Varianz des Prognosefehlers ν1:T
(1) hängt auch von T ab, die Folge ist monotonfallend mit Grenzwert σ2 .
Bem. 5.3.9 (Prognose und AR(∞)-Darstellung)
(i) Für einen invertierbaren ARMA(p, q)-Prozess (Xt ; t ∈ Z) aus Definition 3.19kann man die Definitionsbeziehung mit π0 = 1 schreiben als AR(∞)-Darstellung
Xt =∞∑j=1
(−πj)Xt−j + Zt , t ∈ Z .
(ii) Diese AR(∞)-Darstellung des Prozesses (Xt ; t ∈ Z) ist gut zu Prognosezweckengeeignet, da hier schon der Wert der Zeitreihe zu einem bestimmten Zeitpunkt mitHilfe der Werte zu den vergangenen Zeitpunkten dargestellt wird.
6 Die partielle AutokorrelationsfunktionBem. 6.1Eine weitere Charakteristik eines schwach stationären Prozesses (Xt ; t ∈ Z) ist seine
65

partielle Autokorrelationsfunktion (PACF) αX.
Sie ist für Zeitdifferenzen h ≥ 0 definiert und nimmt Werte im Intervall [−1 ; 1]an. Die Funktionswerte α
X(h) sind jeweils die partiellen Korrelationskoeffizienten der
Zufallsgrößen Xt und Xt+h , wobei ein linearer Einfluss der Werte für die zwischen tund t+ h liegenden Zeitpunkte ausgeschaltet wird.
Bei der Definition der partiellen Autokorrelationsfunktion wird hier die BezeichnungProgY1,...,YnY für die Zufallsgröße der Form a1Y1 + . . . anYn mit kleinstmöglichemquadratischen Abstand E[(Y − (a1Y1 + . . . anYn))2] verwendet, d.h. für die Zufallsgrö-ße, welche die beste lineare Prognose von Y mit Hilfe von Y1, . . . , Yn realisiert. Zuderen Berechnung werden nur die ersten und zweiten Momente (auch gemischte) derbeteiligten Zufallsgrößen benötigt.
Def. 6.2Die partielle Autokorrelationsfunktion des schwach stationären Prozesses (Xt ; t ∈ Z)wird definiert durch
αX
(0)=0 ;
αX
(1)=Corr[X2, X1] = ρX
(1) ;
αX
(h)=Corr[Xh+1 −Prog1,X2,...,Xh
Xh+1, X1 −Prog1,X2,...,XhX1
],
h ∈ N , h ≥ 2 .
Bem. 6.3
• Gilt E[Xt] = 0 , t ∈ Z , kann die Konstante 1 bei der Prognose weggelassen werden,d.h. Prog1,X2,...,Xh
Xh+1 = ProgX2,...,XhXh+1 und analog Prog1,X2,...,Xh
X1 =ProgX2,...,Xh
X1 .
• Die Definition kann auch auf h ∈ Z mittels αX
(h) = αX
(−h) für h < 0fortgesetzt werden.
Algorithmus 6.4 (Durbin-Levinson-Algorithmus)Die partielle Autokorrelationsfunktion des schwach stationären Prozesses (Xt ; t ∈ Z)kann z.B. mit Hilfe des Durbin-Levinson-Algorithmus aus der gewöhnlichen Autokor-relationsfunktion ρ
Xberechnet werden.
αX
(0) = 0
αX
(1) = ρX
(1) =: a11
αX
(2) =ρ
X(2)− ρ
X(1)2
1− ρX
(1)2=: a22
a21 = a11 − a22 · a11
αX
(3) =ρ
X(3)− a21 · ρX
(2)− a22 · ρX(1)
1− a21 · ρX(1)− a22 · ρX
(2)=: a33
a31 = a21 − a33 · a22a32 = a22 − a33 · a21 usw.
66

Die allgemeinen Formeln lauten für h ≥ 2
ah j := ah−1 j − ahh · ah−1h−j , j = 1, . . . , h− 1 ,
αX
(h) =
ρX
(h)−h−1∑j=1
ah−1 j · ρX(h− j)
1−h−1∑j=1
ah−1 j · ρX(j)
=: ahh .
Bsp. 6.5 (kausaler AR(1)-Prozess)Für einen kausalen AR(1)-Prozess mit Definitionsgleichung Xt = φXt−1 + Zt (0 <|φ| < 1) , erhält man
αX
(0) = 0 , αX
(1) = φ , αX
(h) = 0 , h ∈ N , h ≥ 2 .
Dies kann z.B. für h = 2 auch aus den Formeln
X3 = φX2 + Z3 und ProgX2X3 = φX2,
d.h. X3 − ProgX2X3 = Z3 , und den Eigenschaften des Weißen Rauschens abgelesen
werden, da für einen kausalen AR(1)-Prozess die Zufallsgröße
X1 −ProgX2X1 = X1 − φX2 = −φZ2 + (1− φ2)
∞∑j=0
φjZ1−j
nur von denWerten des Weißen Rauschens Zt für t ≤ 2 abhängt und damit unkorreliertzu Z3 ist.
Bsp. 6.6 (kausaler AR(p)-Prozess)Analog kann man für kausale AR(p)-Prozesse mit p ≥ 2 zeigen, dass für die partielleAutokorrelationsfunktion gilt
αX
(h) = 0 für h > p .
Bsp. 6.7 (invertierbarer MA(q)-Prozess)Für invertierbare MA(q)-Prozesse gilt
Zt =∞∑j=0
πjXt−j und folglich Xt = −∞∑j=1
πjXt−j + Zt .
Damit bleiben auch nach Berücksichtigung des linearen Einflusses der Größen Xt−1, . . . , Xt−h+1
die Zufallsgrößen zu den Zeitpunkten vor t − h relevant, so dass die partielle Auto-korrelationsfunktion im Allgemeinen nicht Null für große Argumente wird. Allerdingskonvergieren die Beträge |α
X(h)| für h→∞ exponentiell schnell gegen Null.
Man kann zeigen, dass für einen MA(1)-Prozess mit Definitionsgleichung Xt = Zt+θZt−1(|θ| < 1) für h ≥ 1 gilt
αX
(h) = − (−θ)h
1 + θ2 + . . .+ θ2h= −(−θ)h(1− θ2)
1− θ2(h+1).
67

Partielle Autokorrelationsfunktionen ARMA(p, q)-Prozesse
Bem. 6.8Damit ergeben sich bei ARMA(p, q)-Prozessen folgende Eigenschaften der Werte |α
X(h)|
für Argumente |h| > maxp, q :
Prozess ρX
(h) αX
(h)AR(p) exponentielles Fallen =0(p ≥ 1)MA(q) = 0 exponentielles Fallen(q ≥ 1)ARMA(p, q) exponentielles Fallen exponentielles Fallen(p, q ≥ 1)WN(0;σ2) = 0 =0
(|h| > 0) (|h| > 0)
Bem. 6.9 (Schätzung partielle Autokorrelationsfunktion)Funktionswerte der partiellen Autokorrelationsfunktion können geschätzt werden, in-dem in die Formeln zur Berechnung der theoretischen Funktionswerte die Schätzwertefür die Korrelationskoeffizienten ρ(h) eingesetzt werden. Dann können Grafiken derAutokorrelationsfunktion und der partiellen Autokorrelationsfunktion genutzt werdenum zu entscheiden, durch welchen Typ (WN(0;σ2), AR(p), MA(q), ARMA(p, q)) diebetrachtete konkrete Zeitreihe beschreibbar sein könnte.
In bestimmten Fällen können auch asymptotische Verteilungen der Schätzer angegebenwerden, dies ermöglicht wieder die Angabe von Konfidenzintervallen bzw. die Konstruk-tion von statistischen Tests.
Beispiele: Autokorrelationsfunktion WN(0;1)
Bsp. 6.10(i – a) WN(0;1) : Autokorrelationsfunktion
68

Beispiele: partielle Autokorrelationsfunktion WN(0;1)
(i – p) WN(0;1) : partielle Autokorrelationsfunktion
Beispiele: Autokorrelationsfunktion AR(1)
(ii – a) Xt = 0.4Xt−1 + Zt ; (Zt) ∼WN(0; 1)
Beispiele: partielle Autokorrelationsfunktion AR(1)
(ii – p) Xt = 0.4Xt−1 + Zt ; (Zt) ∼WN(0; 1)
69

Beispiele: Autokorrelationsfunktion AR(2)
(iii – a) Xt = 0.4Xt−1 − 0.2Xt−2 + Zt ; (Zt) ∼WN(0; 1)
Beispiele: partielle Autokorrelationsfunktion AR(2)
(iii – p) Xt = 0.4Xt−1 − 0.2Xt−2 + Zt ; (Zt) ∼WN(0; 1)
Beispiele: Autokorrelationsfunktion MA(1)
(iv – a) Xt = Zt + 0.6Zt−1 ; (Zt) ∼WN(0; 1)
70

Beispiele: partielle Autokorrelationsfunktion MA(1)
(iv – p) Xt = Zt + 0.6Zt−1 ; (Zt) ∼WN(0; 1)
Beispiele: Autokorrelationsfunktion ARMA(1,1)
(v – a) Xt = 0.6Xt−1 + Zt + 0.8Zt−1 ; (Zt) ∼WN(0; 1)
Beispiele: partielle Autokorrelationsfunktion ARMA(1,1)
(v – p) Xt = 0.6Xt−1 + Zt + 0.8Zt−1 ; (Zt) ∼WN(0; 1)
71

7 Die Schätzung von ARMA-ModellenBem. 7.1 (Vorgehensweise bei der Schätzung von ARMA-Modellen)Die Modellierung eines stochastischen Prozesses durch ARMA-Modelle, basierend aufeiner Realisierung x1, . . . , xT , erfolgt in der Regel durch folgende Schritte:
1. Transformation zur Erreichung der Stationarität;
2. Wahl der Ordnungen p und q ;
3. Schätzung der Parameter in der ARMA(p, q)-Definitionsgleichung;
4. Prüfung auf Plausibilität;
Ist die Anpassung des Modells an die Daten unzufriedend, können die Schritte wiederholtdurchlaufen werden, z.B. durch eine andere Wahl der Ordnungen p und q oder durchSchätzung der Parameter durch andere Schätzverfahren.
Bem. 7.2 (Transformationen zur Erreichung der Stationarität)
• Transformationen zur Erreichung der Stationarität können z.B. in der Bereinigungvon
– deterministischen Trends (beschrieben z.B. durch ein Polynom in der Zeitva-riable, welches durch die Methode der kleinsten Quadrate geschätzt werdenkann) oder
– deterministischen saisonalen Komponenten
bestehen, so wie das in Kapitel 1 beschrieben wurde.
• Die Untersuchung der durch Differenzenbildung erhaltenen stationären Zeitreihenführt auf sogenannte ARIMA-Prozesse, die im nächsten Kapitel behandelt werden.
• Weitere oft verwendete Transformationen sind das Logarithmieren der Werte oder
die Box-Cox-Transformation Yt =(Xt + c)λ − 1
λfür ein λ 6= 0 (die Konstante
c dient dazu, dass alle zu potenzierende Werte positiv werden).
Bem. 7.3 (Wahl der Ordnungen p und q)
• Eine Wahl der Ordnungen p und q kann z.B. mit Hilfe der Grafik der empirischengewöhnlichen bzw. partiellen Korrelationsfunktionen erfolgen. Sind beide Wertenicht zu groß (p + q ≤ 2), zeigen zumindest die entsprechenden theoretischenFunktionen ein prinzipiell unterschiedliches Verlaufsmuster.
• Für reine AR- und reine MA-Prozesse können zusätzlich statistische Tests aufdie Gleichheit zu Null von gewöhnlichen oder partiellen Korrelationskoeffizienten,basierend auf einer asymptotischen Normalverteilung (bei geeigneten Annahmen),durchgeführt werden.
72

• Oft wählt man systematisch Ordnungen p und q , schätzt die Parameter und be-wertet die Güte des Modells mit Hilfe von sogenannten Informationskriterien. Mankann dann die Ordnungen p und q wählen, für die der Wert des entsprechendenInformationskriteriums minimal wird.
Bem. 7.4 (Schätzung der Parameter)
• Zur Schätzung der Parameter in der ARMA(p, q)-Definition können unterschied-liche Verfahren angewandt werden, wobei manche Verfahren in bestimmten Si-tuationen schwieriger anzuwenden sind und sich auch Eigenschaften der Schätzerunterscheiden.
• Im Folgenden soll kurz auf
– Yule-Walker-Schätzer eines AR(p)-Modells ;– Kleinste-Quadrate-Schätzer eines AR(p)-Modells und– Maximum-Likelihood-Schätzer eines ARMA(p, q)-Modells
eingegangen werden.
Bem. 7.5 (Yule-Walker-Schätzer eines AR(p)-Modells)Für einen kausalen AR(p)-Prozess mit p ≥ 1 und Definitionsgleichung
Φ(L)Xt = Zt , (Zt) ∼WN(0;σ2)
erhält man durch Multiplikation der Differenzengleichung mit Xt−j , j = 0, 1, . . . , p ,und Erwartungswertbildung das folgende Yule-Walker-Gleichungssystem zur Bestim-mung von φ = (φ1, . . . , φp)
T und σ2 :
γX
(0) − φ1γX(1) − . . . − φpγX
(p) = σ2
γX
(1) − φ1γX(0) − . . . − φpγX
(p− 1) = 0. . .
γX
(p) − φ1γX(p− 1) − . . . − φpγX
(0) = 0 .
Setzt man statt der theoretischenWerte der Kovarianzfunktion die Schätzwerte γX
(j) , j =0, . . . , p , ein, erhält man als Lösung des linearen Gleichungssystems einen Schätzwert σ2
für die Varianz σ2 des Weißen Rauschens und den geschätzten Vektor φ = (φ1, . . . , φp)T
für den theoretischen Vektor φ .
Man kann zeigen, dass falls (Xt ; t ∈ Z) ein kausaler AR(p)-Prozess bezüglich desWeißen Rauschens (Zt) ∼ IID(0;σ2) ist, die Schätzungen konsistent und asymptotischerwartungstreu sind und außerdem
√T(φ− φ
)in Verteilung gegen die Normalver-
teilung N(0, σ2Γ−1p ) konvergiert, dabei ist
Γp =
γ
X(0) γ
X(1) . . . γ
X(p− 1)
γX
(1) γX
(0) . . . γX
(p− 2)...
... . . . ...γ
X(p− 1) γ
X(p− 2) . . . γ
X(0)
.
73

Bem. 7.6 (Kleinste-Quadrate-Schätzer eines AR(p)-Modells)Fasst man ein AR(p)-Modell als Regressionsmodell mit jeweils abhängiger VariablerXt , Regressoren Xt−1, . . . , Xt−p und Störterm Zt (t = p + 1, . . . , T ) auf, kann mandie übliche Methode der kleinsten Quadrate zur Schätzung der unbekannten Parameterφ1, . . . , φp und σ2 nutzen, indem man für die Funktion von p Variablen
S(φ1, . . . , φp) =T∑
t=p+1
(Xt − φ1Xt−1 − . . .− φpXt−p)2
einen Punkt eines absoluten Minimums φ = (φ1, . . . , φp)T sucht.
• Dies nennt man oft OLS-Schätzung (OLS=”ordinary least squares”).
• Man kann keine Regressionsgleichungen für die ersten p Beobachtungen aufstellen,einige Bedingungen für übliche Regressionsmodelle sind nicht erfüllt und man er-hält nicht immer ein kausales Modell. Die Grenzverteilungen stimmen mit denendes Yule-Walker-Schätzers überein.
Der Schätzer φ = (φ1, . . . , φp)T kann für eine konkrete Realisierung (x1, . . . , xT ) mit
Hilfe des linearen Gleichungssystems
xTx φ = xTy
mit dem Vektor y = (xp+1, . . . , xT)T und der Matrix
x =
xp xp−1 . . . x1xp+1 xp . . . x2...
... . . . ...x
T−1x
T−2. . . x
T−p
berechnet werden. Die Schätzung σ2 von σ2 erfolgt durch
σ2 =1
TzTz ,
hierbei ist z = y − x φ der Vektor der geschätzten Residuen.
Bem. 7.7 (Maximum-Likelihood-Schätzer eines ARMA(p, q)-Modells)Beim Standardverfahren zur Schätzung der Parameter eines kausalen und invertier-baren ARMA(p, q)-Prozesses, der Maximum-Likelihood-Methode, geht man von einembekannten Verteilungstyp des Zufallsvektors X
1:T= (X1, . . . , XT
)T aus. Insbesonderewird oft angenommen, dass das Weiße Rauschen (Zt ; t ∈ Z) ein Gaußsches WeißesRauschen ist, so dass der Zufallsvektor X
1:Tmultivariat normalverteilt ist. Die Dich-
tefunktion hängt von den Parametern φ1, . . . , φp, θ1, . . . , θq, σ2 ab.
74

Die Maximum-Likelihood-Methode zur Schätzung der Parameter besteht nun darin, die-jenigen Parameterwerte als Schätzwerte zu bestimmen, für welche der Wert der Dich-tefunktion mit der gegebenen Realisierung x1, . . . , xT
maximal wird, wobei Zusatzbe-dingungen, wie die Kausalität und Invertierbarkeit des geschätzten Modells auch mitberücksichtigt werden können.Dies kann auf Grundlage geeigneter numerischer Verfahren mit Hilfe von Computerpro-grammen erfolgen.
Die Schätzfunktionen besitzen unter geeigneten Voraussetzungen auch gute Eigenschaf-ten, wie z.B. eine asymptotische Normalverteilung.
Bem. 7.8 (Prüfung des geschätzten Modells)Mögliche Fragestellungen bei einer Prüfung eines geschätzten Modells können sein:
• Können die Residuen als Weißes Rauschen modelliert werden ?
• Gibt es Ausreisser in den Residuen ?
• Sind die Parameter plausibel ?
• Inwieweit folgt das Modell den Daten (sehen simulierte Zeitreihen ähnlich aus) ?
• Liefert das Modell sinnvolle Prognosen ?
• Gibt es Strukturbrüche, d.h. sollten eventuell die Parameter zeitabhängig gewähltwerden ?
Bem. 7.9 (Wahl von p und q bei Selektionsverfahren)
• Die Bestimmung der richtigen Ordnungen p und q spielt ein große Rolle, daauch die Schätzverfahren für die Parameter bei einem ”overfitting” (p, q zu groß)oder ”underfitting” (p, q zu klein) oft nicht mehr zuverlässig funktionieren.
• Bei automatischen Selektionsverfahren werden die Ordnungen so gewählt, dass einbestimmtes sogenanntes Informationskriterium minimal wird. In diesen werdeneine zu schlechte Anpassung des geschätzten Modells an die Daten, gemessen inder geschätzten Varianz der Residuen σ2
p,q , und auch zu große Werte von p und qbestraft (größere Werte der Ordnungen führen im Allgemeinen zu einer besserenAnpassung und so zu kleineren Werten von σ2
p,q) .
Bem. 7.10 (Verschiedene Informationskriterien)Die wichtigsten Informationskriterium sind vom Typ
ln(σ2p,q
)+ (p+ q)
C(T )
T
mit einer in T nichtfallenden Funktion C(T ) , insbesondere
75

• das Akaike-Informationskriterium
AIC(p, q) = ln(σ2p,q
)+ (p+ q)
2
T;
• das Schwarzsche oder Bayessche-Informationskriterium
BIC(p, q) = ln(σ2p,q
)+ (p+ q)
ln(T )
T;
• das Hannan-Quinn-Informationskriterium
HQ(p, q) = ln(σ2p,q
)+ (p+ q)
ln(ln(T ))
T.
Bem. 7.11
• Die geschätzte Varianz der Residuen σ2p,q kann z.B. mit den geschätzten Re-
siduen zj berechnet werden, welche ihrerseits z.B. mit Hilfe der geschätztenMA(∞)-Darstellung des Weißen Rauschens aufgrund der Invertierbarkeitsbedin-gung bestimmt werden können.
• Die Informationskriterien BIC und HQ liefern konsistente Schätzungen der Ord-nungen p und q .
• Das Informationskriterium AIC wird am häufigsten verwendet, überschätzt jedochtendenziell die Ordnungen der Modelle. Dies kann manchmal wünschenswert sein,z.B. bei Tests auf Einheitswurzeln.
• Da der zweite Summand mit wachsendem T fällt, lassen die Informationskriterienbei steigendem T Modelle mit höheren Ordnungen zu.
8 Integrierte ProzesseBem. 8.1Von einem ARIMA(p, d, q)-Prozess („Autoregressiver Integrierter Moving Average Pro-zess“) spricht man, wenn eine d-malige Differenzenbildung auf einen ARMA(p, q)-Prozessführt. Damit gehören derartige stochastische Prozesse im Allgemeinen zu den nichtsta-tionären Prozessen.
Def. 8.2Für d ∈ N0 heißt der stochastische Prozess (Xt ; t ∈ Z) ein ARIMA(p, d, q)-Prozess,falls der stochastische Prozess (Yt ; t ∈ Z) mit Yt = (1 − L)dXt , t ∈ Z , ein kausalerARMA(p, q)-Prozess ist. Damit genügt ein ARIMA(p, d, q)-Prozess der Differenzenglei-chung
Φ∗(L)Xt := Φ(L)(1− L)dXt = Φ(L)Yt = Θ(L)Zt (1)
76

mit einem Prozess des Weißen Rauschens (Zt) ∼WN(0;σ2) .
Bem. 8.3
• Für d ≥ 1 kann ein deterministisches oder zufälliges Polynom in t vom Grad ≤ d−1 zu Xt addiert werden, ohne das sich an der Gültigkeit der Differenzengleichung(1) etwas ändert.
• Zum Beispiel genügt für den ARIMA(p, d, q)-Prozess (Xt ; t ∈ Z) mit d ≥ 1gemäß Differenzengleichung (1) der stochastische Prozess (Xt + X ; t ∈ Z) miteiner Zufallsgröße X mit endlicher Varianz derselben Differenzengleichung.
• Erwartungswert- und Kovarianzfunktion werden in diesem Fall durch die Differen-zengleichung (1) nicht eindeutig festgelegt.
Satz 8.4 (Erste Differenzen eines ARMA(p, q)-Prozesses)Sei (Yt ; t ∈ Z) ein kausaler ARMA(p, q)-Prozess mit Definitionsgleichung
Φ(L)Yt = Θ(L)Zt ,
die Nullstellen des MA-Teils seien z1, . . . , zq .Dann bilden die ersten Differenzen
Xt = ∆Yt = (1− L)Yt = Yt − Yt−1
einen ARMA(p, q+1)-Prozess, bei dem sich der autoregressive Teil nicht ändert und dieNullstellen des MA-Teils sind z1, . . . , zq, 1 .
Für d = 1 wird auch definiert
Def. 8.5 (differenzenstationäre Prozesse)Der stochastische Prozess (Xt ; t ∈ Z) heißt integriert der Ordnung 1 oder differenzen-stationär, symbolisch (Xt) ∼ I(1) , falls
∆Xt = (1− L)Xt = Xt −Xt−1 , t ∈ Z ,
die Differenzengleichung
∆Xt = δ + Ψ(L)Zt , t ∈ Z , (2)
für δ ∈ R , (Zt) ∼ WN(0;σ2) , Ψ(z) =∞∑j=0
ψjzj mit Ψ(1) 6= 0 und
∞∑j=0
j|ψj| < ∞
erfüllt.
Bem. 8.6
• Ein kausaler ARMA(p, q)-Prozess mit Erwartungswert δ ∈ R besitzt die Darstel-lung auf der rechten Seite von (2).
77

• Die Bedingung Ψ(1) 6= 0 garantiert, dass nicht schon der Prozess (Xt ; t ∈ Z)ein schwach stationärer Prozess ist.
• Aus der Bedingung∞∑j=0
j|ψj| < ∞ folgen die Eigenschaften∞∑j=0
|ψj| < ∞ und
∞∑j=0
|ψj|2 <∞ .
Neben den differenzenstationären stochastischen Prozessen spielen aber auch die soge-nannten trendstationären stochastischen Prozesse eine große Rolle in der Zeitreihenana-lyse.
Def. 8.7 (trendstationäre stochastische Prozesse)Der stochastische Prozess (Xt ; t ∈ Z) heißt trendstationär, falls für eine deterministi-sche Funktion µ : Z→ R der stochastische Prozess (Yt ; t ∈ Z) mit
Yt := Xt − µ(t) , t ∈ Z ,
ein schwach stationärer stochastischer Prozess ist. Dabei kann die Funktion µ(t) immerso gewählt werden, dass E[Yt] = 0 für beliebige t ∈ Z gilt.
Bem. 8.8
• Oft (z.B. für kausale ARMA(p, q)-Prozesse) besitzt der schwach stationäre Prozess(Yt ; t ∈ Z) in der vorigen Definition die Darstellung
Yt = µ+ Ψ(L)Zt = µ+∞∑j=0
ψjZt−j , t ∈ Z ,
mit µ ∈ R , (Zt) ∼WN(0;σ2) und∞∑j=0
ψ2j <∞ .
• Aus obiger Darstellung folgt z.B. die „mean-reverting“ Eigenschaft
limh→∞
Prog1:tYt+h = µ = E[Yt] , t ∈ Z .
Bem. 8.9 (Unterscheidung von Differenzen- und Trendstationarität)
• Differenzenstationarität und Trendstationarität bewirken zum Teil wesentlich un-terschiedliche Eigenschaften, deshalb ist es wichtig herauszufinden, welcher Typvon Instationarität vorliegt (dabei gibt es auch noch weitere Formen der Instatio-narität bei stochastischen Prozessen).
• So lässt zum Beispiel der Einfluss eines betragsmäßig großen Schocks zt0 zumZeitpunkt t0 bei einem trendstationären Prozess mit der Zeit nach, währendz.B. bei einem differenzenstationären Prozess mit Ψ(z) = 1 der entsprechendeSummand in der ungeänderten Form für spätere Zeitmomente erhalten bleibt.
78

• Unter geeigneten Voraussetzungen können sogenannte Tests auf Einheitswurzeln(„Unit Root Tests“) durchgeführt werden, um eine statistische Entscheidung überdie „Stationärität“ (stationär / trendstationär / differenzenstationär) vorzuneh-men.
Bem. 8.10 (Der Dickey-Fuller-Test)Der Dickey-Fuller-Test beruht auf der sogenannten Dickey-Fuller-Regression,der Regression der Werte Xt auf Xt−1 und ggf. deterministische Ansatzfunktionen,insbesondere auf eine deterministische Konstante und einen linearen Zeittrend.
Für die allgemeine geschätzte Regressionsgleichung (Fall 4)
Xt = α + δt+ φXt−1 + Zt
ergeben sich Sonderfälle mit
• Xt = φXt−1 + Zt (Fall 1) sowie
• Xt = α + φXt−1 + Zt (Fall 2 und Fall 3)
(Zt) ist dabei ein Gaußsches Weißes Rauschen (für lange Zeitreihen kann diese Forderungabgeschwächt werden).
Unter der Nullhypothese φ = 1 gelten als Modellgleichungen im Fall
1) Xt = Xt−1 + Zt (zufällige Irrfahrt);
2) Xt = Xt−1 + Zt bei zusätzlicher Hypothese α = 0 ;
3) Xt = α +Xt−1 + Zt (α 6= 0) (zufällige Irrfahrt mit Drift);
4) Xt = α +Xt−1 + Zt bei zusätzlicher Hypothese δ = 0 .
Als Statistik für φ kann T(φ− 1
)(diese Statistik wird oft ρ-Statistik genannt)
oder die so genannte t-Statistik tφ =φ− 1
σφdienen. Die asymptotischen Verteilungen
dieser Statistik liegen tabelliert in der Literatur vor, sie sind abhängig vom Fall und dendeterministischen Komponenten.
Als Alternativhypothese dient bei den Tests bezüglich φ der Bereich −1 < φ < 1 .
Alternativ kann die Dickey-Fuller-Regression auch durch
∆Xt = α + δt+ βXt−1 + Zt
mit β = φ− 1 geschrieben werden. Die Hypothesen sind dann
H0 : β = 0 H1 : −2 < β < 0 ,
dies zeigt, dass der Test ein einseitiger Test ist.
79

Die Nullhypothese beschreibt den Fall einer vorhandenen Einheitswurzel (also falls keinTrend auftritt, den Fall der Differenzenstationarität).
Eine zusätzliche Berücksichtigung weiterer verzögerter Differenzen ∆Xt−1, . . . ,∆Xt−p+1
führt auf den erweiterten Dickey-Fuller-Test („augmented Dickey-Fuller-Test“,ADF-Test).
Bem. 8.11 (Der Phillips-Perron-Test (PP-Test))
• Der Phillips-Perron-Test basiert ebenfalls auf der Dickey-Fuller-Regression,hier kann der Prozess (Zt) aber ein allgemeiner stationärer Prozess mit E[Zt] =0 , t ∈ Z , sein. Dies ist ein Vorteil, da an dieser Stelle eine genauere Modellierungnicht notwendig ist. Man arbeitet hier mit modifizierten Teststatistiken, die wiedervom Fall und den deterministischen Komponenten abhängen.
• Der Phillips-Perron-Test hat gegenüber dem Dickey-Fuller-Test eine grö-ßere Mächtigkeit (die Wahrscheinlichkeit H0 abzulehnen, falls sie falsch ist, istgrößer), aber im Vergleich zum Dickey-Fuller-Test lehnt er auch öfter die Null-hypothese ab, wenn sie richtig ist.
Bem. 8.12 (Der KPSS-Test)Der KPSS-Test (Kwiatkowski, Phillips, Schmidt, Shin) ist ein statistischer Test,bei demdie Nullhypothese: der Prozess ist trendstationär gegendie Alternativhypothese: der Prozess ist integriert,überprüft wird. Konkreter geht man von einem Prozess der Form
Xt = α + δt+ dt∑
j=1
Zj + Ut , t ∈ N ,
mit reellen Zahlen α, δ, d , einem Weißen Rauschen (Zt) und einem stationären Prozess(Ut) aus. Die Hypothesen sind
H0 : d = 0 ; H1 : d 6= 0 .
Die Formel der Teststatistik und asymptotische kritische Werte der Teststatistik sind inder Literatur zu finden.
9 ARCH- und GARCH-ModelleBem. 9.1
• Die Untersuchung bestimmter konkreter Zeitreihen zeigt, dass ARMA- oder ARIMA-Modelle nicht immer ausreichend gute Modelle liefern.
80

• So zeigt sich für bestimmte Zeitreihen, die als stationär angesehen werden kön-nen, dass sich Zeitperioden mit starken Schwankungen („mit hoher Volatilität“)und Zeitperioden mit geringen Schwankungen („mit niedriger Volatilität“) zufäl-lig abwechseln. Eine solche Erscheinung kann nicht gut durch ARMA-Modelle be-schrieben werden, da bei ihnen die bedingte Varianz (auch die unbedingte Varianz)konstant ist.
• Da bei ARMA-Modellen eher der bedingte Erwartungswert modelliert wird, wurdenach geeigneten Modellierungen der Varianz gesucht und so die ARCH-Modelleund deren Verallgemeinerungen entwickelt.
Def. 9.2 (ARCH(1)-Prozess)Der stochastische Prozess (Zt ; t ∈ Z) heißt autoregressiv bedingt heteroskedastischerProzess erster Ordnung oder ARCH(1)-Prozess („autoregressive conditional heteroskedastic“),falls er der (nichtlinearen) Differenzengleichung
Zt = νt
√α0 + α1Z2
t−1 (ARCH(1))
mit α0 > 0 , 0 < α1 < 1 , νt ∼ IIN(0; 1) genügt und νt und Zt−1 für alle t ∈ Zunabhängig voneinander sind.
Bem.
• Es können auch anders verteilte Zufallsgrößen νt in der Modellierung genutztwerden.
• Jetzt wird die Unabhängigkeit statt der schwächeren Unkorreliertheit vorausge-setzt, da nichtlineare Zeitreihenmodelle betrachtet werden.
Satz 9.3 (stationäre Lösung der Definitionsgleichung)Unter den Annahmen in Definition 9.2 besitzt die Differenzengleichung (ARCH(1)) einefast sicher eindeutige stark stationäre Lösung mit E[Z2
t ] < ∞ (die also auch schwachstationär ist)
Zt = νt
√√√√α0
(1 +
∞∑j=1
αj1 · ν2t−1 · ν2t−2 · . . . · ν2t−j
), t ∈ Z .
Satz 9.4 (Eigenschaften der stationären Lösung)Unter den Voraussetzungen in Satz 9.3 besitzt der stochastische Prozess (Zt ; t ∈ Z)die Eigenschaften
(i) E[Zt] = E[νt]E
[√α0 + α1Z2
t−1
]= 0 , t ∈ Z .
(ii) E[ZtZt−h] = 0 , t ∈ Z , h 6= 0 .
81

(iii) Var [Zt] = E[Z2t
]= E
[ν2t] (α0 + α1E
[Z2t−1])
⇒ 0 < Var [Zt] =α0
1− α1
<
∞, t ∈ Z .
(iv) E[Z3t
]= E
[ν3t]E[(α0 + α1Z
2t−1) 3
2
]= 0 , t ∈ Z .
(v) Im Fall E[Z4t ] <∞ gilt für die Kurtosis κ = κ(Zt)
κ =E[Z4
t ]
(E[Z2t ])
2 = 3 · 1− α21
1− 3α21
> 3 , t ∈ Z .
Bem. 9.5
• Aus den Eigenschaften in Satz 9.4 folgt, dass (Zt ; t ∈ Z) ein Prozess des Wei-ßen Rauschens ist, d.h. aus unkorrelierten Zufallsgrößen besteht. Allerdings sinddie Zufallsgrößen nicht unabhängig. Dies sieht man z.B. an der entsprechendenGleichung
Z2t = ν2t
(α0 + α1Z
2t−1), t ∈ Z , .
• Es gilt 0 < E[Z4t ] <∞ genau dann, wenn 0 < α1 < 1/
√3 ≈ 0.5774 . In diesem
Fall besitzen die Zufallsgrößen Zt eine Verteilung mit schweren Enden („heavytails“, „leptokurtisch“).
Der Prozess (Yt ; t ∈ Z) mit Yt =Z2t
α0
hat die selbe Autokorrelationsfunktion wie
der AR(1)-Prozess (Wt ; t ∈ Z) mit der Definitionsgleichung Wt = α1Wt−1 + Utmit (Ut) ∼WN(0; 1) .
Def. 9.6 (ARCH(p)-Prozess)Der stochastische Prozess (Zt ; t ∈ Z) heißt autoregressiv bedingt heteroskedastischerProzess p-ter Ordnung oder ARCH(p)-Prozess („autoregressive conditional heteroskedastic“),falls er der (nichtlinearen) Differenzengleichung
Zt = νtσt mit σ2t = α0 +
p∑j=1
αjZ2t−j (ARCH(p))
mit α0 > 0 , αj ≥ 0 , νt ∼ IIN(0; 1) genügt und νt und Zt−j für alle t ∈ Z , j ≥ 1unabhängig voneinander sind.
Def. 9.7 (GARCH(p, q)-Prozess)Der stochastische Prozess (Zt ; t ∈ Z) heißt verallgemeinert autoregressiv bedingt he-teroskedastischer Prozess der Ordnung (p, q) oder GARCH(p, q)-Prozess („generalizedautoregressive conditional heteroskedastic“), falls er der (nichtlinearen) Differenzenglei-chung
Zt = νtσt mit σ2t = α0 +
p∑j=1
αjZ2t−j +
q∑k=1
βkσ2t−k (GARCH(p,q))
82

mit α0 > 0 , αj ≥ 0 , βk ≥ 0 , νt ∼ IIN(0; 1) genügt und νt und Zt−j für alle t ∈ Z ,j ≥ 1 unabhängig voneinander sind.
Bem. 9.8Man kann zeigen, dass ein stark stationärer Prozess mit endlichen zweiten Momentenals Lösung genau dann existiert, wenn gilt
p∑j=1
αj +
q∑k=1
βk < 1 .
Unter dieser Voraussetzung gilt (Zt) ∼WN(0;σ2Z) mit
σ2Z = Var [Zt] =
α0
1−p∑j=1
αj −q∑
k=1
βk
.
Man kann zeigen, dass dann (Z2t ; t ∈ Z) ein kausaler und invertierbarer ARMA(maxp, q, q)-
Prozess ist.Am häufigsten werden GARCH(1,1)-Modelle genutzt.
Bsp. 9.9Als Beispiel soll eine Zeitreihe aus dem BuchJonathan D. Cryer, Kung-Sik Chan: Time Series Analysis. With Applications in R,Springer, 2008, Kapitel 12,bzw. dem R-Paket „TSA“ dienen. Dies ist die Zeitreihe des CREF-Fonds („College Reti-rement Equities Fund“), tägliche Werte (Arbeitstage) vom 26.8.2004 bis zum 15.8.2006.
Hierbei ist insbesondere die Zeitreihe der Returns (in Prozent) von Interesse, also fallsXt jeweils den Wert des Fonds zum Zeitpunkt t bezeichnet, die Zeitreihe (Zt) mit
Zt = 100 · (ln(Xt)− ln(Xt−1)) = 100 · ln(
Xt
Xt−1
).
Zeitreihe CREF
83

Zeitreihe Returns CREF
Empirische Autokorrelationsfunktion Returns CREF
Partielle Autokorrelationsfunktion Returns CREF
84

Zeitreihe Beträge Returns CREF
Autokorrelationsfunktion Beträge Returns CREF
Partielle Autokorrelationsfunktion Beträge Returns CREF
85

Zeitreihe Quadrate Returns CREF
Autokorrelationsfunktion Quadrate Returns CREF
Partielle Autokorrelationsfunktion Quadrate Returns CREF
86

Q-Q-Plot Returns CREF
Histogramm Returns CREF
Bemerkungen
• Das Verhalten der gewöhnlichen bzw. partiellen Korrelationsfunktionen zeigt, dassdie Returns nicht gut durch unabhängige Zufallsgrößen modelliert werden können.
• Außerdem sind Abweichungen von einer Normalverteilung zu erkennen, dies wirdauch durch Tests bestätigt.
• Eine Anpassung eines GARCH(1,1)-Modells ergibt die Schätzwerte
α0 = 0.01633
α1 = 0.04414
β1 = 0.91704 .
87

• Für die geschätzten standardisierten Residuen εt =zt
σt|t−1dieses Modells erhält
man dann die folgenden Grafiken.
Residuen zu GARCH(1,1)-Modell für Returns CREF
Autokorrelationsfunktion Residuen zu GARCH(1,1)-Modell für Returns CREF
Partielle Autokorrelationsfunktion Residuen zu GARCH(1,1)-Modell für Re-turns CREF
88

Autokorrelationsfunktion Beträge Residuen zu GARCH(1,1)-Modell für Re-turns CREF
Partielle Autokorrelationsfunktion Beträge Residuen zu GARCH(1,1)-Modellfür Returns CREF
Autokorrelationsfunktion Quadrate Residuen zu GARCH(1,1)-Modell fürReturns CREF
89

Partielle Autokorrelationsfunktion Quadrate Residuen zu GARCH(1,1)-Modellfür Returns CREF
Q-Q-Plot Residuen zu GARCH(1,1)-Modell für Returns CREF
Histogramm Residuen zu GARCH(1,1)-Modell für Returns CREF
90

10 Zeitreihenanalyse mit SingulärspektrumanalyseDie Singulärspektrumanalyse
• ist ein Verfahren der Zeitreihenanalyse und Vorhersage;
• kombiniert Elemente der klassischen Zeitreihenanalyse, multivariaten Statistik,multivariaten Geometrie, der Theorie dynamischer Systeme und der Signalver-arbeitung;
• setzt kein parametrisches Modell und keine Stationaritätsannahmen voraus, istdemzufolge flexibel anwendbar und konnte schon für viele Anwendungen erfolg-reich eingesetzt werden.
• Engl. ”Singular spectrum analysis” (SSA), ”Caterpillar methodology” (russ. ”Gu-senitsa”).
• Erste Artikel 1986, z.B. Broomhead, King, Extracting qualitative dynamicsfrom experimental data, Physica D.
• Enge Verbindung z.B. zur Hauptkomponentenanalyse und zur Karhunen-Loève-Entwicklung.
Zielstellung der Singulärspektrumanalyse
Die Singulärspektrumanalyse zielt auf die (additive) Zerlegung einer gegebenen Zeitreihein eine kleine Anzahl interpretierbarer Komponenten, wie einem sich langsam änderndemTrend, einer oszillierenden Komponente und einem „strukturlosen“ Rauschen.
Algorithmus
• Geg. konkrete Zeitreihe X = XN = (x1, . . . , xN) ,N > 2 , N ∈ N , ∃ i ∈ 1, . . . , N :xi 6= 0 .
• Wahl des Parameters L ∈ N (1 < L < N) (Fensterlänge); K := N − L+ 1 .
• 1. Stufe Zerlegung
– 1. Schritt Einbettung (Aufstellen der Trajektorienmatrix X)– 2. Schritt Singulärwertzerlegung der Trajektorienmatrix
• 2. Stufe Rekonstruktion
– 3. Schritt Gruppierung der Eigentripel– 4. Schritt Diagonale Mittelung
• Ergebnis Zerlegung der Ausgangszeitreihe in die Summe von m (m ∈ N,m ≤ L)rekonstruierten Zeitreihen,
xn =m∑k=1
xn(k) (n = 1, . . . , N) .
91

1. Schritt: Einbettung
• Folge von K = N − L+ 1 verschobenen Vektoren der Länge L
Xi = T(xi, . . . , xi+L−1) (i = 1, . . . , K) .
• L-Trajektorienmatrix (Trajektorienmatrix)
X = [X1 : . . . : XK ] = (xij)L,Ki,j=1 =
x1 x2 x3 . . . xKx2 x3 x4 . . . xK+1
x3 x4 x5 . . . xK+2...
...... . . . ...
xL xL+1 xL+2 . . . xN
.
• L×K-Matrix; (i, j)-tes Element ist xij = xi+j−1 ⇒ übereinstimmende Elementeauf den Gegendiagonalen i+ j = const (Hankel-Matrix).
Bemerkungen zur Einbettung
• Die univariate Zeitreihe X = (x1, . . . , xN) wird in eine multivariate ZeitreiheX1, . . . , XK mit Vektoren Xi = T(xi, . . . , xi+L−1) ∈ RL umgewandelt.
• Ist X die L-Trajektorienmatrix einer univariaten Zeitreihe X , dann ist TX dieK-Trajektorienmatrix derselben Zeitreihe.
• Für N,L,K ∈ N mit K = N − L + 1 ist eine L ×K-Matrix genau dann dieL-Trajektorienmatrix einer univariaten Zeitreihe, wenn sie eine Hankel-Matrixist.
• Die Fensterlänge L sollte hinreichend groß sein, damit die verschobenen Vek-toren einen wesentlichen Teil des Verhaltens der Ausgangszeitreihe repräsentierenkönnen.
• Man kann immer L ≤ N/2 wählen; günstige Werte für L hängen von den Datenund dem Ziel der Untersuchung ab, ggf. sollte man die Analyse für verschiedeneWerte von L durchführen und die Ergebnisse miteinander vergleichen.
Zerlegungen von Zeitreihen und Trajektorienmatrizen
Sind univariate Zeitreihen
X(1) = (x(1)1 , . . . , x
(1)N ) und X(2) = (x
(2)1 , . . . , x
(2)N )
mit zugehörigen L-Trajektorienmatrizen X(1) und X(2) gegeben, dann gilt für L-Trajektorienmatrix X der Summenzeitreihe
X = X(1) + X(2) = (x(1)1 + x
(2)1 , . . . , x
(1)N + x
(2)N )
die Beziehung X = X(1) + X(2) , ebenso für mehr Summanden und umgekehrt.
92

2. Schritt: Singulärwertzerlegung der Trajektorienmatrix X
• S = XTX symmetrische, positiv semidefinite L× L−Matrix.
• λ1 ≥ . . . ≥ λL ≥ 0 Eigenwerte von S , monoton fallend.
• U1, . . . , UL orthonomiertes System der Eigenvektoren der Matrix S zu diesenEigenwerten.
• d := rankX = maxi ∈ N mit λi > 0(in der Praxis üblicherweise d = L∗ := minL,K).
• Vi = TXUi/√λi (i = 1, . . . , d).
• ⇒ Mit den Matrizen vom Rang 1 Xi =√λiUiTVi (elementare Matrizen) gilt
X = X1 + . . .+ Xd .
• (√λi, Ui, Vi) ist i-tes Eigentripel der Singulärwertzerlegung,√λi i-ter Singulärwert, Ui i-ter linker Singulärvektor,
Vi i-ter rechter Singulärvektor (i-ter Faktorvektor).
Die Matrix S = XTX
• S = (sij)Li,j=1 mit
sij =K−1∑t=0
xi+txj+t ,
so dass für Differenzen der Indizes gilt j + t− i− t = j − i .
• Damit wäre für einen zugrundeliegenden zentrierten schwach stationären Prozesssij/K ein Schätzwert für den Wert der Kovarianzfunktion γ(j − i) .
• Eine andere Variante der Singulärspektrumanalyse nutzt statt der Matrix S dieMatrix der Schätzwerte der Kovarianzfunktion mit Einträgen
cij =1
N − k
N−k∑t=1
xtxt+k mit i, j = 1, . . . , L und k = |i− j| .
3. Schritt: Gruppierung der Eigentripel
• Zerlegung der Indexmenge 1, . . . , d in m disjunkte Teilmengen I1, . . . , Im .
• Für k ∈ 1, . . .m sei XIk =∑
`∈Ik X` .
• Die Zerlegung der Indexmenge führt so zur gruppierten Zerlegung
X = XI1 + . . .+ XIm
der Trajektorienmatrix.
• Im Fall m = d und Ij = j , j = 1, . . . , d , wird die entsprechende Gruppierungelementare Gruppierung genannt.
93

4. Schritt: Diagonale Mittelung
• Für jeder der Matrizen XIj der gruppierten Zerlegung werden die Elemente aufden Gegendiagonalen durch ihren Mittelwert ersetzt, dadurch entstehen Hankel-Matrizen, denen entsprechende Zeitreihen zugeordnet werden können.
• Man spricht auch von einer Hankelisierung, diese besitzt auch bestimmte Opti-malitätseigenschaften.
• Ergebnis Zerlegung der Ausgangszeitreihe in die Summe von m (m ∈ N,m ≤ L)rekonstruierten Zeitreihen,
xn =m∑j=1
xn(j) (n = 1, . . . , N) .
Beispiel CO2-Konzentration in Mauna Loa (Hawaii)
Beispiel CO2 Eigenwerte
94

Beispiel CO2 Anteile kumulierte Eigenwerte
Beispiel CO2 Eigenvektoren
Beispiel CO2 Paare der Eigenvektoren
95

Beispiel CO2 W-Korrelationsmatrix
Beispiel CO2 W-Korrelationsmatrix Rekonstruktion
Beispiel CO2 Zerlegung
96





























