Embed Size (px)
Citation preview

1Mar 16, 2011
Automatic Transformation and Optimization of
Applications on GPUs and GPU Clusters
PhD Oral Defence: Wenjing Ma
Advisor: Dr Gagan Agrawal
The Ohio State University

2Mar 16, 2011
Outline of Contents• Motivation
• Accelerators, GPGPU and GPU cluster• Difficulty of GPU programming
• Framework and Approaches• Code generation for data mining applications
•Translation system for enabling data mining applications on GPUs
•Automatic translation of data mining applications from MATLAB to GPUs
•Automatic code generation for data mining on clusters with GPU support
•Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions•Auto-tuning approach for tensor contractions on GPUs
•Loop transformation for tensor contraction sequences on multi-level memory architecture

3Mar 16, 2011
Introduction• Accelerators, GPGPU and GPU cluster
– Multi-core architectures are more and more popular in high performance computing
– GPU, Cell Processor, FPGA– GPU has good performance/price ratio
• Difficulty of Programming – How to program a cluster with accelerators on
each node ?

4Mar 16, 2011
Our Approach
• Provide high-level support for programming emerging high-end configurations
• Effective and simple optimization strategies• Focus on specific application classes
• Data mining application • Tensor contraction expressions

5Mar 16, 2011
Outline of Contents• Motivation
• Accelerators, GPGPU and GPU cluster• Difficulty of GPU programming
• Framework and Approaches• Code generation for data mining applications
•Translation system for enabling data mining applications on GPUs
•Automatic translation of data mining applications from MATLAB to GPUs
•Automatic code generation for data mining on clusters with GPU support
•Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions•Auto-tuning approach for tensor contractions on GPUs
•Loop transformation for tensor contraction sequences on multi-level memory architecture

6Mar 16, 2011
Shared memory on GPU
• Features of shared memory on GPU– Small in size– Software controllable– Much faster than device memory– …
• Need a strategy to arrange data on shared memory– Arrange by hand: Time consuming and not optimal– Previous work: intuitive solution

7Mar 16, 2011
An Example to show shared memory usage
Void Kernel_function(float *A, float *C, …) {__shared__ float s_C[r*NUM_THREADS];__shared__ float s_A[r*NUM_THREADS];for(int i=0;i<n;i+=NUM_THREADS) { for(int j=0;j<r;j++) /* load A in device memory into s_A */ for(int j=0;j<m;j++) for(int k=0;k<r;k++) /* load C in device memory into s_C*/ ......}/* write C in s_C to device memory… */

8Mar 16, 2011
Problem Formulation for Shared Memory Arrangement
What to Consider A kernel function (with a number of basic blocks)Array, section of array, element of arrayLive ranges of each variable
Determine in which basic block a variable is allocated to shared memoryAssign_point[i][k]: variable i, basic block k

9Mar 16, 2011
Integer Linear Programming
Linear ProgrammingObjective function
Maximize z = CT xConstraints
Ax≤bSolution
Values of x
Special case of linear programmingAll the unknown variables are integers (within
{1,0} in our case)Solvable for reasonable size of problems

10Mar 16, 2011
Integer Programming for Shared Memory Arrangement (cnt’d)
• Objective Function• Maximize shared memory usage • Minimize data transfer between memory
hierarchies
Maximize z = ∑i {1…nVar}, k {1…nLive[i]}∈ ∈ Agg_SMrefik –
∑ i {1..nVar}, k {1…nLive[i]}∈ ∈ Total_memcopyik

11Mar 16, 2011
Integer Programming for Shared Memory Arrangement
• Objective Function
Agg_SMrefik =∑j {live_blocks[i][j]}∈ Is_assignedi
j×Refsij×itersj
Total_memcopyik =Data_transi
j×itersj
2×size_allocij , if Accessi
k = readwriteData_transi
j = 0 , if Accessik = temp
size_allocij , otherwise
{

12Mar 16, 2011
An Example to Show size_alloc
for (int i=0; i<n; i++)
for (int j=0; j<m; j++)
for (int k = 0; k<r; k++)
C[k] += A[i][k]- B[j][k]; ......
Size_alloc = r
Size_alloc = 1
Size_alloc = r*m
Size_alloc = r*m

13Mar 16, 2011
Integer Programming for Shared Memory Arrangement
ConstraintsTotal allocation does not exceed the limit of
shared memory at any time
Only at most one assign_point is 1 in each live range
∑i {live_list[j]}∈ Is_assignedij×size_alloci
j≤limit
∑i {live_blocks[j][k]}∈ assign_pointij≤1

14Mar 16, 2011
An Example
A: n*rB: m*rC: rn: 2048m: 3r: 3NUM_THREADS: 256
assign_point[0][1]=1;assign_point[1][0]=1;assign_point[2][0]=1;/* all other elements of assign_point are 0 */
for (int i=0; i<n; i++) for (int j=0; j<m; j++) for (int k = 0; k<r; k++) C[k] += A[i][k]- B[j][k]; ......
Integer Programming
Solver
assign_point[i][j]:i denotes variable I, j denotes basic block j.
Variables 0, 1, 2 correspond to A, B, C in the code.

15Mar 16, 2011
An Example (cnt’d)Generated Code:
__shared__ float s_B[m][r];__shared__ float s_C[r*NUM_THREADS];__shared__ float s_A[r*NUM_THREADS];/* load B to s_B */for(int i=0;i<n;i+=NUM_THREADS) { for(int j=0;j<r;j++) s_A[tid*r+j]=A[tid+i][j]; for(int j=0;j<m;j++) for(int k=0;k<r;k++) s_C[k*tid]+=s_A[tid*r+k]-s_B[j][k]; ......}/* Synchronize and combination of C */
for (int i=0; i<n; i++) for (int j=0; j<m; j++) for (int k = 0; k<r; k++) C[k] += A[i][k]- B[j][k]; ......

16Mar 16, 2011
Suggesting Loop Transformationfor (int rc = 0; rc < nRowCl; rc++) { tempDis = 0; for(int c = 0;c<numCol;c++) tempDis = tempDis + data[r][c] * Acomp[rc][colCL[c]];}
for (int rc = 0; rc < nRowCl; rc++) { tempDis[rc] = 0;}for(int c = 0;c<numCol;c++) {
/* load into shared memory */ for (int rc = 0; rc < nRowCl; rc++) { tempDis[rc] += data[r][c] * Acomp[rc][colCL[c]]; }}

17Mar 16, 2011
Experiment ResultsK-means EM
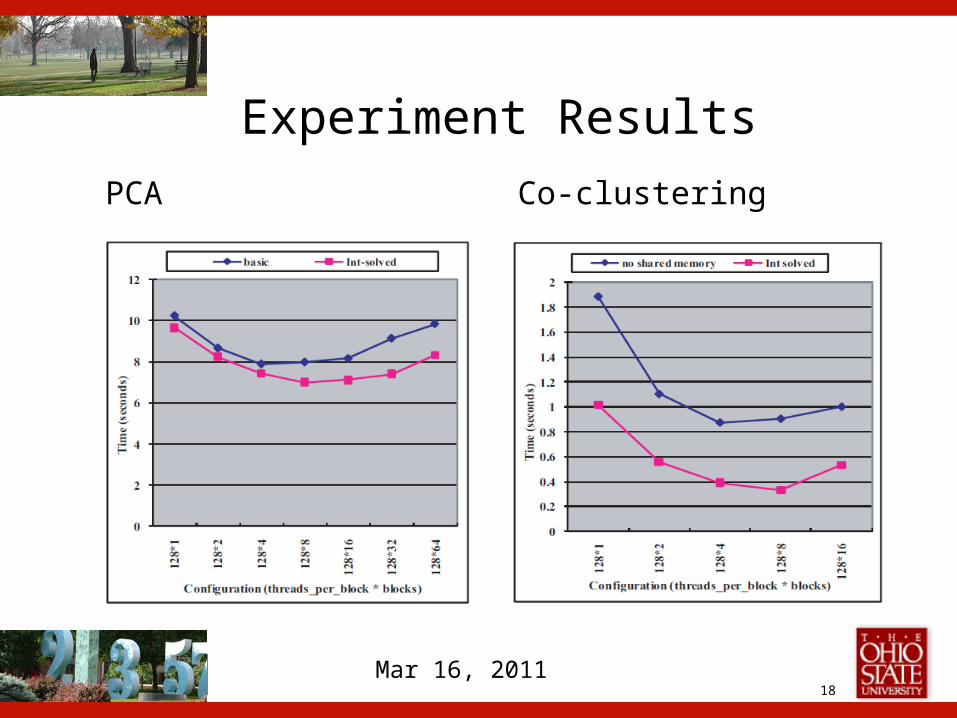
18Mar 16, 2011
Experiment Results
PCA Co-clustering
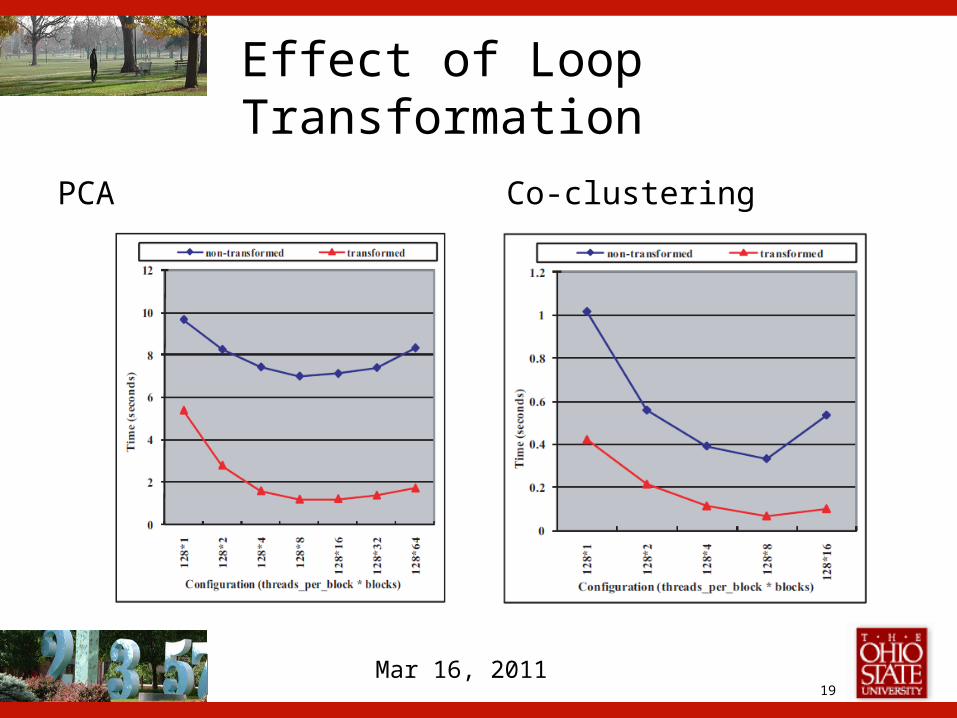
19Mar 16, 2011
Effect of Loop Transformation
PCA Co-clustering

20Mar 16, 2011
Outline of Contents• Motivation
• Accelerators, GPGPU and GPU cluster• Difficulty of GPU programming
• Framework and Approaches• Code generation for data mining applications
•Translation system for enabling data mining applications on GPUs
•Automatic translation of data mining applications from MATLAB to GPUs
•Automatic code generation for data mining on clusters with GPU support
•Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions•Auto-tuning approach for tensor contractions on GPUs
•Loop transformation for tensor contraction sequences on multi-level memory architecture

21Mar 16, 2011
Tensor Contraction on GPU and Auto-tuning
• Tensor contraction expressions– Motivated by the CCSD(T) part of NWchem– In the form of high-dimensional matrix multiplication– Example:
• r[h1 h2 p3 p4] += t[h6 h7 h1 h2] * v[p3 p4 h6 h7]• Auto-tuning
– Compile-time and Run-time optimization– Selecting best implementation with given input
problem

22Mar 16, 2011
Original Algorithm and Optimization
• Original Algorithm on T10 GPU– Loading input matrices to shared memory– Index Calculation
• Flattening and index combination• Optimization for Fermi
– Register tiling• Larger shared memory and register file on Fermi
– Modified index calculation order• Different output/input access ratio for each thread• r[h1 h2 p4 p3] += t[h6 h7 h1 h2] * v[p3 p4 h6 h7]

23Mar 16, 2011
Motivation of auto-tuning for tensor contractions on GPU
• Algorithm modification for different architectures
• Different algorithm choices for different inputs
Favor
input
Favor
output
Ex 1 (a) 0.425 0.504
(b) 0.487 0.584
(c) 0.51 0.671
(d) 0.681 0.881
Ex 2 (A) 13.6 11
(B) 105.5 41.5
(C) 199.7 149.9
(D) 27.1 22.6
Running time of two functions on Fermi with different index orders

24Mar 16, 2011
Approaches of Auto-tuning
• Existing approaches– Analytical cost model
• Hard to capture complex architecture features
– Empirical search• Not practical when search space is large
• Our approach– Parametrizable micro-benchmarks– Focusing on main features that affect performance

25Mar 16, 2011
Auto-tuning Approach for Tensor Contractions on Different GPUs
• Auto-tuning tool– Parametrizable micro-benchmarks
• Auto-tuning parameters– Memory access pattern– Kernel Consolidation

26Mar 16, 2011
Auto-tuning with Parametrizable Micro-benchmarks
Different Implementations
Target Expressions
Architecture Features
Micro Benchmark
Parameter Space
ExecutionModels andThresholds
Implementation Choice
Expression and problem
size in application

27Mar 16, 2011
Micro-benchmark Evaluation for Memory Access
• Access Stride on device memory makes big difference– Coalesced accesses:
• adjacent threads access contiguous words in device memory
– Cache• L1 and L2
– …
• Mapping to tensor contractions– Index calculation order– For uncommon index: favor input/output– For common index: favor each of the input

28Mar 16, 2011
Mapping to tensor contractions
r[h1 h2 p4 p3] += t[h6 h7 h1 h2] * v[p3 p4 h6 h7]
• calculate with input order: p3 is the inner loop– Accessing v
• Loading v from device memory to shared memory• Strides between two thread with adjacent x index: 1
– Accessing r• Update r in device memory• Strides between two threads with adjacent x index:
h1*h2*p4

29Mar 16, 2011
Micro-benchmark Evaluation for Memory Access
• A simple micro-benchmark
• Three types of : stride_x, stride_y, stride_iter
0
2
4
6
8
10
12
14
16
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Value of Parameter T
Tim
e (m
s)
x=T,y=T^2, iter=1 x=T,y=1,iter=T^3
x=T, y=T^3, iter=16
0
5
10
15
20
25
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Value of Parameter T
Tim
e (m
s)
x=1, y=T^3, iter=T^2 x=T, y=1, iter=T^2
Fermi
T10
A[tid.x*stride_x + tid.y*stride_y+ i*stride_iter]/* i is the index of iterations */

31Mar 16, 2011
Choice of kernel consolidation• Tightly coupled consolidation
– For functions with large data movement cost
• Loosely coupled consolidation– For functions with comparable computation and
data movement
Foreach (task i)data copy (host to device)
Foreach (task i)launch the kernels
Foreach (task i)data copy (device to host)
Foreach (task i)data copy for task i (host to device)launch kernel(i)data copy for task i (device to host)
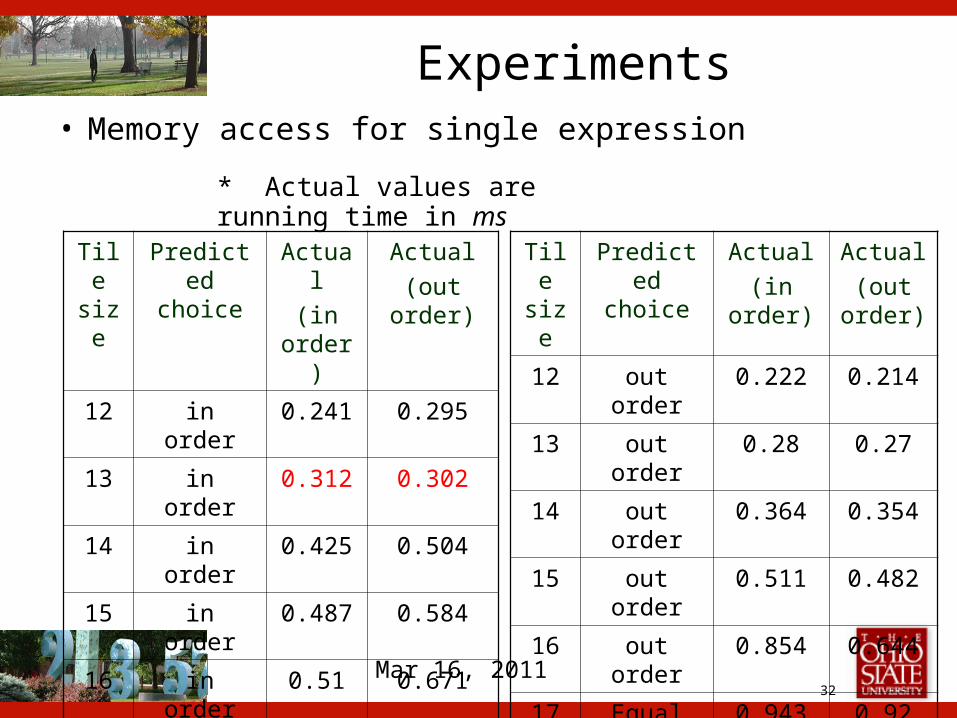
32Mar 16, 2011
Experiments• Memory access for single expression
Tile size
Predicted choice
Actual
(in order)
Actual
(out order)
12 in order 0.241 0.295
13 in order 0.312 0.302
14 in order 0.425 0.504
15 in order 0.487 0.584
16 in order 0.51 0.671
17 in order 0.681 0.881
18 in order 1.078 1.471
* Actual values are running time in ms
Tile size
Predicted choice
Actual
(in order)
Actual
(out order)
12 out order 0.222 0.214
13 out order 0.28 0.27
14 out order 0.364 0.354
15 out order 0.511 0.482
16 out order 0.854 0.644
17 Equal 0.943 0.92
18 Equal 1.193 1.124

34Mar 16, 2011
Experiment
• Running on collections of tensor contractions
0
0.4
0.8
1.2
1.6
2
14 16 18 14(L) 16(L) 18(L)
Tile size
Tim
e (s
econ
ds)
baseline tuned
01234567
14 16 18
14 (L
)
16(L
)
18(L
)
tile size
Tim
e (m
s)
baseline tuned
T10: without data copy
Fermi: without data copy
0
1
2
3
4
5
6
14 16 18 14(L) 16(L) 18(L)
Tile size
Tim
e (m
s)
baseline tuned
Fermi: with data copy

35Mar 16, 2011
Outline of Contents• Motivation
• Accelerators, GPGPU and GPU cluster• Difficulty of GPU programming
• Framework and Approaches• Code generation for data mining applications
•Translation system for enabling data mining applications on GPUs
•Automatic translation of data mining applications from MATLAB to GPUs
•Automatic code generation for data mining on clusters with GPU support
•Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions•Auto-tuning approach for tensor contractions on GPUs
•Loop transformation for tensor contraction sequences on multi-level memory architecture

36Mar 16, 2011
Motivation of loop fusion for sequence of tensor contractions
• Tensor contraction Sequence
= ∑pC4(p, a) ×A(p, q, r, s);
= ∑qC3(q, b) ×
= ∑rC2(r, c)×
B(a, b, c, d) = ∑sC1(s, d)× T1(a, b, c, s);
T2(a, b, r, s);T1(a, b, c, s)
T2(a, b, r, s) T3(a, q, r, s);
T3(a, q, r, s)
• Need to find the “fusion chains” • Memory limit at different levels
– With GPU, memory limitation is more strict

37Mar 16, 2011
Tensor contractions in multi-level memory hierarchy
• Memory hierarchy in GPU clusters– α: disk– β: global memory– γ: local memory/GPU memory
• None of the levels could be bypassed• A higher level is smaller and faster than a lower
level

38Mar 16, 2011
Loop transformation for tensor contraction sequences on multi-
level memory architecture
• Single tensor contraction– Memory and data movement cost on multi-level
memory
• Loop fusion for sequence of tensor contractions– Condition for fusion– Fusion on multi-level memory hierarchy

39Mar 16, 2011
Single Tensor Contraction on Multi-level memory Hierarchy
• One array fits in memory– X[x; y], Y [y; z], Z[x; z] , assume X fits in memory
– Memory cost: Nx×Ny+min(Nx, Ny)+1 ≤ Mβ
– No redundant data movement
• No array fits in memory– To minimize data movement, a preferred solution is
• Ti = Tj = T ≈
• Multi-level memory hierarchy– Tile size determined with particular system parameters
and problem sizes
M

40Mar 16, 2011
Fusion Conditions• A sequence
• Only consider the case where communication dominates– Common index of the first contraction
– Uncommon index of the smaller matrix in the second contraction
I1(d, c2,..., cn) = I0(d, c1, …, cn) ×B0(d, c1, …, cn)I2(d, c3,…, cn) = I1(d, c2, …, cn) ×B1(d, c2, …, cn) … In(d) = In-1(d, cn) × Bn-1(d, cn)
flop
αβ
Cfrac
Λ
2
|Ii(ci+1)| ≤
flop
αβ
Cfrac
Λ
2
n
ij
iji dBcB2
|)(||)(|

41Mar 16, 2011
Fusion Conditions
• Size of the matrix that is not eliminated
• The first B and the last B could be large– Tile sizes are determined as in single contraction
flop
αβ
Cfrac
Λ
2
|Bi|≤

42Mar 16, 2011
Algorithm to determine fusion chains
• For a “fusable” contraction list– With one matrix fitting to memory in each
contraction– Memory cost:
– When memory cost exceeds memory limit, a split is made to break the fusion chain
)),1(),1,(max(||
||min
,jkfkif
Common
I
ji
kj
ik
=
f(i, j) = 0, if j<i
, otherwise
j
ik kji ICommon ,
==

43Mar 16, 2011
Fusion in multi-level memory hierarchy
• With given chains at the lower level, determine subchains at the higher level– Reduced memory requirement forβ level
– Same procedure to select fusion chains
j
ik kji ICommon ,
f(i, j) = 0, if j<i
, otherwise)),1(),1,(max(||
||min
,jkfkif
Common
I
ji
kj
ik
=
ji
ji
II
II
||||
= , if memoryγ(i, j) ≤Mγ

44Mar 16, 2011
Evaluation
Fusion at Global Memory level Fusion at disk level

45Mar 16, 2011
Outline• Motivation
• Accelerators, GPGPU and GPU cluster• Difficulty of GPU programming
• Framework and Approaches• Code generation for data mining applications
•Translation system for enabling data mining applications on GPUs
•Automatic translation of data mining applications from MATLAB to GPUs
•Automatic code generation for data mining on clusters with GPU support
•Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions•Auto-tuning approach for tensor contractions on GPUs
•Loop transformation for tensor contraction sequences on multi-level memory architecture

46Mar 16, 2011
GREENRIDE: A Translation system for enabling data mining applications
on GPUs• User input• Code analyzer
– Analysis of variables (variable type and size)– Analysis of reduction functions (sequential code
from the user)
• Code Generator ( generating CUDA code and C++ code invoking the kernel function)– Optimization

47Mar 16, 2011
GREENRIDE: A Translation system for enabling data mining applications
on GPUs
Variable information
Reduction functions
Optional functions Code
Analyzer( In LLVM)
Variable Analyzer
Code Generato
r
Variable Access
Pattern and Combination Operations
Host Program
Data copy and thread
grid configuration
Kernel functions
Executable
User Input
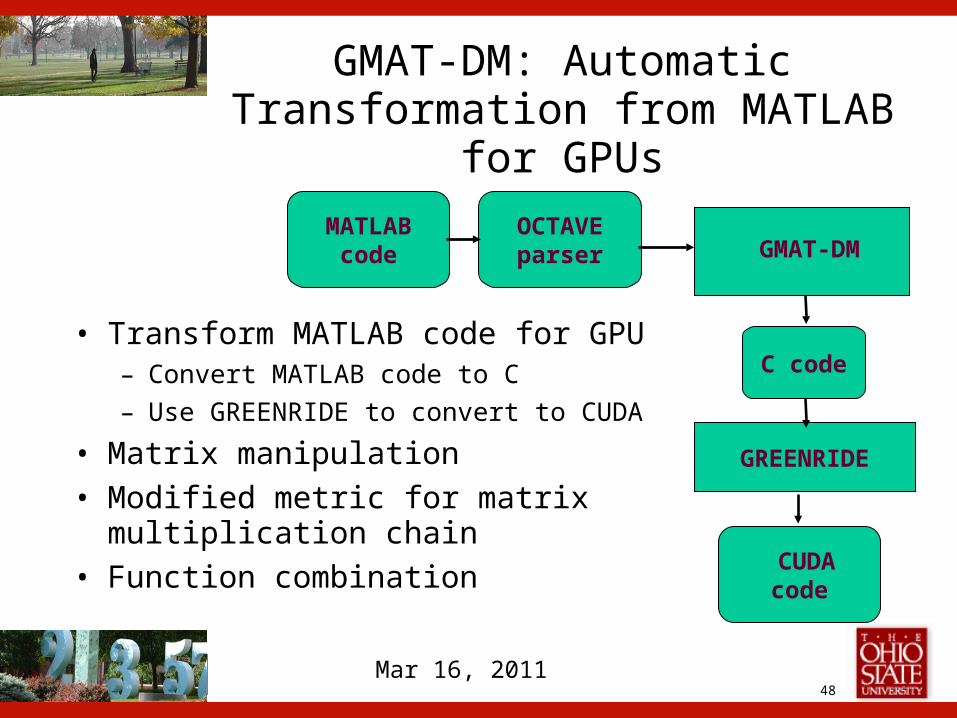
48Mar 16, 2011
GMAT-DM: Automatic Transformation from MATLAB for
GPUs
MATLAB code
OCTAVE parser
C code
CUDA code
GREENRIDE
GMAT-DM
• Transform MATLAB code for GPU– Convert MATLAB code to C
– Use GREENRIDE to convert to CUDA
• Matrix manipulation
• Modified metric for matrix multiplication chain
• Function combination
49Mar 16, 2011
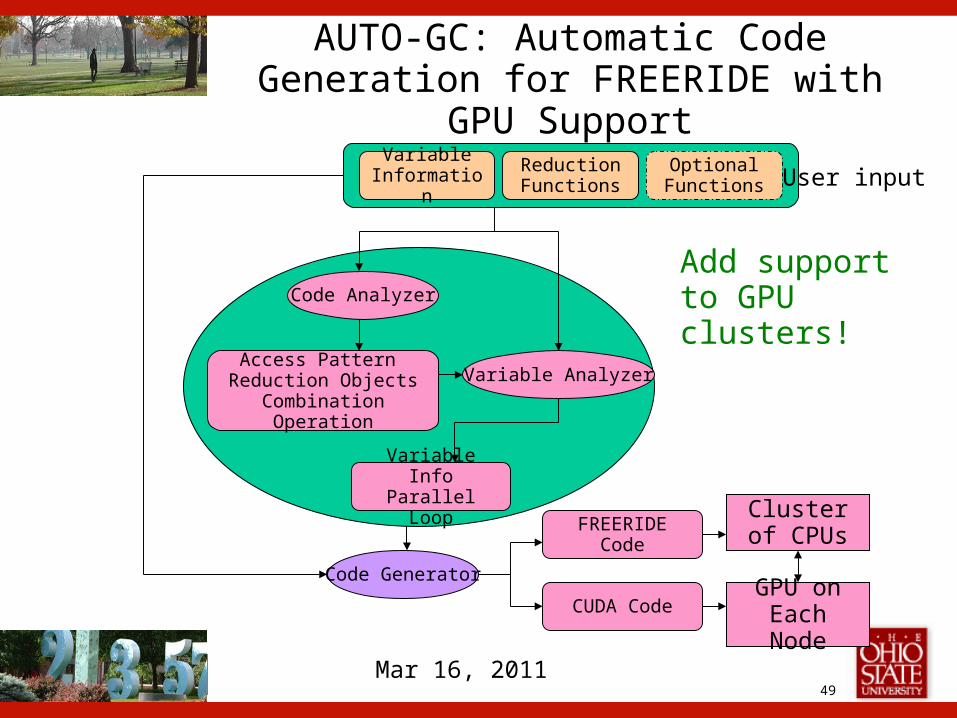
AUTO-GC: Automatic Code Generation for FREERIDE with GPU Support
Add support to GPU clusters!
Variable Information
Reduction Functions
Optional Functions
Variable Info Parallel Loop
Access Pattern Reduction Objects
Combination Operation
Code Analyzer
Variable Analyzer
Code Generator
FREERIDE Code
CUDA Code
Cluster of CPUs
GPU on Each Node
User input

50Mar 16, 2011
Future Work
• Extend the code generation system for data mining applications to more structures
• Improve and apply ILP approach for shared memory arrangement for other architectures
• Include more parameters in the auto-tuning framework
• Extend loop transformation to heterogeneous structures
• …

51Mar 16, 2011
Conclusion
• Code generation for data mining applications– Translation system for enabling data mining applications on
GPUs– Automatic translation of data mining applications from
MATLAB to GPUs– Automatic code generation for data mining on clusters with
GPU support– Arranging data on shared memory with ILP Solver
• Code optimization for tensor contractions– Auto-tuning approach for tensor contractions on GPUs– Loop transformation for tensor contraction sequences on
multi-level memory architecture

52Mar 16, 2011
Thank you !





























