Embed Size (px)
Citation preview

ManifoldModel-agnostic visual debugging tool for MLLezhi Li, Yunfeng Bai, Yang WangOpML’19 May 20, 2019
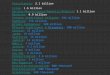
Manifold: model-agnostic visual debugging tool for ML

01 Motivation02 Workflow03 Integration
Manifoldhttps://eng.uber.com/manifoldMichelangelohttps://eng.uber.com/scaling-michelangelo
Agenda
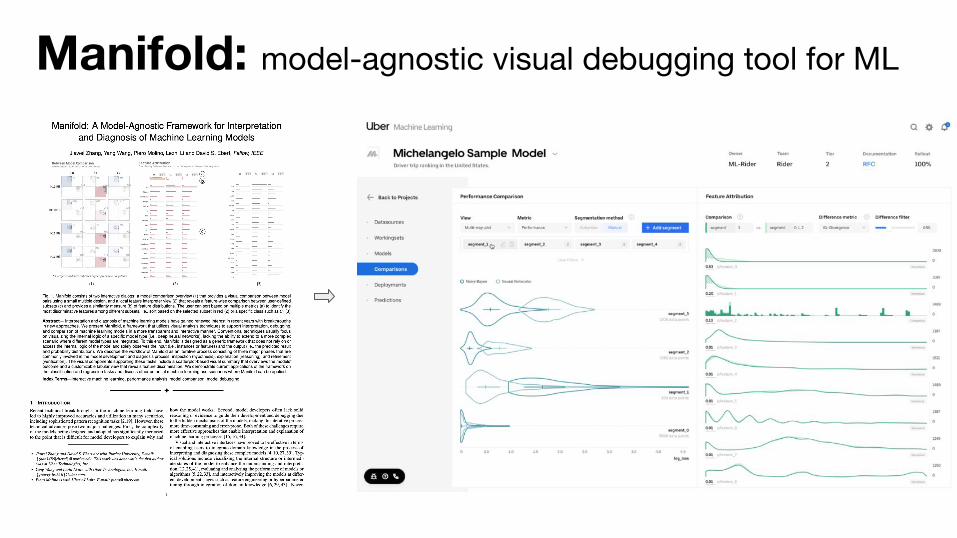
Importance of Model Debugging
20%building initial models
80%improving model performance
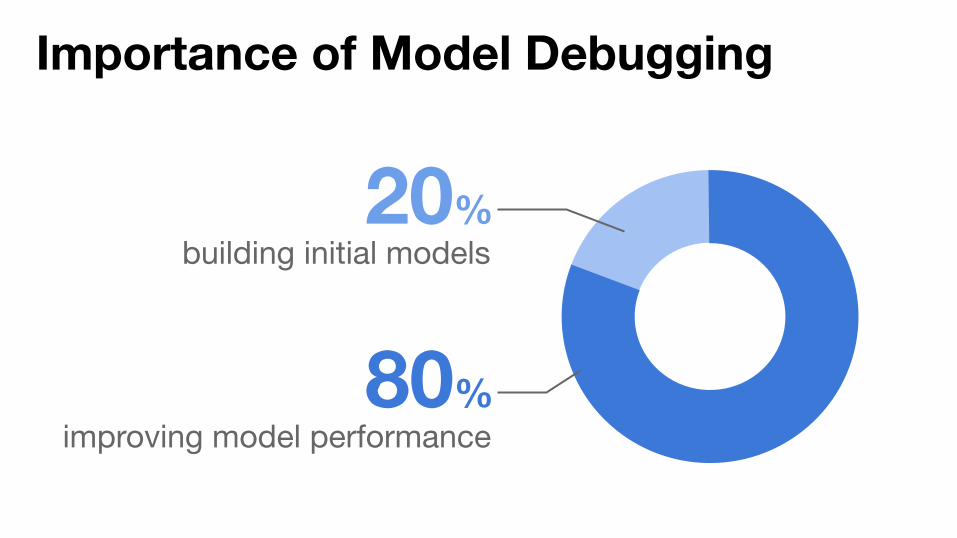
Inadequacy of performance metrics
1.000.00 0.25 0.50
0.00
0.75
0.25
0.50
0.75
1.00
ROC
FPR
TPR
AUC: 0.81Great! but what’s Next?
not actionable...
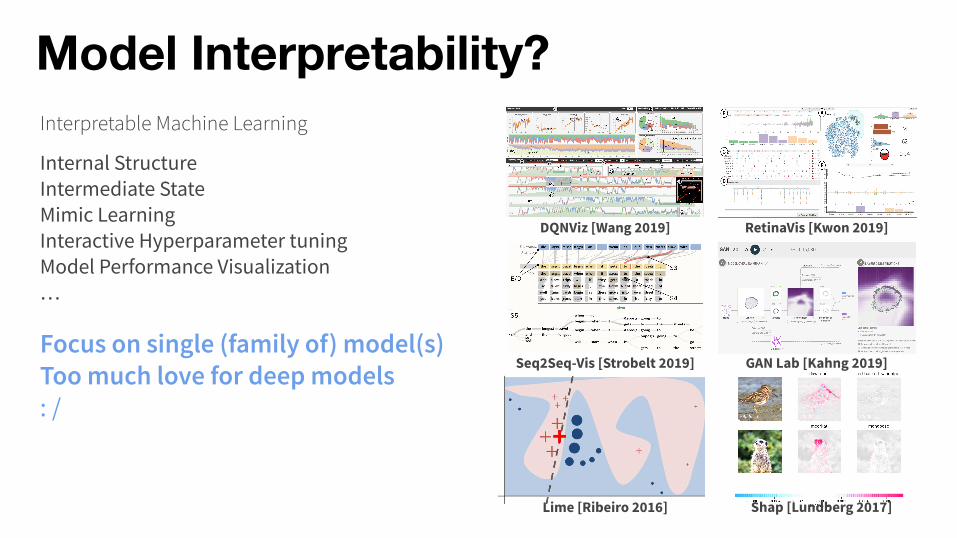
Model Interpretability?
Internal StructureIntermediate StateMimic LearningInteractive Hyperparameter tuningModel Performance Visualization…
Focus on single (family of) model(s)Too much love for deep models: /
Interpretable Machine Learning
Shap [Lundberg 2017]Lime [Ribeiro 2016]
DQNViz [Wang 2019] RetinaVis [Kwon 2019]
Seq2Seq-Vis [Strobelt 2019] GAN Lab [Kahng 2019]

Model-agnostic?Machine Learning at Uber
Predicting Supply & DemandOne-click ChatRestaurant RecommendationSensor Intelligence and LocationAutonomous VehiclesSupport Ticket RoutingIncentive OptimizingFraud DetectionFinancial Planning…
Interpretable Machine Learning
Internal StructureIntermediate StateMimic LearningInteractive Hyperparameter tuningModel Performance Visualization…
Model-specific interpretability
will not scalefrom the operational perspective

ML Revisited
y = f*(x)+ε

Model space => Data space
What went wrong with the model?Which data subset did the model(s) make mistake?
Why the model made such mistake?Which feature has contributed to the mistakes?
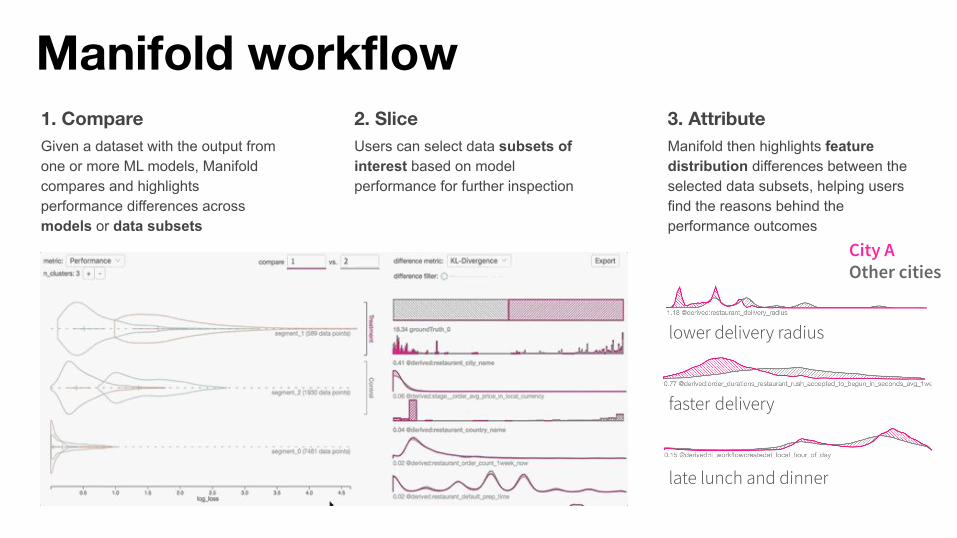
Manifold workflow1. CompareGiven a dataset with the output from one or more ML models, Manifold compares and highlights performance differences across models or data subsets
2. SliceUsers can select data subsets of interest based on model performance for further inspection
3. AttributeManifold then highlights feature distribution differences between the selected data subsets, helping users find the reasons behind the performance outcomes
lower delivery radius
late lunch and dinner
faster delivery
City AOther cities
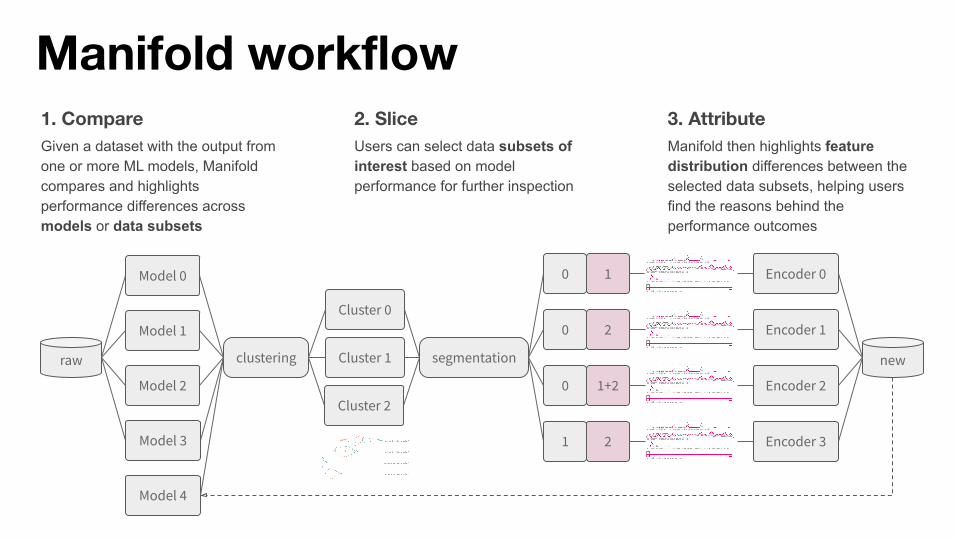
Model 0
Model 1
Model 2
Model 3
Model 4
Cluster 0
Cluster 1
Cluster 2
raw
0 1
0 2
0 1+2
1 2
Encoder 0
Encoder 1
Encoder 2
Encoder 3
clustering segmentation new
Manifold workflow1. CompareGiven a dataset with the output from one or more ML models, Manifold compares and highlights performance differences across models or data subsets
2. SliceUsers can select data subsets of interest based on model performance for further inspection
3. AttributeManifold then highlights feature distribution differences between the selected data subsets, helping users find the reasons behind the performance outcomes

Challenges
01 Interactivity √02 Scalability ?
OperationalComputational
=> Michelangelo
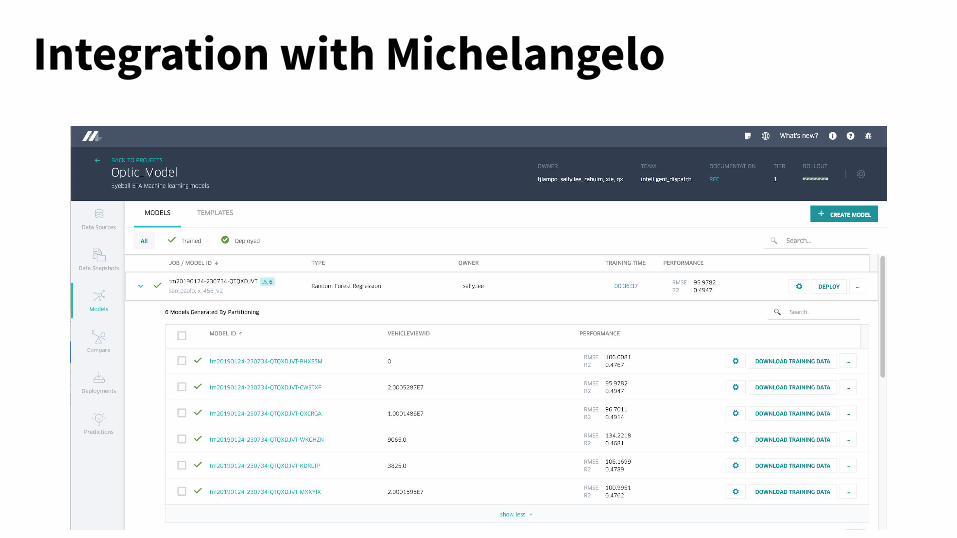
Integration with Michelangelo
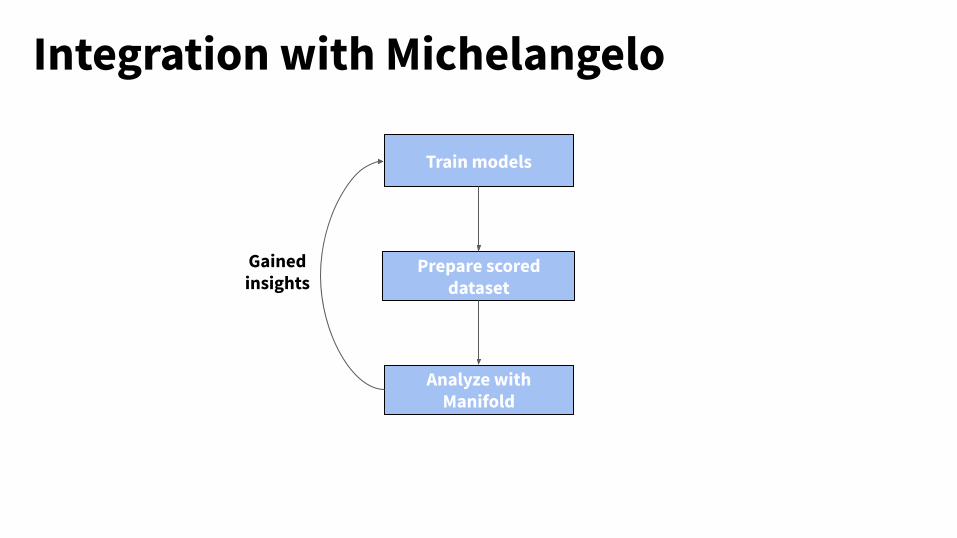
Integration with Michelangelo
Train models
Prepare scored dataset
Analyze with Manifold
Gained insights

Integration with Michelangelo
Case Study:Identify useful features
- A team at Uber is evaluating the value of an extra set of features
- Adding new features did not change model’s overall performance
- Are the new features still worth adding?
- Yes, improvement on hard-to-predict data

ArchitectureMichelangelo UI
Manifold
Michelangelo API services
Workflow execution
Dataset storage
Fetch data for display
Start workflow
Report status
Start dataset preparation
Store scored datasets
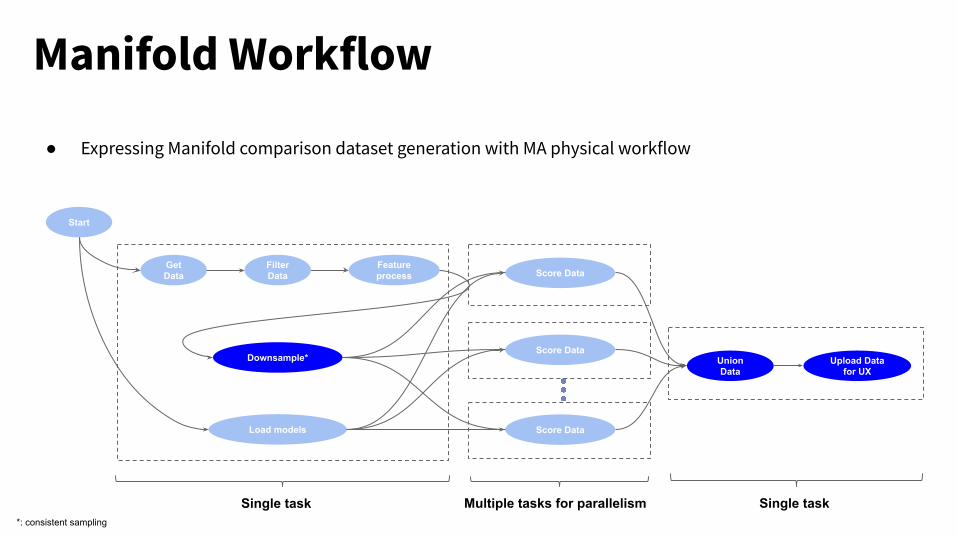
Manifold Workflow
● Expressing Manifold comparison dataset generation with MA physical workflow
Start
Load models
Feature process
Get Data
Downsample*
Score Data
Union Data
Score Data
Score Data
Upload Data for UX
Single task Multiple tasks for parallelism Single task
Filter Data
*: consistent sampling

Thank You!
Questions?
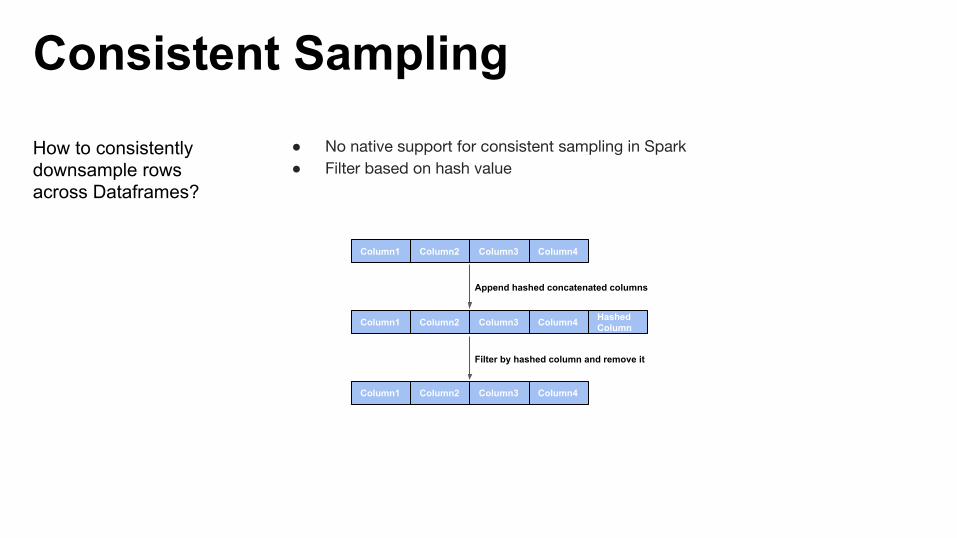
Consistent Sampling
How to consistently downsample rows across Dataframes?
● No native support for consistent sampling in Spark● Filter based on hash value
Column1 Column2 Column3 Column4
Column1 Column2 Column3 Column4 Hashed Column
Column1 Column2 Column3 Column4
Append hashed concatenated columns
Filter by hashed column and remove it