Embed Size (px)
DESCRIPTION
Managing Wire Delay in CMP Caches. Brad Beckmann Dissertation Defense Multifacet Project http://www.cs.wisc.edu/multifacet/ University of Wisconsin-Madison 8/15/06. L2 Bank. L2 Bank. Current CMP: AMD Athlon 64 X2. CPU 0. CPU 1. 2 CPUs. 2 L2 Cache Banks. CPU 0. CPU 1. L1 D$. - PowerPoint PPT Presentation
Citation preview

Managing Wire Delay in Managing Wire Delay in CMP CachesCMP Caches
Brad BeckmannDissertation Defense
Multifacet Projecthttp://www.cs.wisc.edu/multifacet/University of Wisconsin-Madison
8/15/06

2
Current CMP: AMD Athlon 64 X2Current CMP: AMD Athlon 64 X2
L2Bank
L2Bank
2 CPUs
2 L2CacheBanks
CPU 0 CPU 1

3future technology (< 45 nm)
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
today technology (~90 nm)
CMP Cache TrendsCMP Cache Trends
CPU 0L1 I$ L1 D$
CPU 1L1 D$ L1 I$
CPU 2L1 I$ L1 D$
CPU 3L1 D$ L1 I$
CPU 4L1 I$ L1 D$
CPU 5L1 D$ L1 I$
CPU 6L1 I$ L1 D$
CPU 7L1 D$ L1 I$
L2Bank
L2Bank

4
Baseline: Baseline: CMP-SharedCMP-Shared
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
L2Bank
A
MaximizeCache
Capacity40+ Cycles
SlowAccessLatency

5
Baseline: Baseline: CMP-PrivateCMP-Private
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
Private
L2
Private
L2
Private
L2
Private
L2
Private
L2
Private
L2
Private
L2
PrivateL2
FastAccessLatencyA
LowerEffectiveCapacity
A
A Thesis: bothFast Access &High Capacity

6
Thesis ContributionsThesis Contributions
• Characterizing CMP workloads—sharing types1. Single requestor2. Shared read-only3. Shared read-write
• Techniques to manage wire delay• Migration ← Previously discussed• Selective Replication ← Talk’s focus • Transmission Lines ← Previously discussed
1. Combination outperforms isolated techniques
#1
#2
#3#4
#5

7
OutlineOutline• Introduction• Characterization of CMP working sets
– L2 requests– L2 cache capacity– Sharing behavior– L2 request locality
• ASR: Adaptive Selective Replication• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

8
Characterizing CMP Working SetsCharacterizing CMP Working Sets
• 8 processor CMP– 16 MB shared L2 cache– 64-byte block size– 64 KB L1 I&D caches
• Profile L2 blocks during their on-chip lifetime• Three L2 block sharing types
1. Single requestor– All requests by a single processor
2. Shared read only– Read only requests by multiple processors
3. Shared read-write– Read and write requests by multiple processors
• Workloads– Commercial: apache, jbb, otlp, zeus– Scientific: (SpecOMP) apsi & art (Splash) barnes & ocean

9
Percent of L2 Cache RequestsPercent of L2 Cache Requests
Benchmark
Single
Requestor
Shared
Read Only
Shared
Read-Write
Apache 13% 44% 43%
Jbb 57 42 1
Oltp 4 71 25
Zeus 20 55 26
Apsi > 99 < 1 < 1
Art 56 44 < 1
Barnes 20 74 7
Ocean 94 1 5
Majority of commercial workloadrequests for shared blocks
Request Types

10
Percent of L2 Cache CapacityPercent of L2 Cache Capacity
Benchmark
Single
Requestor
Shared
Read Only
Shared
Read-Write
Apache 51% 21% 28%
Jbb 91 9 < 1
Oltp 53 20 27
Zeus 72 11 16
Apsi > 99 < 1 < 1
Art 77 24 < 1
Barnes 92 4 22
Ocean 99 < 1 1
Majority of Capacity for Single Requestor Blocks

11
Costs of ReplicationCosts of Replication
1. Decrease effective cache capacity – Storing replicas instead of unique blocks– Analyze average number of sharers
• During on-chip lifetime
2. Increase store latency– Invalidate remote read-only copies– Run length [Eggers & Katz ISCA 88]
• Average intervening remote reads between writes from the same processor + intervening reads between writes from different processors
• For L2 requests

12
Sharing BehaviorSharing BehaviorShared Read-only Shared Read-write
Benchmark
Avg. # of Sharers Avg. # of Sharers
Run Length
Apache 3.6 2.8 1.2
Jbb 3.4 2.4 1.1
Oltp 4.5 3.6 1.4
Zeus 3.0 2.3 1.3
Apsi 7.2 2.7 1.5
Art 3.0 2.3 3.1
Barnes 3.2 2.1 4.2
Ocean 4.7 2.1 4.6
Widely Shared:All Workloads
Few intervening requests:Commercial Workloads
requests breakdown

13
NoLocality
LowLocality
HighLocality
Locality GraphsLocality Graphs
Inter.Locality

14
Request to Block Distribution: Request to Block Distribution: Single Requestor BlocksSingle Requestor Blocks
LowerLocality
15
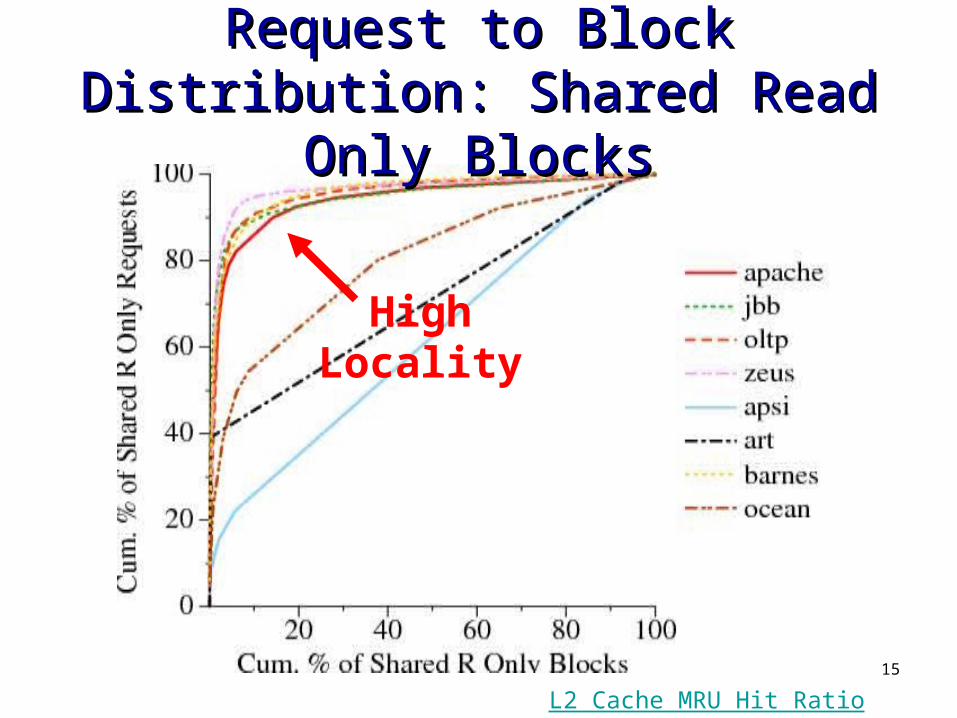
Request to Block Distribution: Request to Block Distribution: Shared Read Only BlocksShared Read Only Blocks
HighLocality
L2 Cache MRU Hit Ratio

16
Request to Block Distribution: Request to Block Distribution: Shared Read-Write BlocksShared Read-Write Blocks
IntermediateLocality

17
Workload Characterization: Workload Characterization: SummarySummary
• Commercial workloads– significant shared read-only activity – Most of requests 42-71%– Little capacity without replication 9-21%– Highly shared 3.0-4.5 avg. processors– High request locality 3% of blocks account for 70%
of requests
Shared read-only data great candidate for selective replication

18
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication
– Replication effect on memory performance – SPR: Selective Probabilistic Replication– Monitoring and adapting to workload behavior– Evaluation
• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

19
Replication and Memory CyclesReplication and Memory Cycles
Memory cycles + (Pmiss x Lmiss)
Instruction Instructions
Average cycles for L1 cache misses
=(PlocalL2 x LlocalL2) + (PremoteL2 x LremoteL2)

20
Replication BenefitReplication Benefit:: L2 Hit Cycles L2 Hit Cycles
L2 H
it C
ycle
s
Replication Capacity

21
Replication and Memory CyclesReplication and Memory Cycles
Memory cycles (PlocalL2 x LlocalL2) + (PremoteL2 x LremoteL2) +
Instruction Instructions
Average cycles for L1 cache misses
=(Pmiss x Lmiss)

22
Replication CostReplication Cost::L2 Miss CyclesL2 Miss Cycles
L2 M
iss
Cyc
les
Replication Capacity
23
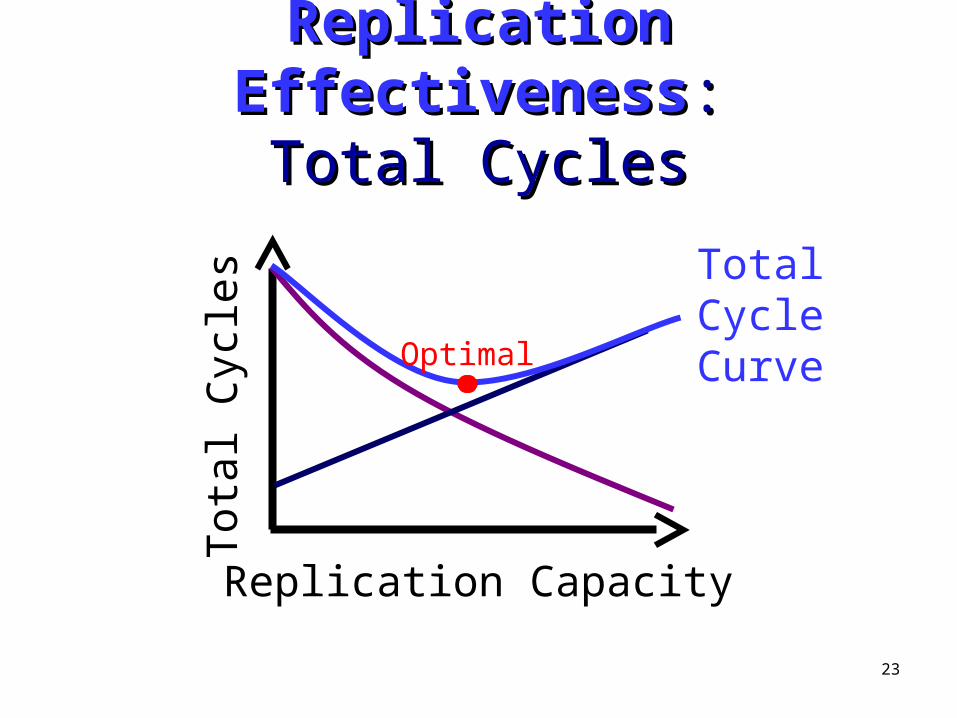
Replication EffectivenessReplication Effectiveness::Total CyclesTotal Cycles
Tot
al C
ycle
s
Replication Capacity
Optimal
TotalCycleCurve

24
OutlineOutline• Wires and CMP caches• Characterization of CMP working sets• ASR: Adaptive Selective Replication
– Replication effect on memory performance – SPR: Selective Probabilistic Replication– Monitoring and adapting to workload behavior– Evaluation
• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

25
Identifying and Replicating Identifying and Replicating Shared Read-onlyShared Read-only
• Minimal coherence impact
• Per cache block identification• Heuristic - not perfect
• Dirty bit– Indicates written data– Leverage current bandwidth reduction optimization
• Shared bit– Indicates multiple sharers– Set for blocks with multiple requestors

26
SPR: SPR: Selective Probabilistic Selective Probabilistic ReplicationReplication
• Mechanism for Selective Replication– Control duplication between L2 caches in CMP-Private– Relax L2 inclusion property
• L2 evictions do not force L1 evictions• Non-exclusive cache hierarchy
– Ring Writebacks• L1 Writebacks passed clockwise between private L2 caches• Merge with other existing L2 copies
• Probabilistically choose between– Local writeback allow replication– Ring writeback disallow replication
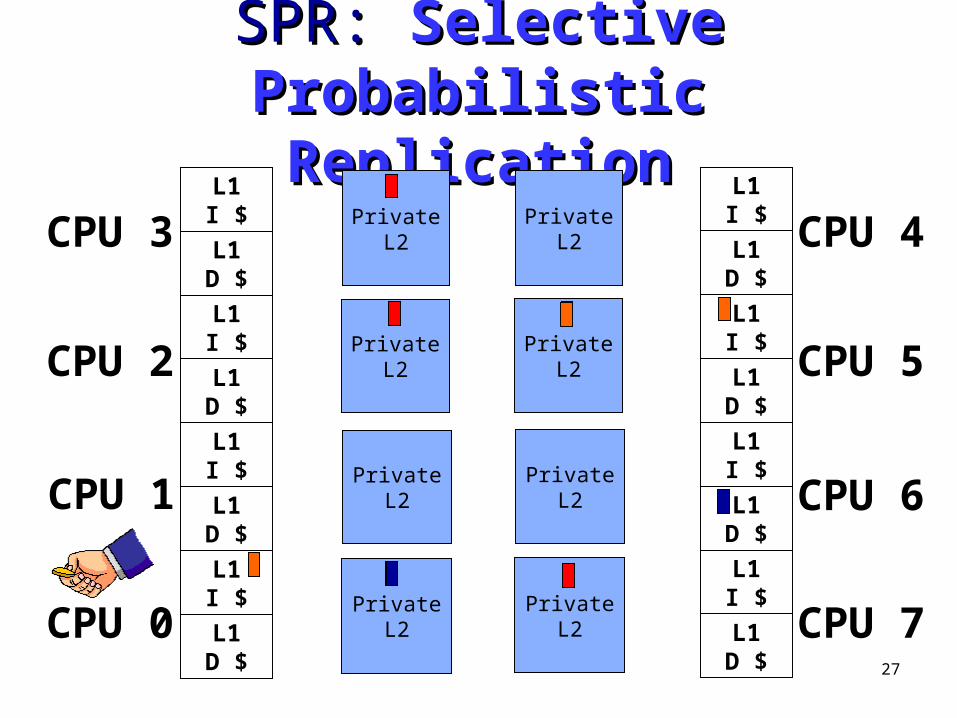
27
PrivateL2
PrivateL2
SPR: SPR: Selective Probabilistic Selective Probabilistic ReplicationReplication
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
PrivateL2
PrivateL2
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
PrivateL2
PrivateL2
PrivateL2
PrivateL2

28
SPR: SPR: Selective Probabilistic Selective Probabilistic ReplicationReplication
Rep
licat
ion
Cap
acity
Replication Levels0 1 2 3 4 5
Replication Level 0 1 2 3 4 5
Prob. of Replication 0 1/64 1/16 1/4 1/2 1
CurrentLevel
real workloads

29
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication
– Replication effect on memory performance – SPR: Selective Probabilistic Replication– Implementing ASR– Evaluation
• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

30
Implementing ASRImplementing ASR
• Four mechanisms estimate deltas1. Decrease-in-replication Benefit
2. Increase-in-replication Benefit
3. Decrease-in-replication Cost
4. Increase-in-replication Cost
• Triggering a cost-benefit analysis

31
ASR: ASR: Decrease-in-replication Decrease-in-replication BenefitBenefit
L2 H
it C
ycle
s
Replication Capacity
current levellower level

32
ASR: ASR: Decrease-in-replication Decrease-in-replication BenefitBenefit
• Goal– Determine replication benefit decrease of the next lower level
• Mechanism– Current Replica Bit
• Per L2 cache block• Set for replications of the current level• Not set for replications of lower level
– Current replica hits would be remote hits with next lower level
• Overhead– 1-bit x 256 K L2 blocks = 32 KB
33
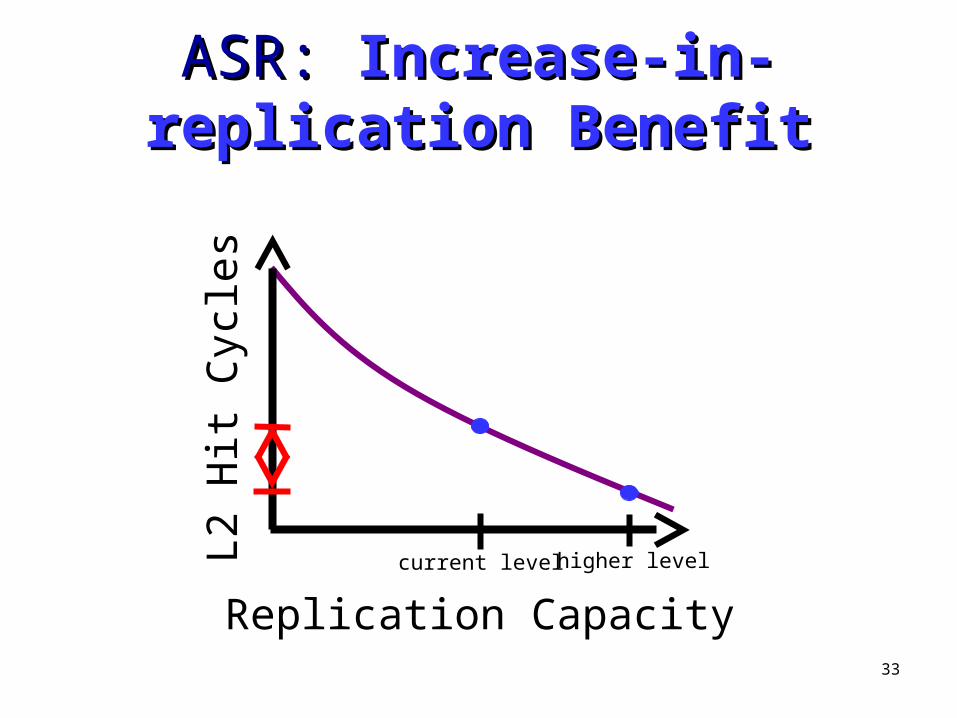
ASR: ASR: Increase-in-replication Increase-in-replication BenefitBenefit
L2 H
it C
ycle
s
Replication Capacity
current level higher level

34
ASR: ASR: Increase-in-replication Increase-in-replication BenefitBenefit
• Goal– Determine replication benefit increase of the next higher level
• Mechanism– Next Level Hit Buffers (NLHBs)
• 8-bit partial tag buffer• Store replicas of the next higher
– NLHB hits would be local L2 hits with next higher level
• Overhead– 8-bits x 16 K entries x 8 processors = 128 KB

35
ASR: ASR: Decrease-in-replicationDecrease-in-replicationCostCost
L2 M
iss
Cyc
les
Replication Capacitycurrent levellower level

36
ASR: ASR: Decrease-in-replication Decrease-in-replication CostCost
• Goal– Determine replication cost decrease of the next lower level
• Mechanism– Victim Tag Buffers (VTBs)
• 16-bit partial tags • Store recently evicted blocks of current replication level
– VTB hits would be on-chip hits with next lower level
• Overhead– 16-bits x 1 K entry x 8 processors = 16 KB

37
ASR: ASR: Increase-in-replicationIncrease-in-replicationCostCost
L2 M
iss
Cyc
les
Replication Capacitycurrent level higher level

38
ASR: ASR: Increase-in-replication Increase-in-replication CostCost
• Goal– Determine replication cost increase of the next higher level
• Mechanism– Way and Set counters [Suh et al. HPCA 2002]
• Identify soon-to-be-evicted blocks• 16-way pseudo LRU• 256 set groups
– On-chip hits that would be off-chip with next higher level
• Overhead– 255-bit pseudo LRU tree x 8 processors = 255 B
Overall storage overhead: 212 KB or 1.2% of total storage

39
ASR: ASR: Triggering a Cost-Triggering a Cost-Benefit AnalysisBenefit Analysis
• Goal– Dynamically adapt to workload behavior– Avoid unnecessary replication level changes
• Mechanism– Evaluation trigger
• Local replications or NLHB allocations exceed 1K
– Replication change• Four consecutive evaluations in the same direction

40
ASR: ASR: Adaptive AlgorithmAdaptive AlgorithmDecrease in
Replication Cost > Increase in Replication Benefit
Decrease in
Replication Cost < Increase in Replication Benefit
Decrease in
Replication Benefit > Increase in Replication Cost
Go in direction with greater value
Increase
ReplicationDecrease in
Replication Benefit < Increase in Replication Cost
Decrease
Replication
Do
Nothing

41
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication
– Replication effect on memory performance – SPR: Selective Probabilistic Replication– Implementing ASR– Evaluation
• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

42
MethodologyMethodology
• Full system simulation– Simics– Wisconsin’s GEMS Timing Simulator
• Out-of-order processor• Memory system
• Workloads– Commercial
• apache, jbb, otlp, zeus
– Scientific• Not shown here, in dissertation

43
System ParametersSystem Parameters
Memory System Dynamically Scheduled Processor
L1 I & D caches 64 KB, 2-way, 3 cycles Clock frequency 5.0 GHz
Aggregate L2 cache 16 MB, 16-way Reorder buffer / scheduler
128 / 64 entries
Avg. shared / local / remote L2 latency
44 / 20 / 52 cycles
L1 / L2 cache block size 64 Bytes Pipeline width 4-wide fetch & issue
Memory latency 250 cycles Pipeline stages 12
Memory bandwidth 50 GB/s Direct branch predictor 3.5 KB YAGS
Memory size 4 GB of DRAM Return address stack 64 entries
Outstanding memory request / CPU
16 Indirect branch predictor 256 entries (cascaded)
[ 8 core CMP, 45 nm technology ]
44
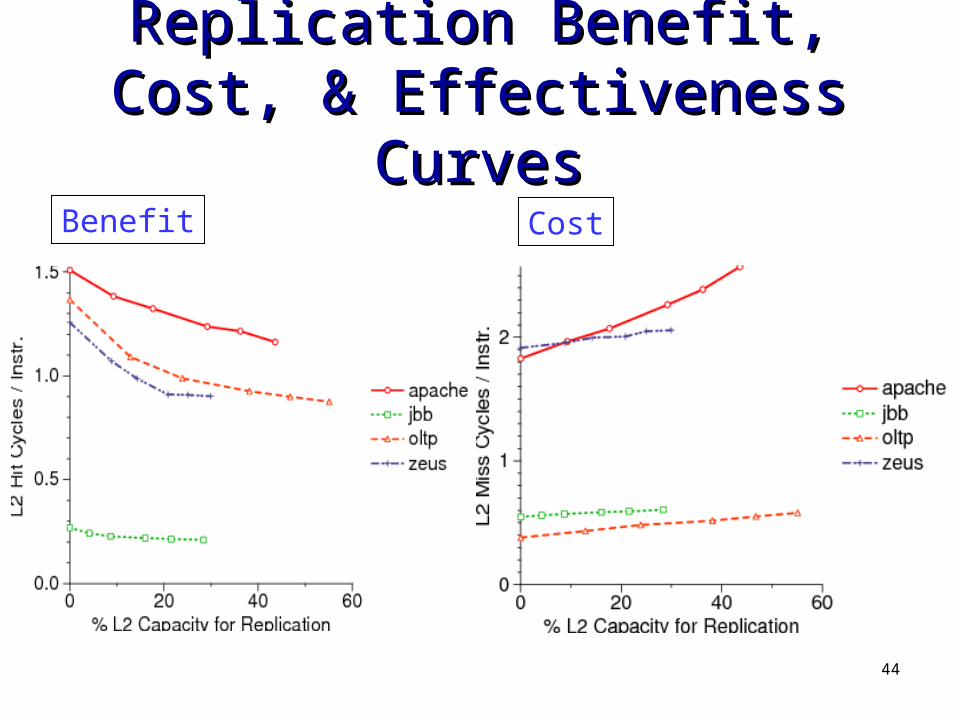
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Benefit Cost
45
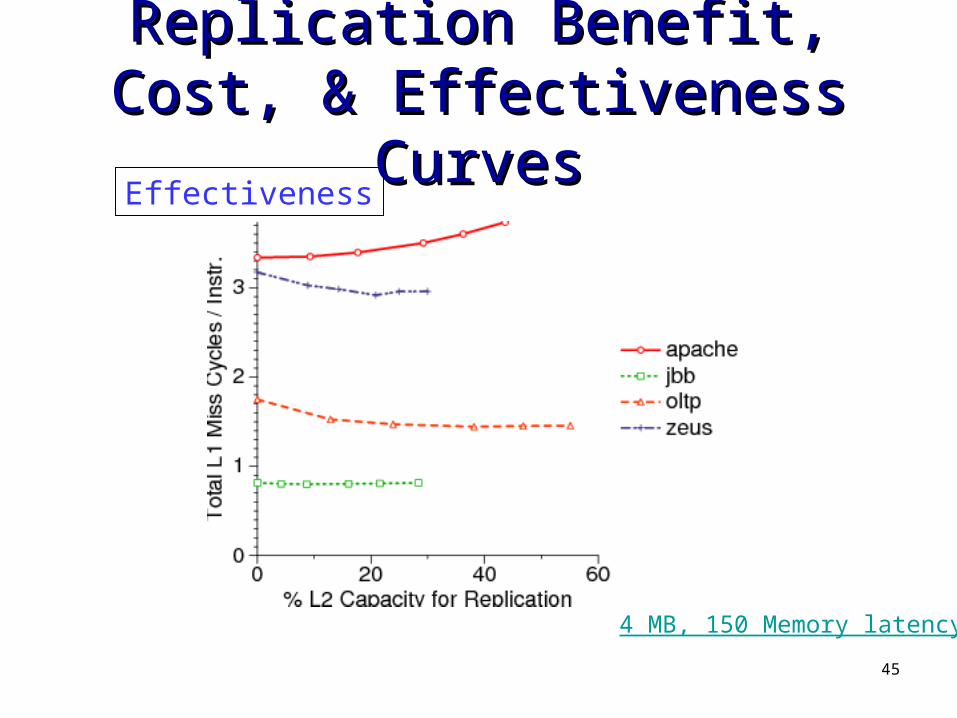
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Effectiveness
4 MB, 150 Memory latency

46
ASR: ASR: Adapting to Workload Adapting to Workload BehaviorBehavior
Oltp: All CPUs
47
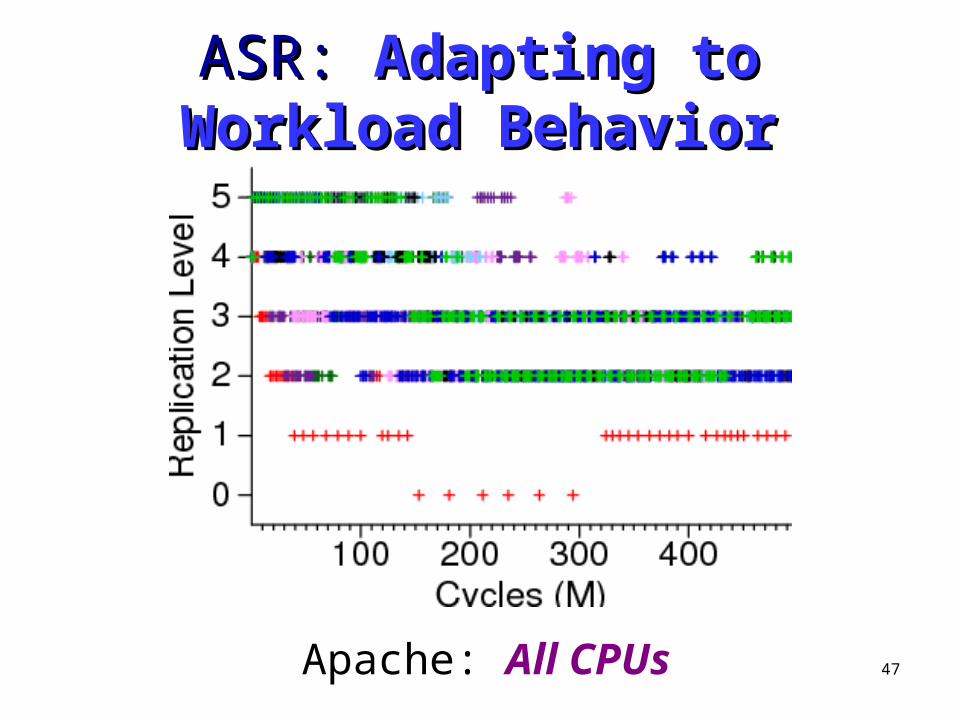
ASR: ASR: Adapting to Workload Adapting to Workload BehaviorBehavior
Apache: All CPUs
48
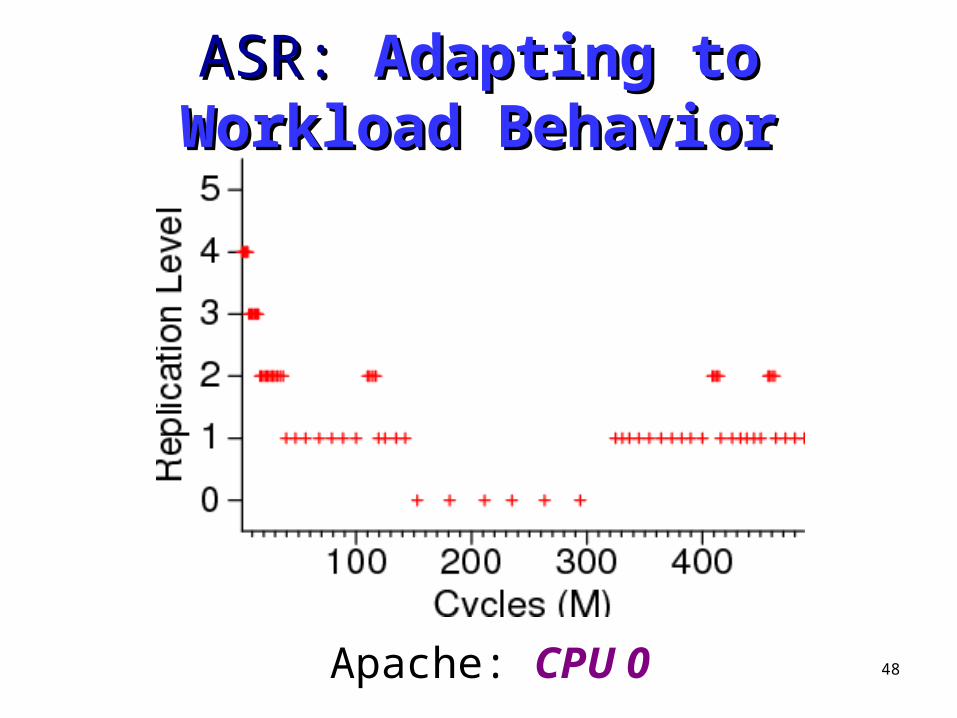
ASR: ASR: Adapting to Workload Adapting to Workload BehaviorBehavior
Apache: CPU 0

49
ASR: ASR: Adapting to Workload Adapting to Workload BehaviorBehavior
Apache: CPUs 1-7

50
Comparison of Replication Comparison of Replication PoliciesPolicies
• SPR multiple possible policies• Evaluated 4 shared read-only replication policies
1. VR: Victim Replication– Previously proposed [Zhang ISCA 05]– Disallow replicas to evict shared owner blocks
2. NR: CMP-NuRapid1. Previously proposed [Chishti ISCA 05]2. Replicate upon the second request
– CC: Cooperative Caching1. Previously proposed [Chang ISCA 06]2. Replace replicas first3. Spill singlets to remote caches4. Tunable parameter 100%, 70%, 30%, 0%
– ASR: Adaptive Selective Replication– My proposal– Monitor and adjust to workload demand
LackDynamic
Adaptation

51
ASR: ASR: Memory CyclesMemory Cycles
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
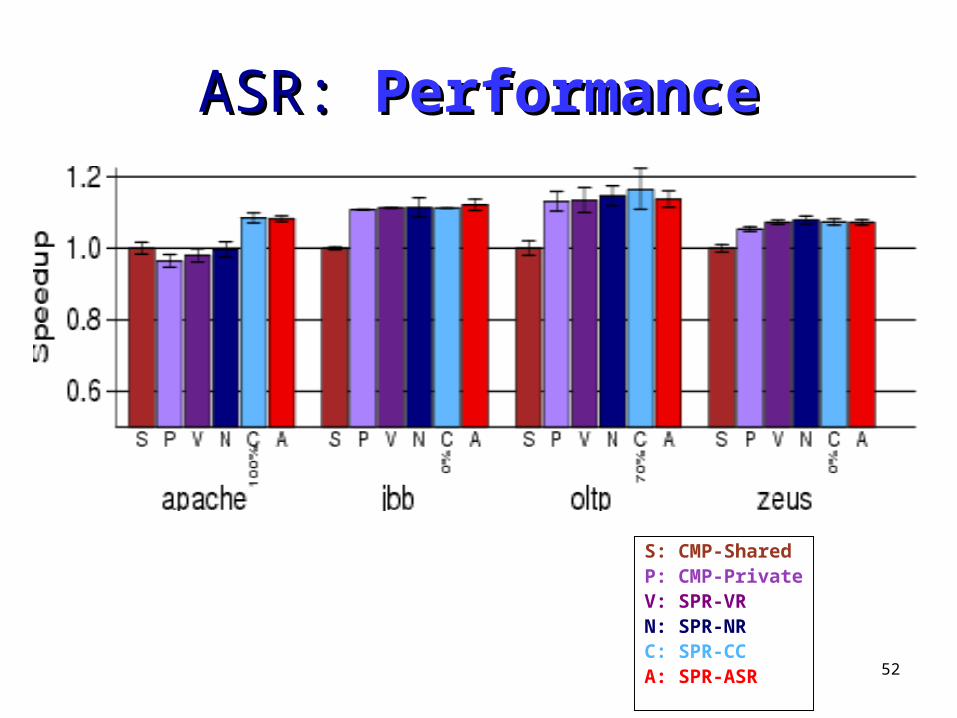
52
ASR: ASR: PerformancePerformance
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR

53
ASR: ASR: ConclusionsConclusions
• Shared Read-only Data– 42-71% of commercial workload requests– High locality top 3% of blocks account for 70% of requests
• Adaptive Selective Replication– Monitor replication benefit & cost– Replicate benefit > cost– Probabilistic policy favors frequently requested blocks– Improves performance up to 12% vs. previous schemes

54
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

55
Cache Block Migration: Cache Block Migration: SummarySummary
• Originally proposed for uniprocessor caches– Exploited Non-Uniform Cache Architectures (NUCA)– Migrated frequently requested blocks to closer banks– Offered impressive speedups
• Less performance benefit for CMP caches– Limited by sharing– More dependent on smart searches– Uneven bank utilization increased cache conflicts
More Detail

56
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication• Cache block migration• TLC: Transmission Line Caches
• Private CMP-TLC introduce & summarize • Shared CMP-TLC summarize
• Combination of techniques
57
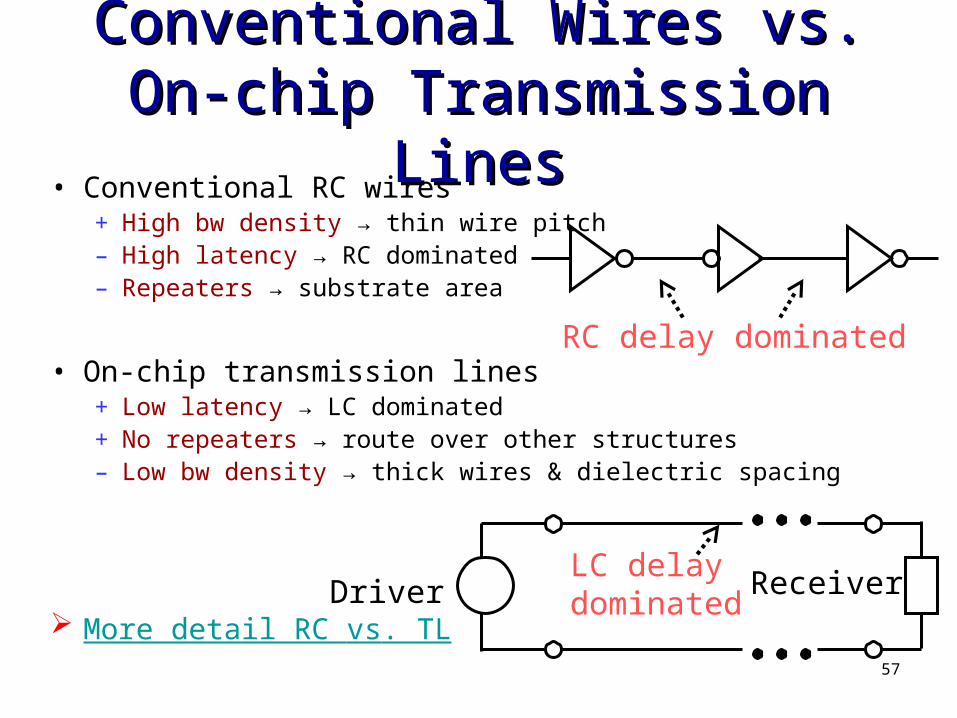
Conventional Wires vs.Conventional Wires vs.On-chip Transmission LinesOn-chip Transmission Lines
• Conventional RC wires+ High bw density → thin wire pitch– High latency → RC dominated– Repeaters → substrate area
• On-chip transmission lines+ Low latency → LC dominated+ No repeaters → route over other structures– Low bw density → thick wires & dielectric spacing
More detail RC vs. TL
RC delay dominated
ReceiverLC delaydominatedDriver

58
Private CMP-TLCPrivate CMP-TLC
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
Private
L2
tags
Private
L2
tags
Private
L2
tags
Private
L2
tags
Private
L2
tags
Private
L2
tags
Private
L2
tags
Private
L2
tags
PrivateCMP-TLC-Request• 4-byte wide links• send only requests• other messages RC network

59
TLC: TLC: SummarySummary
• Consistently improve performance• Shared CMP cache
– TLs connect to distant L2 cache banks– Fast L1 cache-to-cache transfers– Improves all L2 requests
• Private CMP cache– TLs connect private cache banks– Improves only private L2 misses– Can combine with ASR
more detail

60
OutlineOutline• Introduction• Characterization of CMP working sets• ASR: Adaptive Selective Replication• Cache block migration• TLC: Transmission Line Caches• Combination of techniques

61
Combination of TechniquesCombination of Techniques
• CMP-Shared– Baseline shared CMP cache
• CMP-Private– Baseline private CMP cache
• Private CMP-TLC-Request– Private cache with TL request network
• SPR-ASR– Private cache with Adaptive Selective Replication
• Combination– Private cache with ASR & TL request network

62
Combination: Combination: Single Single Requestor On-chip LatencyRequestor On-chip Latency
S: CMP-Shared A: SPR-ASPP: CMP-Private O: CombinationR: Private CMP-TLC-Request

63
Combination: Combination: SharedSharedRead-only On-chip LatencyRead-only On-chip Latency
S: CMP-Shared A: SPR-ASPP: CMP-Private O: CombinationR: Private CMP-TLC-Request
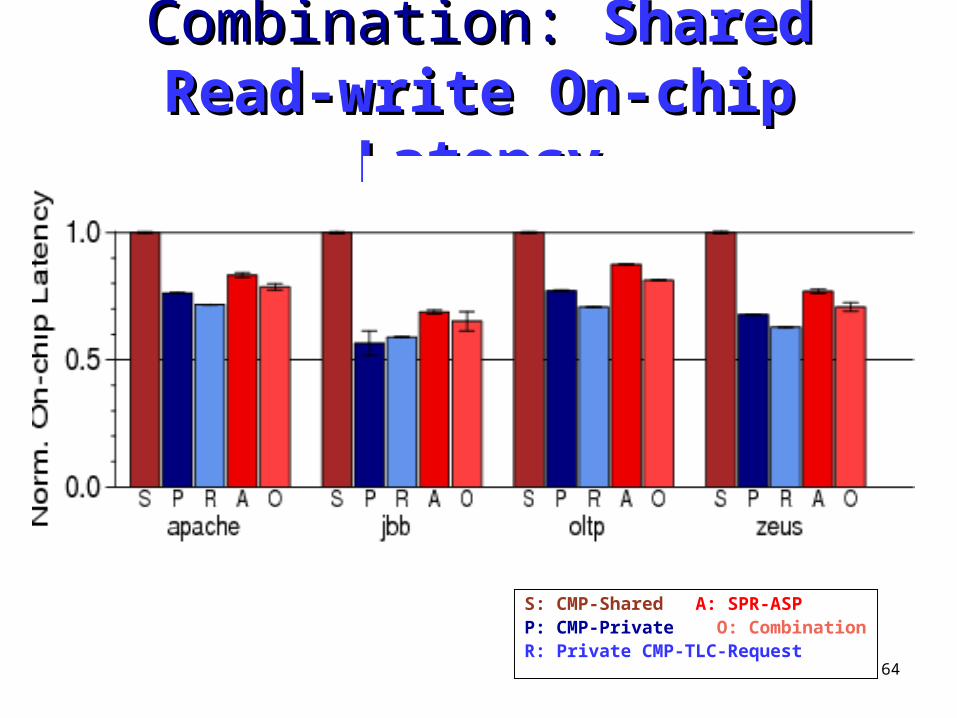
64
Combination: Combination: SharedSharedRead-write On-chip LatencyRead-write On-chip Latency
S: CMP-Shared A: SPR-ASPP: CMP-Private O: CombinationR: Private CMP-TLC-Request
65
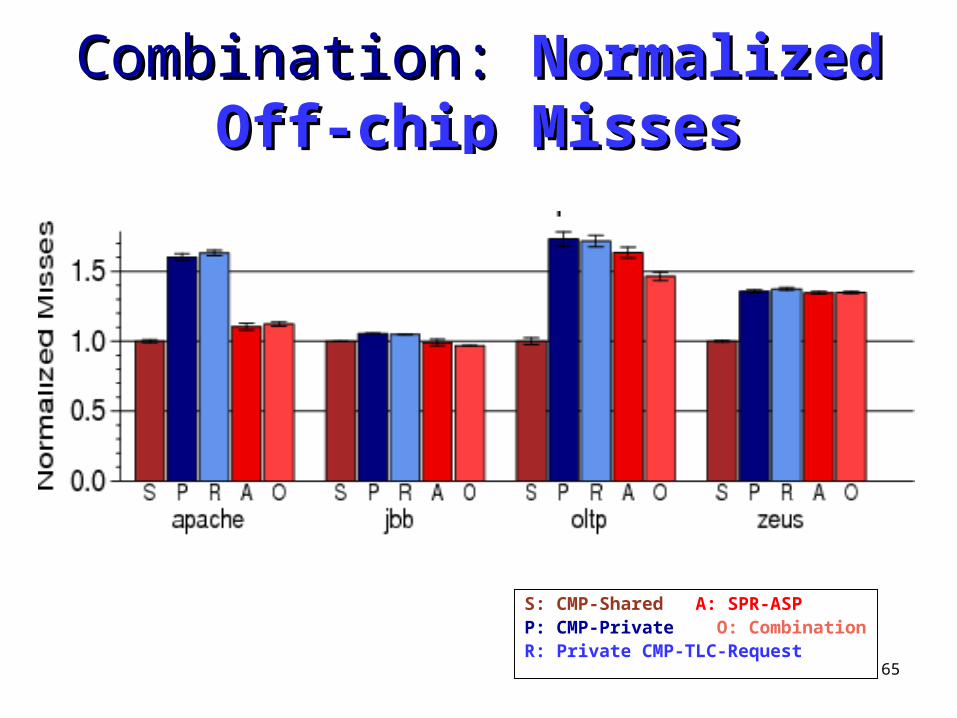
Combination: Combination: NormalizedNormalizedOff-chip MissesOff-chip Misses
S: CMP-Shared A: SPR-ASPP: CMP-Private O: CombinationR: Private CMP-TLC-Request
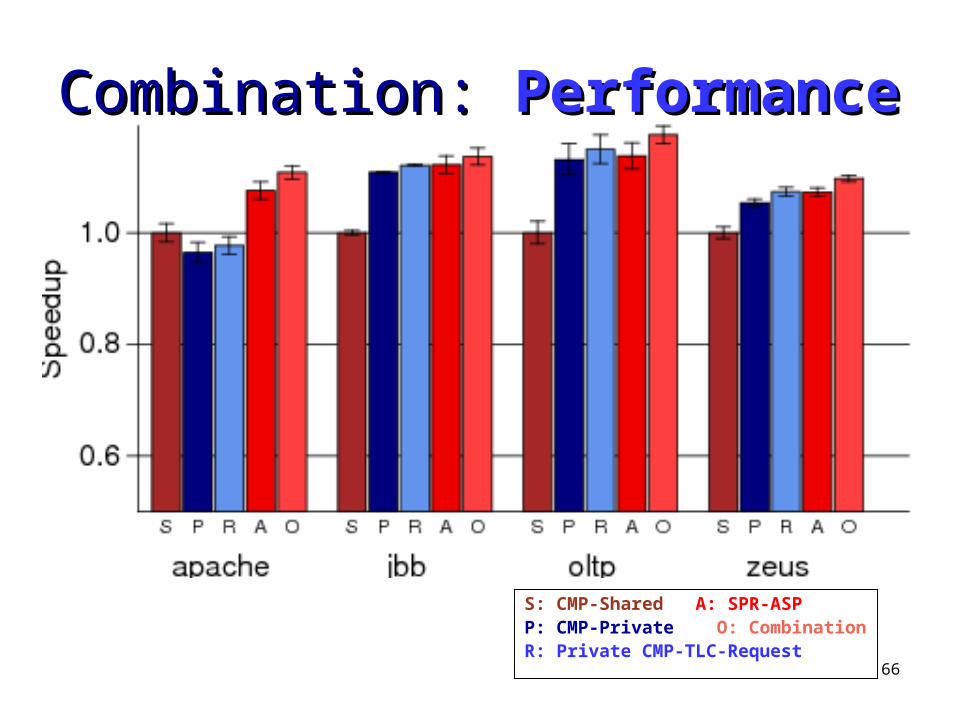
66
Combination: Combination: PerformancePerformance
S: CMP-Shared A: SPR-ASPP: CMP-Private O: CombinationR: Private CMP-TLC-Request

67
Conclusion Conclusion Cache Design
Cache Block Migration
Selective Replication
Transmission Lines
Shared CMP-DNUCA
- limited by sharing
- ineffective
Shared CMP-TLC- efficient layout- very effective- bw limited
Private Default- static integrated- effective for certain workloads
ASR- adapt dynamically- robust cache- leverage remote capacity
Private CMP-TLC- between nodes- less effective- low remote latency
CombinationPerforms Best
Private Combinationvs. Shared CMP-TLC

Backup SlidesBackup Slides

69
Best Performers: Best Performers: PerformancePerformance
64: CMP-SNUCA (64 banks)O: Combination (8 banks)T: Shared CMP-TLC (64 banks)F: Combination w/ faster cache banksB: Best (private latency & shared capacity)
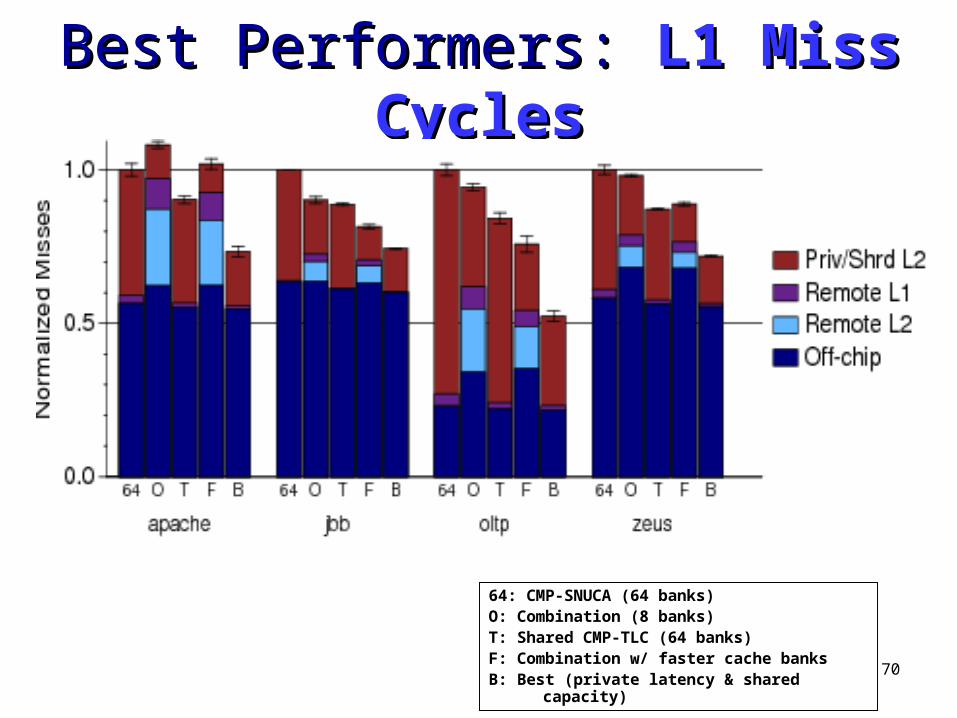
70
Best Performers: Best Performers: L1 Miss CyclesL1 Miss Cycles
64: CMP-SNUCA (64 banks)O: Combination (8 banks)T: Shared CMP-TLC (64 banks)F: Combination w/ faster cache banksB: Best (private latency & shared capacity)

71
Best Performers: Best Performers: ConclusionsConclusions
• Sensitive to bank access latency• Private CMP-TLC-Request w/ ASR vs.
Shared CMP-TLC– Both achieve substantial speedup– Different cost
• TL bandwidth• Storage overhead
• Further room for improvement– Not yet private latency with shared capacity– Ex. Oltp

L2 Cache Requests BreakdownL2 Cache Requests Breakdown
Back to talk

L2 Cache Requests Breakdown: L2 Cache Requests Breakdown: User & OSUser & OS
Back to talk
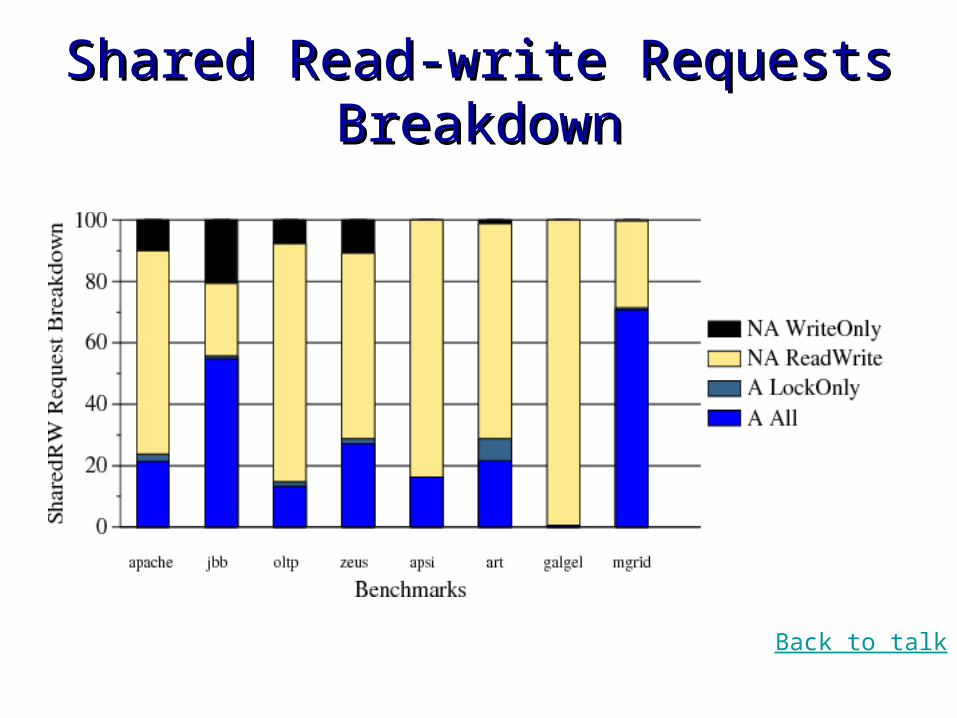
Shared Read-write Requests Shared Read-write Requests BreakdownBreakdown
Back to talk

Shared Read-write Block Shared Read-write Block BreakdownBreakdown
Back to talk

L2 Cache MRU Hit RatioL2 Cache MRU Hit RatioSmall Change
In Hits
Back to talk
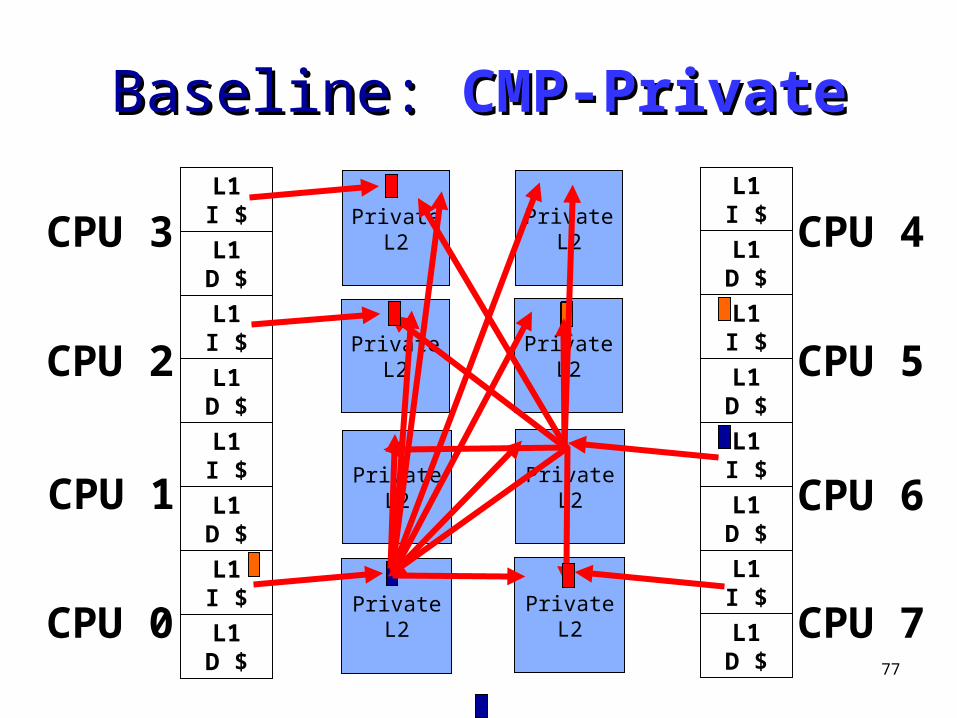
77
PrivateL2
PrivateL2
Baseline: Baseline: CMP-PrivateCMP-Private
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
PrivateL2
PrivateL2
PrivateL2
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
PrivateL2
PrivateL2
PrivateL2

78
PrivateL2
PrivateL2
SPR:SPR: Replication Control Replication Control
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
PrivateL2
PrivateL2
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
PrivateL2
PrivateL2
PrivateL2
PrivateL2

79
Replication CapacityReplication Capacity
Back to talk
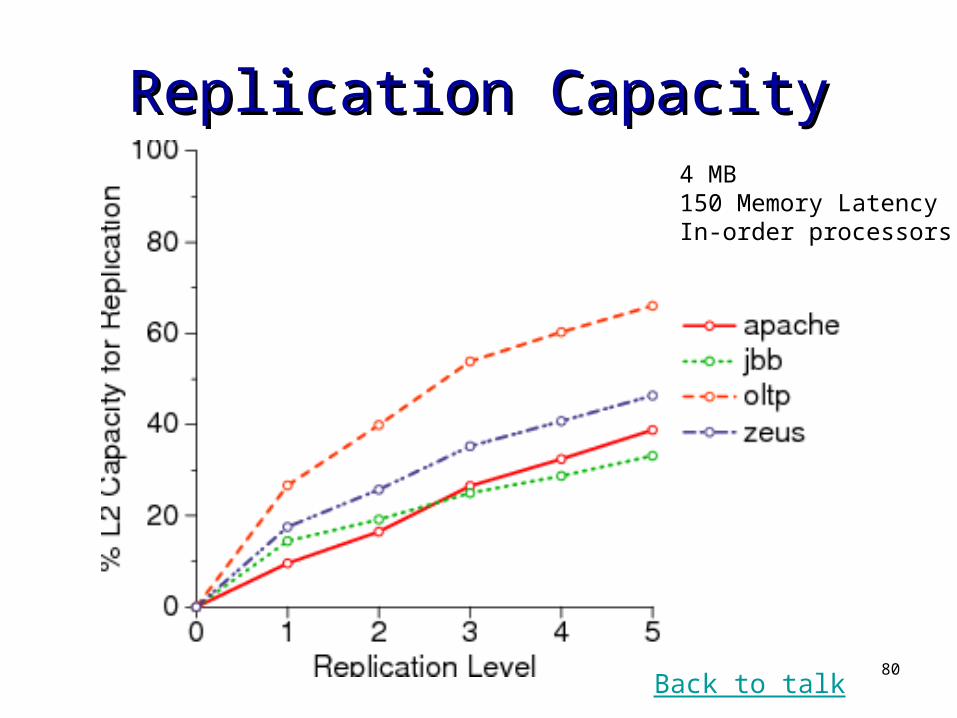
80
Replication CapacityReplication Capacity4 MB150 Memory LatencyIn-order processors
Back to talk
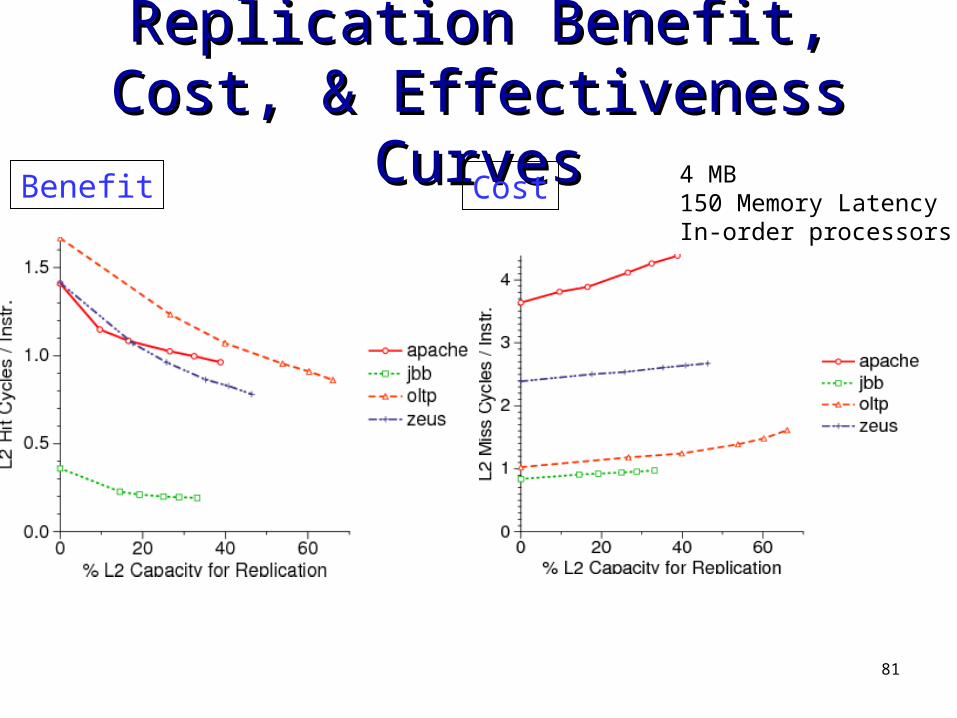
81
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Benefit Cost 4 MB150 Memory LatencyIn-order processors
82
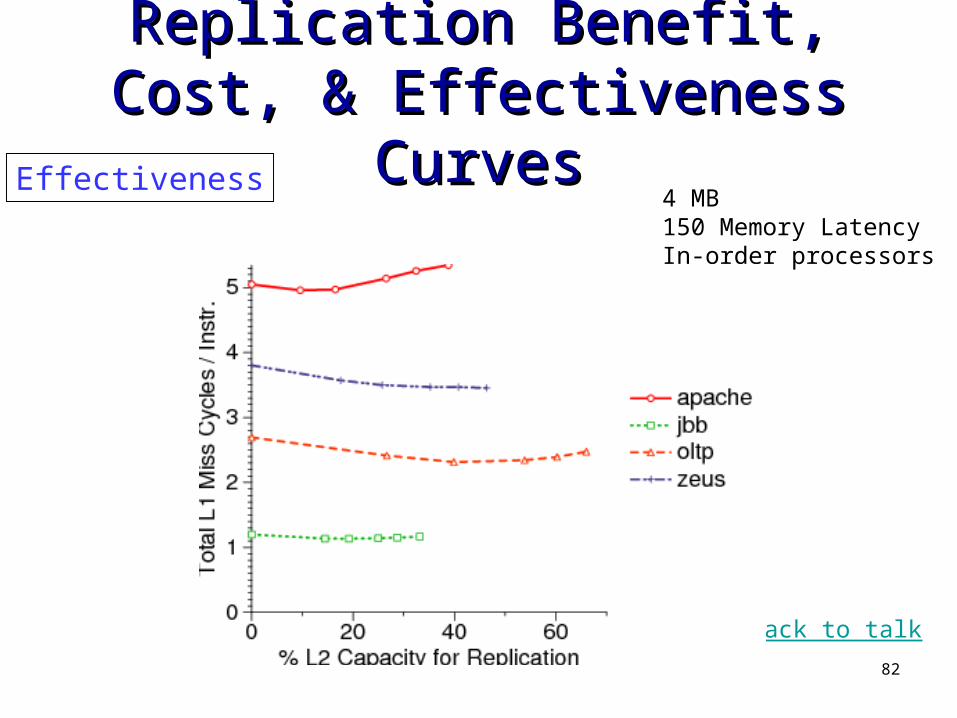
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Effectiveness4 MB150 Memory LatencyIn-order processors
Back to talk

83
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Benefit Cost 16 MB500 Memory LatencyIn-order processors

84
Replication Benefit, Cost, & Replication Benefit, Cost, & Effectiveness CurvesEffectiveness Curves
Effectiveness16 MB500 Memory LatencyIn-order processors
Back to talk

85
Replication Analytic ModelReplication Analytic Model
• Utilize workload characterization data
• Goal: initutition not accuracy
• Optimal point of replication– Sensitive to cache size– Sensitive to memory latency

86
Replication Model: Replication Model: Selective Selective ReplicationReplication
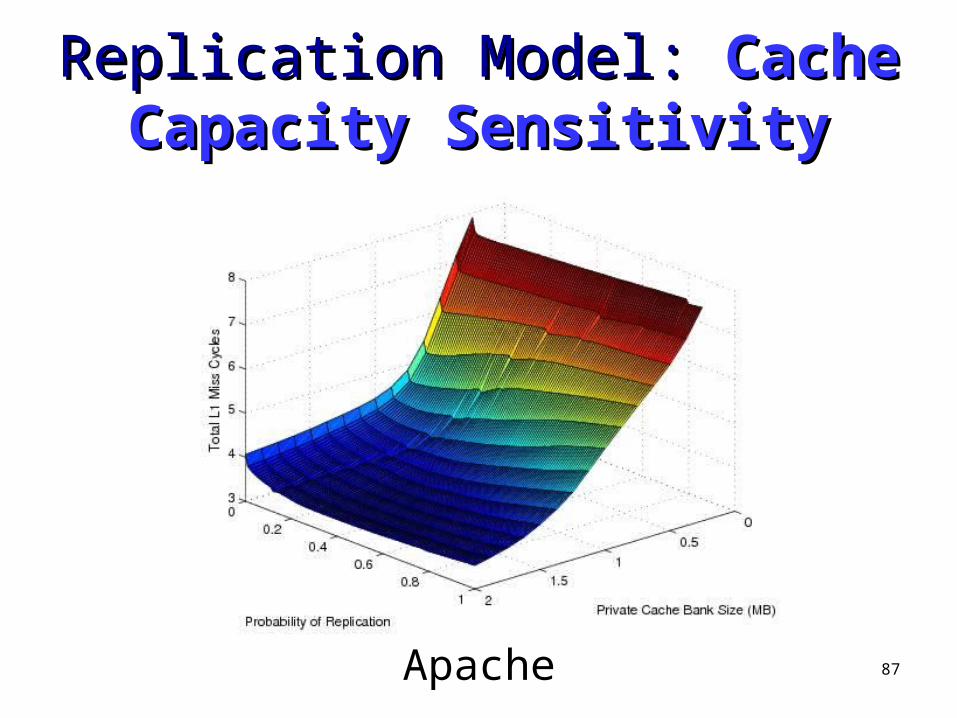
87
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Apache
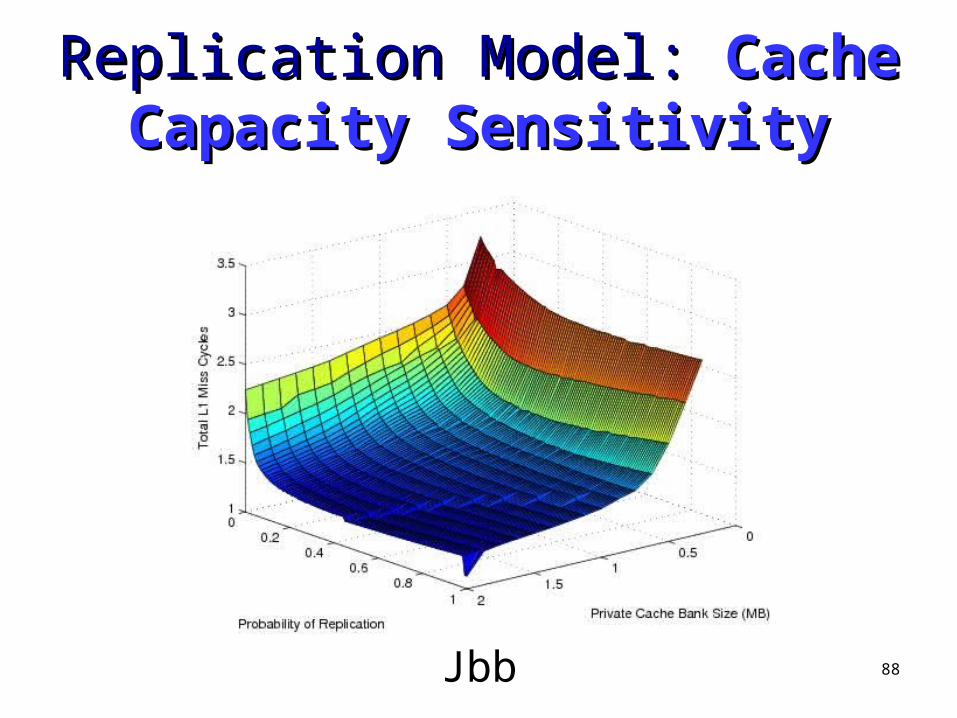
88
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Jbb
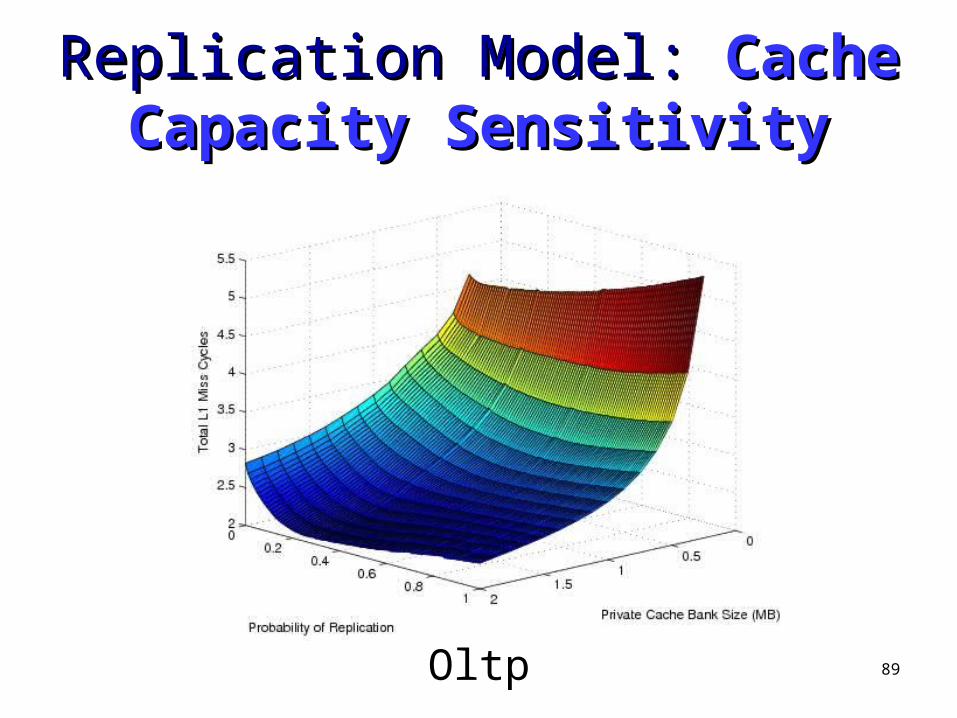
89
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Oltp

90
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Zeus
91
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
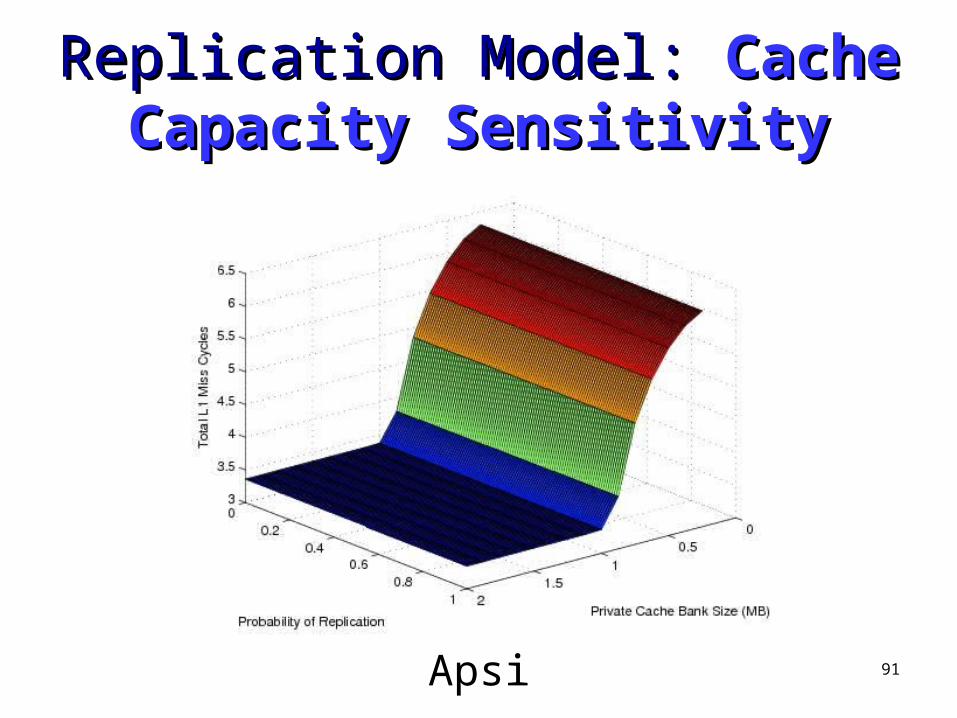
Apsi

92
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Art
93
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
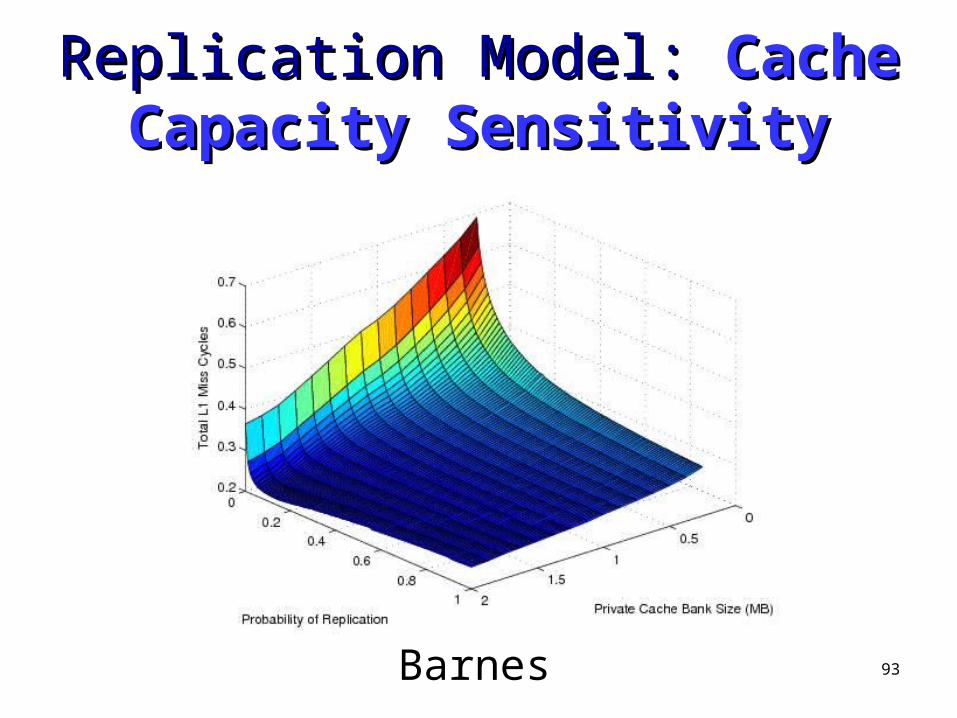
Barnes
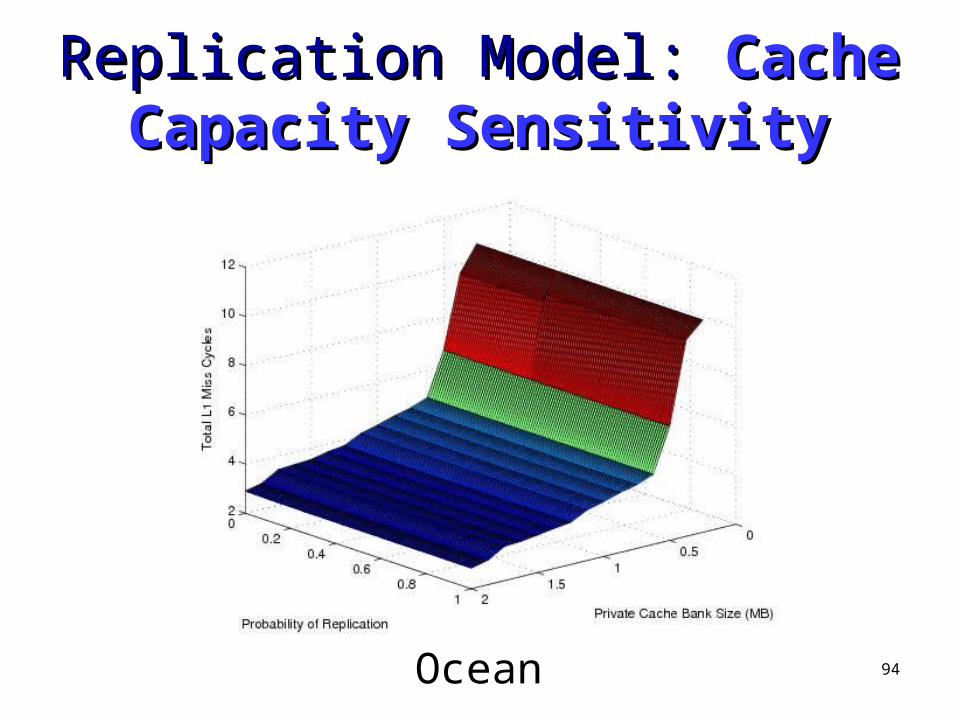
94
Replication Model: Replication Model: Cache Cache Capacity SensitivityCapacity Sensitivity
Ocean

95
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Apache
96
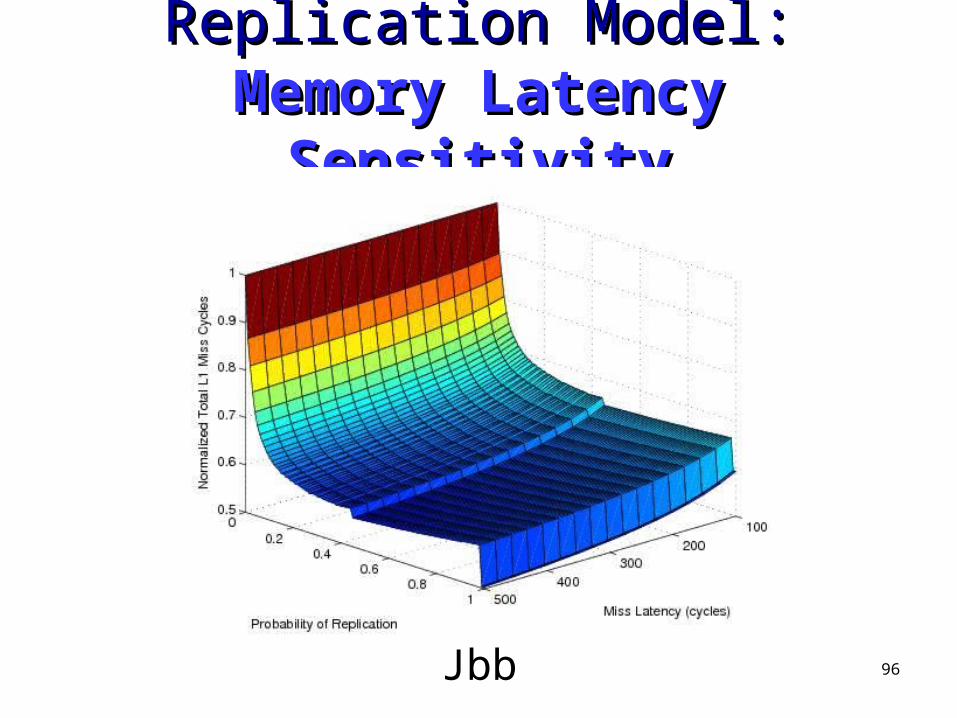
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Jbb

97
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Oltp

98
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Zeus
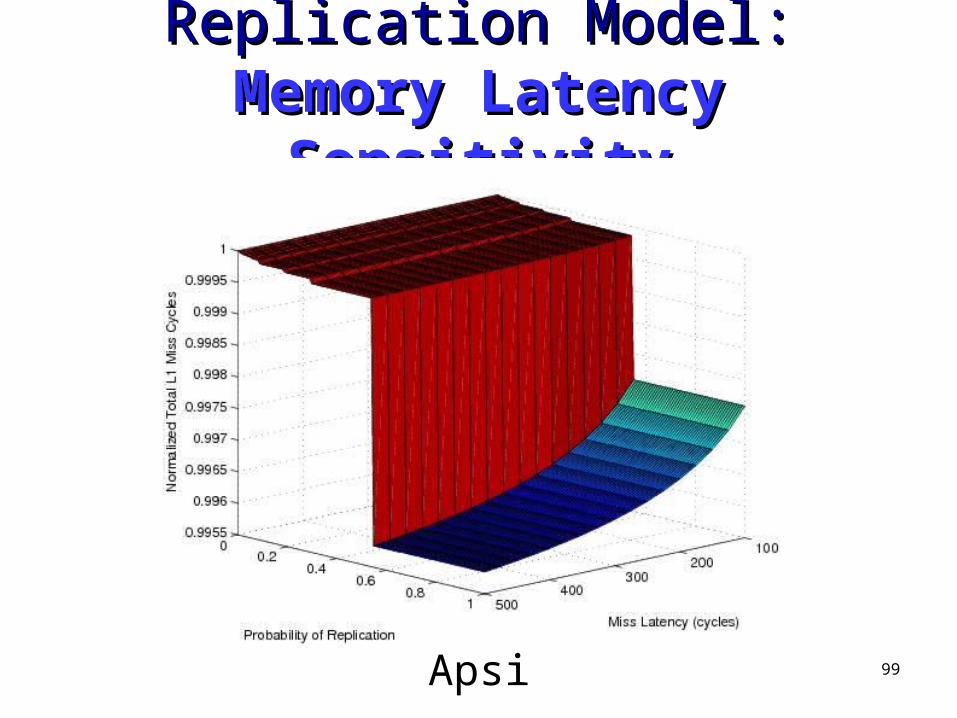
99
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Apsi
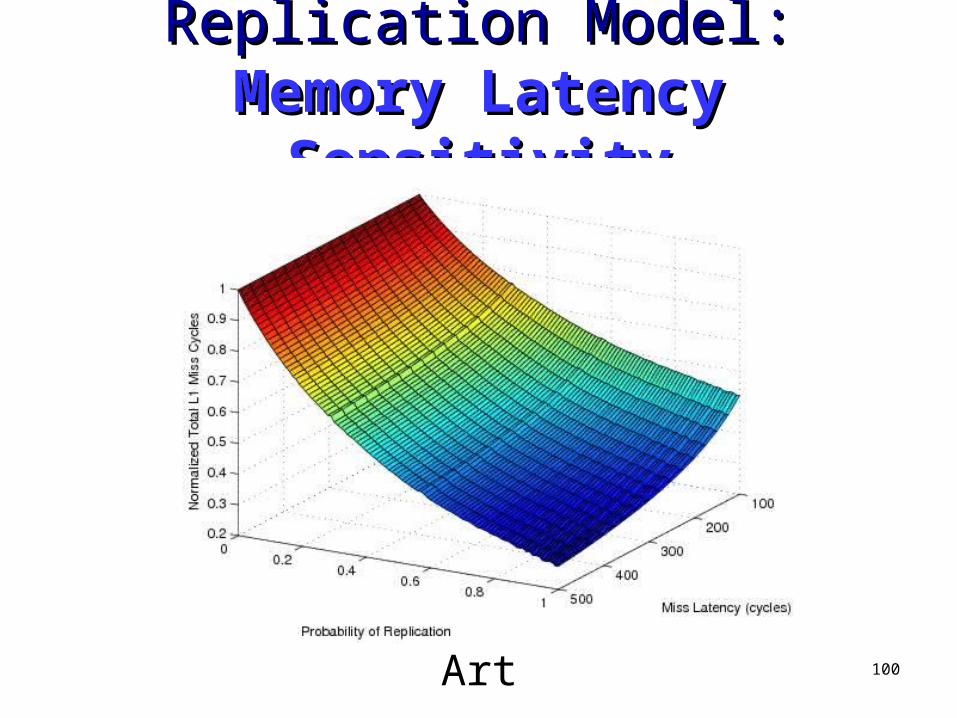
100
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Art

101
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Barnes

102
Replication Model: Replication Model: Memory Memory Latency SensitivityLatency Sensitivity
Ocean

103
ASR: ASR: Memory CyclesMemory Cycles
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
4 MB150 Memory LatencyIn-order processors

104
ASR: ASR: PerformancePerformance
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
4 MB150 Memory LatencyIn-order processors
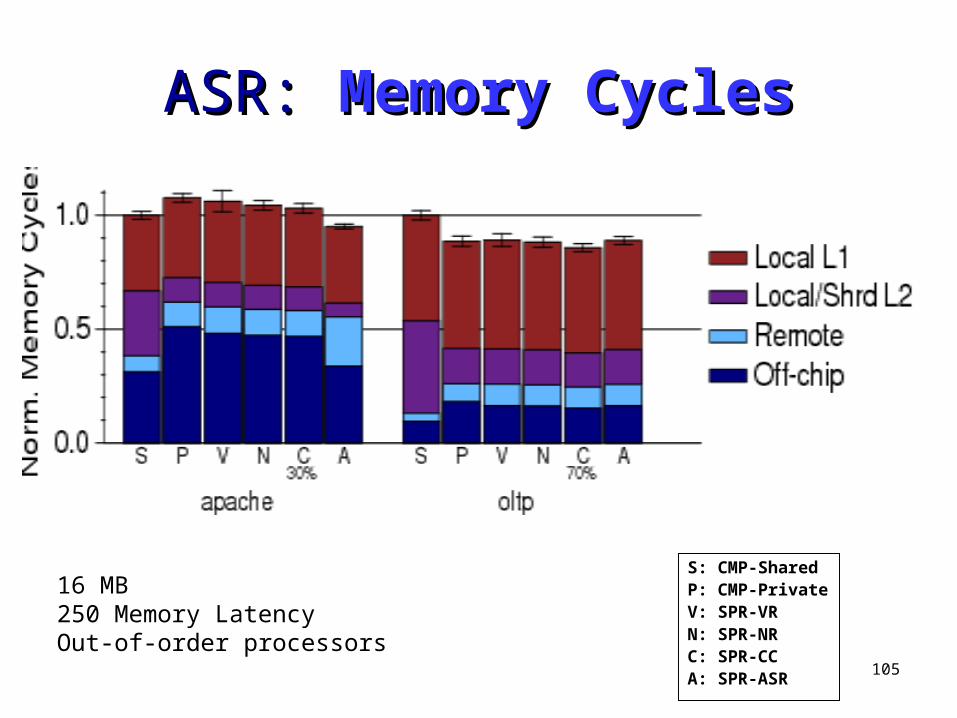
105
ASR: ASR: Memory CyclesMemory Cycles
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
16 MB250 Memory LatencyOut-of-order processors

106
ASR: ASR: PerformancePerformance
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
16 MB250 Memory LatencyOut-of-order processors
107
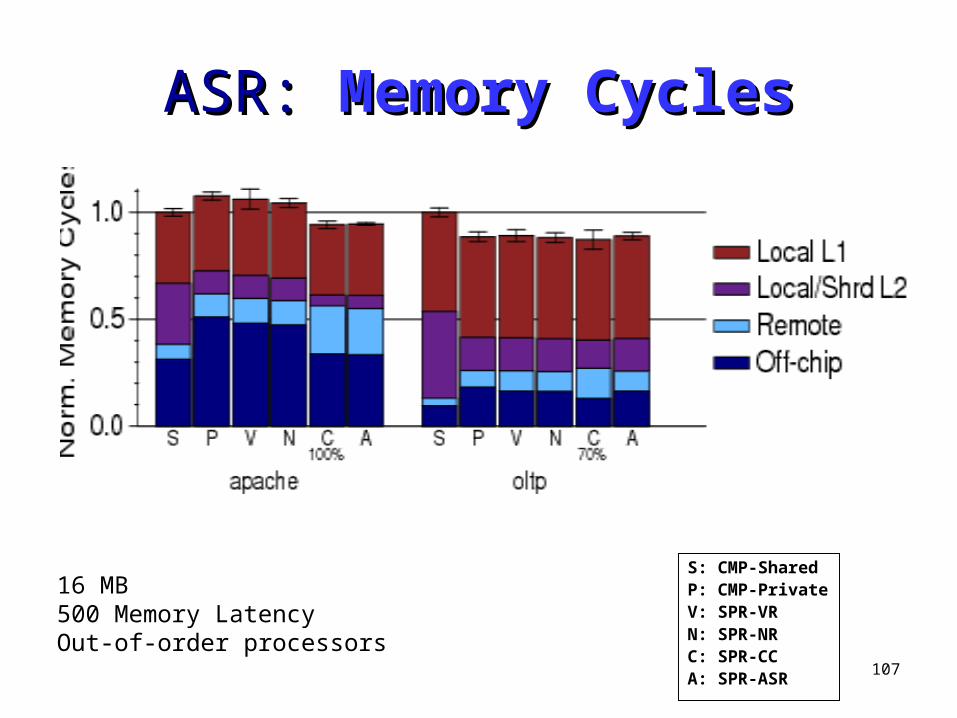
ASR: ASR: Memory CyclesMemory Cycles
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
16 MB500 Memory LatencyOut-of-order processors

108
ASR: ASR: PerformancePerformance
S: CMP-SharedP: CMP-PrivateV: SPR-VRN: SPR-NRC: SPR-CCA: SPR-ASR
16 MB500 Memory LatencyOut-of-order processors

109
A
B
CMP-DNUCA: CMP-DNUCA: Block MigrationBlock MigrationL1I $L1D $
CPU 2L1I $L1D $
CPU 3
L1D $L1I $
CPU 7L1D $L1I $
CPU 6
L1
D $L1
I $C
PU
1L
1D
$L1
I $C
PU
0
L1
I $L1
D $
CP
U 4
L1
I $L1
D $
CP
U 5
B
A

110
CMP-DNUCA: CMP-DNUCA: OrganizationOrganization
Bankclusters
Local
Center
CPU 2 CPU 3
CPU 7 CPU 6
CP
U 1
CP
U 0
CP
U 4
CP
U 5
16 Possible Locations
My clusters

111
CMP-DNUCA: CMP-DNUCA: MigrationMigration
• Migration policy– Gradual movement– Increases local hits and reduces distant hits– Works well for single requestor data
otherbankclusters
other centerbankcluster
my centerbankcluster
my localbankcluster

112
CMP-DNUCA: CMP-DNUCA: Hit Distribution Hit Distribution Grayscale ShadingGrayscale Shading
CPU 2 CPU 3
CPU 7 CPU 6
CP
U 1
CP
U 0
CP
U 4
CP
U 5
Greater %of L2 Hits

113
CMP-DNUCA: CMP-DNUCA: Hit Distribution Hit Distribution Ocean per CPUOcean per CPU
CPU 0 CPU 1 CPU 2 CPU 3
CPU 4 CPU 5 CPU 6 CPU 7

114
CMP-DNUCA: CMP-DNUCA: Hit Distribution Hit Distribution Ocean all CPUsOcean all CPUs
Block migration successfully separates the data sets

115
CMP-DNUCA: CMP-DNUCA: Hit Distribution Hit Distribution OLTP all CPUsOLTP all CPUs
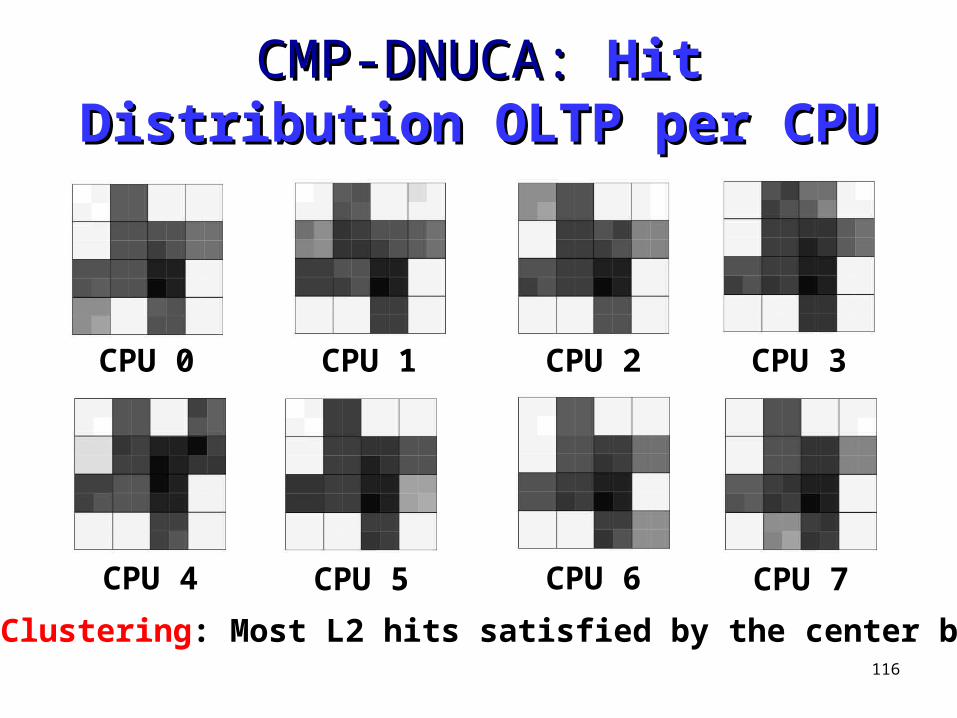
116
CMP-DNUCA: CMP-DNUCA: Hit Distribution Hit Distribution OLTP per CPUOLTP per CPU
Hit Clustering: Most L2 hits satisfied by the center banks
CPU 0 CPU 1 CPU 2 CPU 3
CPU 4 CPU 5 CPU 6 CPU 7

117
CMP-DNUCA: CMP-DNUCA: L2 Hit LatencyL2 Hit Latency
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA

118
CMP-DNUCA: CMP-DNUCA: Single Single Requestor On-chip LatencyRequestor On-chip Latency
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA

119
CMP-DNUCA: CMP-DNUCA: Shared Read-Shared Read-only On-chip Latencyonly On-chip Latency
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA
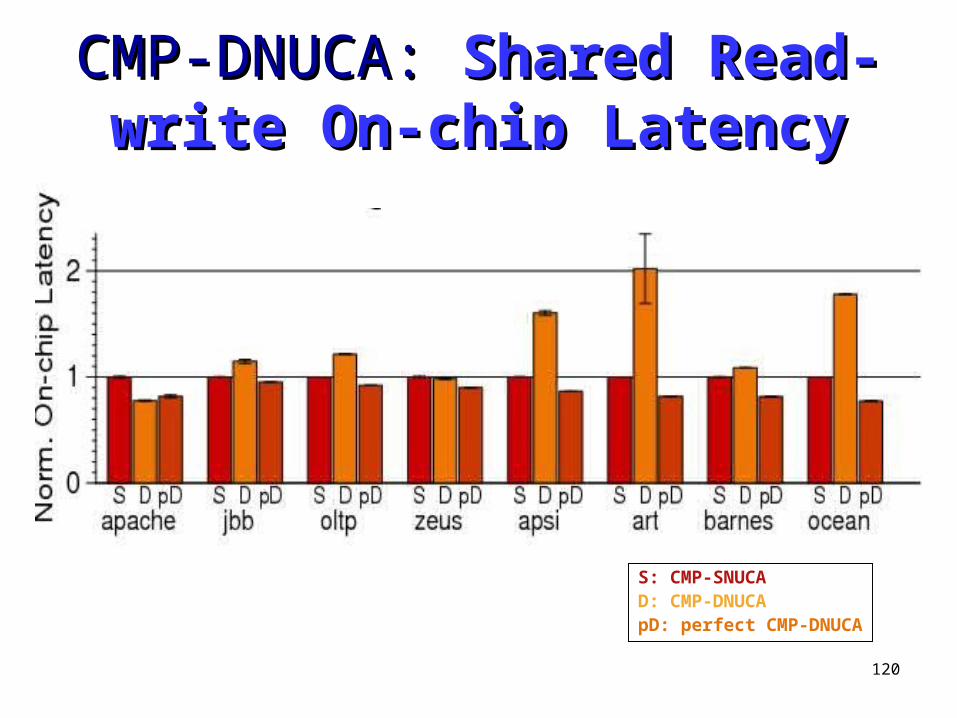
120
CMP-DNUCA: CMP-DNUCA: Shared Read-Shared Read-write On-chip Latencywrite On-chip Latency
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA
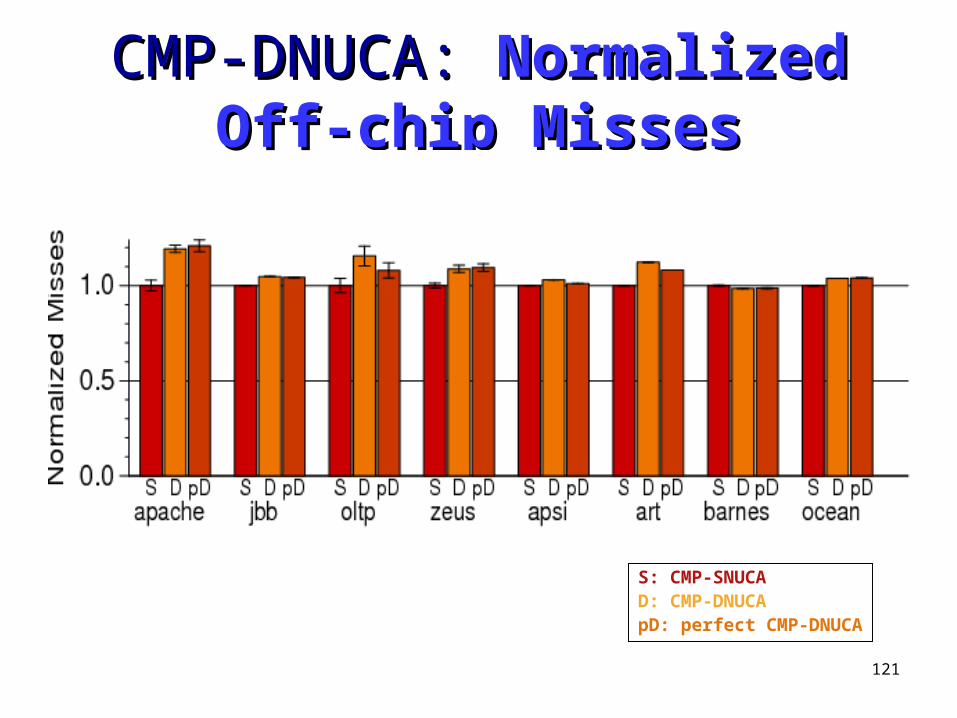
121
CMP-DNUCA: CMP-DNUCA: Normalized Off-Normalized Off-chip Misseschip Misses
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA
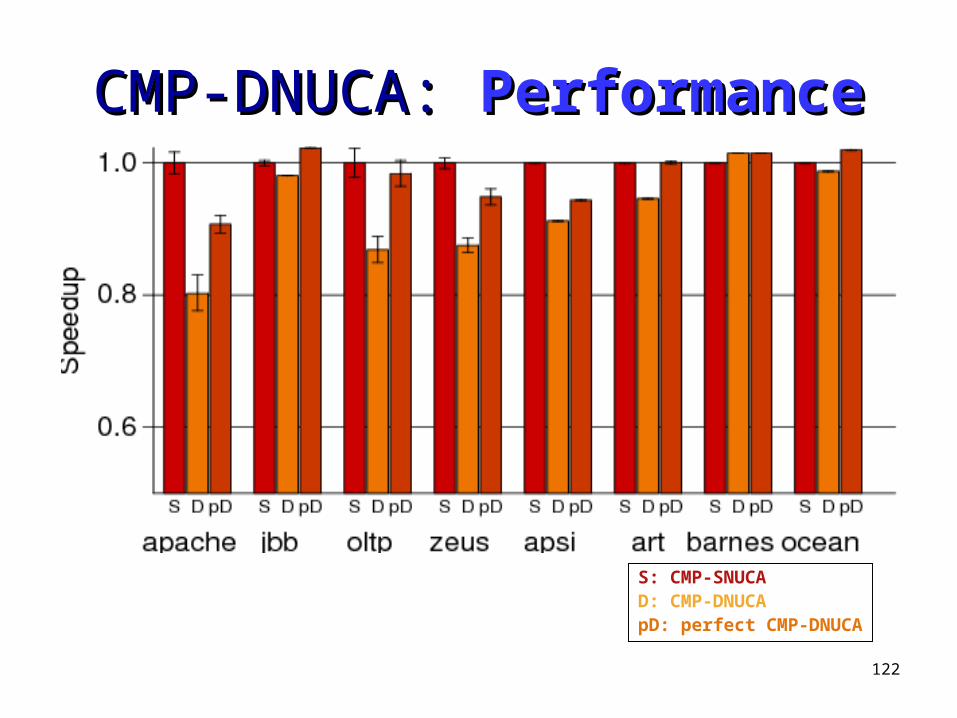
122
CMP-DNUCA: CMP-DNUCA: PerformancePerformance
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA

123
CMP-DNUCA: CMP-DNUCA: Memory CyclesMemory Cycles
S: CMP-SNUCAD: CMP-DNUCApD: perfect CMP-DNUCA
Back to talk

124
CMP-DNUCA:CMP-DNUCA: Conclusions Conclusions
• Success limited by sharing– Ocean successfully splits
• Regular scientific workload - little sharing
– Oltp congregates in the center• Commercial workload - significant sharing
• Smart search mechanism– Necessary for performance improvement– Implementation complexity– Upper bound - perfect search
• Off-chip miss increase– Unbalanced bank utilization– Increase in conflict misses

125
RC vs. TL CommunicationRC vs. TL CommunicationConventional Global Wire
On-chip Transmission Line
Voltage Voltage
DistanceVt
Driver Receiver
Voltage Voltage
DistanceVt
Driver Receiver
0.1 - 0.5 mm
10 mm
RC delay dominated
LC delaydominated
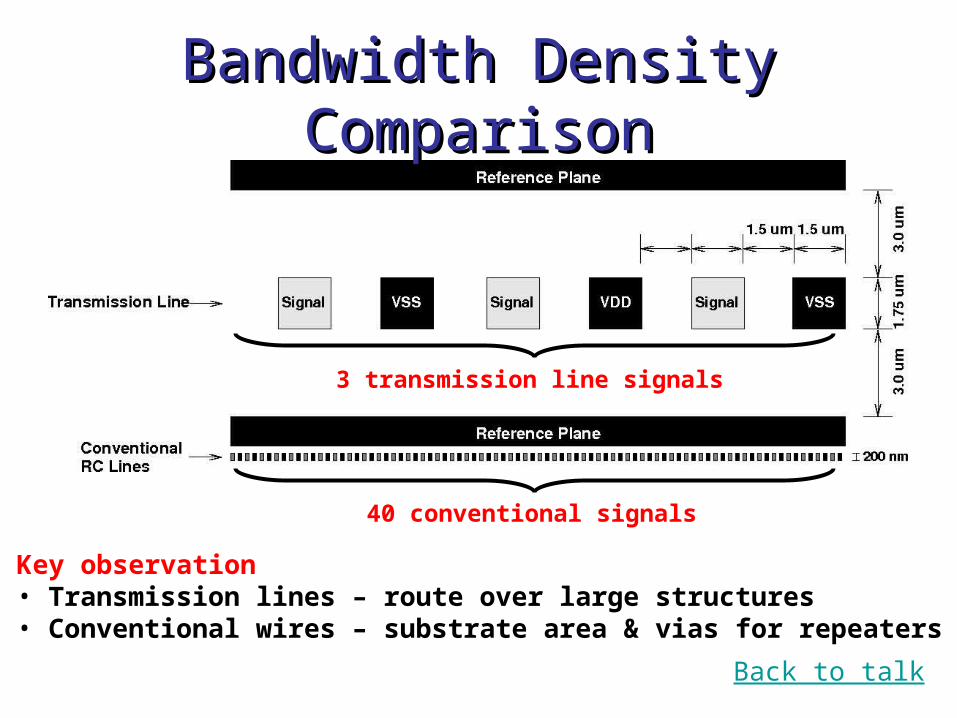
Bandwidth Density ComparisonBandwidth Density Comparison
3 transmission line signals
40 conventional signals
Key observation• Transmission lines – route over large structures• Conventional wires – substrate area & vias for repeaters
Back to talk

127
RC delay dominated
ReceiverDriver
On-chip Transmission Line
Conventional Global RC Wire
LC delay dominated
~0.1 mm
~10 mm
RC Wire vs. TL Design

128
Dynamic Power ComparisonDynamic Power Comparison
• Conventional RC SignalingDynamic Power = x CRC x V2 x f
• Voltage Mode Transmission Line SignalingDynamic Power = x tb x (V2 /(RD + Z0)) x f
• For source-terminated TLs (~ 1cm)CRC tb / (2 x Z0)

129
Shared CMP-TLCShared CMP-TLC
CPU 3L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
L1I $
L1D $
CPU 2
CPU 1
CPU 0
CPU 4
CPU 5
CPU 6
CPU 7
Default16
8-bytelinks
Fast L1L1 transfers
WaveDivision
Multiplexing
1680-byte
links
Back to talk

130
CMP-TLC Cache InterfaceCMP-TLC Cache InterfaceTransmission Lines
Repeaters
TransmissionLines
TransmissionLineTransceivers
Centralized Interface adds significant delay and complexity
Multi-cycledelay
Latches

131
Uncontended Latency Uncontended Latency ComparisonComparison
19 cycles
35 cycles
18 cycles
54 cycles
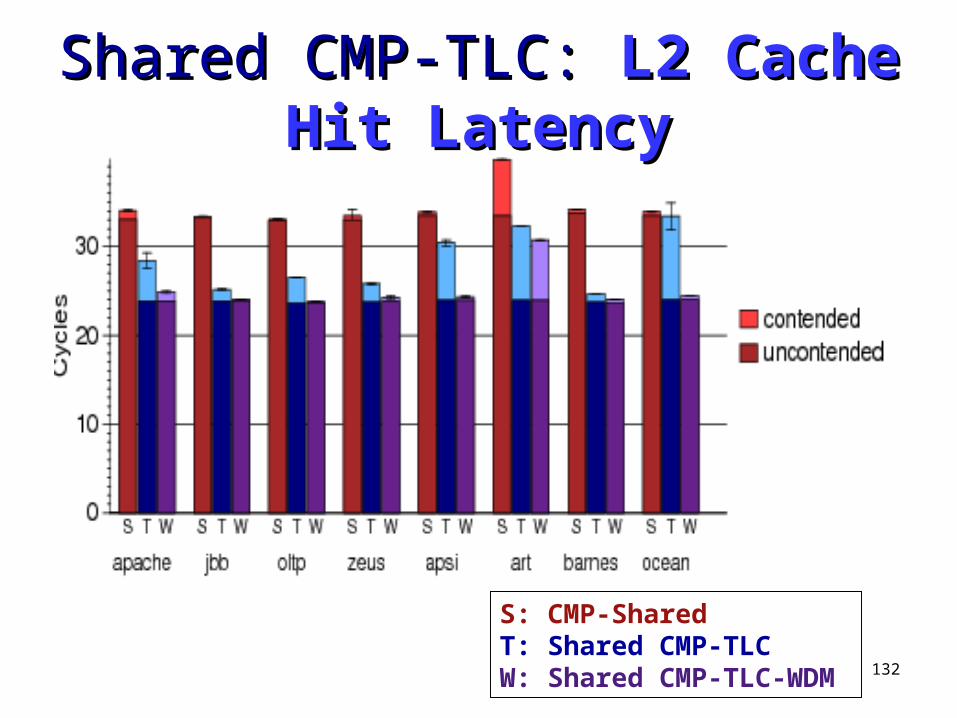
132
Shared CMP-TLC: Shared CMP-TLC: L2 Cache L2 Cache Hit LatencyHit Latency
S: CMP-SharedT: Shared CMP-TLCW: Shared CMP-TLC-WDM

133
Shared CMP-TLC: Shared CMP-TLC: Remote L1 Remote L1 Cache Hit LatencyCache Hit Latency
S: CMP-SharedT: Shared CMP-TLCW: Shared CMP-TLC-WDM
134
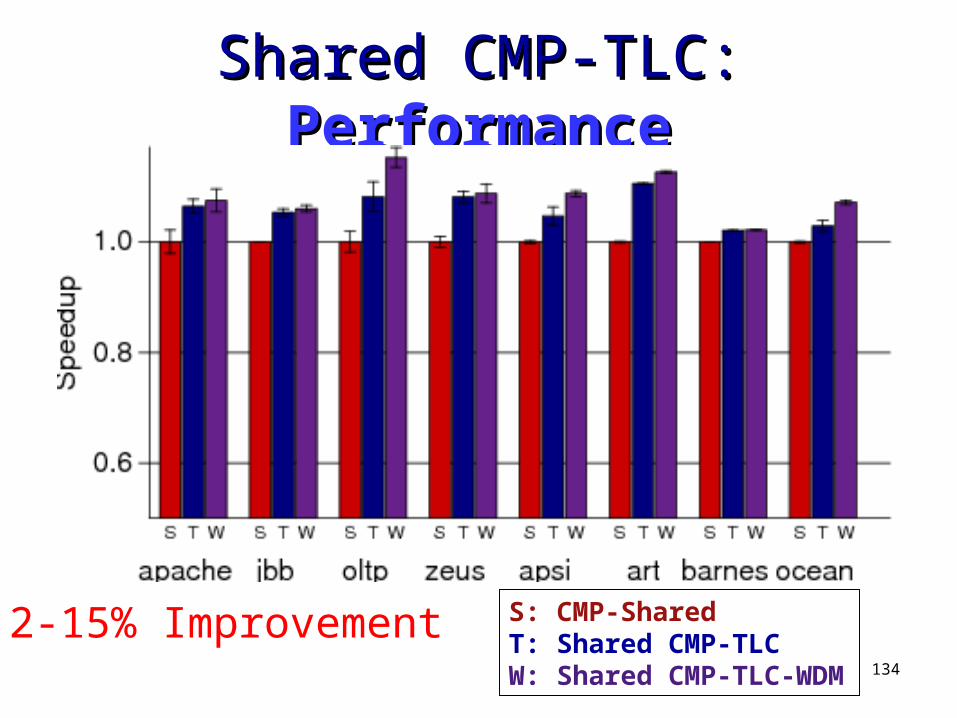
Shared CMP-TLC: Shared CMP-TLC: PerformancePerformance
2-15% Improvement S: CMP-SharedT: Shared CMP-TLCW: Shared CMP-TLC-WDM

135
Shared CMP-TLC: Shared CMP-TLC: L1 Miss CyclesL1 Miss Cycles
S: CMP-SharedT: Shared CMP-TLCW: Shared CMP-TLC-WDM

136
Shared CMP-TLC: Shared CMP-TLC: ConclusionsConclusions
• Transmission lines offer a different latency/bandwidth tradeoff
• CMP-TLC advantages– Consistent high performance– Simple logical design– Direct routing over large structures: compact layout
• CMP-TLC limitations– Centralized interface– Greater circuit verification effort: noise constraints– Manufacturing cost
Back to talk

137
Private CMP-TLC: Private CMP-TLC: PerformancePerformance
P: Private-CMPT: Private CMP-TLCR: Private CMP-TLC-RequestW: Private CMP-TLC-WDM
138
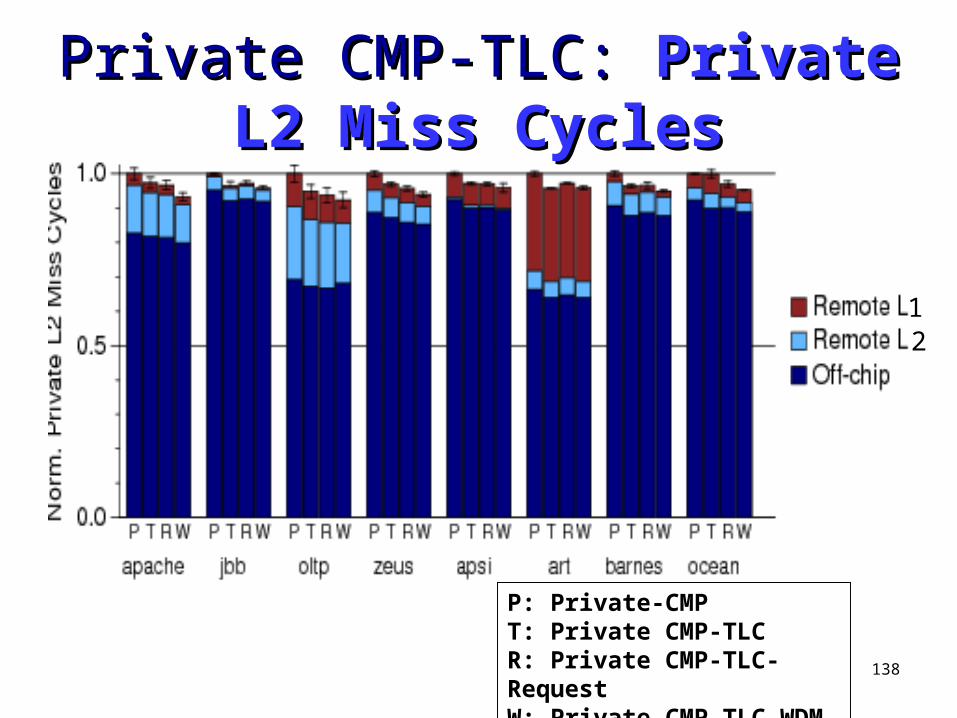
Private CMP-TLC: Private CMP-TLC: Private L2 Private L2 Miss CyclesMiss Cycles
P: Private-CMPT: Private CMP-TLCR: Private CMP-TLC-RequestW: Private CMP-TLC-WDM
12

139
Private CMP-TLC w/ASR: Private CMP-TLC w/ASR: PerformancePerformance
A: Private-CMP w/ASRT: Private CMP-TLC w/ASRR: Private CMP-TLC-Request w/ASRW: Private CMP-TLC-WDM w/ASR
140
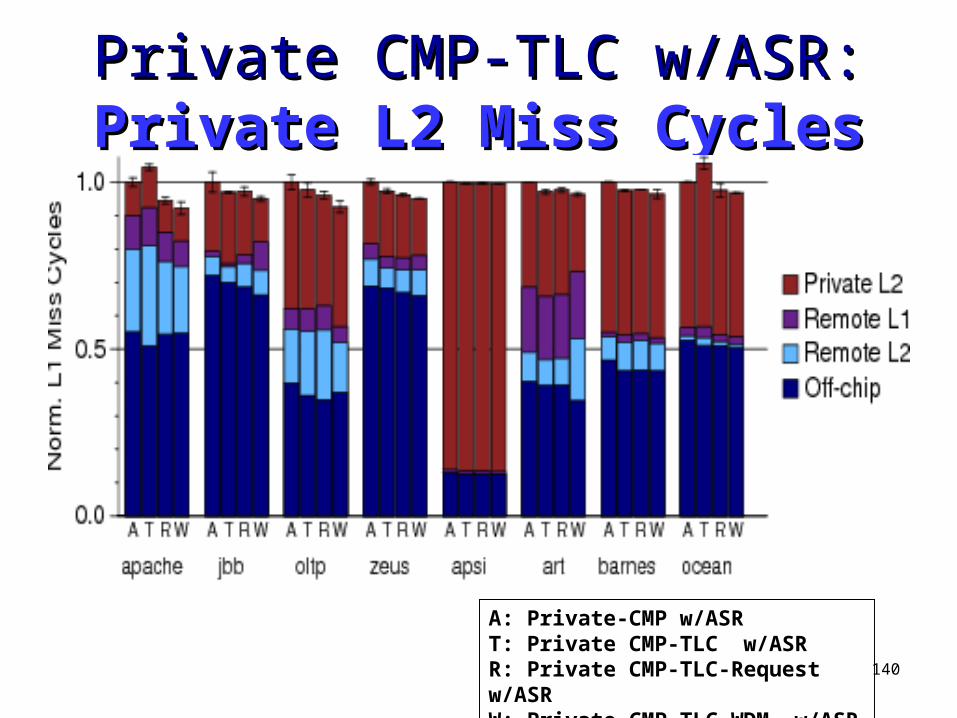
Private CMP-TLC w/ASR: Private CMP-TLC w/ASR: Private Private L2 Miss CyclesL2 Miss Cycles
A: Private-CMP w/ASRT: Private CMP-TLC w/ASRR: Private CMP-TLC-Request w/ASRW: Private CMP-TLC-WDM w/ASR

Determining CMP-SNUCADetermining CMP-SNUCAHit LatencyHit Latency
Description Cycles
L1 miss determination 3
1-7 network links (link + switch) 4 * (2 + 1) = 12
Bank access 9
1-7 network links (link + switch) 4 * (2 + 1) = 12
Total 18-54

Determining CMP-SharedDetermining CMP-SharedHit LatencyHit Latency
Description Cycles
L1 miss determination 3
Network access 1
1-7 network links (link + switch) 4 * (2 + 1) = 12
Network departure 1
Bank access 15
Network access 1
1-7 network links (link + switch) 4 * (2 + 1) = 12
Network departure 1
Total 46

Determining CMP-TLCDetermining CMP-TLCHit LatencyHit Latency
Description Cycles
L1 miss determination 3
Network access 1
2-5 network links (link + switch) 5 * (1 + 1) = 10
Network departure 1
Bank access 8
Network access 1
2-5 network links (link + switch) 5 * (1 + 1) = 10
Network departure 1
Total 35

Determining CMP-TLC Determining CMP-TLC BandwidthBandwidth
Distance Width Spacing Height Thickness
8 mm 1.5 um 1.5 um 1.75 um 3.0 um
9 mm 2.0 2.0 1.75 3.0
11 mm 2.5 2.5 1.75 3.0
13 mm 3.0 3.0 1.75 3.0
CMP-TLC:side width = 8 channels width (2 0.9cm, 2 1.0cm, 2 1.1cm, 2 1.3cm) = 2*(0.9cm channel width) + 2*(1.0cm channel width) + 2*(1.1cm channel width) + 2*(1.3cm channel width) = 2*2*8*8*8um + 2*2*8*8*9um + 2*2*8*8*10um + 2*2*8*8*12um = 0.009984 m
~ 1 cm

Latency ComparisonLatency Comparison
0
2
4
6
8
10
12
14
0 2 4 6 8 10 12
Distance (mm)
Cycles
Repeated RC
Single TL

146
Token CoherenceToken Coherence
• Proposed for SMPs [Martin 03], CMPs [Marty 05]• Provides a simple correctness substrate
– One token to read– All tokens to write
• Advantages– Permits a broadcast protocol on unordered network without
acknowledgement messages– Supports multiple allocation policies
• Disadvantages– All blocks must be written back (cannot destroy tokens)– Token counts at memory– Persistent request can be a performance bottleneck





























