Embed Size (px)
Citation preview

Managing Information Quality in e-Science
using Semantic Web technology
Alun Preece, Binling Jin, Edoardo PignottiDepartment of Computing Science, University of Aberdeen
Paolo Missier, Suzanne Embury, Mark GreenwoodSchool of Computer Science, University of Manchester
David Stead, Al Brown Molecular and Cell Biology, University of Aberdeen
www.qurator.orgDescribing the Quality of Curated e-Science Information
Resources

Combining the strengths of UMIST andThe Victoria University of Manchester
E-scienceexperiment
Information and quality in e-science
• Scientists required to place their data in the public domain
• Scientists use other scientists' experimental results as part of their own work
Labexperiment
In silico experiments(eg Workflow-based)
How can I decide whether I can trust
this data?
• Variations in the quality of the data
• No control over the quality of public data
• Difficult to measure and assess quality - No standards
Public BioDBs
Combining the strengths of UMIST andThe Victoria University of Manchester
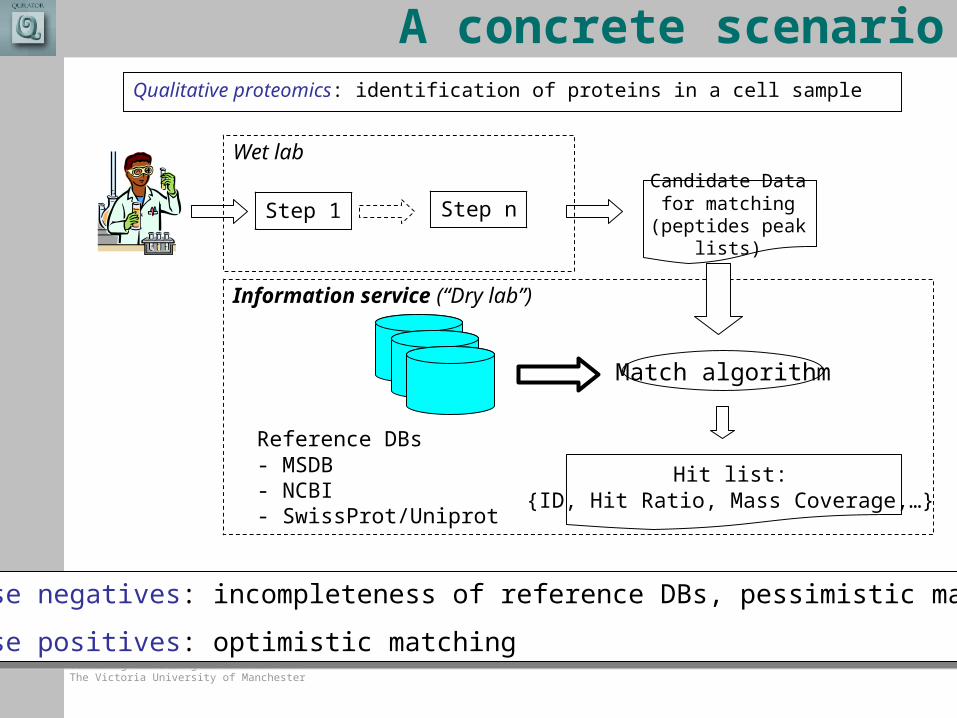
A concrete scenarioQualitative proteomics: identification of proteins in a cell sample
Step 1 Step nCandidate Data
for matching(peptides peak lists)
Match algorithm
Reference DBs- MSDB- NCBI- SwissProt/Uniprot
Wet lab
Information service (“Dry lab”)
Hit list:{ID, Hit Ratio, Mass Coverage,…}
False negatives: incompleteness of reference DBs, pessimistic matching
False positives: optimistic matching
False negatives: incompleteness of reference DBs, pessimistic matching
False positives: optimistic matching

Combining the strengths of UMIST andThe Victoria University of Manchester
Quality is personal
Scientists tend to express their quality requirements for data by giving acceptability criteria
These are personal and vary with the expected use of the data
“What is the right trade-off between false positives and false negatives?”

Combining the strengths of UMIST andThe Victoria University of Manchester
Requirements for IQ ontology
1. Establish a common vocabulary
– Let scientists express quality concepts and criteria in a controlled way
– Within homogeneous scientific communities
– Enable navigation and discovery of existing IQ concepts
2. Sharing and reuse: let users contribute to the ontology while ensuring consistency
– Achieve cost reduction
3. Making IQ computable in practice
– Automatically apply acceptability criteria to the data

Combining the strengths of UMIST andThe Victoria University of Manchester
Quality Indicators
Quality Indicators: measurable quantities that can be used to define acceptability criteria:
• “Hit Ratio”, “Mass Coverage”, “ELDP”
– provided by the matching algorithm
Match algorithm
Information service (“Dry lab”)
Hit list:{proteinID
Hit Ratio, Mass Coverage,…}
Experimentally established correlation between these indicators and the probability of mismatch
Experimentally established correlation between these indicators and the probability of mismatch

Combining the strengths of UMIST andThe Victoria University of Manchester
Data acceptability criteria
• Indicators used as indirect “clues” to assess quality
• Quality Assertions (QA) formally capture these clues as functions of indicators
• Data classification or ranking functions:
ex: PIClassifier defined as
f(proteinID, Hit Ratio, Mass Coverage, ELDP) { (proteinID, rank) }
– This provides a custom ranking of the match results
• Formalized acceptability criteria are conditions on QAs
accept(proteinID) if PIClassifier(ProteinID,…) > X OR …
Combining the strengths of UMIST andThe Victoria University of Manchester
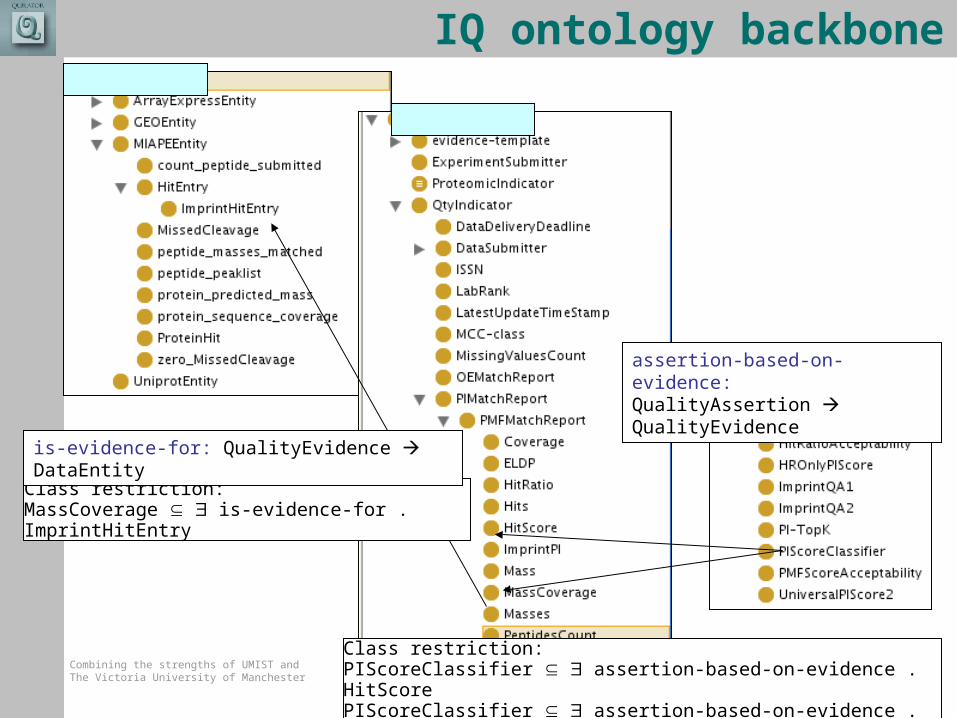
IQ ontology backbone
Class restriction:MassCoverage is-evidence-for . ImprintHitEntry
Class restriction:PIScoreClassifier assertion-based-on-evidence . HitScorePIScoreClassifier assertion-based-on-evidence . Mass Coverage
assertion-based-on-evidence: QualityAssertion QualityEvidence
is-evidence-for: QualityEvidence DataEntity
Combining the strengths of UMIST andThe Victoria University of Manchester
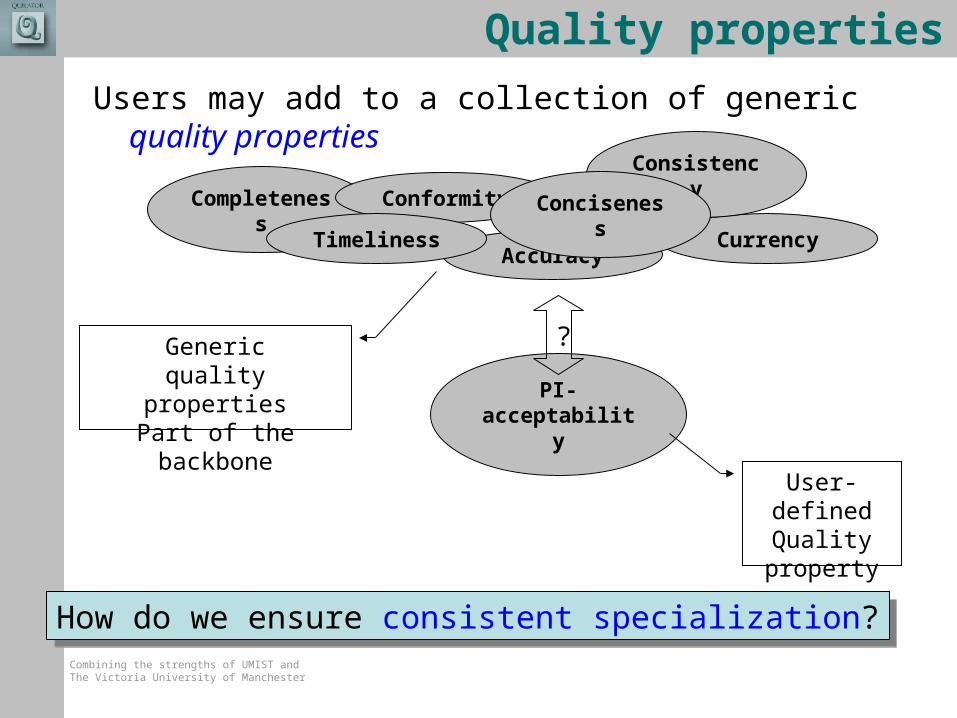
Quality properties
Users may add to a collection of generic quality properties
AccuracyCurrency
ConsistencyCompletenes
sConformity
TimelinessConciseness
PI-acceptability
?
User-definedQualityproperty
Genericquality properties
Part of the backbone
How do we ensure consistent specialization?How do we ensure consistent specialization?
Combining the strengths of UMIST andThe Victoria University of Manchester
…
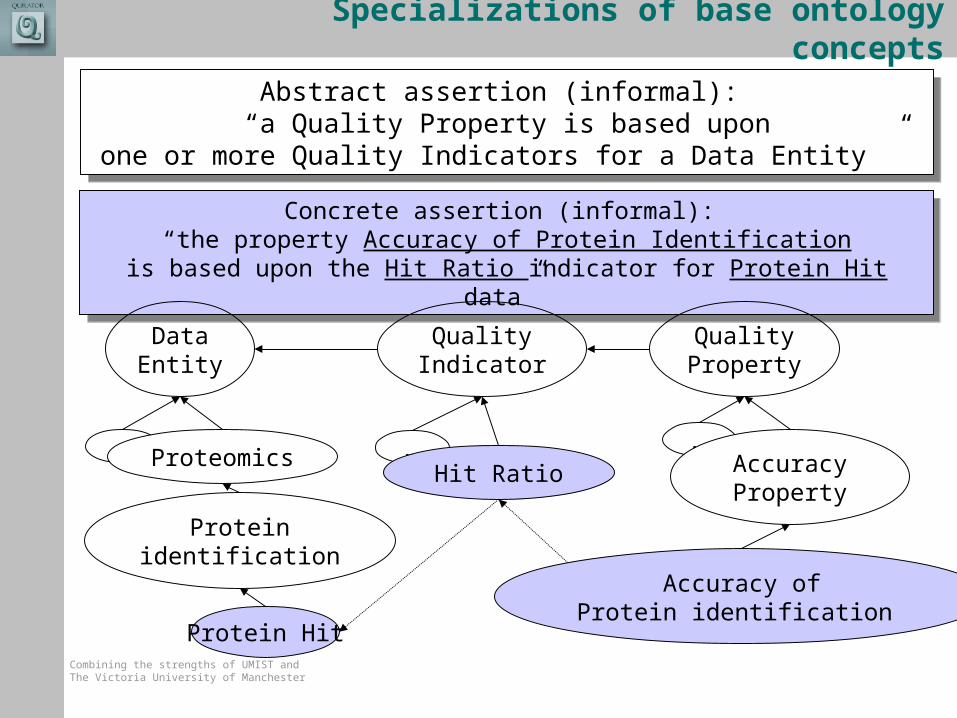
Specializations of base ontology concepts
Concrete assertion (informal): “the property Accuracy of Protein Identification
is based upon the Hit Ratio indicator for Protein Hit data”
Concrete assertion (informal): “the property Accuracy of Protein Identification
is based upon the Hit Ratio indicator for Protein Hit data”
Proteomics
Proteinidentification
DataEntity
QualityIndicator
…
Abstract assertion (informal): “a Quality Property is based upon
one or more Quality Indicators for a Data Entity ”
Abstract assertion (informal): “a Quality Property is based upon
one or more Quality Indicators for a Data Entity ”
QualityProperty
…AccuracyProperty
Protein Hit
Accuracy ofProtein identification
Hit Ratio
Combining the strengths of UMIST andThe Victoria University of Manchester
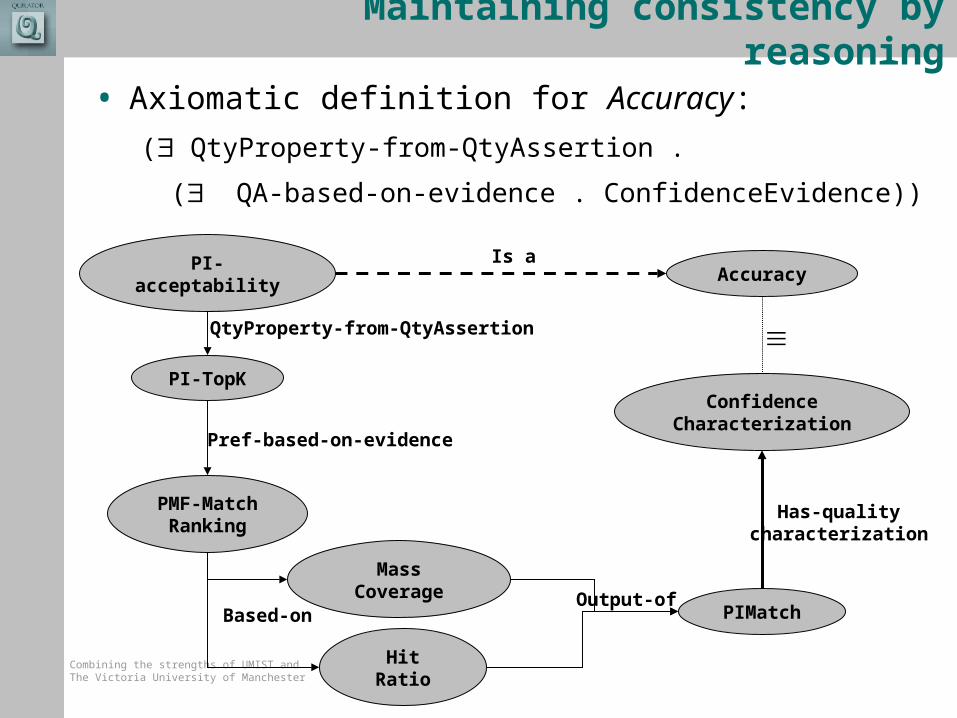
Maintaining consistency by reasoning
• Axiomatic definition for Accuracy:
( QtyProperty-from-QtyAssertion .
( QA-based-on-evidence . ConfidenceEvidence))
PI-TopK
PMF-MatchRanking
PI-acceptability
Mass Coverage
Hit Ratio
PIMatch
ConfidenceCharacterization
Accuracy
QtyProperty-from-QtyAssertion
Pref-based-on-evidence
Based-onOutput-of
Has-qualitycharacterization
Is a

Combining the strengths of UMIST andThe Victoria University of Manchester
Computing quality in practice
• Annotation model:Representation of indicator values as semantic annotations:
– model: RDF schema
– annotation instances: RDF metadata
• Binding model:Representation of the mapping between
• Data ontology classes data resources
• Functions ontology classes service resources
Goal:to make quality assertions defined in the ontology
computable in practice
Goal:to make quality assertions defined in the ontology
computable in practice
Combining the strengths of UMIST andThe Victoria University of Manchester
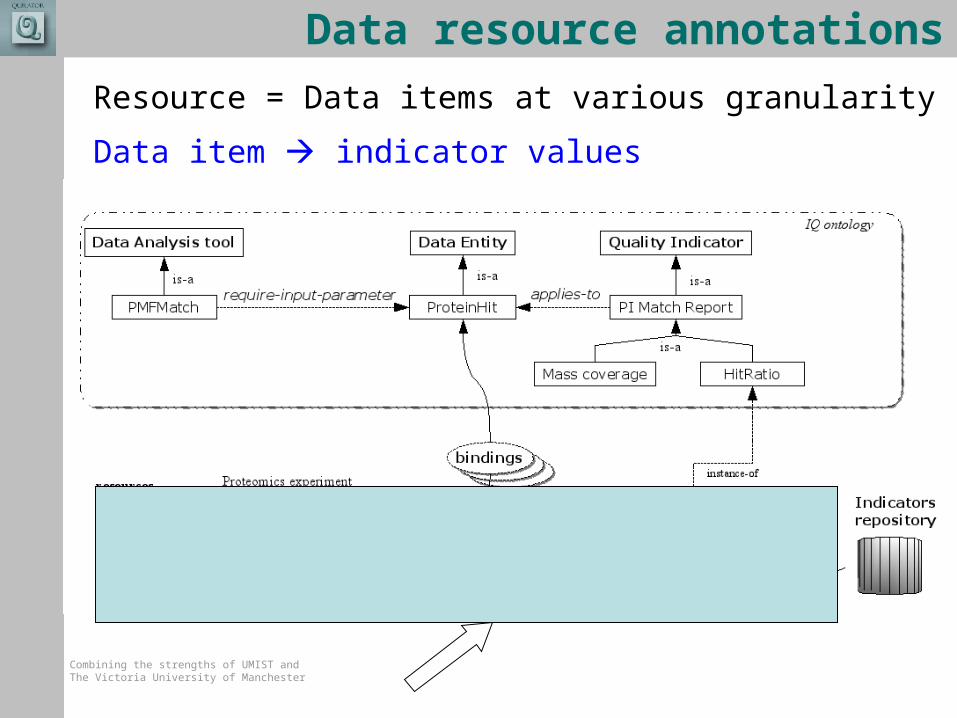
Data resource annotations
Resource = Data items at various granularity
Data item indicator values

Combining the strengths of UMIST andThe Victoria University of Manchester
Data resource bindings
Data class data resource
• Account for different granularities, data types
Combining the strengths of UMIST andThe Victoria University of Manchester
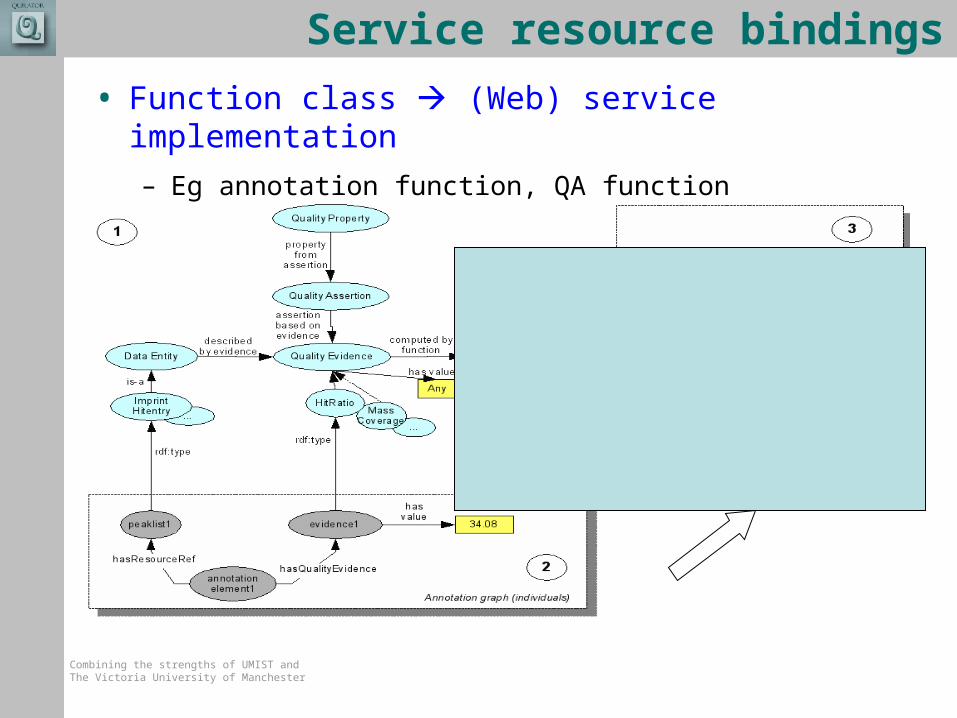
Service resource bindings
• Function class (Web) service implementation
– Eg annotation function, QA function

Combining the strengths of UMIST andThe Victoria University of Manchester
The complete quality model

Combining the strengths of UMIST andThe Victoria University of Manchester
IQ Service Example

Combining the strengths of UMIST andThe Victoria University of Manchester
Summary
• An extensible OWL DL ontology for Information Quality
– Consistency maintained using DL reasoning
• Used by e-scientists to share and reuse:
– Quality indicators and metrics
– Formal criteria for data acceptability
• Annotation model:
generic schema for associating quality metadata to data resources
• Binding model:
generic schema for mapping ontology concepts to (data, service) resources
• Model tested on data for proteomics experiments





























