Embed Size (px)
Citation preview

Main Benefits of
Task Parallel Frameworks
Rafael Asenjo
Dept. of Computer Architecture
University of Málaga
http://www.ac.uma.es/~asenjo

Agenda
• Motivation
– Task-parallel frameworks
– Work Stealing
• Putting tasks to work
– Pipeline
– Wavefront
– Heterogeneous
• Conclusions
Sept 13, 2012 HPC-AC. Rafael Asenjo. 2

Motivation • Yes, we are in the multicore era!
– Execution performance is …
• Not a HW main problem any more
• But a SW responsibility must parallelize the apps
– Sequential program Slow program
– SW developer Parallelizer
– Think in parallel
• Needed:
– New languages and tools to help developers
Sept 13, 2012 HPC-AC. Rafael Asenjo. 3

Parallel languages and tools • Parallel frameworks
– Distributed memory
• Message passing: MPI, SHMEM, GASNet, …
– Shared memory
• Pthreads, OpenMP
• Task frameworks:
– Intel TBB, Cilk, Intel CnC, OpenMP 3.0, MS TPL, Java Conc.
• Parallel Languages • Partitioned Global Address Space (PGAS)
– UPC, Co-array Fortran (CAF), Titanium (Parallel Java)
• High Performance Computing Systems (HPCS)
– Chapel (Cray), X10 (IBM), Fortress (Sun/Oracle)
• Heterogeneous: CUDA, OpenCL, OpenACC
Sept 13, 2012 HPC-AC. Rafael Asenjo. 4

Task vs. Threads • Tasks: much lighter-weight than threads
– Typically a function or class method
– TBB: Task vs. thread
• Linux: 18x faster to start and terminate a task
• Windows: 100x faster
– GCD (Apple’s Grand Central Dispatch)
• Create a traditional thread: 100s instructions
• Create a task: 15 instructions
– In general: user level scheduler
• The OS kernel does not see the tasks
• The task scheduler’s mainly focus: performance
Sept 13, 2012 HPC-AC. Rafael Asenjo. 5

Thread Pool: Work Stealing
Worker
Thread 1
Worker
Thread 2
Program
Thread
Work-stealing scheduler
Local
Queue
Local
Queue
Local
Queue
Task 1 Task 2
Task 3 Task 5
Task 4
Task 6
Core 1 Core 2
Sept 13, 2012
Core 0
Task 0
HPC-AC. Rafael Asenjo. 6

Task scheduler advantages • Automatic load balancing
– With less overhead than work-sharing
• Without the OS scheduler restrictions
– No OS scheduler preemption, no Round-Robin
– Unfair scheduling: can sacrifices fairness for efficiency
– Can be guided by the user
• You don’t need to be “root” nor rely on RT priorities
• Can be cache-conscious
– Avoid oversubscription, and therefore:
• Avoid context switching overhead
• Avoid cache cooling penalty
• Avoid lock preemption and convoying
Sept 13, 2012 HPC-AC. Rafael Asenjo. 7

The PARSEC suite • Princeton Application Repository for Shared-
Memory Computers (http://parsec.cs.princeton.edu) – Emerging multithreaded workloads
– Diverse enough: RMS, streaming, multimedia, engineering, …
– Originally implemented with Pthreads
Sept 13, 2012 HPC-AC. Rafael Asenjo. 8

ferret: similarity search
• Two serial stages and 4 middle parallel stages
– Read a set of key images
– Return the list of the most similar images in the
database
Sept 13, 2012 HPC-AC. Rafael Asenjo. 9

ferret performance
• Target machine: HP9000 Superdome SMP (picasso)
– 64 dual-core Itanium2, 1.6GHz, 380GB RAM, 9MB L3
Sept 13, 2012 HPC-AC. Rafael Asenjo. 10

ferret performance
• Efficiency problems:
– Stage load imbalance and input bottleneck
Sept 13, 2012 HPC-AC. Rafael Asenjo. 11

dedup: data compression
• Main differences from ferret
– S2 generate more output items than there were input
– Some items may skip stage S4
Sept 13, 2012 HPC-AC. Rafael Asenjo. 12

dedup performance
• On Superdome
Sept 13, 2012 HPC-AC. Rafael Asenjo. 13

dedup performance
Same problems: load imbalance and output bottleneck
Sept 13, 2012 HPC-AC. Rafael Asenjo. 14

Scalability issues and solutions
• Scalability gated by
– Load imbalance for small number of threads
– I/O bottleneck for larger number of threads
• Solutions
– Load imbalance
• Collapsing all the parallel stages into one (not general)
• Oversubscription: semi-dynamic scheduling
• Work stealing: dynamic scheduling
– I/O bottleneck
• Parallel I/O
Sept 13, 2012 HPC-AC. Rafael Asenjo. 15

TBB vs. Pthreads
37% 42%
63%
Sept 13, 2012 HPC-AC. Rafael Asenjo. 16

Summary of results (I) • Advantages of using TBB to implement work
stealing
– Productivity (easier to write, # stages is not an issue)
– Automatic load balance
– Cache-conscious, thanks to the TBB pipeline template
– Negligible overheads (measured with Vtune)
• PACT 2009:
– “Analytical Modeling of Pipeline Parallelism”, A.
Navarro, R. Asenjo, S. Tabik and C. Cascaval.
Sept 13, 2012 HPC-AC. Rafael Asenjo. 17

Wavefront problems
• Wavefront is a programming pattern
– Appears in important scientific applications
• Dynamic programming or sequence alignment.
• Checkerboard, Floyd, Financial, H.264 video compression.
• 2D wave problem
• gs (grain size): vary the workload
Sept 13, 2012 HPC-AC. Rafael Asenjo. 18

2D Wavefront problem
1 2
2
3
3
3
4
4
4
4
A[i,j] = foo(gs, A[i,j], A[i-1,j], A[i, j-1]);
Sept 13, 2012 HPC-AC. Rafael Asenjo. 19

Task-based implementations
(pseudocode)
Dependencies/counters
1
0 0
0
Each element computation is done by a task
Sept 13, 2012 HPC-AC. Rafael Asenjo. 20

OpenMP 3.0 OpenMP peculiarities
No atomic capture:
omp critical & omp task
--x==0
is not atomic
Memory conpsumption
increases due to array of locks
omp_set_lock(&locks[i][j+1]);
ready = --counter[i][j+1]==0;
omp_unset_lock(&locks[i][j+1]);
omp_set_lock(&locks[i+1][j]);
ready = --counter[i][j+1]==0;
omp_unset_lock(&locks[i+1][j]);
OpenMP_v1 (critical)
OpenMP_v2 (locks)
Sept 13, 2012 HPC-AC. Rafael Asenjo. 21

TBB_v1 implementation o TBB_v1 peculiarities
Atomic<int>
Override task::execute
spawn
Sept 13, 2012 HPC-AC. Rafael Asenjo. 22

TBB_v2 implementation o TBB_v2 peculiarities
atomic <int>
parallel_do_feeder templ.
feeder.add method
Sept 13, 2012 HPC-AC. Rafael Asenjo. 23

Cilk Implementation o Cilk peculiarities
No atomic operation
cilk_spawn, locks
cilk_sync
Sept 13, 2012 HPC-AC. Rafael Asenjo. 24

o CnC peculiarities Atomic<int>
Operation Collection
Element Tag
CnC Implemt.
Sept 13, 2012 HPC-AC. Rafael Asenjo. 25

Experimental results • Two Quad-Core Intel Xeon CPU X5355 at 2.66
GHz.
• Running example case study.
– Matrix size = 1,000 x 1,000
• Speedup (with respect to the fastest sequential
code)
• Task granularity:
– Fine (200 FLOP), medium (2,000 FLOP) and coarse
(20,000 FLOP) grain
Sept 13, 2012 HPC-AC. Rafael Asenjo. 26

Constant granularity:
Speedups
Notes:
• Cilk sometimes does not complete
• Similar behavior of TBB_v1 and TBB_v2
• OpenMP has the worst scalability
• CnC is between TBB and OpenMP
fine medium
coarse
Sept 13, 2012 HPC-AC. Rafael Asenjo. 27

Optimizations to reduce
overheads in TBB Exploiting task passing
mechanism available
in TBB
TBB_v4
Number of spawns:
O(n2) O(n)
Sept 13, 2012 HPC-AC. Rafael Asenjo. 28

Optimizations: reducing overheads in
TBB
TBB_v3 is similar to TBB_v4 but without
exploiting cache locality
• Scalability improvement: ~ 3x
• Overhead reduction: ~ 7x
• Cache improvement: ~ 4x
speedup overhead ratio
L2 cache misses
Sept 13, 2012 HPC-AC. Rafael Asenjo. 29

Sep
t 13
, 20
12
HPC-AC. Rafael Asenjo. 30
Wavefront template

Wavefront template examples
a) Checkerboard
//Data grid[0:m-1,0:n-1]//Task grid[1:m-1,:]//Indices(i,j)//Dependence vectors[1:m-1,1:n-2]->(1,-1);(1,0);(1,1)[1:m-2,0]->(1,-1);(1,0)[1:m-2,n-1]->(1,0);(1,1)//Counter values[1,:]=0[2:m-1,0]=2[2:m-1,n-1]=2[2:m-1,1:n-2]=3
//Data grid
[0:m-1,0:m-1]
//Task grid
[:,:]
//Indices
(k,i)
//Dependence vectors
[0:m-2,k+1]->(1,-i:m-i-1)
[0:m-2,!(k+1)]->(1,0)
//Counter values
[0,:]=0
[1:m-1,k]=1
[1:m-1,!(k)]=2
//Data grid
[0:m-1,0:n-1]
//Task grid
[1:m-1,1:n-1]
//Indices
(i,j)
//Dependence vectors
[1:m-2,1:n-1]->(1,0:n-j-1)
//Counter values
[1,1:n-1]=0
[2:m-1,1:n-1]=j
//Data grid
[0:h-1,0:w-1]
//Task grid
[:,:]
//Indices
(i,j)
//Dependence vectors
[0:h-2,1:w-2]->(0,1);(1,-1)
[0:h-1,0]->(0,1)
[0:h-2,w-1]->(1,-1)
[h-1,1:w-2]->(0,1)
//Counter values
[0,0]=0
[0,1:w-2]=1
[0:h-1,w-1]=1
[1:h-1,0:w-2]=2
ji
1
3
\ 0 1 3
2
0
2
3 3 22
0 0 00
3 3 22 1 2 3
1 2 3
0 0 0
i
1
3
\ 0 1 3
2
0
2j
2 2 1
2 2 1
2 2 1
1 1 1
2
2
2
0
i
1
3
\ 0 1 3
2
0
2j
2 2 1
2 1 2
1 2 2
0 0 0
2
2
2
0
k
1
3
\ 0 1 3
2
0
2i
b) Financial c) Floyd d) H.264
Figure 6. Dependence pattern, count er s matrix and definition files for four wavefront algorithms
Note that in Fig. 6-b, the dependence
vector for the Financial case is described with
[ 1: m- 2, 1: n- 1] - >( 1, 0: n- j - 1) , which means
that for each one of the cells in the region, there are n − j
dependent cells, identified by vector ( 1, 0: n- j - 1) . So,
for example, for cell [ 2, 1] , the dependent cells are those
in the next row (row 2+ 1), and in columns within the range
1 + (0 : n − 1 − 1). Thus, the dependent cells are [3,1],
[3,2] and [3,3], if n = 4. Although the optional counter
values section of the definition file can be omitted because
it is possible to generate the matrix of counters from the
dependence vector, this would add an extra initialization
time. The reason is that in this case, for each cell, a loop
has to increment the counter of each dependent cell. On
the other hand, if the programmer directly provides the
counter values ([ 2: m- 1, 1: n- 1] =j in Fig. 6-b), then a
single traverse of the matrix will initialize each counter to
the column index value, which is actually the number of
arrows reaching each cell. In our experiments, for a 300
× 300 matrix of counters in this problem, it is possible to
speedup the matrix of counter initialization time by a factor
of 70 if the counter values section is provided (in 8 cores).
However, this is an extreme case: in the basic 2D wavefront
example for wich each counter would be incremented at
most twice, the 1,000 × 1,000 matrix initialization is 5
times slower if we do not specify the initial values.
The Floyd’s algorithm [8] uses dynamic programming to
solve the all-pairs shortest-path problem on a dense graph.
The method makes efficient use of an adjacency matrix
D (i , j ) to solve the problem. The new values of that matrix
are computed by eq. 3.
D k (i , j ) = mink ≥ 1
{ D k − 1 ( i , j ), D k − 1( i , k) + D k − 1(k, j )} (3)
In Fig. 6-c, the indices in the task region has been de-
fined as <k, i >. In that file, the subregion [ 0: m- 2, k+1]
identifies the cells in the super-diagonal, i.e. those cells
that verify i =k+1 for k=0: m- 2. On the other hand, the
subregion [ 0: m- 2, ! ( k+1) ] represents all the cells that
verify i ! =k+1.
Finally, we have also implement the H.264 decoder.
H.264 or AVC (Advanced Video Coding) is a standard
for video compression. In H.264 a video sequence has
multiple video pictures called frames. A frame has several
slices, which are self contained partitions of a frame and
contain anumber of MacroBlocks (MBs). MBs are blocks of
16× 16 pixels and are the basics unit for coding a decoding.
In [9] a 2D wavefront version of the H.264 decoder is
implemented using Pthreads. In particular, we focus on
the t f _decode_mb_cont r ol _di st r i but ed function
where the MBs are processed following the wavefront pat-
tern. The original wavefront code consists in a master thread
and a pool of worker threads that wait for work on a task
queue. The master thread is responsible for handling the
initialization and finalization operations. The dependencies
Sept 13, 2012 HPC-AC. Rafael Asenjo. 31

Wavefront template results
1. Programmer specifies: i) definition file with dependence pattern information and ii) the task function.
2. The template is a productive tool (50% less programming effort) with low overhead costs (less than 5%).
Sept 13, 2012 HPC-AC. Rafael Asenjo. 32

Sumary of results (II)
• TBB features allow more efficient
implementations:
– Atomic capture and task recycling
• OpenMP greatly benefits from atomic capture
• CnC is competitive for coarse grain
• Cilk++ implementation is not robust enough
• HiPC 2011: – “High-level template for the task-based parallel wavefront pattern”,
A. Dios, R. Asenjo, A. Navarro, F. Corbera, E.L. Zapata
• ParCo 2011: – “A case study of the task-based parallel wavefront pattern”, A. Dios,
R. Asenjo, A. Navarro, F. Corbera, E.L. Zapata Sept 13, 2012 HPC-AC. Rafael Asenjo. 33

Tasks for heterogeneous
• Oversubscribe if there are GPUs
• A dedicated thread wrapping the GPU
• This thread has a work-stealing scheduler to feed the GPU
• The GPU thread does not consume core cycles while the
GPU is working
Sept 13, 2012
Core GPU TH
core
TH
GPU
HPC-AC. Rafael Asenjo. 34

TBB for heterogeneous
– Higer level approach
• TBB pipeline template:
– A pipeline stage served by a GPU
» Should be the bottleneck stage
• TBB Parallel_for template:
– Adjust the grain size of the blocked_range iteration space for
the tasks that will be mapped in the GPU
Sept 13, 2012
1
2 GPU 4
5
2 GPU 4
HPC-AC. Rafael Asenjo. 35

maxGPU ? ? ? ?
free
GPU?
Generate
GPU maxGPU Generate
CPU ?
1st stage 2nd stage
GPU
Block?
Process
GPU maxGPU CPU
CPU
CPU
Process
CPU ?
parallel_for with GPU • Relying on a two-stages pipeline:
– 1st serial stage: generates chunks for CPU or GPU
– 2nd parallel stage: computes a chunk in CPU or GPU
• Second approach: variable chunk size
Sept 13, 2012 HPC-AC. Rafael Asenjo. 36

Experimental results
Sept 13, 2012
38.55
38.555
38.56
38.565
38.57
38.575
8 9 12
MxV: 8 cores
CFS
POX
20
20.5
21
21.5
22
22.5
23
8 9 10
MxV: 8 cores + 1 GPU
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
13.5
14
14.5
15
15.5
16
8 10 12
MxV: 8 cores + 2 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
8
8.5
9
9.5
10
10.5
8 12 16
MxV: 8 cores + 4 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
HPC-AC. Rafael Asenjo. 37

Experimental results
Sept 13, 2012
131450
131500
131550
131600
131650
131700
8 9 12
Barnes-Hut: 8 cores
CFS
POX
70000
72000
74000
76000
78000
80000
82000
84000
86000
88000
90000
92000
8 10 12
Barnes-Hut: 8 cores + 2 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
0
10000
20000
30000
40000
50000
60000
70000
80000
8 12 16
Barnes-Hut: 8 cores + 4 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
92000
94000
96000
98000
100000
102000
104000
106000
108000
110000
8 9 10
Barnes-Hut: 8 cores + 1 GPU
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
ASYNC_CFS
ASYNC_POX
HPC-AC. Rafael Asenjo. 38
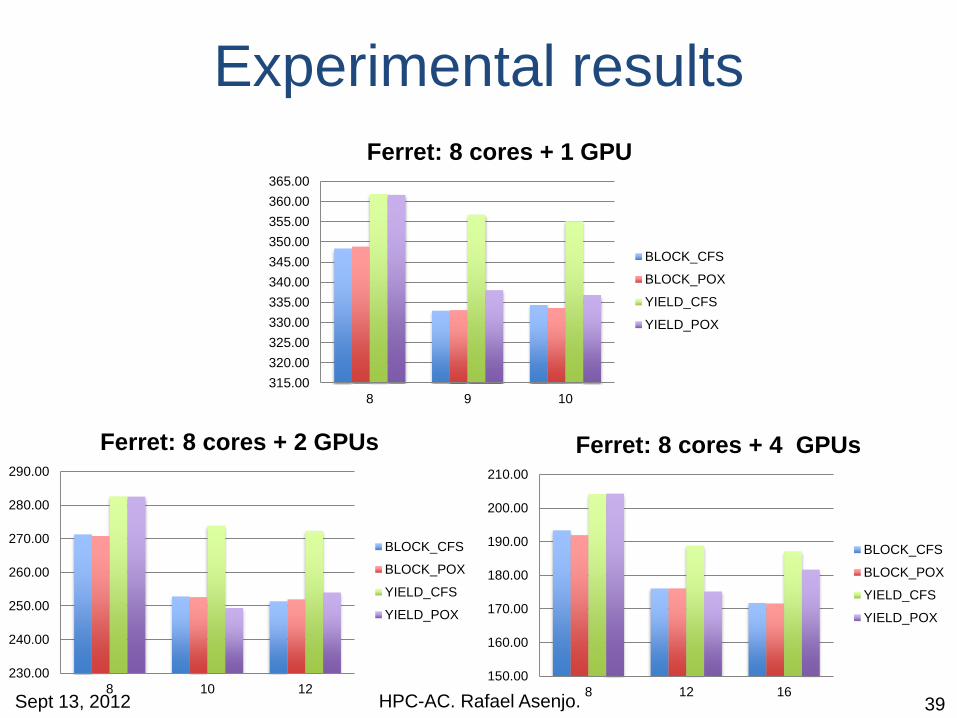
Experimental results
Sept 13, 2012
315.00
320.00
325.00
330.00
335.00
340.00
345.00
350.00
355.00
360.00
365.00
8 9 10
Ferret: 8 cores + 1 GPU
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
230.00
240.00
250.00
260.00
270.00
280.00
290.00
8 10 12
Ferret: 8 cores + 2 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
150.00
160.00
170.00
180.00
190.00
200.00
210.00
8 12 16
Ferret: 8 cores + 4 GPUs
BLOCK_CFS
BLOCK_POX
YIELD_CFS
YIELD_POX
HPC-AC. Rafael Asenjo. 39

Conclusions Advantages of task-based programming models
• Automatic load balancing
• Programmer can provide hints that improve cache
behavior
• Portable; easier to parallelize the codes
• Well-suited for fine grain problems
• With some libraries:
– Interoperability with other languages and tools
– Templates available: parallel_for, pipeline, parallel
containers…
Sept 13, 2012 HPC-AC. Rafael Asenjo. 40





























