Embed Size (px)
Citation preview

Machine Translation MT &
Computer-Assisted Translation CAT

Machine Translation• Introduction to MT systems
• Generations of MT systems
• Different types of MT systems
• Construction of MT systems• Knowledge representation• Knowledge processing• MT engines• New directions of MT systems
• Evaluation of MT & CAT systems

Machine Translation: Introduction
• Machine translation ( MT) is a long-term scientific dream of enormous social, political and commercial importance.
• It was one of the earliest applications suggested for digital computers, but turning this dream into reality has turned out to be a much harder.
• Despite different problems and difficulties, some degree of Machine translation is now a daily reality and it is likely that in the future, the bulk of routine technical and business translation will be done with some kind of machine translation tools.

Machine Translation: History
• The history of MT research has gone through a number of phases in which certain frameworks have dominated.• First generation: From the late 1960s the syntactic orientation
was dominant with syntactic transfer approaches.• Second generation: In the 1980s the AI orientation was popular
and more attention was paid to semantics.• Third generation: from 1990s the corpus-based model with
example-based methodologies is the focus of much translation activity. (e.g. old versions of Electronic Dictionaries)
• Forth generation: from 2000s research on spoken translation has developed into a major focus of MT activity. (e.g. latest versions of Electronic Dictionaries )
• Last ten years: research on Computer-Assisted Translation CAT has developed into a major focus of translation activity.

How To Construct an MT system

Knowledge Representation• Different kinds of knowledge are generally needed for
Machine translation and must be represented in such a way it can be processed automatically by MTs• Knowledge of the source language• Knowledge of the target language• Knowledge of the various correspondences between source
language and target language (at least knowledge of how individual words can be translated)
• Knowledge of the culture, social conventions, etc.• Etc.
• Several kinds of linguistic knowledge are usually distinguished:• Phonological knowledge• Morphological knowledge• Syntactic knowledge• Semantic knowledge

Knowledge Representation: Dictionary
• The central and largest component of an MT system is Dictionary.
• The size and quality of the dictionary limits the scope and coverage of a system and the quality of translation that can be expected.
• “Electronic dictionaries” of MT must at least represent the information we can find in “paper dictionaries” in an appropriate fashion.

Knowledge Representation: Paper Dictionaries

Knowledge Representation: Electronic Dictionaries
• Entries in MT monolingual-dictionary will be equivalent to collection of attributes and values, like the following:• Lex = button, cat=n, ntype=common, number=sing, human=no,
concrete=yes.• Lex=button, cat=v, vtype=main, finite=, person=, number=,.
• Entries can be implemented as records in a database.
• Entries in MT bilingual-dictionary are generally represented by translation rules, like the following: Button ... / إلخ / / زود زرر برعم زرThis allows the replacement of certain source language oriented
information with corresponding target language information.

Knowledge Representation: Morphology
• Morphology is concerned with the internal structure of words and how words can be formed.
• MT & CAT systems must add a morphological components that can recognize different word formation processes:
• Inflection: a word is derived from another word form by maintaining the same part of speech or category: walk walks
• Describe regular inflections by general rules, like:Lex= walks, cat=v, +finite, person=3rd,number=sing, tense=pres) V+s• Describe irregular inflections by explicit rules, like:Lex=be, cat=v, +finite, person=3rd,number=sing, tense=pres) is
• Derivation: a word of a different category is derived from another
word or word stem by application of a process involving stems and affixes: grammar, grammatical, arrive arrival
• regular derivational processes can be described by rules• Irregular derivations can be solved simply by listing all derived words
• Compounding: a new word or unit is formed by combination of two or more words

Knowledge Representation: Syntax and Grammars
• Syntax is concerned with how sentences can be made up out of words.• To describe syntax, a grammar (set of rules) is generally used in MT & CAT.
• For the first kind of information, programmers and developers with consultations of linguists have to represent the concerned divisions of the sentence into their constituent parts and the categorization of these parts as nominal, verbal, and so on.
• Consider that in English “a sentence consists of noun phrase followed by an auxiliary verb followed by a verb phrase. Noun phrase consists of …etc”. We can represent these knowledge by the following grammar:• S NP (AUX) VP• NP (DET) (ADJ) N PP*• VP V (NP) PP*• PP P NP• N user | printer • V clean • AUX should• DET the | a• P with
• “a user should clean the printer” is a sentence in the above grammar

Knowledge Representation: Meaning
• Knowledge about the meaning of sentences are an important part of the translation process and allow MT & CAT systems to produce better results.
• Three useful kinds of knowledge relating to the meaning can be distinguished:
• Semantic knowledge: meaning of words and sentences independently of the context they appear in.
• Pragmatic knowledge: meaning of expressions in situations• Real world or common sense knowledge
• It is useful to represent these kind of knowledge in MT & CAT systems in order to increase their performance. Accomplishing this goal proved to be the most difficult task in the developing the MT & CAT systems.

Knowledge Processing• We give now an idea of how knowledge can be
manipulated automatically by MT systems
• This can be done in two stages: parsing and generation
• Parsing: is the process of taking an input string of expressions and producing representations appropriate to the translation
• Generation: is the process of taking an appropriate representation and producing the corresponding sentence
• A graphical representation will be used for parsing and generation processes. However, the internal representations are lists (very useful data structures).

Knowledge Processing: Parsing
• The task of a parser is to take a formal grammar and a sentence and
• Check if it is indeed grammatical• Show how the words are combined into phrases
• Different parsing methods exist and are subdivided into two categories: Top-Down parsing method and Bottom-Up parsing method.
• Examples of parsing using grammars defined in the previous sections and sentence “the user should clean the printer” are given bellow.
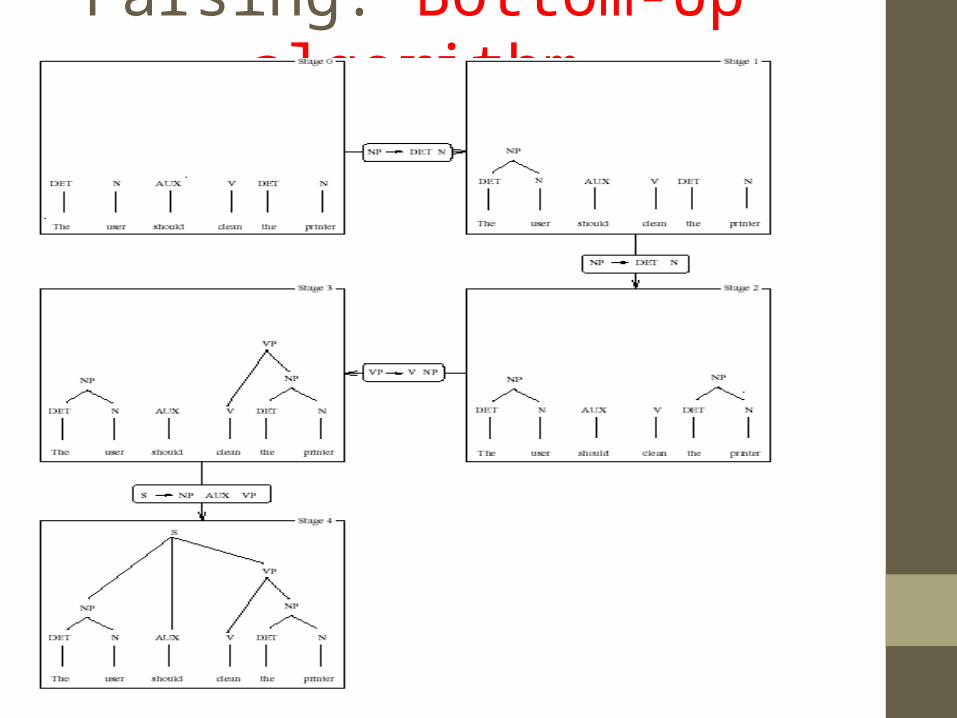
Parsing: Bottom-Up algorithm

Parsing: Top-Down algorithm

Latest Engines in MT:
• Speech Recognition MT: trying to apply to MT techniques which have been highly successful in Automatic Speech Recognition.
• Computer-assisted Translation: the idea is to collect a bilingual corpus of translation pairs and then use a best match algorithm to find the closest example to the source phrase in question. Ex; Trados, Worsfast …etc.

What is a CAT Tool?
• CAT stands for "Computer Aided Translation Tool". The terms "Translation Memory" and "TM" are sometimes used to refer to the same type of tool. A CAT tool is a computer program that helps a translator to work efficiently.
This is achieved through three main functions:• A CAT tool breaks texts into segments (sentences or
sentence fragments) and presents the segments in a convenient way, to make translating easier and faster. In some tools, for example Tardos , each segment is presented in a special box, and the translation can be entered in another box right below the source text.

• The translation of each segment is saved together with the source text. Source text and translation will always be treated and presented as a translation units (TU). You can return to a segment at any time to check the translation. There are special functions which help to navigate through the text and to find segments which need to be translated or revised (quality control).
• The main function of a CAT tool is to save the translation units in a database, called translation memory , so that they can be re-used for any other text, or even in the same text. Through special "search" features. The search functions of CAT tools can also find segments which do not match 100%. This saves time and effort and helps the translator to use consistent terminology.
•

Evaluation of MT & CAT Systems
• The evaluation of MT & CAT systems is a complex task. This is not only because many different factors are involved, but because measuring translation performance is itself difficult.
• Clarity: a traditionally way of assessing the quality of translation is to assign scores to output sentences.
• Accuracy: It is important to check whether the meaning of the source is preserved in the translation.
• Error Analysis: tries to establish how seriously errors affect the translation output.
• Test Suite: running the system on a large corpus of test texts will reveal different possible problems.

How to start using Trados ?
Steps to follow for creating, opening and exporting a translation memory, and further basic features of the software.
You have to take into account that these steps correspond to SDL Trados 2006, so some menus can be different in other Trados versions.

To create a translation memory:1. Go to Windows / Start /All programas/ SDL Internacional
SDL Trados 2006 / Translator’s Workbench. The software will start running and will request the user name.
2. Go to File / New.3. A window will show where you have to choose the source
and target language by clicking on Add…. Then, click on Create….
4. A window will display where you have to enter the name for the TM and browse where to save it.
Note:Next time you open Translator’s Workbench, the last memory used will be opened by default.



To open a translation memory:
There are two ways of opening a translation memory:
1. You can double click on the icon of the TM you wish to open, or open Trados Translator’s Workbench.
2. Go to File / Open
3. A window will be displayed, were you have to look for the TM you want to open, and once found, click on it.

• The Trados TM will provide an existing equivalent sentence in the TL if it matches 100%.
• The Trados TM will provide suggested words or phrases in different colors if the equivalent sentence does not match 100%.
• Easily select from the possible suggestions offered by the MT. • Confirm these suggestions offered by MT or simply type your
own words or phrases.• click Ctrl & Enter to confirm and move on to another
sentence.• Once finished translating the whole text, click File …. Save as
….. rename the file …. Saving is accomplished .

Some pieces of advice:
• Don’t press Enter when you are inside a translation unit since you can break it.
• Using the commands from the keyboard speeds up the job.
• If you have any problems go to Help/Help Topics in Translator’s Workbench.

Creating a Multiterm Termbase to Use in SDL Trados Studio
TWO IMPORTANT NOTES BEFORE YOU GET STARTED:
1. Multiterm is a separate program, it's not part of Trados or Studio. It needs to be downloaded and installed separately, and it appears as a standalone program in your SDL folder in your All Programs list in Windows. If you don't see it there, make sure to go to your SDL account and download and install the program from the My Downloads page.
2. Termbases cannot be created in Trados or Studio. The "Create New Termbase" you see in the SDL Trados main page or the "Terminology Management" button in the Studio home page are merely links that will take you to Multiterm, if it's installed in your computer.

Creating a simple Multiterm termbase Multiterm can be as simple or as complex as you want it to be. In this example, the simplest kind of termbase will created: source term = target term. No other index fields will be included.1. Open SDL Multiterm Desktop, Go to File, then select Create Termbase then Save your termbase in the dialog box that opens:
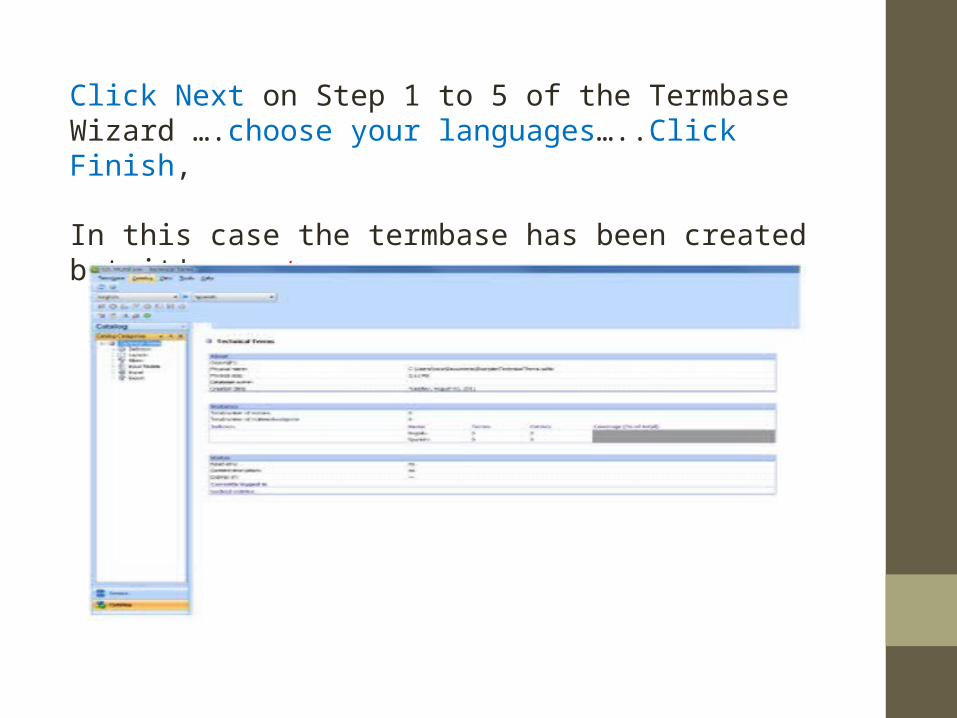
Click Next on Step 1 to 5 of the Termbase Wizard ….choose your languages…..Click Finish,
In this case the termbase has been created but it's empty.

To manually add terms, click on the Terms tab on the bottom left of your screen, click F3 or click on the Add New Entry icon right under the Edit menu. You will see the Entry screen, as shown below.

Double click on the little box next to the pencil icon and enter the term for each entry.

Press F12 to save the changes.
The term is now part of your termbase and therefore will be available when you use the termbase in Studio.
This concludes the basics of termbase creation.





























