Embed Size (px)
Citation preview

LYRIC-BASED ARTIST NETWORKMETHODOLOGY
Derek Gossi
CS 765
Fall 2014

Topics
• Review • The Music Recommendation Problem
• Existing Research• A Quick Review
• The Dataset• Methodology

REVIEWThe Music Recommendation Problem

Approaches to Recommendation• Collaborative Filtering
• Users that liked this artist/song also liked that artist/song• Amazon, iTunes store, Spotify
• Tagging• Categorization based on user-generated or pre-defined tags
• Calm, sad, romantic, cheerful, anxious, depressed
• Last.fm
• Content-based• Look at the audio signal• Not widely used in industry yet• Pandora, Spotify (in progress)• What can the lyrics tell us?

The Issue• Collaborative Filtering works well when there is lots of
user feedback, but it doesn’t scale well• Content-based methods scale very well, because no user
data is required• Results are mixed and not widely used in practice
• What would a lyric-based recommendation network look like, and how would it compare to existing collaborative filtering networks?

EXISTING RESEARCHA Quick Review

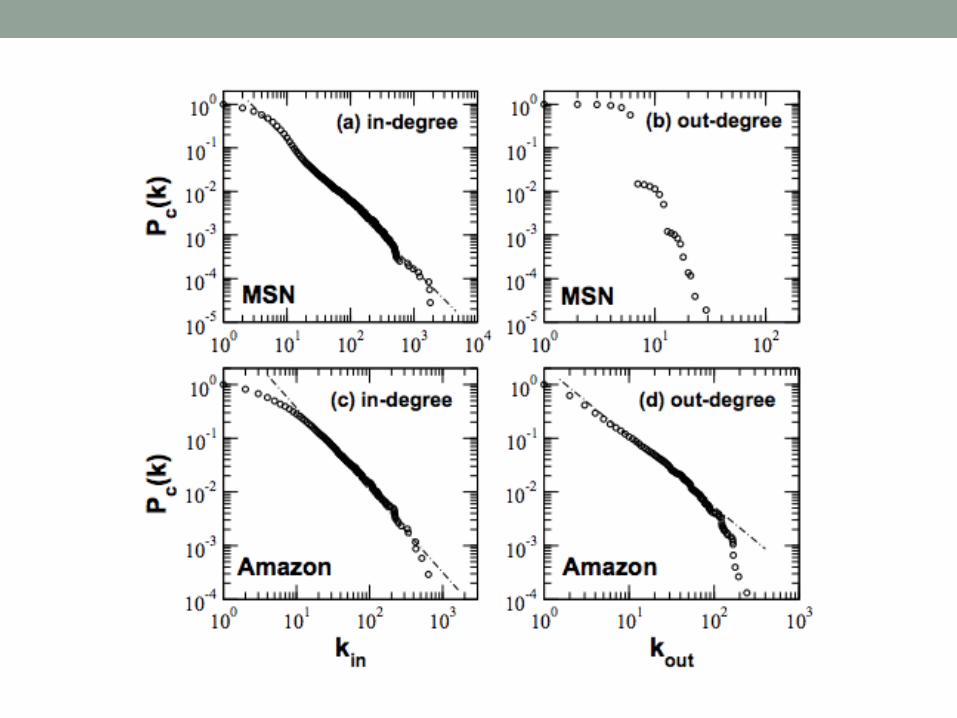
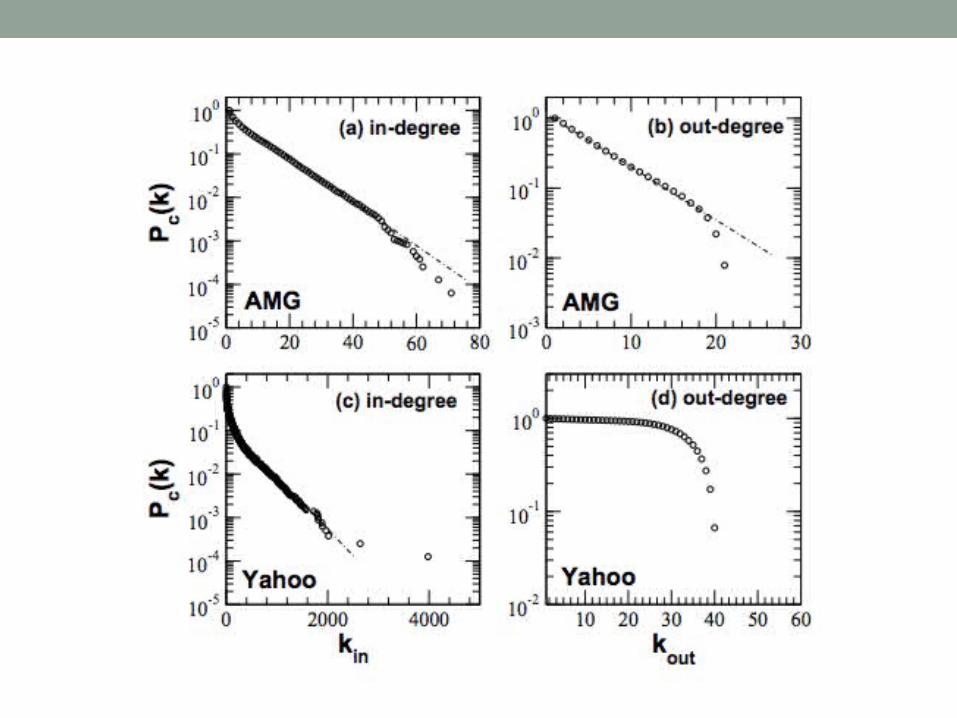
Network Topology• P. Cano, O. Celma, and M. Koppenberger. “The topology
of music recommendation networks,” Feb 2008. • Analyzes four music recommendation systems from a
network perspective• Directed edges• n = 16,302 (Yahoo) to 51,616 (MSN)• m = 158,866 (AMG) to 511,539 (Yahoo)• Small-world properties in all networks
• Average shortest path < 8
• Clustering coefficient from 0.14 (Amazon) to 0.54 (MSN)

THE DATASETThe Million Song Dataset (MSD)

Million Song Dataset• Open source dataset released in Feb 2011• Metadata and audio features for a million contemporary
audio tracks• Linked to separate datasets with lyrical data, Last.fm tags,
and actual user data

METHODOLOGY

Main Idea• What can lyrics tell us about music recommendation?• Build a network of musical artists where edges represent
lyrical similarity• Build a comparable network based on actual user play
count data utilizing a collaborative filtering methodology• Analyze and compare topology of both networks• Use a clustering algorithm on both networks to obtain
clusters with strongly connected neighbors• Figure out which tag categories, if any, are associated
with these clusters• What are users saying?

Data Cleaning• Lyrics provided in bag-of-words format• Stop words removed• Porter2 stemming algorithm• “Dictionary” limited to top 5,000 words
• 92% of complete set• Terms outside limited list are
generally noisy and unusable

Term Frequency Matrix• Vector Space Model (VSM)
• Represent songs as sparse vectors in n-dimensional space• n = 5,000

Term Frequency Matrix• Could sum song vectors together for a particular artist to
get term frequencies of an entire artist’s catalog • However, this would lose important information about
variance of individual song vectors for a given artist• Reduce to artist level after song links are formed

TD-IDF Weighting• Term frequency matrix can be used to directly compare
similarity of two songs• But what about frequently used and statistically
unimportant words?• The, at, which, on, by
• Idea: make words used frequently across all songs in the dataset less important
• Multiply term frequency (TF) by inverse document frequency (IDF)

Pairwise Similarity Matrix• As songs are vectors, we can calculate similarity in terms
of the angle between them in the vector space• Cosine similarity is often used in document classification
• 0 implies two songs are orthogonal (completely different) and 1 implies two songs are identical

Threshold Selection• We now have a [0,1] range of how similar each song in
the dataset is to every other song• Simplest idea: Pick some threshold in [0,1] and create an
edge if threshold is exceeded• Issues: Network topology can be significantly impacted by
threshold selection, no intuitive explanation, some songs are left out of network (scale issues)
• Instead, fix outdegree by using a weighted k shared neighbors approach
• Given a user liked a given song, which k songs would be recommended based on lyrics?
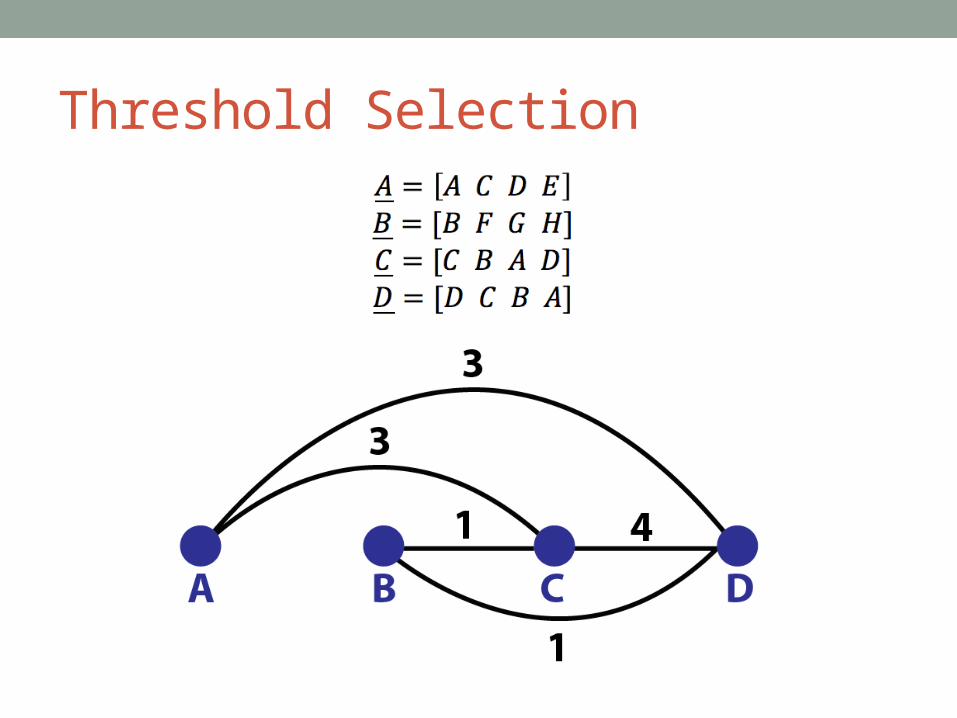
Threshold Selection

Reduction to Artist Level • How many songs from artist i to artist j have edges
between them? • Create an edge if 1 or greater, weight edge if strictly
greater than 1 by summing existing weights

Collaborative Filtering Network• Echo Nest Taste Profile Subset• Play counts for 1,019,318 users and 48,373,586
user/song/count triples• Item-based collaborative filtering• Once again, song are represented as vectors• For a given song, ith component of a song vector is
number of plays by user i• Pairwise similarity computed and network generated to
match lyric network

Tag Data• Last.fm tags are linked to the nodes in both networks• Restricted to high-frequency tags representing:
• Genre• Mood• Musical Style

Topology Comparison• We now have two networks with fixed outdegree of k and
indegree of unknown distribution• What are the most important nodes, and what are the
tags associated with these nodes?• Degree distribution• How clustered is the network by genre, style, or mood?

Clustering• We want to see what the strongest communities are in
each of the two networks• L. Ertoz, M. Steinbach, V. Kumar. “Finding topics in
collections of documents: a shared nearest neighbors approach”
• Main idea: avoid clustering two nodes together that are in different classes by ensuring every node shares strongly connected neighbors
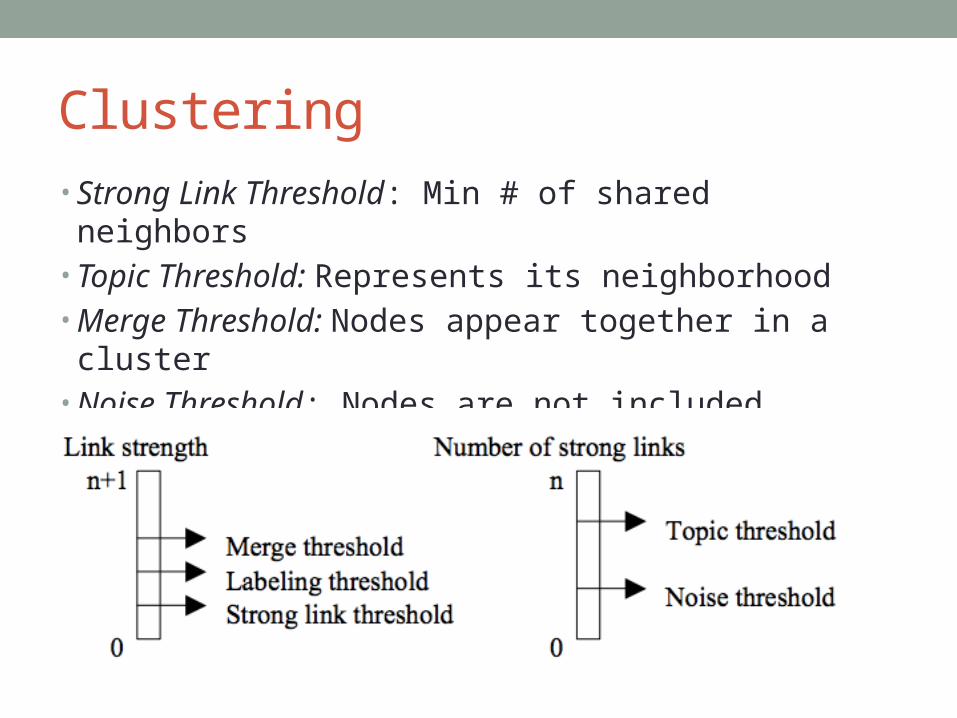
Clustering• Strong Link Threshold: Min # of shared neighbors• Topic Threshold: Represents its neighborhood• Merge Threshold: Nodes appear together in a cluster• Noise Threshold: Nodes are not included• Labeling Threshold: Scan clusters and add strong links

Clustering• Which tags are associated with these clusters?• How do the two networks compare to each other?• What can this tell us about music recommendation?
• Collaborative filtering works well in practice

Conclusion• How do we recommend music without user data?
• Content-based methods may work
• Do the lyrics correspond to what people say about music?• What does this tell us about lyrical expression in general?

QUESTIONS?





























