Embed Size (px)
Citation preview

LOGO
Classification III
Lecturer Dr Bo Yuan
E-mail yuanbsztsinghuaeducn
Overview
Artificial Neural Networks
2
Biological Motivation
3
1011 The number of neurons in the human brain
104 The average number of connections of each neuron
10-3 The fastest switching times of neurons
10-10 The switching speeds of computers
10-1 The time required to visually recognize your mother
Biological Motivation
The power of parallelism
The information processing abilities of biological neural systems follow from highly parallel processes operating on representations that are distributed over many neurons
The motivation of ANN is to capture this kind of highly parallel computation based on distributed representations
Sequential machines vs Parallel machines
Group A
Using ANN to study and model biological learning processes
Group B
Obtaining highly effective machine learning algorithms regardless of how
closely these algorithms mimic biological processes4
Neural Network Representations
5
Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Overview
Artificial Neural Networks
2
Biological Motivation
3
1011 The number of neurons in the human brain
104 The average number of connections of each neuron
10-3 The fastest switching times of neurons
10-10 The switching speeds of computers
10-1 The time required to visually recognize your mother
Biological Motivation
The power of parallelism
The information processing abilities of biological neural systems follow from highly parallel processes operating on representations that are distributed over many neurons
The motivation of ANN is to capture this kind of highly parallel computation based on distributed representations
Sequential machines vs Parallel machines
Group A
Using ANN to study and model biological learning processes
Group B
Obtaining highly effective machine learning algorithms regardless of how
closely these algorithms mimic biological processes4
Neural Network Representations
5
Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Biological Motivation
3
1011 The number of neurons in the human brain
104 The average number of connections of each neuron
10-3 The fastest switching times of neurons
10-10 The switching speeds of computers
10-1 The time required to visually recognize your mother
Biological Motivation
The power of parallelism
The information processing abilities of biological neural systems follow from highly parallel processes operating on representations that are distributed over many neurons
The motivation of ANN is to capture this kind of highly parallel computation based on distributed representations
Sequential machines vs Parallel machines
Group A
Using ANN to study and model biological learning processes
Group B
Obtaining highly effective machine learning algorithms regardless of how
closely these algorithms mimic biological processes4
Neural Network Representations
5
Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Biological Motivation
The power of parallelism
The information processing abilities of biological neural systems follow from highly parallel processes operating on representations that are distributed over many neurons
The motivation of ANN is to capture this kind of highly parallel computation based on distributed representations
Sequential machines vs Parallel machines
Group A
Using ANN to study and model biological learning processes
Group B
Obtaining highly effective machine learning algorithms regardless of how
closely these algorithms mimic biological processes4
Neural Network Representations
5
Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Neural Network Representations
5
Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Robot vs Human
6
Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Perceptrons
7
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xw
0
0
010
otherwise
xwifo
n
iii
0
01)( 110
1 otherwise
xwxwwifxxo nnn
Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Power of Perceptrons
8
-08
05 05
-03
05 05
Input sum Output
0 0 -08 0
0 1 -03 0
1 0 -03 0
1 1 03 1
Input sum Output
0 0 -03 0
0 1 02 1
1 0 02 1
1 1 07 1
AND OR
Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Error Surface
9
Error
w1
w2
Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Gradient Descent
10
2)(
2
1)(
Dd
dd otwE
nw
E
w
E
w
EwE )(
10
iiiii w
Ewwherewww
Learning Rate
Batch Learning
Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Delta Rule
11
)()(
)()(
)()(22
1
)(2
1
)(2
1
2
2
idDd
dd
ddiDd
dd
ddiDd
dd
Dddd
i
ddDdii
xot
xwtw
ot
otw
ot
otw
otww
E
iddDd
di xotw )(
xwxo )(
Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Batch Learning
GRADIENT_DESCENT (training_examples η)
Initialize each wi to some small random value
Until the termination condition is met Do
Initialize each Δwi to zero
For each ltx tgt in training_examples Do
bull Input the instance x to the unit and compute the output o
bull For each linear unit weight wi Do
ndash Δwi larr Δwi + η(t-o)xi
For each linear unit weight wi Do
bull wi larr wi + Δwi
12
Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Stochastic Learning
13
iiiii xotwwherewww )(
For example if xi=08 η=01 t=1 and o=0
Δwi = η(t-o)xi = 01times(1-0) times 08 = 008
+
-
++
+
--
-+
+
-
-
Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Stochastic Learning NAND
14
InputTarget
Initial
Weights
Output
Error CorrectionFinal
WeightsIndividual SumFinal
Output
x0 x1 x2 t w0 w1 w2 C0 C1 C2 S o E R w0 w1 w2
x0 w0
x1 w1
x2 w2
C0+C1+C2
t-o LR x E
1 0 0 1 0 0 0 0 0 0 0 0 1 +01 01 0 0
1 0 1 1 01 0 0 01 0 0 01 0 1 +01 02 0 01
1 1 0 1 02 0 01 02 0 0 02 0 1 +01 03 01 01
1 1 1 0 03 01 01 03 01 01 05 0 0 0 03 01 01
1 0 0 1 03 01 01 03 0 0 03 0 1 +01 04 01 01
1 0 1 1 04 01 01 04 0 01 05 0 1 +01 05 01 02
1 1 0 1 05 01 02 05 01 0 06 1 0 0 05 01 02
1 1 1 0 05 01 02 05 01 02 08 1 -1 -01 04 0 01
1 0 0 1 04 0 01 04 0 0 04 0 1 +01 05 0 01
1 1 0 1 08 -2 -1 08 -2 0 06 1 0 0 08 -2 -1threshold=05 learning rate=01
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33
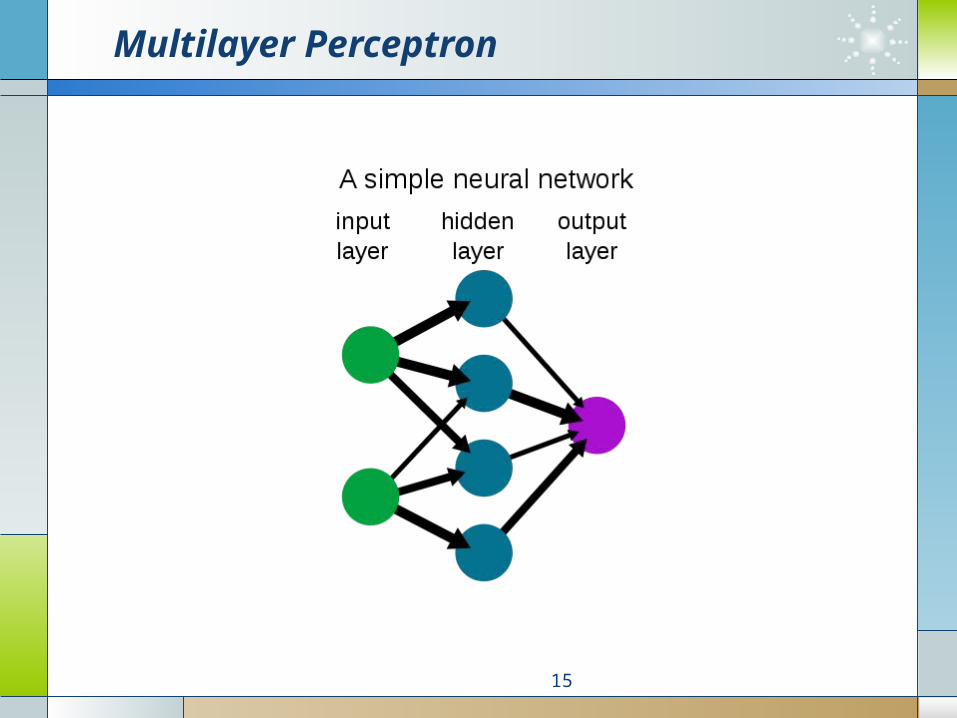
Multilayer Perceptron
15
XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

XOR
16
-
-
))(( pqqpqpqpqp
Input Output
0 0 0
0 1 1
1 0 1
1 1 0
Cannot be separated by a single line
+
+
p
q
XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

XOR
17
)()( qpqpqp
OR NAND
AND
OR
NAND-
+
+
-
p
q
p q
Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Hidden Layer Representations
18
p q OR NAND AND
0 0 0 1 0
0 1 1 1 1
1 0 1 1 1
1 1 1 0 0
Input Hidden Output
- + +
-
AND
OR
NA
ND
The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

The Sigmoid Threshold Unit
19
sum
x1
x2
xn
w1
w2
wn
w0
x0=1
n
iii xwnet
0
neteneto
1
1)(
))(1()()(
1
1)( yy
dy
yd
ey
FunctionSigmoid
y
Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Backpropagation Rule
20
ji
dji w
Ew
outputsk
kkd otwE 2)(2
1)(
bull xji = the i th input to unit j
bull wji = the weight associated with the i th input to unit j
bull netj = sumwjixji (the weighted sum of inputs for unit j )
bull oj= the output of unit j
bull tj= the target output of unit j
bull σ = the sigmoid function
bull outputs = the set of units in the final layer
bull Downstream (j ) = the set of units directly taking the output of unit j as inputs
jij
d
ji
j
j
d
ji
d xnet
E
w
net
net
E
w
E
j
i
Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Training Rule for Output Units
21
j
j
j
d
j
d
net
o
o
E
net
E
outputskkk
jj
d otoo
E 2)(2
1
)(
)()(2
2
1
)(2
1 2
jj
j
jjjj
jjjj
d
ot
o
otot
otoo
E
)1()(
jjj
j
j
j oonet
net
net
o
)1()( jjjjj
d oootnet
E
jijjjjji
dji xooot
w
Ew )1()(
Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Training Rule for Hidden Units
22
)()(
)( )(
)1( jDownstreamk
jjkjkj
j
jDownstreamkkjk
jDownstreamk j
j
jDownstreamk j
kk
j
k
k
d
j
d
oownet
ow
net
o
o
net
net
net
net
E
net
E
)(
)1(jDownstreamkkjkjjj woo
jijji xw
k
dk net
E
k
j
jnet
k
BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

BP Framework
BACKPROPAGATION (training_examples η nin nout nhidden)
Create a network with nin inputs nhidden hidden units and nout output units
Initialize all network weights to small random numbers
Until the termination condition is met Do
For each ltx tgt in training_examples Do
bull Input the instance x to the network and computer the output o of every unit
bull For each output unit k calculate its error term δk
bull For each hidden unit h calculate its error term δh
bull Update each network weight wji 23
))(1( kkkkk otoo
outputsk
kkhhhh woo )1(
jijjijijiji xwwww
More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

More about BP Networks hellip
Convergence and Local Minima
The search space is likely to be highly multimodal
May easily get stuck at a local solution
Need multiple trials with different initial weights
Evolving Neural Networks
Black-box optimization techniques (eg Genetic Algorithms)
Usually better accuracy
Can do some advanced training (eg structure + parameter)
Xin Yao (1999) ldquoEvolving Artificial Neural Networksrdquo Proceedings of the IEEE
pp 1423-1447
Representational Power
Deep Learning
24
More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

More about BP Networks hellip
Overfitting
Tend to occur during later iterations
Use validation dataset to terminate the training when necessary
Practical Considerations
Momentum
Adaptive learning ratebull Small slow convergence easy to get stuck
bull Large fast convergence unstable
25
)1()( nwxnw jijijji
Time
Error
Training
Validation
Weight
Error
Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Beyond BP Networks
26
Elman Network
XOR
0 1 1 0 0 0 1 1 0 1 0 1 hellip
1 0 0 1 hellip
In
Out
Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Beyond BP Networks
27
Hopfield Network Energy Landscape of Hopfield Network
Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Beyond BP Networks
28
When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

When does ANN work
Instances are represented by attribute-value pairs Input values can be any real values
The target output may be discrete-valued real-valued or a vector of several real- or discrete-valued attributes
The training samples may contain errors
Long training times are acceptable Can range from a few seconds to several hours
Fast evaluation of the learned target function may be required
The ability to understand the learned function is not important Weights are difficult for humans to interpret
29
Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Reading Materials
Text Book
Richard O Duda et al Pattern Classification Chapter 6 John Wiley amp Sons Inc Tom Mitchell Machine Learning Chapter 4 McGraw-Hill httppagemifu-berlinderojasneuralindexhtmlhtml
Online Demo
httpneuronengwayneedusoftwarehtml httpwwwcbuedu~pongaihopfieldhopfieldhtml
Online Tutorial
httpwwwautonlaborgtutorialsneural13pdf httpwwwcscmueduafscscmueduusermitchellftpfaceshtml
Wikipedia amp Google
30
Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Review
What is the biological motivation of ANN
When does ANN work
What is a perceptron
How to train a perceptron
What is the limitation of perceptrons
How does ANN solve non-linearly separable problems
What is the key idea of Backpropogation algorithm
What are the main issues of BP networks
What are the examples of other types of ANN31
Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Next Weekrsquos Class Talk
Volunteers are required for next weekrsquos class talk
Topic 1 Applications of ANN
Topic 2 Recurrent Neural Networks
Hints
Robot Driving
Character Recognition
Face Recognition
Hopfield Network
Length 20 minutes plus question time
32
Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33

Assignment
Topic Training Feedforward Neural Networks
Technique BP Algorithm
Task 1 XOR Problem
4 input samplesbull 0 0 0
bull 1 0 1
Task 2 Identity Function
8 input samplesbull 10000000 10000000
bull 00010000 00010000
bull hellip
Use 3 hidden units
Deliverables
Report
Code (any programming language with detailed comments)
Due Sunday 14 December
Credit 15 33
























