Embed Size (px)
Citation preview

Load Balancing and Load Reduction for Multiple Resource-Bounded
Real-Time Agents
Edmund H. DurfeeUniversity of Michigan
FALSE2002 WorkshopVanderbilt UniversityNovember 15, 2002

Talk Outline• Agents
• Real-Time Agents
• Resource-Bounded Real-Time Agents
• Multiple Resource-Bounded Real-Time Agents
• Load Balancing/Reduction for Multiple Resource-Bounded Real-Time Agents

Caveats• Very biased march through these topics!
• Emphasis of our work on the Cooperative Intelligent Real-Time Control Architecture (CIRCA)
• Participants have included: Professor Kang Shin; former students Dave Musliner, Ella Atkins; current students Haksun Li, Dmitri Dolgov.

Agent• Entity to which it is convenient to ascribe characteristics such
as:– choices (capabilities, actions, plans, policies)– awareness (beliefs, knowledge)– preferences (goals, desires)
• Typically:– declarative representations– taskable/adaptable– sociable
PA
B
1 2SOA
2 0
0 2
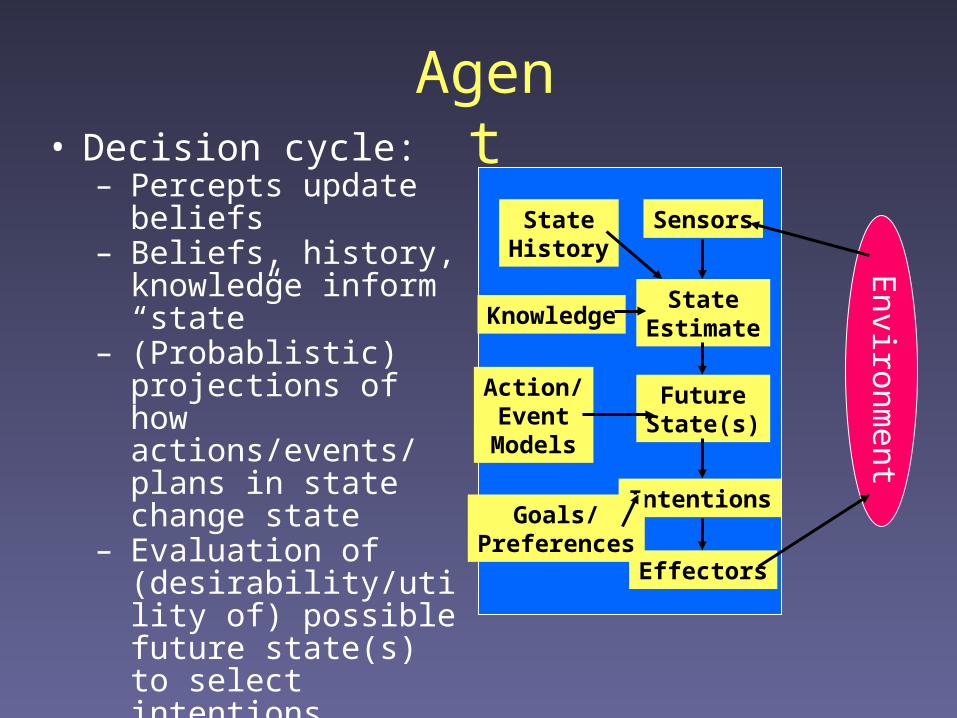
Agent• Decision cycle:
– Percepts update beliefs– Beliefs, history,
knowledge inform “state”– (Probablistic) projections
of how actions/events/ plans in state change state
– Evaluation of (desirability/utility of) possible future state(s) to select intentions
– Intentions map to effector actions
Environm
ent
SensorsStateHistory
FutureState(s)
Knowledge
Effectors
StateEstimate
IntentionsGoals/
Preferences
Action/Event
Models

Real-Time Agent
• Some agent aspects are time-dependent:– Preferences change (e.g., goal deadlines)– Capabilities evolve (e.g., depletable resources)– Dynamic environment (e.g., outside events)

Real-Time Agent
Get there before fuel runs out!
Better stop ifthe light turns red! Getting to airport
important until flighthas left!

Real-Time Agent
• Agent could be “coincidentally real-time”• Real-time agent explicitly reasons about
time, deadlines, dynamics, etc. and knows what level of performance it can guarantee
• Emphasis here: Dynamic environment• Real-time agent knows that it can preempt
external events to pursue goals and avoid failure

Traffic Light Example
• Preference: Avoid running red light• Action to take: Stop the car• Timing issues: Car requires time/distance to stop• Heralding event: Light turns yellow• Minimum time delay between yellow and red• Real-time agent must guarantee time it takes to
notice yellow light (detect hazardous state) and stopping (take proper response) is less than minimum delay between yellow and red

Probability Rate Function
t
p
p0
t0
• Specifies probability of transition (state-changing event) occurring during a time interval as a function of the time spent in the heralding state
• Example: t0 is duration of yellow light, p0 is 1.

t t t
Pr(tt,t) Pr(tt,t) Pr(tt,t)
a) Heads-to-tails tt . c) Min/Max delay ttf . b) Engine failure tt .
min
0.5
max break-in
Other Probability Rate Functions

Preemptive Actions• There is uncertainty over transition times into states
• Safest case is to assume a heralding state could happen at any time
• Strategy: Monitor for state heralding periodically, frequently enough to leave time to take action before transition to failure state
• Period is based on the minimum preemption time (between when a heralding state entered and earliest that failure transition could occur) minus the worst-case-execution-time for the action (monitoring plus response)

maxp) (t 0
)maxpt (0 )(max
1
),Pr(
i
iii tptac
Action Probability Rate Function
t
p
p0
t0maxp
• (t0 – maxp) is worst-case duration of the action
• maxp is the maximum period for the periodically-scheduled action

Other Temporal Transitions
• Events that change the agent’s state• New state isn’t a “failure”• Therefore, preemptive actions need not be
guaranteed• However, some states might be more desirable
than others (e.g., closer to some objective state), so actions might be considered when guaranteed actions don’t take their worst-case, so as to steer system in promising directions
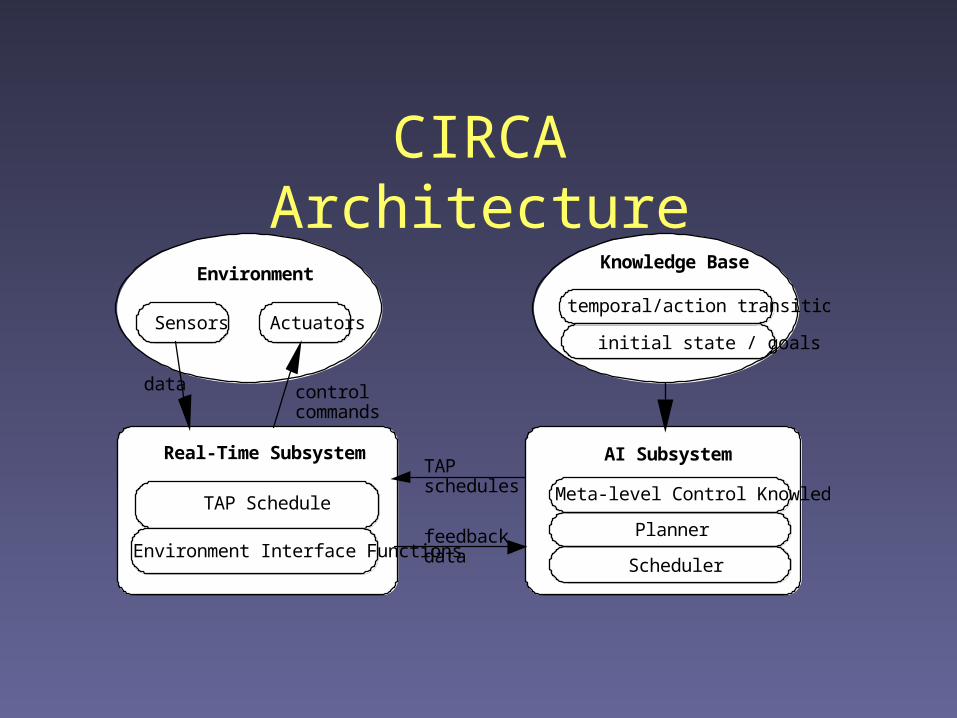
CIRCA Architecture
Real-Time Subsystem
TAP Schedule
Environment Interface Functions
TAP schedules
feedback data
data control commands
Environment
Sensors Actuators
AI Subsystem
Planner
Scheduler
Meta-level Control Knowledge
Knowledge Base
initial state / goals
temporal/action transitions
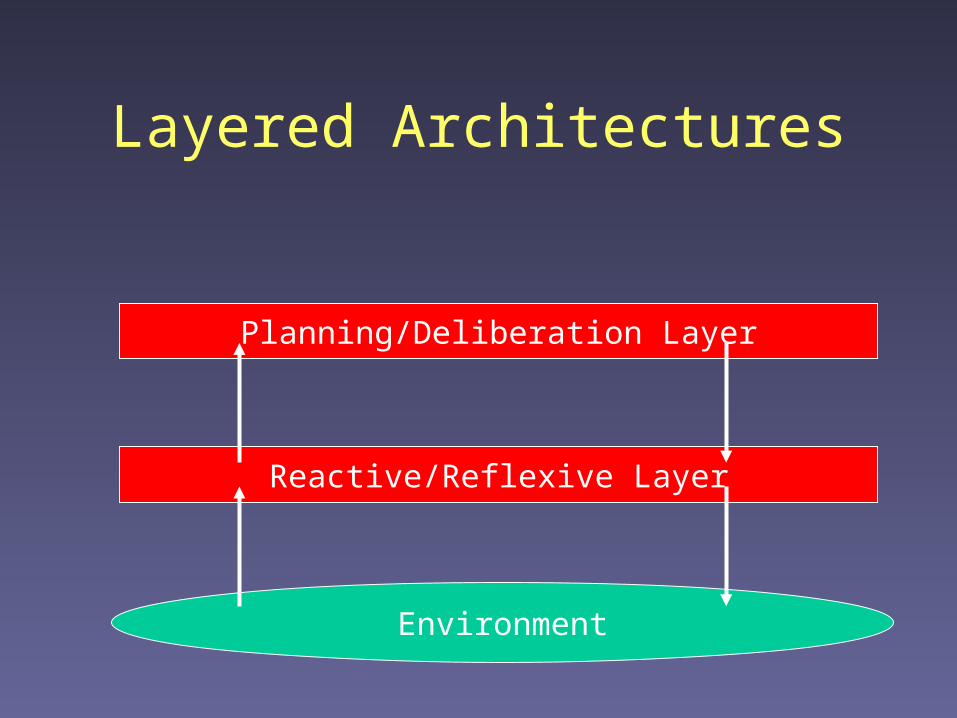
Layered Architectures
Environment
Reactive/Reflexive Layer
Planning/Deliberation Layer
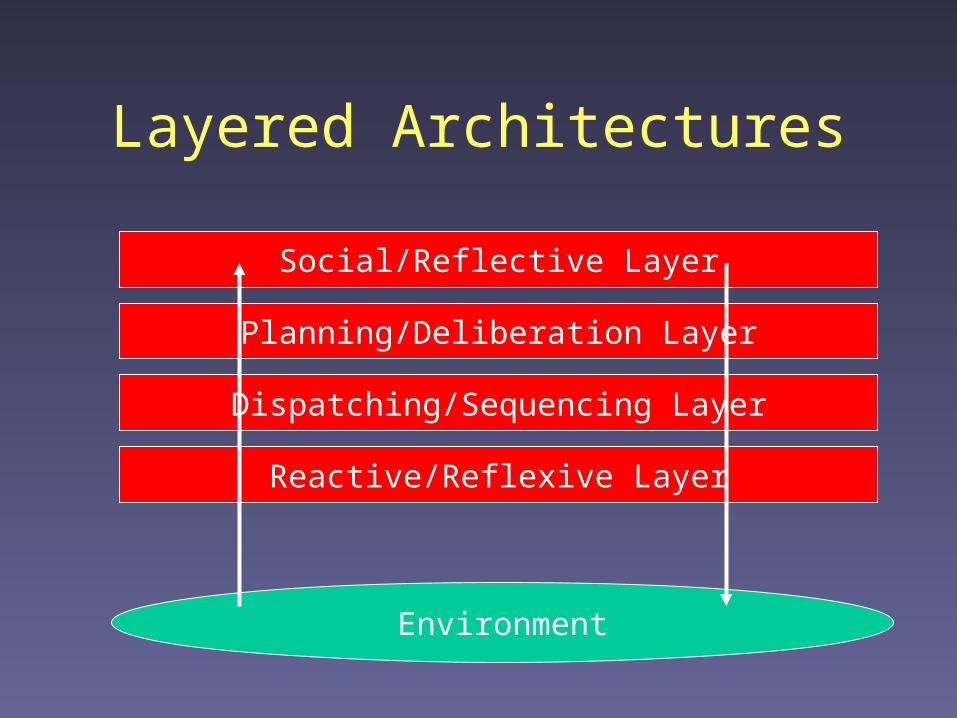
Layered Architectures
Environment
Reactive/Reflexive Layer
Planning/Deliberation Layer
Dispatching/Sequencing Layer
Social/Reflective Layer

Resource Bounded Agent in Real-Time Environment

Failure Preemption
preempts failure
dangerous
accident
Hit Car
Action: BreakCar in Front
Breaks
safe
failure
transition to failure
worldstates
Brake

Control ScheduleEvent Preemption Test and React Schedule
t
t
t
tSchedule:Schedule:
min T

Resource-Bounded Real-Time Agent
• What if it cannot schedule everything?• Does it “stretch” the periods of everything out
until they fit, in a “best-effort” mode?• Does it selectively guarantee some by dropping
others?• Our approach: Be selective• Our strategy: Drop actions that are least likely to
be needed – those that preempt events that arise in states that are unlikely to be reached
• Note: Other possibilities could include favoring preemptions for states to be reached sooner…
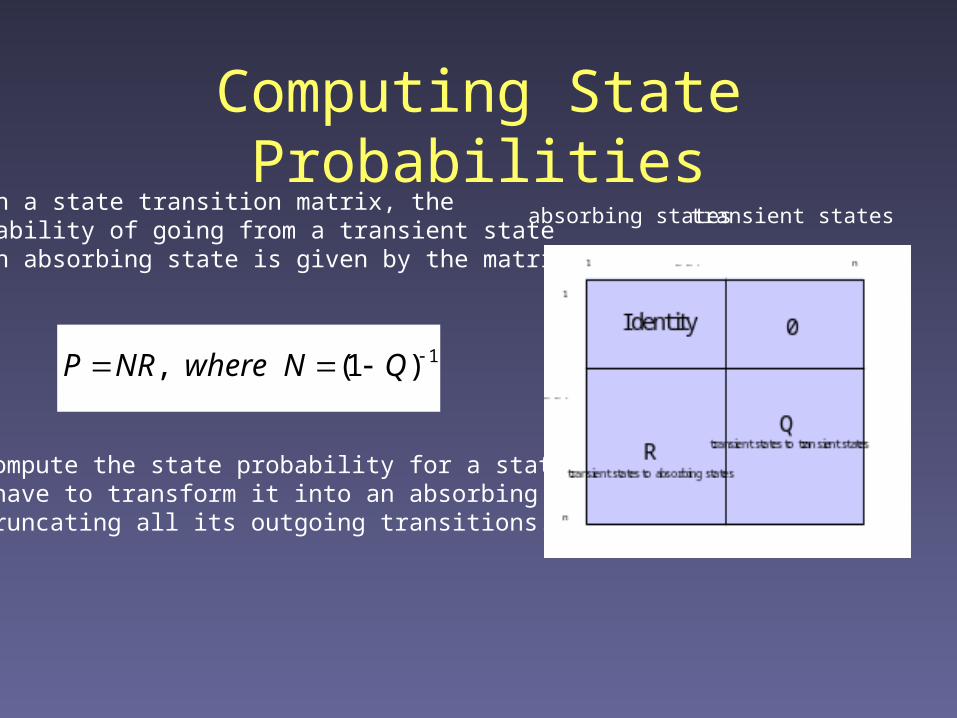
Computing State Probabilitiesabsorbing states transient states
Given a state transition matrix, theprobability of going from a transient stateto an absorbing state is given by the matrix:
1)1(, QNwhereNRP
To compute the state probability for a state, wemay have to transform it into an absorbing stateby truncating all its outgoing transitions.

Transition Probabilities• We describe the probabilistic dynamics of the temporal and
actions transitions by probability density/cumulative functions.• The transition probability of the i-th temporal transition is the
probability that its firing time, Ti, equals the minimum of all firing times, min{T1, …, Tn}.
0
111
0
111
0
111
0
111
1
,,...,,...,
)(......
)(,...,,,...,
)(|,...,,,...,min
,...,min
n transitiofiring theis
dxxttfxttFxttFxttFxttF
dxxTPxTPxTPxTPxTP
dxxTPxTxTxTxTP
dxxTPxTTTTTTP
TTTP
TP
inii
inii
inii
iiniii
ni
i

Making the Computation Tractable
•To make this calculation tractable, we need to use approximation.
•Model each transition (temporal or action) using the probability rate function over discrete intervals
•Assume all transition rates are independent
•For any time interval, probability of a transition will depend on other enabled transitions

)(
,,1ln
,,1 ,,1ln,,
kr stranstranskrrate
kratekjratekjcond shtransP
shnonePshtransPshtransP
Prate(none)
Prate(none) Prate(none)
Time = 0Time = 1
Time = 2 Time = 3tt1 = 0.4,tt2 = 0.8,over all time intervals
The probability that nothing happens is (1-.4)(1-.8) = .12
The probability of “something happens” is 0.88.
0.2112
0.66880.2112
0.66880.2112
0.66880.2112
0.6688
From Unconditional Rate Functions To Conditional Rate Functions
kr stranstrans
kjratekrate shtransPshnoneP ,,1),,(

From Conditional Rate Functions To Conditional Cumulative Probability
Functions
hsPshtransPstransP kh
kjcondkjcum , ,,,0
The maximum of the cumulative probability function is the transition probability.
For previous case, Pcum(tt1)= .2112 + (.12).2112 + (.12)2 .2112 + … = .241 Pcum(tt2)= .6688 + (.12).6688 + (.12)2 .6688 + … = .759
0.10, ,,1,1,, kkratekk sPwhereshnonePhsPhsP

Heuristic Justification
• It is a numerical method approximation, but is accurate if the piecewise Markov assumption holds.
• The heuristic agrees with what we would get should we use a continuous time model for constant rate functions, or for functions for which the piecewise Markov assumption holds.
• Our empirical testing shows that even for functions for which the piecewise Markov assumption does not hold, the error in approximation decreases as one more finely discretizes the timeline into smaller intervals.

Employing Probability ThresholdsGenerate entire reachable state space and compute probabilities of states and actions/periods for all states
Until actions are schedulable, interatively raise a pruning probability threshold, removing states (and associated actions) with lower probabilities
Optionally, define expansion probability threshold to incrementally lower, to iteratively generate increasingly more complete schedules in “any-time” mode

Search SchematicI

Search Pseudocodewhile ((goal not found) OR (not all states with state prob. > expansion threshold expanded)) { find the state with the largest state probability which is not expanded; if (no state with state prob. > expansion threshold is found) { do a full and accurate state probability analysis; find again the state with the largest state probability; if (no state with state prob. > expansion threshold is found) { expansion is done; break the while loop; } }
apply all temporal transitions to the state found; choose the best action for the state; estimate the state probabilities for its children; mark the unexpanded children for expansion;}
If (pruning threshold > expansion threshold) { do a full and accurate state probability analysis; prune states/actions in ascending order of their state probabilities;}
pass the set of TAPs to scheduler for scheduling;

What About Fault Adaptation?
• Control cycle assures performance within an envelope of situations
• System could exit the envelope:– Unmodelled transitions– Removed unlikely states that in fact occur
• These could be because of internal events (faults) as well as external events
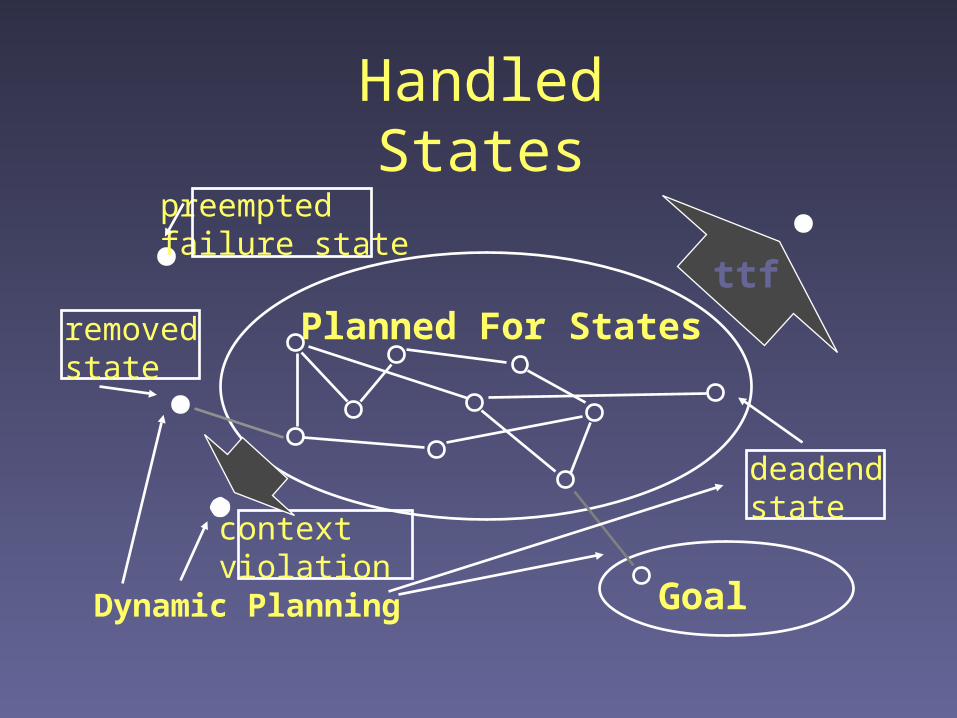
Handled States
Planned For States
preemptedfailure state
Goal
ttf
Dynamic Planning
deadendstate
removedstate
contextviolation

Adaptation• Design monitoring actions to detect when
envelope has been left• Response could be to replan, or to dispatch a
previously constructed contingency plan• Can guarantee response – if leaving the envelope
heralds possible failure, can preempt by dispatching corrective schedule
• Requires that fault detection/adaptation tasks must be scheduled alongside other tasks– More ready to adapt consumes more resources– Leaves less resources for achieving goals – reduces the
set of situations to be prepared for
• Tradeoffs can be explicitly reasoned about!

Multiple Resource-BoundedReal-Time Agents
• Utilize the limited resources of each better through partitioning and assigning subsets of objectives to agents
• A task allocation (negotiation) problem– Contracting– Auctioning
• Even so, demands on agents could outstrip resources
• Could individually prune unlikely states/actions• Could communicate to build better (smaller due to
less uncertainty) state reachability graphs!

Agents with Models of Each Other• Agents can recognize situations that will
trigger others to (re)act • Possible (re)actions are known non-locally• If actions are redundant, then resolve by
converging on a consistent allocation• If others’ actions introduce uncertainty that
significantly reduces expected performance of local plan, communicate to reduce uncertainty
• If others’ actions lead to unsafe world trajectories, communicate to change actions

Convergence Protocol - Overview
• In a multiagent setting, an agent may generate more actions than necessary to preempt failures if the agents plan independently.– An agent may prepare for contingencies associated with
each of the actions another agent might take in a situation.
– The other agent, however, will locally know which of those actions it will actually take.
• Solution – Use a protocol to allow over-constrained agents to learn which contingencies are definitely not going to be caused by other agents, and so can be safely ignored.

Convergence Protocol Example
ID
aci
acl
ack
acj
ttac
ttac
ttac
ttac
ttac
• Represent possible actions of other agents as temporal transitions (ttac labels).
• Both agents may handle dangerous state D.

Convergence Protocol Example
ID
aci
acl
ack
acj
ttac
ttac
ttac
ttac
ttac
Knowing which actions other agent plans can restrict which states this agent must worry about.
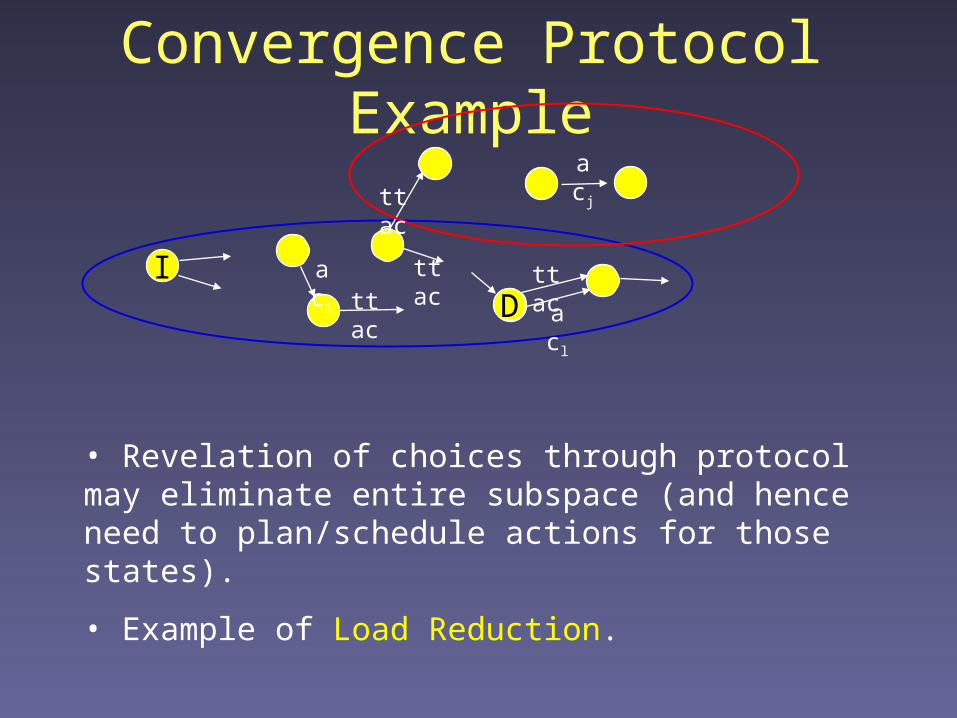
Convergence Protocol Example
ID
aci
acl
acj
ttac
ttac
ttac
ttac
• Revelation of choices through protocol may eliminate entire subspace (and hence need to plan/schedule actions for those states).
• Example of Load Reduction.
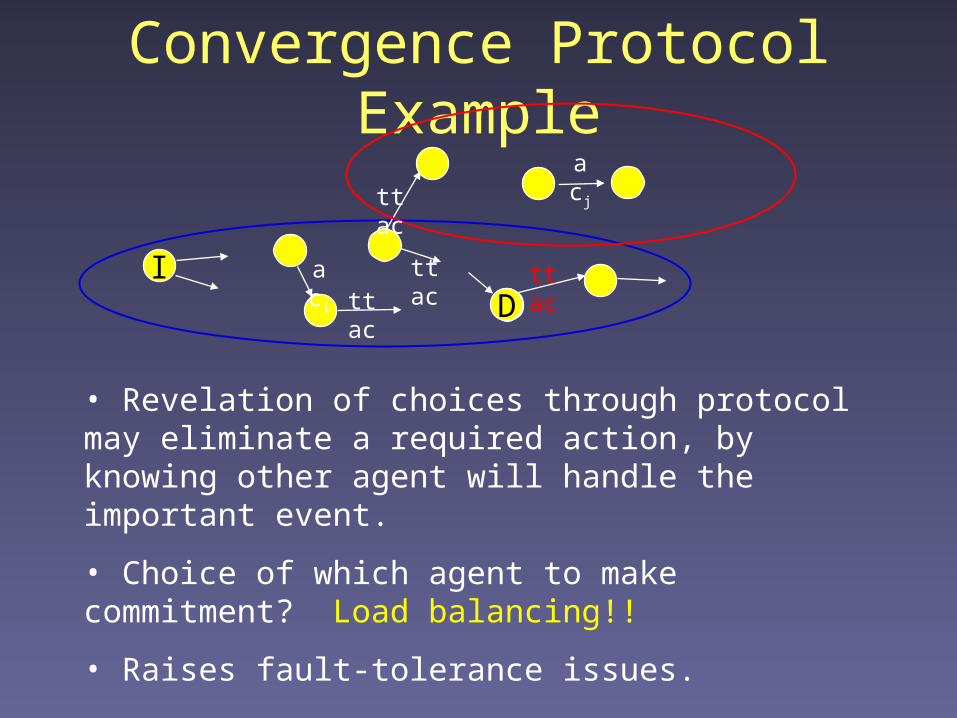
Convergence Protocol Example
ID
aci
acj
ttac
ttac
ttac
ttac
• Revelation of choices through protocol may eliminate a required action, by knowing other agent will handle the important event.
• Choice of which agent to make commitment? Load balancing!!
• Raises fault-tolerance issues.

Convergence Protocol - Description• At each iteration of protocol, an agent selects a state in which some
other agent has a choice of actions, and asks that agent what it would execute in that state.
– Ultimately, one or both agents might discover that the state cannot be reached anyway (due to other upstream choices).
– Current research: allow inquiring agent to express a preference about others’ action choice, leading to fuller negotiation.
• An agent can stop inquiring when it knows enough to successfully schedule actions for the reduced set of states.
– Further reduction is possible but unnecessary.
• Protocol assured to terminate after all states examined.
• Order of inquiry can affect efficiency and composition of partial reductions, but not ultimate reduction (when agents converge on exactly the states that really will be reached).
• Use heuristic to order states to inquire about.

Convergence Protocol HeuristicsStrategies for selecting a state to inquire about:• Random Branching Point
– Agent selects randomly from states with multiple action choices
• Sequential Branching Point– Agent selects states in the order of their forward
expansions during planning. Pruning “upstream” can have more impact.
• Load Branching Point– Agent selects states in descending order of the number of
actions that would be removed if the states are pruned.
• Utilization Branching Point– Agent selects states in descending order of the marginal
decrease in schedule utilization if the states are pruned.

Convergence ProtocolSome Sample Domains
• 287 domains; 1626 agents• Each domain has from 2 to 10 agents, chosen randomly
and uniformly.• Each KB has 7 private and public binary features
combined.• The number of public features in a domain is random
(from 0 – 7). It measures how tightly coupled the agents are.
• Each agent has 15 private and public actions.• Each KB has 7 private and public temporal transitions
that flip a random number of features.

Convergence ProtocolTAP Pruning
• # of agents that are able to schedule for all their TAPs before running the protocol = 202 (12.42%).
• # of agents that are able to schedule for all their TAPs after running the protocol = 704 (43.30%).
• # of agents that become able to schedule for all their TAPs after running the protocol = 502 (30.87%).

Combined with Probabilistic Pruning
• Protocol can greatly improve safety guarantees.• Even after using the protocol, however, some
agents can be overconstrained.• Combine pruning with protocol with pruning
the least likely actions to be needed.• Agents could also do this before the protocol
finishes, in an “anytime” mode.

Convergence ProtocolAny-time Property
Team Failure Prob. vs. Rounds of Inquiry
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 2 4 6 8 10 12 14 16 18 20 22
# of Rounds of Inquiry
Sys
tem
Fai
lure
Pro
bab
ilit
y
Sequential
Random1
Random2
Random3
Average (Random)
i
iFF )1(1
Fi is probability of agent i reaching a failure stateSystem failure probability:Simple 2 agents, 91 states each
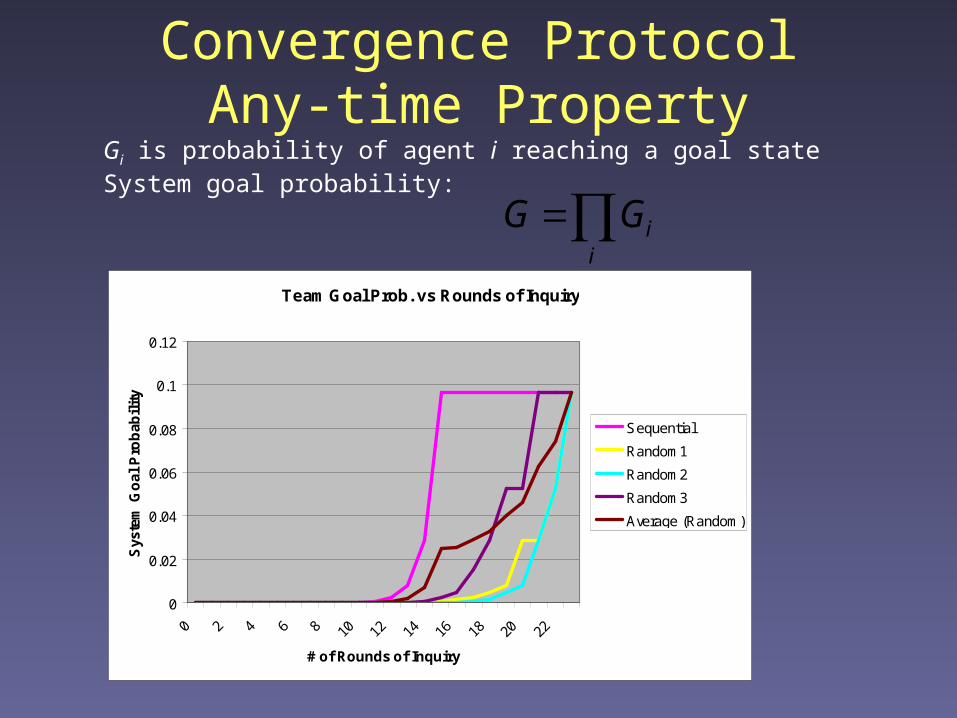
Convergence ProtocolAny-time Property
Team Goal Prob. vs Rounds of Inquiry
0
0.02
0.04
0.06
0.08
0.1
0.12
0 2 4 6 8 10 12 14 16 18 20 22
# of Rounds of Inquiry
Sys
tem
Go
al P
rob
abil
ity
Sequential
Random1
Random2
Random3
Average (Random)
Gi is probability of agent i reaching a goal stateSystem goal probability:
iiGG

Convergence ProtocolAny-time Property
Utility Function U = (1-F)G(1-) (here =.9)
Team Utility vs. Rounds of Inquiry
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 2 4 6 8 10 12 14 16 18 20 22
#of Rounds of Inquiry
Te
am
Uti
lity Sequential
Random1
Random2
Random3
Average (Random)

Scale Up Issues
• Description so far has emphasized agents modeling what others might/will do
• As number of agents grows, complexity of reasoning will too!
• How to scale up:– Model less about each agent– Treat multiple agents as one– Model only (few) relevant agents
• Strategies exist for all of these…

Summary
• Described some specific ideas about guaranteeing real-time agent behavior
• Emphasized challenges that arise when demands on agents outstrip their resources
• Outlined how multiple agents can accomplish more by relying on each other to reduce load and to balance load

Ongoing Work
• At the single-agent level, solve control cycle scheduling problem as a constrained optimization for various constraint types
• For multiple agents, investigate more sophisticated load-balancing given commitment to local plans
• For multiple agents, extend to negotiation where agents change local plans to make things better for other agents
• Ultimately, applied constrained optimization techniques in a distributed manner to the multiagent problem

Questions?





























