Embed Size (px)
Citation preview

LLNL-PRES-652730This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
DE-AC52-07NA27344. Lawrence Livermore National Security, LLC
Power, Resilience, Capacity, Oh My!I/O-integrated computing with NVRAM
Maya Gokhale, LLNL

Lawrence Livermore National Laboratory LLNL-PRES-652730
Amount of DRAM per core is severely constrained in exascale node• Many cores per node• Number of nodes• Total power requirements dominated by DRAM
Scale of an exaflop computer makes frequent checkpointing to global file system infeasible
• Peer-to-peer checkpoints (SCR) harder due to less memory per core
NVRAM in the compute fabric is required for energy, capacity, resilience
Exascale node architectures add NVRAM to memory hierarchy

Lawrence Livermore National Laboratory LLNL-PRES-652730
Exascale machine incorporates NVRAM at every level
X-Stack I NoLoSS

Lawrence Livermore National Laboratory LLNL-PRES-652730
Memory and storage are regarded as different in kind by the entire software stack: direct access to memory, but read and write operations to storage
Emerging persistent memories support efficient random, byte level, read/write access, filling a gap in memory/storage hierarchy
• Disk is a factor of 100,000 slower access latency of DRAM
• PCM is a factor of 2× slower (in read) than DRAM latency
NVRAM bridges memory/storage latency gap
Read Latency
Write Latency
DDR3 .01μs .01μs
PCM .05μs 1μs
NAND 10μs 100μs
Disk 1000μs 1000μs
With this new hardware technology, can we …• directly operate on arrays and tables that are too big
to fit in main memory• make permanent updates to arrays and tables without file I/O• traverse large graphs “as if” in memory• save lightweight checkpoints by flushing cache to persistent memory
• enable scalable applications to transition to exascale

Lawrence Livermore National Laboratory LLNL-PRES-652730
Out-of-core memory map runtime for block device• Customized page cache management for persistent
memory data store • Applications
— Graph traversal framework
— Metagenomic analysis and classification
Active storage• Future generations of byte-addressable NVRAM storage • Compute logic co-located with storage controller
Outline

Lawrence Livermore National Laboratory LLNL-PRES-652730
Systems software for data intensive computing: data intensive memory map
Brian Van Essen, LLNL

Lawrence Livermore National Laboratory LLNL-PRES-652730
I/O bus
Block device/File system
Persistent memory/Extended memory
Memory hardware interface
Views of node local NVRAM

Lawrence Livermore National Laboratory LLNL-PRES-652730
Optimize system software for application-specific access patterns
Performance measurements of system mmap were disappointing
We want abstraction of memory mapping but improve its implementation for data-centric application classes
Data intensive memory mapping (DI-MMAP)• DRAM as cache to persistent memory• Data intensive runtime manages the cache in a pre-allocated memory buffer• Differentiates between frequently used locations vs. random access

Lawrence Livermore National Laboratory LLNL-PRES-652730
Buffer management applies caching techniques to NVRAM pages
Minimize the amount of effort needed to find a page to evict:
In the steady state a page is evicted on each page fault
Track recently evicted pages to maintain temporal reuse
Allow bulk TLB operations to reduce inter-processor interrupts

Lawrence Livermore National Laboratory LLNL-PRES-652730
DI-MMAP is being integrated with Livermore Computing software stack Scalable out-of-core performance provides an
opportunity for working with node-local storage in HPC• Catalyst system
— 150 teraflop/s: 324 nodes, 7776 cores
— 40 TB DRAM + 253 TB Flash
— Each node: 128 GiB DRAM + 800 GiB Flash
DI-MMAP is integrated with SLURM• Can be loaded by user• Allocated per job• User specified total memory used for buffering external Flash
https://bitbucket.org/vanessen/di-mmap/

Lawrence Livermore National Laboratory LLNL-PRES-652730
Parallel graph traversal framework High visibility data intensive supercomputing application class Traverse scale free graph with trillions of edges
– Social network, web Developed parallel, latency tolerant asynchronous traversal framework Uses visitor abstraction
– Visitor is an application-specific kernel that the framework applies to each graph vertex
– Visit results in traversal of graph edges to queue work on target vertices– Visitor is queued to the vertex using priority queue
Scalable: single server with NVRAM to data intensive cluster to BG/P– 15% faster than best Intrepid result
Demonstrated with multiple traversal algorithms: Breadth first search, Single source shortest path,(Strongly) Connected components, Triangle counting, K-th core
Multiple Graph500 submissions Code has been open sourced (https://bitbucket.org/PerMA/havoqgt) and
will continue to be updatedRoger Pearce, LLNL

Lawrence Livermore National Laboratory LLNL-PRES-652730
BFS Graph Analysis performance shows DI-MMAP advantagesDI-MMAP provides …
High-performance
7.44x faster than mmap• with 256 threads
• and 40 GiB of DRAM
Scalable out-of-core performance
50% less DRAM• 20 GiB vs 40 GiB DRAM
• Only 23% slower

Lawrence Livermore National Laboratory LLNL-PRES-652730
Application: Livermore Metagenomics Analysis Toolkit• Challenge: Given an
“anonymous” sample give as complete a report on the pathogen contents as possible.
• Standard method: sequence alignment – align every read in sample against every known genome
Our Approach:Use highly concurrent search and large persistent memory to store and access reference data in a “pre-processed” form that supports efficient runtime queries.
375 GB k-mer database mapped into memory with DI-MMAP (24.5 billion k-mer keys) with tens to hundreds of threads querying database
Jonathan Allen, LLNL

Lawrence Livermore National Laboratory LLNL-PRES-652730
We’ve designed a two-level index optimized for NVRAM
COTS Hash tables aren’t suitable for page-access storage
Solution: split k-mer key• Manage prefix with array• Suffixes managed in lists typically
span no more than one page
Results: up to 74X speedup over gnu hashmap
Need to determine split parameter– can depend on input data set and k-mer length
Sasha Ames, LLNL

Lawrence Livermore National Laboratory LLNL-PRES-652730
LMAT + DI-MMAP performance
LMAT on ramdisk, flash vs other methods1 GB first-level size
Two-level vs hash – ERR data set index configuration (below) includes first level table size
General Experimental Setup• 22 GB original reference index
containing microbial (with fungi+protozoa) and human sequences.
• LMAT (version 1.1) runs with 160 threads on 40 intel core with 1.2TB FusionIO node, and DI-MMAP with 16 GB buffer
LMAT DI-MMAP vs linux mmap8 GB first-level size

Lawrence Livermore National Laboratory LLNL-PRES-652730
Analyze human genomes consisting of samples from 2948 individuals collected as part of the NIH “1000” human genome project, 100TB+ compressed
LMAT can answer science questions• Can we build a "more complete" human reference for screening
samples such as the microbiome or cancer sequences?• Are there any interesting previously undetected microbial
components in the samples?• What is the statistical profile of k-mer uniqueness across
individuals?
Replicate database on node-local flash, distribute dataset across nodes
LMAT experiment runs at scale on the Catalyst cluster
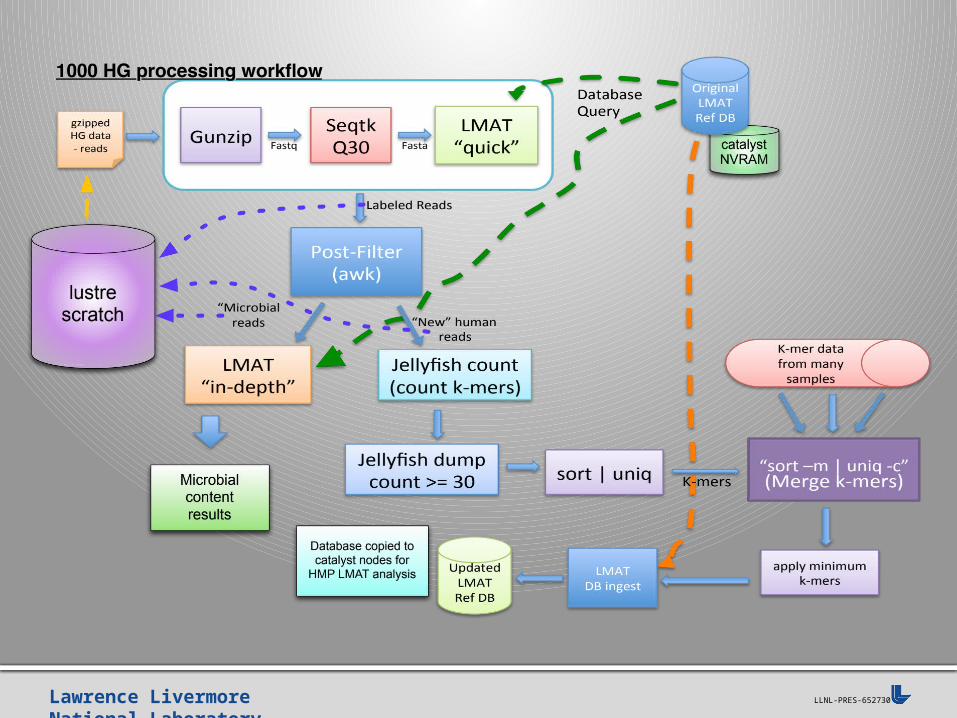
Lawrence Livermore National Laboratory LLNL-PRES-652730
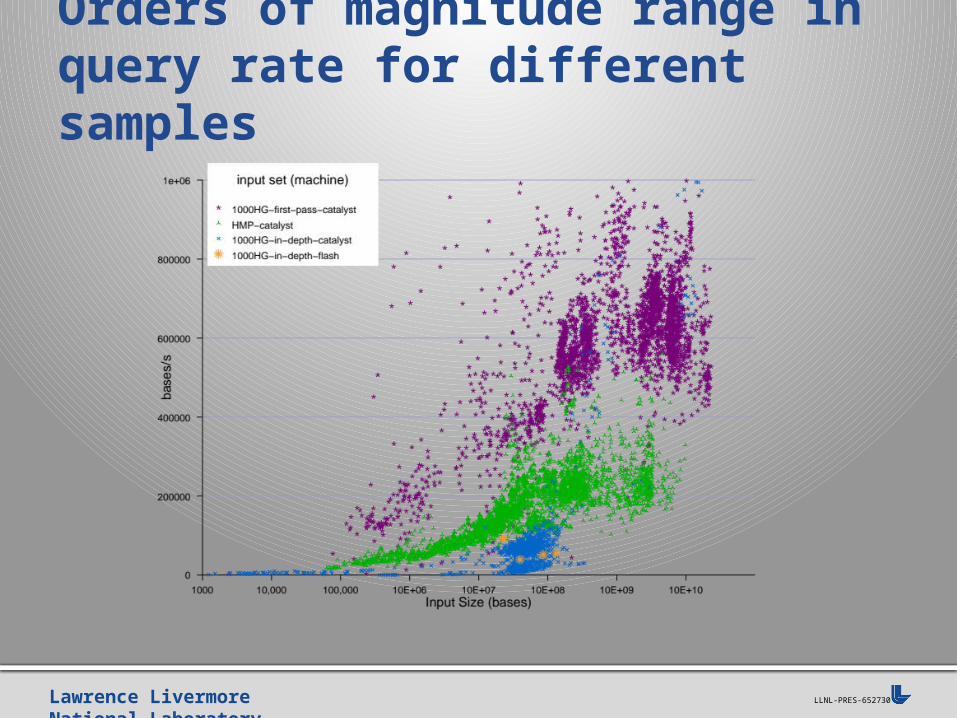
Lawrence Livermore National Laboratory LLNL-PRES-652730
Orders of magnitude range in query rate for different samples

Lawrence Livermore National Laboratory LLNL-PRES-652730
Modest database increase with additional human genomes
Database 1 - original LMAT databaseDatabase 2 - addition of GenBank human referenceDatabase 3 - (2) + addition of K-mers from from 1000 Genome project samples .

Lawrence Livermore National Laboratory LLNL-PRES-652730
More accurate DB means more labeled reads

Lawrence Livermore National Laboratory LLNL-PRES-652730
Expanded database with human variants improves classification
https://computation-rnd.llnl.gov/lmat/

Lawrence Livermore National Laboratory LLNL-PRES-652730
Active storage with Minerva (UCSD and LLNL)
Designed for future generations of NVRAM that are byte addressable, very low latency on read
Based on computation close to storage
Moved data or I/O intensive computations to the storage to minimize data transfer between the host and the storage
Processing scales as storage expands
Power efficiency and performance gain
Arup De, UCSD/LLNL
Prototyped on BEE-3 system • 4 Xilinx Virtex 5, each with
16GB memory, ring interconnect
Emulate PCM controller by inserting appropriate latency on reads and writes, emulate wear leveling to store blocks
Get advantage of fast PCM and FPGA-based hardware acceleration

Lawrence Livermore National Laboratory LLNL-PRES-652730
Minerva architecture provides concurrent access, in-storage processing units

Lawrence Livermore National Laboratory LLNL-PRES-652730
Minerva Programming Model
Normal reads and writes bypass storage processor
Remote procedure call-like interface for computational “reads” and “writes”
Storage processor generates interrupt for assistance whenever requires the host intervention to resolve
The software driver is responsible for setup, manage, monitor and finally release the storage processor on behalf of a given application
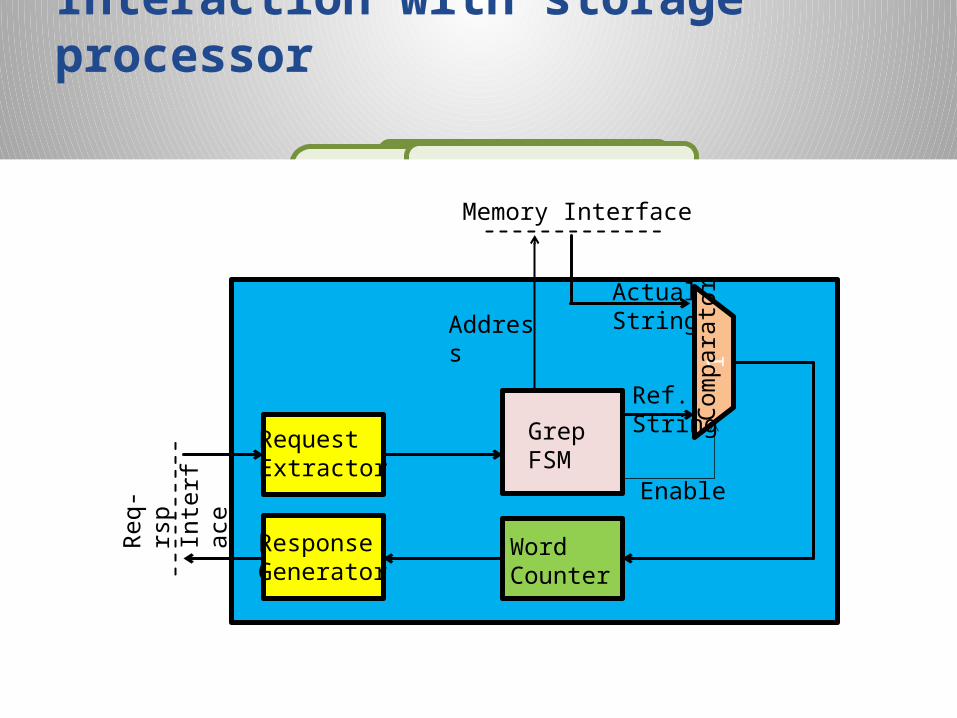
Lawrence Livermore National Laboratory LLNL-PRES-652730
Interaction with storage processor
Local Interface
Compute Kernel
Ring Interface
Loca
l Mem
oryControl
Processor
Spl
itter
Data Manager
Compute Manager
DataScheduler
DMA Engine
ComputeScheduler
Local Memory
K0 K1
K3K2
KnKn-1
Request Manager
Command 1
Command 2
Status 1
Status 211
Receives commandReads command
Initiate computations via request manager Receives result
Sends back completion notification
Loads it to memorySends DMA request via
request managerUpdate statusLoads data to memory
Request Extractor
Response Generator
1
Word Counter
Memory Interface
GrepFSM
Address
Ref.String
Actual String
Com
para
tor
Enable
Req
-rsp
Inte
rfac
e

Lawrence Livermore National Laboratory LLNL-PRES-652730
Minerva Prototype
Built on BEE3 board
PCIe 1.1 x8 host connection
Clock frequency 250MHz
Virtex 5 FPGA implements• Request scheduler• Network• Storage processor• Memory controller
DDR2 DRAM emulates PCM

Lawrence Livermore National Laboratory LLNL-PRES-652730
Minerva FPGA emulator allows us to estimate performance, power
Compare standard I/O with computational offload approach
Design alternative storage processor architectures and evaluate trade-offs
Run benchmarks and mini-apps in real-time
Estimate power draw and energy for different technology nodes
Streaming string search• 8+× performance• 10+× energy efficiency
Saxpy• 4× performance• 4.5× energy efficiency
Key-Value store (key lookup)• 1.6× performance• 1.7× energy efficiency
B+ tree search• 4+× performance• 5× energy efficiency

Lawrence Livermore National Laboratory LLNL-PRES-652730
Active storage• Arup De (Lawrence Scholar, UCSD)
Data-intensive memory map• Brian Van Essen
Metagenomic analysis• Sasha Ames• Jonathan Allen – PI of Metagenomics LDRD
Graph algorithms• Roger Pearce
Collaborators• UCSD – active storage • SDSC – data intensive architectures• UCSC – Resistive RAM as Content Addressable Memory• TAMU – graph algorithms
• Argonne, ASCR – data intensive memory map for the exascale
Contributors Further reading• Arup De, Maya Gokhale, Rajesh Gupta, and Steven
Swanson , Minerva: Accelerating Data Analysis in Next-Generation SSDs, in Proceedings of Field-Programmable Custom Computing Machines (FCCM), April 2013.
• Brian Van Essen, Henry Hsieh, Sasha Ames, Roger Pearce, Maya Gokhale, DI-MMAP: a scalable memory map runtime for out-of-core data-intensive applications, Cluster Computing, Oct. 2013 (open access)
• Sasha K. Ames, David A. Hysom, Shea N. Gardner, G. Scott Lloyd, Maya B. Gokhale and Jonathan E. Allen, Scalable metagenomic taxonomy classification using a reference genome database, Bioinformatics, July 2, 2013 (open access).
• Roger Pearce, Maya Gokhale, Nancy Amato, Scaling Techniques for Massive Scale-Free Graphs in Distributed (External) Memory, IEEE International Parallel and Distributed Processing Symposium, May 2013.

Lawrence Livermore National Laboratory LLNL-PRES-652730
In-storage computing can improve performance and EDP, particularly for low latency, byte-addressable persistent memory on attached I/O bus.
Extending the in-memory model to present day flash based block devices has demonstrated significant performance gains.
Highly concurrent throughput-driven algorithms can achieve excellent performance when accessing NVRAM through the optimized software stack.
In-cluster persistent memory addresses capacity, power, and latency/bandwidth gaps





























