Embed Size (px)
Citation preview

8Lineær regressionsanaLyse

336 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Lineær regressionsanaLyseFra kapitel 4 i Mat C-bogen ved vi, at man kan indtegne en række punkter i et koordinatsystem, for at afgøre, hvor ”tæt” på en ret linie disse punkter ligger. Dette gennemgik vi under overskriften Lineær regression, side 166, og vi bestemte denne lineære funktion ved hjælp af bl.a. CAS-værktøj.
Lineær regression er altså en måde, hvorpå man til et givet an-tal punkter i koordinatsystemet kan bestemme den lineære funktion, hvis graf passer ”bedst” på disse punkter. Den til-passede linje (eller estimerede) skriver vi som y ax b= + . Sym-bolet over y læses som ”y hat”.
yi = f (xi) = axi + b
y = ax + b
e = yi – yi = yi – (axi + b) = yi – axi – b yi
xi
Figur 1
Vi kan på punkterne i figur 1 se, at de er fordelt omkring den indtegnede rette linie. Derfor vil det være naturligt at vælge regressionsfunktionen som den tilpassede linje, dvs. y ax b= + .
Bemærk, at vi altså forlanger, at vi, inden regressionsanaly-sen foretages, ved, hvilken type funktion der er tale om. Dette kan f.eks. som i ovenstående tilfælde kontrolleres grafisk.På figuren er der indtegnet en ret linie, der på øjemål ser ud

3378 . L i n e æ r r e g r e s s i o n s a n a l y s e
til at være den ”bedste”. Men hvad vil det sige at finde den ”bedste” linie, og hvorfor er det den ”bedste”? I det følgende skal vi ud fra nogle givne kriterier forsøge at finde den linie, der repræsenterer alle punkterne bedst, dvs. vi skal bestemme a og b i denne linies ligning: y ax b= + . Det er ofte sådan, at ingen af de afsatte punkter ligger på grafen for den fundne rette linie.
Et kriterium for at bestemme den ”bedste” rette linie kan være, at den lodrette afstand, der måles fra punktet og op/ned til li-nien, samlet set skal være så lille som muligt. Dvs. vi kan måle afstanden fra punktet til linien for hvert eneste målepunkt og derefter summere alle disse afstande. Hvis linien er den ”bed-ste”, vil den samlede summerede afstand være så lille som over-hovedet muligt.
Forestiller vi os, at der på figur 1 er afsat n punkter ( , ),( , ),...,( , )x y x y x yn n1 1 2 2 vil et vilkårligt punkt kunne betegnes ( , )x yi i , hvor i n= 1, ... , . Denne betegnelse vil vi benytte frem-over.
I hvert eneste punkt er y-værdien yi , og funktionsværdien for den rette linie er ˆ ( )y f x ax bi i i= = + . Derved kan vi nu beregne den lodrette afstand ei (se figur 1) mellem punkt og linie. Denne forskel kalder vi for den estimerede models residualer og be-tegnes med ei . Vi har derfor at
ˆ ˆ ( )e y y y ax b y ax bi i i i i i i= − = − + = − −se figur 1

338 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Lad os se på et eksempel.
eksempeL 1Sammenhængen mellem X og Y fremgår af tabel 1.
X Y
150 2,24
160 2,48
165 2,61
175 3,03
180 3,35
185 3,44
200 4,48
210 4,43
215 4,60
220 4,76
Tabel 1
Lad os prøve at bestemme residualerne. Ved hjælp af CAS-værktøj bestemmer vi først den ”bedste” linje til ˆ , , .y xi = −0 039 3 685
Se figur 2:
4,8
4,4
4,0
3,6
3,2
2,8
2,4
2,0150 160 170 180 190 200 210 120
Figur 2

3398 . L i n e æ r r e g r e s s i o n s a n a l y s e
Residsualerne, som er afrundet til hele tal, fremgår af ta-bel 2:
Obs. nr. Xi Yi
Bedste linjeˆ , , .y xi = −0 039 3 685
Residualˆ ˆe y yi i i= −
1 150 2,24 2,165 0,075
2 160 2,48 2,555 -0,070
3 165 2,61 2,750 -0,140
4 175 3,03 3,140 -0,110
5 180 3,35 3,335 0,015
6 185 3,44 3,530 -0,090
7 200 4,48 4,115 0,365
8 210 4,43 4,505 -0,075
9 215 4,6 4,700 -0,100
10 220 4,76 4,895 -0,135
Tabel 2
Summen af residualerne får vi til: eii=∑ = −
1
100 139, . Symbolet
eii=∑
1
10
betegner summen af de 10 residualer, dvs. summen:e1+e2+e3+ … +e10. Dette vender vi tilbage til i afsnittet om test af forudsætninger, dvs. modelkontrol.
Da afstanden ei kan antage positive såvel som negative vær-dier, kan man opnå, at summen eii
n
=∑ =
10 , selvom alle punkter
ligger langt fra linien, derfor bruges kvadratet på afstanden, ei
2.
Vi vil derfor undersøge den kvadrerede afstand:
e y yi i i2 2= −( ˆ )
Ved at regne med kvadratet på afstanden, er de enkelte bidrag ei
2 0≥ , så den samlede sum eii
n
=∑ ≥
1
2 0 . Lighedstegnet gælder kun, hvis alle punkter ligger på den rette linie.
Summen af de kvadrerede afstande fra alle punkter til linien bliver nu:
har opløftet ”i anden”, dvs. kvadreret

340 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
e e e e y yn ii
n
i ii
n
12
22 2 2
1
2
1
+ + + = = −= =∑ ∑... ( ˆ )
= − − + − − + + − −( ) ( ) ... ( )y ax b y ax b y ax bn n1 12
2 22 2
Denne størrelse udtrykker altså, hvor stor den ”samlede” (kva-drerede) afstand er fra punkterne til regressionslinien, og for-målet må være, at gøre denne sum så lille som muligt.
Meningen er nu, at vi skal bestemme a og b, således at denne sum bliver minimeret. a og b er altså variable og ikke konstan-ter, som de plejer at være.
Den metode vi skal anvende til at bestemme a og b kaldes Mindste Kvadraters Metode (MKM), da a og b jo netop bestem-mes således, at eii
n
=∑
1 bliver så lille som muligt.
eksempeL 2Lad der være givet punkterne ( , )−3 1 , (1,2) og ( ; )5 8 . Ved indtegning fås følgende
x
y
1
-3
3
5
7
-2 -1 0 1 2
(-3,1)
(1,2)
(5,8)
3 4 5
Figur 3
har lagt alle afstandene sammen
har indsat e y y y ax bi i i i i= − = +ˆ ˆhvor

3418 . L i n e æ r r e g r e s s i o n s a n a l y s e
Vi ønsker ved hjælp af MKM at bestemme den rette linie, der passer bedst til punkterne, forstået sådan, at ei
i
n2
1=∑ bli-
ver så lille som muligt:
e e e12
22
32+ +
= − − + − − + − −( ) ( ) ( )y ax b y ax b y ax b1 1
22 2
23 3
2
= − ⋅ − − + − ⋅ − + − ⋅ −( ( ) ) ( ) ( )1 3 2 1 8 52 2 2a b a b a b
= + − + − − + − −( ) ( ) ( )1 3 2 8 52 2 2a b a b a b
Ideen er nu, at vi skal bestemme a og b således, at udtryk-ket ( ) ( ) ( )1 3 1 8 52 2 2+ − + − − + − −a b a b a b minimeres, dvs. bliver så lille som muligt.
Vi ved fra kapitel 3 i B-bogen, at en måde at minimere en funktion på, er ved at differentiere og sætte lig med 0. Så når vi skal bestemme værdien af ikke én men to varia-ble størrelser (nemlig a og b), vil vi opfatte ( ) ( ) ( )1 3 1 8 52 2 2+ − + − − + − −a b a b a b først som en funktion, hvor a er den variable størrelse, og derefter som en funk-tion, hvor b er den variable størrelse. At differentiere så-dan en funktion af to variable kaldes at differentiere par-tielt (partiel = delvis).
1) a er variabel:
h a a b a b a b( ) ( ) ( ) ( )= + − + − − + − −1 3 2 8 52 2 2
h a a b a b a b'( ) ( ) ( ) ( ) (= ⋅ + − ⋅ + ⋅ − − ⋅ − + ⋅ − −2 1 3 3 2 2 1 2 8 5 )) ( )⋅ −5
h a a b a b a b'( ) = + − − + + − + +6 18 6 4 2 2 80 50 10
h a a b'( ) = + −70 6 78
har skrevet de tre kva-drerede afstande op (da der er tre punkter)
har indsat i e y ax bi i i= − −
har indsat koordina-terne
har reduceret
har indført funktionen h
har differentieret, bl.a. ved hjælp af reglen om differentiation af sam-mensatte funktioner, se sætning 4 kapitel 2 i B-bogen. Bemærk, at a er variabel og b er konstant.
har ganget ind i paren-teserne
har reduceret

342 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
2) b er variabel:
k b a b a b a b( ) ( ) ( ) ( )= + − + − − + − −1 3 2 8 52 2 2
k b a b a b'( ) ( ) ( ) ( ) ( ) (= ⋅ + − ⋅ − + ⋅ − − ⋅ − + ⋅ −2 1 3 1 2 2 1 2 8 5aa b− ⋅ −) ( )1
k b a b a b a b'( ) = − − + − + + − + +2 6 2 4 2 2 16 10 2
k b a b'( ) = + −6 6 22
Vi ved også, at hvis begge funktioner skal minimeres, skal der gælde:
h a'( ) = 0 og k b'( ) = 0
70 6 78 0a b+ − = og 6 6 22 0a b+ − =
Dette er to ligninger med to ubekendte, som vi kender fra MAT C, og hvis vi løser dem med de metoder, der blev gen-nemgået i MAT C, kapitel 3, fås:
a = 0 875, og b = 2 792,
og derved bliver regressionsfunktionen, den bedste rette linie, ˆ , ,y x= +0 875 2 792 .
Anvender vi et CAS-værktøj får vi følgende output:”RegEqn” ”m*x+b””m” 0.875”b” 2.7916666666667”r²” 0.8546511627907”r” 0.9244734516419
Og vi ser, at a = 0 875, og b = 2 792, . Samme resultat som vi fik ved brug af den ovenfor gennemgåede metode, MKM. Se figur 4.
har indført funktionen k
har differentieret, bl.a. ved hjælp af reglen om differentiation af sam-mensatte funktioner, se kapitel 2 i B-bogen. Bemærk, at b er varia-bel og a er konstant.
har ganget ind i paren-teserne
har reduceret
ifølge sætning 2 kapitel 3 i B-bogen
har indsat h a'( ) og k b'( )

3438 . L i n e æ r r e g r e s s i o n s a n a l y s e
x
y
1
-3
3
5
7
-2 -1 0 1 2
(-3,1)
(1,2)
y = 0,875 · x + 2.70167
(5,8)
3 4 5
Figur 4
ØveLse 1Skitsér i samme koordinatsystem såvel punkter som re-gressionslinie fra eksempel 1.
At vi virkelig har fundet et minimum i eksempel 1, kan vi se af udtrykket, der skulle minimeres:
( ) ( ) ( )1 3 1 8 52 2 2+ − + − − + − −a b a b a b
Hvis man forestillede sig, at vi orkede at udregne dette udtryk, ville man se, at der samlet set vil komme til at stå 35 2a som et af leddene, og 3 2b som et andet af leddene.
Begge disse led har positive tal foran variablene a2 og b2 (nem-lig 35 og 3), og så ved vi fra MAT C om andengradsfunktioner, at det er parabler, der vender grenene opad.
Så ved at sætte de afledede lig med 0, må det være parabler-nes toppunkter, i dette tilfælde altså deres minimumspunkter, vi finder.
Vi kan let overbevise os selv om, at den gennemgåede metode i eksempel 6 er tidkrævende med flere punkter end de tre i ko-ordinatsystemet. Så vi konkluderer følgende uden bevis:

344 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
har udregnet de to gen-nemsnit
ifølge sætning 1
har indsat koordinaterne
har udregnet
ifølge sætning 1
har indsat de kendte størrelser
har udregnet
sætning 1
Lad ( , ),( , ), ... ,( , )x y x y x yn n1 1 2 2 være en række punkter i et koordinatsystem. Den rette
linie f x ax b( ) = + minimerer e y ax bii
n
i ii
n2
1
2
1= =∑ ∑= − −( ) , hvis:
ax x y y
x x
i ii
n
ii
n=
− ⋅ −
−
=
=
∑
∑
( ) ( )
( )
1
2
1
og b y ax= −
x og y står for gennemsnittene for x- og y-koordinaterne, og det viser sig, at re-gressionslinien går gennem punktet ( , )x y .
Lad os se, hvordan disse formler fungerer i praksis:
eksempeL 3Vi vender tilbage til eksempel 2 med punkterne (-3,1), (1,2) og ( , )5 8 . Vi udregner:
x = − + + =3 1 53
1 og y = + + =1 2 83
3 667,
Herefter fås ved brug af sætning 1:
ax x y y
x x
i ii
n
ii
n=
− ⋅ −
−
=
=
∑
∑
( ) ( )
( )
1
2
1
a = − − ⋅ − + − ⋅ − + − ⋅( ) ( , ) ( ) ( , ) ( ) (3 1 1 3 667 1 1 2 3 667 5 1 8 −−− − + − + −
3 6673 1 1 1 5 12 2 2
, )( ) ( ) ( )
a = 0 875,
b y ax= −
b = − ⋅3 667 0 875 1, ,
b = 2 792,
Dermed er værdierne for a og b de samme som i eksempel 1.

3458 . L i n e æ r r e g r e s s i o n s a n a l y s e
Af CAS-udskriften ovenfor fremgår tillige at r = 0 924, og r2 0 855= , .
Tallet r kaldes korrelationskoefficienten, og det angiver hvor god overensstemmelse, der er mellem den beregnede funktion og de punkter, der er opgivet. Hvis der er fuldstændig overens-stemmelse, er r r= ∨ = −1 1 , og hvis der slet ikke er nogen over-ensstemmelse, er r = 0 . Hvis linien er aftagende er r negativ. Værdierne af r vil ligge i intervallet: − ≤ ≤1 1r .
Tallet r2 kaldes determinationskoefficienten, og den angiver tilpasningsgraden af en estimeret regressionslinie. Hvis der er fuldstændig tilpasning, er r2 1= , og hvis der slet ikke er nogen tilpasning, er r2 0= . Værdierne af r2 vil ligge i intervallet: 0 12≤ ≤r , hvilket betyder, at r2 kan opfattes som en procent-del, og det er meget almindeligt at konklusionen for r2 0 855= , er, at 85,5 % af variationen i den afhængige variabel (y) kan forklares af variationen i den uafhængige variabel (x).
Vi kan gennemføre regressionsanalyser som er baseret på an-dre end lineære sammenhænge. Vi bestemmer altså på for-hånd hvilken type regression vi vil gennemføre.
Nedenfor fremgår resultatet af en eksponentiel regressions-analyse med de samme punkter som ovenfor. Som det ses, har både r og r2 bedre værdier, hvorfor den eksponentielle funk-tion f x x( ) , ,= ⋅1 943 1 297 er bedre i overensstemmelse med de givne data. Vi skal ikke gå nærmere ind de forskellige regres-sionstyper, men alene se på lineære regressioner.Resultat af eksponentiel regressionsanalyse:
”RegEqn” ”a*b^x””a” 1.9430638823072”b” 1.296839554651”r²” 0.96428571428571”r” 0.98198050606197

346 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
eksempeL 4Sammenhængen mellem X og Y fra eksempel 1 er:
X Y
150 2,24
160 2,48
165 2,61
175 3,03
180 3,35
185 3,44
200 4,48
210 4,43
215 4,60
220 4,76
Tabel 3
Vi ønsker at bestemme korrelations- og determinationsko-efficenten. Ved hjælp af CAS-værktøj får vi følgende resul-tat:
”r²” 0.9744998927252
”r” 0.98716761126224
Som det ses, er der en høj grad af lineær overensstemmelse samt tilpasningsgrad mellem X og Y. Anvender vi fortolk-ningen af r2 som vi så ovenfor, betyder det i dette eksem-pel, at 97,4 % af variationen (udsving) i den afhængige va-riabel (Y) kan forklares af variationen (udsving) i den uafhængige variabel (X).
ØveLse 2Sammenhængen mellem disponibel indkomst efter fradrag af faste udgifter og dagligvareforbrug pr. husholdning, fremgår af tabel 4.

3478 . L i n e æ r r e g r e s s i o n s a n a l y s e
Indkomst Forbrug
54600 32400
55200 33240
54000 47700
55800 33000
55800 32400
55800 31920
57150 33228
58200 34200
63600 36900
67800 35400
70200 37340
75138 41400
Tabel 4
Bestem den ”bedste” rette linie samt r og r2 vha. lineær regression.
ØveLse 3Sammenhængen mellem ugentlig salg i tusinde kr. og test-scores for en stikprøve bestående af 8 salgskonsulenter fremgår af tabel 5:
Ugentlig salg 10 12 28 24 18 16 15 12
Test scores 55 60 85 75 80 85 65 60
Tabel 5
Bestem den ”bedste” rette linie samt r og r2 vha. lineær re-gression.

348 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
ØveLse 4Prisen på DVD-afspillere sættes forskelligt i 8 forskellige regioner af landet, se nedenfor.Prisen er opgivet i hundrede dollar, se tabel 6:
Antal solgt 420 380 350 400 440 380 450 420
Pris 5,5 6,0 6,5 6,0 5,0 6,5 4,5 5,0
Tabel 6
Bestem den ”bedste” rette linie samt r og r2 vha. lineær regression.
test i Lineære regressionerSpørgsmålet er, om det vi har gennemgået ovenfor, er tilstræk-kelig til at anvende resultatet fra en lineær regression til prog-noser? Når vores resultater baseres på populationsdata, vil re-sultatet af undersøgelsen være sand. Men, som vi har set i kapitlet om test i MAT B-bogen, vil vi i praksis sjældent un-dersøge et spørgsmål ved at bruge data fra hele populationen, men ved at udtage en stikprøve fra populationen. Det betyder, at resultatet af sådan en stikprøve er behæftet med usikker-hed, idet en anden stikprøve fra samme population jo kunne give et andet resultat. Vi må derfor supplere ovenstående med gennemførelse af test i lineære regressioner. I denne sammen-hæng vil vi koncentrere os to test: 1. Test af forudsætninger. 2. Test af om stigningstallet β antager visse værdier, herun-
der konfidensinterval for linjens stigningstal. β er det te-oretiske stigningstal i den lineære regressionsmodel: y a x= + β .
Læg mærke til at i forhold til den måde vi normalt skriver li-niens ligning y ax b= + på, er det almindeligt i statistikbøger at skrive det som y a x= + β .
β er det græske bogstav, der svarer til b

3498 . L i n e æ r r e g r e s s i o n s a n a l y s e
Styrken ved lineær regression ligger endvidere i det faktum, at modellen, som nævnt, kan anvendes til forudsigelser (prog-noser), hvorfor det er særdeles vigtigt, at vi kan ”stole” på mo-dellens resultater.
Når vi gennem lineær regression fastlægger den ”bedste” li-nie, er det udtryk for et estimat, som vi i resten af kapitlet skri-ver således: y a bx= + . Læg mærke til, at modellen har en ”hat” over y’et, hvilket betyder, som vi så ovenfor, at der er tale om et bedste bud (= estimat) for den lineære sammenhæng. b an-giver stigningstallet og a skæring med y-aksen.
Vi gennemfører altså ikke en test af modellens hældnings-koefficienten b, men af den teoretiske hældningskoefficient β .
test af forudsætninger, modeLkontroLSom vi har set ovenfor definerede vi residualerne som forskel-len mellem de observerede og de tilpassede y-værdier, dvs.:ˆ ˆe y yi i i= − . Den vigtigste forudsætning, som skal være opfyldt,
for gennemførelse af simpel lineær regressionsanalyse er, at:E ei( ) = 0 , dvs. at middelværdien af residualerne skal være 0, eller tæt på 0. Hvis der ikke eksisterer en lineær sammenhæng mellem de to variable, vil den bedste linje ikke give de rigtige værdier for de fleste x-værdier, og middelværdien af residua-lerne vil være forskellig fra 0. Normalt vil man, udover at te-ste om E ei( ) = 0 , skulle undersøge om yderligere fire forudsæt-ninger er opfyldt. Vi nøjes i denne sammenhæng med at nævne to af disse forudsætninger:
1. ei ’erne er normalfordelte2. σ σei( ) = , dvs. samme spredning for alle residualerne
eksempeL 5Lad os se på de data vi har fra eksempel 1, og undersøge om forudsætningen E ei( ) = 0 er opfyldt.
Ved hjælp af CAS-værktøj får vi tegnet en tendenslinje, se figur 2 og figur 5 øverst.

350 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Som vi kan se af figur 5 er punkterne pænt og jævnt for-delt omkring regressionslinien, hvorfor forudsætningen ser ud til at være opfyldt. Vi så endvidere, at e E ei
ii=
∑ = − ( ) =1
100 139, , hvilket betyder, at −−0 0139, , som er meget tæt på 0.
hvilket betyder, at e E eii
i=∑ = − ( ) =
1
100 139, , hvilket betyder, at −−0 0139, , som er meget tæt på 0. som er meget tæt på 0.
Vi kan endvidere tegne et såkaldt residualplot over residu-alerne, jfr. tabel 2.
Residualplottet ses nedenfor i figur 5 sammen med ten-denslinjen:
y
x
-0,15
0,00
0,15
0,30
2,0
2,4
2,8
3,2
3,6
4,0
4,4
4,8
150 160 170 180 190 200 210 220
y = 0,038854 · x – 3.68483
Figur 5
Nedenfor i figur 6 har vi medtaget et plot og en tendensli-nie hvor forudsætningen ikke er opfyldt, da punkterne ikke ligger pænt og jævnt fordelt omkring regressionslinien, men ligger i klumper på hver side af regressionslinien.

3518 . L i n e æ r r e g r e s s i o n s a n a l y s e
x
y
1
2
10
12
14
16
3 4 5 6 7 8 9 10 11 12 13
y = 0,396553 · x + 8,9076
Figur 6
ØveLse 5Anvend data fra henholdsvis øvelse 2, 3 og 4 og undersøg ved hjælp af tendenslinien om forudsætningen E ei( ) = 0 ser ud til at være opfyldt. Beregn eventuelt E ei( ) . Suppler eventuelt med et residualplot.
β -TesT
I en β -test tester man følgende hypoteser:
H0 0: ;β = ingen lineær sammenhæng mellem X og YYlineær sammenhæng mellem X og YH1 0: ;β ≠
Man undersøger om der er en lineær sammenhæng mellem den afhængige variabel (Y) og den uafhængige variabet (X). Af H0 ses det, at hvis β = 0 vil alle X-værdier blive ganget med 0, og X-værdierne vil dermed ikke påvirke Y-værdierne. Kun hvis H0 afvises, dvs. at β ≠ 0 , tyder det på, at der findes en lineær sammenhæng.Når vi gennemfører en β -test undersøger vi altså om β anta-ger visse værdier.

352 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Følgende definition er vigtig:
definitionDen lineære regressionsmodel
y a x= + β
er signifikant, hvis β ≠ 0
Det skal fastslås at en model, som er signifikant betyder, at alle p-værdierne, med hensyn til hældningskoefficienten β , er mindre end signifikansniveauet α . Se kapitel 7 i B-bogen.
Lad os se på et eksempel, hvor der er udtaget en stikprøve og hvor vi ønsker at gennemføre en β -test.
eksempeL 6For at få undersøgt årsagerne til udsvingene i salget af cy-kelhjelme, har man sammenlignet salget med en række andre variable. De enkelte data er indsamlet for 14 tilfæl-digt udvalgte måneder og gengives i nedenstående tabel. I undersøgelsen indgik der 3 forskellige variable, salg af cyk-ler, reklameindex og prisindex, der havde indflydelse på sal-get af cykelhjelme. Vi vil koncentrere os salg af cykler, dvs. én variabel (= simpel lineær regression), idet vi ikke skal komme nærmere ind på det, der betegnes som multipel li-neær regressionsanalyse.

3538 . L i n e æ r r e g r e s s i o n s a n a l y s e
Sammenhængen mellem salg af cykler og salget af cykel-hjelme.
Salg af cyklerx
Salg af cykelhjelmey
6153 238
5081 199
6342 260
7126 301
6528 298
7414 319
5392 163
6128 241
6688 294
5842 207
5444 222
4987 182
5312 176
5677 211
Tabel 7
Anvender vi et CAS værktøj får vi følgende resultat:
”RegEqn” ”m*x+b””m” 0.063746932500087”b” -146.50067716517”r²” 0.88096357709014”r” 0.93859659976485

354 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
y
x
160
4800
200
240
280
320
5000 5200 5400 5600 5800 6000 6200 6400 6600 6800 7000 7200 7400 7600
y = 0,063747 · x – 146,501
Figur 7
Som det ses af plottet og CAS-udskriften kan den estime-rede model fastlægges således: ˆ , ,y x= − +146 5007 0 0637 .
Af værdierne r og r2 kan vi endvidere se, at der er en god overensstemmelse og forklaringsgrad mellem salget af cyk-ler og salget af cykelhjelme.
For at gennemføre en β -test, opstiller vi, jfr. ovenfor, følgende hypoteser:
HH
0
1
00
::
ββ
=≠
Som det ses af H0 har salget af cykler ingen indflydelse på sal-get af cykelhjelme. På samme måde ses det af H1 at salget af cykler vil have indflydelse på salget af cykelhjelme.
Vi skal ikke gå i detaljer med selve teorien bag denne test, men koncentrere os om testresultatet, hvor vi vil fokusere på p-vær-dien.

3558 . L i n e æ r r e g r e s s i o n s a n a l y s e
BesLutningsregeL 1Ved fastlæggelse af et signifikansniveau på α = 0 05, vil vi afvise nulhypotesen hvis p < α .
eksempeL 7Anvender vi data fra eksempel 6 og bruger et CAS-værk-tøj får vi følgende resultat:
”Alternativ Hyp” ”β ≠ 0””RegEqn” ”a+b*x””PVal” 6.7733525760999E-7“df” 12.
Vi skal fokusere på tallet PVal = p-værdi. Ved p-værdien for-stås sandsynligheden for at observere noget, der er mindst lige så ekstremt som det foreliggende, på betingelse af at nul-hypotesen er korrekt. Sagt på en anden måde: Signifi-kanssandsynlighed kan fortolkes som sandsynligheden for at forskellen mellem det forventede (hypotetiske) og det ob-serverede (= observerede salg af cykelhjelme på basis af solgte cykler) er tilfældig. Er sandsynligheden tilstrække-ligt lille, dvs. p < α, antages forskellen (afvigelsen) ikke til-fældig og så forkastes påstanden dvs. nulhypotesen (Ho).
Tallet er skrevet på såkaldt eksponentiel form, hvilket be-
tyder, at tallet 6,7733… skal ganges med10 110
77
− = , eller
mere populært sagt, så skal du flytte kommaet 7 pladser til venstre, hvilket giver os en p-værdi = 0,0000006773.
Ifølge beslutningsreglen kan vi afvise nulhypotesen (vi si-ger at parameteren salg af cykler er signifikant, da p-vær-dien er stort set 0), hvilket betyder, at det med 95 % sand-synlighed må antages, at der findes en lineær sammenhæng mellem salget af cykler og salget af cykelhjelme.

356 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Som tidligere nævnt ligger styrken i den lineære regression i, at man kan anvende modellen til prognoser eller forudsigelser. I vores eksempel vil det være interessant at kunne forudsige salget af cykelhjelme på basis af et antal solgte cykler, hvor de anvendte data ikke har været en del af stikprøven. Det skal dog bemærkes, at man skal være meget forsigtig med at lave forudsigelser, når man anvender x-værdier (dvs. salg af cyk-ler) udenfor det observerede interval, da vi jo ikke kan have sikkerhed for, at udviklingen i salg af cykelhjelme fortsætter lineært.Den estimerede model er, jævnfør eksempel 6:
ˆ , ,y x= − +146 5007 0 0637 , for 4987 < x < 7414.
Ønsker vi at forudsige antallet af solgte cykelhjelme ved et salg på 6.500 cykler, som ligger indenfor intervallet, se tabel 7, så kan vi bestemme dette vha. følgende:
ˆ ˆ ˆy a bx= + .Vi indsætter i modellen: ˆ , , , .y = − + ⋅ =146 5007 0 0637 6500 267 5493
Det må altså forudsiges, at ved et salg på 6.500 cykler, vil det kunne forventes at der sælges 267 cykelhjelme. Problemet med denne forudsigelse er, at der ikke tages højde for den usikker-hed der er knyttet hertil. Vi vil derfor i stedet bestemme det såkaldte 95 % forudsigelsesinterval.
Igen skal vi ikke komme nærmere ind på formlerne bag be-stemmelsen af dette interval, men anvende et CAS-værktøj til at beregne det.
Vi får vi følgende: Antal solgte cykelhjelme vil med 95% sand-synlighed ligge mellem 226 og 309, når der sælges 6500 cykler.
ØveLse 6I denne øvelse skal du arbejde videre med eksemplet oven-for, idet salget af cykelhjelme nu søges forklaret vha. rekla-meindex. Reklameindex er et index for det anvendte beløb til reklame. Tallene fremgår af tabel 8.

3578 . L i n e æ r r e g r e s s i o n s a n a l y s e
Reklame-indexx
Salg af cykelhjelmey
131 238
112 199
152 260
198 301
177 298
230 319
76 163
152 241
160 294
122 207
132 222
94 182
94 176
134 211
Tabel 8
a) Bestem den bedste lineære model, der forklarer salget af cykelhjelme på basis af reklameindex.
b) Vurder modellens holdbarhed vha. r og r2.c) Gennemfør en β -test.d) Bestem et 95 % forudsigelsesinterval på salget af cykel-
hjelme, hvis reklameindex er 180.
ØveLse 7I denne øvelse skal du igen arbejde videre med eksemplet ovenfor, idet salget af cykelhjelme nu søges forklaret vha. prisindexet. Prisindexet er udtryk for det generelle prisni-veau i samfundet i de valgte måneder. Tallene fremgår af tabel 9.
Sammenhængen mellem prisindex og salget af cykelhjelme.

358 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
Prisindexx
Salg af cykelhjelmey
123 238
121 199
123 260
123 301
121 298
120 319
120 163
121 241
123 294
119 207
119 222
118 182
121 176
123 211
Tabel 9
a) Bestem den bedste lineære model, der forklarer salget af cykelhjelme på basis af prisindex.
b) Vurder modellens holdbarhed vha. r og r2 .c) Test forudsætningen om at E ei( ) = 0 . Suppler eventu-
elt med et residualplot.d) Gennemfør en β - test.e) Bestem et 95 % forudsigelsesinterval på salget af cykel-
hjelme, hvis prisindex er henholdsvis 122 og 126.
Til sidst vil vi se på fastlæggelse af konfidensinterval for liniens hældningskoefficient. Et konfidensinterval er, som vi så i kapitel 7 i MAT B-bogen, et interval hvor vi med en vis stor sandsynlighed har tillid til, at den sande værdi for liniens hældningskoefficient ligger. Uden at vi kommer yderligere ind på det, bestemmes et konfidensinterval for liniens hældningskoefficient ved hjælp af CAS-værktøj.

3598 . L i n e æ r r e g r e s s i o n s a n a l y s e
eksempeL 8Lad os igen tage udgangspunkt i de data vi har fra eksem-pel 1.
Ved hjælp af CAS-værktøj får vi følgende 95 % -konfidens-interval for hældningskoefficienten b:
0 0337 0 0439, ,< <b .
Det betyder, at b med 95 % sikkerhed ligger mellem 0,0337 og 0,0439.
eksempeL 9Lad os nu tage udgangspunkt i eksempel 6, hvor vi så på sammenhængen mellem salg af cykler og salg af cykel-hjelme.
Ved hjælp af CAS-værktøj får vi følgende 95 % -konfidens-interval for hældningskoefficienten b:
0 0490 0 0785, , .< <b
Af dette kan vi tolke, at b med 95 % sikkerhed ligger mel-lem 0,0490 og 0,0785. Vi er altså 95 % sikre på, at antallet af solgte cykelhjelme stiger med et antal mellem 0,0490 og 0,0785, når salget af cykler stiger med 1.
ØveLse 8Anvend data fra øvelse 2, 3 og 4 til bestemmelse af et 95 % -konfidensinterval for hældningskoefficienten b.

360 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
opgaver
opgave 1Marketingafdelingen i en større virksomhed har i samar-bejde med deres brancheorganisation besluttet at investere i salgsfremmende foranstaltninger. Salget af vare A påvir-kes selvfølgelig af prisen. For at vurdere denne faktor har de i første omgang bedt statistikafdelingen om at udarbejde en regressionsanalyse, som beslutningsgrundlag. Resulta-tet fremgår af tabel 10.
Prisindeks for vare A Antal solgte vare A
110 1700
100 722
110 2244
111 3276
109 3198
115 3733
112 1200
113 1766
116 3095
99 913
120 1310
Tabel 10
a) Bestem den bedste lineære model, der forklarer salget af vare A på basis af prisindex.
b) Vurder modellens holdbarhed vha. r og r2 .c) Test forudsætningen om at E ei( ) = 0 . Suppler eventu-
elt med et residualplot.d) Gennemfør en β -test.e) Bestem et 95 % forudsigelsesinterval på salget af vare
A, hvis prisindex er 105.

3618 . L i n e æ r r e g r e s s i o n s a n a l y s e 361
opgave 2Virksomheden IT Online, som ikke i øjeblikket har hard-disk-optagere i sit sortiment, ønsker på grund af den store efterspørgsel at udvide sit sortiment til også at omfatte harddisk-optagere. For at få en fornem melse af hvilke hard-disk-optagere der sælger bedst, har virksomheden indhen-tet salgsoplysninger på 15 tilfældig forskellige harddisk-optagere for april 2011. I første omgang har man koncentreret sig om sammenligning af pris og afsætning. Resultatet ses i tabel 11.
Afsætning Pris i kr.
630 746
610 787
870 1430
910 332
987 558
630 450
1000 933
833 663
730 1702
1000 398
1100 1203
599 1723
887 905
796 176
951 770
Tabel 11
a) Bestem den bedste lineære model, der forklarer salget af harddisk-optagere på basis af prisen.
b) Vurder modellens holdbarhed vha. r og r2 .c) Test forudsætningen om at E ei( ) = 0. Suppler eventuelt
med et residualplot.d) Gennemfør en β -test.e) Bestem et 95 % forudsigelsesinterval på salget af hard-
disk-optagere, hvis prisen er 1820 kr.

362 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
opgave 3En virksomhed sælger hængelåse og marketingafdelingen har undersøgt sammenhængen mellem antal solgte hæn-gelåse og prisen på hængelåsene, udtrykt ved henholdsvis prisindekset samt den korte rente.
Sammenhængen fremgår af tabel 12.
Antal solgte hængelåse
Den korte rentePrisindeks for
hængelåse
1700 3,00 110
722 2,90 100
2244 2,90 110
3276 3,12 111
3198 3,40 109
3733 2,80 115
1200 3,30 112
1766 3,10 113
3095 3,30 116
913 3,70 99
1310 3,20 120
Tabel 12
Gennemfør en lineær regressionsanalyse samt β -test for-klaret ved henholdsvis den korte rente og prisindeks.
Vurder hvilken model, der bedst giver en forklaring på an-tal solgte hængelåse.
Du kan også gennemføre forudsigelser.

3638 . L i n e æ r r e g r e s s i o n s a n a l y s e 363
opgave 4Udviklingen i prisindeks for ejendomssalg fordelt på enfa-miliehuse i perioden 1992-2006.
Sammenhængen fremgår af tabel 13.
Prisindeks for ejendomssalg (2006=100) efter tid og ejendomskategori
Enfamiliehuse
2009 88,1
2008 101,1
2007 104,9
2006 100,0
2005 82,3
2004 70,1
2003 64,4
2002 62,5
2001 60,2
2000 56,9
1999 53,4
1998 50,0
1997 45,9
1996 41,2
1995 37,2
1994 34,6
1993 31,0
1992 31,2
Tabel 13
Kilde: statistikbanken, Danmarks statistik.
a) Gennemfør en lineær regressionsanalyse samt β -test.b) Test forudsætningen om at E ei( ) = 0 . Suppler eventu-
elt med et residualplot.c) Bestem et 95 % -konfidensinterval for hældningskoeffi-
cienten b.
Du kan eventuelt overveje hvad der er årsagerne til, at pris-indekset er faldet fra 2006 til 2009.
364 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
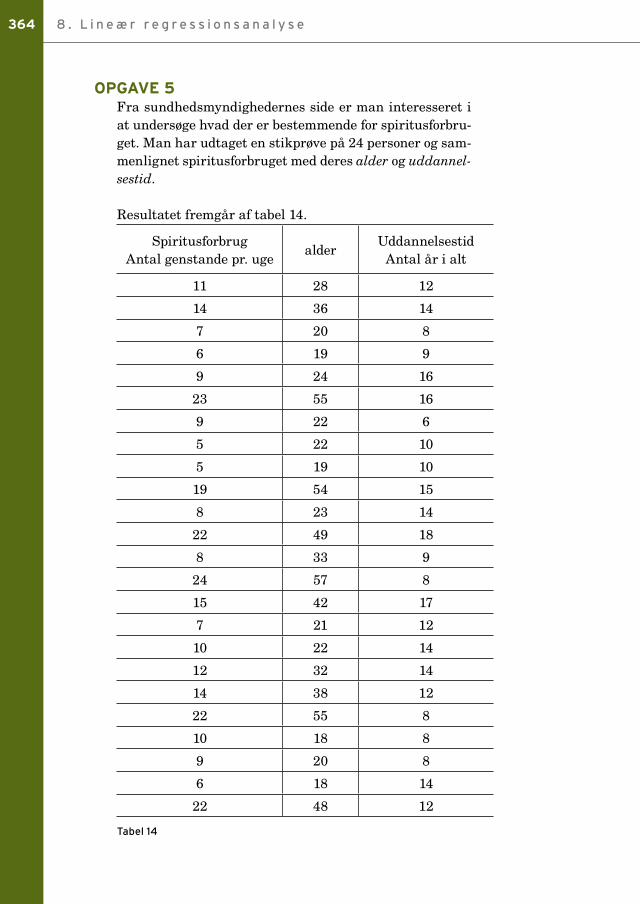
opgave 5Fra sundhedsmyndighedernes side er man interesseret i at undersøge hvad der er bestemmende for spiritusforbru-get. Man har udtaget en stikprøve på 24 personer og sam-menlignet spiritusforbruget med deres alder og uddannel-sestid.
Resultatet fremgår af tabel 14.
SpiritusforbrugAntal genstande pr. uge
alderUddannelsestid
Antal år i alt
11 28 12
14 36 14
7 20 8
6 19 9
9 24 16
23 55 16
9 22 6
5 22 10
5 19 10
19 54 15
8 23 14
22 49 18
8 33 9
24 57 8
15 42 17
7 21 12
10 22 14
12 32 14
14 38 12
22 55 8
10 18 8
9 20 8
6 18 14
22 48 12
Tabel 14

3658 . L i n e æ r r e g r e s s i o n s a n a l y s e 365
a) Gennemfør to lineære regressionsanalyser, hvor den for-klarende variabel er henholdsvis alder og uddannelses-tid.
b) Undersøg gennem en β -test af de to regressioner hvil-ken af de to variable (alder eller uddannelsestid), der gi-ver den bedste forklaring på det ugentlige spiritusfor-brug.
opgave 6Brug Danmarks Statistiks Databank til at gennemføre li-neære regressionsanalyser samt β -test.

366 8 . L i n e æ r r e g r e s s i o n s a n a l y s e
sammenfatning
• I lineær regressionsanalyse bestemmes den bedste li-neære sammenhæng mellem måleresultater af to vari-able x og y.
• Residualerne bestemmes som: ˆ ˆe y yi i i= − .
• Test forudsætningen om at E ei( ) = 0 .
• Metoden til bestemmelse af den bedste linie kaldes Mindste Kvadraters Metode (MKM).
• β-test ( β = det græske bogstav beta): Den lineære re-gressionsmodel y a x= + β er signifikant, hvis β ≠ 0.
• For at gennemføre en β -test opstiller vi følgende hypo-teser:
HH
0
1
00
::
ββ
=≠
• Beslutningsregel vedr. β -test: Vi fastsætter signifikans-niveauet til α = 0 05, og vil afvise nulhypotesen hvisp < α
.
• Konfidensinterval for liniens hældningskoefficient be-stemmes ved hjælp af CAS-værktøj.
• 95 % forudsigelsesinterval: Angiver med 95 % sandsyn-lighed i hvilket interval det må antages at det afhæn-gige variabel ville ligge.





























