Embed Size (px)
Citation preview

Limited Dependent VariableModels
• Logit• Probit
• Tobit

Modelli Logit e Probit
• Latent variable models for binarychoice
• Models for descrete dependentvariable

Traducendo…
Spesso vogliamo studiare (le determinanti de) la probabilità di un attributo (o evento):
esempi:prob di essere disoccupato prob di sposarsiprob di essere razionati sul mercato del
creditoprob di possedere una casa

Problema:
• Non osserviamo la probabilità• Osserviamo l’ attributo (o evento)
• Esempi• Persona disoccupata/non disoccupata• Persona coniugata/non coniugata• Impresa razionata/non razionata• Famiglia proprietaria/non proprietaria della
propria abitazione

Variabili dipendenti discrete
In altri termini, osserviamo la realizzazione di variabili discrete (Y), che assumono il valore
• Y=1 se l’evento (attributo) si verifica• Y=0 se non si verifica

Interesse
• P(Y=1|X)
Probabilità dell’evento Y=1, dato un set di variabili esplicative X

Linear Probability Model
• Yi=a+bXi+ui
• Y dummy =1 se la famiglia è proprietaria• X=reddito• u=errore , E(u)=0
• E(Yi|Xi)= a+bXi = Pr (Yi=1|Xi)valore atteso conditional on Xi=conditional
probability

LPM: Scatterplot
• Asse ascisse: valori di X
• Asse ordinate: valori di Y
0 . . . . .. . ………
1 ……… . . . . .

LPM: retta regressione• Asse ascisse: X• Asse ordinate: valori reali
di Y ed E(Y|X) = P(Y=1| X)
• Retta di regressione passa attraverso i valori reali di Y (0-1) nei punti di maggiore concentrazione degli stessi
• NOTA BENE: valori di R^2 bassi
1 . .. . … .. ………
0………. .. … . . .

LPM: retta regressione
• Asse ascisse: X
• Asse ordinate: E(Y|X) = P(Y=1| X)
• valori di R^2 alti solo in casi del genere 1 ………
0……

ESEMPIO
• fittedYi=- 0.9457+0.1021 Xi
t (-7.7) (12.5)
Intercetta= prob che una famiglia con zero reddito possieda una casa: negativa!!
Coeff di X= per un incremento unitario di X , in media, la prob di possedere una casa aumenta di 0.1021, circa il 10%

PROBLEMI
PROBLEMI DI PROBLEMI DI PROBLEMI DI INFERENZAINFERENZAINFERENZA
Le assunzioni di normalità/omoschedasticità degli errori sono violate (residui dicotomi ed eteroschedastici)
PROBLEMI DI FORMA PROBLEMI DI FORMA PROBLEMI DI FORMA FUNZIONALEFUNZIONALEFUNZIONALE
• Predicted probabilitiesillimitate
P(D=1| X) >1P(D=1| X) < 0
• Relazione lineare tra probabilità e variabili esplicative
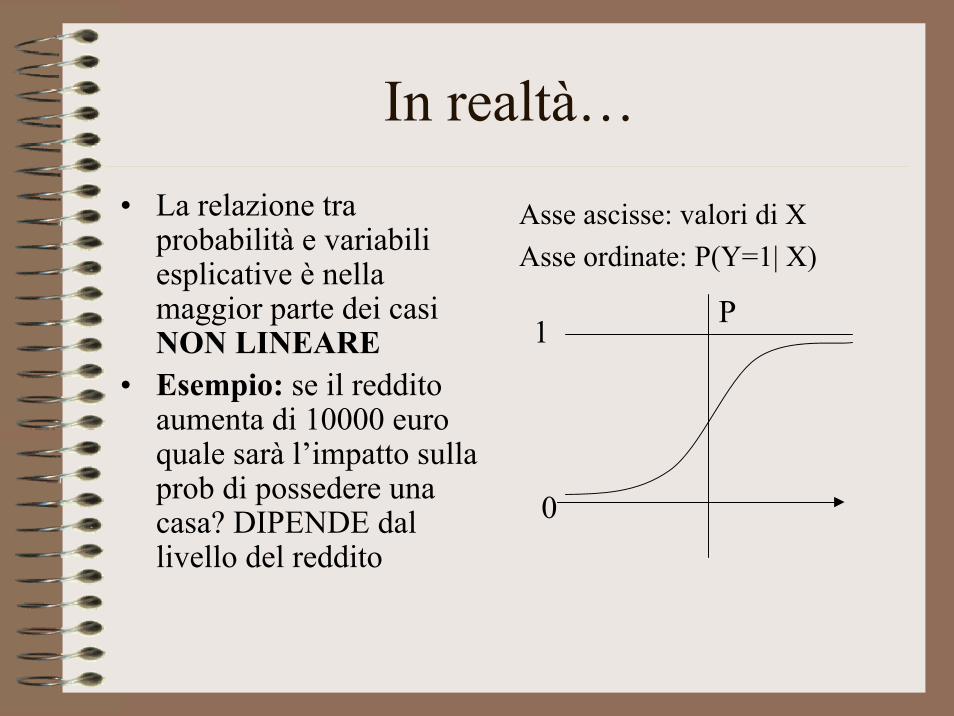
In realtà…• La relazione tra
probabilità e variabili esplicative è nella maggior parte dei casi NON LINEARE
• Esempio: se il reddito aumenta di 10000 euro quale sarà l’impatto sulla prob di possedere una casa? DIPENDE dal livello del reddito
Asse ascisse: valori di XAsse ordinate: P(Y=1| X)
0
1 P

Ricapitolando:
• abbiamo bisogno che la prob non ecceda i limiti di 0 e 1, e che
• la relazione tra probabilità e variabili esplicative sia non lineare.
A tal fine dobbiamo ricorrere a delle FUNZIONI DI DISTRIBUZIONE
CUMULATE. Le CDFs più usate sono quella LOGISTICA e quella NORMALE
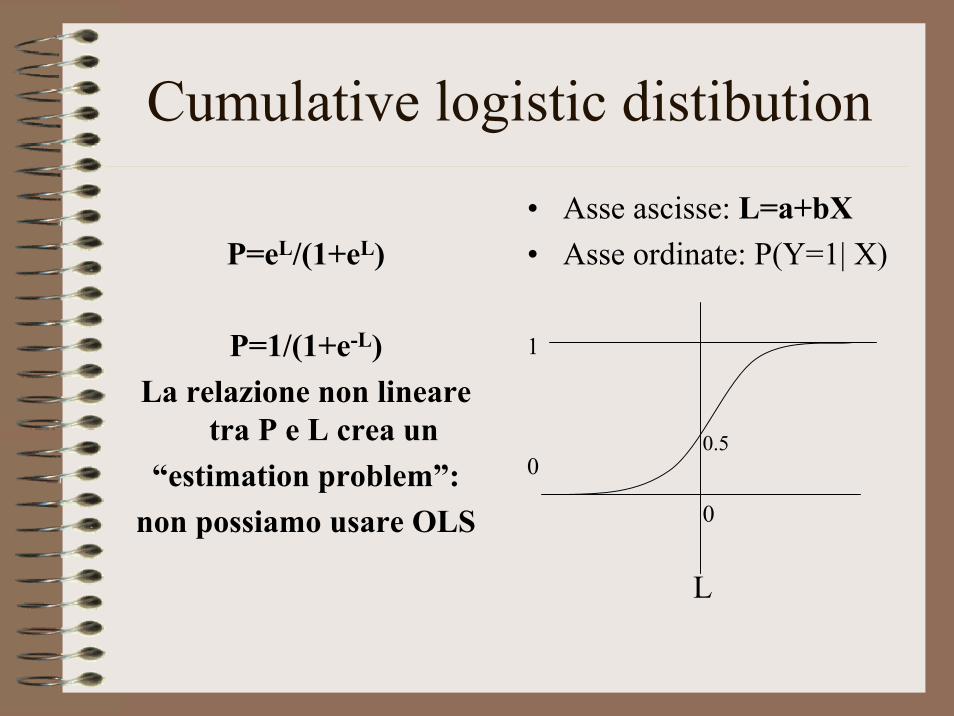
Cumulative logistic distibution
P=eL/(1+eL)
P=1/(1+e-L)La relazione non lineare
tra P e L crea un“estimation problem”:
non possiamo usare OLS
• Asse ascisse: L=a+bX• Asse ordinate: P(Y=1| X)
0
1
0
L
0.5

Soluzione: trasformiamo probabilità in logits
La cd “logit transformation” consta di due stadi:
1. Calcolare the odds ratio =P/(1-P)=(1+eL)/(1+e-L)= eL
1. Assumere il log dell’odds ratioln(P/1-P)=L

NON-Linear Probability Model
• Grazie a questa trasformazione possiamo esprimere una relazione lineare tra la nuova variabile dipendente (espressa in logits “L”) e la variabile esplicativa X:
L=ln(P/1-P)=a+bX• Tale relazione implica una relazione NON
lineare tra PROBABILITA’ ed X
P=ea+bX/(1+ea+bX)P=eL/(1+eL)

LOGIT: Regressione
L=a+bX+eIl coefficiente b rappresenta la variazione in E(L) al variare
di X (se X è una variabile continua b è la derivata di E(L) rispetto a X). Gli effetti di X su L sono LINEARI e ADDITIVI
L’interpretazione di b è la stessa che viene data in ogni retta di regressione, MA le unità in cui è misurata la variabile dipendente rendono l’interpretazione degli effetti di X meno intuitiva

Interesse
• Vogliamo conoscere gli effetti di X (reddito) sulla probabilità di possedere una casa (P)
• Per cui dobbiamo convertire l’effetto stimato di X su L (cioè b) (δL/ δX)
nell’effetto di X su P (δP/ δX)

Ricordiamo che
la relazione (NON lineare) tra PROBABILITA’ ed X
èP=ea+bX/(1+ea+bX)δP/ δX=b*P*(1-P)
NB. L’effetto di X su P non è costante: dipende dal livello di P (che a sua volta
dipende dal livello di X!)

Se …
P=0.5δP/ δX=b*P*(1-P)δP/ δX=b*0.25massimo effetto
Se P 1 o P 0l’effetto si riduce
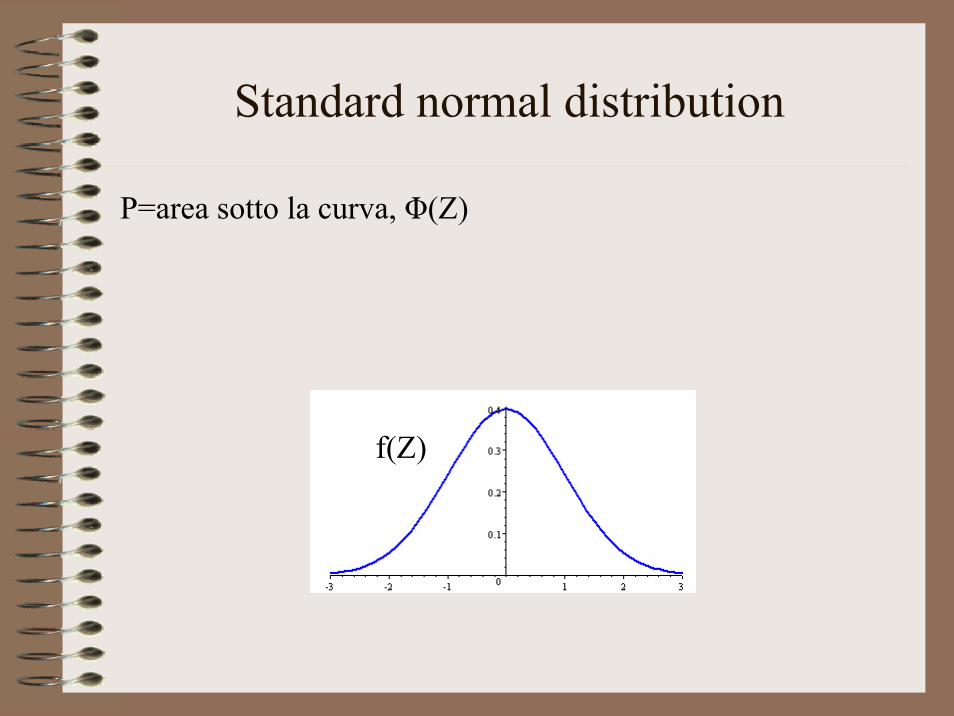
Standard normal distribution
P=area sotto la curva, Φ(Z)
f(Z)

Cumulative standard normaldistribution
• Asse ascisse: Z=a+bX• Asse ordinate: P(Y=1|
X)Usiamo la distribuzione cumulata per ottenere:
1. prob comprese tra 0 e 12. relazione non lineare
0
1
Z
P=Φ(Z)
Z=Φ-1(P)

Probit analysis
trasformiamo probabilità (limitate tra 0 e 1) in Z-scores (valori critici della distribuzione normale standardizzata), che variano tra –infinito e + infinito
Z-scores rappresentano la variabile dipendente nel modello Probit

Analogamente a quanto detto per la trasformazione LOGIT
• Grazie a questa trasformazione possiamo esprimere una relazione lineare tra la nuova variabile dipendente (espressa in Probits “Z”) e la variabile esplicativa X:
Z= Φ-1(P) =a+bX• Tale relazione implica una relazione
NON lineare tra PROBABILITA’ ed X

Effetto marginale di X su P
δP/ δX=b*Φ(Z)
NB. L’effetto di X su P non è costante: dipende dal livello di Z (che dipende da X, infatti
Z =a+bX )
Nota: Φ è la funzione di densità della normale standardizzata

TOBIT model
• La variabile dipendente:• è zero per una parte rilevante del
campione, • continua per valori >0• Esempi:• Spesa in alcolici• Ammontare preso a prestito

Tobit model
• Assumiamo che la decisione di acquistare dipenda da una variabile nascosta “underlyinglatent variable” (utilità)
(vedi Wooldridge “Introductoy Econometrics”)
• Y*=a+bX+u dove u|X ˜ N(0, σ2)• Y=max(0,Y*)
Ciò implica che Y=Y* quando Y*>=0

Interpretazione coefficienti
• b rappresenta l’effetto parziale di X su E(Y*|X), dove Y* è una variabile latente, che spesso non rappresenta il focusdell’analisi.
• Negli esempi di prima il focus è l’ammontare speso in alcolici, l’ammontare preso a prestito

Effetto marginale di X su Y
Due valori attesi sono di particolare interesse:• E(Y|Y>0,X)• E(Y|X)Due effetti parziali• δ E(Y|Y>0,X) / δX=b*[fattore che dipende da
X e da tutti i parametri del modello]• δ E(Y|X) / δX=b*[fattore che dipende da X e
da tutti i parametri del modello]

Metodo di stima: maximumlikelihood estimation
• Tale metodo restituisce le stime dei parametri che rendono massima la probabilità di osservare le realizzazioni della dummy così come si presentano nel nostro campione

La procedura
• Prima di tutto si esprime la probabilità delle realizzazioni osservate (si scrive la likelihoodfunction)
Ad esempio nel Logit: Π[ Piyi (1-Pi)1-yi ]
( prob. function for a sample of Bernoulli trials)
yi=valore osservato della dummy Y per il caso i,
• E poi si massimizza tale funzione rispetto ai parametri della regressione [nel logit ricorda che: P=ea+bX/(1+ea+bX)]


![LIMITED DEPENDENT VARIABLES - BASICminiahn/ecn726/cn_limited.pdf · 2006. 10. 27. · LIMITED DEPENDENT VARIABLES - BASIC [1] Binary choice models • Motivation: • Dependent variable](https://img.dokumen.tips/doc/110x75/60f7d4918b31c671c84c8122/limited-dependent-variables-miniahnecn726cnlimitedpdf-2006-10-27-limited.jpg)


























