Embed Size (px)
Citation preview

Lecture 8Chi-Square
STAT 3120Statistical Methods I

STAT3120 – Chi Square
Dependent Variable
Independent (predictor) Variable
Statistical Test
Comments
Quantitative Categorical T-TEST (one, two or paired sample)
Determines if categorical variable (factor) affects dependent variable; typically used for experimental or planned change studies
Quantitative Quantitative Correlation/Regression Analysis
Test establishes a regression model; used to explain, predict or control dependent variable
Categorical Categorical Chi-Square Tests if variables are statistically independent (i.e. are they related or not?)

STAT3120 – Chi Square
When presented with categorical data, one common method of analysis is the “Contingency Table” or “Cross Tab”. This is a great way to display frequencies -
For example, lets say that a firm has the following data:
120 male and 80 female employees
40 males and 10 females have been promoted

STAT3120 – Chi Square
Using this data, we could create the following 2x2 matrix:
Promoted Not Promoted
Total
Male 40 80 120
Female 10 70 80
Total 50 150 200

STAT3120 – Chi Square
Now, a few questions…
1)From the data, what is the probability of being promoted?2)Given that you are MALE, what is the probability of being promoted? 3)Given that you are promoted, what is the probability that you are MALE? 4)Given that you are FEMALE, what is the probability of being promoted? 5)Given that you are promoted, what is the probability that you are female?

STAT3120 – Chi Square
The answers to these questions help us start to understand if promotion status and gender are related.
Specifically, we could test this relationship using a Chi-Square. This is the test used to determine if two variables are related.
The relevant hypothesis statements for a Chi-Square test are:
H0: Variable 1 and Variable 2 are NOT RelatedHa: Variable 1 and Variable 2 ARE Related
Develop the appropriate hypothesis statements and testing matrix for the gender/promotion data.

STAT3120 – Chi Square
The Chi-Square Test uses the Χ2 test statistic, which has a distribution that is skewed to the right (it approaches normality as the number of obs increases). You can see an example of the distribution on pg 641.
The Χ2 test statistic calculation can be found on page 640.
The observed counts are provided in the dataset.The expected counts are the counts which would be expected if there was NO relationship between the two variables.

STAT3120 – Chi Square
Promoted Not Promoted
Total
Male 40 80 120
Female 10 70 80
Total 50 150 200
Going back to our example, the data provided is “observed”:
What would the matrix look like if there was no relationship between promotion status and gender? The resulting matrix would be “expected”…

STAT3120 – Chi Square
From the data, 25% of all employees were promoted. Therefore, if gender plays no role, then we should see 25% of the males promoted (75% not promoted) and 25% of the females promoted…
Promoted Not Promoted
Total
Male 120*.25 = 30 120*.75 = 90 120
Female 80*.25 = 20 80*.75 = 60 80
Total 50 150 200
Notice that the marginal values did not change…only the interior values changed.

STAT3120 – Chi Square
Now, calculate the X2 statistic using the observed and the expected matrices:
((40-30)2/30)+((80-90)2/90)+((10-20)2/20)+((70-60)2/60) =
3.33+1.11+5+1.67 = 11.11
This is conceptually equivalent to a t-statistic or a z-score.

To determine if this is in the rejection region, we must determine the df and then use the table on page 732.
Df = (r-1)*(c-1)…
In the current example, we have two rows and two columns. So the df = 1*1 = 1.
At alpha = .05 and 1df, the critical value is 3.84…our value of 11.11 is clearly in the reject region…so what does this mean?
STAT3120 – Chi Square

STAT3120 – Chi Square
From the book Outliers, Malcolm Glidewell makes the point that the month in which a boy is born will determine his probability of playing in the NHL.
The months of birth for players in the NHL are on the next page…
(data taken from http://sports.espn.go.com/espn/page2/story?page=merron/081208)

January 51 February 46
March 61 April 49 May 46 June 49 July 36
August 41 September 36
October 34 November 33 December 30
STAT3120 – Chi Square
Now, if there is NO relationship between birth month and playing hockey, what SHOULD the distribution of months look like?
Lets do this one in EXCEL…
Note that this is technically referred to as a “goodness of fit” test – where we are assessing if the actual distribution “fits” what would be expected.

STAT3120 – Chi Square
Practice Problems for Chi-Square:
15.5515.5615.5715.58
For all of these, identify the hypothesis statements, the testing matrix, and the decision.

Categorical Example
Using credit data.

Credit
• Sample Data Set– Purchase: $: 1=$250+, 0=<$250– Age: Customer Age– Gender: male,female– Income: Low, Medium, High

What do we have?
• Predictors• Gender
• Income
• Age
• Outcome• GT $250
• LT $250

Determine ‘Scale’
• Nominal variables: – Values with no logical ordering.
» Gender
• Ordinal variables:– Variables have values with a logical ordering.
» Income

Lets Examine!?
• Determine distribution of categorical values• Recognize possible associations among variables
• Association ?– Two variables when one level or value of the
other changes.– No changes? Distribution of the variable is the
same regardless of the level of the other variable

Determine Association• No Association?
– Statistic professor temperament changes with golf.
Great golf Bad Golf
Sunshine
Raining65% 35%
65% 35%

Watch Out!
• Association?– Statistic professor temperament changes with
golf. Great golf Bad Golf
Sunshine
Raining95% 5%
30% 70%
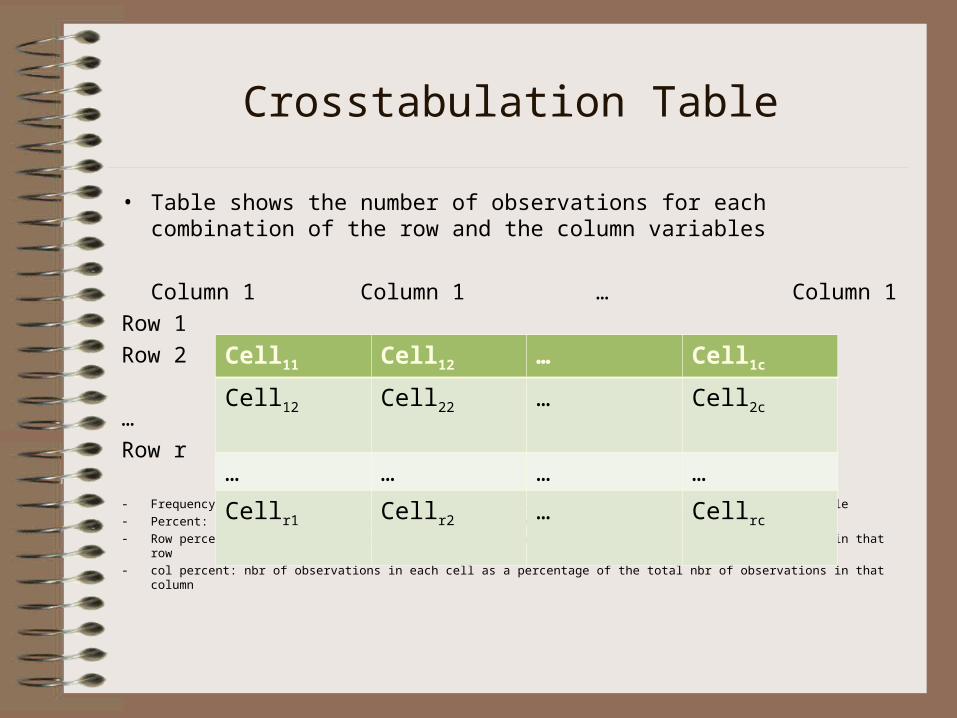
Crosstabulation Table
• Table shows the number of observations for each combination of the row and the column variables
Column 1 Column 1 … Column 1
Row 1
Row 2
…
Row r
- Frequency: nbr of observations falling into a category formed by row variable and column variable
- Percent: nbr of observations in each cell as a percentage of the total nbr of observations
- Row percent: nbr of observations in each cell as a percentage of the total nbr of observations in that row
- col percent: nbr of observations in each cell as a percentage of the total nbr of observations in that column
Cell11 Cell12 … Cell1c
Cell12 Cell22 … Cell2c
… … … …
Cellr1 Cellr2 … Cellrc

Distributions
• SAS Freq procedure– Examine distributions– Ordering values

SAS Proc Freq Distributions• libname JLLP 'E:\JenniferPriestly\Chi_Square';
• %let outpath=E:\JenniferPriestly\Chi_Square;
• %let libpath=E:\JenniferPriestly\Chi_Square;
• options nodate nonumber ls=95 ps=80;
• run;
• Proc format;
• value purfmt 1 = "$ 100 +"
• 0 = "< $100"
• ;
• Run;
• ods graphics on;
• ods listing close;
• ods Rtf path="&outpath"
• style=journal
• file='freq.rtf';
• proc freq data=JLLP.Online;
• tables purchase gender income
• gender*purchase income*purchase /
• plots(only)=(freqplot);
• format purchase purfmt.;
• run;
• ods select histogram probplot;
• proc univariate data=JLLP.Online;
• var age;
• histogram age / normal (mu=est sigma=est);
• probplot age / normal (mu=est sigma=est);
• run;
• ods rtf close;
• ods listing;

SAS Ordering Values
• Change Income• ods graphics on;
• ods listing;
• data JLLP.Online_inc;
• set JLLP.Online;
• if income='Low' then IncLevel=1;
• else if income='Medium' then IncLevel=2;
• else if income='High' then IncLevel=3;
• run;
• proc format;
• value incfmt 1='Low Income'
• 2='Medium Income'
• 3='High Income';
• run;
• ods graphics on;
• ods rtf path="&outpath"
• style=statistical
• file='freq2.rtf';
• proc freq data=JLLP.Online_inc;
• tables IncLevel*Purchase;
• format IncLevel incfmt. Purchase purfmt.;
• title1 'Change Variable IncLevel to Correct Income';
• run;
• ods rtf close;

Tests for Association
• Determine– Chi-square test for association– Examine strength of the association– Calculate exact p-value– Cramer’s V

Chi-Square Test
• ods graphics on;
• ods rtf path="&outpath"
• style=statistical
• file='freq3.rtf';
• proc freq data=JLLP.Online_inc;
• tables Gender*purchase
• / chisq expected cellchi2 nocol nopercent
• relrisk;
• format purchase purfmt.;
• Title1 'Association Between Gender and Purchase';
• run;
• ods rtf close;

Gender by Purchase
Table of Gender by PurchaseGender Purchase
FrequencyPercentRow PctCol Pct < $100
$ 100 + Total
Female 13932.2557.9251.67
10123.4342.0862.35
24055.68
Male 13030.1668.0648.33
6114.1531.9437.65
19144.32
Total 26962.41
16237.59
431100.00
Table of Gender by PurchaseGender Purchase
FrequencyPercentRow PctCol Pct < $100
$ 100 + Total
Female 13932.2557.9251.67
10123.4342.0862.35
24055.68
Male 13030.1668.0648.33
6114.1531.9437.65
19144.32
Total 26962.41
16237.59
431100.00

Chi-Square Test
• No association• Observed frequencies=expected frequencies
– Null Hypothesis:• No association between Gender and Purchase
• Probability of purchasing items more than $100 is the same for both sexes.
• Association• Observed frequencies≠expected frequencies
– Alternative Hypothesis:• There is an association between Gender and Purchase
• Probability of purchasing items more than $100 is the same for both sexes.

Pearson Chi-square Test
• Commonly used test to determine whether there is association between 2 categorical values
• Test measure the difference between the observed cell frequencies and the cell frequencies that are expected if there is no association between the variables
• Significant test statistic, strong evidence an association exists

Frequencies Calculation
• Expected frequencies are calculated by:» (row total * column total) / sample size
No association between Row and Column variable the expected percentage in any R*C will be equal to the percentage in that cell rows (R/T) times the percentage in the cell column (C/T). The expected percentage times the total sample size.
Expected count=(R/T)*(C/T)*T=(R*C)/T

Chi-square tests
• Measures of association
– P-value tests only indicates how confident you can be that the null hypothesis if no association exists.
– Cramer’s V statistics: measures association between two nominal variables. Range from -1 to 1 for a 2-by-2 table. 0 to 1 for larger tables. Values further from 0 indicate the presence of a relativity strong association.
– Odds Ratios indicates how much more likely, with the respect to odds a certain event occurs in one group relative to its occurrence in another group.

Odds Ratio

Probability of odds of an outcome
No Yes Total
Group A 20 60 80
Group B 10 90 100
Total 30 150 180
Prob of Yes outcome in Group B = 90/100 (.90)
Prob of a No Outcome in Group B = 10/100 (.10)

Odds Ratio
• Odds of outcome in Group B» .90 / .10 = 9
• Odds of outcome in Group A» .75 / .25 = 3
• Odds Ratio of Group B to Group A» 9 / 3 = 3
Odds ratio of Group B to Group A is 3 times .

Properties of the Odds Ratio, B to A
• Odds ratio shows strength of association.– If odds ration is 1 then there is no association– If odds ratio is greater than 1then Grp B is
more likely to have the outcome.– If odds ratio is less than 1 then Grp A is more
likely to have the outcome

Example
• Determine association between Gender and purchase.
• Generate expected cell frequencies and the cell’s contribution to the total chi-square statistic

Results
Table of Gender by Purchase
Gender PurchaseFrequencyExpectedCell Chi-SquareRow Pct < $100 $ 100 + TotalFemale 139
149.790.777457.92
10190.2091.290942.08
240
Male 130119.210.976968.06
6171.7911.622131.94
191
Total 269 162 431
Calculate cell Chi-square

Results
Statistic DF Value ProbChi-Square 1 4.6672 0.0307
Likelihood Ratio Chi-Square 1 4.6978 0.0302
Continuity Adj. Chi-Square 1 4.2447 0.0394
Mantel-Haenszel Chi-Square 1 4.6564 0.0309
Phi Coefficient -0.1041
Contingency Coefficient 0.1035
Cramer's V -0.1041
Fisher's Exact TestCell (1,1) Frequency (F) 139
Left-sided Pr <= F 0.0195
Right-sided Pr >= F 0.9883
Table Probability (P) 0.0078
Two-sided Pr <= P 0.0355
Estimates of the Relative Risk (Row1/Row2)
Type of Study Value 95% Confidence LimitsCase-Control (Odds Ratio) 0.6458 0.4339 0.9612
Cohort (Col1 Risk) 0.8509 0.7360 0.9839
Cohort (Col2 Risk) 1.3177 1.0214 1.7000
P-value is 0.0307<.05 , reject the Null hypothesisAppendix A.5: .05<p-value<.025
Cramer’s V indicates association is relatively weak. Relative Risk at 95% CI that Males in the right column (+100) compared to Females has value of .6458. Males has a 65% odds of purchasing more then $100Odds ratio (OR-1)*100, (0.6458-1)*100=-35.42%, males have a 35.42% lower odds than females.

Gender by Purchase





























