Embed Size (px)
Citation preview

Lecture 14: Population Assignment and Individual Identity
October 8, 2015

Last Time
Sample calculation of FST
Defining populations on genetic criteria: introduction to Structure

Structure Program
One of the most widely-used programs in population genetics (original paper cited >15,000 times since 2000)
Very flexible model can determine:
The most likely number of uniform groups (populations, K)
The genomic composition of each individual (admixture coefficients)
Possible population of origin

Structure is Hierarchical: Groups reveal more substructure when examined separately
Rosenberg et al. 2002 Science 298: 2381-2385

Today
Principal Components Analysis
Genotype likelihoods
Population assignment
Forensic identification

Alternative clustering method: Principal Components Analysis Structure is very computationally intensive
Often no clear best-supported K-value
Alternative is to use traditional multivariate statistics to find uniform groups
Principal Components Analysis is most commonly used algorithm
EIGENSOFT (PCA, Patterson et al., 2006; PloS Genetics 2:e190).
Eckert, Population Structure, 5-Aug-2008 49
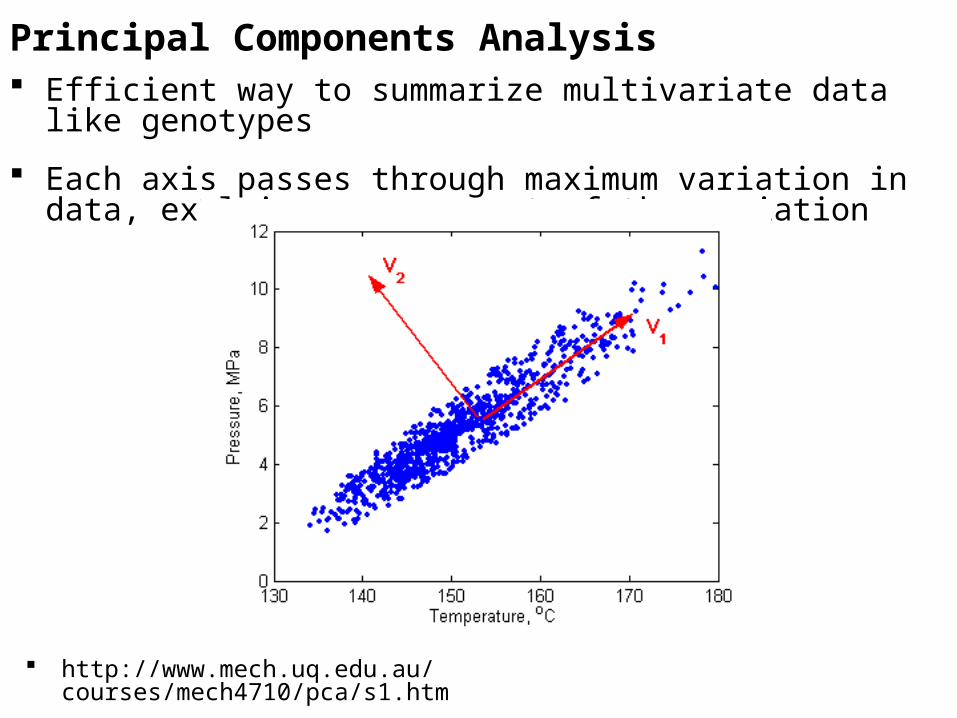
Principal Components Analysis Efficient way to summarize multivariate data like genotypes
Each axis passes through maximum variation in data, explains a component of the variation
http://www.mech.uq.edu.au/courses/mech4710/pca/s1.htm

Once you have populations defined, can you assign a migrant individual to their population of origin?

Human Population Assignment with SNP Assayed 500,000 SNP genotypes for 3,192 Europeans
Used Principal Components Analysis to ordinate samples in space
High correspondence betweeen sample ordination and geographic origin of samples
Individuals assigned to populations of origin with high accuracy
Novembre et al. 2008 Nature 456:98

Population Assignment: Likelihood Assume you find skin cells and blood under fingernails of
a murder victim
Victim had major debts with the Sicilian mafia as well as the Chinese mafia
Can population assignment help to focus investigation?
,)|(
)|()|,(
2
121 HGP
HGPLRGHHL
What is H1 and what is H2?

Population Assignment: Likelihood "Assignment Tests" based on allele
frequencies in source populations and genetic composition of individuals
Likelihood-Based Approaches
Calculate likelihood that individual genotype originated in particular population
Assume Hardy-Weinberg and linkage equilibria
Genotype frequencies corrected for presence of sampled individual
Usually reported as log10 likelihood for origin in given population relative to other population
Implemented in ‘GENECLASS’ program (http://www.montpellier.inra.fr/URLB/geneclass/geneclass.html)
for m loci
m
kkPP
1
2lilk pP
for homozygote AiAi in population l at locus k
ljlilk ppP 2for heterozygote AiAj in population l at locus k

Power of Population Assignment using Likelihood
Assignment success depends on: Number of markers used Polymorphism of markers Number of possible source populations Differentiation of populations Accuracy of allele frequency estimations
Rules of Thumb (Cornuet et al. 1999) for 100% assignment success, for 10 reference populations need: 30 to 50 reference individuals per population 10 microsatellite loci HE > 0.6 FST > 0.1

Population Assignment Example: A Fish Story
Fishing competition on Lake Saimaa in Southeast Finland
Contestant allegedly caught a 5.5 kg salmon, much larger than usual for the lake
Compared fish from the lake to fish from local markets (originating from Norway and Baltic sea)
7 microsatellites
Based on likelihood analysis, fish was purchased rather than caught in lake
Lake Saimaa Market
--log10 of likelihood that the observed genotype could occur in Lake Saimaa

Genetic Typing in Forensics Highly polymorphic loci provide unique ‘fingerprint’ for
each individual
Tie suspects to blood stains, semen, skin cells, hair
Revolutionized criminal justice in last 20 years
Also used in disasters and forensic anthropology
Principles of population genetics must be applied in calculating and interpreting probability of identity

Markers in Genetic Typing Standard set of 13 core loci for
forensics: CODIS (Combined DNA Index System)
Sets of highly polymorphic microsatellites (also called VNTR (Variable Number of Tandem Repeats), STR (Short Tandem Repeat) or SSR (Simple Sequence Repeat))
Most are amplified in a single multiplex reaction and analyzed in a single capillary
Very high “exclusion power” (ability to differentiate individuals)
http://www.cstl.nist.gov/div831/strbase//mlt_abiid.htm

Individual Identity: Likelihood Assume you find skin cells and blood under fingernails of
a murder victim
A hitman for the Sicilian mafia is seen exiting the apartment
You gather DNA evidence from the skin cells and from the suspect
They have identical genotypes
What is the likelihood that the evidence came from the suspect?
,)|(
)|()|,(
2
121 HGP
HGPLRGHHL
What is H1 and what is H2?

Match Probability
Probability of observing a genotype at locus k by chance in population is a function of allele frequencies:
for m loci
m
kkPP
1
2ik pP
Homozygote
jik ppP 2Heterozygote
Assumes unlinked (independent loci) and Hardy-Weinberg equilibrium

Probability of Identity
Probability 2 randomly selected individuals have same profile at locus k:
i ji
jii
ikID pppP 24 )2(
Homozygotes Heterozygotes
for m loci
m
kkIDPP
1
Exclusion Probability (E): E=1-P

Which allele frequency to use? Human populations show
some level of substructuring
FST generally < 0.03
Challenge is to choose proper ethnic group and account for gene flow from other groups
http://books.nap.edu/openbook/0309053951/gifmid/95.gif
Illinois Caucasian
Georgia Caucasian
U.S. Black

Substructure in human populations
GST is quite high among the 5 major groups of human populations for CODIS microsatellites
Relatively low within groups, but not 0!

NRC (1996) recommendations
Use population that provides highest probability of observing the genotype (unless other information is known)
Correct homozygous genotypes for substructure within selected population (e.g., Native Americans, hispanics, African Americans, caucasians, Asian Americans)
No correction for heterozygotes
jiSTiii ppFpppP 2])1([' 2
Homozygotes Heterozygotes
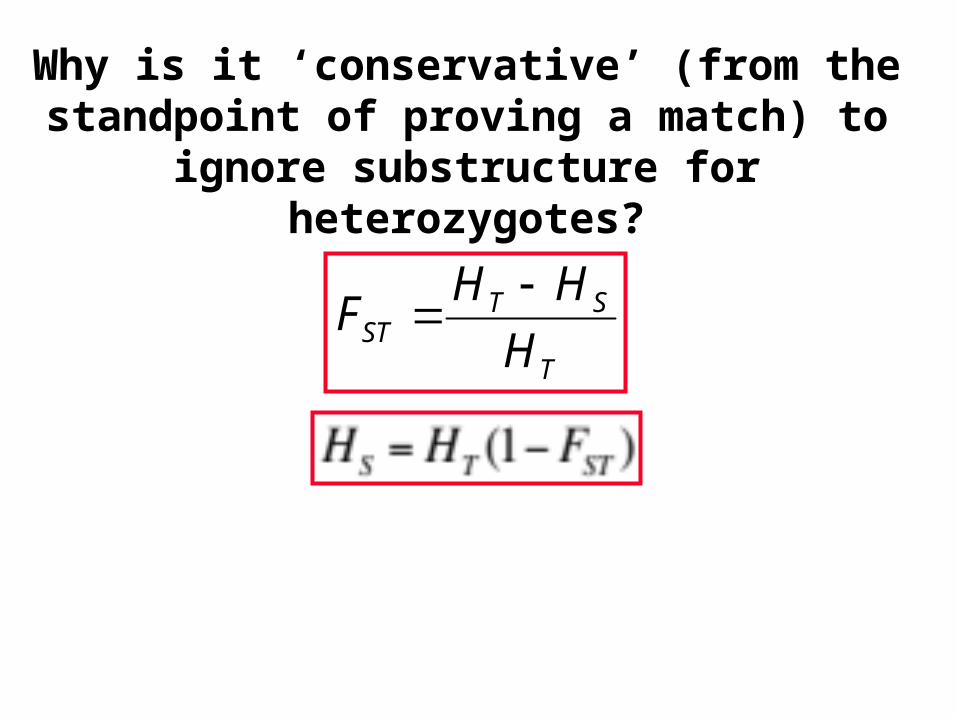
Why is it ‘conservative’ (from the standpoint of proving a match) to ignore substructure for
heterozygotes?
T
STST H
HHF

What if the slimy mob defense attorney argues that the most likely perpetrator is the mob hitman’s brother, who has conveniently “disappeared”?
Does the general match probability apply to near relatives?

Probability of identity for full sibs
Heterozygotes
)21(4
1 2iiksibhoID ppP
2 alleles IBD1 allele IBD
0 alleles IBD
)21(4
1jijiksibheID ppppP
General Probability of Identity for Full Sibs:
Homozygotes 2 alleles IBD
0 alleles IBD
i iii
iiksibID pppP
2
224
2
11
4
1

Probability of identity for full sibs
i iii
iiksibID pppP
2
224
2
11
4
1
For a locus with 5 alleles, each at a frequency of 0.2:PID = 0.072PIDsib = 0.368
i ji
jii
ikID pppP 24 )2(
Probability of identity unrelated individuals

What is minimum probability of identity for full sibs?
i iii
iiksibID pppP
2
224
2
11
4
1

Example: World Trade Center Victims Match victims using
DNA collected from toothbrushes, hair brushes, or relatives
Exact matches not guaranteed
Why not?
Use likelihood to match samples to victims





























