Embed Size (px)
Citation preview

Large Scale Machine Large Scale Machine Translation ArchitecturesTranslation ArchitecturesQin Gao

OutlineOutlineTypical Problems in Machine TranslationProgram Model for Machine Translation
MapReduceRequired System Component
Supporting softwareDistributed streaming data storage systemDistributed structured data storage system
Integrating – How to make a full-distributed system
23/4/20 2Qin Gao, LTI, CMU

Why large scale MTWhy large scale MT
We need more data..
But…
23/4/20 3Qin Gao, LTI, CMU

Some representative MT Some representative MT problemsproblemsCounting events in corpora
◦ Ngram countSorting
◦ Phrase table extractionPreprocessing Data
◦Parsing, tokenizing, etcIterative optimization
◦ GIZA++ (All EM algorithms)
23/4/20 4Qin Gao, LTI, CMU

Characteristics of different Characteristics of different taskstasksCounting events in corpora
◦Extract knowledge from dataSorting
◦Process data, knowledge is inside dataPreprocessing Data
◦Process data, require external knowledgeIterative optimization
◦For each iteration, process data using existing knowledge and update knowledge
23/4/20 5Qin Gao, LTI, CMU

Components required for Components required for large scale MTlarge scale MT
23/4/20 6Qin Gao, LTI, CMU

Components required for Components required for large scale MTlarge scale MT
23/4/20 7Qin Gao, LTI, CMU
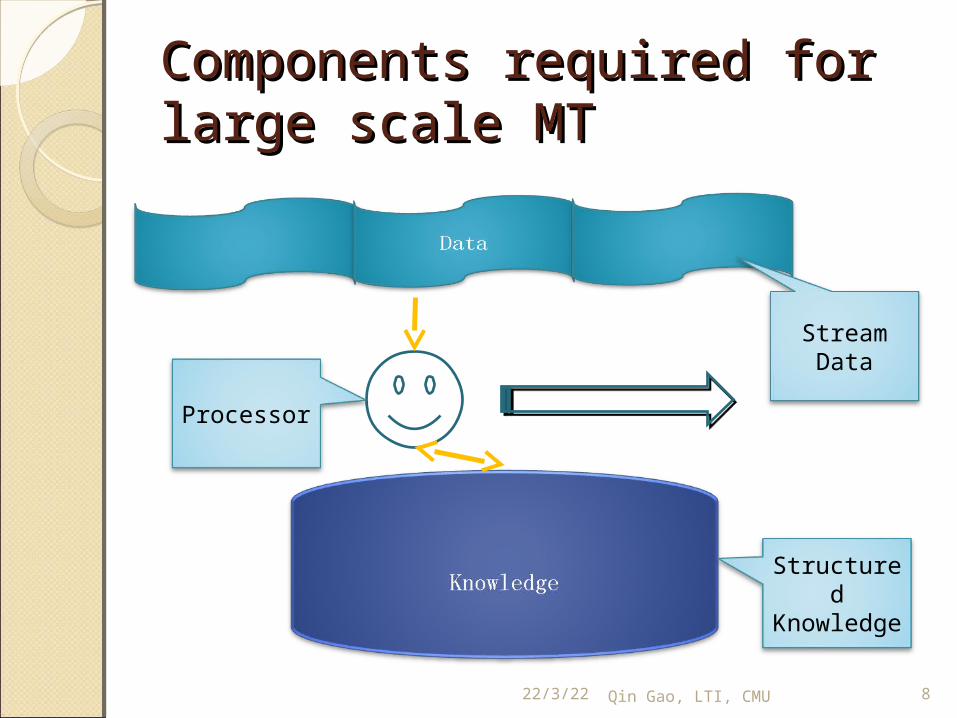
Components required for Components required for large scale MTlarge scale MT
Stream Data
Structured Knowledg
e
Processor
23/4/20 8Qin Gao, LTI, CMU

Problem for each Problem for each componentcomponentStream data:
◦As the amount of data grows, even a complete navigation is impossible.
Processor:◦Single processor’s computation power
is not enoughKnowledge:
◦The size of the table is too large to fit into memory
◦Cache-based/distributed knowledge base suffers from low speed
23/4/20 9Qin Gao, LTI, CMU

Make it simple: What is the Make it simple: What is the underlying problem?underlying problem?We have a huge cake and we want
to cut them into pieces and eat.
Different cases:◦We just need to eat
the cake.◦We also want to
count how many peanuts inside the cake
◦(Sometimes)We have only one folk!
23/4/20 10Qin Gao, LTI, CMU
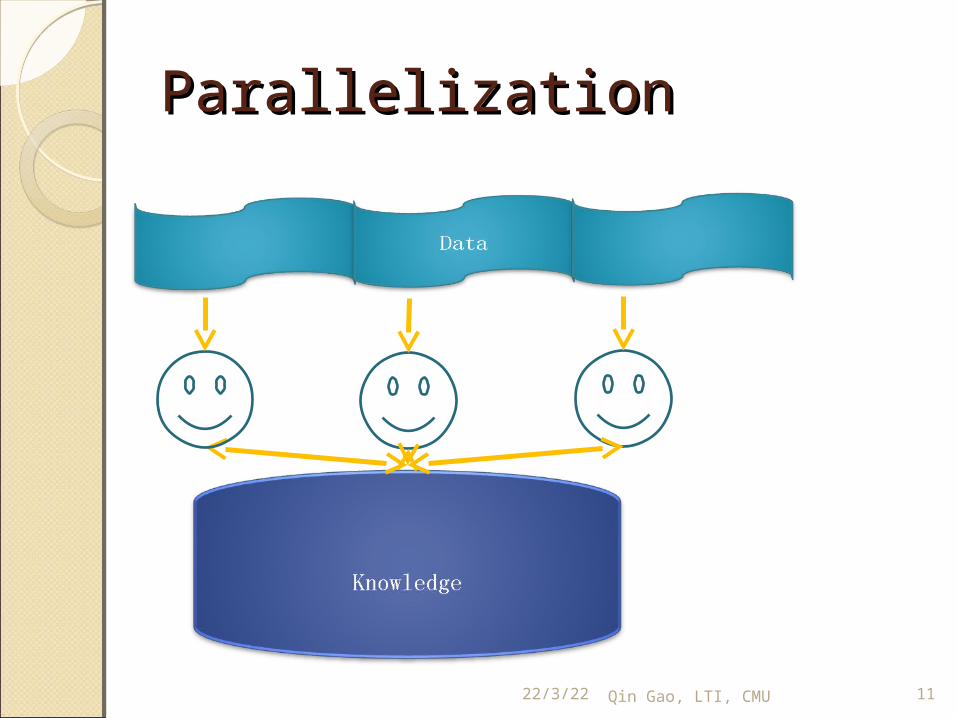
ParallelizationParallelization
23/4/20 11Qin Gao, LTI, CMU

SolutionsSolutionsLarge-scale distributed processing
◦ MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean, Sanjay Ghemawat, Communications of the ACM, vol. 51, no. 1 (2008), pp. 107-113.
Handling huge streaming data◦ The Google File System, Sanjay Ghemawat, Howard Gobioff, Shun-
Tak Leung, Proceedings of the 19th ACM Symposium on Operating Systems Principles, 2003, pp. 20-43.
Handling structured data◦ Large Language Models in Machine Translation, Thorsten Brants,
Ashok C. Popat, Peng Xu, Franz J. Och, Jeffrey Dean, Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), pp. 858-867.
◦ Bigtable: A Distributed Storage System for Structured Data, Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber, 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2006, pp. 205-218.
23/4/20 12Qin Gao, LTI, CMU

MapReduceMapReduceMapReduce can refer to
◦A programming model that deal with massive, unordered, streaming data processing tasks(MUD)
◦A set of supporting software environment implemented by Google Inc
Alternative implementation:◦Hadoop by Apache fundation
23/4/20 13Qin Gao, LTI, CMU

MapReduce programming MapReduce programming modelmodelAbstracts the computation into
two functions:◦MAP◦Reduce
User is responsible for the implementation of the Map and Reduce functions, and supporting software take care of executing them
23/4/20 14Qin Gao, LTI, CMU

Representation of dataRepresentation of dataThe streaming data is abstracted
as a sequence of key/value pairsExample:
◦(sentence_id : sentence_content)
23/4/20 15Qin Gao, LTI, CMU

MapMap function functionThe Map function takes an input
key/value pair, and output a set of intermediate key/value pairs
Key1 : Value1
Key2 : Value2
Map()
Key1 : Value1
Key2 : Value2
Key3 : Value3
……..
Map()
Key1 : Value2
Key2 : Value1
Key3 : Value3
……..
23/4/20 16Qin Gao, LTI, CMU

ReduceReduce function functionReduce function accepts one
intermediate key and a set of intermediate values, and produce the result
Key1 : Value1
Key1 : Value2
Key1 : Value3
……..Key2 : Value1
Key2 : Value2
Key2 : Value3
……..
Reduce()
Reduce()
Result
Result
23/4/20 17Qin Gao, LTI, CMU
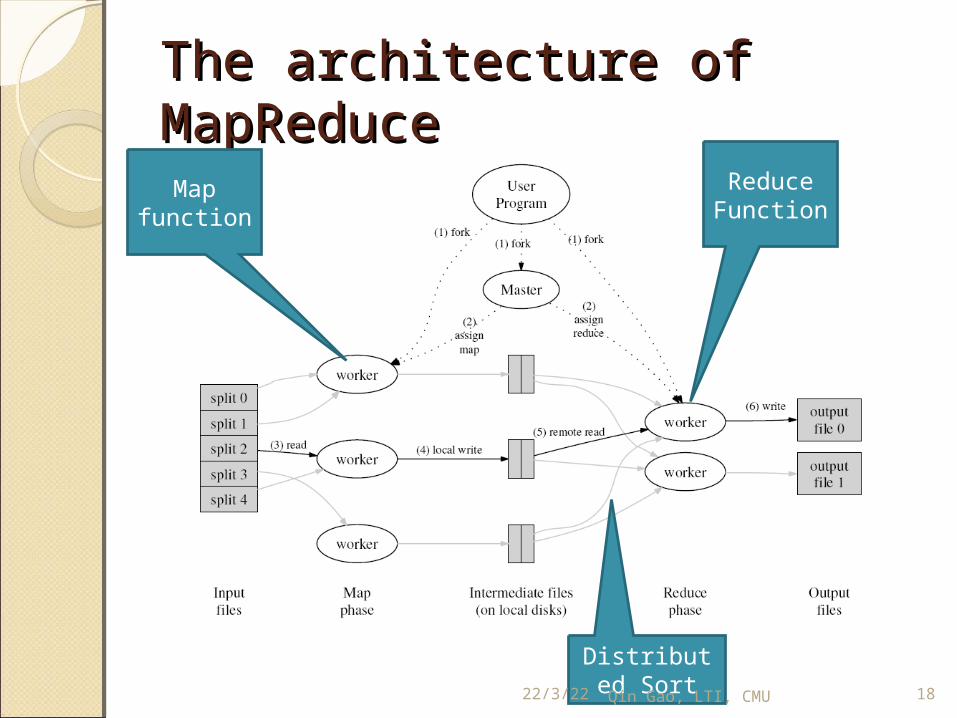
The architecture of The architecture of MapReduceMapReduceMap
function
Reduce Function
Distributed Sort23/4/20 18Qin Gao, LTI, CMU

Benefit of MapReduceBenefit of MapReduceAutomatic splitting dataFault toleranceHigh-throughput computing, uses
the nodes efficientlyMost important: Simplicity, just
need to convert your algorithm to the MapReduce model.
23/4/20 19Qin Gao, LTI, CMU

Requirement for expressing Requirement for expressing algorithm in MapReducealgorithm in MapReduceProcess Unordered data
◦The data must be unordered, which means no matter in what order the data is processed, the result should be the same
Produce Independent intermediate key◦Reduce function can not see the
value of other keys
23/4/20 20Qin Gao, LTI, CMU

ExampleExampleDistributed Word Count (1)
◦ Input key : word◦ Input value : 1◦ Intermediate key : constant◦ Intermediate value: 1◦ Reduce() : Count all intermediate values
Distributed Word Count (2)◦ Input key : Document/Sentence ID◦ Input value : Document/Sentence content◦ Intermediate key : constant◦ Intermediate value: number of words in the
document/sentence◦ Reduce() : Count all intermediate values
23/4/20 21Qin Gao, LTI, CMU

Example 2Example 2Distributed unigram count
◦ Input key : Document/Sentence ID◦ Input value : Document/Sentence content◦ Intermediate key : Word◦ Intermediate value: Number of the word
in the document/sentence◦ Reduce() : Count all intermediate values
23/4/20 22Qin Gao, LTI, CMU

Example 3Example 3Distributed Sort
◦Input key : Entry key◦Input value : Entry content◦Intermediate key : Entry key
(modification may be needed for ascend/descend order)
◦Intermediate value: Entry content◦Reduce() : All the entry content
Making use of built-in sorting functionality
23/4/20 23Qin Gao, LTI, CMU

Supporting MapReduce: Supporting MapReduce: Distributed StorageDistributed StorageReminder what we are dealing with in
MapReduce:◦ Massive, unordered, streaming data
Motivation: ◦ We need to store large amount of data◦ Make use of storage in all the nodes◦ Automatic replication
Fault tolerant Avoid hot spots client can read from many
servers
Google FS and Hadoop FS (HDFS)
23/4/20 24Qin Gao, LTI, CMU

Design principle of Google FSDesign principle of Google FS
Optimizing for special workload:◦Large streaming reads, small random
reads◦Large streaming writes, rare modification
Support concurrent appending ◦It actually assumes data are unordered
High sustained bandwidth is more important than low latency, fast response time is not important
Fault tolerant
23/4/20 25Qin Gao, LTI, CMU

Google FS Architecture Google FS Architecture Optimize for large streaming
reading and large, concurrent writing
Small random reading/writing is also supported, but not optimized
Allow appending to existing filesFile are spitted into chunks and
stored in several chunk serversA master is responsible for storage
and query of chunk information23/4/20 26Qin Gao, LTI, CMU

Google FS architectureGoogle FS architecture
23/4/20 27Qin Gao, LTI, CMU

ReplicationReplicationWhen a chunk is frequently or
“simultaneously” read from a client, the client may fail
A fault in one client may cause the file not usable
Solution: store the chunks in multiple machines.
The number of replica of each chunk : replication factor
23/4/20 28Qin Gao, LTI, CMU

HDFSHDFSHDFS shares similar design
principle of Google FSWrite-once-read-many : Can only
write file once, even appending is now allowed
“Moving computation is cheaper than moving data”
23/4/20 29Qin Gao, LTI, CMU

Are we done?Are we done?
NO… Problems about the existing architecture
23/4/20 30Qin Gao, LTI, CMU

We are good at dealing with We are good at dealing with data data What about knowledge? I.E.
structured data?What if the size of the knowledge
is HUGE?
23/4/20 31Qin Gao, LTI, CMU
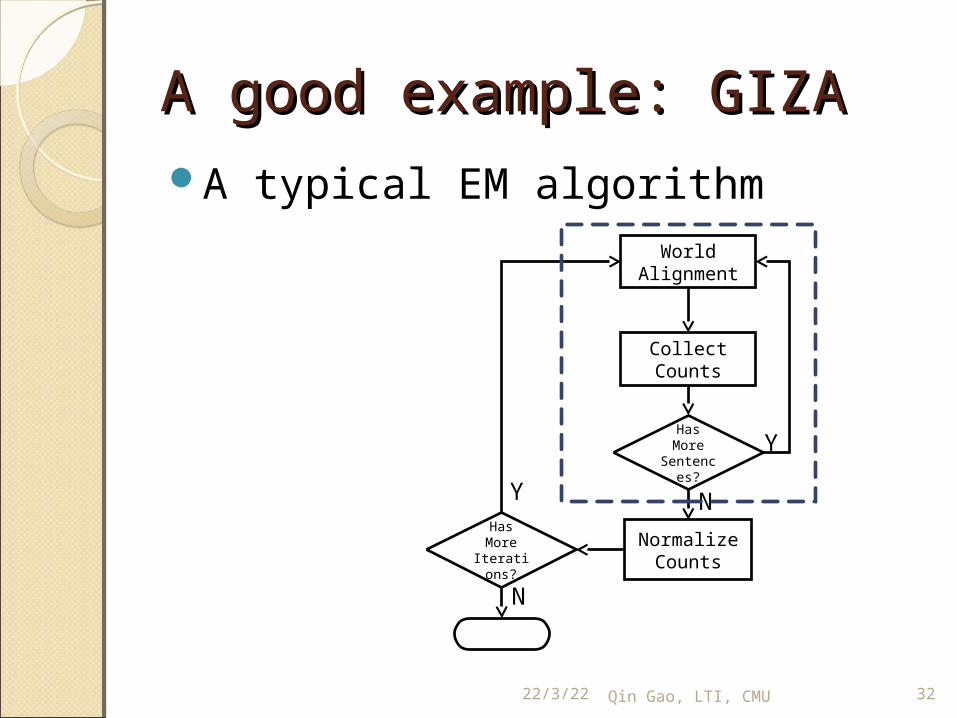
A good example: GIZAA good example: GIZAA typical EM algorithm
WorldAlignment
Collect Counts
Has More
Sentences?
Y
NormalizeCounts
NHas More
Iterations?
Y
N
23/4/20 32Qin Gao, LTI, CMU
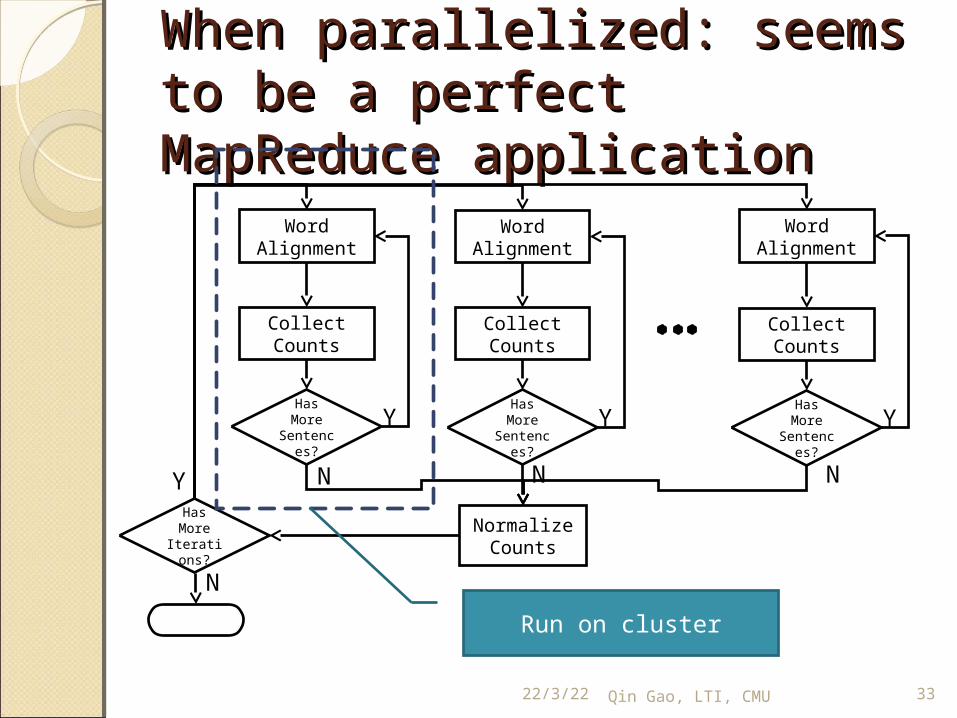
When parallelized: seems to When parallelized: seems to be a perfect MapReduce be a perfect MapReduce applicationapplication
Word Alignment
Collect Counts
Has More
Sentences?
Y
NormalizeCounts
NHas More
Iterations?
Y
N
WordAlignment
Collect Counts
Has More
Sentences?
Y
Word Alignment
Collect Counts
Has More
Sentences?
Y
N N
Run on cluster
23/4/20 33Qin Gao, LTI, CMU
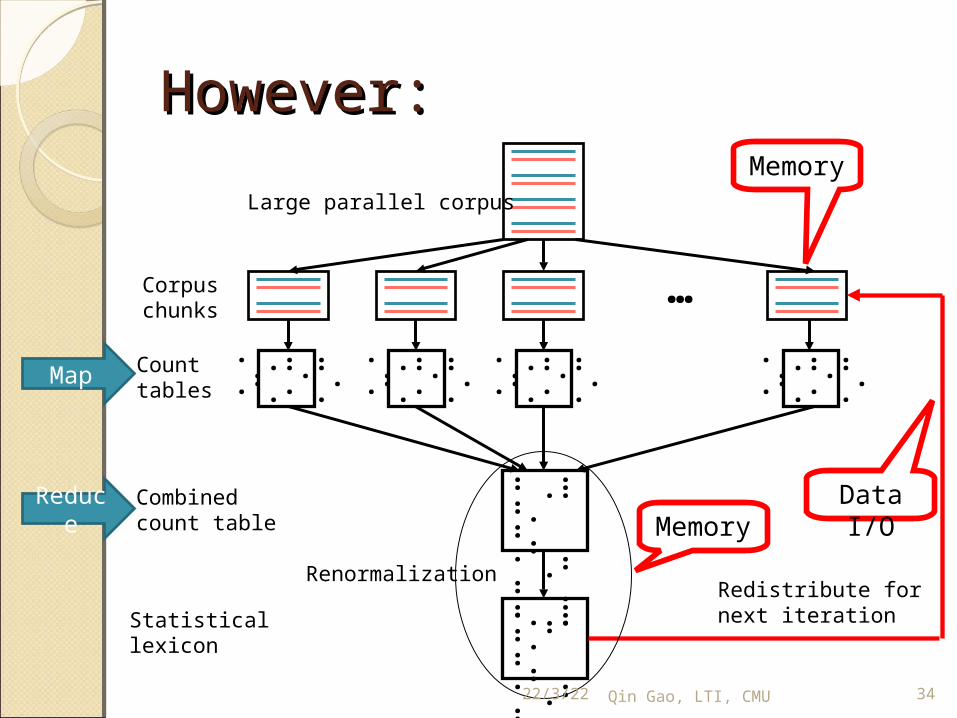
However:However:
…
. . . .. . . . . .. . . .
. . . .. . . . . .. . . .
. . . .. . . . . .. . . .
. . . .. . . . . .. . . .
. . . . .. . . . . . . .. . . . . . . . . . .
. . . . .. . . . . . . .. . . . . . . . . . .
Large parallel corpus
Corpuschunks
Counttables
Combinedcount table
Statisticallexicon
RenormalizationRedistribute fornext iteration
MemoryData I/O
Map
Reduce
Memory
23/4/20 34Qin Gao, LTI, CMU

Huge tablesHuge tablesLexicon probability table: T-TableUp to 3G in early stagesAs the number of workers
increases, they all need to load this 3G file!
And all the nodes need to have 3G+ memory – we need a cluster of super computers?
23/4/20 35Qin Gao, LTI, CMU

Another example, Another example, decodingdecodingConsider language models, what
can we do if the language model grows to several TBs
We need storage/query mechanism for large, structured data
Consideration:◦Distributed storage◦Fast access: network has high latency
23/4/20 36Qin Gao, LTI, CMU

Google Language ModelGoogle Language ModelStorage:
◦Central storage or distributed storageHow to deal with latency?
◦Modify the decoder, collect a number of queries and send them in one time.
It is a specific application, we still need something more general.
23/4/20 37Qin Gao, LTI, CMU

Again, made in Google:Again, made in Google:BigtableBigtableIt is the specially optimized for
structured dataServing many applications nowIt is not a complete databaseDefinition:
◦A Bigtable is a sparse, distributed, persistent, multi-dimensional, sorted map
23/4/20 38Qin Gao, LTI, CMU

Data model in BigtableData model in BigtableFour dimension table:
◦Row◦Column family◦Column◦Timestamp
Row
Column family Column
Timestamp 23/4/20 39Qin Gao, LTI, CMU

Distributed storage unit : Distributed storage unit : TabletTabletA tablet consists a range of rowsTablets can be stored in different
nodes, and served by different servers
Concurrent reading multiple rows can be fast
23/4/20 40Qin Gao, LTI, CMU

Random access unit : Random access unit : Column familyColumn familyEach tablet is a string-to-string
map(Though not mentioned, the API
shows that: ) In the level of column family, the index is loaded into memory so fast random access is possible
Column family should be fixed
23/4/20 41Qin Gao, LTI, CMU

Tables inside table: Column Tables inside table: Column and Timestampand TimestampColumn can be any arbitrary
string valueTimestamp is an integerValue is byte arrayActually it is a table of tables
23/4/20 42Qin Gao, LTI, CMU

PerformancePerformanceNumber of 1000-byte values read/write per
second.
What is shocking: ◦ Effective IO for random read (from GFS) is
more than 100 MB/second◦ Effective IO for random read from memory is
more than 3 GB/second
23/4/20 43Qin Gao, LTI, CMU

An example : Phrase TableAn example : Phrase TableRow: First bigram/trigram of the
source phraseColumn Family: Length of source
phrase or some hashed number of remaining part of source phrase
Column: Remaining part of the source phrase
Value: All the phrase pairs of the source phrase
23/4/20 44Qin Gao, LTI, CMU

BenefitBenefitDifferent source phrase comes
from different serversThe load is balanced and the
reading can be concurrent and much faster.
Filtering the phrase table before decoding becomes much more efficient.
23/4/20 45Qin Gao, LTI, CMU

Another Example: GIZA++Another Example: GIZA++Lexicon table:
◦Row: Source word id◦Column Family: nothing◦Column: Target word id◦Value: The probability value
With a simple local cache, the table loading can be extremely efficient comparing to current implemenetation
23/4/20 46Qin Gao, LTI, CMU

ConclusionConclusionStrangely, the talk is all about
how Google does itA useful framework for
distributed MT systems require three components:◦MapReduce software◦Distributed streaming data storage
system◦Distributed structured data storage
system23/4/20 47Qin Gao, LTI, CMU

Open Source AlternativesOpen Source AlternativesMapReduce Library HadoopGoogleFS Hadoop FS (HDFS)BigTable HyperTable
23/4/20 48Qin Gao, LTI, CMU

THANK YOU!THANK YOU!
23/4/20 49Qin Gao, LTI, CMU





























