Embed Size (px)
Citation preview

Patrick Valduriez, Esther Pacitti, Cédric CoulonAtlas group, INRIA and LINA,
University of Nantes
ACI MDP2P 2003-2006http://www.sciences.univ-nantes.fr/lina/ATLAS/MDP2P/
Large-scale Experimentation with Preventive Replication in a
Database Cluster

2
Outline
Context and architecturePreventive Replication Replication Manager ArchitectureOptimizationsRepDB* PrototypeExperimentsConclusion

3
Related workEager replication in DB clusters
Kemme and Alonso [VLDB00, TODS00]Pedonne and Schiper [DISC98]
Lazy replication in dist. systemsPacitti et al. [VLDB99, VLDBJ00, DAPD01]
Replication in middlewareAmza et al. [Middleware03]Cecchet [OPODIS03]Gançarski et al. [CoopIS02, Info. Syst.05]Jiménez-Peris et al. [ICDCS02, Middleware04]
Preventive replicationPacitti et al. [Europar03, Vecpar04, BDA05, IEEE ICPADS05, VLDB-WDDIR05, DAPD05]

4
Context
Update-intensive applicationse.g. Application Service Providers
Database cluster with shared-nothing architecture and fast, reliable networkData replication to improve availability and performance
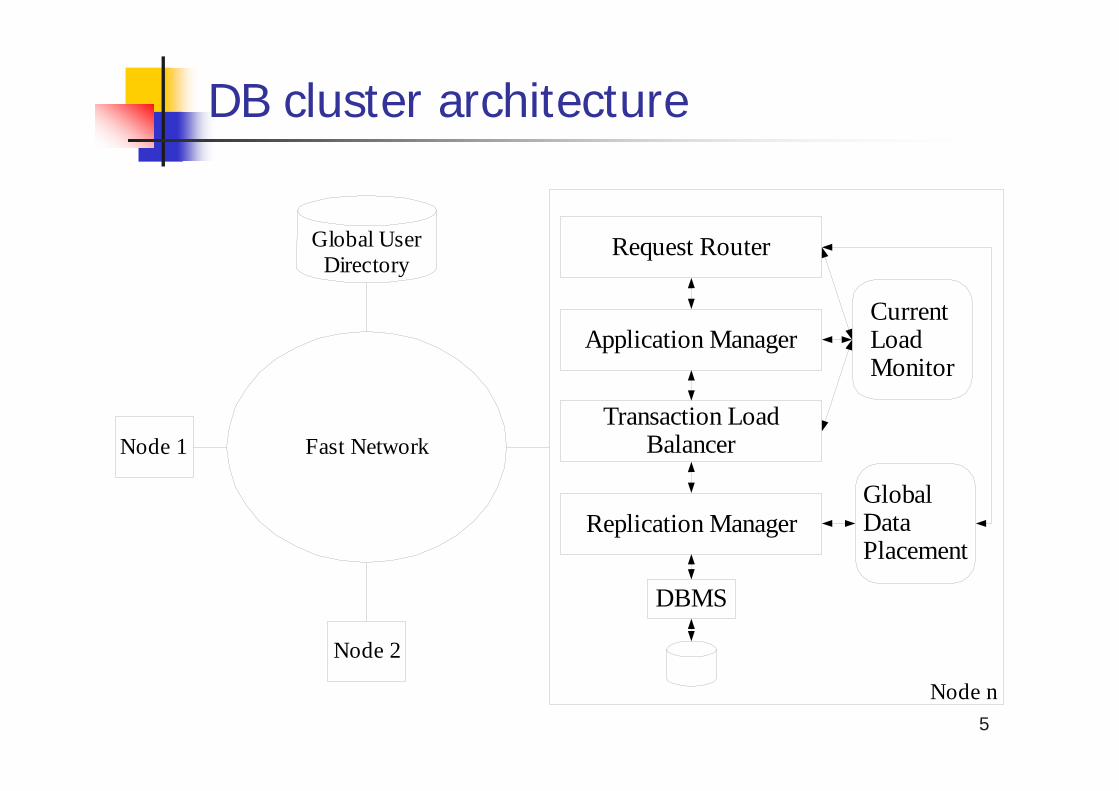
5
DB cluster architecture
Fast NetworkNode 1
Node 2
Request Router
Replication Manager
Transaction LoadBalancer
Application Manager
DBMS
CurrentLoadMonitor
Node n
Global UserDirectory
GlobalDataPlacement

6
Preventive replication - objectives
Multi-master replicationEach node can update replicas
Database autonomySupport black-box DBMS
Strong replica consistencyEquiv. to ROWA (read one – write all)
Non-blockingUnlike 2PC
PerformanceScale-up and speed-up

7
Preventive Replication - assumptions
Network interface provides FIFO reliable multicastMax is the upper bound of the time needed to multicast a message Clocks are ε-synchronizedEach transaction has a chronological timestamp C (its arrival time)

8
Preventive replication - consistencyConsistency Criteria = total order
Transactions are received in the same order at all nodes involved: this corresponds to the execution order
To enforce total order, transactions are chronologically ordered at each node using their delivery time
delivery_time = C + Max + εAfter Max+ε, all transactions that may have committed before C are supposed to be receivedand executed before T

9
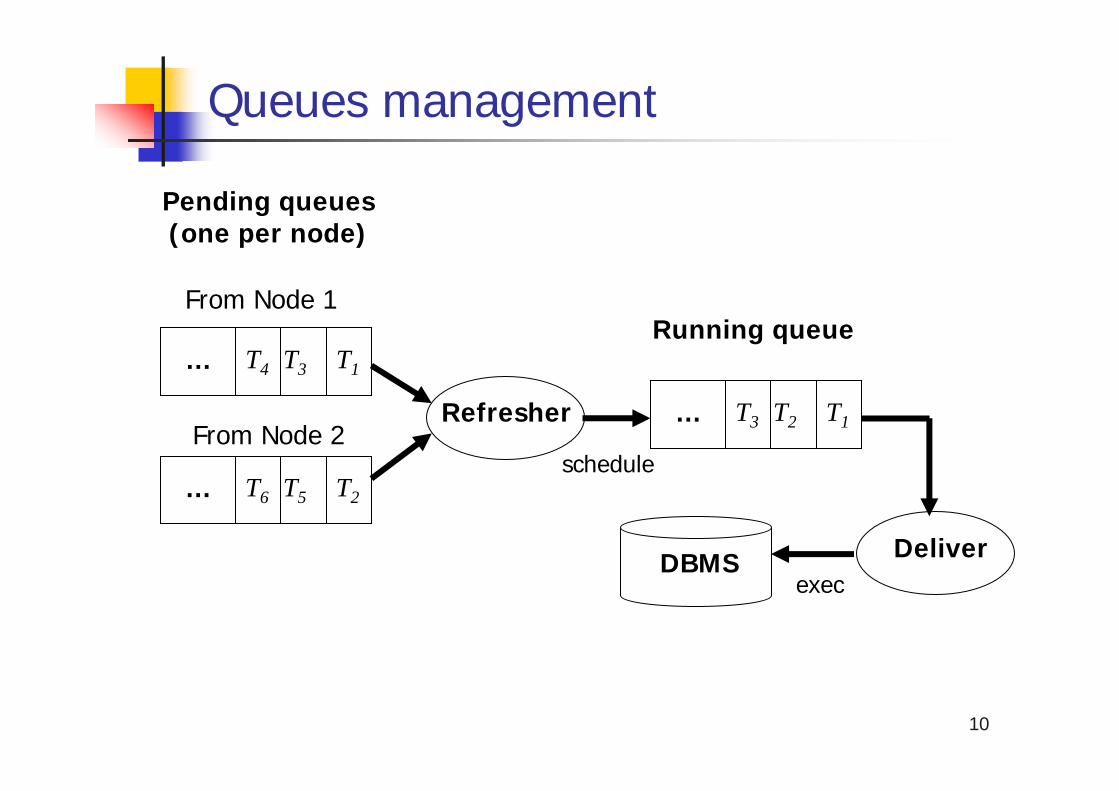
Preventive replication - principlePropagation
When a node i receives a trans. T, itmulticasts it to all nodes including itself
Each node putsT in pending queue qi in FIFO order
SchedulingAt each node, all pending transactions are ordered wrt delivery times
After expiration of its delivery time, T is put in running queue
ExecutionTransactions in running queue are submittedto the DBMS for execution
10
Queues management
T1T3T4…
T2T5T6…
Refresher
Pending queues(one per node)
From Node 1
From Node 2T1T2T3…
Running queue
DeliverDBMS
schedule
exec
11
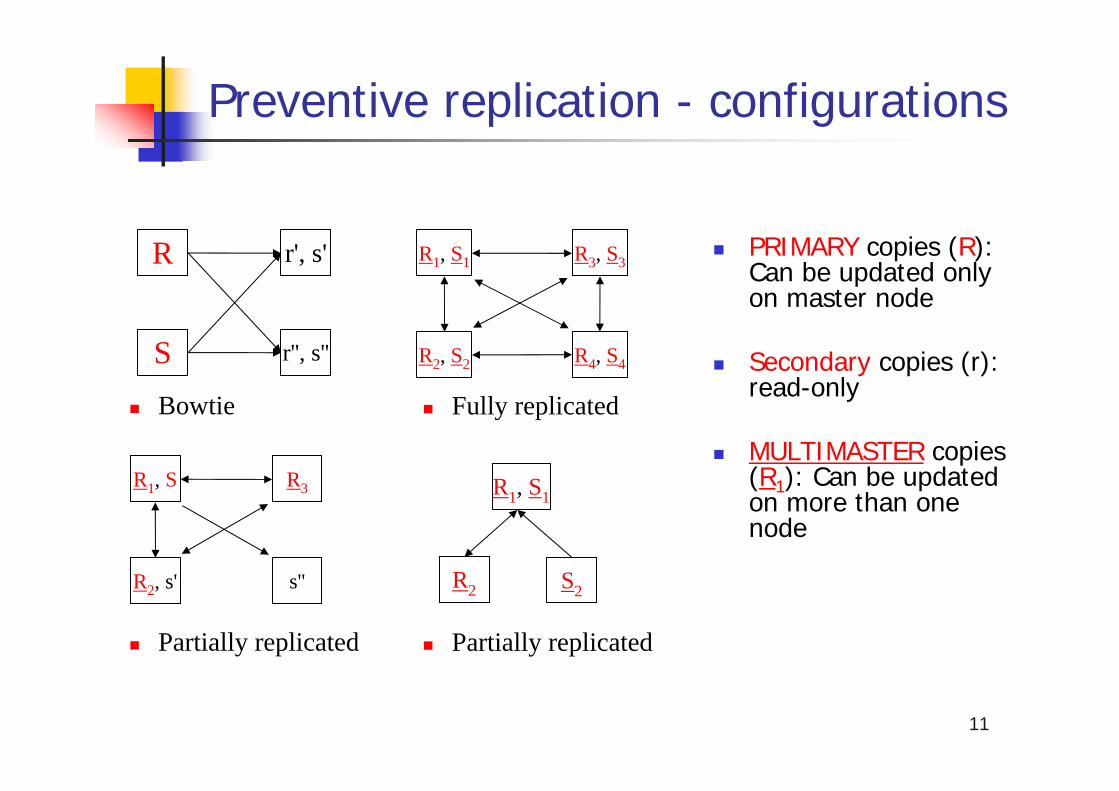
R
S
r', s'
r'', s''
R1, S1
R2, S2
R3, S3
R4, S4
Bowtie Fully replicated
Partially replicated
R1, S1
S2R2
Partially replicated
R1, S
R2, s'
R3
s''
Preventive replication - configurations
PRIMARY copies (R): Can be updated only on master node
Secondary copies (r): read-only
MULTIMASTER copies (R1): Can be updated on more than one node

12
Some transactions cannot be executed
N2
T1(R, S)
R1, S1
S2R2
N3
N1
Partially replication - problem
Example@N2UPDATE R SET c1 WHERE c2 IN
(SELECT c3 FROM S);

13
On the target nodes, T1 waits (Step 3)After execution on the origin node, a Refresh Transaction (RT1) is multicast to target nodes (Step 4)RT1 is executed to update replicated data
R1, S1
R2 S2
N1
N2 N3
ClientT1(rS, wR)
R1, S1
R2 S2
N1
N2 N3
R1, S1
R2 S2
N1
N2 N3
Client
Answer T1
R1, S1
R2 S2
N1
N2 N3
Step 1
R1, S1
R2 S2
N1
N2 N3
Step 2 Step 3 Step 4 Step 5
T1(rS, wR)
Standby
RT1(wR)
Perform
Partially Replicated Configurations (2)

14
Replication Manager Architecture

15
Optimization: eliminating delay times (1)
In a cluster network, messages are naturally totally ordered [Pedonne & Schiper, 1998]We can parallelize transaction scheduling and execution
Submit a transaction to execution as soon as it is receivedSchedule the commit order of the transactions
A transaction can be committed only after Max + ε
If a transaction is received out of order, abort and re-execute all younger transactions
Yields concurrent execution of non conflicting transactions

16
Optimization: Eliminating delay times (2)
Scheduling
Execution
TCommit
Scheduling CommitExecutionT
Abort
Basic Preventive replication
Optimized Preventive Replication
T’s refreshment time = Max + ε + t
T’s refreshment time = maximum (Max + ε, t)

17
RepDB* Prototype: Architecture
DBMSClients
ReplicaInterfaceJDBC server
LogMonitor
DBMS specific
Propagator Receiver
Refresher
Deliver
Network
JDBC JDBC
RepDB*

18
RepDB* Prototype: Implementation
Open Source Software under GPL200 downloads after one month of releaseJava (10K+ lines)DBMS is a black-box
PostgreSQL, Oracle
JDBC interface (RMI-JDBC)Uses Spread toolkit (Center for Networking and Distributed Systems - CNDS) to manage the network
Simulation version in SimJava
http://www.sciences.univ-nantes.fr/ATLAS/RepDB

19
TPC-C benchmark
1 / 5 / 10 Warehouses10 clients per WarehouseTransactions’ arrival rate is 1s / 200ms / 100msLoad = combination of
Update transactionsNew-order: high frequency (45%)Payment: high frequency (45%)
Read-only transactionsOrder-status: low frequency (5%)Stock-level: low frequency (5%)

20
Experiments
Cluster of 64 nodes ([email protected])PostgreSQL 7.3.2 on Linux1 Gb/s network
2 ConfigurationsFully Replicated (FR)Partially Replicated (PR): each type of TPC-C transaction runs using ¼ of the nodes

21
Scale up
0
200
400
600
800
1000
1200
0 16 32 48 64
number of nodesR
espo
nse
times
(ms) 1
510
a) Fully Replicated (FR) b) Partially Replicated (PR)
0
200
400
600
800
1000
1200
0 16 32 48 64
number of nodes
Res
pons
e tim
es (m
s)
1510
Response time of update transactions

22
Speed upLaunch 128 clients that submit Order-status
transactions (read-only)
0
400
800
1200
1600
2000
0 16 32 48 64
number of nodes
Que
ries
per s
econ
d 1510
a) Fully Replicated (FR) b) Partially Replicated (PR)
0
400
800
1200
1600
2000
0 16 32 48 64
number of nodesQ
uerie
s pe
r sec
ond 1
510

23
Impact of optimistic execution
0
1
2
3
4
5
6
0 16 32 48 64
number of nodes
perc
enta
ge
UnordoredAborted
a) Fully Replicated (FR) b) Partially Replicated (PR)
0
1
2
3
4
5
6
0 16 32 48 64number of nodes
perc
enta
ge
UnordoredAborted
24
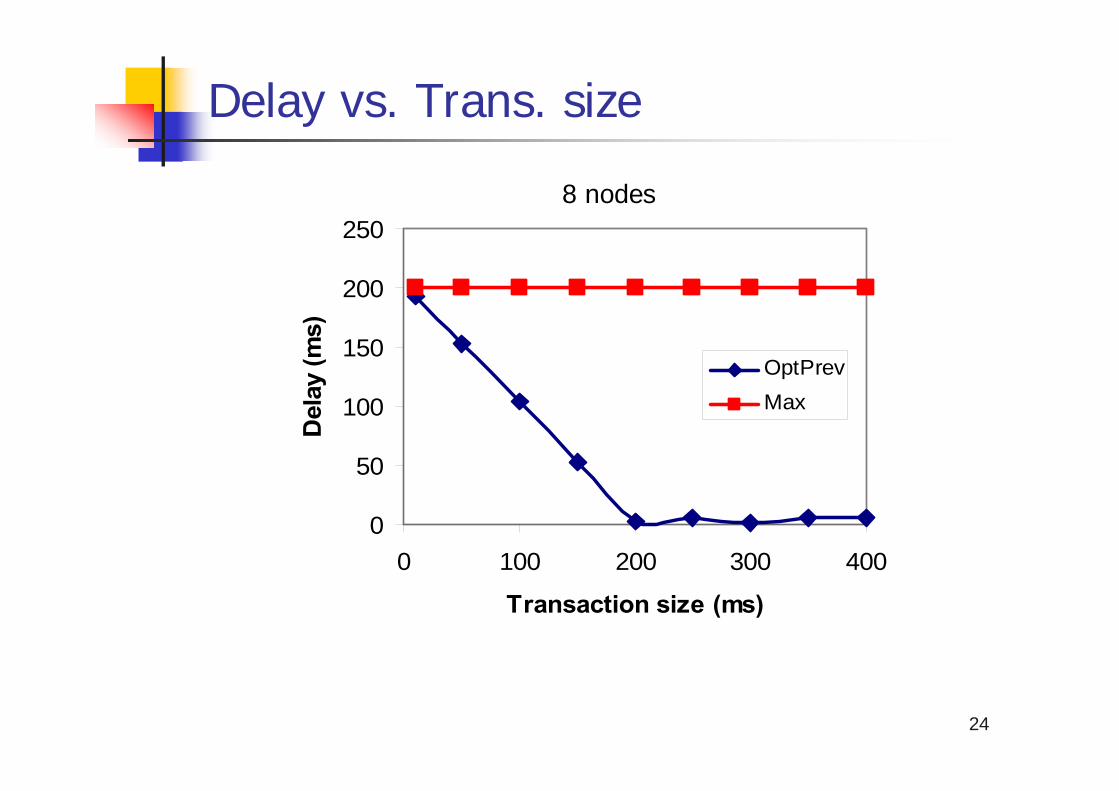
Delay vs. Trans. size
0
50
100
150
200
250
0 100 200 300 400
Transaction size (ms)
Del
ay (m
s)
OptPrevMax
8 nodes

25
Conclusion
Large-scale experimentation with 64-node cluster
Excellent scale-up and speed-up for typical OLTPImportant impact of optimizationsTime-consuming activity
Future workMore experimentation going on with various loadsExtensions to WAN for GRID5000

![Dominique Coulon & Associés, Eugeni Pons, David Romero ... · DOMINIQUE COULON & ASSOCIÉS ( /AUTHORS/2144706109-DOMINIQUE-COULON-ASSOCIES) MEDIA LIBRARY [THIRD-PLACE] IN THIONVILLE](https://img.dokumen.tips/doc/110x75/5e0f3d06d8075048a93a99d4/dominique-coulon-associs-eugeni-pons-david-romero-dominique-coulon.jpg)


![Rémi Coulon & Denis Osin · 20 R. Coulon & D. Osin namely the parabolic action on a combinatorial horoball [13]. Thus to obtain an interestingclassofgroupswehavetostrengthenourpropernessassumptions](https://img.dokumen.tips/doc/110x75/602b80427159a4191e7e1a57/rmi-coulon-denis-osin-20-r-coulon-d-osin-namely-the-parabolic-action.jpg)















![[Web Starter 2016] Competitive Analysis - Valentina Pacitti](https://img.dokumen.tips/doc/110x75/586e7f881a28aba0038b4f35/web-starter-2016-competitive-analysis-valentina-pacitti.jpg)








