Embed Size (px)
Citation preview

Languages and Compilers for High Performance Computing
Kathy YelickEECS Department
U.C. Berkeley

Research Problems in High Performance
Organ Simulation: Domain-Specific
Tools
BeBOP: Architecture-Specific Optimization
(with Demmel)
Titanium: Language for Parallel Scientific
Computing(with Graham, Hilfinger)

Titanium
• Language for grid-based scientific computing
• Based on Java (but compiled)• Extensions:
– Multidimensional arrays with iterators – Immutable (“value”) classes– Templates– Operator overloading– Checked Synchronization – Zone-based memory management

Is High Performance Java an Oxymoron?
Performance on a Pentium IV (1.5GHz)
050
100150200250300350400450
Overall FFT SOR MC Sparse LU
MF
lop
s
java C (gcc -O6) Ti Ti -nobc

Parallel Dependence Analysis: Cycle Detection• First, find potential race conditions
– If none, then use traditional sequential analysis– Analysis of shared/private data can help
• Code defines a “program order” on accesses P is the union of these across processors
• Memory system defines an “access order” A is access order (read/write & write/write
pairs)
• Avoid reordering along edges of a cycle– Intuition: time cannot flow backwards.
write data read flag
write flag read data

Parallel Control Analysis: Synchronization• Given a program P, determine which
segments of P could run in parallel.– Match barriers (single analysis in Titanium)– Match synchronized regions
• Both analyses can be used to:– Detect bugs (race conditions)– For optimizations:
• Prefetching, split-phase memory, loop transformations, scheduling,…

Titanium Research Problems
• Designed for block-structured grids; add support for unstructured.
• Optimizations for local memory hierarchies (more on this later)
• Design of low-cost communication layers for read/write
• Add communication optimizations• See the projects we page:
http://titanium.cs.berkeley.edu/tasks.html

Performance Tuning• Motivation: performance of many
applications dominated by a few kernels•Heart simulation Navier-Stokes
– Sparse matrix-vector multiply (Multigrid)– Fast Fourier Transforms
•Information retrieval LSI, LDA– Sparse matrix-vector multiply
•Image processing filtering, segmentation– Sorting/Histograms, Cosine transform, Sparse
matrix-vector multiply
•Many other examples
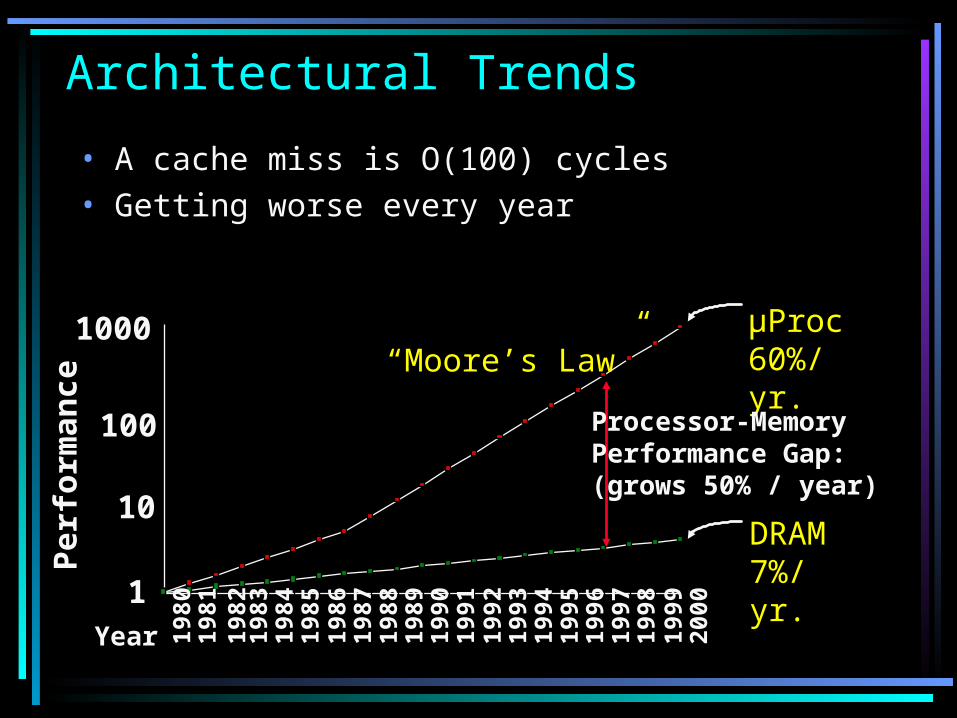
Architectural Trends
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000
198
0198
1 198
3198
4198
5198
6198
7198
8198
9199
0199
1199
2199
3199
4199
5199
6199
7199
8199
9200
0
DRAM
CPU
198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Year
“Moore’s Law”
• A cache miss is O(100) cycles• Getting worse every year

Conventional Performance Tuning
• Vendor or user hand tunes kernels• Drawbacks:
–Very time consuming and difficult work–Even with intimate knowledge of architecture and compiler, performance hard to predict
–Must be redone for every architecture, compiler
–Not just a compiler problem: • Best algorithm may depend on input, so some
tuning must occur at run-time.• Multiple algorithms for the same problem may not
be provably equivalent by program analysis

Automatic Performance Tuning
• Approach: for each kernel1. Identify and generate a space of algorithms2. Search for the fastest one, by running them3. Constrain search space using performance
models
• What is a space of algorithms?– Depends on kernel and input– May vary
• instruction mix and order• memory access patterns• data structures • mathematical formulation
• Search both off-line and on-the-fly

How Much Does Tuning Help?
• Experience from PHiPAC: ~10x on matmul

Sparse Matrices as Graphs
• Sparse matrix is adjacency matrix for a graph– Matrix vector multiplication is nearest neighbor
computation
• Optimizations:– Register blocking: look for fixed size cliques
• Unroll loops and optimize “dense” kernels
– Cache blocking: partition graph and layout in memory by partitions
– Multiple vectors: Assume each node holds a vector, update them all simultaneously
• Common in some types of solvers
– Exploit symmetry (undirected graph)– Exploit bounded degree or other special
structures

Speedups from Sparsity with 1 Vector
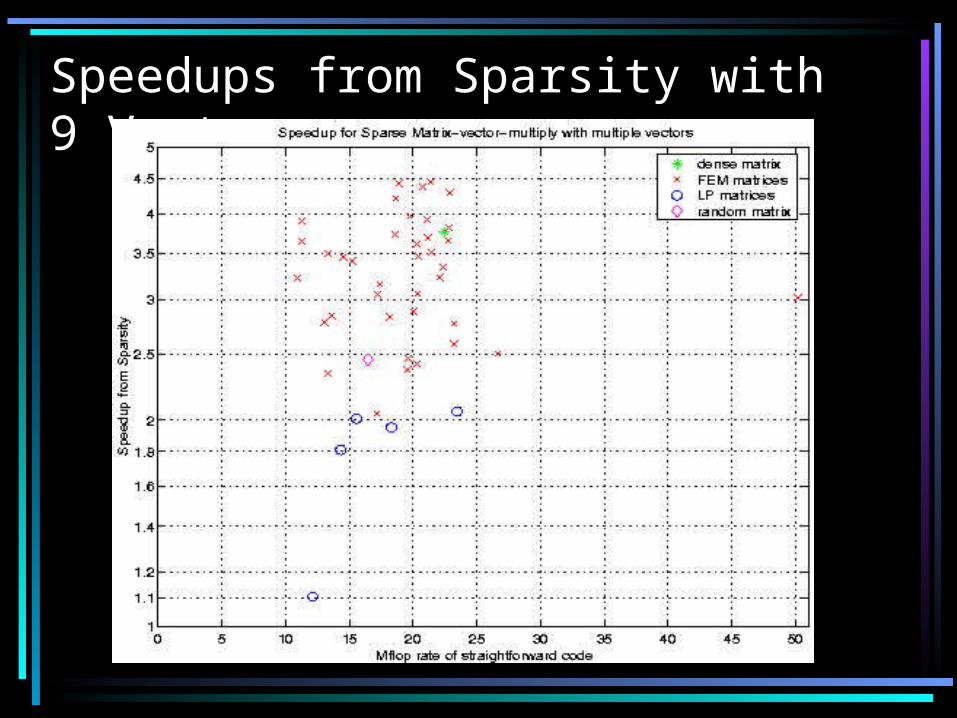
Speedups from Sparsity with 9 Vectors

BeBop Research
• BeBop: Berkeley Benchmarking and optimization group
• Hand optimizations:– Understood for some problems
• How to build tools– Work across machines (self-tuning)– Work on multiple problems (code
generation)

Application-Specific Tools
• Simulation of the human body• Imagine a “digital body double”
– 3D image-based medical record– Includes diagnostic, pathologic, and other
information
• Used for:– Diagnosis– Less invasive surgery-by-robot– Experimental treatments
Where are we today?

From Visible Human to Digital Human
Source: John Sullivan et al, WPI
Source: www.madsci.org
Building 3D Models from images

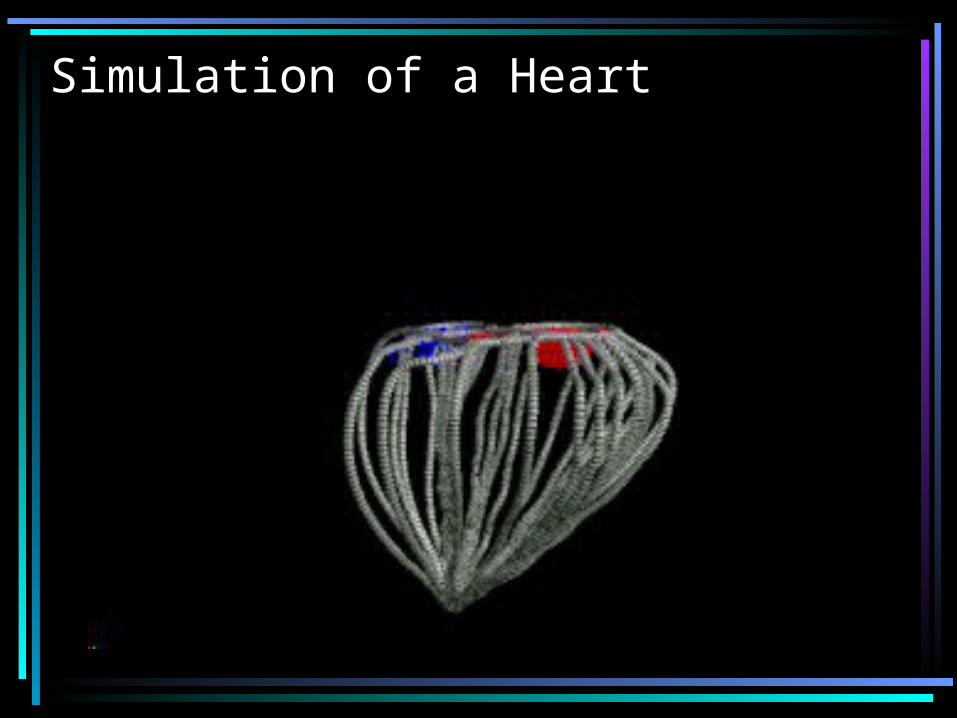
Heart Simulation Calculation
Developed by Peskin and McQueen at NYU– Done on a Cray C90: 1 heart-beat in 100 hours– Used for evaluating artificial heart valves– Scalable parallel version done here
• Implemented in Titanium
–Model also used for: • Inner ear
• Blood clotting
• Embryo growth
• Insect flight
• Paper making
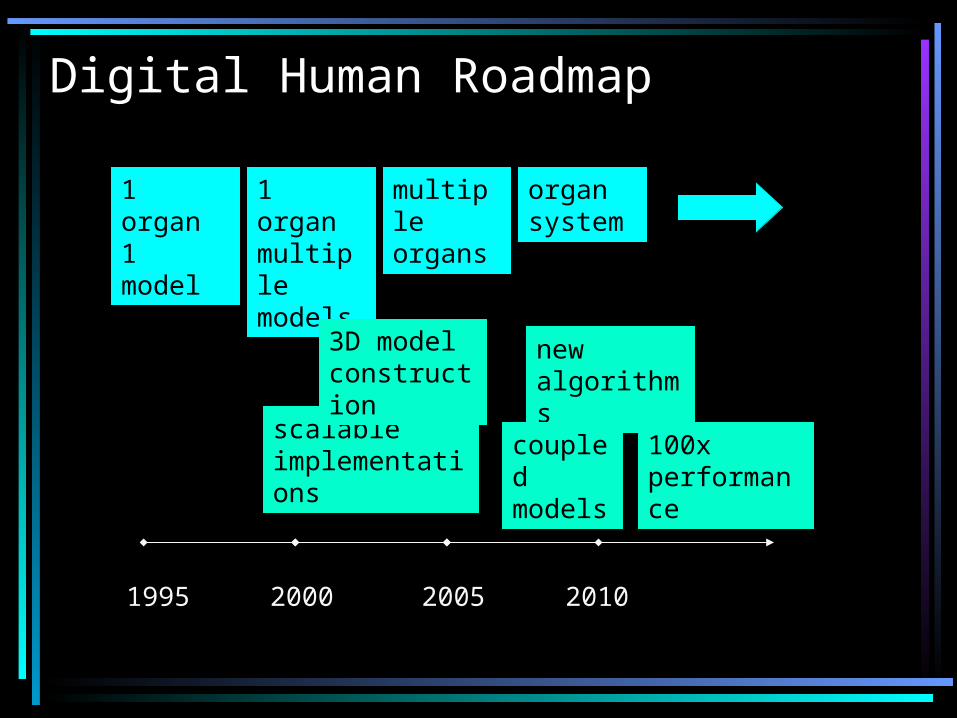
Digital Human Roadmap
1995 2000 2005 2010
1 organ 1 model
scalable implementations
1 organ multiple models
multiple organs
3D model construction
new algorithms
organ system
coupled models
100x performance

Summary
• Three related projects– Titanium
• http://titanium.cs.berkeley.edu
– BeBop• http://www.cs.berkeley.edu/~richie/bebo
p
– Organ Simulation• Research issues
– How to make high performance easy• Increasing complex applications• Increasing complex machines
Simulation of a Heart





























