Embed Size (px)
Citation preview

1
Course web page:
ECE 545
Digital System Design with VHDL
ECE web page → Courses → Course web pages → ECE 545
http://ece.gmu.edu/coursewebpages/ECE/ECE545/F10/
Kris Gaj
Office hours: Monday, 7:30-8:30 PM, Wednesday, 6:00-7:00 PM, and by appointment
Research and teaching interests: • reconfigurable computing • computer arithmetic • cryptography • network security
Contact: The Engineering Building, room 3225
ECE 545
Part of:
MS in Electrical Engineering
MS in Computer Engineering
Digital Systems Design Microprocessor and Embedded Systems
Strongly suggested for two concentration areas:
Elective
Elective course in the remaining concentration areas
One of five core courses (must be passed with B or better)
algorithmic
Design level
register-transfer
gate
transistor
layout
devices
Courses Computer Arithmetic
Digital System Design with VHDL
Digital Integrated Circuits Physical
VLSI Design
VLSI Test Concepts
ECE 545
ECE 645
ECE 586
ECE 680
ECE 682
ECE684 MOS Device Electronics
ECE 584 Semiconductor Device Fundamentals
ECE 681
VLSI Design for ASICs
DIGITAL SYSTEMS DESIGN
Concentration advisors: Kris Gaj, Jens-Peter Kaps, Ken Hintz
1. ECE 545 Digital System Design with VHDL – K. Gaj, project, FPGA design with VHDL,
Aldec/Mentor Graphics, Xilinx/Altera
2. ECE 645 Computer Arithmetic – K. Gaj, project, FPGA design with VHDL or Verilog,
Aldec/Mentor Graphics, Xilinx/Altera
3. ECE 681 VLSI Design for ASICs – N. Klimavicz, project/lab, back-end ASIC design with Synopsys tools
4. ECE 586 Digital Integrated Circuits – D. Ioannou, R. Mulpuri
5. ECE 682 VLSI Test Concepts – T. Storey
Grading Scheme
• Homework - 10%
• Project - 40%
• Midterm Exam - 20%
• Final Exam - 30%

2
Midterm exam 1
2 hours 30 minutes
in class
design-oriented
open-books, open-notes
practice exams will be available on the web
Monday, November 1st
Tentative date:
Final exam
2 hours 45 minutes
in class
design-oriented
open-books, open-notes
practice exams will be available on the web
Monday, December 20, 7:30-10:15pm
Date:
9
Project
Project
individual
semester-long
related to the research project conducted by Cryptographic Engineering Research Group (CERG) at GMU
supporting NIST (National Institute of Standards and Technology) in the evaluation of candidates for a new cryptographic standard
11
Background
Hash Function
arbitrary length
message
hash function
hash value h(m)
h
m
fixed length
It is computationally infeasible to find such
m and m’ that h(m)=h(m’)

3
Main Application: Digital Signature
Signature
DIGITAL HANDWRITTEN
A6E3891F2939E38C745B 25289896CA345BEF5349 245CBA653448E349EA47
Main Goals: • unique identification • proof of agreement to the contents of the document
Message
Hash function
Public key cipher
Alice Signature
Alice’s private key
Bob
Hash function
Alice’s public key
Typical Digital Signature Scheme
Hash value 1
Hash value 2
Hash value
Public key cipher
yes no
Message Signature
Handwritten and Digital Signatures Common Features
Handwritten signature Digital signature
1. Unique 2. Impossible to be forged 3. Impossible to be denied by the author 4. Easy to verify by an independent judge 5. Easy to generate
Handwritten and Digital Signatures Differences
Handwritten signature Digital signature
6. Associated physically with the document
7. Almost identical for all documents 8. Usually at the last page
6. Can be stored and transmitted independently of the document 7. Function of the document 8. Covers the entire document
Hash function algorithms
Customized (dedicated)
Based on block ciphers
Based on modular arithmetic
MDC-2 MDC-4
IBM, Brachtl, Meyer, Schilling, 1988
MASH-1 1988-1996
MD2 Rivest 1988
MD4 Rivest 1990
MD5 Rivest 1990
SHA-0
SHA-1
RIPEMD
RIPEMD-160
European RACE Integrity Primitives Evaluation Project, 1992
NSA, 1992
NSA, 1995
SHA-256, SHA-384, SHA-512 NSA, 2000
Attacks against dedicated hash functions known by 2004
MD2
MD4
MD5 SHA-0
SHA-1
RIPEMD
RIPEMD-160
partially broken
broken, H. Dobbertin, 1995 (one hour on PC, 20 free bytes at the start of the message)
partially broken, collisions for the compression function, Dobbertin, 1996 (10 hours on PC)
weakness discovered, 1995 NSA, 1998 France
reduced round version broken, Dobbertin 1995
SHA-256, SHA-384, SHA-512
4
MD4
MD5 SHA-0
SHA-1
RIPEMD
RIPEMD-160
SHA-256, SHA-384, SHA-512
broken; Wang, Feng, Lai, Yu Crypto 2004 (1 hr on a PC)
attack with 240 operations Crypto 2004
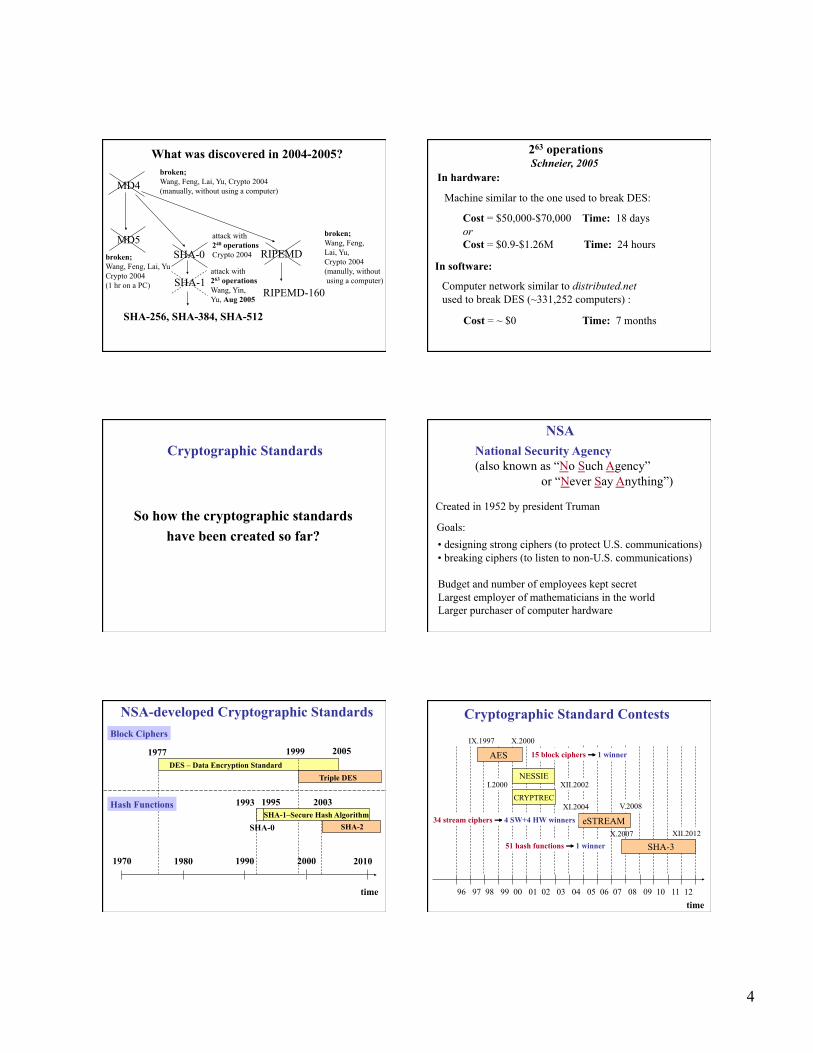
What was discovered in 2004-2005? broken; Wang, Feng, Lai, Yu, Crypto 2004 (manually, without using a computer)
broken; Wang, Feng, Lai, Yu, Crypto 2004 (manully, without using a computer)
attack with 263 operations Wang, Yin, Yu, Aug 2005
263 operations Schneier, 2005
In hardware:
Machine similar to the one used to break DES:
Cost = $50,000-$70,000 Time: 18 days or Cost = $0.9-$1.26M Time: 24 hours
In software:
Computer network similar to distributed.net used to break DES (~331,252 computers) :
Cost = ~ $0 Time: 7 months
Cryptographic Standards
So how the cryptographic standards have been created so far?
National Security Agency (also known as “No Such Agency” or “Never Say Anything”)
Created in 1952 by president Truman
Goals: • designing strong ciphers (to protect U.S. communications) • breaking ciphers (to listen to non-U.S. communications)
Budget and number of employees kept secret Largest employer of mathematicians in the world Larger purchaser of computer hardware
NSA-developed Cryptographic Standards
time
1970 1980 1990 2000 2010
DES – Data Encryption Standard 1977 1999
Triple DES
SHA-1–Secure Hash Algorithm SHA-2
Block Ciphers
Hash Functions 1995 2003 1993
SHA-0
2005
Cryptographic Standard Contests
time 96 97 98 99 00 01 02 03 04 05 06 07 08 09 10 11 12
AES
NESSIE
CRYPTREC
eSTREAM
SHA-3
34 stream ciphers → 4 SW+4 HW winners
51 hash functions → 1 winner
15 block ciphers → 1 winner
IX.1997 X.2000
I.2000 XII.2002
V.2008
X.2007 XII.2012
XI.2004

5
25
SHA-3 Contest - NIST Evaluation Criteria
Security
So*ware Efficiency
Hardware Efficiency
Simplicity
FPGAs ASICs
Flexibility Licensing
Software or hardware?
SOFTWARE HARDWARE security of data
during transmission
flexibility (new cryptoalgorithms,
protection against new attacks)
speed
random key generation
access control to keys
tamper resistance
low cost resistance to
side-channel attacks
Memory
Power consumption
Primary efficiency indicators
Software Hardware
Speed Memory Speed Area
Efficiency parameters Latency Throughput = Speed
Encryption/ decryption
Time to encrypt/decrypt a single block
of data
Mi
Ci Number of bits
encrypted/decrypted in a unit of time
Encryption/ decryption
Mi Mi+1 Mi+2
Ci Ci+1 Ci+2
Throughput = Block_size · Number_of_blocks_processed_simultaneously Latency
Advanced Encryption Standard (AES) Contest 1997-2001
15 Candidates from USA, Canada, Belgium,
France, Germany, Norway, UK, Israel, Korea, Japan, Australia, Costa Rica
June 1998
August 1999
October 2000 1 winner: Rijndael
Belgium
5 final candidates
Mars, RC6, Rijndael, Serpent, Twofish
Round 1
Round 2
Security Software efficiency
Flexibility
Security Hardware efficiency
0 50 100 150 200 250 300 350 400 450 500
Serpent Rijndael Twofish RC6 Mars
Speed of the final AES candidates in Xilinx FPGAs Speed [Mbit/s] K.Gaj, P. Chodowiec, AES3, April, 2000

6
0 10 20 30 40 50 60 70 80 90 100
Serpent Rijndael Twofish RC6 Mars
Survey filled by 167 participants of the Third AES Conference, April 2000
# votes
Serpent Rijndael Twofish RC6 Mars
Results of the NSA group ASICs Speed [Mbit/s]
606
414
0
100
200
300
400
500
600
700
202
105 103 57
431
177 143
61
NSA ASIC
GMU FPGA
AES3, April, 2000
0
5
10
15
20
25
30
Serpent Rijndael Twofish RC6 Mars
Efficiency in software: NIST-specified platform
128-bit key 192-bit key 256-bit key
200 MHz Pentium Pro, Borland C++ Speed [Mbits/s] Security
Complexity
High
Adequate
Simple Complex
NIST Report: Security
Rijndael
MARS Serpent Twofish
RC6
AES Final Report, October 2000
35
NIST SHA-3 Contest - Timeline
51 candidates
Round 1 14
5-6 1-2 Round 2 Round 3
July 2009 End of 2010 Mid 2012 Oct. 2008
36
• Fair and comprehensive methodology for evaluation of hardware performance in FPGAs
• High-speed fully autonomous implementations of all 14 SHA-3 candidates & SHA-2 256-bit & 512-bit variants
optimized for the maximum throughput to area ratio
• Open-source benchmarking tool supporting optimization of tool options and efficient generation of results for multiple FPGA families
GMU Team Goals

7
Primary Designers of GMU Codes Ekawat Homsirikamol
a.k.a “Ice” Marcin Rogawski
Developed optimized VHDL implementations of 14 Round 2 SHA-3 candidates + SHA-2 in two variants each (256 & 512-bit output),
for some functions using several alternative architectures 38
Methodology
39
Comprehensive Evaluation
• two major vendors: Altera and Xilinx (~90% of the market) • multiple high-performance and low-cost families
Altera Xilinx
Technology Low-cost High- performance
Low-cost High- performance
90 nm Cyclone II Stratix II Spartan 3 Virtex 4
65 nm Cyclone III Stratix III Virtex 5
40
• Language: VHDL
• Tools: FPGA vendor tools
• Interface
• Performance Metrics
• Design Methodology
• Benchmarking
Uniform Evaluation
41
Why Interface Matters?
• Pin limit
Total number of i/o ports ≤ Total number of an FPGA i/o pins
• Support for the maximum throughput
Time to load the next message block ≤ Time to process previous block
42
Interface: Two possible solutions
Length of the message communicated at the beginning
+ easy to implement passive source circuit
− area overhead for the counter of message bits
Dedicated end of message port
− more intelligent source circuit required
+ no need for internal message bit counter
msg_bitlen
zero_word
message end_of_msg SHA core

8
43
SHA Core: Interface & Typical Configuration
• SHA core is an active component; surrounding FIFOs are passive and widely available • Input interface is separate from an output interface • Processing a current block, reading the next block, and storing a result for the previous message can be all done in parallel
fifoin_empty
fifoin_read
idata w w
odata
fifoout_full
fifoout_write
fifoin_full
fifoin_write
fifoout_empty
fifoout_read
Input FIFO
SHA core
clk rst
ext_idata
w
ext_odata din dout
src_ready
src_read
dst_ready
dst_write
din dout
full empty
write read
Output FIFO
din dout
full empty
write read
w
clk rst
clk rst clk rst
clk rst
clk rst
44
SHA Core: Interface & Typical Configuration
fifoin_empty
fifoin_read
idata w w
odata
fifoout_full
fifoout_write
fifoin_full
fifoin_write
fifoout_empty
fifoout_read
Input FIFO SHA core
clk rst
ext_idata
w
ext_odata din dout
src_ready
src_read
dst_ready
dst_write
din dout
full empty
write read
Output FIFO
din dout
full empty
write read
w
clk rst
io_clk rst io_clk rst
clk rst
clk rst
io_clk
io_clk
• Some functions may require a faster input/output clock in order to load input data at a faster rate
45
Primary Secondary
1. Throughput (single long message)
2. Area
3. Throughput / Area 3. Hash Time for Short Messages (up to 1000 bits)
Performance Metrics
46
Performance Metrics - Area
We force these vectors to look as follows through the synthesis and implementation options:
0
0
0
0
Areaa
47
Primary Optimization Target: Throughput to Area Ratio
Features: • practical: good balance between speed and cost • very reliable guide through the entire design process,
facilitating the choice of high-level architecture implementation of basic components choice of tool options
• leads to high-speed, close-to-maximum-throughput designs
Choice of Optimization Target
48
Our Design Flow
Specification Interface
Datapath Block diagram
Controller ASM Chart
VHDL Code
Formulas for Throughput & Hash time
Max. Clock Freq. Resource Utilization
Throughput, Area, Throughput/Area, Hash Time for Short Messages
Controller Template
Library of Basic Components

9
49
Basic Operations of 14 SHA-3 Candidates
49 NTT – Number Theoretic Transform, GF MUL – Galois Field multiplication,
MUL – integer multiplication, mADDn – multioperand addition with n operands
ATHENa – Automated Tool for Hardware Evalua?oN
50
Benchmarking open-‐source tool, wriGen in Perl, aimed at an
AUTOMATED genera?on of OPTIMIZED results for MULTIPLE FPGA plaSorms
Under development at George Mason University.
http://cryptography.gmu.edu/athena
ATHENa Server
FPGA Synthesis and Implementation
Result Summary + Database Entries
2 3
HDL + scripts + configuration files
1
Database Entries
Download scripts and
configuration files8
Designer
4
HDL + FPGA Tools
User
Database query
Ranking of designs
5 6
Basic Dataflow of ATHENa
0 Interfaces
+ Testbenches 51 52
synthesizable source files
configuraKon files
testbench
constraint files
result summary
(user-‐friendly)
database entries
(machine-‐ friendly)
ATHENa Major Features (1) • synthesis, implementa?on, and ?ming analysis in batch mode
• support for devices and tools of mulKple FPGA vendors:
• genera?on of results for mulKple families of FPGAs of a given vendor
• automated choice of a best-‐matching device within a given family
53
ATHENa Major Features (2)
• automated verificaKon of designs through simula?on in batch mode
• support for mulK-‐core processing
• automated extracKon and tabulaKon of results
• several opKmizaKon strategies aimed at finding
– op?mum op?ons of tools
– best target clock frequency
– best star?ng point of placement
OR
54

10
55
• batch mode of FPGA tools
• ease of extraction and tabulation of results • Excel, CSV (available), LaTeX (coming soon)
• optimized choice of tool options
Generation of Results Facilitated by ATHENa
vs.
56
Relative Improvement of Results from Using ATHENa Virtex 5, 256-bit Variants of Hash Functions
0
0.5
1
1.5
2
2.5
Groestl
Shavite-
3 Luf
fa
Keccak
Hamsi
Echo
Skein
Fugue
Sha-2
BMW
CubeHash
Blak
e
Shabal
SIMD JH
Area Thr Thr/Area
Ratios of results obtained using ATHENa suggested options vs. default options of FPGA tools
58
Results
59
Throughput [Mbit/s] Virtex 5, 256-bit variants of algorithms
0
2000
4000
6000
8000
10000
12000
14000
16000
ECHO
Kecca
k
Groestl
Lu
ffa
BMW
JH
CubeH
ash
Fugue
SHAvite-3
BLAKE
Skein
Hamsi
Shaba
l
SIMD
SHA-2
60
Throughput [Mbit/s] Virtex 5, 512-bit variants of algorithms
0.0
2000.0
4000.0
6000.0
8000.0
10000.0
12000.0
14000.0
Groestl
BMW
Luffa
Kecca
k
ECHO
SIMD
JH
SHAvite-3
BLAKE
CubeH
ash
Skein
Shaba
l
SHA-2
Hamsi
Fugue

11
61
Normalization & Compression of Results
• Absolute result
e.g., throughput in Mbits/s, area in CLB slices
• Normalized result
• Overall normalized result
Geometric mean of normalized results for
all inves?gated FPGA families
€
normalized _ result =result _ for_ SHA − 3_candidate
result _ for_ SHA − 2
62
Normalized Throughput & Overall Normalized Throughput
63
Overall Normalized Throughput: 256-bit variants of algorithms Normalized to SHA-256, Averaged over 7 FPGA families
0
1
2
3
4
5
6
7
8
Kecca
k
ECHO Lu
ffa
BMW
Groestl
JH
CubeH
as
h Fugue
SHAvite-3
BLAKE
Hamsi
Skein
Shaba
l
SIMD
64
Overall Normalized Throughput: 512-bit variants of algorithms Normalized to SHA-512, Averaged over 7 FPGA families
0
0.5
1
1.5
2
2.5
3
3.5
4
Groestl
Lu
ffa
BMW
ECHO
Kecca
k JH
SIMD
CubeH
ash
SHAvite-3
BLAKE
Skein
Shaba
l
Hamsi
Fugue
65
Area [CLB slices] Virtex 5, 256-bit variants of algorithms
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
SHA-2
CubeH
ash
Hamsi
Fugue
JH
SHAvite-3
Lu
ffa
Kecca
k
Shaba
l
Skein
Groestl
BLAKE
BMW
ECHO
SIMD
66
Area [CLB slices] Virtex 5, 512-bit variants of algorithms
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
SHA-2
CubeH
ash
Fugue
JH
Kecca
k
Shaba
l
Skein
SHAvite-3
Lu
ffa
Hamsi
Groestl
BLAKE
ECHO
BMW
SIMD

12
67
Overall Normalized Area: 256-bit variants of algorithms Normalized to SHA-256, Averaged over 7 FPGA families
0
5
10
15
20
25
30
CubeH
ash
Hamsi
BLAKE
Luffa
Shaba
l JH
Kecca
k
SHAvite-3
Skein
Fugue
Groestl
BMW
SIMD
ECHO
68
Overall Normalized Area: 512-bit variants of algorithms Normalized to SHA-512, Averaged over 7 FPGA families
0
5
10
15
20
25
30
CubeH
ash
Fugue
Kecca
k
Shaba
l JH
Skein
BLAKE
Hamsi
Luffa
SHAvite-3
Groestl
BMW
ECHO
SIMD
69
Overall Normalized Throughput/Area: 256-bit variants Normalized to SHA-256, Averaged over 7 FPGA families
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Kecca
k Lu
ffa
CubeH
ash
Groestl
JH
Hamsi
BLAKE
Fugue
SHAvite-3
Shaba
l
Skein
BMW
ECHO
SIMD
70
Overall Normalized Throughput/Area: 512-bit variants Normalized to SHA-512, Averaged over 7 FPGA families
0
0.2
0.4
0.6
0.8
1
1.2
1.4
Kecca
k
CubeH
ash
Luffa
JH
Groestl
Shaba
l
BLAKE
Skein
SHAvite-3
Fugue
Hamsi
BMW
ECHO
SIMD
71
Throughput vs. Area Normalized to Results for SHA-256 and Averaged over 7 FPGA Families – 256-bit variants
best
worst
72
Throughput vs. Area Normalized to Results for SHA-512 and Averaged over 7 FPGA Families – 512-bit variants
best
worst

13
73
Execution Time for Short Messages up to 1000 bits Virtex 5, 256-bit variants of algorithms
74
Execution Time for Short Messages up to 1000 bits Virtex 5, 512-bit variants of algorithms
75
Thr/Area Thr Area Short msg. Thr/Area Thr Area Short msg.
256-bit variants 512-bit variants
BLAKE BMW CubeHash ECHO Fugue Groestl Hamsi JH Keccak Luffa Shabal SHAvite-3 SIMD Skein
76
• Throughput/Area & Throughput most crucial for high-speed implementations
• Area cannot be easily traded for Throughput
Best performers so far 1-2. Keccak & Luffa 3. Groestl
Worst performers so far: 14. SIMD 13. ECHO 12. BMW
Summary of Results
77
• Cryptology e-Print Archive - 2010/445 (100+ pages) • Detailed hierarchical block diagrams • Corresponding formulas for execution time and throughput
• FPL 2010 paper • ATHENa features • Case studies
• ATHENa web site • Most recent results • Comparisons with results from other groups • Optimum options of tools
More About our Designs & Tools
78
Comparison with
Other Groups

14
79
OTHER GROUPS GMU
Area Thr Thr/Area Source Area Thr Thr/Area
BLAKE 1660 2676 1.61 Kobayashi et al. 1871 2854 1.53
CubeHash 590 2960 5.02 Kobayashi et al. 707 3445 4.87
ECHO 9333 14860 1.59 Lu et al. 5445 13875 2.55 Groestl 1722 10276 5.97 Gauvaram
et al. 1884 8677 4.61
Hamsi 718 1680 2.34 Kobayashi et al. 946 2646 2.80
Keccak 1412 6900 4.89 Bertoni et al. 1229 10807 8.79 Luffa 1048 6343 6.05 Kobayashi
et al. 1154 8008 6.94
Shabal 153 2051 13.41 Detrey et al. 1266 2624 2.07 Skein (estimated) 1632 3535 2.17 Tillich 1463 2812 1.92
Comparison with Best Results Reported by Other Groups Virtex 5, 256-bit variants of algorithms
80
BEST REPORTED RESULTS
Area Thr Thr/Area Source
BLAKE 1660 2676 1.61 Kobayashi et al. BMW 4400 5577 1.27 GMU CubeHash 590 2960 5.02 Kobayashi et al. ECHO 5445 13875 2.55 GMU Fugue 956 3151 3.30 GMU Groestl 1722 10276 5.97 Gauvaram et al. Hamsi 946 2646 2.80 GMU JH 1108 3955 3.57 GMU Keccak 1229 10807 8.79 GMU Luffa 1154 8008 6.94 GMU Shabal 153 2051 13.41 Detrey et al. SHAvite-3 1130 2887 2.55 GMU SIMD 9288 2326 0.25 GMU Skein 1632 3535 2.17 Tillich et al.
Best Overall Reported Results as of Aug. 6, 2010 Virtex 5, 256-bit variants of algorithms
81
Throughput vs. Area: Best reported results Virtex 5, 256-bit variants of algorithms
best
worst
82
Your Project
83
Analysis of Alternative Architectures - Unrolled
r times r/2 times
84
Analysis of Alternative Architectures - Folded
r times 2⋅r times 2⋅r times
Basic Folded
Vertically-2x (fv2)
Folded Horizontally-2x
(fh2)

15
85
Preliminary results for CubeHash, Groestl, Keccak & Luffa in Virtex 5
0
1
2
3
4
5
6
7
8
0 1 2 3 4 5 6 7
Nor
mal
ized
Thr
ough
put
Normalized Area
CubeHash
Groestl
Luffa
Keccak
x1 x2 x4
fv3 ^2
x1 x2
fv4
fv2
x1
x1 x2
CubeHash
Luffa
Keccak
Groestl
Your Project • 14 SHA-3 candidates left in the contest
• Given: specification of the function reference implementation in C interface testbench and test vectors GMU implementation of the basic version including
block diagrams ASM charts short description formulas for execution time & throughput source codes results for Xilinx and Altera FPGAs
Your Project Develop:
Block diagram ASM chart Formulas for execution time & throughput Synthesizable code in VHDL Results for multiple families of FPGAs from Xilinx and
Altera for at least one architecture from each of the following
three classes of architectures: – Unrolled architecture – Folded architecture – Architecture based on the use of embedded FPGA
resources (BRAMs, multipliers, DSP units, etc.) [256 bit only, 512-bit only, or both]
88
Block R
AM
s and MU
Ls
Block R
AM
s and MU
Ls
Configurable Logic Blocks
I/O Blocks
What is an FPGA?
Block RAMs & Embedded Multipliers
89
RAM Blocks and Multipliers in Xilinx FPGAs
The Design Warrior’s Guide to FPGAs Devices, Tools, and Flows. ISBN 0750676043
Copyright © 2004 Mentor Graphics Corp. (www.mentor.com)
90
Using Embedded FPGA Resources
Basic design
Your design
( 1536, 0, 0)
( 768, 2, 4)
Basic design
Your design
( 3010, 0, 0)
( 1505, 32 kbit, 4)

16
91
Block RAM
Spartan-3 Dual-Port
Block RAM
Port A
Port B
Block RAM
• Most efficient memory implementation • Dedicated blocks of memory
• Ideal for most memory requirements • 4 to 104 memory blocks
• 18 kbits = 18,432 bits per block (16 k without parity bits) • Use multiple blocks for larger memories
• Builds both single and true dual-port RAMs • Synchronous write and read (different from distributed RAM)
92
Block RAM can have various configurations (port aspect ratios)
0
16,383
1
4,095
4 0
8,191
2 0
2047
8+1 0
1023
16+2 0
16k x 1
8k x 2 4k x 4
2k x (8+1)
1024 x (16+2)
93
Port A Out 18-Bit Width
Port B In 1k-Bit Depth
Port A In 1K-Bit Depth
Port B Out 18-Bit Width
DOA[17:0]
DOB[17:0]
WEA
ENA
RSTA
ADDRA[9:0]
CLKA
DIA[17:0]
WEB
ENB
RSTB
ADDRB[9:0]
CLKB
DIB[17:0]
Dual-Port Bus Flexibility
94
Embedded Multipliers in Spartan 3
18x18 bit signed multipliers with optional input/output registers
95
The Design Warrior’s Guide to FPGAs Devices, Tools, and Flows. ISBN 0750676043 Copyright © 2004 Mentor Graphics Corp. (www.mentor.com)
Multiplier-Accumulator - MAC
96
Xilinx XtremeDSP
• Starting with Virtex 4 family, Xilinx introduced DSP48 block for high-speed DSP on FPGAs
• Essentially a multiply-accumulate core with many other features
• Now also Spartan-3A and Virtex 5 have DSP blocks

17
97
DSP48 Slice: Virtex 4
98
Simplified Form of DSP48
Technology Low-‐cost High-‐performance
120/150 nm Virtex 2, 2 Pro
90 nm Spartan 3 Virtex 4
65 nm Virtex 5
45 nm Spartan 6
40 nm Virtex 6
Xilinx FPGA Devices Altera FPGA Devices
Technology Low-‐cost Mid-‐range High-‐performance
130 nm Cyclone Stra?x
90 nm Cyclone II StraKx II
65 nm Cyclone III Arria I StraKx III
40 nm Cyclone IV Arria II StraKx IV
All Projects - Organization
• Projects divided into phases
• Deliverables for each phase submitted through Blackboard at selected checkpoints and evaluated by the instructor and/or TA
• Feedback provided to students on a best effort basis
• Final report and codes submitted using Blackboard at the end of the semester
Honor Code Rules
• All students are expected to write and debug their codes individually
• Students are encouraged to help and support each other in all problems related to the - operation of the CAD tools, - basic understanding of the problem.

18
103
Course Objectives
• At the end of this course you should be able to: • Code in VHDL for synthesis • Decompose a digital system into a controller (FSM) and datapath,
and code accordingly • Write VHDL testbenches • Synthesize and implement digital systems on FPGAs • Effectively code digital systems for cryptography, signal
processing, and microprocessor applications • This knowledge will come about through homework, exams,
and an extensive project • The project in particular will help you know VHDL and the FPGA
design flow from beginning to end
104
Additional Skills Learned in the Project
• Reading & understanding specification of a complex algorithm
• Design of new hardware architectures based on existing architectures (datapath & controller) • Reading, understanding, and modifying existing
VHDL code • Using embedded resources of modern FPGAs • Characterizing performance of your codes for multiple FPGA families
105
Project Task 1
• Read the following chapters from the GMU technical report published at http://eprint.iacr.org/2010/445
• Chapter 1 Introduction & Motivation • Chapter 2 Methodology • Chapter 3 Comprehensive Designs of SHA-3 Candidates 3.1, 3.2 + subsection concerning your algorithm • Chapter 4 Design Summary and Results
• Download and get familiar with the package of a hash function assigned to you
http://csrc.nist.gov/groups/ST/hash/sha-3/Round2/submissions_rnd2.html • Read carefully the specification of your algorithm
106
Project Task 1 – cont.
In one week: Meeting with the instructor devoted to fully understanding the GMU report, specification, block diagrams, interface, and timing formulas.
In two weeks: Draft block diagrams of the - selected unrolled architecture - selected folded architecture. Corresponding timing formulas for execution time &
throughput.





























