Embed Size (px)
Citation preview

1
Knowledge Elicitation Plug-in for Protégé - Card Sorting and Laddering
A thesis submitted to the University of Manchester for the degree of Master
of Science in the Faculty of Science and Engineering
2005
Yimin Wang
School of Computer Science

2
List of Contents
List of Contents....................................................................................... 2
List of Figures......................................................................................... 5
Abstract ................................................................................................... 6
Declaration.............................................................................................. 7
Copyright Statement ............................................................................... 8
Acknowledgement .................................................................................. 9
1. Introduction....................................................................................... 10
1.1 Motivation ...................................................................................................10
1.2 Approach .....................................................................................................12
1.3 Thesis Outline..............................................................................................13
2. Knowledge Elicitation ...................................................................... 14
2.1 Overview .....................................................................................................14
2.1.1 History ............................................................................................................... 14
2.1.2 Traditional Knowledge Elicitation Methods ..................................................... 15
2.2 Card Sorting.................................................................................................17
2.3 Laddering.....................................................................................................19
2.4 AKT Project.................................................................................................20
2.5 PCPACK Toolkits .......................................................................................24
3. The Semantic Web............................................................................ 26
3.1 The Semantic Web Overview......................................................................26
3.2 Ontology and Ontology Engineering...........................................................28
3.2.1 Introduction ....................................................................................................... 28
3.2.2 Ontology Engineering ....................................................................................... 29
3.3 The CO-ODE Project ..................................................................................30
3.4 Protégé.........................................................................................................33
4. User-centered Design........................................................................ 35
4.1 Introduction to User-centered Design .........................................................35
4.2 Plug-in Design Principles ............................................................................37
4.3 Interview for User Participant Design.........................................................39
4.3.1 Unstructured Interview Design ......................................................................... 39
4.3.2 Structured Interview Design.............................................................................. 39

3
4.4 Analysis and Conclusion .............................................................................41
4.4.1 Unstructured Interview...................................................................................... 42
4.4.2 Structured Interview .......................................................................................... 42
4.5 Conclusion...................................................................................................44
5. Implementation of Knowledge Elicitation Plug-in........................... 46
5.1 Scope and Requirements .............................................................................46
5.2 Designing Issues and Structure ...................................................................48
5.2.1 Case Study of Interviews ................................................................................... 48
5.2.2 Requirement Analysis ........................................................................................ 49
5.2.3 System Structure Design.................................................................................... 53
5.2.4 Software Development Platform........................................................................ 54
5.2.5 Output Format................................................................................................... 55
5.3 Plug-in for Protégé ......................................................................................56
5.3.1 Common Technical Requirements ..................................................................... 56
5.3.2 Integration Method............................................................................................ 56
5.4 Implementation............................................................................................57
5.4.1 Implement Concepts .......................................................................................... 57
5.4.2 Software Java Classes ....................................................................................... 59
5.5 Conclusion...................................................................................................65
6. Software Testing and User Evaluation ............................................. 66
6.1 User Evaluation Methodology.....................................................................66
6.1.1 Software Setup................................................................................................... 66
6.1.2 Elicit Knowledge using card sorting ................................................................. 66
6.1.3 Laddering the Result.......................................................................................... 69
6.1.4 Using the transaction manager ......................................................................... 70
6.2 User Evaluation ...........................................................................................71
6.2.1 Interface Evaluation .......................................................................................... 72
6.2.2 Functional Evaluation ....................................................................................... 72
6.3 Evaluation Result Analysis and Conclusion................................................73
7. Conclusion and Future Works .......................................................... 75
7.1 General Conclusion .....................................................................................75
7.2 Future Work.................................................................................................76
References............................................................................................. 78
Appendix............................................................................................... 85
A. The Interviewees’ Profile .............................................................................85

4
B. User Testing and Evaluation Results ............................................................86
B.1 Results from Knowledge Management Community ............................................. 86
B.2 Results from Computer Science Students ............................................................. 87
B.3 Results from Business Student.............................................................................. 88
C. Software Setup..............................................................................................89

5
List of Figures Figure 2. 1: The Traditional card sorting (Nielsen, 1995)........................................18
Figure 2. 2: The Snapshot of Adaptiva System........................................................22
Figure 2. 3: The COHSE Structure...........................................................................23
Figure 2. 4: Amilcare System Snapshot ...................................................................23
Figure 2. 5: The PCPACK System Structure ...........................................................24
Figure 3. 1: The Classic Cake Diagram....................................................................26
Figure 3. 2: OWLViz Snapshot ................................................................................31
Figure 3. 3: Protégé Wizards Snapshot ....................................................................31
Figure 3. 4: OWLDoc Snapshot ...............................................................................32
Figure 3. 5: The Manchester Pizza Finder Snapshot ................................................33
Figure 3. 6: An Example of OWL Syntax................................................................34
Figure 4. 1: An Example of User Participant Design Activities ..............................37
Figure 5. 1: System Structure Diagram ....................................................................54
Figure 5. 2: Sample Code of Using Protégé API......................................................57
Figure 5. 3: A Diagram of Workflow Prototype ......................................................59
Figure 5. 4: Java Class JTransaction UML Diagram ...............................................60
Figure 5. 5: Java Class KE UML Diagram...............................................................61
Figure 5. 6: Java Class JCardSorting UML Diagram...............................................62
Figure 5. 7: Java Class JDocElicitation UML Diagram...........................................63
Figure 5. 8: Java Class JLadderingUML Diagram...................................................64
Figure 6. 1: The Document Elicitation Frame..........................................................67
Figure 6. 2: Card Sorting Tool .................................................................................68
Figure 6. 3: Card Sorting and Laddering Tool Appears Simultaneously .................69
Figure 6. 4: Laddering Tool......................................................................................70
Figure A. 1: Snapshot of Choosing KEToolTab ......................................................90

6
Abstract The next generation of Web is expected to be the Semantic Web. Ontologies have
been widely accepted as the primary method of representing knowledge in the
Semantic Web. Knowledge elicitation is usually the first step in building ontologies.
A number of knowledge elicitation toolkits such as Protégé have been developed to
assist users in this process. However, traditional knowledge elicitation techniques,
such as card sorting and laddering, are performed manually and therefore lack the
potential efficiency and correctness of automated or partially automated approaches.
In this thesis we implement a plug-in for Protégé that allows graphically eliciting
knowledge from document using card sorting and laddering approaches, hereby
promoting the process of building and maintaining ontologies. There is also an
opportunity to employ user-centred design principles to make user involved in the
design session that might be noticeably helpful while implementing the software
user interface. Furthermore, the future research will benefit from user testing and
evaluation. The current feedback from the user evaluation procedure shows that the
knowledge elicitation plug-in for Protégé developed in this project has already met
many of the users’ expectations and indeed saves users considerable time in their
daily work.

7
Declaration No portion of the work referred to in the thesis has been submitted in support of an
application for another degree or qualification of this or any other university or
other institute of learning.

8
Copyright Statement 1) Copyright in text of this thesis rests with the Author. Copies (by any process)
either in full, or of extracts, may be made only in accordance with instructions
given by the Author and lodged in the John Rylands University Library of
Manchester. Details may be obtained from the Librarian. This page must form
part of any such copies made. Further copies (by any process) of copies made
in accordance with such instructions may not be made without the permission
(in writing) of the Author.
2) The ownership of any intellectual property rights which may be described in
this thesis is vested in the University of Manchester, subject to any prior
agreement to the contrary, and may not be made available for use by third
parties without the written permission of the University, which will prescribe
the terms and conditions of any such agreement.
3) Further information on the conditions under which disclosures and exploitation
may take place is available from the Head of the School of Computer Science.

9
Acknowledgement I would like to express my appreciation to Prof. Alan Rector and Dr. Robert
Stevens from the School of Computer in University of Manchester for their sound
supervision, theoretical and practical guidance throughout this M.Sc. project. I also
want to express my special gratitude to those who have participated in the
user-centered design activities, including the pre-implementation design, software
testing and evaluation. They are Ms. Yiwen Zhu, Mr. Peihong Ke, Mr. Yun Zhang,
Mr. Dominic Matchett, Mr. Ian Pettman, Mr. Kearon McNicol, Mr. Matthew
Horridge and the other four anonymous users in W3China.org BBS forum system.
Thanks again for their kind help and valuable suggestions. Finally, I am sincerely
grateful for the support from my parents, Mr. Xiaohua Wang and Ms. Shuhua Chen.
Thank you for all.

10
1. Introduction 1.1 Motivation In today’s world, big organizations, like international enterprises or universities,
find it difficult to manage the large amount of documents and get knowledge from
them. Finding the accurate information effectively becomes an increasingly
noticeable topic, and especially while the information is mainly contained in the
internet-based documents. Many real cases show that the existing search engines
are not satisfiable in locating the information which has many different meanings in
different domains and people are easily getting confused while facing the versatile
sources of knowledge.
One example of the issues discussed in this thesis is the following. A philosopher
wants to search the state-of-the-art of the ontology concept development in the
philosophy domain and put the term “ontology” in an entry of search engine. While
the “enter” key is pressed, the philosopher will find the contents mainly focus on
the Semantic Web research, which is one of the most active interdisciplinary
research topics recently. Assume that our philosopher is so skilful in using search
engines that he can guess the key words which are best-fit to the proposed search
results. He inputs “ontology in philosophy” and finally gets a sort of
semi-philosopher-oriented result, which is still less philosophical. Another example
is the people’s name search problem - nearly everyone has tried to search his/her
name on internet and often, for those who are not famous enough, they will be
dizzy about the result and surprised by the number of people who share a same
name.
Semantically free documents will lead to the problems aforementioned, and the
scientists find out that the Semantic Web technologies will provide a solution by
generating semantically annotated documents. The terms in the documents have
their concepts and relationships, which are described by the ontologies, so that the
ontology-based Semantic Web query can eliminate the drawbacks of the key
word-based search, which might misunderstand the goal of search tasks. Ontology
is the essential component of such powerful Semantic Web tooling. Basically, now,
ontology is not only a philosophical term, but also widely cited by computer

11
scientist, especially by people from knowledge engineering community and Web
community, which emerge to form the Semantic Web community.
Building ontology usually includes knowledge elicitation as the first step, which is
also known as an important branch of knowledge acquisition. Traditional
knowledge elicitation is a kind of labour-intensive manual work and extremely
time-consuming, so more usable and handy toolkits for building ontology are
highly needed. Protégé (Noy, Sintek, Decker, Crubezy, Fergerson, Musen, 2001) is
the one of the most popular ontology editors (Lambrix, Habbouche, Pérez, 2002),
enabling user to create ontologies by defining the concepts, specifications,
relationships, annotations and other information of terms in a certain domain.
To do so, domain experts need to be able to visualize and manipulate their ideas
thoroughly and flexibly before they structure it in the Protégé system. Several
standard knowledge acquisition/elicitation techniques, such as repertory grid and
laddering, have been developed to help in organising domain experts’ ideas into
basic structures and to recover tacit knowledge. Card sorting have been used for
several decades, and was systematically formalised by Rugg and McGeorge during
1990s, and it is remarkably useful for finding out how people categorise things
(Rugg & McGeoge, 1997). Laddering was firstly introduced by Hinkle (1965), a
clinical psychologist, in order to model the concepts and beliefs of people and by an
unambiguous and systematic approach. In the field of market research, laddering
plays an essential part in evaluating people’s concepts of goals and values. Most of
these knowledge acquisition/elicitation techniques are visual or graphical. But the
traditional card sorting and laddering methods are extremely difficult to be
managed and tracked back - you will find it is nearly impossible to keep the record
for hundreds of cards or paper pieces and go back to previous status without a
complicated series of actions, such as video tape recording, searching and playing.
We do need some computer-aided knowledge elicitation tools to automate those
activities.
The goal of this thesis and its corresponding projects will be to develop a Protégé
plug-in to help people in this process. Otherwise, there is an opportunity for a
graphical direct manipulation interface and user-centered design, i.e. interviews are

12
required to collect the users’ manners information while they are eliciting
knowledge.
1.2 Approach This thesis introduces a straightforward framework for building a knowledge
elicitation tool as Protégé plug-in. The approach combines classical methodologies
for manual knowledge elicitation activities with support of a heuristic toolkit. Two
methods for knowledge elicitation are applied in this toolkit. The first one is card
sorting. This step is supported by manually retrieving interested concepts from a set
of domain texts, which come from the selection of domain experts. The second
elicitation approach, laddering, takes a completed card sorting results as a basic
vocabulary reference set, and the users convert it into a bottom-up representation by
adopting some pre-defined or user-defined relationships. Alternatively, users may
directly use an existing pile of terms to start their laddering process. Heuristic
questions defined with each relationship will appear to help user in organising the
hierarchical structure of the laddering session. The results of these steps are
assessed to assemble a first version of the output information, which is then
accessible by this plug-in or Protégé system for future development. The format of
this output file will be one of the design concerns, and the pros and cons will be
also discussed. The output can eventually be extended and converted to the domain
ontologies by possibly, an automatic ontology generator.
User-centered design methods were used to interview the real users to collect the
traditional or intuitive manners of using card sorting and laddering, by which the
protocols between the users and the software system are established. Furthermore,
the user-defined relationships in laddering tool are other applications for
user-centered design techniques.
In collaboration with the CO-ODE project (Rector, 2002) of Medical Informatics
group in University of Manchester, the main focus of this thesis is to develop a
plug-in for building the knowledge elicitation environment in a widely used
software system. The process of building such a plug-in has been applied to build
the card sorting and laddering plug-in for Protégé. Within this context, the

13
conversion of a human concept into a machine readable output document and
evaluation of two knowledge elicitation tools which especially, constitute the
central parts of the scientific research work. The first evaluation is to get software
testing feedback from domain experts and other potential users, then it will be
analysed and evaluated in comparison with the traditional card sorting and
laddering actions.
1.3 Thesis Outline Chapter 2 - 4 provide the theoretical background for this thesis, in which the second
chapter introduces traditional knowledge elicitation techniques, including the
limitation of these methods, and two recent applications of knowledge elicitation
techniques, the AKT project and PCPACK toolkits are also briefly investigated. In
Chapter 3, a referral of the Semantic Web technology is given, comprising the
theory of ontology engineering approaches and their various representations. It also
gives an overview about the Protégé system the CO-ODE project, which provides a
broader context within which the research work of this thesis is embedded. Chapter
4 describes the basic concepts and principles of user-centered design and the
contriving of user interviews for collecting guidelines to framing the plug-in.
In Chapter 5 the application of the entire plug-in design session will be planned in
terms of the above-mentioned project to establish a plug-in for the popular software
system - Protégé. The conversional procedure of human conceptual structure to
machine-based output is discussed there in detail.
Chapters 6 show the result and analysis of the testing and evaluation of this plug-in
implemented by using collaborative design methods, constituting parts of the
framework. Finally, Chapter 7 summarise the findings of this project and offers an
overview for future work and complementary research.

14
2. Knowledge Elicitation Knowledge is everywhere. It could be the texts in the books, the web-based
documents, the sound from cassettes or the video recorded on DVD disc. Many
people in the Knowledge Management community are working on how to manage
the various kinds of knowledge with effectiveness, efficiency and correctness,
whereas sometimes they are not very successful in doing this. Why? Because
knowledge is too versatile to be easily handled, e.g. it is quite difficult to find out a
specific sentence in a book in the library, although we know this sentence should be
there.
Things are getting changed after the growing popularity of personal computer,
obviously, because its storage system makes people easy to save their books by
converting them into digital version - although usually typing is a labour-intensive
work. Now we have numerous sources of texts over the internet, from which we
elicit knowledge to acquire the information we are interested or expertise in.
Knowledge acquisition is a process which extracts knowledge from sources of
expertise and transfers it into knowledge base. Knowledge elicitation is the most
important branch of knowledge acquisition, obtaining knowledge from a human
domain expert for use in a specific area (Cooke, 1994).
2.1 Overview As knowledge elicitation is usually the first step to build ontologies, it becomes the
first thing to be investigated in this thesis.
2.1.1 History From mid 1980s, people began to do research on expert systems as a sub-discipline
of knowledge engineering, and it was also the starting point of scientific research
on knowledge elicitation. Expert systems are built to help people in problem
solving and decision making processes and they have specific knowledge in certain
domain which is acquired from human domain experts. To solve expert problems, it
is getting clear that it could not be done by a common strategy, as much as to some
domain issues (Glaser & Chi, 1988).

15
Knowledge elicitation is not easy to implement, because:
Experts are normally busy and difficult to find
Experts may have different points of view of knowledge
Uses of knowledge vary based on different background of experts.
It is reasonable to make it unambiguous that the domain experts’ common sense, as
well as their origin and explanations of different knowledge. The knowledge in a
certain domain includes:
Domain concepts
Specification of concepts
Relationship between concepts
Related activities about concepts
Thus, people begin to try to develop knowledge elicitation techniques to get
knowledge with effectiveness, efficiency and correctness. A number of these
methods are borrowed from cognitive science and other disciplines such as
anthropology, ethnography, and business administration (Boose & Gaines, 1988;
1990; Hoffman, 1987). In the mean time, other applications, including computer
interface design, agent system, e-learning system, began to use knowledge
elicitation methods to enhance the functionality of their software system. Taking
Human-Computer Interaction and human factors design (e.g., Benysh, Koubek, &
Calvez, 1993) for example, knowledge elicitation techniques are effectively used in
early 1990s, with the popularity of graphical based personal computer system
(Shadbolt & Burton, 1995).
Knowledge elicitation has its new additional aspects from the influence of the
Semantic Web technology on knowledge engineering in early 2000s, which will be
discussed in Chapter 3 of this thesis.
2.1.2 Traditional Knowledge Elicitation Methods There are four categories of knowledge elicitation methods identified and briefly
described. Within each group there are a number of knowledge elicitation methods
and variations on individual methods (Cooke, 1994).

16
Observation
Knowledge elicitation usually starts with observations of tasks within the
domain of expertise. Observations can provide an overall impression of the
specific domain, can help people to generate initial concepts of the domain, and
identify any issues to be dealt with during later phases of knowledge elicitation.
Observations can occur in the natural process, thus providing preliminary
glimpses of actual behavior that can be used for future tasks and other resource
for potential knowledge elicitation activities.
Interviews
It is the most straightforward to directly ask someone to know something. This
is a kind of unstructured interview, the most frequently application of all the
eliciting methods in 1980s (Cullen & Bryman, 1988). Unlike the free and open
unstructured interview, structured interviews have pre-determined contents or
orders. The two kinds of interview have their own proper purposes and should
be used in different scenario.
Process Tracing
Process tracing includes a collection of sequential behaviours and the analysis
of the outcome event protocols so that the inferences can be deduced from
underlying cognitive procedures. Therefore, these techniques are usually used
to elicit session-based information, for instance, conditional rules used in
making decisions, or the sequence to which various cues are eventually
attended.
Conceptual Methods
Conceptual methods elicit conceptual structure in the domain specified
knowledge and their inter-connections. Several stages are normally required
and each of them is associated with a variety of approaches. The stages are:
a) The elicitation of classes or concepts through interviews or analysis of
documentation.
b) The empirical concepts relationship from experts.
c) Eliminate the redundancy the concepts.
d) Interpretation of the output conceptualisation.

17
The four groups of knowledge elicitation methods embrace the major current
existing techniques. However, new approaches are continuously being developed
for a specified usage or other purposes. In a nutshell, the traditional knowledge
elicitation methods are the origin of the more specified techniques such as laddering
and card sorting that will be addressed in detail in the following sections.
2.2 Card Sorting Card sorting is a comprehensive technique of knowledge elicitation and now is
being used in several disciplines such as knowledge engineering, Psychology, and
Marketing. In the field of knowledge elicitation, card sorting is considered to be one
of the most effective ways for eliciting the domain experts’ idea about the
knowledge structure.
The traditional card sorting method generally consists of a pile of cards with size of
credit card, created by the researchers, who write or print the domain concepts on
cards. The domain experts or other users sort the cards to piles or groups and
describe the reasons and criteria of the way of sorting. Video tape recording both
the acts and voices of the entire procedure is the best approach for future analysis
because it is the most convenience way to track back, although it is somewhat
complicated to get the equipments prepared.
Many evidences show that card sorting has a lot of positive aspects in making a
useful and reasonable elicitation experiment, including helping the respondents to
recall the domain concepts; identifying the problems with different level;
discovering the feedback from different groups of people; providing a structuralised,
tree-like concepts pile for future processing, like laddering; fast acting and easy
handling (Rugg, Corbridge, Major, Shadbolt & Burton, 1992; Rugg, McGeorge,
1997; Nurmuliani, Zowghi & Williams, 2004).
The diagram below shows a snapshot of a typical card sorting performed manually,
in which we can find a general concept about how people sort the cards.

18
Figure 2. 1: The Traditional card sorting (Nielsen, 1995)
Nevertheless, the drawbacks of manual card sorting are also clear:
Easy to be destroyed
Imagine if a blast of wind blows the window agape while we are sorting, the
order of the cards will be disarranged, especially if the piles consist of hundreds
of cards. Although the card sorting can be performed in a windtight office, a
cup of coffee might cause the same result.
Difficult to be managed
If we record the whole procedure by the video tape recorder, it is difficult to
find the tape directly without watching the contents, because the information on
side strip of the tape is usually not sufficient enough. Consider when the
researchers want to find a specific task performed on an unknown date, they
have to search the tape from the start to the end and try another one if the
current tape is not the want.
Transfer bottle-neck
Basically, the video file is much difficult to be handled. It is time consuming to
transfer the video information from tapes to PC and compress it to a small size
file, or just interchange the large size video file via internet. Make a duplicate
of the tape and send it as a postal parcel could be done but an extra tape

19
duplicator will be required and unexpectable exception which makes the tape
unreadable may occur while delivering.
In this thesis, a computer based card sorting tool will be introduced and the
problems aforecited are completely solved. With computers involved with back-up
copies of documents, people are no longer afraid of the physical violation caused by
the environment. Transaction based management mechanism makes the task
handling straightforward and the documents are comparatively small size,
syntax-based text files with ease of delivery via internet. A detailed introduction,
design implementation and evaluation of this software system will be given in
Chapter 5 and 6.
2.3 Laddering Laddering was first introduced by Hinkle (1965) as an approach of eliciting the
conceptualised and structuralised person’s ideas in a straightforward and systematic
mean. Based on the Personal Construct Theory (Kelly, 1955), Hinkle mainly
focused on the clinical psychology. Thereafter, laddering was well-developed to be
used in market research to discover the goals and values of the customers in
choosing the different brands of products (e.g. Reynolds & Gutman, 1988; Wansink,
2003).
Recently, laddering were widely used in the field of knowledge elicitation, with the
increasing popularity of knowledge engineering and expert system research,
whereas the purposes of eliciting people’s goals and values remained the same (e.g.
Corbridge, Rugg, Major, Shadbolt & Burton, 1994; Rugg, Eva, Mahmood, Rehman,
Andrews & Davies, 2002). The people from knowledge elicitation community have
developed a well-established range of formal semantics, procedures and notation
for building ladders. But obviously the Requirements Engineering in this field has
different and broader theoretical foundations than in clinical psychology and in
market research (Rugg & McGeorge 2002).
Ontology development is normally starting with the knowledge elicitation phase
therefore laddering techniques plays an important role in discovering the potential

20
relationships between the domain concepts. The laddering method is usually used
combining with other knowledge elicitation methods such as card sorting. The
subjects and objects within the ontology are inter-connected with several kinds of
relationships elicited from the domain experts via laddering, and the structural
source of subjects and objects are built via card sorting. As ontology is the
structuralised domain knowledge base from experts, we can realise that laddering is
undoubtedly essential while developing ontologies.
Based on the Rugg and McGeorge’s (1995; 2002) categorisation, the laddering can
be used for three major purposes.
laddering to elicit sub-classes
Taking fruit concepts for example, when the system gives the hints to users by
telling them to give some subclasses for “fruit”, the users might say “apple”
and “orange”. This question continues and the user says “granny smith” and
“royal gala” as the subclasses of “apple”. The questioning system interactively
gives hints to the users and help user to build the ladders.
laddering to elicit explanations
If the problem here is to elicit the explanations from the users, or interviewees,
the questioning system will ask “Which one do you prefer, apple or meat?”,
and then record down the feedback from the users as the explanation of their
choices.
laddering to elicit goals and values
At this stage the system have the fundamental structure and explanations of the
concepts, so it is possible to discover the goals and values for each user. If user
chooses the apple, or always prefers vegetables or fruit, he might be a
vegetarian; oppositely, if he loves meat more, he should be a meat-fan.
2.4 AKT Project The big AKT project is a collaborative framework between five internationally
recognised UK universities, and it aims to develop and extend a range of

21
technologies providing integrated methods and services for the capture, modelling,
publishing, reuse and management of knowledge (Shadbolt, 2003). The AKT
project consists of six major aspects in the field of knowledge technologies, and
they are interrelated with each other with various research topics. The six aspects
are:
knowledge acquisition
Knowledge Modelling
Knowledge Retrieval
Knowledge Reuse
Knowledge Publishing
Knowledge Maintenance
In this thesis, we are more concerning about the knowledge acquisition
technologies because knowledge elicitation is a major sub-field of knowledge
acquisition. There are many research works with different emphasises within the
knowledge acquisition section of AKT project, in which three projects are tightly
related to this thesis and will be introduced below.
The first one is Adaptiva, A user-centered ontology building environment, based on
using multiple strategies to construct ontology, minimising user input by using
adaptive information extraction (Brewster, Ciravegna & Wilks, 2002; 2003).
Potentially, this project will help building the document elicitation tool by
enhancing its functionality.

22
Figure 2. 2: The Snapshot of Adaptiva System
Secondly, the COHSE project researches methods to improve significantly the
quality, consistency and breadth of linking of WWW documents at retrieval and
authoring time (Carr, Bechhofer, Goble, Hall, 2001; Bechhofer, Goble, Carr &
Kampa, 2002). COHSE project could be used to annotate the web documents to
help users in eliciting the concepts from the documents directly on popular web
browsers (e.g. Firefox, 2005) via a proxy server, which are used to pre-process to
webpages.

23
Figure 2. 3: The COHSE Structure
The third one is an adaptive information extraction tool designed to support
document annotation for the Semantic Web, called Amilcare (Ciravegna, 2001). It
gives a new algorithm to automatically extract knowledge from documents with
comparatively high correctness and efficiency.
Figure 2. 4: Amilcare System Snapshot

24
In all, the three projects provide new approaches in helping the users to elicit
knowledge from various sources of documents, including pure text, hyper text and
other web documents, which are also the major information resource of the plug-in
introduced in this dissertation.
2.5 PCPACK Toolkits There is a powerful toolkit called PCPACK for modelling, distributing,
management and reuse of knowledge within business context. This toolkit has been
published for over 10 years and many global enterprises have used this system and
given the feedbacks for the future development. With the growing popularity of
new technologies and market demands, for instance, the integration of
commonKADS method (Schreiber, Akkermans, Anjewierden, de Hoog, Shadbolt,
van de Velde & Wielinga, 2000), the PCPACK has released several updated
versions and now it becomes one of the most popular knowledge engineering
toolkits around the world.
The functionalities of PCPACK are mainly capturing, structuring, validating and
reusing knowledge, and implemented with several independent, but connected tools,
including Ladder Tool, Matrix Tool, Annotation Tool, Diagram Tool, Protocol Tool,
Publisher Tool, Diagram Template Tool (Milton, 2005).
Figure 2. 5: The PCPACK System Structure
The Ladder Tool in PCPACK enables the user to build various hierarchies of

25
knowledge. The laddering tool in the knowledge elicitation plug-in software system
introduced in this thesis is not a simple transplant of the Ladder Tool in the
PCPACK whereas they have a shared theoretical background about laddering
method. The laddering tool in this knowledge elicitation plug-in is developed
purely based on the results of practical interviews participated by a certain number
of domain experts and potential users, using empirical approach on performing the
laddering method. Furthermore, combining the card sorting and laddering tool is
also a reasonable implementation because many domain experts are using the result
of card sorting while doing laddering. The detailed information of the experiments
and interviews for designing this knowledge elicitation plug-in, with emphasis of
user-centered design and user-participant design will be discussed in the Chapter 4
and also in Appendix.

26
3. The Semantic Web This chapter introduces the overview of the Semantic Web technology, the theory
of ontology engineering, a summary of the CO-ODE project and the Protégé system
as parent platform of this knowledge elicitation plug-in. In general, this chapter
provides the theoretical foundations in the domain of Semantic Web for this thesis.
3.1 The Semantic Web Overview Firstly introduced by Tim Berners-Lee (Berners-Lee, 1996), the Semantic Web
technology now is one of the most active research topics during the recent years. It
combines the strength of knowledge engineering community and Web community
to discovery the new technologies for various research domains, such as
Knowledge System Design, Web Service, Grid Computing, e-Science, e-Commerce
and so on. Tim Berners-Lee and his colleagues have stated a clear definition: “The
Semantic Web is an extension of the current web in which information is given
well-defined meaning, better enabling computers and people to work in
cooperation” (Berners-Lee, Hendler & Lassila, 2001).
Figure 3. 1: The Classic Cake Diagram
Basically the Semantic Web technologies aim to link multiple source of information
to help people to easily access and make information machine readable. The large
amount of information on the Web makes people difficult to locate their targets
whereas the information has been published on the Web. Although search engines
can help people in this task but almost everyone has experienced finding topics in
tens of thousands search results, which is tough. XML technology (Bray, Paoli,

27
Sperberg-McQueen & Maler, 2000) are employed so that machine can directly
process the large scale information data sets and make them reusable. But
unfortunately, neither the traditional HTML nor the XML documents can provide
semantically annotated information which is required in locating resource with
specific demands.
One the one hand, we need the extensible feature of XML because it will be useful
for future potential extensions. On the other hand, we want to add semantic
information into the HTML documents with XML syntax, thereafter the
information is unambiguously defined and identified on the World Wide Web and
interconnected with semantic relationships. The source of the information in the
Semantic Web technology is defined as URI (Uniform Resource Identifier) for the
purpose of being unique and linked (Berners-Lee, Fielding, Irvine & Masinter,
1998). A URI is a string for identifying an abstract or physical resource on the web
with traditional URL-like format.
In order to define the relationships between the resources on the Web, we need a
new syntax-based document to exchange machine readable information on the Web
by providing the functionality of machine understandable statement so that the
machines are interoperable. The triple structure is therefore introduced here to
implement the Resource Description Frame work, and we use RDF as the extension
file name (Lassila & Swick, 1999). This triple structure is natural language
expression format which consists of a subject, predicate and object. An example of
RDF expression is:
<http://yimin.wang.cn> <http://www.family.com/schema/isSonOf> <http://shuhua.chen.cn>
Yimin Wang here is a person as the subject, is son of Shuhua Chen, which
“isSonOf” is the predicate and Shuhua Chen is the object. RDF statement like this
enables people directly locate the resource using URI published on WWW, and can
be reused by others. As aforementioned, while the RDF statements are encoded
with XML syntax, it will be machine readable and interchangeable. The remaining
problem here is that the RDF statements are semantically free and while computers
are performing searching tasks on the WWW, they don’t understand Yimin Wang is

28
a human being but not a car or other things, although a knowledgeable person will
understand this. In order to make machine understandable of the expression we
have made, ontologies are applied to explain the properties of the relationships.
3.2 Ontology and Ontology Engineering The plug-in described in this thesis aims to provide the first step to build ontologies
- it elicits the knowledge from domain experts who will consequently structure the
knowledge. This section will basically introduce the development of ontology
theories and the ontology engineering techniques.
3.2.1 Introduction The term “ontology” is borrowed from the Philosophy discipline and extended to
the Semantic Web field as the knowledge base. In the domain of the Semantic Web
research area, ontology is described as an explicit formal description of
conceptualisation (Gruber, 1993), so it is reasonable that people may have totally
different descriptions and explanations for a same object they want to describe,
based on their culture backgrounds, knowledge level, conceptual model, cognitive
methods and many other aspects. Ontologies, therefore, are difficult to be built.
There are many different ways of representing the ontologies, including
syntax-based ontology language and UML diagram. Many research groups has
developed several different ontology languages: RDFS (Brickley & Guha, 2002);
DAML+OIL (Conolly, Harmelen, Horrocks, McGuinness, Patel-Schneider & Stein,
2001), OWL (Patel-Schneider, Horrocks & Harmelen, 2002) and KAON developed
by AIFB in Karlsruhe, in which DAML+OIL and KAON are extensions of RDFS
while OWL extends the DAML+OIL. The UML diagram presentation of ontologies
is not widely employed because of its limitation as diagrams, which is difficult to
be processed by machine and represented in large scale, although easy to be
understood by human beings.
By using ontologies, it is no longer difficult to semantically describe the example
mentioned in the section introducing RDF, defining the relationships between the
subjects and objects. After building the ontology including the information from

29
RDF statement, the contents of syntax-based document are:
<?xml version=“1.0” ?>
- <rdf:RDF xmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:xsd=“http://www.w3.org/2001/XMLSchema#”
xmlns:rdfs=“http://www.w3.org/2000/01/rdf-schema#”
xmlns:owl=“http://www.w3.org/2002/07/owl#”
xmlns=“http://www.owl-ontologies.com/unnamed.owl#”
xml:base=“http://www.owl-ontologies.com/unnamed.owl”>
<owl:Ontology rdf:about=““ />
<owl:Class rdf:ID=“Shuhua Chen” />
- <owl:Class rdf:ID=“Yimin Wang”>
<rdfs:subClassOf rdf:resource=“http://www.w3.org/2002/07/owl#Thing” />
- <rdfs:subClassOf>
- <owl:Restriction>
- <owl:onProperty>
<owl:ObjectProperty rdf:ID=“isSonOf” />
</owl:onProperty>
<owl:someValuesFrom rdf:resource=“#Shuhua Chen” />
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
</rdf:RDF>
From encapsulated structure of this document, it is easy to discover the syntax level
relationships between XML, RDF, RDFS and OWL.
3.2.2 Ontology Engineering How to build ontologies with efficiency and reusability is one of the major concerns
in the domain of ontology engineering. As one of the most popular ontology editor,
Protégé are widely used by researchers to build ontologies and their experience
show that manually building ontologies is quite a labour-intensive work. The
Protégé users need to input and edit the concepts in ontology one by one, including
typing the names, editing the annotation, choosing the different properties and
defining the restrictions. If there are thousands of concepts in one task, this work
will be extremely time consuming. Researchers obviously don’t want to spend their
time on this repetitive, non-innovative work.
Actually, not many general approaches have been invented for building ontologies
and few of them have been sufficiently proved to be domain-free. The published
methodologies are mainly general frameworks with abstract descriptions and
outlines without a detailed guideline of how to build ontologies (Fernandez,

30
Gomez-Perez, Pazos Sierra, 1999), thus thereafter many ontology engineering
projects has been launched to find out a proper way to build ontologies.
Ideally the goal of ontology engineering is to enable the machine to build a certain
amount of the ontologies, but even in this case, human beings are required to create
ontologies by hand, so what they need is a more efficient approach to achieve their
demands. The card sorting tool in this knowledge elicitation plug-in gives an
opportunity to create ontologies graphically, by firstly initialising the ontology
structure and basic relationship between concepts. Thereafter, people are able to
save the raw ontology and load it into a broader ontology editor like Protégé for
future development. This tool releases people from the most intensive work in the
process of ontology engineering - modelling the basic structure of ontologies.
3.3 The CO-ODE Project Collaborative Open Ontology Development Environment, CO-ODE is a two year
project which is focused on developing tools of ontology building (Rector, 2002).
The knowledge elicitation plug-in described in this thesis is also part of this project.
The aims and objectives of this project are, in short, to provide an enhanced
ontology development and knowledge acquisition environment for domain experts
and to integrate other research outcomes, e.g. the AKT project, into the existing
popular tool like Protégé, using User participant design techniques. As a part of
the CO-ODE project, this knowledge elicitation plug-in undoubtedly share the same
design principles with the CO-ODE project, which include putting user cooperation
in an essential position while developing the tools in existing toolkits.
The research outcome of CO-ODE project is a range of Protégé plug-ins includes
(Drummond, 2005):
OWLViz - A Plug-in for graphical and structural view of the ontology.
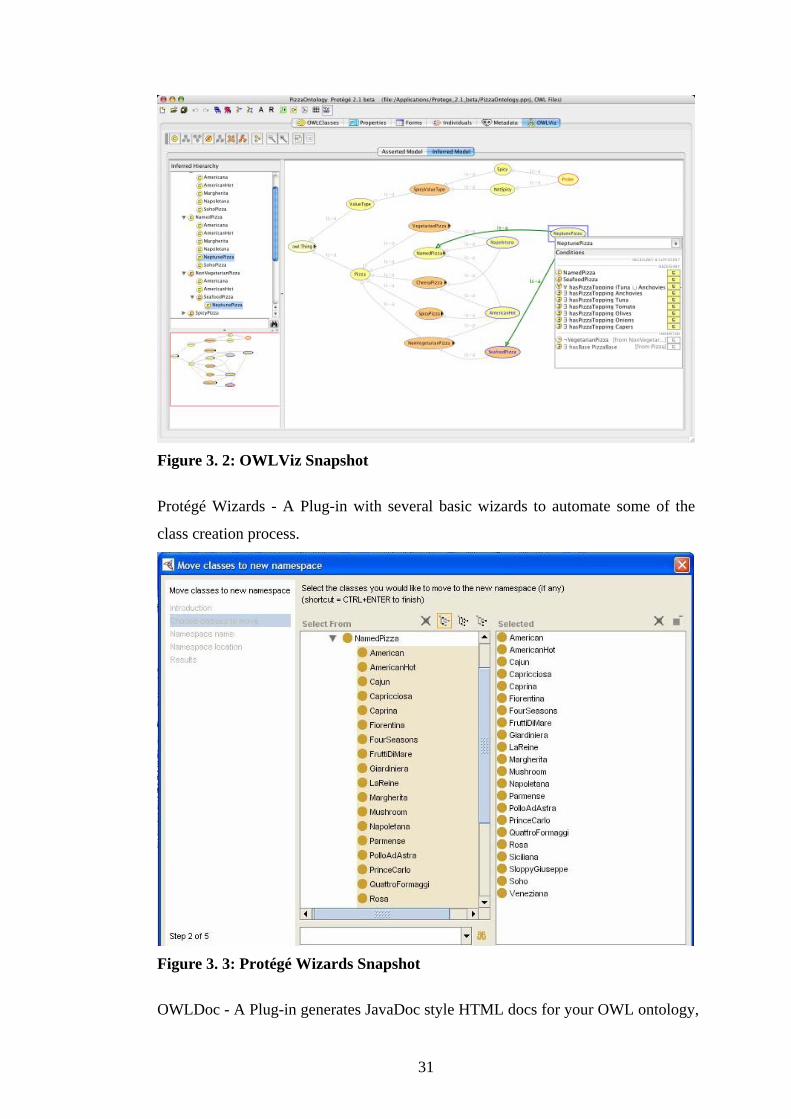
31
Figure 3. 2: OWLViz Snapshot
Protégé Wizards - A Plug-in with several basic wizards to automate some of the
class creation process.
Figure 3. 3: Protégé Wizards Snapshot
OWLDoc - A Plug-in generates JavaDoc style HTML docs for your OWL ontology,

32
which can be used to have a straightforward view of the ontology structure.
Figure 3. 4: OWLDoc Snapshot
The Manchester Pizza Finder is an interesting application, with user-friendly
interface which uses pizza ontology and the RACER inference system to query the
valid pizza types. It is a good start point for the beginners who don’t have much
knowledge about how the classifier and the ontology work together to implement
semantic query.

33
Figure 3. 5: The Manchester Pizza Finder Snapshot
They are just part of the plug-in set within the CO-ODE project with more
emphasis on ontology engineering based on the view of knowledge elicitation
techniques. Now the CO-ODE project has a one year extension and is expected to
publish more applications with refinements, including the plug-in introduced in this
thesis.
3.4 Protégé Protégé is an ontology editor and knowledge acquisition tool mainly developed by
Medical Informatics group of Stanford University. Meanwhile, Protégé is a
community work, and a number of outstanding research groups around the world
have contributed over 70 plug-ins, including the Medical Informatics group in
University of Manchester, where the tools in thesis is being developed.
Protégé allows users to create ontologies and edit the data entry forms for data input.
The Graphical User Interface (GUI) of Protégé is well-designed and being
improved along with the release of the updated versions. The example of editing
“Yimin Wang is the son of Shuhua Chen” statement and saving it into ontology in

34
Protégé 2000, 3.1 Beta, is like the following screenshot. Through this example, we
may find that the layout, working procedure and outcome of the Protégé user
interface are quite straightforward and easy to be identified.
Figure 3. 6: An Example of OWL Syntax
The Protégé has a good extendibility so that the researchers can develop their own
tools to extend the functionalities of Protégé system, and then integrate their tools
into Protégé system easily and seamlessly. In terms of the productivity and
compatibility with the existing Protégé system, Protégé use Java (Sun
Microsystems, Inc., 2005) platform as a unified development environment,
herewith cross operation system developers could generate and test their codes
smoothly. The plug-in development for Protégé is using the Protégé 2000
application programming interface (API) (Musen, Fergerson, Grosso, Noy, Crubezy
& Gennari, 2000).
To check the satisfiability of the ontologies, it is crucial to link to the reasoners
from Protégé user interface. Protégé 2000 also supports reasoners such as FaCT
(Horrocks, 1998) and RACER (Haarslev & Möller 2001).
Protégé now is a well-established toolkit and expected to be continually developed
collaboratively within the Protégé community.

35
4. User-centered Design This chapter aims to generate a series of principles for designing the plug-in with
strong emphasis in the user interface design approaches. We plan to employ
user-participant design techniques to achieve this demanding goal. Thus, by given a
brief introduction of user-centered design methods and principles, the guidelines for
designing this plug-in will be brought forward. Consequently, we will discuss the
user interview motivations, procedures and results, which are expected to play an
important role in the future development.
4.1 Introduction to User-centered Design In the Human-Computer Interaction (HCI) research field, user-centered design, also
known as usability engineering, is one of the most essential methodology which is
now widely used in various disciplines, including Software Engineering,
Knowledge Management, Information System and so on (Norman & Draper, 1986;
Shneiderman, 1998). Otherwise, one of the aims and objectives of CO-ODE project
is to provide a user-oriented toolset (Rector, 2002), so the user-centered design
techniques will be kept in mind throughout the entire plug-in design life cycle.
The importance of usability engineering has been repeatedly stated by outlining
principles or case studying from difference research agencies and groups. The
NASA usability engineering team (2002) listed “10 Great Reasons to do Usability”,
which are very sensible and interesting. Generally, they think it could make
developers look smart and professional, users more productive and happy; it saves
the development cycle time, money, maintenance effort and support resource; and
finally, it gives you a better sleep. It is a list of casual reasons, whereas probably
with redundancy. A famous case is the IBM website example, (Tedeschi, 1999) in
which shows that the most frequently used function is “search”, because users
cannot locate the target resource while they are navigating the IBM website. And
the second place belongs to the “help” link - obviously people want to get some
help after their have failed in searching the information. After a ten-week project to
redesign the IBM website, although the costs is over million dollars, the help link
decreased 84% click times and the web-based sales amount is 4 times increased.

36
The user-centered design techniques include a range of procedures, guidelines and
software tools which are used to help researchers and developers in determining the
system design matters. The importance of the user-centered design techniques is to
assist the developer in assuring that their relevant design activities are considered to
be a user-oriented manner (Rauterberg 2003). There are three main categories of
principles to support user-centered design: learnability, flexibility and robustness
(Dix, Finlay, Abowd & Beale, 2004). Learnability focuses on the design
performance when the users initialise the use of the system at the first time.
Flexibility concerns with the various means of users and system exchanging
information. Robustness is clear to have the steady, dependable and fault-tolerance
system running environment. All those principles refer to a high standard design
procedure and the use of various design techniques.
User participant design is to make users involved in the software design process, by
interviewing various groups of users based on certain requirements, such as age,
occupation, gender, culture and so on. The interview result will be gathered and
analysed in order to discover the goals and values of the target user group. The
techniques of user participant design are obligatory while designing this knowledge
elicitation plug-in, because the target user group is mainly scientific researchers
with different disciplines, requirements, personal preferences, ways of working and
thinking.
The User participant design includes a sort of manual activities, such as using the
paper as window frames; cutting the paper into rectangles with difference size as
dialogues and menus; choosing difference colours as different selection feedback;
drawing, dragging while necessary to modify the interface; taking the picture while
performing activities and many other actions. All these are performed by the real
users. The photo below is made by this thesis author and taken from the CS617
Interactive System Design learning module in University of Manchester, taught by
Dr. Mark van Harmelen.

37
Figure 4. 1: An Example of User Participant Design Activities
4.2 Plug-in Design Principles While developing the plug-in of an existing system, including the design of system
structure and user interface, it is essential to outline a list of design principles. In
this system, based on the requirements and features as a knowledge elicitation tool
and a Protégé plug-in, this plug-in should:
have simple and tidy interface
This plug-in is user-oriented software but not a program running at the
background, so a well-designed and intuitionistic user interface is highly
required, making users familiarise the software fast and easily.
have flexible operating options
According to the book written by Dix and his colleagues (2004), as one of the
important categories of guidance for usability engineering, flexibility is
considered to be a core design issue. Providing versatile means of operating
options will make users easily adapt to the workflow of this software, and they

38
can find their preferred way of performing tasks.
make user participate in the design procedure
Both the card sorting and laddering methods are traditionally performed
manually, so it is sensible to hold some interviews to find out the ways of
people sorting cards and doing laddering, which will be the substantial sources
of experience while monitoring those activities on machine. This knowledge
elicitation plug-in aims to elicit knowledge following different disciplines,
environments and use cases, thus the interviewees are required to be diverse in
fields of expertise, culture backgrounds and manners.
use existing APIs (Application Program Interface)
Java has a strong extensibility and many existing APIs can be directly used by
developers to speed up their development. Java API doesn’t consist the
methods for processing RDF and OWL syntax-based documents, but many
other APIs, like Jena (McBride, 2002) API and Protégé OWL Plug-in
(Knublauch, Musen & Rector, 2004) API, provide many options to handle web
documents with RDF and OWL syntax. When users need to output the runtime
status into RDF or OWL file, the program could load those APIs to complete
this task.
work compatibly with Protégé
As a plug-in for Protégé, this software should certainly work well with the
Protégé system. Concerning the compatibility of other important plug-ins such
as Protégé OWL plug-in, it is ideal to share some tab-widgets with this
software, though it requires the collaboration of the developers from different
groups. Obviously it will enhance the overall performance for this knowledge
elicitation plug-in.
be extensible for future development
Because obviously, besides card sorting and laddering, there are many other
methods in the field of knowledge elicitation, this plug-in is reasonable to have
the extensibility to have another tools integrated, like repertory grid tool,
diagram tool, matrix tool and other tools mentioned in Chapter 2. Thanks to

39
Java’s flexible and strong extensibility, it is easy to integrate other independent
Java programs into an existing system. So what need to do is just designing a
suitable interface layout to arrange the location for the extra tools.
4.3 Interview for User Participant Design It is necessary to set a predefined series of interviews and invite potential users to
participate in these interviews in order to collect the design clues. Some interview
methods such as unstructured interview and structured interview should be
employed for different purposes.
4.3.1 Unstructured Interview Design As unstructured interview usually tends to be used in early stages of the interview
session, in which the users will be asked some general unprepared questions.
The unstructured interview doesn’t require any prepared question, thus the design
of unstructured interview highly relies on the interviewer’s personal communication
and facilitation skills. It is therefore important to make it clear that the interviewer
should try to focus on the topics related to the users’ general impression of this
plug-in and to facilitate the interviewees to provide some key points for their
thoughts.
In this project, at first, we need to know the users’ general ideas and points of view
about both the card sorting and laddering tool, the user’s attitudes towards the
perspectives of this plug-in and probably, and their personal manners of using
computer software. Unstructured interview results will provide the developer with
appropriate concepts and ways of thinking, rather than the technical details of the
software.
4.3.2 Structured Interview Design Comparatively, it is much easier for the interviewer to hold an interview with a sort
of predefined questions. The structured interview design is more important for the
software designer because all the interviewees will be asked a same set of questions
related to the software technical details. The analysis of the structured interview

40
will be crucial since the detailed technical issues in software design phase will be
settled down mainly based on the analysed result. In this project, the questions
listed below are defined and asked.
a) Do you know card sorting method before? (If not, the interviewer will give
users some background knowledge about card sorting.)
This question aims to give the interviewee a general idea about the card sorting
method if he doesn’t have any experience before. In fact, it is best to have a
number of knowledge engineering research experts to take this interview.
b) How do you think the automated card sorting method will be?
This is one of the core questions designed to discover the user’s first
impression on the computer-based card sorting method.
c) Here are some cards with different concepts, so could you please sort them in
your own way?
The users’ manners are different, and their intuitive activities decide their way
of using software. Making the way of using card sorting tool fit in well with the
manners of majority is essential.
d) Could you please sort it again by groups?
When we want to build ontologies, the major job of card sorting method is to
group the cards in to different piles and name the pile with a new concept. To
get the users’ way of performing this task is a guideline to implement this
functionality.
e) If the cards are put in one limited area of the desk, where will you put the
sorted piles?
This question is related to the layout of the user interface which is the
arrangement for the positions of each component.
f) What the colour of card is the best for you?
Basically, the colour of the card should not be very bright or dark, and it is
reasonable to normalise the colour layout based on the difference users’ favour

41
and the cognitive methods.
g) Do you know laddering before? (If not, the interviewer will give the users some
background knowledge about laddering technique.) And how do you think the
laddering method will be?
These two questions are designed for the same reason of card sorting related
questions.
h) Some of the cards now are sorted but some not, how will you related the cards
with difference relationships?
This question is asked for capturing how users add existing card items to the
ladder.
i) Do you want to see the card sorting result and laddering result simultaneously
on the desk?
There is a trade-off between the simple user interface and the flexible ease of
use principle, so let the user decide.
j) How do you think about the output?
This question will get the users’ prospects about software output.
After the completion of the interviews with a group of people, the results are being
collected and processed. The details of the interview results will be presented in
Appendix C.
4.4 Analysis and Conclusion From the interview results listed in Appendix C, it is not difficult to find out some
valuable points. We are concerning about the user’s general viewpoints of this
knowledge elicitation tool that have been acquired from unstructured interviews,
and also several detailed technical aspects which have been asked in the structured
interviews. Hereby we will analyse the results of unstructured and structured
interview respectively.

42
4.4.1 Unstructured Interview In terms of the unstructured interview, we can conclude that the majority of the
interviewees have the common perspectives listed below.
For the whole software system, the system should:
have straightforward and simple user interface
be ease of use
give multiple options to users
have a unified output
be easy to manage the task
For the card sorting tool, the tool should
have a range of cards with shape of credit card
make people understand the sorting mechanism
For the laddering tool, the tool should
shape as a real ladder structure
explain to users what the ladder is
It is unpractical to collect the detailed software perspectives from users at this stage,
and the results of unstructured interviews just only provide the software developer
with some general concepts and guidelines. However, those original and raw ideas
from real users are not neglectable.
4.4.2 Structured Interview The structured interview result could be concluded by listing the questions in
section 4.3.2.
a) Do you know card sorting method before?
From the results, we find most people who haven’t been involved in the
knowledge management research domain nearly know nothing about the card
sorting.
b) How do you think the automated card sorting method will be?

43
By given some backgrounds of card sorting method, the amateur people tend to
imagine the cards are a pile of paper, metal or plastic pieces with size of poker,
credit cards or name cards, which is a five centimetres wide, eight centimetres
long, round rectangle. And then they often choose to sort the cards like playing
poker. On the other hand, the experts in the knowledge management domain
like to see the paper pieces with concepts written on them and sort them into
different piles, then name the piles.
c) Here are some cards with different concepts, so could you please sort them in
your own way?
The knowledge management experts lack of imagination at this time because
their thoughts are limited within the formal routine of card sorting method.
Their own way of sorting cards are disorderly and unsystematic, and actually
sometimes they are totally confused of what they are doing. The other way
round, non-experts are likely to have a common sense that cards should be
sorted with piles in which the cards shares some similarities in first instance,
after that they may consider to sort the cards by different relationships.
d) Could you please sort it again by groups?
Our experts are very willing to do this and they can complete this job fast and
correctly, while the amateurs are not proficient in doing his. But the major
concern in this question is to record down the tracks of sorting the cards and
the manners the respondents are likely to have, rather than the sorting results.
Obviously, all the people like to drag and drop and cards into piles, or
alternatively, catch the cards in hand and put them into groups. Those two
actions share approximately the same quantity.
e) If the cards are put in one limited area of the desk, where will you put the
sorted piles?
Concerning the layout of this software, most people like to put the sorted cards
on top of or at the left of the original area where cards located.
f) What the colour of card is the best for you?
Basically, this question is not well designed because all the people involved in

44
the interviews tend to choose their favourite colours which are almost totally
different.
g) Do you know laddering before?
This question has the same result as the card sorting problem, so the interview
question could be reduced to “Do you know card sorting and laddering
before?”
h) How do you think the laddering method will be?
The knowledge management community people certainly have the similar
understanding about laddering technique, while people in other areas will
intuitively think about the real ladder which is only going up and down, rather
than going sideways.
i) Some of the cards now are sorted but some not, how will you related the cards
with difference relationships?
Most people like to write the relationships on the back of cards, whereas few
people use extra cards with different colours to demonstrate different
relationships.
j) Do you want to see the card sorting result and laddering result simultaneously
on the desk?
Unexpectedly, all the people have the same answer – YES, to this question,
because maybe people are more likely to see the source and the destination at
the same time while they doing laddering.
k) How do you think about the output?
The experts want the output well-formatted and can be reused by other
programs, but the non-experts don’t have much idea about this.
4.5 Conclusion The result shows a remarkable difference between people with difference academic
backgrounds, however, it also tells that the age, gender, and cultural background

45
don’t play essential roles in the interviews. Probably, that’s because of the
statistical analysis requires a much larger sample which cannot be provided in this
series of interviews due to the limitation of the size and costs of M.Sc. project, but
fortunately we have collected enough expected information required by the design
of this knowledge elicitation plug-in.
In next chapter, according to the results from the interviews, this thesis will give a
detailed technical design of the plug-in.

46
5. Implementation of Knowledge Elicitation Plug-in As pointed in Chapter 1, while people are eliciting knowledge from various source
of information, they often suffer from a sort of labour-intensive knowledge
elicitation techniques, which are fragile and difficult to be managed. Thus there is
an opportunity to automate the knowledge elicitation techniques, such as card
sorting and laddering, so that people are released from the tradition,
time-consuming tasks by performing the elicitation sessions on machine.
This chapter describes the design and implementation of a tool for knowledge
elicitation. It includes the scope, requirements, design issues, structure and
implementation of the software system. The section of “Plug-in of Protégé”
describes the technical factors for embedding this software into the Protégé
platform and other related issues.
5.1 Scope and Requirements This knowledge elicitation software system aims to reduce the work-load for
knowledge engineers and domain experts; increase the reusability of laddering and
card sorting processes; effectively manage the knowledge elicitation tasks; and
seamlessly build with existing software system.
As mentioned in Chapter 2, experts are usually busy and their time is valuable, but
in the mean time, knowledge elicitation tasks which involves many kinds of
interviews and takes large amounts of time to perform. Thus the system developers
have to face a trade-off between the quality of interview process and the cost of
inviting domain experts. Traditional card sorting method requires many cards made
from paper, and usually it could be hundreds of cards. Sorting of hundreds of cards
might take a couple of hours, and imagine if the window is open, and there is a blast
of wind comes, everything will be damaged in one second. Not only wind may
cause the accident, but a cup of water, or even an unskilled internship student could
also do this. In all, the tradition means of knowledge elicitation methods is tough
and fragile.
If we transplant the task into computer, we are no longer worrying about the issues

47
above. You can save the task in the permanent storage devices and have as many
back-up copies as you like, and of course, moving hundreds of cards in computer is
obviously much easier than doing such a paper-based, dazzling task.
The second problem for manual knowledge elicitation methods is they are
extremely difficult to be reused and tracked back. While people are performing
laddering method based on the result of card sorting, to find their real demanding
goals and true values, they have to record down the results of card sorting as well as
their real-time thinking. But when they finish doing this, it is not possible to
maintain the structure of the card sorting by leaving the cards on the table
permanently. We should collect the cards but we immediately find out there is a big
problem to track back to the previous activities. We could record it on paper,
however it will become another heavy task to put down everything, including the
structure, ways of thinking, comments and annotations, on the paper in a reasonable
mean. Otherwise, video tape recording has already been rejected in previous
chapters, so we have to find out a more beneficial approach.
Redo and undo mechanisms in text editor give us a hint to solve this problem by
automating the task in computer. The whole procedure and all its related matters -
we call it transaction - will be temporary stored in the memory and saved to the
permanent storage devices if necessary. By doing this, the domains experts and
developers are able to go back to anywhere if they want, all they need to do is to
store the transactions (one step of the card sorting process) while they are standing
at a milestone.
Normally, people organise the card sorting and laddering results by documenting or
filing them to folders (both the physical folders and virtual folders in computer). It
is time-consuming to locate the exact folder and requires independent mechanism to
support the resource manager, such as Windows Explorer (formerly Windows
Resource Manager). Therefore, a build-in ladder and transaction manager for this
knowledge elicitation software system is necessarily to be developed with
principles of usability engineering. Software users could easily manage their
transactions and ladders graphically by a well-established Graphical User Interface
(GUI), and they can add, select, edit or delete a transaction or ladder.

48
Forth, as part of the ongoing project CO-ODE, it is essential to build the software
system in an existing popular ontology editor and knowledge acquisition system -
Protégé. People are familiar with a widely used toolkit rather than a brand new
software system, so they will spend much less time on training of using the new
system. With respect to the Protégé toolkit, which has been introduced in Chapter 3,
hence we can pay more attention to the technical implementation of the plug-in
building problems.
5.2 Designing Issues and Structure About the modern software engineering design patterns (Gamma, Helm, Johnson &
Vlissides 1995), the life cycle of this project should include requirements analysis,
system design, implementation, testing and evaluation. This section does not
involve the implementation, testing and evaluation phase but it focuses more on the
designing issues and provides an overall structure of the system. The
implementation will be introduced in the fifth section of this chapter, and in
Chapter 6 there will be detailed user-testing and evaluation.
5.2.1 Case Study of Interviews Learning from the analysis of interview results, some detailed design basics and
principles can be found, which are also based on the design principles listed in
Chapter 4, theoretical backgrounds in Chapter 2 and 3.
This software system should have 1) a input from document and terms elicitation
functionality from user interface; 2) a series of cards generated from the terms with
round rectangle and the colour style of Protégé, that’s because the users are not able
to meet an agreement on the colour, using the colour style of an existing popular
base system, like Protégé, tends to be sensible; 3) a flexible, simple and
straightforward user interface with layout of placing the working panel - both the
card sorting and laddering tool, at the left as tabbed widgets, and putting the
operation result on the right, as well as a number of buttons reasonably arranged; 4)
a well-formatted output.

49
In order to implement these design principles, a requirements analysis will be
employed, using requirements engineering techniques (Sommerville & Sawyer,
1997).
5.2.2 Requirement Analysis Requirement engineering is an important branch of Software Engineering. Software
developers identify the needs or requirements of users and find out the possible
solutions to the proposed problems. The scope and aims of this project has been
defined in the first section of this chapter, now we should firstly list out all possible
functions and concerns of this knowledge elicitation tool. Brain storming is
performed at this stage, but the feasibility, costs, time or any other practical matters
are not considered here.
Transaction related functions
record detailed user information
save and track transactions freely
transaction and ladder manager
User interface related functions
put a straightforward GUI for arranging cards
enable multi-tab allocation for large set of cards
user-friendly GUI
plug-in of Protégé
Input related functions
get terms from multi-format documents
get terms from formatted documents
automatically processing the terms
speech/Scanning input
Card sorting functions
generate cards
edit cards with multi-source information
enable user defined cards

50
sort cards by user
ontology-based automatic card sorting
Laddering and output related functions
formatted file output
laddering by user
user defined laddering relationship
The second step is to define categories for the tasks listed above, the tasks are
divided into 4 categories - Tasks MUST, SHOULD, MAY or CANNOT be
implemented, and it depends on the consideration of feasibility, costs on time and
money, technical difficulty, and so on. The functionalities are categorised by
analysing the user’s preference and developer’s implementing priority.
Along with the classification of tasks, the analysis of the task will also be listed.
MUST tasks:
get terms from formatted document
The input information must be a set of terms which are used for sorting, and the
formatted file is the best for machine processing.
record detailed user information
In terms of the domain experts’ different personalities and culture backgrounds,
they might perform card sorting and laddering activities in dissimilar ways.
Therefore it is important to record down the detailed user information of each
transaction which will be analyzed in the future in a high probability.
generate cards
Card sorting is a fundamental functionality in this software system, so it is
mandatory to set this task to “MUST”.
edit cards with multi-source information
Like annotations for ontologies, domains experts normally are willing to write
down their ways of thinking during the process of card sorting. This mechanism

51
enables users relating their thoughts with cards easily.
sort cards by user
It is another basic requirement of this project which have to allow user sort cards by
themselves.
enable user defined cards
Besides the cards generated from input file, users often want to create their own
cards.
save and track transactions freely
As the traditional knowledge elicitation tasks are difficult to save the process and
track back to previous activities freely, this project aims to provide this function by
recording the transaction activities in a output file.
laddering by user
As one of the core tools in this plug-in, laddering by user must be implemented.
transaction and ladder manager
Users manage the transactions and ladders by performing tasks listed below by
selecting them; add a new transaction or ladder; edit an existing transaction or
ladder; delete a transaction or ladder.
SHOULD tasks:
put a straightforward GUI for arranging cards
This function will make people more effective to sorting cards than a normal GUI.
user defined laddering relationship
Other than pre-defined laddering relationship, users usually want to create a
personalized ladder relationship.
formatted file output
It is smooth for other programs read the output information of this plug-in if the
output file is formatted in a good manner. The details of the format will be

52
discusses in the fifth part of this section.
user-friendly GUI
Considering the usability matters, people are working efficiently and smoothly with
a user-friendly GUI.
plug-in of Protégé
If the project is built seamlessly as a Protégé plug-in, it is a great advantage for its
future development. Protégé is widely used so this plug-in will have more testing
cases to help in future extending.
MAY tasks:
get terms from multi-format documents
This function enables people to get the input information from difference document
formats, whereas it costs much development time on integrating the file format
processors to this program.
speech/scanning input
It is an ideal input way with ease of use and best for interview, however the
technical problem is that the speech/image processing will be a huge module and
not very practical for MSc project. It might be developed in a light version but it
depends on the progress of this project.
enable multi-tab allocation for large set of cards
While people are dealing with large set of cards, they will find the graphical
interfaces is too small to display all the cards. Multi-tab allocation for displaying is
a helpful function, although it does increase the complexity of implementation.
ontology-based automatic card sorting
From existing knowledge base users may get some sorting information and
grouping method, so users are able to perform automatic card sorting. It might be
useful while the ontologies are will-established, nevertheless currently, not much
ontology can meet this requirement.

53
CANNOT tasks
automatically processing the terms
Deploying this component is ideally quite efficient in daily work, but due to the
focus of this thesis is not related to the Natural Language Processing (NLP)
techniques, we are not going to implement this function. Furthermore, the current
NLP techniques don’t meet the project requirements on performance and accuracy -
they are usually both CPU and memory-intensive.
5.2.3 System Structure Design The system structure diagram shows the basic structure of this software. Typical
ways of path are listed below.
Start [Set of Terms] - card sorting and/or laddering- Output
Start - Term Extraction [Set of Terms] - card sorting and/or laddering - Output
Start - Term Extraction [Set of Terms] - card sorting and/or laddering - Relationship
Building – Output
The first path is that the system starts with a set of terms available in required
format document for eliciting knowledge and users directly load the document into
the software. The second process is to do some term extraction task manually by
several mouse-clicking actions and then perform card sorting and laddering
methods. The third routine enables users to set relationship among terms and finally
get the output.
In the Figure 5.1, we can see the dash lines split the figure into three parts: the
starting processes, the task-performing actions and the output session. They are
comparatively independent processes and management by the transaction manager
in the broader context.

54
Figure 5. 1: System Structure Diagram
Normally, the result of card sorting is the input of laddering process but ladder
could directly get input from existing file if necessary. Building relationship is also
not mandatory in the whole system.
5.2.4 Software Development Platform Three choices are available for the development platform of this plug-in, C++,
Python and Java.
As traditional object oriented programming language, C++ has its advantages of
fast execution and ease of coding. Nevertheless C++ program often can not be
compiled and executed cross-operating system because of the limitation of
programming library interface.

55
Python is famous for its high productivity and it becomes more and more popular in
knowledge engineering domain (Python Patterns - Implementing Graphs, 2003). It
should be a good choice if the Protégé system is developed by Python. But
Python-based software may cause some compatibility problems while working as a
Java system’s plug-in, so it is not wise to develop a Protégé plug-in using Python.
In order to be coordinated with the parent system, the knowledge elicitation plug-in
for Protégé is proposed to be developed in Java platform, with purposes of
unification and compatibility.
5.2.5 Output Format The format of output is one of most important design issues because a primary
consideration of this plug-in system is extendibility, which emphasises of unified
input/output. This software system might have many possibilities of input, thus the
output format should be discussed here. Basically, the proposed output file formats
are:
ASCII/Pure Text
HTML
Developer-defined format with specific syntax
RDF/XML
The decision making principles are:
Feasibility - Program could efficiently parse it.
Portability - It should be easy to transfer over internet.
Acceptability - It should be widely accepted in different machines.
ASCII/Pure text is the most common way to store information, and the generated
file size is small and easy to be transferred. However, the pure text files may have
different default format while they are processed in difference operating system.
HTML is a well-defined syntax-based mark-up language and easy to be parsed. It is
the most widely used document format in today’s world, thus there is no
compatibility problem. Maybe it is a good idea to develop a specific format for the
output information in this project, so that the problems of pure text and HTML are

56
eliminated. Nevertheless the self-defined format will also cause portable problems
which break the rule of unification.
Resource Description Framework (RDF) is based on the URI and XML
technologies and it aims to describe the resource over World Wide Web. It is W3C
standards so certainly it is widely accepted. Because the initial purpose of RDF is
resource description, the semantically annotated information is well-described here.
Based on XML, RDF is machine readable and the processing of RDF is
well-implemented by some third party programming language APIs.
As matters stand, the most sensible choice is to use RDF format for information
storage in this software because of the consideration of feasibility, portability and
acceptability. Another possible output is to use the existing Protégé components
such as Protégé OWL Plug-in to directly transfer the output to the ontology tree for
future development.
5.3 Plug-in for Protégé This section introduces the design requirements and procedure of integrating a
piece of independent Java software into an existing software system, Protégé. Let’s
firstly look at the common technical requirements of being a plug-in of Protégé.
5.3.1 Common Technical Requirements Because Java is memory intensive, basically, the hardware requirements for a
desktop computer to develop Protégé plug-in are at least 512 Megabytes memory -
it is running tremendously low while the memory is 256 Megabytes. As the
software requirements, the major operating systems can be used as the system
platform if the Java Virtual Machine (JVM) can be executed, otherwise, a Protégé
system must be properly installed. In the program level, the software which will be
plugged in Protégé system has to be able to run independently.
5.3.2 Integration Method For the testing purposes, it is not reasonable to create a JAR archive to store the
Java classes and put it in the plug-in folder of Protégé installation path. In this

57
project, developers create a path in the Protégé plug-in path and set the Java
compiler directly put the classes into this path. Then a Java manifest file must be
edited to show the classes are running as the Protégé tab-widget, as well as the
name of class which will be executed via the “main” method.
In the programming level, the plug-in must import the Protégé library first and
rewrite the “Initialize” method in the main class, in which the plug-in software is
initialised and executed. Finally, a method call to the Protégé system must be
included in the “main” method. Thereafter, we can run this program and we can see
the Protégé has the plug-in integrated. Figure 5.2 is the example code of the “main”
method
Figure 5. 2: Sample Code of Using Protégé API
5.4 Implementation The details of implementation of the knowledge elicitation plug-in will be given in
this section, which includes the first step to build the concepts of implement, the
design of runtime classes and their corresponding UML diagram.
5.4.1 Implement Concepts In this knowledge elicitation tool, laddering and card sorting is two different
sub-tools, and they are divided into two tabs.
For laddering tool:
Users are able to select the relationships of ladders, or define their own relationship
and questions.
a) Use existing concepts/classes in the existing ladders to manipulate more
ladders by different relationships.

58
b) Define relationship to elicit explanations.
c) Define new relationship to elicit goals and values, e.g. hasGoal
For card sorting tool:
a) User defines the number of the piles and gives their names and specifications.
b) User should record their name down on it.
c) User saves the initialization of the piles/groups.
d) Knowledge elicitation
There is two alternative means for eliciting terms and concepts from documents.
Firstly, user opens a document to elicit knowledge.
a) Select words, right click to display menu and put each word into a pile. Make
notes/annotations if necessary.
b) The words selected are displayed as different colours.
Secondly, user adds concepts/terms into the pile, and makes notes/annotations if
necessary.
c) Open document and the terms defined will be displayed in different colours to
demonstrate their groups.
d) Make notes/annotations if necessary.
Finally, save the knowledge elicitation process and output knowledge elicitation
result as RDF file.

59
Figure 5. 3: A Diagram of Workflow Prototype
5.4.2 Software Java Classes This project consists of seven major classes that link with each other. The KE class
is the main class here and JTransaction class plays a major role in handling the
runtime operations and data. The detailed UML diagrams of primary classes and
descriptions are listed below.

60
a) JTransaction
The overall transaction management is provided by this class. The transaction
handling makes user easy to track back to their previous status and by simply
saving/loading and switching between transactions. This transaction-based system
managing mechanism is an essential feature of this project and can be thought as a
primitive ontology versioning system that enables users to manage their footsteps
while developing ontologies. It also can be extended to have more formats, for
example, OWL file, as output document to fit future requirements,
Figure 5. 4: Java Class JTransaction UML Diagram

61
b) KE
The main knowledge elicitation class has the most complex structure and functions.
It initialises the components of the interface and set action listeners for each activity,
which will cause future operations.
Figure 5. 5: Java Class KE UML Diagram

62
c) JCardSorting
This class defines a card instance which will be showed in the card sorting panel,
and its related operations.
Figure 5. 6: Java Class JCardSorting UML Diagram

63
d) JDocElicitation
The program uses this class to create a frame to enable users eliciting terms directly
from texts.
Figure 5. 7: Java Class JDocElicitation UML Diagram

64
e) JLaddering
The laddering procedure class is initialised and showed in the laddering tool panel,
including the basic properties of the ladder.
Figure 5. 8: Java Class JLadderingUML Diagram

65
5.5 Conclusion In this Chapter, the project of knowledge elicitation plug-in for Protégé is designed
and implemented using Java language. The system structure and prototype diagram
illustrate the basic functionalities of this plug-in with a black-box methodology,
while the UML diagrams using while-box methodology to show the inner structure
of this program (Pressman, 1997).
The plug-in now is running well with Protégé system, and the next phase will be the
user testing and evaluation of this software, by which we are able to see the quality
of works in this chapter.

66
6. Software Testing and User Evaluation After the implementing the software system, an essential stage of this project is to
test and evaluate the plug-in by employing usability engineering techniques, and
then the developer is able to refine its interface and functionalities. Another purpose
of user evaluation is to collect the comments on this plug-in by rating the quality of
this project, which can be used to partially prove the correctness of entire
development procedure and methodology.
The testing and evaluation phases are discussed in two separate sections after which
the analysis and conclusion will be given. The testing and evaluation are also taken
by both experts and non-experts in order to discover the feedbacks from the
different groups of users.
6.1 User Evaluation Methodology The testing process includes a brief guideline of plug-in installation and usage. In
the final version of this plug-in, most bugs reported have been fixed, and the
suggestions on the possible improvements have been carefully considered and
partly implemented while applicable.
6.1.1 Software Setup The initial setup is not straightforward because this system are being developed and
tested under a specific Java software developing environment, in which developers
are able to simply design software user interface by generating GUI forms.
Furthermore, many third-party Application Program Interfaces (APIs) are loaded to
minimise the programming task, thereby we also need to install those packages in
local paths before compilation.
The detailed software setup procedure is listed in the appendix.
6.1.2 Elicit Knowledge using card sorting All the tasks start from creating a new transaction, which will be discussed in detail
later. Considering the principles of flexibility, the plug-in provides three options for
users creating cards:

67
a) Document elicitation
By clicking the “Document Elicitation” button, the users can load documents from
pure text files with a system recognisable format. The users can select a term either
by a normal selecting action or a double clicking on the term, then the users can
either make it to a class appeared in the card sorting panel, or in a tree storing group
on the left bottom side of the main frame window.
Figure 6. 1: The Document Elicitation Frame
b) Loading formatted pure text
The second option is to load a well formatted pure text that the text is a set of terms
which are separated by a space or enter key. This format restriction is predefined by
the system and can be modified to meet other requirements.
c) Creating new card directly
This option is implemented by clicking the “New” button in the card sorting
tab-widget. A new card with a system generated name will be created for the future
editing. It is flexible when users find it necessary to add some new cards to this

68
transaction.
Accordingly, there are also a number of different options to group cards into
different piles. The users can select one or more cards and click “Add to Group”
button, the cards selected will be put into the current selected group in the tree laid
on left bottom. We can also “Make Group” instead of “Adding to Group”, and in
this case, a new group with a system defined name will be created under current
selected group with a set of cards. The “Add to Group” option is also provided in
the right mouse clicking menu. Further more, if the users want to see the contents of
a group, they can click the “Show” button at the top of the group tree and a new
tab-widget which contains the cards in the group will appear on the right side of the
card sorting and laddering tabs. The users can also perform actions on the cards in
the new created tab.
Ideally, the users are very willing to use drag-and-drop actions to move the cards
around, but unfortunately because of the limitation of programming timetable of
this M.Sc. project, this functionality is not applicable at this moment. It will also be
discussed in the Chapter 7 as a part of future work.
Figure 6. 2: Card Sorting Tool

69
6.1.3 Laddering the Result As mentioned in Chapter 2, the laddering and card sorting are usually coming
together. In the CO-ODE project in the Medical Information Group, we are
concerning more with the management of medical and biological terminology. The
users, hence, tend to use laddering tool to define the relationships and find out the
common concepts based upon the result of card sorting.
When we have a sort of cards grouped, we want to build a conceptual ladder, so we
can either click the “Add to Ladder” button in the card sorting tab or in the mouse
right clicking popup menu. Alternatively, we can add concepts in the grouping tree
to the ladder. But whatever the concept is, wherever it comes from, the first concept
added to the laddering tab will be the root of the ladder, and if the users don’t select
this ladder node, all the subsequent added concepts are treated as the new ladders.
This series of actions are similar to the grouping tree’s operations.
According to the comments from testers, the button of “Show Card” is deployed to
help user to see the card sorting and laddering tab simultaneously. In addition, the
user testing and evaluation result will be appended in the section of Appendix C.
Figure 6. 3: Card Sorting and Laddering Tool Appears Simultaneously

70
In most cases, the users want to move a whole group, or a node and all its sub-node
to the ladder. “Set Parent” function, located at the top of the grouping tree and the
right mouse clicking popup menu, is designed to do this task. A message box giving
the hints to the users will also display while clicking the “Set Parent” button.
The properties of a certain ladder can be edited by clicking the “Ladder Settings”
button and users are able to add and edit relationships of this ladder, which
demonstrate the relationship between the parent and children node of this laddering
tree. Here the ladder relationships’ attributes are established to show the
descriptions by clicking the “Ladder Hints” button, which gives information to
facilitate the user in building the ladder and could be extended to other
computer-aided ladder design functions, for instance, an automatic questioning
system.
Figure 6. 4: Laddering Tool
6.1.4 Using the transaction manager The transaction manager is a significant component in this project, and herewith
this transaction concept comes from the informal talk within the research group
(Wang, Rector, Stevens, 2005). This function is implemented by saving the runtime
status of the software, both the information of the laddering and grouping tree, as
well as the contents in card sorting tab, to the main memory, via a JTransaction
class instance. The depository of the trees’ structure are encoded and decoded by a

71
fresh Java API, XMLEncoder/Decoder, which are quite flexible in processing the
structure of Java objects.
We make use of this manager to organise the global actions performed by the users
so that users are able to track back to their previous software runtime status by
simply choosing and loading the transaction they created and saved before. The
users just need to choose a target transaction and press the “Save Status” button and
the system will give a message to tell the users whether the transaction is
successfully saved or not. Once the users come back from other transactions, and
select this transaction again, they can simply load this transaction into the working
tabs and trees immediately by pressing the “Load Status” button. This component
lays on the upper right side of the interface.
It is worth mentioning that the result of user testing and evaluation shows that most
people are approving this component very much.
6.2 User Evaluation User evaluation shows the users’ attitudes towards the quality of this software.
Based on the requirements of user-centered design, the feedbacks from user
evaluation will be treated as an essential guideline for software testing and
debugging procedure.
In this project, the user evaluation has two different parts. One is the interface
evaluation which concerns the plug-in’s GUI, including ease of use, look and feel,
and so on. And the other one is functional evaluation whose emphasises are the
background functionalities. This evaluation methodology aims to detect the users’
comments on two basic aspects in the domain of user-centered design - the software
should be powerful, flexible and robustness.
There are eleven people involved in the user evaluation activities, and they are
diverse in academic and cultural backgrounds. In order to quantify the result, a
grading system similar to the university examination will be borrowed, that is, 5 is a
pass, 6 is a good pass, and 7 is a distinction. In the arrays of the scores introduced

72
below, the first five scores in each array come form the experts or frequent users of
knowledge systems.
6.2.1 Interface Evaluation In terms of the user interface design, the grading result will be given to four
different aspects. The users are asked for the grades of the four points, and their
grading results are listed below. To be statistically accurate, the average score is
calculated by eliminating the highest and the lowest scores in each array.
Domain Experts (n = 6) Non-experts (n = 5) Avg.
Look and feel 9 7 7 8 9 7 7 6 7 8 6 7.3
Interface layout 7 7 9 6 8 6 9 5 6 5 6 7.3
Ease of use 7 7 6 7 8 7 6 6 6 6 5 6.4
Flexibility 7 8 8 6 5 6 6 6 9 6 8 6.8
The overall score is calculated by formula using standard deviation (Kenney &
Keeping, 1962), and we get 6.7 here.
6.2.2 Functional Evaluation The functional evaluation involves the grading of each basic component, including
card sorting, laddering, relationship setting and transaction manager. They are four
major components provided by this plug-in and users are easily getting familiar
with them, so the grading of these components is direct.
Domain Experts Non-experts Avg.
Card sorting 9 8 7 9 9 7 8 8 7 7 8 7.9
Laddering 7 6 7 7 7 7 6 7 7 9 8 7.0
Relationship setting 6 7 6 6 6 8 7 9 7 8 8 7.0
Transaction manager 9 9 8 8 9 8 7 8 9 8 9 8.4
We can see that the overall is: 7.6. After taking the scores from users, we can
analyse the result and make a conclusion for this user evaluation procedure.

73
6.3 Evaluation Result Analysis and Conclusion From the scores, we can simply find out that the users are mostly satisfied with the
functionalities of the plug-in, which stands that the primary user-centered design
procedure are well-established. With respect to the interface of this plug-in,
although the score is not such shining, the users also generously have given positive
comments.
To discover more from the evaluation results, we find that the interface look and
feel, card sorting and transaction management components have the highest ratings,
which are explicitly the best implemented. Meanwhile, the elements related to the
ease of use principle and interface layout arrangement require much future
improvement.
If we go further, we may find that the plug-in’s interface are more appreciated by
the experts rather than the amateurs, because the knowledge engineering experts are
more familiar with the existing Protégé system, card sorting and laddering
approaches. They find that this software have a unified style with the Protégé
system, which doesn’t quite make sense to the non-experts, though. Otherwise,
contrarily the experts are not fully satisfied with the laddering tool and relationship
setting component. Their feedbacks express the way of their working is somewhat
different from how this plug-in does. That’s because, as mentioned in the Chapter 2,
people from different disciplines are likely to use laddering tool in many different
ways for different purposes, and the plug-in is developed according to the design
principles of CO-ODE project with strong emphasises in the medial and biological
domain.
It is worthwhile to mention that staffs from the wholly independent UK Freshwater
Life Biological Association evaluated the plug-in, and their comment on this
software is:
“It was good to see what he has been doing and looks like a potentially very useful
tool. We’d really like to get our hands on a copy to play around with. Even in its
current state it could save us considerable time.” (McNicol, 2005)

74
In a nutshell, this plug-in are commonly considered to be a well-implemented and
powerful tool in real use, whereas probably, the interface is only recognised by the
knowledge system experts. All the evidences in user evaluation show that people
are very willing to see the future development of this plug-in.

75
7. Conclusion and Future Works 7.1 General Conclusion The explosion of information and data on today’s World Wide Web has left people
with the complicated tasks to organise and manage the web resource. Especially,
people find it difficult to locate the interdisciplinary information while the web
search engines are not able to identify the property of the information intelligently.
Therefore with the advent of the Semantic Web technology, ontology, which is the
term borrowed from Philosophy, is now widely applied as the knowledge base of
this technological frontier. Consequently, the study of ontology engineering, which
supports the building and managing ontologies, is undeniably important while
developing the Semantic Web applications. The first step in building ontologies is
usually to elicit knowledge from various sources of information, including pure text,
documents, voice and video. Using traditional knowledge elicitation techniques to
build the basic concept structures is usually time-consuming and labour-intensive,
thus the demands of a graphical-based tool as a Protégé plug-in to help in this
process are importunate.
In this project, a knowledge elicitation plug-in with card sorting and laddering tools
was built using user-centered design techniques to help users in eliciting knowledge
and output them into a document. It shows that the knowledge elicitation techniques
can be integrated in to Protégé. Potentially, this project can be well-linked to the
Protégé OWL Plug-in by providing the initial ontology structure tree. The project in
this thesis is part of the ongoing project - CO-ODE from the Medical Informatics
group in University of Manchester. The development of this project looks plausible
but remains to be tested through user evaluation process.
As another major aspect this the thesis, usability engineering methods have been
widely employed throughout the entire project, including the design process, testing
and user evaluation phase. The users have actively participated in designing, testing
and evaluating this plug-in about which they have given valuable feedbacks.
Due to the size-limitation of a Master project, the number of users participated in
this project is comparatively small, but there still have been eleven people from

76
various disciplines given comments on each stage of this project. This project not
only has collected the ideas from experts in knowledge management domain, but
many other people who are not IT specialists also have contributed a lot. Therefore,
I would expect the people involved in the user-centered design sessions are
representative enough to complete a basic design cycle.
On the one hand, the empirical evaluation from the knowledge management experts
has illustrated that the software has made a considerable progress to help them in
eliciting, building and structuring knowledge. On the other hand, the opinions from
non-IT people have revealed that this plug-in has a user-friendly look and feel and
is particularly learnable. While they are testing and evaluating this tool, many bugs
of this software are reported and fixed, which will also be appended.
In all, in terms of the requirements of this Master project and the results of the user
evaluation, this knowledge elicitation Plug-in for Protégé has been successfully
accomplished and mostly met the proposed software specification. In addition, it
has already attracted the real users’ attention and made them eager to see the public
released version of the plug-in to effectively facilitate their daily work.
This project also provides a example of which might be developed into a
framework which gives a routine to build knowledge elicitation tools within an
existing pluggable software system. Such a framework enables people to develop
similar knowledge elicitation tools, like repertory grid tool, diagram tool, matrix
and so on, within Protégé environment or other systems. It is also possible to
borrow the ideas of user-centred design principles learned from actual users in this
project to help the tools development within the framework.
7.2 Future Work There are four major aspects for the future development of the plug-in, including
the input of the terms, the output of this knowledge base, the interface and the
functionality.
First of all, there are many other means for terms input, such as automatically

77
extraction of terms from web documents based on the data mining and natural
language processing techniques, so the eliciting process will be much effective than
current pure text manual elicitation. This add-on requires in-depth knowledge in
upper listed research topics but fortunately a number of existing tools have been
developed (e.g. the AKT project), there is an opportunity to transplant those tools
into this plug-in.
Secondly, by cooperating with the Protégé OWL Plug-in term, this plug-in can
directly output the tree-like structure to the ontology structural tree in Protégé OWL
Plug-in, so that users can edit their card sorting and laddering results in the Protégé
OWL Plug-in and output it to document with RDF or OWL syntax smoothly.
The third potential development is to enhance the user interface of this plug-in. The
user evaluation results make out that the users are not fully satisfied with the
interface, so future improvements are required. Actions like drag-and-drop and
direct-grouping on the card sorting tab widget are highly proposed.
Finally, as mentioned in Chapter 2, the knowledge elicitation techniques are not
only limited in card sorting and laddering, but there are also many other options like
diagram tool, repertory grid tool and matrix tool can also be deployed as other
tab-widgets. By doing this, the functionalities of this plug-in will be considerably
enhanced.
For future work, tightly collaboration with the CO-ODE and Protégé community is
essential, and alternatively it is possible to use software public license and build an
open source project to make people join in the development. At this moment, at
least four people in the knowledge engineering research domain are interested in
developing this plug-in and willing to join in the team.

78
References Bechhofer, S., Goble, C., Carr, L., Kampa, S. (2002) COHSE: Semantic Web gives
a Better Deal for the Whole Web? Poster presentation at ISWC International
Semantic Web Conference, Sardinia.
Berners-Lee, T. (1996). The World Wide Web: Past, Present and Future. In IEEE
Computer special issue, v.29 n.10, pp.69-77.
Berners-Lee, T., Fielding, R., Irvine, U.C., Masinter, L. (1998). Uniform Resource
Identifiers (URI): Generic Syntax. IETF Request for Comments: 2396. [Online:
http://www.ietf.org/rfc/rfc2396.txt]. Date accessed: 15th July 2005.
Berners-Lee, T., Hendler, J., Lassila, O. (2001). The Semantic Web. In Scientific
American, 284(5), pp. 34-43.
Benysh, D. V., Koubek, R. J., & Calvez, V. (1993). A comparative review of
knowledge structure measurement techniques for interface design. International
Journal of Human-Computer Interaction, 5, pp. 211-237.
Boose, J. H., & Gaines, B. R., (Eds.) (1990). The Foundations of knowledge
acquisition, Knowledge Based Systems, Vol. 4 San Diego, CA: Academic Press.
Boose, J. H., & Gaines, B. R., (Eds.) (1988). Knowledge acquisition Tools for
Expert Systems, Knowledge Based Systems Vol. 2. San Diego, CA: Academic
Press.
Bray, T., Paoli, J., Sperberg-McQueen, C.M., Maler, E. (2000). Extensible Markup
Language (XML) 1.0 (Second Edition). W3C Recommendation. [Online:
http://www.w3.org/TR/REC-xml]. Date accessed: 15th July 2005.
Brewster, C., Ciravegna, F. & Wilks, Y. (2002). User-Centred Onlology Learning
for Knowledge Management. In Proceedings 7th International Workshop on
Applications of Natural Language to Information Systems, Stockholm.

79
Brewster, C., Ciravegna, F. & Wilks, Y. (2003). Background and Foreground
Knowledge in Dynamic Ontology Construction: Viewing Text as Knowledge
Maintenance. In Proceedings Proceedings of the Semantic Web Workshop, SIGIR,
Toronto, Canada.
Brickley, D., Guha, R.V. (2002) RDF Vocabulary Description Language 1.0: RDF
Schema. W3C Working Draft. [Online: http://www.w3.org/TR/rdf-schema/]. Date
accessed: 15th July 2005.
Carr, L., Bechhofer, S., Goble, C., Hall, W. (2001). Conceptual Linking:
Ontology-based Open Hypermedia. WWW10, Tenth World Wide Web Conference,
Hong Kong.
Ciravegna, F. (2001). Adaptive Information Extraction from Text by Rule Induction
and Generalisation. In Proceedings 17th International Joint Conference on Artificial
Intelligence (IJCAI 2001), Seattle.
Cooke, N. J. (1994). Varieties of knowledge elicitation techniques. International
Journal of Human-Computer Studies, 41, pp. 801-849.
Conolly, D., Harmelen, F. van, Horrocks, I., McGuinness, D., Patel-Schneider, P.F.,
Stein, L.A. (2001) Annotated DAML+OIL Ontology Markup. W3C Note. [Online:
http://www.w3.org/TR/daml+oil-walkthru/]. Date accessed: 15th July 2005.
Corbridge, C., Rugg, G., Major, N.P., Shadbolt, N.R. & Burton, A.M. (1994)
Laddering: Technique and Tool Use in knowledge acquisition. Knowledge
acquisition, 6, pp. 315-341.
Dix, A., Finlay, J., Abowd G., Beale, R. (2004). Human-Computer Interaction,
Third Edition. Prentice Hall. Upper Saddle River, NJ, USA. ISBN: 0-13-437211-5.
Gamma, E., Helm, R., Johnson, R. & Vlissides, J. (1995). Design Patttems:
Elements of Reusable Object-Oriented Software. Addison-Wesley. Boston, MA,

80
USA. ISBN: 0-201-63361-2.
Fernandez, M., Gomez-Perez, A., Pazos Sierra, A., Pazos Sierra, J. (1999). Building
a Chemical Ontology Using METHONTOLOGY and the Ontology Design
Environment. In IEEE Expert (Intelligent Systems and Their Applications), 14(1):
pp. 37-46.
Glaser, R., & Chi, M. T. H. (1988). Overview. In M. T. H. Chi, R. Glaser, and M. J.
Farr (Eds.), The nature of expertise (pp. xv-xxviii). Hillsdale, NJ: Erlbaum.
Gruber, T.R. (1993). Toward Principles for the Design of Ontologies Used for
Knowledge Sharing. Formal Ontology in Conceptual Analysis and Knowledge
Representation. Kluwer Academic Publishers.
Haarslev, V. & Möller R. (2001). RACER System Description. In R. Goré, A.
Leitsch, and T. Nipkow, editors, International Joint Conference on Automated
Reasoning, IJCAR’2001, June 18-23, Siena, Italy, pages 701–705. Springer-Verlag.
Hinkle, D. (1980). The change of personal constructs from the viewpoint of a
theory of construct implications. Unpublished Ph.D Thesis, Ohio State University,
1965 Cited in: Bannister, D. & Fransella, F. Inquiring Man. Penguin,
Harmondsworth.
Hoffman, R. R. (1987). The problem of extracting the knowledge of experts from
the perspective of experimental psychology. AI Magazine, 8, pp. 53-67.
Horrocks, I. (1998). The FaCT system. Proc. Automated Reasoning with Analytic
Tableaux and Related Methods: Int’l Conf. Tableaux 98, Lecture Notes in Artificial
Intelligence, no. 1397, Springer-Verlag, Berlin, 1998, pp. 307–312.
Kenney, J. F. and Keeping, E. S. (1962). “The Standard Deviation” and
“Calculation of the Standard Deviation.” §6.5-6.6 in Mathematics of Statistics, Pt. 1,
3rd ed. Princeton, NJ: Van Nostrand, pp. 77-80.

81
Knublauch, H., Musen, M. A., Rector, A. (2004). Editing Description Logic
Ontologies with the Protégé OWL Plugin. International Workshop on Description
Logics - DL2004, Whistler, BC, Canada.
Lambrix, P., Habbouche, M. & Pérez, M. (2002) Evaluation of ontology
development tools for bioinformatics. Bioinformatics Vol. 19 no. 12 2003, pp.
1564–1571.
Lassila, O., Swick, R.R. (1999). Resource Description Framework (RDF) Model
and Syntax Specification. W3C Recommendation. [Online:
http://www.w3.org/TR/REC-rdf-syntax/]. Date accessed: 17th July 2005.
Milton, N. (2005) PCPACK. [Online:
http://www.epistemics.co.uk/Notes/55-0-0.htm]. Date accessed: 29th April 2005.
McBride, B. (2002). Jena: a semantic Web toolkit. Internet Computing, IEEE,
Volume: 6, Issue: 6, pp. 55 - 59. ISSN: 1089-7801.
McNicol, K. (2005). Comments on the knowledge elicitation Plug-in. Personal
commmunications. Windermere, Lancashire, UK.
Mozilla.org. (2005). Firefox Browser. [Online:
http://www.mozilla.org/products/firefox/]. Date accessed: 15th July 2005.
Musen, M. A., Fergerson, R. W.,Grosso, W. E.,Noy, N. F.,Crubezy, M., & Gennari,
J. H. (2000) Component-Based Support for Building Knowledge-Acquisition
Systems. Conference on Intelligent Information Processing (IIP 2000) of the
International Federation for Information Processing World Computer Congress
(WCC 2000), Beijing.
Nielsen, J. (1995). Card sorting to Discover the Users' Model of the Information
Space. [Online: http://www.useit.com/papers/sun/cardsort.html]. Date accessed:
15th July 2005.

82
Nurmuliani, N., Zowghi, D., Williams, S. P. (2004). Using Card Sorting Technique
to Classify Requirements Change. Proceedings of the 12th IEEE International
Requirements Engineering Conference.
Norman, D.A. & S.W. Draper, (E&). (1986). User Centered System Design - New
perspectives on Human Computer Interactwn. Lawrence Erlbaum Associates:
Hillsdale, NJ.
Noy, N. F., Sintek, M., Decker, S., Crubezy, M., Fergerson, R. W. & Musen M. A.
(2001). Creating Semantic Web Contents with Protege-2000. IEEE Intelligent
Systems 16(2): 60-71.
Pressman, R.S. (1997). Software Engineering: A Practitioner’s Approach, McGraw
Hill, New York.
Python Patterns - Implementing Graphs. (2003). Retrieved January 20, 2003.
[Online: www.python.org/docs/essays/graphs.html]. Date accessed: 21th July 2005.
Rauterberg, M. (2003). User Centered Design: What, Why, and When. tekom;
Jahrestagung 2003 (E. Graefe; ed.), Usability Forum, pp. 175-178.
Rector, A. (2002). CO-ODE: Collaborative Open Ontology Development
Environment. Proposal to JISC under the Semantic Web Initiative.
Reynolds, T. J. & Gutman, J. (1988). Laddering theory, method, analysis, and
interpretation. Journal of Advertising Research, February-March 1988, pp. 11-31.
Rugg, G., Corbridge, C., Major, N.P., Shadbolt, N.R. & Burton, A.M. (1992). A
comparison of Sorting Techniques in knowledge elicitation. Knowledge acquisition,
vol. 4, pp. 279-291.
Rugg, G., Eva, M., Mahmood, A., Rehman, N., Andrews S., & Davies, S. (2002).
Eliciting information about organizational culture via laddering. Info Systems J
(2002) 12, pp. 215–229.

83
Rugg, G., & McGeorge, P. (2002). Eliciting Hierarchical Knowledge Structures:
Laddering. Encyclopedia of Microcomputers, vol. 28, supplement 7, pp. 69-110
Marcel Dekker, Inc, New York.
Rugg, G., & McGeorge, P. (1995). Laddering. Expert Systems, 12, 339–346.
Rugg, G., & McGeorge, P. (1997). The Sorting Techniques: A Tutorial Paper on
Card Sorts, Picture Sorts and Item sorts. Expert Systems, vol. 14, pp. 80 - 93.
Shadbolt, N. (ed.) (2003b) Advanced Knowledge Technologies: Selected Papers,
ISBN 0854-327932.
Shadbolt, N.R. & Burton, M. (1995). Knowledge elicitation: a systematic approach,
in Evaluation of human work: A practical ergonomics methodology 2nd Edition J.
R. Wilson and E. N. Corlett Eds, Taylor and Francis, London, England, 1995.
pp.406-440. ISBN-07484-0084-2.
Schneider, P., Horrocks, I., Harmelen, F. (2002). OWL Web Ontology Language
1.0 Abstract Syntax. W3C Working Draft. [Online:
http://www.w3.org/TR/2002/WD-owl-absyn-20020729/]. Date accessed: 5th June
2005.
Schreiber, A.Th., Akkermans, H., Anjewierden, A., de Hoog, R., Shadbolt, N., van
de Velde, W., & Wielinga, B.J. (2000). Knowledge Engineering and Management:
CommonKADS Method, MIT Press, Cambridge.
Shneiderman B. (1998). Designing the User Interface 3rd Edition, Addison Wesley,
Reading, Massachusetts.
Sommerville I. & Sawyer, P. (1997) REQUIREMENTS ENGINEERING John
Wiley & Sons, Chichester/New York/Weinheim/Brisbane/Singapore/Toronto.
Sun Microsystems, Inc. (2005). Java Technology Overview. [Online:

84
http://java.sun.com/overview.html]. Date accessed: 10th May 2005.
Tedeschi, B (1999). Good Web Site Design Can Lead to Healthy Sales. New York
Times, August 30, 1999.
Wang, Y., Rector, A., Stevens, R. (2005) Discussion of knowledge elicitation
Plug-in Deisgn. M.Sc. Project Meeting. Manchester, UK.
Wansink, B. (2003). Using laddering to understand and leverage a brand’s equity.
Qualitative Market Research: An International Journal Volume 6, Number 2, pp.
111-118.
yWorks. (2005). yDoc: A Javadoc UML Extension. [Online:
http://www.yworks.com/en/products_ydoc.htm]. Date accessed: 26th July 2005.

85
Appendix A. The Interviewees’ Profile There are eleven people involved in the software testing and evaluation procedure.
For the purpose of protecting the personal data, the profile is only shown as groups.
Fields of expertise
There are 5 people working in the Knowledge Management related domain, 3
people have Computer Science major but focus on other field, and 2 people is
working on Biological Science, as well as a person with business study
background.
Cultural Backgrounds
There are 7 Chinese people and 4 western people participated in the interviews.
Years of using computer
8 Computer Science people have used computer for over 7 years, and 2 of them
have a more than 15 years experience in using computer. Other 3 people just
began to use computer when they were college student.
Operating system preference
5 people would like to use Unix – like system, and 3 of them are western
people. 6 people choose Windows and 1 person prefer to use Mac OS.
Gender
There are 3 female and 8 male interviewees.

86
B. User Testing and Evaluation Results Three typical testing and evaluation results will be introduced here.
B.1 Results from Knowledge Management Community The results are taken from the 5 people from Knowledge Management community
and contribute the first 5 column of the grades array in Chapter 6.
Gender: Male
Major: B.Sc. Informatics; M.Sc. Bioinformatics; Ph.D. Computer Science
Ethic: Western, Chinese
Suggestions after testing:
Grouping cards on the panel
Make comments on logs
Stable output like OWL
Moving the cards here and there, visually, grouping just on the panel
Drag and drop
Relationships other than trees.
Interface evaluation:
Look and feel. Grades: 9 7 7 8 9
Interface layout. Grades: 7 7 9 6 8
Ease of use. Grades: 7 7 6 7 8
Flexibility. Grades 7 8 8 6 5
Functional evaluation:
Card sorting. Grades: 9 8 7 9 9
Laddering. Grades: 7 6 7 7 7
Relationship setting. Grades: 6 7 6 6 6
Transaction manager. Grades: 9 9 8 8 9
Knowledge Management community people’s real work:
Begin with excel file

87
First thing is things
Make words fuller, complete words automatically
Using Microsoft Visio to lay cards
Show small piles in big piles
Moving the cards to new groups
Hierarchically show the cards
Different relationships, different colors
A task panel for working. Like visa, put things altogether.
B.2 Results from Computer Science Students The results contribute the 6th column of the grades array in Chapter 6. Gender: Male
Major: M.Sc. Advanced Computer Science
Ethic: Chinese
Suggestions on laddering and card sorting tool:
A message box should appear while add group tree concepts to ladder
Reset button reminder
Multiple selection to add to the group by ALT+click
Node selection mode, blank mode message warning
Give feedback about how to select words
Step track back
Bigger trees
Interface evaluation:
Look and feel. Grades: 7
Interface layout. Grades: 6
Ease of use. Grades: 7
Flexibility. Grades 6
Functional evaluation:
Card sorting. Grades: 7
Laddering. Grades: 7
Relationship setting. Grades: 8

88
Transaction manager. Grades: 8
B.3 Results from Business Student The results contribute the 6th column of the grades array in Chapter 6. Gender: Female
Major: M.Sc. Finance
Ethic: Chinese
Suggestions on laddering and card sorting tool:
In the card sorting panel, right button menu to rename the card
Document Elicitation could automatically remove blank characters
After loading status, the color should change back to yellow
Save/Load status exceptions.
Direct grouping by single click selection while press ALT
Edit ladder from right click popup menu
Give feedback while click the ladder settings by mistake.
Interface evaluation:
Look and feel. Grades: 7
Interface layout. Grades: 9
Ease of use. Grades: 6
Flexibility. Grades 6
Functional evaluation:
Card sorting. Grades: 8
Laddering. Grades: 6
Relationship setting. Grades: 7
Transaction manager. Grades: 7

89
C. Software Setup The first task is to install Java compiler, we are using Java 2 Platform Standard
Edition Development Kit 5.0 (JDK 5.0) (Sun Microsystems, 2005) as the
development toolkit. This toolkit can be downloaded from:
http://java.sun.com/j2se/1.5.0/download.jsp
After download and installing the JDK 5.0, we can run Java programs via Java
Virtual Machine (JVM) provided by this toolkit.
The second crucial software support required by this project is the Protégé system.
The current release is Protégé 2000 version 3.1, which can be obtained from:
http://protege.stanford.edu/download/download.html
The Protégé installation is quite ordinary - the users will download the binary
executable files. Another API commonly required by the Semantic Web related
applications is Jena (McBride, 2002). The download page and guideline can be
found at:
http://jena.sourceforge.net/
For this project, the users can extract the required packages directly to the root path
so that we can compile and run the plug-in easily. After all the packages are
installed and ready to be loaded, we can either execute the Java code in the IDE
development environment or just system console by defining the parameters
required by each package. A typical execution command typed below is long and
complicated, which is suggested to be executed via a written executable script
document.
java -Dprotege.dir=C:\Protege_3.1_beta
-classpath “C:\Protege_3.1_beta\plugins\uk.ac.man.cs.mig.coode.ke;
C:\Jena-2.2\lib\xercesImpl.jar;C:\Jena-2.2\lib\jena.jar;
C:\Jena-2.2\lib\junit.jar;C:\Jena-2.2\lib\jakarta-oro-2.0.5.jar;
C:\Jena-2.2\lib\commons-logging.jar;C:\Jena-2.2\lib\log4j-1.2.7.jar;
C:\Jena-2.2\lib\xml-apis.jar;C:\Jena-2.2\lib\antlr.jar;
C:\Jena-2.2\lib;C:\Jena-2.2\lib\concurrent.jar;
C:\Jena-2.2\lib\icu4j.jar;C:\Protege_3.1_beta\looks.jar;
C:\Protege_3.1_beta\protege.jar;C:\Protege_3.1_beta\unicode_panel.jar”
KE

90
If this knowledge elicitation plug-in is successfully integrated into the Protégé
system, the user will find an option to tick this plug-in in the Protégé plug-in list as
screenshot follows. After ticking this plug-in, a tab-widget will appear beside the
existing widgets, and now we can perform tasks on it.
Figure A. 1: Snapshot of Choosing KEToolTab





























