Embed Size (px)
Citation preview

KNIME – podstawy obsługi programu
Pracownia Chemometrii Środowiska
Katedra Chemii i Radiochemii Środowiska
Wydział Chemii UG

KNIME
• KNIME jest programem działającym na licencji GNU – można go pobrać za darmo z oficjalnej strony: http://www.knime.org/knime-analytics-platform-sdk-download
• Program ma wiele zastosowań w obróbce oraz analizie danych, dzięki czemu stanowi idealne narzędzie do celów analizy statystycznej oraz chemometrycznej.
• Ogromną zaletą programu jest graficzny, przyjazny użytkownikowi interfejs.• Przydatne wprowadzenie do programu w języku angielskim:
https://tech.knime.org/files/KNIME_quickstart.pdf• Możliwość przechowywania zastosowanych rozwiązań w postaci algorytmu
postępowania, dzięki czemu można rozwiązywać podobne problemy na innych danych.
2
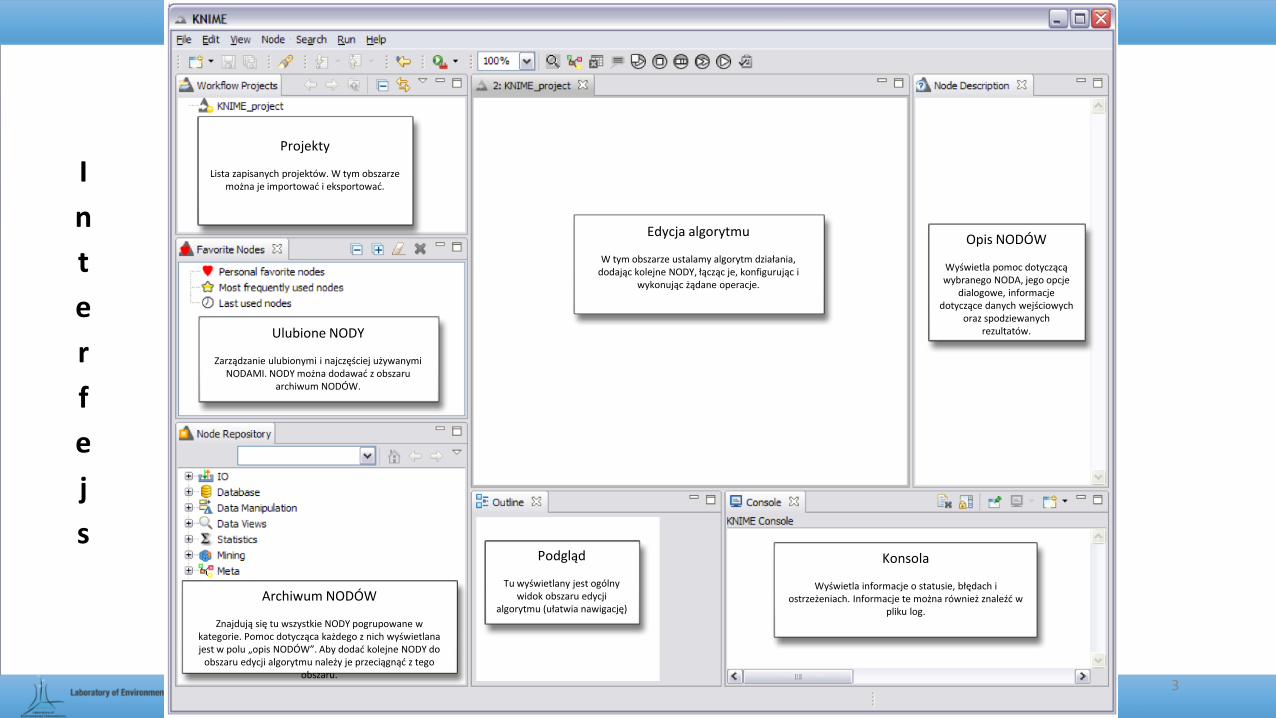
Projekty
Lista zapisanych projektów. W tym obszarze można je importować i eksportować.
Ulubione NODY
Zarządzanie ulubionymi i najczęściej używanymi NODAMI. NODY można dodawać z obszaru
archiwum NODÓW.
Archiwum NODÓW
Znajdują się tu wszystkie NODY pogrupowane w kategorie. Pomoc dotycząca każdego z nich wyświetlana jest w polu „opis NODÓW”. Aby dodać kolejne NODY do
obszaru edycji algorytmu należy je przeciągnąć z tego obszaru.
Edycja algorytmu
W tym obszarze ustalamy algorytm działania, dodając kolejne NODY, łącząc je, konfigurując i
wykonując żądane operacje.
Podgląd
Tu wyświetlany jest ogólny widok obszaru edycji
algorytmu (ułatwia nawigację)
Konsola
Wyświetla informacje o statusie, błędach i ostrzeżeniach. Informacje te można również znaleźć w
pliku log.
Opis NODÓW
Wyświetla pomoc dotyczącą wybranego NODA, jego opcje
dialogowe, informacje dotyczące danych wejściowych
oraz spodziewanych rezultatów.
3
I
n
t
e
r
f
e
j
s
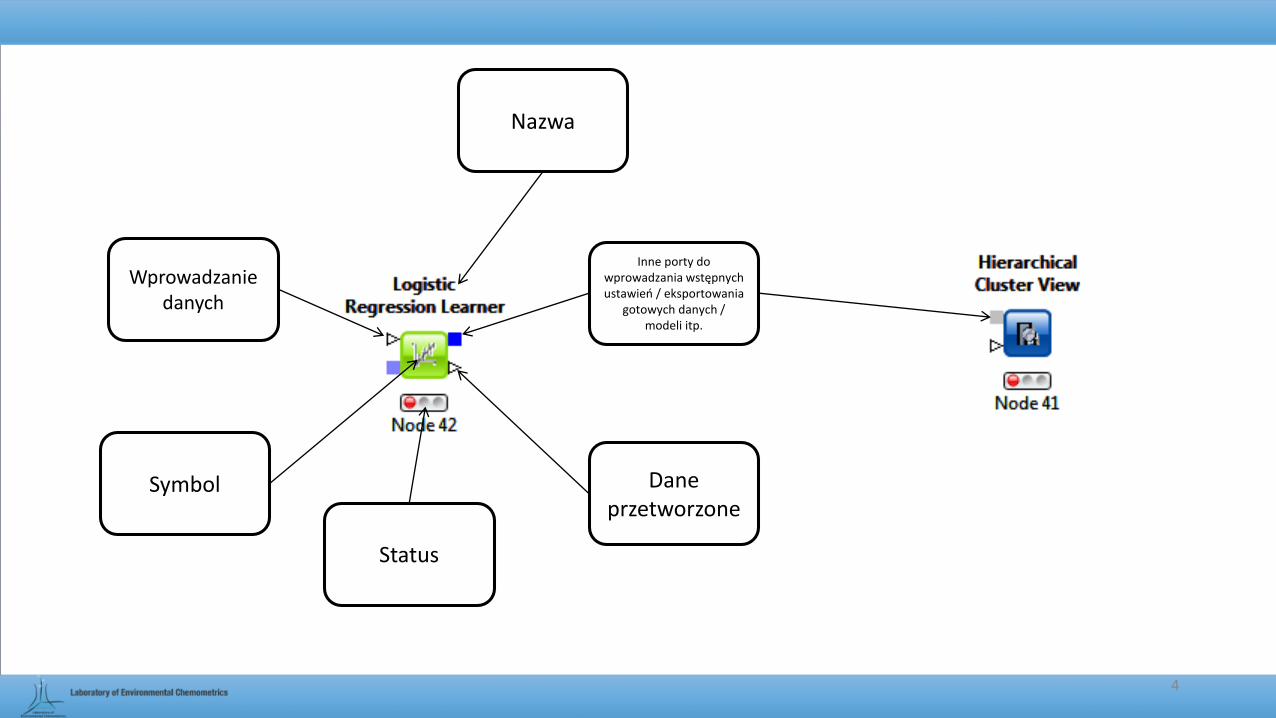
Dane przetworzone
Nazwa
Wprowadzanie danych
Status
Symbol
Inne porty do wprowadzania wstępnych ustawień / eksportowania
gotowych danych / modeli itp.
4
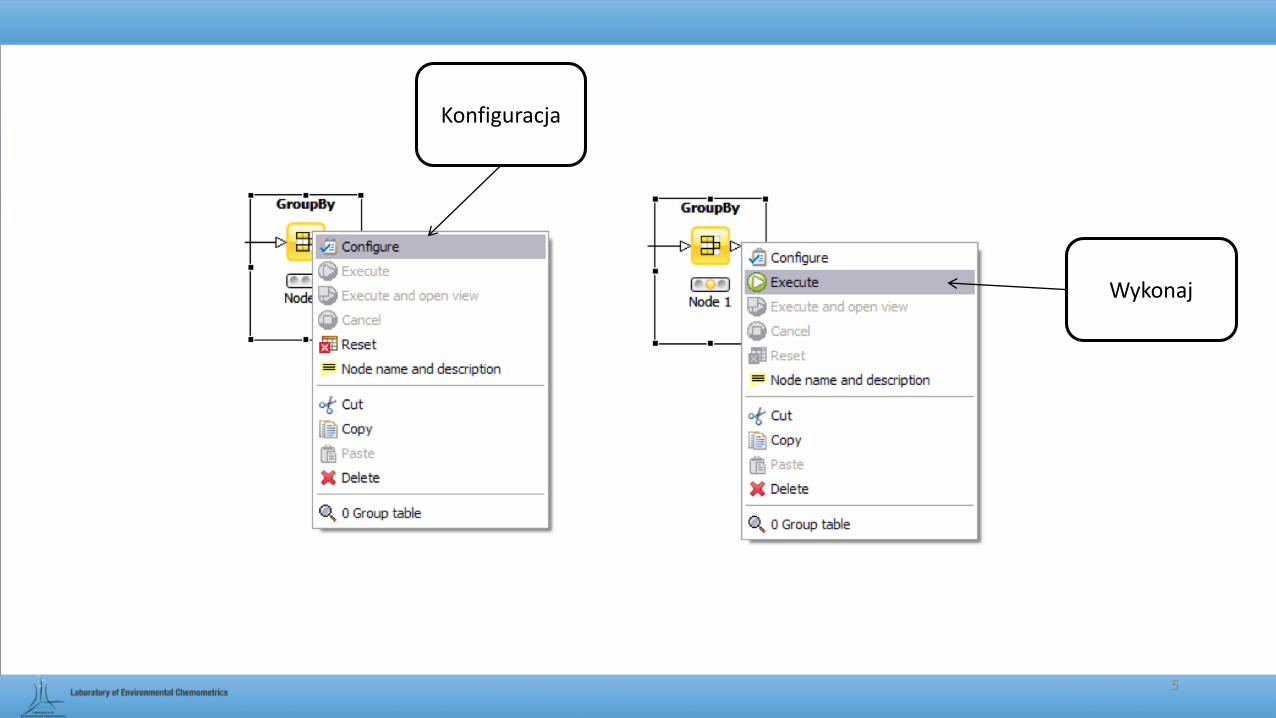
Konfiguracja
Wykonaj
5
6
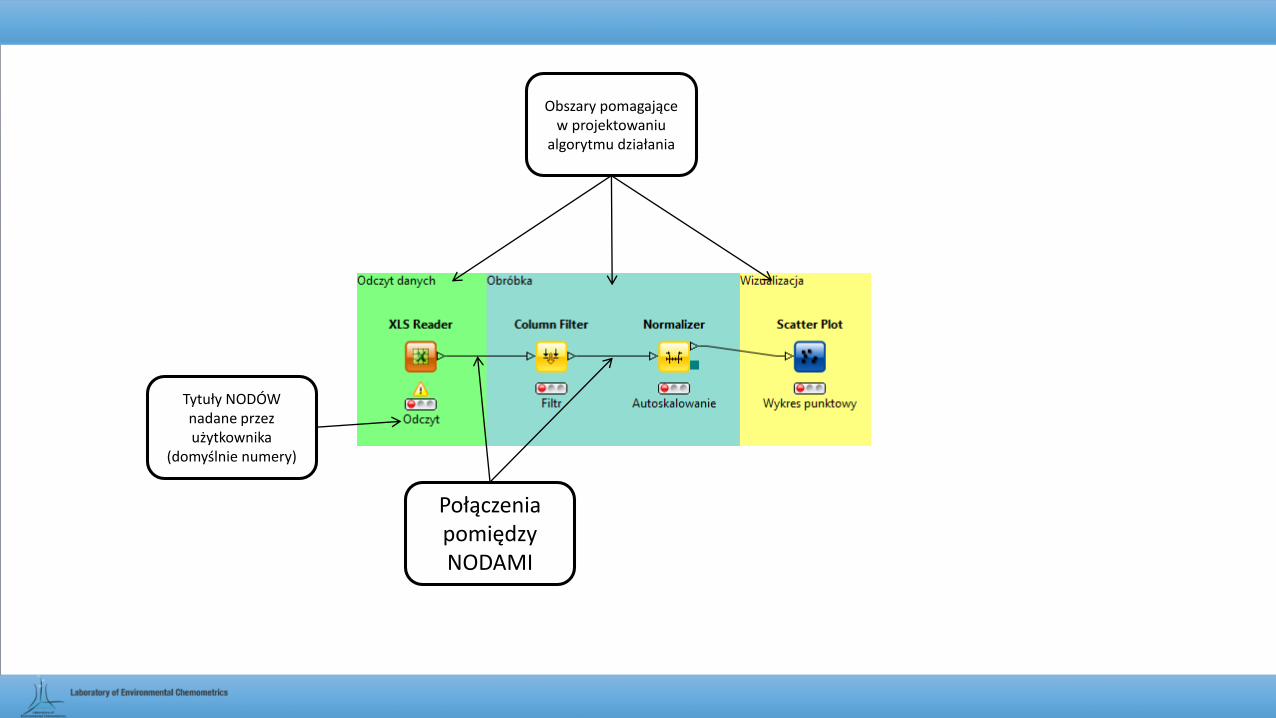
Tytuły NODÓW nadane przez użytkownika
(domyślnie numery)
Obszary pomagające w projektowaniu
algorytmu działania
Połączenia pomiędzy NODAMI

Opis przeznaczenia wybranych „NODÓW” oraz konfiguracja ustawień
8
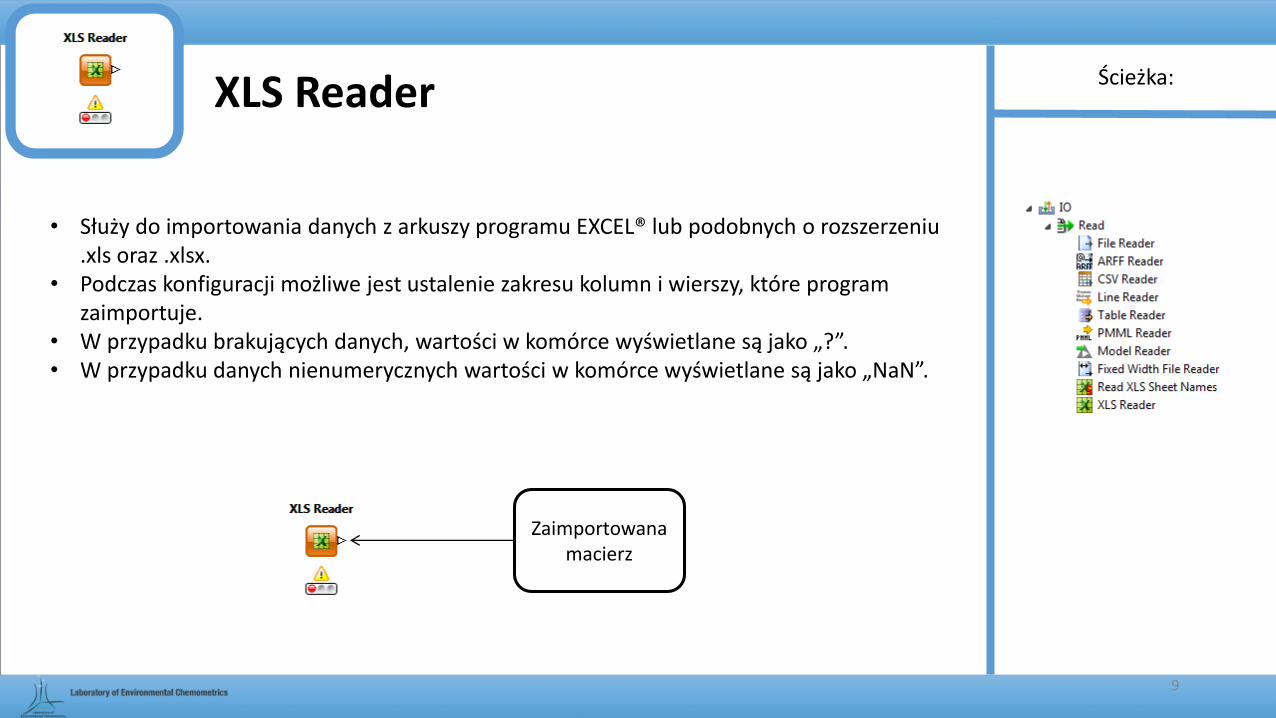
XLS Reader
• Służy do importowania danych z arkuszy programu EXCEL® lub podobnych o rozszerzeniu .xls oraz .xlsx.
• Podczas konfiguracji możliwe jest ustalenie zakresu kolumn i wierszy, które program zaimportuje.
• W przypadku brakujących danych, wartości w komórce wyświetlane są jako „?”. • W przypadku danych nienumerycznych wartości w komórce wyświetlane są jako „NaN”.
Zaimportowana macierz
Ścieżka:
9
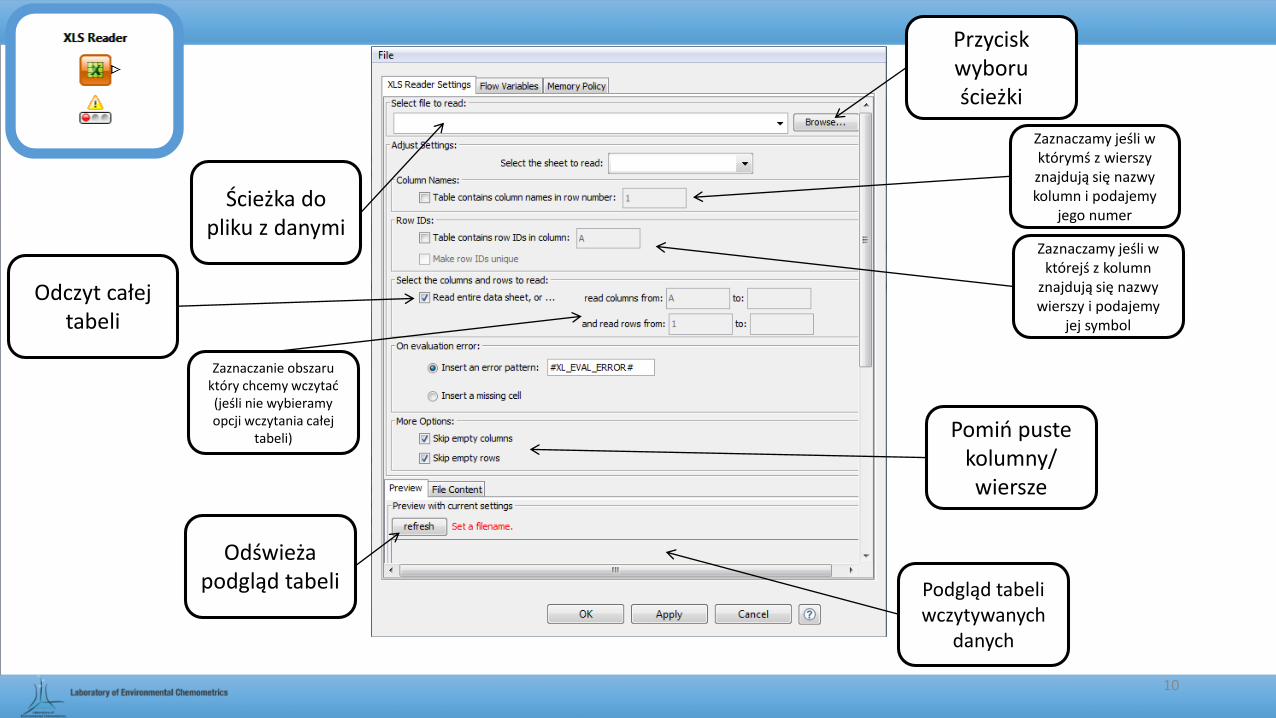
Ścieżka do pliku z danymi
Przycisk wyboru ścieżki
Zaznaczamy jeśli w którymś z wierszy znajdują się nazwy kolumn i podajemy
jego numer
Podgląd tabeli wczytywanych
danych
Zaznaczamy jeśli w którejś z kolumn
znajdują się nazwy wierszy i podajemy
jej symbol
Odświeża podgląd tabeli
Zaznaczanie obszaru który chcemy wczytać (jeśli nie wybieramy opcji wczytania całej
tabeli)
Odczyt całej tabeli
Pomiń puste kolumny/wiersze
10

CSV Reader
• Służy do importowania danych z plików o rozszerzeniu .csv.• Można zdefiniować zarówno znak podziału komórek jak i symbol separatora dziesiętnego. • Podczas konfiguracji możliwe jest ustalenie zakresu kolumn i wierszy, które program
zaimportuje. • W przypadku brakujących danych, wartości w komórce wyświetlane są jako „?”. • W przypadku danych nienumerycznych wartości w komórce wyświetlane są jako „NaN”.
Zaimportowana macierz
Ścieżka:
11
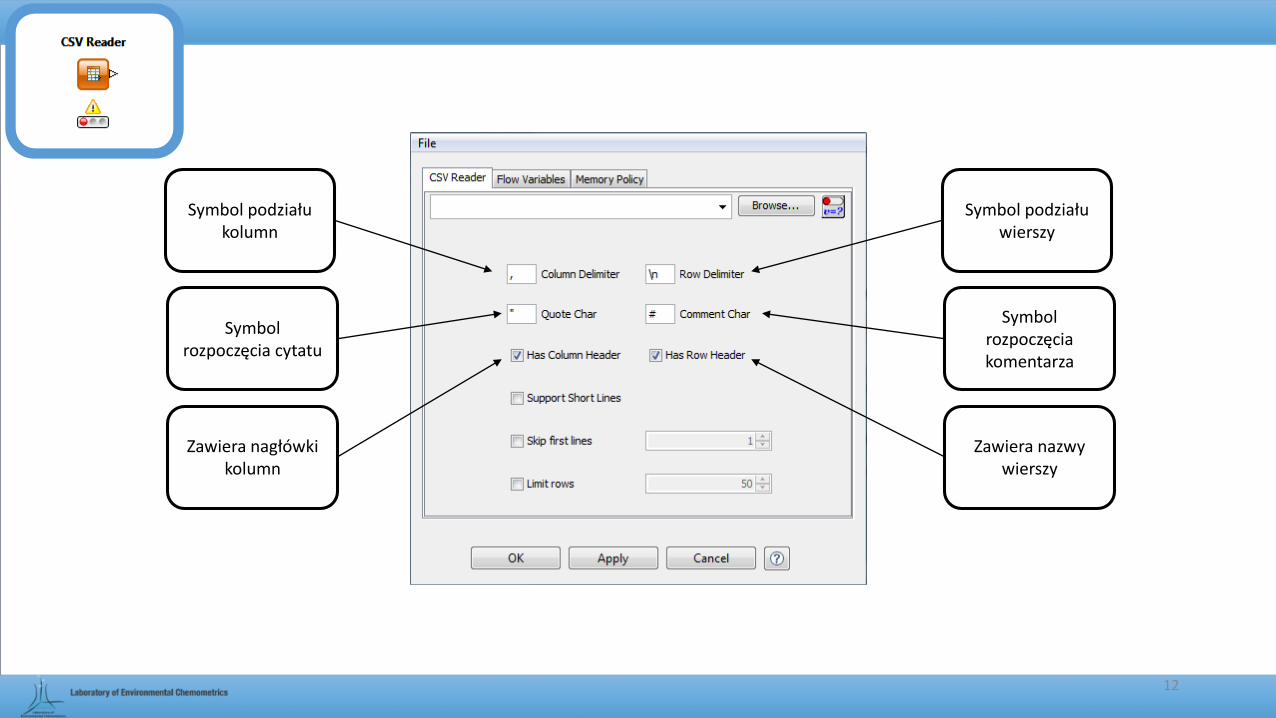
Symbol podziału kolumn
12
Symbol podziału wierszy
Symbol rozpoczęcia cytatu
Symbol rozpoczęcia komentarza
Zawiera nazwy wierszy
Zawiera nagłówki kolumn

Table Creator
• Służy do tworzenia macierzy z danymi wewnątrz programu KNIME.• Do macierzy można wprowadzać dane zarówno liczbowe jak i tekstowe. Wyboru klasy
zmiennej dokonuje się w ustawieniach właściwości poszczególnych kolumn.
13
Utworzona macierz danych

Edycja właściwości
kolumny
14
Obszar wpisywania
danych
Nie włączaj kolumny do
ostatecznej tabeli
Typ zmiennej (integrer – liczba
całkowita, double –złożona, string -
tekst)
Nazwa kolumny

Column Filter
• Pozwala na zredukowanie wymiarów macierzy poprzez wyselekcjonowanie odpowiednich kolumn.
Macierz wejściowa
Macierz zredukowana
Ścieżka:
15
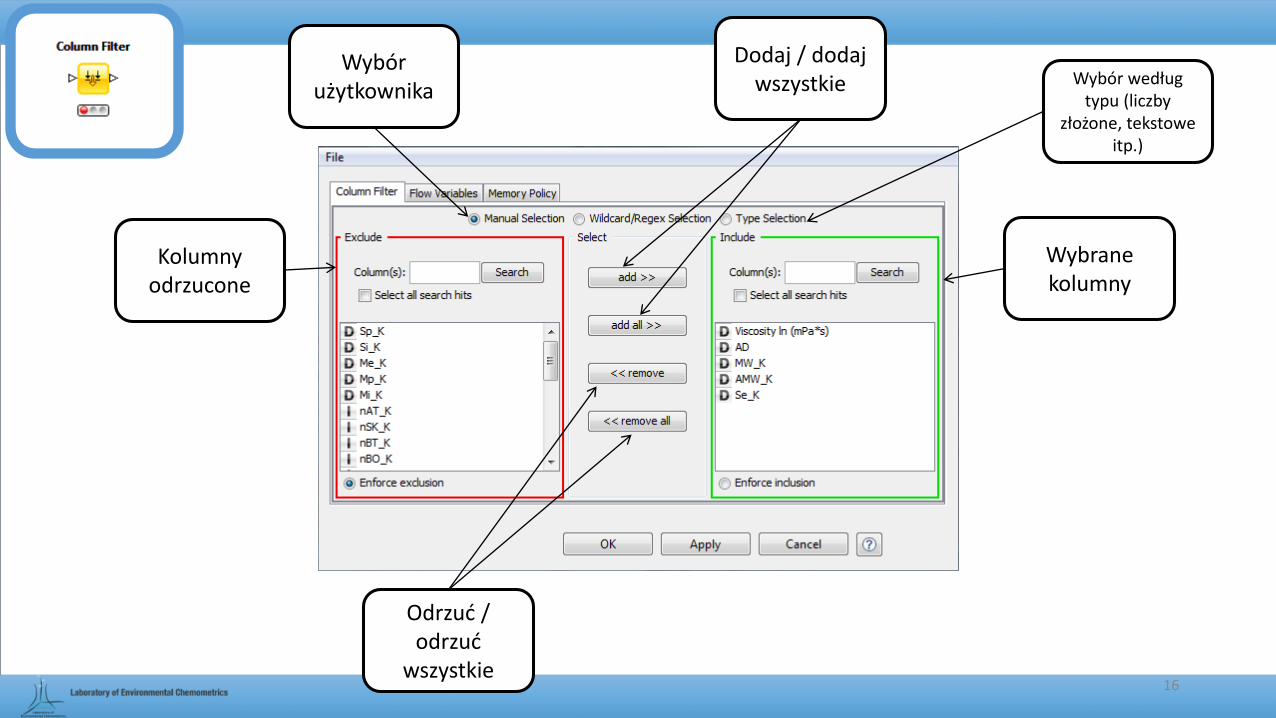
Kolumny odrzucone
Wybrane kolumny
Dodaj / dodaj wszystkie
Odrzuć / odrzuć
wszystkie
Wybór użytkownika
Wybór według typu (liczby
złożone, tekstowe itp.)
16
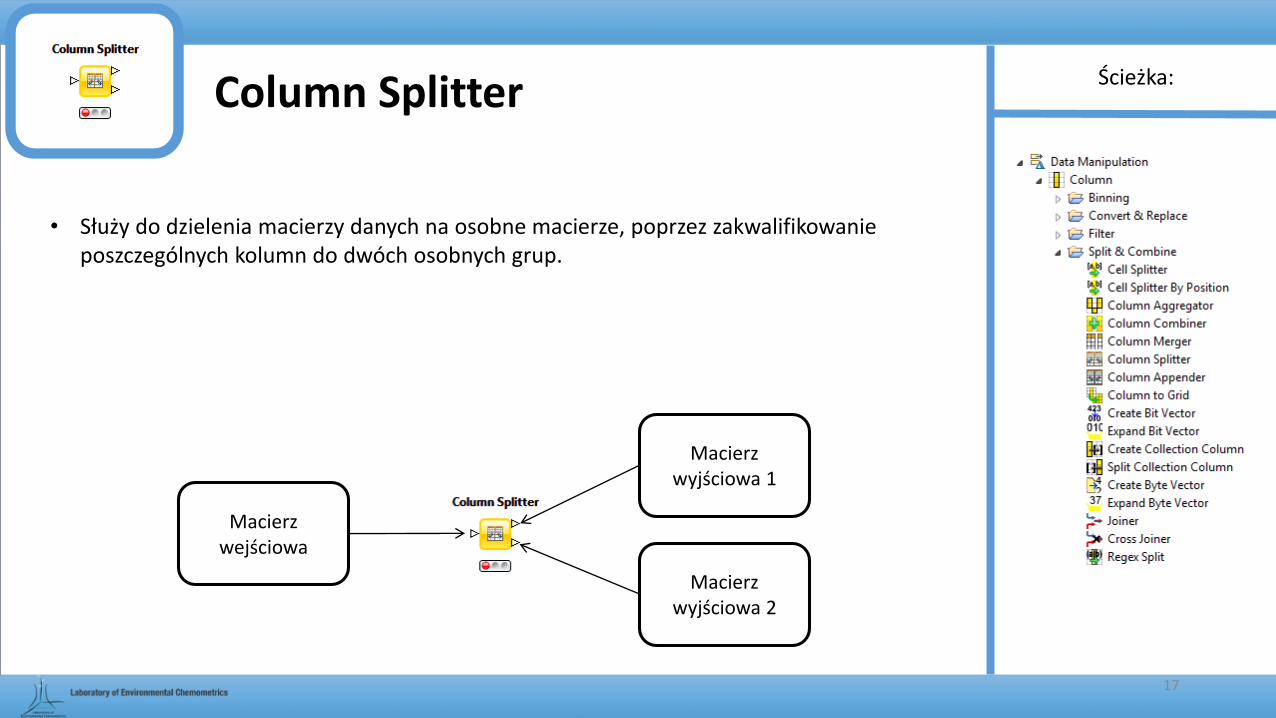
Column Splitter
• Służy do dzielenia macierzy danych na osobne macierze, poprzez zakwalifikowanie poszczególnych kolumn do dwóch osobnych grup.
Macierz wejściowa
Macierz wyjściowa 1
Macierz wyjściowa 2
Ścieżka:
17
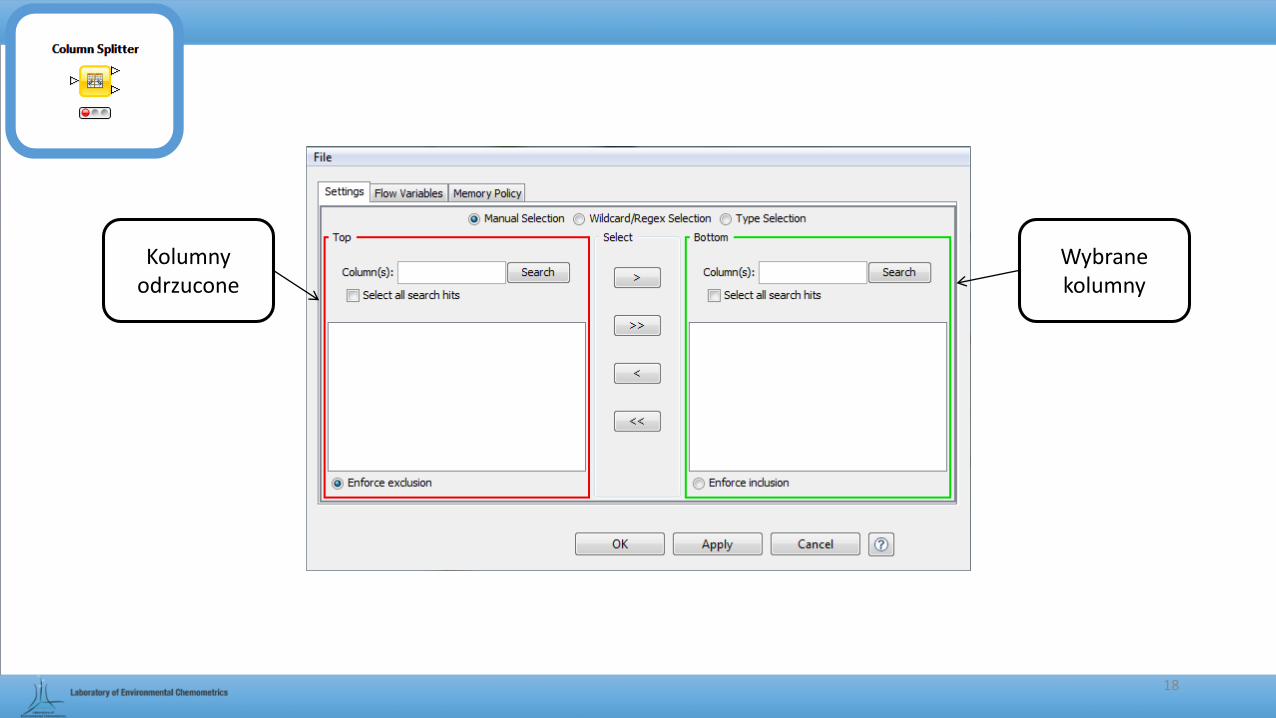
18
Kolumny odrzucone
Wybrane kolumny
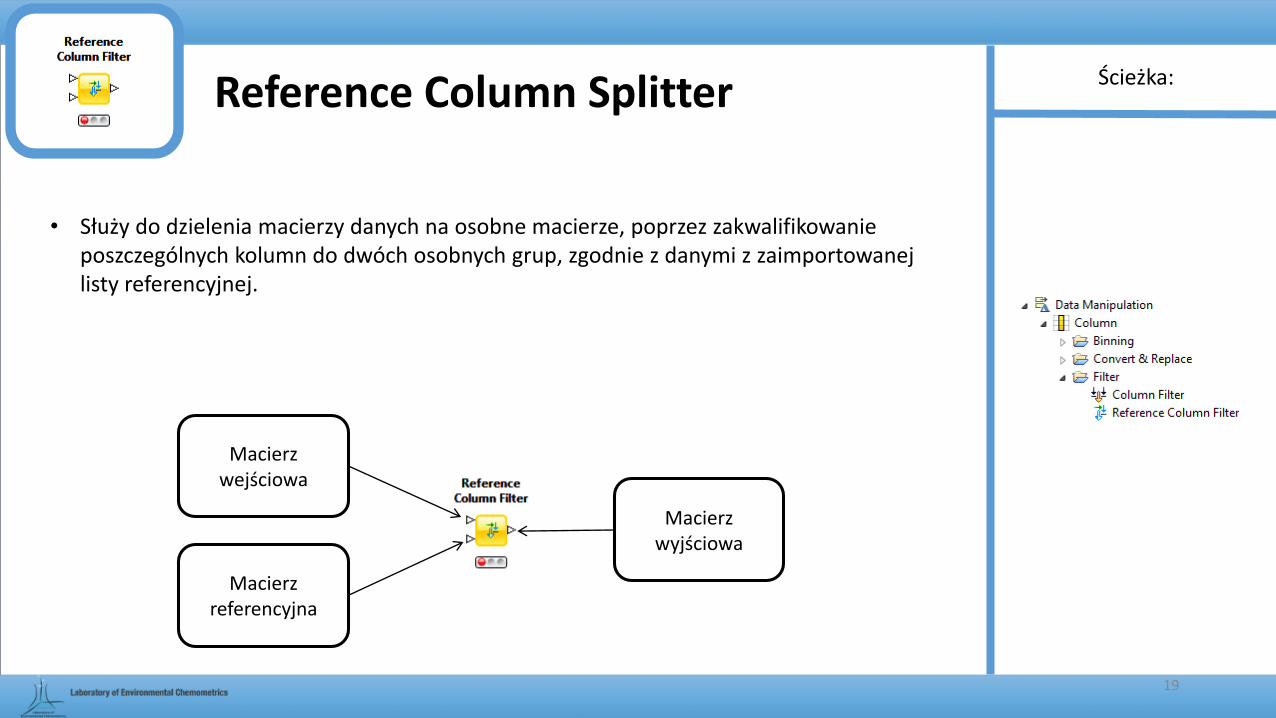
Reference Column Splitter
• Służy do dzielenia macierzy danych na osobne macierze, poprzez zakwalifikowanie poszczególnych kolumn do dwóch osobnych grup, zgodnie z danymi z zaimportowanej listy referencyjnej.
Macierz wejściowa
Macierz referencyjna
Macierz wyjściowa
Ścieżka:
19
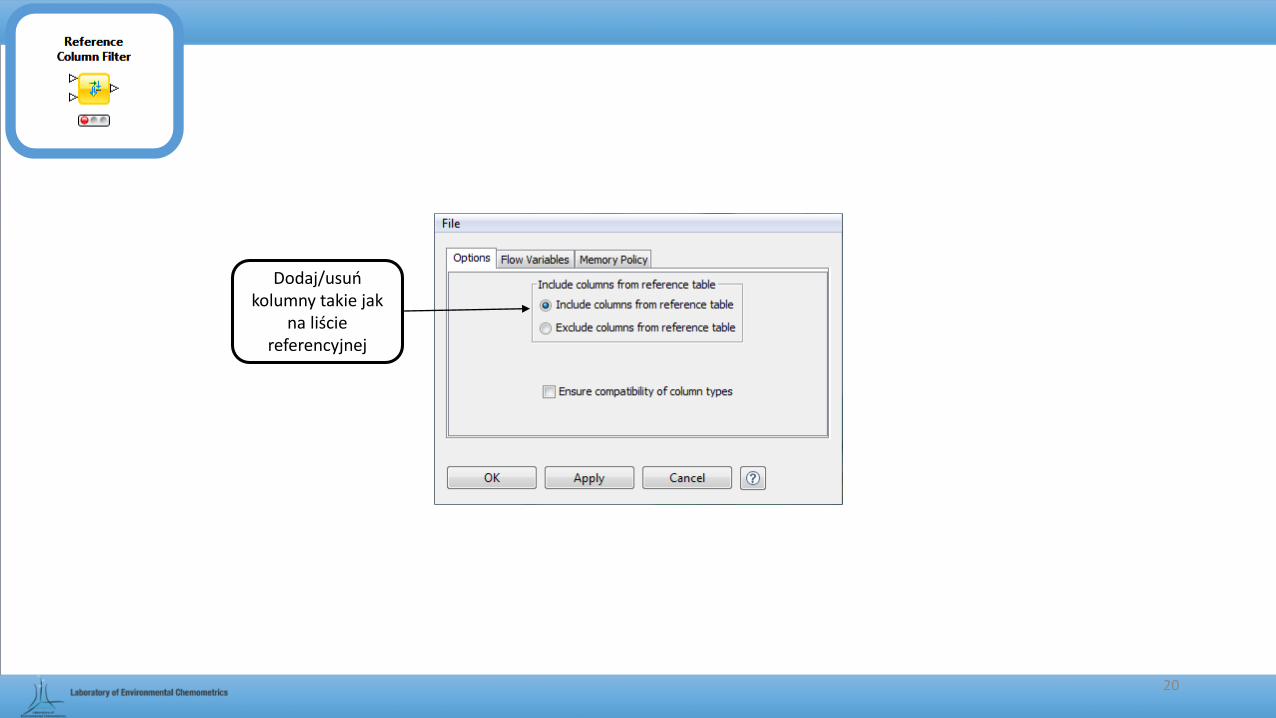
Dodaj/usuń kolumny takie jak
na liście referencyjnej
20

Row Filter
• Pozwala na zredukowanie wymiarów macierzy poprzez wyselekcjonowanie odpowiednich wierszy.
Macierz wejściowa
Macierz zredukowana
Ścieżka:
21
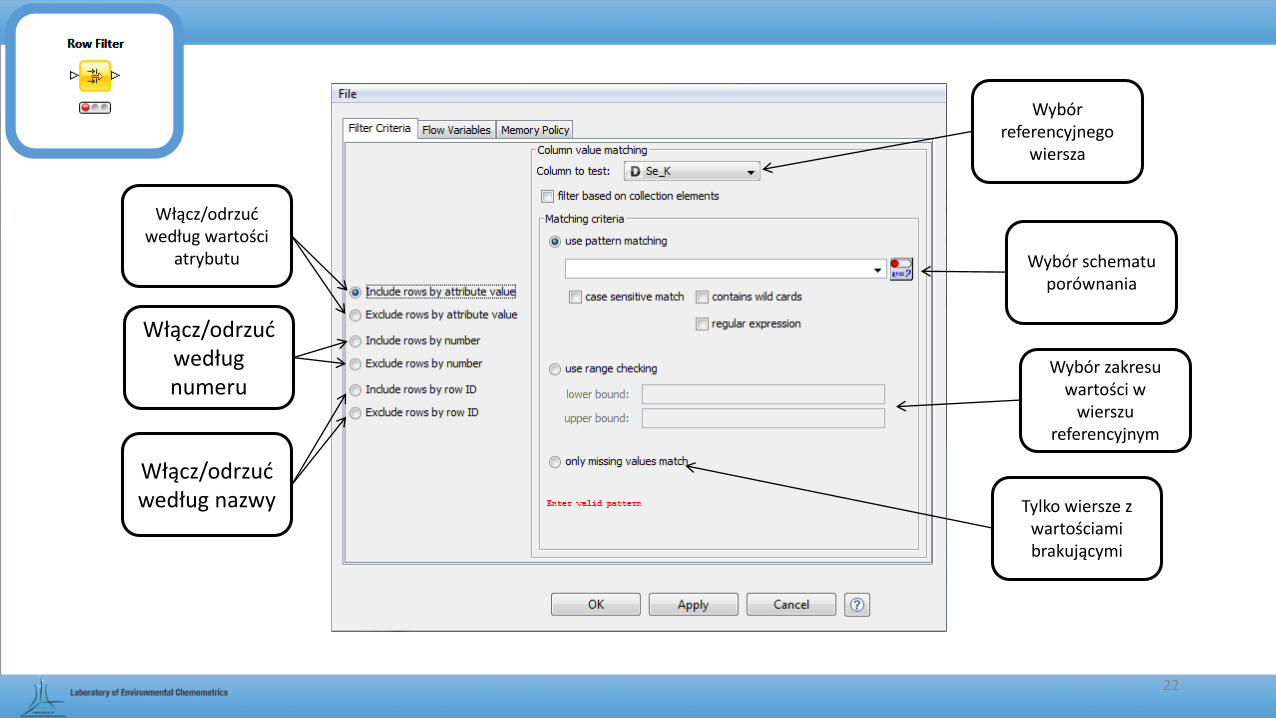
Włącz/odrzuć według wartości
atrybutu
Włącz/odrzuć według numeru
Włącz/odrzuć według nazwy
Wybór referencyjnego
wiersza
Wybór zakresu wartości w
wierszu referencyjnym
Tylko wiersze z wartościami brakującymi
Wybór schematu porównania
22

Włącz/odrzuć według wartości
atrybutu
Włącz/odrzuć według numeru
Włącz/odrzuć według nazwy
Ustawienia zakresu wierszy
23
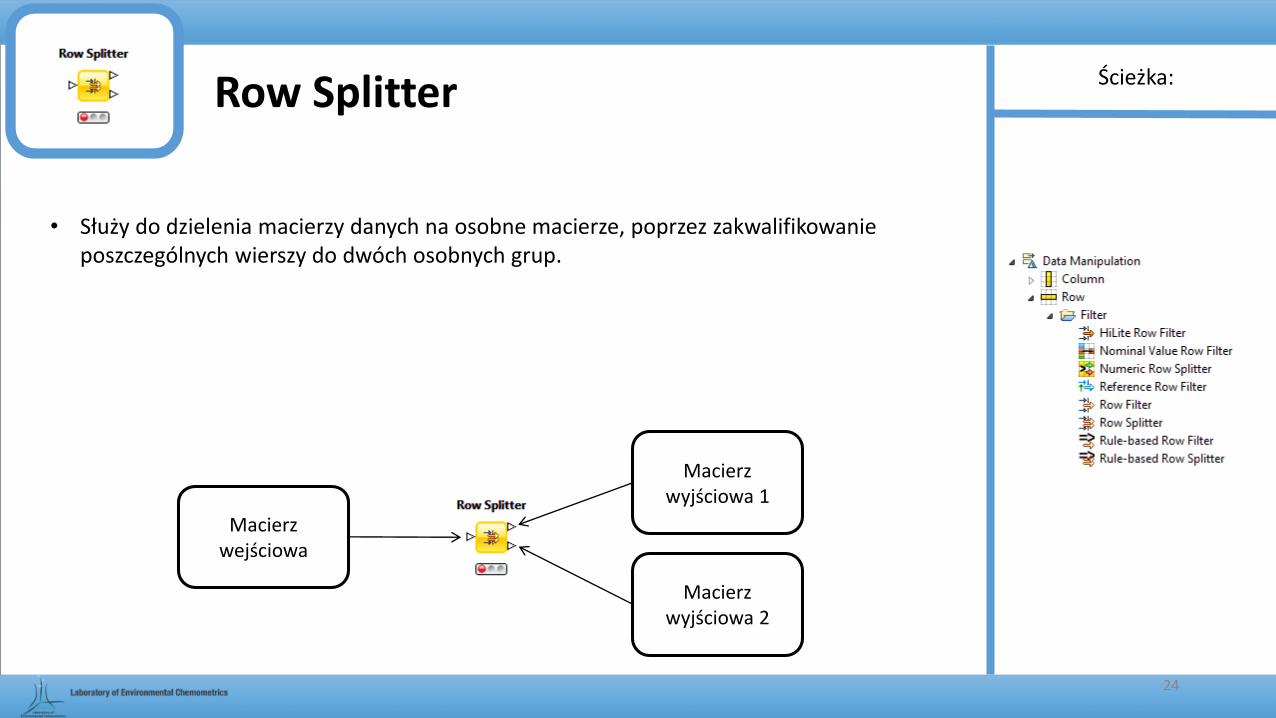
Row Splitter
• Służy do dzielenia macierzy danych na osobne macierze, poprzez zakwalifikowanie poszczególnych wierszy do dwóch osobnych grup.
Macierz wejściowa
Macierz wyjściowa 1
Macierz wyjściowa 2
Ścieżka:
24
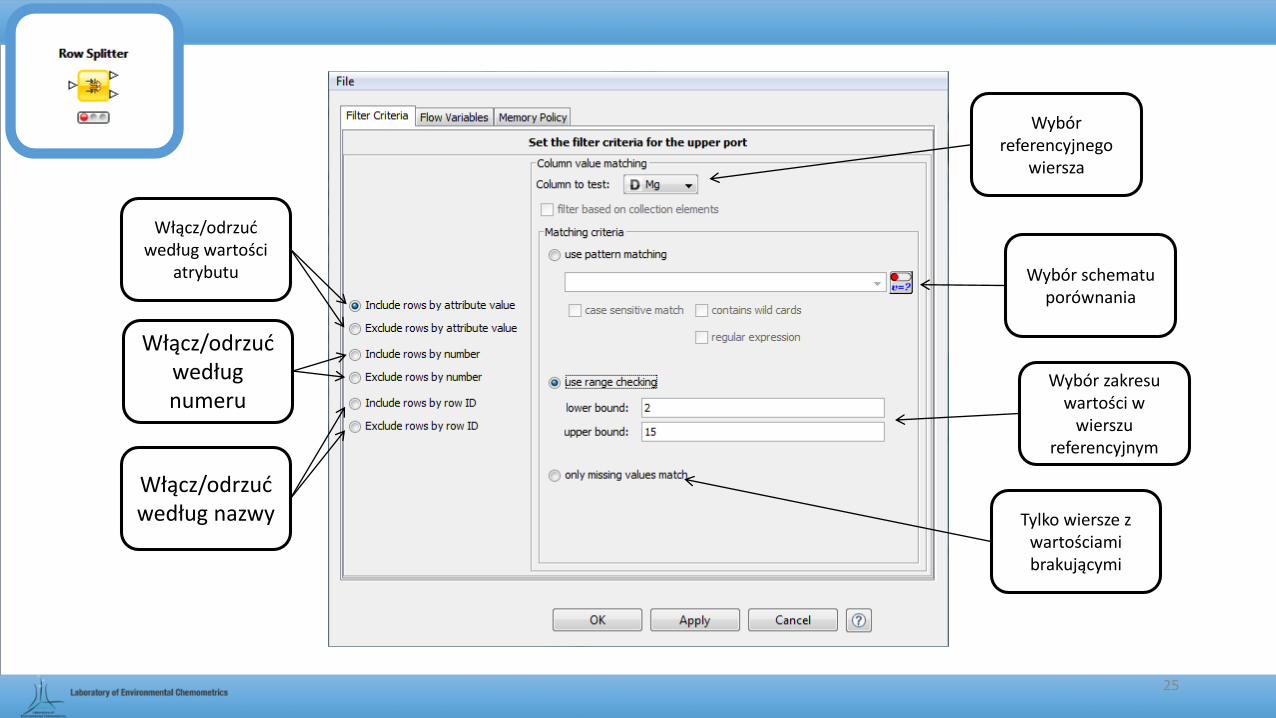
25
Włącz/odrzuć według wartości
atrybutu
Włącz/odrzuć według numeru
Włącz/odrzuć według nazwy
Wybór referencyjnego
wiersza
Wybór zakresu wartości w
wierszu referencyjnym
Tylko wiersze z wartościami brakującymi
Wybór schematu porównania
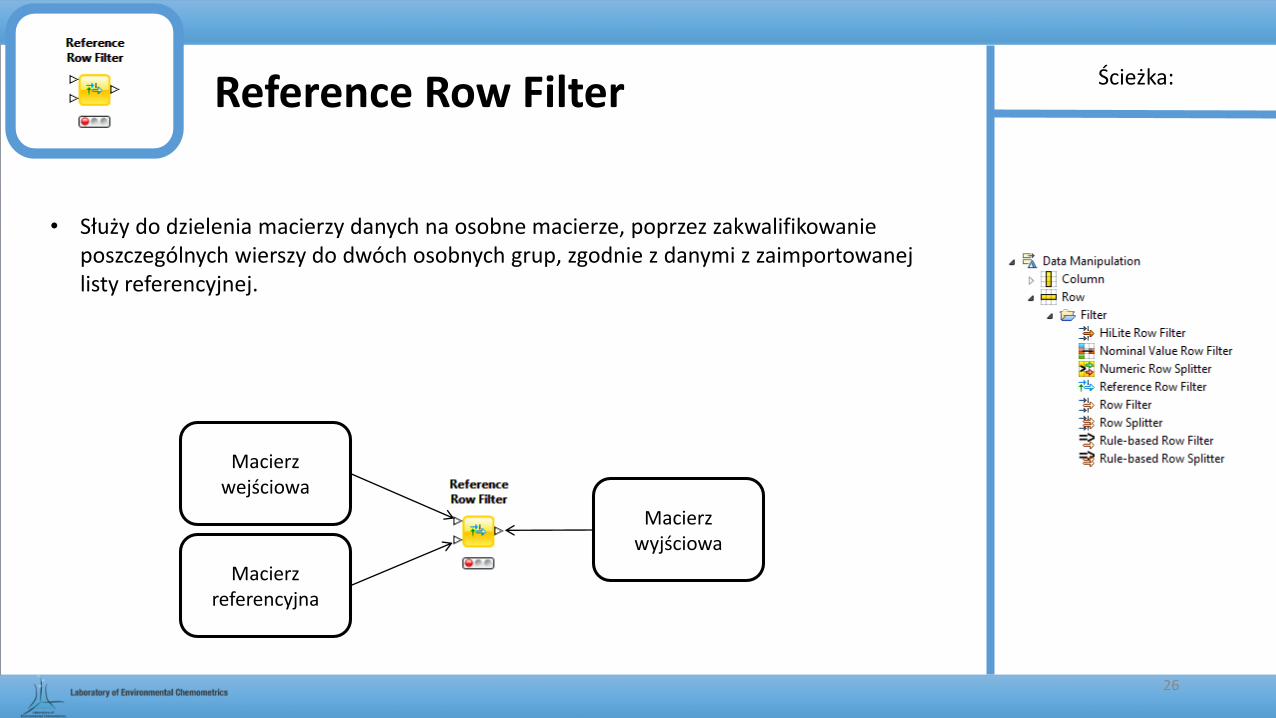
Reference Row Filter
• Służy do dzielenia macierzy danych na osobne macierze, poprzez zakwalifikowanie poszczególnych wierszy do dwóch osobnych grup, zgodnie z danymi z zaimportowanej listy referencyjnej.
Macierz wejściowa
Macierz referencyjna
Macierz wyjściowa
Ścieżka:
26
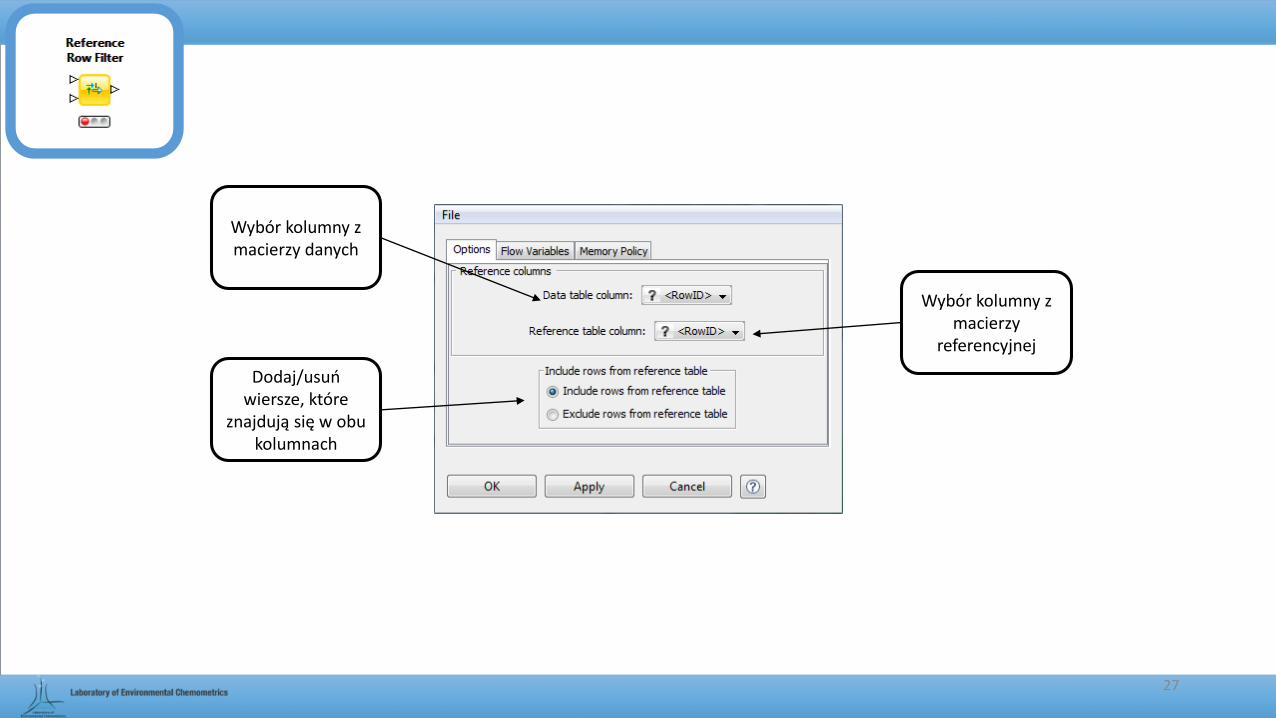
Wybór kolumny z macierzy danych
27
Wybór kolumny z macierzy
referencyjnej
Dodaj/usuń wiersze, które
znajdują się w obu kolumnach

Transpose
• Służy do transponowania macierzy.
Macierz wejściowa
Macierz transponowana
Ścieżka:
28

Ilość kolumn odczytywana podczas
jednej iteracji algorytmu – zwiększenie wartości zwiększa szybkość ale i
zużycie pamięci
29
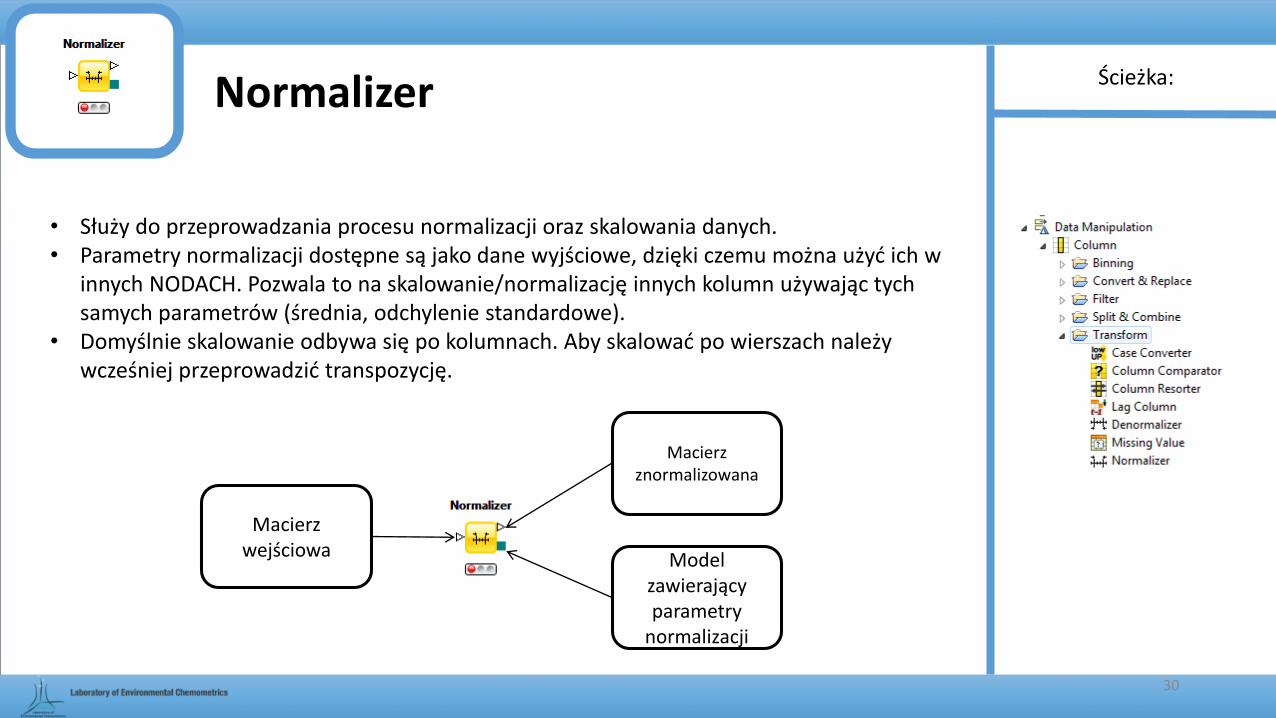
Normalizer
• Służy do przeprowadzania procesu normalizacji oraz skalowania danych. • Parametry normalizacji dostępne są jako dane wyjściowe, dzięki czemu można użyć ich w
innych NODACH. Pozwala to na skalowanie/normalizację innych kolumn używając tych samych parametrów (średnia, odchylenie standardowe).
• Domyślnie skalowanie odbywa się po kolumnach. Aby skalować po wierszach należy wcześniej przeprowadzić transpozycję.
Macierz wejściowa
Macierz znormalizowana
Model zawierający parametry
normalizacji
Ścieżka:
30
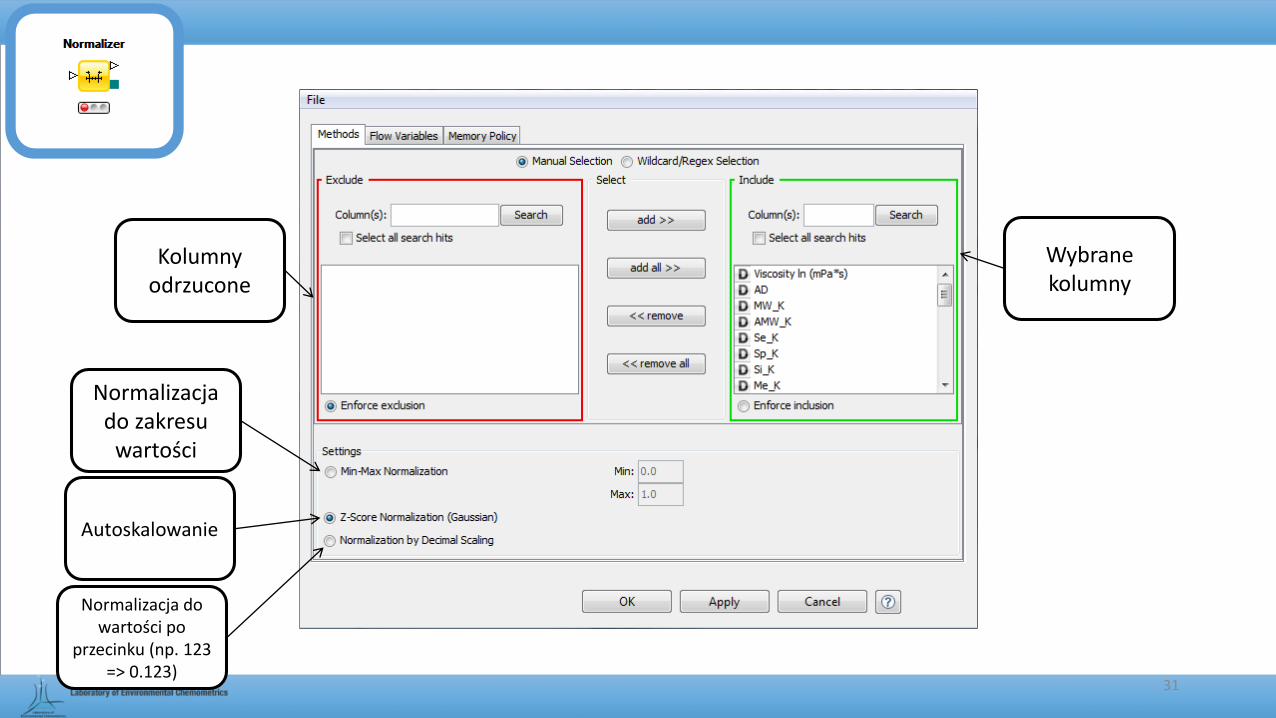
Kolumny odrzucone
Wybrane kolumny
Normalizacja do zakresu
wartości
Autoskalowanie
Normalizacja do wartości po
przecinku (np. 123 => 0.123)
31
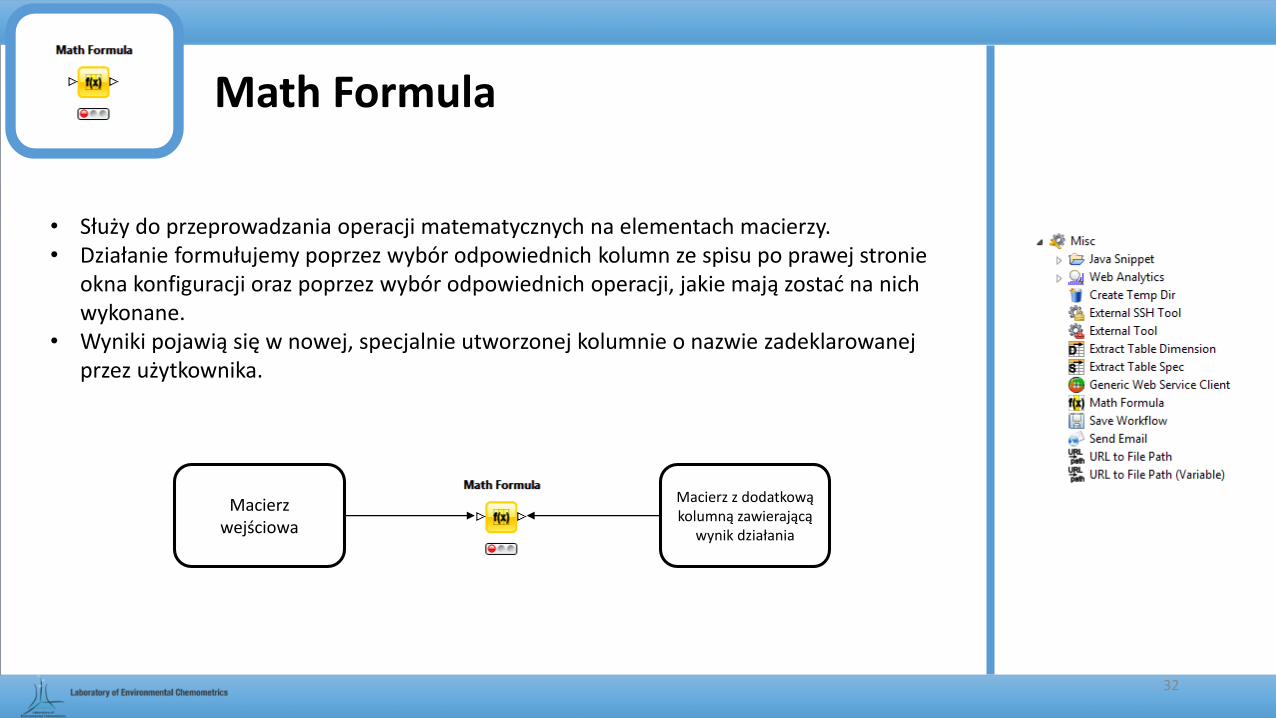
Math Formula
• Służy do przeprowadzania operacji matematycznych na elementach macierzy.• Działanie formułujemy poprzez wybór odpowiednich kolumn ze spisu po prawej stronie
okna konfiguracji oraz poprzez wybór odpowiednich operacji, jakie mają zostać na nich wykonane.
• Wyniki pojawią się w nowej, specjalnie utworzonej kolumnie o nazwie zadeklarowanej przez użytkownika.
32
Macierz wejściowa
Macierz z dodatkową kolumną zawierającą
wynik działania

Lista kolumn w macierzy
33
Spis kategorii funkcji
Opis zaznaczonej funkcji
Funkcje
Postać działania, które zostanie
wykonane
Dodaj kolumnę (z wynikami)
Zastąp wynikiem kolumnę (wybór z
listy)
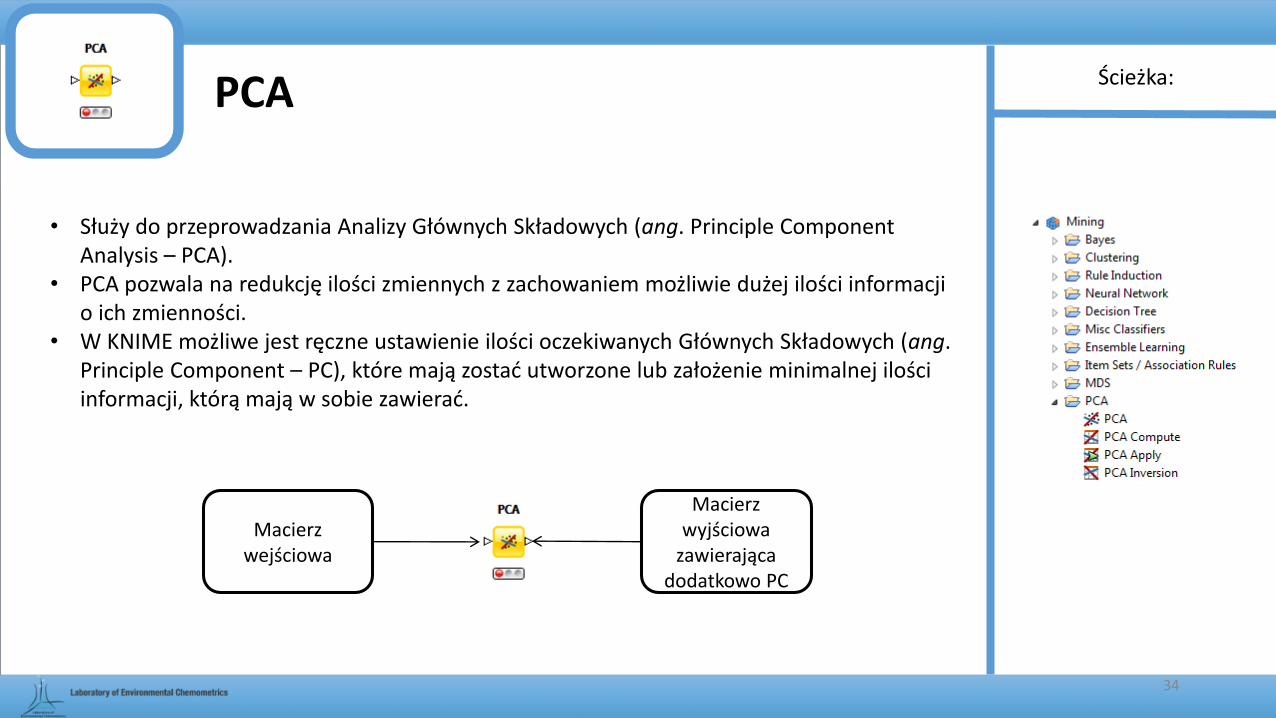
PCA
• Służy do przeprowadzania Analizy Głównych Składowych (ang. Principle Component Analysis – PCA).
• PCA pozwala na redukcję ilości zmiennych z zachowaniem możliwie dużej ilości informacji o ich zmienności.
• W KNIME możliwe jest ręczne ustawienie ilości oczekiwanych Głównych Składowych (ang. Principle Component – PC), które mają zostać utworzone lub założenie minimalnej ilości informacji, którą mają w sobie zawierać.
Macierz wejściowa
Macierz wyjściowa
zawierająca dodatkowo PC
Ścieżka:
34

Kolumny odrzucone
Wybrane kolumny
Ilość PC, które mają zostać utworzone
Do jakiej minimalnej wartości sumarycznej wariancji zredukować
zbiór
35
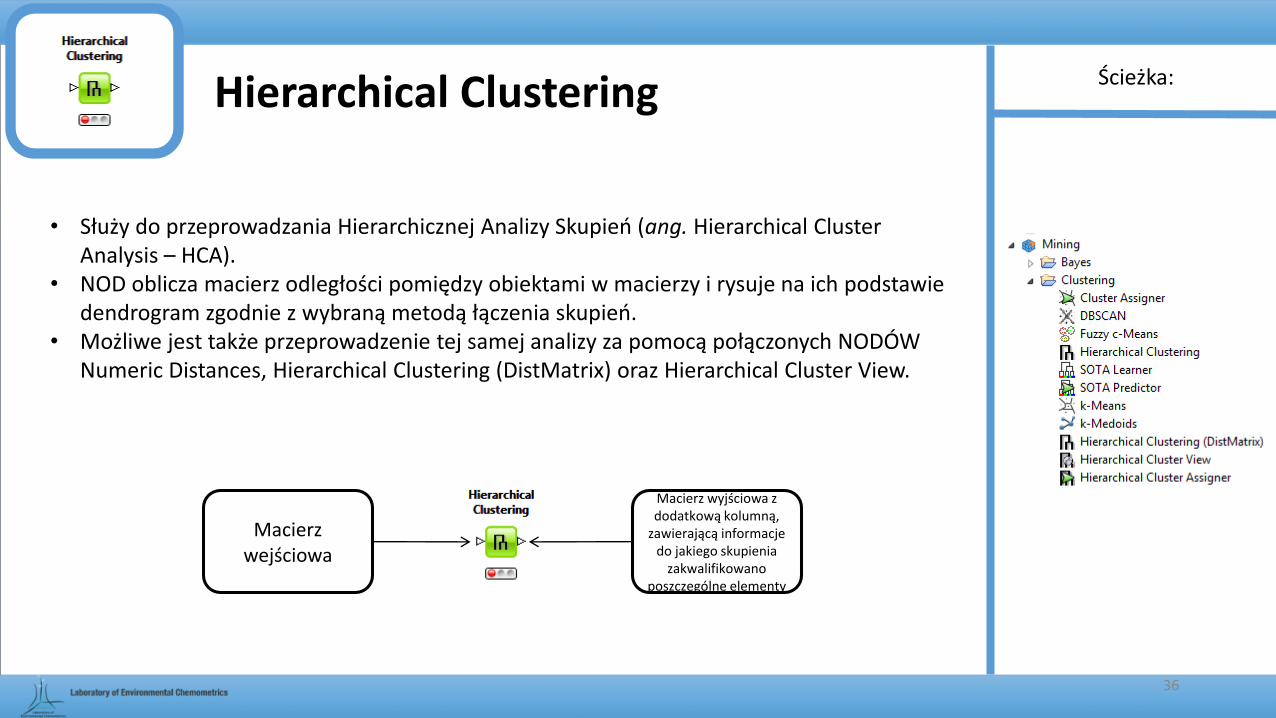
Hierarchical Clustering
• Służy do przeprowadzania Hierarchicznej Analizy Skupień (ang. Hierarchical Cluster Analysis – HCA).
• NOD oblicza macierz odległości pomiędzy obiektami w macierzy i rysuje na ich podstawie dendrogram zgodnie z wybraną metodą łączenia skupień.
• Możliwe jest także przeprowadzenie tej samej analizy za pomocą połączonych NODÓW Numeric Distances, Hierarchical Clustering (DistMatrix) oraz Hierarchical Cluster View.
Macierz wejściowa
Macierz wyjściowa z dodatkową kolumną,
zawierającą informacje do jakiego skupienia
zakwalifikowano poszczególne elementy
Ścieżka:
36
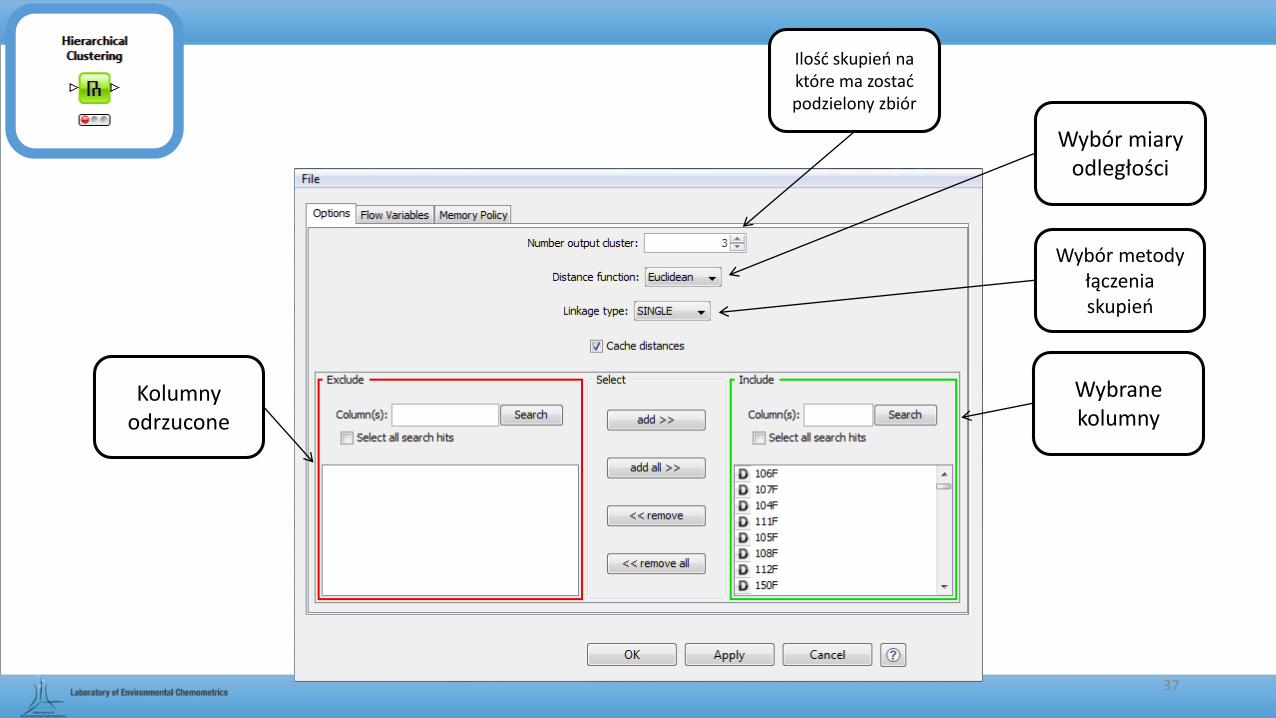
Kolumny odrzucone
Wybrane kolumny
Ilość skupień na które ma zostać podzielony zbiór
Wybór miary odległości
Wybór metody łączenia skupień
37
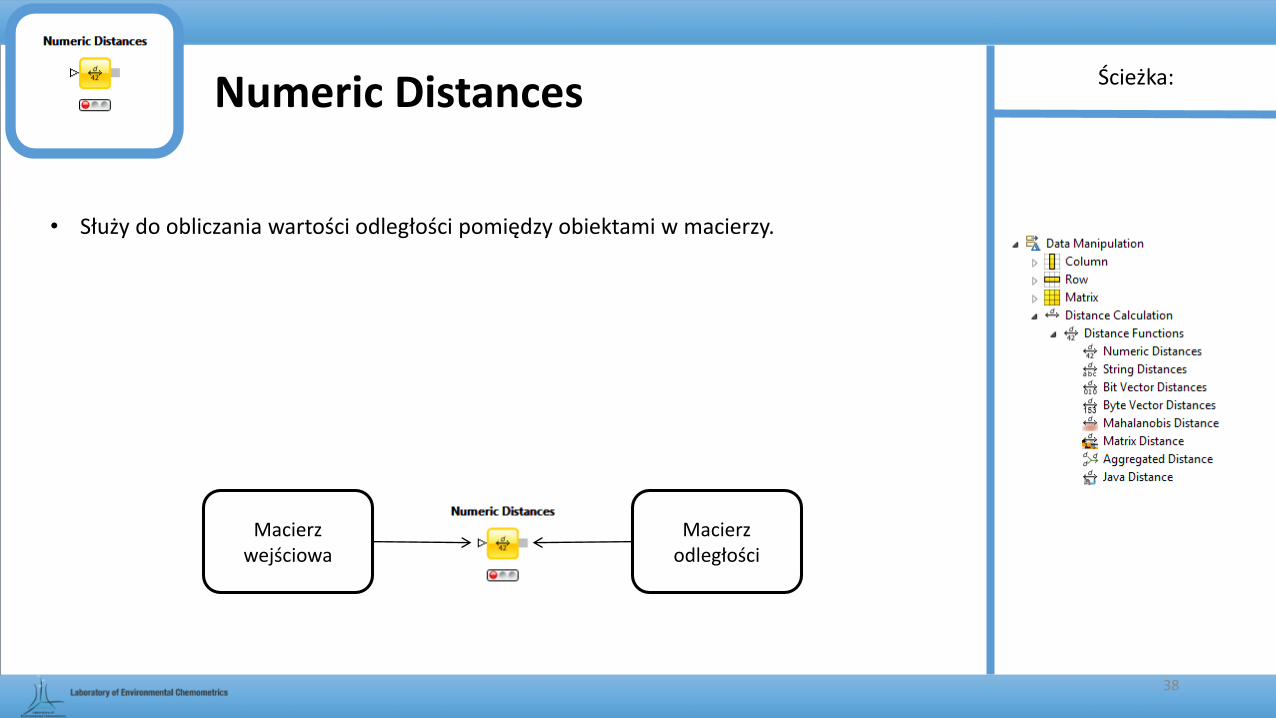
Numeric Distances
• Służy do obliczania wartości odległości pomiędzy obiektami w macierzy.
Macierz wejściowa
Macierz odległości
Ścieżka:
38
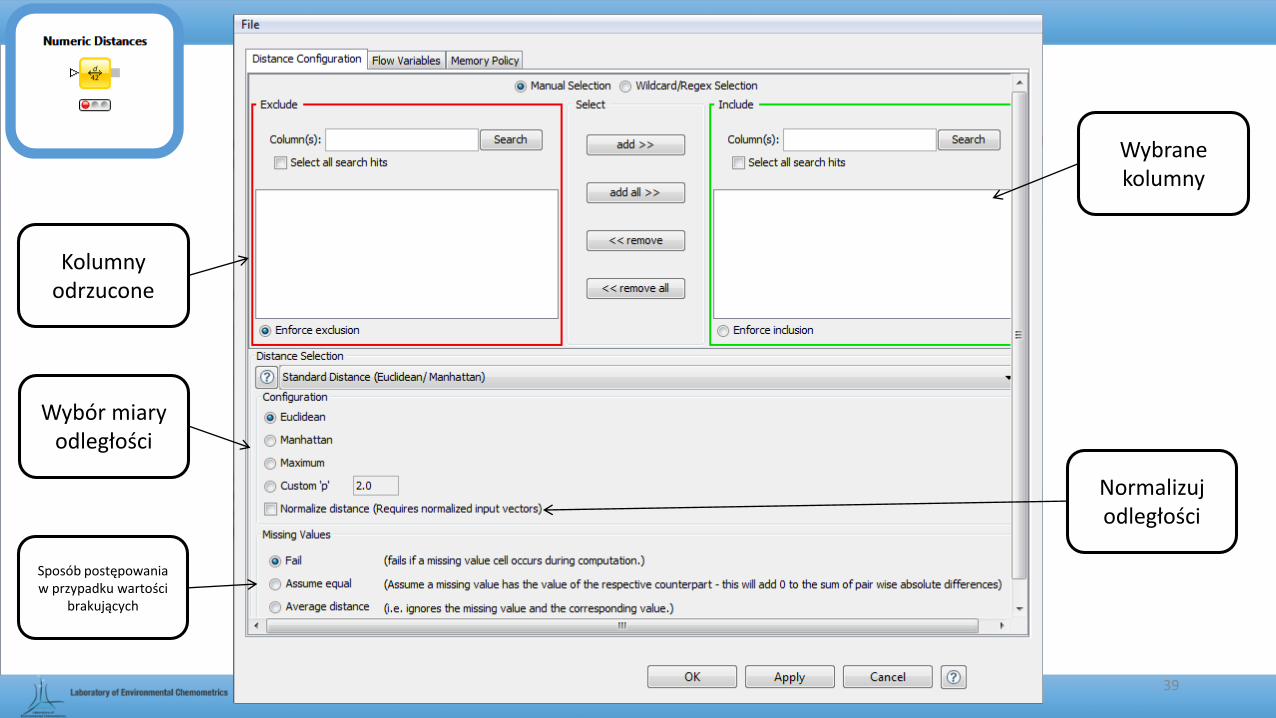
Kolumny odrzucone
Wybrane kolumny
Wybór miary odległości
Sposób postępowania w przypadku wartości
brakujących
Normalizuj odległości
39
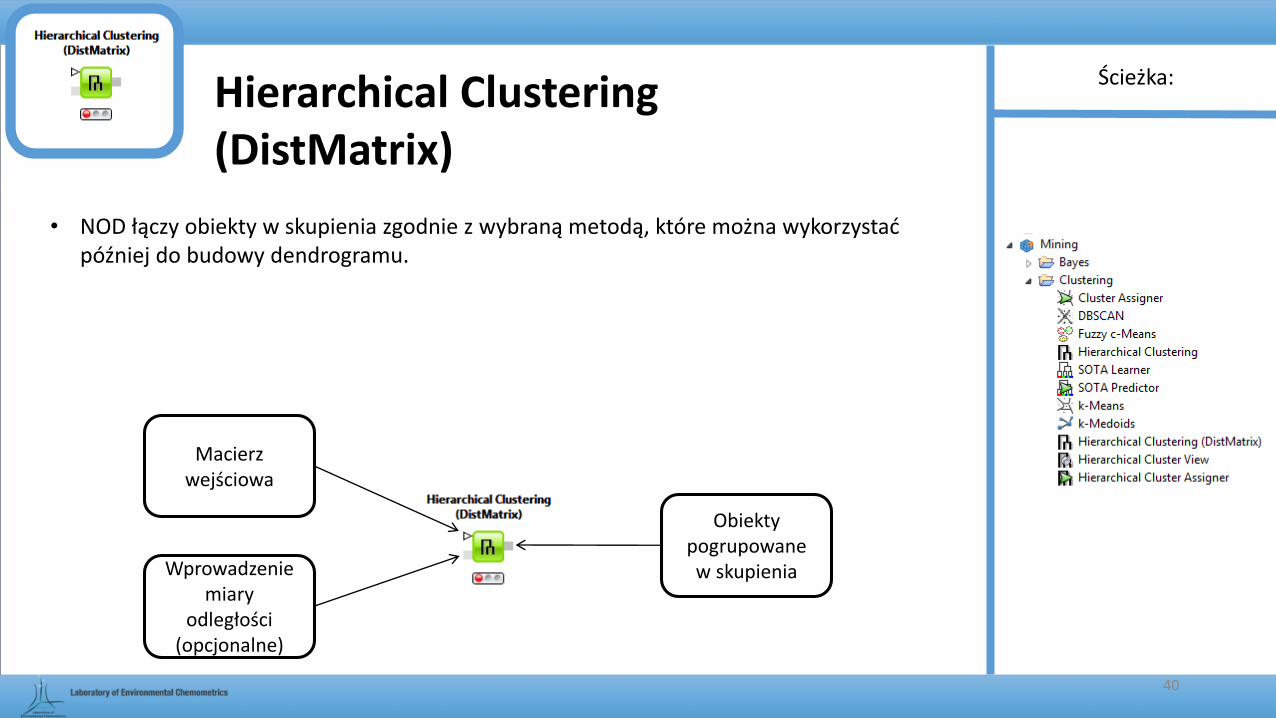
• NOD łączy obiekty w skupienia zgodnie z wybraną metodą, które można wykorzystać później do budowy dendrogramu.
Hierarchical Clustering (DistMatrix)
Macierz wejściowa
Wprowadzenie miary
odległości (opcjonalne)
Obiekty pogrupowane w skupienia
Ścieżka:
40

Informacje o wskazanej macierzy
odległości
Ignoruj brakujące wartości
Metoda łączenia skupień
41
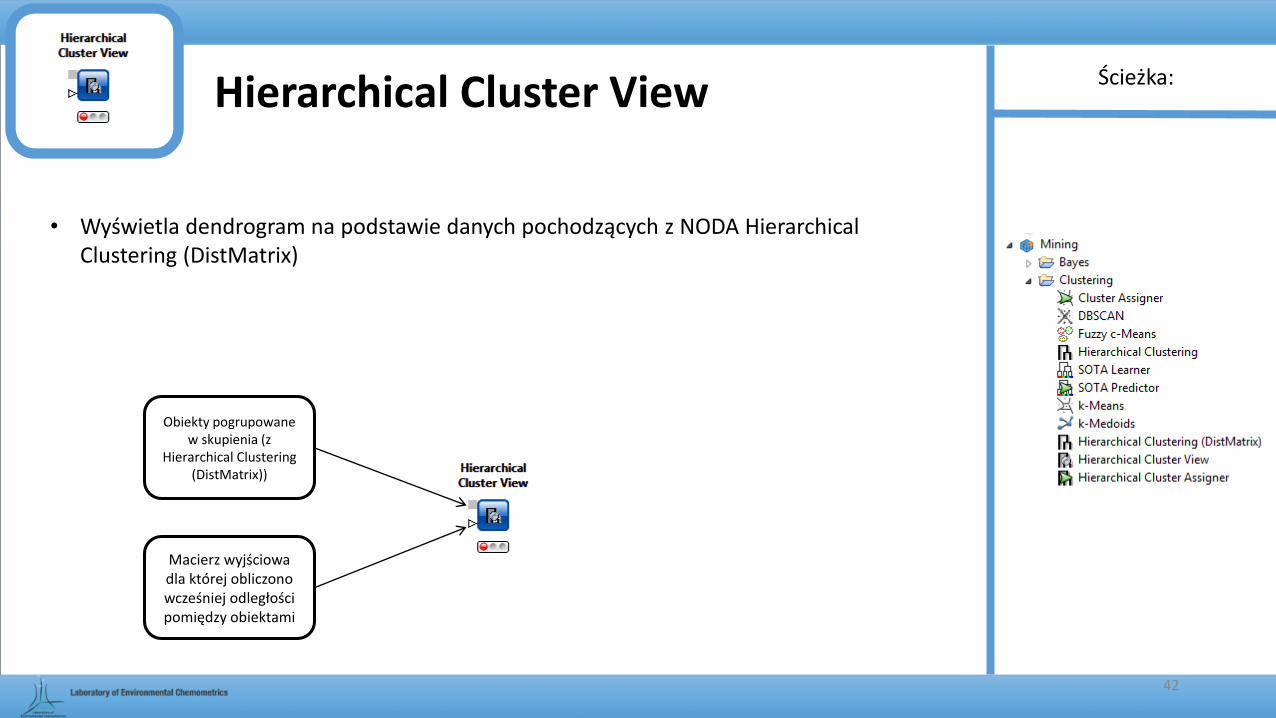
Hierarchical Cluster View
• Wyświetla dendrogram na podstawie danych pochodzących z NODA Hierarchical Clustering (DistMatrix)
Obiekty pogrupowane w skupienia (z
Hierarchical Clustering (DistMatrix))
Macierz wyjściowa dla której obliczono wcześniej odległości pomiędzy obiektami
Ścieżka:
42
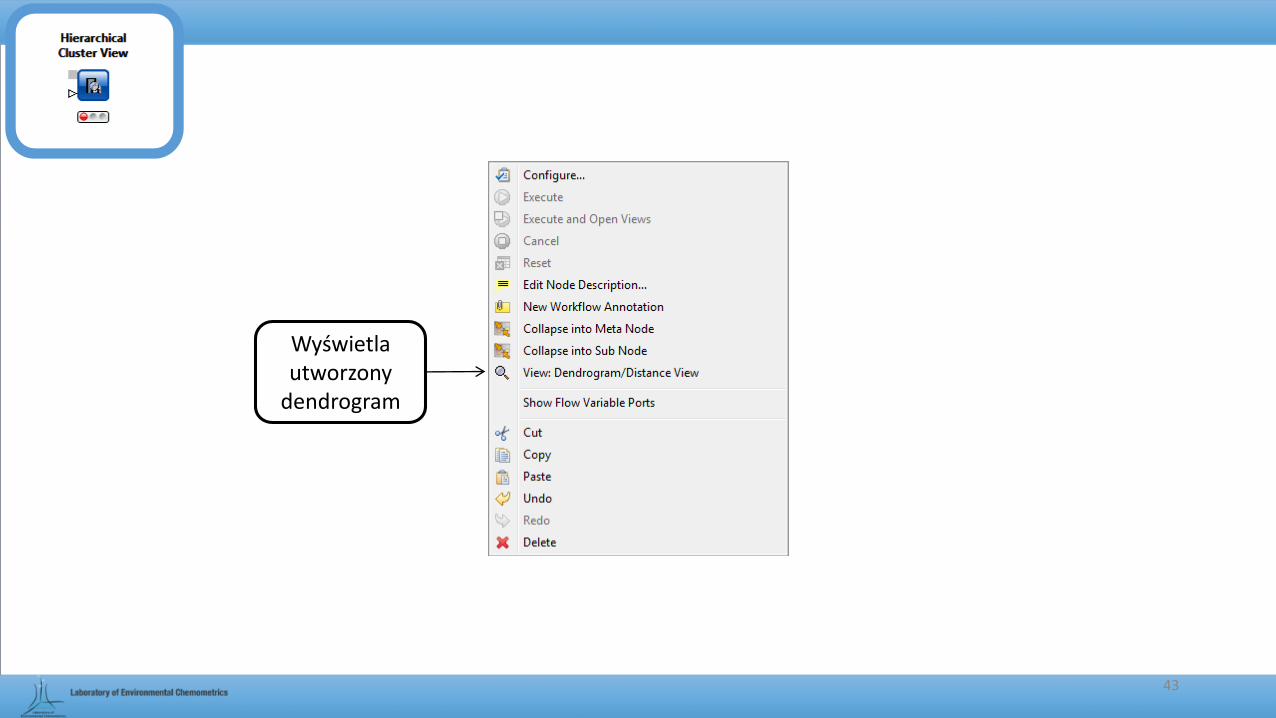
Wyświetla utworzony
dendrogram
43

Scatter Plot
• Służy do prezentacji przebiegu zmiennej Y w funkcji zmiennej X na wykresie punktowym.
Macierz wejściowa
Ścieżka:
44
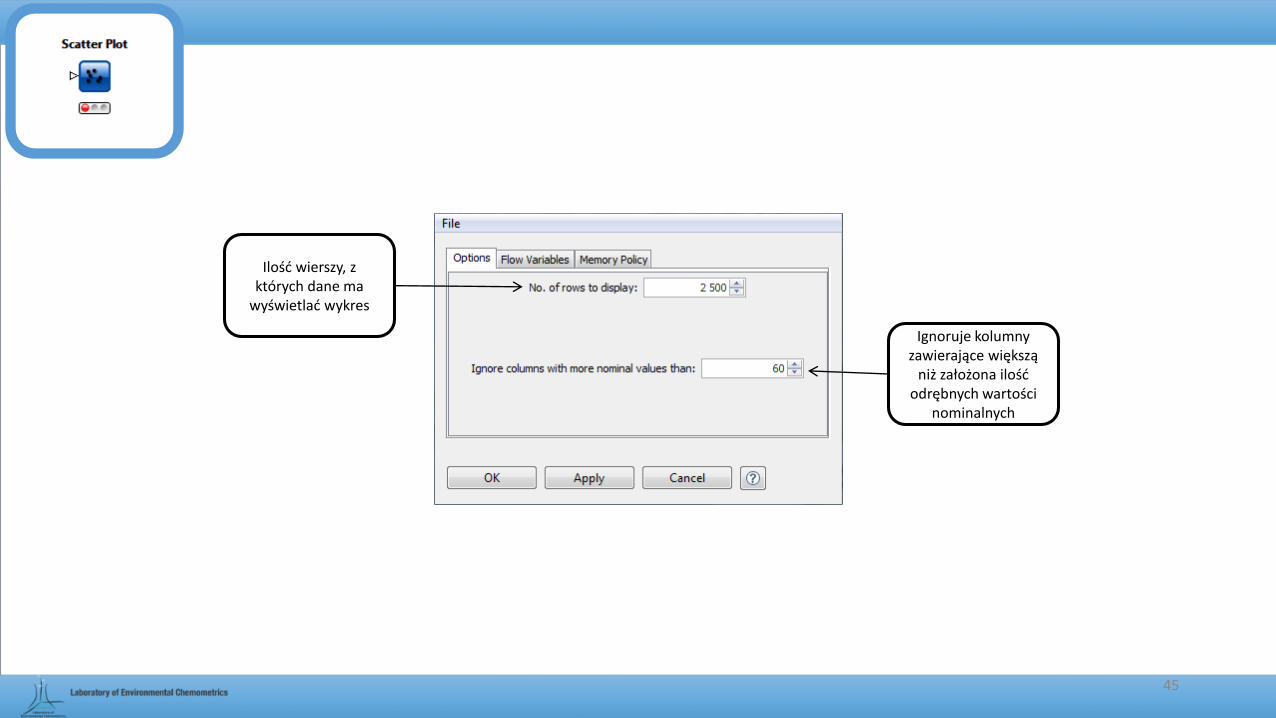
Ilość wierszy, z których dane ma
wyświetlać wykres
Ignoruje kolumny zawierające większą
niż założona ilość odrębnych wartości
nominalnych
45

Wyświetla okno
wykresów
46
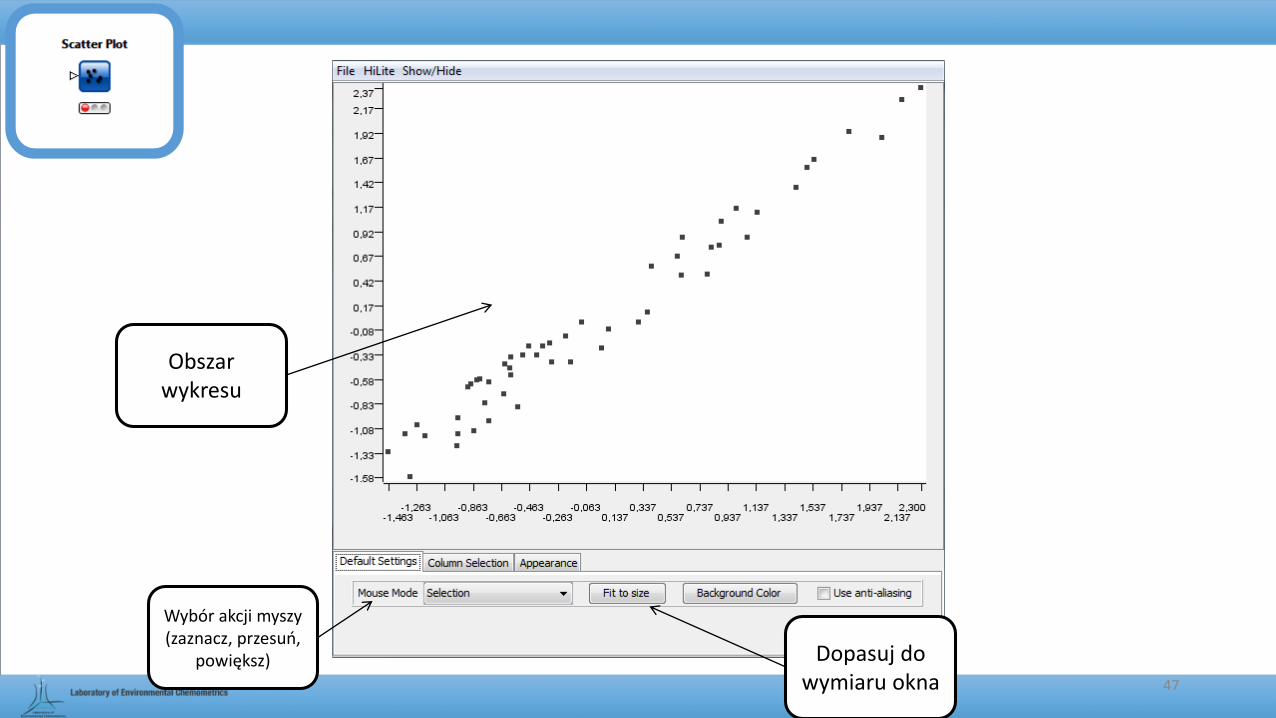
Obszar wykresu
Dopasuj do wymiaru okna
Wybór akcji myszy (zaznacz, przesuń,
powiększ)
47
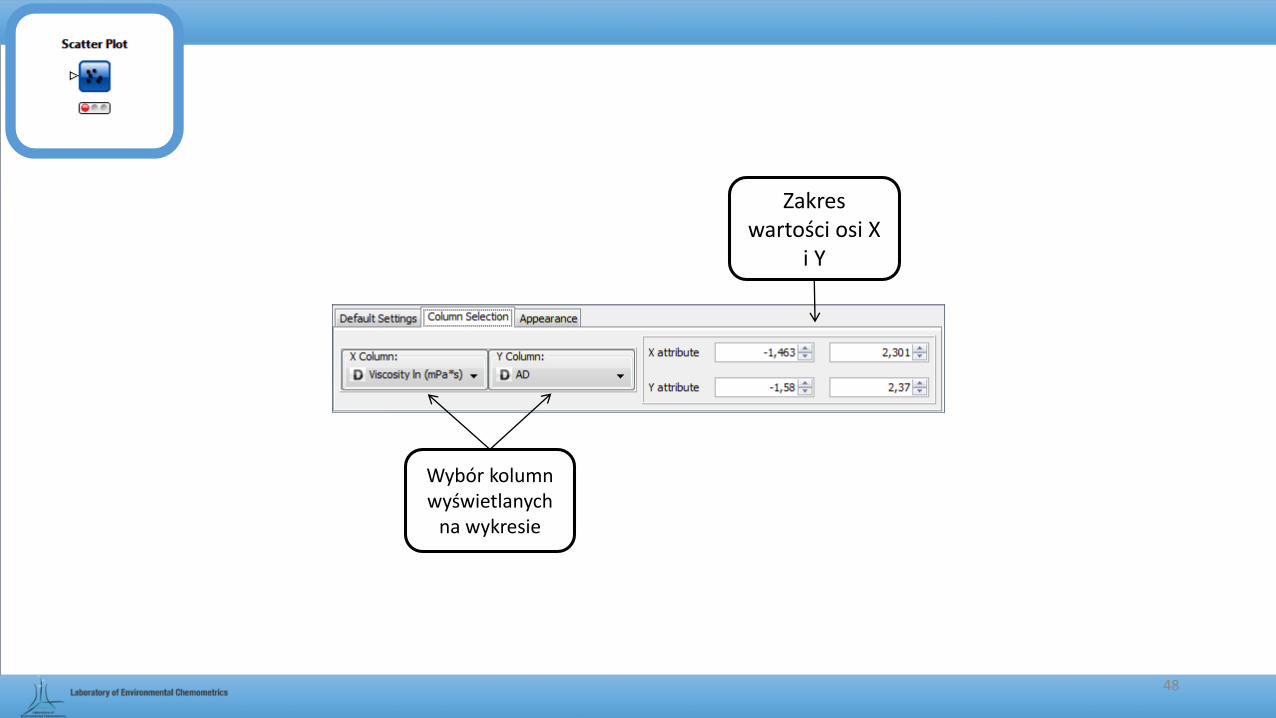
Wybór kolumn wyświetlanych
na wykresie
Zakres wartości osi X
i Y
48
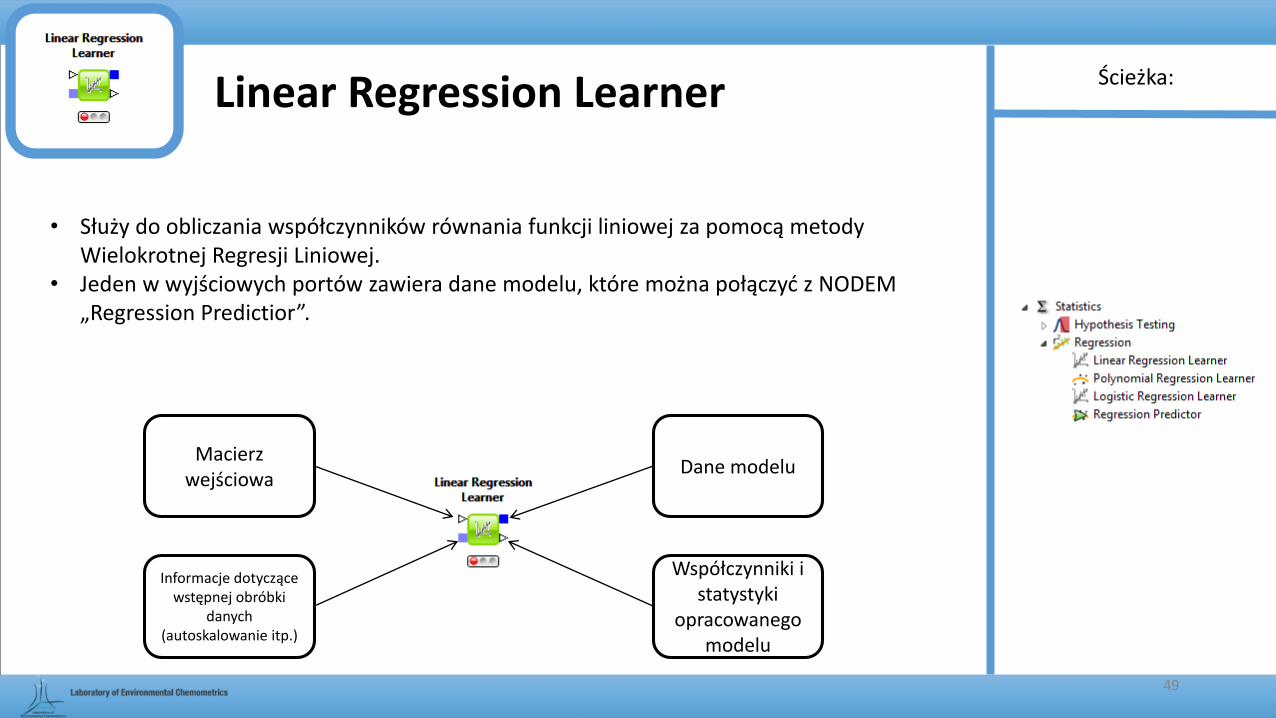
Linear Regression Learner
• Służy do obliczania współczynników równania funkcji liniowej za pomocą metody Wielokrotnej Regresji Liniowej.
• Jeden w wyjściowych portów zawiera dane modelu, które można połączyć z NODEM „Regression Predictior”.
Macierz wejściowa
Informacje dotyczące wstępnej obróbki
danych (autoskalowanie itp.)
Dane modelu
Współczynniki i statystyki
opracowanego modelu
Ścieżka:
49
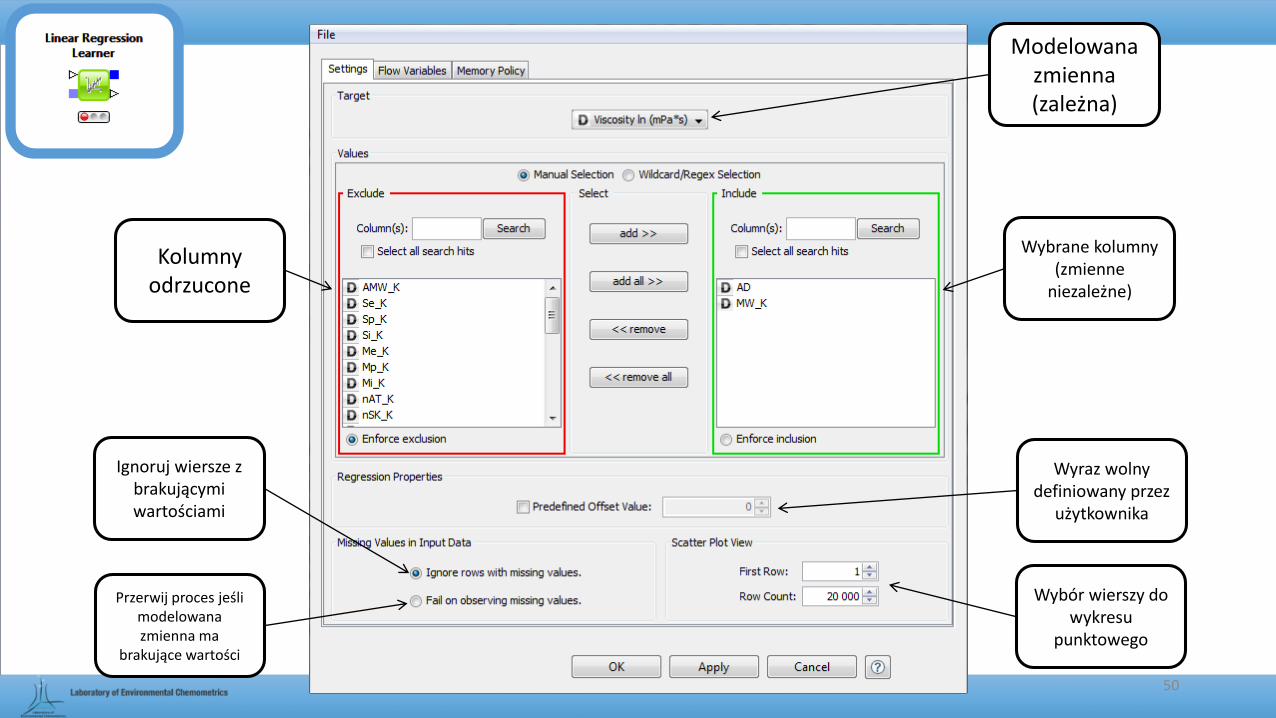
Kolumny odrzucone
Wybrane kolumny (zmienne
niezależne)
Modelowana zmienna (zależna)
Ignoruj wiersze z brakującymi wartościami
Wyraz wolny definiowany przez
użytkownika
Wybór wierszy do wykresu
punktowego
Przerwij proces jeśli modelowana zmienna ma
brakujące wartości
50
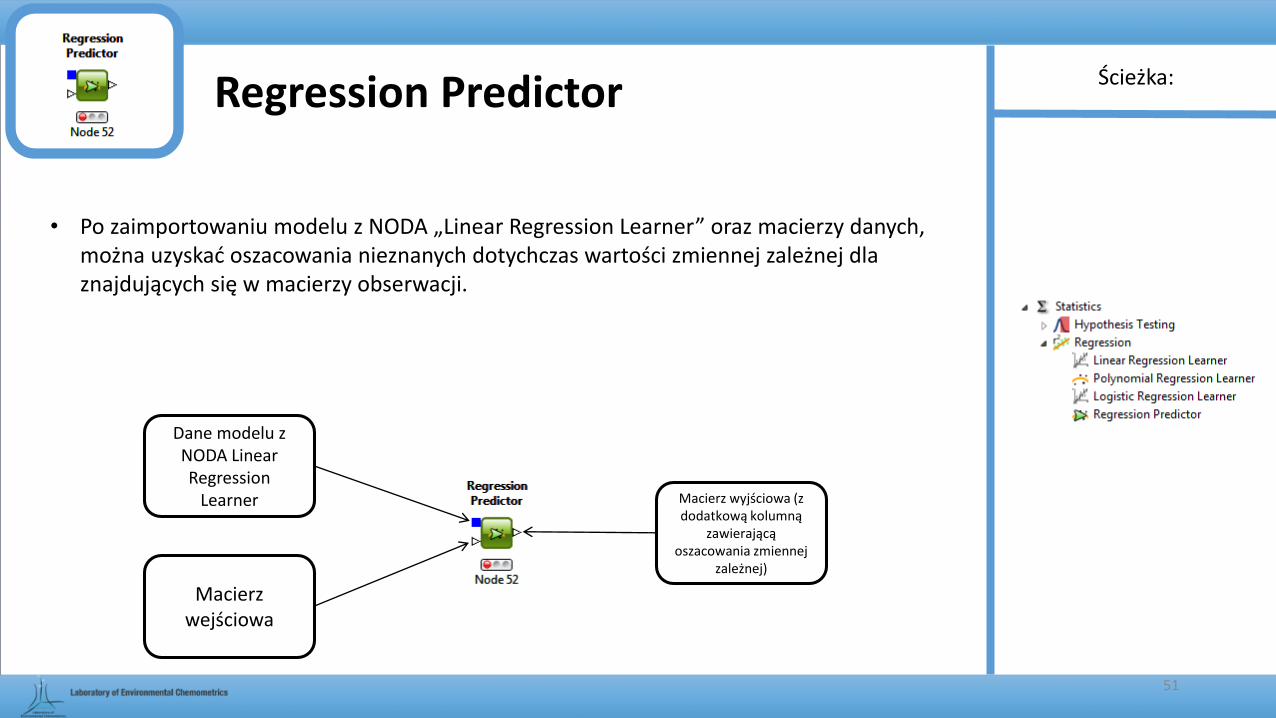
Regression Predictor
• Po zaimportowaniu modelu z NODA „Linear Regression Learner” oraz macierzy danych, można uzyskać oszacowania nieznanych dotychczas wartości zmiennej zależnej dla znajdujących się w macierzy obserwacji.
Dane modelu z NODA LinearRegression
Learner
Macierz wejściowa
Macierz wyjściowa (z dodatkową kolumną
zawierającą oszacowania zmiennej
zależnej)
Ścieżka:
51
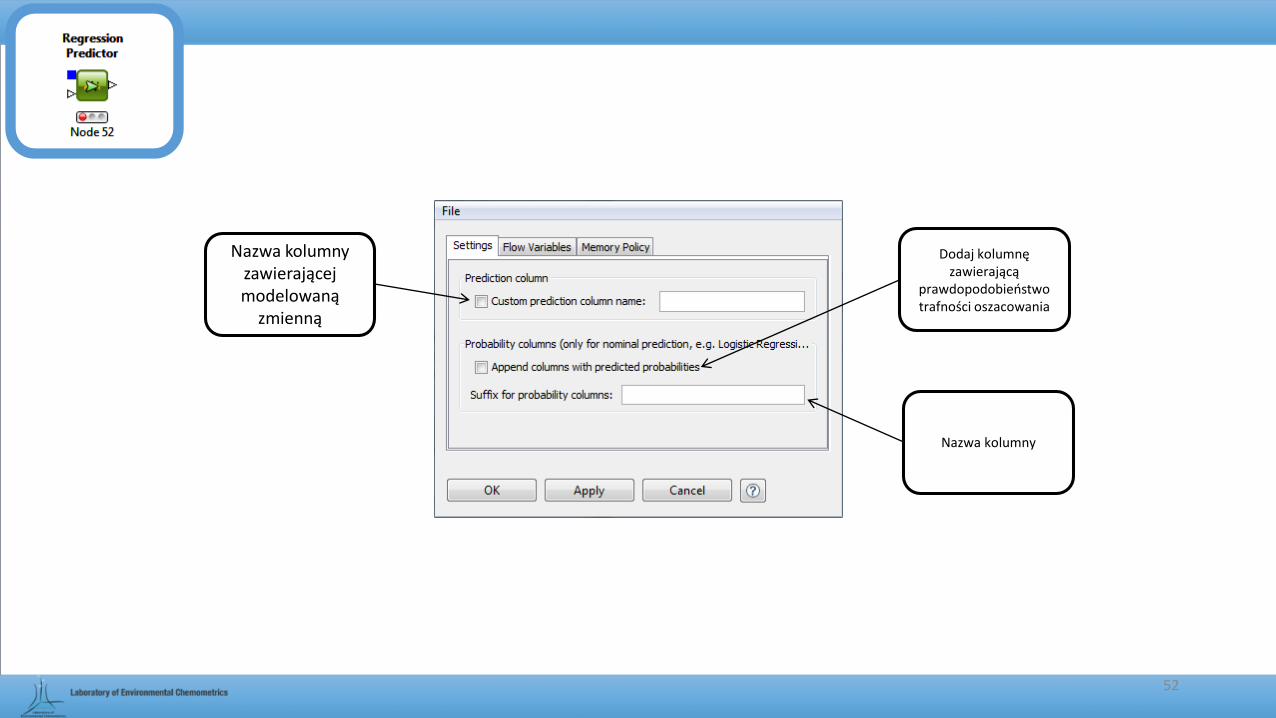
Nazwa kolumny zawierającej modelowaną
zmienną
Dodaj kolumnę zawierającą
prawdopodobieństwo trafności oszacowania
Nazwa kolumny
52
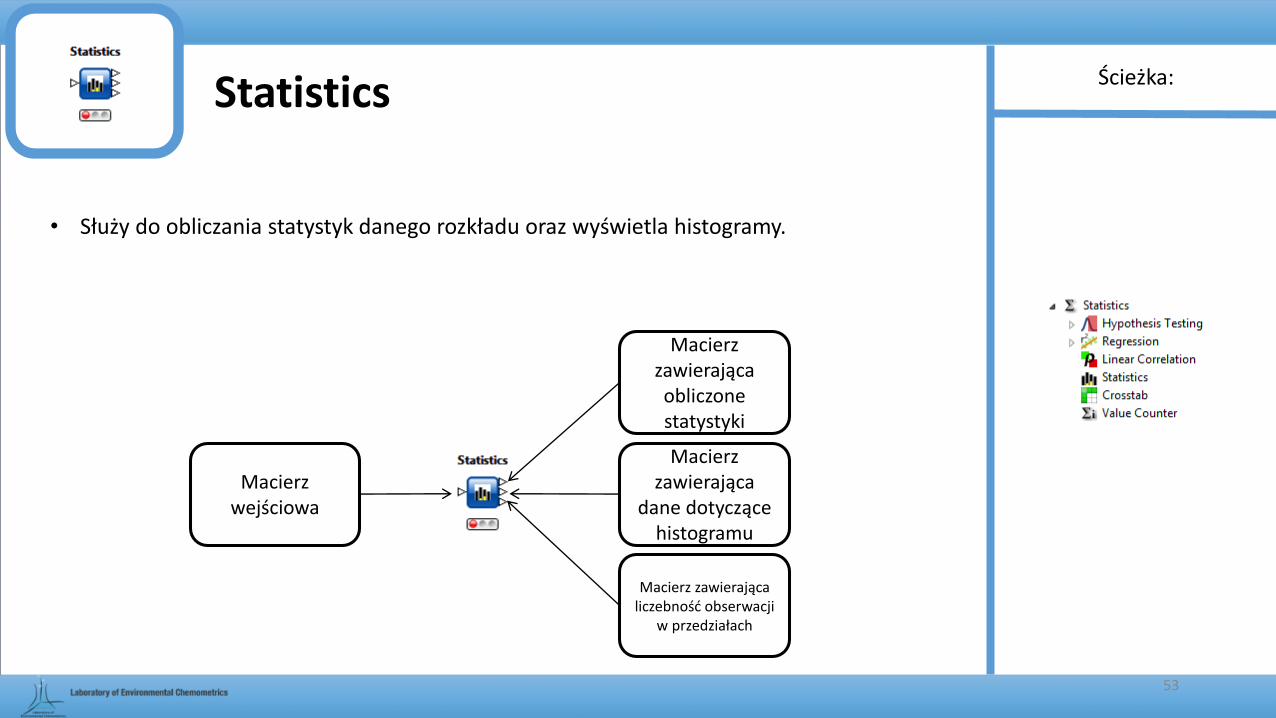
Statistics
• Służy do obliczania statystyk danego rozkładu oraz wyświetla histogramy.
Macierz wejściowa
Macierz zawierająca
dane dotyczące histogramu
Macierz zawierająca liczebność obserwacji
w przedziałach
Macierz zawierająca obliczone statystyki
Ścieżka:
53
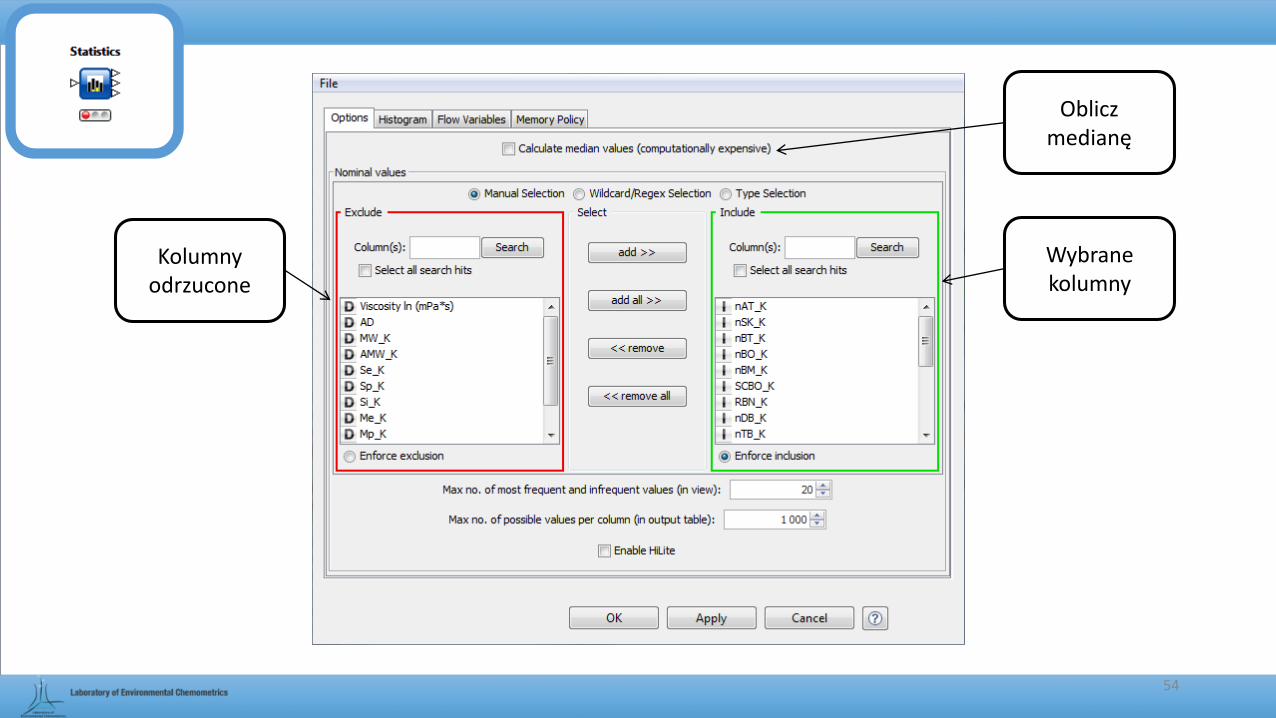
Kolumny odrzucone
Wybrane kolumny
Oblicz medianę
54
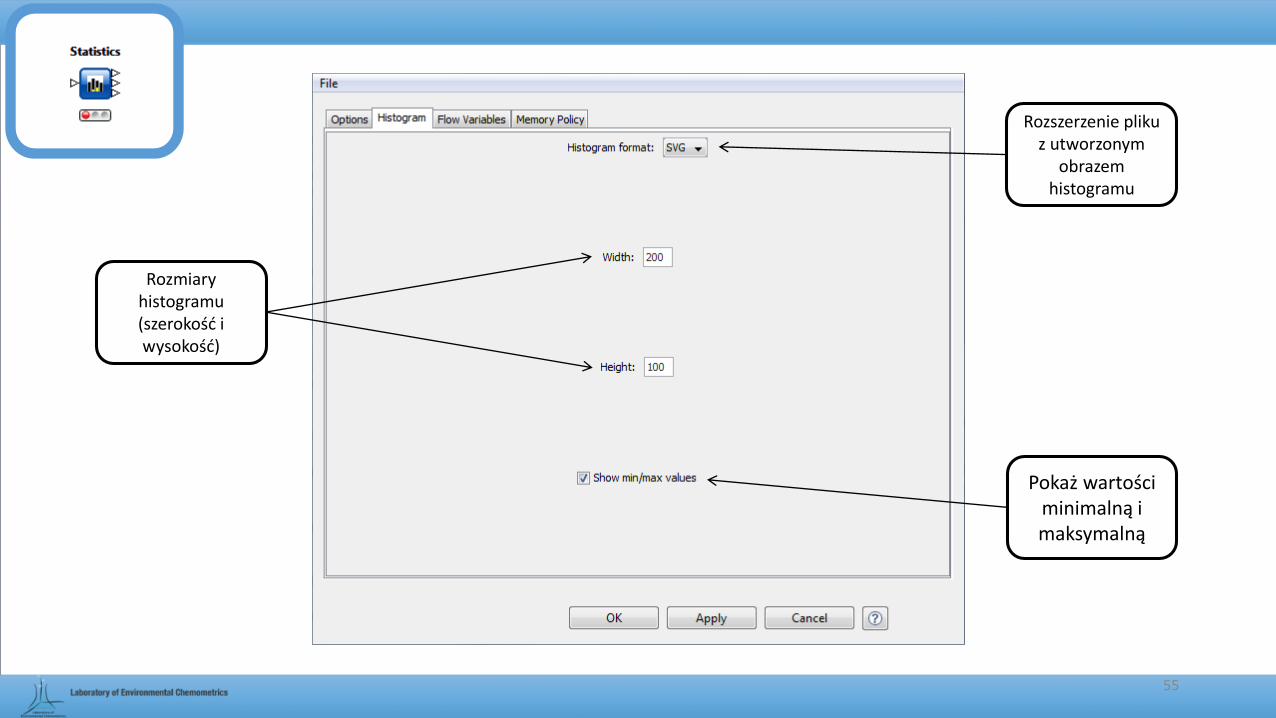
Rozmiary histogramu (szerokość i wysokość)
Rozszerzenie pliku z utworzonym
obrazem histogramu
Pokaż wartości minimalną i maksymalną
55
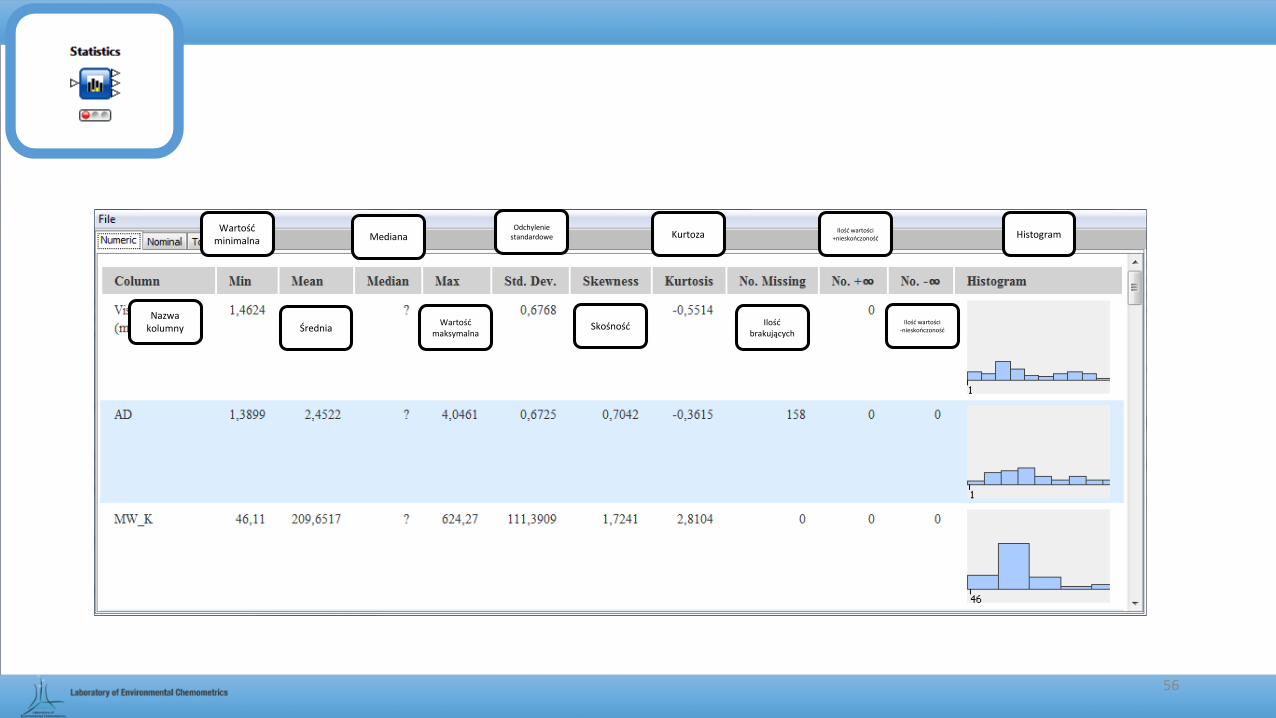
Wartość minimalna
Średnia
Mediana
Wartość maksymalna
Odchylenie standardowe
Skośność
Kurtoza
Ilość brakujących
Ilość wartości +nieskończoność
Ilość wartości -nieskończoność
Histogram
Nazwa kolumny
56

Histogram
• Służy do tworzenia histogramów.
Macierz wejściowa
Ścieżka:
57
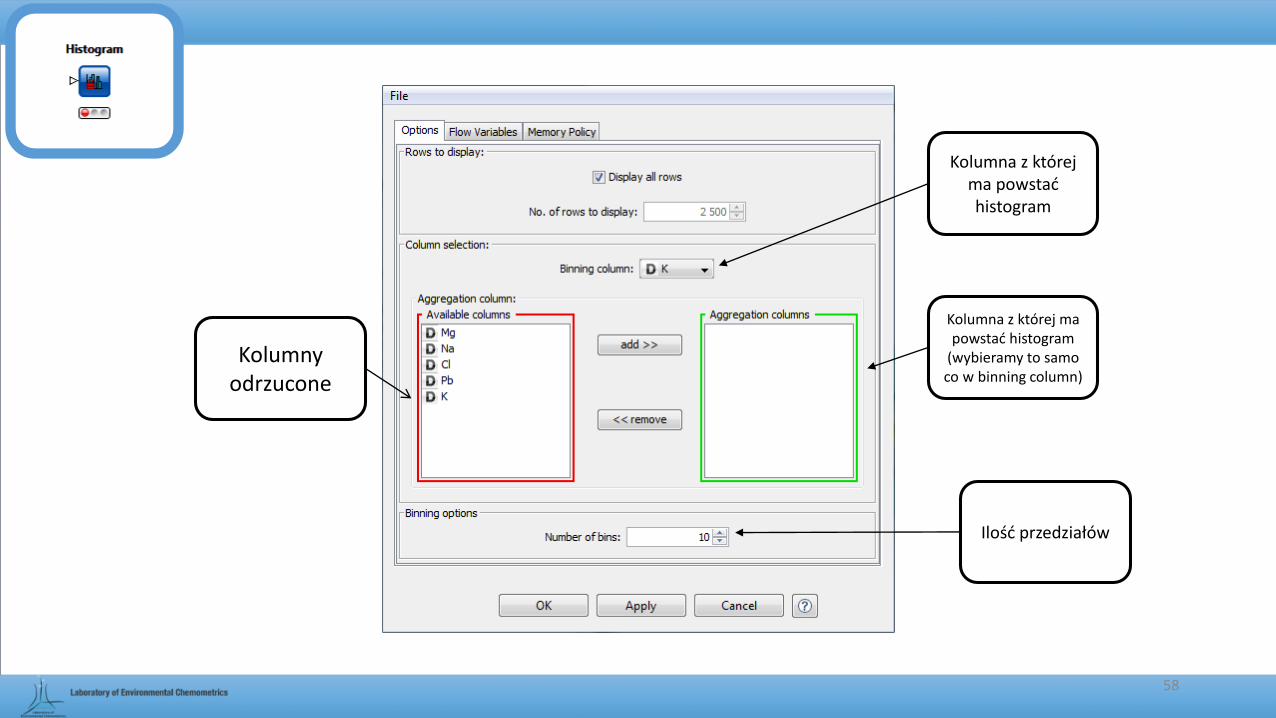
Kolumna z której ma powstać histogram
58
Kolumny odrzucone
Kolumna z której ma powstać histogram
(wybieramy to samo co w binning column)
Ilość przedziałów
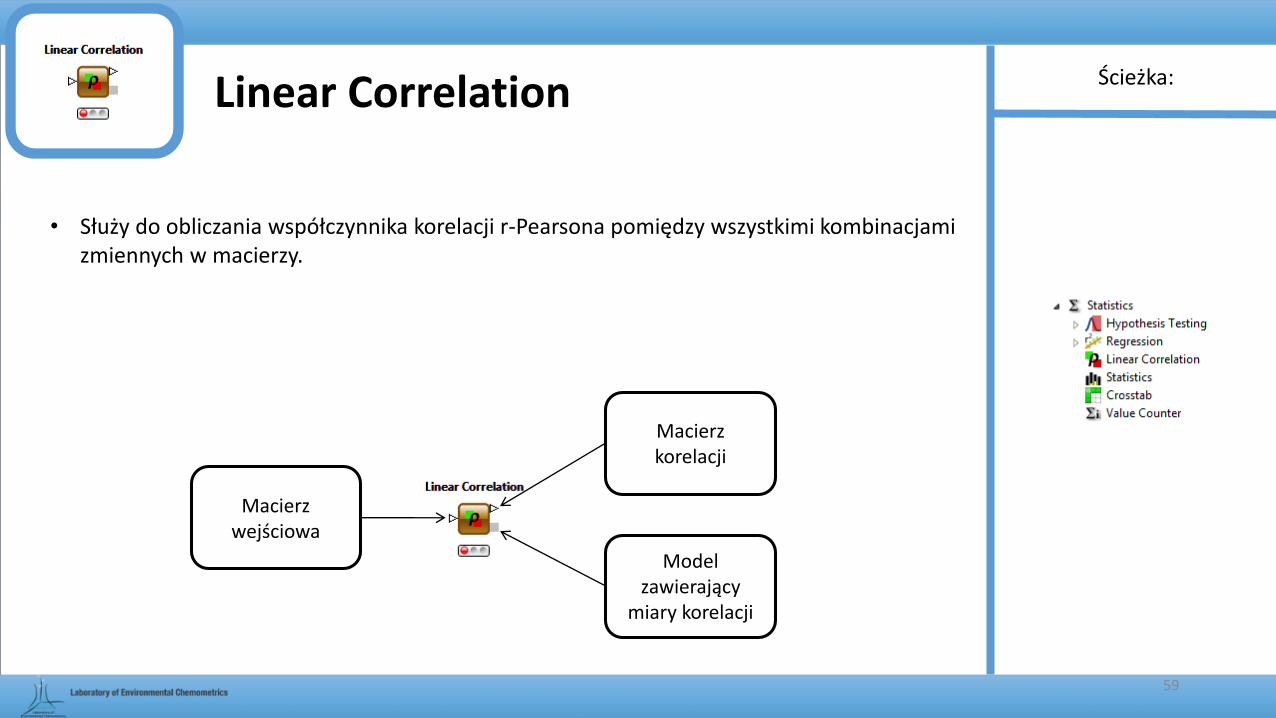
Linear Correlation
• Służy do obliczania współczynnika korelacji r-Pearsona pomiędzy wszystkimi kombinacjami zmiennych w macierzy.
Macierz wejściowa
Macierz korelacji
Model zawierający
miary korelacji
Ścieżka:
59
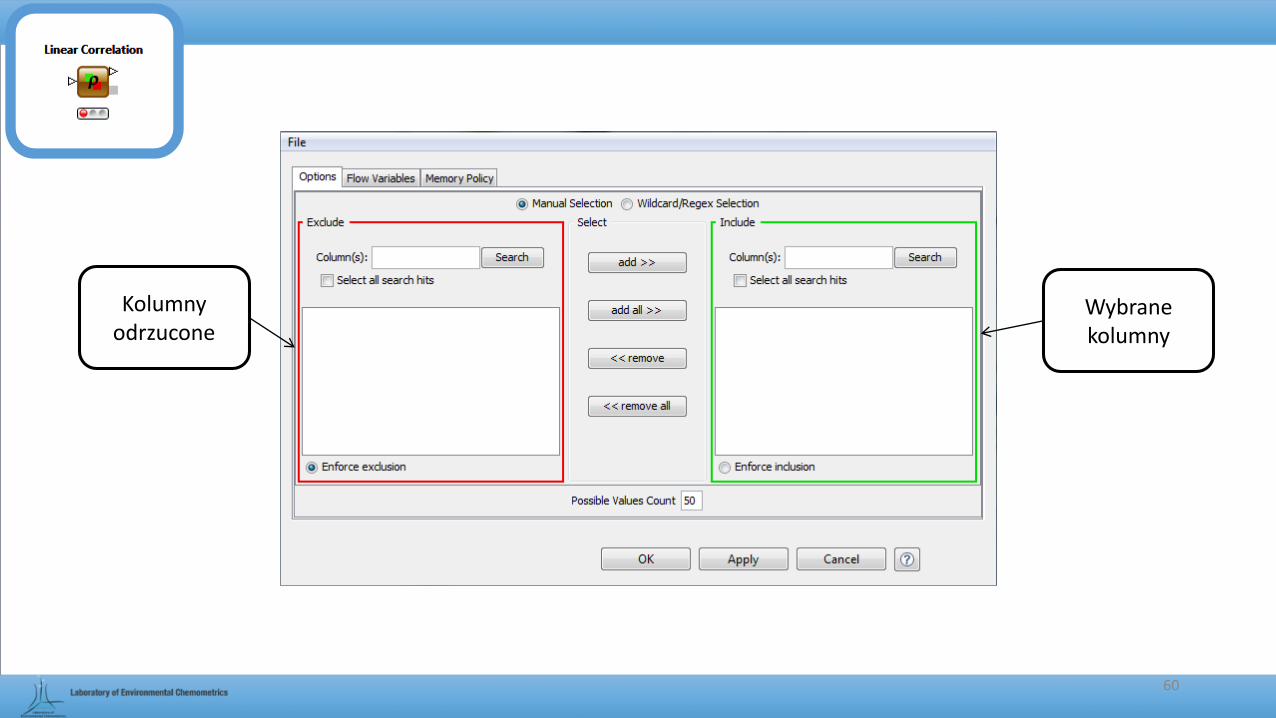
60
Kolumny odrzucone
Wybrane kolumny
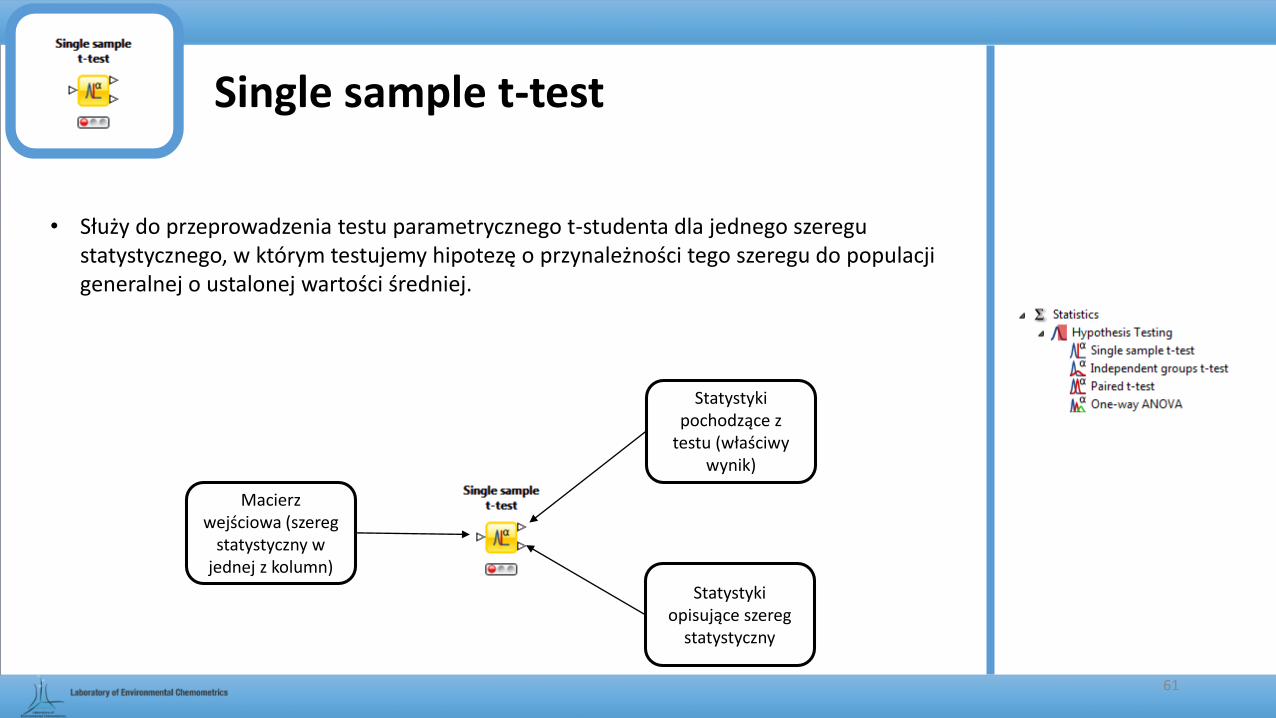
Single sample t-test
• Służy do przeprowadzenia testu parametrycznego t-studenta dla jednego szeregu statystycznego, w którym testujemy hipotezę o przynależności tego szeregu do populacji generalnej o ustalonej wartości średniej.
61
Macierz wejściowa (szereg
statystyczny w jednej z kolumn)
Statystyki pochodzące z
testu (właściwy wynik)
Statystyki opisujące szereg
statystyczny
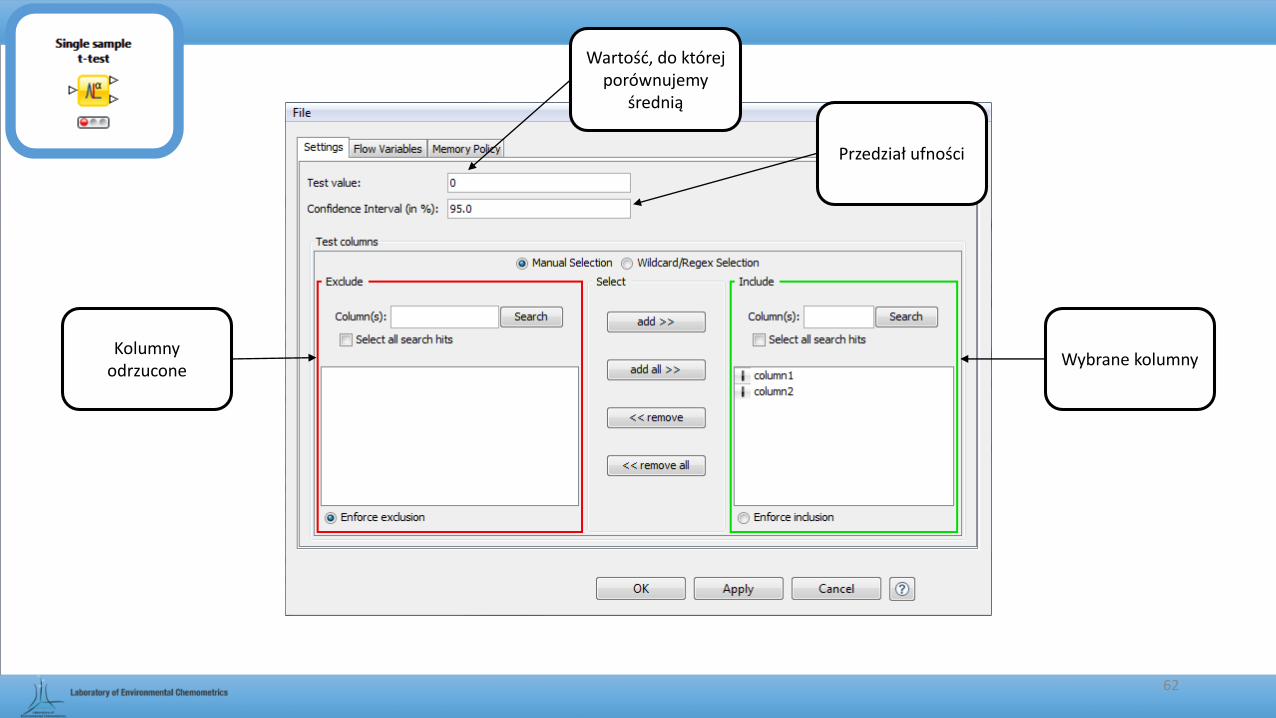
62
Przedział ufności
Wartość, do której porównujemy
średnią
Kolumny odrzucone
Wybrane kolumny
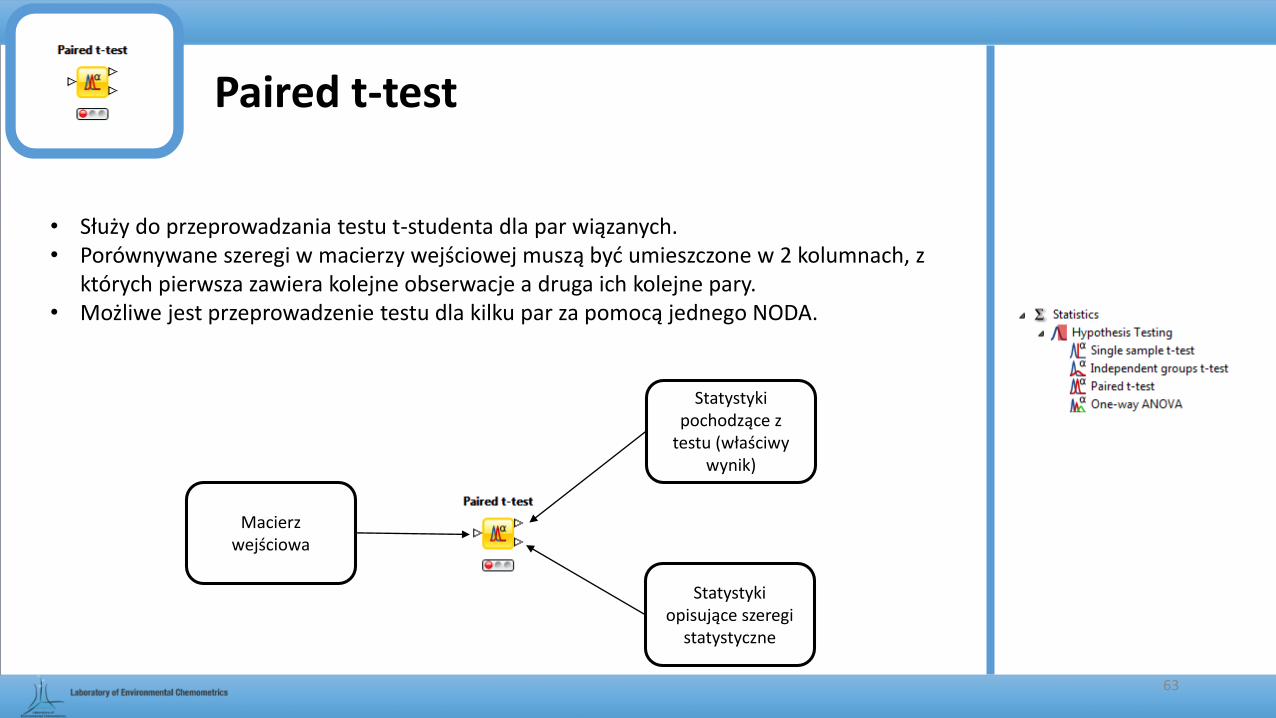
Paired t-test
• Służy do przeprowadzania testu t-studenta dla par wiązanych.• Porównywane szeregi w macierzy wejściowej muszą być umieszczone w 2 kolumnach, z
których pierwsza zawiera kolejne obserwacje a druga ich kolejne pary.• Możliwe jest przeprowadzenie testu dla kilku par za pomocą jednego NODA.
63
Macierz wejściowa
Statystyki pochodzące z
testu (właściwy wynik)
Statystyki opisujące szeregi
statystyczne
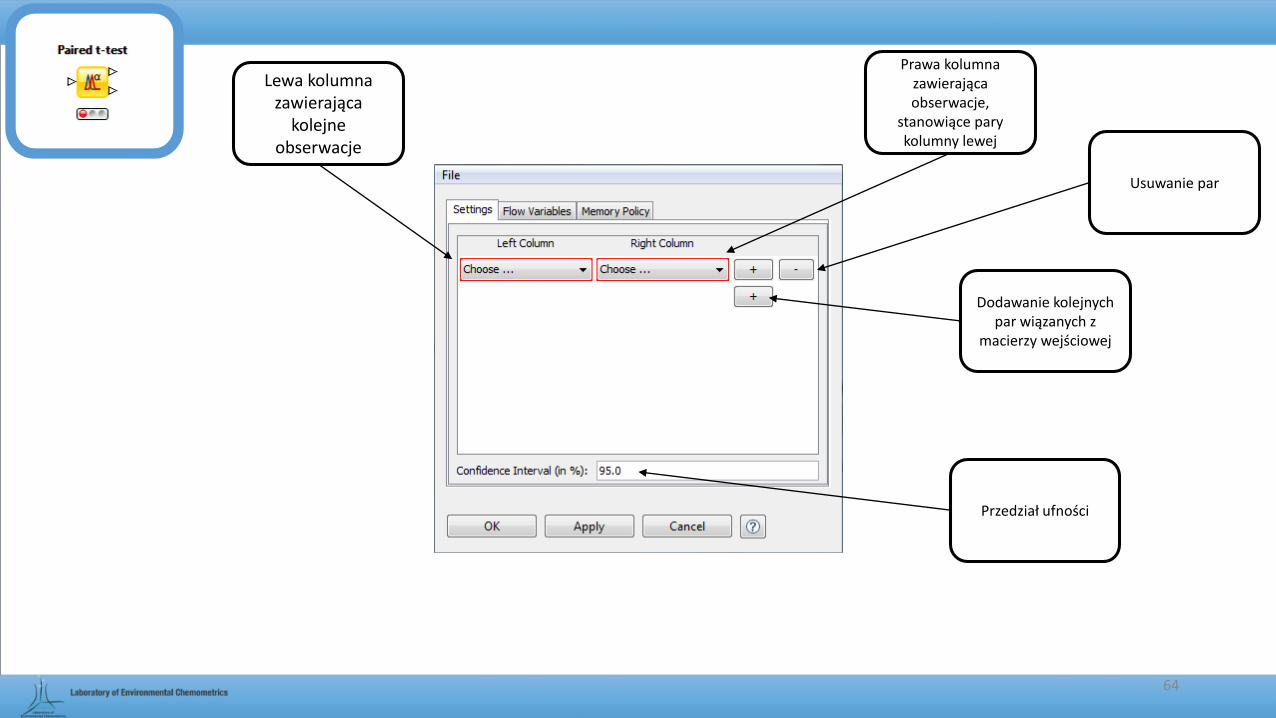
Lewa kolumna zawierająca
kolejne obserwacje
64
Prawa kolumna zawierająca obserwacje,
stanowiące pary kolumny lewej
Dodawanie kolejnych par wiązanych z
macierzy wejściowej
Usuwanie par
Przedział ufności
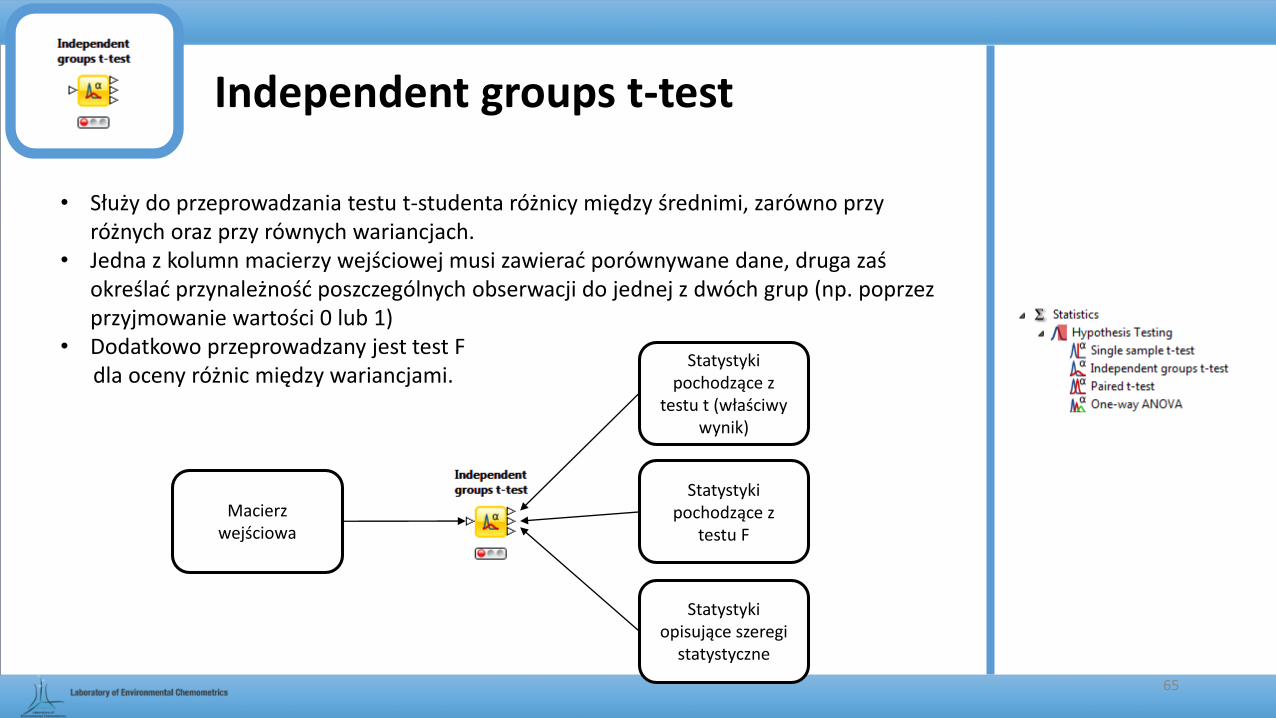
Independent groups t-test
• Służy do przeprowadzania testu t-studenta różnicy między średnimi, zarówno przy różnych oraz przy równych wariancjach.
• Jedna z kolumn macierzy wejściowej musi zawierać porównywane dane, druga zaś określać przynależność poszczególnych obserwacji do jednej z dwóch grup (np. poprzez przyjmowanie wartości 0 lub 1)
• Dodatkowo przeprowadzany jest test F dla oceny różnic między wariancjami.
65
Macierz wejściowa
Statystyki pochodzące z
testu t (właściwy wynik)
Statystyki opisujące szeregi
statystyczne
Statystyki pochodzące z
testu F

66
Przykładowe dane wejściowe do NODA „Independent groups
t-test"

Przedział ufności
67
Kolumna (grupująca) zawierająca informacje o
przynależności danych do 2 grup
Wartości jakie przyjmują dane dla 2 różnych dwóch grup
w kolumnie grupującej
Kolumny odrzucone
Wybrane kolumny
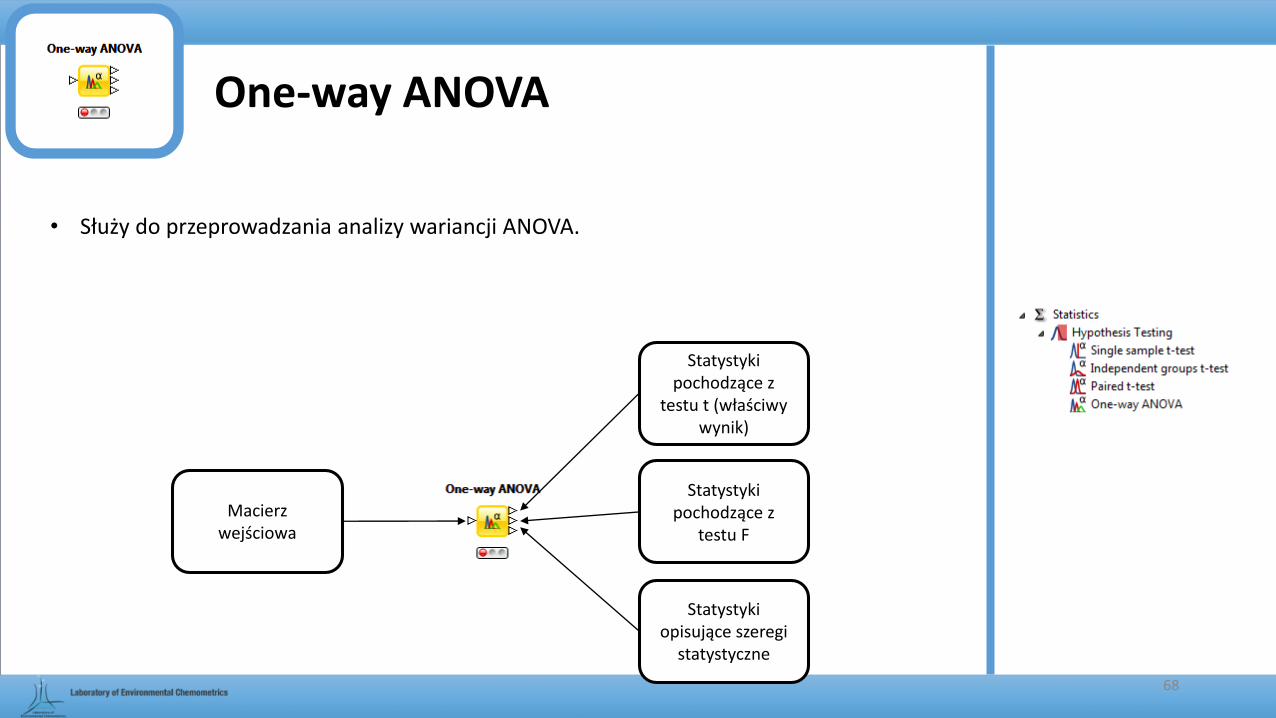
One-way ANOVA
• Służy do przeprowadzania analizy wariancji ANOVA.
68
Macierz wejściowa
Statystyki pochodzące z
testu t (właściwy wynik)
Statystyki opisujące szeregi
statystyczne
Statystyki pochodzące z
testu F
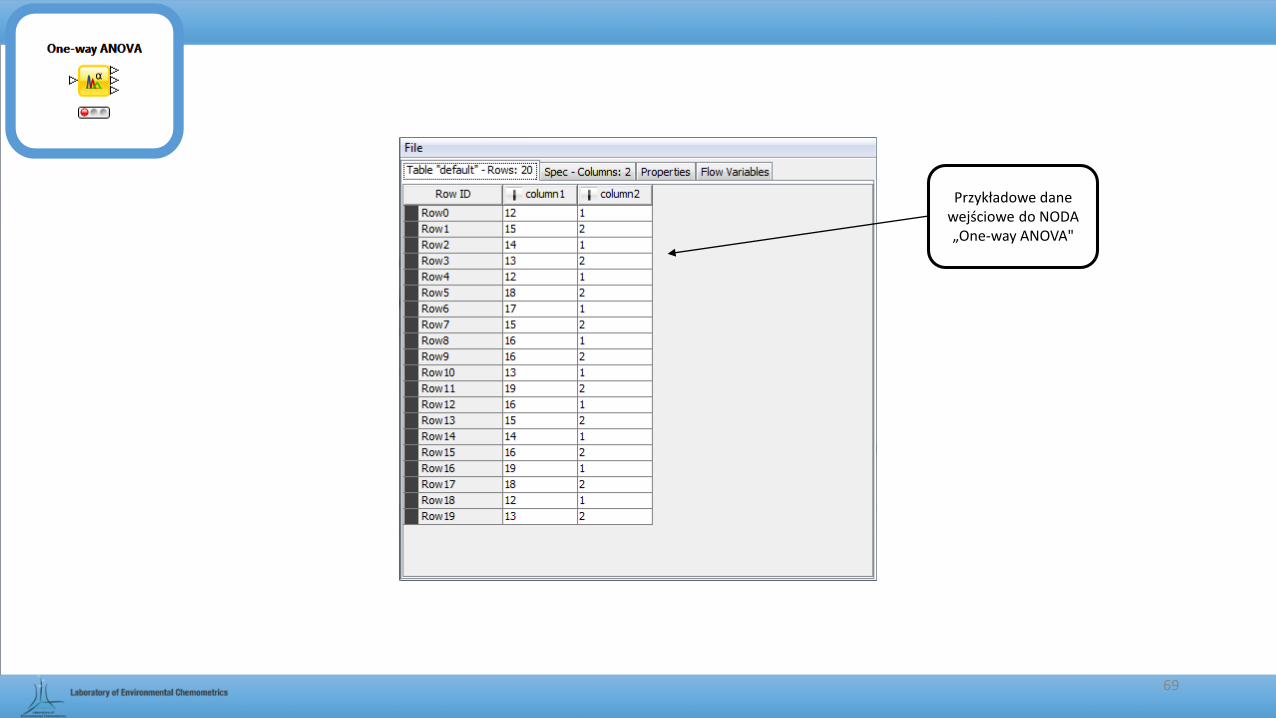
69
Przykładowe dane wejściowe do NODA „One-way ANOVA"
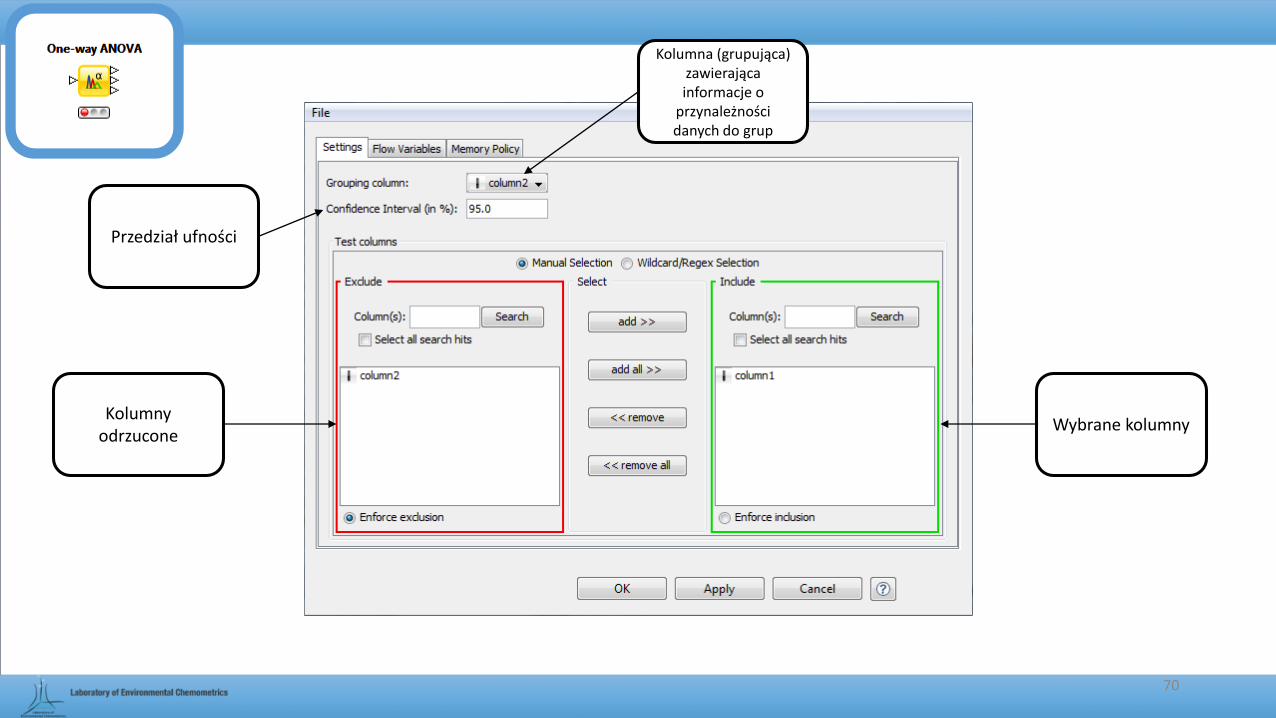
70
Kolumna (grupująca) zawierająca informacje o
przynależności danych do grup
Kolumny odrzucone
Wybrane kolumny
Przedział ufności

Przykłady zastosowania programu KNIME
71

Schemat pracy z programem
• Otwieramy program i tworzymy nowy algorytm („workflow”).
• W oknie archiwum wybieramy odpowiednie NODY, które posłużą do realizacji celu.
• Tworzymy schemat analizy w oknie 2.
• Łączymy i konfigurujemy kolejne NODY a następnie używamy ich do wykonania poszczególnych etapów (okno 2).
• Odczytujemy i interpretujemy wyniki.
72

Przykład 1
• Problem: Jak wygląda wzajemna relacja pomiędzy zawartością sodu i chloru w próbkach gleby.
Nazwa Mg Na Cl Pb K
A 0,276025 0,90152 0,168143 0,35166 0,166879
B 0,679703 0,306114 0,050856 0,830829 0,11869
C 0,655098 0,607148 0,162857 0,585264 1,167755
D 0,162612 0,838892 0,048705 0,549724 1,714168
E 0,118998 1,069084 0,185853 0,917194 2,054824
F 0,498364 1,15115 0,069997 0,285839 0,285794
G 0,959744 0,656659 0,039319 0,7572 1,251412
H 0,340386 0,166349 0,050217 0,753729 1,032659
I 0,585268 0,179153 0,123209 0,380446 0,026185
J 0,223812 0,30901 0,094658 0,567822 0,74167
Tabela 1: zawartość poszczególnych pierwiastków w próbkach gleby (A-J)
73

Przykład 1
• Cel: obliczenie współczynnika korelacji pomiędzy dwiema zmiennymi oraz graficzna prezentacja ich wzajemnej relacji na wykresie punktowym.
• Kroki:• Import danych z tabeli (plik *.xlsx)
• Wybór kolumn do dalszej analizy
• Autoskalowanie danych
• Prezentacja zmiennych na wykresie
• Obliczenie współczynnika korelacji
74
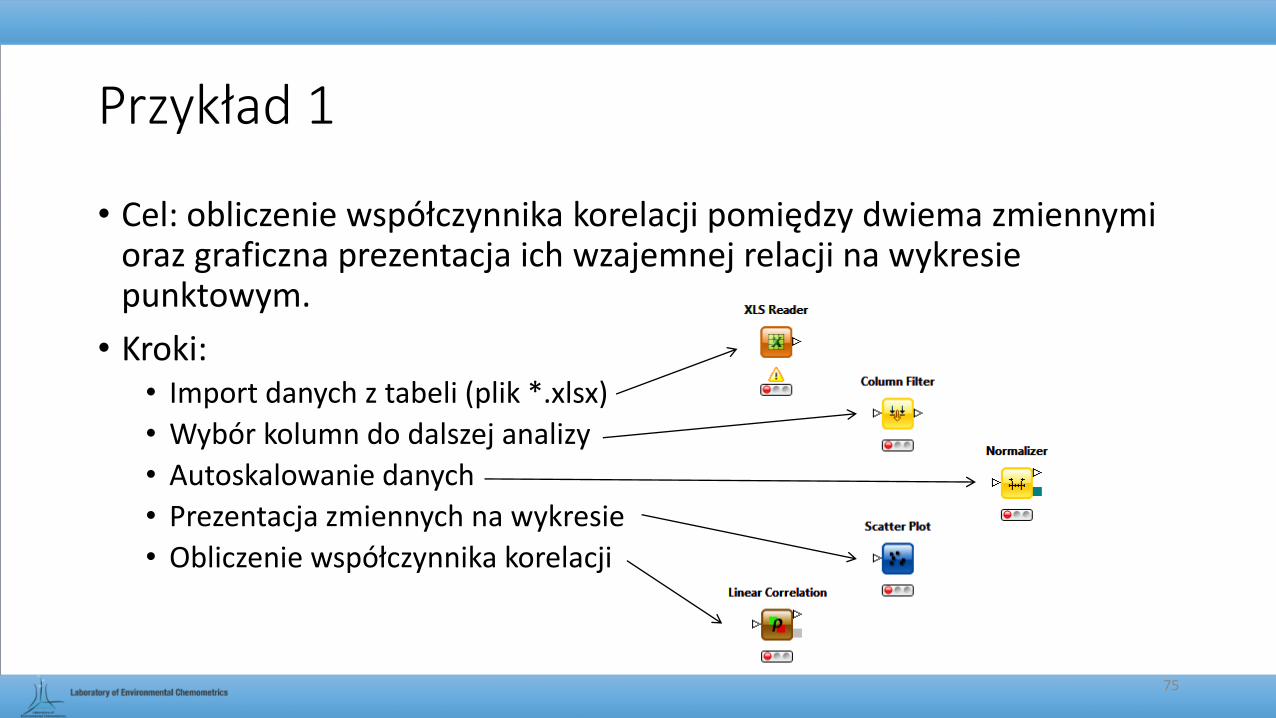
Przykład 1
• Cel: obliczenie współczynnika korelacji pomiędzy dwiema zmiennymi oraz graficzna prezentacja ich wzajemnej relacji na wykresie punktowym.
• Kroki:• Import danych z tabeli (plik *.xlsx)
• Wybór kolumn do dalszej analizy
• Autoskalowanie danych
• Prezentacja zmiennych na wykresie
• Obliczenie współczynnika korelacji
75

Przykład 1
• Tworzymy algorytm
76
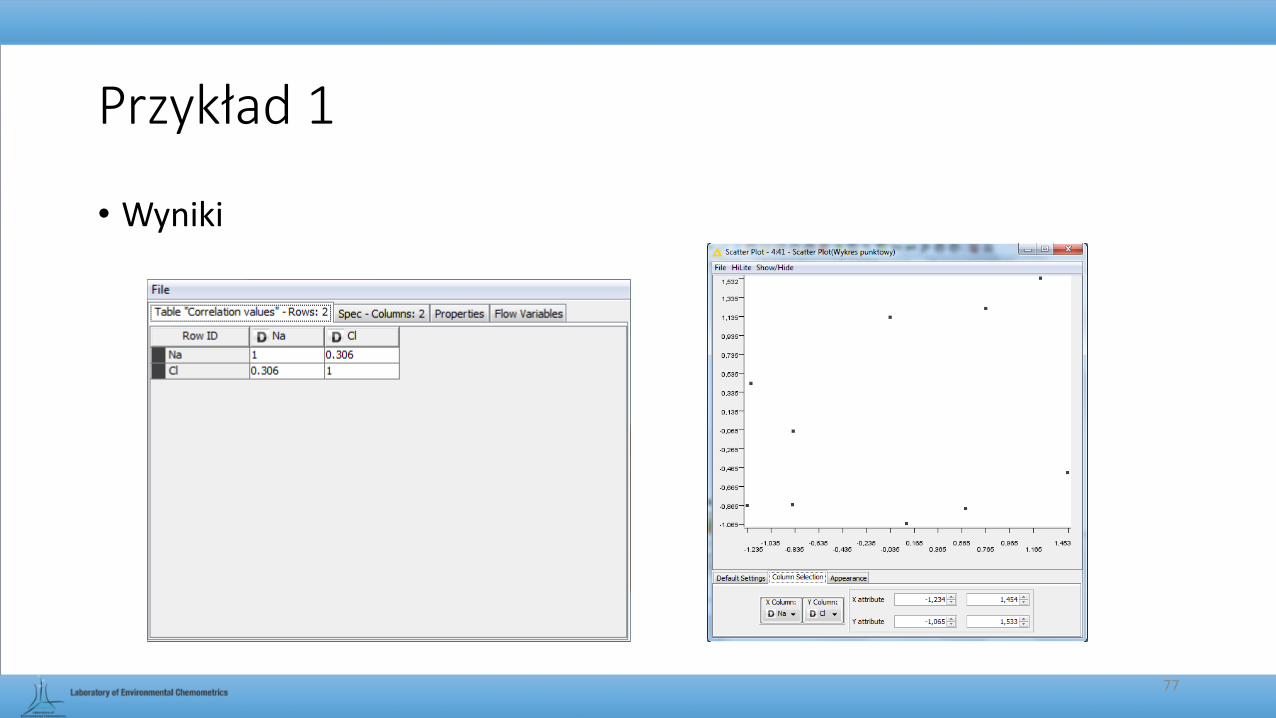
Przykład 1
• Wyniki
77
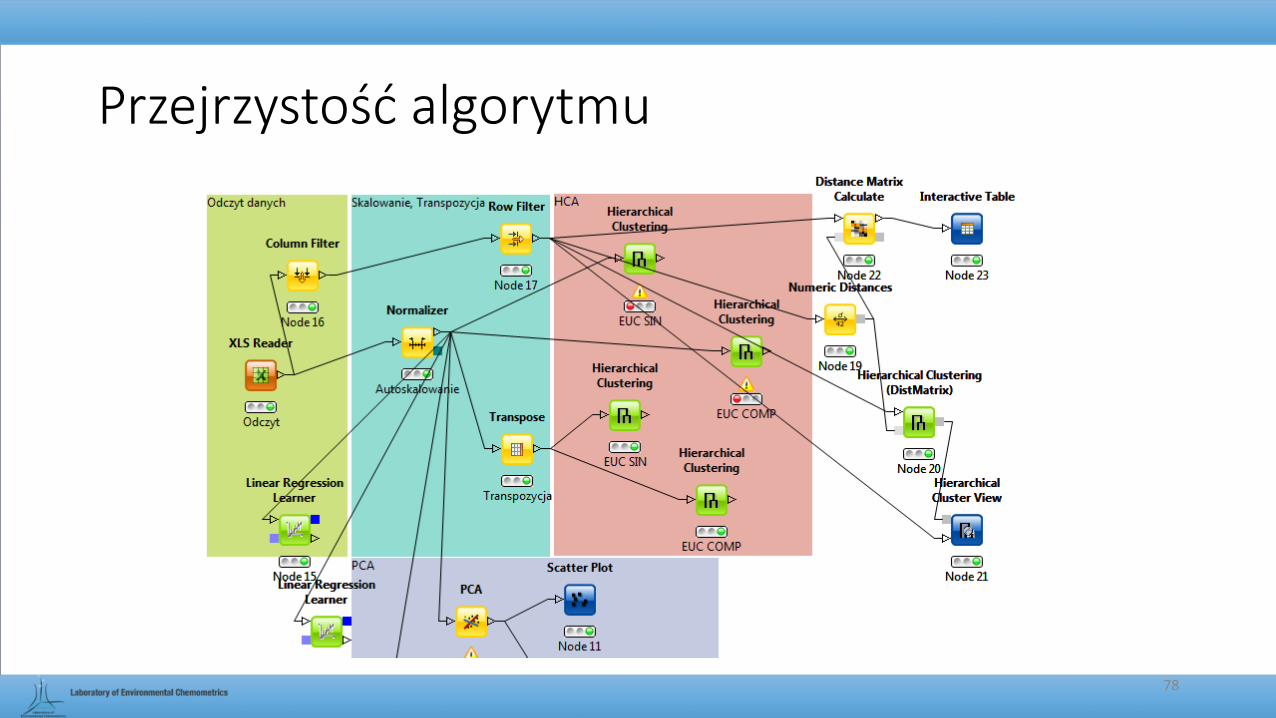
Przejrzystość algorytmu
78

Przykład 2
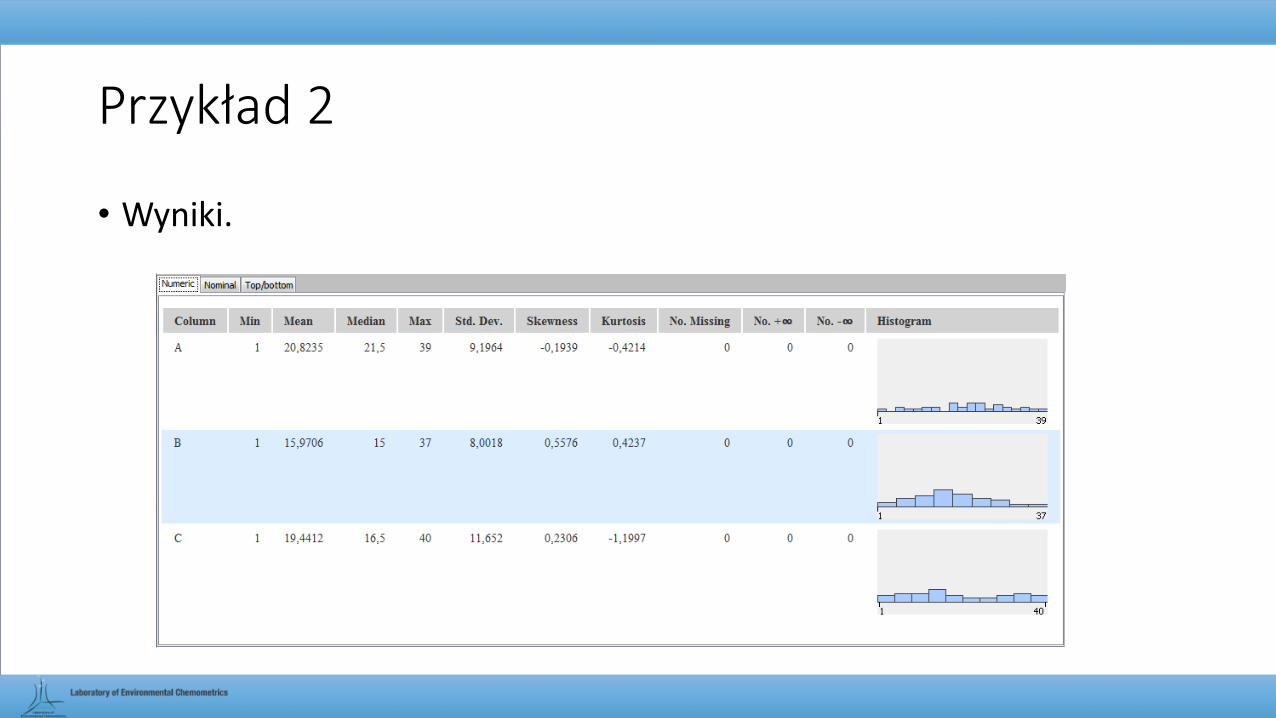
• Problem: jaki jest rozkład zmiennych A, B i C na histogramie oraz jakie są dla nich wartości skośności, kurtozy, odchylenia standardowego, średniej oraz mediany.
79
A B C19 16 1
21 16 16
32 28 15
1 8 33
29 27 12
6 17 17
22 8 37
21 25 35
19 14 2
23 18 16
11 7 35
29 19 14
33 13 38
18 6 6
5 3 18
24 14 6
12 18 18
34 1 34
24 14 3
9 23 22
18 14 31
35 17 14
8 9 40
26 18 7
17 13 23
14 21 32
27 32 26
17 9 8
39 22 13
14 22 9
27 37 12
28 12 28
22 11 11
24 11 29

Przykład 2
• Cel: obliczenie poszczególnych wielkości oraz graficzna utworzenie histogramów.
• Kroki:• Import danych z tabeli (plik *.xlsx)
• Prezentacja danych na histogramach
• Obliczenie skośności
• Obliczenie kurtozy
• Obliczenie średniej
• Obliczenie mediany
• Obliczenie odchylenia standardowego
80
Przykład 2
• Cel: obliczenie współczynnika korelacji pomiędzy dwiema zmiennymi oraz graficzna prezentacja ich wzajemnej relacji na wykresie punktowym.
• Kroki:• Import danych z tabeli (plik *.xlsx)• Prezentacja danych na histogramach• Obliczenie skośności• Obliczenie kurtozy• Obliczenie średniej• Obliczenie mediany• Obliczenie odchylenia standardowego
81
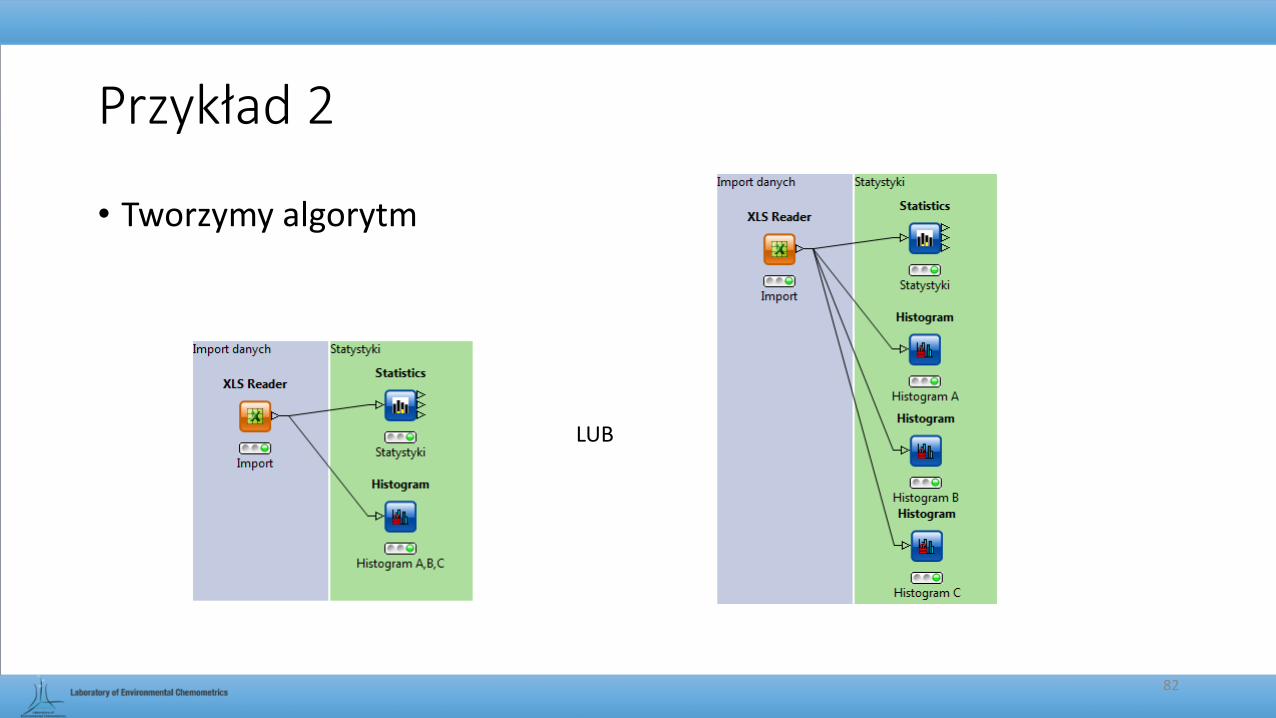
Przykład 2
• Tworzymy algorytm
82
LUB
Przykład 2
• Wyniki.
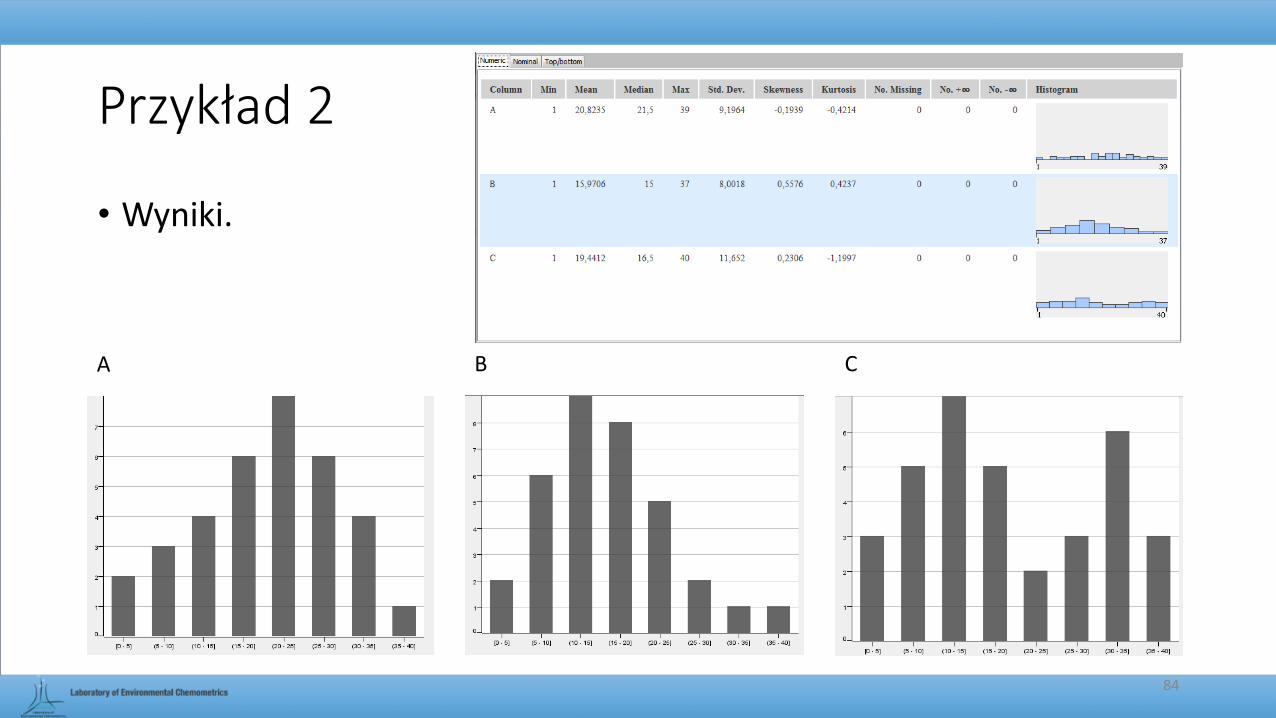
Przykład 2
• Wyniki.
84
A B C
Przykład 2
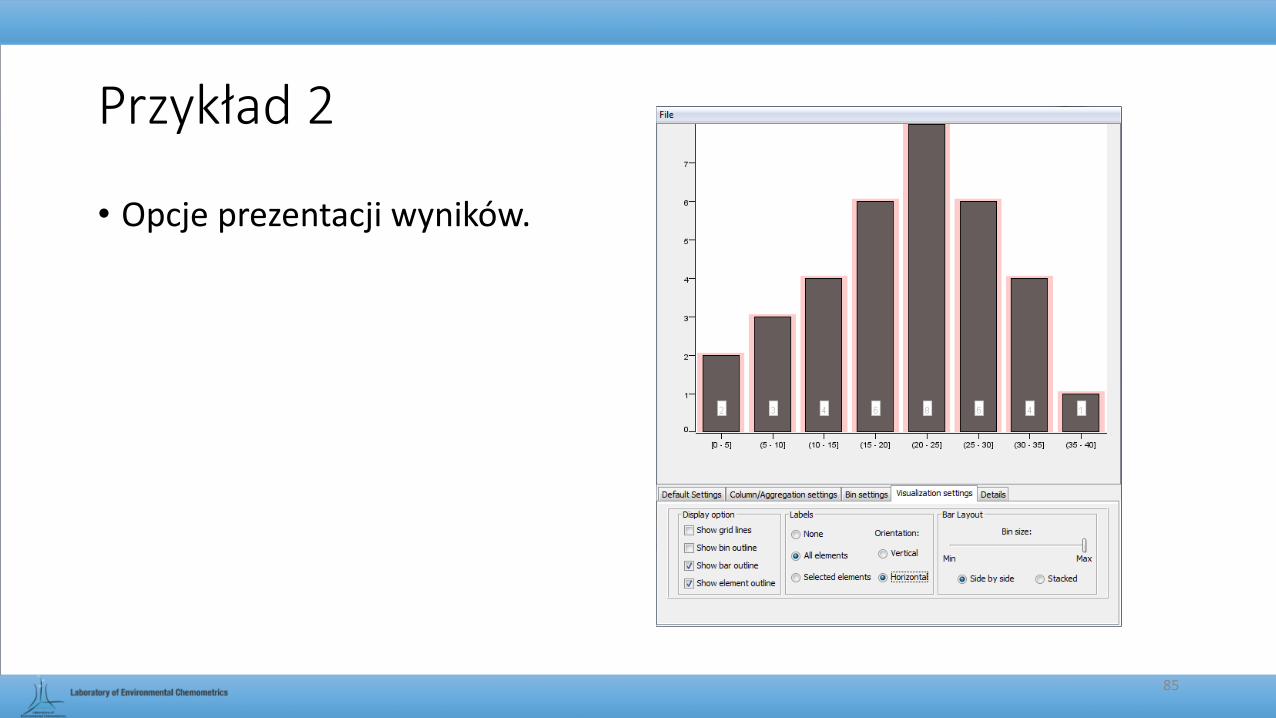
• Opcje prezentacji wyników.
85





























