Embed Size (px)
DESCRIPTION
Kernels for Relation Extraction & Semi-Markov Models. William Cohen 3-27-2007. …and announcements. Projects and such: Last class is (officially) Thus May 3. Projects due Fri May 11. But I was soft about allowing small projects…so We’ll meet May 8 and May 10 also - PowerPoint PPT Presentation
Citation preview

Kernels for Relation Extraction& Semi-Markov Models
William Cohen
3-27-2007

…and announcements
• Projects and such:– Last class is (officially) Thus May 3.– Projects due Fri May 11.– But I was soft about allowing small projects…so
• We’ll meet May 8 and May 10 also– Send me mail if you can’t attend
• Project presentations start April 17 – two per session, 30min each, plus questions.
• Preliminary reports are ok in your presentation

Announcements
• Lectures thru mid-April:
– SRL overview on this Thus
– Bootstrapping next week• Critique for Etzioni paper due Tues.
– Please keep talks to 20min talking

Kernels vs Structured Output Spaces
• Two kinds of structured learning:– HMMs, CRFs, VP-trained HMM, structured
SVMs, stacked learning, ….: the output of the learner is structured.
• Eg for linear-chain CRF, the output is a sequence of labels—a string Yn
– Bunescu & Mooney (EMNLP, NIPS): the input to the learner is structured.
• EMNLP: structure derived from a dependency graph.
New!


x1 × x2 × x3 × x4 × x5
= 4*1*3*1*4 = 48 featuresx1 x2 x3 x4 x5
…
K( x1 × … × xn, y1 × … × yn ) =
( x1 × … × xn ) ∩ (y1 × … × yn)
x x’

and the NIPS paper…
• Similar representation for relation instances: x1 × … × xn where each xi is a set….
• …but instead of informative dependency path elements, the x’s just represent adjacent tokens.
• To compensate: use a richer kernel

Subsequence kernels
• Example strings:– “Elvis Presley was born on Jan 8” s1) PERSON was born on DATE.– “William Cohen was born in New York City on April 6” s2) PERSON was born in LOCATION on DATE.
• Plausible pattern: – PERSON was born … on DATE.
• What we’ll actually learn:– u = PERSON … was … born … on … DATE.– u matches s if exists i=i1,…,in so that s[i]=s[i1]…s[in]=u– For string s1, i=1234. For string s2, i=12367
i=i1,…,in are
increasing indices in s
[Lohdi et al, JMLR 2002]

Subsequence kernels
s1) PERSON was born on DATE. s2) PERSON was born in LOCATION on DATE.
• Pattern: – u = PERSON … was … born … on … DATE.– u matches s if exists i=i1,…,in so that s[i]=s[i1]…s[in]=u– For string s1, i=1234. For string s2, i=12367
• How to we say that s1 matches better than s2?– Weight a match of s to u by λlength(i) where length(i)=in-i1+1
• Now let’s define K(s,t) = the sum over all u that match both s and t of matchWeight(u,s)*matchweight(u,t)

K’i(s,t) = #patterns u that match s and t where the last index is at the very end of s and t.
These recursions allow dynamic programming

Subsequence kernel with features
set of all sparse subsequences u of x1 × … × xn with each u
downweighted according to sparsity
Relaxation of old kernel: 1. We don’t have to match everywhere, just at selected locations2. For every position we decide to match at, we get a penalty of λ
To pick a “feature” inside (x1 … xn)’
1. Pick a subset of locations i=i1,…,ik and then2. Pick a feature value in each location3. In the preprocessed vector x’ weight every feature for i by λlength(i) = λik-i1+1

Subsequence kernel
][],[ :,
)()(),(jiji,
ji
tusuu
lengthlengthtsK
or
Where c(x,y) = Number of ways x and y match (i.e number of common features)


all j
* c(x,t[j])
Number of ways x and t[j] match (i.e number of common features)

all j
* c(x,t[j])
* c(x,t[j])

Additional details
• Special domain-specific tricks for combining the subsequences for what matches in the fore, aft, and between sections of a relation-instance pair.– Subsequences are of length less than 4.
• Is DP needed for this now?
– Count fore-between, between-aft, and between subsequences separately.

ResultsProtein-protein interaction

Semi-Markov Models

State-of-the-art NER: Sequential Word Classification
I met Prof. F. Douglas at the zoo
1 2 3 4 5 6 7 8
I met Prof F. Douglas at the zoo.
Other Other Person Person Person other other Location
t
x
y
Question: how can we guide this using a
dictionary D?
Simple answer: make membership in D a feature fd
what about a dictionary entry like “Fred Douglis”?

Semi-Markov models
1 2 3 4 5 6 7 8
I met Prof. F. Douglas at the zoo.
Other Other Person Person Person other other Location
l1=u1=1 l2=u2=2 l3=3, u3=5 l4=6,u4=6 l5=u5=7 l6=u6=8
I met Prof. F. Douglas at the zoo.
Other Other Person other other Location
t
x
y
l,u
x
y

Prediction
Viterbi finds this efficiently.
Many models fit this framework
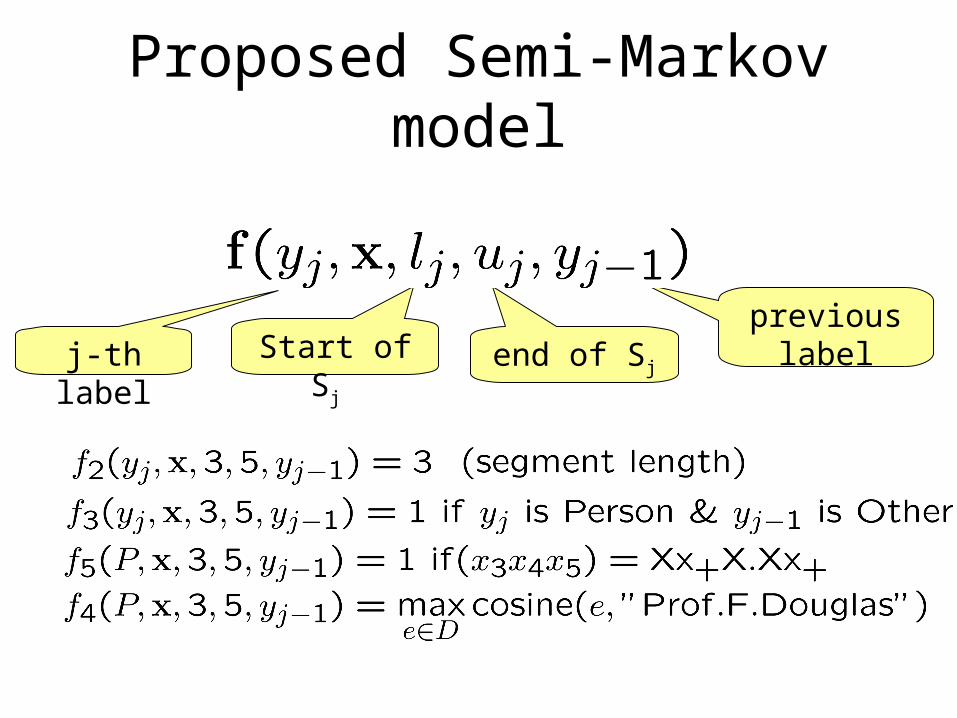
Proposed Semi-Markov model
j-th label Start of Sj previous
labelend of Sj

1 2 3 4 5 6 7 8
I met Prof. F. Douglas at the zoo.
V(5,L)
V(5,O)
V(5,P)?
V(4,L)
V(4,P)
V(4,O)
V(3,L)
V(3,P)
V(3,O)
V(2,L)
V(2,P)
V(2,O)
V(1,L)
V(1,P)
V(1,O)
Modified Viterbi
Best segmentation ending at position i and assigned label y
Maximum segment length
L=4

Internal dictionary: formed from training examples
External dictionary: from external source
[Sarawagi & Cohen, NIPS 2004]

Learning Rates for Semi-Markov CRFs














![Generalized expectation with general kernels on g ...library.utia.cas.cz/separaty/2017/E/mesiar-0477104.pdfIn Markov diffusion process, Lerner [15] proved a Jensen’s inequality for](https://img.dokumen.tips/doc/110x75/5f0397777e708231d409cf59/generalized-expectation-with-general-kernels-on-g-in-markov-diffusion-process.jpg)














