Embed Size (px)
Citation preview

POLITECHNIKA WARSZAWSKA
Wydział Elektroniki i Technik Informacyjnych Instytut Systemów Elektronicznych
Kamil Kierklo Nr albumu: 210437
Praca dyplomowa inżynierska
Optymalizacja średniokwadratowej maszyny wektorów nośnych metodą ewolucji różnicowej do
predykcji reakcji fosforylacji
Praca wykonana pod kierunkiem dr inż. Stanisława Jankowskiego
Warszawa, 2011

Optymalizacja średniokwadratowej maszyny wektorów nośnych metodą ewolucji różnicowej do predykcji reakcji fosforylacji
Poruszanym w pracy problemem jest optymalizacja klasyfikatora LS-SVM metodą ewolucji różnicowej. Parametrami optymalizowanymi są: współczynnik regularyzacji oraz parametr jądra RBF . Model wykorzystano do sklasyfikowania zbiorów sekwencji aminokwasów biorących udział w reakcji fosforylacji z wybranymi enzymami: PKA, PKB, PKC, CDK, MAPK. Otrzymano wzrost precyzji klasyfikatora w granicach 5-10%. Differential Evolution Optimzation of LS-SVM for Prediction of Phosphorylation Reaction This project deals with the problem of least-squares support vector machine optimization by using differential evolution. The optimized parameters are: regularization coefficient and the RBF kernel width . The model was applied to classification the ability of sets of amino-acid sequences to phosphorylation reaction with some enzymes: PKA, PKB, PKC, CDK, MAPK. The gain of the classification precision was obtained in the interval 5-10 %.

ŻYCIORYS
Urodziłem się 28.09.1987 r. w Augustowie. Szkołę Podstawową im. Karola
Brzostowskiego w Sztabinie ukończyłem w 2000 roku a trzy lata później zostałem
absolwentem Gimnazjum w Sztabinie. Latach 2003 – 2006 uczęszczałem do I Liceum
Ogólnokształcącego im. Grzegorza Piramowicza w Augustowie do klasy o profilu
matematyczno–informatycznym. Następnie w 2006 roku zdałem egzamin maturalny.
W lutym 2007 roku rozpocząłem studia dzienne na Wydziale Elektroniki i Technik
Informacyjnych Politechniki Warszawskiej. Wybraną przeze mnie specjalnością jest
Elektronika i Inżynieria Komputerowa. Interesuję się wszystkim co związane z branżą IT oraz
nowymi technologiami.

Spis treści
1. WSTĘP ............................................................................................................................ 6
1.1. REAKCJA FOSFORYLACJI ......................................................................................... 6
1.2. CEL I ZAKRES PRACY ................................................................................................ 6
2. MASZYNA WEKTORÓW NOŚNYCH ........................................................................ 8
2.1. PERCEPTRON................................................................................................................ 8
2.2. LINIOWA MASZYNA WEKTORÓW NOŚNYCH .................................................... 10
2.3. NIELINIOWA MASZYNA WEKTORÓW NOŚNYCH ............................................. 13
2.4. ŚREDNIOKWADRATOWA MASZYNA WEKTORÓW NOŚNYCH ...................... 17
2.5. ROZRZEDZANIE ......................................................................................................... 19
3. ALGORYTMY EWOLUCYJNE .................................................................................. 20
3.1. PODSTAWOWE POJĘCIA .......................................................................................... 21
3.2. EWOLUCJA RÓŻNICOWA ........................................................................................ 22
3.2.1. Mutacja ............................................................................................................... 22
3.2.2. Krzyżowanie ....................................................................................................... 23
3.2.3. Selekcja ............................................................................................................... 23
3.2.4. Pseudokod ........................................................................................................... 24
3.2.5. Dobór parametrów .............................................................................................. 25
3.2.6. Parametry domyślne ........................................................................................... 25
4. OCENA JAKOŚCI ........................................................................................................ 26
4.1. MACIERZ KLASYFIKACJI ........................................................................................ 26
4.2. KRZYWE ROC ............................................................................................................. 27
5. BADANIA ..................................................................................................................... 30
5.1. BAZA DANYCH .......................................................................................................... 30
5.1.1. Dane wejściowe .................................................................................................. 31
5.2. OPIS DZIAŁANIA ....................................................................................................... 31
5.3. PROCEDURA BADAWCZA ....................................................................................... 32
5.4. WYNIKI KLASYFIKACJI DLA PEŁNYCH ZBIORÓW DANYCH ........................ 33
5.5. WERYFIKACJA BAZY DANYCH ............................................................................. 41
5.6. WYNIKI KLASYFIKACJI DANYCH ZWERYFIKOWANYCH .............................. 42
5.6.1. Badanie wpływu redukcji liczby wektorów nośnych na jakość klasyfikacji ..... 48
6. PODSUMOWANIE I WNIOSKI KOŃCOWE ............................................................ 51

7. OPIS PROGRAMU ....................................................................................................... 53
8. BIBLIOGRAFIA ........................................................................................................... 55

6
1. WSTĘP
Tematyka pracy dyplomowej porusza zagadnienia z zakresu bioinformatyki, klasyfikacji
i optymalizacji z wykorzystaniem algorytmów genetycznych. Opierając się na zebranych
danych stworzono klasyfikator w postaci średniokwadratowej maszyny wektorów nośnych
LS–SVM – ang. Least Square Support Vector Machine. Jego zadaniem jest
przyporządkowanie sekwencji aminokwasów do określonych przez ekspertów klas. Poniżej
opisane są podstawy biologicze poruszanego problemu oraz zakres i cel prezentowanej pracy.
1.1. REAKCJA FOSFORYLACJI
Fosforylacja białka jest procesem chemicznym zachodzącym w organizmach żywych i polega
na przyłączenia reszty fosforanowej (PO4). Katalizatorem są specjalne enzymy zwane
kinazami białkowymi. Uproszczony zapis omawianej reakcji:
białkoA + kinazaATP → białko– PO4 + kinazaADP
Rolą fosforylacji i reakcji do niej odwrotnej – defosforylacji, jest regulacja aktywności
białek (w tym enzymów), zdolności do reagowania z innymi białkami albo przemieszczenia
cząsteczki w obrębie komórki. Mówiąc w uproszczeniu para tych reakcji może stawić element
włączający lub wyłączający szlaku metabolicznego.
Zaburzenia aktywności kinaz często prowadzą do chorób metabolicznych czy nawet
nowotworowych. Dzięki pogłębieniu wiedzy nad kinazami opracowano nowe terapie i kilka
inhibitorów kinaz. Konieczne jest jednak dalsze prowadzenie badań w tym temacie. Nie są
one ani łatwe ani tanie, więc powinny być one prowadzone na takich próbkach, dla których
prawdopodobieństwo sukcesu będzie największe. Wytypowanie obiektów może ułatwić
właśnie bioinformatyka. Przewidywanie odpowiedzi z wykorzystaniem klasyfikacji na
podstawie zebranych danych umożliwi wybór istotnych sekwencji aminokwasów.
Klasyfikator w oparciu o najbardziej istotne atrybuty przyporządkuje daną sekwencję do
określonej grupy z którą może reagować (PKA, PKB, PKC, CDK, MAPK).
1.2. CEL I ZAKRES PRACY
Celem pracy dyplomowej było skonstruowanie modeli umożliwiających zaklasyfikowanie
sekwencji aminokwasów do rodzajów kinaz umożliwiających zajście reakcji fosforylacji.
Zbiory danych pochodzą z Centrum Onkologii w Warszawie. Wejściowy wycinek składający

7
się z ciągów znakowych został opisany za pomocą parametrów liczbowych. Następnie
dokonano selekcji parametrów z wykorzystaniem ortogonalizacji Grama-Schmidta.
Tak przygotowane dane zostały wykorzystane do stworzenia klasyfikatorów LS–SVM.
Losowa część zbioru posłużyła do testowania wyników klasyfikacji. W celu dalszej poprawy
zoptymalizowano hiperparametry metodą ewolucji różnicowej DE (ang. Differential
Evolution). Zbadano również wpływ usunięcia części wektorów nośnych wnoszących
najmniej istotnych informacji na jakość klasyfikacji.
W kolejnych rozdziałach pracy dyplomowej opisano algorytmy LS–SVM oraz DE.
Następnie omówiono zawartość bazy danych. W dalszej części zaprezentowano otrzymane
rezultaty a także je skomentowano. Rozdział 6 stanowi podsumowanie całej pracy
i przedstawia możliwości udoskonalenia opracowanych rozwiązań.

8
2. MASZYNA WEKTORÓW NOŚNYCH
W latach 1995 – 1998 Vladimir Vapnik [18, 19] opracował koncepcję maszyny wektorów
nośnych (SVM – Support Vector Machine) do rozwiązywania zagadnień klasyfikacji oraz
aproksymacji. Klasyfikatory SVM dzięki większej zdolności do generalizacji dają lepsze
rezultaty niż sieci neuronowe, są również mniej narażone na problem nadmiernego
dopasowanie (ang. overfitting) wynikający ze sposobu uczenia sieci.
SVM należy do grona maszyn uczących na podstawie danych wzorcowych.
W przeciwieństwie do innych rozwiązań maszyna wektorów nośnych traktuje te dane
selektywnie, skupiając się na tych najbardziej istotnych czyli w otoczeniu granicy klas.
Dane wejściowe maszyny to zbiór par x, y , przy czym x jest wektorem atrybutów
a y etykietą klasy. Klasyfikacja polega na znalezieniu położenia hiperpowierzchni separującej
klasy z maksymalnym marginesem, która jest wyznaczona za pomocą danych leżących na
granicach klas – tzw. wektorów nośnych. Im mniej jest wektorów nośnych tym większa
zdolność modelu do generalizacji.
Po zakończeniu procesu uczenia wyznaczone wektory nośne pozwalają na
zaklasyfikowanie przychodzących danych do odpowiadających im klas. Maszyny wektorów
nośnych najczęściej wykorzystuje się do klasyfikacji binarnej, ale istnieją implementacje
wieloklasowe. W niniejszej pracy skupiono się na tych pierwszych.
2.1. PERCEPTRON
Aby lepiej zrozumieć ideę maszyny wektorów nośnych warto przyjrzeć się perceptronowi
Rosenblatta. Algorytm ten ma zastosowanie tylko dla danych separowalnych liniowo. Wraz
z kolejnymi, błędnie zaklasyfikowanymi punktami położenie prostej separującej zmienia się.
W zależności od kolejności klasyfikowanych punktów położenie końcowe płaszczyzny może
się znacząco różnić. Omawiane zagadnienie zaprezentowane zostało na rys 2.1.
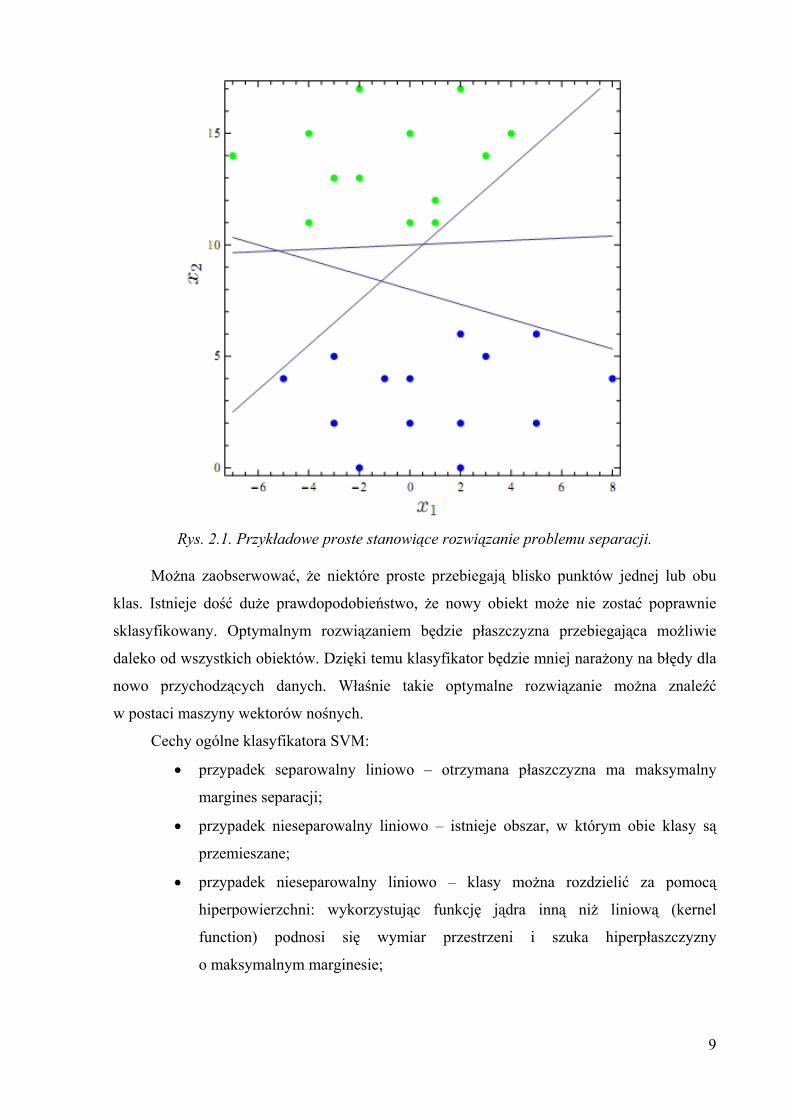
9
Rys. 2.1. Przykładowe proste stanowiące rozwiązanie problemu separacji.
Można zaobserwować, że niektóre proste przebiegają blisko punktów jednej lub obu
klas. Istnieje dość duże prawdopodobieństwo, że nowy obiekt może nie zostać poprawnie
sklasyfikowany. Optymalnym rozwiązaniem będzie płaszczyzna przebiegająca możliwie
daleko od wszystkich obiektów. Dzięki temu klasyfikator będzie mniej narażony na błędy dla
nowo przychodzących danych. Właśnie takie optymalne rozwiązanie można znaleźć
w postaci maszyny wektorów nośnych.
Cechy ogólne klasyfikatora SVM:
• przypadek separowalny liniowo – otrzymana płaszczyzna ma maksymalny
margines separacji;
• przypadek nieseparowalny liniowo – istnieje obszar, w którym obie klasy są
przemieszane;
• przypadek nieseparowalny liniowo – klasy można rozdzielić za pomocą
hiperpowierzchni: wykorzystując funkcję jądra inną niż liniową (kernel
function) podnosi się wymiar przestrzeni i szuka hiperpłaszczyzny
o maksymalnym marginesie;

10
2.2. LINIOWA MASZYNA WEKTORÓW NOŚNYCH
Do trenowania służy zbiór N – elementowych par , , ,…, , gdzie jest m–
wymiarowym wektorem wejściowym a 1, 1 stanowi etykietę klasy. Przyjęcie
oznaczenia klas jako pary liczb, dodatniej i ujemnej, jest spowodowane pewną wygodą
rachunkową.
Klasyfikacja statystyczna wymaga spełnienia podstawowego warunku matematycznego.
Z twierdzenia T. Covera wynika, że liczba elementów zbioru uczącego N musi być co
najmniej równa 2(m+1), gdzie m – liczba zmiennych opisujących. Wynika z tego, że
korzystnie jest ograniczyć liczbę atrybutów do najbardziej istotnych. Gdy zbiór trenujący nie
spełnia powyższego twierdzenia klasyfikator określony jest w sposób losowy.
Warunek ten można wyrazić następująco:
· , (1)
gdzie sgn – funkcja signum;
w – wektor kierunkowy
hiperpłaszczyzny (wektor wag);
x – wektor wejściowy;
b – obciążenie (ang. bias)
Operator · oznacza we wzorze iloczyn skalarny dwóch wektorów. Współczynnik b stanowi
przesunięcie prostej (szczególny przypadek hiperpłaszczyzny) względem początku układu
współrzędnych. Rozwiązanie problemu stanowi znalezienie wektora wag w oraz wyrazu
wolnego b. Dążymy do jak największej generalizacji modelu w celu poprawnej klasyfikacji
nowych danych. Aby to osiągnąć prosta powinna przebiegać możliwie daleko od wektorów
każdej z klas.
Wprowadźmy pojęcie marginesu separacji. Nazywamy tak przestrzeń wokół
hiperpłaszczyzny separującej, w obrębie której nie leżą żadne punkty. Przestrzeń tą
ograniczają dwie hiperpłaszczyzny stanowiące przesuniętą granicę decyzyjną o pewien
wektor.
Wykorzystując wzór na odległość punktu od płaszczyzny można określić szerokość
marginesu. W przestrzeni dwuwymiarowej dla prostej 0 i punktu ,
przyjmuje on postać:
| |√
| · | (2)

11
Zapis oznacza normę euklidesową wektora w.
Podsumowując, celem metody SVM jest znalezienie optymalnej płaszczyzny, która
umożliwia poprawną klasyfikację i dodatkowo posiada największy margines separacji
(rys 2.2).
Rys. 2.2. Prosta z maksymalnym marginesem separacji
Maksymalizując szerokość marginesów należy pamiętać, że nie mogą w nim leżeć punkty
należące do zbioru wejściowego. Takie ograniczenie można wyrazić następująco:
1 11 1 (3)
lub zapisując jako jedno wyrażenie
1 (4)
Ostateczne zadanie optymalizacji polega na minimalizacji wektora w normy w postaci
(5)
przy ograniczeniach 1

12
Tak sformułowany problem optymalizacji można już rozwiązywać, gdyż należy do
klasy programowania kwadratowego (ang. QP - quadratic programming) np. przy użyciu
procedury quadprog(…) w programie MATLAB.
Jeszcze inne, równoważne wyrażenie można zapisać z wykorzystaniem mnożników
Lagrange'a. Pozwoli to na lepsze uzmysłowienie znaczenia i wagi wektorów nośnych
wykorzystywanych przy SVM. W procesie uczenia ograniczeniami są wszystkie punkty ze
zbioru wejściowego. Funkcja Lagrange'a:
12 1
12
0 (6)
Należy zauważyć, że przy ∞ całe wyrażenie staje się trywialne do minimalizacji,
gdyż przyjmuje wartość ∞ . Takie skrajne założenie pokazuje, iż minimalizacja musi
odbywać się ze względu na w i b, natomiast ze względu na maksymalizować.
Rozwiązaniem problemu optymalizacji powyższego lagrangianu jest wyznaczenie punktu
siodłowego (rys. 2.3).
Rys. 2.3. Symboliczna ilustracja punktu siodłowego

13
Warunek konieczny istnienia punktu siodłowego jest taki sam jak warunek konieczny
istnienia ekstremum a mianowicie zerowanie się pochodnych:
0 (7)
0 (8)
Z powyższych pochodnych otrzymujemy odpowiednio, że:
∑ (9)
∑ 0 (10)
Po wstawieniu (9) i (10) do Lagrangianu:
∑ ∑ (11)
Zapis (10) stanowi wyrażenie do optymalizacji określone za pomocą samych tylko
mnożników Lagrange'a. Wartości w stanowiące część równania hiperpłaszczyzny można
wyznaczyć z (9) znając wartość . Wyraz wolny b oblicza się z dowolnego ograniczenia
1 0 przy czym musi być wektorem nośnym.
Warto wspomnieć, że otrzymane rozwiązanie stanowi liniowa kombinację wektorów
wejściowych. Dla większości punktów mnożniki Lagrange'a są równe zeru.
Zarówno postać (5) jak i (11) daje taki sam rezultat. Optymalizacja z pierwszej postaci
wyznacza od razu równanie płaszczyzny. W drugim przypadku najpierw otrzymuje się
mnożniki Lagrange'a i informację, które wektory są nośnymi a dopiero w kolejnym etapie
właściwą granicę decyzyjną.
2.3. NIELINIOWA MASZYNA WEKTORÓW NOŚNYCH
Jest to przypadek zdecydowanie częściej spotykany w praktyce. Przykładem takiego zbioru
nieseparowalnego liniowo jest rys 2.4.
Dzięki modyfikacjom stosowanym przez samego Vapnika nadal można wykorzystywać
SVM do poszukiwania optymalnej w pewnym sensie hiperpłaszczyzny. Tym razem należy
pozwolić na to, aby niektóre dane wejściowe leżały wewnątrz marginesu a nawet po złej
stronie granicy.
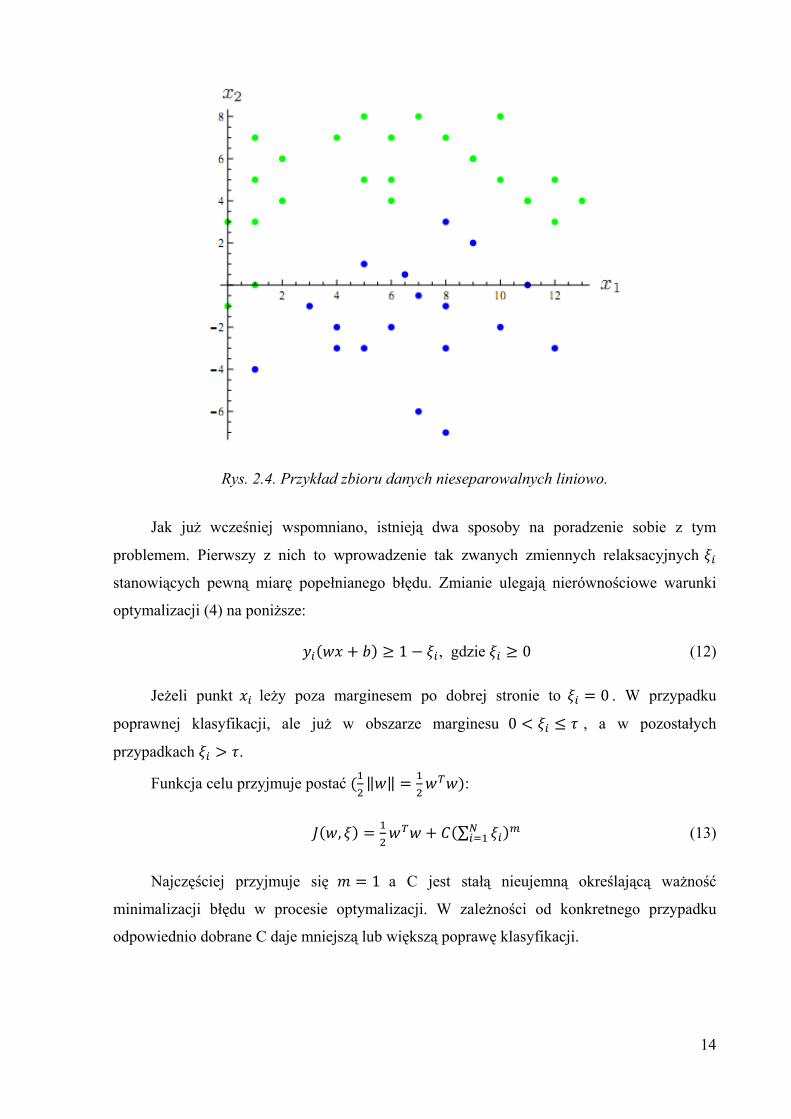
14
Rys. 2.4. Przykład zbioru danych nieseparowalnych liniowo.
Jak już wcześniej wspomniano, istnieją dwa sposoby na poradzenie sobie z tym
problemem. Pierwszy z nich to wprowadzenie tak zwanych zmiennych relaksacyjnych
stanowiących pewną miarę popełnianego błędu. Zmianie ulegają nierównościowe warunki
optymalizacji (4) na poniższe:
1 , gdzie 0 (12)
Jeżeli punkt leży poza marginesem po dobrej stronie to 0 . W przypadku
poprawnej klasyfikacji, ale już w obszarze marginesu 0 , a w pozostałych
przypadkach .
Funkcja celu przyjmuje postać :
, ∑ (13)
Najczęściej przyjmuje się 1 a C jest stałą nieujemną określającą ważność
minimalizacji błędu w procesie optymalizacji. W zależności od konkretnego przypadku
odpowiednio dobrane C daje mniejszą lub większą poprawę klasyfikacji.
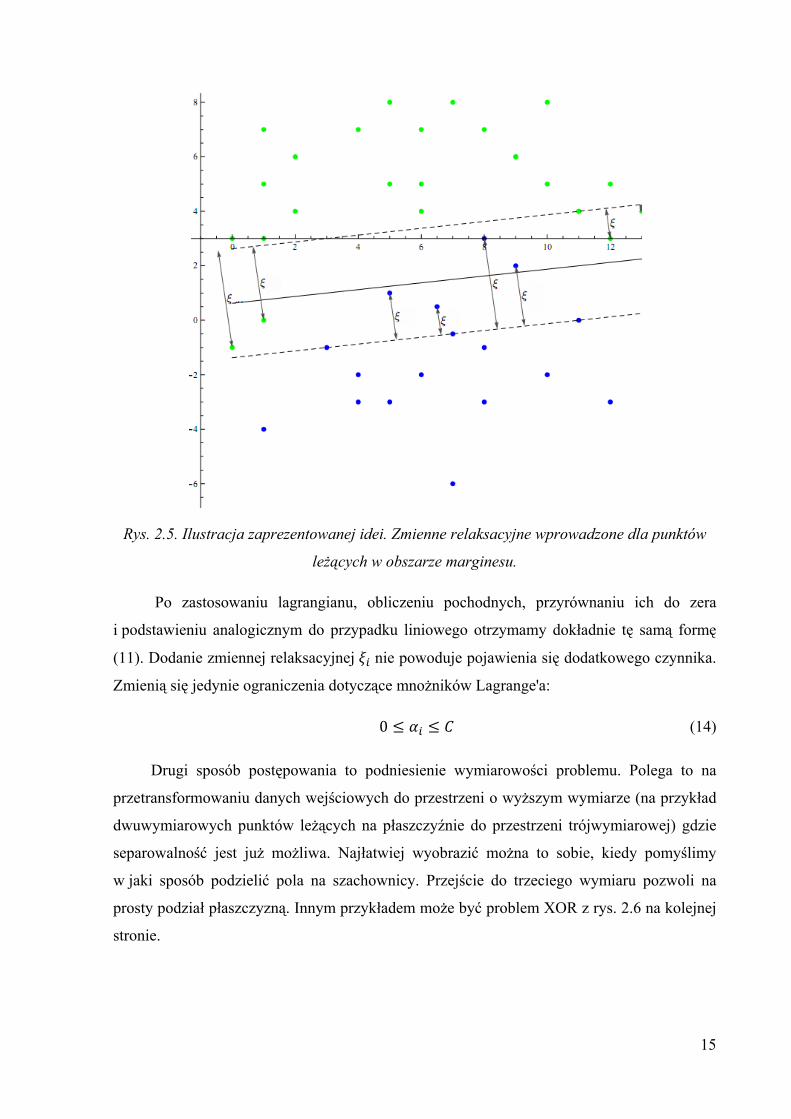
15
Rys. 2.5. Ilustracja zaprezentowanej idei. Zmienne relaksacyjne wprowadzone dla punktów
leżących w obszarze marginesu.
Po zastosowaniu lagrangianu, obliczeniu pochodnych, przyrównaniu ich do zera
i podstawieniu analogicznym do przypadku liniowego otrzymamy dokładnie tę samą formę
(11). Dodanie zmiennej relaksacyjnej nie powoduje pojawienia się dodatkowego czynnika.
Zmienią się jedynie ograniczenia dotyczące mnożników Lagrange'a:
0 (14)
Drugi sposób postępowania to podniesienie wymiarowości problemu. Polega to na
przetransformowaniu danych wejściowych do przestrzeni o wyższym wymiarze (na przykład
dwuwymiarowych punktów leżących na płaszczyźnie do przestrzeni trójwymiarowej) gdzie
separowalność jest już możliwa. Najłatwiej wyobrazić można to sobie, kiedy pomyślimy
w jaki sposób podzielić pola na szachownicy. Przejście do trzeciego wymiaru pozwoli na
prosty podział płaszczyzną. Innym przykładem może być problem XOR z rys. 2.6 na kolejnej
stronie.

16
Rys. 2.6. Problem XOR. W dwóch wymiarach nie jest możliwe odseparowanie od siebie
punktów pojedynczą prostą.
Takie przekształcenie do wyższej przestrzeni oznaczmy przez Φ . :
Φ: R (15)
Odwzorowanie to przekształca dane z przestrzeni o wymiarze d do innej przestrzeni
euklidesowej H charakteryzującej się większą liczbą wymiarów. Często zdarza się, że
zwiększenie wymiaru wektorów wejściowych powoduje wzrost ilości obliczeń koniecznych
do stworzenia modelu. Unika się tego stosując funkcję jądra (ang. kernel function). Przyjmuje
ona postać:
k x , x Φ x Φ x (16)
Zmianie ulega funkcja klasyfikująca:
∑ , (17)
Funkcję jądra stosuje się zawsze, nawet nie będąc do końca tego świadomym. Dla
przypadku liniowego istnieje bowiem liniowe jądro (tab. 2.1). Takie podejście sprawia, że
powyższy wzór ma charakter uniwersalnego klasyfikatora. Postać (16) jądra sprawia, że nie
17
trzeba znać przekształcenia Φ . , istotny jest jedynie iloczyn skalarny przekształconych
wektorów.
Istnieje wiele przykładów takich funkcji [3]. W zadaniach klasyfikacji poprawiają
separowalność a przy aproksymacji stają się funkcją bazową. Najczęściej spotykane zebrano
w tabeli.
Nazwa funkcji Postać Parametry
Liniowa , · Brak
Wielomianowa stopnia d , · 1 d - stopień wielomianu
Radialna (gaussowska) ,2
σ - szerokość funkcji Gaussa
Perceptron wielowarstwowy , · θ - przesunięcie
κ - nachylenie
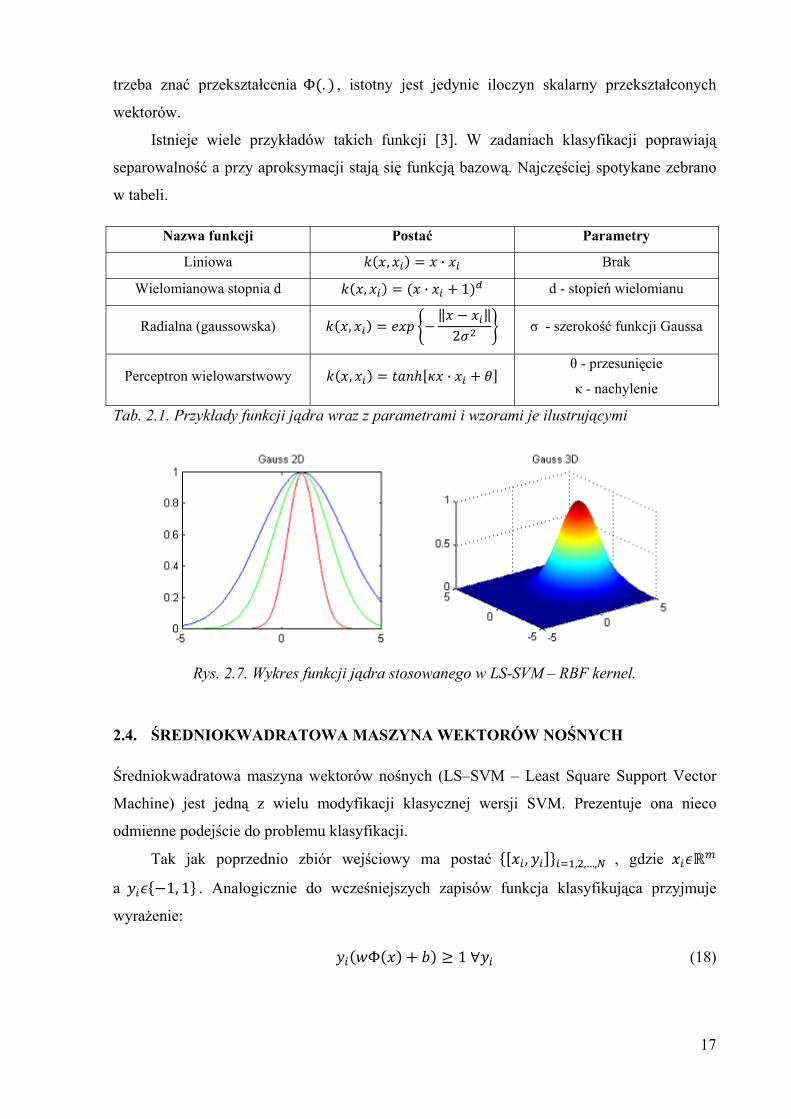
Tab. 2.1. Przykłady funkcji jądra wraz z parametrami i wzorami je ilustrującymi
Rys. 2.7. Wykres funkcji jądra stosowanego w LS-SVM – RBF kernel.
2.4. ŚREDNIOKWADRATOWA MASZYNA WEKTORÓW NOŚNYCH
Średniokwadratowa maszyna wektorów nośnych (LS–SVM – Least Square Support Vector
Machine) jest jedną z wielu modyfikacji klasycznej wersji SVM. Prezentuje ona nieco
odmienne podejście do problemu klasyfikacji.
Tak jak poprzednio zbiór wejściowy ma postać , , ,…, , gdzie
a 1, 1 . Analogicznie do wcześniejszych zapisów funkcja klasyfikująca przyjmuje
wyrażenie:
Φ 1 (18)

18
Jak widać, LS–SVM wykorzystuje przekształcenia z użyciem jądra. Problem do optymalizacji
przedstawia się następująco:
, ∑ , gdzie Φ (19)
Drugi człon, podobnie jak w przypadku nieliniowym, reprezentuje błędy spowodowane
brakiem separowalności. Jak już sama nazwa tej modyfikacji maszyny sugeruje, jest to błąd
średniokwadratowy. Hiperparametr określa jak istotne jest minimalizowanie błędów
w procesie optymalizacji.
Kolejną zmianą w stosunku do wersji klasycznej jest fakt, że błąd
przyporządkowany jest każdemu punktowi, ze zbioru uczącego. Co więcej wektorami
nośnymi są wszystkie elementy zbioru uczącego. Powoduje to, że model staje się znacznie
większy niż poprzednio.
Rozwiązaniem wyrażenia optymalizowanego jest kombinacja liniowa jądra
i mnożników Lagrange’a:
∑ , (20)
Wykorzystując podstawienia za w oraz e otrzymujemy równanie w postaci macierzowej:
0Ω
01 (21)
Symbol I oznacza macierz diagonalną. Ω oznacza przekształcenie przez jądro:
Ω , y y Φ x Φ x y y k x , x (22)
Mnożniki w tym wypadku są proporcjonalne do błędów punktów danych a nie jak
wcześniej w większości równe 0. Dobór hiperparametrów czyli oraz (parametr jądra
gaussowskiego – RBF kernel) może stanowić oddzielny problem. Dodatkowo może zaistnieć
potrzeba zmniejszenia liczby parametrów modelu.
Współczynnik regularyzacji i parametr jądra mogą istotnie wpływać na wyniki
klasyfikacji. Jeżeli poprzez zmianę tylko tych dwóch wielkości można uzyskać poprawę to
trzeba skorzystać z takiej możliwości. Literatura sugeruje jedynie zakres ich doboru dla
przypadku liniowego. W każdym innym przypadku ustala się je empirycznie.

19
2.5. ROZRZEDZANIE
Pod tym pojęciem (ang. pruning) kryje się proces zmniejszenia liczby wektorów nośnych.
Model średniokwadratowej maszyny wykorzystuje wszystkie wejściowe wektory trenujące
jako nośne. Często ma to uzasadnienie jednak nie jest to rozwiązanie optymalne. Stąd bierze
się pomysł, aby najmniej istotne wektory usunąć. Zanim przystąpi się do rozrzedzania
maszyny trzeba przyjąć kryterium selekcji.
Jednym z podstawowych kryteriów jest usuwanie wektorów, których mnożniki mają
najmniejszą wartość bezwzględną. Uzasadnia się to faktem, że są one proporcjonalne do
błędów zgodnie ze wzorem:
(23)
Inne możliwe kryteria selekcji proponuje literatura [8]. Zaprezentowany sposób
wykorzystano przy implementacji procedury optymalizacji.
20
3. ALGORYTMY EWOLUCYJNE
Algorytmy i strategie ewolucyjne swoją inspirację (podobnie jak sieci neuronowe) czerpią
z obserwacji przyrody. Tymi heurystycznymi metodami dochodzenia do rozwiązania rządzą
elementy zaczerpnięte z darwinowskiej teorii ewolucji – dobór naturalny, krzyżowanie,
mutacje. W naturze to właśnie osobniki najlepiej przystosowane do otoczenia mają
największe szanse na przeżycie. Na drodze krzyżowania przekazują swoje cechy kolejnym
pokoleniom. Propagują się dzięki temu geny pożądane a eliminacji ulegają słabsze.
Programowanie genetyczne i algorytmy ewolucyjne przenoszą te proste zjawiska na
modele matematyczne. Początki badań miały swoje miejsce już w latach 50-tych i 60-tych
ubiegłego wieku. Obecnie metody te znajdują zastosowanie w takich dziedzinach jak
inżynieria, statystyka czy bankowość.
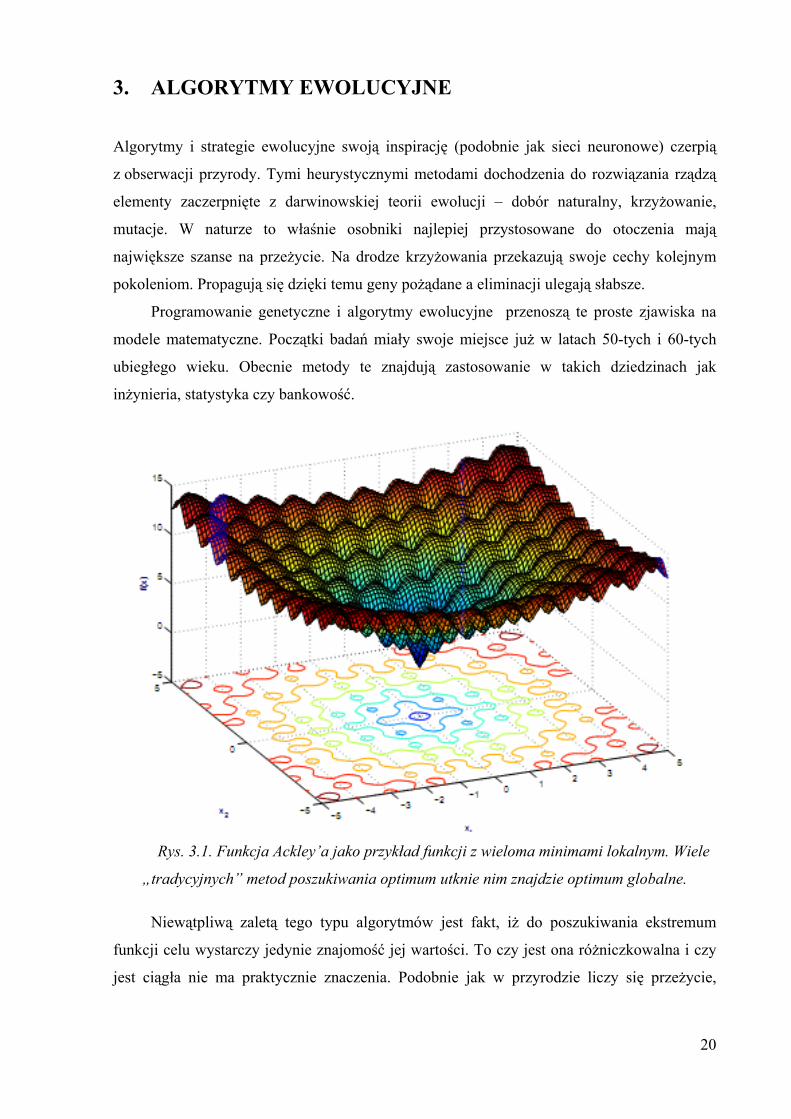
Rys. 3.1. Funkcja Ackley’a jako przykład funkcji z wieloma minimami lokalnym. Wiele
„tradycyjnych” metod poszukiwania optimum utknie nim znajdzie optimum globalne.
Niewątpliwą zaletą tego typu algorytmów jest fakt, iż do poszukiwania ekstremum
funkcji celu wystarczy jedynie znajomość jej wartości. To czy jest ona różniczkowalna i czy
jest ciągła nie ma praktycznie znaczenia. Podobnie jak w przyrodzie liczy się przeżycie,

21
z punktu widzenia optymalizacji ważne jest osiągnięcie pewnej wartości określonej przez
funkcję celu.
Dobry algorytm optymalizacji ewolucyjnej spełnia następujące warunki:
– umożliwia działanie na nieróżniczkowalnych i nieciągłych funkcjach celu;
– poszukiwania nie są prowadzone z jednego punkt, lecz z pewnej populacji;
– jest łatwy w użyciu i posiada kilka parametrów sterujących;
– ma dobrą zbieżność;
3.1. PODSTAWOWE POJĘCIA
Przed zagłębieniem się w tematykę algorytmów genetycznych warto zapoznać się ze
stosowaną terminologią. Pozwoli to na szybsze i lepsze zrozumienie ich idei.
Osobnik – pojedyncze rozwiązanie badanego problemu.
Populacja – zbiór rozwiązań w danej generacji. Tworzą ją osobniki czyli konkretne
rozwiązania danego problemu. Stanowią one pulę z której dokonuje się wyboru do dalszych
iteracji.
Gen – jedno z podstawowych pojęć. Oznacza cechę tworzącą genotyp. Zbiór genów
osobniczych stanowi chromosom danego osobnika.
Mutacja – proces tworzenia nowego osobnika poprzez dodanie lub odjęcie pewnej
liczby od cech innego w danej populacji. Dobór osobnika ma charakter losowy. Otrzymane
rozwiązanie powinno znaleźć się w pobliżu tego, z którego powstało. Może się jednak
zdarzyć, że dana cecha będzie miała wartość poza zakresem zainteresowania. Konieczne jest
w takim wypadku zaimplementowanie odpowiedniej funkcji naprawy takiego osobnika lub
jego usunięcie.
Krzyżowanie – operacja podczas którego z przynajmniej dwóch osobników – rodziców,
powstaje nowy – potomek. Swoje cechy dziedziczy po obydwu rodzicach. To które mają
pochodzić np. od pierwszego rozstrzygane jest w sposób losowy.
Selekcja – obejmuje wybór osobników powstałych dzięki procesom krzyżowania
i mutacji , które utworzą kolejną generację.
Działanie operacje mutacji i krzyżowania można regulować za pomocą odpowiednich
współczynników.

22
3.2. EWOLUCJA RÓŻNICOWA
Wszystkie wymienione wcześniej warunki posiada algorytm ewolucji różnicowej (DE –Differential Evolution). Został opracowany przez Rainera Storna i Kennetha Price’a w 1996 roku. W czasie prac nad problemem dopasowania wielomianu Czebyszewa powstał pomysł modyfikowania wektora zmiennych poprzez zaburzanie go ważoną różnicą innych. Nowy wektor ma większe prawdopodobieństwo przesunięcia się w kierunku zapewniającym lepszą optymalizację.
Prostota i intuicyjność a przede wszystkim efektywność algorytmu sprawiły, że zdobył on dużą popularność. DE pozwala na znalezienie globalnego optimum problemów o ciągłej dziedzinie. Poszukiwanie prowadzone jest w sposób bezpośredni i równoległy.
Przestrzeń rozwiązań stanowią D-wymiarowe wektory parametrów zakodowanych liczbami rzeczywistymi:
, 1, 2, … , Dla każdej generacji G liczba NP jest stała. Początkowa populacja generowana jest
losowo o rozkładzie normalnym, w taki sposób aby pokryć całą przestrzeń wartości cech. 3.2.1. Mutacja
Dla każdego wektora docelowego z populacji NP tworzony jest mutant, z którym następnie będzie rekombinować (krzyżować). Powstaje on zgodnie ze wzorem: , , · , , (24) Indeksy , , 1, 2, … , wybierane są losowo. Muszą się różnić od siebie i od wektora docelowego. Parametr F jest stałą, rzeczywistą wartością z przedziału 0, 2 . Odpowiada za kontrolę wzmocnienia różnicy , , . Minimalną liczbą wektorów spełniającą powyższe warunki jest cztery.
Rys. 3.2. Proces generowania wektora ,

23
3.2.2. Krzyżowanie
Proces krzyżowania (ang. crossover) pozwala na uzyskanie jeszcze większej różnorodności wektorów powstałych w kolejnych generacjach. Dzięki temu wektor końcowy
, , , , , … , , tworzony jest według następującego wzoru:
,, ż 0, 1
, ż 0, 1 (25)
Operator 0, 1 losuje liczbę rzeczywistą o rozkładzie równomiernym z przedziału 0, 1 . 0, 1 i podobnie jak F jest stałym parametrem wejściowym algorytmu.
Współczynnik krzyżowania CR kontroluje proporcjonalny udział wektora zmutowanego , w procesie tworzenia wektora końcowego , . W początkowym etapie warto ustalić
CR bliskie 1 aby sprawdzić czy możliwe jest uzyskanie szybkiej zbieżności. Zmienna jest losowo generowaną liczbą całkowitą 1, 2, … , . Dodatkowe warunki zapewniają, że przynajmniej jeden parametr zawsze zostanie przekazany. Ilustrację tego etapu prezentuje rys. 3.3.
Rys. 3.3. Krzyżowanie wektorów o przestrzeni cech D = 8.
3.2.3. Selekcja
Ostatnim etapem tworzenia nowej populacji jest selekcja osobników, które stworzą generację G+1. Wektor końcowy , porównywany jest ze swoim rodzicem , pod względem kryteriów funkcji celu. Decyduje tutaj kryterium chciwości, tzn jeśli lepiej przystosowany jest nowy wektor , , to zostanie on włączony do kolejnej generacji. W przeciwnym wypadku jego miejsce zajmie rodzic czyli , , . Jeżeli funkcja celu jest złożona to wystarczy poprawa jednej z nich, aby wyselekcjonować osobniki do następnych iteracji. Możliwe jest także zastąpienie kilku funkcji celu nowym pojedynczym wyrażeniem.

24
3.2.4. Pseudokod
Poniżej przedstawiono główną pętlę algorytmu ewolucji różnicowej. Pominięto w nim część inicjalizacyjną parametrów kontrolnych i proces tworzenia generacji zerowej.
/* zatrzymanie po gen_max generacjach */ while (count < gen_max)
/* dla każdego wektora z populacji */ for (i = 0; i < NP; i++)
/* losowanie unikalnych osobników*/ /****Mutacja / Krzyżowanie****/ a = randi(NP); while (a == i) a = randi(NP); b = randi(NP); while (b == i || b == a) b = randi(NP); c = randi(NP); while (c == i || c == a || c == b) c=randi(NP);
/* wybierz losowo pierwszą cechę*/ j=randi(D);
/* utwórz nowy wektor trial(i) na podstawie wektora x1(i) i mutanta */ for (k = 1; k < D; k++)
/* warunek zapewnia, że przynajmniej jedna cecha */ /* zostanie wymieniona z wektorem zaburzonym */
if (rand() < CR || k == D) trial(i, k) = x1(a, k) + F * (x1(b, k) ‐ x1(c, k)); else trial(i, k) = x1(i, k); j = (j + 1) % D;
/* obliczanie wartości funkcji celu utworzonego wektora */ /**** Selekcja ****/ score = evaluate(trial);
/* porównanie kosztów obu i wybór do kolejnej */ /* generacji lepiej przystosowanego */
if (score <= cost(i)) cost(i) = score; else x2(i) = x1(i);
25
/*po każdej generacji następuje zamiana */ /*populacji testowej z bieżącą */
x1 = x2; count++;
3.2.5. Dobór parametrów
Sugeruje się aby liczbę generacji ustalić w przedziale 5 , … , 10 . W celu sprawdzenia czy możliwa jest szybka zbieżność 0,8. Jeśli nie jest możliwe jej osiągnięcie, stopniowo zmniejsza się tę wartość. Istnieją modyfikacje, które ustalają współczynnik krzyżowania indywidualnie dla każdego osobnika. Nowe wektory dziedziczą go później tak jak inne geny. Parametr F ustala się najczęściej na poziomie 0,5. Wielkość populacji NP uzależniona jest od zakresu cech. Dolna wartość ograniczona jest przez warunki mutacji.
3.2.6. Parametry domyślne
Zdecydowano, że parametry kontrolne optymalizacji domyślnie mają następujące wartości:
Parametr kontrolny Wartość / Zakres
Liczba generacji [gen_max] 10 Wielkość populacji [NP] 20 Parametr mutacji [F] 0.5 Współczynnik krzyżowania [CR] 0.3 Zakres optymalizowanych
hiperparametrów 1, 200 0, 100
Funkcja celu Precision Procentowo usunięte wektory nośne 0
Tab. 3.1. Parametry sterujące DE w procesie optymalizacji użyte w programie.

26
4. OCENA JAKOŚCI
Celem każdej klasyfikatora jest możliwość poprawnego wskazania klasy lub klas, do której należy badany obiekt. Decyzję podejmuje się na podstawie cechy lub grupy cech. Taki charakterystyczny element nazywany jest predykatorem (rys. 4.1).
Rys. 4.1. Proces decyzyjny. Na wykresie zaznaczono punkt przecięcia krzywych A i B ustalają
w ten sposób granicę klas.
Niezależnie od tego jaką metodą dokonywana jest klasyfikacja lub aproksymacja wymaga ona oceny. Metod pozwalających zbadać jakość to między innymi błąd średniokwadratowy, metoda walidacji krzyżowej (ang. cross-validation), metoda krzywych ROC. W prezentowanej pracy skupimy się właśnie na tej ostatniej.
4.1. MACIERZ KLASYFIKACJI
Często zdarza się, że jedna klasa jest ważniejsza od drugiej. Przykładowo eksperci z zakresu medycyny posługują się klasyfikatorami binarnymi stwierdzając, czy dany człowiek jest chory (patologia występuje lub nie). Popełnia się mniejszy błąd wskazując zdrowego człowieka jako chorego niż na odwrót. Przyjmując jako klasyfikator podział pacjentów otrzymujemy tablicę trafień taką jak tabela 4.2.

27
Tab. 4.2. Macierz klasyfikacji dla opisywanego przykładu
Prawidłowa interpretacja wraz z definicjami jest następująca: • TP (ang. True Positive) – liczba poprawnie sklasyfikowanych obiektów z pierwszej
klasy (pacjenci chorzy poprawnie rozpoznani jako przez system); • FN (ang. False True) – liczba błędnie sklasyfikowanych obiektów z pierwszej klasy
(pacjenci chorzy błędnie rozpoznani przez system jako zdrowi); • TN (ang. True Negative) – liczba poprawnie sklasyfikowanych obiektów z drugiej
klasy (pacjenci zdrowi poprawnie zakwalifikowani do grupy zdrowych); • FP (ang. False Positive) – liczba błędnie sklasyfikowanych obiektów z drugiej klasy
(pacjenci zdrowi błędnie zakwalifikowani do grupy chorych); 4.2. KRZYWE ROC
Krzywe ROC (ang. Receiver Operating Characteristic) stanowią graficzą reprezentację zmian wskaźnika czułości (ang. recall, sensivity, TP-rate) oraz specyficzności (ang. specifity) w zależności od przyjętej granicy decyzyjnej.
Czułość określa prawdopodobieństwo zakwalifikowania przykładów z klasy
pozytywnej do negatywnej. Posługując się przykładem – miara ta mówi jaki jest procent osób, które są chore i test wyszedł u nich poprawnie, w stosunku do wszystkich chorych.
Specyficzność określa prawdopodobieństwo, że osobę zdrową zakwalifikuje się jako
zdrową. Tworząc krzywą ROC na jednej z osi (najczęściej pionowej) odkładana jest wartość
sensivity a na drugiej 1 – specifity. Krzywa obrazuje w ten sposób stosunek wielkości TP do FP i szybko pozwala ocenić czy dany klasyfikator jest dobry.
Wysoka czułość (bliska wartości równej 1) oznacza, że system prawidłowo klasyfikuje obiekty z klasy wyróżnionej. Mała wartość 1 – specyficzność informuje, iż klasyfikator niewiele obiektów negatywnych zalicza do grupy pozytywnych. Nawiązując do wcześniejszego przykładu – niewielu pacjentów zdrowych zostaje uznanych za chorych.
28
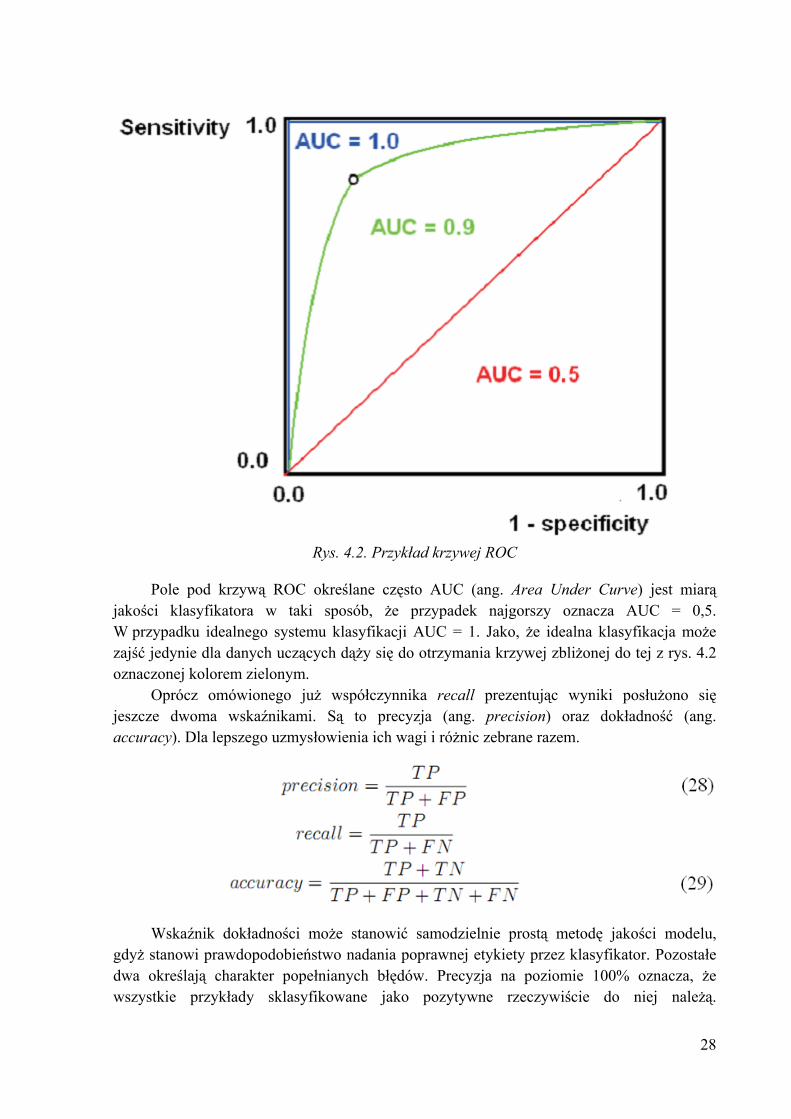
Rys. 4.2. Przykład krzywej ROC
Pole pod krzywą ROC określane często AUC (ang. Area Under Curve) jest miarą jakości klasyfikatora w taki sposób, że przypadek najgorszy oznacza AUC = 0,5. W przypadku idealnego systemu klasyfikacji AUC = 1. Jako, że idealna klasyfikacja może zajść jedynie dla danych uczących dąży się do otrzymania krzywej zbliżonej do tej z rys. 4.2 oznaczonej kolorem zielonym.
Oprócz omówionego już współczynnika recall prezentując wyniki posłużono się jeszcze dwoma wskaźnikami. Są to precyzja (ang. precision) oraz dokładność (ang. accuracy). Dla lepszego uzmysłowienia ich wagi i różnic zebrane razem.
Wskaźnik dokładności może stanowić samodzielnie prostą metodę jakości modelu, gdyż stanowi prawdopodobieństwo nadania poprawnej etykiety przez klasyfikator. Pozostałe dwa określają charakter popełnianych błędów. Precyzja na poziomie 100% oznacza, że wszystkie przykłady sklasyfikowane jako pozytywne rzeczywiście do niej należą.

29
Stuprocentowa czułość informuje, że wszystkie przykłady pozytywne ze zbioru zostały poprawnie oznaczone.
Ocena jakości z pomocą krzywych ROC stała się popularnym metodą porównywania metod klasyfikacji. Przyczyniły się do tego zalety takie jak:
• niezależność od jednostek próbek poddanych analizie, • prostota działania i szybkość oceny, • pozwala na ocena działania różnych klasyfikatorów, • opis całego zakresu klasyfikatora,
Jako wadę można podać brak większej ilości cech klasyfikatora takich jak np. złożoność modelu czy szerokość marginesów.

30
5. BADANIA
Przed prezentacją wyników badań warto zapoznać się ze strukturą i operacjami, na bazie
danych . Jak się okaże działania te mają znaczący wpływ na dalsze rezultaty. Wprowadzają
one również pewne ograniczenia sprawiające, że dalsza poprawa osiągnięć nie jest już
możliwa.
5.1. BAZA DANYCH
W Centrum Onkologii w Warszawie przygotowano zbiór 17-znakowych sekwencji
aminokwasów pogrupowanych według ich reakcji z wybranymi enzymami. Na rys. 5.1
zaprezentowano kilka sekwencji. Wiersze rozpoczynające się od „#” zawierają nazwy
enzymów. Warto zauważyć, że niektóre sekwencje należą do kilku klas.
Rys. 5.1. Sekwencje aminokwasów zakodowane symbolicznie.
Aby umożliwić klasyfikację z użyciem LS–SVM należało przejść z zapisu
symbolicznego na liczby rzeczywiste. Każdy znak zastąpiono, zgodnie z jego
odpowiadającym indeksem ze zbioru AAindex, z użyciem wybranych 193 nieskorelowanych
zmiennych (z 544 możliwych). Dało to sekwencje opisane za pomocą 3218 parametrów. Tak
duża liczba powoduje, że trudno spełnić założenia twierdzenia Covera. Większa część z nich
była nieistotna i należało je usunąć.
Drugi etap to zastosowanie procedur rankingowych i ortogonalizacji Grama – Schmidta.
Pozwoliło to na uszeregowanie parametrów według ich istotności a ich liczba spadła do
zaledwie 200. Z punktu widzenia klasyfikacji to nadal dużo, na szczęście z pomocą przyszły

31
procedury rankingowe. Ostatecznie pod uwagę bierze się od 3 do 17 parametrów, co
zaprezentowano w tabeli.
Nazwa klasy Liczba parametrów
PKA 16 PKB 5 PKC 12 CDK 3 MAPK 17
Tab. 5.1. Zestawienie enzymów i liczby atrybutów branych pod uwagę w procesie klasyfikacji.
5.1.1. Dane wejściowe
Każda klasa posiada swój własny plik z posegregowanymi zmiennymi rzeczywistymi. Nazwa
zbioru al_xxx_kkkkk.mat oznacza wszystkie sparametryzowane przykłady. Zmienne zapisane
są w kolejnych kolumnach macierzy według rankingu istotności. Oznaczenia literowe xxx–
nazwa klasy, kkkkk – identyfikator zbioru.
W każdym zbiorze znajduje się 1641 przykładów stanowiących wiersze macierzy.
Zauważono, że dodatkowo posortowano je klasami. Ostatnia kolumna zawiera identyfikatory
klas +1 oraz -1.
5.2. OPIS DZIAŁANIA
Program jako całość działa w oparciu o następujące powtarzalne punkty:
– Podział danych na zbiór trenujący i testujący. Po wczytaniu danych z plików
w sposób losowy (z użyciem procedu randi(…) ) dzieli się próbki na dwa zbiory. Jako
macierz do uczenia służy 60% wektorów. Pozostałe wykorzystane są w procedurze
testowania.
– Tworzenie klasyfikatora. Posłużono się toolboxem LSSVMLab do MATLABa
opracowanym na Uniwersytecie Katolickim Leuven w Belgii. Użyto dwóch funkcji:
trenującej maszynę trainlssvm(…) oraz symulującej jej działanie simlssvm(…). Wartości
domyślne zasugerował raport wewnętrzny.
– Ocena jakości klasyfikacji. Do przedstawienia wyników wykorzystano krzywe ROC
oraz określane przy ich powstawaniu współczynniki. Z powodu losowej generacji zbiorów
aby wyniki były bardziej miarodajne uśredniono je. Przy okazji obliczając odchylenie
standardowe.

32
– Rozrzedzanie. Jest to próba zmniejszenia wielkości modelu. Ustalając procentowo ile
wektorów nośnych ma pozostać. Stanowi ona element opcjonalny przed optymalizacją.
Przyjmując wartość 100% model nie będzie rozrzedzany.
– Optymalizacja. Ta część realizowana jest przy udziale ewolucji różnicowej.
Implementacja opiera się na pseudokodzie prezentowanym w punkcie 3.2.4. Parametrami
optymalizowanymi są współczynnik regularyzacji i szerokość funkcji Gaussa . Funkcją
celu jest precyzja.
Oparcie się w dużej mierze na skryptach zamiast na funkcjach sprawia, że schemat
blokowy w każdej chwili może zmienić swój wygląd. Próba stworzenia takiego schematu
została zaprezentowana w rozdziale 7. Przykład działania prezentuje rys. 5.3.
Test result of PKA:
============================
gamma: 130.00 sigma: 10.00 RBF kernel
TP: 58.00
TN: 496.00
FP: 33.00
FN: 69.00
Precision: 63.74%
Recall: 45.67%
Score: 84.45%
Rys. 5.3. Przykład wydruku po skończonej pracy programu dla klasy PKA przy domyślnych
wartościach hiperparametrów.
5.3. PROCEDURA BADAWCZA
Zaprezentowane w następnym podrozdziale wyniki otrzymano uśredniając 20 pomiarów dla
każdej z klas. Jeden pomiar obejmował wylosowanie zbiorów, stworzenie klasyfikatora dla
wartości domyślnych oraz ocenę jego jakości. Wartości domyślne pozwalają na porównanie
z raportem wewnętrznym [4]. Następnie takie zestawy poddano optymalizacji parametrycznej
z użyciem DE i powtórnie oceniono ich jakość.
Określono dla każdego enzymu wymiar problemu oraz liczbę próbek klasy +1. Dla
przypomnienia 985 sekwencji posłużyło do uczenia, kolejne 656 do testowania. Wyniki
pogrupowane są w tabele z podziałem na otrzymane przy wartościach domyślnych i po
optymalizacji.
33
5.4. WYNIKI KLASYFIKACJI DLA PEŁNYCH ZBIORÓW DANYCH
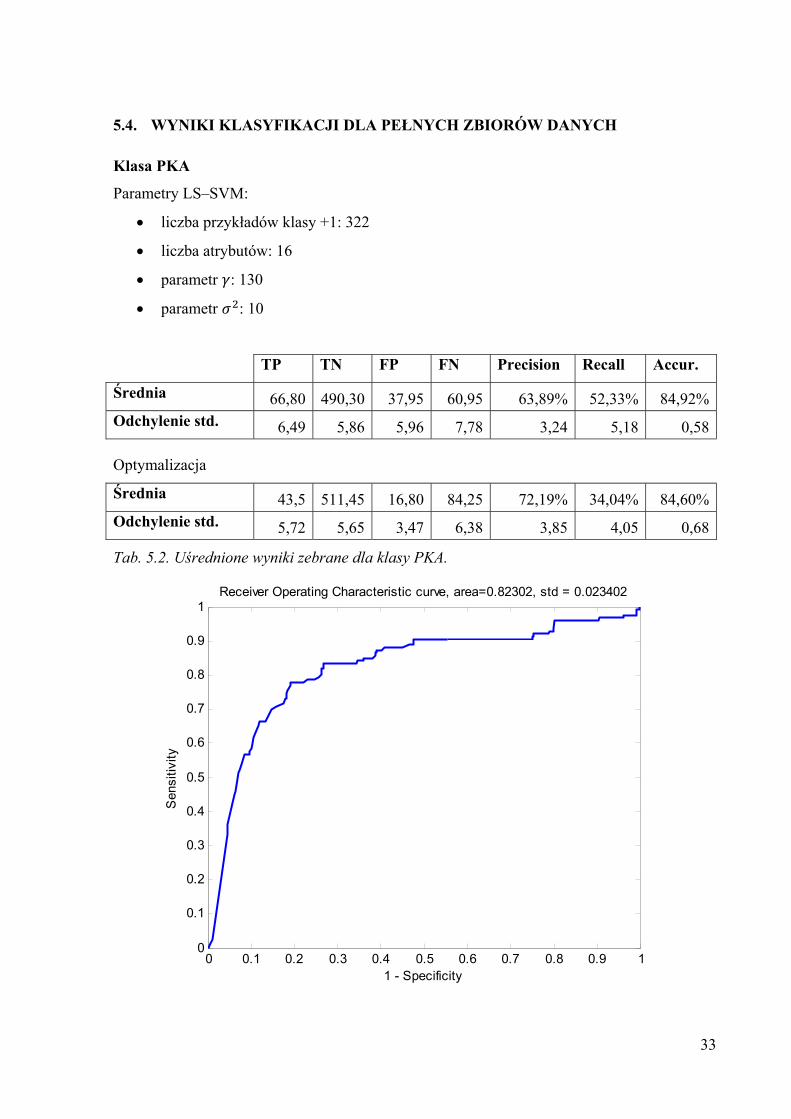
Klasa PKA
Parametry LS–SVM:
• liczba przykładów klasy +1: 322
• liczba atrybutów: 16
• parametr : 130
• parametr : 10
TP TN FP FN Precision Recall Accur.
Średnia 66,80 490,30 37,95 60,95 63,89% 52,33% 84,92%Odchylenie std. 6,49 5,86 5,96 7,78 3,24 5,18 0,58
Optymalizacja Średnia 43,5 511,45 16,80 84,25 72,19% 34,04% 84,60%Odchylenie std. 5,72 5,65 3,47 6,38 3,85 4,05 0,68
Tab. 5.2. Uśrednione wyniki zebrane dla klasy PKA.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.82302, std = 0.023402
1 - Specificity
Sen
sitiv
ity
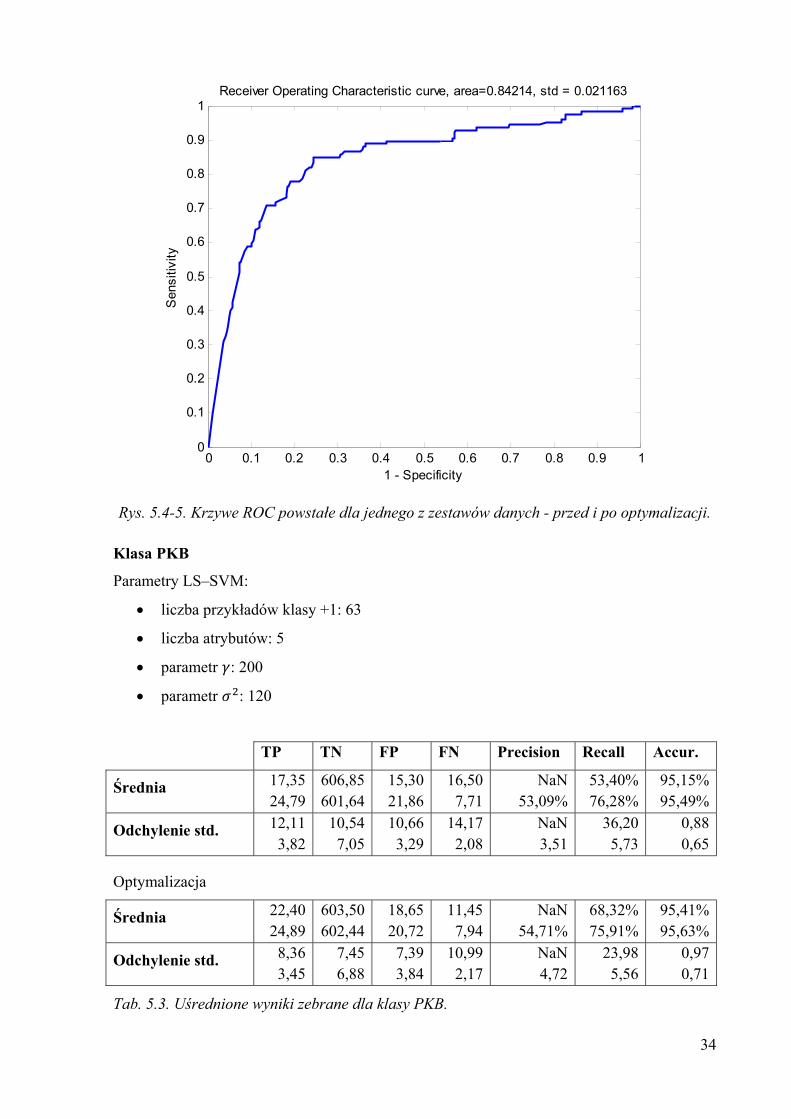
34
Rys. 5.4-5. Krzywe ROC powstałe dla jednego z zestawów danych - przed i po optymalizacji.
Klasa PKB
Parametry LS–SVM:
• liczba przykładów klasy +1: 63
• liczba atrybutów: 5
• parametr : 200
• parametr : 120
TP TN FP FN Precision Recall Accur.
Średnia 17,35 24,79
606,85601,64
15,3021,86
16,507,71
NaN 53,09%
53,40% 76,28%
95,15%95,49%
Odchylenie std. 12,11 3,82
10,547,05
10,663,29
14,172,08
NaN 3,51
36,20 5,73
0,880,65
Optymalizacja
Średnia 22,40 24,89
603,50602,44
18,6520,72
11,457,94
NaN 54,71%
68,32% 75,91%
95,41%95,63%
Odchylenie std. 8,36 3,45
7,456,88
7,393,84
10,992,17
NaN 4,72
23,98 5,56
0,970,71
Tab. 5.3. Uśrednione wyniki zebrane dla klasy PKB.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.84214, std = 0.021163
1 - Specificity
Sen
sitiv
ity
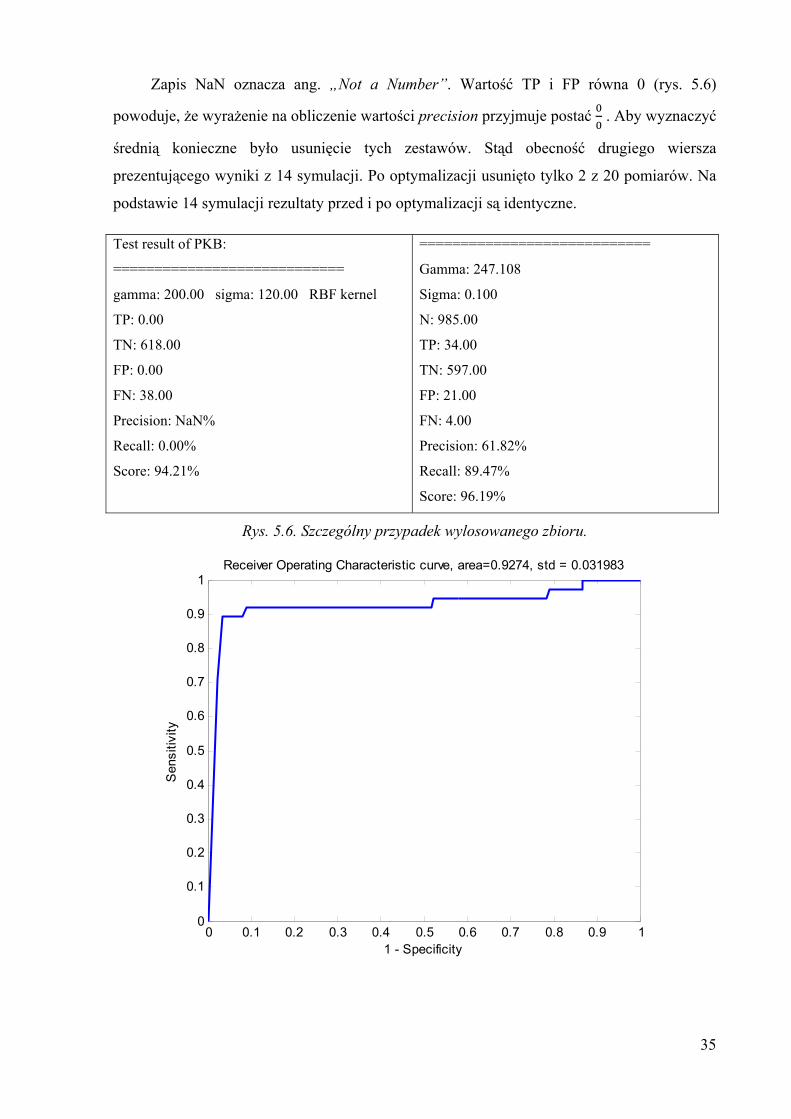
35
Zapis NaN oznacza ang. „Not a Number”. Wartość TP i FP równa 0 (rys. 5.6)
powoduje, że wyrażenie na obliczenie wartości precision przyjmuje postać . Aby wyznaczyć
średnią konieczne było usunięcie tych zestawów. Stąd obecność drugiego wiersza
prezentującego wyniki z 14 symulacji. Po optymalizacji usunięto tylko 2 z 20 pomiarów. Na
podstawie 14 symulacji rezultaty przed i po optymalizacji są identyczne.
Test result of PKB:
============================
gamma: 200.00 sigma: 120.00 RBF kernel
TP: 0.00
TN: 618.00
FP: 0.00
FN: 38.00
Precision: NaN%
Recall: 0.00%
Score: 94.21%
============================
Gamma: 247.108
Sigma: 0.100
N: 985.00
TP: 34.00
TN: 597.00
FP: 21.00
FN: 4.00
Precision: 61.82%
Recall: 89.47%
Score: 96.19%
Rys. 5.6. Szczególny przypadek wylosowanego zbioru.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.9274, std = 0.031983
1 - Specificity
Sen
sitiv
ity
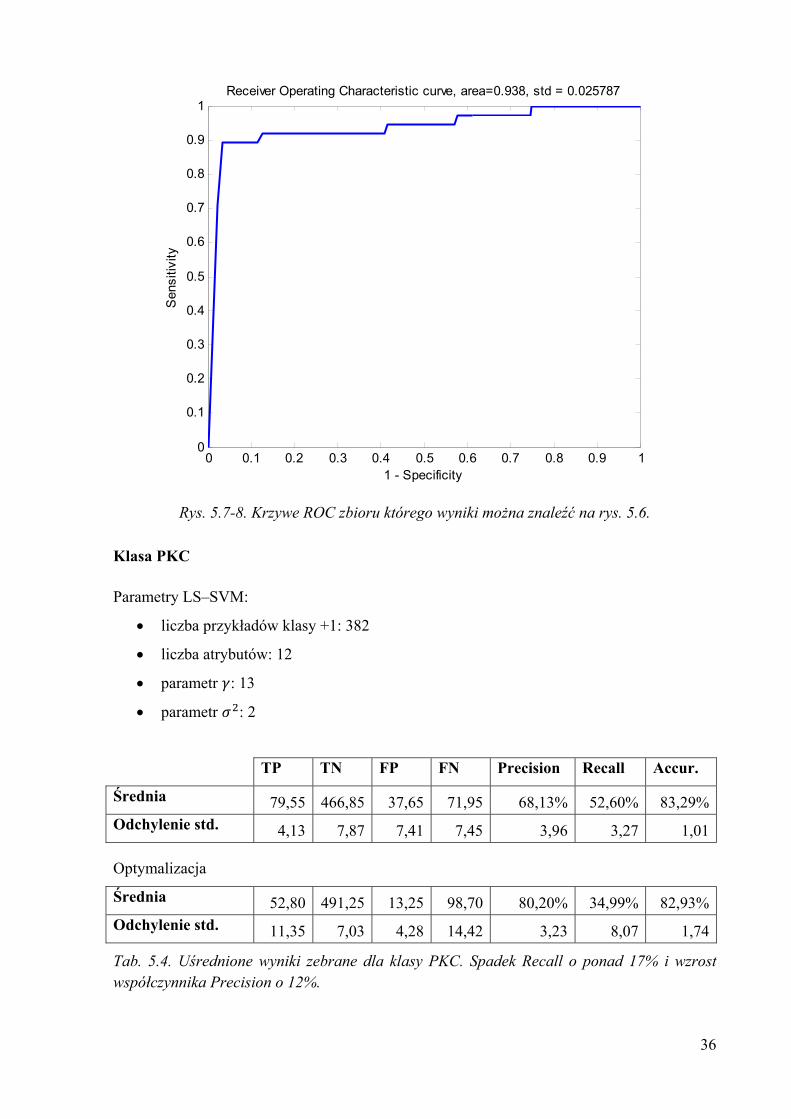
36
Rys. 5.7-8. Krzywe ROC zbioru którego wyniki można znaleźć na rys. 5.6.
Klasa PKC
Parametry LS–SVM:
• liczba przykładów klasy +1: 382
• liczba atrybutów: 12
• parametr : 13
• parametr : 2
TP TN FP FN Precision Recall Accur.
Średnia 79,55 466,85 37,65 71,95 68,13% 52,60% 83,29%Odchylenie std. 4,13 7,87 7,41 7,45 3,96 3,27 1,01
Optymalizacja Średnia 52,80 491,25 13,25 98,70 80,20% 34,99% 82,93%Odchylenie std. 11,35 7,03 4,28 14,42 3,23 8,07 1,74
Tab. 5.4. Uśrednione wyniki zebrane dla klasy PKC. Spadek Recall o ponad 17% i wzrost współczynnika Precision o 12%.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.938, std = 0.025787
1 - Specificity
Sen
sitiv
ity
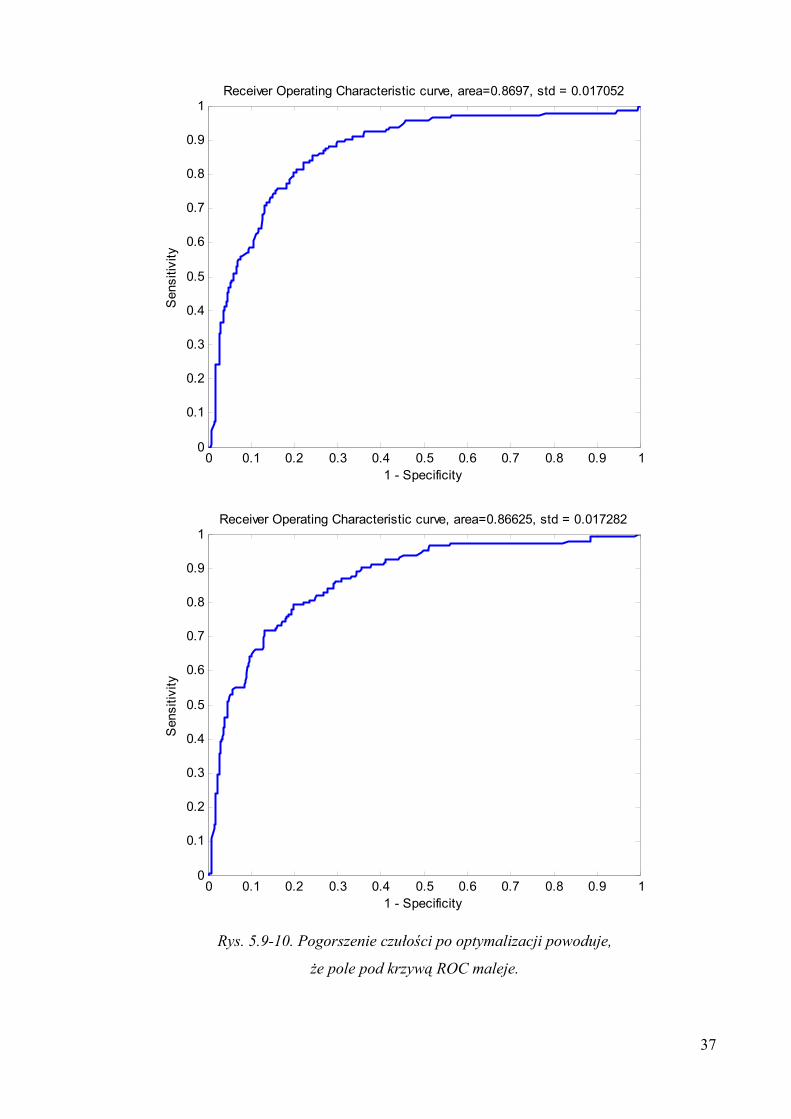
37
Rys. 5.9-10. Pogorszenie czułości po optymalizacji powoduje,
że pole pod krzywą ROC maleje.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.8697, std = 0.017052
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.86625, std = 0.017282
1 - Specificity
Sen
sitiv
ity

38
Klasa CDK
Parametry LS–SVM:
• liczba przykładów klasy +1: 325
• liczba atrybutów: 3
• parametr : 1,3
• parametr : 1
TP TN FP FN Precision Recall Accur.
Średnia 125,37 417,00 109,63 4,00 53,36% 96,91% 82,68%Odchylenie std. 7,18 9,50 7,29 1,65 2,37 1,26 1,16
Optymalizacja Średnia 125,37 417,00 109,63 4,00 53,36% 96,91% 82,68%Odchylenie std. 7,18 9,50 7,29 1,65 2,37 1,26 1,16
Tab. 5.5. Uśrednione wyniki zebrane dla klasy CDK z 19 zbiorów. Brak poprawy sugeruje problem z danymi.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.86914, std = 0.014943
1 - Specificity
Sen
sitiv
ity

39
Rys. 5.11-12. Kształt podobnie jak wskaźniki jakości klasyfikacji nie uległy zmianie.
Klasa MAPK
Parametry LS–SVM:
• liczba przykładów klasy +1: 249
• liczba atrybutów: 17
• parametr : 1300
• parametr : 100
TP TN FP FN Precision Recall Accur.
Średnia 37,70 529,05 27,95 61,30 57,43% 38,12% 86,39%Odchylenie std. 4,28 7,51 3,64 6,32 4,06 3,42 0,94
Optymalizacja Średnia 37,65 529,70 27,30 61,35 57,95% 38,08% 86,49%Odchylenie std. 4,33 7,21 3,45 6,54 4,14 3,60 0,95
Tab. 5.6. Uśrednione wyniki klasy MAPK.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.88713, std = 0.013498
1 - Specificity
Sen
sitiv
ity

40
Rys. 5.13-14. Para krzywych ROC dla klasy MAPK. Łatwo zauważyć zmianę krzywej w
górnej części wykresu.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.8846, std = 0.016678
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.89001, std = 0.01577
1 - Specificity
Sen
sitiv
ity
41
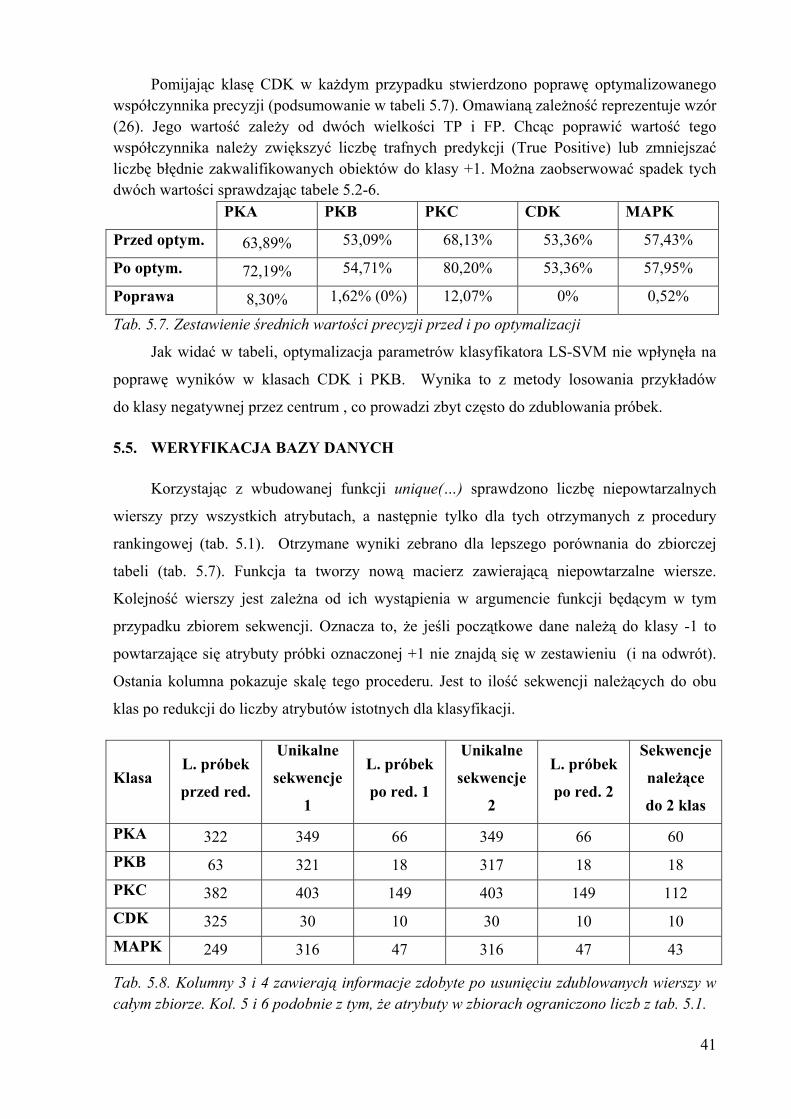
Pomijając klasę CDK w każdym przypadku stwierdzono poprawę optymalizowanego współczynnika precyzji (podsumowanie w tabeli 5.7). Omawianą zależność reprezentuje wzór (26). Jego wartość zależy od dwóch wielkości TP i FP. Chcąc poprawić wartość tego współczynnika należy zwiększyć liczbę trafnych predykcji (True Positive) lub zmniejszać liczbę błędnie zakwalifikowanych obiektów do klasy +1. Można zaobserwować spadek tych dwóch wartości sprawdzając tabele 5.2-6. PKA PKB PKC CDK MAPK
Przed optym. 63,89% 53,09% 68,13% 53,36% 57,43%
Po optym. 72,19% 54,71% 80,20% 53,36% 57,95%
Poprawa 8,30% 1,62% (0%) 12,07% 0% 0,52%
Tab. 5.7. Zestawienie średnich wartości precyzji przed i po optymalizacji
Jak widać w tabeli, optymalizacja parametrów klasyfikatora LS-SVM nie wpłynęła na
poprawę wyników w klasach CDK i PKB. Wynika to z metody losowania przykładów
do klasy negatywnej przez centrum , co prowadzi zbyt często do zdublowania próbek.
5.5. WERYFIKACJA BAZY DANYCH
Korzystając z wbudowanej funkcji unique(…) sprawdzono liczbę niepowtarzalnych
wierszy przy wszystkich atrybutach, a następnie tylko dla tych otrzymanych z procedury
rankingowej (tab. 5.1). Otrzymane wyniki zebrano dla lepszego porównania do zbiorczej
tabeli (tab. 5.7). Funkcja ta tworzy nową macierz zawierającą niepowtarzalne wiersze.
Kolejność wierszy jest zależna od ich wystąpienia w argumencie funkcji będącym w tym
przypadku zbiorem sekwencji. Oznacza to, że jeśli początkowe dane należą do klasy -1 to
powtarzające się atrybuty próbki oznaczonej +1 nie znajdą się w zestawieniu (i na odwrót).
Ostania kolumna pokazuje skalę tego procederu. Jest to ilość sekwencji należących do obu
klas po redukcji do liczby atrybutów istotnych dla klasyfikacji.
Klasa L. próbek
przed red.
Unikalne
sekwencje
1
L. próbek
po red. 1
Unikalne
sekwencje
2
L. próbek
po red. 2
Sekwencje
należące
do 2 klas
PKA 322 349 66 349 66 60 PKB 63 321 18 317 18 18 PKC 382 403 149 403 149 112 CDK 325 30 10 30 10 10 MAPK 249 316 47 316 47 43
Tab. 5.8. Kolumny 3 i 4 zawierają informacje zdobyte po usunięciu zdublowanych wierszy w całym zbiorze. Kol. 5 i 6 podobnie z tym, że atrybuty w zbiorach ograniczono liczb z tab. 5.1.
42
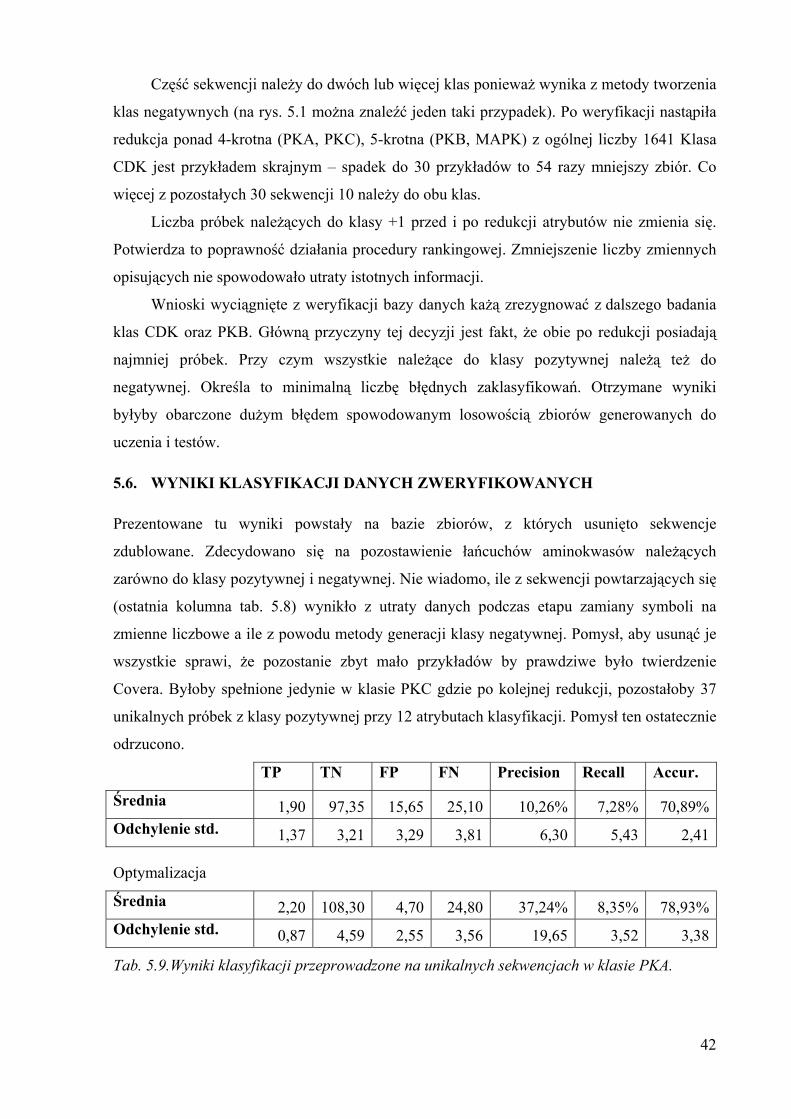
Część sekwencji należy do dwóch lub więcej klas ponieważ wynika z metody tworzenia
klas negatywnych (na rys. 5.1 można znaleźć jeden taki przypadek). Po weryfikacji nastąpiła
redukcja ponad 4-krotna (PKA, PKC), 5-krotna (PKB, MAPK) z ogólnej liczby 1641 Klasa
CDK jest przykładem skrajnym – spadek do 30 przykładów to 54 razy mniejszy zbiór. Co
więcej z pozostałych 30 sekwencji 10 należy do obu klas.
Liczba próbek należących do klasy +1 przed i po redukcji atrybutów nie zmienia się.
Potwierdza to poprawność działania procedury rankingowej. Zmniejszenie liczby zmiennych
opisujących nie spowodowało utraty istotnych informacji.
Wnioski wyciągnięte z weryfikacji bazy danych każą zrezygnować z dalszego badania
klas CDK oraz PKB. Główną przyczyny tej decyzji jest fakt, że obie po redukcji posiadają
najmniej próbek. Przy czym wszystkie należące do klasy pozytywnej należą też do
negatywnej. Określa to minimalną liczbę błędnych zaklasyfikowań. Otrzymane wyniki
byłyby obarczone dużym błędem spowodowanym losowością zbiorów generowanych do
uczenia i testów.
5.6. WYNIKI KLASYFIKACJI DANYCH ZWERYFIKOWANYCH
Prezentowane tu wyniki powstały na bazie zbiorów, z których usunięto sekwencje
zdublowane. Zdecydowano się na pozostawienie łańcuchów aminokwasów należących
zarówno do klasy pozytywnej i negatywnej. Nie wiadomo, ile z sekwencji powtarzających się
(ostatnia kolumna tab. 5.8) wynikło z utraty danych podczas etapu zamiany symboli na
zmienne liczbowe a ile z powodu metody generacji klasy negatywnej. Pomysł, aby usunąć je
wszystkie sprawi, że pozostanie zbyt mało przykładów by prawdziwe było twierdzenie
Covera. Byłoby spełnione jedynie w klasie PKC gdzie po kolejnej redukcji, pozostałoby 37
unikalnych próbek z klasy pozytywnej przy 12 atrybutach klasyfikacji. Pomysł ten ostatecznie
odrzucono.
TP TN FP FN Precision Recall Accur.
Średnia 1,90 97,35 15,65 25,10 10,26% 7,28% 70,89%Odchylenie std. 1,37 3,21 3,29 3,81 6,30 5,43 2,41
Optymalizacja Średnia 2,20 108,30 4,70 24,80 37,24% 8,35% 78,93%Odchylenie std. 0,87 4,59 2,55 3,56 19,65 3,52 3,38
Tab. 5.9.Wyniki klasyfikacji przeprowadzone na unikalnych sekwencjach w klasie PKA.
43
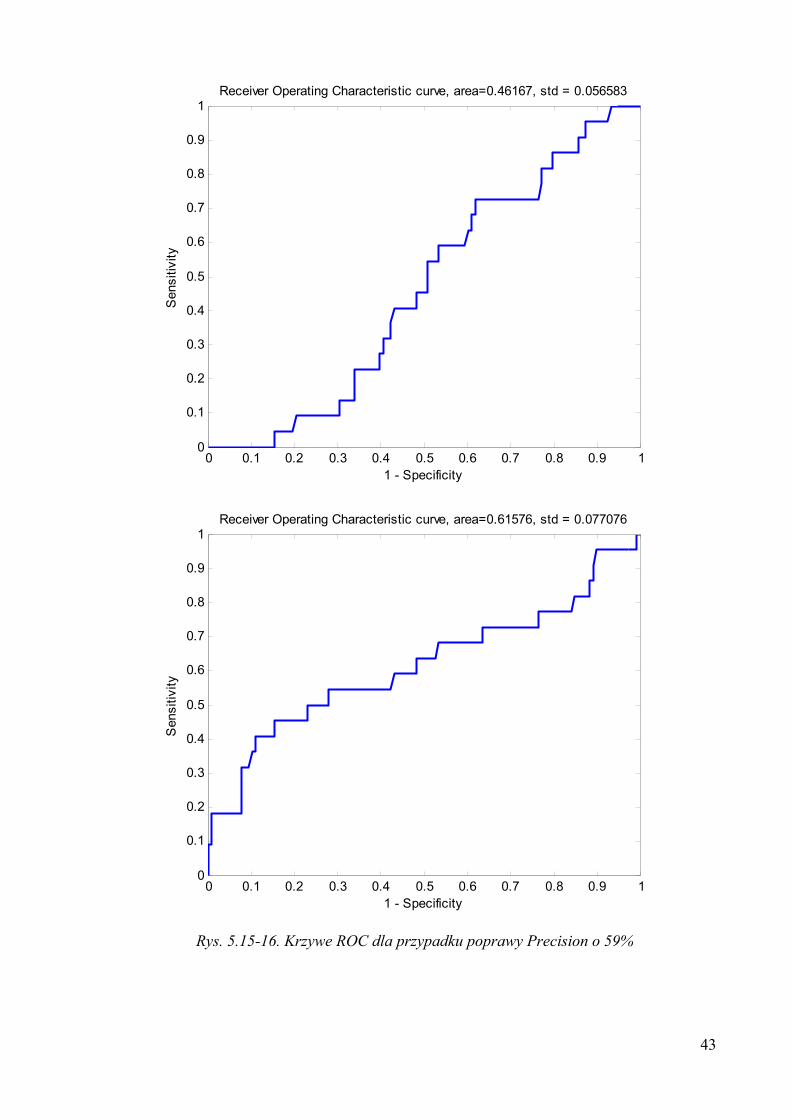
Rys. 5.15-16. Krzywe ROC dla przypadku poprawy Precision o 59%
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.46167, std = 0.056583
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.61576, std = 0.077076
1 - Specificity
Sen
sitiv
ity

44
TP TN FP FN Precision Recall Accur.
Średnia 12,50 59,20 43,20 46,10 22,23% 21,52% 44,53%Odchylenie std. 3,54 4,82 5,30 6,05 4,85 6,44 3,32
Optymalizacja Średnia 7,05 94,20 8,20 51,55 57,84% 12,33% 62,89%Odchylenie std. 4,68 8,74 9,55 7,53 16,83 8,72 3,46
Tab. 5.10. Wyniki klasyfikacji przeprowadzone na unikalnych sekwencjach w klasie PKC.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.42564, std = 0.045145
1 - Specificity
Sen
sitiv
ity
45
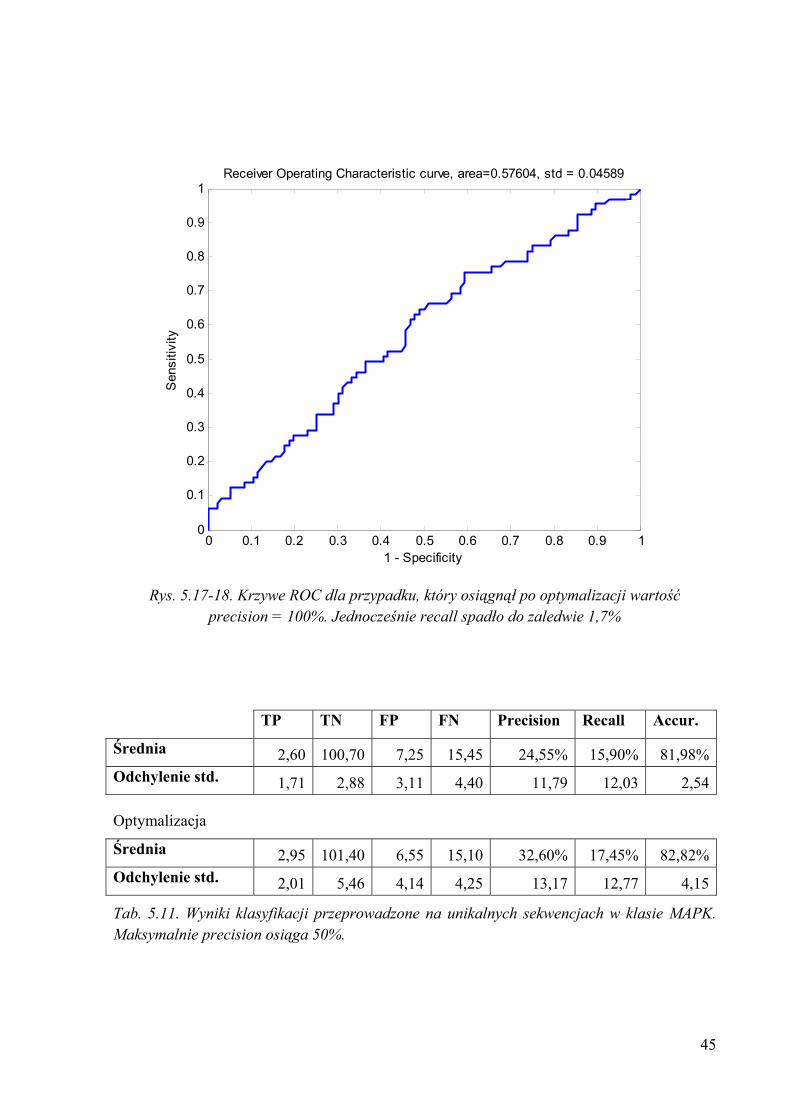
Rys. 5.17-18. Krzywe ROC dla przypadku, który osiągnął po optymalizacji wartość
precision = 100%. Jednocześnie recall spadło do zaledwie 1,7%
TP TN FP FN Precision Recall Accur.
Średnia 2,60 100,70 7,25 15,45 24,55% 15,90% 81,98%Odchylenie std. 1,71 2,88 3,11 4,40 11,79 12,03 2,54
Optymalizacja Średnia 2,95 101,40 6,55 15,10 32,60% 17,45% 82,82%Odchylenie std. 2,01 5,46 4,14 4,25 13,17 12,77 4,15
Tab. 5.11. Wyniki klasyfikacji przeprowadzone na unikalnych sekwencjach w klasie MAPK. Maksymalnie precision osiąga 50%.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.57604, std = 0.04589
1 - Specificity
Sen
sitiv
ity
46
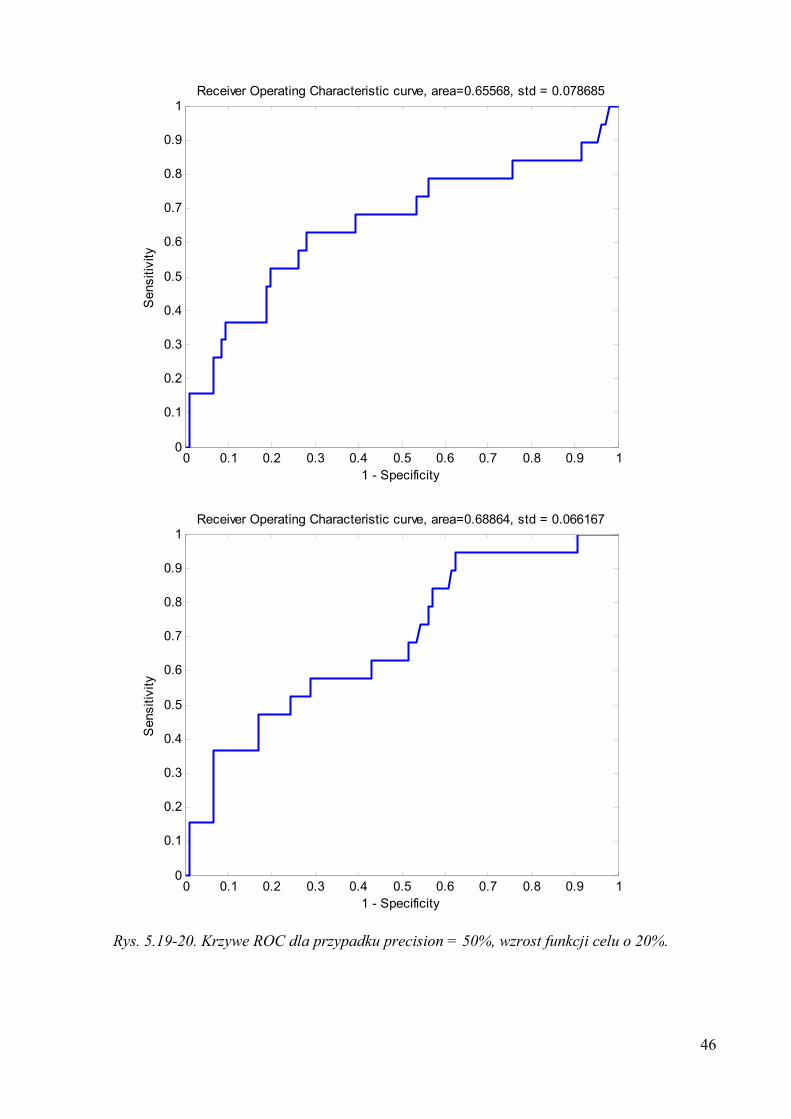
Rys. 5.19-20. Krzywe ROC dla przypadku precision = 50%, wzrost funkcji celu o 20%.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.65568, std = 0.078685
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.68864, std = 0.066167
1 - Specificity
Sen
sitiv
ity
47
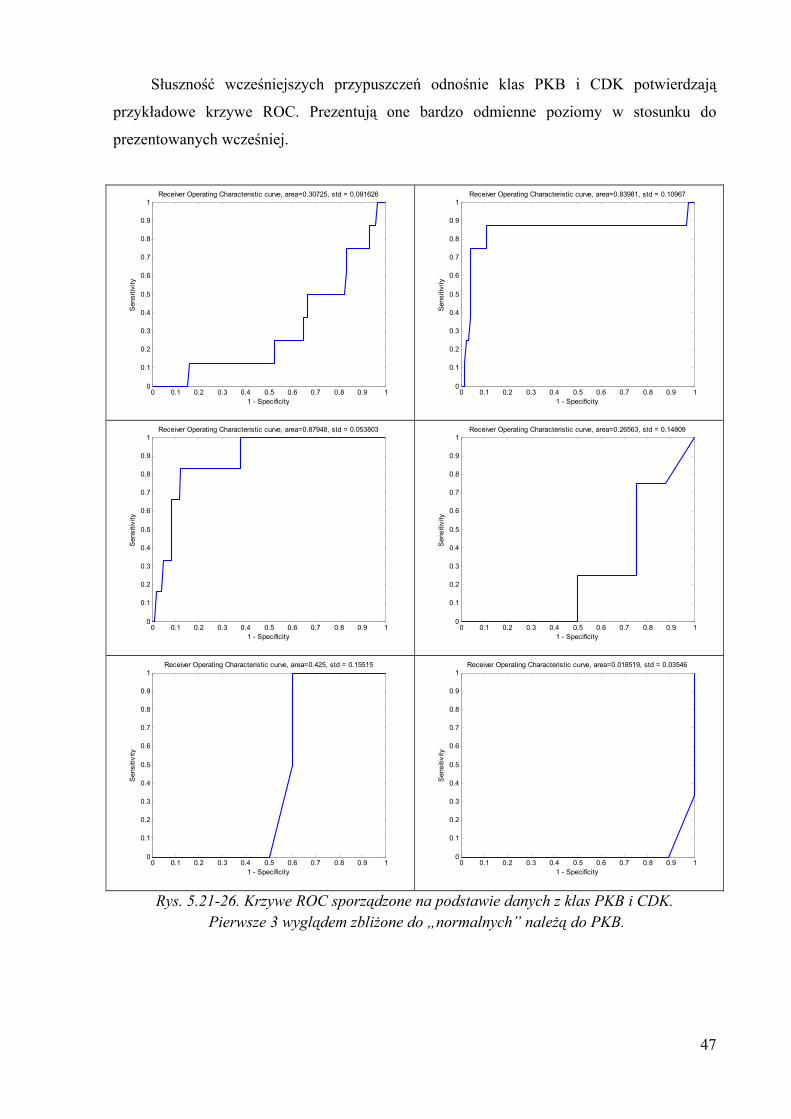
Słuszność wcześniejszych przypuszczeń odnośnie klas PKB i CDK potwierdzają
przykładowe krzywe ROC. Prezentują one bardzo odmienne poziomy w stosunku do
prezentowanych wcześniej.
Rys. 5.21-26. Krzywe ROC sporządzone na podstawie danych z klas PKB i CDK. Pierwsze 3 wyglądem zbliżone do „normalnych” należą do PKB.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.30725, std = 0.091626
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.83981, std = 0.10967
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.87948, std = 0.053803
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.26563, std = 0.14809
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.425, std = 0.15515
1 - Specificity
Sen
sitiv
ity
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Receiver Operating Characteristic curve, area=0.018519, std = 0.03546
1 - Specificity
Sen
sitiv
ity
48
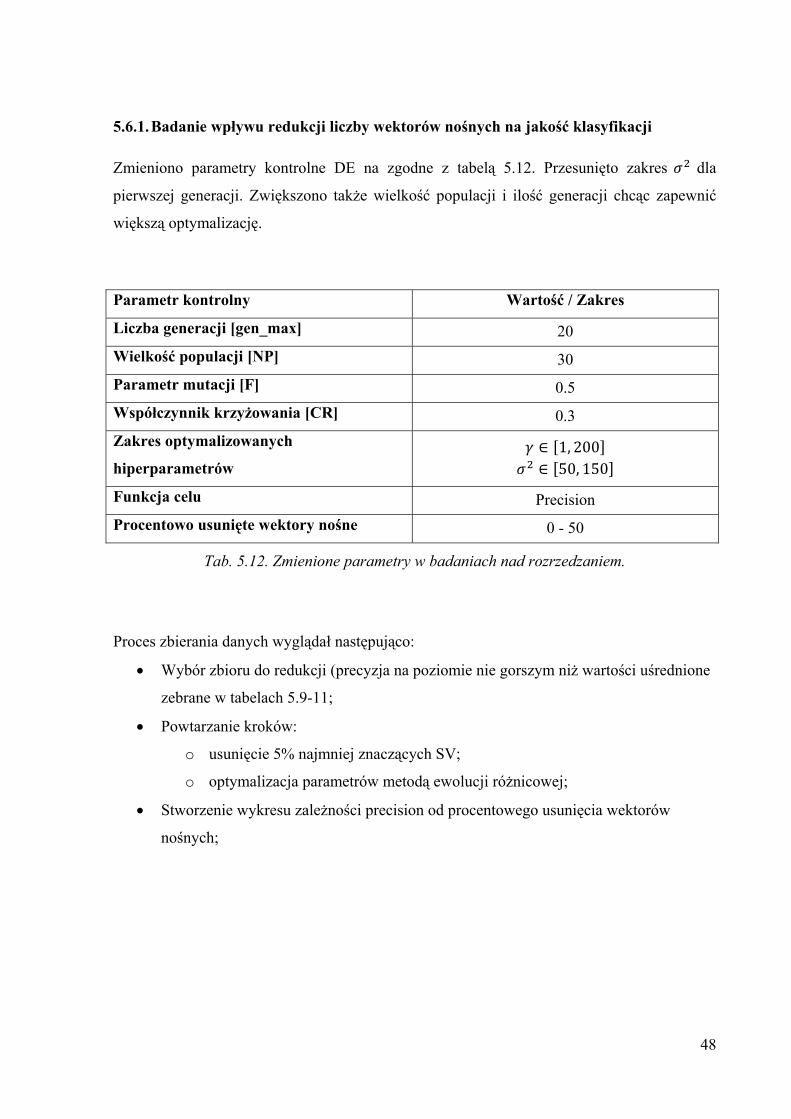
5.6.1. Badanie wpływu redukcji liczby wektorów nośnych na jakość klasyfikacji
Zmieniono parametry kontrolne DE na zgodne z tabelą 5.12. Przesunięto zakres dla
pierwszej generacji. Zwiększono także wielkość populacji i ilość generacji chcąc zapewnić
większą optymalizację.
Parametr kontrolny Wartość / Zakres
Liczba generacji [gen_max] 20 Wielkość populacji [NP] 30 Parametr mutacji [F] 0.5 Współczynnik krzyżowania [CR] 0.3 Zakres optymalizowanych
hiperparametrów 1, 200 50, 150
Funkcja celu Precision Procentowo usunięte wektory nośne 0 - 50
Tab. 5.12. Zmienione parametry w badaniach nad rozrzedzaniem.
Proces zbierania danych wyglądał następująco:
• Wybór zbioru do redukcji (precyzja na poziomie nie gorszym niż wartości uśrednione
zebrane w tabelach 5.9-11;
• Powtarzanie kroków:
o usunięcie 5% najmniej znaczących SV;
o optymalizacja parametrów metodą ewolucji różnicowej;
• Stworzenie wykresu zależności precision od procentowego usunięcia wektorów
nośnych;
49
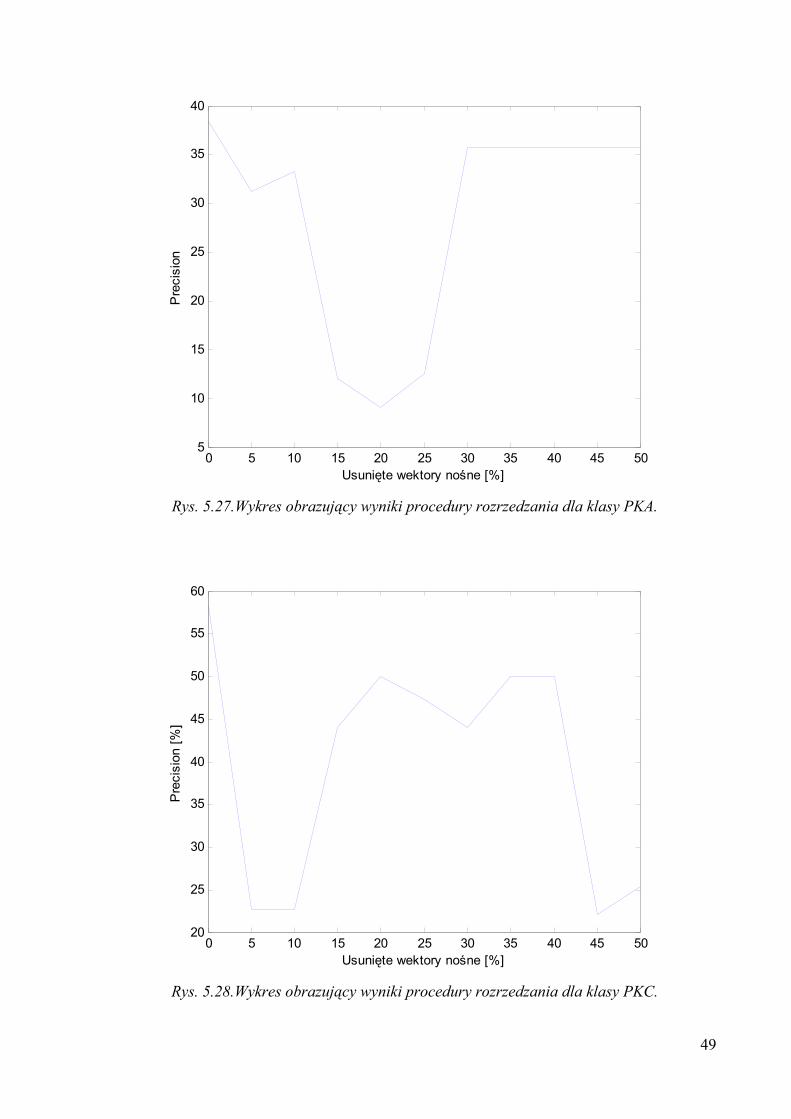
Rys. 5.27.Wykres obrazujący wyniki procedury rozrzedzania dla klasy PKA.
Rys. 5.28.Wykres obrazujący wyniki procedury rozrzedzania dla klasy PKC.
0 5 10 15 20 25 30 35 40 45 505
10
15
20
25
30
35
40
Usunięte wektory nośne [%]
Pre
cisi
on
0 5 10 15 20 25 30 35 40 45 5020
25
30
35
40
45
50
55
60
Usunięte wektory nośne [%]
Pre
cisi
on [%
]

50
Rys. 5.27.Wykres obrazujący wyniki procedury rozrzedzania dla klasy MAPK.
Zmniejszenie złożoności modelu poprzez usunięcie najmniej istotnych wektorów
nośnych pomimo początkowego spadku wzrasta i utrzymuje się na pewnym poziomie. Daje
to możliwość zmiany złożoności modelu bez dramatycznego pogorszenia jakości klasyfikacji.
Wielkość modelu PKA PKC MAPK
Początkowa 209 242 190
W obszarze wypłaszczenia
146 - 105 157 - 145 152 - 124
Minimalna precyzja 9,09% 22,03% 11,1%
Tab. 5.13. Podsumowanie rozrzedzonych modeli.
0 5 10 15 20 25 30 35 40 45 5010
15
20
25
30
35
40
Pre
cisi
on [%
]
Usunięte wektory nośne [%]
51
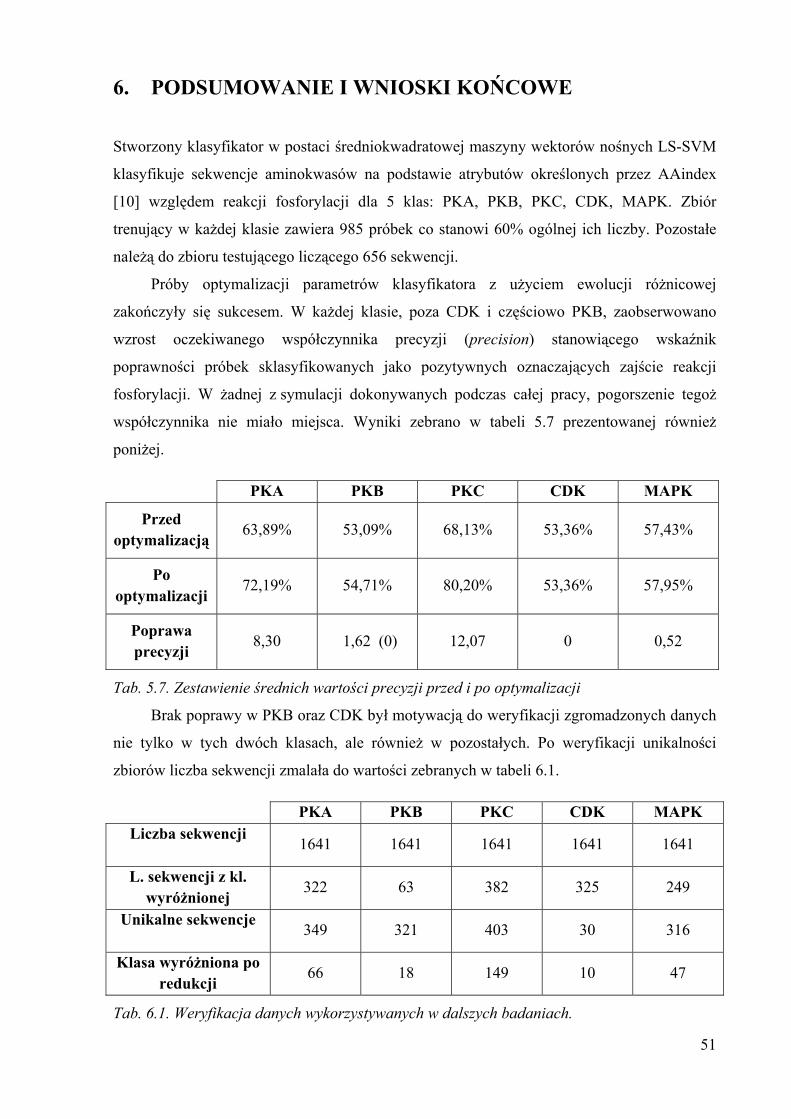
6. PODSUMOWANIE I WNIOSKI KOŃCOWE
Stworzony klasyfikator w postaci średniokwadratowej maszyny wektorów nośnych LS-SVM
klasyfikuje sekwencje aminokwasów na podstawie atrybutów określonych przez AAindex
[10] względem reakcji fosforylacji dla 5 klas: PKA, PKB, PKC, CDK, MAPK. Zbiór
trenujący w każdej klasie zawiera 985 próbek co stanowi 60% ogólnej ich liczby. Pozostałe
należą do zbioru testującego liczącego 656 sekwencji.
Próby optymalizacji parametrów klasyfikatora z użyciem ewolucji różnicowej
zakończyły się sukcesem. W każdej klasie, poza CDK i częściowo PKB, zaobserwowano
wzrost oczekiwanego współczynnika precyzji (precision) stanowiącego wskaźnik
poprawności próbek sklasyfikowanych jako pozytywnych oznaczających zajście reakcji
fosforylacji. W żadnej z symulacji dokonywanych podczas całej pracy, pogorszenie tegoż
współczynnika nie miało miejsca. Wyniki zebrano w tabeli 5.7 prezentowanej również
poniżej.
PKA PKB PKC CDK MAPK
Przed optymalizacją
63,89% 53,09% 68,13% 53,36% 57,43%
Po optymalizacji
72,19% 54,71% 80,20% 53,36% 57,95%
Poprawa precyzji
8,30 1,62 (0) 12,07 0 0,52
Tab. 5.7. Zestawienie średnich wartości precyzji przed i po optymalizacji
Brak poprawy w PKB oraz CDK był motywacją do weryfikacji zgromadzonych danych
nie tylko w tych dwóch klasach, ale również w pozostałych. Po weryfikacji unikalności
zbiorów liczba sekwencji zmalała do wartości zebranych w tabeli 6.1.
PKA PKB PKC CDK MAPK Liczba sekwencji 1641 1641 1641 1641 1641
L. sekwencji z kl. wyróżnionej
322 63 382 325 249
Unikalne sekwencje 349 321 403 30 316
Klasa wyróżniona po redukcji
66 18 149 10 47
Tab. 6.1. Weryfikacja danych wykorzystywanych w dalszych badaniach.

52
Liczba sekwencji aminokwasów w klasie CDK zmalała ponad 54 razy. W pozostałych
przypadkach spadek jest ponad 4-ro lub 5-cio krotny w porównaniu do początkowej liczby
1641. Uwzględniając problem łańcuchów aminokwasów należących zarówno do klasy
pozytywnej oraz negatywnej (szerzej omówiony w punkcie 5.5.1) zdecydowano o skupieniu
się na zbiorach PKA, PKC oraz MAPK.
Analogicznie do wcześniejszego etapu dokonano optymalizacji parametrów na 20
losowo generowanych zbiorach testowych.
PKA PKC MAPK Precyzja TP+TN Precyzja TP+TN Precyzja TP+TN
Przed optymalizacją
10,26% 99,25 22,23% 71,70 24,55% 103,30
Po optymalizacji
37,24% 110,50 57,84% 101,25 32,60% 104,35
Poprawa wielkości
26,98 11,25 35,61 29,55 8,06 1,05
Tab. 6.2. Zestawienie średnich wartości przed i po optymalizacji. TP+TN oznacza liczbę trafnych predykcji.
Zebrane dane pozwoliły wybór bardziej optymalnych hiperparametrów niż wartości
domyślne. Proponowane wielkości stanowią wartość średnią z 20 symulacji. Zestawienie
zawiera również średnią precyzję i różnicę między wielkościami otrzymanymi przy
domyślnych parametrach a tymi z tabeli.
Precyzja Różnica PKA 77,06 101,82 21,40% 10,27 PKC 35,61 118,17 75,41% 6,27 MAPK 76,37 77,25 55,73% 0,23 Tab. 6.3 Wyniki ukazują różnicę wpływy parametrów na klasyfikację
W celu osiągnięcia dalszej poprawy wyników należy stworzyć bardziej unikalne zbiory
z większą ilością unikalnych sekwencji oraz liczbą próbek należących do klasy wyróżnionej.
Proponuje się także modyfikację procedury optymalizacji. Zamiast jednej funkcji celu,
w niniejszej pracy była to precyzja, warto zastosować też drugą w postaci minimalizacji
liczby wektorów nośnych.

53
7. OPIS PROGRAMU
Prowadzone badania wymagały zdobywania wielu różnych informacji czy to własności
modelu, bazy danych, trafności klasyfikacji czy też wszystkich naraz. Zdecydowało to o tym,
że elastyczność była na pierwszym miejscu. Zamiast posługiwać się tylko funkcjami
zdecydowana większość programu stanowią skrypty (m-pliki). Schemat blokowy prezentuje
rysunek 7.1.
Rys. 7.1. Schemat blokowy programu
Każdy zbiór ma własne skrypty odpowiedzialne za tworzenie klasyfikatora, jego
optymalizację i częściowo rozrzedzanie. Nazewnictwo <skrót gł. metody>_<klasa>.m
pozwala jednoznacznie określić którego zbioru dotyczą, np. DE_pkc.m oznacza
optymalizację dla zbioru pkc.
Wczytanie danych do przestrzeni roboczej MATLABa dokonuje skrytp load_data.m.
Struktura większości plików jest następująca:
• parametry modelu, atrybuty danych;
• podział sekwencji na trenujące i testowe (60% trenujące);

54
• funkcja właściwa (tworzenie klasyfikatora, optymalizacja, rozrzedzanie);
• ocena jakościowa modelu;
• prezentacja wyników;
Rys. 7.2. Struktura zawartości pliku na podstawie skryptu lssvm_pkc (tworzenie klasyfikatora
bez optymalizacj)

55
8. BIBLIOGRAFIA
1. ABBAS, H. A.; SARKER, R.; NEWTON, C. PDE: A Pareto–frontier Differential
Evolution Approach for Multi-objective Optimization Problems
2. ABBAS, H. A. The Self–Adaptive Pareto Differential Evolution Algorithm
3. BURGES, C. J. C; SCHOLKOPF, B; SMOLA, A. J. Advances in Kernel Methods:
Support Vector Learning, The MIT Press 1999
4. DWULIT, M; JANKOWSKI, S; SZYMANSKI, Z. Feature selection and mapping of
data from short amino acid sequences., Raport wewnętrzny, Instytut Informatyki PW,
2010
5. FAWCETT, T. An introduction to ROC analysis, Pattern Recognition Letters 27, 2006
6. FAWCETT, T. ROC Graphs: Notes and Practical Considerations for Researchers,
2004
7. GUYON, I.; STORK, D. G. Linear Discriminant and Support Vector Classifiers.
The MIT Press, 2000
8. HOEGARTS, L.; SUYKENS, J. A. K; VANDEWALLE, J.; DE MOOR, B.
A Comparison of Pruning Algorithms for Sparse Least Squares Support Vector
Machines. Katholieke Universiteit Leuven, ESAT -SISTA
9. KARABOGA, D.; OKDEM, S.; A Simple and Global Optimization Algorithm for
Engineering Problems: Diferential Evolution, ElecEngin,VOL.12, NO.1 2004
10. Kawashima, S.; Kanehisa, M.; AAindex: amino acid index database. Nucleic Acids
Res. 28, 374 (2000)
11. KUH, A; WILDE, P. Comments on “Pruning Error Minimization in Least Squares
Support Vector Machines”. IEEE TRANSACTIONS ON NEURAL NETWORKS,
VOL.18, NO.2, 2007
12. NOWAK-BRZEZIŃSKA, A. Krzywe operacyjne odbiornika ROC, Konspekt do zajęć
Statystyczne metody analizy danych, 2010
13. STORN, R.; PRICE, K. Differential Evolution – A Simple and Efficient Heuristic for
Global Optimization over Continuous Spaces
14. SUYKENS, J. A. K; VANDEWALLE, J. Least Squares Support Vector Machine
Classifiers, Kluwer Academic Publishers, 1999
15. SUYKENS, J. A. K; LUKAS, L.; VANDEWALLE Sparse Least Squares Support
Vector Machine Classifiers

56
16. STOPPIGLIA, H.; DREYFUS, G.; DUBOIS, R.; OUSSAR, Y. Ranking a Random
Feature for Variable and Feature Selection, Journal of Machine Learning Research 3
(2003), 1399-1414
17. STRYER, L. Biochemia. Warszawa: Wydawnictwo Naukowe PWN, 2000
18. VAPNIK, V. The nature of statistical learning theory. Springer-Verlag: New York,
1995.
19. VAPNIK, V. Statistical learning theory. John Wiley: NewYork, 1998.
20. LS-SVMlab Toolbox User’s Guide [Czerwiec, 2011]
http://www.esat.kuleuven.ac.be/sista/lssvmlab/





























