Embed Size (px)
Citation preview

k-fold Subsampling based Sequential Backward Feature Elimination
Park, J., Li, K., & Zhou, H. (2016). k-fold Subsampling based Sequential Backward Feature Elimination. InProceedings of the 5th International Conference on Pattern Recognition Applications and Methods (pp. 423-430). SciTePress. DOI: 10.5220/0005688804230430
Published in:Proceedings of the 5th International Conference on Pattern Recognition Applications and Methods
Document Version:Peer reviewed version
Queen's University Belfast - Research Portal:Link to publication record in Queen's University Belfast Research Portal
Publisher rightsCopyright 2016 SciTePress
General rightsCopyright for the publications made accessible via the Queen's University Belfast Research Portal is retained by the author(s) and / or othercopyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associatedwith these rights.
Take down policyThe Research Portal is Queen's institutional repository that provides access to Queen's research output. Every effort has been made toensure that content in the Research Portal does not infringe any person's rights, or applicable UK laws. If you discover content in theResearch Portal that you believe breaches copyright or violates any law, please contact [email protected].
Download date:10. Jun. 2018

Queen's University Belfast - Research Portal
k-fold Subsampling based Sequential Backward FeatureElimination
Park, J., Li, K., & Zhou, H. (2016). k-fold Subsampling based Sequential Backward Feature Elimination. Paperpresented at International Conference on Pattern Recognition Applications and Methods (ICPRAM), Rome, Italy.
Document Version:Peer reviewed version
Link:Link to publication record in Queen's University Belfast Research Portal
General rightsCopyright for the publications made accessible via the Queen's University Belfast Research Portal is retained by the author(s) and / or othercopyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associatedwith these rights.
Take down policyThe Research Portal is Queen's institutional repository that provides access to Queen's research output. Every effort has been made toensure that content in the Research Portal does not infringe any person's rights, or applicable UK laws. If you discover content in theResearch Portal that you believe breaches copyright or violates any law, please contact [email protected].
Download date:16. Mar. 2016

k-fold Subsampling based Sequential Backward Feature Elimination
Jeonghwan Park, Kang Li and Huiyu ZhouSchool of Electronics, Electrical Engineering and Computer Science, Queen’s University Belfast, Belfast, United Kingdom
[email protected], [email protected], [email protected]
Keywords: Feature Selection, Appearance Model, Human Detection
Abstract: We present a new wrapper feature selection algorithm for human detection. This algorithm is a hybrid featureselection approach combining the benefits of filter and wrapper methods. It allows the selection of an optimalfeature vector that well represents the shapes of the subjects in the images. In detail, the proposed featureselection algorithm adopts the k-fold subsampling and sequential backward elimination approach, while thestandard linear support vector machine (SVM) is used as the classifier for human detection. We apply theproposed algorithm to the publicly accessible INRIA and ETH pedestrian full image datasets with the PASCALVOC evaluation criteria. Compared to other state of the arts algorithms, our feature selection based approachcan improve the detection speed of the SVM classifier by over 50% with up to 2% better detection accuracy.Our algorithm also outperforms the equivalent systems introduced in the deformable part model approach witharound 9% improvement in the detection accuracy.
1 INTRODUCTION
A feature is an individual measurable property of aprocess being observed. Using a set of features, a ma-chine learning algorithm can perform necessary clas-sification [Chandrashekar and Sahinn, 2014]. Com-pared to the situation back to the early years in the pat-tern recognition community, the space of features tobe handled has been significantly expanded. High di-mensionality of a feature vector is known to decreasethe machine learning performance [Guyon and Elis-seeff, 2003], and directly affects applications such ashuman detection systems whose system performancerelies heavily on both the classification speed and ac-curacy. A feature with no association with a class isregarded as a redundant or irrelevant feature. A re-dundant feature represents a feature which does notcontribute much or at all to the classification task. Anirrelevant feature can be defined as a feature whichmay only lead to decreased classification accuracyand speed. Blum (Blum, 1997) defined the relevantfeature f as a feature which is useful to a machinelearning algorithm L with respect to a subset of fea-tures {S}: the accuracy of an hypothesized algorithmusing the feature set { f ∪ S} is higher than that onlyusing {S}. In pattern recognition, the aim of fea-ture selection is to select relevant features (an opti-mal subset), which can maximise the classificationaccuracy, from the full feature space. When a fea-
ture selection process is applied to pattern recogni-tion, it can be seen as an embedded automated pro-cess which removes redundant or irrelevant features,and selects a meaningful subset of features. Featureselection offers many benefits in understanding data,reducing computational cost, reducing data dimen-sionality and improving the classifier’s performance[Chandrashekar and Sahinn, 2014]. In general, fea-ture selection is distinguished from vector dimension-ality reduction techniques such as Principal Compo-nent Analysis (PCA) [Alpaydin, 2004], as feature se-lection merely selects an optimal subset of featureswithout altering the original information. Feature se-lection requires a scoring mechanism to evaluate therelevancy of features to individual classes. The scor-ing mechanism is also named the feature selection cri-terion, which must be followed by an optimal subsetselection procedure. Naively evaluating all the sub-sets of features (2N) becomes an NP-hard problem(Amaldi and Kann, 1998) as the number of featuresgrows, and this search becomes quickly computation-ally intractable. To overcome this computation prob-lem, a wide range of search strategies have been intro-duced, including best-first, branch-and-bound, simu-lated annealing and genetic algorithms [Kohavi andJohn, 1997] [Guyon and Elisseeff, 2003], etc. Interms of feature scoring, feature selection methodshave been broadly categorised into filter and wrappermethods [Kohavi and John, 1997]. Filter methods al-

Figure 1: Proposed Feature Selection System Overview.
low one to rank features using a proxy measure suchas the distance between features and a class, and se-lect the most highly ranked features to be a candidatefeature set. Wrapper methods score features using thepower of a predictive model to select an optimal sub-set of features.
In this paper, we propose a hybrid feature selec-tion approach which combines the benefits of filterand wrapper methods, and discuss the performanceimprovement of the human detection system achievedusing the proposed algorithm. We also demonstratehow optimal features selected by the proposed algo-rithm can be used to train an appearance model. Therest of the report is organised as follows. In section2, feature selection methods and their core techniquesare briefly reviewed. Section 3 introduces the pro-posed feature selection algorithm. The experimentresults of the pedestrian detection system using theproposed algorithm is described in Section 4. Finally,Section 5 concludes the paper.
2 RELATED WORK
One way for feature selection is simply evaluat-ing features based on their information content, us-ing measures like interclass distance, statistical de-pendence or information-theoretic measures [Estevezet al., 2009]. The evaluation is independently per-formed against different features, and the evaluationresult called “feature rank” is directly used to de-fine the usefulness of each feature for classification.Entropy and Mutual information are popular rank-ing methods to evaluate the relevancy of features[Foithong et al., 2012] [Peng et al., 2005] [Javed et al.,2012] [Estevez et al., 2009]. Zhou et al. [Zhou et al.,2011] used the Renyi entropy for feature relevanceevaluation of overall inputs in their automatic scal-ing SVM. Battiti proposed the MIFS algorithm [Bat-titi, 1994], which selects the most relevant k featureelements from an initial set of n feature dimensions,using a greedy selection method. Many MIFS vari-ations have been introduced since then such as themRMR [Peng et al., 2005], which used the first-order
incremental search mechanism to select the most rele-vant feature element at a time. Estevez et al. [Estevezet al., 2009] replaced the mutual information calcu-lation in the MIFS by the minimum entropy of twofeatures.
Wrapper methods utilise classifier’s performanceto evaluate feature subsets. Wrapper methods have asignificant advantage over filter methods as the classi-fier (learning machine) used for evaluation is consid-ered as a black box. This flexible framework was pro-posed in [Kohavi and John, 1997]. Gutlein et al. [Gut-lein et al., 2009] proposed to shortlist k ranked featureelements firstly, and then applied a wrapper sequen-tial forward search over the features. Ruiz et al. [Ruizet al., 2006] proposed an incremental wrapper-basedsubset selection algorithm (IWSS), which identifiedthe optimal feature area before the exhaustive searchwas applied. Bermejo et al. [Bermejo et al., 2011]improved the IWSS by introducing a feature replace-ment approach. Foithong et al. [Foithong et al., 2012]used the CMI algorithm to guide the search of an op-timal feature space, and applied the VPRMS as an in-termediate stage before the wrapper method started.Pohjalainen et al. [Pohjalainen et al., 2013] proposedthe RSFS which used the dummy feature relevancescore as a selection criterion. Li and Peng [Li andPeng, 2007] introduced a fast model-based approachto select a set of significant inputs to a non-linearsystem. Heng et al. [Heng et al., 2012] addressedthe overfitting problem of the wrapper methods byproposing a shrink boost method. Yang et al. [Yanget al., 2012] proposed a wrapper method with theLRGA algorithm to learn a Laplacian matrix for thesubset evaluation.
3 PROPOSED ALGORITHM
In this section, a novel feature selection algorithm ispresented. The proposed feature selection algorithmis a wrapper method which adopts the k-fold subsam-pling method in the validation step. The search strat-egy is an exhaustive search, namely the sequentialbackward elimination (SBE, Marill and Green 1963).The proposed algorithm is a classifier dependent fea-ture selection method, and the linear SVM is used asthe classifier to evaluate the selected feature subsets.
3.1 Frame Work
First, the entire feature set {F} is randomly dividedinto j small subsets where an evaluation process isperformed, Sn ∈ F, f or n = 1,2, .., j. Square rootcalculation on the size of the full feature set {F} is

Figure 2: Performance illustration: (a) Step performance curve of the proposed feature selection algorithm. (b) HumanDetection performance using different HOG detectors trained with different feature subsets. The evaluation was carried outon the first 100 INRIA Full Images. The computed miss rates between 0.01 and 1 false positives per-image (FPPI) are shownin the legend. HOG Detectors trained with optimal feature subsets perform better than or similar to 100HOG showing a smalloverfitting problem.
used to determine the size of a subset. When the localstopping criterion Lc is satisfied, another relevancescore I contributes to the computation of featurerelevance scores, and considerably a large number ofirrelevant/redundant feature elements (from the leastsignificant one, LSFs) are subtracted. The processcontinues on until the global stopping criterion issatisfied. The whole process is sketched in Fig.1.
Random Subsets : When the remaining featureset {Fl} is reset, a temporary ID is given to individualvector elements for backtracking which gives them anequal opportunity in the evaluation. The temporaryID is only valid within one step. A step refers tothe point where the local stopping criterion Lc issatisfied, LSFs are subtracted and all the iterationparameters are re-initialised. An iteration refers tothat the evaluation has completed over all the subsets,and each vector element has been evaluated once.At the beginning of each iteration within one step,the feature vector elements of the remaining featureset {Fl} is randomly re-arranged and divided intosubsets, n×{S}. The size of a subset is chosen as√
N where N is the number of the remaining features.
Relevance Score : The algorithm uses two scores,step performance score P and feature relevance scoreR. During each iteration in the exhaustive searchstage, the relevance score of individual features is up-dated according to the prediction power score over thesubset where the feature participates. In this paper,the Unweighted Average Recall (UAR) is used to cal-
culate the prediction power score over the subsets:
P{Sn}=1N
N
∑i=1
( CiP
CiP +CiF
)(1)
where Sn is nth subset, i is the class index, CiP is theclass true positive (correct prediction) and CiF is theclass false negative (wrong prediction).
The individual feature relevance score is then up-dated as [Pohjalainen et al., 2013]:
R f = R f +P{Sn}−E, f ∈ Sn, (2)
where E is the UAR of the cumulated CP and CF overa step. As the search continues, the feature score R frepresents how much the corresponding feature hascontributed to the prediction.
Stopping Criterion : The local stopping criterionLc is calculated using the standard deviation of thestep’s performance with a specific predictor. Lc is de-fined as:
Lc =
√√√√ 1N
N
∑i=1
(Pi−
1N
N
∑j=1
Pj
)2(3)
where Pi is the step performance score. Lc is thencompared with a supervised parameter (0.6 in thisstudy) to decide the evaluation fairness over allthe features. The global stopping criterion Gc is asupervised parameter, and the number of features tobe finally selected is used here.
Counter Score : Even though an algorithm hasperformed a large number of iterations and the lo-cal stopping criterion Lc has been satisfied, it can
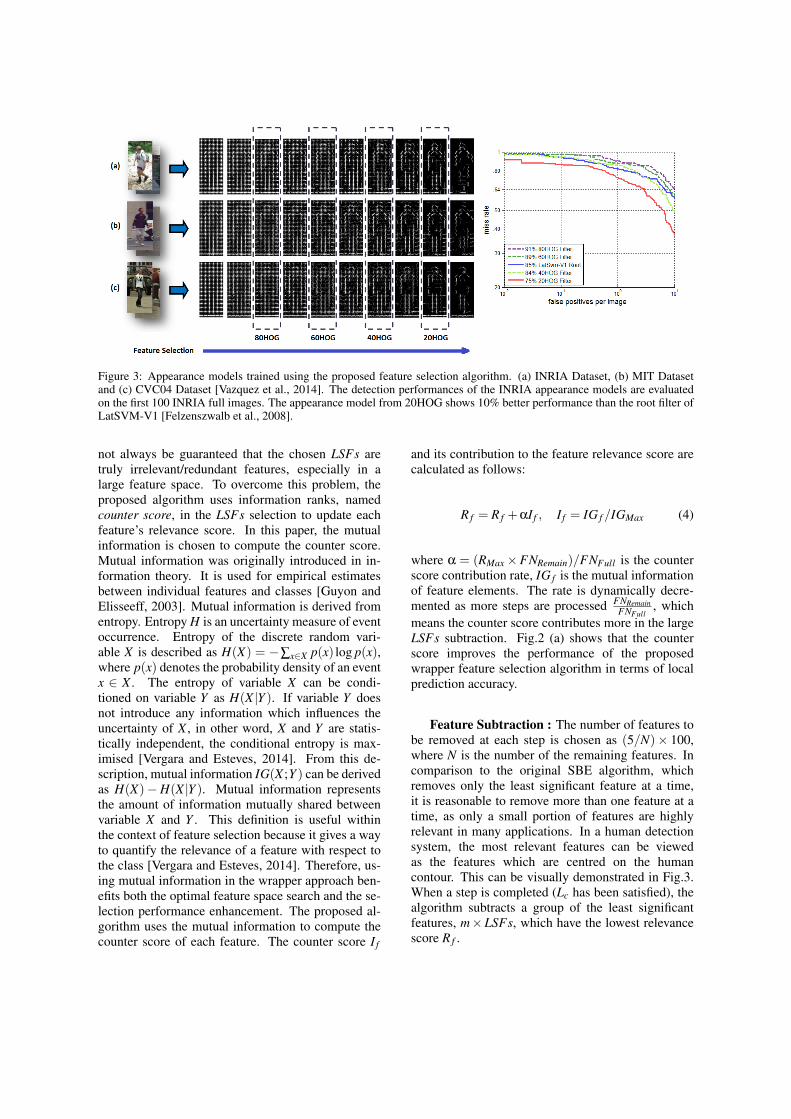
Figure 3: Appearance models trained using the proposed feature selection algorithm. (a) INRIA Dataset, (b) MIT Datasetand (c) CVC04 Dataset [Vazquez et al., 2014]. The detection performances of the INRIA appearance models are evaluatedon the first 100 INRIA full images. The appearance model from 20HOG shows 10% better performance than the root filter ofLatSVM-V1 [Felzenszwalb et al., 2008].
not always be guaranteed that the chosen LSFs aretruly irrelevant/redundant features, especially in alarge feature space. To overcome this problem, theproposed algorithm uses information ranks, namedcounter score, in the LSFs selection to update eachfeature’s relevance score. In this paper, the mutualinformation is chosen to compute the counter score.Mutual information was originally introduced in in-formation theory. It is used for empirical estimatesbetween individual features and classes [Guyon andElisseeff, 2003]. Mutual information is derived fromentropy. Entropy H is an uncertainty measure of eventoccurrence. Entropy of the discrete random vari-able X is described as H(X) = −∑x∈X p(x) log p(x),where p(x) denotes the probability density of an eventx ∈ X . The entropy of variable X can be condi-tioned on variable Y as H(X |Y ). If variable Y doesnot introduce any information which influences theuncertainty of X , in other word, X and Y are statis-tically independent, the conditional entropy is max-imised [Vergara and Esteves, 2014]. From this de-scription, mutual information IG(X ;Y ) can be derivedas H(X)−H(X |Y ). Mutual information representsthe amount of information mutually shared betweenvariable X and Y . This definition is useful withinthe context of feature selection because it gives a wayto quantify the relevance of a feature with respect tothe class [Vergara and Esteves, 2014]. Therefore, us-ing mutual information in the wrapper approach ben-efits both the optimal feature space search and the se-lection performance enhancement. The proposed al-gorithm uses the mutual information to compute thecounter score of each feature. The counter score I f
and its contribution to the feature relevance score arecalculated as follows:
R f = R f +αI f , I f = IG f /IGMax (4)
where α = (RMax×FNRemain)/FNFull is the counterscore contribution rate, IG f is the mutual informationof feature elements. The rate is dynamically decre-mented as more steps are processed FNRemain
FNFull, which
means the counter score contributes more in the largeLSFs subtraction. Fig.2 (a) shows that the counterscore improves the performance of the proposedwrapper feature selection algorithm in terms of localprediction accuracy.
Feature Subtraction : The number of features tobe removed at each step is chosen as (5/N)× 100,where N is the number of the remaining features. Incomparison to the original SBE algorithm, whichremoves only the least significant feature at a time,it is reasonable to remove more than one feature at atime, as only a small portion of features are highlyrelevant in many applications. In a human detectionsystem, the most relevant features can be viewedas the features which are centred on the humancontour. This can be visually demonstrated in Fig.3.When a step is completed (Lc has been satisfied), thealgorithm subtracts a group of the least significantfeatures, m×LSFs, which have the lowest relevancescore R f .

Figure 4: Filter Score Computation: The positive filter score is subtracted from the negative filter score.
3.2 Appearance Model
In a human detection system, the optimal feature el-ements tend to represent the human contour as illus-trated in Fig.3. This was also pointed out in [Dalaland Triggs, 2006] as the most important cells are theones that typically contain major human contours. Inother words, the optimal feature elements are usefulto build an appearance model. To evaluate the dis-criminative power of the selected feature elements, asimple appearance model is created. The model con-sists of a positive filter and a negative filter. The pos-itive filter is formed with the average HOG of the se-lected feature elements from the positive examples.The negative filter is generated with the negative ex-amples in the same manner. The HOG scheme allowsus to divide the appearance of an object into geomet-rical units called cells. A cell is then represented withn angles and their weighted magnitudes. The HOGfeature of an example is an one-dimensional array ofmagnitudes whose indexes indicate the angle and thelocation of the cell. The proposed feature selectionalgorithm outputs the array indexes of an optimal fea-ture subset. Each element fi of a filter is computed asfollows:
fi =1n
n
∑j=1
β ji (5)
where fi is the array element of the proposed filter,β is the vector of an example of dataset. The scoreof region Sr is the regional similarity and computedwith the euclidean distances between the ROI and thefilters as shown in the following Equation:
Sr = d(Ns,Os)−d(Ps,Os) (6)
where Ns and Ps are the optimal sub-vectors of thenegative and positive filters, Os is the sub-vector ofROI feature vector, and d(x,y) is the euclidean dis-tance.
4 Experimental Work
Dollar [Dollar et al., 2012] [Dollar et al., 2009]provided 288 INRIA pedestrian full images for the
benchmarking purpose. The majority of tests in thispaper are carried out against 288 full images. How-ever, some of the tests are conducted on the first 100images, which show similar results as for the case of288 full images. To evaluate the generalisation of theproposed approach, the test is also performed on theETH Bahnhof sequence [Ess et al., 2008], which con-tains 999 street scenes. The performance of the hu-man detection systems in terms of the detection ac-curacy are evaluated using the PASCAL VOC crite-ria [Everingham et al., 2007]. All the algorithms andsystems in the experiments are realised using Matlab2014 with the relevant mex files. The test computer isof 2.49GHz Intel i5-4300U CPU running with Win-dow 8.
4.1 Feature Vectors
Feature Vector: The feature used in the exper-iments is the Histograms of Oriented Gradients(HOG) [Dalal and Triggs, 2006]. First of all, a linearSVM classifier is trained using the MIT pedestriandataset. The MIT dataset consists of up-straightperson images which have less dynamic poses. Thepositive examples shortlisted from other datasetsusing this classifier tends to include rather staticpose examples. The dataset consisting of static poseexamples is used to build an appearance model.Secondly, a subset of the INRIA dataset is selectedby the classifier. The INRIA dataset offers cropped2416 positive examples, and also allows to generate12180 negative examples in the random selectionmanner for the training purpose. The classifierselects 1370 positive and 1579 negative examplesfrom the training dataset. The negative examplesinclude 79 false positive examples called ”hardnegative example”. Thirdly, the feature extrac-tion algorithm introduced in [Felzenszwalb et al.,2008] is used to compute HOG descriptors for theexperiments with LatSvm-V1 (Feature Vector A).The algorithm in [Felzenszwalb et al., 2010] is alsoused for the tests with LatSvm-V2 (Feature Vector B).
Feature Selection: The proposed feature selec-

Figure 5: Localisation accuracy: The human localisation accuracy of the 10HOG-V2 Filter is compared to that of the rootfilter of the LatSvm-V2 Model [Felzenszwalb et al., 2010]. Top - Score maps of the 10HOG-V2 filter at three scales. Bottom- Score maps from the LatSvm-V2 root filter at the identical scale. The score map from the 10HOG-V2 filter shows less noisethan the one of the LatSvm-V2 root filter.
tion algorithm is applied to the extracted feature vec-tors shown above. From Feature Vector A, the algo-rithm selects four optimal feature subsets which have80%, 60%, 40% and 20% elements of the full fea-ture vector. The detection system trained with thesefeature subsets are referred to as 80HOG, 60HOG,40HOG, and 20HOG respectively. 100HOG repre-sents the system trained with the full feature vector.The algorithm also selects 20%, 15% and 10% ele-ments from Feature Vector B. They are referred toas 20HOG-V2, 15HOG-V2 and 10HOG-V2 respec-tively.
4.2 Full Image Results
Feature Vector A: To evaluate the feature selectionperformance, a simple human detection system usingthe HOG and the linear SVM [Dalal and Triggs,2006] is created. Fig.2 (b) shows the detection accu-racy of the systems trained with the selected featuresubsets from Feature Vector A. The 40HOG, 60HOGand 80HOG slightly improve the accuracy up to 2%compared to the system trained with the full featureset, 100HOG. The detection accuracy is improveduntil the 40HOG is applied, which uses less than halfof the full feature vector dimension. The 20HOGshows no improvement in the detection performanceeven though 20% feature vector has the best score inthe local classification score curve as shown in Fig.2(a). The results of the evaluation reveal that as thefeature selection progresses the proposed algorithmgradually introduces the overfitting problem. Thewindow sliding speed is significantly improved. The100HOG takes 478.634s to scan 1060× 605 pixelsimage. Compared to this, the 20HOG takes onlyone tenth of the search time required by the original
system completing the same search within 45.895s.
Feature Vector B: The proposed appearancemodel is trained with the 20HOG-V2, 15HOG-V2and 10HOG-V2. Fig.6(a) shows the evaluation resultsof the appearance models. The evaluation is carriedout on the 288 INRIA Full Images, and compared tothe LatSvm-V2 Root filter [Felzenszwalb et al., 2010]and the appearance models trained with the other fea-ture selection algorithms. Unlike the classifier depen-dent systems, the appearance model shows better per-formance as the feature vector is better optimised, andno overfitting problem is observed with the appear-ance models. The 10HOG-V2 model outperforms theLatSvm-V2 Root filter scoring with a 9% better de-tection rate. To test the generalisation performanceof the proposed approach, filters trained with the IN-RIA dataset are directly applied in the experiments onthe ETH Bahnhof sequence [Ess et al., 2008], whichconsists of 999 street scenes. The 10HOG-V2 out-performs all the other filters achieving 2% better per-formance compared to the LatSvm-V2 root filter asshown in Fig.6 (b). The root filter of the LatSvmapproach [Felzenszwalb et al., 2008] [Felzenszwalbet al., 2010] is equivalent to the model from Dalal’soriginal HOG approach [Dalal and Triggs, 2006].Therefore, the proposed appearance model can simplyreplace the LatSvm root filter. Fig.6 (c) illustrates thedetection performance evaluation of the DeformablePart Model, LatSvm+10HOG-V2, which has the pro-posed appearance model as a root filter. The eval-uation on the 288 INRIA Full Images shows thatthe improved performance of the 10HOG-V2 filteris slightly worse than the LatSvm+10HOG-V2. Theperformance decrease can be explained in two-folds:Firstly, the part filters of the Deformable Part Model

Figure 6: Performance comparison: (a) Filter detection performance comparison on the 288 INRIA Full Images. (b) Filterdetection performance on the ETH Bahnhof sequence, (c) Comparison to the state-of-the-arts on the 288 INRIA Full Images.
contributes more than the root filter does. On thefirst 100 INRIA Full Images, the part filters scores a44% detection rate, while the root filter achieves 91%.Secondly, there are many supervised parameters in-volved in the Deformable Part Model, and the super-vised parameters appear to affect the performance ofthe LatSvm+10HOG-V2. Therefore, the further op-timisation is required to make the proposed filter fitwith the Deformable Part Model.
5 Conclusion
We have presented a feature selection algorithmwhich can generate the optimal feature subset. Wehave demonstrated the chosen feature subset can beused to improve the human detection system, whichrelies on the classifier performance, in both speed andaccuracy. It has also been shown that the optimal fea-tures represent the object shape. Base on this obser-vation, we have demonstrated that the optimal featurevector can be directly used to form the appearancemodels. This approach does not require highly ac-curate annotation data of objects to generate models.Therefore, it can be easily applied to a wide range ofdatasets.
REFERENCES
Alpaydin, E. (2004). In Introduction to Machine Learning.The MIT Press.
Battiti, R. (1994). In Using Mutual Information for Select-ing Features in Supervised Neural Net Learning. IEEETransactions on Neural Networks, Vol. 5, No. 4.
Bermejo, P., Gamez, J. A., and Puerta, J. M. (2011). InImproving Incremental Wrapper-based Subset Selec-tion via Replacement and Early Stopping. Interna-tional Journal of Pattern Recognition and Artificial In-telligence. Vol. 25.
Chandrashekar, G. and Sahinn, F. (2014). In A survey onfeature selection methods. Journal of Computers andElectrical Engineering 40, P. 16-28.
Dalal, N. and Triggs, B. (2006). In Histograms of OrientedGradients for Human Detection. IEEE Conference onComputer Vision and Pattern Recognition.
Dollar, P., Wojek, C., Schiele, B., and Perona, P. (2009).In Pedestrian Detection: A benchmark. IEEE Confer-ence on Computer Vision and Pattern Recognition.
Dollar, P., Wojek, C., Schiele, B., and Perona, P. (2012).In Pedestrian Detection: An Evaluation of the Stateof the Art. IEEE Transactions on Pattern Analysis andMachine Intelligence.
Ess, A., Leibe, B., Schindler, K., , and van Gool, L. (2008).In A Mobile Vision System for Robust Multi-PersonTracking. IEEE Conference on Computer Vision andPattern Recognition.
Estevez, P. A., Tesmer, M., Perez, C. A., and Zurada, J. M.(2009). In Normalized Mutual Information FeatureSelection. IEEE Transactions on Neural Networks,Vol. 20, No.2.
Everingham, M., Zisserman, A., Williams, C., and Gool,L. (2007). In The PASCAL visual obiect classes chal-lenge 2007 results. Technical Report, PASCAL chal-lenge 2007.
Felzenszwalb, P., Girshick, R., McAllester, D., and Ra-manan, D. (2010). In Object Detection with Discrim-inatively Trained Part Based Models. IEEE Confer-ence on Computer Vision and Pattern Recognition.
Felzenszwalb, P., McAllester, D., and Ramanan, D.(2008). In A Discriminatively Trained, Multiscale,Deformable Part Model. IEEE Conference on Com-puter Vision and Pattern Recognition.
Foithong, S., Pinngern, O., and Attachoo, B. (2012). InFeature Subset Selection Wrapper based on MutualInformation and Rough sets. Journal of Expert Sys-tems with Applications 39, P.574-584, Elsevier.
Gutlein, M., Frank, E., Hall, M., and Karwath, A. (2009). InLarge-scale attribute selection using wrappers. IEEESymposium Series on Computational Intelligence andData Mining.
Guyon, I. and Elisseeff, A. (2003). In An Introduction toVariable and Feature Selection. Journal of MachineLearning Research 3, 1157-1182.

Heng, C. K., Yokomitsu, S., Matsumoto, Y., and Tmura,H. (2012). In Shrink Boost for Selecting Multi-LBPHistogram Features in Object Detection. IEEE Con-ference on Computer Vision and Pattern Recognition.
Javed, K., Babri, H. A., and Saeed, M. (2012). In Fea-ture Selection Based on Class-Dependent Densitiesfor High-Dimensional Binary Data. IEEE Transac-tions on Knowledge and Data Engineering, Vol. 24,P. 465-477.
Kohavi, R. and John, G. H. (1997). In Wrappers for featuresubset selection. Artificial Intelligence.
Li, K. and Peng, J. (2007). In Neural Input Selection - A fastmodel-based approach. Journal of Neurocomputing,Vol. 70, P. 762-769.
Peng, H., Long, F., , and Ding, C. (2005). In Feature Selec-tion Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy.IEEE Transactions on Pattern Analysis and MachineIntelligence, Vol. 27, No. 8.
Pohjalainen, J., Rasanen, O., and Kadioglu, S. (2013). InFeature Selection methods and Their combinations inHigh-dimensional Classification of Speaker Likabil-ity, Intelligibility and Personality Traits. Journal ofComputer Speech and Language. Elsevier.
Ruiz, R., Riquelme, J., and Aguilar-Ruiz, J. S. (2006).In Incremental wrapper-based gene selection frommicroarray data for cancer classification. PatternRecognition, Vol. 39.
Vazquez, D., Marin, J., Lopez, A., Ponsa, D., and Geron-imo, D. (2014). In Virtual and Real World Adaptationfor Pedestrian Detection. IEEE Transactions on Pat-tern Analysis and Machine Intelligence.
Vergara, J. R. and Esteves, P. A. (2014). In A review ofFeature Selection method based on Mutual Informa-tion. Journal of Neural Computing and Applications24, 175-186.
Yang, Y., Nie, F., Xu, D., Luo, J., Zhuang, Y., and Pan,Y. (2012). In A Multimedia Retrieval FrameworkBased on Semi-Supervised Ranking and RelevanceFeedback. IEEE Transactions on Pattern Analysis andMachine Intelligence, Vol. 34, No. 4, P. 723-742.
Zhou, H., Miller, P., and Zhang, J. (2011). In Age classifica-tion using Radon transform and entropy based scalingSVM. British Machine Vision Conference.





























