Embed Size (px)
Citation preview

KEPLER + HADOOPA GENERAL ARCHITECTURE FACILITATING DATA-INTENSIVE APPLICATIONS IN SCIENTIFIC WORKFLOW SYSTEMS
Jianwu Wang, Daniel Crawl, Ilkay AltintasSan Diego Supercomputer Center, University of California, San Diego
9500 Gilman Drive, MC 0505
La Jolla, CA 92093-0505, U.S.A.
{jianwu, crawl, altintas}@sdsc.edu
Presentation by Woodrow H. Edwards

Kepler
Open source scientific workflow system Executable model of the many stages
transforming data into the desired result in a scientific domain
Scientific domains using KeplerBioinformatics, Computational Chemistry,Ecoinformatics, and Geoinformatics
All have large data sets and require a lot of computation

Kepler
User friendly GUI to connect data sources to built-in procedures or independent applications with the ease of drag and drop
Promotes component reuse and sharing Written in Java Designed to run on clusters, grids, or the
Web A nice match to integrate with MapReduce

Kepler Components of a Kepler workflow
Actors○ Independently process data○ Atomic or composite○ Ports input and ouput data (tokens) or signals○ Could be R or MATLAB scripts or an outside application
Channels○ Link actors○ Carry data or other signals
Directors○ Specify when actors run○ Sequential (SPD) or parallel (PN)

Figure 1: Example Kepler workflow [2]

Hadoop
Open source implementation of MapReduce map(in_key, in_value) (out_key, intermediate_value) list reduce(out_key, intermediate_value list) out_value list
HDFS Data partitioning, scheduling, load
balancing, and fault tolerance Also written in Java
Kepler + Hadoop
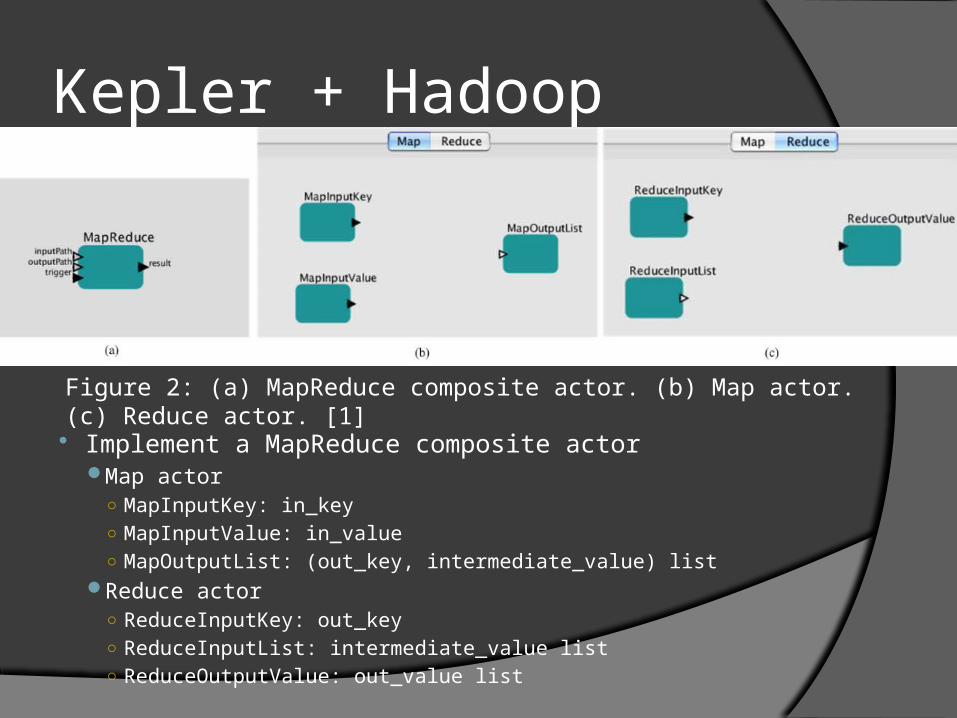
Implement a MapReduce composite actor Map actor
○ MapInputKey: in_key○ MapInputValue: in_value○ MapOutputList: (out_key, intermediate_value) list
Reduce actor○ ReduceInputKey: out_key○ ReduceInputList: intermediate_value list○ ReduceOutputValue: out_value list
Figure 2: (a) MapReduce composite actor. (b) Map actor. (c) Reduce actor. [1]

Kepler + Hadoop
Figure 3: Hierarchical execution of MapReduce composite actor with Hadoop [1]

Kepler + Hadoop
Figure 4: (a) Word Count workflow. (b) Map actor. (c) Reduce actor.(d) IterateOverArray actor. [1]

Kepler + Hadoop
Takes 10 to 15% longer over native Hadoop MapReduce
Makes up for it in ease of implementation
Scientist can use MapReduce without needing to know the framework
They only need to know where they can benefit from parallelism in their workflow

References
1. J. Wang, D. Crawl, and I. Altintas. Kepler + Hadoop: A General Architecture Facilitating Data-Intensive Applications in Scientific Workflow Systems. In WORKS 09, ACM, Nov. 2009.
2. The Kepler Project. https://kepler-project.org.
3. The Apache Hadoop Project. http://hadoop.apache.org.





























