Embed Size (px)
Citation preview

Invited Talk 5:“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”
ICIEV 2014Dhaka, Bangladesh
Dr. Abu Asaduzzaman,Assistant Professor and DirectorWichita State University (WSU)
Computer Architecture & Parallel Programming Laboratory (CAPPLab)Wichita, Kansas, USA
May 23, 2014

Dr. Zaman 2
“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”
Outline ►■ Introduction
Single-Core to Multicore Architectures
■ Performance Improvement Simultaneous Multithreading (SMT) (SMT enabled) Multicore CPU with GPUs
■ Energy-Efficient Computing Dynamic GPU Selection
■ CAPPLab “People First” Resources Research Grants/Activities
■ Discussion
QUESTIONS? Any time, please!

Dr. Zaman 3
Introduction
Single-Core to Multicore Architecture■ History of Computing
Word “computer” in 1613 (this is not the beginning) Von Neumann architecture (1945) – data/instructions memory Harvard architecture (1944) – data memory, instruction memory
■ Single-Core Processors In most modern processors: split CL1 (I1, D1), unified CL2, … Intel Pentium 4, AMD Athlon Classic, …
■ Popular Programming Languages C, …

Dr. Zaman 4
(Single-Core to) Multicore Architecture
Courtesy: Jernej Barbič, Carnegie Mellon University
Input Process/Store Output
Multi-tasking Time sharing (Juggling!)
Cache not shown
Introduction

Dr. Zaman 5
Single-Core “Core”
Introduction
a single core
Courtesy: Jernej Barbič, Carnegie Mellon University
A thread is a running “process”

Dr. Zaman 6
Introduction
Thread 1: Integer (INT) Operation(Pipelining Technique)
1: InstructionFetch
2: InstructionDecode
(3) Operand(s)Fetch
4: IntegerOperation
ArithmeticLogicUnit
(5) ResultWrite Back
FloatingPointOperation
Thread 1: Integer Operation

Dr. Zaman 7
Introduction
Thread 2: Floating Point (FP) Operation
(Pipelining Technique)
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Thread 2: Floating Point Operation

Dr. Zaman 8
Introduction
Threads 1 and 2: INT and FP Operations
(Pipelining Technique)
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Thread 1: Integer Operation
Thread 2: Floating Point Operation
POSSIBLE?

Dr. Zaman 9
Performance
Threads 1 and 2: INT and FP Operations
(Pipelining Technique)
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Thread 1: Integer Operation
Thread 2: Floating Point Operation
POSSIBLE?

Dr. Zaman 10
Performance Improvement
Threads 1 and 3: Integer Operations
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Thread 1: Integer Operation
Thread 3: Integer Operation
POSSIBLE?

Dr. Zaman 11
Performance Improvement
Threads 1 and 3: Integer Operations
(Multicore)
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Thread 1: Integer Operation
Thread 3: Integer Operation
POSSIBLE?
Core 1
Core 2

Dr. Zaman 12
Performance Improvement
Threads 1, 2, 3, and 4: INT & FP Operations
(Multicore)InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Core 2
Thread 1: Integer Operation
Thread 3: Integer Operation
Thread 4: Floating Point Operation
Thread 2: Floating Point Operation
POSSIBLE?
Core 1

Dr. Zaman 13
More Performance?
Threads 1, 2, 3, and 4: INT & FP Operations
(Multicore)InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
InstructionFetch
InstructionDecode
Operand(s)Fetch
IntegerOperation
ArithmeticLogicUnit
ResultWriteBack
FloatingPointOperation
Core 2
Thread 1: Integer Operation
Thread 3: Integer Operation
Thread 4: Floating Point Operation
Thread 2: Floating Point Operation
POSSIBLE?
Core 1

Dr. Zaman 14
“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”
Outline ►■ Introduction
Single-Core to Multicore Architectures
■ Performance Improvement Simultaneous Multithreading (SMT) (SMT enabled) Multicore CPU with GPUs
■ Energy-Efficient Computing Dynamic GPU Selection
■ CAPPLab “People First” Resources Research Grants/Activities
■ Discussion

Dr. Zaman 15
Parallel/Concurrent Computing
Parallel Processing – It is not fun!Let’s play a game: Paying the lunch bill together
Started with $30; spent $29 ($27 + $2)Where did $1 go?
Friend Before Eating
Total Bill
Return Tip After Paying
A $10 $1
B $10 $25 $5 $2 $1
C $10 $1
Total $30 $2
Total Spent
$9
$9
$9
$27
SMT enabled Multicore CPU with Manycore GPU for Ultimate Performance!

Dr. Zaman 16
Performance Improvement
Simultaneous Multithreading (SMT)■ Thread
A running program (or code segment) is a process Process processes / threads
■ Simultaneous Multithreading (SMT) Multiple threads running in a single-processor at the same time Multiple threads running in multiple processors at the same time
■ Multicore Programming Language supports OpenMP, Open MPI, CUDA, …C

Dr. Zaman 17
Identify Challenges■ Sequential data-independent problems
C[] A[] + B[]♦ C[5] A[5] + B[5]
A’[] A[]♦ A’[5] A[5]
SMT capable multicore processor; CUDA/GPU Technology
Core 1 Core 2
Performance Improvement

Dr. Zaman 18
■ CUDA/GPU Programming■ GP-GPU Card
A GPU card with 16 streaming multiprocessors (SMs)
Inside each SM:• 32 cores
• 64KB shared memory
• 32K 32bit registers
• 2 schedulers
• 4 special function units
■ CUDA GPGPU Programming Platform
Performance Improvement

Dr. Zaman 19
Performance Improvement
CPU-GPU Technology■ Tasks/Data exchange mechanism
Serial Computations – CPU Parallel Computations - GPU
Dr. Zaman 20
Performance Improvement
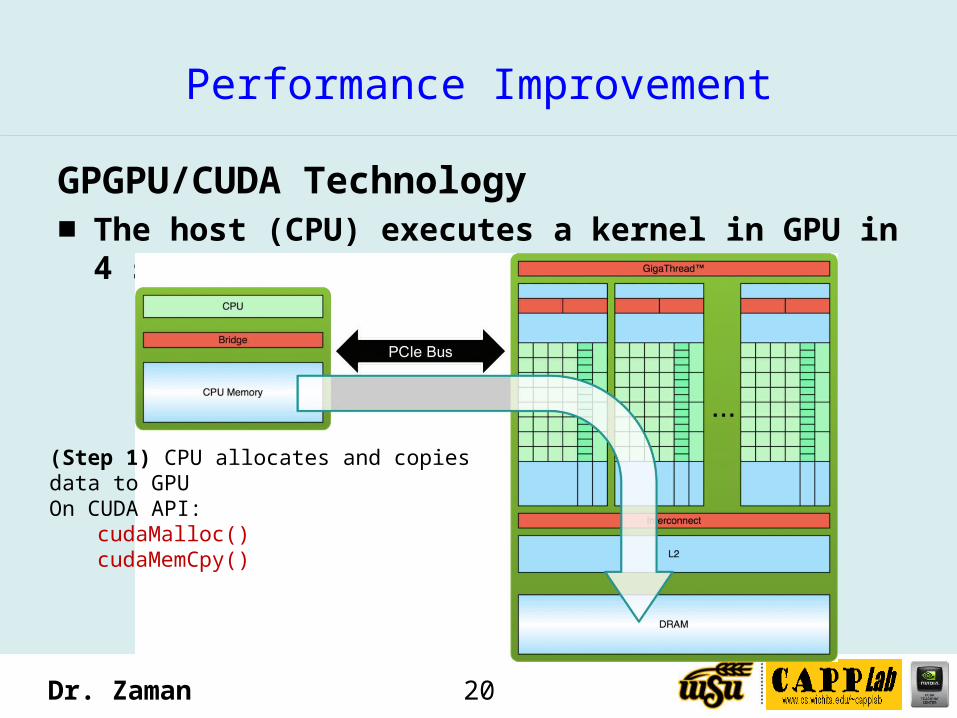
GPGPU/CUDA Technology■ The host (CPU) executes a kernel in GPU in 4 steps
(Step 1) CPU allocates and copies data to GPUOn CUDA API:
cudaMalloc()cudaMemCpy()

Dr. Zaman 21
Performance Improvement
GPGPU/CUDA Technology■ The host (CPU) executes a kernel in GPU in 4 steps
(Step 2) CPU Sends function parameters and instructions to GPU
CUDA API:
myFunc<<<Blocks, Threads>>>(parameters)

Dr. Zaman 22
Performance Improvement
GPGPU/CUDA Technology■ The host (CPU) executes a kernel in GPU in 4 steps
(Step 3) GPU executes instruction as scheduled in warps
(Step 4) Results will need to be copied back to Host memory (RAM) using cudaMemCpy()

Dr. Zaman 23
Performance Improvement
Case Study 1 (data independent computation without GPU/CUDA)
■ Matrix Multiplication
Matrices Systems

Dr. Zaman 24
Performance Improvement
Case Study 1 (data independent computation without GPU/CUDA)
■ Matrix Multiplication
Execution Time Power Consumption

Dr. Zaman 25
Performance Improvement
Case Study 2 (data dependent computation without GPU/CUDA)
■ Heat Transfer on 2D Surface
Execution Time Power Consumption

Dr. Zaman 26
Performance Improvement
Case Study 3 (data dependent computation with GPU/CUDA)
■ Fast Effective Lightning Strike Simulation The lack of lightning strike protection for the composite materials
limits their use in many applications.

Dr. Zaman 27
Performance Improvement
Case Study 3 (data dependent computation with GPU/CUDA)
■ Fast Effective Lightning Strike Simulation■ Laplace’s Equation■ Simulation
CPU OnlyCPU/GPU w/o shared memoryCPU/GPU with shared memory
Dr. Zaman 28
Performance Improvement
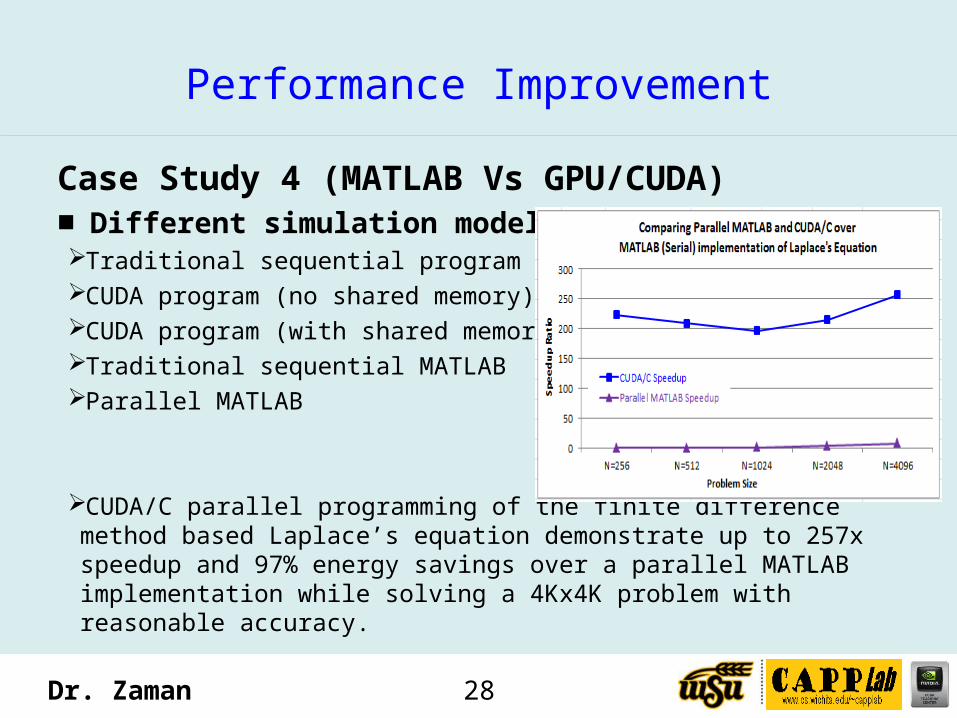
Case Study 4 (MATLAB Vs GPU/CUDA)■ Different simulation modelsTraditional sequential programCUDA program (no shared memory)CUDA program (with shared memory)Traditional sequential MATLABParallel MATLAB
CUDA/C parallel programming of the finite difference method based Laplace’s equation demonstrate up to 257x speedup and 97% energy savings over a parallel MATLAB implementation while solving a 4Kx4K problem with reasonable accuracy.
Dr. Zaman 29
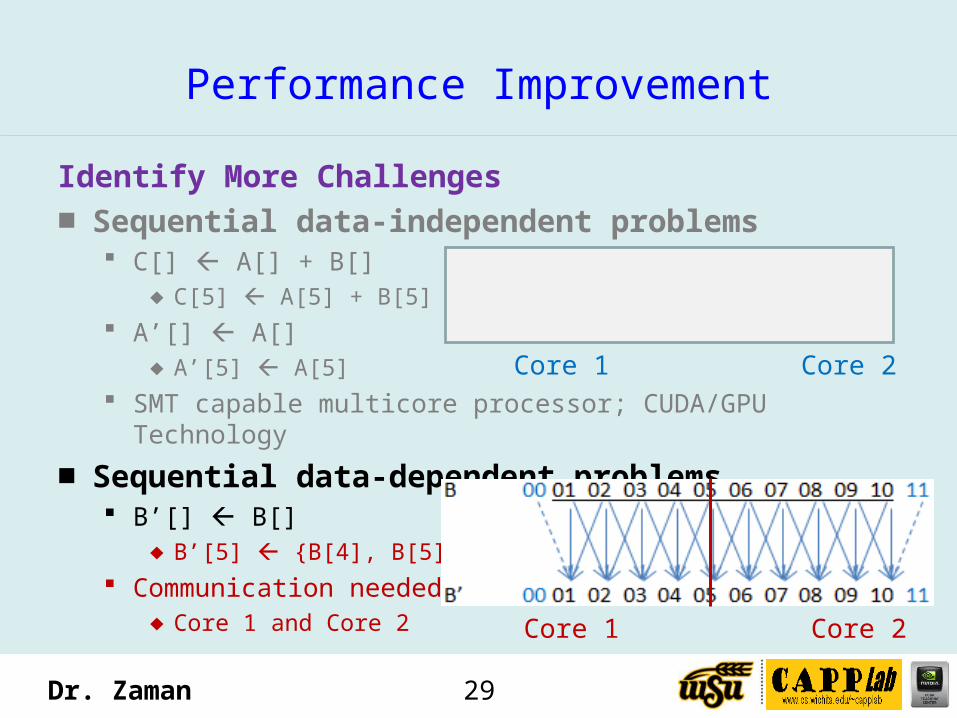
Identify More Challenges■ Sequential data-independent problems
C[] A[] + B[]♦ C[5] A[5] + B[5]
A’[] A[]♦ A’[5] A[5]
SMT capable multicore processor; CUDA/GPU Technology
■ Sequential data-dependent problems B’[] B[]
♦ B’[5] {B[4], B[5], B[6]}
Communication needed♦ Core 1 and Core 2
Core 1 Core 2
Core 1 Core 2
Performance Improvement

Dr. Zaman 30
Develop Solutions■ Task Regrouping
Create threads
■ Data Regrouping Regroup data Data for each thread
Threads with G2s first Then, threads with G1s
(Step 2 of 5) CPU copies data to GPUOn CUDA API:
cudaMemCpy()
Performance Improvement

Dr. Zaman 31
Assess the Solutions■ What is the Key?■ Synchronization
With synchronization Without synchronization
♦ Fast Vs. Accuracy
Threads with G2s first Then, threads with G1s
(Step 2 of 5) CPU copies data to GPUOn CUDA API:
cudaMemCpy()
Performance Improvement

Dr. Zaman 32
“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”
Outline ►■ Introduction
Single-Core to Multicore Architectures
■ Performance Improvement Simultaneous Multithreading (SMT) (SMT enabled) Multicore CPU with GP-GPU
■ Energy-Efficient Computing Dynamic GPU Selection
■ CAPPLab “People First” Resources Research Grants/Activities
■ Discussion

Dr. Zaman 33
Kansas Unique Challenge■ Climate and Energy
Protect environment from harms due to climate change
Save natural energy
Energy-Efficient Computing

Dr. Zaman 34
“Power” Analysis■ CPU with multiple GPU
GPU usages vary
■ Power Requirements NVIDIA GTX 460 (336-core) - 160W [1] Tesla C2075 (448-core) - 235W [2] Intel Core i7 860 (4-core, 8-thread) -
150-245W [3, 4]
■ Dynamic GPU Selection Depending on
♦ the “tasks”/threads
♦ GPU usages
CPU
GPU
GPUGPU
Energy-Efficient Computing

Dr. Zaman 35
CPU-to-GPU Memory Mapping■ GPU Shared Memory
Improves performance CPU to GPU global memory GPU global to shared
■ Data Regrouping CPU to GPU global memory
Energy-Efficient Computing

Dr. Zaman 36
Integrate Research into Education■ CS 794 – Multicore Architectures Programming
Multicore Architecture Simultaneous Multithreading Parallel Programming
Moore’s law Amdahl’s law Gustafson’s law Law of diminishing returns Koomey's law
Teaching Low-Power HPC Systems

Dr. Zaman 37
“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”
Outline ►■ Introduction
Single-Core to Multicore Architectures
■ Performance Improvement Simultaneous Multithreading (SMT) (SMT enabled) Multicore CPU with GP-GPU
■ Energy-Efficient Computing Dynamic GPU Selection
■ CAPPLab “People First” Resources Research Grants/Activities
■ Discussion

Dr. Zaman 38
WSU CAPPLab
CAPPLab■ Computer Architecture & Parallel Programming
Laboratory (CAPPLab) Physical location: 245 Jabara Hall, Wichita State University URL: http://www.cs.wichita.edu/~capplab/ E-mail: [email protected]; [email protected] Tel: +1-316-WSU-3927
■ Key Objectives Lead research in advanced-level computer architecture, high-
performance computing, embedded systems, and related fields. Teach advanced-level computer systems & architecture, parallel
programming, and related courses.

Dr. Zaman 39
WSU CAPPLab
“People First”■ Students
Kishore Konda Chidella, PhD Student Mark P Allen, MS Student Chok M. Yip, MS Student Deepthi Gummadi, MS Student
■ Collaborators Mr. John Metrow, Director of WSU HiPeCC Dr. Larry Bergman, NASA Jet Propulsion Laboratory (JPL) Dr. Nurxat Nuraje, Massachusetts Institute of Technology (MIT) Mr. M. Rahman, Georgia Institute of Technology (Georgia Tech) Dr. Henry Neeman, University of Oklahoma (OU)

Dr. Zaman 40
WSU CAPPLab
Resources■ Hardware
3 CUDA Servers – CPU: Xeon E5506, 2x 4-core, 2.13 GHz, 8GB DDR3; GPU: Telsa C2075, 14x 32 cores, 6GB GDDR5 memory
2 CUDA PCs – CPU: Xeon E5506, … Supercomputer (Opteron 6134, 32 cores per node, 2.3 GHz, 64
GB DDR3, Kepler card) via remote access to WSU (HiPeCC) 2 CUDA enabled Laptops More …
■ Software CUDA, OpenMP, and Open MPI (C/C++ support) MATLAB, VisualSim, CodeWarrior, more (as may needed)

Dr. Zaman 41
WSU CAPPLab
Scholarly Activities■ WSU became “CUDA Teaching Center” for 2012-13
Grants from NSF, NVIDIA, M2SYS, Wiktronics Teaching Computer Architecture and Parallel Programming
■ Publications Journal: 21 published; 3 under preparation Conference: 57 published; 2 under review; 6 under preparation Book Chapter: 1 published; 1 under preparation
■ Outreach USD 259 Wichita Public Schools Wichita Area Technical and Community Colleges Open to collaborate

Dr. Zaman 42
WSU CAPPLab
Research Grants/Activities■ Grants
WSU: ORCA NSF – KS NSF EPSCoR First Award M2SYS-WSU Biometric Cloud Computing Research Grant Teaching (Hardware/Financial) Award from NVIDIA Teaching (Hardware/Financial) Award from Xilinx
■ Proposals NSF: CAREER (working/pending) NASA: EPSCoR (working/pending) U.S.: Army, Air Force, DoD, DoE Industry: Wiktronics LLC, NetApp Inc, M2SYS Technology

Thank You!Contact: Abu Asaduzzaman
E-mail: [email protected]: +1-316-978-5261
http://webs.wichita.edu/aasaduzzaman/http://www.cs.wichita.edu/~capplab/
“Discovering Energy-Efficient High-Performance Computing Systems? WSU CAPPLab may help!”





























