Embed Size (px)
Citation preview

INTRODUCTION TO
Machine Learning
ETHEM ALPAYDIN© The MIT Press, 2004
[email protected]://www.cmpe.boun.edu.tr/~ethem/i2ml
Lecture Slides for

CHAPTER 10:
Linear Discrimination

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
3
Likelihood- vs. Discriminant-based Classification
Likelihood-based: Assume a model for p(x|Ci), use Bayes’ rule to calculate P(Ci|x)
gi(x) = log P(Ci|x)
Discriminant-based: Assume a model for gi(x|Φi); no density estimation
Estimating the boundaries is enough; no need to accurately estimate the densities inside the boundaries

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
4
Linear Discriminant
Linear discriminant:
Advantages:Simple: O(d) space/computation
Knowledge extraction: Weighted sum of attributes; positive/negative weights, magnitudes (credit scoring)Optimal when p(x|Ci) are Gaussian with shared cov matrix; useful when classes are (almost) linearly separable
( ) 01
00| ij
d
jiji
Tiiii wxwww,g +=+= ∑
=
xwwx

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
5
Generalized Linear Model
Quadratic discriminant:
Higher-order (product) terms:
Map from x to z using nonlinear basis functions and use a linear discriminant in z-space
215224
2132211 xxz,xz,xz,xz,xz =====
( ) 00| iTii
Tiiii ww,,g ++= xwxxwx WW
( ) ( )∑=
=k
jjiji wg
1
xx φ

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
6
Two Classes( ) ( ) ( )
( ) ( )( ) ( )
0
201021
202101
21
w
ww
ww
ggg
T
T
TT
+=
−+−=
+−+=
−=
xw
xww
xwxw
xxx
( )⎩⎨⎧ >
otherwise
0if choose
2
1
C
gC x
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
7
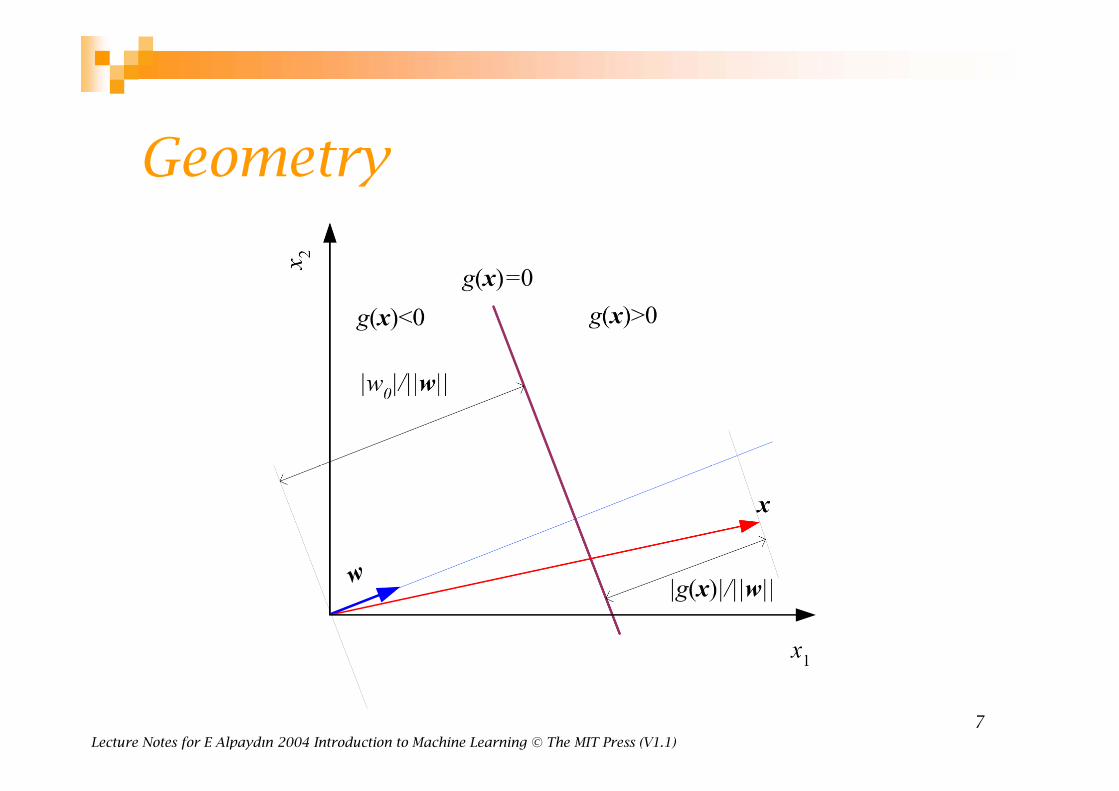
Geometry

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
8
Multiple Classes( ) 00| i
Tiiii ww,g += xwwx
Classes arelinearly separable
( ) ( )xx j
K
ji
i
gg
C
1max
if Choose
==

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
9
Pairwise Separation( ) 00| ij
Tijijijij ww,g += xwwx
( )⎪⎩
⎪⎨
⎧∈≤∈>
=otherwisecare tdon'
if 0
if 0
j
i
ij C
C
g x
x
x
( ) 0
if choose
>≠∀ xij
i
g,ij
C

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
10
From Discriminants to Posteriors
When p (x | Ci ) ~ N ( µi , ∑)
( )
( )iiTiiii
iTiiii
CPw
ww,g
log21
|
10
1
00
+−==
+=
−− µµµ ΣΣw
xwwx
( ) ( )
( )( )[ ]
otherwise and
01 log
11
50
if choose
1| and |
21
21
C
y/y
y/y
.y
C
yCPCPy
⎪⎩
⎪⎨
⎧
>−>−
>
−=≡ xx

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
11
( )( ) ( )( )
( )( )
( )( )
( )( )
( ) ( )( ) ( )[ ]( ) ( )( ) ( )[ ]
( )( )
( ) ( ) ( )
( )( )
( ) ( ) ( )[ ]001
01
1
211
210211
0
2
1
21
2
212
11
1
212
2
1
2
1
2
1
1
11
exp1
1sigmoid|
|1
|log
logitof inverse The 21
where
log21exp2
21exp2log
log|
|log
|
|log
|1
|log|logit
wwCP
wCP
CP
w
w
CP
CP
/
/
CP
CP
Cp
Cp
CP
CP
CP
CPCP
TT
T
T
T
T//d
T//d
+−+=+=
+=−
−+−=−=
+=
+−−−π
−−−π=
+=
=−
=
−−
−−−
−−−
xwxwx
xwx
x
w
xw
xx
xx
x
x
x
x
x
xx
µµµµµµ
µµ
µµ
ΣΣ
ΣΣ
ΣΣ

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
12
Sigmoid (Logistic) Function
( ) ( )( ) 50if choose and sigmoid Calculate 2.
or ,0if choose and Calculate 1.
10
10
.yCwy
gCwgT
T
>+=
>+=
xw
xxwx

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
13
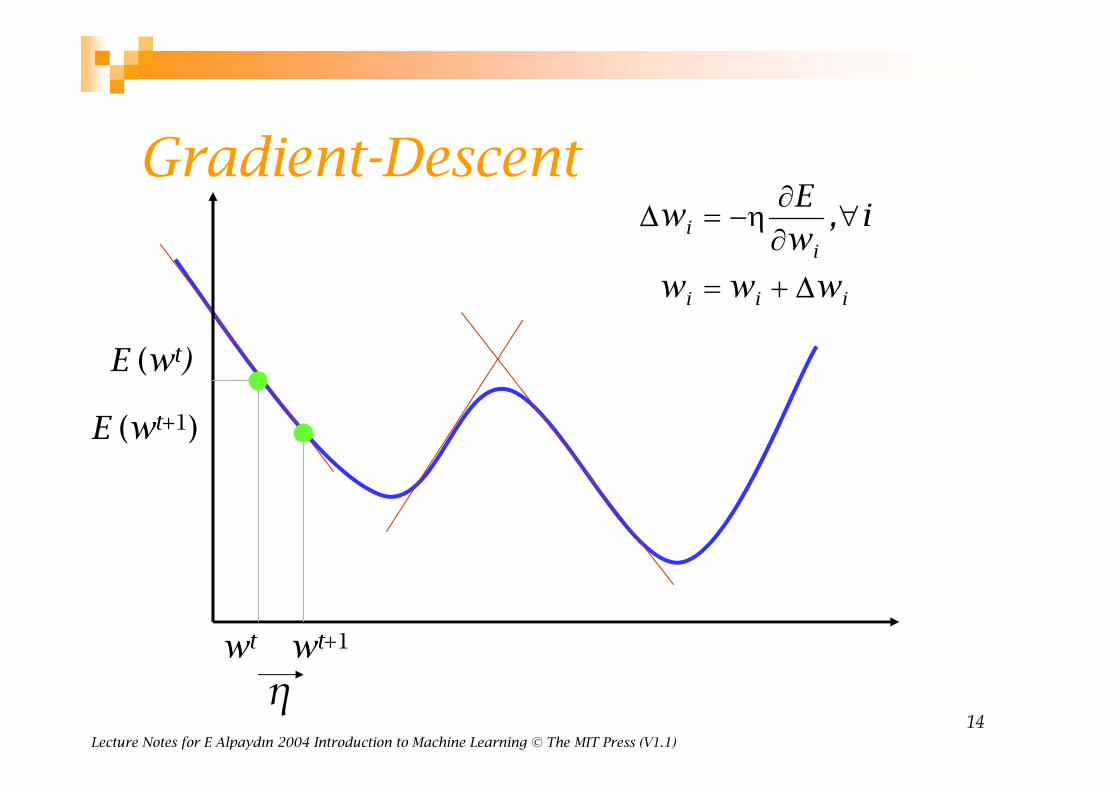
Gradient-Descent
E(w|X) is error with parameters w on sample Xw*=arg minw E(w | X)
Gradient
Gradient-descent: Starts from random w and updates w iteratively in the negative direction of gradient
T
dw w
E,...,
wE
,wE
E ⎥⎦
⎤⎢⎣
⎡∂∂
∂∂
∂∂
=∇21
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
14
Gradient-Descent
wt wt+1
η
E (wt)
E (wt+1)
iii
ii
www
i,wE
w
∆
∆
+=
∀∂∂
η−=

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
15
Logistic Discrimination
Two classes: Assume log likelihood ratio is linear
( )( )
( )( ) ( )( )
( )( )
( )( )
( )( )
( ) ( )[ ]01
2
100
0
2
1
2
1
1
11
02
1
exp1
1|
log where
log|
|log
|1
|log|logit
|
|log
wCP̂y
CP
CPww
w
CP
CP
Cp
Cp
CP
CPCP
wCp
Cp
T
o
T
oT
+−+==
+=
+=
+=−
=
+=
xwx
xw
x
x
x
xx
xwx
x

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
16
Training: Two Classes
{ } ( )( ) ( )[ ]
( ) ( )( )( )( )
( ) ( ) ( )ttt
t
t
rt
t
rt
T
tttt
tt
yryrw,E
lE
yyw,l
wCPy
y~rr,
tt
−−+−=
−=
−=
+−+==
=
∑
∏ −
1 log1 log|
log
1|
exp11
|
Bernoulli|
0
1
0
01
X
X
X
w
w
xwx
xx

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
17
Training: Gradient-Descent( ) ( ) ( )
( ) ( )
( )
( )
( )∑
∑
∑
∑
−=∂∂
−=∆
=−=
−⎟⎟⎠
⎞⎜⎜⎝
⎛−−
−=∂∂
−=∆
−==
−−+−=
t
tt
t
tj
tt
tj
tt
tt
t
t
t
jj
ttt
t
t
yrwE
w
d,...,j,xyr
xyyyr
yr
wE
w
yydady
y
yryrw,E
ηη
η
ηη
00
0
1
111
1 asigmoidIf
1 log1 log| Xw

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
18

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
19
10
100 1000

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
20
{ } ( )( )( )
( ) [ ][ ]
{ }( ) ( )( )
{ }( )
( ) ( )∑∑
∑
∏∏∑
−η=−η=
−=
=
=+
+==
+=
=
=
t
tj
tjj
t
t
tj
tjj
ti
t
tiiii
t i
rtiiii
K
j jTj
iTi
i
oi
Ti
K
i
tK
ttt
tt
yrwyr
yrw,E
yw,l
K,...,i,w
wCP̂y
wCpCp
,~r,
ti
0
0
0
1 0
0
0
log|
|
1exp
exp|
||
log
1Mult|
∆∆ xw
w
w
xw
xwx
xwxx
yxrx
X
X
X
K>2 Classes
softmax

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
21

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
22
Example

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
23
Generalizing the Linear Model
Quadratic:
Sum of basis functions:
where φ(x) are basis functions Kernels in SVM
Hidden units in neural networks
( )( ) 0|
|log i
Tii
T
K
i wCpCp
++= xwxxxx
W
( )( ) ( ) 0|
|log i
Ti
K
i wCpCp
+φ= xwxx

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
24
Discrimination by Regression
Classes are NOT mutually exclusive and exhaustive
( )( ) ( )[ ]
( ) ( )
( ) ( )( ) ( ) ttt
t
tt
t
tt
tt
t
tTtTt
tt
yyyr
yrw,E
yrw,l
wwy
,~yr
xw
w
w
xwxw
−−η=
−=
⎥⎥⎦
⎤
⎢⎢⎣
⎡
σ−
−πσ
=
+−+=+=
σεε+=
∑
∑
∏
1
21
|
2exp
2
1|
exp1
1sigmoid
0 where
2
0
2
2
0
00
2
∆
X
X
N

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
25
Optimal Separating Hyperplane
(Cortes and Vapnik, 1995; Vapnik, 1995)
{ }
( ) 1
as rewritten be can which
1 for 1
1 for 1
that such and find
if 1
if 1 where
0
0
0
0
2
1
+≥+
−=+≤+
+=+≥+
⎩⎨⎧
∈−∈+
==
wr
rw
rw
w
C
Crr,
tTt
ttT
ttT
t
tt
ttt
xw
xw
xw
w
x
xxX

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
26
Margin
Distance from the discriminant to the closest instances on either side
Distance of x to the hyperplane is
We require
For a unique sol’n, fix ρ||w||=1and to max margin
w
xw 0wtT +
( )t,
wr tTt
∀ρ≥+
w
xw 0
( ) t,wr tTt ∀+≥+ 1 to subject 21 min 0
2xww

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
27

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
28
( )
( )[ ]
( )
00
0
21
121
1 to subject 21 min
10
1
110
2
10
2
0
2
=α⇒=∂
∂
α=⇒=∂
∂
α++α−=
−+α−=
∀+≥+
∑
∑
∑∑
∑
=
=
==
=
N
t
ttp
N
t
tttp
N
t
tN
t
tTtt
N
t
tTttp
tTt
rw
L
rL
wr
wrL
t,wr
xww
xww
xww
xww

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
29
Most αt are 0 and only a small number have αt >0; they are the support vectors
( )
( )
( )
∑
∑∑∑
∑
∑ ∑∑
∀≥=
+−=
+−=
+−−=
t
0
0 and 0 to subject
21
21
21
t,r
rr
rwrL
ttt
t
tsTtst
t s
st
t
tT
t t
ttt
t
tttTTd
αα
ααα
α
ααα
xx
ww
xwww

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
30
Soft Margin Hyperplane
Not linearly separable
Soft error
New primal is
( ) ttTt wxr ξ−≥+ 10w
∑ξt
t
( )[ ] ∑∑∑ ξµ−ξ+−+α−ξ+=t
tt
t
ttTtt
t
tp wxrCL 1
21
0
2ww

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
31
( )
( ) ( ) ( ) ( )
( ) ( )∑
∑
∑∑
α=
α==
α=α=
t
ttt
t
TtttT
t
ttt
t
ttt
,Krg
rg
rr
xxx
xφxφxφwx
xφzw
Kernel Machines
Preprocess input x by basis functions
z = φ(x) g(z)=wTz
g(x)=wT φ(x)
The SVM solution

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
32
Kernel Functions
Polynomials of degree q:
Radial-basis functions:
Sigmoidal functions:
( ) ( )qtTt ,K 1+= xxxx
(Cherkassky and Mulier, 1998)
( ) ( )( )
( ) [ ]T
T
x,x,xx,x,x,
yxyxyyxxyxyx
yxyx
,K
22
212121
22
22
21
2121212211
22211
2
2221
2221
1
1
=φ
+++++=
++=
+=
x
yxyx
( )⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
σ
−−= 2
2
expxx
xxt
t ,K
( ) ( )12tanh += tTt ,K xxxx
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
33
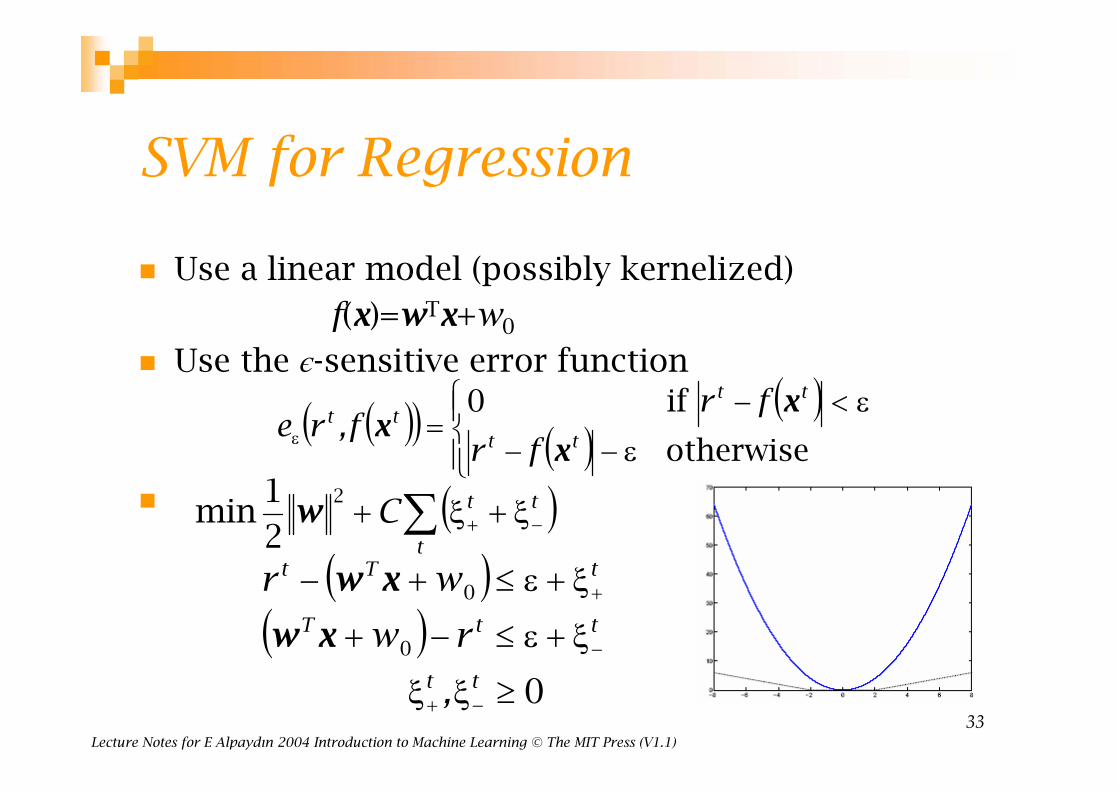
SVM for Regression
Use a linear model (possibly kernelized)
f(x)=wTx+w0
Use the є-sensitive error function
( )( ) ( )( )⎪⎩
⎪⎨⎧
ε−−
ε<−=ε otherwise
if 0tt
tttt
fr
frf,re
x
xx
( )( )
00
0
≥ξξ
ξ+ε≤−+
ξ+ε≤+−
−+
−
+
tt
ttT
tTt
,
rw
wr
xw
xw
( )∑ −+ ξ+ξ+t
ttC2
21
min w





























