Embed Size (px)
Citation preview

Intro to Machine Learning
Parameter Estimation for Bayes NetsNaïve Bayes

Recall: Key Components of Intelligent Agents
Representation Language: Graph, Bayes Nets
Inference Mechanism: A*, variable elimination, Gibbs sampling
Learning Mechanism: For today!
-------------------------------------Evaluation Metric

Machine Learning
Determining a model for how something works, based on examples of it working (data).
This is a very general problem, that has lots of applications.
Many big companies today are getting rich by doing this well.

Quiz: Companies doing ML
For each company below, think of a type of data that the company can use to learn something useful.
Company What kind of data?
What can the company learn from the data?
Amazon
Netflix

Answer: Companies doing ML
For each company below, think of a type of data that the company can use to learn something useful.
Company What kind of data? What can the company learn from the data?
Google Email Spam vs. not spam (ham)
Amazon Who buys what How to recommend products to people
Netflix Who views what How to recommend videos to people
Facebook Who knows whom How to display ads effectively

ML in Research Systems• DARPA Grand Challenge
Some of my own research: Learning to understand English sentences
“Secretary of Energy Steven Chu announced Friday that he was resigning pending the confirmation of a successor.”
System can predict:- announced is an action- Secretary of Energy Steven Chu is a person who is doing the action- Friday is a date/time describing when the action happened- he was resigning pending the confirmation of a successor is the thing being
announced.
Very few AI systems today have no learning component.

Example: Parameter Estimation in BNs
Recall this BN from before.
Let’s pretend now that none of the parameters were given to you.
Happy?
Sunny? Raise?
S P(S)
+s 0.7
R P(R)
+r 0.01
H S R P(H|S,R)
+h +s +r 1.0
+h +s -r 0.7
+h -s +r 0.9
+h -s -r 0.1

Example: Parameter Estimation in BNs
How can we figure out what these parameters should be?
The ML answer:1. Collect some data2. Find parameters that explain this data
Happy?
Sunny? Raise?
S P(S)
+s ?
R P(R)
+r ?
H S R P(H|S,R)
+h +s +r ?
+h +s -r ?
+h -s +r ?
+h -s -r ?

Example: Parameter Estimation in BNs
Example Data1. +s, -r, +h2. +s, +r, +h3. +s, -r, +h4. -s, -r, -h5. +s, -r, +h6. -s, -r, -h
Happy?
Sunny? Raise?
S P(S)
+s ?
R P(R)
+r ?
H S R P(H|S,R)
+h +s +r ?
+h +s -r ?
+h -s +r ?
+h -s -r ?

Quiz: Parameter Estimation in BNs
Example Data1. +s, -r, +h2. +s, +r, +h3. +s, -r, +h4. -s, -r, -h5. +s, -r, +h6. -s, -r, -h
Given the data above, what would you estimate forP(+s) = P(+r) = P(+h | +s, -r) =
Happy?
Sunny? Raise?
S P(S)
+s ?
R P(R)
+r ?
H S R P(H|S,R)
+h +s +r ?
+h +s -r ?
+h -s +r ?
+h -s -r ?

Answer: Parameter Estimation in BNs
Example Data1. +s, -r, +h2. +s, +r, +h3. +s, -r, +h4. -s, -r, -h5. +s, -r, +h6. -s, -r, -h
Given the data above, what would you estimate forP(+s) = 4 / 6 = 0.67P(+r) = 1 / 6 = 0.167P(+h | +s, -r) = 2 / 3 = 0.67
Happy?
Sunny? Raise?
S P(S)
+s ?
R P(R)
+r ?
H S R P(H|S,R)
+h +s +r ?
+h +s -r ?
+h -s +r ?
+h -s -r ?

Maximum Likelihood Parameter Estimation
To estimate a parameter P(X1=a1, …, XN=aN | Y1=b1, …, YM=bM)
Maximum Likelihood Estimation (MLE) Algorithm:1. Cjoint = Count how many times (X1=a1, …, XN=aN,
Y1=b1, …, YM=bM) appears in the dataset.
2. Cmarginal = Count how many times (Y1=b1, …, YM=bM) appears in the dataset
3. Set the parameter = Cjoint / Cmarginal

Quiz: MLE
What’s the difference between MLE and rejection sampling?

Answer: MLE
What’s the difference between MLE and rejection sampling?
The parameter estimation procedure is the same, but rejection sampling gets its samples by generating them from the Bayes Net. This requires knowing the parameters of the BN.
MLE gets its samples from some external source.

Where does data come from?This is a fundamental practical consideration for machine learning.
The answer: wherever you can get it the easiest.
Some examples: - For medical diagnosis ML systems, the system needs examples of X-ray images that
are labeled with a diagnosis, e.g. “bone broken” or “bone not broken”. Typically, this data needs to be gotten from a “human expert”, in this case a doctor trained in radiology. These people’s time is EXPENSIVE, so there’s usually not a lot of this data available.
- For speech recognition ML systems, the system needs examples of speech recordings (audio files), labeled with the corresponding English words. You can pay users of Amazon’s Mechanical Turk a couple of pennies per example to label these audio files.
- “Language models” are systems that are really important for processing human language. These systems try to predict the next word in a sequence of words. These systems need examples of English sentences. There are billions of such sentences available on the Web and other places; to get these, you just need to write some software to crawl the Web and grab the sentences.

Likelihood
Likelihood is a term to refer to the following probability:
P(D | M), where D is your data, and M is your model (in our case, a Bayes Net).
When the data consists of multiple examples, most often (but not always) ML assumes that these examples are independent.
This means we can re-write the likelihood like this:P(d1, …, dk | M) = P(d1 | M) P(d2 | M) P(dk | M)

Quiz: Likelihood
Example Data1. +s, -r, +h2. +s, +r, +h
What is the likelihood of this data, given this BN?Happy?
Sunny? Raise?
S P(S)
+s 0.7
R P(R)
+r 0.01
H S R P(H|S,R)
+h +s +r 1.0
+h +s -r 0.7
+h -s +r 0.9
+h -s -r 0.1

Answer: Likelihood
Example Data1. +s, -r, +h2. +s, +r, +h
What is the likelihood of this data, given this BN?
Likelihood is P(D | BN)= P(d1 | BN) * P(d2 | BN)= P(+s, -r, +h) * P(+s, +r, +h)= P(+s)P(-r)P(+h | +s, -r) *
P(+s)P(+r)P(+h | +s, +r)= .7*.99*.7 * .7*.01*1 = .0034
Happy?
Sunny? Raise?
S P(S)
+s 0.7
R P(R)
+r 0.01
H S R P(H|S,R)
+h +s +r 1.0
+h +s -r 0.7
+h -s +r 0.9
+h -s -r 0.1

Maximum Likelihood
“Maximum Likelihood Estimation” is called that because the parameters it finds for dataset D are the parameters that make P(D | BN) biggest.
Data1. +s, -r, +h2. +s, +r, +h3. +s, -r, +h4. -s, -r, -h5. +s, -r, +h6. -s, -r, -h
Let m be the maximum likelihood estimate for P(S).
P(D | BN) = m * P(-r) * P(-h|+s, -r) * m * P(+r) * P(+h | +s, +r) * m * P(-r) * P(+h | +s, -r) * (1-m) * P(-r) * P(-h | -s, -r) * m * P(-r) * P(+h | +s, -r) * (1-m) * P(-r) * P(-h | -s, -r)

Maximum LikelihoodMathematical trick: Finding the biggest point of f(m) is equivalent to finding the biggest point of log f(m).
P(D | BN) = m * P(-r) * P(-h|+s, -r) * m * P(+r) * P(+h | +s, +r) * m * P(-r) * P(+h | +s, -r) * (1-m) * P(-r) * P(-h | -s, -r) * m * P(-r) * P(+h | +s, -r) * (1-m) * P(-r) * P(-h | -s, -r)
l og𝑃 (𝐷|𝐵𝑁 ¿¿=¿ log𝑚+log 𝑃 (−𝑟 )+ log 𝑃 (−h|+𝑠 ,−𝑟 ¿ ¿+ log𝑚+ log 𝑃 (+𝑟 )+ log𝑃 (+h∨+𝑠 ,+𝑟 )¿
+log𝑚+ log 𝑃 (−𝑟 )+log 𝑃 (+h∨+𝑠 ,−𝑟 )+ log(1−𝑚)+log 𝑃 (−𝑟 )+ log 𝑃 (−h∨−𝑠 ,−𝑟 )
+log𝑚+ log 𝑃 (−𝑟 )+log 𝑃 (+h∨+𝑠 ,−𝑟 )+ log(1−𝑚)+log 𝑃 (−𝑟 )+ log 𝑃 (−h∨−𝑠 ,−𝑟 )
¿

Maximum LikelihoodTo find the largest point of P(D | BN), we’ll take the derivative:
𝑑 log 𝑃 (𝐷|𝐵𝑁 ¿𝑑𝑚
¿=¿ 1𝑚
¿+ 1𝑚
¿
+1𝑚
−1
1−𝑚+1𝑚
−1
1−𝑚
¿
l og𝑃 (𝐷|𝐵𝑁 ¿¿=¿ log𝑚+log 𝑃 (−𝑟 )+ log 𝑃 (−h|+𝑠 ,−𝑟 ¿ ¿+ log𝑚+ log 𝑃 (+𝑟 )+ log𝑃 (+h∨+𝑠 ,+𝑟 )¿
+log𝑚+ log 𝑃 (−𝑟 )+log 𝑃 (+h∨+𝑠 ,−𝑟 )+ log(1−𝑚)+log 𝑃 (−𝑟 )+ log 𝑃 (−h∨−𝑠 ,−𝑟 )
+log𝑚+ log 𝑃 (−𝑟 )+log 𝑃 (+h∨+𝑠 ,−𝑟 )+ log(1−𝑚)+log 𝑃 (−𝑟 )+ log 𝑃 (−h∨−𝑠 ,−𝑟 )
¿

Maximum LikelihoodTo find the largest point of P(D | BN), we’ll set the derivative equal to zero:
𝑑 log 𝑃 (𝐷|𝐵𝑁 ¿𝑑𝑚
¿=¿ 4𝑚−
21−𝑚
=0¿¿¿4𝑚
=2
1−𝑚
4−4𝑚=2𝑚
𝑚=46=23
Notice: This is the same value that you got by doing the MLE algorithm!

More typical ML example: Spam Detection
Dear Anita, We love our customers! To show our appreciation, Pita Delite is happy to announce the $5.99 Meal Deal. For only $5.99, get a sandwich (hot or cold), one side and a drink at Pita Delite. Offer valid in the Greensboro and High Point locations until February 28, 2013. We hope to see you soon! The Pita Delite Team PS Like us Facebook and follow us on Twitter for special offers.
...and here's a gift from us to you. Enter the discount code LOVE2LOVE during the checkout and get 10% off your purchase.
I'm sorry for how late this email is. I was planning on getting youinformation sooner but I have been very busy. Here is my resume, itshould be enough information about me that would be useful in a letterof recommendation. Thank you for doing this.
SPAM SPAM
HAM!

Email users supply labeled dataInbox Report Spam?
From: Mom, Subject: coming over for dinner tonight?
From: student, Subject: help with assignment
From: Pita Delite, Subject: $5.99 Deal Meal from Pita Delite
From: Cash Loan Providers, Subject: Big Bills and No Way to pay them?
From: AAAI-13, Subject: tentative assignment
…
X
X
X Yf

Building a classifier, Step 1
Text is complicated, and systems aren’t good enough yet to be able to understand it.
Step 1 is to simplify the X variable to something that is computationally easy to handle.

“Bag of Words” Representation
1. Construct a dictionary, which contains the set of distinct words in all of your examples.
...and here's a gift from us to you. Enter the discount code LOVE2LOVE during the checkout and get 10% off your purchase.
I'm sorry for how late this email is. I was planning on getting youinformation sooner but I have been busy. …
Dear Anita, We love our customers! To show our appreciation, Pita Delite is happy to announce the $5.99 Meal Deal. …
Dictionarydearanitaweloveourcustomerstoshowappreciationpita
deliteishappyannouncethe$5.99mealdealandhere’sa
giftfromusyouenterdiscountcodelove2loveduringcheckoutget
10%offyourpurchasei’msorryforhowlatethisemail
iwasplanningongettinginformationsoonerbuthavebeenbusy

“Bag of Words” Representation
2. For each email, for each word w in the dictionary, count how many times w appears in the email.
Dear Anita, We love our customers! To show our appreciation, Pita Delite is happy to announce the $5.99 Meal Deal. …
dear we to show … gift 10% … sorry late
1 1 2 1 0 0 0 0

“Bag of Words” Representation
2. For each email, for each word w in the dictionary, count how many times w appears in the email.
dear we to show … gift 10% … sorry late
1 1 2 1 0 0 0 0
0 0 1 0 1 1 0 0
...and here's a gift from us to you. Enter the discount code LOVE2LOVE during the checkout and get 10% off your purchase.

“Bag of Words” Representation
2. For each email, for each word w in the dictionary, count how many times w appears in the email.
dear we to show … gift 10% … sorry late
1 1 2 1 0 0 0 0
0 0 1 0 1 1 0 0
0 0 0 0 0 0 1 1
I'm sorry for how late this email is. I was planning on getting youinformation sooner but I have been busy. …

“Bag of Words” Representationdear we to show … gift 10% … sorry late Spam?
1 1 2 1 0 0 0 0 +spam
0 0 1 0 1 1 0 0 +spam
0 0 0 0 0 0 1 1 +ham
X now consists of a number of numerical “features” or “attributes”, X1 up to XN.
We’ll use these features to construct the classifier.
You can think of each of these features as an observable random variable.

Quiz: Bag of words
Below are three (contrived) email messages. Construct a bag of words representation for each.
Message
i love sports
sports fans love energy drink
you will love this energy drink

Quiz: Bag of words (answer)
Below are three (contrived) email messages. Construct a bag of words representation for each.
Message
i love sports
sports fans love energy drink
you will love this energy drink
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0
0 1 1 1 1 1 0 0 0
0 1 0 0 1 1 1 1 1

Quiz: Bayesian spam classifier
If you had to come up with a Bayes Net to predict which of these messages was Spam, what would it look like?
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Answer: Bayesian spam classifier
If you had to come up with a Bayes Net to predict which of these messages was Spam, what would it look like?
Lots of possible answers for this, I’ll show a common kind of BN used for this next.
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Building a classifier, Step 2
Once you’ve got a set of features for your examples, it’s time to decide on what type of classifier you’d like to use.
Technically, this is called choosing a hypothesis space – a set (or “space”) of possible classifiers (or “hypotheses”).
Bayes Nets can make fine classifiers. However, the space of ALL Bayes Nets is too big for building a good spam detector. We’re going to restrict our attention to a special class of Bayes Nets called Naïve Bayes models.

Naïve Bayes Classifier
Naïve Bayes is a simple and widely-used model in ML for many different problems.
It is a Bayes Net with one parent node and N children. The children are typically observable, and the parent is typically unobservable.
Y
X1 XNX2…
…
Notice the conditional independence assumption:Each Xi is conditionally independent of every Xj, given Y.

Learning a Naïve Bayes Classifier
Parameter Estimation for NBCs are the same as for other BNs.
To simplify our problem, we’ll assume all Xi variables are boolean (1 or 0).

Quiz: Learning a Naïve Bayes Classifier
How many parameters do we need to learn for our NBC for spam detection?
If we use MLE, what parameter would be learned for P(+spam)?
How about for P(+energy | +spam)?
How about for P(+will | +ham)?
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Answer: Learning a Naïve Bayes Classifier
How many parameters do we need to learn for our NBC for spam detection? 19 = 1 (+spam) + 9 (+word | +spam) + 9 (+word | +ham)
If we use MLE, what parameter would be learned for P(+spam)?2/3How about for P(+energy | +spam)?2/2 = 1.0How about for P(+will | +ham)?1/2 = 0.5
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Quiz: Prediction with an NBC Spam? P(S)
+spam 0.67
+ham 0.33
Word: i love sports fans energy drink you will this
P(+word|+spam): 0 1 0.5 0.5 1 1 0.5 0.5 0.5
P(+word|+ham): 1 1 1 0 0 0 0 0 0
Spam
I thislove …
…
What is P(Spam | “sports fans love this”)?
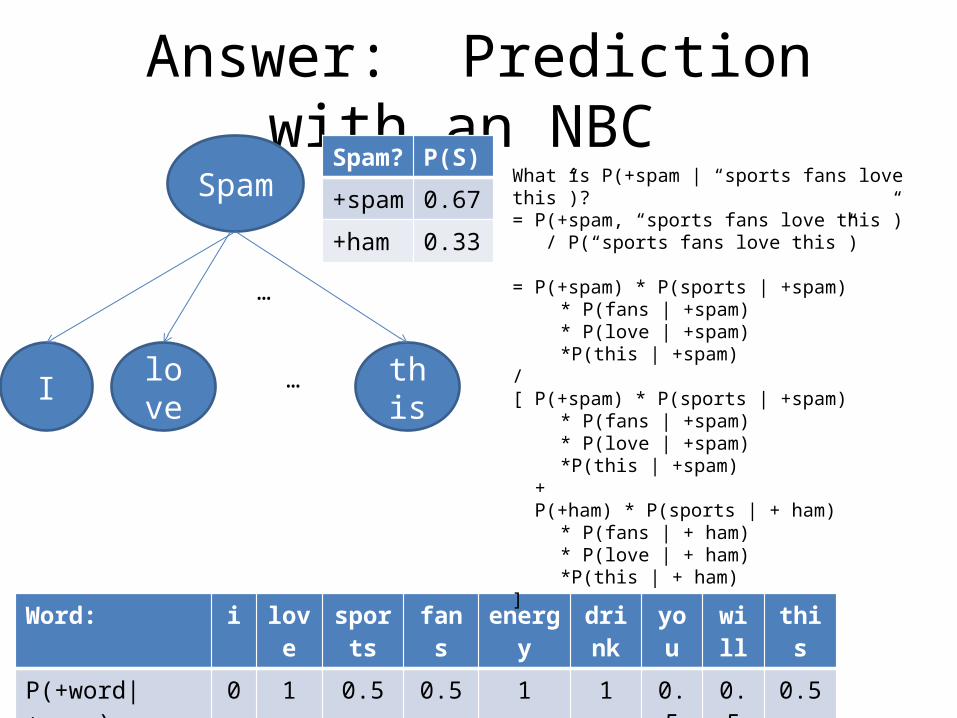
Answer: Prediction with an NBC Spam? P(S)
+spam 0.67
+ham 0.33
Word: i love sports fans energy drink you will this
P(+word|+spam): 0 1 0.5 0.5 1 1 0.5 0.5 0.5
P(+word|+ham): 1 1 1 0 0 0 0 0 0
Spam
I thislove …
…
What is P(+spam | “sports fans love this”)?= P(+spam, “sports fans love this”) / P(“sports fans love this”)
= P(+spam) * P(sports | +spam)* P(fans | +spam)* P(love | +spam)*P(this | +spam)
/ [ P(+spam) * P(sports | +spam)
* P(fans | +spam)* P(love | +spam)*P(this | +spam)
+ P(+ham) * P(sports | + ham)
* P(fans | + ham)* P(love | + ham)*P(this | + ham)
]

Answer: Prediction with an NBC Spam? P(S)
+spam 0.67
+ham 0.33
Word: i love sports fans energy drink you will this
P(+word|+spam): 0 1 0.5 0.5 1 1 0.5 0.5 0.5
P(+word|+ham): 1 1 1 0 0 0 0 0 0
Spam
I thislove …
…
What is P(+spam | “sports fans love this”)?= P(+spam) * P(+sports | +spam)
* P(+fans | +spam)* P(+love | +spam)*P(+this | +spam)
/ [ P(+spam) * P(+sports | +spam)
* P(+fans | +spam)* P(+love | +spam)*P(+this | +spam)
+ P(+ham) * P(+sports | + ham)
* P(+fans | + ham)* P(+love | + ham)*P(+this | + ham)
]= .67 * .5 * .5 * 1 * .5 / [.67 * .5 * .5 * 1 * .5 + .33 * 1 * 0 * 1 * 0]= 1.0
Note: the true answer would also include terms for P(-i | +spam), P(-energy | +spam), P(-drink | +spam), etc. I left them out for brevity.

Overfitting
Overfitting occurs when a statistical model (aka, a “classifier” in ML) describes random error or noise instead of the underlying relationship.
Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations.
A model which has been overfit will generally have poor predictive performance, as it can exaggerate minor fluctuations in the data.

Overfitting our NBCOur model has overfit. For instance, it believes there is ZERO CHANCE of seeing “I” in a spam message.
This is true in the 3 training messages, but it’s too strong of a conclusion to make from just 3 training examples.
It leads to poor predictions on new examples, such as P(+spam | “I love energy drink”)
Spam? P(S)
+spam 0.67
+ham 0.33
Word: i love sports fans energy drink you will this
P(+word|+spam): 0 1 0.5 0.5 1 1 0.5 0.5 0.5
P(+word|+ham): 1 1 1 0 0 0 0 0 0
Spam
thislove …
…
I

Laplace Smoothing
For binary variable X,
MLE from N examples:
Laplace-smoothed estimate: pretend we start with 2K (fake) examples, half with +x and half with –x.

Quiz: Laplace smoothing
Let K=1.
Assume our training data contains
1 example, of which 1 is +spam. P(+spam)=?10 examples, 4 of which are +spam. P(+spam)=?100 examples, 40 of which are +spam. P(+spam)=?1000 examples, 400 of which are +spam. P(+spam)=?

Answers: Laplace smoothingLet K=1.
Assume our training data contains
1 example, of which 1 is Spam. P(Spam)=(Count(spam)+1) / (N+2) = (1+1) / (1+2)= 2/3
10 examples, 4 of which are Spam. P(Spam)=(4+1) / (10+2) = 5/12 = 0.41666667
100 examples, 40 of which are Spam. P(Spam)= (40+1) / (100+2) = 41/102 = 0.401961
1000 examples, 400 of which are Spam. P(Spam)= (400+1) / 1000+2) = 401/1002 = 0.4001960
As the number of training examples increases, the Laplace smoothing has a smaller and smaller effect. It’s only when there’s not much training data that it has a big effect.

Quiz: Laplace SmoothingSpam? P(S)
+spam
+ham
Word: i love sports fans energy drink you will this
P(+word|+spam):
P(+word|+ham):
Spam
thislove …
… Fill in the parameters using Laplace smoothing, with K=1.
I
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Answers: Laplace SmoothingSpam? P(S)
+spam .6
+ham .4
Word: i Love sports fans energy drink you will this
P(+word|+spam): .25 .75 .5 .5 .75 .75 .5 .5 .5
P(+word|+ham): .67 .67 .67 .33 .33 .33 .33 .33 .33
Spam
thislove …
… Fill in the parameters using Laplace smoothing, with K=1.
I
i love sports fans energy drink you will this Spam?
1 1 1 0 0 0 0 0 0 +ham
0 1 1 1 1 1 0 0 0 +spam
0 1 0 0 1 1 1 1 1 +spam

Quiz: Laplace SmoothingSpam? P(S)
+spam .6
+ham .4
Word: i love sports fans energy drink you will this
P(+word|+spam): .25 .75 .5 .5 .75 .75 .5 .5 .5
P(+word|+ham): .67 .67 .67 .33 .33 .33 .33 .33 .33
Spam
thislove …
…
I
What is P(+spam | “sports fans love this”)?

Answer: Laplace SmoothingSpam? P(S)
+spam .6
+ham .4
Word: i love sports fans energy drink you will this
P(+word|+spam): .25 .75 .5 .5 .75 .75 .5 .5 .5
P(+word|+ham): .67 .67 .67 .33 .33 .33 .33 .33 .33
Spam
thislove …
…
I
What is P(+spam | “sports fans love this”)?= P(+spam) * P(+sports | +spam)
* P(+fans | +spam)* P(+love | +spam)*P(+this | +spam)
/ [ P(+spam) * P(+sports | +spam)
* P(+fans | +spam)* P(+love | +spam)*P(+this | +spam)
+ P(+ham) * P(+sports | + ham)
* P(+fans | + ham)* P(+love | + ham)*P(+this | + ham)
]= .6 * .5 * .75 * .5 / [.6 * .5 * .75 * .5 + .4 * .5 * .5 * .75 * .5]= .75 (not 1.0, like before)
Note: the true answer would also include terms for P(-i | +spam), P(-energy | +spam), P(-drink | +spam), etc. I left them out for brevity.

Types of LearningThe techniques we have discussed so far are examples of a particular kind of learning:
Supervised: the training examples included the correct labels or outputs.Vs. Unsupervised (or semi-supervised, or distantly-supervised, …): None (or some, or only part, …) of the labels in the training data are known.
Parameter Estimation: We only tried to learn the parameters in the BN, not the structure of the BN graph.Vs. Structure learning: The BN graph is not given as an input, and the learning algorithm’s job is to figure out what the graph should look like.
The distinctions below aren’t actually about the learning algorithm itself, but rather about the type of model being learned:
Classification: the output is a discrete value, like Happy or not Happy, or Spam or Ham.Vs. Regression: the output is a real number.
Generative: The model of the data represents a full joint distribution over all relevant variables.Vs. Discriminative: The model assumes some fixed subset of the variables will always be “inputs” or “evidence”, and it creates a distribution for the remaining variables conditioned on the evidence variables.
Parametric vs. Nonparametric: I will explain this later.
We won’t talk much about structure learning, but we will cover some other kinds of learning (regression, unsupervised, discriminative, nonparameteric, …) in later lectures.





























