Embed Size (px)
Citation preview

Intel® Processor Architecture:
SIMD Instructions
Intel® Software College

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Objectives
After completion of this module you will be able to understand
• SIMD rationale
• Intel SIMD instructions

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Agenda
SIMD Rationale
Intel SIMD History
SIMD Data Types
Intel SIMD Instructions Sets
Programming with Intel SIMD Instructions
Backup – Instructions Reference Table

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
• Increase processor throughput by performing multiple computations in a single instruction
• MMX™ technology, SSE, SSE2 and SSE3 are architectural extensions
Example (SSE 2)
Performs two double precision ops in one cycle
• a1+b1=c1 in parallel with a0+b0=c0
Useful for matrix operations
128-bit Registers
a1 a0
b1 b0
c1 c0
++ ++
SIMD (Single Instruction Multiple Data) Technology

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
MMX™ technology - Intel® Pentium® with MMX™ and Pentium® II processors• Introduced 64-bit MMX registers for SIMD integer operations• Supports SIMD operations on packed byte, word, and double-word integers• Useful for multimedia and communications software
SSE – Intel® Pentium® III processor• Introduced 128-bit extended memory manager (XMM) registers for SIMD integers and FP-SP operands• Executes FP and SIMD simultaneously• Introduced data prefetch instructions• Useful for 3D geometry, 3D rendering, and video encoding/decoding
SSE2 – Intel® Pentium® 4 and Intel® Xeon™ processors• Added extra 64-bit SIMD integer support• Has same XMM registers for SIMD integer and floating point double precision (FP-DP)• Has 144 new instructions for data support (no new registers)• Adds support for cacheability and memory ordering operations• Useful for 3D graphics, video encoding/decoding and encryption
SSE3 – Intel® Pentium® 4 Processor• Accelerates performance of Streaming SIMD Extensions technology, Streaming SIMD Extensions 2
technology, and X87-FP math capabilities.• Useful in some 3D operations (Quaternions), complex arithmetic and video codec algorithms
SSSE3 – Intel® Core® 2 Processor• application performance improvement.• potential for specifc application domains
Streaming SIMD Extensions
A brief history

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SSE Registers
128
Eight 128-bit registersEight 128-bit registers Hold data only:Hold data only:
4 x single FP numbers4 x single FP numbers 2 x double FP numbers2 x double FP numbers 128-bit packed integers128-bit packed integers
Direct access to the registersDirect access to the registers Use simultaneously with FP / Use simultaneously with FP / MMX TechnologyMMX Technology
MMX™ Technology / IA-FP Registers
8064
Eight 80/64-bit registersEight 80/64-bit registers Hold data onlyHold data only Stack access to FP0..FP7Stack access to FP0..FP7 Direct access to Direct access to MM0..MM7MM0..MM7 No MMX™ Technology / No MMX™ Technology / FP interoperabilityFP interoperability
IA-INT Registers
32
Fourteen 32-bit registersFourteen 32-bit registers Scalar data & addressesScalar data & addresses Direct access to regsDirect access to regs
X86 Register SetsSSE-Registers introduced first in Pentium® 3
mm0mm0
mm7mm7
xmm0xmm0
xmm7xmm7
st0st0
st7st7
eaxeax
ediedi
……

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
64-Bit Packed Integer Data Types 8 packed bytes
4 packed words
2 doublewords
63 31 0
63 31 0
63 31 0
SIMD Data Types (1)

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
128-bit Floating-Point and Integer Data Types 16 packed bytes integer
8 packed words integer
4 packed doublewords Single Precision Floating Point or Integer
2 quadwords Double Precision Floating Point or Integer127 63 0
127 63 03132
127 63 01516
127127 00776363 88
SIMD Data Types (2)

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
• Packed BCD data-type Packed BCD Integers
80-Bit Packed BCD Decimal Integers
BCD BCD
7 3 0
SIMD Data Types (3)
79 0
X D17
71
D16 …… D0

Copyright © 2006, Intel Corporation. All rights reserved.
2001 PTE Engineering Enabling Conference
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SSE-Instructions Set Extensions
Introduced by Pentium® 3 in 1999; now frequently called SSE-1
Only new data type supported: 4x32Bit (Single Precision) floating point data
Some 70 instructions
• Arithmetic, compare, convert operations on SSE SP FP data• PACKED, UNPACKED
• Data load/store
• Prefetch
• Extension of MMX
• Streaming Store (store without using cache in between)
• …

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SSE Sample: Branch Removal
R = (R = (AA < < BB)? )? CC : : DD //remember: everything packed
0.00.0A
B
0.00.0 -3.0-3.0 3.03.0
0.00.0 1.01.0 -5.0-5.0 5.05.0
cmpltcmplt
0000000000 1111111111 0000000000 1111111111
andand
c3c3 c2c2 c1c1 c0c0
0000000000 c2c2 0000000000 c0c0
nandnand
d3d3 d2d2 d1d1 d0d0
d3d3 0000000000 d1d1 0000000000
oror
d3d3 c2c2 d1d1 c0c0

Copyright © 2006, Intel Corporation. All rights reserved.
2001 PTE Engineering Enabling Conference
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SSE-2 Instructions Set Extensions
Introduced by Intel® Pentium®4 processor in 2000
Some 140 new instructions
Added double precision floating point data (2x64Bit) and all related instructions including conversion
Again some extensions to MMX
Added all possible combinations of integer data to SSE ( 1x128, 2x64, 4x32, 8x16, 16x8) and related operations

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SIMD Single vs. SIMD Double
002222232330303131
SIMD SP FP Operand = 4 Elements
Element = SP FP Number
005151525262626363
SIMD DP FP Operand = 2 Elements
Element = DP FP Number
4 x Single Precision:4 x Single Precision:SSE-1SSE-1
2 x Double Precision:2 x Double Precision:SSE-2 SSE-2
X3X3 X2X2 X1X1 X0X0
SS ExponentExponent SignificandSignificand
X1X1 X0X0
SS ExponentExponent SignificandSignificand
00127127
127127 00

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Sample for SSE-2: SIMD Double SIMD Int Conversion
SIMD Double SIMD Int: conversion to two lower ints, two higher ints cleared
x1x1 x0x0
0000000000 0000000000 (int)x1(int)x1 (int)x0(int)x0
__m128d x;__m128i ix;ix = _mm_cvtpd_epi32(x);
???????? ???????? ix1ix1 ix0ix0
(double)x1(double)x1 (double)x0(double)x0
x = _mm_cvtepi32_pd(ix);
SIMD Int SIMD Int SIMD Double: conversion from SIMD Double: conversion from two lower two lower intintss

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SIMD FP using AOS format*
Thread Synchronization
Video encoding
Complex arithmetic
FP to integer conversions
HADDPD, HSUBPD
HADDPS, HSUBPS
MONITOR, MWAIT
LDDQU
ADDSUBPD, ADDSUBPS,
MOVDDUP, MOVSHDUP,
MOVSLDUP
FISTTP
* Also benefits Complex and Vectorization
SSE3: No new Data Types but new Instructions

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Streaming SIMD Extensions 313 new instructions
Three have limited use for application performance improvement• FISTTP - X87 to integer conversion (requires –longdouble
switch)
• MONITOR/MWAIT - thread synchronization• Available today in Ring 0 only; being used by newer Windows* and
Linux* thread packages
The other ten have some potential for specifc application domains
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
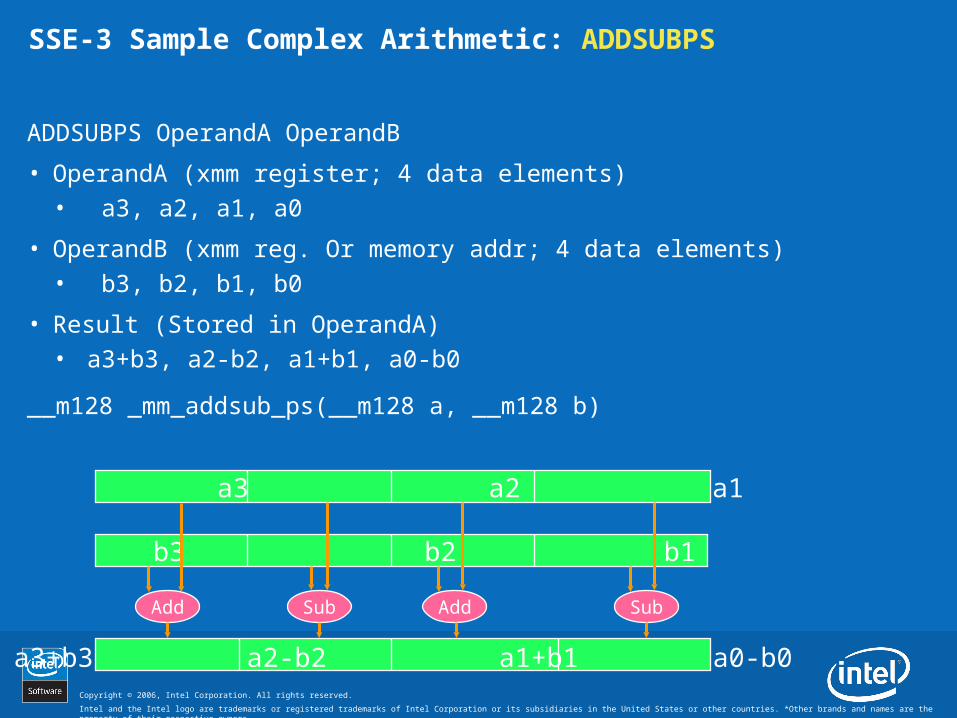
SSE-3 Sample Complex Arithmetic: ADDSUBPS
ADDSUBPS OperandA OperandB
• OperandA (xmm register; 4 data elements)• a3, a2, a1, a0
• OperandB (xmm reg. Or memory addr; 4 data elements)• b3, b2, b1, b0
• Result (Stored in OperandA)• a3+b3, a2-b2, a1+b1, a0-b0
__m128 _mm_addsub_ps(__m128 a, __m128 b)
a3 a2 a1 a0
a3+b3 a2-b2 a1+b1 a0-b0
Add Sub
b3 b2 b1 b0
AddSub

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Supplemental SSE-3 (SSSE-3)Extension introduced by Intel® Core™ Architecture
Horizontal Addition/Subtraction
Packed Absolute Values
Multiply and Add Packed Signed/Unsigned bytes
Packed multiply High with Round and Scale
Packed Shuffle Bytes
Packed SIGN
Packed Align Right
PSIGNB/W/D
PSHUFB
PMULHRSW
PALIGNR
PMADDUBSW
PABSB, PABSW, PABSD
PHADDW, PHADDSW, PHADDD, PHSUBW, PHSUBSW, PHSUBD

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
SSSE-3 New Instructions
Useful for media and imaging
16 new packed integer instructions
Six new Instructions categories
All instructions come in both 128-bit and 64-bit (MMX) flavors
64-bit SIMD latencies
128-bit SIMD latencies
Absolute value and Integer “Sign” 1 clock 1 clock
Byte multiply and add 3 clocks 3 clocks
Word multiply high with round and shift 3 clocks 3 clocks
Byte Permute 1 clock 3 clocks
Byte Concatenate with Shift 1 clock 2 clocks
Integer Horizontal Adds and Subtracts 4 clocks 5 clocks
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
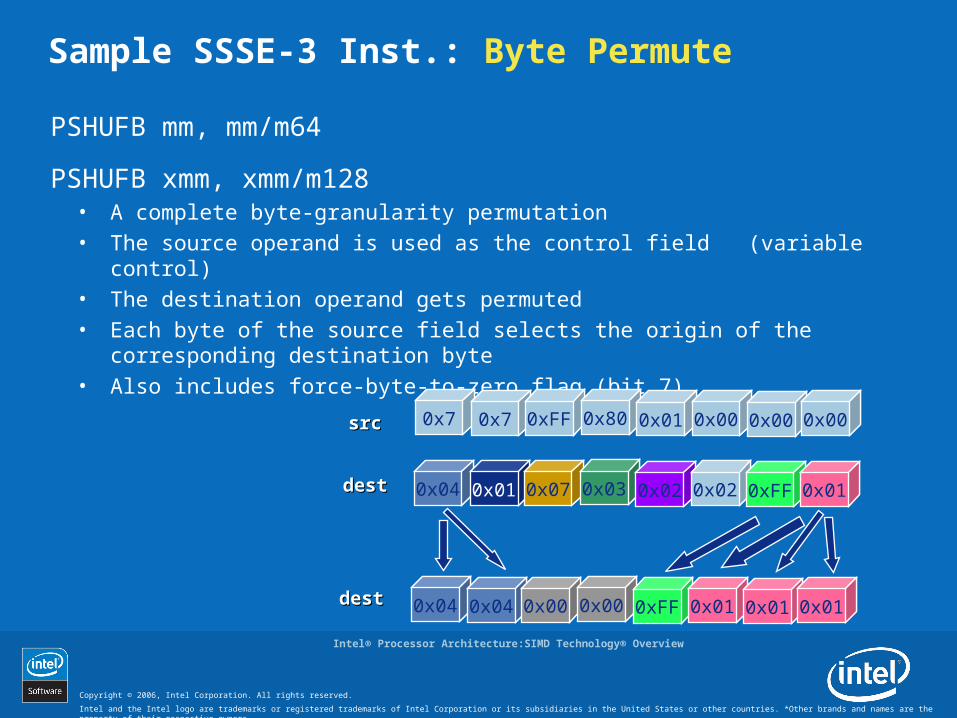
Sample SSSE-3 Inst.: Byte Permute
PSHUFB mm, mm/m64
PSHUFB xmm, xmm/m128• A complete byte-granularity permutation• The source operand is used as the control field (variable control)• The destination operand gets permuted• Each byte of the source field selects the origin of the corresponding
destination byte• Also includes force-byte-to-zero flag (bit 7)
0x04 0x01 0x07 0x03 0x02 0x02 0xFF 0x01
0x7 0x7 0xFF 0x80 0x01 0x00 0x00 0x00
0x04 0x04 0x00 0x00 0xFF 0x01 0x01 0x01
srcsrc
destdest
destdest

Copyright © 2006, Intel Corporation. All rights reserved.
2001 PTE Engineering Enabling Conference
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Ways to SSE/SIMD programming
Coding using SSE/SSE2/3/4 assembler instructions• Very tedious (manually schedule) – discouraged: Don’t do it !
• E.g.: How do you exploit the benefits of having now 16 instead of 8 SSE registers for Intel® 64 without maintaining two versions ?
Intel® compiler’s C/C++ SIMD intrinsics• No need to take care of register allocation, scheduling etc
Intel® compiler’s C++ Vector Class Library• Use this if you are heavy into C++ classes
Vectorizer of Intel® C++ and Fortran Compilers• Recommended for most cases – easy and efficient
Use ready-to-go vectorized code from a library like Intel® Math Kernel Library (MKL)
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
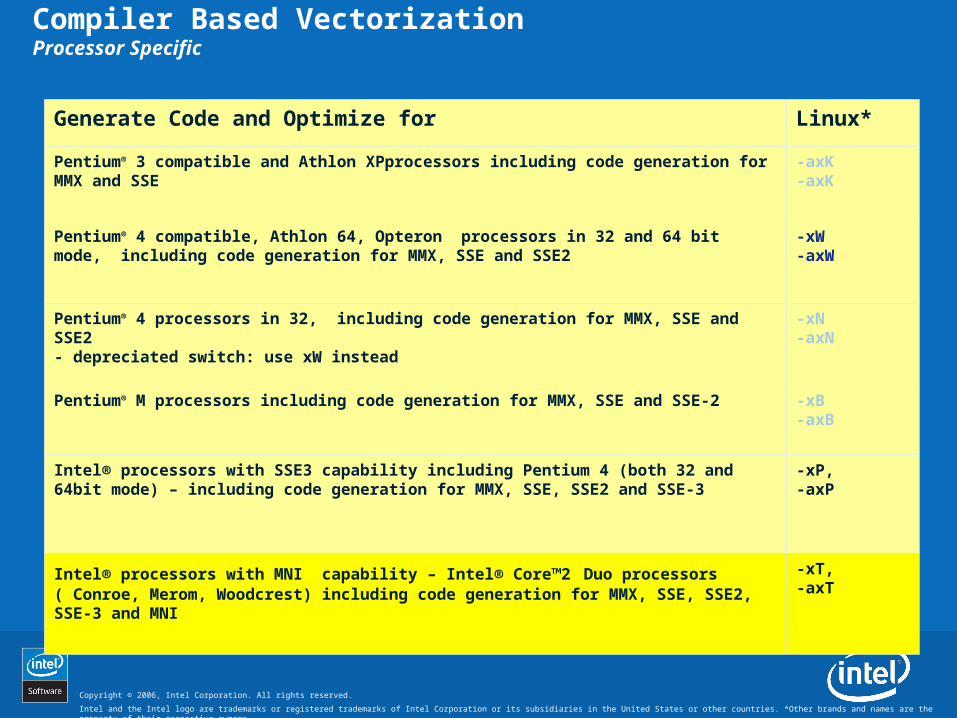
Compiler Based VectorizationProcessor Specific
Generate Code and Optimize for Linux*
Pentium® 3 compatible and Athlon XPprocessors including code generation for MMX and SSE
-axK-axK
Pentium® 4 compatible, Athlon 64, Opteron processors in 32 and 64 bit mode, including code generation for MMX, SSE and SSE2
-xW-axW
Pentium® 4 processors in 32, including code generation for MMX, SSE and SSE2- depreciated switch: use xW instead
-xN-axN
Pentium® M processors including code generation for MMX, SSE and SSE-2 -xB-axB
Intel® processors with SSE3 capability including Pentium 4 (both 32 and 64bit mode) – including code generation for MMX, SSE, SSE2 and SSE-3
-xP,-axP
Intel® processors with MNI capability – Intel® Core™2 Duo processors ( Conroe, Merom, Woodcrest) including code generation for MMX, SSE, SSE2, SSE-3 and MNI
-xT,-axT

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Beginning in 2008: ~50 new instructions in 13 groups
All function in 32-bit and 64-bit modes
Improvements in Commercial Data Integrity i-SCSI, Video Processing, String and Text Processing, 2D & 3D Imaging, Vectorizing Compiler Performance
New Instructions Added to Intel® Processors
5670
144
13
32
50
0
20
40
60
80
100
120
140
160
Jan-97 Feb-99 Dec-00 Feb-04 Jul-06 2008+
MMX™ Streaming SIMDExtensions (SSE)
Streaming SIMDExtensions 2 (SSE2)
Streaming SIMDExtensions 3 (SSE3)
Supplemental SSE3(SSSE3)
Future Intel instructionset extensions
350 250 180 90 65 45Process (nm)
~
24
Instruction Set Extensions
32
FutureSSE-4
45 nm
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
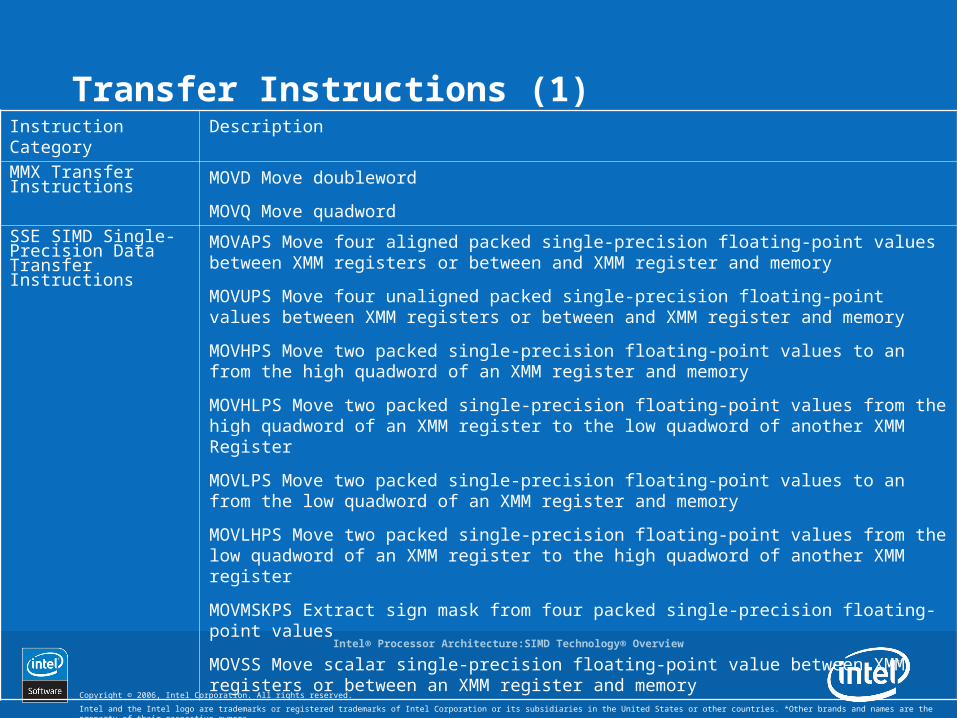
Transfer Instructions (1)Instruction Category Description
MMX Transfer Instructions MOVD Move doubleword
MOVQ Move quadwordSSE SIMD Single-Precision Data Transfer Instructions
MOVAPS Move four aligned packed single-precision floating-point values between XMM registers or between and XMM register and memory
MOVUPS Move four unaligned packed single-precision floating-point values between XMM registers or between and XMM register and memory
MOVHPS Move two packed single-precision floating-point values to an from the high quadword of an XMM register and memory
MOVHLPS Move two packed single-precision floating-point values from the high quadword of an XMM register to the low quadword of another XMM Register
MOVLPS Move two packed single-precision floating-point values to an from the low quadword of an XMM register and memory
MOVLHPS Move two packed single-precision floating-point values from the low quadword of an XMM register to the high quadword of another XMM register
MOVMSKPS Extract sign mask from four packed single-precision floating-point values
MOVSS Move scalar single-precision floating-point value between XMM registers or between an XMM register and memory
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
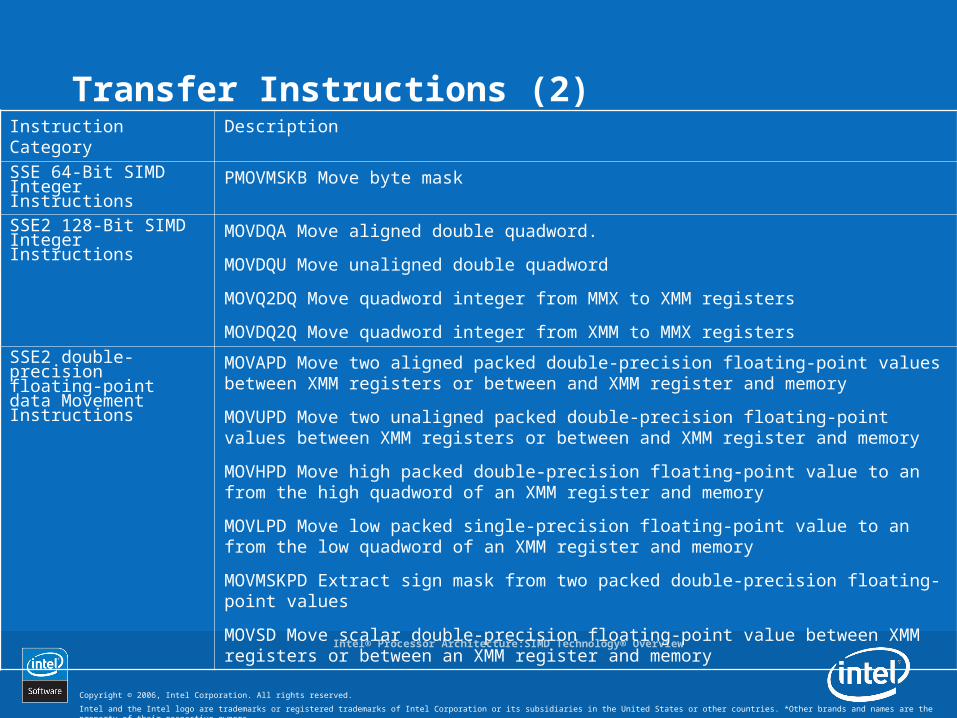
Transfer Instructions (2)Instruction Category DescriptionSSE 64-Bit SIMD Integer Instructions PMOVMSKB Move byte mask
SSE2 128-Bit SIMD Integer Instructions MOVDQA Move aligned double quadword.
MOVDQU Move unaligned double quadword
MOVQ2DQ Move quadword integer from MMX to XMM registers
MOVDQ2Q Move quadword integer from XMM to MMX registersSSE2 double-precision floating-point data Movement Instructions
MOVAPD Move two aligned packed double-precision floating-point values between XMM registers or between and XMM register and memory
MOVUPD Move two unaligned packed double-precision floating-point values between XMM registers or between and XMM register and memory
MOVHPD Move high packed double-precision floating-point value to an from the high quadword of an XMM register and memory
MOVLPD Move low packed single-precision floating-point value to an from the low quadword of an XMM register and memory
MOVMSKPD Extract sign mask from two packed double-precision floating-point values
MOVSD Move scalar double-precision floating-point value between XMM registers or between an XMM register and memory

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Transfer Instructions (3)Instruction Category DescriptionSSE3 SIMD Floating-Point LOAD/MOVE/DUPLICATE
Instructions
MOVSHDUP Loads/moves 128 bits; duplicating the second and fourth 32-bit data elements
MOVSLDUP Loads/moves 128 bits; duplicating the first and third 32-bit data elements
MOVDDUP Loads/moves 64 bits (bits[63:0] if the source is a register) and returns the same 64 bits in both the lower and upper halves of the 128-bit result register; duplicates the 64 bits from the source
SSE3 Specialized 128-bit Unaligned Data Load Instruction
LDDQU Special 128-bit unaligned load designed to avoid cache line splits
64-BIT MODE INSTRUCTIONS LODSQ Load qword at address (R)SI into RAX
MOVSQ Move qword from address (R)SI to (R)DI
MOVZX (64-bits) Move doubleword to quadword, zero-extension
STOSQ Store RAX at address RDI
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
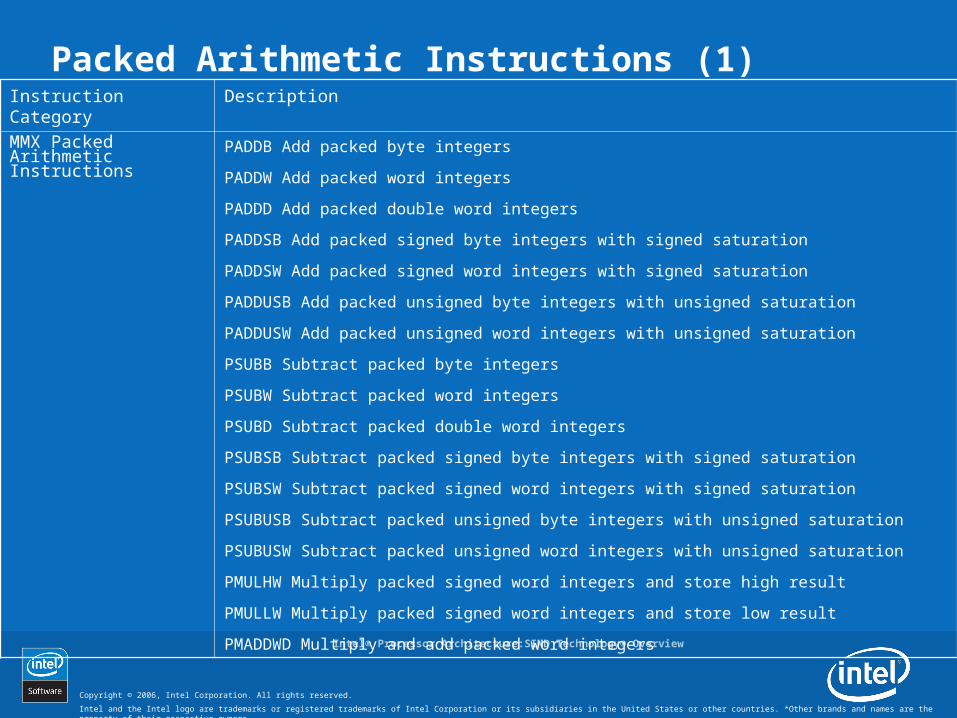
Packed Arithmetic Instructions (1)Instruction Category DescriptionMMX Packed Arithmetic Instructions
PADDB Add packed byte integers
PADDW Add packed word integers
PADDD Add packed double word integers
PADDSB Add packed signed byte integers with signed saturation
PADDSW Add packed signed word integers with signed saturation
PADDUSB Add packed unsigned byte integers with unsigned saturation
PADDUSW Add packed unsigned word integers with unsigned saturation
PSUBB Subtract packed byte integers
PSUBW Subtract packed word integers
PSUBD Subtract packed double word integers
PSUBSB Subtract packed signed byte integers with signed saturation
PSUBSW Subtract packed signed word integers with signed saturation
PSUBUSB Subtract packed unsigned byte integers with unsigned saturation
PSUBUSW Subtract packed unsigned word integers with unsigned saturation
PMULHW Multiply packed signed word integers and store high result
PMULLW Multiply packed signed word integers and store low result
PMADDWD Multiply and add packed word integers

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Packed Arithmetic Instructions (2)Instruction Category DescriptionSSE Packed Arithmetic Instructions ADDPS Add packed single-precision floating-point values
ADDSS Add scalar single-precision floating-point values
SUBPS Subtract packed single-precision floating-point values
SUBSS Subtract scalar single-precision floating-point values
MULPS Multiply packed single-precision floating-point values
MULSS Multiply scalar single-precision floating-point values
DIVPS Divide packed single-precision floating-point values
DIVSS Divide scalar single-precision floating-point values
RCPPS Compute reciprocals of packed single-precision floating-point values
RCPSS Compute reciprocal of scalar single-precision floating-point values
SQRTPS Compute square roots of packed single-precision floating-point values
SQRTSS Compute square root of scalar single-precision floating-point values
RSQRTPS Compute reciprocals of square roots of packed single-precision floating point
values
RSQRTSS Compute reciprocal of square root of scalar single-precision floating-point
values
MAXPS Return maximum packed single-precision floating-point values
MAXSS Return maximum scalar single-precision floating-point values
MINPS Return minimum packed single-precision floating-point values
MINSS Return minimum scalar single-precision floating-point values

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Packed Arithmetic Instructions (3)Instruction Category DescriptionSSE 64-Bit SIMD Integer Instructions
PMULHUW Multiply packed unsigned integers and store high result
SSE2 Packed Arithmetic Instructions
ADDPD Add packed double-precision floating-point values
ADDSD Add scalar double precision floating-point values
SUBPD Subtract scalar double-precision floating-point values
SUBSD Subtract scalar double-precision floating-point values
MULPD Multiply packed double-precision floating-point values
MULSD Multiply scalar double-precision floating-point values
DIVPD Divide packed double-precision floating-point values
DIVSD Divide scalar double-precision floating-point values
SQRTPD Compute packed square roots of packed double-precision floating-point
Values
SQRTSD Compute scalar square root of scalar double-precision floating-point
values
MAXPD Return maximum packed double-precision floating-point values
MAXSD Return maximum scalar double-precision floating-point values
MINPD Return minimum packed double-precision floating-point values
MINSD Return minimum scalar double-precision floating-point values

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Packed Arithmetic Instructions (4)Instruction Category Description
SSE2 128-Bit SIMD Integer Instructions
PMULUDQ Multiply packed unsigned doubleword integers
PADDQ Add packed quadword integers
PSUBQ Subtract packed quadword integers
SSE3 SIMD Floating-Point Packed ADD/SUB Instructions
ADDSUBPS Performs single-precision addition on the second and fourth pairs of 32-bit data elements within the operands; single-precision subtraction on the first and third pairs
ADDSUBPD Performs double-precision addition on the second pair of quad words, and double-precision subtraction on the first pair

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Packed Arithmetic Instructions (5)Instruction Category DescriptionSSE3 SIMD Floating-Point Horizontal ADD/SUB
Instructions
HADDPS Performs a single-precision addition on contiguous data elements. The first data element of the result is obtained by adding the first and second elements of the first operand; the second element by adding the third and fourth elements of the first operand; the third by adding the first and second elements of the second operand; and the fourth by adding the third and fourth elements of the second operand.
HSUBPS Performs a single-precision subtraction on contiguous data elements. The first data element of the result is obtained by subtracting the second element of the first operand from the first element of the first operand; the second element by subtracting the fourth element of the first operand from the third element of the first operand; the third by subtracting the second element of the second operand from the first element of the second operand; and the fourth by subtracting the fourth element of the second operand from the third element of the second operand.
HADDPD Performs a double-precision addition on contiguous data elements. The first data element of the result is obtained by adding the first and second elements of the first operand; the second element by adding the first and second elements of the second operand.
HSUBPD Performs a double-precision subtraction on contiguous data elements. The
first data element of the result is obtained by subtracting the second element of the first operand from the first element of the first operand; the second element by subtracting the second element of the second operand from the first element of the second operand.
SSSE3 Packed Arithmetic Instructions
phaddw/d/sw Pairwise integer horizontal addition + pack
phsubw/d/sw Pairwise integer horizontal subtract + pack
PMADDUBSW Multiply signed & unsigned bytes. Accumulate result to signed-words. (Multiply Accumulate)
PMULHRSW Signed 16 bits multiply, return high bits

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Conversion Instructions (1)Instruction Category DescriptionMMX Conversion Instructions
PACKSSWB Pack words into bytes with signed saturation
PACKSSDW Pack double words into words with signed saturation
PACKUSWB Pack words into bytes with unsigned saturation.
PUNPCKHBW Unpack high-order bytes
PUNPCKHWD Unpack high-order words
PUNPCKHDQ Unpack high-order double words
PUNPCKLBW Unpack low-order bytes
PUNPCKLWD Unpack low-order words
PUNPCKLDQ Unpack low-order double words
SSE Conversion Instructions
CVTPI2PS Convert packed double word integers to packed single-precision floating point values
CVTSI2SS Convert double word integer to scalar single-precision floating-point value
CVTPS2PI Convert packed single-precision floating-point values to packed double word integers
CVTTPS2PI Convert with truncation packed single-precision floating-point values to packed double word integers
CVTSS2SI Convert a scalar single-precision floating-point value to a double word integer
CVTTSS2SI Convert with truncation a scalar single-precision floating-point value to a scalar double word integer

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Conversion Instructions (2)Instruction Category DescriptionSSE2 Conversion Instructions
CVTPD2PI Convert packed double-precision floating-point values to packed doubleword integers.
CVTTPD2PI Convert with truncation packed double-precision floating-point values to packed doubleword integers
CVTPI2PD Convert packed doubleword integers to packed double-precision floatingpoint values
CVTPD2DQ Convert packed double-precision floating-point values to packed doubleword integers
CVTTPD2DQ Convert with truncation packed double-precision floating-point values to packed doubleword integers
CVTDQ2PD Convert packed doubleword integers to packed double-precision floatingpoint values
CVTPS2PD Convert packed single-precision floating-point values to packed doubleprecision floating-point values
CVTPD2PS Convert packed double-precision floating-point values to packed singleprecision floating-point values
CVTSS2SD Convert scalar single-precision floating-point values to scalar doubleprecision floating-point values
CVTSD2SS Convert scalar double-precision floating-point values to scalar singleprecision floating-point values
CVTSD2SI Convert scalar double-precision floating-point values to a doubleword integer
CVTTSD2SI Convert with truncation scalar double-precision floating-point values to scalar doubleword integers
CVTSI2SD Convert doubleword integer to scalar double-precision floating-point Value

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Conversion Instructions (3)Instruction Category DescriptionSSE2 Conversion Instructions
CVTDQ2PS Convert packed doubleword integers to packed single-precision floatingpoint values
CVTPS2DQ Convert packed single-precision floating-point values to packed doubleword integers
CVTTPS2DQ Convert with truncation packed single-precision floating-point values to packed doubleword integers
SSE3 x87-FP Integer Conversion Instruction
FISTTP Behaves like the FISTP instruction but uses truncation, irrespective of the
rounding mode specified in the floating-point control word (FCW)
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
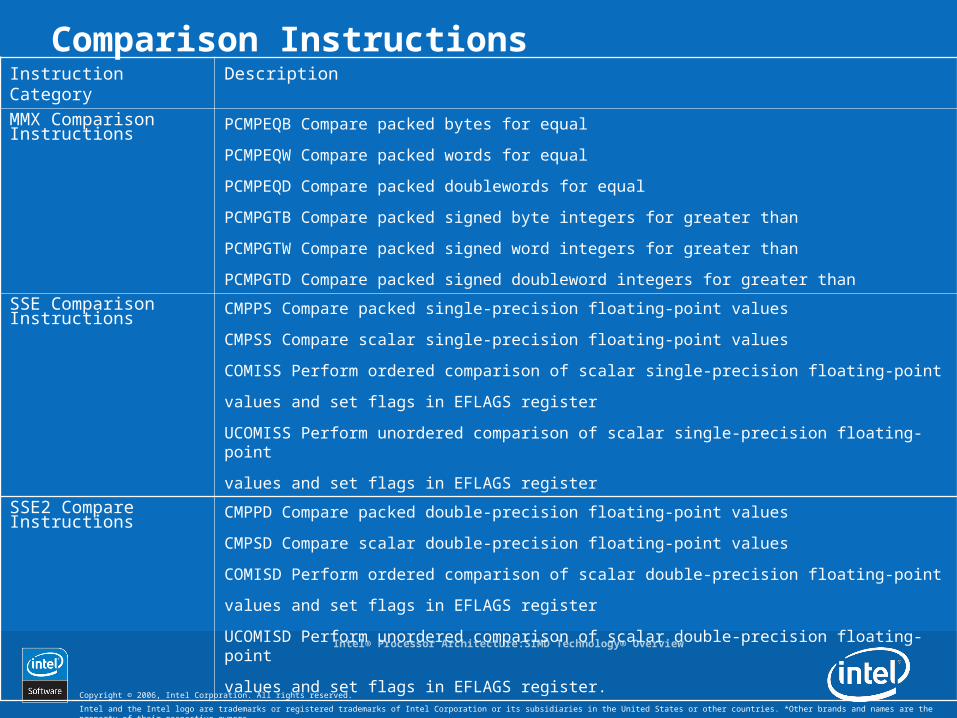
Comparison InstructionsInstruction Category DescriptionMMX Comparison Instructions
PCMPEQB Compare packed bytes for equal
PCMPEQW Compare packed words for equal
PCMPEQD Compare packed doublewords for equal
PCMPGTB Compare packed signed byte integers for greater than
PCMPGTW Compare packed signed word integers for greater than
PCMPGTD Compare packed signed doubleword integers for greater than
SSE Comparison Instructions
CMPPS Compare packed single-precision floating-point values
CMPSS Compare scalar single-precision floating-point values
COMISS Perform ordered comparison of scalar single-precision floating-point
values and set flags in EFLAGS register
UCOMISS Perform unordered comparison of scalar single-precision floating-point
values and set flags in EFLAGS register
SSE2 Compare Instructions
CMPPD Compare packed double-precision floating-point values
CMPSD Compare scalar double-precision floating-point values
COMISD Perform ordered comparison of scalar double-precision floating-point
values and set flags in EFLAGS register
UCOMISD Perform unordered comparison of scalar double-precision floating-point
values and set flags in EFLAGS register.

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Logical InstructionsInstruction Category DescriptionMMX Logical Instructions
PAND Bitwise logical AND
PANDN Bitwise logical AND NOT
POR Bitwise logical OR
PXOR Bitwise logical exclusive OR
SSE Logical Instructions
ANDPS Perform bitwise logical AND of packed single-precision floating-point values
ANDNPS Perform bitwise logical AND NOT of packed single-precision floatingpoint values
ORPS Perform bitwise logical OR of packed single-precision floating-point values
XORPS Perform bitwise logical XOR of packed single-precision floating-point Values
SSE2 Logical Instructions
ANDPD Perform bitwise logical AND of packed double-precision floating-point values
ANDNPD Perform bitwise logical AND NOT of packed double-precision floatingpoint values
ORPD Perform bitwise logical OR of packed double-precision floating-point values
XORPD Perform bitwise logical XOR of packed double-precision floating-point Values

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Shift and Rotate InstructionsInstruction Category DescriptionMMX Shift and Rotate Instructions
PSLLW Shift packed words left logical
PSLLD Shift packed doublewords left logical
PSLLQ Shift packed quadword left logical
PSRLW Shift packed words right logical
PSRLD Shift packed doublewords right logical
PSRLQ Shift packed quadword right logical
PSRAW Shift packed words right arithmetic
PSRAD Shift packed doublewords right arithmetic
SSE2 128-Bit SIMD Integer Instructions
PSLLDQ Shift double quadword left logical
PSRLDQ Shift double quadword right logical
Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
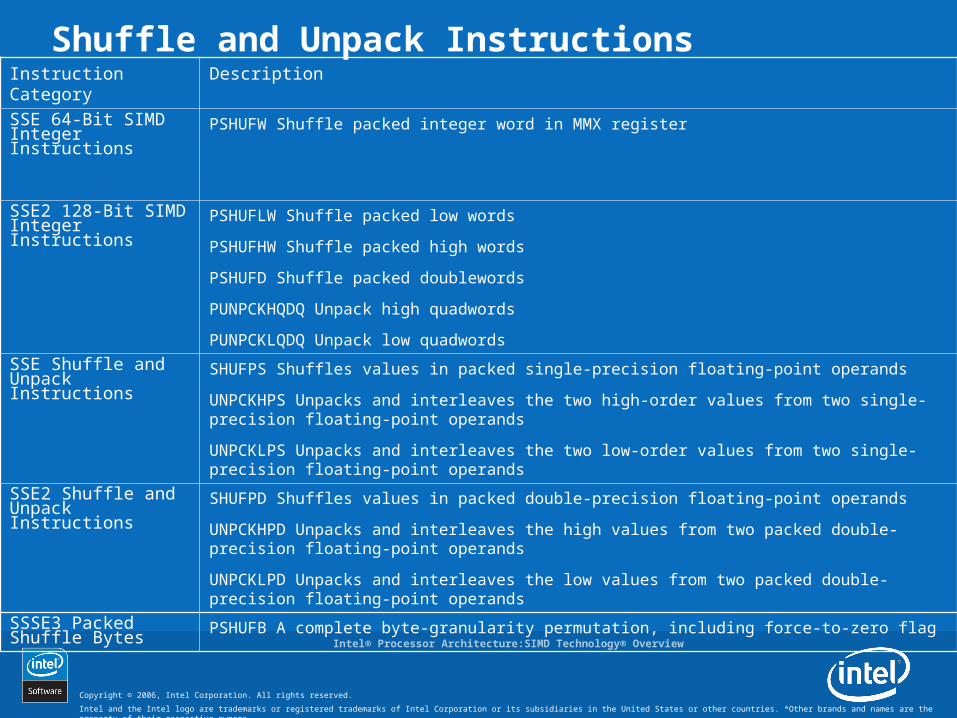
Shuffle and Unpack InstructionsInstruction Category DescriptionSSE 64-Bit SIMD Integer Instructions
PSHUFW Shuffle packed integer word in MMX register
SSE2 128-Bit SIMD Integer Instructions
PSHUFLW Shuffle packed low words
PSHUFHW Shuffle packed high words
PSHUFD Shuffle packed doublewords
PUNPCKHQDQ Unpack high quadwords
PUNPCKLQDQ Unpack low quadwords
SSE Shuffle and Unpack Instructions
SHUFPS Shuffles values in packed single-precision floating-point operands
UNPCKHPS Unpacks and interleaves the two high-order values from two single-precision floating-point operands
UNPCKLPS Unpacks and interleaves the two low-order values from two single-precision floating-point operands
SSE2 Shuffle and Unpack Instructions
SHUFPD Shuffles values in packed double-precision floating-point operands
UNPCKHPD Unpacks and interleaves the high values from two packed double-precision floating-point operands
UNPCKLPD Unpacks and interleaves the low values from two packed double-precision floating-point operands
SSSE3 Packed Shuffle Bytes
PSHUFB A complete byte-granularity permutation, including force-to-zero flag

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Functional InstructionsInstruction Category DescriptionSSE 64-Bit SIMD Integer Instructions
PAVGB Compute average of packed unsigned byte integers
PAVGW Compute average of packed unsigned byte integers
PEXTRW Extract word
PINSRW Insert word
PMAXUB Maximum of packed unsigned byte integers
PMAXSW Maximum of packed signed word integers
PMINUB Minimum of packed unsigned byte integers
PMINSW Minimum of packed signed word integers
PSADBW Compute sum of absolute differences
SSSE3 Instructions psignb/w/d Per element, if the source operand is negative, multiply the destination operand by -1
pabsb/w/d Per element, overwrite destination with absolute value of source
PALIGNR Extract any continuous 16 (8 in the 64 bit case) bytes from the pair [dst, src] and store them to the dst register
PMULHRSW Signed 16 bits multiply, return high bits

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
System Related InstructionsInstruction Category DescriptionMMX State Management Instructions
EMMS Empty MMX state
SSE MXCSR State Management Instructions
LDMXCSR Load MXCSR register
STMXCSR Save MXCSR register state
SSE3 Agent Synchronization Instructions
MONITOR Sets up an address range used to monitor write-back stores
MWAIT Enables a logical processor to enter into an optimized state while waiting for a write-back store to the address range set up by the MONITOR Instruction

Copyright © 2006, Intel Corporation. All rights reserved.
Intel® Processor Architecture:SIMD Technology® Overview
Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. *Other brands and names are the property of their respective owners.
Cacheability Control, Prefetch, and Instruction Ordering Instructions
Instruction Category DescriptionSSE Cacheability Control, Prefetch, and Instruction
Ordering Instructions
MASKMOVQ Non-temporal store of selected bytes from an MMX register into memory
MOVNTQ Non-temporal store of quadword from an MMX register into memory
MOVNTPS Non-temporal store of four packed single-precision floating-point values from an XMM register into memory
PREFETCHh Load 32 or more of bytes from memory to a selected level of the processor’s cache hierarchy
SFENCE Serializes store operations
SSE2 Cacheability Control and Ordering Instructions
CLFLUSH Flushes and invalidates a memory operand and its associated cache line from all levels of the processor’s cache hierarchy
LFENCE Serializes load operations
MFENCE Serializes load and store operations
PAUSE Improves the performance of “spin-wait loops”
MASKMOVDQU Non-temporal store of selected bytes from an XMM register into memory
MOVNTPD Non-temporal store of two packed double-precision floating-point values from an XMM register into memory
MOVNTDQ Non-temporal store of double quadword from an XMM register into memory
MOVNTI Non-temporal store of a doubleword from a general-purpose register into Memory





























