Embed Size (px)
Citation preview

Inherently Lower-Power Inherently Lower-Power High-Performance High-Performance
Superscalar Superscalar ArchitecturesArchitecturesRami Abielmona
Prof. Maitham Shams
95.575
March 4, 2002
Paper Review

Flynn’s Classifications Flynn’s Classifications (1972) [1](1972) [1] SISD – Single Instruction stream, Single Data stream
Conventional sequential machines
Program executed is instruction stream, and data operated on is data stream
SIMD – Single Instruction stream, Multiple Data streams
Vector machines (superscalar)
Processors execute same program, but operate on different data streams
MIMD – Multiple Instruction streams, Multiple Data streams
Parallel machines
Independent processors execute different programs, using unique data streams
MISD – Multiple Instruction streams, Single Data stream
Systolic array machines
Common data structure is manipulated by separate processors, executing different instruction streams (programs)
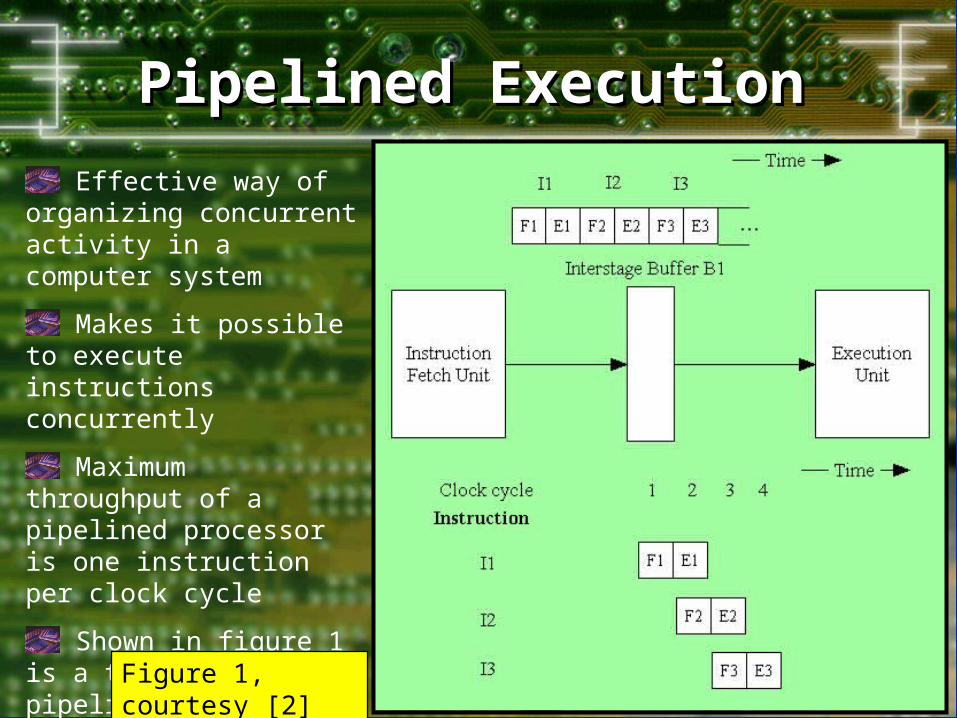
Pipelined ExecutionPipelined Execution
Effective way of organizing concurrent activity in a computer system
Makes it possible to execute instructions concurrently
Maximum throughput of a pipelined processor is one instruction per clock cycle
Shown in figure 1 is a two-stage pipeline, with buffer B1 receiving new information at the end of each clock cycle
Figure 1, courtesy [2]

Superscalar ProcessorsSuperscalar Processors Processors equipped with multiple
execution units, in order to handle several instructions in parallel [11]
Maximum throughput is greater than one instruction per cycle (multiple-issue)
Baseline architecture is shown in figure 2 [3]
Figure 2, courtesy [3]

Important Terminology Important Terminology [2] [4][2] [4]
Issue Width The metric designating how many instructions are issued per cycle
Issue Window Comprises the last n entries of the instruction buffer
Register File Set of n-byte, dual read, single write bank of registers
Register Renaming Technique used to prevent stalling the processor for false data dependencies between instructions
Instruction Steering Technique used to send decoded instructions to appropriate memory banks
Memory Disambiguation Unit Mechanism for enforcing data dependencies through memory

Motivations and Motivations and ObjectivesObjectives To analyze the high-end processor market for
BOTH power and area-performance trade-offs (not previously done)
To propose a superscalar architecture which achieves a power reduction without compromising performance
Analysis to be carried out on structures that increase energy dissipation, with an increasing issue width
Register rename logic
Instruction issue window
Memory disambiguation unit
Data bypass mechanism
Multiported register file
Instruction and data caches

Energy Models [5]Energy Models [5] Model 1 – Multiported RAMModel 1 – Multiported RAM
Access energy (R or W) = Edecode + Earray + ESA + EctlSA + Epre + Econtrol
Word line energy = Vdd2 Nbits( Cgate Wpass,r + ( 2Nwrite+ Nread ) Wpitch
Cmetal )
Bit line energy = Vdd Mmargin Vsense Cbl,read Nbits
Model 2 – CAM (Content-Addressable Model 2 – CAM (Content-Addressable Memory)Memory)
Using IW write word lines and IW write bitline pairs
Model 3 – Pipeline latches and clocking treeModel 3 – Pipeline latches and clocking tree Assume balanced clocking tree (less power dissipation than
grids)
Assume lower power single phase clocking scheme
Near minimum transistor sizes used in latches
Model 4 – Functional UnitsModel 4 – Functional Units Eavg = Econst + Nchange x Echange
Energy complexity is independent of issue widthEnergy complexity is independent of issue width

Preliminary Simulation Preliminary Simulation ResultsResults
Wrote own simulator, incorporating all the developed energy models (based on SimpleScalar tool set)
Ran simulations for 5 superscalar designs, with IW ranging from 4 to 16
Results show that total total committed energy increases committed energy increases with IWwith IW, as wider processors rely on deeper speculation to exploit ILP
Energy/instruction grows linearly for all structures except functional units (FUs)
Results obtained using 35-micron and Vdd = 3.3V technologies, which FUs scale well with. However, RAMs, CAMs and long wires do not scale well, and thus have to be LOW-POWER structures
E ~ (IW)γ
Structure Energy growth
parameter
Register rename logic
γ = 1.1
Instruction issue window
γ = 1.9
Memory disam. unit
γ = 1.5
Multiported register file
γ = 1.8
Data bypass mechanism
γ = 1.6
Functional units
γ = 0.1
All caches γ = 0.7Table 1

Problem FormulationProblem Formulation
Energy-Delay Product
E x D = energy/operation x cycles/operation
E x D = (energy/cycle) / IPC2
E x D = [ IPC x (IW)γ ] / IPC2 ~ (IW)γ / IPC
E x D ~ (IW)γ - α ~ (IPC) (γ – α) / α
Problem Definition
If α = 1, then E x D ~ (IPC)γ-1 ~ (IW)γ-1
If α = 0.5, then E x D ~ (IPC)γ-1/2 ~ (IW)2γ-1
Need new techniques to achieve more ILP with conventional superscalar design

Intermediary RecapIntermediary Recap
We have discussed
Superscalar processsor design and terminology
Energy modeling of microarchitecture structures
Analysis of energy-delay metric
Preliminary simulation results
We will introduce
General solution methodology
Previous decentralization schemes
Proposed strategy
Simulation results of multicluster architecture
Conclusions

General Design SolutionGeneral Design Solution
Decentralization of microarchitecture
Replace tightly coupled CPU with a set of clusters, each capable of superscalar processing
Can ideally reduce γ to zero, with good cluster partitioning techniques
Solution introduces the following issues
1. Additional paths for intercluster communication
2. Need for cluster assignment algorithms
3. Interaction of cluster with common memory system

Previous Decentralized Previous Decentralized SolutionsSolutions
Particular Solution Main Features Limited Connectivity VLIWs [6]
RF is partitioned into banks
Every operation specifies a destination bank
Multiscalar Architecture [7] PEs organized in a circular chain
RF is decentralized
Trace Window Architecture [8]
RF and issue window are partitioned
All instructions must be buffered
Multicluster Architecture [9] RF, issue window and FUs are decentralized
Special instruction used for intercluster communication
Dependence-Based Architecutre [10]
Contains instruction dispatch intelligence
2-cluster Alpha 21264 Processor [11]
Both clusters contain copy of RF

Proposed Multicluster Proposed Multicluster Architecture (1)Architecture (1)
Instead of tightly coupled CPUs, proposed architecture will involve a set of clusters, each containing:
instruction issue window
local physical register file
set of execution units
local memory disambiguation unit
one bank of interleaved data cache
Refer to figure 3 on next slide
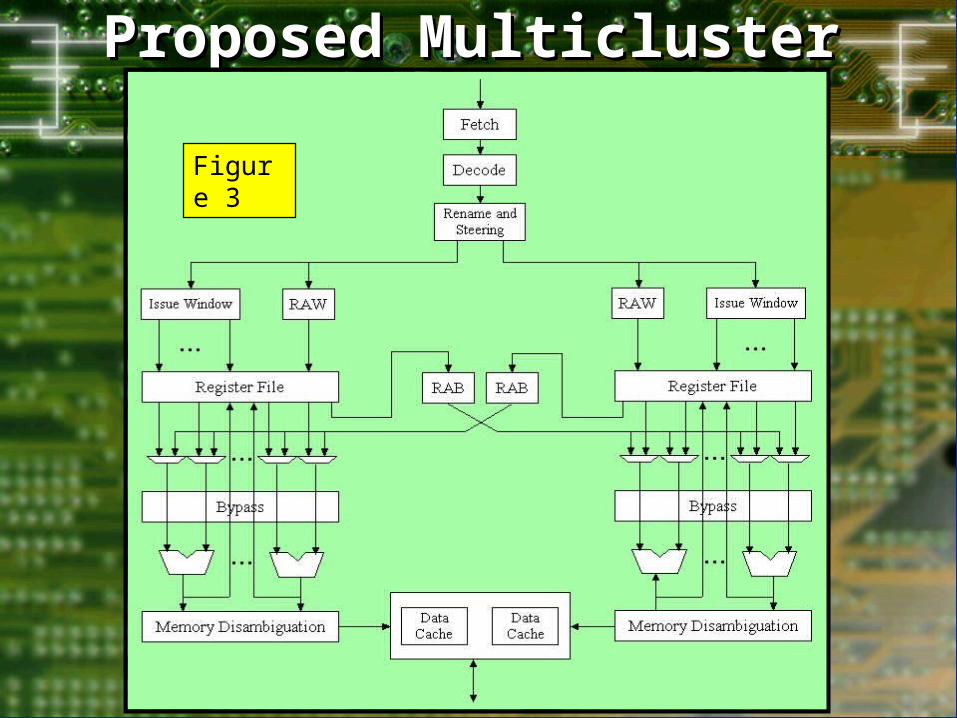
Proposed Multicluster Proposed Multicluster Arch. (2)Arch. (2)
Figure 3

Multicluster Architecture Multicluster Architecture DetailsDetails Register Renaming and Instruction Steering
Each cluster is provided with a local physical RF
Global Map Table maintains mapping between architectural registers and physical registers
Cluster Assignment Algorithm
Tries to minimize
intercluster register dependencies
delay through cluster assignment logic
Whole graph solution is NP-complete, therefore near-optimal solutions devised by divide & conquer method
Intercluster Communication
Remote Access Window (RAW) used for remote RF calls
Remote Access Buffer (RAB) used to keep the remote source operand
One cycle penalty incurred for a remote RF
Multicluster Architecture Multicluster Architecture DetailsDetails(Cont’d)(Cont’d) Memory Dataflow
Centralized memory disambiguation unit does not scale with increasing issue width and bigger sizes of the load/store window
Proposed scheme: Every cluster is provided with a local load/store window that is hardwired to a particular data cache bank
Developed a bank predictor in order to combat not knowing which cluster the instruction is being routed to at the decode stage
Stack Pointer (SP) References
Realized an eager mechanism for handling SP references
With a new reference to SP, an entry is allocated in RAB
Upon instruction completion, results written into RF and RAB
RAB entry is not freed after instruction reads contents
RAB entry is freed only when a new SP reference commits

Results and AnalysisResults and Analysis
A single address transfer bus is sufficient for handling intercluster address transfers
A single bus is used to handle intercluster data transfers arising from bank mispredictions
4-6 entries are used in the RAB for low-power
2 extra entries are sufficient in the RAB for SP refs.
Intercluster traffic is reduced by 20 % and performance improved by 3 % using SP eager mechanism
Multicluster architecture showed 20 % better performance than the best configurations with centralized architectures, with a 50 % reduction in power dissipation

ConclusionsConclusions Main Result of Work
Using this architecture will allow the development of high-performance
processors while keeping the microarchitecture energy-efficient, as proven by the energy-delay product
Main Contribution of WorkA methodology for doing energy-efficiency analysis was derived for use with the next generation high-performance decentralized superscalar processors
Other Major Contributions Opened analyst’s eyes to the 3-D IPC-area-energy space
A roadmap for future high-performance low-power microprocessor development has been proposed
Coined the energy-efficient family concept, composed of equally optimal energy-efficient configurations

References (1)References (1)[1] M.J. Flynn, “Very High-Speed Computing Systems,” Proceedings of the IEEE, vol. 54, December 1966, p.p. 1901-1909.
[2] C. Hamacher, Z. Vranesic and S. Zaky, “Computer Organization,” fifth edition, McGraw-Hill: New York, 2002.
[3] V. Zyuban and P. Kogge, “Inherently Lower-Power High-Performance Superscalar Architectures,” IEEE Transactions on Computers, vol. 50, no. 3, March 2001, p.p. 268-285.
[4] E. Rotenberg, “AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors,”, Proceedings of the 29th Fault-Tolerant Computing Symposium, June 1999
[5] V. Zyuban, “Inherently Lower-Power High-Performance Superscalar Architectures,” PhD thesis, Univ. of Notre Dame, Mar. 2000.
[6] R. Colwell et al., “A VLIW Architecture for a Trace Scheduling Compiler,” IEEE Trans. Computers, vol. 37, no. 8, pp. 967-979, Aug. 1988.
[7] M. Franklin and G.S. Sohi, “The Expandable Split Window Architecture for Exploiting Fine-Grain Parallelism,” Proc. 19th Ann. Int’l Symp. Microarchitecture, May 1992.

References (2)References (2)
[8] S. Vajapeyam and T. Miltra, “Improving Superscalar Instruction Dispatch and Issue by Exploiting Dynamic Code Sequences,” Proc. 24th Ann. Int’l Symp. Computer Architecture, June 1997.
[9] K. Farkas, P. Chow, N. Jouppi, and Z. Vranesic, “The Multicluster Architecture: Reducing Cycle Time through Partitioning,” Proc. 30th Ann. Int’l Symp. Microarchitecture, Dec. 1997.
[10] S. Palacharla, N. Jouppi and J. Smith, “Complexity-Effective Superscalar Processor,” Proc. 24th Ann. Int’l Symp. Computer Architecture, pp. 206-218, June 1997.
[11] K. Hwang, “Advanced Computer Architecture: Parallelism, Scalability, Programmability,” McGrawHill: New York, 1993.

Questions/CommentsQuestions/Comments
?





























