Embed Size (px)
Citation preview

Information Retrieval

Topics
• Information Retrieval (IR)– What is it– Inverted Indexes– Web search

Information Retrieval
• Its not just searching for books in libraries anymore
• Wikipedia definition:– Information retrieval (IR) is the area of study
concerned with searching for documents, for information within documents, and for metadata about documents, as well as that of searching structured storage, relational databases, and the World Wide Web.

Databases Today – NoSQL, Big Data• Unstructured data
– Data can be of any type, may have no format or sequence
– cannot be represented by any type of schema• Web pages in HTML• Video, sound, images
• Semi-structured – Data has certain structure, but not all items
identical – NoSQL– Schema info may be mixed in with data values– Similar entities grouped together – may have
different attributes– Self-describing data, e.g. XML, displayed as graph

DBs vs. IRDatabases Information Retrieval Systems
Structured Data Unstructured Data
Schema driven No fixed schema; various data models (vector space)
Relational or OODB model -Structured query model
Free-form query models
Rich metadata operations Rich data operations
Query returns data Search request returns list or pointers to documents
Results based on exact matching (always correct)
Results based on approximate matching and measures of effectiveness (imprecise and ranked)

Some of the slides are from Information Retrieval with MapReduce
Jimmy LinThe iSchool

Searching Documents:How do we represent text?
• Remember: computers don’t “understand” anything!• “Bag of words”
– Treat all the words in a document as index terms for that document
– Assign a “weight” to each term based on “importance”– Disregard order, structure, meaning, etc. of the words– Simple, yet effective!
• Assumptions– Term occurrence is independent– Document relevance is independent– “Words” are well-defined

What’s a word?天主教教宗若望保祿二世因感冒再度住進醫院。這是他今年第二度因同樣的病因住院。 - باسم الناطق ريجيف مارك وقال
قبل - شارون إن اإلسرائيلية الخارجيةبزيارة األولى للمرة وسيقوم الدعوة
المقر طويلة لفترة كانت التي تونس،لبنان من خروجها بعد الفلسطينية التحرير لمنظمة الرسمي
1982عام .
Выступая в Мещанском суде Москвы экс-глава ЮКОСа заявил не совершал ничего противозаконного, в чем обвиняет его генпрокуратура России.
भा�रत सरका�र ने आर्थि �का सर्वे�क्षण में� विर्वेत्ती�य र्वेर्ष� 2005-06 में� स�त फ़ी�सदी� विर्वेका�स दीर हा�सिसल कारने का� आकालने विकाय� हा" और कार स$धा�र पर ज़ो(र दिदीय� हा"
日米連合で台頭中国に対処…アーミテージ前副長官提言
조재영 기자 = 서울시는 25 일 이명박 시장이 ` 행정중심복합도시 '' 건설안에 대해 ` 군대라도 동원해 막고싶은 심정 '' 이라고 말했다는 일부 언론의 보도를 부인했다 .

Sample DocumentMcDonald's slims down spudsFast-food chain to reduce certain types of fat in its french fries with new cooking oil.NEW YORK (CNN/Money) - McDonald's Corp. is cutting the amount of "bad" fat in its french fries nearly in half, the fast-food chain said Tuesday as it moves to make all its fried menu items healthier.But does that mean the popular shoestring fries won't taste the same? The company says no. "It's a win-win for our customers because they are getting the same great french-fry taste along with an even healthier nutrition profile," said Mike Roberts, president of McDonald's USA.But others are not so sure. McDonald's will not specifically discuss the kind of oil it plans to use, but at least one nutrition expert says playing with the formula could mean a different taste.Shares of Oak Brook, Ill.-based McDonald's (MCD: down $0.54 to $23.22, Research, Estimates) were lower Tuesday afternoon. It was unclear Tuesday whether competitors Burger King and Wendy's International (WEN: down $0.80 to $34.91, Research, Estimates) would follow suit. Neither company could immediately be reached for comment.…
16 × said 14 × McDonalds12 × fat11 × fries8 × new6 × company, french, nutrition5 × food, oil, percent, reduce,
taste, Tuesday…
“Bag of Words”

Text Preprocessing
• Commonly used words expected to occur in 80% or more of documents in a collection
• Most frequent 50 account for 40% of all text
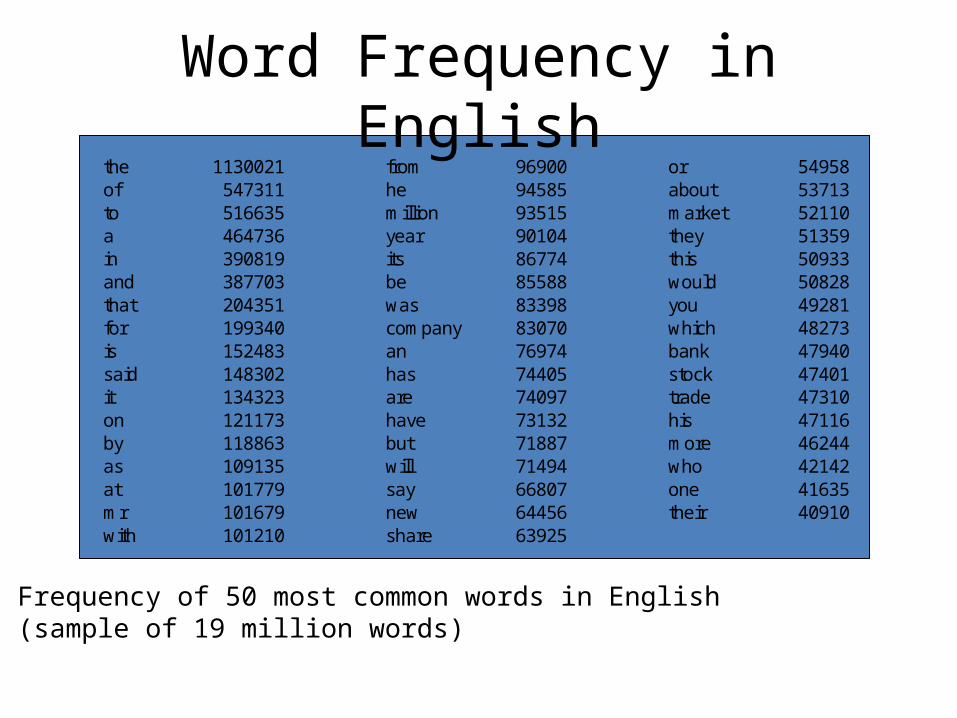
Word Frequency in Englishthe 1130021 from 96900 or 54958of 547311 he 94585 about 53713to 516635 million 93515 market 52110a 464736 year 90104 they 51359in 390819 its 86774 this 50933and 387703 be 85588 would 50828that 204351 was 83398 you 49281for 199340 company 83070 which 48273is 152483 an 76974 bank 47940said 148302 has 74405 stock 47401it 134323 are 74097 trade 47310on 121173 have 73132 his 47116by 118863 but 71887 more 46244as 109135 will 71494 who 42142at 101779 say 66807 one 41635mr 101679 new 64456 their 40910with 101210 share 63925
Frequency of 50 most common words in English (sample of 19 million words)

Text Preprocessing - Stop Words
• First 6 most frequent words account for 20% of all words
• Many frequent words do not contribute much to relevance, so useless and remove them
• Stop list (there is more than one such list):– http://www.lextek.com/manuals/onix/stopwords1
.html

Text Preprocessing - Stemming
• Stem – word obtained after trimming suffix and prefix
• ‘compute’ is stem for ‘computing’, ‘computer’, ‘computation’
• Stemming algorithms to reduce any word to its stem

Representing Documents
The quick brown fox jumped over the lazy dog’s back.
Document 1
Document 2
Now is the time for all good men to come to the aid of their party.
the
isfor
to
of
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
00110110110010100
11001001001101011
Term Doc
umen
t 1
Doc
umen
t 2
Stopword List

Inverted Index
• Inverted indexing is fundamental to all IR models, also used sometimes in DBs
• Consists of postings lists, one with each term in the collection
• Posting list – document id (d) and payload (p)– Payload can be term frequency or number of
times occurs on document, position of occurrence, properties, etc.
– Can be ordered by document id, page rank, etc.– Data structure necessary to map from document
id to e.g. URL

Inverted Index
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
00110000010010110
01001001001100001
Term
Doc
1D
oc 2
00110110110010100
11001001001000001
Doc
3D
oc 4
00010110010010010
01001001000101001
Doc
5D
oc 6
00110010010010010
10001001001111000
Doc
7D
oc 8
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
4 82 4 61 3 71 3 5 72 4 6 83 53 5 72 4 6 831 3 5 7
1 3 5 7 8
2 4 82 6 8
1 5 72 4 6
1 36 8
Term Postings


Process query - retrieval
• Given a query:– fetch posting lists associated with query– traverse postings to compute result set– Top k documents extracted

In order to process the query
1. Construct inverted index (indexing)2. Gather web content (crawling)3. Ranking documents given a query (retrieval)

Crawling, Indexing, Querying
• Crawling and indexing – share similar characteristics and requirements– Both are offline problems, no need for real-time– Tolerable for a few minutes delay before content searchable– OK to run smaller-scale index updates frequently
• Querying – online problem – Demands sub-second response time– Low latency high throughput– Loads can very greatly

Architecture of IR SystemsDocumentsQuery
Hits
RepresentationFunction
RepresentationFunction
Query Representation Document Representation
ComparisonFunction Index
offlineonline

Web Crawler
• To acquire the document collection over which indexes are built– Copies the document
• Acquiring web content requires crawling– Traverse web by repeatedly following hyperlinks
and storing downloaded pages– Start by populating a queue with seed pages

Web Crawler Issues
• Shouldn’t overload web servers• Prioritize order in which unvisited pages downloaded• Avoid downloading page multiple times – coordination
and load balancing• Robust when failures• Learn update patterns so content current• Identify near duplicates and select best for index• Identify dominant language on page

How much of the web is crawled?
• Deep web - Tor• Google, Bing, Chrome do not go there

Indexing – Non-deep Web
• Creating inverted index– Must be relatively fast, but need not be real time– For Web, incremental updates are important
• How large is the inverted index?

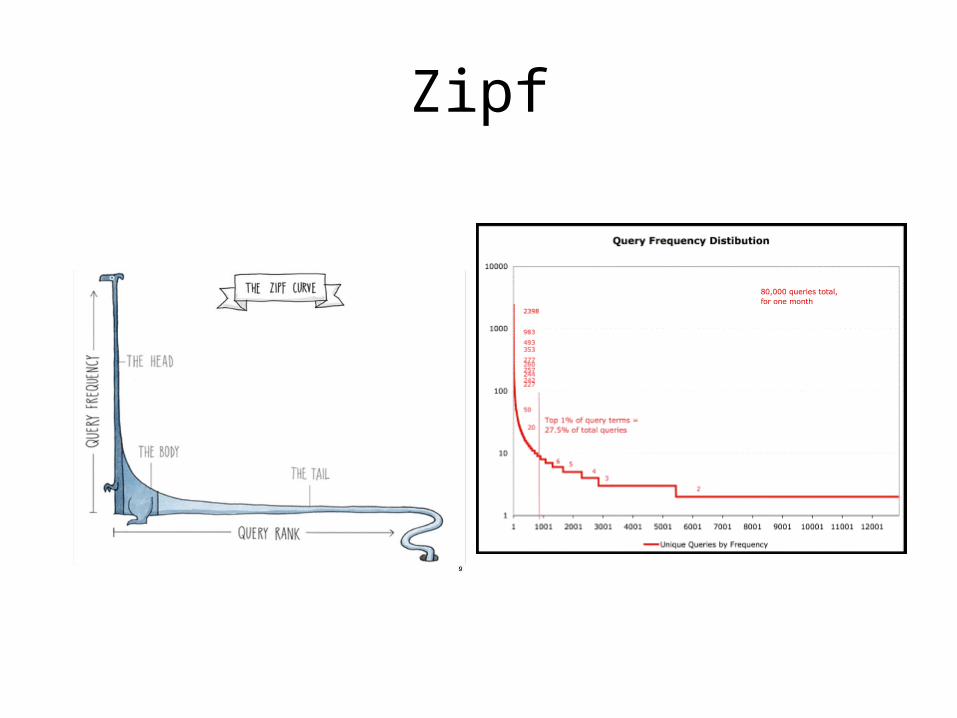
Postings Size: Zipf’s Law• George Kingsley Zipf (1902-1950) observed the following
relation between frequency and rank
• In other words:– A few elements occur very frequently– Many elements occur very infrequently
• Zipfian distributions:– English words– Library book checkout patterns– DB queries– Website popularity (almost anything on the Web)
crf or
r
cf f = frequency
r = rankc = constant
Zipf

Vocabulary Size: Heaps’ Law
KnV V is vocabulary sizen is corpus size (number of documents)K and are constants, determineempirically
Typically, K is between 10 and 100, is between 0.4 and 0.6
When adding new documents, the system is likely to have seen most terms already… but the postings keep growing
Heaps' law means that as more instance text is gathered, there will be diminishing returns in terms of discovery of the full vocabulary from which the distinct terms are drawn.

Inverted Index
• How large is the inverted index?– Size of vocabulary– Size of postings– Well-optimized inverted index can be 1/10 of size
of original document collection• Fundamentally, a large sorting problem
– Terms usually fit in memory– Postings usually don’t

Process query
• Given a query, fetch posting lists associated with query, traverse postings to compute result set– Optimization strategies to reduce # postings must
examine– Query document scores must be computed
• Partial scores stored in accumulators
• Top k documents extracted

Retrieval• The retrieval problem
– Must have sub-second response– For Web, only need relatively few results
• Types of queries in IR systems– Keyword Queries– Boolean Queries– Phrase Queries– Proximity Queries– Wildcard Queries– Natural Language Queries

Ranked Retrieval• Order documents by how likely they are to be relevant
to the information need• How do we estimate relevance?
– What characteristics to use?– Google’s Page Rank Algorithm





























