Embed Size (px)
Citation preview

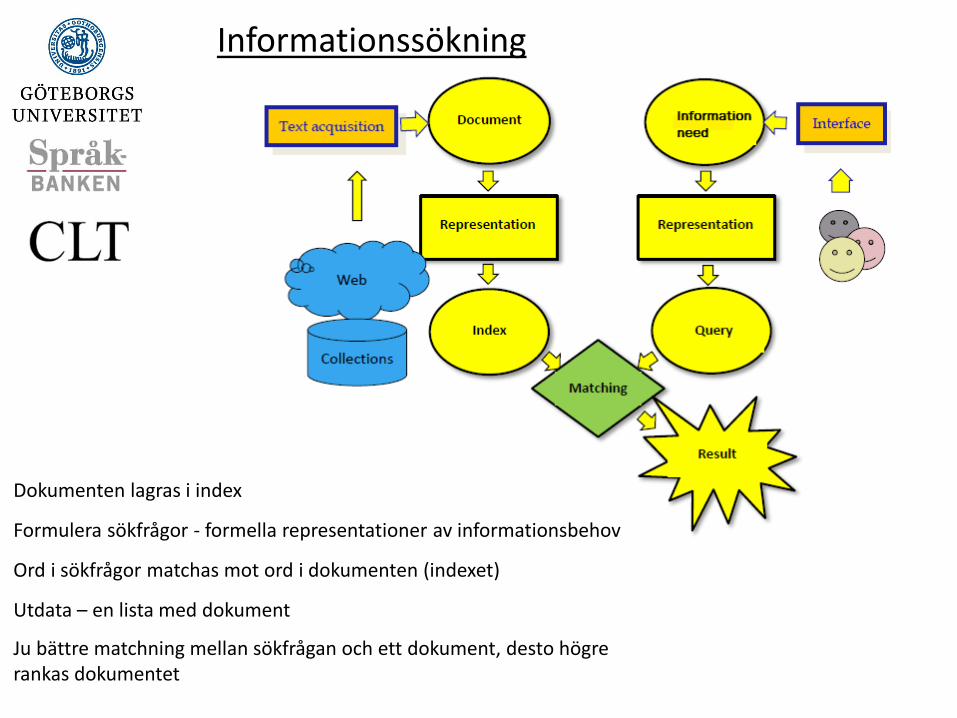
Informationssökning Information Retrieval - IR
Karin Friberg Heppin Språkdata
Institutionen för svenska språket
Göteborgs Universitet
2
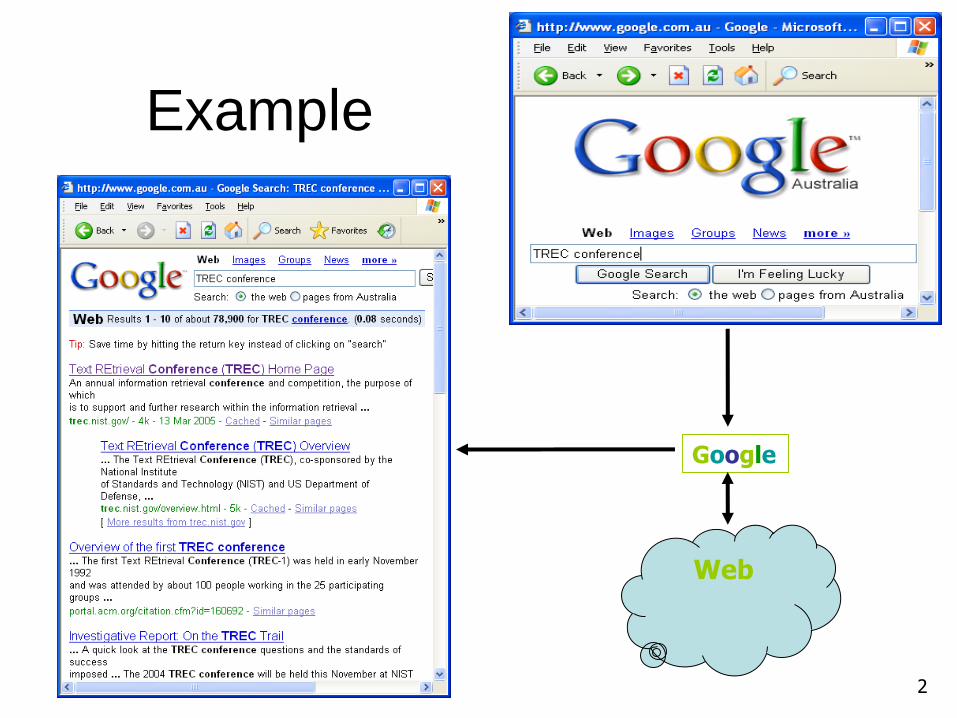
Example
Web

3
Retriving documents
• Goal = find documents large document collection relevant to an information need
Document collection
Information need
Query
Answer list
IR system Retrieval

General definition
• Retrieval of unstructured data
Usually it is • Retrieval of text documents in big collections • Web Search But it can also be • Image retrieval • Video retrieval • Music retrieval ….
What is Information Retrieval?

IR Research ranges from…
computer science - researching the
frame, the modeling of relations
between documents and queries …
… to information science -
investigating the search behavior and
preferences of the users
… over linguistics - optimizing the
language of document representation
and queries …

Information retrieval
Information retrieval is about finding
documents relevant to an information
need, which are stored and indexed.
This is done by posing a query to a search
engine
which matches the terms used as search
keys to the terms used to store the documents in the index.
Informationssökning
Dokumenten lagras i index
Formulera sökfrågor - formella representationer av informationsbehov
Ord i sökfrågor matchas mot ord i dokumenten (indexet)
Utdata – en lista med dokument
Ju bättre matchning mellan sökfrågan och ett dokument, desto högre rankas dokumentet
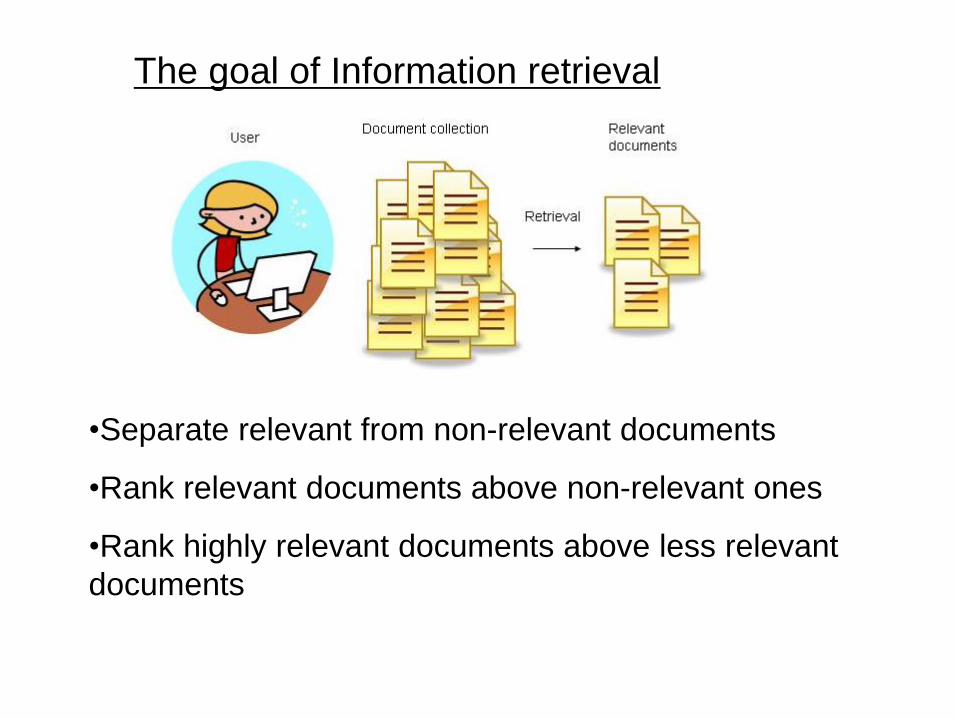
The goal of Information retrieval
•Separate relevant from non-relevant documents
•Rank relevant documents above non-relevant ones
•Rank highly relevant documents above less relevant
documents

Relevance
The relevance of a document, is a measure of how well the document satisfies the user's information need - A relevant document contains the information that a
person was looking for when they submitted a query to the search engine
- Many factors influence a person’s decision about what is relevant: e.g., task, context, novelty, style
- Topical relevance (same topic) vs. user relevance (what is useful for the user)
- Relevance may be binary: relevant/irrelevant or have a multilevel scale: e.g. 0-3

What IR is usually not about
Not about structured data
Retrieval from databases is usually not considered
• Queries in databases assumes that the data is in a standardized format
Database queries have a right answer
- How much money did you make last year?
IR problems usually don’t
- Find all documents relevant to “hippos in a zoo”
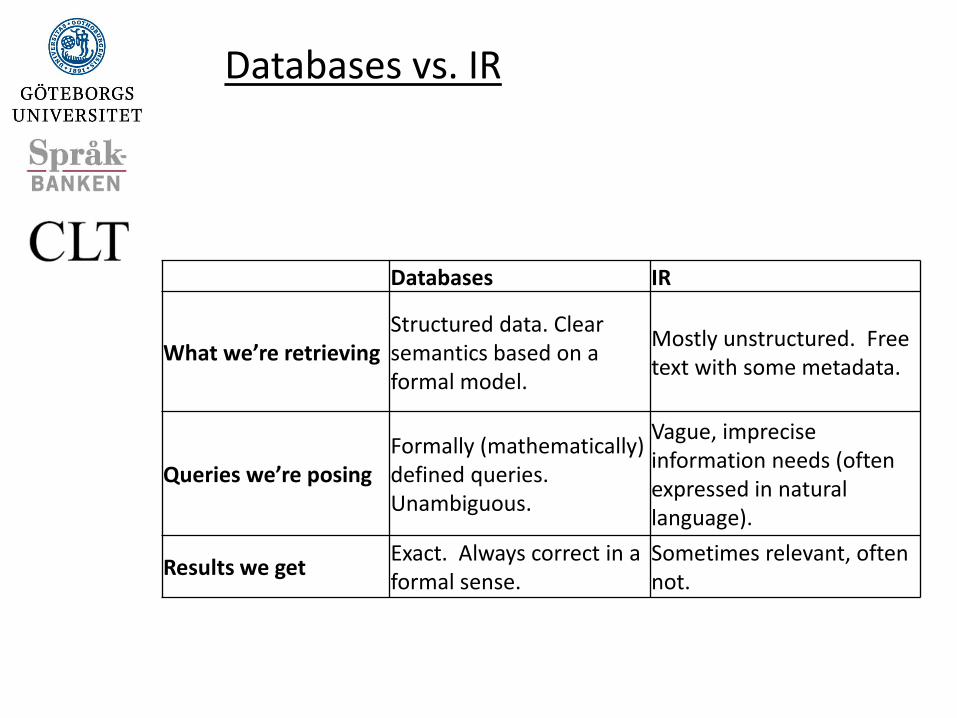
Databases IR
What we’re retrieving Structured data. Clear semantics based on a formal model.
Mostly unstructured. Free text with some metadata.
Queries we’re posing Formally (mathematically) defined queries. Unambiguous.
Vague, imprecise information needs (often expressed in natural language).
Results we get Exact. Always correct in a formal sense.
Sometimes relevant, often not.
Databases vs. IR

12
What to study in IR
• Document and query indexing
• How to best represent their contents?
• Query evaluation (or retrieval process)
• To what extent is a document relevant to a query?
• System evaluation
• How good is a system?
• Are the retrieved documents relevant? (precision)
• Are all the relevant documents retrieved? (recall)

13
How do we find the documents?
1. String matching (linear search in documents)
- Slow
- Difficult to improve
- Like browsing through a whole book
2. Indexing
- Fast
- Flexible to further improvement
- Like consulting the index at the back of the book
Possible approaches:

Word-Level Issues
• Morphological variation
= different forms of the same concept
– Inflectional morphology: same part of speech
– Derivational morphology: different parts of speech
• Synonymy
= different words, same meaning
• Polysemy
= same word, different meanings
{dog, canine, doggy, puppy, etc.} concept of dog
Bank: financial institution or side of a river?
Crane: bird or construction equipment?
Is: depends on what the meaning of “is” is!
break, broke, broken; sing, sang, sung; etc.
destroy, destruction; invent, invention, reinvention; etc.

Textoperationer
Tokenisering – omvandla en följd av tecken till en följd av ord
Ta bort skiljetecken och siffror
Stoppordlista – ta bort vanliga funktionsord
Hitta flerordsfraser som bör betraktas som ett ord
Stemming/lemmatisering – föra samman olika böjningsformer och avledningar till en stam eller grundform

Tokenization
Tokenization: separating text into terms
Word separators: Space - most common separator
But it is not so easy

What is a word / token?
I'll send you Luca's book
IBM360, IBM-360, ibm 360
Richard Brown
brown paint
flowerpot
flower-pot
flower pot

Capitalized words can have different meaning
from lower case words
Bush, Apple
But they can also represent the same word
Horse horse HORSE
Apostrophes can be a part of a word, a part of
a possessive, or just a mistake
rosie o'donnell, can't, don't, 80's, 1890's
men's straw hats, master's degree
england's ten largest cities, shriner's
Tokenizing Problems

Numbers are vague
1992 - year or number? Numbers can be important, including decimals: nokia3250, top 10 courses united 93, B-52, 7-eleven Periods can occur in numbers, abbreviations, URLs, ends of sentences, and other situations I.B.M., Ph.D., cs.umass.edu, F.E.A.R.
Tokenizing Problems

Small words can be important in some queries,
usually in combinations xp, ma, pm, el paso, pm,
j lo, world war II
Both hyphenated and non-hyphenated forms of
many words are common
Sometimes hyphen is not needed e-bay, wal-mart,
active-x, cd-rom, t-shirts
At other times, hyphens should be considered
either as part of the word or a word separator
Winston-salem, mazdarx-7, e-cards, pre-diabetes,
t-mobile, spanish-speaking
Tokenizing Problems

Many morphological variations of words
In most cases, these have the same or very
similar meanings
Stemmers attempt to reduce morphological
variations of words to a common stem
Usually involves removing suffixes
The alternative is to use several variations
of the words in the queries
Stemming/lemmatization

Lemmatization:
Dictionary-based - uses lists of related words
Produces morphologically valid units
Stemming:
Algorithmic: uses program to determine
related words
The product is not neccessarily
morphologically valid units
Stemming vs lemmatization

Over-stemming/under-stemming
Errors of comission:
doe/doing
execute/executive
ignore/ignorant
Errors of omission:
create/creation
europe/european
cylinder/cylindrical
Incorrectly lumps unrelated
terms together
Fails to lump related
terms together
Over-stemming:
Under-stemming:

Generally a small but significant effectiveness
improvement
Crucial for some languages:
5-10% improvement for English, up to 50% in
Arabic
Effect of stemming/lemmatization
Example of mean relative improvement due to stemming: +4% with the English language +4% Dutch +7% Spanish +9% French +15% Italian +19% German +29% Swedish +34% Bulgarian +40% Finnish +44% Czech

Stemmer Comparison

Undesirable tokens can be eliminated:
Non-content bearing tokens
Special characters
Numbers: dates, amounts…
Very short or very long tokens, ...
Full text index or not
Not as important anymore as storage space is cheap

Removed:
- Function words, determiners,
prepositions, which have little meaning on
their own
- High occurrence frequencies
Reason:
- To reduce index space, improve
response time, improve effectiveness
Downside:
Can be important in combinations
“to be or not to be”
Stopping

I a about an are as at be
by com for from how in is it
of on or that the this to was
what when wherewho will with the www
Example of a stopword list

Diacritics differ from one language to another:
résumé, Äpfel
Often they distinguish the meaning:
tache (task) or tâche (mark, spot)
Spelling of named entities may change with
languages:
Gorbachev ↔ Gorbacheff ↔ Gorbachov
Mona Lisa ↔ La Joconde ↔ La Gioconda
Normalization
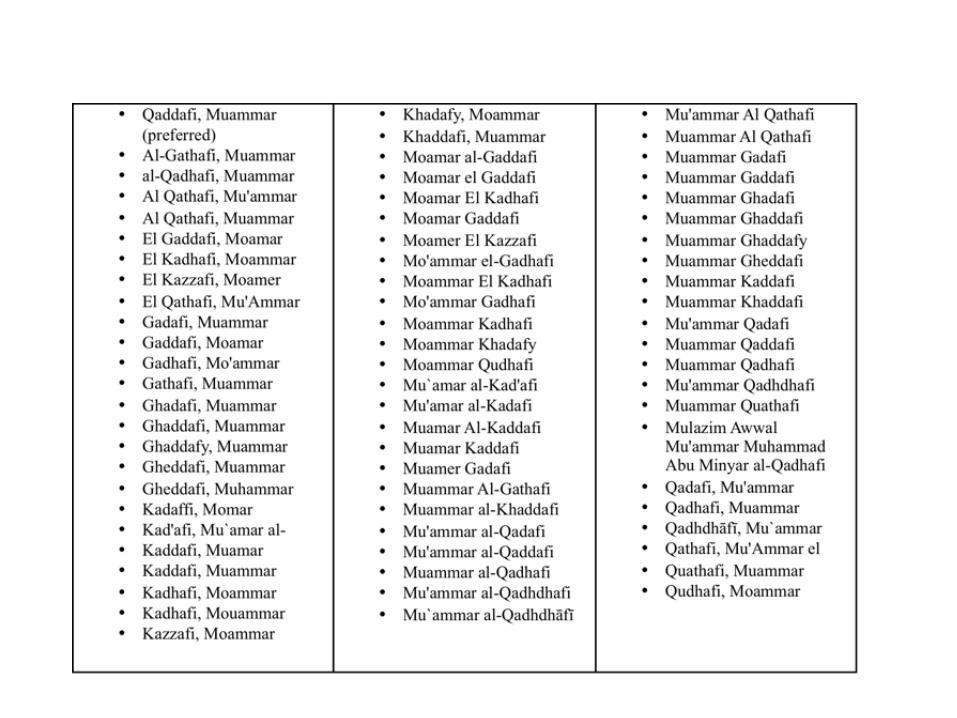

Problems
• Synonymy - different words, same meaning
– Effect: lower recall
• Polysemy - same word, different meanings
– Effect: lower precision
dog, canine, doggy, puppy concept of dog
Bank: financial institution or side of a river?
Crane: bird or construction equipment?

Paraphrase
Who killed Abraham Lincoln?
(1) John Wilkes Booth killed Abraham Lincoln.
(2) John Wilkes Booth altered history with a bullet. He will forever be
known as the man who ended Abraham Lincoln’s life.
When did Wilt Chamberlain score 100 points?
(1) Wilt Chamberlain scored 100 points on March 2, 1962 against the
New York Knicks.
(2) On December 8, 1961, Wilt Chamberlain scored 78 points in a triple
overtime game. It was a new NBA record, but Warriors coach Frank
McGuire didn’t expect it to last long, saying, “He’ll get 100 points
someday.” McGuire’s prediction came true just a few months later in
a game against the New York Knicks on March 2.
Language provides different ways of saying the same thing

Ambiguity in Action
• Different documents with the same keywords may have different meanings…
What do frogs eat?
(1) Adult frogs eat mainly insects
and other small animals,
including earthworms, minnows,
and spiders.
(2) Alligators eat many kinds of
small animals that live in or near
the water, including fish,
snakes, frogs, turtles, small
mammals, and birds.
(3) Some bats catch fish with their
claws, and a few species eat
lizards, rodents, small birds,
tree frogs, and other bats.
keywords: frogs, eat
What is the largest volcano in the
Solar System?
(1) Mars boasts many extreme
geographic features; for example,
Olympus Mons, is the largest
volcano in the solar system.
(2) The Galileo probe's mission to
Jupiter, the largest planet in the
Solar system, included amazing
photographs of the volcanoes on Io,
one of its four most famous moons.
(3) Even the largest volcanoes found
on Earth are puny in comparison to
others found around our own cosmic
backyard, the Solar System.
keywords: largest, volcano, solar, system

Informationssökning

Dokument <DOC> docid: gp1994-3 <TEXT> Magasinera TV ! Ett förslag i frågetramsets tid B ARNEN SÄGER att det var synd om TV-tittarna på nollkanalens tid då det bara fanns en kanal . Inget att välja på . Man försöker då förklara för dem att det fortfarande inte finns några valmöjligheter . Programutbudet är nämligen sådant att det alltid bara finns en enda möjlig kanal eftersom programmen i de båda övriga ( jag har tre ; ett , två och fyra ) är fullkomligt outhärdliga , Loket och Oldsberg eller Det kommer merar eller frågetävling , frågetävling eller frågtävling . … </TEXT> </DOC>

Idexes
• Indexes are data structures designed to make search faster
• Text search has unique requirements, which leads to unique data structures
• Most common data structure is inverted index
–general name for a class of structures
– ‘inverted’ because documents are associated with words, rather than words with documents
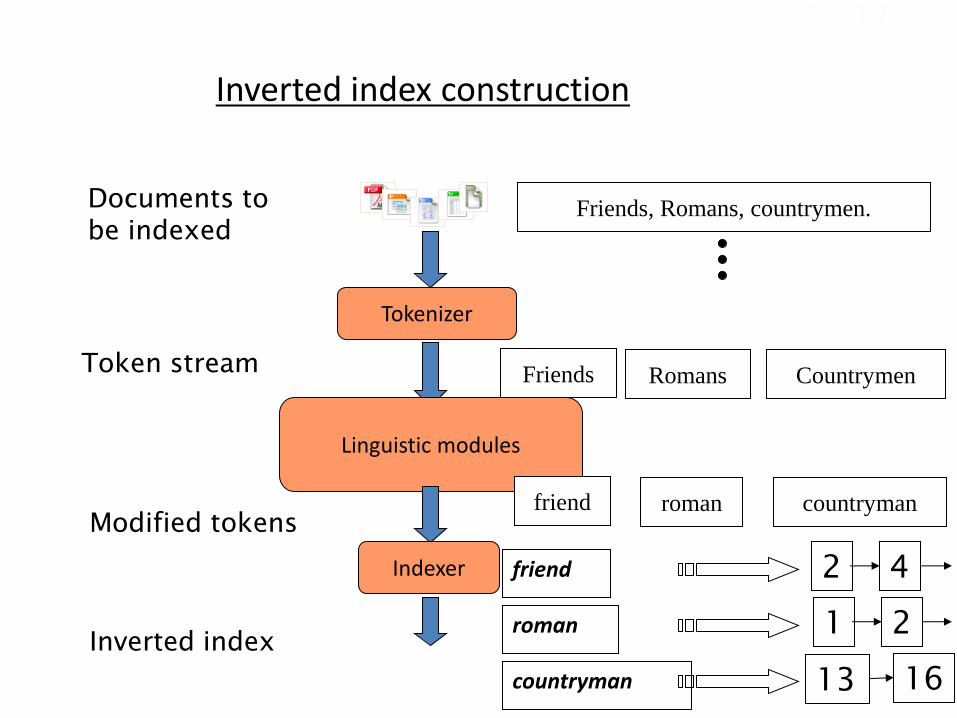
Tokenizer
Token stream Friends Romans Countrymen
Inverted index construction
Linguistic modules
Modified tokens
friend roman countryman
Indexer
Inverted index
friend
roman
countryman
2 4
2
13 16
1
Documents to
be indexed
Friends, Romans, countrymen.
Sec. 1.2

38
38
Four documents to index

39
39
Simple inverted index

40
• supports better ranking algorithms
40
Inverted index with counts
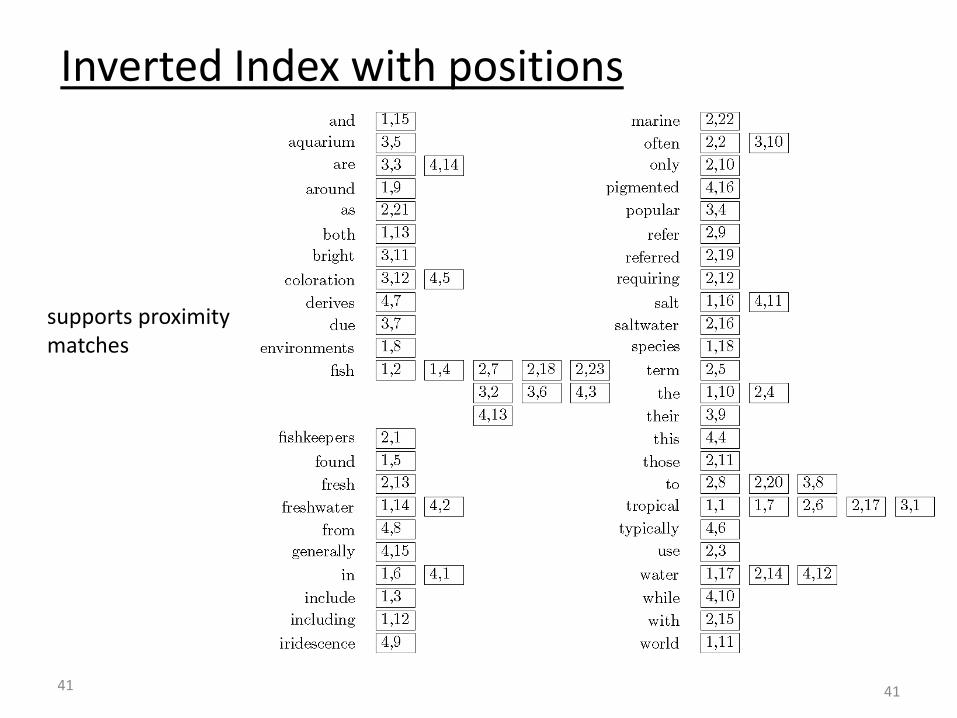
41
supports proximity matches
41
Inverted Index with positions

42
•Matching phrases or words within a window –e.g., ‘tropical fish’, or ‘find tropical within 5 words of fish’ •Word positions in inverted lists make these types of query features efficient
42
Proximity Matches

Boolean Retrieval
• Weights assigned to terms are either “0” or “1”
– “0” represents “absence”: term isn’t in the document
– “1” represents “presence”: term is in the document
• Build queries by combining terms with Boolean operators
– AND, OR, NOT
• The system returns all documents that satisfy the query
Why do we say that Boolean retrieval is “set-based”?
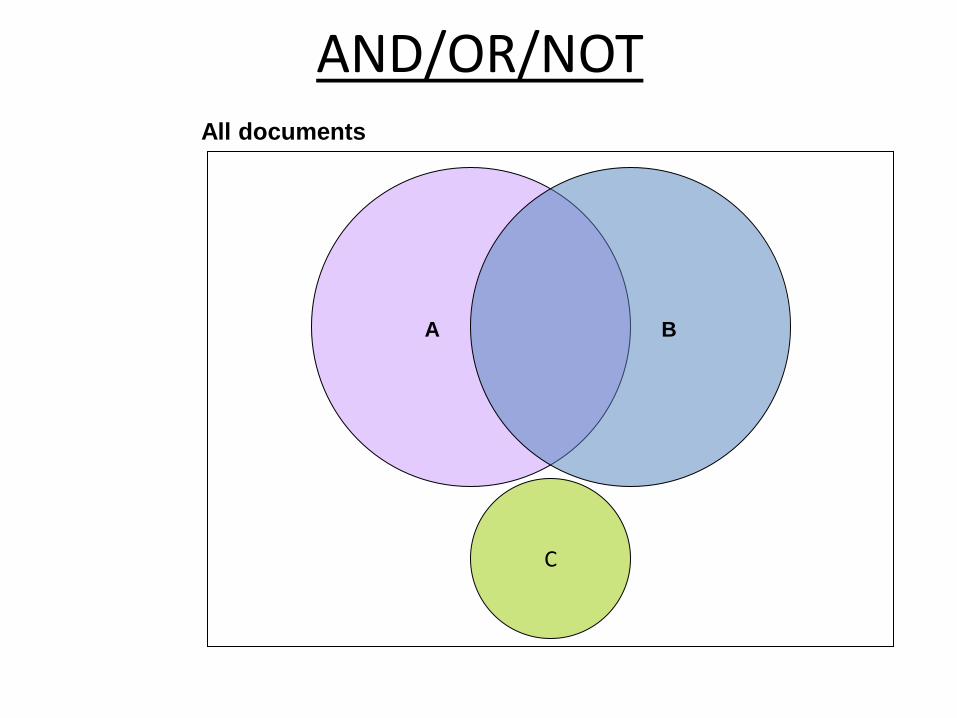
AND/OR/NOT
A B
All documents
C

Boolean queries: Exact match
• The Boolean retrieval model is being able to ask a query that is a Boolean expression:
– Boolean Queries use AND, OR and NOT to join query terms
• Views each document as a set of words
• Is precise: document matches condition or not.
– Perhaps the simplest model to build an IR system on
• Primary commercial retrieval tool for 3 decades.
• Many search systems you still use are Boolean:
– Email, library catalog, Mac OS X Spotlight 45
Sec. 1.3

Exempel på sökning
<num> 033 </num> <SV-title> Cancergenetik </SV-title> <SV-desc> Sök dokument som behandlar nyligen gjorda
upptäckter om sambandet mellan gener och cancer </SV-desc>
<SV-narr> Man har nyligen upptäckt den gen som har
samband med vissa tumörer. Alla dokument som innehåller information om detta nya diagnosinstrument är relevanta. </SV-narr>
</top>

Expansion av sökfråga
Baseline
#sum(upptäckt samband gen cancer)
Böjning
#sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet) #syn(gen genen gener) #syn(cancer cancern))
Böjning + synonymer
#sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet orsak orsaka) #syn(gen gener arvsmassa arvsmassan) #syn(cancer cancern tumör tumörer))

The result for baseline query 1
1 Q0 ntdk-0077 1 -6.68144 indri 1 Q0 nmdc-0652 2 -6.76833 indri 1 Q0 ltxx-1297 3 -6.813 indri 1 Q0 ntdk-0074 4 -6.88695 indri 1 Q0 ltxx-2525 5 -6.94228 indri 1 Q0 svrd-1865 6 -6.9971 indri 1 Q0 mdll-0226 7 -7.01527 indri 1 Q0 pfzr-0047 8 -7.02031 indri 1 Q0 nmdc-0937 9 -7.07394 indri 1 Q0 vrdg-0434 10 -7.12576 indri 1 Q0 svdx-0089 11 -7.13687 indri 1 Q0 svdx-0087 12 -7.15393 indri 1 Q0 svrd-0614 13 -7.19322 indri 1 Q0 svrd-1443 14 -7.19562 indri 1 Q0 nmdc-0843 15 -7.20493 indri 1 Q0 flkb-0015 16 -7.23677 indri 1 Q0 nmdc-0621 17 -7.29184 indri 1 Q0 fyss-0025 18 -7.30071 indri 1 Q0 bmsx-2066 19 -7.30643 indri 1 Q0 bmsx-0044 20 -7.31138 indri 1 Q0 ltxx-1087 21 -7.34271 indri 1 Q0 ltxx-3768 22 -7.4061 indri 1 Q0 svrd-1867 23 -7.43562 indri 1 Q0 dnxx-0683 24 -7.51783 indri 1 Q0 dagm-0549 25 -7.54264 indri 1 Q0 ltxx-1255 26 -7.57046 indri 1 Q0 bmsx-0021 27 -7.57146 indri 1 Q0 frsk-0461 28 -7.5796 indri 1 Q0 svrd-1862 29 -7.58203 indri 1 Q0 bmsx-2305 30 -7.58903 indri 1 Q0 nmdc-0086 31 -7.59473 indri 1 Q0 ntdk-1325 32 -7.62016 indri 1 Q0 nmdc-0392 33 -7.63131 indri 1 Q0 lkbk-0015 34 -7.63304 indri
1 Q0 gpxx-0023 35 -7.64715 indri 1 Q0 svrd-1866 36 -7.66673 indri 1 Q0 fyss-0002 37 -7.67032 indri 1 Q0 ltxx-0478 38 -7.67949 indri 1 Q0 elli-0015 39 -7.69401 indri 1 Q0 ltxx-0943 40 -7.69744 indri 1 Q0 svrd-1096 41 -7.70263 indri 1 Q0 mdll-0185 42 -7.70869 indri 1 Q0 frsk-0262 43 -7.71503 indri 1 Q0 frsk-0477 44 -7.71505 indri 1 Q0 frsk-0497 45 -7.72518 indri 1 Q0 dagm-0552 46 -7.72721 indri 1 Q0 elli-0017 47 -7.73269 indri 1 Q0 elli-0012 48 -7.73473 indri 1 Q0 bmsx-2006 49 -7.73993 indri 1 Q0 nmdc-0144 50 -7.74181 indri 1 Q0 schr-0074 51 -7.74259 indri 1 Q0 dnxx-0184 52 -7.77071 indri 1 Q0 nmdc-0306 53 -7.77286 indri 1 Q0 elli-0013 54 -7.7747 indri 1 Q0 ltxx-2526 55 -7.78337 indri 1 Q0 ntdk-2403 56 -7.78677 indri 1 Q0 dagm-0645 57 -7.78689 indri 1 Q0 nmdc-0803 58 -7.7875 indri 1 Q0 ltxx-1043 59 -7.78828 indri 1 Q0 schr-0049 60 -7.78855 indri 1 Q0 ltxx-0944 61 -7.79202 indri 1 Q0 schr-0043 62 -7.79536 indri 1 Q0 dagm-1070 63 -7.79913 indri 1 Q0 ltxx-2514 64 -7.80579 indri 1 Q0 bmsx-1981 65 -7.81331 indri 1 Q0 ntdk-0677 66 -7.82148 indri 1 Q0 mrck-0062 67 -7.82615 indri
1 Q0 mdll-0205 68 -7.84119 indri
1 Q0 bmsx-0035 69 -7.84249 indri
1 Q0 mrck-0087 70 -7.84605 indri
1 Q0 ntdk-2710 71 -7.84657 indri
1 Q0 mrck-0050 72 -7.8479 indri
1 Q0 dagm-0742 73 -7.85168 indri
1 Q0 whpl-0930 74 -7.85455 indri
1 Q0 schr-0040 75 -7.86163 indri
1 Q0 schr-0061 76 -7.86744 indri
1 Q0 bmsx-2140 77 -7.8778 indri
1 Q0 mrck-0086 78 -7.88484 indri
1 Q0 ntdk-2471 79 -7.88642 indri
1 Q0 bmsx-2863 80 -7.89441 indri
1 Q0 pfzr-0054 81 -7.90202 indri
1 Q0 mrck-0074 82 -7.90292 indri
1 Q0 mdll-0361 83 -7.90519 indri
1 Q0 schr-0042 84 -7.90544 indri
1 Q0 abxx-0103 85 -7.91486 indri
1 Q0 svrd-0113 86 -7.91705 indri
1 Q0 dnxx-0105 87 -7.91795 indri
1 Q0 mrck-0063 88 -7.92239 indri
1 Q0 schr-0044 89 -7.92376 indri
1 Q0 bmsx-0045 90 -7.93384 indri
1 Q0 svrd-0032 91 -7.94811 indri
1 Q0 ltxx-3941 92 -7.95155 indri
1 Q0 bmsx-0020 93 -7.95468 indri
1 Q0 ltxx-0918 94 -7.95792 indri
1 Q0 nmdc-0713 95 -7.96319 indri
1 Q0 nmdc-0729 96 -7.9632 indri
1 Q0 dnxx-0101 97 -7.97049 indri
1 Q0 frsk-0575 98 -7.97514 indri
1 Q0 mdll-0057 99 -7.9756 indri
1 Q0 dnxx-0360 100 -7.97735 indri

Key word based queries
The result of word queries for most retrieval models is the set of documents containing at least one of the words of the query
The resulting documents are ranked according to the degree of similarity with respect to the query
To support ranking, two common statistics on word occurrences inside texts are commonly used The first is called term frequency and counts the number of times a word appears inside a document The second is called inverse document frequency and counts the number of documents in which a word appears

Formal Information need / Topic
<TOP> <TOPNO>1</TOPNO> <TITLE> HDL och LDL </TITLE> <DESC> Hur påverkar en fettsnål, energifattig kost
koncentrationerna av HDL och LDL i blodet? </DESC> <NARR> Relevanta dokument ska innehålla information om
lipoproteinerna HDL och LDL och deras funktion, samt beskriva hur en kostförändring med fettsnål, energifattig kost påverkar koncentrationen av dessa i blodet.
</NARR> </TOP>

Queries
A query is the formulation of a user
information need put to the system
Keyword based queries are popular, since
they are intuitive, easy to express, and allow
for fast ranking
However, a query can also be a more
complex combination of operations using
different kinds of operators

Query in the Indri/Lemur query language
#combine(
#syn( fettsnål energifattig )
#syn( kost diet föda dricka kosthållning kostförändring)
#syn( koncentration halt)
#syn( ldl kolesterol lågdensitetslipoprotein kolesterolester #uw5(lätt
lipoprotein))
#syn( hdl kolesterol högdensitetslipoprotein kolesterolester lipoprotein )
#syn( blod )
)

Facets
#combine(
#syn( fettsnål energifattig )
#syn( kost diet föda dricka kosthållning kostförändring)
#syn( koncentration halt)…
Corresponds to the Boolean statement:
( fettsnål OR energifattig ) AND ( kost OR diet OR föda OR dricka
OR kosthållning OR kostförändring) AND ( koncentration OR halt)…

Facets
fettsnål
OR
energifattig
kost
OR
diet
OR
föda
OR
dricka
OR
kosthållning
OR
kostförändring
koncentration
OR
halt
AND AND …

Evaluation
For search evaluation measures based on relevance are used - For example: recall, precision, average precision different recall levels - Recall is the proportion of relevant documents recovered - Precision is the proportion of recovered documents that are relevant

Comparing queries
• Baseline
• #sum(upptäckt samband gen cancer)
• Inflections
• #sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet) #syn(gen genen gener) #syn(cancer cancern))
• Inflection + synonyms
• #sum(#syn(upptäckt upptäckten upptäckter) #syn(samband sambandet orsak orsaka) #syn(gen gener arvsmassa arvsmassan) #syn(cancer cancern tumör tumörer))

Distribution of word frequencies is very skewed
A few words occur very often, many words hardly
ever occur
The two most common words “the” and “of” make
up about 10% of all word occurrences in English
text documents
Zipf’sLaw
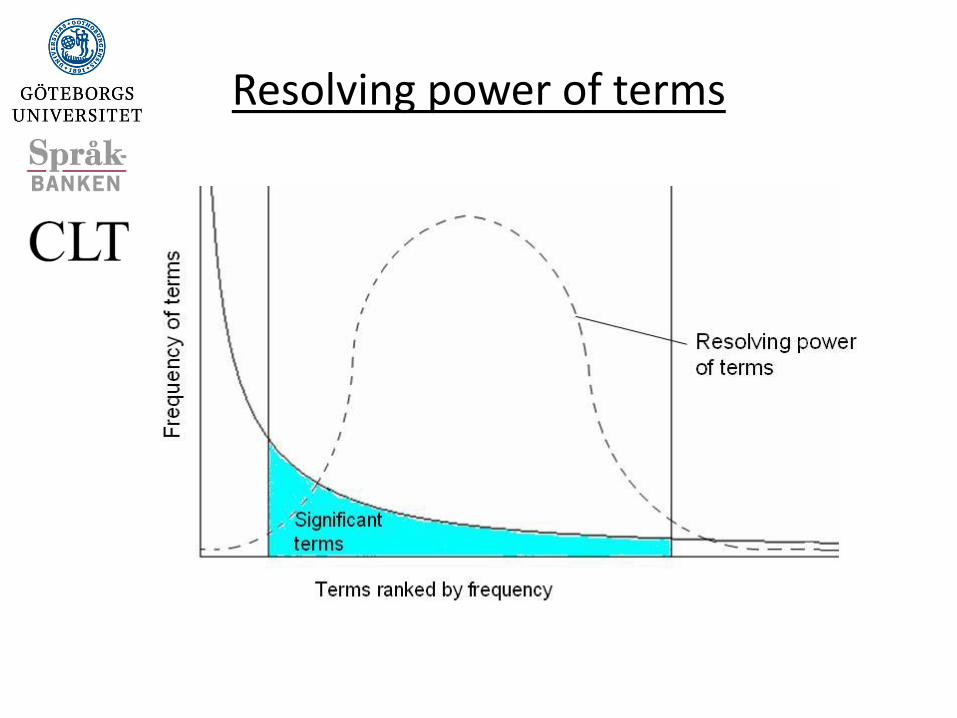
Resolving power of terms
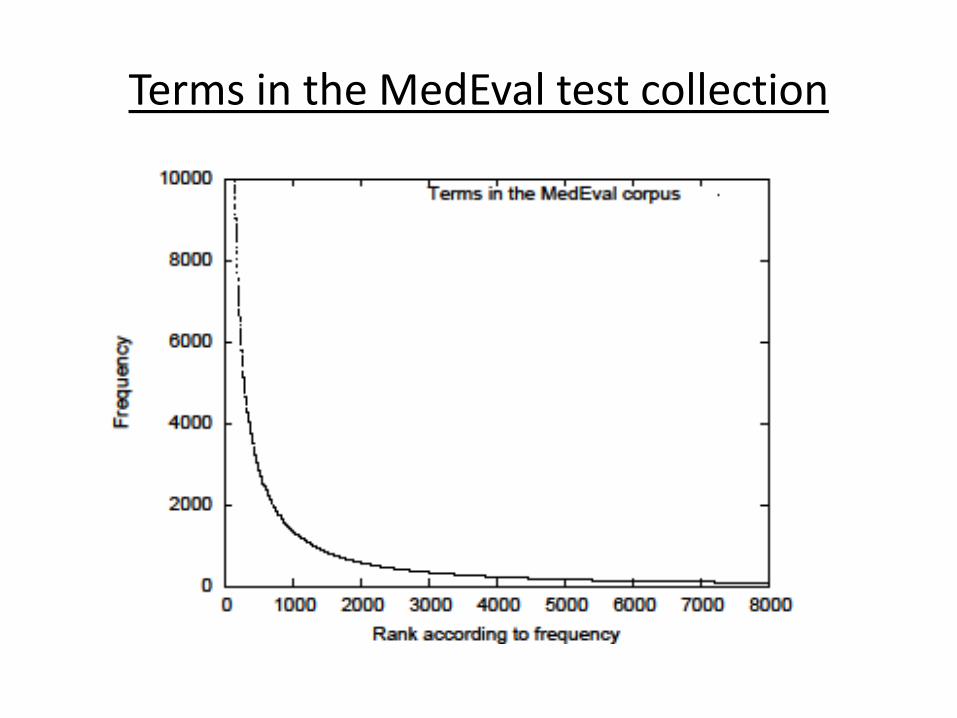
Terms in the MedEval test collection
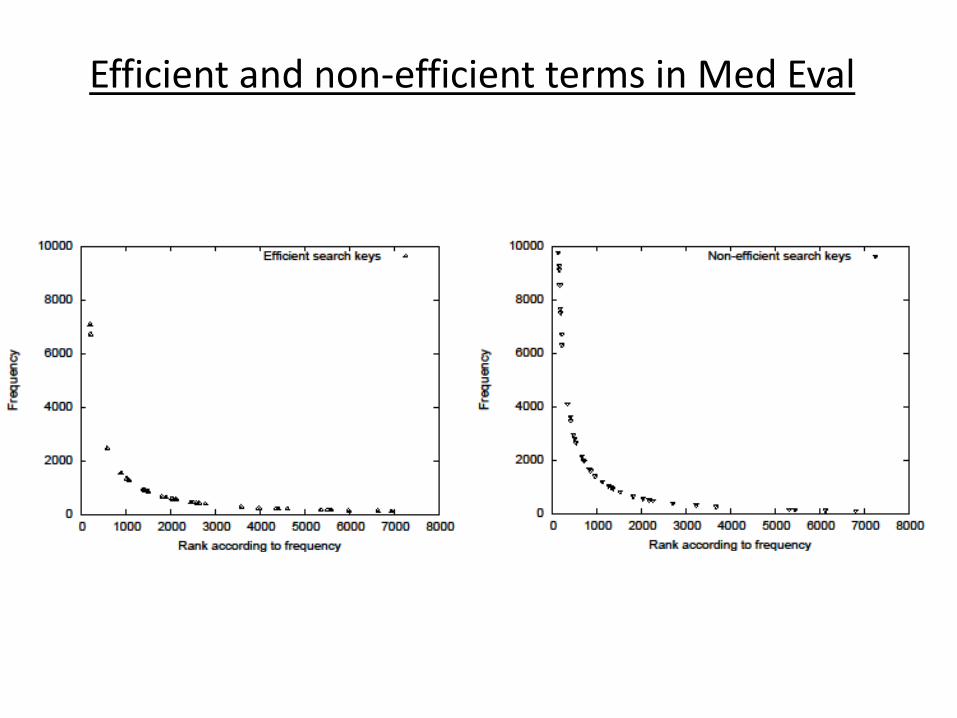
Efficient and non-efficient terms in Med Eval

61
• tf = term frequency – frequency of a term/keyword in a document
The higher the tf, the higher the importance (weight) for the doc.
• df = document frequency – no. of documents containing the term
– distribution of the term
• idf = inverse document frequency – the unevenness of term distribution in the corpus
– the specificity of term to a document
The more the term is distributed evenly, the less it is specific to a document
weight(t,D) = tf(t,D) * idf(t)
tf*idf weighting schema

Recall/precision
The Cranfield experiments culminated in the modern metrics of precision and recall
Recall ratio: the fraction of relevant
documents retrieved Precision ration: the fraction of documents
retrieved that are relevant

Why Ranked Retrieval?
• Arranging documents by relevance is – Closer to how humans think: some documents are
“better” than others
– Closer to user behavior: users can decide when to stop reading
• Best (partial) match: documents need not have all query terms – Although documents with more query terms should
be “better”
• Easier said than done!

How good are the retrieved docs?
• Precision : Fraction of retrieved docs that are relevant to user’s information need
• Recall : Fraction of relevant docs in collection that are retrieved
• More precise definitions and measurements to follow in later lectures
64
Sec. 1.1
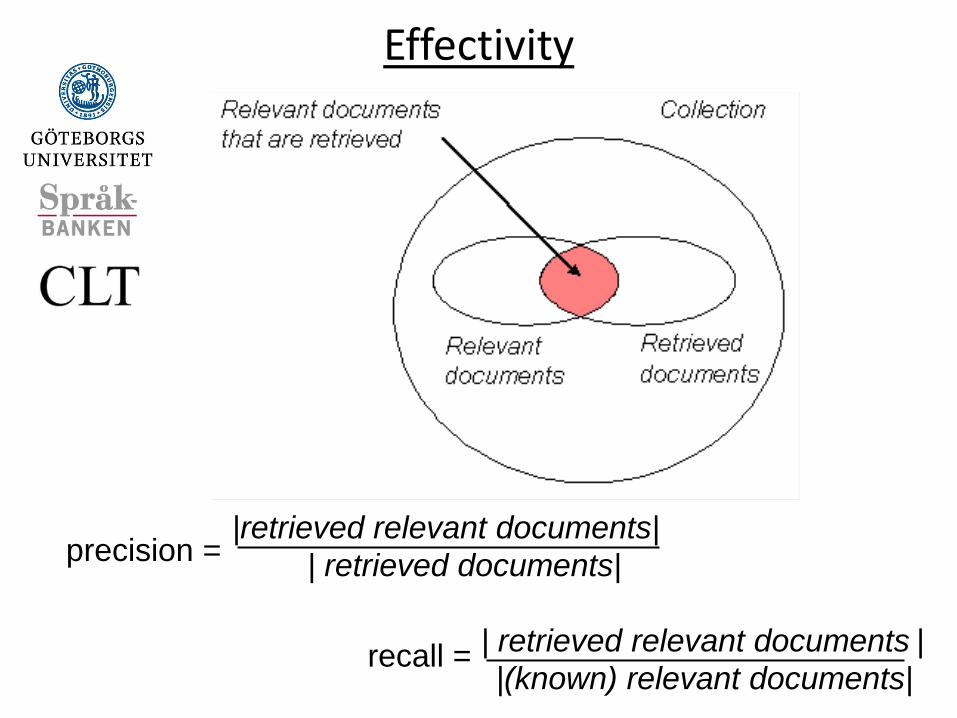
Effectivity
precision =
recall =
|retrieved relevant documents|
| retrieved relevant documents |
| retrieved documents|
|(known) relevant documents|

Find black
cats
Strategy 1
Strategy 2
It depends on what you want

Ranked Retrieval
• Order documents by how likely they are to be relevant to the information need
– Present hits one screen at a time
– At any point, users can continue browsing through ranked list or reformulate query
• Attempts to retrieve relevant documents directly, not merely provide tools for doing so





























